
1. 소개
이 실습에서는 글로벌 물류 회사의 수석 데이터 조사관 역할을 맡게 됩니다. 소중한 Android 피규어 수집품을 싣고 있는 고가치 화물 컨테이너가 사라졌습니다. 마지막으로 알려진 위치를 찾고 경로를 추적하려면 지역 물류 파트너의 조각난 배송 매니페스트와 비구조화된 트랜스폰더 로그 파일을 집계해야 합니다. 이를 위해 최신 Google Cloud 개방형 데이터 레이크하우스를 구성합니다.

실습할 내용
- Cloud Shell 편집기에서 Google Cloud 데이터 에이전트 키트 확장 프로그램을 구성합니다.
- Cloud Storage 버킷을 만들고 Lakehouse Apache Iceberg REST 카탈로그 및 네임스페이스를 프로비저닝합니다.
- BigLake 외부 테이블을 Cloud Storage의 원시 JSON 파트너 매니페스트에 매핑하여 배의 출발 단서를 찾습니다.
- Managed Service for Apache Spark 서버리스를 사용하여 구조화되지 않은 트랜스폰더 텍스트 로그를 로드하고 처리합니다. 정규식 정규화 및 동적 단서 추출을 실행하여 손실된 페이로드 도착 페이지를 타겟팅합니다.
- 파싱된 로그 측정항목을 REST 카탈로그를 통해 Apache Iceberg 테이블로 작성합니다.
- 대화형 분석을 사용하여 AI 에이전트와 Apache Iceberg 데이터에 관해 채팅하여 분실된 배송에 관한 숨겨진 단서를 찾아보세요.
- Knowledge Catalog를 사용하여 자동 데이터 통계를 활용하여 데이터에 관한 메타데이터를 생성하세요.
- 보안 분류를 만들고 Knowledge Catalog를 사용하여 민감한 관리자 ID를 마스킹하여 세분화된 액세스 제어를 적용하여 수집 가이드라인을 설정합니다.
필요한 항목
- 웹브라우저(예: Chrome)
- 결제가 사용 설정된 Google Cloud 프로젝트.
- 기본 SQL 쿼리 및 터미널 명령어에 대한 지식
예상 비용 및 기간
- 소요 시간: 약 45분
- 예상 비용: 5달러 미만
2. 시작하기 전에
Google Cloud 프로젝트 만들기 또는 선택
- Google Cloud 콘솔에서 Google Cloud 프로젝트를 선택하거나 만듭니다.
- Cloud 프로젝트에 결제가 사용 설정되어 있는지 확인합니다. 프로젝트에 결제가 사용 설정되어 있는지 확인하는 방법을 알아보세요.
환경 구성
대부분의 명령어는 개발자 도구와 표준 Google Cloud SDK가 미리 로드된 클라우드 기반 개발 환경인 Cloud Shell 편집기의 통합 터미널에서 실행합니다.
- 새 탭에서 Cloud Shell 편집기를 엽니다.
- 터미널에서 다음 명령어를 실행하여 저장소를 클론합니다.
cd ~/ git clone --filter=blob:none --no-checkout https://github.com/GoogleCloudPlatform/devrel-demos.git cd ~/devrel-demos git sparse-checkout init --cone git sparse-checkout set data-analytics/data-cloud-roadshow/lab1 git checkout main cd data-analytics/data-cloud-roadshow/lab1 - 프로젝트 ID를 설정합니다. Windows/Linux에서는
Ctrl+Shift+V, macOS에서는Cmd+V를 눌러 터미널에 붙여넣을 수도 있습니다.export PROJECT_ID="<YOUR_PROJECT_ID>" - 이제 환경에서 이를 구성합니다.
gcloud config set project $PROJECT_ID - 지역을 선택합니다.
export REGION="<YOUR_REGION>" # Replace with the region you chose, such as "us-central1" - 필요한 API를 사용 설정합니다.
gcloud services enable \ bigquery.googleapis.com \ biglake.googleapis.com \ storage.googleapis.com \ dataplex.googleapis.com \ datacatalog.googleapis.com \ dataproc.googleapis.com \ aiplatform.googleapis.com \ cloudresourcemanager.googleapis.com \ serviceusage.googleapis.com \ cloudaicompanion.googleapis.com \ geminidataanalytics.googleapis.com
확장 프로그램 설치
이제 IDE에서 Google Cloud의 데이터 도구와 직접 상호작용하는 도구인 Google 데이터 에이전트 키트 확장 프로그램을 구성합니다.
- 편집기의 왼쪽 활동 표시줄에서 확장 프로그램 아이콘을 클릭합니다 (또는 Windows/Linux에서는
Ctrl+Shift+X, macOS에서는Cmd+X누름). - 확장 프로그램 검색창에
Google Cloud Data Agent Kit를 입력합니다. - 결과에서 공식 확장 프로그램을 선택하고 설치를 클릭합니다. 메시지가 표시되면 '예, 작성자를 신뢰합니다'를 선택합니다.
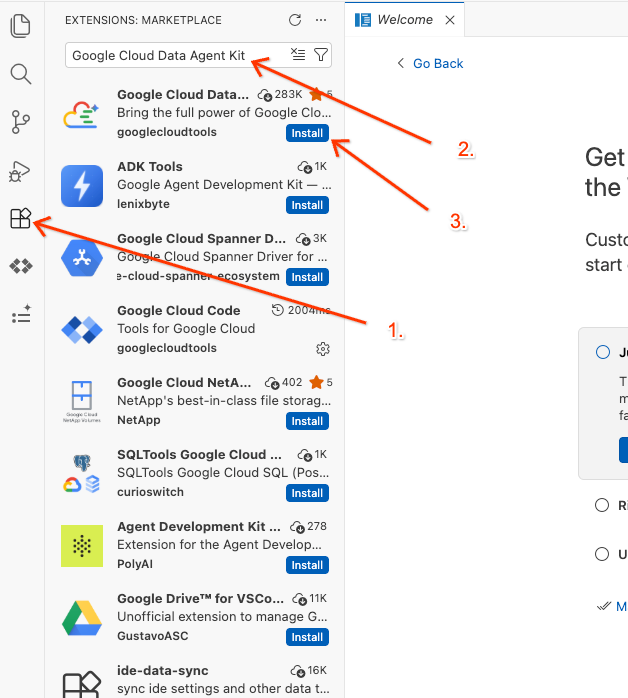
- 설치가 완료되면 작업 표시줄에 Google Cloud Data Agent Kit 아이콘이 표시됩니다. 클릭합니다.
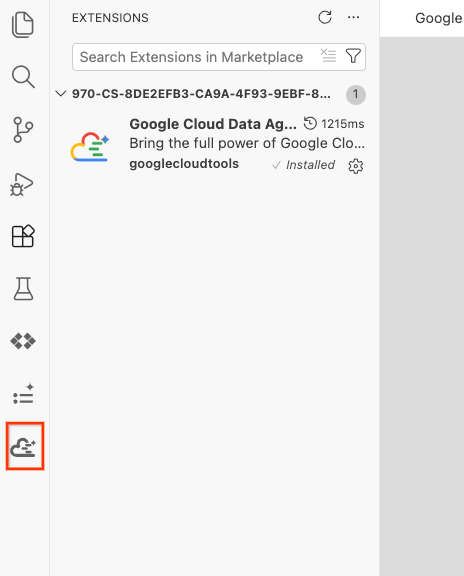
- 클라우드에 로그인을 클릭합니다.
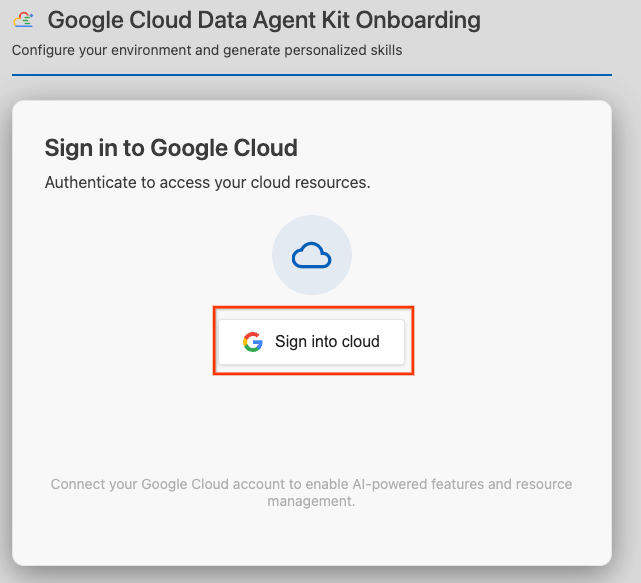
- MCP 서버 구성을 클릭합니다.
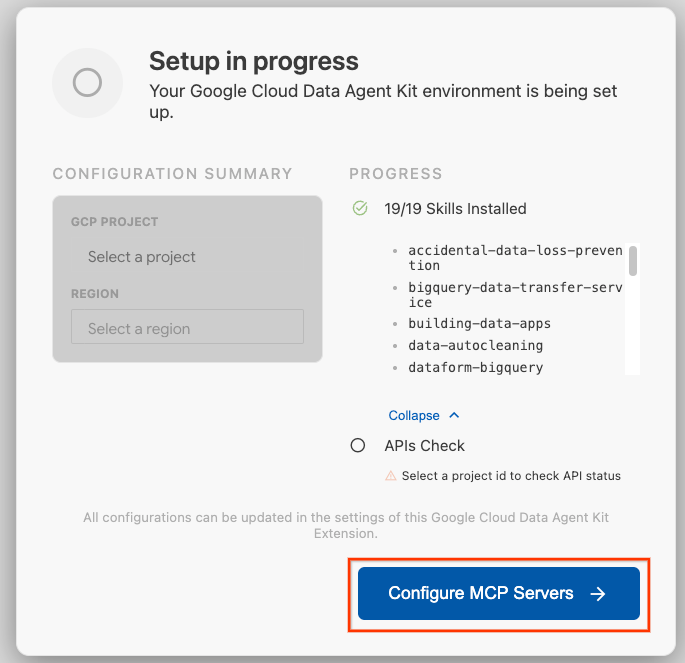
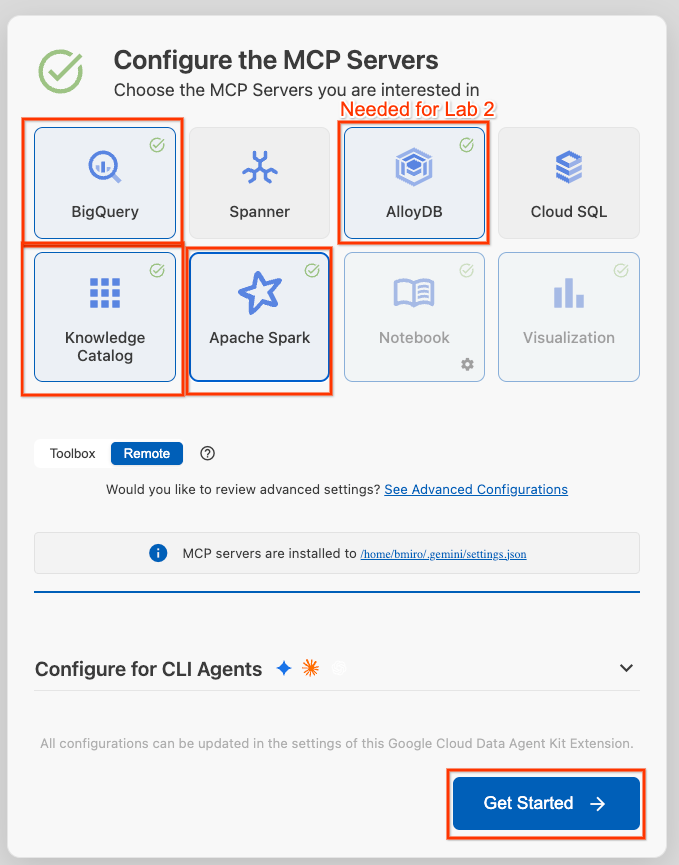
- BigQuery, Knowledge Catalog, Apache Spark, AlloyDB를 선택합니다. 실습 2에서는 AlloyDB를 사용합니다. 그런 다음 시작하기를 클릭합니다.
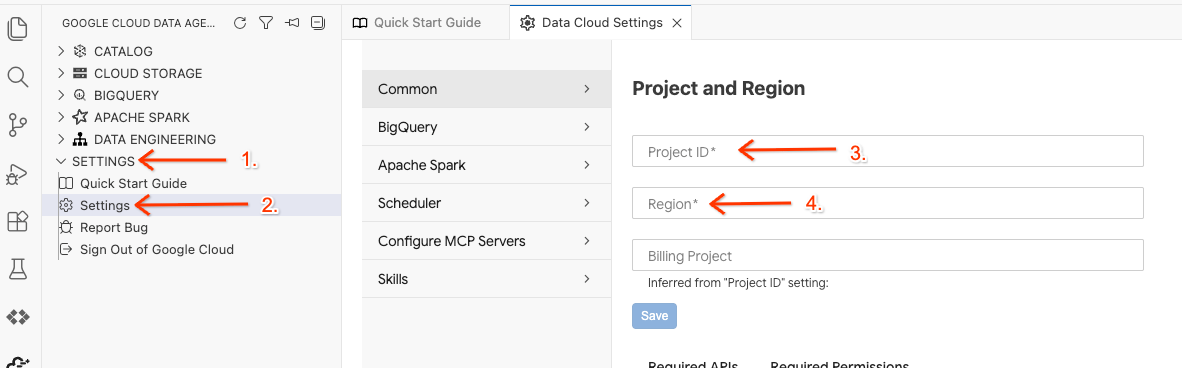
- 하단 상태 표시줄에서 프로젝트 ID 선택기를 클릭하고 활성 Google Cloud 프로젝트를 선택합니다.
- 데이터 에이전트 키트에서 SETTINGS, Settings를 클릭하고 Common 탭에서 실습을 실행할 프로젝트 ID와 리전(예: us-central1)을 선택합니다.
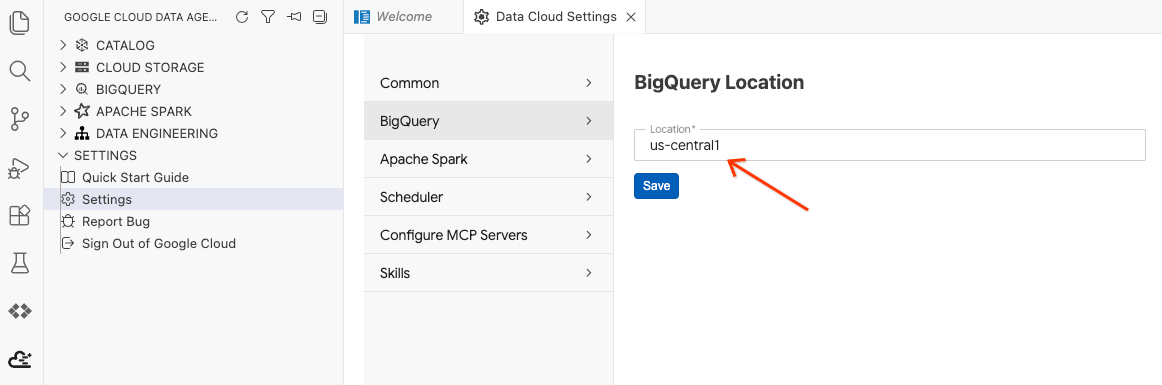
- BigQuery 설정을 클릭하고 리전을 이전에 선택한 리전으로 바꿉니다. 저장을 클릭합니다.
이제 데이터 에이전트 키트를 사용할 수 있습니다.
환경 설정 스크립트 실행
터미널에서 설정 스크립트를 실행하여 이 실습에 필요한 백그라운드 리소스를 만들고 IAM 권한을 구성합니다.
chmod +x setup_lab1.sh
./setup_lab1.sh
source .env
프로비저닝되는 리소스를 보여주는 일련의 출력 단계가 표시됩니다. 이러한 내용은 실습 전반에 걸쳐 다루게 됩니다.
완료 메시지가 표시되면 다음 단계를 진행할 수 있습니다.
==================================================== Environment Setup Complete! ====================================================
이제 검색을 시작해 보겠습니다.
3. 파트너 배송 매니페스트 수집
파트너 선박의 배송 매니페스트 데이터는 버킷(gs://${PROJECT_ID}-lost-cargo-lake/shipping_manifests/manifests.jsonl)에 표준 JSON Lines(JSONL) 형식으로 저장됩니다.
심층 분석을 수행하기 전에 이 비정형 데이터에 대해 관리되는 BigLake 테이블을 만듭니다. 이렇게 하면 중복 가져오기 비용 없이 표준 SQL을 사용하여 파트너 물류 데이터를 즉시 탐색할 수 있습니다.
편집기에서 워크스페이스를 열고 쿼리를 실행합니다.
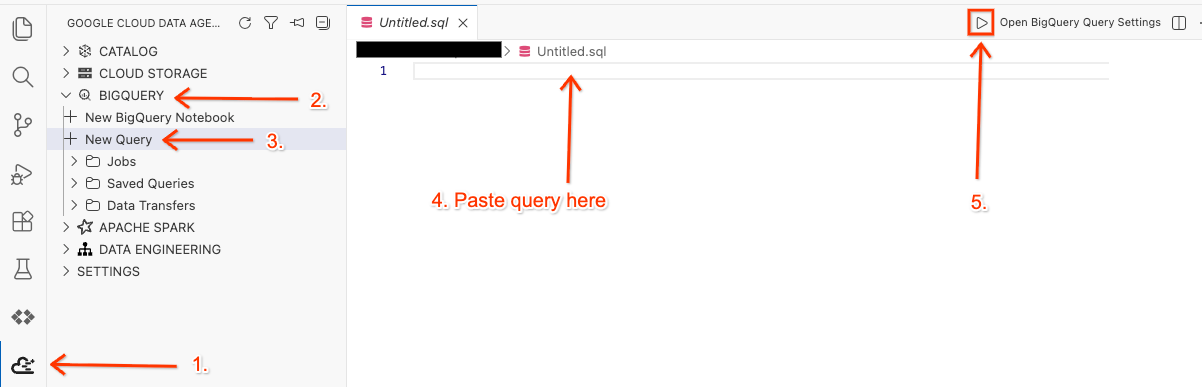
- Cloud Shell 편집기의 측면 패널에서 Google Cloud Data Agent Kit 확장 프로그램 아이콘을 클릭합니다.
- BigQuery로 이동하여 + 새 쿼리를 선택합니다.
- 다음 쿼리를 쿼리 창에 복사합니다.
SET @@location = "<YOUR_REGION>"; --Update to your resource region, such as "us-central1". Make sure it is in quotes.
EXECUTE IMMEDIATE ("""
CREATE OR REPLACE EXTERNAL TABLE `lost_cargo_dataset.shipping_manifests`
(
shipment_id STRING,
timestamp TIMESTAMP,
last_ping_lat FLOAT64,
last_ping_long FLOAT64,
seal_integrity_status INT64,
custodian_id STRING OPTIONS(description='Masked identification token for official cargo custodian personnel.')
)
WITH CONNECTION `""" || @@location || """.conn`
OPTIONS (
format = 'NEWLINE_DELIMITED_JSON',
uris = ['gs://""" || @@project_id || """-lost-cargo-lake/shipping_manifests/*.jsonl']
)
""");
- 실행을 클릭합니다.
- 표가 생성되었는지 확인하려면 하단에 자동으로 슬라이드되는 쿼리 결과 패널에 성공 메시지가 표시되는지 확인합니다.
외부 테이블을 쿼리하여 손상된 트랜스폰더 격리
seal_integrity_status이 0로 설정되었을 때 오류를 찾아 손상된 트랜스폰더를 식별해 보겠습니다. 이전에 연 쿼리 창에서 다음 쿼리를 복사하여 실행합니다.
SELECT shipment_id, last_ping_lat, last_ping_long, custodian_id
FROM `lost_cargo_dataset.shipping_manifests`
WHERE seal_integrity_status = 0;
쿼리 결과 패널에 다음과 비슷한 출력이 표시됩니다.
shipment_id | last_ping_lat | last_ping_long | custodian_id |
MV-CAT-001 | 51.5074 | -0.1278 | usr_999_shadow |
4. Managed Service for Apache Spark로 구조화되지 않은 로그 처리
구조화된 매니페스트에서 시작 위치를 찾았지만 손실된 트랜스폰더가 완전히 꺼졌습니다. 마지막 트랜스폰더 핑은 GCS 경로 gs://${BUCKET_NAME}/raw_logs/maritime_logs.txt의 원시 텍스트 로그 파일 내에 알 수 없는 구조화되지 않은 메시지를 남겼습니다.
이 텍스트 로그를 처리하고 매핑하고, 타임스탬프를 추출하고, 신원을 위장하고, 화물의 다운스트림 경로를 찾으려면 서버리스 Apache Spark (PySpark) 작업을 Managed Service for Apache Spark에 제출합니다.
Managed Service for Apache Spark를 사용하면 클러스터를 프로비저닝하거나 관리하지 않고도 Spark 워크로드를 실행할 수 있습니다. 서비스에서 기본 컴퓨팅 리소스를 처리하고 동적으로 자동 확장하므로 실행 기간에 대해서만 비용을 지불하면 됩니다.
스크립트는 다음을 수행합니다.
- 괄호로 묶인 구조화되지 않은 트랜스폰더 텍스트를 수집합니다.
- PySpark SQL 정규식 추출 필터를 적용하여 타임스탬프, 보관인 메타데이터, 원시 콘텐츠를 분리합니다.
- 복잡한 로그를 정리된 문장 수준 레코드로 분할합니다.
- 손실된 페이로드 출발이 종료된 동적 대상 좌표 타겟을 추출합니다.
- 처리된 로그 데이터 프레임을 BigQuery 내에서 직접 볼 수 있는 새 분석 테이블로 Lakehouse Apache Iceberg REST 카탈로그에 다시 연결하고 씁니다.
PySpark 분석 스크립트 수정
바다에서 Python 해적이 온갖 문제를 일으킨다는 신고가 접수되었습니다.
- 다음 명령어를 실행하여 Cloud Shell 편집기에서
process_maritime_logs파일을 엽니다.cd ~/devrel-demos/data-analytics/data-cloud-roadshow/lab1 cloudshell open ./process_maritime_logs.py - 시간을 내어 코드를 읽고 코드가 수행하는 작업을 이해합니다.
- 코드에 의심스러운 부분이 없는지 확인합니다. 삭제해야 하는 부분이 있으면
Ctrl + S(Windows/Linux) 또는Cmd + S(Mac)를 사용하여 파일을 저장해야 합니다.
서버리스 Spark 작업 제출
gcloud SDK를 사용하여 작업을 제출합니다. 이 구성은 Lakehouse 카탈로그에 액세스하도록 PySpark 작업을 자동으로 구성합니다.
통합 편집기 터미널에서 다음 명령어를 실행합니다.
cd ~/devrel-demos/data-analytics/data-cloud-roadshow/lab1
source .env
gcloud dataproc batches submit pyspark process_maritime_logs.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--version=2.3 \
--deps-bucket=${BUCKET_NAME} \
--properties="\
spark.sql.defaultCatalog=cargo_catalog,\
spark.sql.catalog.${CATALOG_NAME}=org.apache.iceberg.spark.SparkCatalog,\
spark.sql.catalog.${CATALOG_NAME}.type=rest,\
spark.sql.catalog.${CATALOG_NAME}.uri=https://biglake.googleapis.com/iceberg/v1/restcatalog,\
spark.sql.catalog.${CATALOG_NAME}.warehouse=gs://${BUCKET_NAME},\
spark.sql.catalog.${CATALOG_NAME}.header.x-goog-user-project=${PROJECT_ID},\
spark.sql.catalog.${CATALOG_NAME}.rest.auth.type=org.apache.iceberg.gcp.auth.GoogleAuthManager,\
spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions,\
spark.sql.catalog.${CATALOG_NAME}.gcs.oauth2.refresh-credentials-endpoint=https://oauth2.googleapis.com/token, \
spark.sql.catalog.${CATALOG_NAME}.header.X-Iceberg-Access-Delegation=vended-credentials" \
-- ${BUCKET_NAME}
서버리스 환경이 가동되고 스크립트가 업로드되고 처리 로직이 실행될 때까지 몇 분 정도 기다립니다.
다음과 비슷한 출력이 표시되면 처리된 테이블이 Lakehouse 카탈로그에 Apache Iceberg 관리 테이블로 저장된 것입니다.
Batch [1fae0b4b42c045a084dd67917bd0c332] finished.
metadata:
'@type': type.googleapis.com/google.cloud.dataproc.v1.BatchOperationMetadata
batch: projects/<YOUR_PROJECT>/locations/us-central1/batches/1fae0b4b42c045a084dd67917bd0c332
batchUuid: 611b4465-fdac-4974-bc47-5f10adaf2a08
createTime: '2026-06-11T21:35:01.868157Z'
description: Batch
labels:
goog-dataproc-batch-id: 1fae0b4b42c045a084dd67917bd0c332
goog-dataproc-batch-uuid: 611b4465-fdac-4974-bc47-5f10adaf2a08
goog-dataproc-drz-resource-uuid: batch-611b4465-fdac-4974-bc47-5f10adaf2a08
goog-dataproc-location: us-central1
operationType: BATCH
name: projects/<YOUR_PROJECT/regions/us-central1/operations/7e2044db-dd97-3270-b368-4dc4ba417574
처리된 로그 미리보기
데이터 에이전트 키트 확장 프로그램 쿼리 편집기에서 다음 쿼리를 복사하여 데이터를 미리 봅니다.
SET @@location = "<YOUR_REGION>"; -- e.g. "us-central1"
EXECUTE IMMEDIATE FORMAT("""
select log_timestamp, custodian_id, sentence from
`%s.%s-lost-cargo-lake.lost_cargo_namespace.processed_maritime_logs`
limit 5
""", @@project_id, @@project_id);
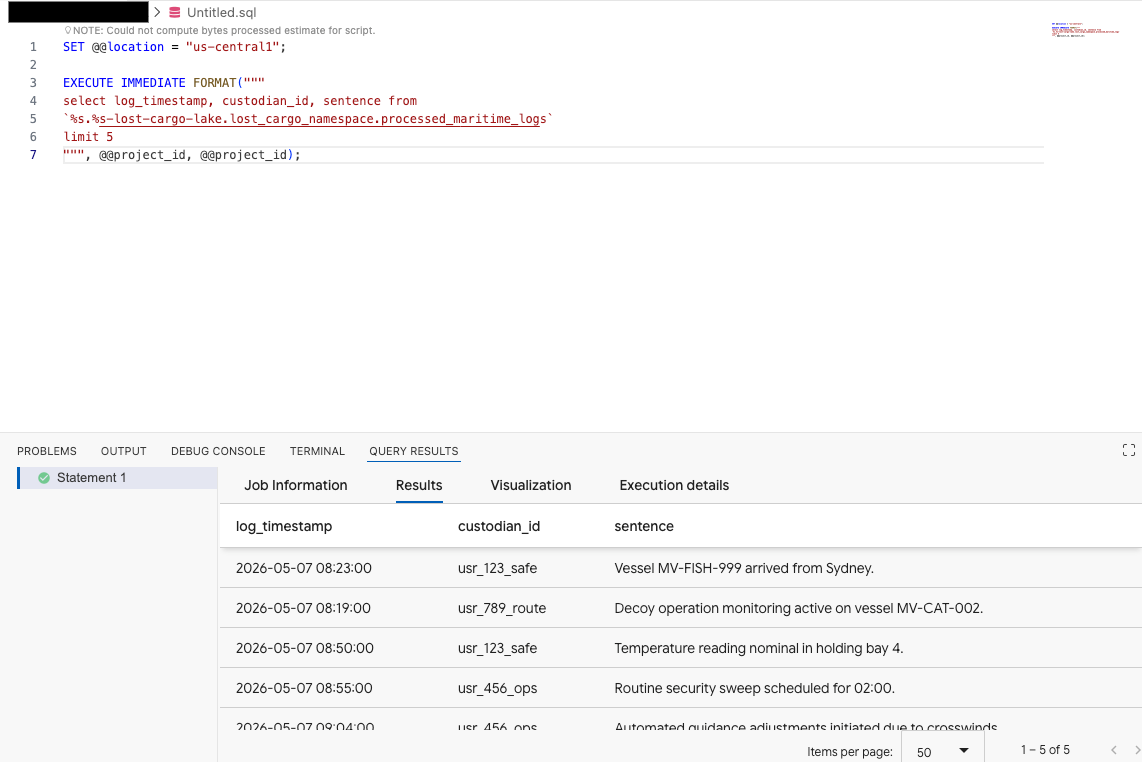
카탈로그에 등록된 Iceberg 테이블이 BigQuery에서 성공적으로 액세스될 수 있음을 보여줍니다.
목적지 단서 추출
이제 처리된 로그가 있으므로 대상 타겟이 포함된 로그를 검색해 보겠습니다. 여기에서 출신 도시가 언급된 로그를 검색할 수 있습니다.
쿼리 편집기에서 다음 쿼리를 실행합니다. 이때 <YOUR_REGION>을 리전으로 바꾸고 <ORIGIN_CITY>를 앞에서 확인한 출발 도시로 바꿉니다.
SET @@location = "<YOUR_REGION>"; --e.g. "us-central1"
DECLARE origin_city STRING;
SET origin_city = "<ORIGIN_CITY>"; --e.g. "Boston". (It's not Boston)
EXECUTE IMMEDIATE FORMAT(r"""
SELECT
log_timestamp AS event_time,
custodian_id,
REGEXP_EXTRACT(raw_message, r'Destination:\s*([^.]+)') AS destination_target
FROM
`%s.%s-lost-cargo-lake.lost_cargo_namespace.processed_maritime_logs`
WHERE
-- STRPOS is highly optimized in BigQuery for a simple .contains() substring check
STRPOS(sentence, '%s') > 0;
""", @@project_id, @@project_id, origin_city);
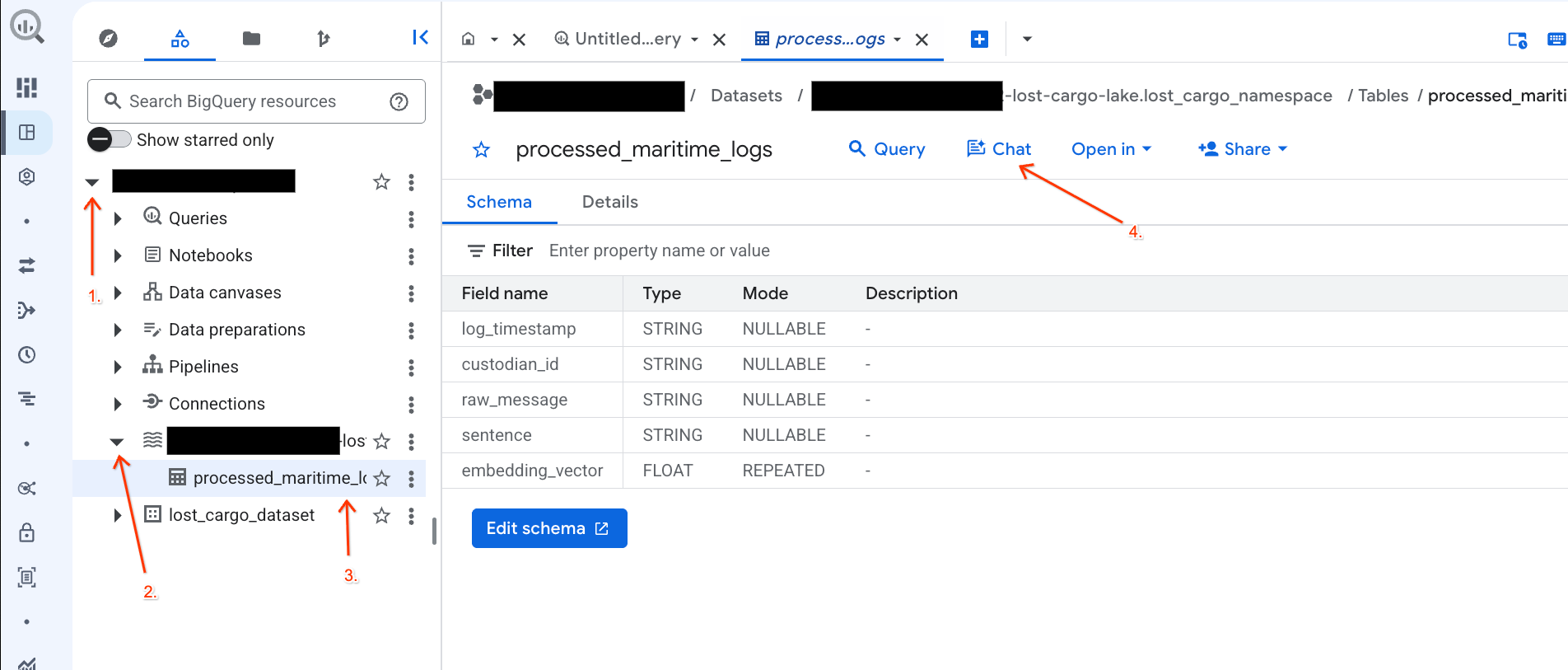
대화형 분석을 사용하여 BigQuery 콘솔에서 데이터로 채팅하기
데이터를 탐색하기 위해 복잡한 SQL 쿼리를 작성하는 대신 대화형 분석을 사용하여 자연어로 테이블과 채팅할 수 있습니다.
- BigQuery 콘솔로 이동합니다.
- 왼쪽의 탐색기 패널에서 프로젝트와 데이터 세트
-lost-cargo-lake.lost_cargo_namespace processed_maritime_logs테이블을 클릭하여 세부정보 탭을 엽니다. - 쿼리 옆에 있는 채팅을 클릭합니다.
- 채팅 패널에 다음 질문을 입력하고 키보드의 Enter 키를 눌러 전송합니다.
Based on this table, what color is the shipping container MV-CAT-001?
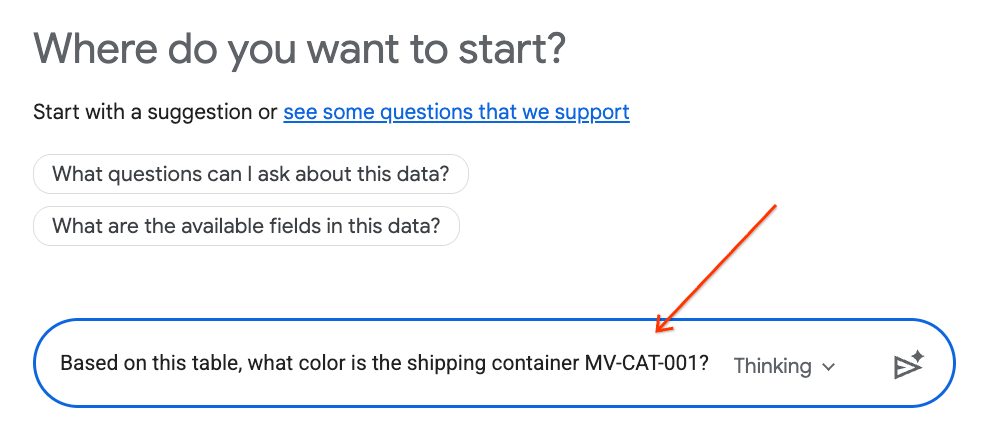
- 대화형 분석 (Gemini 기반)이 활성 표의 데이터를 분석하고 색상으로 대답합니다.
5. 중앙 집중식 Lakehouse 카탈로그 보기
오픈소스 처리 엔진 (예: Apache Spark)을 엔터프라이즈 데이터 엔진 (예: BigQuery)과 안전하고 원활하게 통합하기 위해 설정 스크립트에서 Lakehouse Iceberg REST 카탈로그를 구성했습니다.
Apache Iceberg REST 카탈로그는 테이블 메타데이터의 서버리스 '단일 정보 소스' 역할을 하며, 스키마와 파티셔닝 테이블을 동적으로 관리하는 동시에 Cloud Storage에 실제 Parquet 데이터 파일을 저장합니다.
Google Cloud 콘솔에서 이 카탈로그를 직접 살펴보겠습니다.
- Lakehouse Console을 엽니다.
- 카탈로그 탭에서 활성 Iceberg REST 카탈로그(
-lost-cargo-lake
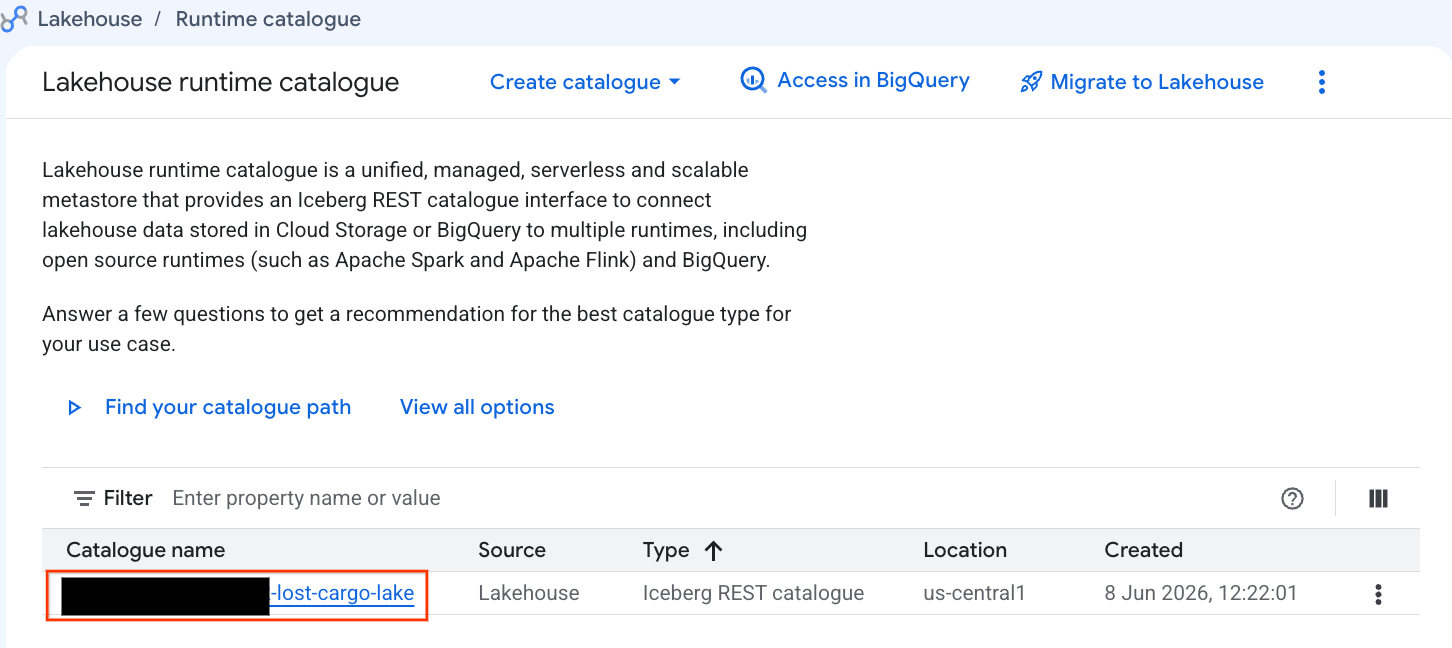
- 카탈로그 세부정보 보기의 네임스페이스에
lost_cargo_namespace가 표시됩니다. 이 탭을 클릭하세요.
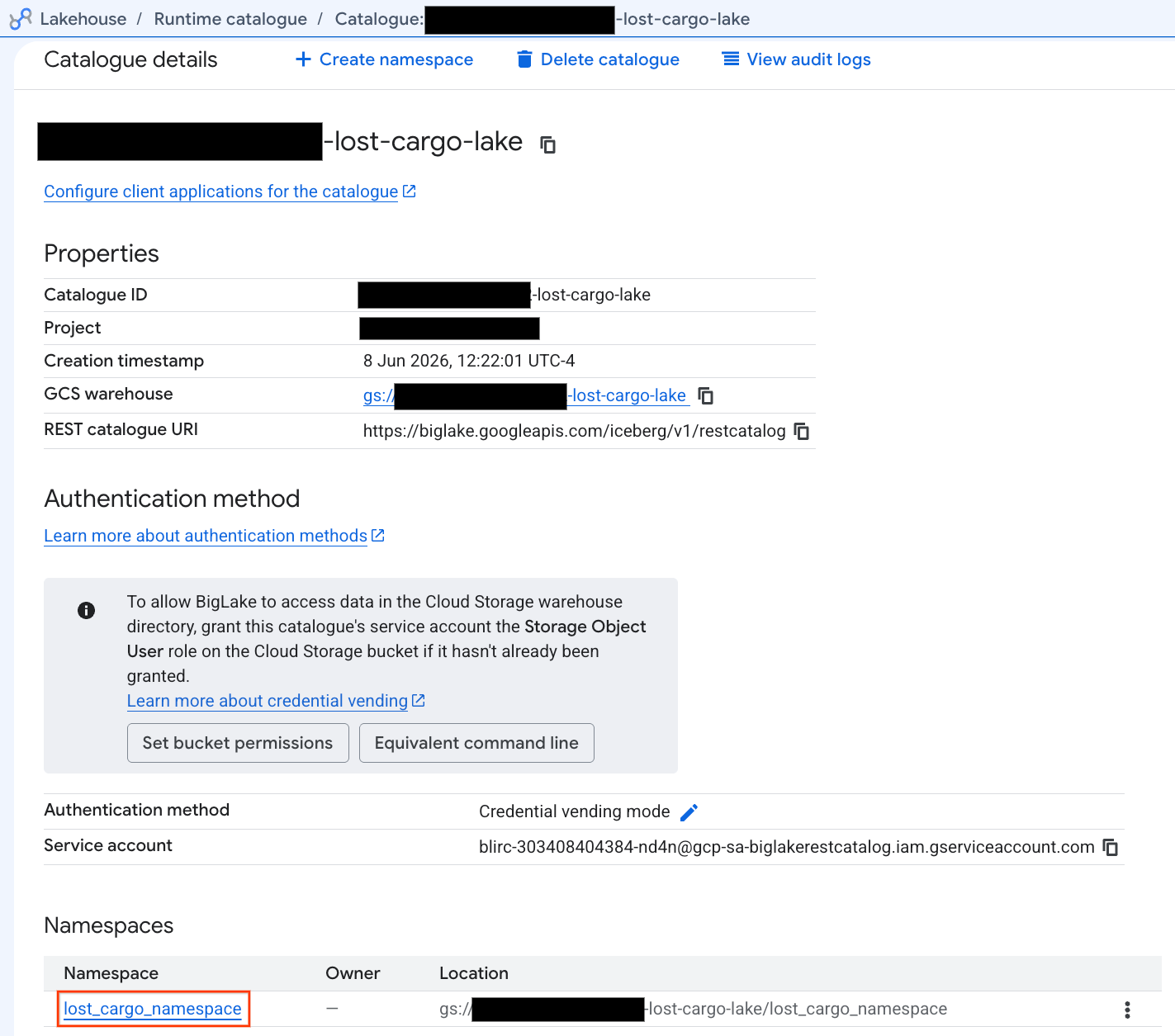
- PySpark로 생성된 새 Apache Iceberg 테이블이 이 metastore 네임스페이스에 자동으로 등록되어 BigQuery에서 즉시 쿼리할 수 있게 되었습니다.
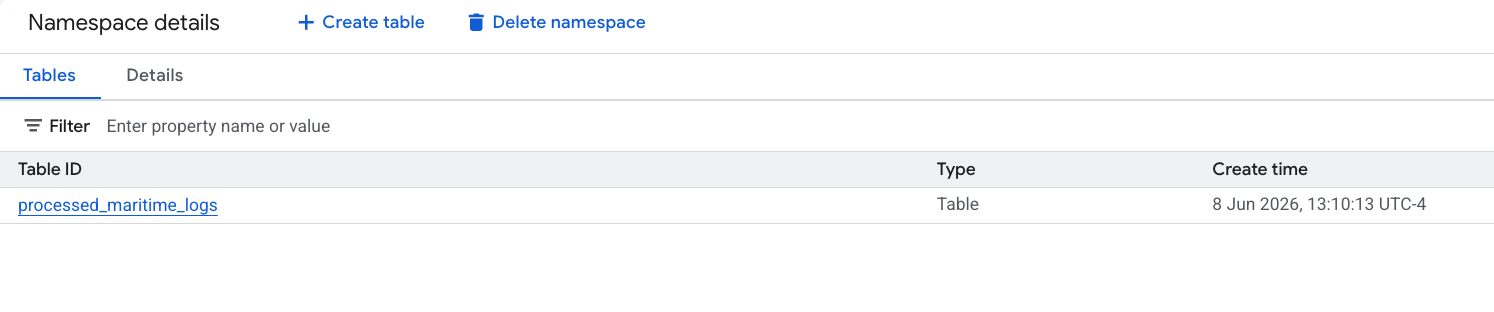
6. 배송 매니페스트 표에 대한 통계 생성
shipping_manifests 표로 돌아가 Knowledge Catalog 데이터 통계를 사용하여 구조와 콘텐츠를 분석해 보겠습니다. 메타데이터를 보강하면 다른 탐색 사용자가 향후 분석을 위해 표를 더 잘 이해할 수 있습니다.
BigQuery Studio에서 테이블 통계 생성
- Google Cloud 콘솔에서 BigQuery Studio로 이동합니다.
- 탐색기 패널에서 프로젝트를 펼치고
lost_cargo_dataset데이터 세트를 펼친 다음shipping_manifests테이블을 클릭합니다. - 오른쪽의 세부정보 패널에서 인사이트 탭을 클릭합니다.
- 드롭다운을 사용하여 생성 및 게시를 선택합니다.
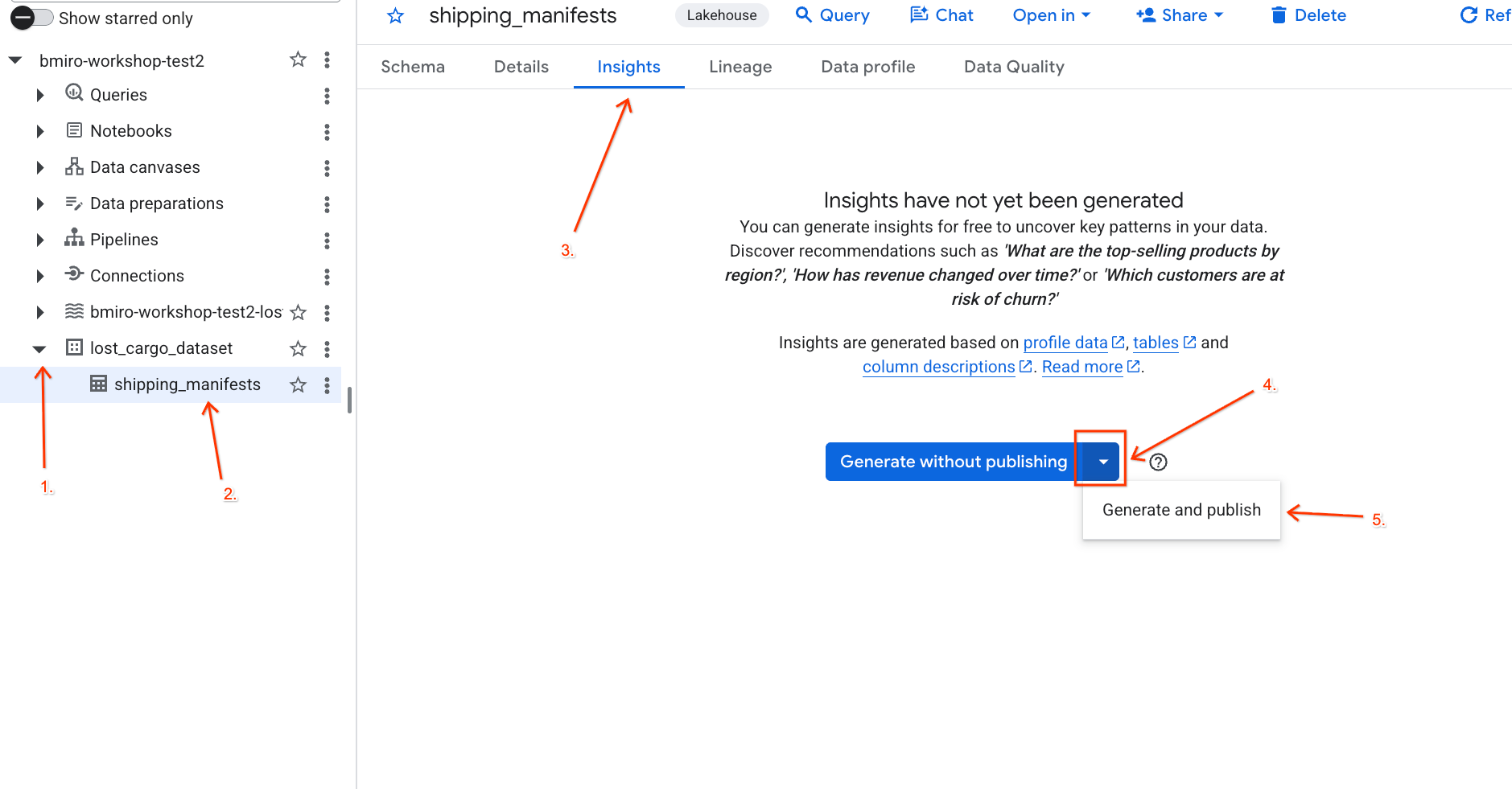
- 인사이트 생성이 완료될 때까지 약 3분 정도 기다립니다. Gemini가 테이블 메타데이터를 분석하고 자연어 질문과 해당 SQL 쿼리를 생성합니다.
- 완료되면 테이블에 대한 자연어 설명이 포함된 표 설명이 표시됩니다.
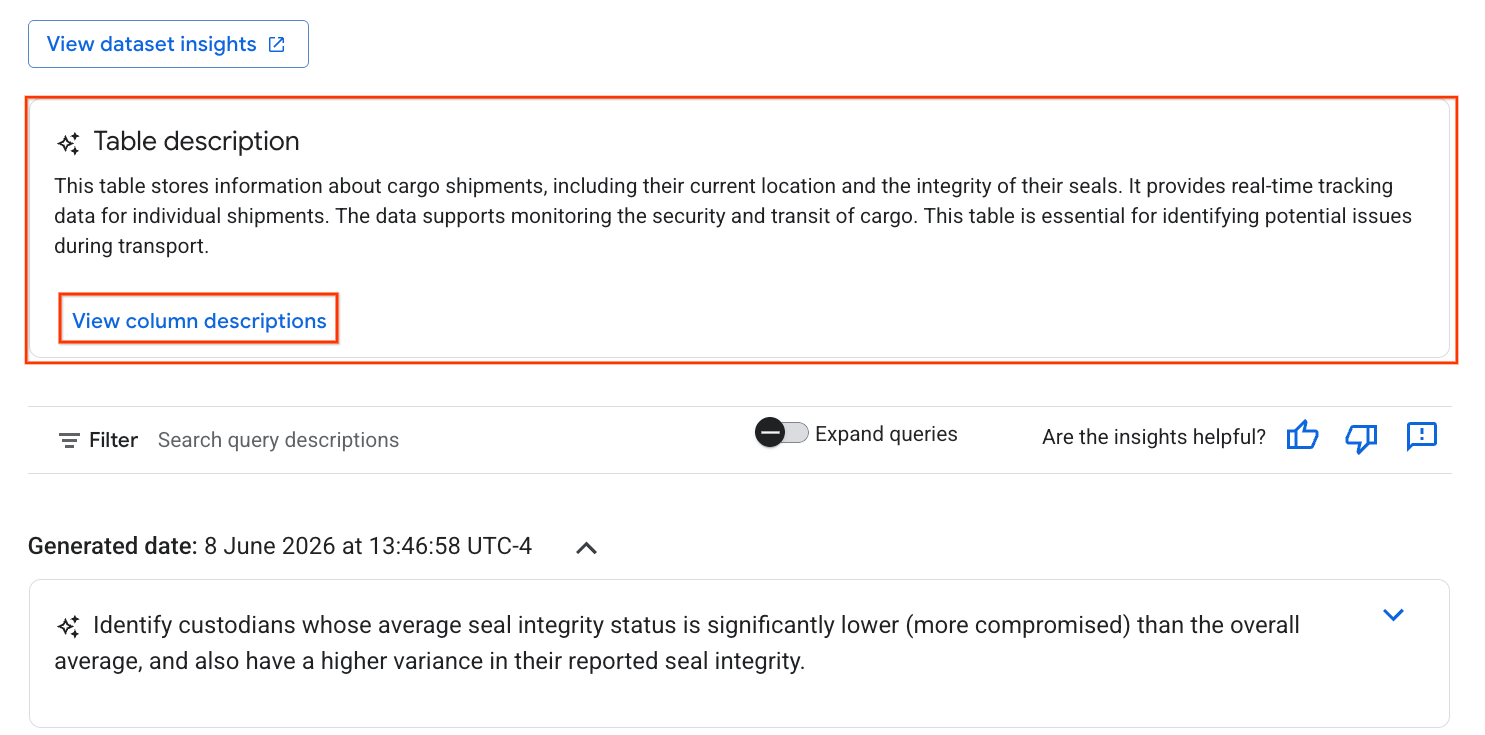
- 열 설명 보기를 클릭하여 개별 열에 대한 정보를 확인합니다.
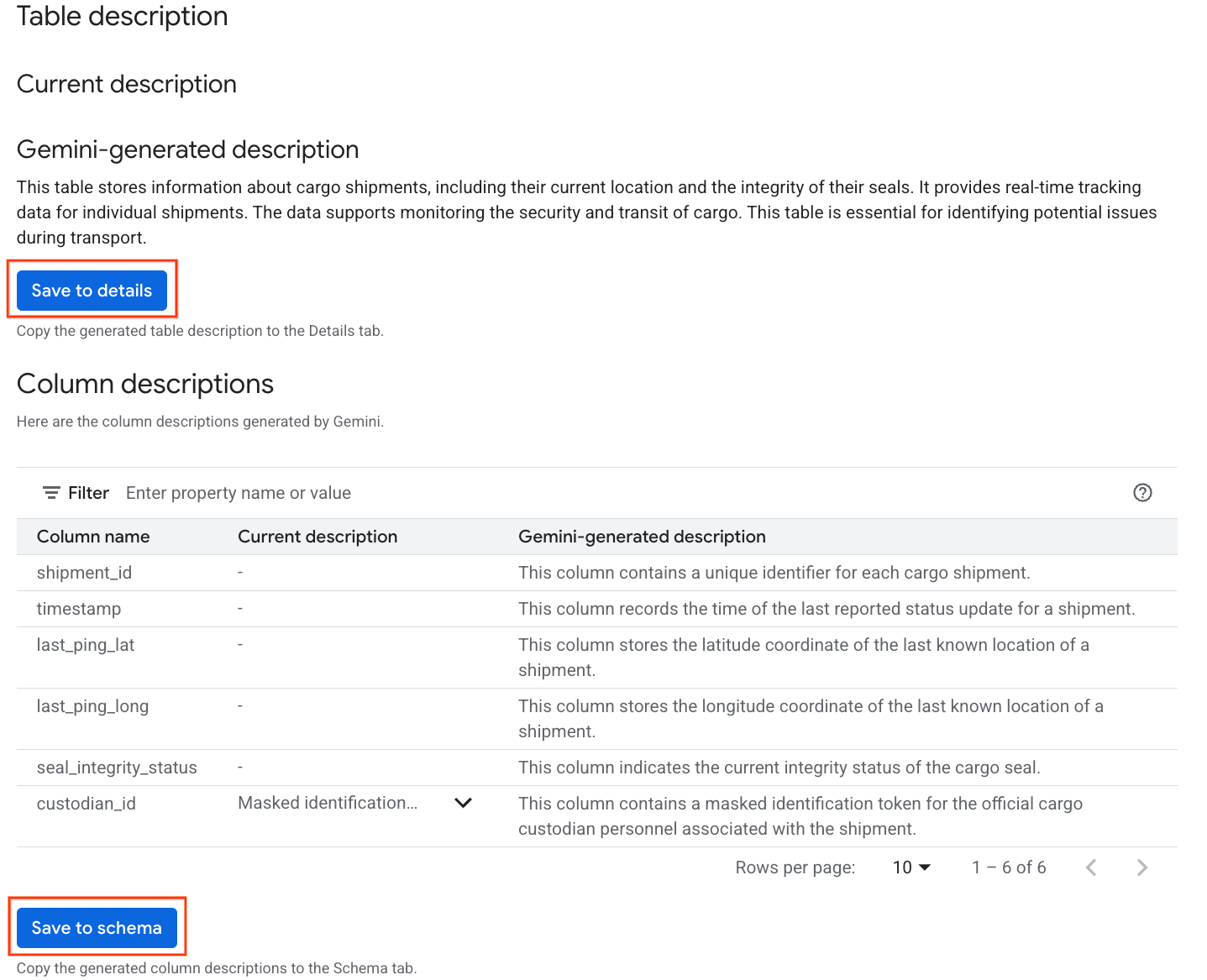
Gemini generated description아래의 세부정보에 저장을 클릭하고 팝업 창에서 세부정보에 저장을 클릭합니다.
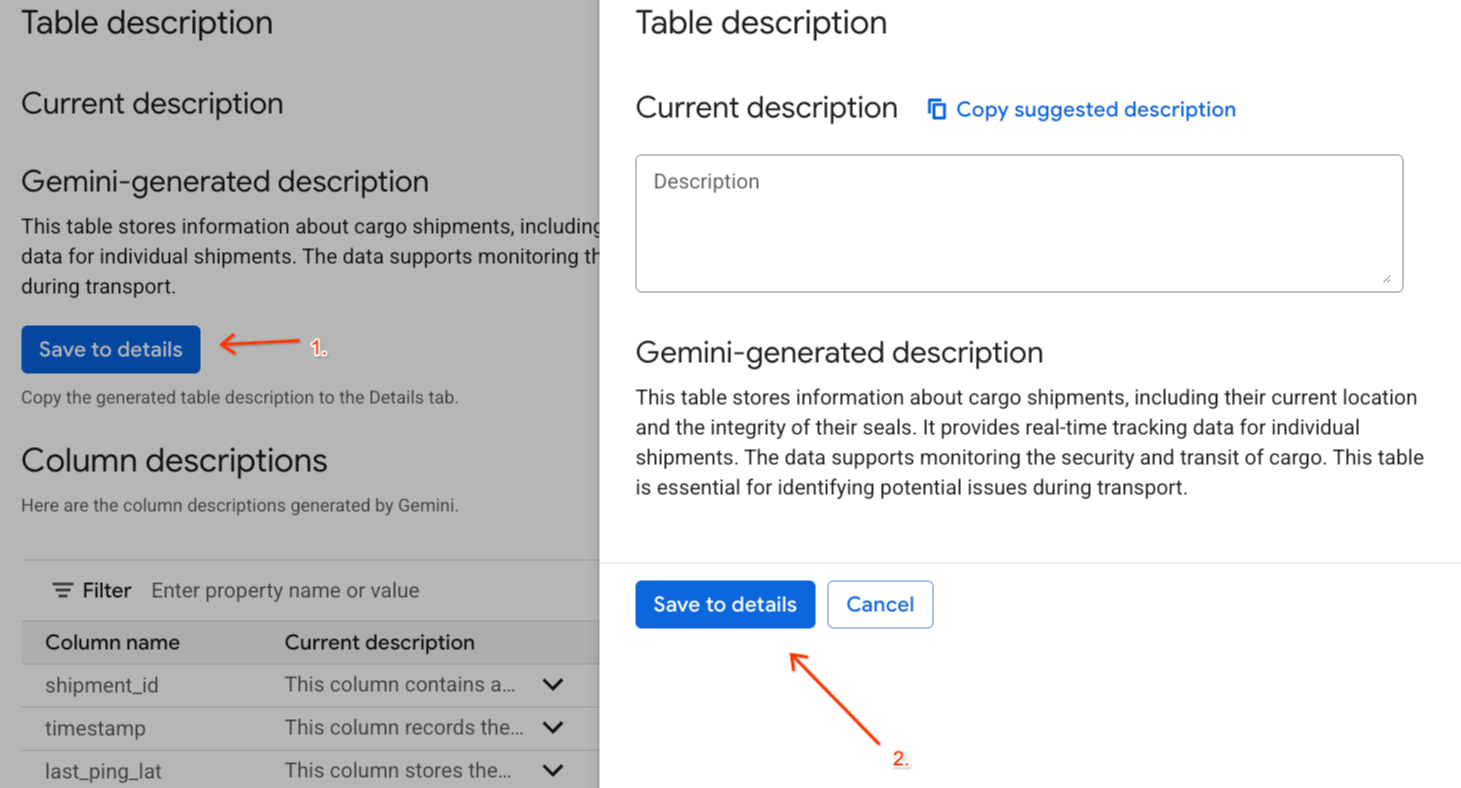
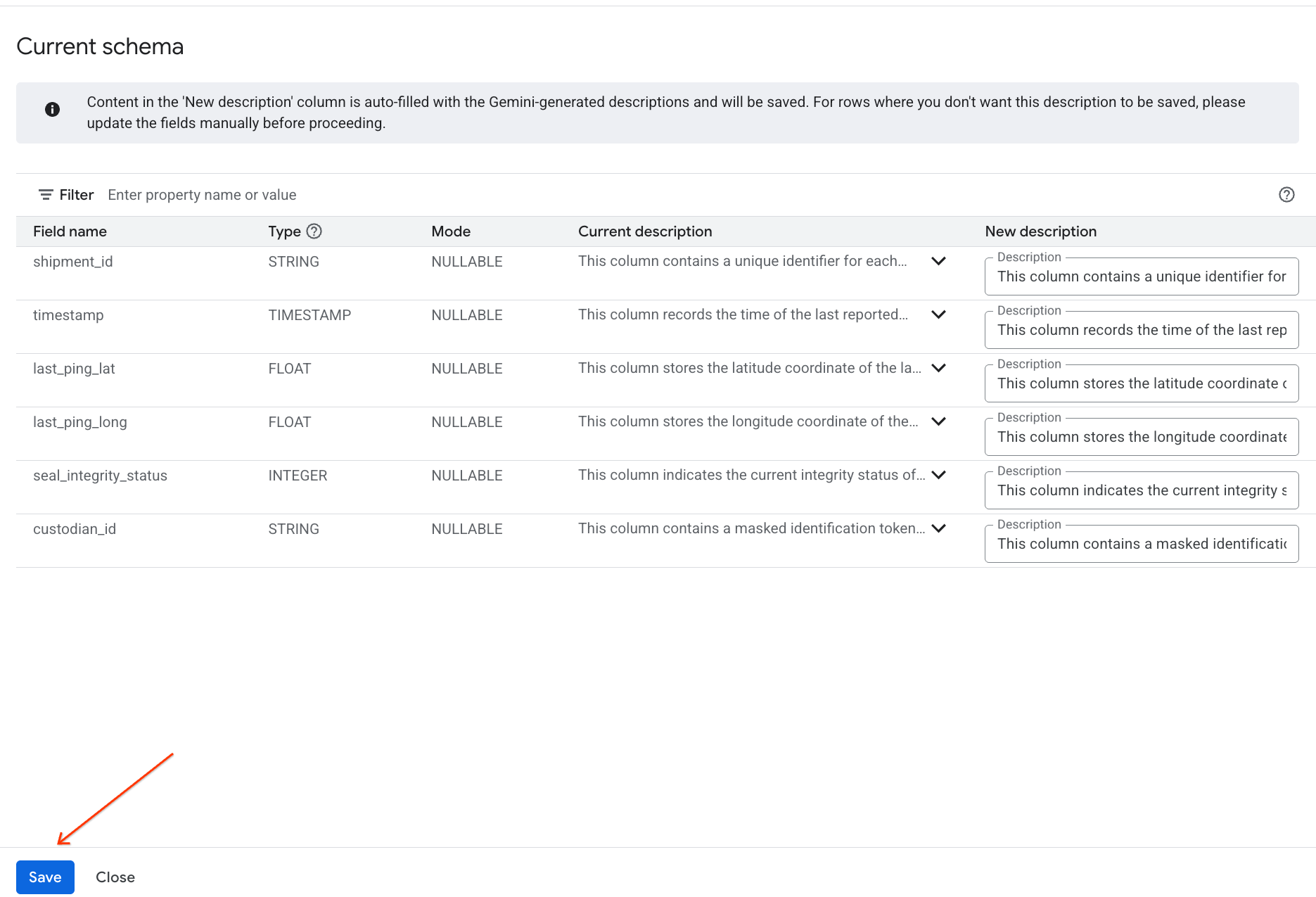
- 마찬가지로 스키마에 저장을 클릭하여 열 설명을 표 메타데이터에 추가합니다.
생성된 인사이트 검토
추천 질문 목록도 표시됩니다. 질문을 클릭하여 생성된 SQL 쿼리를 확인하고 실행하여 데이터를 탐색할 수 있습니다. 예를 들어 다음과 같은 질문이 표시될 수 있습니다.
- '총 배송 건수는 몇 건이야?'
- '고유 보관인 ID를 나열해 줘.'
이러한 쿼리를 실행하면 데이터를 이해하는 데 도움이 됩니다.
7. 데이터 마스킹 및 거버넌스 구현
진행 중인 화물 조사 중에 활성 연구 계정 및 사용자 이름이 유출되지 않도록 하려면 표준 보안 프로토콜을 적용해야 합니다. 보안 정책 태그 분류를 만들고 민감한 custodian_id 열에 Knowledge Catalog 데이터 마스킹을 구성하여 데이터 개인 정보 보호를 확인합니다.
기본적으로 BigQuery는 정책 태그로 보호되는 열에 대한 액세스를 거부합니다. 표를 쿼리하고 활성 데이터 마스크를 확인하려면 사용자 계정에 BigQuery 데이터 정책 마스킹된 리더 역할이 있어야 합니다.
이 역할은 setup_lab1.sh을 처음 실행할 때 활성 사용자 계정에 자동으로 바인딩되었습니다.
분류 및 정책 태그 만들기
데이터 액세스를 관리하기 위한 데이터 분류 및 연결된 정책 태그를 만듭니다.
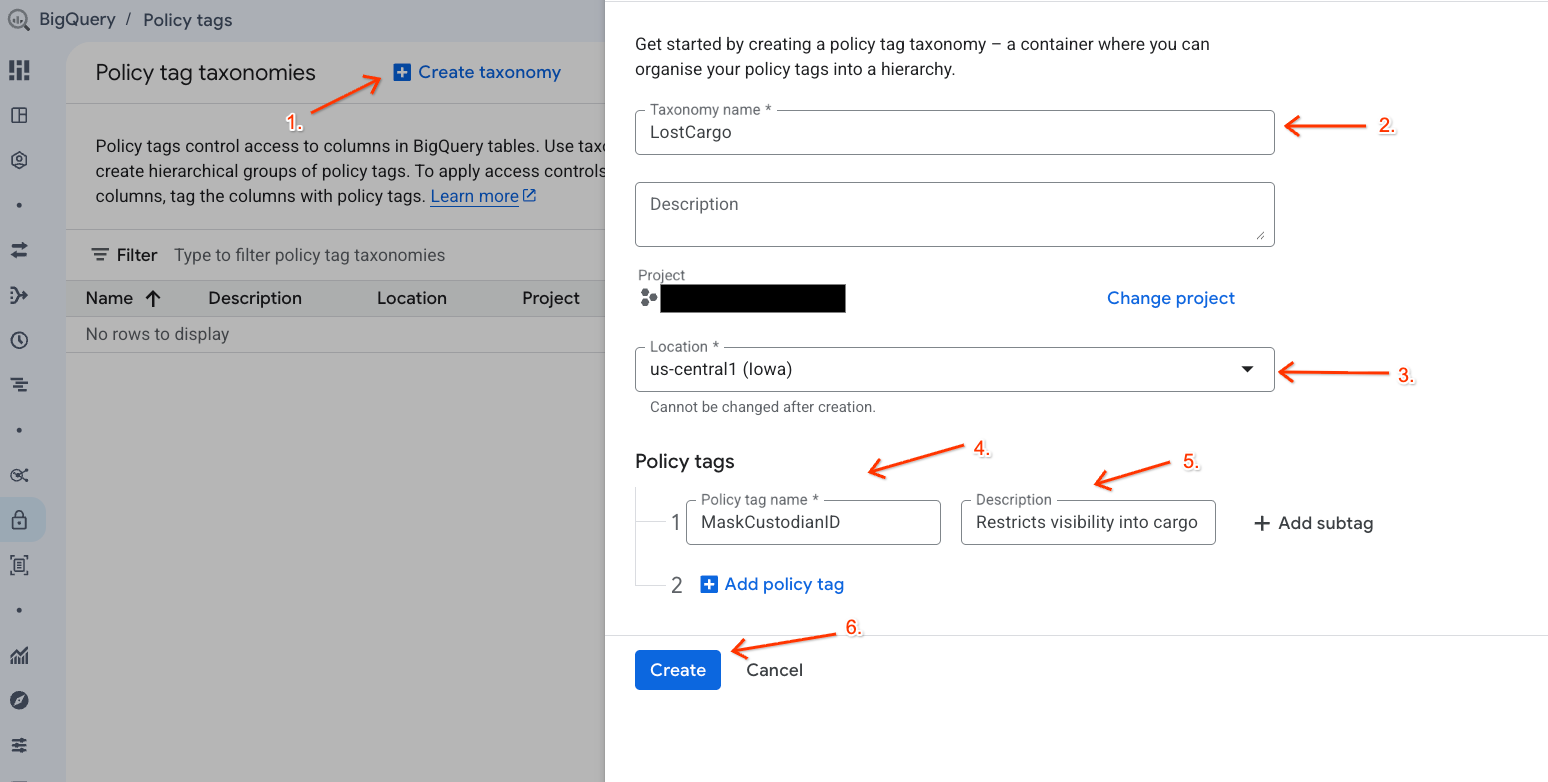
- 정책 태그 분류 페이지로 이동합니다.
- + 분류 만들기를 클릭합니다.
- 매개변수를 구성합니다.
- 분류 이름:
lost-cargo-를 입력하고 프로젝트 ID로 바꿉니다. - 리전: 리전을 선택합니다.
- 정책 태그 이름:
MaskCustodianID입력 - 정책 태그 설명:
Restricts visibility into cargo custodian usernames
- 분류 이름:
- 만들기를 클릭하여 새 분류 및 정책 태그를 등록합니다.
데이터 마스킹 정책 만들기
다음으로 데이터 정책을 구성하여 MaskCustodianID 분류 태그에서 데이터가 마스킹되는 방식을 정의합니다. 항상 Null 마스킹 규칙을 사용합니다 (권한이 없는 모든 행위자에 대해 일치하는 값을 빈/Null 반환으로 대체).
- 정책 태그 분류 페이지의 분류 목록에서 새로 만든 분류를 클릭합니다.
- 계층 구조 목록에서
MaskCustodianID태그를 클릭하여 선택한 다음 데이터 정책 관리를 선택합니다.
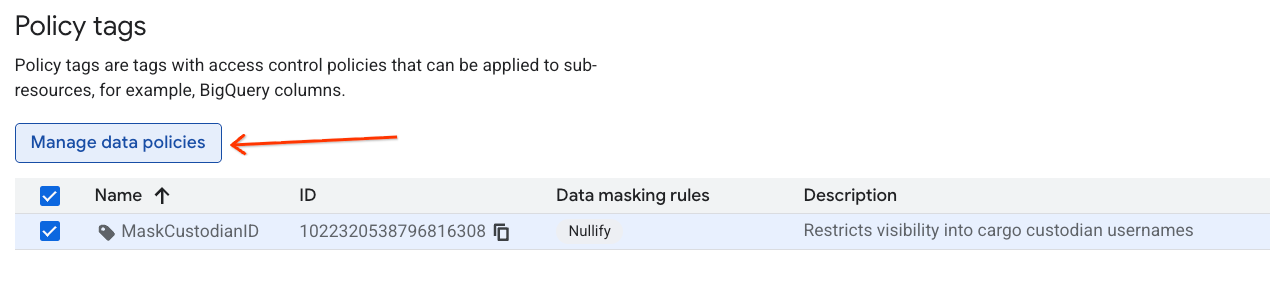
- 오른쪽 패널에서 + 규칙 추가 버튼을 클릭합니다.
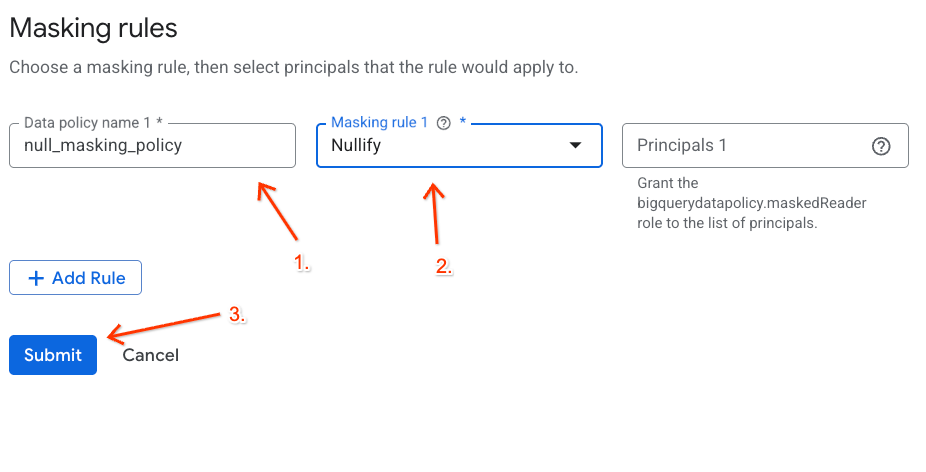
- 표시되는 패널에서 정책 세부정보를 구성합니다.
- 데이터 정책 이름:
null_masking_policy을 입력합니다 (다음 단계에서 이름으로 참조하므로 자동 생성된 상태로 두지 마세요). - 마스킹 규칙: 드롭다운 메뉴에서
Nullify를 선택합니다.
- 데이터 정책 이름:
- 제출을 클릭합니다.
BigQuery 열에 정책 태그 할당
정책 태그와 데이터 마스킹 규칙이 활성화된 상태에서 분류 태그를 BigQuery 파트너 배송 매니페스트 테이블의 custodian_id 열에 직접 매핑합니다.
- BigQuery 콘솔로 이동합니다.
- 왼쪽의 탐색기 패널에서 활성 프로젝트를 펼치고
lost_cargo_dataset데이터 세트를 펼친 다음shipping_manifests테이블을 클릭하여 세부정보 보기를 엽니다. - 스키마 수정을 클릭합니다.
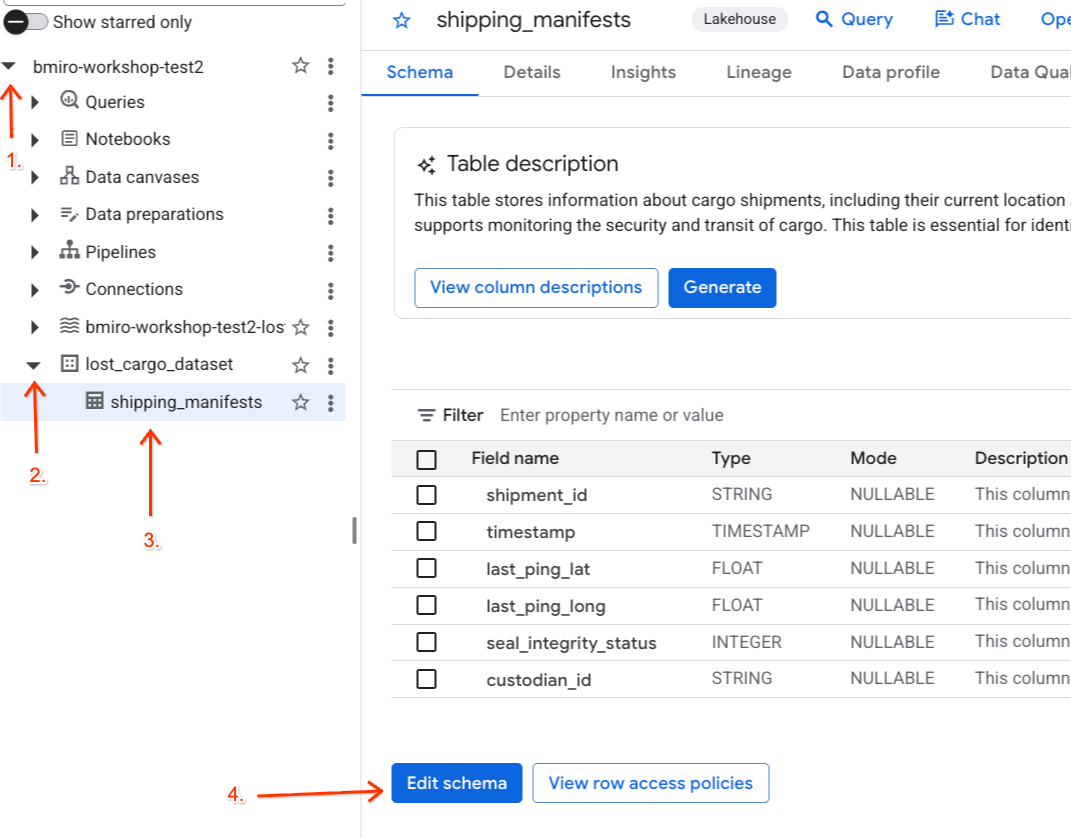
- 열 목록에서
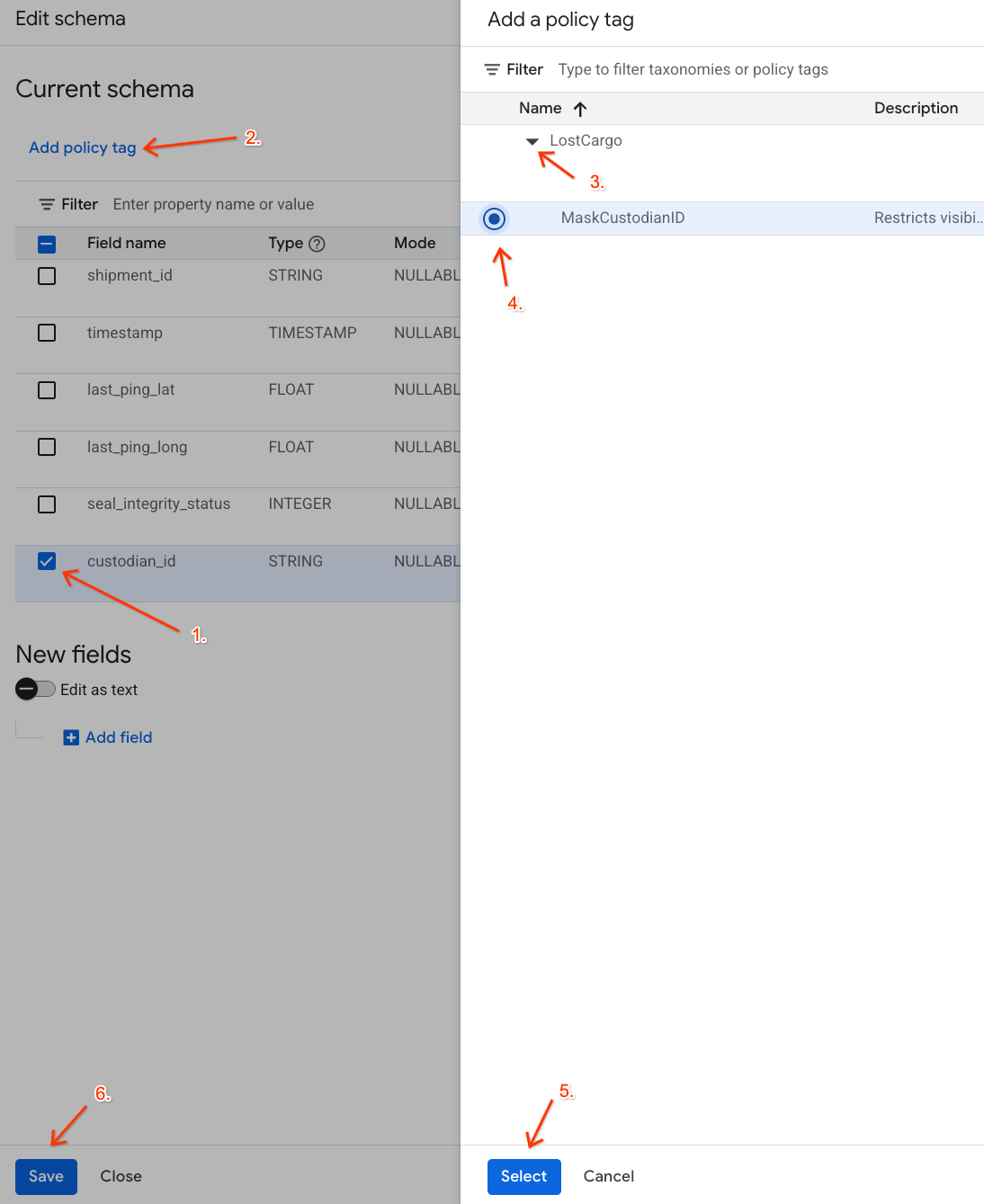
custodian_id옆에 있는 체크박스를 선택합니다. - 스키마 편집기의 상단 툴바에서 정책 태그 추가 버튼을 클릭합니다.
- 정책 태그 추가 패널에서 다음을 수행합니다.
LostCargo분류를 찾아 펼칩니다.MaskCustodianID옆에 있는 풍선을 선택합니다.- 선택을 클릭합니다.
custodian_id을 나타내는 행의 정책 태그 열에MaskCustodianID태그가 표시되는지 확인합니다.- 저장을 클릭합니다.
정책 제한사항 확인
이제 프로젝트 수준에서 마스킹된 리더 역할을 보유하므로 테이블을 쿼리하여 마스킹 정책이 활성 상태인지 확인할 수 있습니다.
데이터 에이전트 키트로 돌아가서 다음 쿼리를 실행합니다.
SELECT shipment_id, custodian_id
FROM lost_cargo_dataset.shipping_manifests
LIMIT 5;
다음과 비슷한 출력이 표시됩니다.
shipment_id | custodian_id |
NORMAL-001 | null |
NORMAL-002 | null |
MV-CAT-001 | null |
완료되었습니다. shipment_id 레코드를 볼 수 있지만 민감한 custodian_id 필드는 유출을 방지하기 위해 안전한 null 마스크를 반환합니다.
8. 삭제
이 Codelab에서 생성한 리소스의 비용이 Google Cloud 계정에 청구되지 않도록 하려면 Cloud Shell 터미널에서 다음 명령어를 실행하여 데이터 세트와 버킷을 삭제하세요.
# Verify active variables
export PROJECT_ID=$(gcloud config get-value project)
export BUCKET_NAME="${PROJECT_ID}-lost-cargo-lake"
# Delete Knowledge Catalog security taxonomies
export TAXONOMY_NAME=$(gcloud data-catalog taxonomies list --location=us-central1 --filter="displayName:LostCargo" --format="value(name)")
if [[ -n "$TAXONOMY_NAME" ]]; then
curl -X DELETE \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
"https://datacatalog.googleapis.com/v1/${TAXONOMY_NAME}" || true
fi
# Delete Lakehouse Iceberg REST Catalog tables and namespaces
gcloud biglake iceberg tables delete processed_maritime_logs \
--catalog=${BUCKET_NAME} \
--namespace=lost_cargo_namespace \
--quiet || true
gcloud biglake iceberg namespaces delete lost_cargo_namespace \
--catalog=${BUCKET_NAME} \
--quiet || true
# Delete Lakehouse Iceberg REST Catalog
gcloud biglake iceberg catalogs delete ${BUCKET_NAME} --quiet || true
# Delete dependencies bucket
gcloud storage rm -r gs://${BUCKET_NAME} || true
# Delete BigQuery dataset and tables
bq rm -r -f -d ${PROJECT_ID}:lost_cargo_dataset || true
9. 축하합니다
축하합니다. 분실된 화물 조사에서 첫 번째 중요한 모듈을 완료했습니다. Lakehouse Iceberg REST 카탈로그, PySpark 로그 정규화, 세부적인 데이터 마스킹을 사용하여 관리 검색 영역을 설정했습니다.
학습한 내용
- IDE 작업공간 내에서 데이터 에이전트 키트 확장 프로그램을 설치, 설정, 구성합니다.
- 판매된 사용자 인증 정보와 계층적 네임스페이스를 활용하여 서버리스 Lakehouse Iceberg REST 카탈로그를 설정합니다.
- 다중 형식 지역 피드를 수집하고 Cloud Storage 버킷을 통해 BigQuery 외부 테이블을 빌드합니다.
- 서버리스 Apache Spark 작업을 실행하여 등록된 Iceberg 카탈로그 테이블로 구조화되지 않은 트랜스폰더 로그를 파싱, 정규화, 세그먼트화하고 BigQuery에 다시 작성합니다.
- 민감한 로그 색인에서 ID 유출을 방지하기 위해 보안 분류를 구축하고 Knowledge Catalog 데이터 마스킹 정책을 매핑합니다.
- BigQuery 데이터 통계를 사용하여 테이블 메타데이터 통계를 생성하고 분석하여 데이터 탐색을 가속화합니다.
수집된 단서 확인
다음 실습 단계로 진행하는 데 필요한 결정적인 단서를 기록했는지 확인합니다.
- 분실된 배송 ID:
MV-CAT-001(마지막 핑 위치: 런던) - 계획된 타겟 대상:
New York(트랜스폰더 실제 별칭:MV-DOG-002) - 컨테이너 색상:
Crimson RED - 거버넌스 액세스 태그:
MaskCustodianID
다음 단계로 넘어갈 준비가 되셨나요?
트랜스폰더 출발 / 도착 경로가 안전해졌으므로 조사가 진행됩니다. 바로 실습 2로 이동하여 멀티모달 Gemini 모델을 사용하여 보안 카메라를 검사하고, 선박을 시각적으로 식별하고, AlloyDB에서 벡터 검색을 실행하여 조작 이상을 확인하세요.
➡️ 2단계: 데이터 분석 및 멀티모달 통계로 계속하기