
1. はじめに
このラボでは、グローバルな物流会社のデータ調査リーダーの役割を担います。貴重な Android フィギュア コレクションを積んだ高価な貨物コンテナが紛失しました。最後に確認された位置を特定してルートを追跡するには、地域の物流パートナーから断片化された配送マニフェストと、構造化されていないトランスポンダー ログファイルを統合する必要があります。これを行うには、最新の Google Cloud Open Data Lakehouse を構成します。

演習内容
- Cloud Shell エディタで Google Cloud Data Agent Kit 拡張機能を構成します。
- Cloud Storage バケットを作成し、Lakehouse Apache Iceberg REST Catalog と namespace をプロビジョニングします。
- BigLake 外部テーブルを Cloud Storage 内の未加工の JSON パートナー マニフェストにマッピングして、船の出発の手がかりを見つけます。
- Managed Service for Apache Spark サーバーレスを使用して、構造化されていないトランスポンダー テキストログを読み込んで処理します。正規表現の正規化と動的ヒントの抽出を行い、失われたペイロードの宛先を特定します。
- 解析されたログ指標を REST カタログを介して Apache Iceberg テーブルとして書き込みます。
- 会話型分析を使用して、Apache Iceberg データについて AI エージェントとチャットし、紛失した荷物に関する隠れた手がかりを見つけます。
- Knowledge Catalog を使用して自動データ分析情報を活用し、データに関するメタデータを生成します。
- セキュリティ分類を作成し、Knowledge Catalogを使用して機密性の高い管理者の ID をマスキングすることで、きめ細かいアクセス制御を適用して取り込みガードレールを確立します。
必要なもの
- ウェブブラウザ(Chrome など)。
- 課金を有効にした Google Cloud プロジェクト
- 基本的な SQL クエリとターミナル コマンドに精通していること。
推定費用と期間
- 所要時間: 約 45 分。
- 推定費用: 5.00 米ドル未満。
2. 始める前に
Google Cloud プロジェクトを作成または選択する
- Google Cloud コンソールで、Google Cloud プロジェクトを選択または作成します。
- Cloud プロジェクトに対して課金が有効になっていることを確認します。プロジェクトで課金が有効になっていることを確認する方法をご覧ください。
環境を構成する
ほとんどのコマンドは、Cloud Shell エディタの統合ターミナルから実行します。これは、デベロッパー ツールと標準の Google Cloud SDK がプリロードされたクラウドベースの開発環境です。
- 新しいタブで Cloud Shell エディタを開きます。
- ターミナルで次のコマンドを実行して、リポジトリのクローンを作成します。
cd ~/ git clone --filter=blob:none --no-checkout https://github.com/GoogleCloudPlatform/devrel-demos.git cd ~/devrel-demos git sparse-checkout init --cone git sparse-checkout set data-analytics/data-cloud-roadshow/lab1 git checkout main cd data-analytics/data-cloud-roadshow/lab1 - プロジェクト ID を設定します。Windows/Linux では
Ctrl+Shift+V、macOS ではCmd+Vを押して、ターミナルに貼り付けることもできます。export PROJECT_ID="<YOUR_PROJECT_ID>" - 環境で構成します。
gcloud config set project $PROJECT_ID - リージョンを選択します。
export REGION="<YOUR_REGION>" # Replace with the region you chose, such as "us-central1" - 必要な API を有効にします。
gcloud services enable \ bigquery.googleapis.com \ biglake.googleapis.com \ storage.googleapis.com \ dataplex.googleapis.com \ datacatalog.googleapis.com \ dataproc.googleapis.com \ aiplatform.googleapis.com \ cloudresourcemanager.googleapis.com \ serviceusage.googleapis.com \ cloudaicompanion.googleapis.com \ geminidataanalytics.googleapis.com
拡張機能をインストール
次に、Google Cloud のデータツールを IDE で直接操作するためのツールである Google Data Agent Kit 拡張機能を構成します。
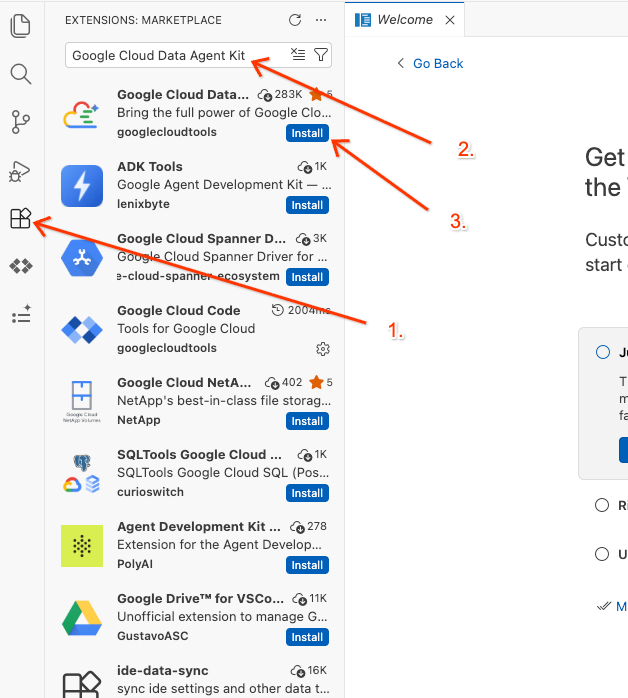
- エディタの左側のアクティビティ バーで、[Extensions] アイコンをクリックします(または、Windows/Linux では
Ctrl+Shift+X、macOS ではCmd+Xを押します)。 - 拡張機能の検索ボックスに「
Google Cloud Data Agent Kit」と入力します。 - 検索結果から公式の拡張機能を選択し、[インストール] をクリックします。メッセージが表示されたら、[はい、この作成者を信用します] を選択します。
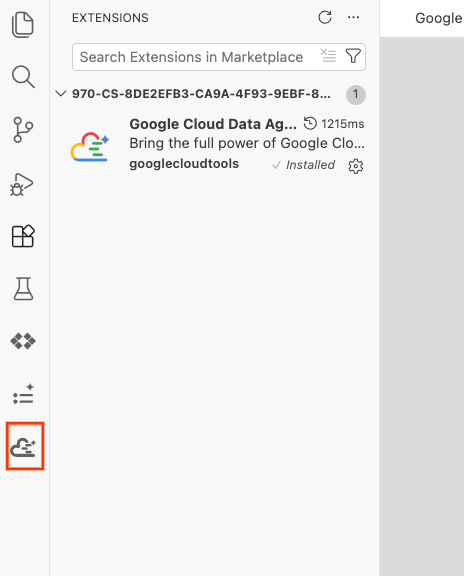
- 正常にインストールされると、アクティビティ バーに Google Cloud Data Agent Kit アイコンが表示されます。これをクリックします。
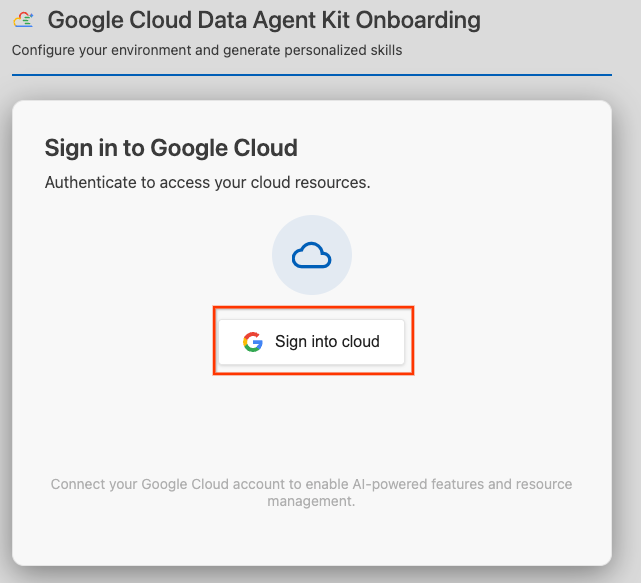
- [Sign into cloud] をクリックします。
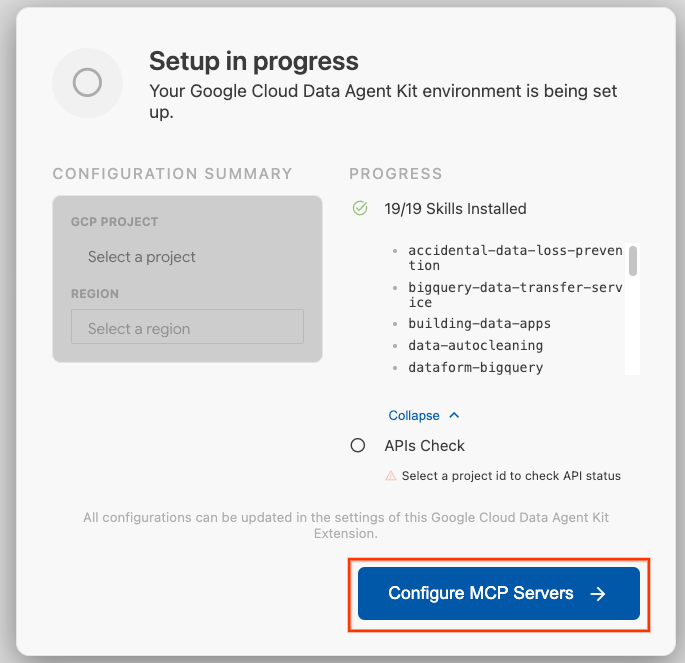
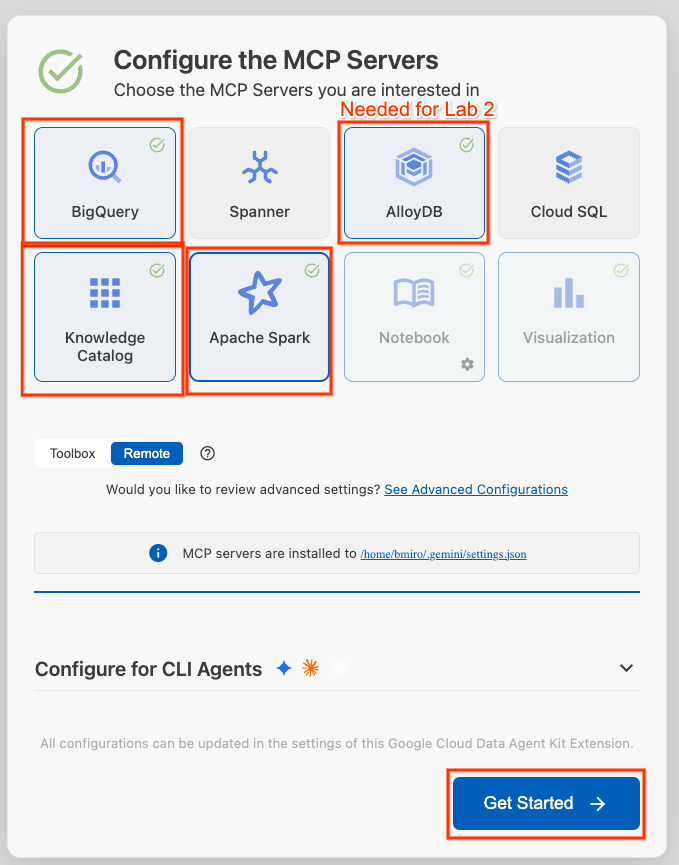
- [Configure MCP Servers] をクリックします。
- [BigQuery]、[Knowledge Catalog]、[Apache Spark]、[AlloyDB] を選択します。ラボ 2 では AlloyDB を使用します。[使ってみる] をクリックします。
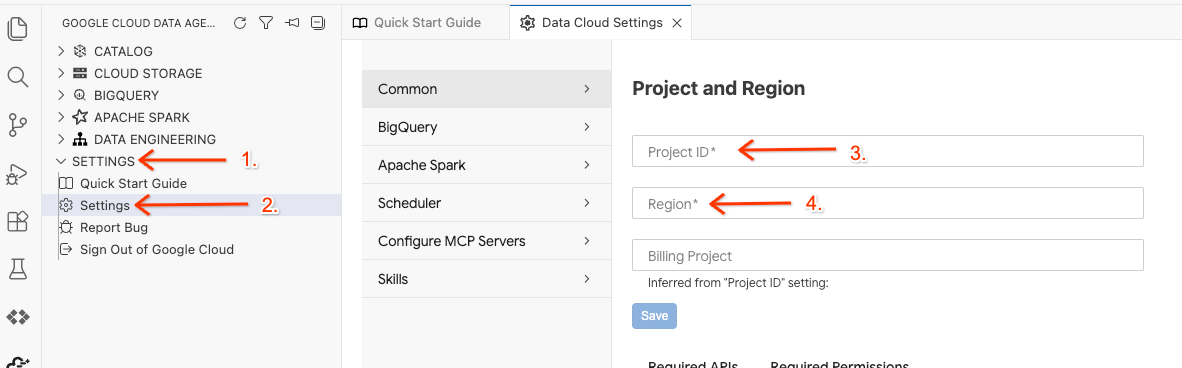
- 下部のステータスバーにある [プロジェクト ID] セレクタをクリックし、アクティブな Google Cloud プロジェクトを選択します。
- Data Agent Kit で、[SETTINGS]、[Settings] の順にクリックします。[Common] タブで、ラボを実行する プロジェクト ID と リージョン(us-central1 など)を選択します。
- [BigQuery 設定] をクリックし、[リージョン] を前に選択したリージョンに置き換えます。[Save] をクリックします。
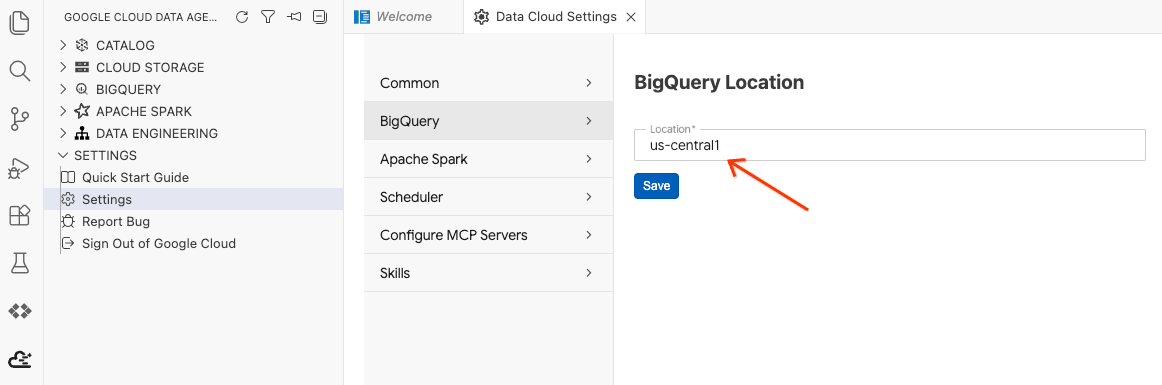
これで、Data Agent Kit を使用する準備が整いました。
環境設定スクリプトを実行する
ターミナルで設定スクリプトを実行して、このラボに必要なバックグラウンド リソースを作成し、IAM 権限を構成します。
chmod +x setup_lab1.sh
./setup_lab1.sh
source .env
プロビジョニングされるリソースを示す一連の出力ステップが表示されます。これらについては、ラボ全体で説明します。
完了メッセージが表示されたら、次の手順に進みます。
==================================================== Environment Setup Complete! ====================================================
それでは、検索を開始しましょう。
3. 取り込みパートナーの配送マニフェスト
パートナーの船舶からの配送マニフェスト データは、バケット gs://${PROJECT_ID}-lost-cargo-lake/shipping_manifests/manifests.jsonl に標準の JSON Lines(JSONL)形式で保存されます。
詳細な分析を行う前に、この非構造化データ用に管理された BigLake テーブルを作成します。これにより、標準 SQL を使用してパートナーのロジスティクス データをすぐに探索できます。インポート費用が重複することはありません。
エディタでワークスペースを開き、クエリを実行する
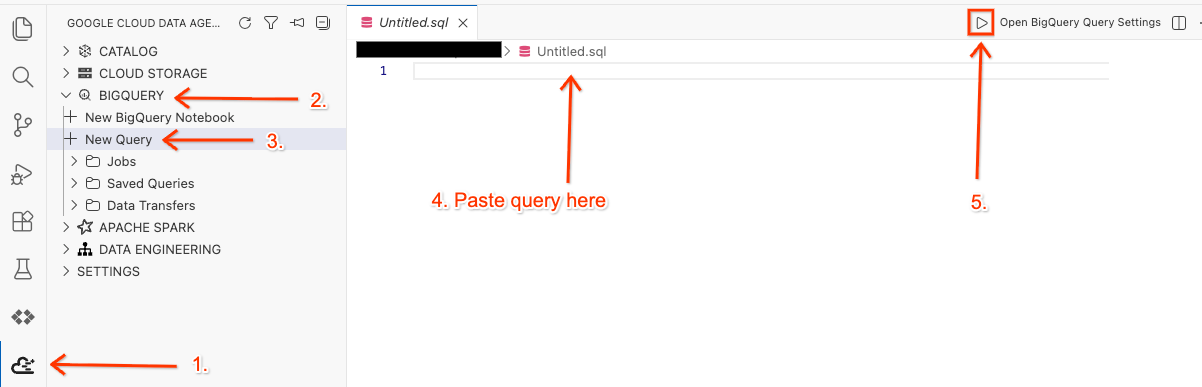
- Cloud Shell エディタで、サイドパネルの Google Cloud Data Agent Kit 拡張機能アイコンをクリックします。
- BigQuery に移動し、[+ 新しいクエリ] を選択します。
- 次のクエリをクエリ ウィンドウにコピーします。
SET @@location = "<YOUR_REGION>"; --Update to your resource region, such as "us-central1". Make sure it is in quotes.
EXECUTE IMMEDIATE ("""
CREATE OR REPLACE EXTERNAL TABLE `lost_cargo_dataset.shipping_manifests`
(
shipment_id STRING,
timestamp TIMESTAMP,
last_ping_lat FLOAT64,
last_ping_long FLOAT64,
seal_integrity_status INT64,
custodian_id STRING OPTIONS(description='Masked identification token for official cargo custodian personnel.')
)
WITH CONNECTION `""" || @@location || """.conn`
OPTIONS (
format = 'NEWLINE_DELIMITED_JSON',
uris = ['gs://""" || @@project_id || """-lost-cargo-lake/shipping_manifests/*.jsonl']
)
""");
- [実行] をクリックします。
- テーブルが作成されたことを確認するには、下部に自動的にスライドして開く [クエリ結果] パネルに成功メッセージが表示されます。
外部テーブルにクエリを実行して、不正使用されたトランスポンダを特定する
seal_integrity_status が 0 に設定されたときに障害が発生した場所を特定して、侵害されたトランスポンダを特定しましょう。前に開いたクエリ ウィンドウで、次のクエリをコピーして実行します。
SELECT shipment_id, last_ping_lat, last_ping_long, custodian_id
FROM `lost_cargo_dataset.shipping_manifests`
WHERE seal_integrity_status = 0;
[クエリ結果] パネルに、次のような出力が表示されます。
shipment_id | last_ping_lat | last_ping_long | custodian_id |
MV-CAT-001 | 51.5074 | -0.1278 | usr_999_shadow |
4. Managed Service for Apache Spark を使用して非構造化ログを処理する
構造化マニフェストから開始位置は見つかったが、紛失したトランスポンダは完全に停止している。最後のトランスポンダの ping は、GCS パス gs://${BUCKET_NAME}/raw_logs/maritime_logs.txt の未加工のテキスト ログファイル内に、不可解な非構造化メッセージを残している。
このテキストログを処理してマッピングし、タイムスタンプを抽出し、ID をカモフラージュして、貨物のダウンストリーム ルートを特定するには、サーバーレスの Apache Spark(PySpark)ジョブを Managed Service for Apache Spark に送信します。
Managed Service for Apache Spark を使用すると、クラスタのプロビジョニングや管理を行うことなく Spark ワークロードを実行できます。このサービスは基盤となるコンピューティング リソースを処理し、動的に自動スケーリングします。料金は実行時間に対してのみ発生します。
このスクリプトによって行われる処理は次のとおりです。
- 生の、角かっこで囲まれた、非構造化のトランスポンダ テキストを取り込みます。
- PySpark SQL 正規表現抽出フィルタを適用して、タイムスタンプ、カストディアン メタデータ、未加工のコンテンツを分離します。
- 整理されていないログを、文レベルのクリーンなレコードに分割します。
- 失われたペイロードの出発が終了した動的宛先座標ターゲットを抽出します。
- 処理されたログ データフレームを Lakehouse Apache Iceberg REST カタログに接続して書き戻し、BigQuery 内で直接表示できる新しい分析テーブルとして保存します。
PySpark 分析スクリプトを修正する
海上で Python Pirates がさまざまな問題を引き起こしているという報告があります。
- 次のコマンドを実行して、Cloud Shell エディタで
process_maritime_logsファイルを開きます。cd ~/devrel-demos/data-analytics/data-cloud-roadshow/lab1 cloudshell open ./process_maritime_logs.py - 時間をかけてコードを読み、コードが何をしているのかを理解してください。
- コードに不審な点がないことを確認してください。削除する必要がある場合は、
Ctrl + S(Windows/Linux)またはCmd + S(Mac)を使用してファイルを保存してください。
サーバーレス Spark ジョブを送信する
gcloud SDK を使用してジョブを送信します。構成により、Lakehouse カタログにアクセスするように PySpark ジョブが自動的に構成されます。
統合エディタのターミナルで次のコマンドを実行します。
cd ~/devrel-demos/data-analytics/data-cloud-roadshow/lab1
source .env
gcloud dataproc batches submit pyspark process_maritime_logs.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--version=2.3 \
--deps-bucket=${BUCKET_NAME} \
--properties="\
spark.sql.defaultCatalog=cargo_catalog,\
spark.sql.catalog.${CATALOG_NAME}=org.apache.iceberg.spark.SparkCatalog,\
spark.sql.catalog.${CATALOG_NAME}.type=rest,\
spark.sql.catalog.${CATALOG_NAME}.uri=https://biglake.googleapis.com/iceberg/v1/restcatalog,\
spark.sql.catalog.${CATALOG_NAME}.warehouse=gs://${BUCKET_NAME},\
spark.sql.catalog.${CATALOG_NAME}.header.x-goog-user-project=${PROJECT_ID},\
spark.sql.catalog.${CATALOG_NAME}.rest.auth.type=org.apache.iceberg.gcp.auth.GoogleAuthManager,\
spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions,\
spark.sql.catalog.${CATALOG_NAME}.gcs.oauth2.refresh-credentials-endpoint=https://oauth2.googleapis.com/token, \
spark.sql.catalog.${CATALOG_NAME}.header.X-Iceberg-Access-Delegation=vended-credentials" \
-- ${BUCKET_NAME}
サーバーレス環境がスピンアップされ、スクリプトがアップロードされ、処理ロジックが実行されるまで数分待ちます。
次のような出力が表示されたら、処理されたテーブルが Apache Iceberg マネージド テーブルとして Lakehouse カタログに保存されています。
Batch [1fae0b4b42c045a084dd67917bd0c332] finished.
metadata:
'@type': type.googleapis.com/google.cloud.dataproc.v1.BatchOperationMetadata
batch: projects/<YOUR_PROJECT>/locations/us-central1/batches/1fae0b4b42c045a084dd67917bd0c332
batchUuid: 611b4465-fdac-4974-bc47-5f10adaf2a08
createTime: '2026-06-11T21:35:01.868157Z'
description: Batch
labels:
goog-dataproc-batch-id: 1fae0b4b42c045a084dd67917bd0c332
goog-dataproc-batch-uuid: 611b4465-fdac-4974-bc47-5f10adaf2a08
goog-dataproc-drz-resource-uuid: batch-611b4465-fdac-4974-bc47-5f10adaf2a08
goog-dataproc-location: us-central1
operationType: BATCH
name: projects/<YOUR_PROJECT/regions/us-central1/operations/7e2044db-dd97-3270-b368-4dc4ba417574
処理済みログをプレビューする
Data Agent Kit 拡張機能のクエリエディタで、次のクエリをコピーしてデータをプレビューします。
SET @@location = "<YOUR_REGION>"; -- e.g. "us-central1"
EXECUTE IMMEDIATE FORMAT("""
select log_timestamp, custodian_id, sentence from
`%s.%s-lost-cargo-lake.lost_cargo_namespace.processed_maritime_logs`
limit 5
""", @@project_id, @@project_id);
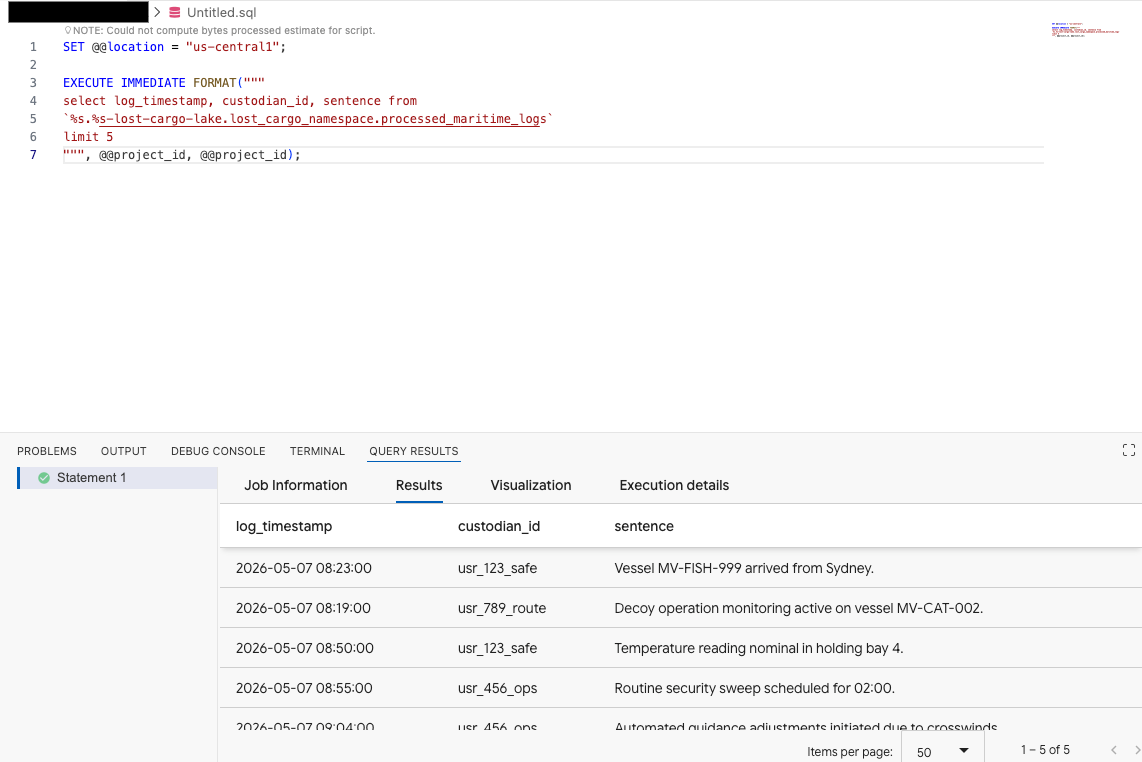
これにより、カタログに登録された Iceberg テーブルに BigQuery から正常にアクセスできることがわかります。
目的地の手がかりを抽出する
処理済みのログが用意できたので、宛先ターゲットを含むログを検索してみましょう。そこから、出発地の都市名を含むログを検索できます。
クエリエディタで次のクエリを実行します。<YOUR_REGION> はリージョンに置き換え、<ORIGIN_CITY> は先ほど特定した出発地に置き換えます。
SET @@location = "<YOUR_REGION>"; --e.g. "us-central1"
DECLARE origin_city STRING;
SET origin_city = "<ORIGIN_CITY>"; --e.g. "Boston". (It's not Boston)
EXECUTE IMMEDIATE FORMAT(r"""
SELECT
log_timestamp AS event_time,
custodian_id,
REGEXP_EXTRACT(raw_message, r'Destination:\s*([^.]+)') AS destination_target
FROM
`%s.%s-lost-cargo-lake.lost_cargo_namespace.processed_maritime_logs`
WHERE
-- STRPOS is highly optimized in BigQuery for a simple .contains() substring check
STRPOS(sentence, '%s') > 0;
""", @@project_id, @@project_id, origin_city);
会話型分析を使用して BigQuery コンソールでデータとチャットする
複雑な SQL クエリを記述してデータを探索する代わりに、会話型分析を使用して自然言語でテーブルとチャットできます。
- BigQuery コンソールに移動します。
- 左側の [エクスプローラ] パネルで、プロジェクトとデータセット
-lost-cargo-lake.lost_cargo_namespace processed_maritime_logsテーブルをクリックして詳細タブを開きます。 - [クエリ] の横にある [チャット] をクリックします。
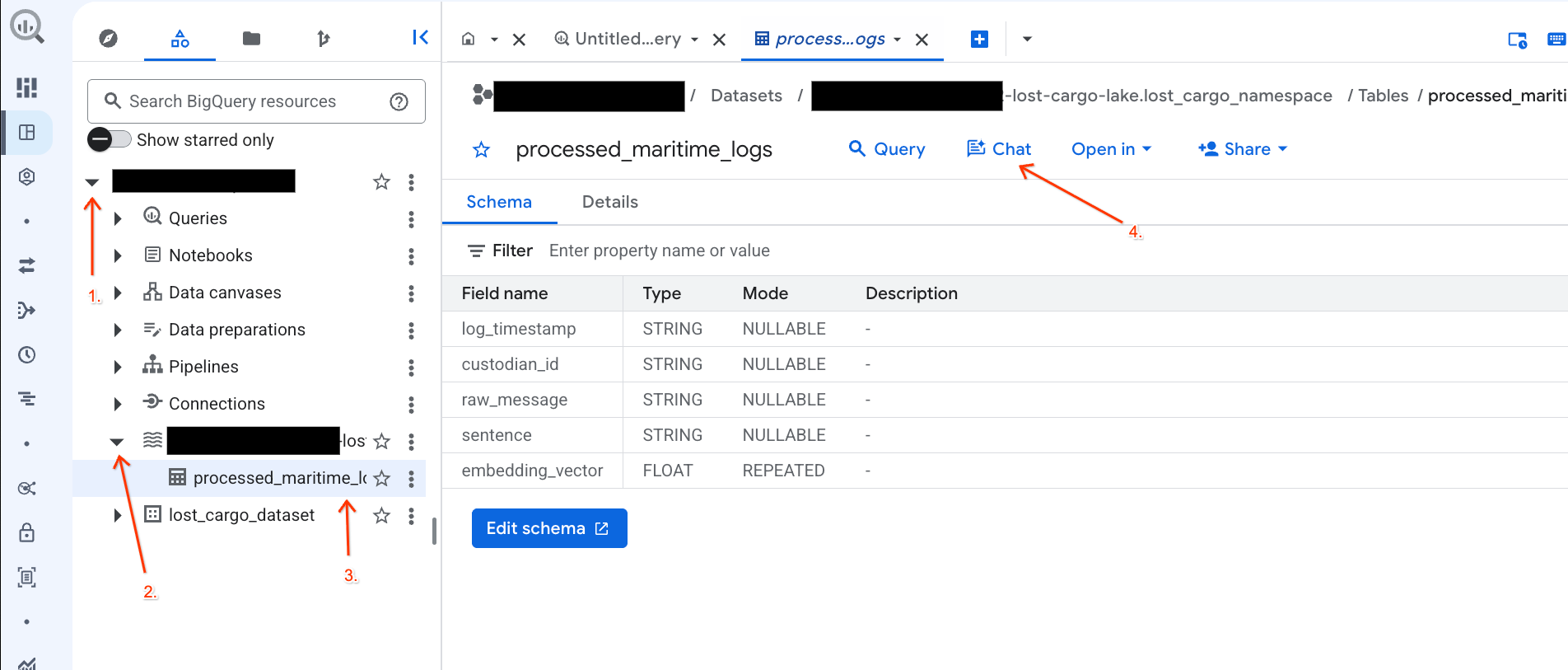
- チャットパネルに次の質問を入力し、キーボードの Enter キーを押して送信します。
Based on this table, what color is the shipping container MV-CAT-001?
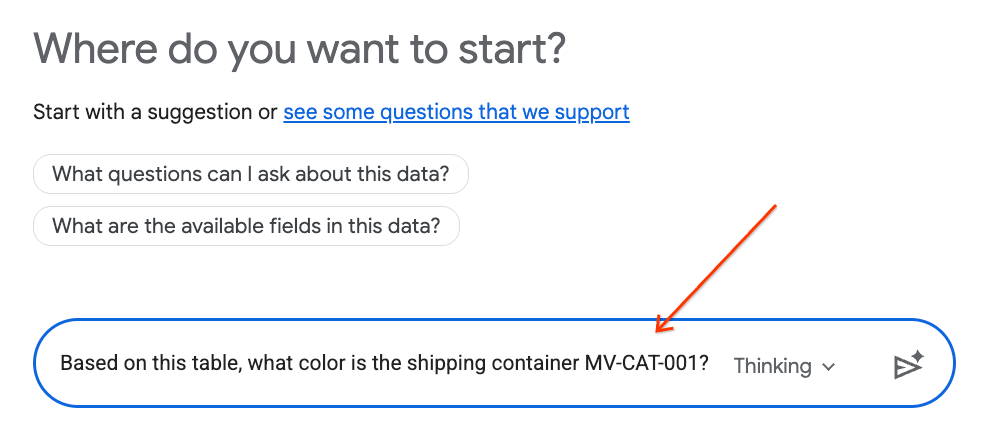
- 会話分析(Gemini を搭載)は、アクティブなテーブルのデータを分析し、色で応答します。
5. 一元化されたレイクハウス カタログを表示する
オープンソースの処理エンジン(Apache Spark など)をエンタープライズ データエンジン(BigQuery など)と安全かつシームレスに統合するために、設定スクリプトで Lakehouse Iceberg REST カタログが構成されました。
Apache Iceberg REST Catalog は、テーブル メタデータ用のサーバーレスの「単一の情報源」として機能し、スキーマとパーティショニング テーブルを動的に管理しながら、物理的な Parquet データファイルを Cloud Storage に保存します。
このカタログを Google Cloud コンソールで直接確認してみましょう。
- Lakehouse Console を開きます。
- [カタログ] タブで、アクティブな Iceberg REST カタログ
-lost-cargo-lake
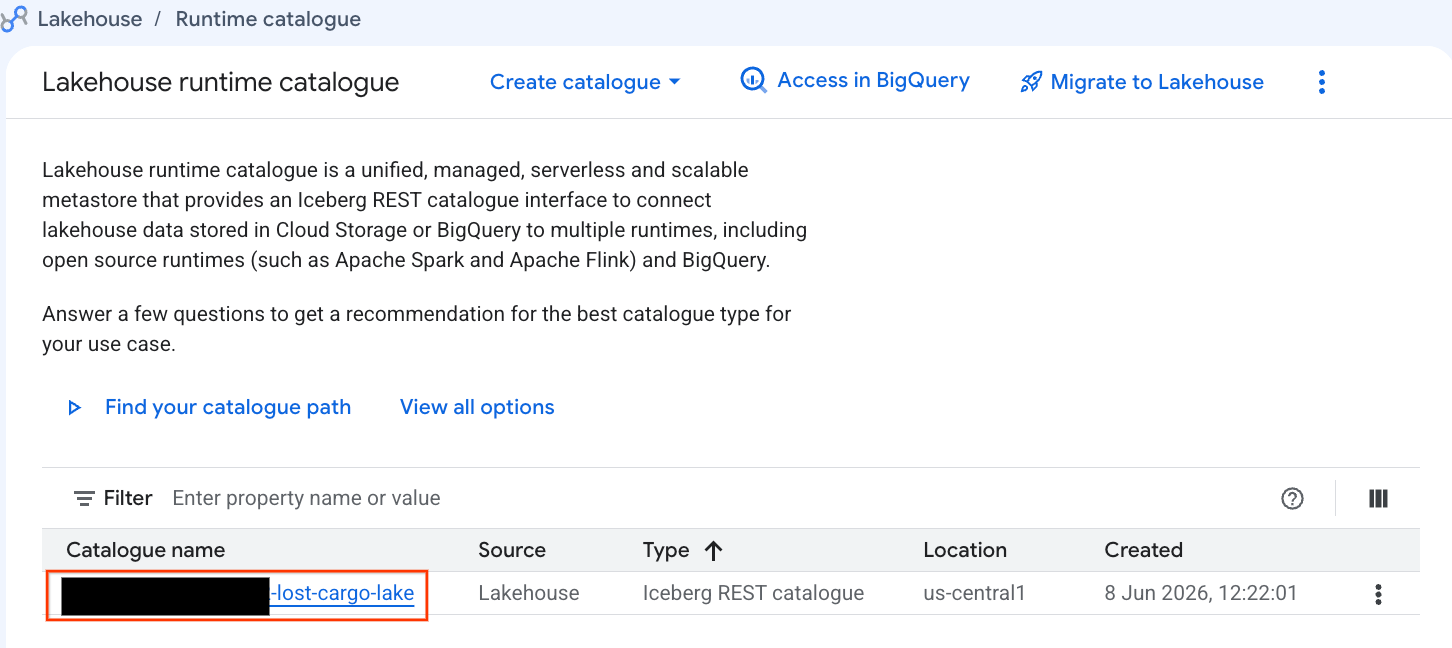
- カタログの詳細ビューの [名前空間] に
lost_cargo_namespaceが表示されます。クリックします。
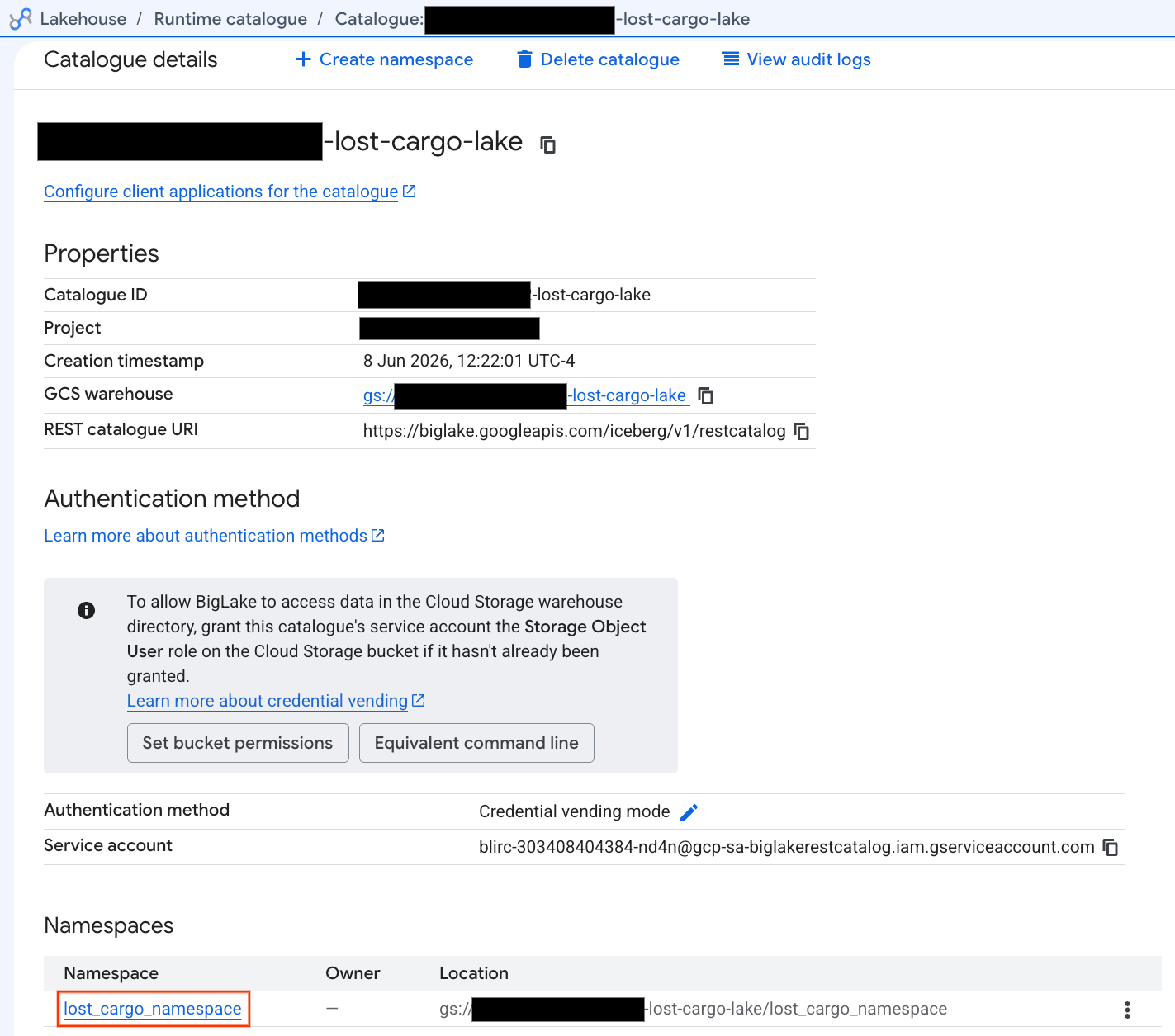
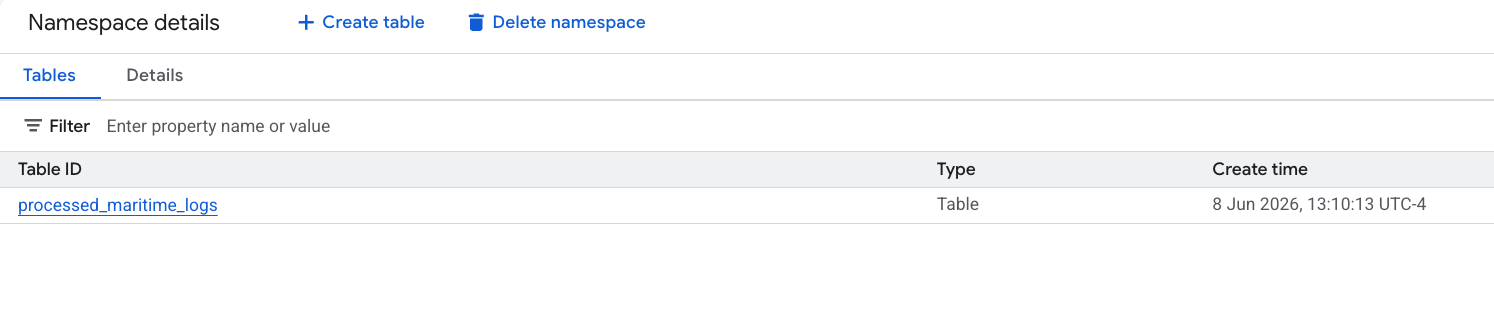
- PySpark によって生成された新しい Apache Iceberg テーブルが、このメタストアの Namespace に自動的に登録され、BigQuery 全体で即座にクエリできるようになりました。
6. 配送マニフェスト テーブルの分析情報を生成する
shipping_manifests テーブルに戻り、Knowledge Catalog Data Insights を使用して構造とコンテンツを分析してみましょう。メタデータを拡充することで、他のエクスプローラは将来の分析のためにテーブルをより深く理解できます。
BigQuery Studio でテーブル分析情報を生成する
- Google Cloud コンソールで、[BigQuery Studio] に移動します。
- [エクスプローラ] パネルで、プロジェクトを開き、
lost_cargo_datasetデータセットを開いて、shipping_manifestsテーブルをクリックします。 - 右側の詳細パネルで、[分析情報] タブをクリックします。
- プルダウンを使用して [生成して公開] を選択します。
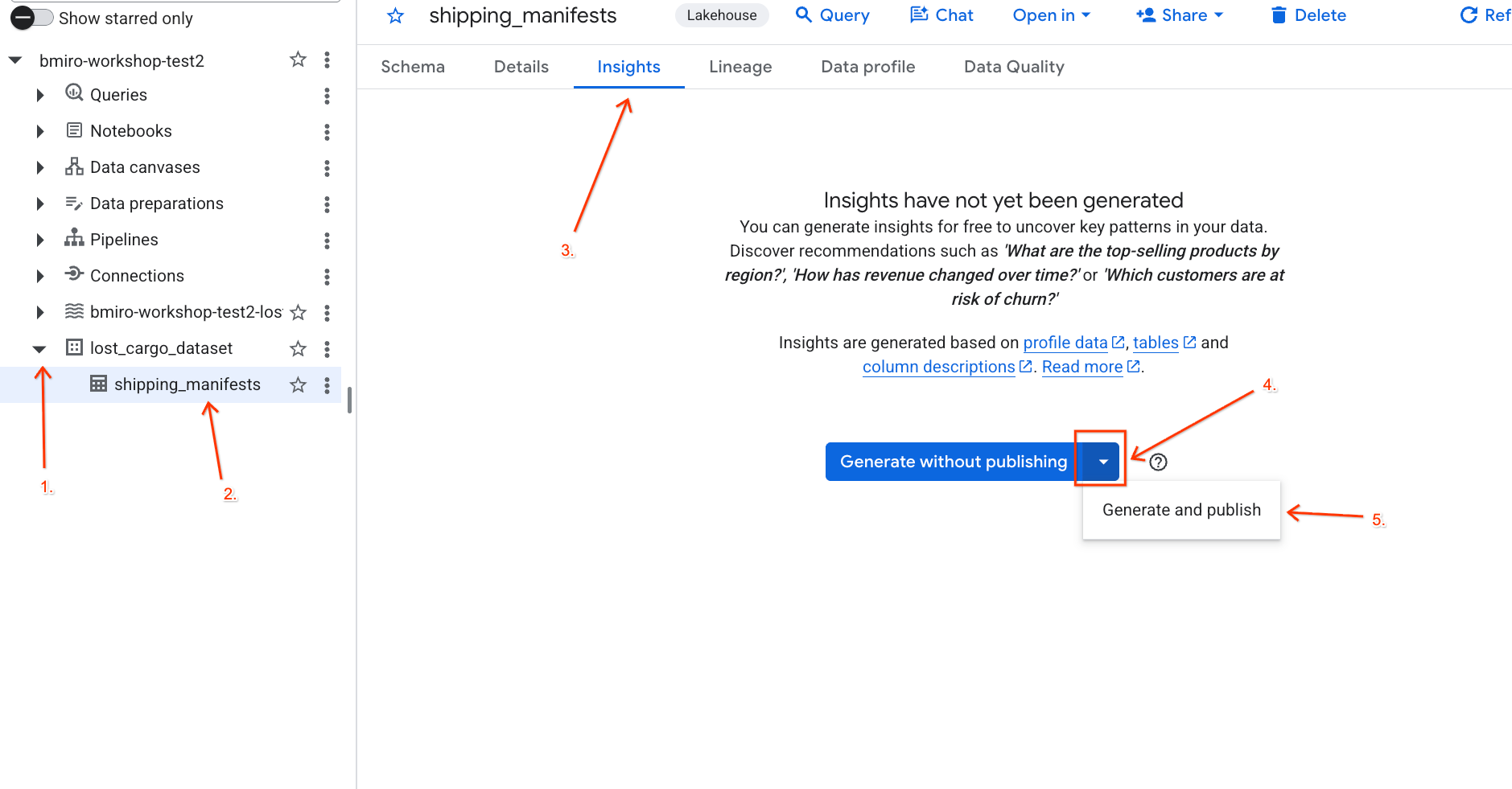
- 分析情報の生成が完了するまで約 3 分待ちます。Gemini はテーブルのメタデータを分析し、自然言語の質問と対応する SQL クエリを生成します。
- 完了すると、テーブルの自然言語の説明を含む [テーブルの説明] が表示されます。
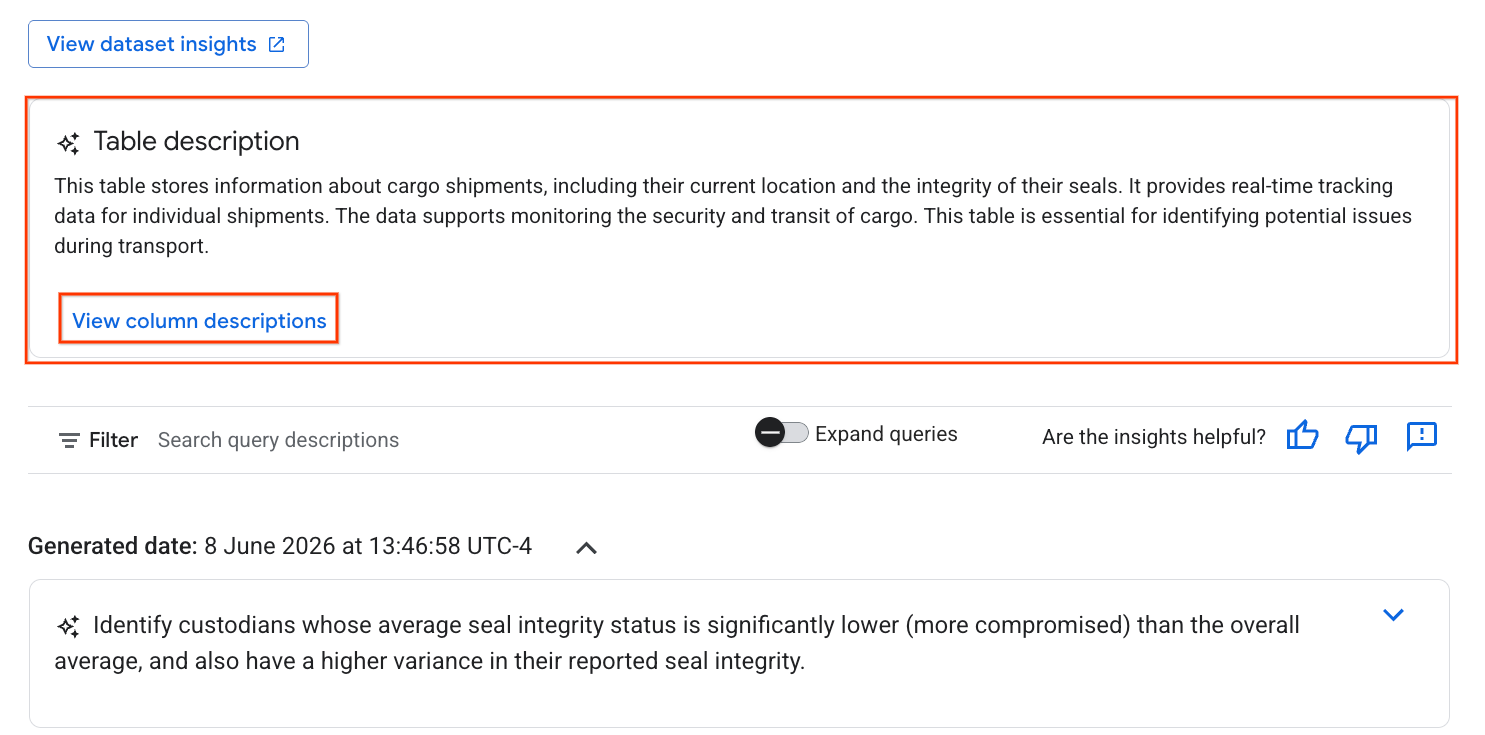
- [列の説明を表示] をクリックして、個々の列に関する情報を確認します。
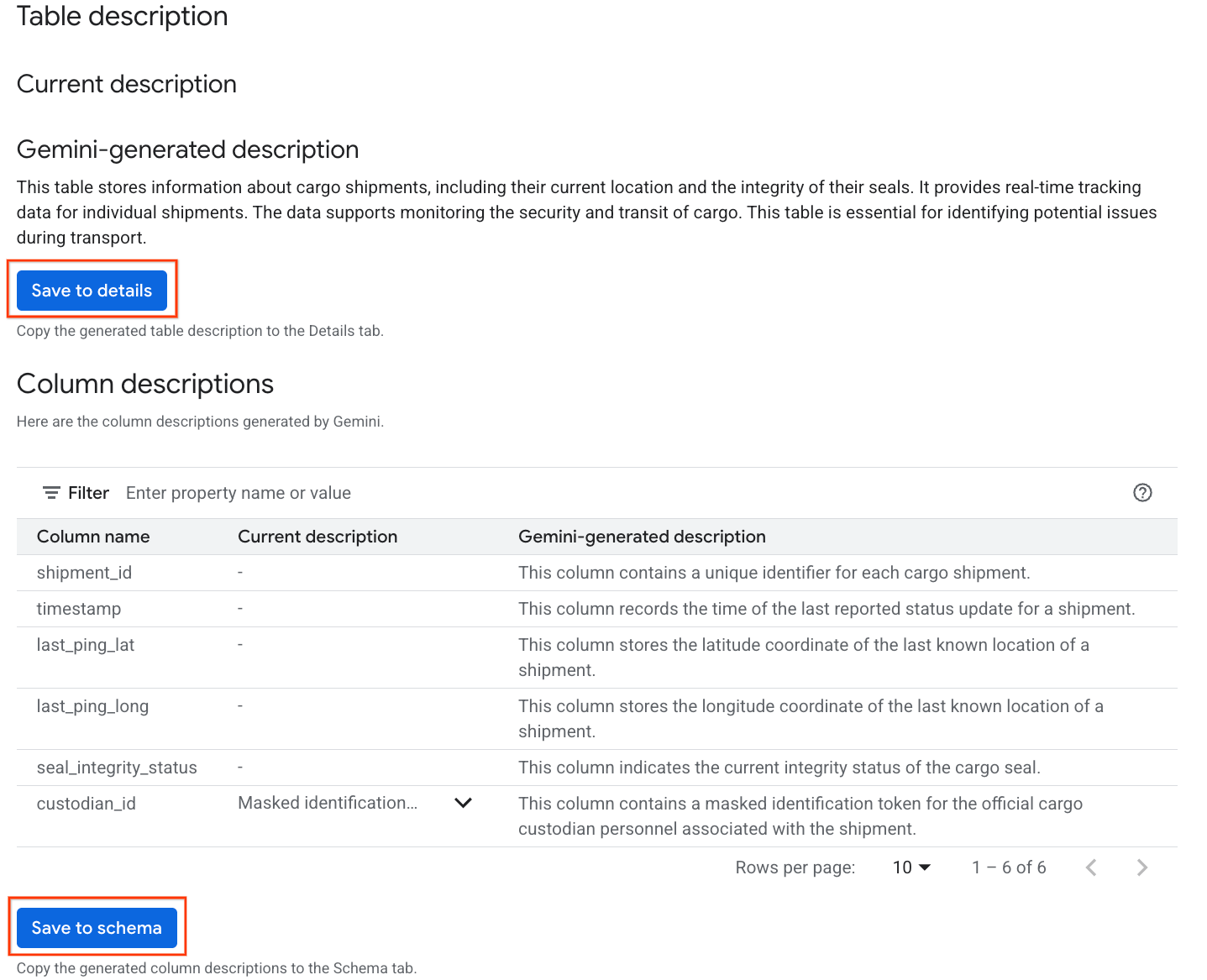
Gemini generated descriptionの [詳細に保存] をクリックし、ポップアップ ウィンドウで [詳細に保存] をクリックします。
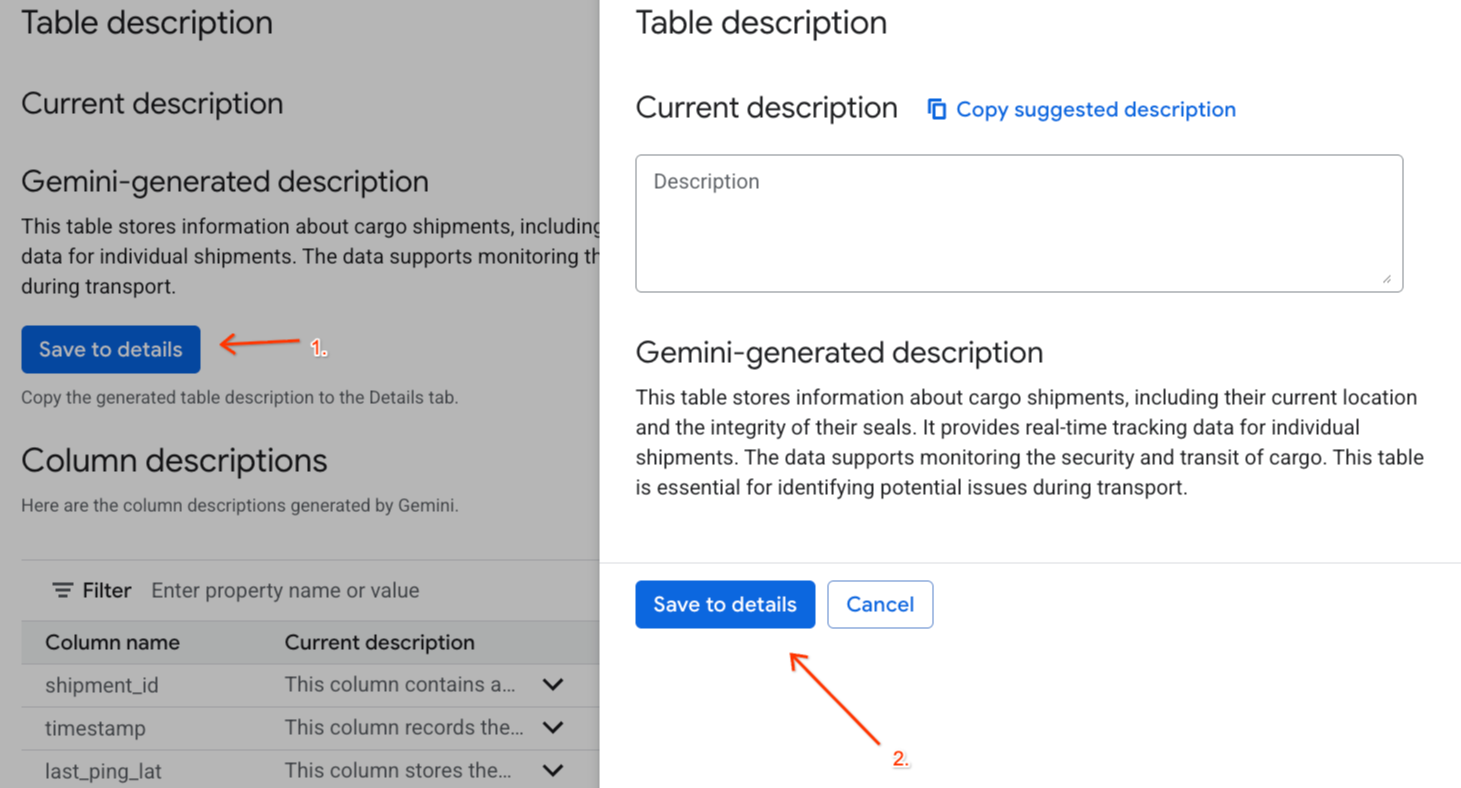
- 同様に、[スキーマに保存] をクリックして、列の説明をテーブルのメタデータに追加します。
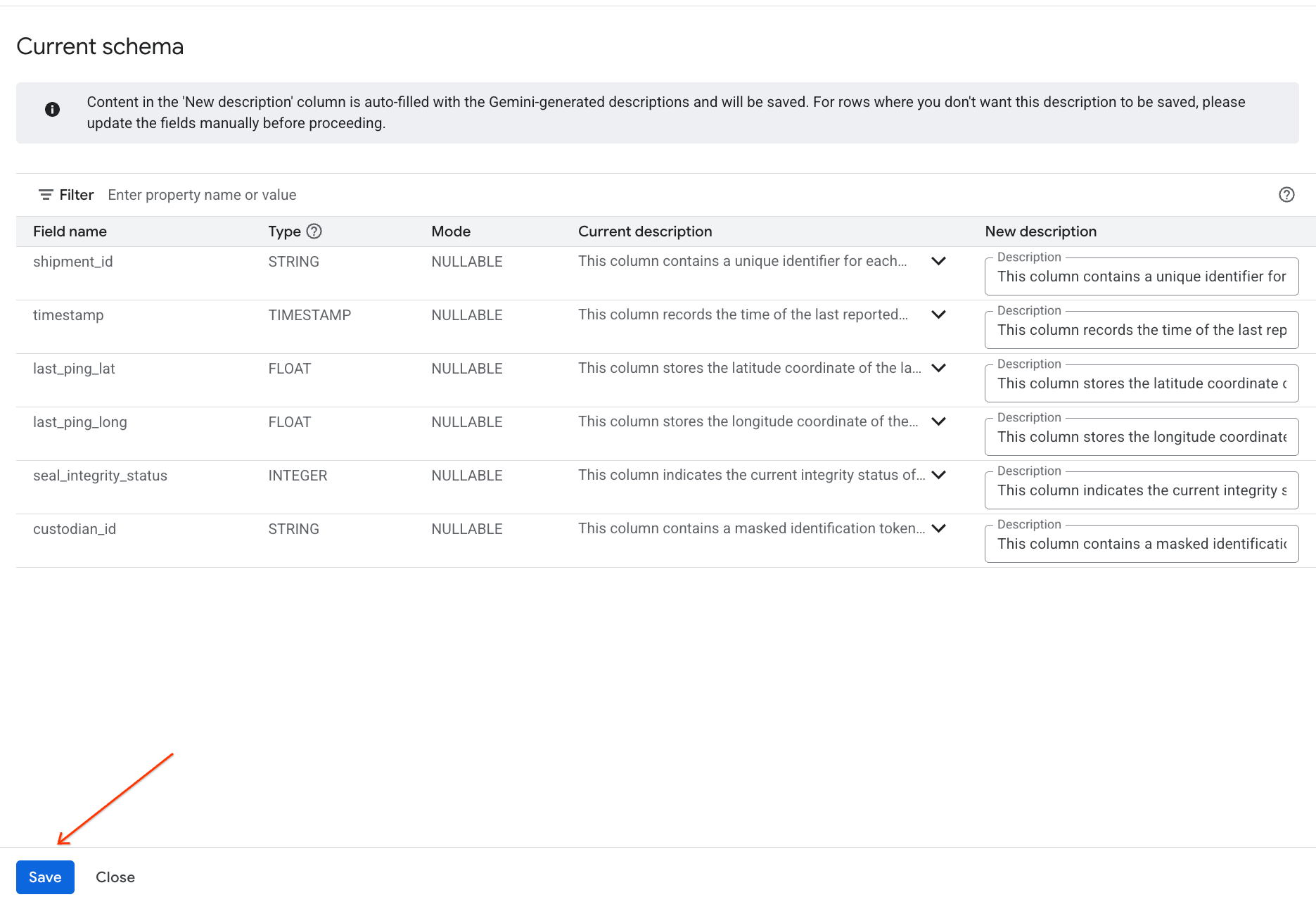
生成された分析情報を確認する
質問の候補も表示されます。質問をクリックすると、生成された SQL クエリが表示され、実行してデータを調べることができます。たとえば、次のような質問が表示されます。
- 「合計出荷数は?」
- 「一意の管理者 ID を一覧表示します。」
これらのクエリを実行すると、データを理解できます。
7. データ マスキングとガバナンスを実装する
この進行中の貨物調査中にアクティブな調査アカウントとユーザー名が漏洩しないようにするには、標準のセキュリティ プロトコルを適用する必要があります。セキュリティ ポリシータグ分類を作成し、機密性の高い custodian_id 列に Knowledge Catalog データ マスキングを構成して、データ プライバシーを確認します。
デフォルトでは、BigQuery はポリシータグで保護された列へのアクセスを拒否します。テーブルをクエリしてアクティブなデータ マスクを確認するには、ユーザー アカウントに BigQuery データポリシーのマスクされた読み取りロールが必要です。
このロールは、setup_lab1.sh の初回実行時にアクティブ ユーザー アカウントに自動的にバインドされました。
分類とポリシータグを作成する
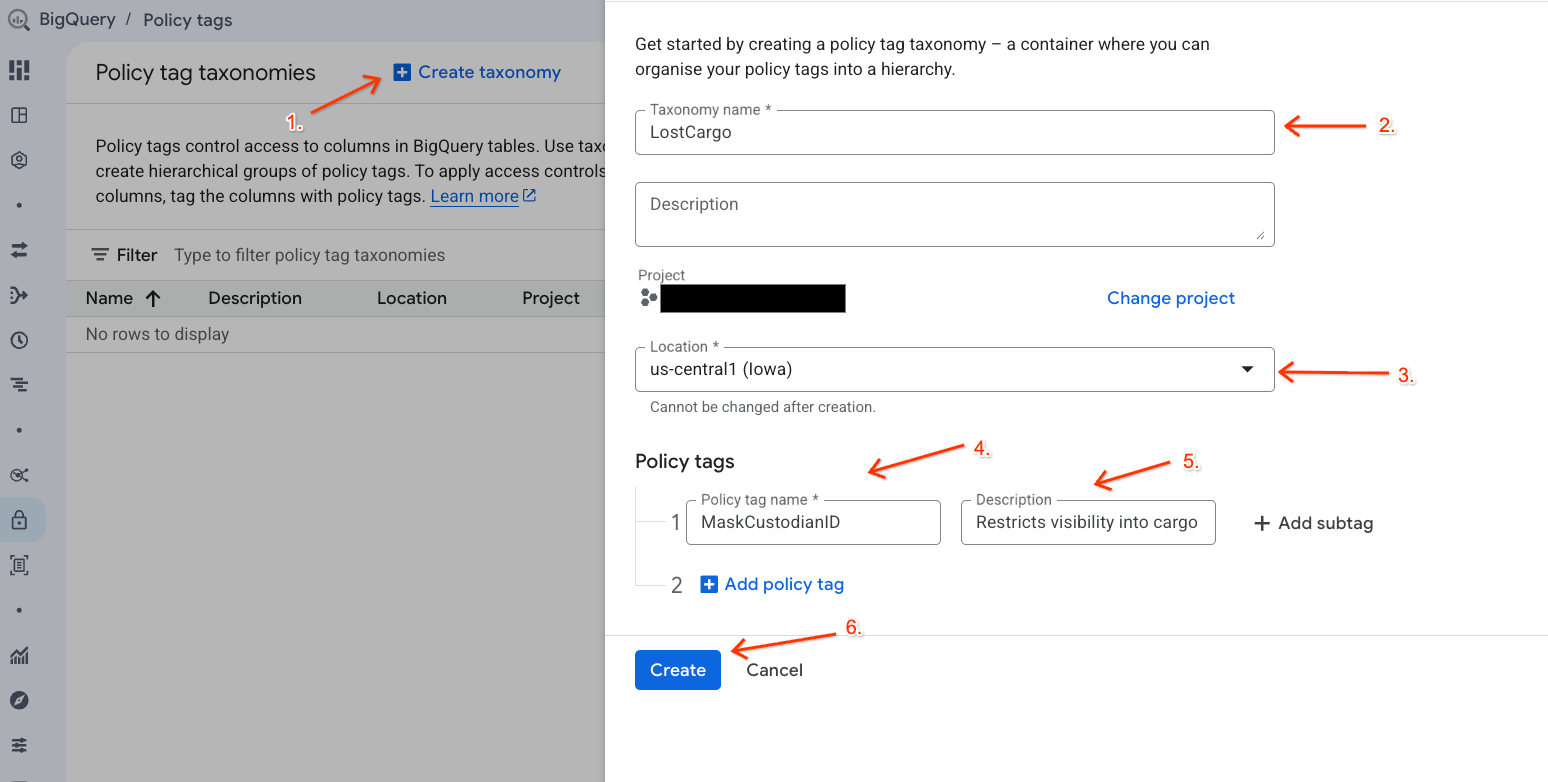
データへのアクセスを管理するためのデータ分類と関連するポリシータグを作成します。
- [ポリシータグの分類] ページに移動します。
- [+ 分類を作成] をクリックします。
- パラメータを構成します。
- 分類名:
lost-cargo-を入力します。実際のプロジェクト ID に置き換えてください。 - リージョン: リージョンを選択します。
- [ポリシータグの名前]: 「
MaskCustodianID」と入力します。 - ポリシータグの [説明]:
Restricts visibility into cargo custodian usernames
- 分類名:
- [作成] をクリックして、新しい分類とポリシータグを登録します。
データ マスキング ポリシーを作成する
次に、MaskCustodianID 分類タグでデータがどのようにマスクされるかを定義するデータポリシーを構成します。常に Null マスキング ルール(一致する値を空の/Null 値に置き換えて、権限のないすべてのユーザーに返す)を使用します。
- [ポリシータグの分類] ページで、分類のリストから新しく作成した分類をクリックします。
- 階層リストで
MaskCustodianIDタグをクリックして選択し、[データポリシーを管理] を選択します。
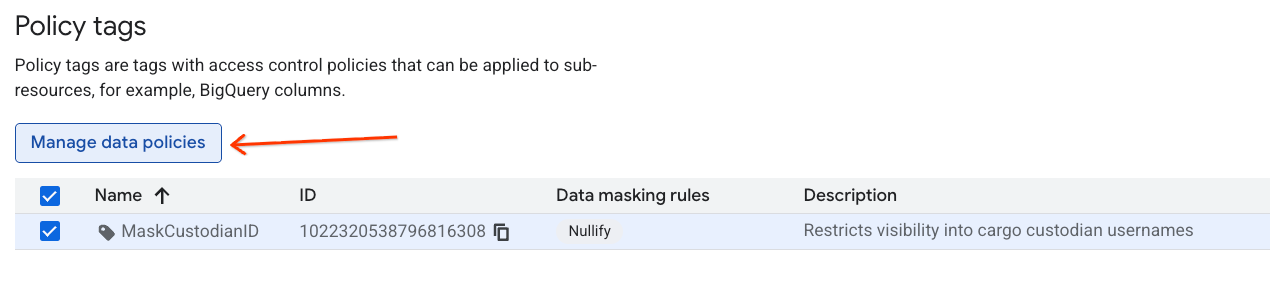
- 右側のパネルで [+ ルールを追加] ボタンをクリックします。
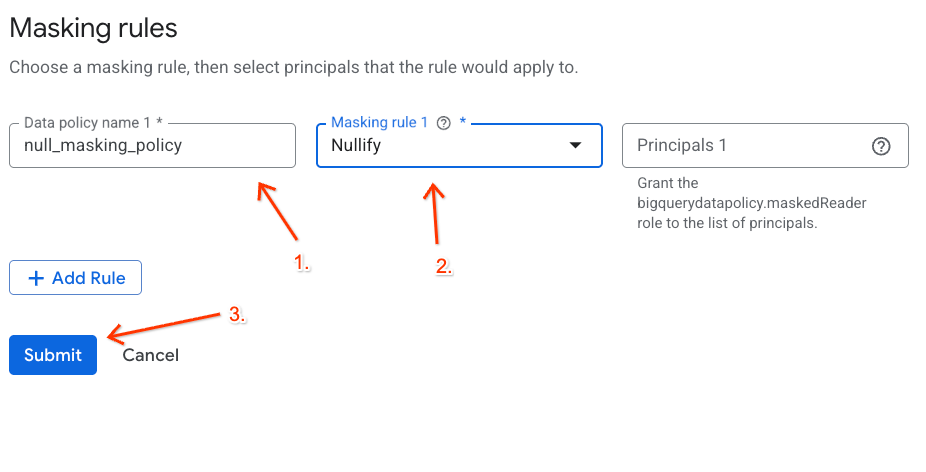
- 表示されるパネルで、ポリシーの詳細を構成します。
- データポリシー名:
null_masking_policyと入力します(次の手順で名前で参照するため、自動生成されたままにしないでください)。 - マスキング ルール: プルダウン メニューから
Nullifyを選択します。
- データポリシー名:
- [送信] をクリックします。
BigQuery 列にポリシータグを割り当てる
ポリシータグとそのデータ マスキング ルールが有効になっている状態で、分類タグを BigQuery パートナーの配送マニフェスト テーブルの custodian_id 列に直接マッピングします。
- BigQueryに移動します。
- 左側の [エクスプローラ] パネルで、アクティブなプロジェクトを開き、
lost_cargo_datasetデータセットを開き、[shipping_manifests] テーブルをクリックして詳細ビューを開きます。 - [スキーマを編集] をクリックします。
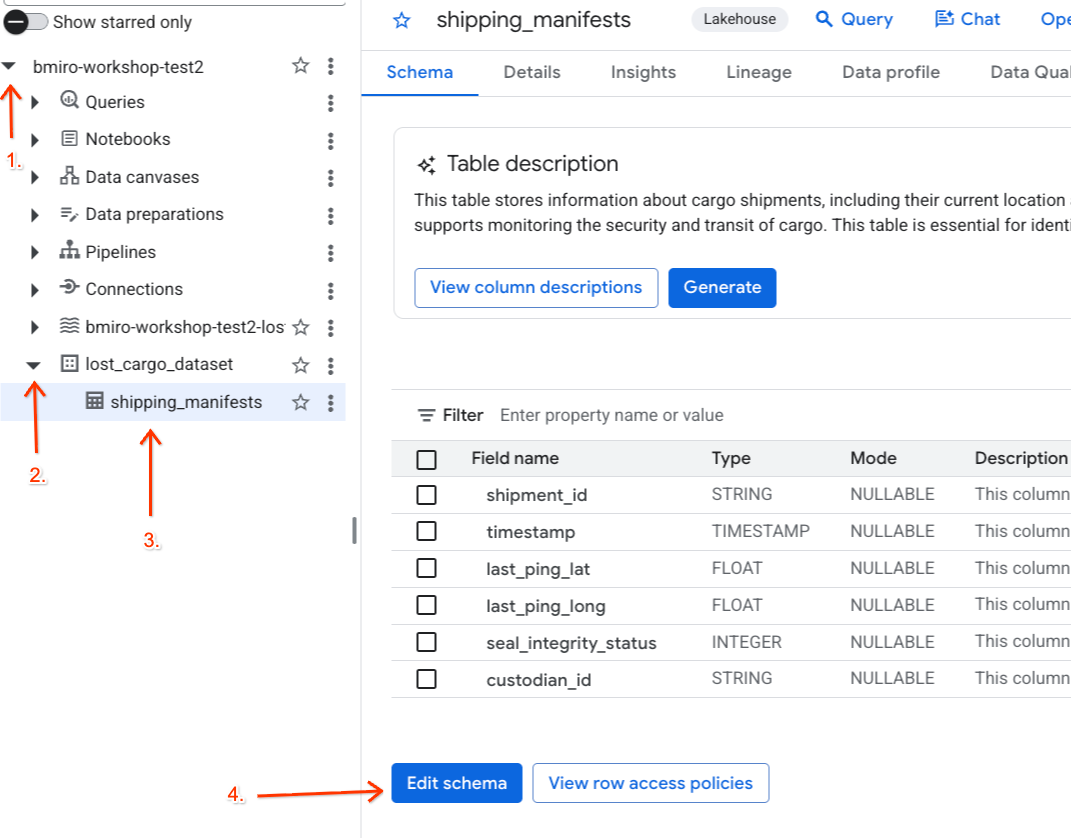
- 列のリストで、[
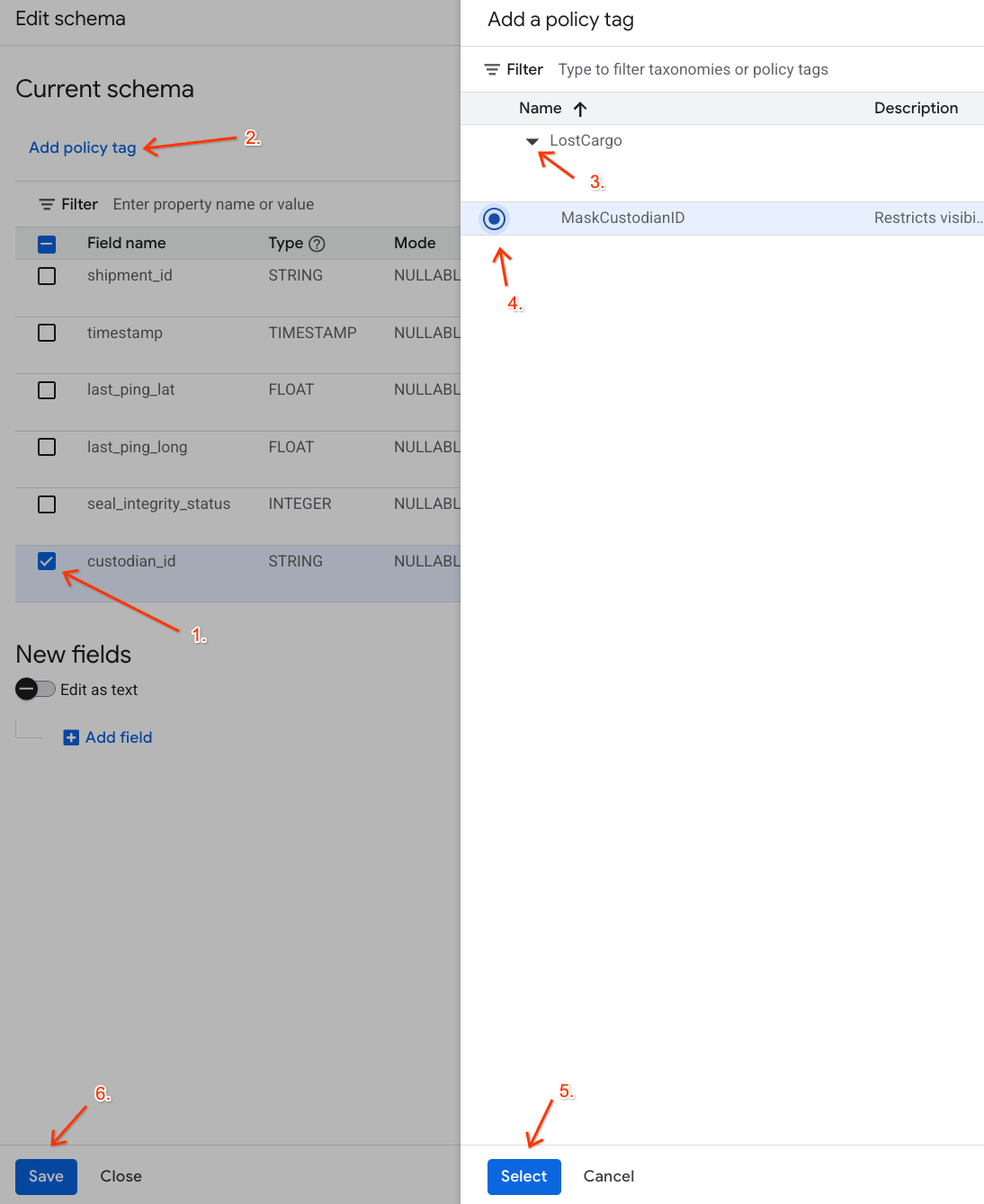
custodian_id] の横にあるチェックボックスをオンにします。 - スキーマ エディタの上部ツールバーにある [ポリシータグを追加] ボタンをクリックします。
- [ポリシータグを追加] パネルで次の操作を行います。
LostCargo分類を見つけて開きます。MaskCustodianIDの横にあるラジオボタンをオンにします。- [選択] をクリックします。
custodian_idを表す行の [ポリシータグ] 列にMaskCustodianIDタグが表示されていることを確認します。- [保存] をクリックします。
ポリシーの制限を確認する
プロジェクト レベルでマスクされた読み取りロールが付与されたので、テーブルに対してクエリを実行して、マスキング ポリシーが有効であることを確認できます。
Data Agent Kit に戻り、次のクエリを実行します。
SELECT shipment_id, custodian_id
FROM lost_cargo_dataset.shipping_manifests
LIMIT 5;
出力は次のようになります。
shipment_id | custodian_id |
NORMAL-001 | null |
NORMAL-002 | null |
MV-CAT-001 | null |
完了しました。shipment_id レコードは表示できますが、機密性の高い custodian_id フィールドは安全な null マスクを返して、漏洩を防ぎます。
8. クリーンアップ
この Codelab で作成したリソースについて、Google Cloud アカウントに継続的に課金されないようにするには、Cloud Shell ターミナルで次のコマンドを実行して、データセットとバケットを削除します。
# Verify active variables
export PROJECT_ID=$(gcloud config get-value project)
export BUCKET_NAME="${PROJECT_ID}-lost-cargo-lake"
# Delete Knowledge Catalog security taxonomies
export TAXONOMY_NAME=$(gcloud data-catalog taxonomies list --location=us-central1 --filter="displayName:LostCargo" --format="value(name)")
if [[ -n "$TAXONOMY_NAME" ]]; then
curl -X DELETE \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
"https://datacatalog.googleapis.com/v1/${TAXONOMY_NAME}" || true
fi
# Delete Lakehouse Iceberg REST Catalog tables and namespaces
gcloud biglake iceberg tables delete processed_maritime_logs \
--catalog=${BUCKET_NAME} \
--namespace=lost_cargo_namespace \
--quiet || true
gcloud biglake iceberg namespaces delete lost_cargo_namespace \
--catalog=${BUCKET_NAME} \
--quiet || true
# Delete Lakehouse Iceberg REST Catalog
gcloud biglake iceberg catalogs delete ${BUCKET_NAME} --quiet || true
# Delete dependencies bucket
gcloud storage rm -r gs://${BUCKET_NAME} || true
# Delete BigQuery dataset and tables
bq rm -r -f -d ${PROJECT_ID}:lost_cargo_dataset || true
9. 完了
おめでとうございます!Lost Cargo の調査の最初の重要なモジュールを完了しました。Lakehouse Iceberg REST カタログ、PySpark ログの正規化、きめ細かいデータ マスキングを使用して、管理された検索ゾーンを確立しました。
学習した内容
- IDE ワークスペース内での Data Agent Kit 拡張機能のインストール、設定、構成。
- ベンダー提供の認証情報と階層型 Namespace を利用したサーバーレスの Lakehouse Iceberg REST カタログを確立します。
- マルチフォーマットの地域別フィードを取り込み、Cloud Storage バケットに BigQuery 外部テーブルを構築する。
- サーバーレスの Apache Spark ジョブを起動して、構造化されていないトランスポンダ ログを解析、正規化、セグメント化し、登録済みの Iceberg カタログ テーブルとして BigQuery に書き戻します。
- セキュリティ分類を作成し、Knowledge Catalog のデータ マスキング ポリシーをマッピングして、機密ログ インデックスでの ID 漏洩を防ぎます。
- BigQuery データ インサイトを使用してテーブル メタデータの分析情報を生成して分析し、データ探索を高速化します。
収集した手がかりの確認
次のラボフェーズに進むために必要な次の決定的な手がかりを記録したことを確認します。
- Lost Shipment ID(紛失した荷物の ID):
MV-CAT-001(最終 ping 位置: London) - Planned Target Destination:
New York(トランスポンダの真のエイリアス:MV-DOG-002) - コンテナの色:
Crimson RED - ガバナンス アクセス タグ:
MaskCustodianID
次のフェーズに進みましょう。
トランスポンダの出発地 / 目的地ルートが安全になったので、調査を進めます。ラボ 2 に直接進み、マルチモーダル Gemini モデルを使用してセキュリティ カメラを調べ、船を視覚的に特定し、AlloyDB でベクトル検索を実行して改ざんの異常を確認します。
➡️ ステップ 2: データ分析とマルチモーダル分析情報に進む