
1. Introduzione
In questo lab, assumerai il ruolo di responsabile delle indagini sui dati per un'azienda di logistica globale. Un container di carico di alto valore contenente preziose statuette da collezione di Android è scomparso. Per trovare la sua ultima posizione nota e tracciare il suo percorso, devi aggregare manifesti di spedizione frammentati di partner logistici regionali e file di log del transponder non strutturati. Per farlo, configurerai un moderno Google Cloud Open Data Lakehouse.

In questo lab proverai a:
- Configura l'estensione Google Cloud Data Agent Kit in Cloud Shell Editor.
- Crea un bucket Cloud Storage e fornisci un catalogo REST Apache Iceberg Lakehouse e un spazio dei nomi.
- Mappa una tabella esterna BigLake ai manifesti JSON non elaborati dei partner in Cloud Storage per scoprire l'indizio della partenza della nave.
- Carica ed elabora i log di testo non strutturati del transponder utilizzando Managed Service for Apache Spark serverless. Esegui normalizzazioni regex ed estrazione dinamica di indizi per scegliere come target la destinazione del payload perso.
- Scrivi le metriche dei log analizzati come tabella Apache Iceberg tramite il catalogo REST.
- Chatta con un agente AI sui tuoi dati Apache Iceberg utilizzando l'analisi conversazionale per scoprire indizi nascosti sulla spedizione smarrita.
- Sfrutta gli approfondimenti automatici sui dati con Knowledge Catalog per generare metadati sui tuoi dati.
- Stabilisci misure di protezione per l'importazione creando una tassonomia di sicurezza e utilizzando Knowledge Catalog per applicare un controllo dell'accesso granulare tramite il mascheramento degli ID custode sensibili.
Che cosa ti serve
- Un browser web come Chrome.
- Un progetto Google Cloud con la fatturazione abilitata.
- Familiarità con le query SQL di base e i comandi del terminale.
Costo e durata previsti
- Tempo di completamento: circa 45 minuti.
- Costo stimato: inferiore a 5$.
2. Prima di iniziare
Crea o seleziona un progetto Google Cloud
- Nella console Google Cloud, seleziona o crea un progetto Google Cloud.
- Verifica che la fatturazione sia attivata per il tuo progetto Cloud. Scopri come verificare che la fatturazione sia abilitata per un progetto.
Configura l'ambiente
Eseguirai la maggior parte dei comandi dal terminale integrato nell'editor di Cloud Shell, un ambiente di sviluppo basato sul cloud precaricato con strumenti per sviluppatori e Google Cloud SDK standard.
- Apri l'editor di Cloud Shell in una nuova scheda.
- Esegui questo comando nel terminale per clonare il repository:
cd ~/ git clone --filter=blob:none --no-checkout https://github.com/GoogleCloudPlatform/devrel-demos.git cd ~/devrel-demos git sparse-checkout init --cone git sparse-checkout set data-analytics/data-cloud-roadshow/lab1 git checkout main cd data-analytics/data-cloud-roadshow/lab1 - Imposta l'ID progetto. Puoi anche
Ctrl+Shift+Vsu Windows/Linux oCmd+Vsu macOS per incollare questo comando nel terminale:export PROJECT_ID="<YOUR_PROJECT_ID>" - Ora configuralo nel tuo ambiente.
gcloud config set project $PROJECT_ID - Seleziona una regione.
export REGION="<YOUR_REGION>" # Replace with the region you chose, such as "us-central1" - Abilita le API richieste.
gcloud services enable \ bigquery.googleapis.com \ biglake.googleapis.com \ storage.googleapis.com \ dataplex.googleapis.com \ datacatalog.googleapis.com \ dataproc.googleapis.com \ aiplatform.googleapis.com \ cloudresourcemanager.googleapis.com \ serviceusage.googleapis.com \ cloudaicompanion.googleapis.com \ geminidataanalytics.googleapis.com
Installa estensione
Ora configurerai l'estensione Google Data Agent Kit, uno strumento per interagire con gli strumenti per i dati di Google Cloud direttamente nel tuo IDE.
- Nella barra delle attività a sinistra dell'editor, fai clic sull'icona Estensioni (o premi
Ctrl+Shift+Xsu Windows/Linux oCmd+Xsu macOS). - Nella casella di ricerca delle estensioni, digita:
Google Cloud Data Agent Kit - Seleziona l'estensione ufficiale dai risultati e fai clic su Installa. Se richiesto, seleziona "Sì, mi fido degli autori".
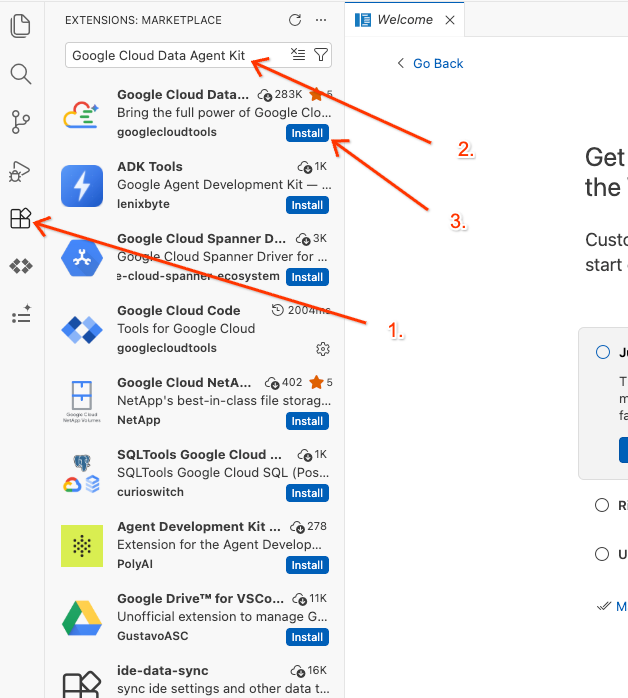
- Una volta installato correttamente, dovresti vedere l'icona del Google Cloud Data Agent Kit nella barra delle attività. Fai clic su di essa.
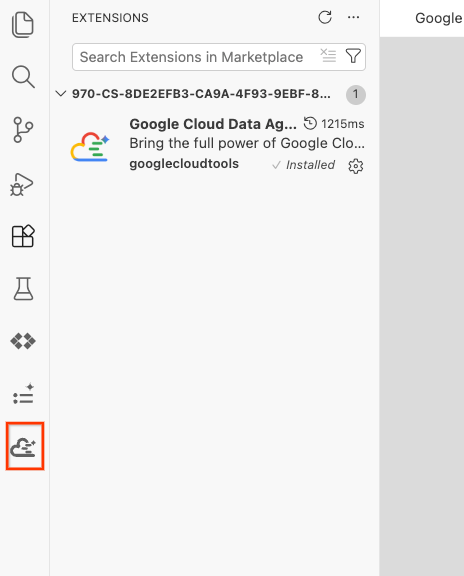
- Fai clic su Accedi al cloud.
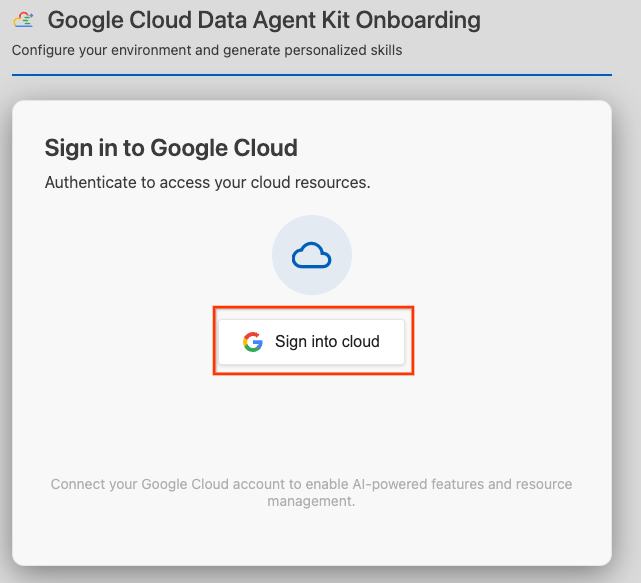
- Fai clic su Configura server MCP.
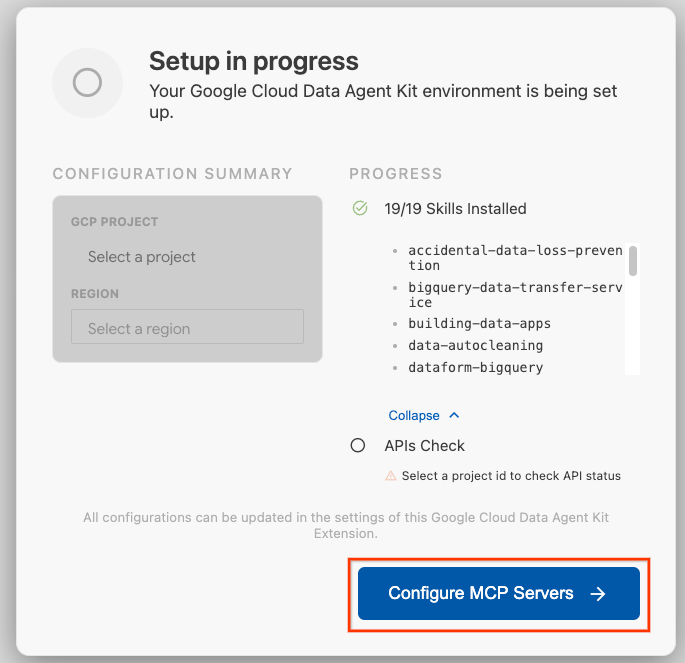
- Seleziona BigQuery, Knowledge Catalog, Apache Spark e AlloyDB. Utilizzerai AlloyDB nel lab 2. Poi fai clic su Inizia.
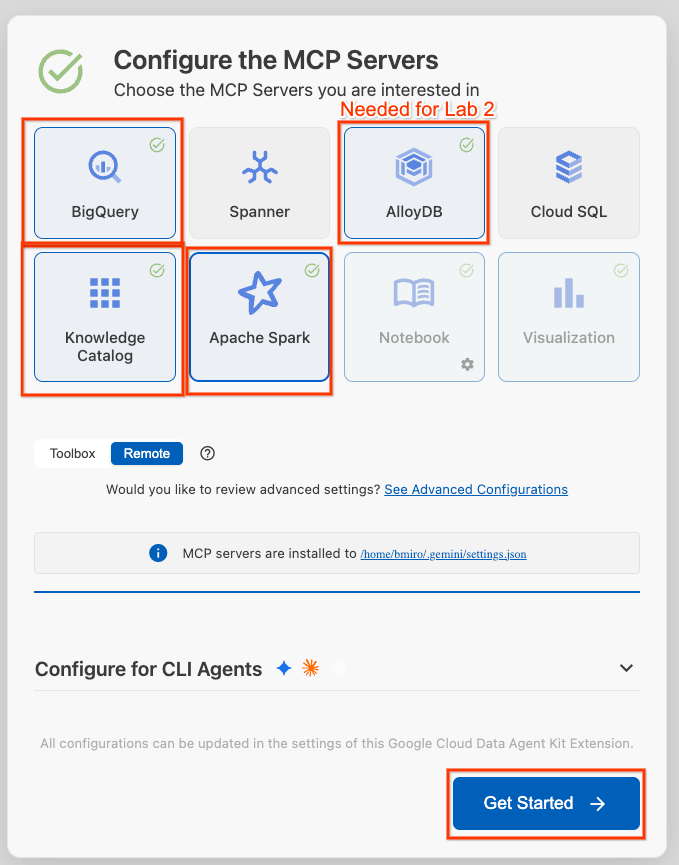
- Fai clic sul selettore ID progetto nella barra di stato in basso e scegli il tuo progetto Google Cloud attivo.
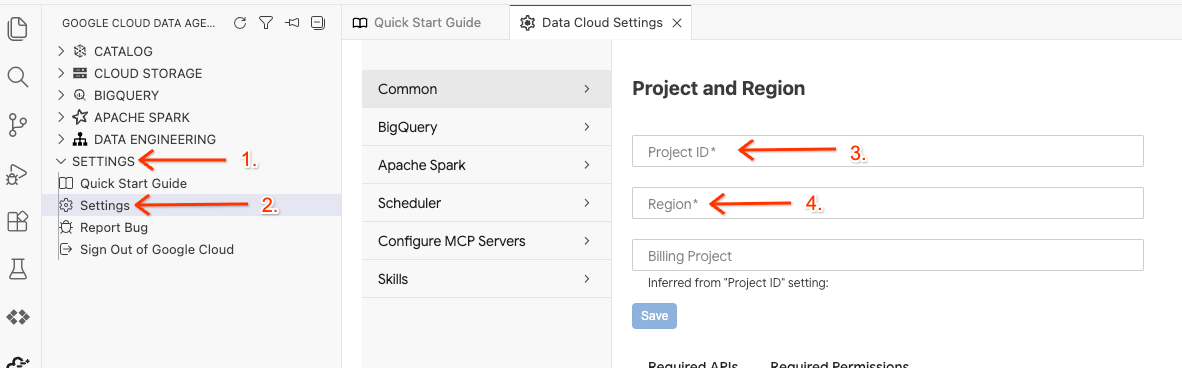
- Nel Data Agent Kit, fai clic su SETTINGS, poi su Settings e nella scheda Common seleziona l'ID progetto e la regione in cui eseguire il lab, ad esempio us-central1.
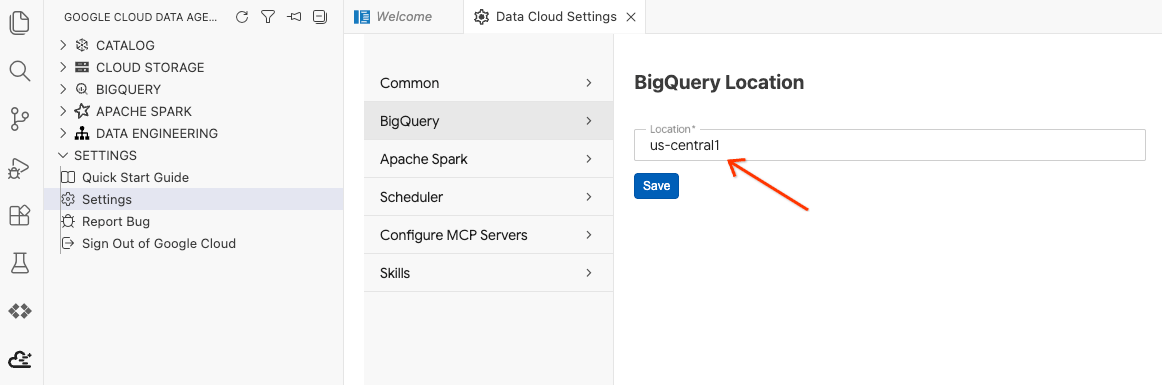
- Fai clic su Impostazioni BigQuery e sostituisci Regione con la regione selezionata in precedenza. Fai clic su Salva.
Ora puoi utilizzare il Data Agent Kit!
Esegui lo script di configurazione dell'ambiente
Nel terminale, esegui lo script di configurazione per creare le risorse di background necessarie per questo lab e configurare le autorizzazioni IAM:
chmod +x setup_lab1.sh
./setup_lab1.sh
source .env
Dovresti visualizzare una serie di passaggi di output che mostrano le risorse di cui viene eseguito il provisioning. Li tratteremo nel corso del lab.
Quando viene visualizzato un messaggio di completamento, puoi procedere:
==================================================== Environment Setup Complete! ====================================================
Ora, iniziamo la nostra ricerca.
3. Importare i manifesti di spedizione dei partner
I dati del manifesto di spedizione delle navi partner vengono archiviati nel bucket in formato JSON Lines (JSONL) standard: gs://${PROJECT_ID}-lost-cargo-lake/shipping_manifests/manifests.jsonl.
Prima di eseguire analisi approfondite, creerai una tabella BigLake controllata per questi dati non strutturati. In questo modo, puoi esplorare immediatamente i dati logistici dei partner utilizzando SQL standard senza costi di importazione duplicati.
Apri lo spazio di lavoro nell'editor ed esegui la query.
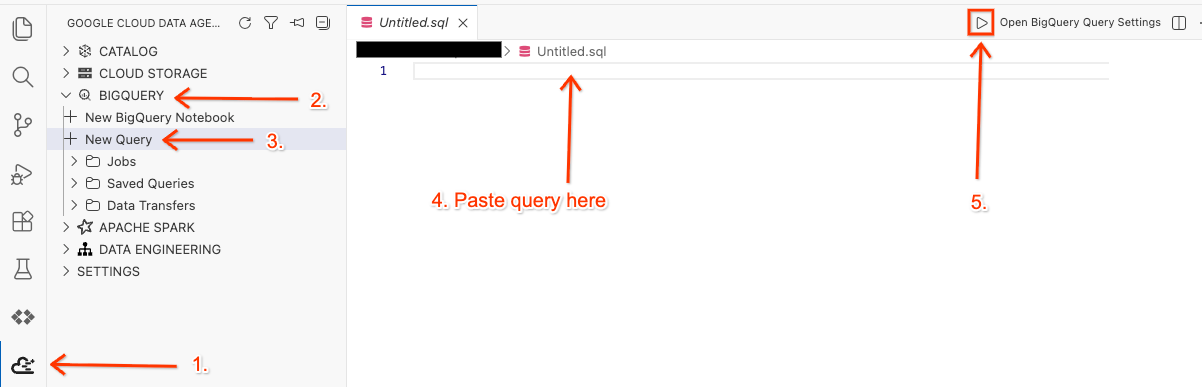
- In Cloud Shell Editor, fai clic sull'icona dell'estensione Google Cloud Data Agent Kit nel riquadro laterale.
- Vai a BigQuery e seleziona + Nuova query.
- Copia la seguente query nella finestra della query.
SET @@location = "<YOUR_REGION>"; --Update to your resource region, such as "us-central1". Make sure it is in quotes.
EXECUTE IMMEDIATE ("""
CREATE OR REPLACE EXTERNAL TABLE `lost_cargo_dataset.shipping_manifests`
(
shipment_id STRING,
timestamp TIMESTAMP,
last_ping_lat FLOAT64,
last_ping_long FLOAT64,
seal_integrity_status INT64,
custodian_id STRING OPTIONS(description='Masked identification token for official cargo custodian personnel.')
)
WITH CONNECTION `""" || @@location || """.conn`
OPTIONS (
format = 'NEWLINE_DELIMITED_JSON',
uris = ['gs://""" || @@project_id || """-lost-cargo-lake/shipping_manifests/*.jsonl']
)
""");
- Fai clic su Esegui.
- Per verificare che la tabella sia stata creata, vedrai un messaggio di conferma nel riquadro Risultati query, che si apre automaticamente in basso.
Esegui una query sulla tabella esterna per isolare i transponder compromessi
Identifichiamo i transponder compromessi individuando gli errori quando seal_integrity_status è stato impostato su 0. Copia ed esegui la seguente query nella finestra di query aperta in precedenza:
SELECT shipment_id, last_ping_lat, last_ping_long, custodian_id
FROM `lost_cargo_dataset.shipping_manifests`
WHERE seal_integrity_status = 0;
Nel riquadro Risultati query, dovresti vedere un output simile a questo:
shipment_id | last_ping_lat | last_ping_long | custodian_id |
MV-CAT-001 | 51.5074 | -0,1278 | usr_999_shadow |
4. Elaborare i log non strutturati con Managed Service for Apache Spark
Hai trovato la posizione iniziale dai manifest strutturati, ma il transponder smarrito è completamente spento. L'ultimo ping del transponder ha lasciato un messaggio criptico e non strutturato all'interno di un file di log di testo non elaborato nel percorso GCS gs://${BUCKET_NAME}/raw_logs/maritime_logs.txt.
Per elaborare e mappare questo log di testo, estrarre i timestamp, camuffare le identità e individuare il percorso a valle del carico, invierai un job Apache Spark (PySpark) serverless a Managed Service for Apache Spark.
Managed Service for Apache Spark ti consente di eseguire workload Spark senza eseguire il provisioning o gestire un cluster. Il servizio gestisce le risorse di calcolo sottostanti, eseguendo la scalabilità automatica in modo dinamico, e paghi solo per la durata dell'esecuzione.
Lo script:
- Inserisci il testo non strutturato e tra parentesi del transponder non elaborato.
- Applica filtri di estrazione delle espressioni regolari PySpark SQL per separare i timestamp, i metadati del custode e i contenuti non elaborati.
- Dividi i log disordinati in record puliti a livello di frase.
- Estrai le coordinate del target della destinazione dinamica in cui è terminato il percorso del carico utile smarrito.
- Connetti e riscrivi il dataframe dei log elaborati nel tuo catalogo REST Apache Iceberg di Lakehouse come nuova tabella di analisi visibile direttamente in BigQuery.
Correggi lo script di analisi PySpark
Sono stati segnalati pirati Python in mare che causano ogni tipo di problema.
- Esegui il comando seguente per aprire il file
process_maritime_logsnell'editor di Cloud Shell.cd ~/devrel-demos/data-analytics/data-cloud-roadshow/lab1 cloudshell open ./process_maritime_logs.py - Dedica un po' di tempo a leggere il codice e a capire cosa fa.
- Assicurati che non ci sia nulla di sospetto nel codice. Se devi eliminare qualcosa, assicurati di salvare il file utilizzando
Ctrl + S(Windows/Linux) oCmd + S(Mac).
Invia il job Spark serverless
Invia il job utilizzando l'SDK gcloud. La configurazione configura automaticamente il job PySpark per accedere al catalogo Lakehouse.
Esegui questo comando nel terminale dell'editor integrato.
cd ~/devrel-demos/data-analytics/data-cloud-roadshow/lab1
source .env
gcloud dataproc batches submit pyspark process_maritime_logs.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--version=2.3 \
--deps-bucket=${BUCKET_NAME} \
--properties="\
spark.sql.defaultCatalog=cargo_catalog,\
spark.sql.catalog.${CATALOG_NAME}=org.apache.iceberg.spark.SparkCatalog,\
spark.sql.catalog.${CATALOG_NAME}.type=rest,\
spark.sql.catalog.${CATALOG_NAME}.uri=https://biglake.googleapis.com/iceberg/v1/restcatalog,\
spark.sql.catalog.${CATALOG_NAME}.warehouse=gs://${BUCKET_NAME},\
spark.sql.catalog.${CATALOG_NAME}.header.x-goog-user-project=${PROJECT_ID},\
spark.sql.catalog.${CATALOG_NAME}.rest.auth.type=org.apache.iceberg.gcp.auth.GoogleAuthManager,\
spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions,\
spark.sql.catalog.${CATALOG_NAME}.gcs.oauth2.refresh-credentials-endpoint=https://oauth2.googleapis.com/token, \
spark.sql.catalog.${CATALOG_NAME}.header.X-Iceberg-Access-Delegation=vended-credentials" \
-- ${BUCKET_NAME}
Attendi qualche minuto affinché l'ambiente serverless venga avviato, carica lo script ed esegui la logica di elaborazione.
Quando vedi un output simile al seguente, la tabella elaborata viene salvata nel catalogo Lakehouse come tabella gestita Apache Iceberg.
Batch [1fae0b4b42c045a084dd67917bd0c332] finished.
metadata:
'@type': type.googleapis.com/google.cloud.dataproc.v1.BatchOperationMetadata
batch: projects/<YOUR_PROJECT>/locations/us-central1/batches/1fae0b4b42c045a084dd67917bd0c332
batchUuid: 611b4465-fdac-4974-bc47-5f10adaf2a08
createTime: '2026-06-11T21:35:01.868157Z'
description: Batch
labels:
goog-dataproc-batch-id: 1fae0b4b42c045a084dd67917bd0c332
goog-dataproc-batch-uuid: 611b4465-fdac-4974-bc47-5f10adaf2a08
goog-dataproc-drz-resource-uuid: batch-611b4465-fdac-4974-bc47-5f10adaf2a08
goog-dataproc-location: us-central1
operationType: BATCH
name: projects/<YOUR_PROJECT/regions/us-central1/operations/7e2044db-dd97-3270-b368-4dc4ba417574
Visualizzare l'anteprima dei log elaborati
Nell'editor di query dell'estensione Data Agent Kit, copia la seguente query per visualizzare l'anteprima dei dati:
SET @@location = "<YOUR_REGION>"; -- e.g. "us-central1"
EXECUTE IMMEDIATE FORMAT("""
select log_timestamp, custodian_id, sentence from
`%s.%s-lost-cargo-lake.lost_cargo_namespace.processed_maritime_logs`
limit 5
""", @@project_id, @@project_id);
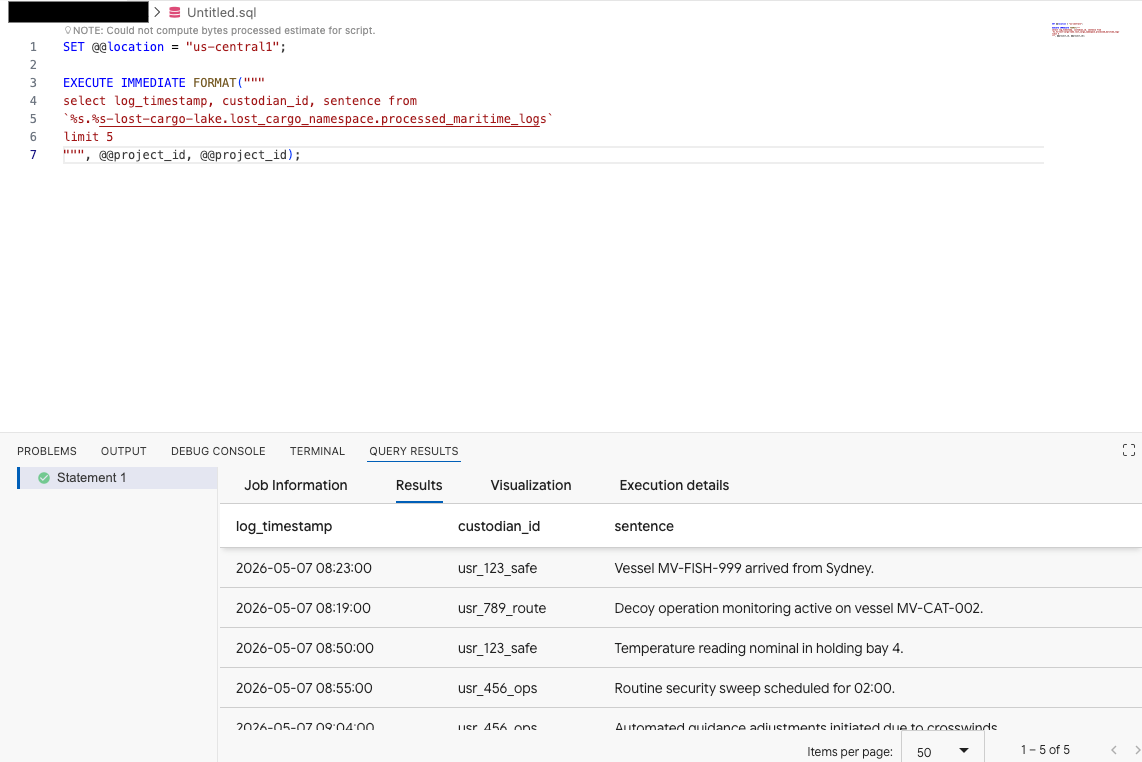
Ciò dimostra che è possibile accedere correttamente alla tabella Iceberg registrata nel catalogo da BigQuery.
Estrai l'indizio sulla destinazione
Ora che abbiamo i log elaborati, cerchiamo quelli che includono una destinazione target. Da qui, possiamo cercare nei log una menzione della nostra città di origine.
Nell'editor di query, esegui la seguente query, sostituendo <YOUR_REGION> con la tua regione e <ORIGIN_CITY> con la città di origine che hai scoperto in precedenza.
SET @@location = "<YOUR_REGION>"; --e.g. "us-central1"
DECLARE origin_city STRING;
SET origin_city = "<ORIGIN_CITY>"; --e.g. "Boston". (It's not Boston)
EXECUTE IMMEDIATE FORMAT(r"""
SELECT
log_timestamp AS event_time,
custodian_id,
REGEXP_EXTRACT(raw_message, r'Destination:\s*([^.]+)') AS destination_target
FROM
`%s.%s-lost-cargo-lake.lost_cargo_namespace.processed_maritime_logs`
WHERE
-- STRPOS is highly optimized in BigQuery for a simple .contains() substring check
STRPOS(sentence, '%s') > 0;
""", @@project_id, @@project_id, origin_city);
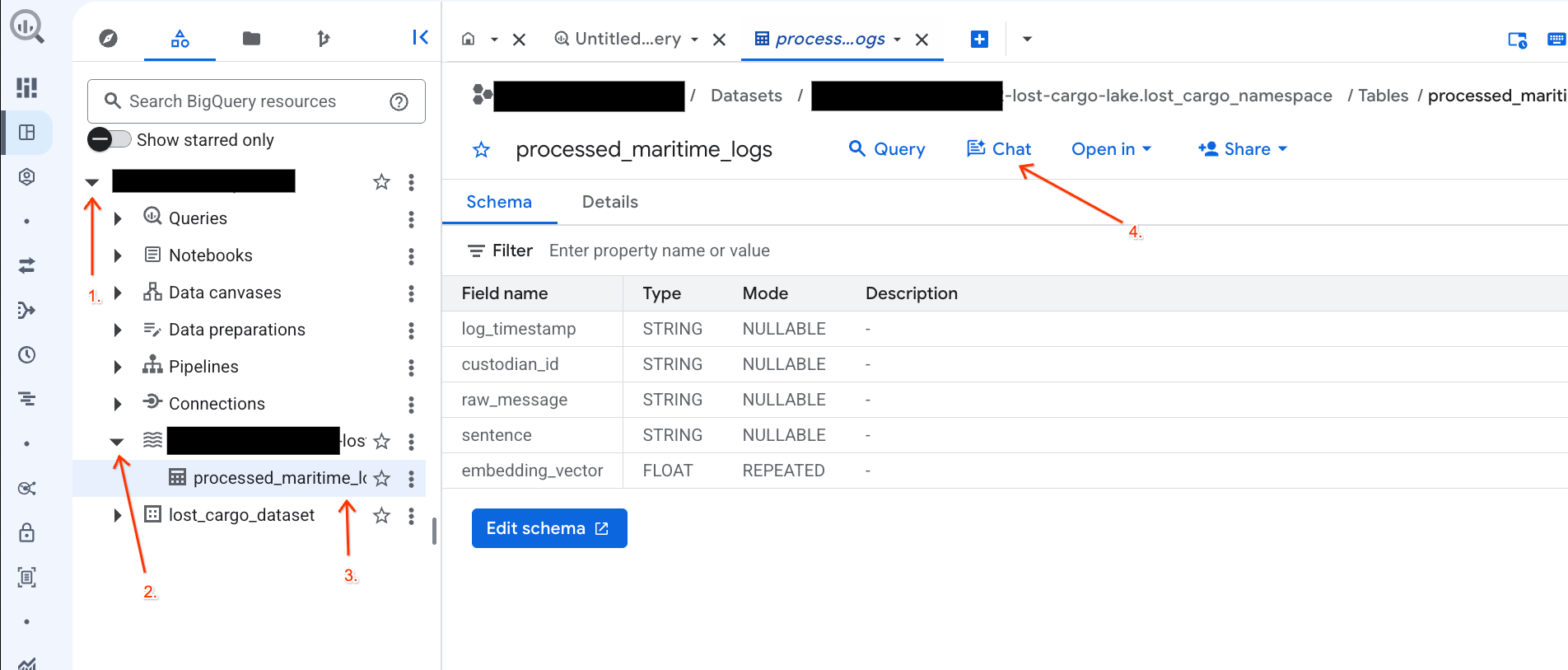
Chattare con i tuoi dati nella console BigQuery utilizzando l'analisi conversazionale
Anziché scrivere query SQL complesse per esplorare i dati, puoi utilizzare l'analisi conversazionale per interagire con le tabelle utilizzando il linguaggio naturale.
- Vai alla console BigQuery.
- Nel riquadro Explorer a sinistra, espandi il progetto e il set di dati
-lost-cargo-lake.lost_cargo_namespace processed_maritime_logsper aprire la scheda dei dettagli. - Accanto a Query, fai clic su Chat.
- Nel riquadro della chat, digita la seguente domanda e premi Invio sulla tastiera per inviarla:
Based on this table, what color is the shipping container MV-CAT-001?
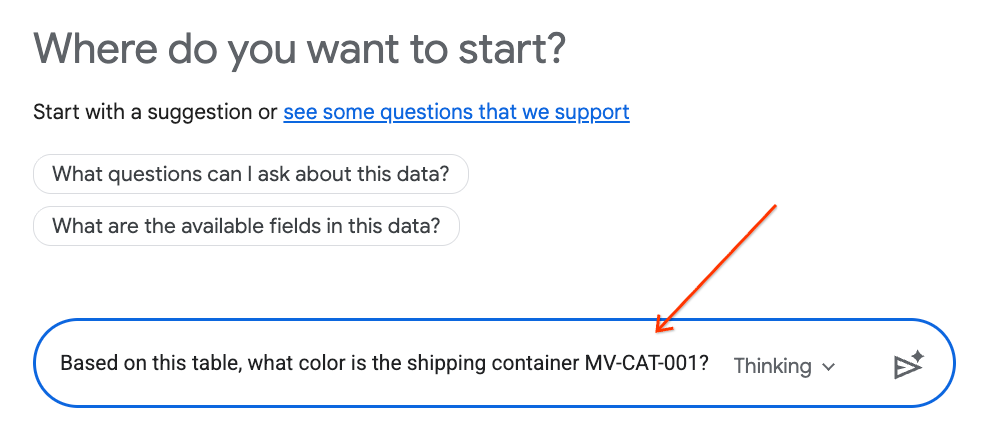
- Analisi conversazionale (basata su Gemini) analizzerà i dati della tabella attiva e risponderà con il colore.
5. Visualizzare il catalogo Lakehouse centralizzato
Per integrare i motori di elaborazione open source (come Apache Spark) in modo sicuro e senza interruzioni con i motori di dati aziendali (come BigQuery), lo script di configurazione ha configurato un catalogo REST Iceberg di Lakehouse.
Il catalogo REST di Apache Iceberg funge da "unica fonte attendibile" serverless per i metadati delle tabelle, gestendo dinamicamente gli schemi e le tabelle di partizionamento durante l'archiviazione dei file di dati Parquet fisici in Cloud Storage.
Esaminiamo questo catalogo direttamente nella console Google Cloud:
- Apri la console Lakehouse.
- Nella scheda Cataloghi, individua e fai clic sul catalogo REST Iceberg attivo:
-lost-cargo-lake
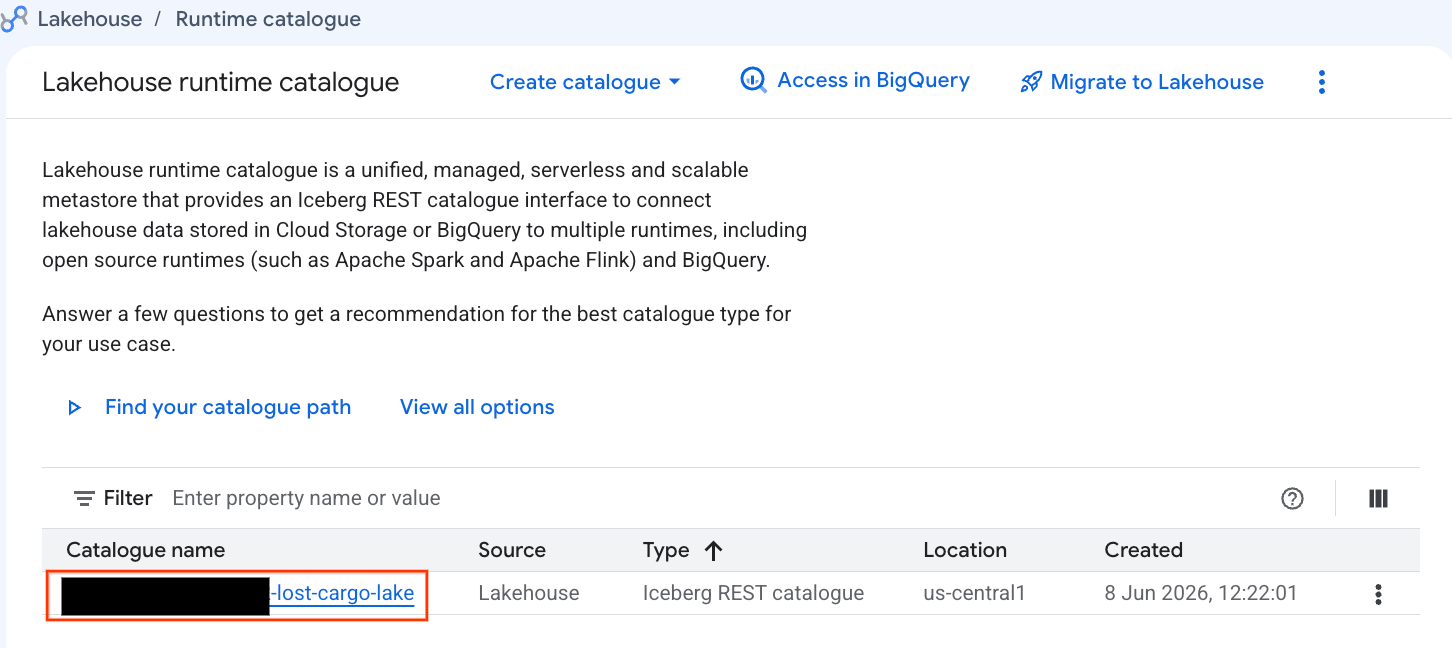
- Nella visualizzazione dei dettagli del catalogo, in Spazi dei nomi dovresti vedere
lost_cargo_namespace. Cliccaci sopra.
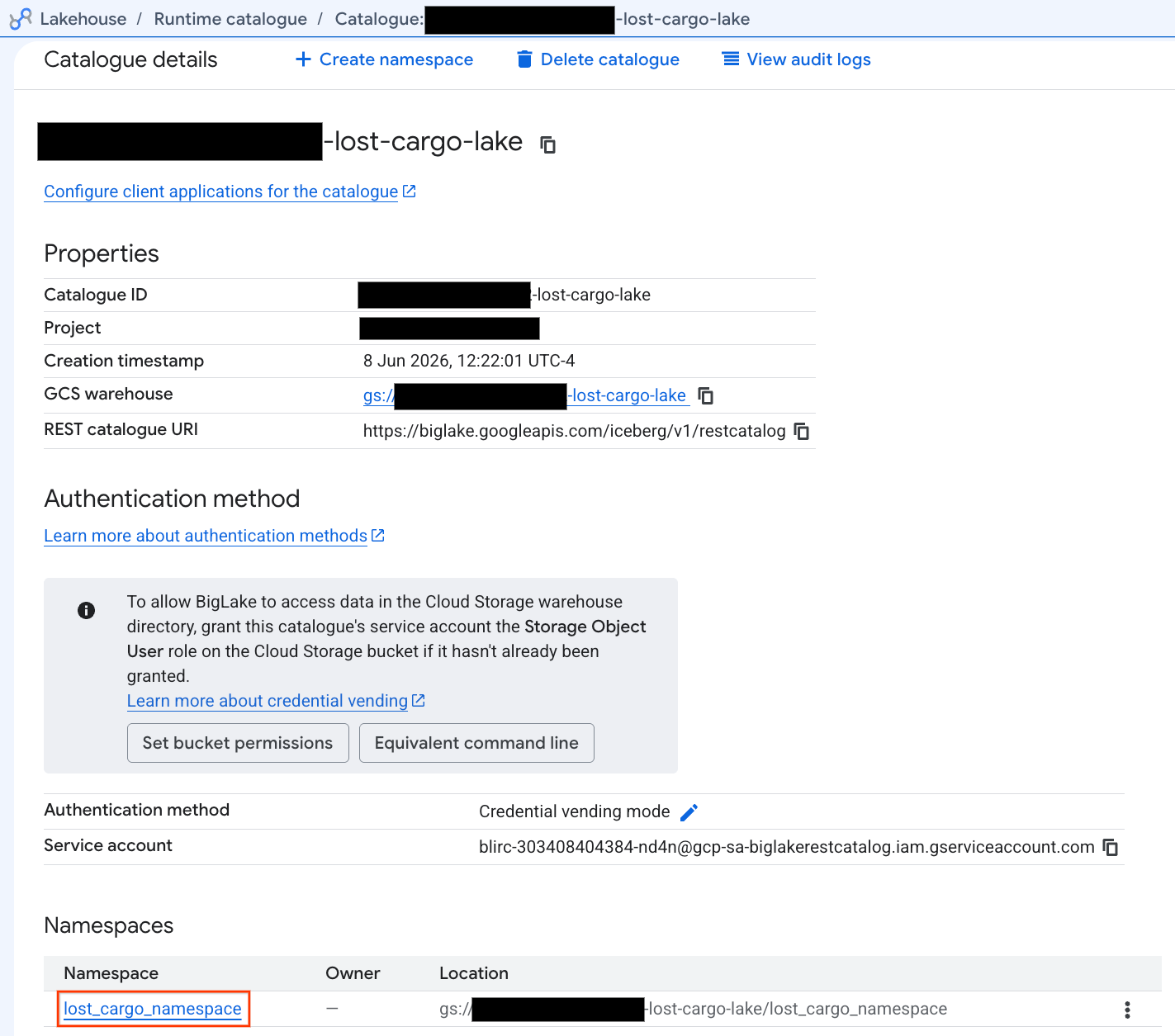
- La nuova tabella Apache Iceberg, generata da PySpark, è stata registrata automaticamente in questo spazio dei nomi del metastore ed è diventata immediatamente interrogabile in BigQuery.
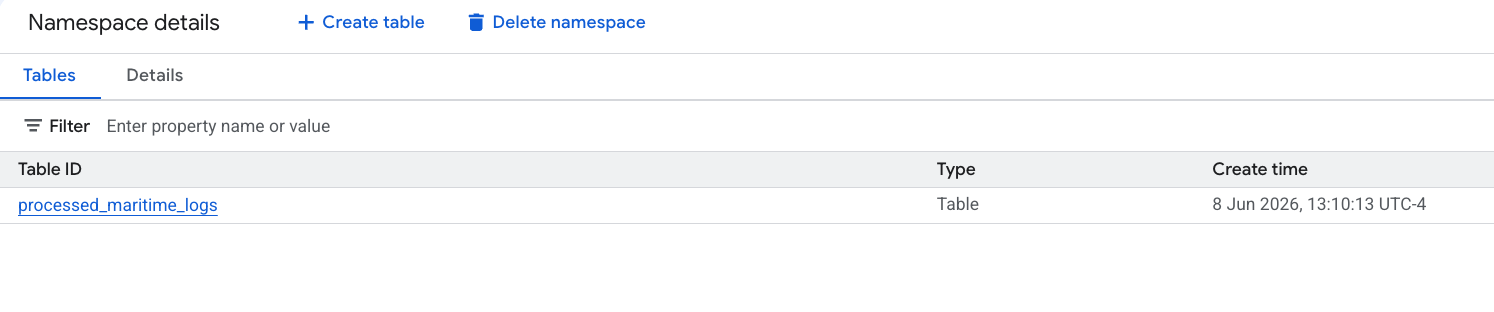
6. Generare insight sulla tabella dei manifesti di spedizione
Torniamo indietro e analizziamo la tabella shipping_manifests per comprenderne la struttura e i contenuti utilizzando Knowledge Catalog Data Insights. Arricchendo i metadati, gli altri esploratori possono comprendere meglio la tabella per le analisi future.
Generare approfondimenti sulle tabelle in BigQuery Studio
- Nella console Google Cloud, vai a BigQuery Studio.
- Nel riquadro Explorer, espandi il progetto, il set di dati
lost_cargo_datasete fai clic sulla tabellashipping_manifests. - Nel riquadro dei dettagli a destra, fai clic sulla scheda Approfondimenti.
- Utilizza il menu a discesa per selezionare Genera e pubblica.
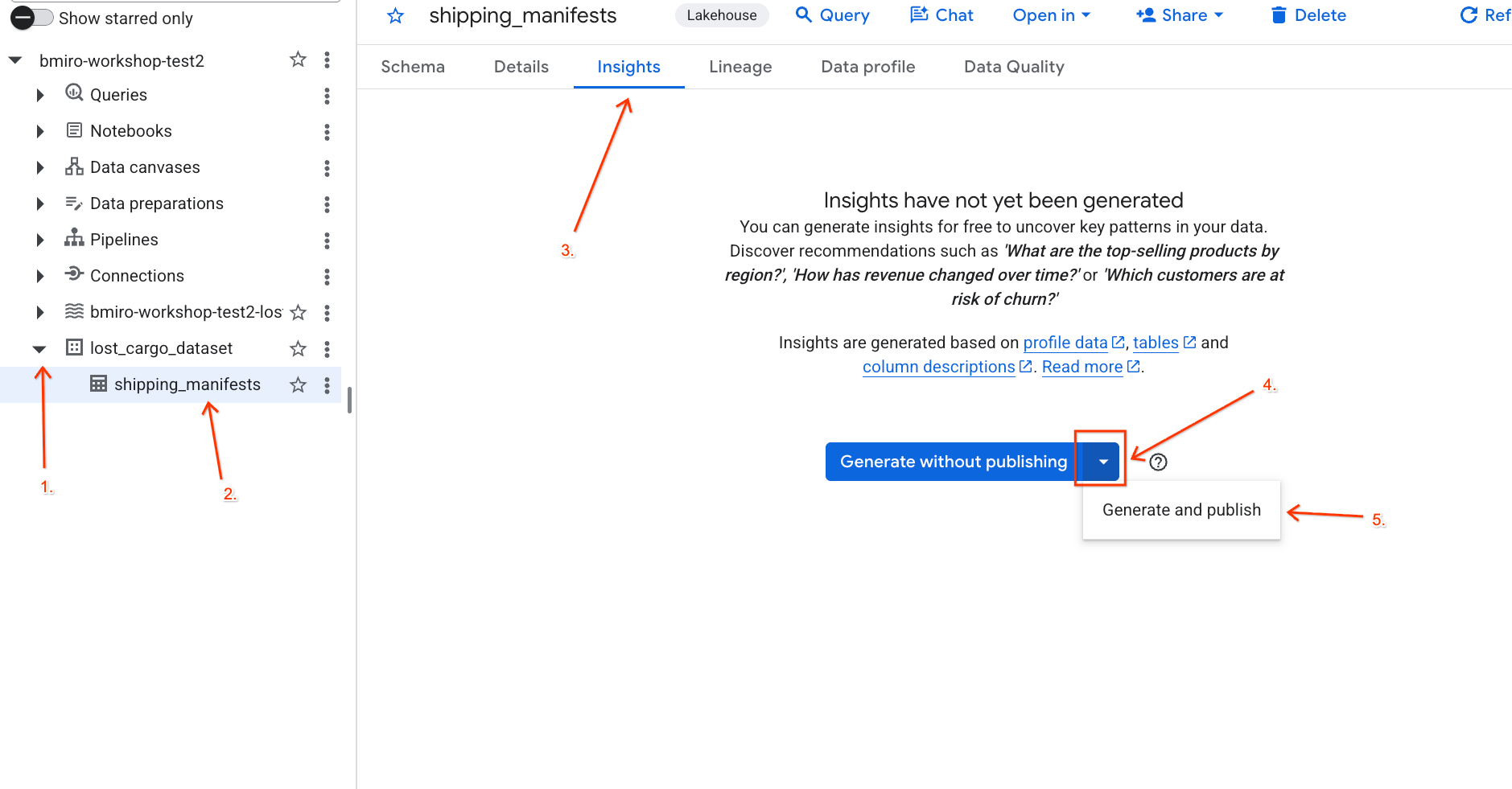
- Attendi circa 3 minuti per il completamento della generazione di insight. Gemini analizzerà i metadati della tabella e genererà domande in linguaggio naturale e query SQL corrispondenti.
- Una volta completata, vedrai una descrizione della tabella con una spiegazione in linguaggio naturale della tabella.
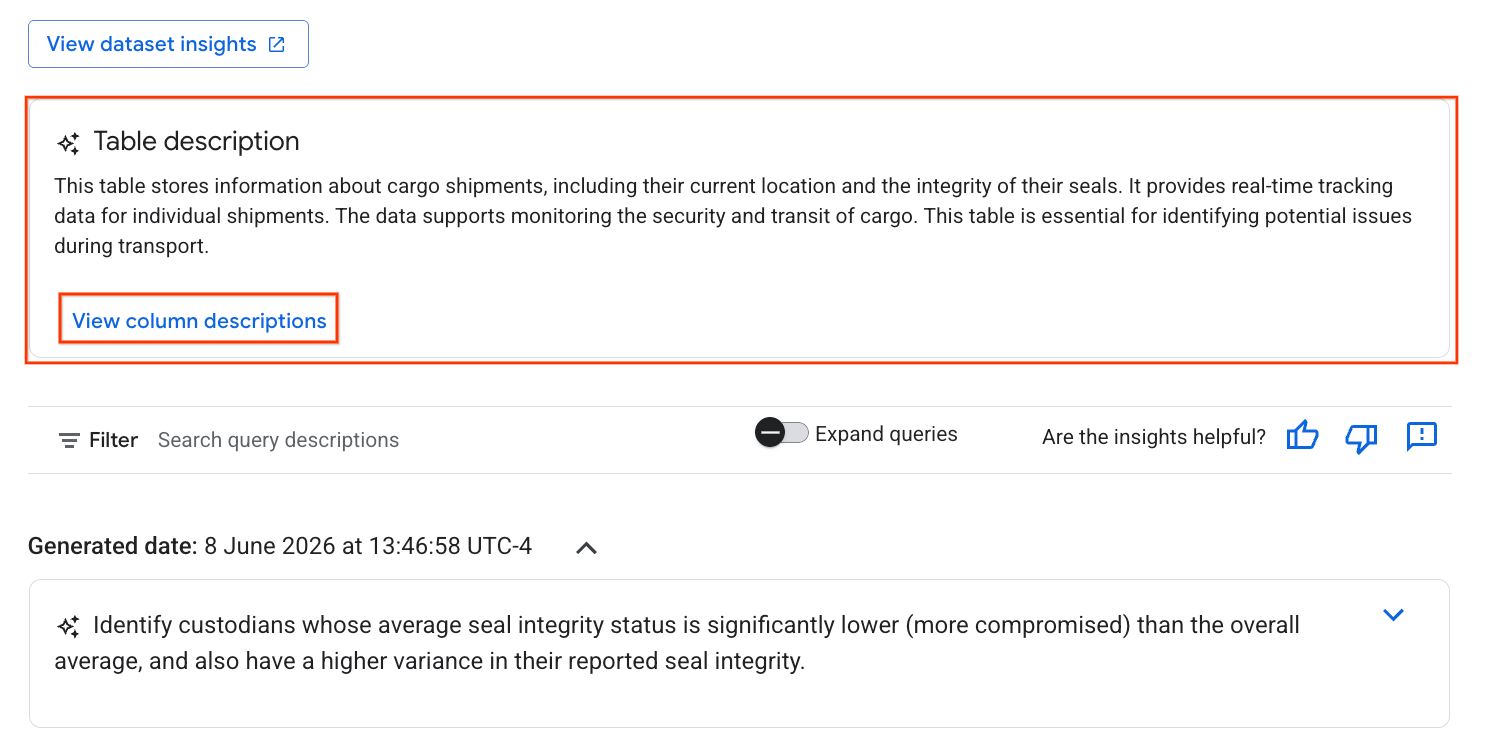
- Fai clic su Visualizza descrizioni delle colonne per visualizzare informazioni sulle singole colonne.
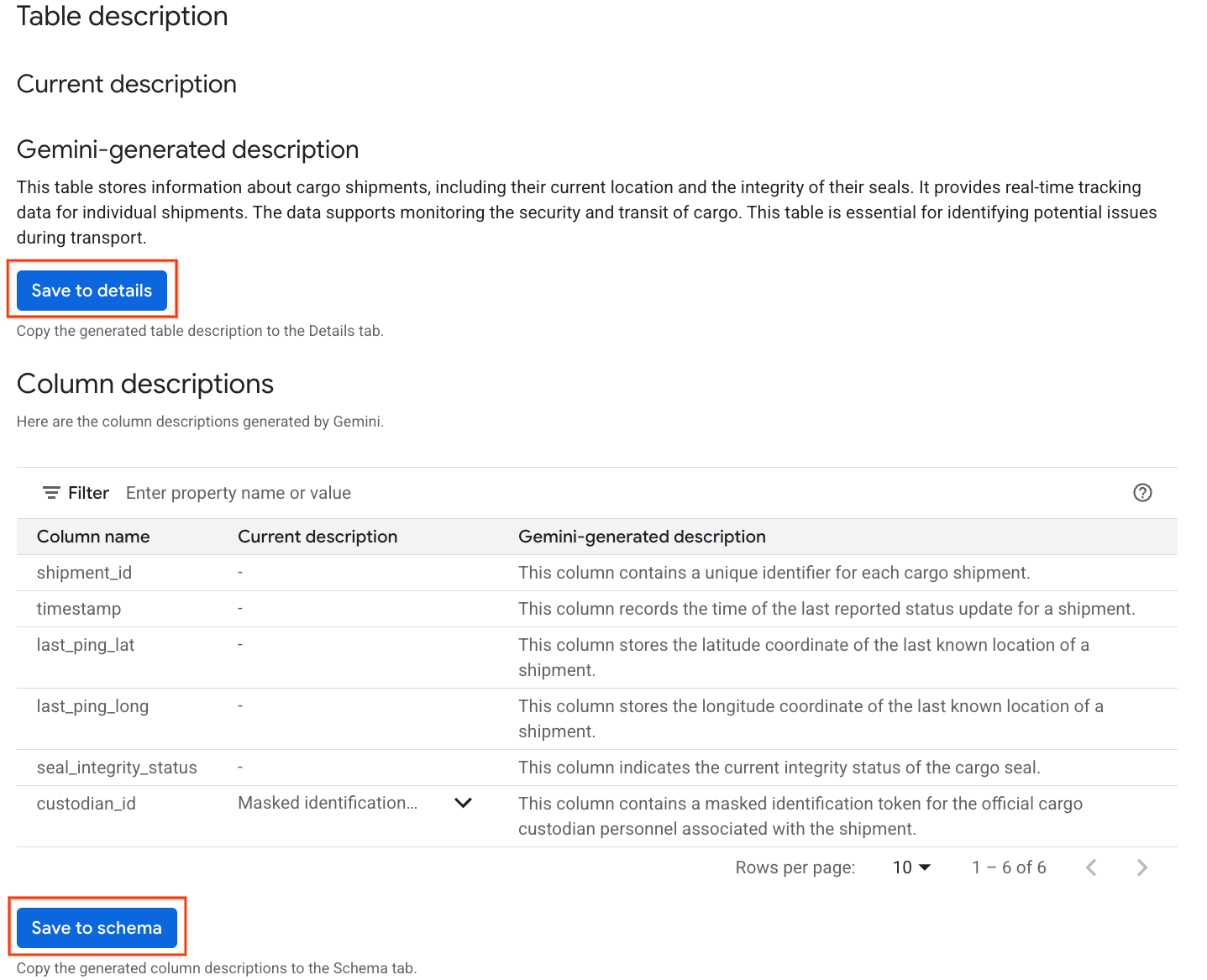
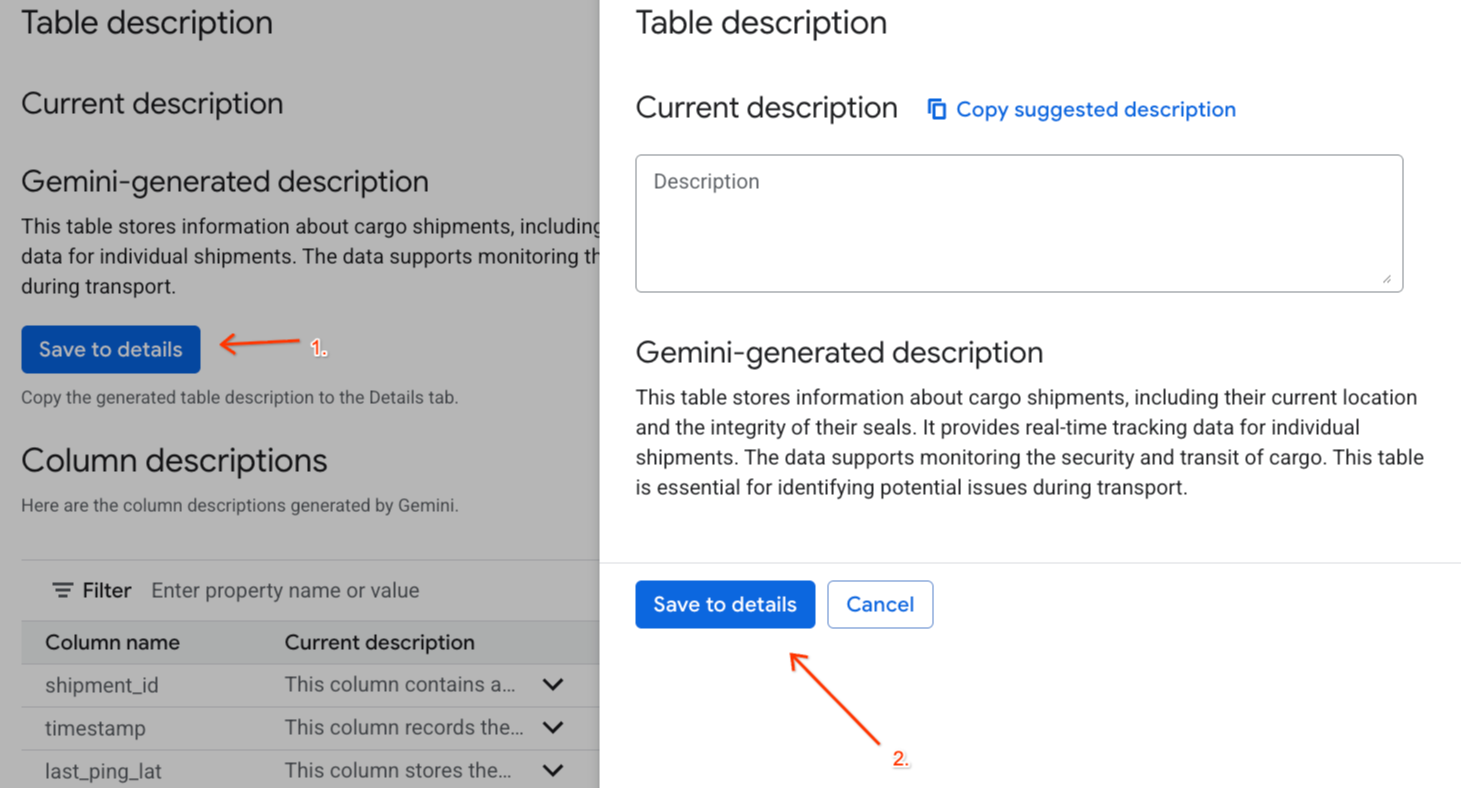
- Fai clic su Salva nei dettagli in
Gemini generated descriptione poi su Salva nei dettagli nella finestra popup.
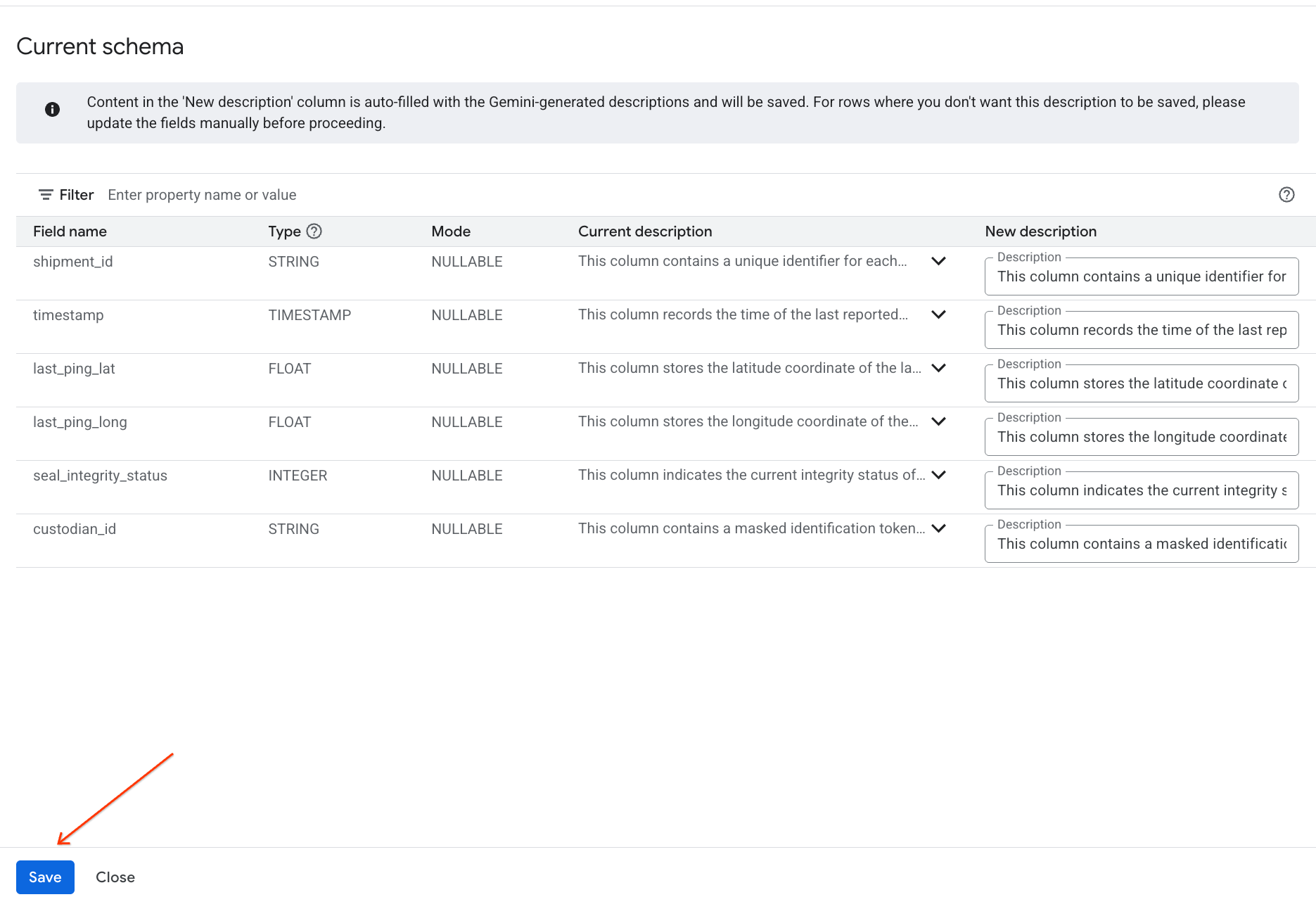
- Allo stesso modo, fai clic su Salva nello schema per aggiungere le descrizioni delle colonne ai metadati della tabella.
Esaminare gli insight generati
Vedrai anche un elenco di domande suggerite. Puoi fare clic su qualsiasi domanda per visualizzare la query SQL generata ed eseguirla per esplorare i dati. Ad esempio, potresti vedere domande come:
- "Qual è il numero totale di spedizioni?"
- "Elenca gli ID custode unici."
L'esecuzione di queste query ti aiuta a comprendere i dati.
7. Implementare il mascheramento e la governance dei dati
Per garantire che gli account di ricerca e i nomi utente attivi non possano essere divulgati durante questa indagine in corso sul carico, devi applicare protocolli di sicurezza standard. Creerai una tassonomia dei tag delle norme di sicurezza e configurerai il mascheramento dei dati di Knowledge Catalog sulla colonna sensibile custodian_id per verificare la privacy dei dati.
Per impostazione predefinita, BigQuery nega l'accesso alle colonne protette dai tag di policy. Per eseguire query sulla tabella e verificare le maschere dei dati attive, il tuo account utente deve avere il ruolo Lettore mascherato dei criteri dei dati BigQuery.
Questo ruolo è stato associato automaticamente al tuo account utente attivo durante l'esecuzione iniziale di setup_lab1.sh.
Crea la tassonomia e il tag di criteri
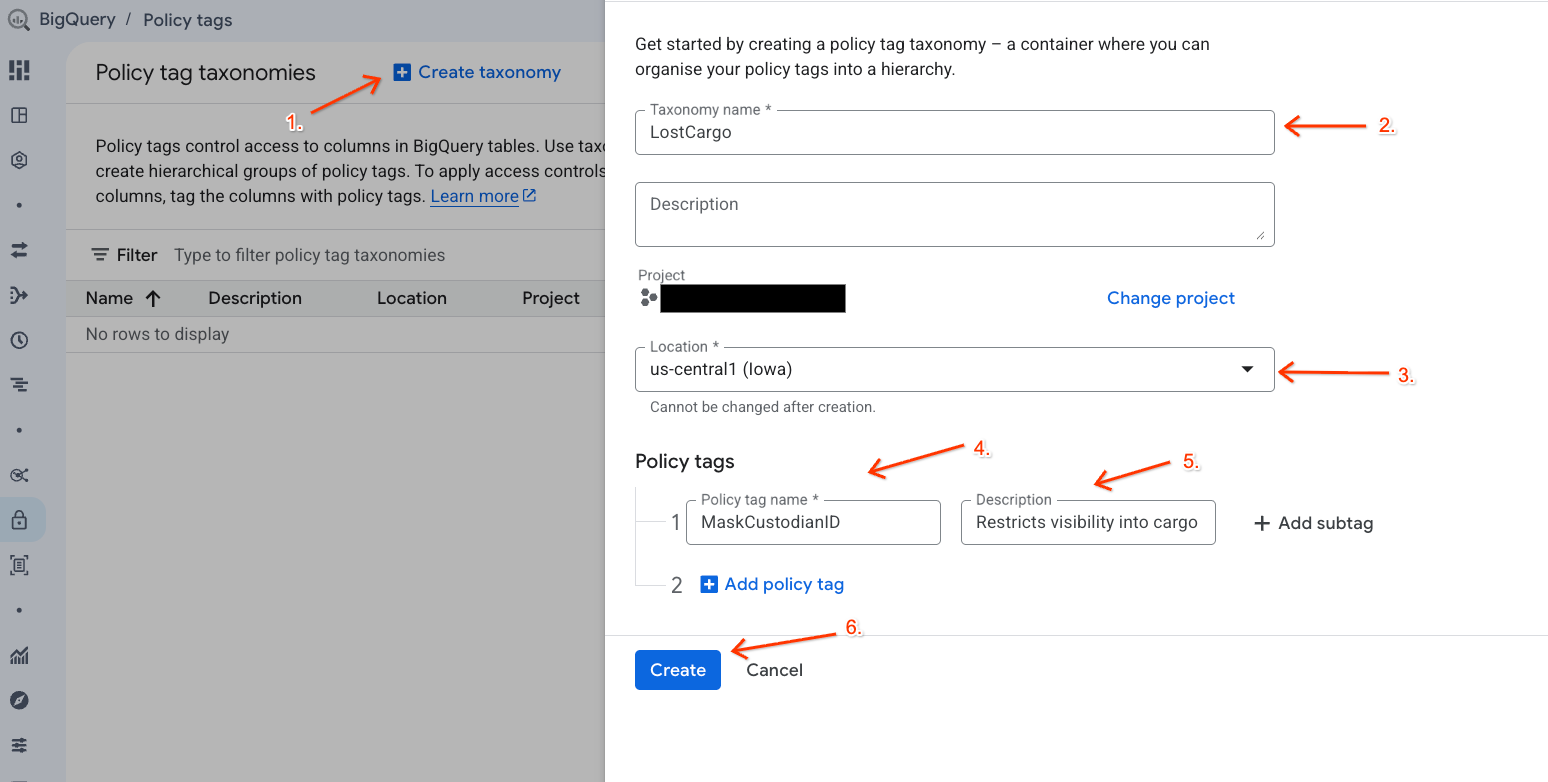
Crea una tassonomia dei dati e un tag di policy associato per gestire l'accesso ai tuoi dati.
- Vai alla pagina Tassonomie di tag di policy.
- Fai clic su + Crea tassonomia.
- Configura i parametri:
- Nome tassonomia: inserisci
lost-cargo-, sostituendo l'ID progetto. - Regione: seleziona la tua regione.
- In Nome tag di policy , inserisci
MaskCustodianID. - Per il tag di policy Descrizione:
Restricts visibility into cargo custodian usernames
- Nome tassonomia: inserisci
- Fai clic su Crea per registrare la nuova tassonomia e il nuovo tag di policy.
Crea la policy di mascheramento dei dati
Successivamente, configura un criterio dei dati per definire come vengono mascherati i dati con il tag di classificazione MaskCustodianID. Utilizzerai la regola di mascheramento Sempre null (che sostituisce i valori corrispondenti con valori vuoti/null per tutti gli attori non privilegiati).
- Nella pagina Tassonomie di tag di policy, fai clic sulla tassonomia appena creata nell'elenco delle tassonomie.
- Nell'elenco della gerarchia, fai clic sul tag
MaskCustodianIDper selezionarlo, quindi seleziona Gestisci i criteri relativi ai dati.
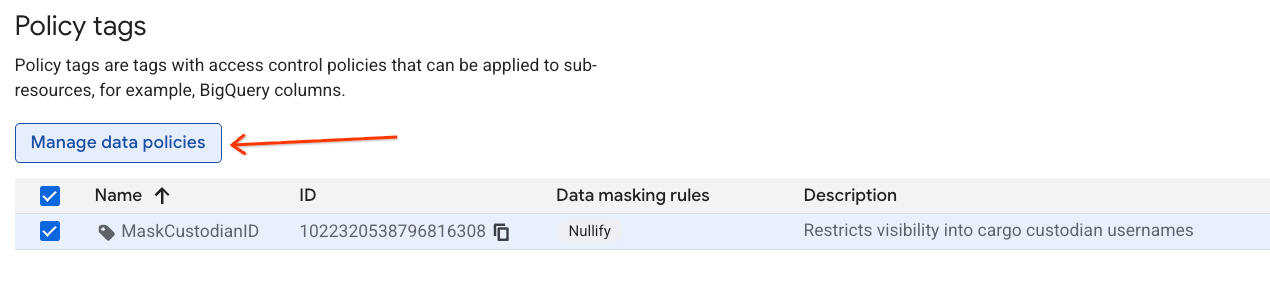
- Nel riquadro a destra, fai clic sul pulsante + Aggiungi regola.
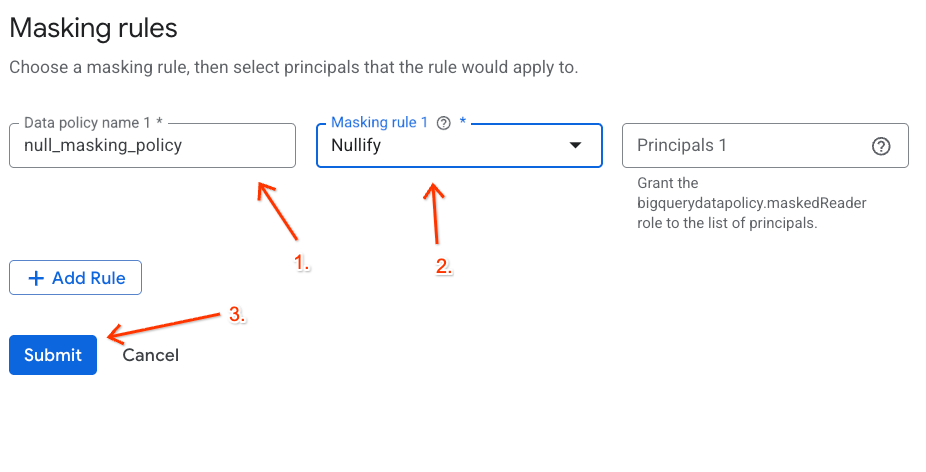
- Configura i dettagli del criterio nel riquadro visualizzato:
- Nome norma sui dati: inserisci
null_masking_policy(non lasciare il nome generato automaticamente, in quanto faremo riferimento a questo nome nei passaggi successivi). - Regola di mascheramento: seleziona
Nullifydal menu a discesa.
- Nome norma sui dati: inserisci
- Fai clic su Invia.
Assegnare il tag di criteri alla colonna BigQuery
Con il tag di policy e la relativa regola di mascheramento dei dati attivi, mappa il tag di classificazione direttamente alla colonna custodian_id nella tabella del manifest di spedizione del partner BigQuery.
- Vai alla BigQuery.
- Nel riquadro Explorer a sinistra, espandi il progetto attivo, il set di dati
lost_cargo_datasete fai clic sulla tabellashipping_manifestsper aprire la visualizzazione dettagliata. - Fai clic su Modifica schema.
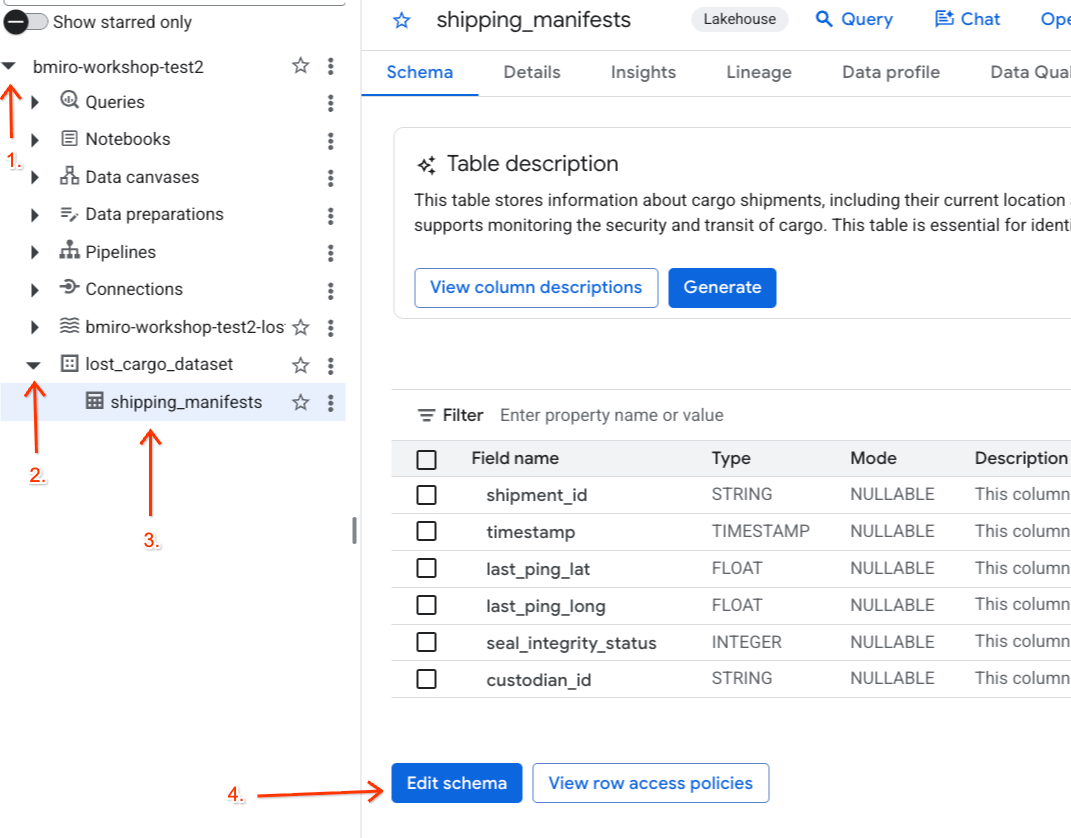
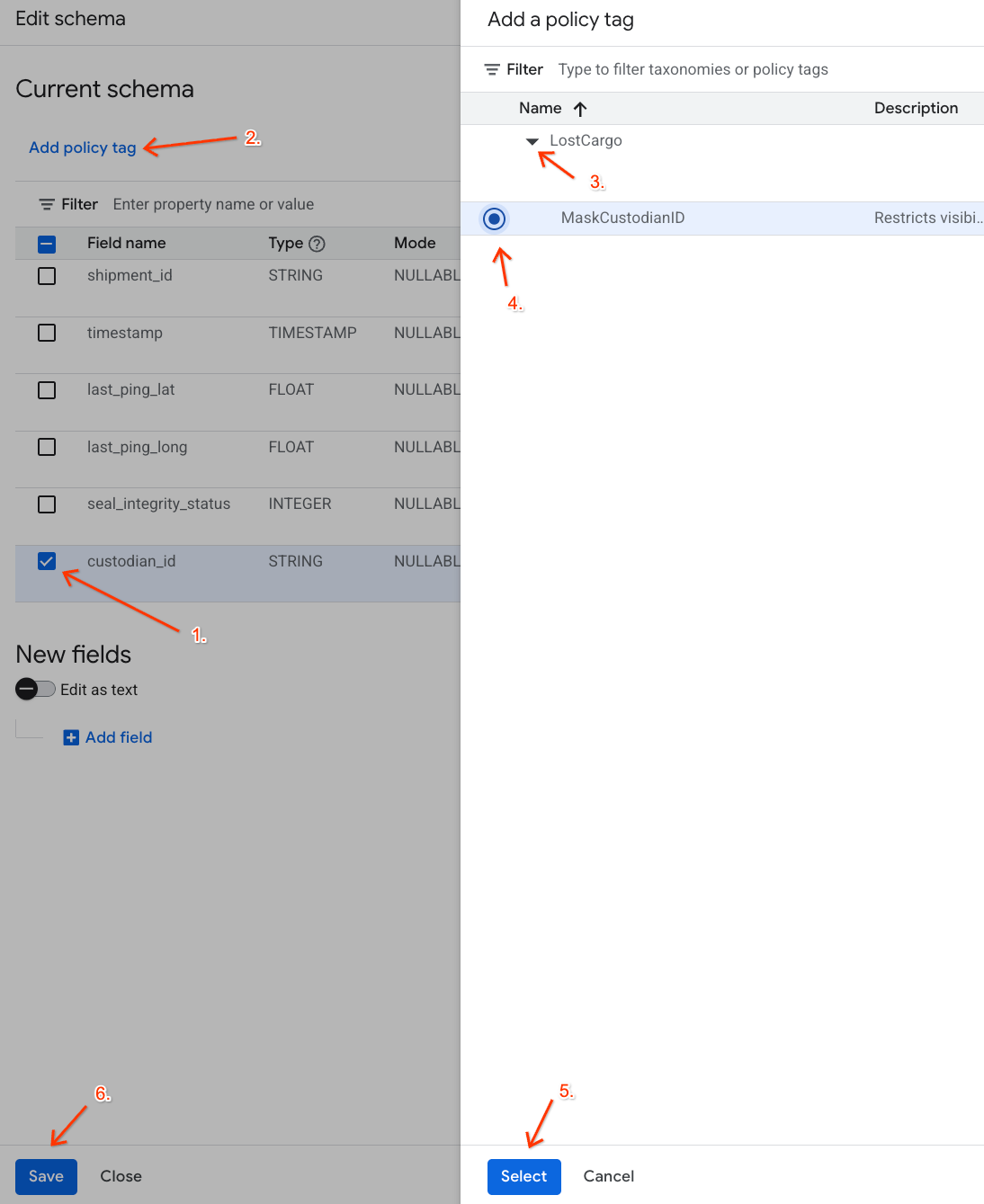
- Nell'elenco delle colonne, seleziona la casella accanto a
custodian_id. - Fai clic sul pulsante Aggiungi tag di policy nella barra degli strumenti in alto dell'editor dello schema.
- Nel riquadro Aggiungi un tag di policy:
- Individua ed espandi la tassonomia
LostCargo. - Seleziona la bolla accanto a
MaskCustodianID. - Fai clic su Seleziona.
- Individua ed espandi la tassonomia
- Verifica che il tag
MaskCustodianIDsia ora visibile nella colonna Tag norme nella riga che rappresentacustodian_id. - Fai clic su Salva.
Verifica le limitazioni dei criteri
Ora che hai il ruolo Lettore mascherato a livello di progetto, puoi eseguire query sulla tabella per verificare che la policy di mascheramento sia attiva.
Torna al Data Agent Kit ed esegui la seguente query:
SELECT shipment_id, custodian_id
FROM lost_cargo_dataset.shipping_manifests
LIMIT 5;
Dovresti vedere un output simile al seguente:
shipment_id | custodian_id |
NORMAL-001 | null |
NORMAL-002 | null |
MV-CAT-001 | null |
Operazione riuscita. Anche se puoi visualizzare i record shipment_id, il campo sensibile custodian_id restituisce maschere sicure null per evitare fughe di dati.
8. Esegui la pulizia
Per evitare che al tuo account Google Cloud vengano addebitati costi relativi alle risorse create durante questo codelab, esegui questi comandi nel terminale Cloud Shell per eliminare i set di dati e i bucket:
# Verify active variables
export PROJECT_ID=$(gcloud config get-value project)
export BUCKET_NAME="${PROJECT_ID}-lost-cargo-lake"
# Delete Knowledge Catalog security taxonomies
export TAXONOMY_NAME=$(gcloud data-catalog taxonomies list --location=us-central1 --filter="displayName:LostCargo" --format="value(name)")
if [[ -n "$TAXONOMY_NAME" ]]; then
curl -X DELETE \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
"https://datacatalog.googleapis.com/v1/${TAXONOMY_NAME}" || true
fi
# Delete Lakehouse Iceberg REST Catalog tables and namespaces
gcloud biglake iceberg tables delete processed_maritime_logs \
--catalog=${BUCKET_NAME} \
--namespace=lost_cargo_namespace \
--quiet || true
gcloud biglake iceberg namespaces delete lost_cargo_namespace \
--catalog=${BUCKET_NAME} \
--quiet || true
# Delete Lakehouse Iceberg REST Catalog
gcloud biglake iceberg catalogs delete ${BUCKET_NAME} --quiet || true
# Delete dependencies bucket
gcloud storage rm -r gs://${BUCKET_NAME} || true
# Delete BigQuery dataset and tables
bq rm -r -f -d ${PROJECT_ID}:lost_cargo_dataset || true
9. Complimenti
Complimenti! Hai completato il primo modulo cruciale dell'indagine su Carico smarrito. Hai creato una zona di ricerca controllata utilizzando i cataloghi REST Lakehouse Iceberg, la normalizzazione dei log PySpark e il mascheramento dei dati granulare.
Cosa hai imparato
- Installazione, configurazione e configurazione dell'estensione Data Agent Kit all'interno dell'area di lavoro dell'IDE.
- Creazione di un catalogo REST Iceberg Lakehouse serverless che utilizza credenziali fornite e spazi dei nomi gerarchici.
- Importazione di feed regionali multiformato e creazione di tabelle esterne BigQuery nei bucket Cloud Storage.
- Avvio di job Apache Spark serverless per analizzare, normalizzare, segmentare e riscrivere i log dei transponder non strutturati in BigQuery come tabelle del catalogo Iceberg registrate.
- Creazione di tassonomie di sicurezza e mappatura dei criteri di mascheramento dei dati di Knowledge Catalog per impedire la divulgazione di identità su indici di log sensibili.
- Generazione e analisi degli approfondimenti sui metadati delle tabelle utilizzando insight dei dati BigQuery per accelerare l'esplorazione dei dati.
Verifica degli indizi raccolti
Verifica di aver registrato i seguenti indizi definitivi necessari per passare alla fase successiva del lab:
- ID spedizione smarrita:
MV-CAT-001(ultima posizione ping: Londra) - Destinazione target pianificata:
New York(e alias vero del transponder:MV-DOG-002) - Colore del contenitore:
Crimson RED - Tag di accesso alla governance:
MaskCustodianID
Tutto pronto per la prossima fase?
Ora che le rotte di partenza / destinazione del transponder sono sicure, l'indagine può proseguire. Passa direttamente al Lab 2 per esaminare le videocamere di sicurezza utilizzando i modelli multimodali Gemini, identificare visivamente l'imbarcazione ed eseguire ricerche vettoriali in AlloyDB per verificare le anomalie di manomissione.
➡️ Continua con il passaggio 2: analisi dei dati e approfondimenti multimodali