
1. Wprowadzenie
W tym module wcielisz się w rolę głównego analityka danych w globalnej firmie logistycznej. Zaginął kontener z cennymi kolekcjonerskimi figurkami Androida. Aby znaleźć ostatnią znaną pozycję przesyłki i prześledzić jej trasę, musisz zebrać pofragmentowane manifesty wysyłki od regionalnych partnerów logistycznych i nieustrukturyzowane pliki dziennika transpondera. W tym celu skonfigurujesz nowoczesną architekturę Google Cloud Open Data Lakehouse.

Jakie zadania wykonasz
- Skonfiguruj rozszerzenie Google Cloud Data Agent Kit w edytorze Cloud Shell.
- Utwórz zasobnik Cloud Storage i udostępnij katalog Apache Iceberg REST Lakehouse oraz przestrzeń nazw.
- Mapuj zewnętrzną tabelę BigLake na nieprzetworzone manifesty partnerów w formacie JSON w Cloud Storage, aby odkryć wskazówkę dotyczącą wypłynięcia statku.
- Wczytywanie i przetwarzanie nieustrukturyzowanych logów tekstowych transpondera za pomocą usługi zarządzanej dla Apache Spark Managed Service for Apache Spark bezserwerowej. Przeprowadzanie normalizacji wyrażeń regularnych i dynamiczne wyodrębnianie wskazówek w celu określenia miejsca docelowego utraconego ładunku.
- Zapisz przeanalizowane dane z logu jako tabelę Apache Iceberg za pomocą katalogu REST.
- Porozmawiaj z agentem AI o danych Apache Iceberg, korzystając z analityki konwersacyjnej, aby odkryć ukryte wskazówki dotyczące zaginionej przesyłki.
- Korzystaj z automatycznych analiz danych w Knowledge Catalog, aby generować metadane dotyczące danych.
- Ustanów zabezpieczenia dotyczące pozyskiwania danych, tworząc taksonomię zabezpieczeń i używając Knowledge Catalog do stosowania szczegółowej kontroli dostępu przez maskowanie poufnych identyfikatorów podmiotów przechowujących dane.
Czego potrzebujesz
- przeglądarka, np. Chrome;
- Projekt Google Cloud z włączonymi płatnościami.
- Znajomość podstawowych zapytań SQL i poleceń terminala.
Spodziewany koszt i czas trwania
- Czas potrzebny do ukończenia: około 45 minut.
- Szacunkowy koszt: mniej niż 5,00 USD.
2. Zanim zaczniesz
Tworzenie lub wybieranie projektu Google Cloud
- W konsoli Google Cloud wybierz lub utwórz projekt w chmurze Google Cloud.
- Sprawdź, czy w projekcie Cloud włączone są płatności. Dowiedz się, jak sprawdzić, czy w projekcie są włączone płatności.
Konfigurowanie środowiska
Większość poleceń będziesz uruchamiać w zintegrowanym terminalu w edytorze Cloud Shell, czyli w środowisku programistycznym w chmurze, które zawiera narzędzia dla deweloperów i standardowy pakiet SDK Google Cloud.
- Otwórz edytor Cloud Shell w nowej karcie.
- Aby sklonować repozytorium, uruchom w terminalu to polecenie:
cd ~/ git clone --filter=blob:none --no-checkout https://github.com/GoogleCloudPlatform/devrel-demos.git cd ~/devrel-demos git sparse-checkout init --cone git sparse-checkout set data-analytics/data-cloud-roadshow/lab1 git checkout main cd data-analytics/data-cloud-roadshow/lab1 - Ustaw identyfikator projektu. Możesz też nacisnąć
Ctrl+Shift+Vw systemie Windows/Linux lubCmd+Vw systemie macOS, aby wkleić go w terminalu:export PROJECT_ID="<YOUR_PROJECT_ID>" - Teraz skonfiguruj go w swoim środowisku.
gcloud config set project $PROJECT_ID - Wybierz region.
export REGION="<YOUR_REGION>" # Replace with the region you chose, such as "us-central1" - Włącz wymagane interfejsy API.
gcloud services enable \ bigquery.googleapis.com \ biglake.googleapis.com \ storage.googleapis.com \ dataplex.googleapis.com \ datacatalog.googleapis.com \ dataproc.googleapis.com \ aiplatform.googleapis.com \ cloudresourcemanager.googleapis.com \ serviceusage.googleapis.com \ cloudaicompanion.googleapis.com \ geminidataanalytics.googleapis.com
Zainstaluj rozszerzenie
Teraz skonfigurujesz rozszerzenie Google Data Agent Kit, czyli narzędzie do interakcji z narzędziami do obsługi danych Google Cloud bezpośrednio w środowisku IDE.
- Na pasku działań po lewej stronie edytora kliknij ikonę Rozszerzenia (lub naciśnij
Ctrl+Shift+Xw systemie Windows/Linux alboCmd+Xw systemie macOS). - W polu wyszukiwania rozszerzeń wpisz:
Google Cloud Data Agent Kit - Wybierz oficjalne rozszerzenie z wyników i kliknij Zainstaluj. Jeśli pojawi się prośba, wybierz „Tak, ufam autorom”.
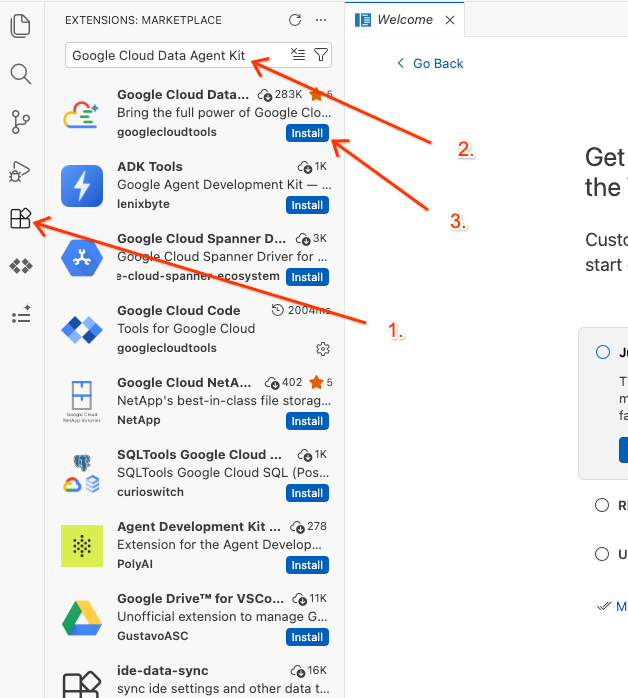
- Po pomyślnym zainstalowaniu na pasku aktywności powinna pojawić się ikona Google Cloud Data Agent Kit. Kliknij ją.
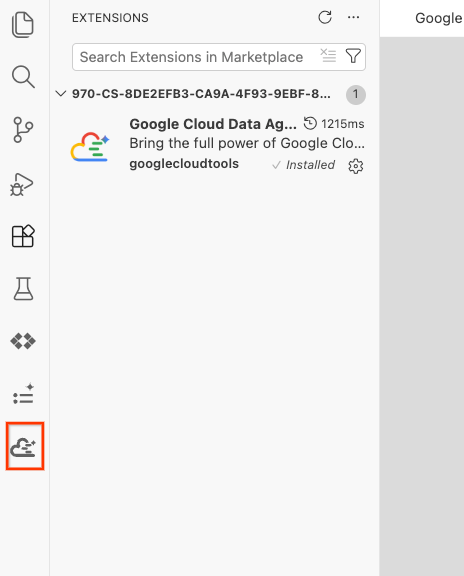
- Kliknij Zaloguj się w chmurze.
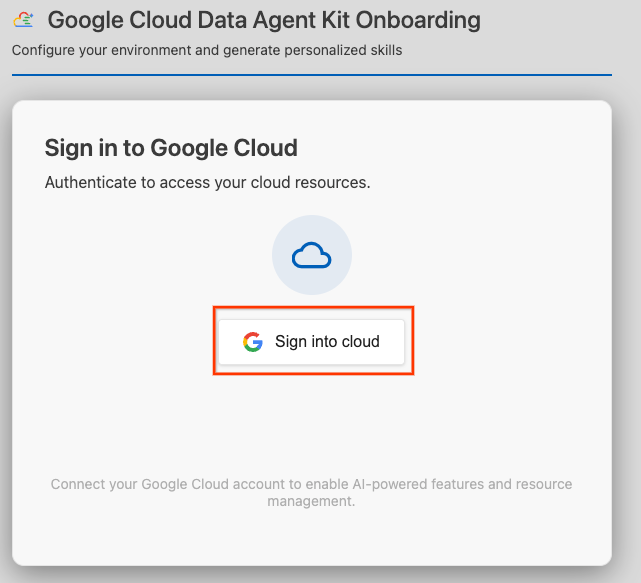
- Kliknij Skonfiguruj serwery MCP.
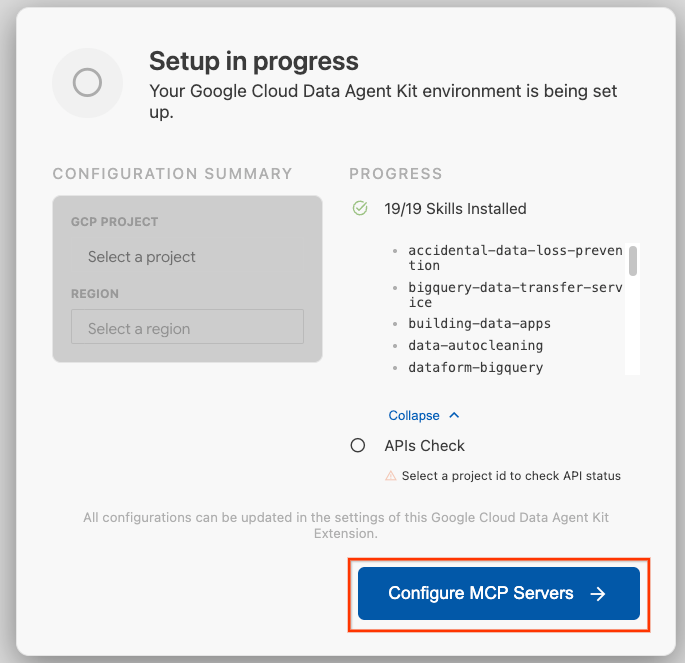
- Wybierz BigQuery, Knowledge Catalog, Apache Spark i AlloyDB. W module 2 użyjesz AlloyDB. Następnie kliknij Rozpocznij.
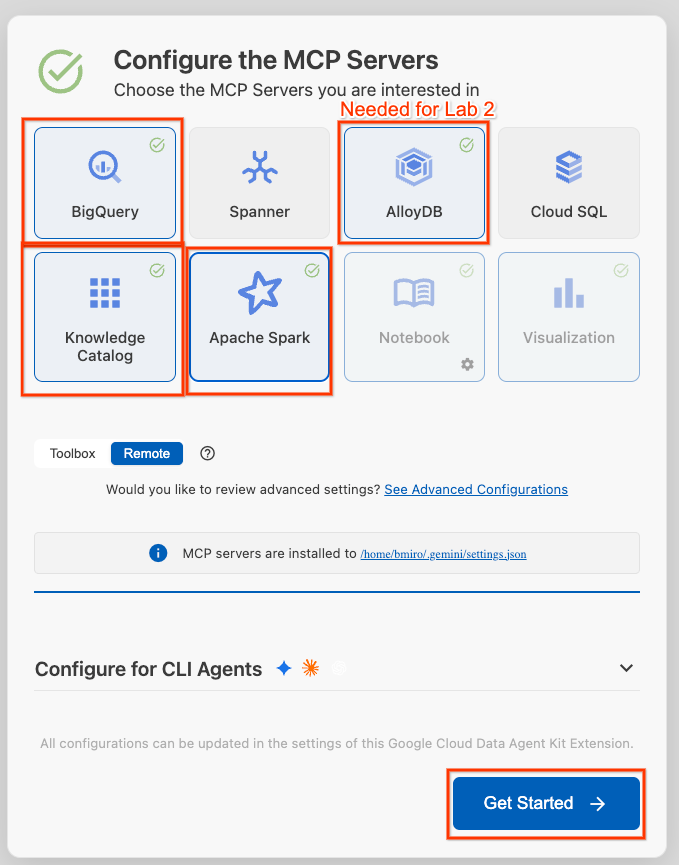
- Na pasku stanu u dołu kliknij selektor Identyfikator projektu i wybierz aktywny projekt Google Cloud.
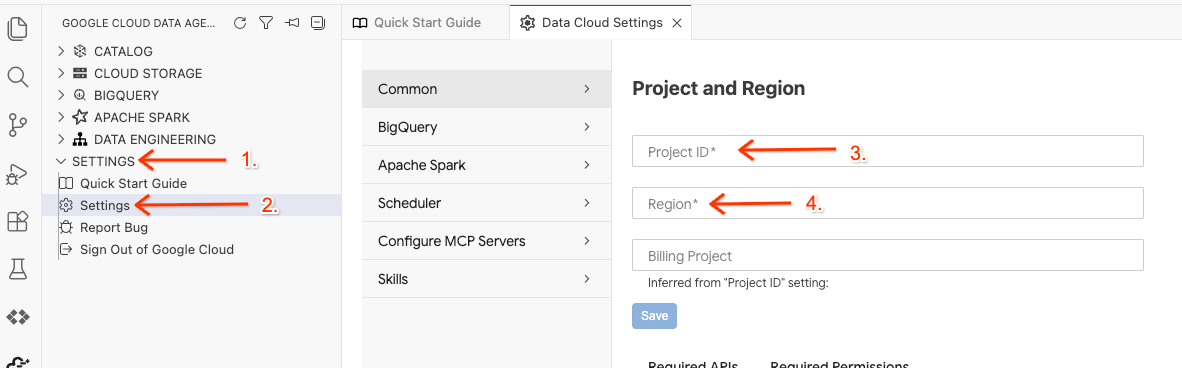
- W zestawie Data Agent Kit kliknij SETTINGS (USTAWIENIA), a potem Settings (Ustawienia). Na karcie Common (Ogólne) wybierz Project ID (Identyfikator projektu) i Region (Region), w którym chcesz uruchomić laboratorium, np. us-central1.
- Kliknij Ustawienia BigQuery i zastąp Region wcześniej wybranym regionem. Kliknij Zapisz.
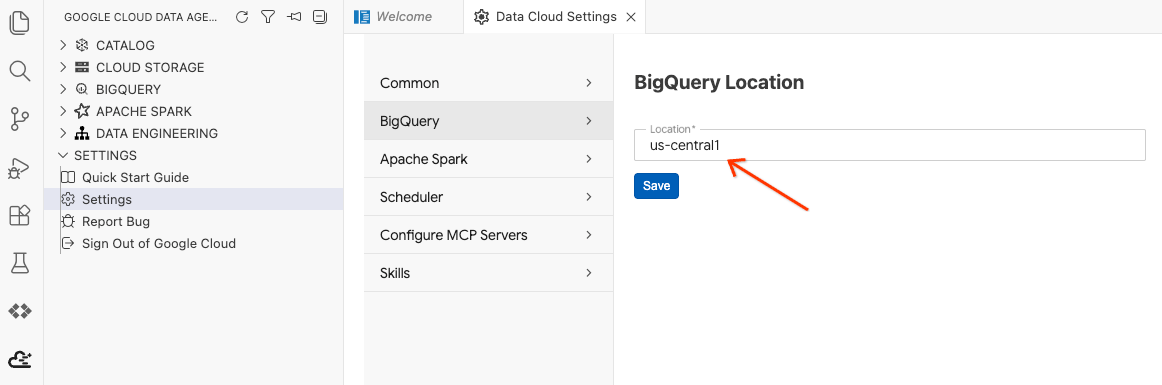
Możesz już korzystać z zestawu Data Agent Kit.
Uruchamianie skryptu konfiguracji środowiska
W terminalu uruchom skrypt konfiguracji, aby utworzyć niezbędne zasoby w tle dla tego modułu i skonfigurować uprawnienia:
chmod +x setup_lab1.sh
./setup_lab1.sh
source .env
Powinny się wyświetlić kolejne kroki danych wyjściowych pokazujące, jakie zasoby są udostępniane. Omówimy je w tym module.
Gdy pojawi się komunikat o zakończeniu, możesz przejść dalej:
==================================================== Environment Setup Complete! ====================================================
Zaczynamy poszukiwania!
3. Pozyskiwanie plików manifestu wysyłki partnera
Dane manifestu wysyłki z statków partnerskich są przechowywane w standardowym formacie JSON Lines (JSONL) w Twoim zasobniku: gs://${PROJECT_ID}-lost-cargo-lake/shipping_manifests/manifests.jsonl.
Przed przeprowadzeniem szczegółowej analizy utworzysz zarządzaną tabelę BigLake dla tych nieustrukturyzowanych danych. Dzięki temu możesz od razu eksplorować dane logistyczne partnera za pomocą standardowej wersji SQL bezpłatnie związanych z duplikowaniem importu.
Otwórz obszar roboczy w edytorze i uruchom zapytanie.
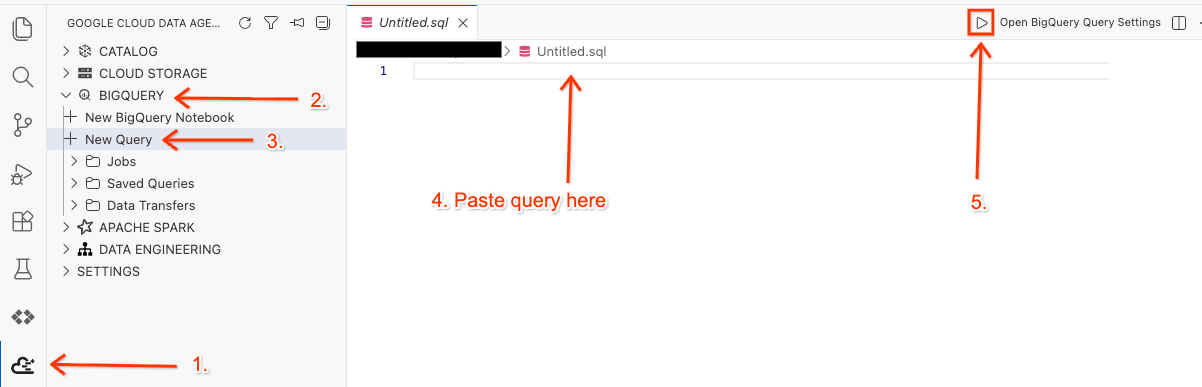
- W edytorze Cloud Shell kliknij ikonę rozszerzenia Google Cloud Data Agent Kit w panelu bocznym.
- Otwórz BigQuery i kliknij + Nowe zapytanie.
- Skopiuj to zapytanie do okna zapytania.
SET @@location = "<YOUR_REGION>"; --Update to your resource region, such as "us-central1". Make sure it is in quotes.
EXECUTE IMMEDIATE ("""
CREATE OR REPLACE EXTERNAL TABLE `lost_cargo_dataset.shipping_manifests`
(
shipment_id STRING,
timestamp TIMESTAMP,
last_ping_lat FLOAT64,
last_ping_long FLOAT64,
seal_integrity_status INT64,
custodian_id STRING OPTIONS(description='Masked identification token for official cargo custodian personnel.')
)
WITH CONNECTION `""" || @@location || """.conn`
OPTIONS (
format = 'NEWLINE_DELIMITED_JSON',
uris = ['gs://""" || @@project_id || """-lost-cargo-lake/shipping_manifests/*.jsonl']
)
""");
- Kliknij Wykonaj.
- Aby sprawdzić, czy tabela została utworzona, w panelu Wyniki zapytania, który automatycznie otworzy się u dołu, zobaczysz komunikat o powodzeniu.
Wykonaj zapytanie do tabeli zewnętrznej, aby wyodrębnić naruszone transpondery.
Zidentyfikujmy przejęte transpondery, wyszukując awarie, gdy wartość seal_integrity_status była ustawiona na 0. Skopiuj i uruchom to zapytanie w otwartym wcześniej oknie zapytania:
SELECT shipment_id, last_ping_lat, last_ping_long, custodian_id
FROM `lost_cargo_dataset.shipping_manifests`
WHERE seal_integrity_status = 0;
W panelu Wyniki zapytania powinny pojawić się dane wyjściowe podobne do tych:
shipment_id | last_ping_lat | last_ping_long | custodian_id |
MV-CAT-001 | 51.5074 | -0,1278 | usr_999_shadow |
4. Przetwarzanie nieustrukturyzowanych logów za pomocą usługi zarządzanej dla Apache Spark
Z manifestów strukturalnych udało Ci się ustalić lokalizację początkową, ale utracony transponder całkowicie zamilkł. Ostatni ping transpondera pozostawił tajemniczą, niestrukturalną wiadomość w pliku dziennika w formacie zwykłego tekstu w ścieżce GCS gs://${BUCKET_NAME}/raw_logs/maritime_logs.txt.
Aby przetworzyć i zmapować ten dziennik tekstowy, wyodrębnić sygnatury czasowe, zamaskować tożsamości i zlokalizować dalszą trasę ładunku, prześlesz zadanie bezserwerowe Apache Spark (PySpark) do usługi zarządzanej dla Apache Spark.
Usługa zarządzana dla Apache Spark umożliwia uruchamianie zbiorów zadań Spark bez udostępniania klastra i zarządzania nim. Usługa obsługuje bazowe zasoby obliczeniowe, dynamicznie je skalując, a Ty płacisz tylko za czas wykonywania.
Skrypt:
- Pobierz nieprzetworzony, nieuporządkowany tekst transpondera w nawiasach.
- Zastosuj filtry wyodrębniania wyrażeń regularnych PySpark SQL, aby oddzielić sygnatury czasowe, metadane opiekuna i surowe treści.
- Podziel chaotyczne logi na przejrzyste rekordy na poziomie zdań.
- Wyodrębnij dynamiczny cel koordynacyjny miejsca docelowego, w którym zakończył się lot utraconego ładunku.
- Połącz się z katalogiem Lakehouse Apache Iceberg REST i zapisz w nim przetworzoną ramkę danych logów jako nową tabelę analityczną widoczną bezpośrednio w BigQuery.
Popraw skrypt analizy PySpark
Na morzu pojawiły się doniesienia o piratach z Pythona, którzy powodują różnego rodzaju problemy.
- Uruchom to polecenie, aby otworzyć plik
process_maritime_logsw edytorze Cloud Shell.cd ~/devrel-demos/data-analytics/data-cloud-roadshow/lab1 cloudshell open ./process_maritime_logs.py - Poświęć trochę czasu na przeczytanie kodu i zrozumienie, co robi.
- Sprawdź, czy w kodzie nie ma nic podejrzanego. Jeśli musisz coś usunąć, zapisz plik, używając
Ctrl + S(Windows/Linux) lubCmd + S(Mac).
Przesyłanie zadania Serverless Spark
Prześlij zadanie za pomocą gcloud SDK. Konfiguracja automatycznie skonfiguruje zadanie PySpark tak, aby miało dostęp do katalogu Lakehouse.
Uruchom to polecenie w terminalu zintegrowanego edytora.
cd ~/devrel-demos/data-analytics/data-cloud-roadshow/lab1
source .env
gcloud dataproc batches submit pyspark process_maritime_logs.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--version=2.3 \
--deps-bucket=${BUCKET_NAME} \
--properties="\
spark.sql.defaultCatalog=cargo_catalog,\
spark.sql.catalog.${CATALOG_NAME}=org.apache.iceberg.spark.SparkCatalog,\
spark.sql.catalog.${CATALOG_NAME}.type=rest,\
spark.sql.catalog.${CATALOG_NAME}.uri=https://biglake.googleapis.com/iceberg/v1/restcatalog,\
spark.sql.catalog.${CATALOG_NAME}.warehouse=gs://${BUCKET_NAME},\
spark.sql.catalog.${CATALOG_NAME}.header.x-goog-user-project=${PROJECT_ID},\
spark.sql.catalog.${CATALOG_NAME}.rest.auth.type=org.apache.iceberg.gcp.auth.GoogleAuthManager,\
spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions,\
spark.sql.catalog.${CATALOG_NAME}.gcs.oauth2.refresh-credentials-endpoint=https://oauth2.googleapis.com/token, \
spark.sql.catalog.${CATALOG_NAME}.header.X-Iceberg-Access-Delegation=vended-credentials" \
-- ${BUCKET_NAME}
Poczekaj kilka minut, aż środowisko bezserwerowe się uruchomi, prześle skrypt i wykona logikę przetwarzania.
Gdy zobaczysz dane wyjściowe podobne do tych poniżej, przetworzona tabela zostanie zapisana w katalogu Lakehouse jako zarządzana tabela Apache Iceberg.
Batch [1fae0b4b42c045a084dd67917bd0c332] finished.
metadata:
'@type': type.googleapis.com/google.cloud.dataproc.v1.BatchOperationMetadata
batch: projects/<YOUR_PROJECT>/locations/us-central1/batches/1fae0b4b42c045a084dd67917bd0c332
batchUuid: 611b4465-fdac-4974-bc47-5f10adaf2a08
createTime: '2026-06-11T21:35:01.868157Z'
description: Batch
labels:
goog-dataproc-batch-id: 1fae0b4b42c045a084dd67917bd0c332
goog-dataproc-batch-uuid: 611b4465-fdac-4974-bc47-5f10adaf2a08
goog-dataproc-drz-resource-uuid: batch-611b4465-fdac-4974-bc47-5f10adaf2a08
goog-dataproc-location: us-central1
operationType: BATCH
name: projects/<YOUR_PROJECT/regions/us-central1/operations/7e2044db-dd97-3270-b368-4dc4ba417574
Wyświetlanie podglądu przetworzonych logów
Aby wyświetlić podgląd danych, skopiuj to zapytanie do edytora zapytań w rozszerzeniu Data Agent Kit:
SET @@location = "<YOUR_REGION>"; -- e.g. "us-central1"
EXECUTE IMMEDIATE FORMAT("""
select log_timestamp, custodian_id, sentence from
`%s.%s-lost-cargo-lake.lost_cargo_namespace.processed_maritime_logs`
limit 5
""", @@project_id, @@project_id);
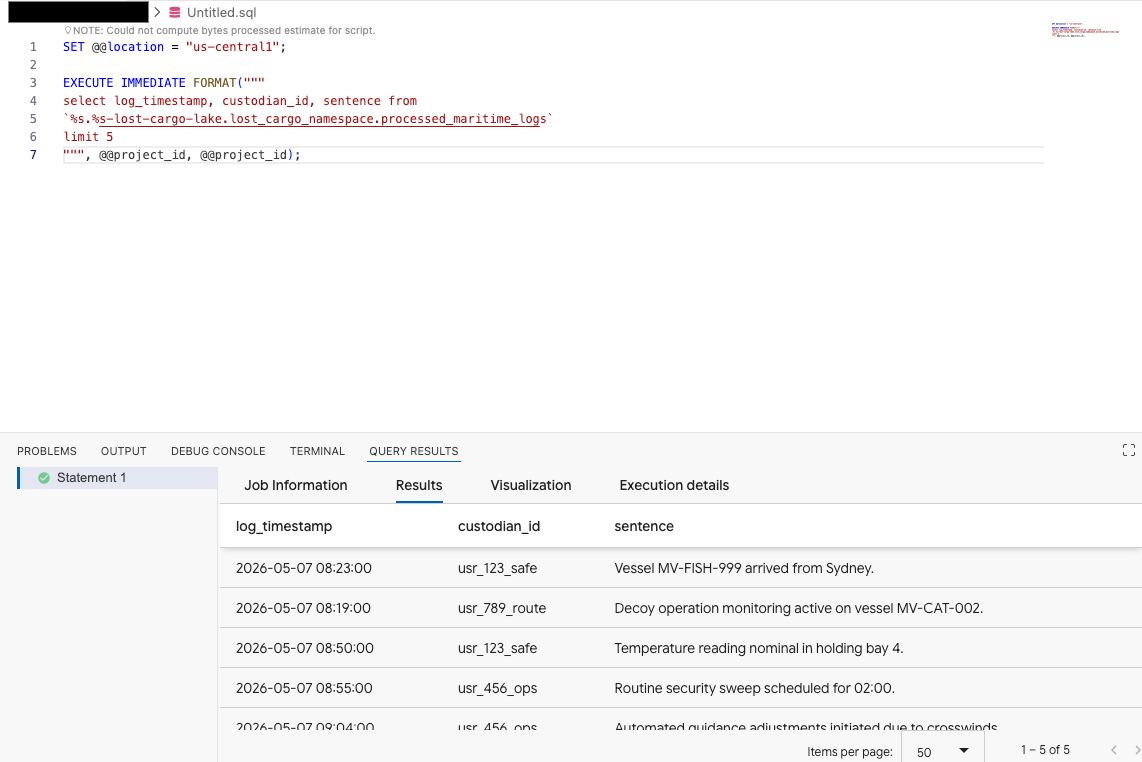
Oznacza to, że do tabeli Iceberg zarejestrowanej w katalogu można uzyskać dostęp z BigQuery.
Wyodrębnij wskazówkę dotyczącą miejsca docelowego
Mając już przetworzone logi, poszukajmy tych, które zawierają miejsce docelowe. Następnie możemy przeszukać dzienniki, aby znaleźć te, które zawierają wzmiankę o naszym mieście pochodzenia.
W edytorze zapytań uruchom to zapytanie, zastępując <YOUR_REGION> swoim regionem, a <ORIGIN_CITY> miastem pochodzenia, które zostało wcześniej wykryte.
SET @@location = "<YOUR_REGION>"; --e.g. "us-central1"
DECLARE origin_city STRING;
SET origin_city = "<ORIGIN_CITY>"; --e.g. "Boston". (It's not Boston)
EXECUTE IMMEDIATE FORMAT(r"""
SELECT
log_timestamp AS event_time,
custodian_id,
REGEXP_EXTRACT(raw_message, r'Destination:\s*([^.]+)') AS destination_target
FROM
`%s.%s-lost-cargo-lake.lost_cargo_namespace.processed_maritime_logs`
WHERE
-- STRPOS is highly optimized in BigQuery for a simple .contains() substring check
STRPOS(sentence, '%s') > 0;
""", @@project_id, @@project_id, origin_city);
Czatowanie z danymi w konsoli BigQuery za pomocą analityki konwersacyjnej
Zamiast pisać złożone zapytania SQL, aby eksplorować dane, możesz używać analityki konwersacyjnej i rozmawiać z tabelami w języku naturalnym.
- Otwórz konsolę BigQuery.
- W panelu Eksplorator po lewej stronie rozwiń projekt i zbiór danych
-lost-cargo-lake.lost_cargo_namespace processed_maritime_logs, aby otworzyć kartę z jej szczegółami. - Obok opcji Zapytanie kliknij Czat.
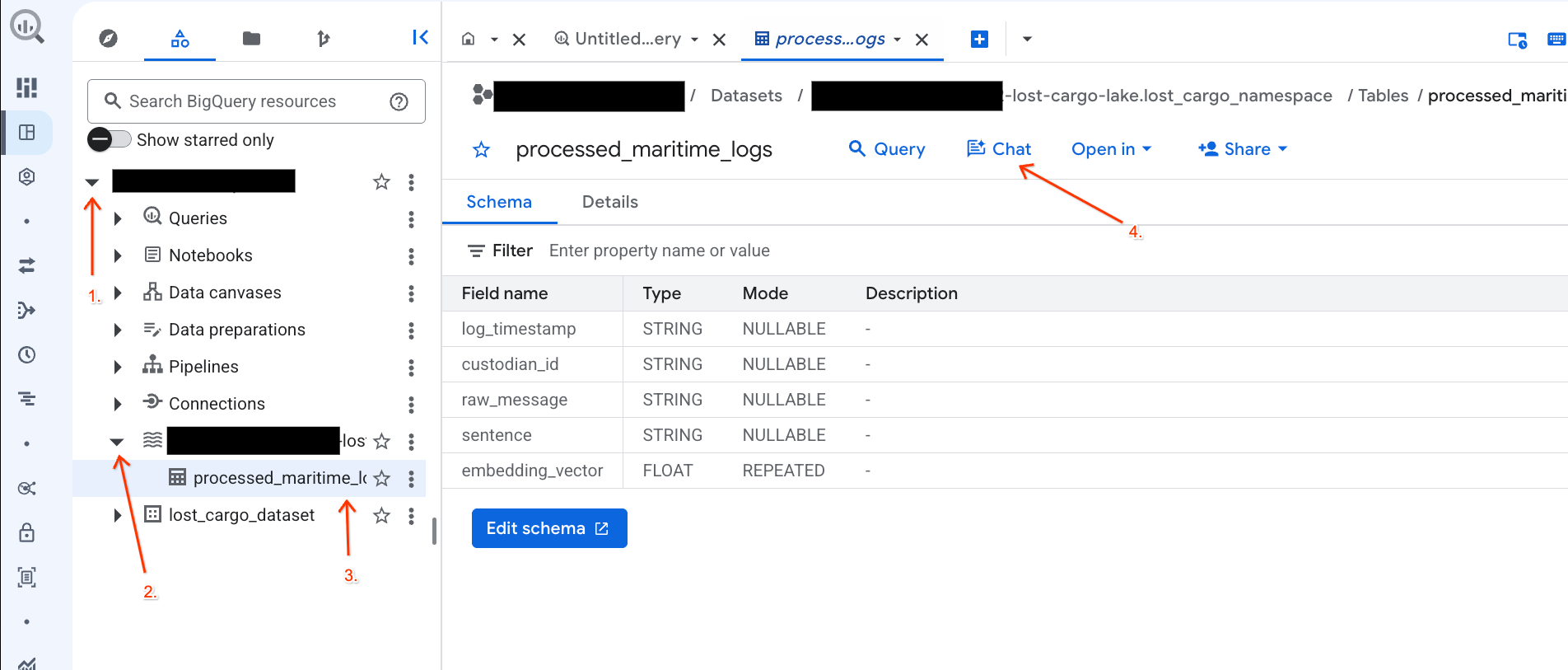
- W panelu czatu wpisz to pytanie i naciśnij Enter na klawiaturze, aby wysłać:
Based on this table, what color is the shipping container MV-CAT-001?
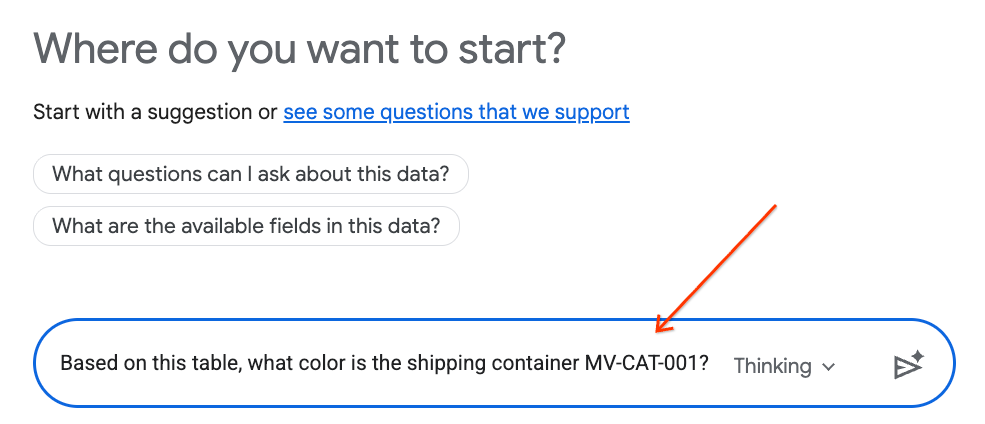
- Analityka konwersacyjna (oparta na Gemini) przeanalizuje dane z aktywnej tabeli i odpowie, podając kolor.
5. Wyświetlanie scentralizowanego katalogu Lakehouse
Aby bezpiecznie i bezproblemowo zintegrować silniki przetwarzania open source (takie jak Apache Spark) z silnikami danych klasy korporacyjnej (takimi jak BigQuery), skrypt konfiguracji skonfigurował katalog Iceberg REST architektury lakehouse.
Katalog Apache Iceberg REST pełni funkcję bezserwerowego „pojedynczego źródła informacji” o metadanych tabeli, dynamicznie zarządzając schematami i partycjonowaniem tabel, a jednocześnie przechowując fizyczne pliki danych Parquet w Cloud Storage.
Sprawdźmy ten katalog bezpośrednio w konsoli Google Cloud:
- Otwórz konsolę Lakehouse.
- Na karcie Katalogi znajdź i kliknij aktywny katalog Iceberg REST:
-lost-cargo-lake
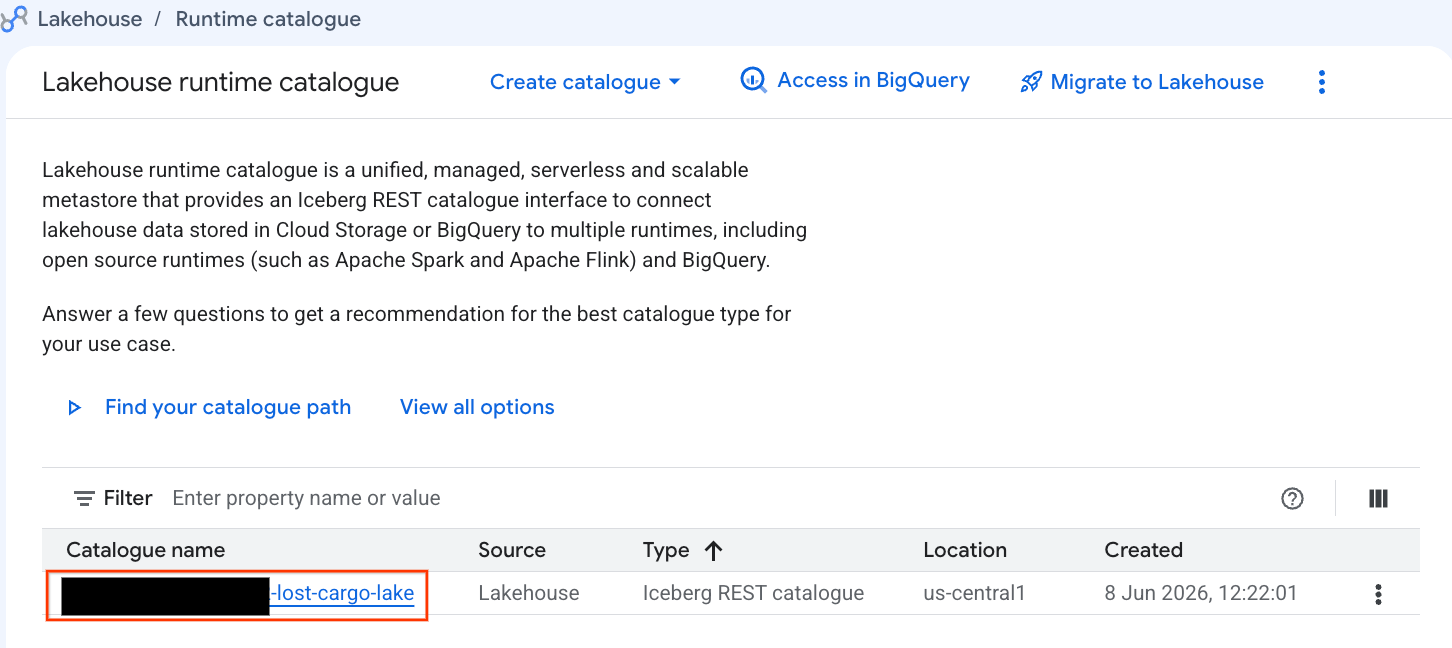
- W widoku szczegółów katalogu w sekcji Przestrzenie nazw powinna być widoczna ikona
lost_cargo_namespace. Kliknij ją.
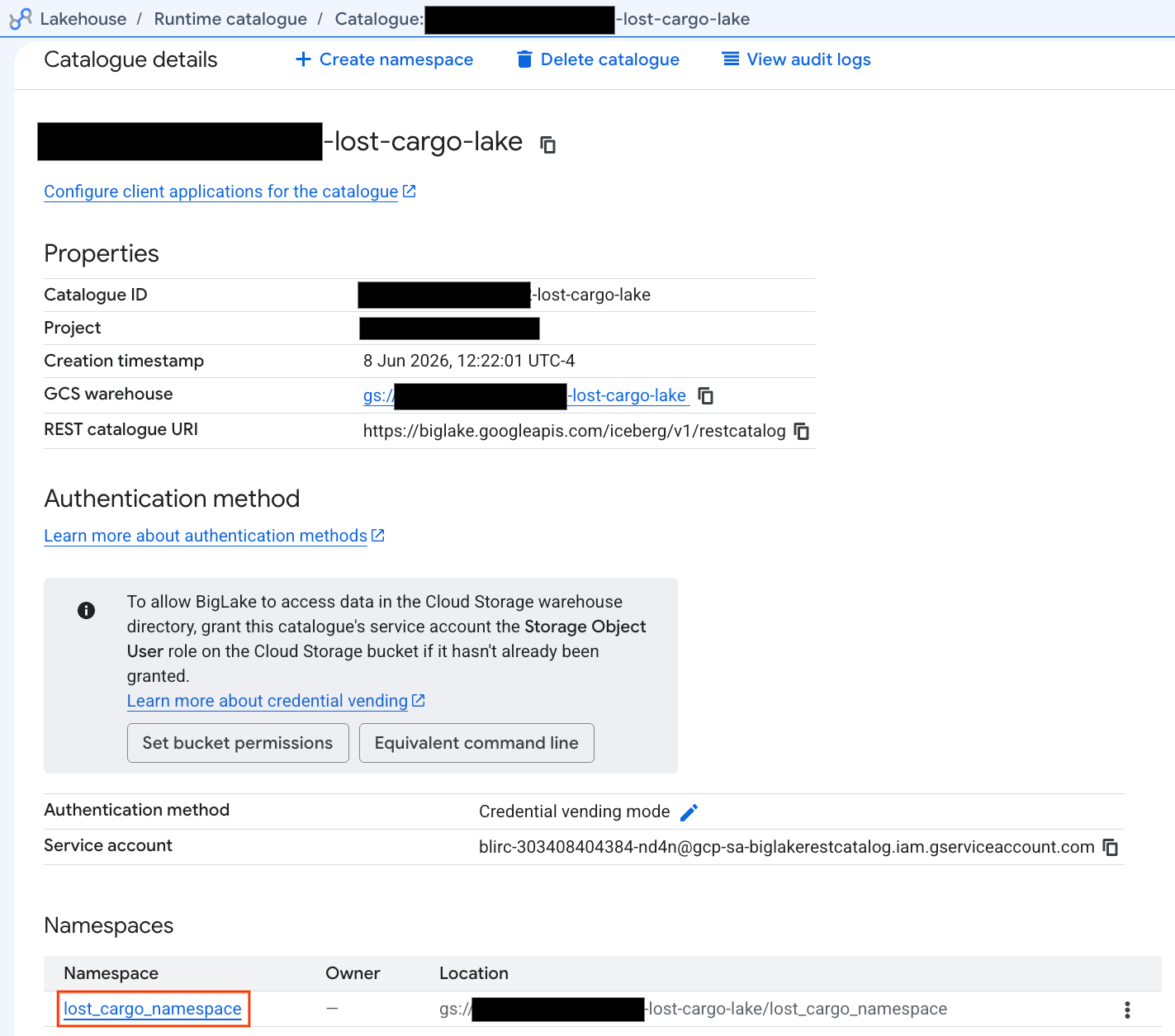
- Nowa tabela Apache Iceberg wygenerowana przez PySpark została automatycznie zarejestrowana w tej przestrzeni nazw metastore i od razu można było wykonywać na niej zapytania w BigQuery.
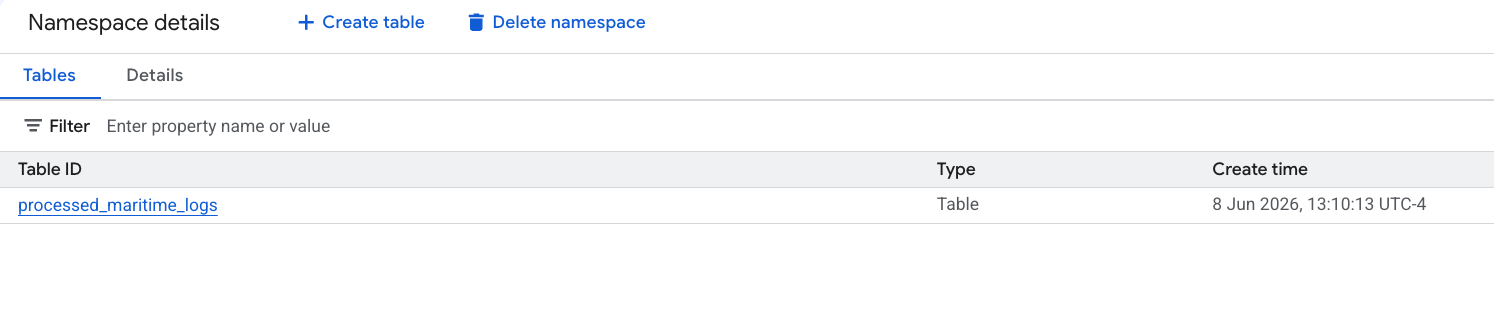
6. Generowanie statystyk w tabeli manifestów wysyłki
Wróćmy do analizy shipping_manifests tabeli, aby poznać jej strukturę i zawartość za pomocą Statystyk danych w Knowledge Catalog. Wzbogacając metadane, inni eksploratorzy mogą lepiej zrozumieć tabelę na potrzeby przyszłych analiz.
Generowanie statystyk tabeli w BigQuery Studio
- W konsoli Google Cloud otwórz BigQuery Studio.
- W panelu Eksplorator rozwiń projekt, rozwiń zbiór danych
lost_cargo_dataseti kliknij tabelęshipping_manifests. - W panelu szczegółów po prawej stronie kliknij kartę Statystyki.
- W menu wybierz Wygeneruj i opublikuj.
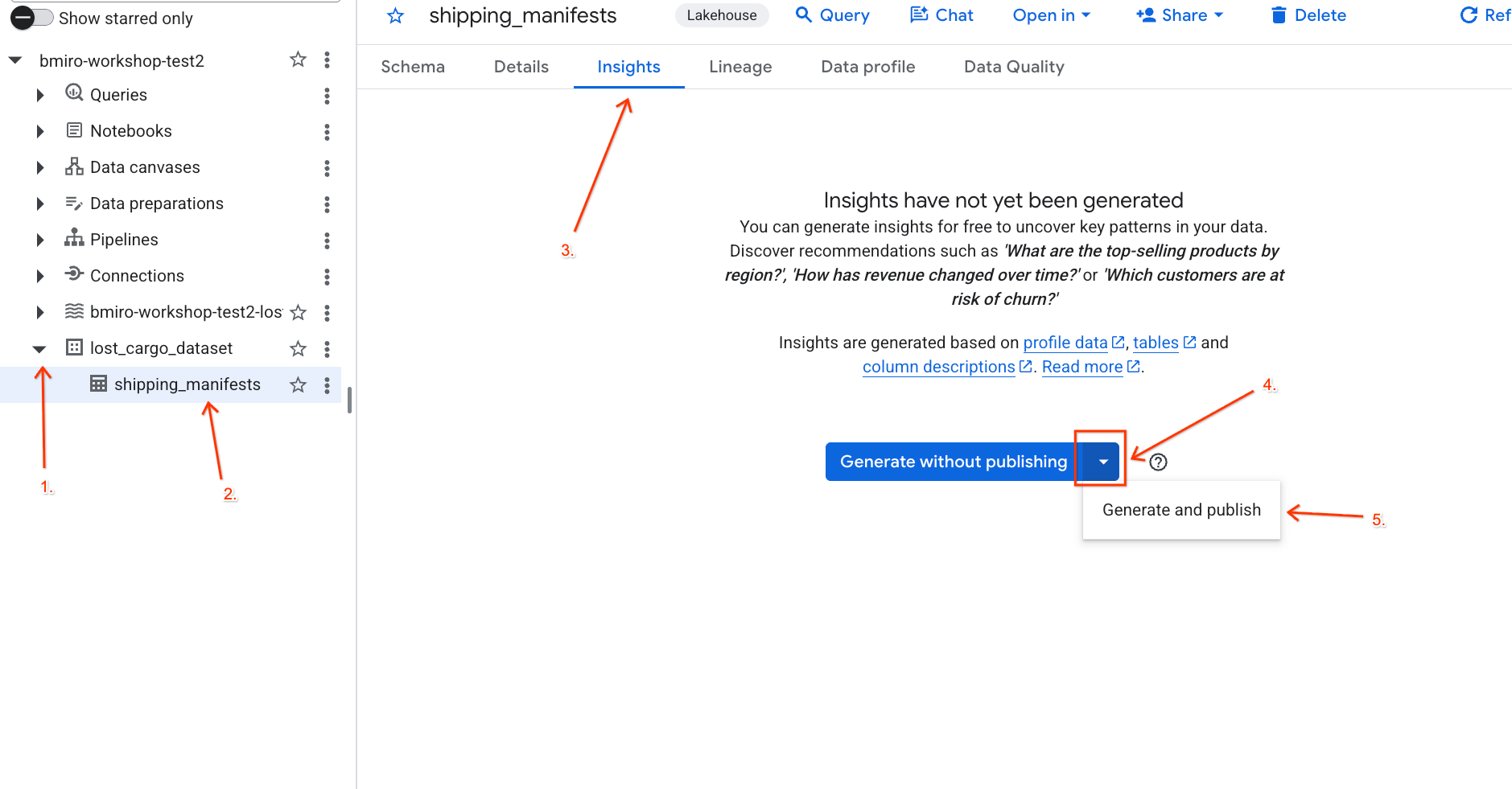
- Poczekaj około 3 minut, aż generowanie statystyk się zakończy. Gemini przeanalizuje metadane tabeli i wygeneruje pytania w języku naturalnym oraz odpowiadające im zapytania SQL.
- Gdy to zrobisz, zobaczysz opis tabeli z wyjaśnieniem w języku naturalnym.
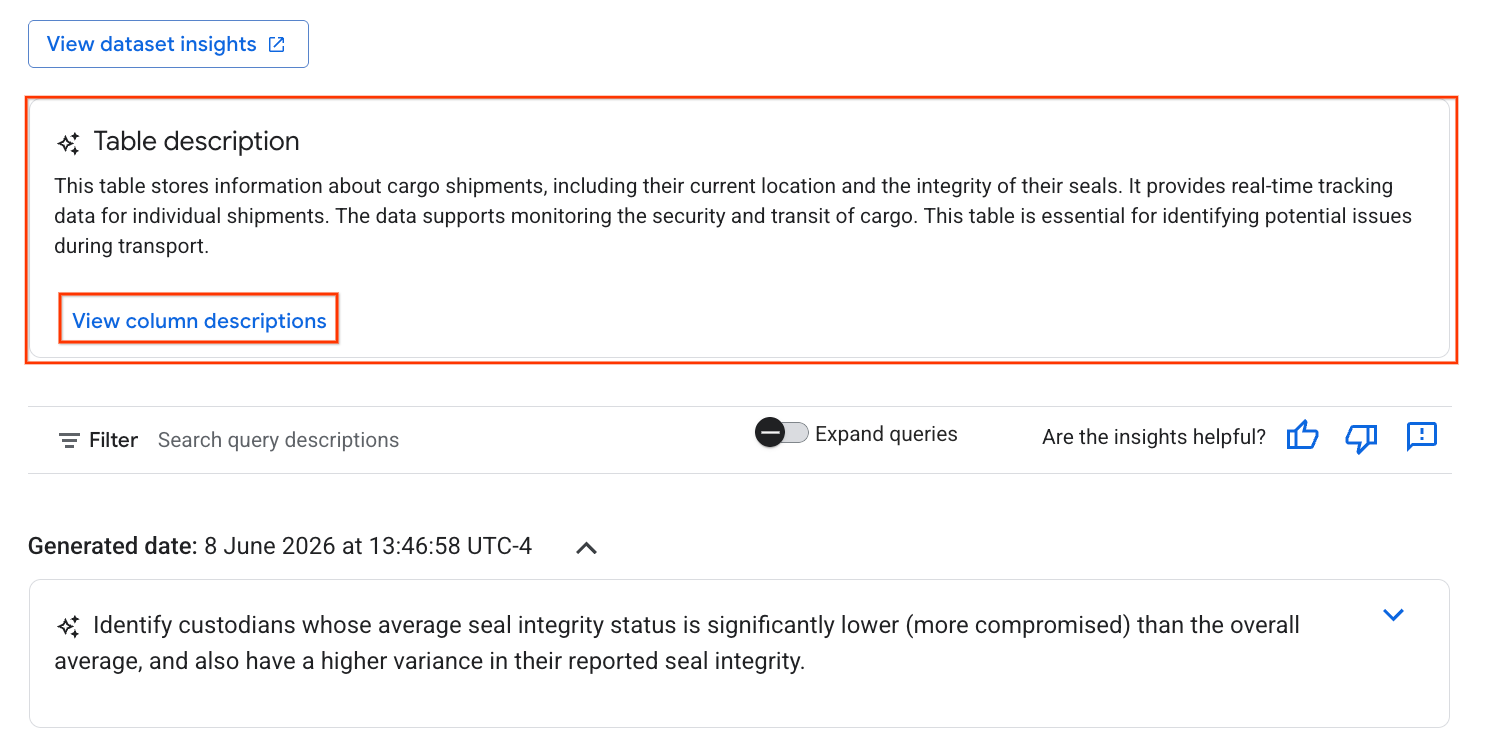
- Aby wyświetlić informacje o poszczególnych kolumnach, kliknij Wyświetl opisy kolumn.
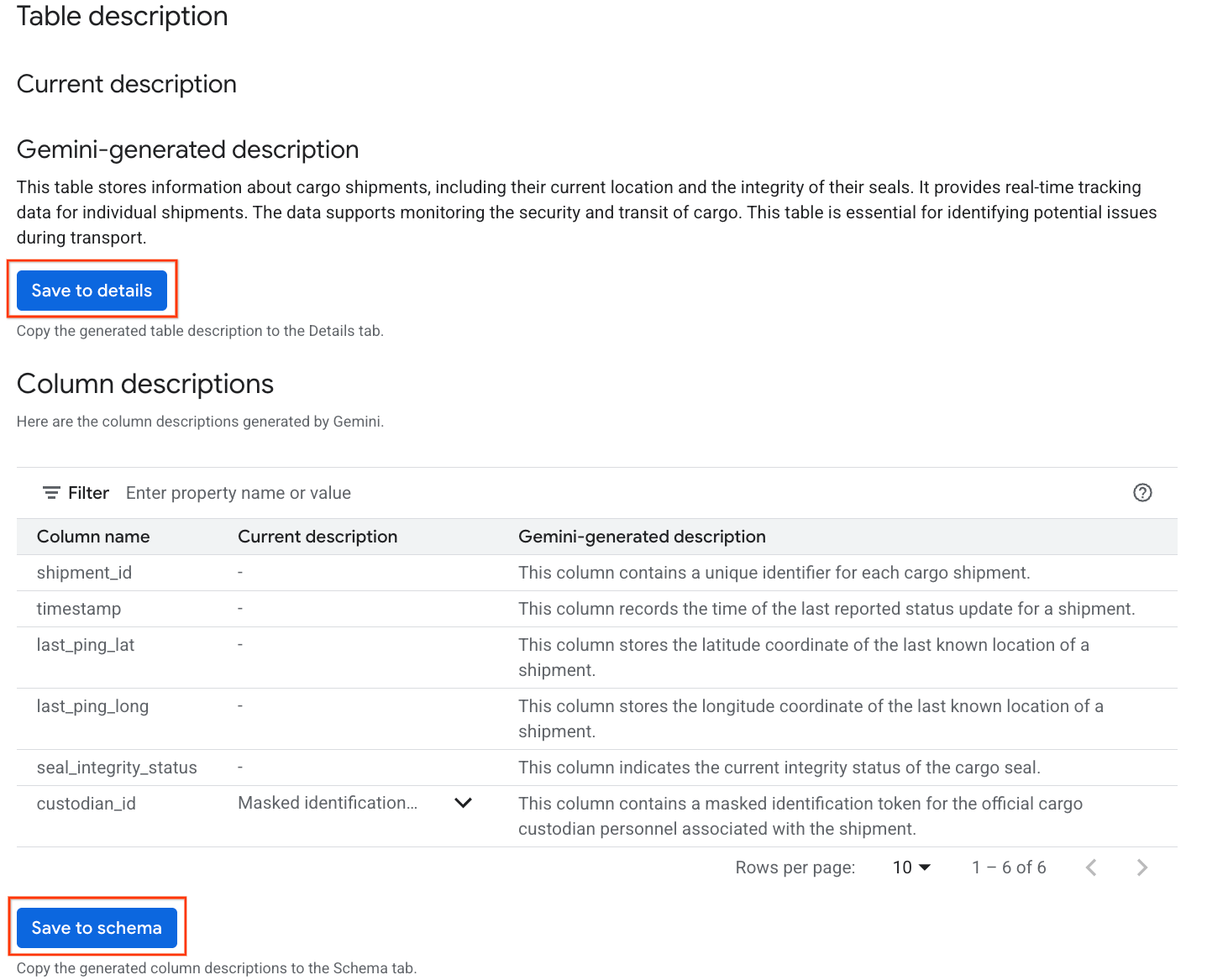
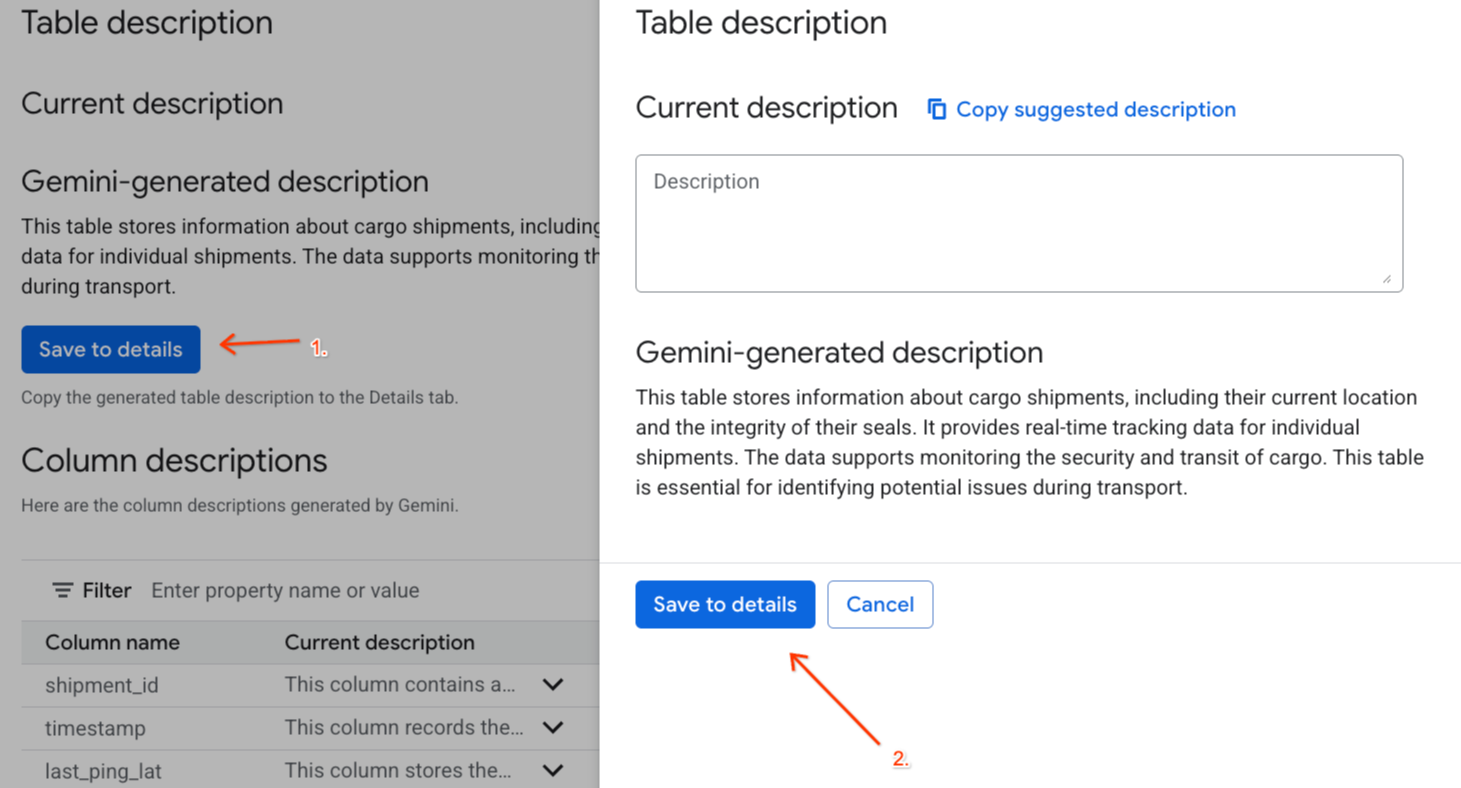
- Kliknij Zapisz w szczegółach pod ikoną
Gemini generated description, a potem w wyświetlonym oknie kliknij Zapisz w szczegółach.
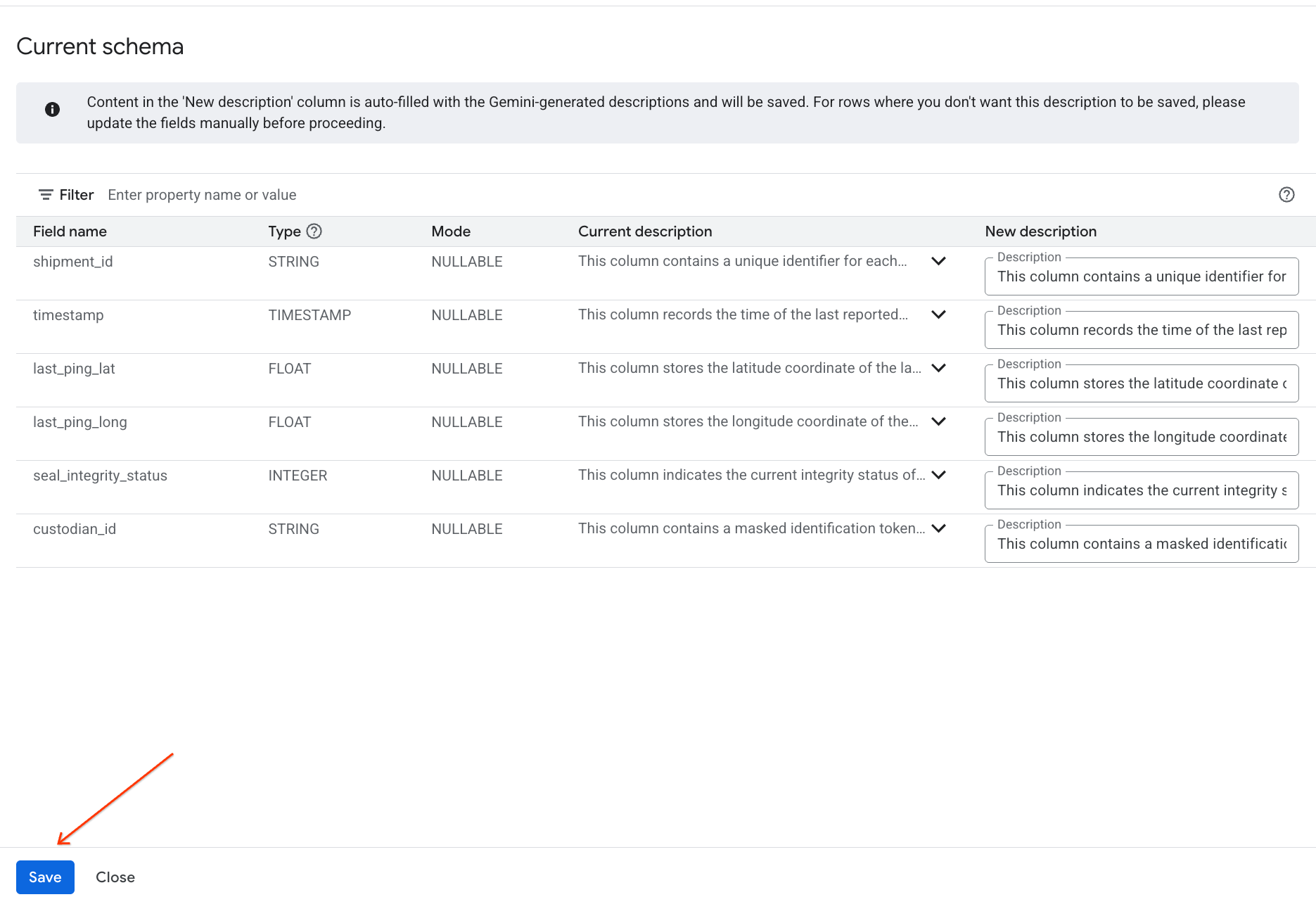
- Podobnie kliknij Zapisz w schemacie, aby dodać opisy kolumn do metadanych tabeli.
Sprawdzanie wygenerowanych statystyk
Zobaczysz też listę sugerowanych pytań. Możesz kliknąć dowolne pytanie, aby wyświetlić wygenerowane zapytanie SQL i uruchomić je w celu zbadania danych. Możesz na przykład zobaczyć pytania takie jak:
- „Jaka jest łączna liczba przesyłek?”
- „Wymień unikalne identyfikatory opiekunów”.
Uruchomienie tych zapytań pomoże Ci zrozumieć dane.
7. Wdrażanie maskowania danych i zarządzania nimi
Aby zagwarantować, że aktywne konta badawcze i nazwy użytkowników nie zostaną ujawnione podczas trwającej analizy zagrożeń związanej z ładunkiem, musisz wdrożyć standardowe protokoły bezpieczeństwa. Utworzysz taksonomię tagów zasad bezpieczeństwa i skonfigurujesz maskowanie danych w Knowledge Catalog w kolumnie custodian_id zawierającej informacje poufne, aby zweryfikować prywatność danych.
Domyślnie BigQuery odmawia dostępu do kolumn chronionych przez tagi zasad. Aby wysyłać zapytania do tabeli i weryfikować aktywne maski danych, Twoje konto użytkownika musi mieć rolę Odczytujący zamaskowane dane w zasadach dotyczących danych BigQuery.
Ta rola została automatycznie powiązana z Twoim aktywnym kontem użytkownika podczas pierwszego wykonania setup_lab1.sh.
Tworzenie taksonomii i tagu zasad
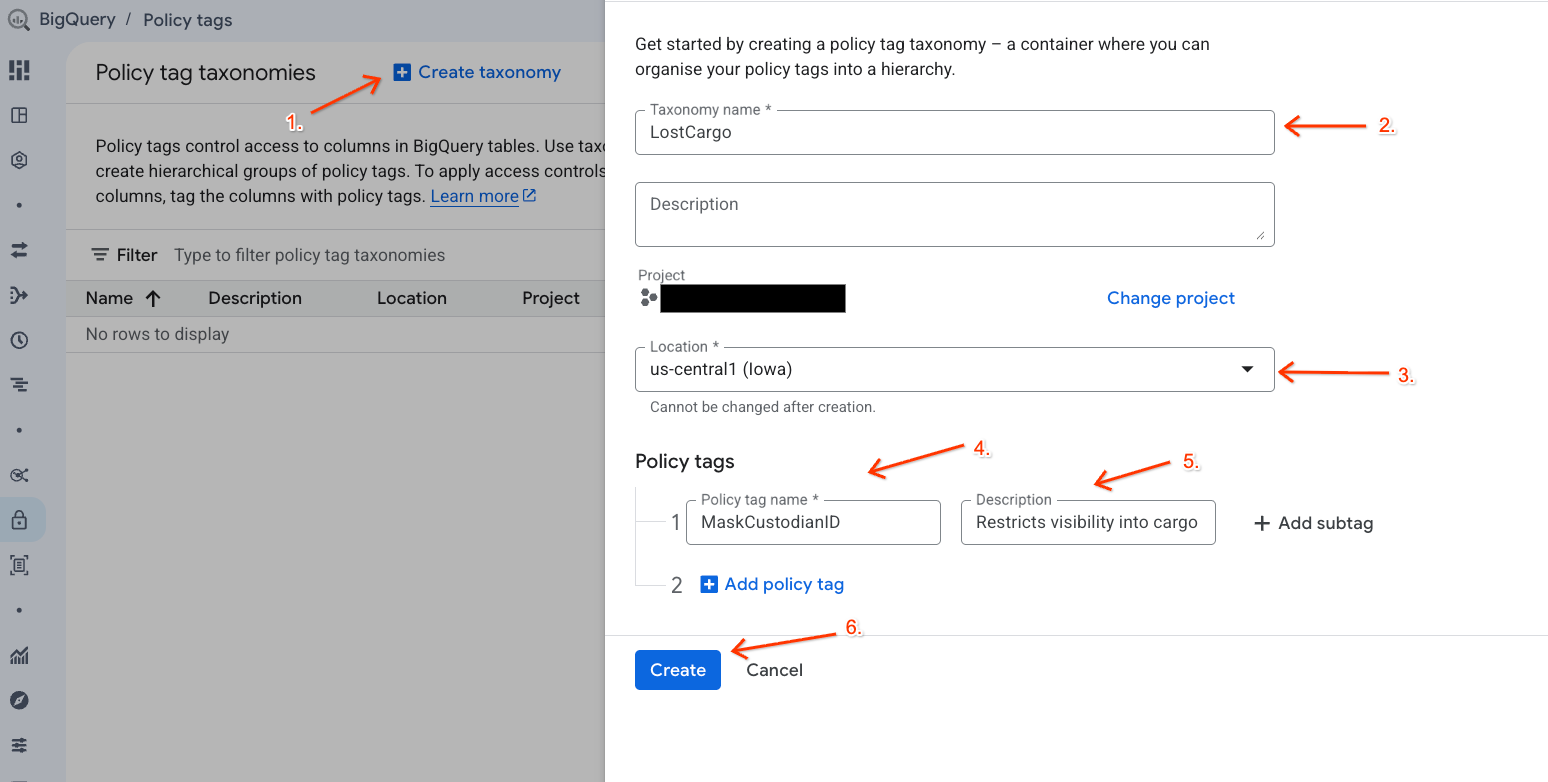
Utwórz taksonomię danych i powiązany z nią tag zasad, aby zarządzać dostępem do danych.
- Otwórz stronę Taksonomie tagów zasad.
- Kliknij + Utwórz taksonomię.
- Skonfiguruj parametry:
- Nazwa taksonomii: wpisz
lost-cargo-, zastępując identyfikatorem projektu. - Region: wybierz region.
- W polu Nazwa tagu zasad wpisz
MaskCustodianID. - W przypadku tagu zasad Opis:
Restricts visibility into cargo custodian usernames
- Nazwa taksonomii: wpisz
- Kliknij Utwórz, aby zarejestrować nową taksonomię i tag zasad.
Tworzenie zasady maskowania danych
Następnie skonfiguruj zasady dotyczące danych, aby określić, jak dane mają być maskowane pod tagiem klasyfikacji MaskCustodianID. Użyjesz reguły maskowania Zawsze wartość null (zastępującej pasujące wartości pustymi/zerowymi wynikami dla wszystkich podmiotów nieuprzywilejowanych).
- Na stronie Taksonomie tagów zasad kliknij nowo utworzoną taksonomię na liście taksonomii.
- Na liście hierarchii kliknij tag
MaskCustodianID, aby go wybrać, a następnie kliknij Zarządzaj zasadami dotyczącymi danych.
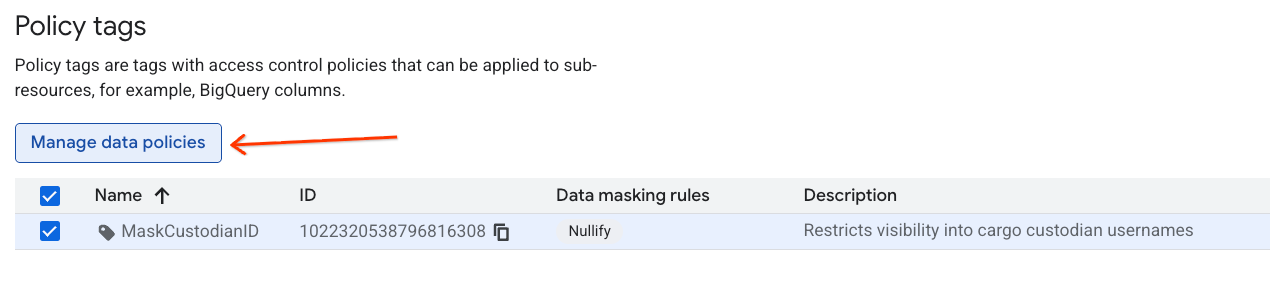
- W panelu po prawej stronie kliknij przycisk + Dodaj regułę.
- W wyświetlonym panelu skonfiguruj szczegóły zasady:
- Nazwa zasad dotyczących danych: wpisz
null_masking_policy(nie pozostawiaj nazwy wygenerowanej automatycznie, ponieważ w kolejnych krokach będziemy się do niej odwoływać). - Reguła maskowania: w menu wybierz
Nullify.
- Nazwa zasad dotyczących danych: wpisz
- Kliknij Prześlij.
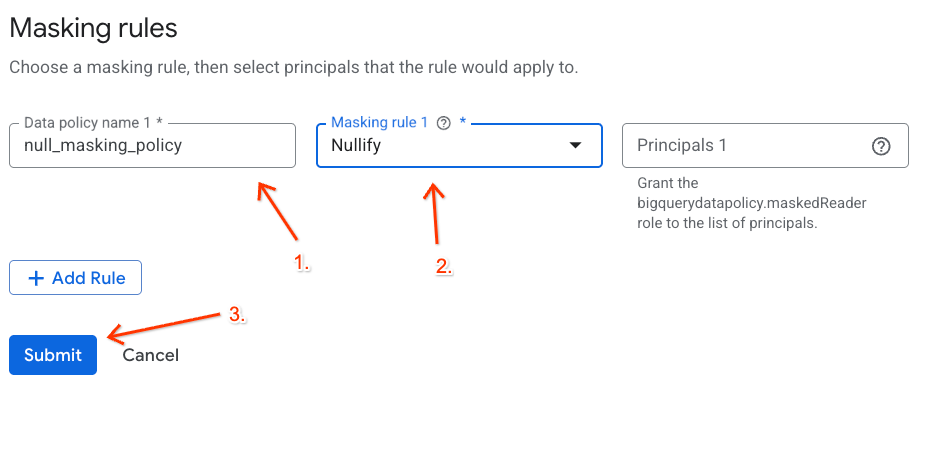
Przypisywanie tagu zasad do kolumny BigQuery
Po aktywowaniu tagu zasad i reguły maskowania danych przypisz tag klasyfikacji bezpośrednio do kolumny custodian_id w tabeli manifestu wysyłki partnera BigQuery.
- Otwórz BigQuery.
- W panelu Eksplorator po lewej stronie rozwiń aktywny projekt i zbiór danych
lost_cargo_dataset, a następnie kliknij tabelęshipping_manifests, aby otworzyć jej widok szczegółowy. - Kliknij Edytuj schemat.
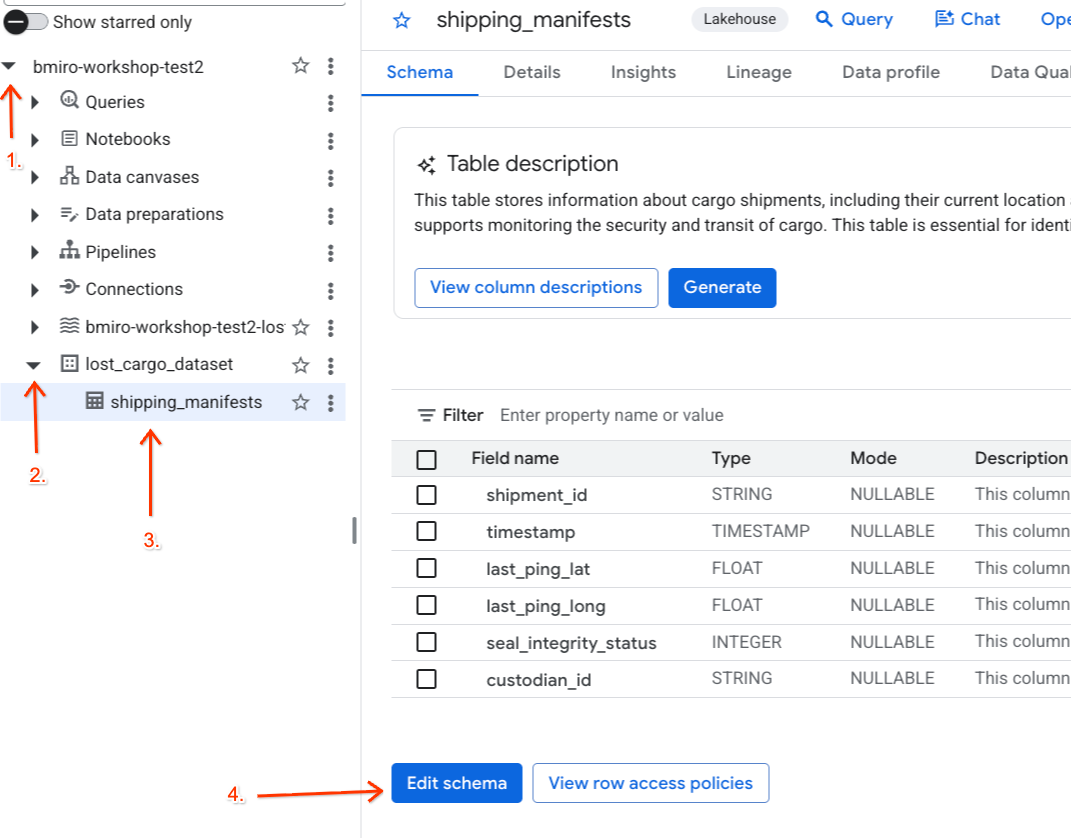
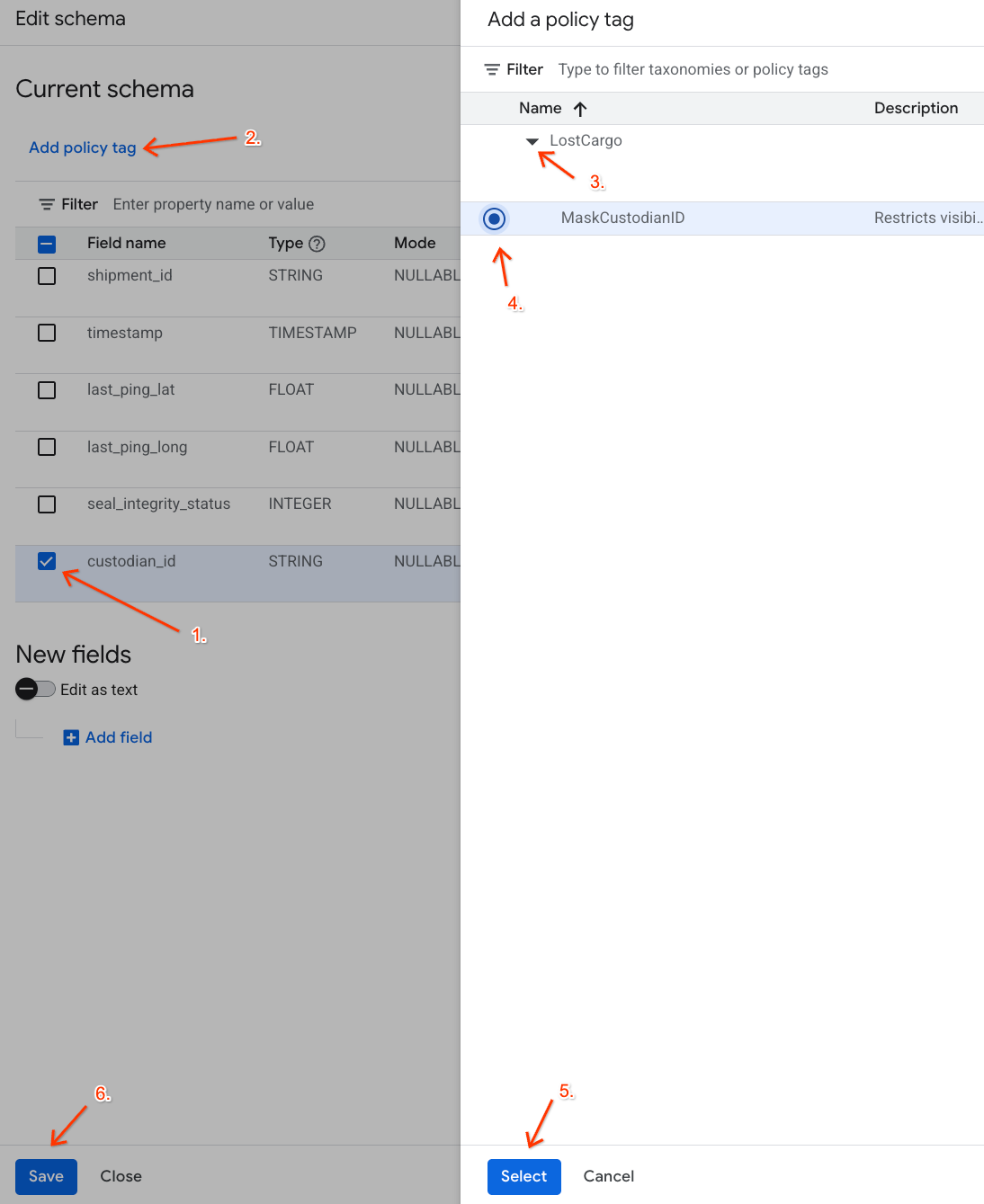
- Na liście kolumn zaznacz pole obok
custodian_id. - Na pasku narzędzi u góry edytora schematu kliknij przycisk Dodaj tag zasad.
- W panelu Dodaj tag zasad:
- Znajdź i rozwiń taksonomię
LostCargo. - Kliknij kółko obok ikony
MaskCustodianID. - Kliknij Wybierz.
- Znajdź i rozwiń taksonomię
- Sprawdź, czy tag
MaskCustodianIDjest teraz widoczny w kolumnie Tag zasad w wierszu reprezentującymcustodian_id. - Kliknij Zapisz.
Sprawdzanie ograniczeń zasad
Teraz, gdy masz rolę Masked Reader na poziomie projektu, możesz wysłać zapytanie do tabeli, aby sprawdzić, czy zasady maskowania są aktywne.
Wróć do Data Agent Kit i uruchom to zapytanie:
SELECT shipment_id, custodian_id
FROM lost_cargo_dataset.shipping_manifests
LIMIT 5;
Zostaną wyświetlone dane wyjściowe podobne do tych:
shipment_id | custodian_id |
NORMAL-001 | null |
NORMAL-002 | null |
MV-CAT-001 | null |
Gotowe! Chociaż możesz wyświetlać rekordy shipment_id, w przypadku pola custodian_id zawierającego informacje poufne zwracane są bezpieczne maski null, aby zapobiec wyciekom danych.
8. Czyszczenie danych
Aby uniknąć obciążenia konta Google Cloud bieżącymi opłatami za zasoby utworzone podczas tego laboratorium, uruchom te polecenia w terminalu Cloud Shell, aby usunąć zbiory danych i zasobniki:
# Verify active variables
export PROJECT_ID=$(gcloud config get-value project)
export BUCKET_NAME="${PROJECT_ID}-lost-cargo-lake"
# Delete Knowledge Catalog security taxonomies
export TAXONOMY_NAME=$(gcloud data-catalog taxonomies list --location=us-central1 --filter="displayName:LostCargo" --format="value(name)")
if [[ -n "$TAXONOMY_NAME" ]]; then
curl -X DELETE \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
"https://datacatalog.googleapis.com/v1/${TAXONOMY_NAME}" || true
fi
# Delete Lakehouse Iceberg REST Catalog tables and namespaces
gcloud biglake iceberg tables delete processed_maritime_logs \
--catalog=${BUCKET_NAME} \
--namespace=lost_cargo_namespace \
--quiet || true
gcloud biglake iceberg namespaces delete lost_cargo_namespace \
--catalog=${BUCKET_NAME} \
--quiet || true
# Delete Lakehouse Iceberg REST Catalog
gcloud biglake iceberg catalogs delete ${BUCKET_NAME} --quiet || true
# Delete dependencies bucket
gcloud storage rm -r gs://${BUCKET_NAME} || true
# Delete BigQuery dataset and tables
bq rm -r -f -d ${PROJECT_ID}:lost_cargo_dataset || true
9. Gratulacje
Gratulacje! Udało Ci się ukończyć pierwszy kluczowy moduł śledztwa Zgubiony ładunek. Masz utworzoną zarządzaną strefę wyszukiwania przy użyciu katalogów Lakehouse Iceberg REST, normalizacji logów PySpark i precyzyjnego maskowania danych.
Czego się dowiedziałeś(-aś)
- instalowanie, konfigurowanie i ustawianie rozszerzenia Data Agent Kit w obszarze roboczym IDE;
- Utworzenie bezserwerowego katalogu Lakehouse Iceberg REST z wykorzystaniem dostarczonych danych logowania i hierarchicznych przestrzeni nazw.
- przetwarzanie regionalnych plików danych w wielu formatach i tworzenie tabel zewnętrznych BigQuery w zasobnikach Cloud Storage;
- Uruchamianie bezserwerowych zadań Apache Spark w celu analizowania, normalizowania, segmentowania i zapisywania nieustrukturyzowanych dzienników transponderów z powrotem w BigQuery jako zarejestrowanych tabel katalogu Iceberg.
- Tworzenie taksonomii zabezpieczeń i mapowanie zasad maskowania danych w Knowledge Catalog, aby zapobiegać wyciekom tożsamości w przypadku indeksów dzienników zawierających informacje poufne.
- Generowanie i analizowanie obserwacji o metadanych tabeli za pomocą obserwacji opartych na danych w BigQuery w celu przyspieszenia eksploracji danych.
Weryfikacja zebranych wskazówek
Sprawdź, czy masz te kluczowe wskazówki, które są potrzebne do rozpoczęcia kolejnego etapu ćwiczenia:
- Identyfikator zagubionej przesyłki:
MV-CAT-001(ostatnia lokalizacja: Londyn) - Planowane miejsce docelowe:
New York(i prawdziwy alias transpondera:MV-DOG-002) - Kolor kontenera:
Crimson RED - Tag dostępu do zarządzania:
MaskCustodianID
Chcesz przejść do następnego etapu?
Trasy transpondera odlotu i przylotu są już bezpieczne, więc możemy kontynuować dochodzenie. Przejdź bezpośrednio do ćwiczenia 2, aby zbadać kamery ochrony za pomocą multimodalnych modeli Gemini, wizualnie zidentyfikować statek i przeprowadzić wyszukiwanie wektorowe w AlloyDB w celu zweryfikowania anomalii związanych z manipulacją.
➡️ Przejdź do kroku 2: analiza danych i wielomodowe statystyki