
1. Introdução
Neste laboratório, você vai assumir o papel de um investigador de dados líder em uma empresa de logística global. Um contêiner de carga de alto valor que transportava preciosas estatuetas colecionáveis do Android desapareceu! Para encontrar a última posição conhecida e rastrear a rota, é necessário agregar manifestos de envio fragmentados de parceiros de logística regionais e arquivos de registro de transponders não estruturados. Para isso, você vai configurar um data lakehouse aberto do Google Cloud moderno.

Atividades deste laboratório
- Configure a extensão do Google Cloud Data Agent Kit no editor do Cloud Shell.
- Crie um bucket do Cloud Storage e provisione um catálogo REST do Apache Iceberg do Lakehouse e um namespace.
- Mapeie uma tabela externa do BigLake para manifestos de parceiros JSON brutos no Cloud Storage e descubra a pista da partida do navio.
- Carregue e processe registros de texto não estruturados do transponder usando o Serviço gerenciado para Apache Spark sem servidor. Faça normalizações de regex e extração dinâmica de pistas para segmentar o destino da carga perdida.
- Grave as métricas de registros analisados como uma tabela do Apache Iceberg pelo catálogo REST.
- Converse com um agente de IA sobre seus dados do Apache Iceberg usando a análise conversacional para descobrir pistas ocultas sobre sua remessa perdida.
- Aproveite os insights de dados automatizados com o Knowledge Catalog para gerar metadados sobre seus dados.
- Estabeleça mecanismos de proteção de ingestão criando uma taxonomia de segurança e usando o Knowledge Catalog para aplicar o controle de acesso refinado mascarando IDs sensíveis de custodiantes.
O que é necessário
- Um navegador da Web, como o Chrome.
- Ter um projeto do Google Cloud com o faturamento ativado.
- Familiaridade com consultas básicas de SQL e comandos de terminal.
Custo e duração esperados
- Tempo para conclusão: ~45 minutos.
- Custo estimado: menos de US$5,00.
2. Antes de começar
Criar ou selecionar um projeto do Google Cloud
- No Console do Google Cloud, selecione ou crie um projeto na nuvem do Google Cloud.
- Verifique se o faturamento está ativado para seu projeto do Cloud. Saiba como confirmar se o faturamento está ativado em um projeto.
Configure o ambiente
Você vai executar a maioria dos comandos no terminal integrado do Cloud Shell Editor, um ambiente de desenvolvimento baseado na nuvem que vem pré-carregado com ferramentas para desenvolvedores e o SDK Google Cloud padrão.
- Abra o editor do Cloud Shell em uma nova guia.
- Execute o seguinte comando no terminal para clonar o repositório:
cd ~/ git clone --filter=blob:none --no-checkout https://github.com/GoogleCloudPlatform/devrel-demos.git cd ~/devrel-demos git sparse-checkout init --cone git sparse-checkout set data-analytics/data-cloud-roadshow/lab1 git checkout main cd data-analytics/data-cloud-roadshow/lab1 - Defina o ID do projeto. Você também pode pressionar
Ctrl+Shift+Vno Windows/Linux ouCmd+Vno macOS para colar isso no terminal:export PROJECT_ID="<YOUR_PROJECT_ID>" - Agora configure no seu ambiente.
gcloud config set project $PROJECT_ID - Selecione uma região.
export REGION="<YOUR_REGION>" # Replace with the region you chose, such as "us-central1" - Ativar as APIs necessárias
gcloud services enable \ bigquery.googleapis.com \ biglake.googleapis.com \ storage.googleapis.com \ dataplex.googleapis.com \ datacatalog.googleapis.com \ dataproc.googleapis.com \ aiplatform.googleapis.com \ cloudresourcemanager.googleapis.com \ serviceusage.googleapis.com \ cloudaicompanion.googleapis.com \ geminidataanalytics.googleapis.com
Instalar extensão
Agora você vai configurar a extensão do Google Data Agent Kit, uma ferramenta para interagir com as ferramentas de dados do Google Cloud diretamente no seu ambiente de desenvolvimento integrado.
- Na barra de atividades à esquerda do editor, clique no ícone Extensões (ou pressione
Ctrl+Shift+Xno Windows/Linux ouCmd+Xno macOS). - Na caixa de pesquisa de extensões, digite:
Google Cloud Data Agent Kit - Selecione a extensão oficial nos resultados e clique em Instalar. Se for solicitado, selecione "Sim, confio nos autores".
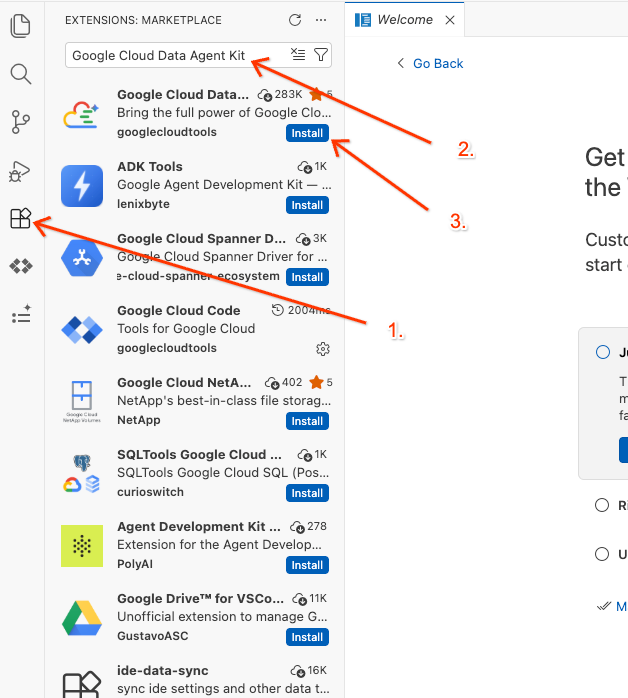
- Depois de instalado, o ícone do Google Cloud Data Agent Kit vai aparecer na barra de atividades. Clique nele.
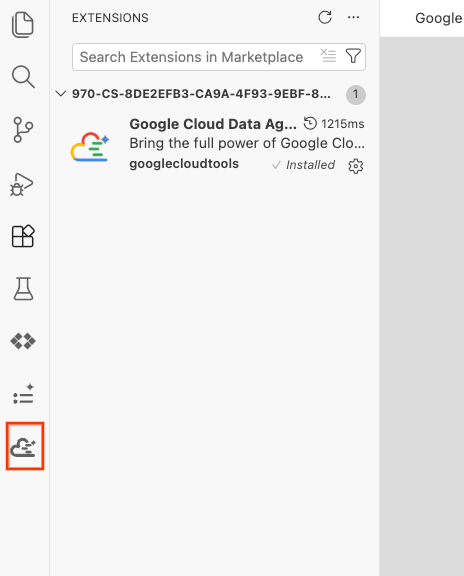
- Clique em Fazer login na nuvem.
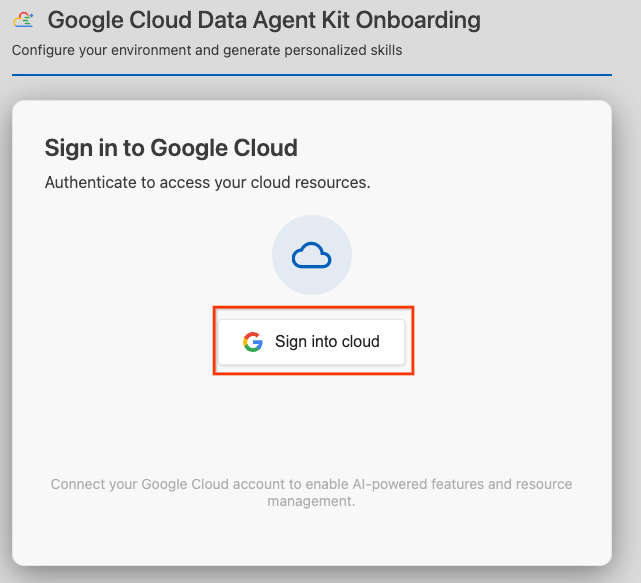
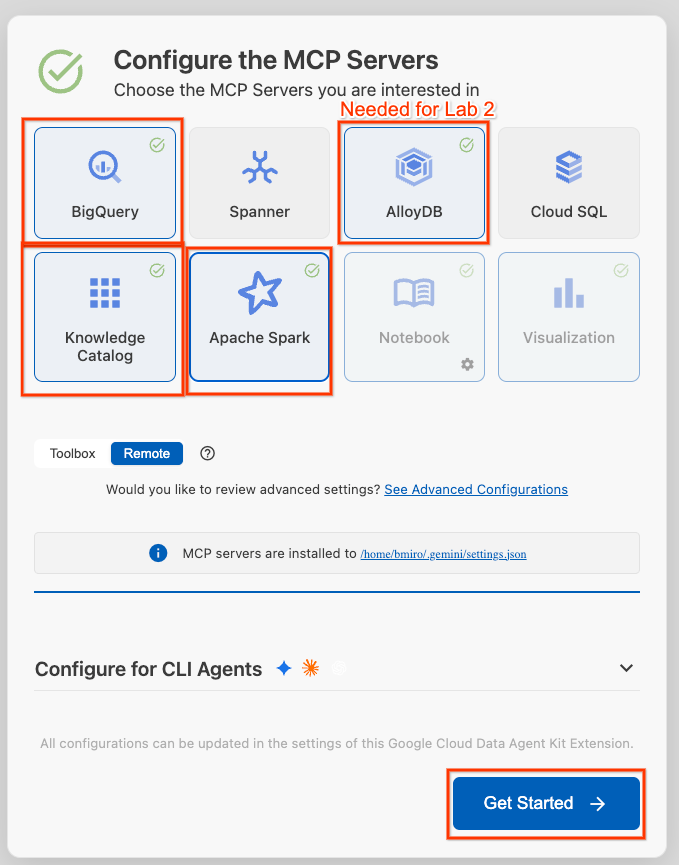
- Clique em Configurar servidores MCP.
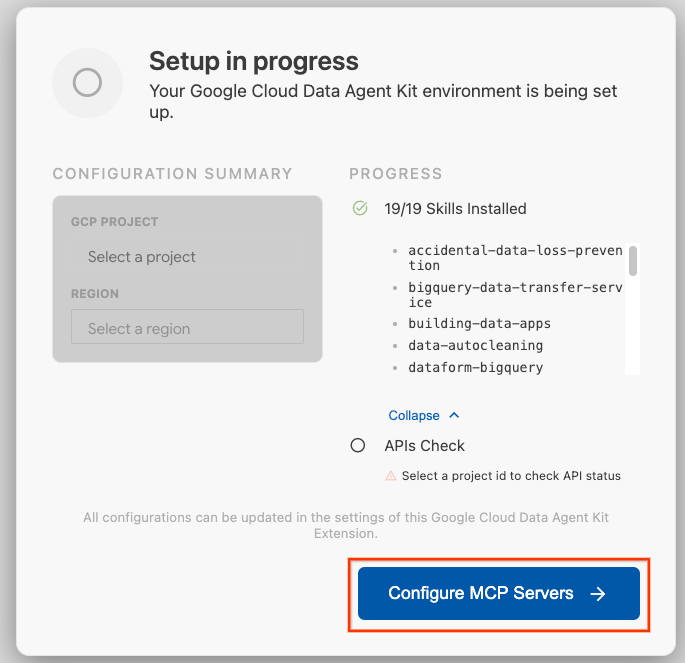
- Selecione BigQuery, Knowledge Catalog, Apache Spark e AlloyDB. Você vai usar o AlloyDB no laboratório 2. Em seguida, clique em Começar.
- Clique no seletor ID do projeto na barra de status da parte de baixo e escolha seu projeto ativo do Google Cloud.
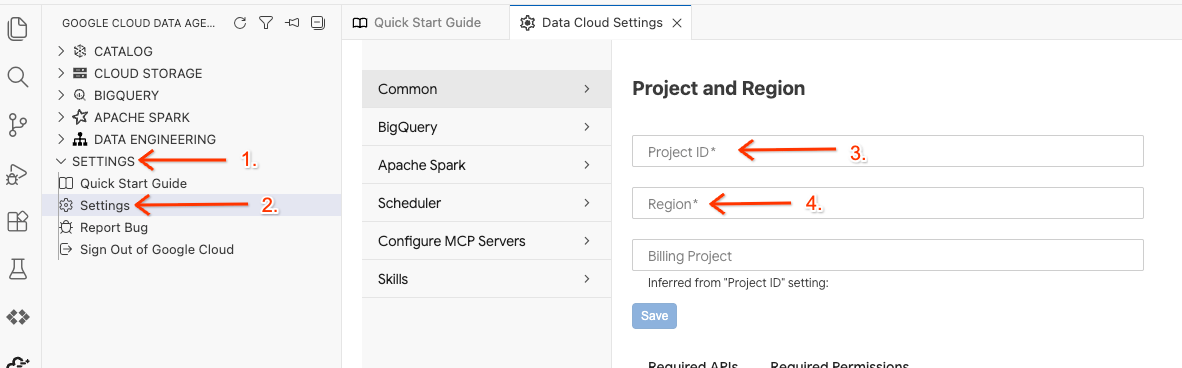
- No Data Agent Kit, clique em SETTINGS e em Settings. Na guia Common, selecione o ID do projeto e a Região para executar o laboratório, como us-central1.
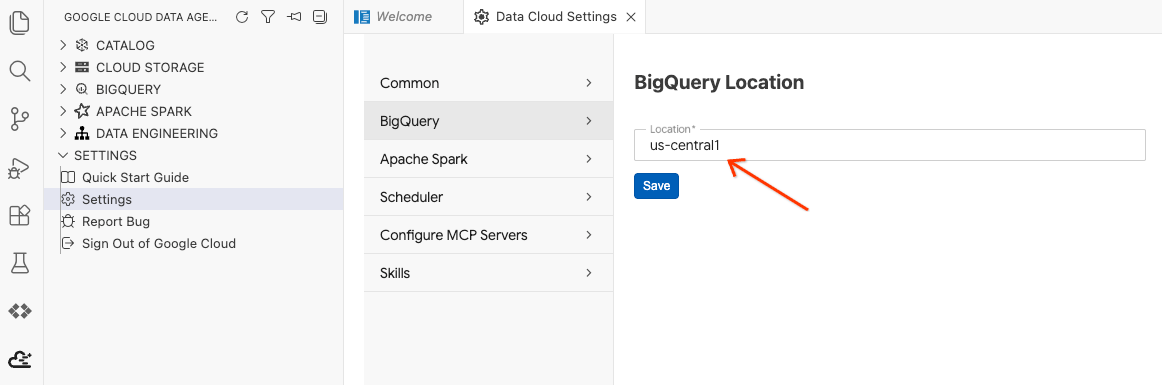
- Clique em Configurações do BigQuery e substitua a Região pela região selecionada anteriormente. Clique em Salvar.
Agora você pode usar o Data Agent Kit.
Executar o script de configuração do ambiente
No terminal, execute o script de configuração para criar os recursos em segundo plano necessários para este laboratório e configurar as permissões do IAM:
chmod +x setup_lab1.sh
./setup_lab1.sh
source .env
Você vai ver uma série de etapas de saída mostrando quais recursos estão sendo provisionados. Vamos abordar esses temas ao longo do laboratório.
Quando uma mensagem de conclusão aparecer, você poderá continuar:
==================================================== Environment Setup Complete! ====================================================
Agora, vamos começar a pesquisa!
3. Ingerir manifestos de envio de parceiros
Os dados do manifesto de embarque de navios parceiros são armazenados no formato padrão JSON Lines (JSONL) no seu bucket: gs://${PROJECT_ID}-lost-cargo-lake/shipping_manifests/manifests.jsonl.
Antes de realizar análises detalhadas, você vai criar uma tabela do BigLake gerenciada para esses dados não estruturados. Assim, é possível analisar os dados de logística do parceiro imediatamente usando o SQL padrão sem custos de importação duplicados.
Abra o espaço de trabalho no editor e execute a consulta
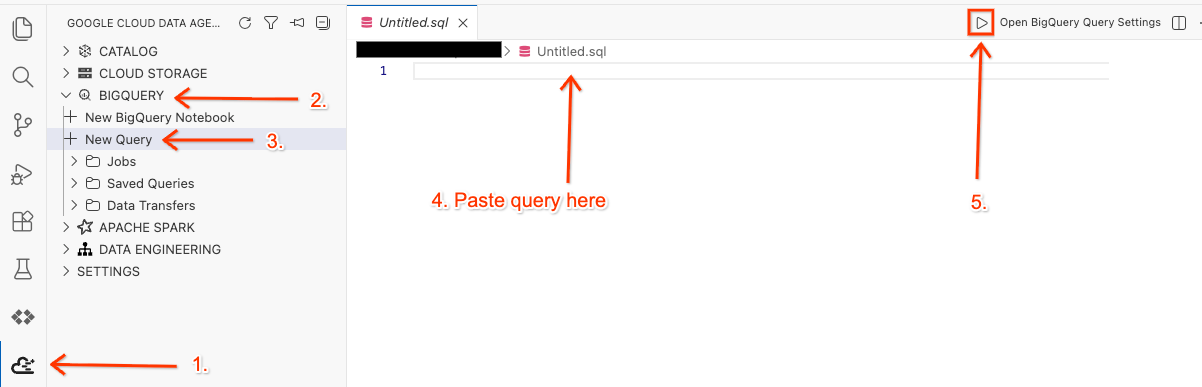
- No editor do Cloud Shell, clique no ícone Extensão do kit de agente de dados do Google Cloud no painel lateral.
- Acesse o BigQuery e selecione + Nova consulta.
- Copie a consulta a seguir na janela de consulta.
SET @@location = "<YOUR_REGION>"; --Update to your resource region, such as "us-central1". Make sure it is in quotes.
EXECUTE IMMEDIATE ("""
CREATE OR REPLACE EXTERNAL TABLE `lost_cargo_dataset.shipping_manifests`
(
shipment_id STRING,
timestamp TIMESTAMP,
last_ping_lat FLOAT64,
last_ping_long FLOAT64,
seal_integrity_status INT64,
custodian_id STRING OPTIONS(description='Masked identification token for official cargo custodian personnel.')
)
WITH CONNECTION `""" || @@location || """.conn`
OPTIONS (
format = 'NEWLINE_DELIMITED_JSON',
uris = ['gs://""" || @@project_id || """-lost-cargo-lake/shipping_manifests/*.jsonl']
)
""");
- Clique em Executar.
- Para verificar se a tabela foi criada, uma mensagem de sucesso vai aparecer no painel Resultados da consulta, que abre automaticamente na parte de baixo.
Consultar a tabela externa para isolar transponders comprometidos
Vamos identificar os transponders comprometidos localizando falhas quando o seal_integrity_status foi definido como 0. Copie e execute a consulta a seguir na janela que você abriu antes:
SELECT shipment_id, last_ping_lat, last_ping_long, custodian_id
FROM `lost_cargo_dataset.shipping_manifests`
WHERE seal_integrity_status = 0;
No painel Resultados da consulta, você vai ver uma saída semelhante a esta:
shipment_id | last_ping_lat | last_ping_long | custodian_id |
MV-CAT-001 | 51.5074 | -0,1278 | usr_999_shadow |
4. Processar registros não estruturados com o Serviço Gerenciado para Apache Spark
Você encontrou o local inicial nos manifestos estruturados, mas o transponder perdido ficou completamente inativo. O último ping do transponder deixou uma mensagem criptografada e não estruturada em um arquivo de registro de texto bruto no caminho do GCS gs://${BUCKET_NAME}/raw_logs/maritime_logs.txt.
Para processar e mapear esse registro de texto, extrair carimbos de data/hora, camuflar identidades e localizar a rota de entrega da carga, você vai enviar um job Apache Spark (PySpark) sem servidor para o Serviço Gerenciado para Apache Spark.
O Serviço Gerenciado para Apache Spark permite executar cargas de trabalho do Spark sem provisionar ou gerenciar um cluster. O serviço processa os recursos de computação subjacentes, escalonando-os automaticamente de forma dinâmica, e você só paga pela duração da execução.
O script faz o seguinte:
- Ingira o texto bruto, entre colchetes e não estruturado do transponder.
- Aplique filtros de extração de regex do PySpark SQL para separar carimbos de data/hora, metadados do custodiante e conteúdo bruto.
- Divida os registros confusos em registros limpos no nível da frase.
- Extraia a coordenada de destino dinâmica em que as partidas de payload perdido terminaram.
- Conecte e grave o dataframe de registros processados de volta no catálogo REST do Lakehouse Apache Iceberg como uma nova tabela de análise visível diretamente no BigQuery.
Corrigir o script de análise do PySpark
Há relatos de piratas do Python no mar causando todo tipo de problema.
- Execute o seguinte comando para abrir o arquivo
process_maritime_logsno editor do Cloud Shell.cd ~/devrel-demos/data-analytics/data-cloud-roadshow/lab1 cloudshell open ./process_maritime_logs.py - Leia o código e entenda o que ele faz.
- Verifique se não há nada suspeito no código. Se você precisar excluir algo, salve o arquivo usando
Ctrl + S(Windows/Linux) ouCmd + S(Mac).
Enviar o job do Spark sem servidor
Envie o job usando o SDK gcloud. A configuração configura automaticamente o job do PySpark para acessar o catálogo do Lakehouse.
Execute o seguinte comando no terminal do editor integrado.
cd ~/devrel-demos/data-analytics/data-cloud-roadshow/lab1
source .env
gcloud dataproc batches submit pyspark process_maritime_logs.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--version=2.3 \
--deps-bucket=${BUCKET_NAME} \
--properties="\
spark.sql.defaultCatalog=cargo_catalog,\
spark.sql.catalog.${CATALOG_NAME}=org.apache.iceberg.spark.SparkCatalog,\
spark.sql.catalog.${CATALOG_NAME}.type=rest,\
spark.sql.catalog.${CATALOG_NAME}.uri=https://biglake.googleapis.com/iceberg/v1/restcatalog,\
spark.sql.catalog.${CATALOG_NAME}.warehouse=gs://${BUCKET_NAME},\
spark.sql.catalog.${CATALOG_NAME}.header.x-goog-user-project=${PROJECT_ID},\
spark.sql.catalog.${CATALOG_NAME}.rest.auth.type=org.apache.iceberg.gcp.auth.GoogleAuthManager,\
spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions,\
spark.sql.catalog.${CATALOG_NAME}.gcs.oauth2.refresh-credentials-endpoint=https://oauth2.googleapis.com/token, \
spark.sql.catalog.${CATALOG_NAME}.header.X-Iceberg-Access-Delegation=vended-credentials" \
-- ${BUCKET_NAME}
Aguarde alguns minutos para que o ambiente sem servidor seja ativado, faça upload do script e execute a lógica de processamento.
Quando você vir uma saída semelhante à seguinte, a tabela processada será salva no catálogo do Lakehouse como uma tabela gerenciada do Apache Iceberg.
Batch [1fae0b4b42c045a084dd67917bd0c332] finished.
metadata:
'@type': type.googleapis.com/google.cloud.dataproc.v1.BatchOperationMetadata
batch: projects/<YOUR_PROJECT>/locations/us-central1/batches/1fae0b4b42c045a084dd67917bd0c332
batchUuid: 611b4465-fdac-4974-bc47-5f10adaf2a08
createTime: '2026-06-11T21:35:01.868157Z'
description: Batch
labels:
goog-dataproc-batch-id: 1fae0b4b42c045a084dd67917bd0c332
goog-dataproc-batch-uuid: 611b4465-fdac-4974-bc47-5f10adaf2a08
goog-dataproc-drz-resource-uuid: batch-611b4465-fdac-4974-bc47-5f10adaf2a08
goog-dataproc-location: us-central1
operationType: BATCH
name: projects/<YOUR_PROJECT/regions/us-central1/operations/7e2044db-dd97-3270-b368-4dc4ba417574
Visualizar os registros processados
No editor de consultas da extensão Data Agent Kit, copie a consulta abaixo para visualizar os dados:
SET @@location = "<YOUR_REGION>"; -- e.g. "us-central1"
EXECUTE IMMEDIATE FORMAT("""
select log_timestamp, custodian_id, sentence from
`%s.%s-lost-cargo-lake.lost_cargo_namespace.processed_maritime_logs`
limit 5
""", @@project_id, @@project_id);
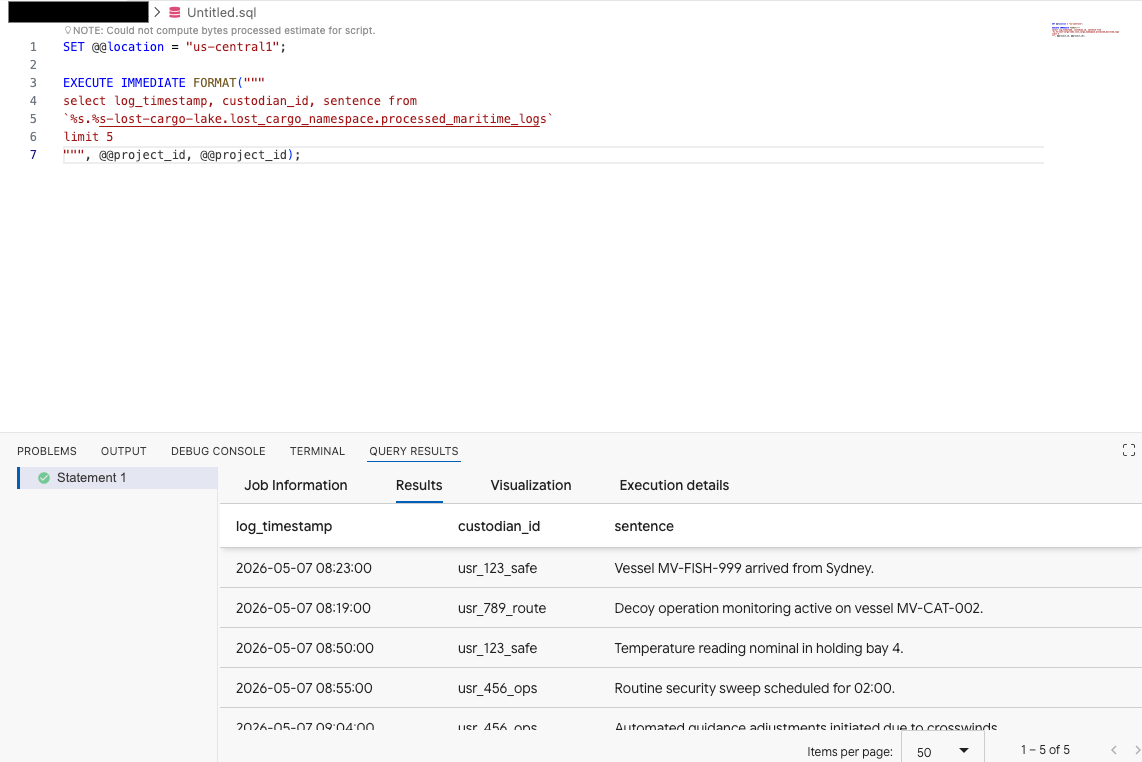
Isso mostra que a tabela do Iceberg registrada no catálogo pode ser acessada com sucesso no BigQuery.
Extrair a pista de destino
Agora que temos os registros processados, vamos procurar aqueles que incluem um destino. Depois, podemos pesquisar os registros que mencionam a cidade de origem.
No editor de consultas, execute a consulta a seguir, substituindo <YOUR_REGION> pela sua região e <ORIGIN_CITY> pela cidade de origem descoberta anteriormente.
SET @@location = "<YOUR_REGION>"; --e.g. "us-central1"
DECLARE origin_city STRING;
SET origin_city = "<ORIGIN_CITY>"; --e.g. "Boston". (It's not Boston)
EXECUTE IMMEDIATE FORMAT(r"""
SELECT
log_timestamp AS event_time,
custodian_id,
REGEXP_EXTRACT(raw_message, r'Destination:\s*([^.]+)') AS destination_target
FROM
`%s.%s-lost-cargo-lake.lost_cargo_namespace.processed_maritime_logs`
WHERE
-- STRPOS is highly optimized in BigQuery for a simple .contains() substring check
STRPOS(sentence, '%s') > 0;
""", @@project_id, @@project_id, origin_city);
Conversar com seus dados no console do BigQuery usando a análise conversacional
Em vez de escrever consultas SQL complexas para analisar seus dados, use a Análise de conversação para conversar com suas tabelas usando linguagem natural.
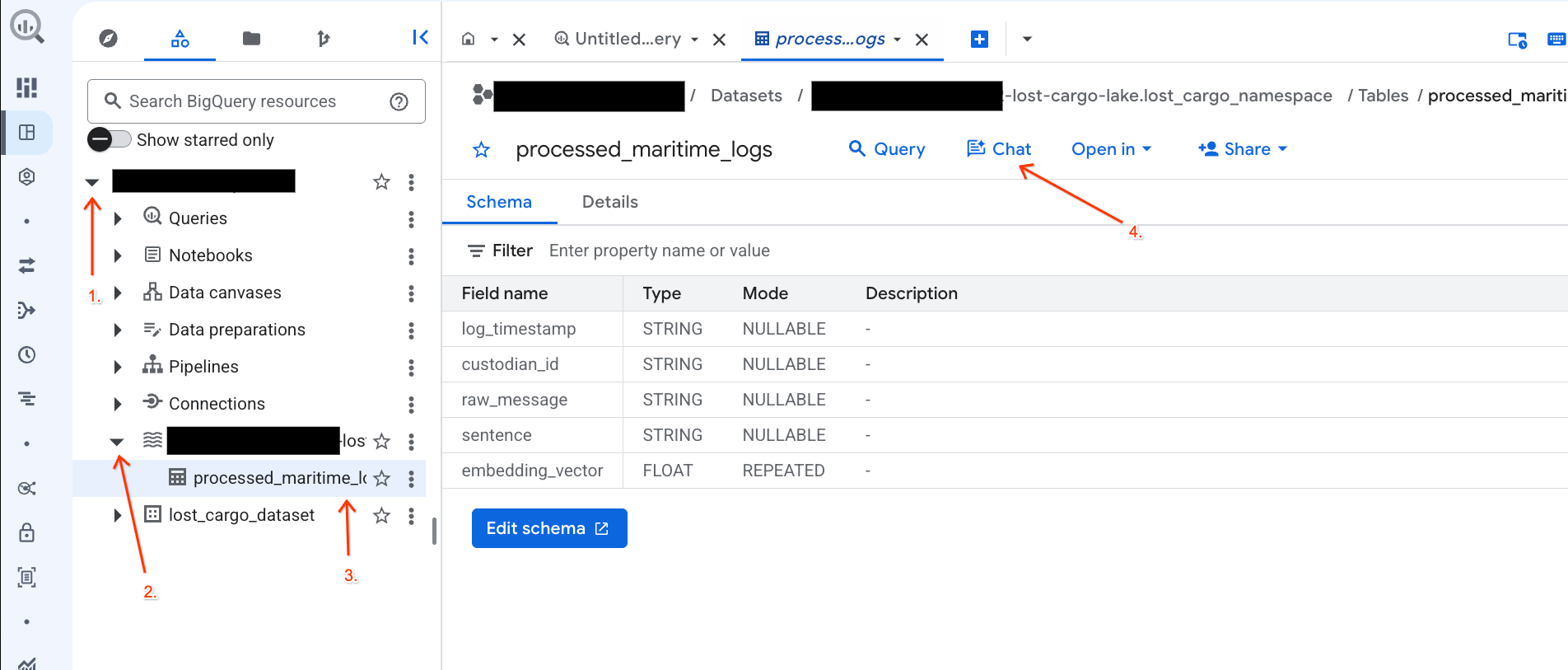
- Acesse o console do BigQuery.
- No painel Explorer à esquerda, expanda seu projeto e o conjunto de dados
-lost-cargo-lake.lost_cargo_namespace processed_maritime_logspara abrir a guia de detalhes dela. - Ao lado de Consulta, clique em Chat.
- No painel de chat, digite a seguinte pergunta e pressione Enter no teclado para enviar:
Based on this table, what color is the shipping container MV-CAT-001?
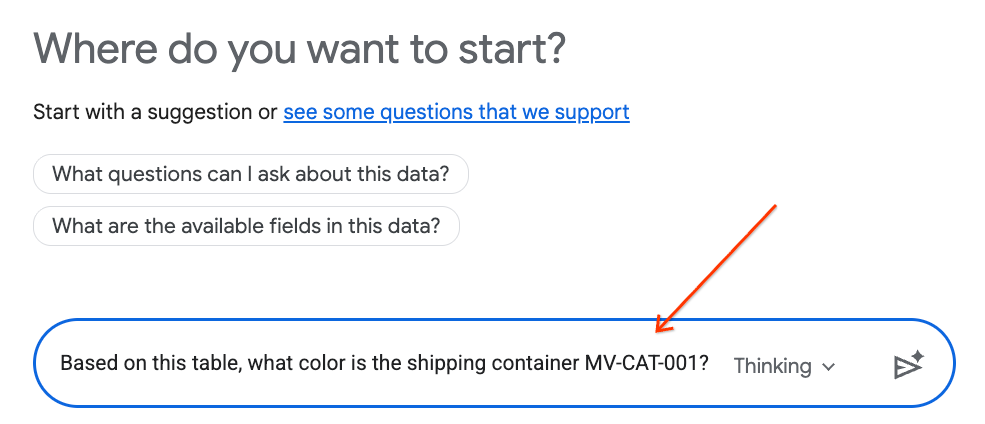
- As Análises de conversação (com tecnologia do Gemini) vão analisar os dados da tabela ativa e responder com a cor.
5. Ver o catálogo centralizado do Lakehouse
Para integrar mecanismos de processamento de código aberto (como o Apache Spark) de maneira segura e perfeita com mecanismos de dados empresariais (como o BigQuery), seu script de configuração configurou um catálogo REST do Iceberg do Lakehouse.
O catálogo REST do Apache Iceberg serve como a "única fonte de verdade" sem servidor para metadados de tabelas, gerenciando esquemas e particionando tabelas de forma dinâmica enquanto armazena arquivos de dados Parquet físicos no Cloud Storage.
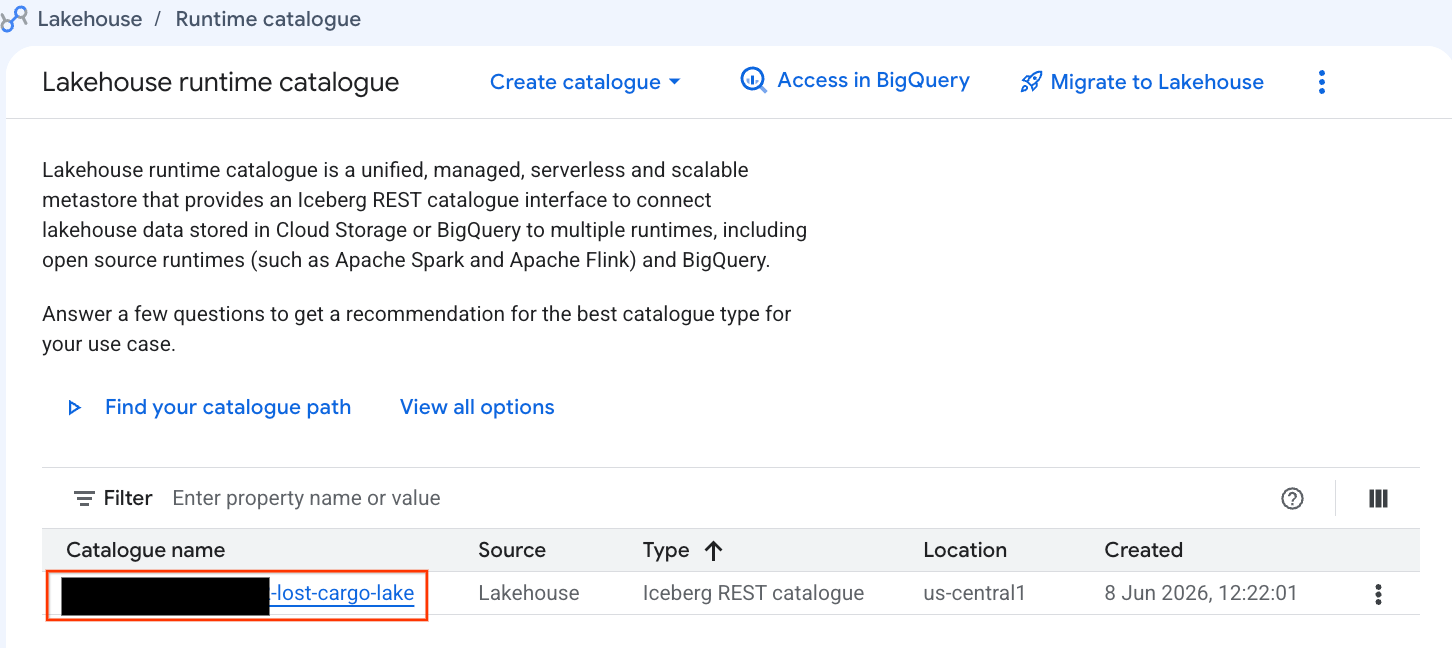
Vamos examinar esse catálogo diretamente no console do Google Cloud:
- Abra o console do Lakehouse.
- Na guia Catálogos, localize e clique no catálogo REST do Iceberg ativo:
-lost-cargo-lake
- Na visualização de detalhes do catálogo, em Namespaces, você vai encontrar
lost_cargo_namespace. Clique nele.
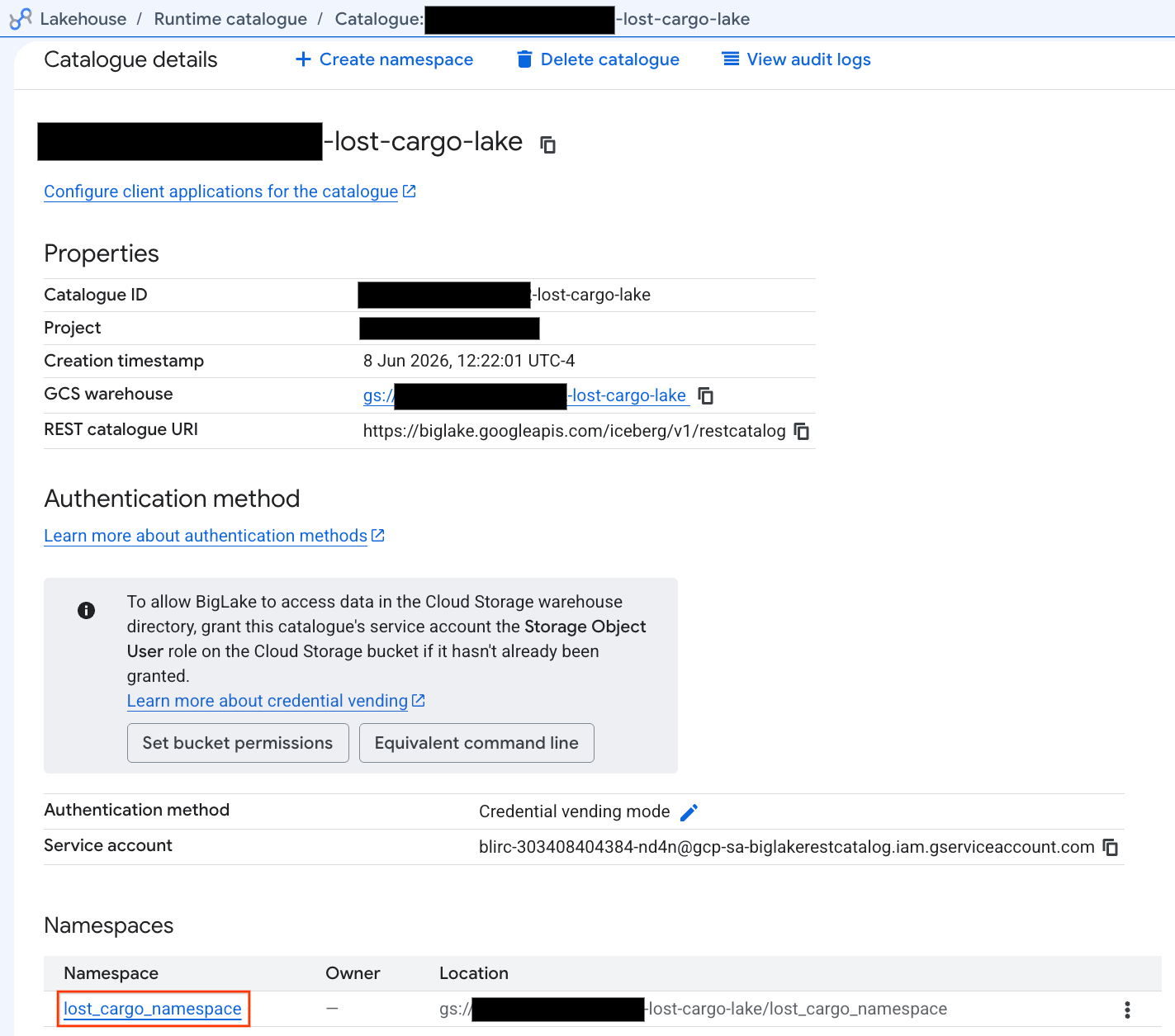
- A nova tabela do Apache Iceberg, gerada pelo PySpark, foi registrada automaticamente no namespace do metastore e ficou disponível para consultas no BigQuery.
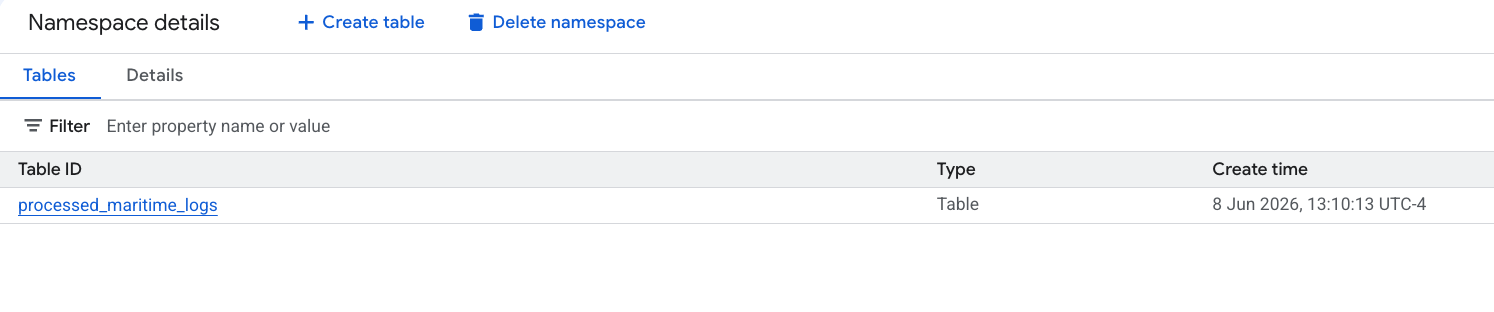
6. Gerar insights na tabela de manifesto de envio
Vamos voltar e analisar a tabela shipping_manifests para entender a estrutura e o conteúdo dela usando os insights de dados do Knowledge Catalog. Ao enriquecer os metadados, outros usuários do Explorador podem entender melhor a tabela para análises futuras.
Gerar insights de tabela no BigQuery Studio
- No console do Google Cloud, acesse BigQuery Studio.
- No painel Explorer, expanda o projeto, o conjunto de dados
lost_cargo_datasete clique na tabelashipping_manifests. - No painel de detalhes à direita, clique na guia Insights.
- Use o menu suspenso para selecionar Gerar e publicar.
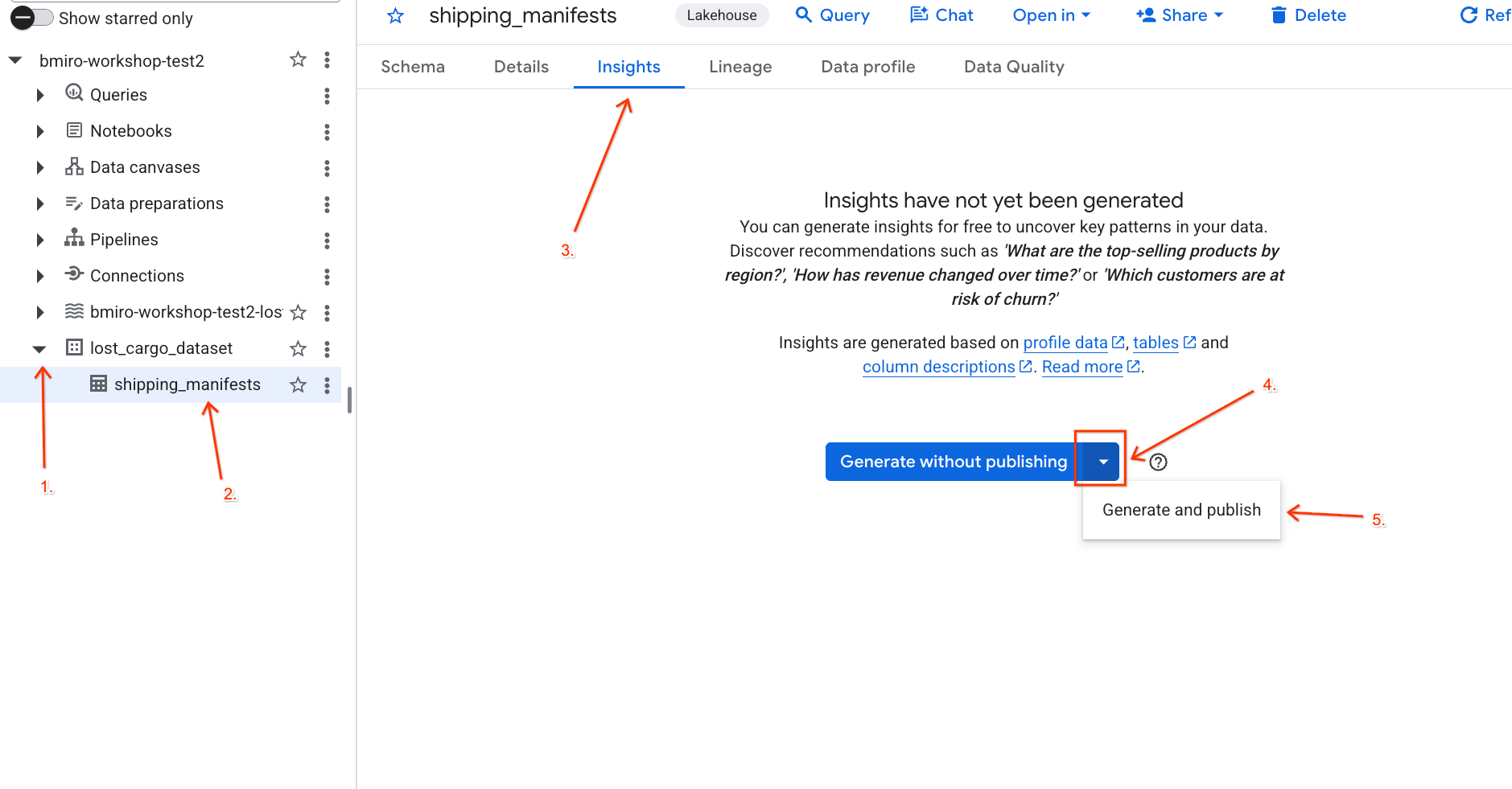
- Aguarde cerca de 3 minutos para que a geração de insights seja concluída. O Gemini vai analisar os metadados da tabela e gerar perguntas em linguagem natural e consultas SQL correspondentes.
- Depois disso, você vai encontrar uma Descrição da tabela com uma explicação em linguagem natural.
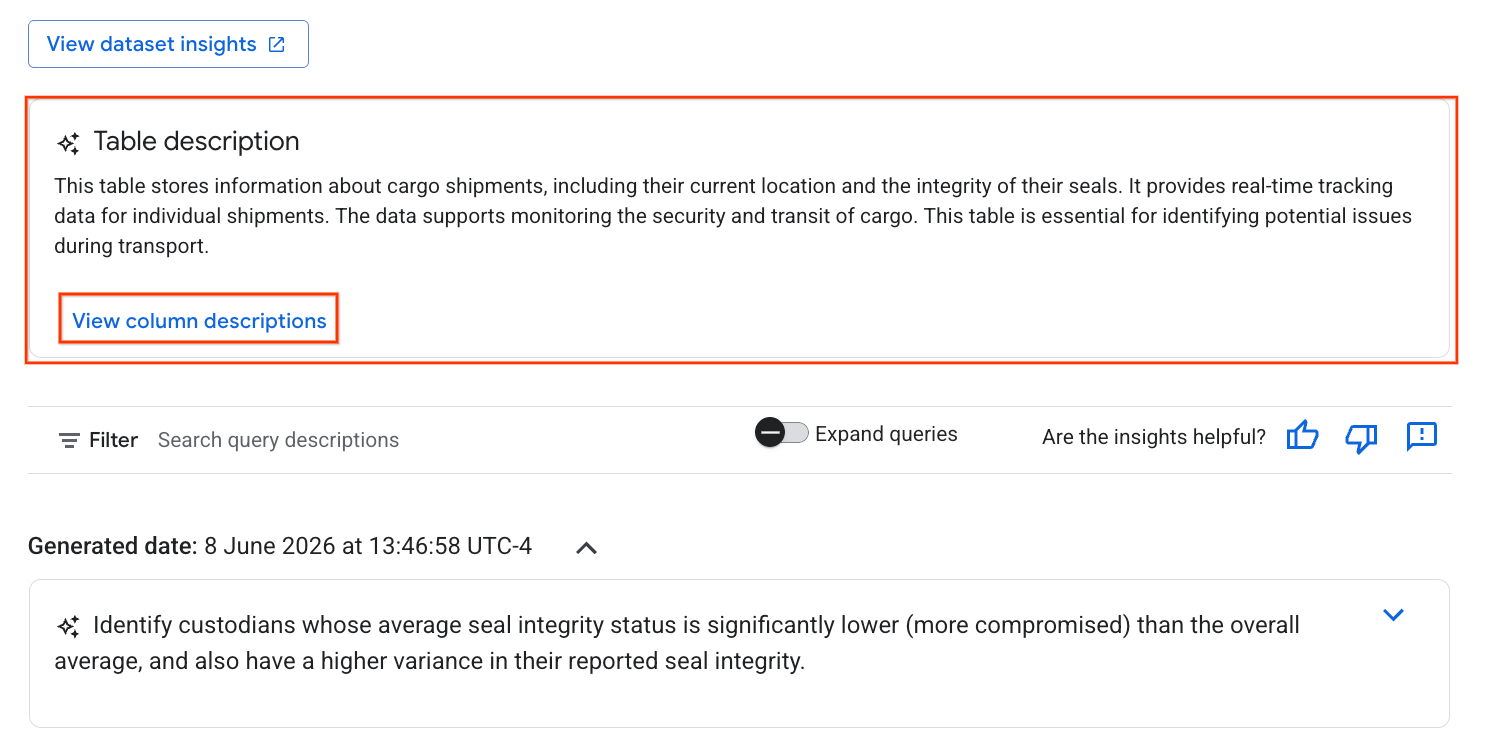
- Clique em Ver descrições das colunas para conferir informações sobre as colunas individuais.
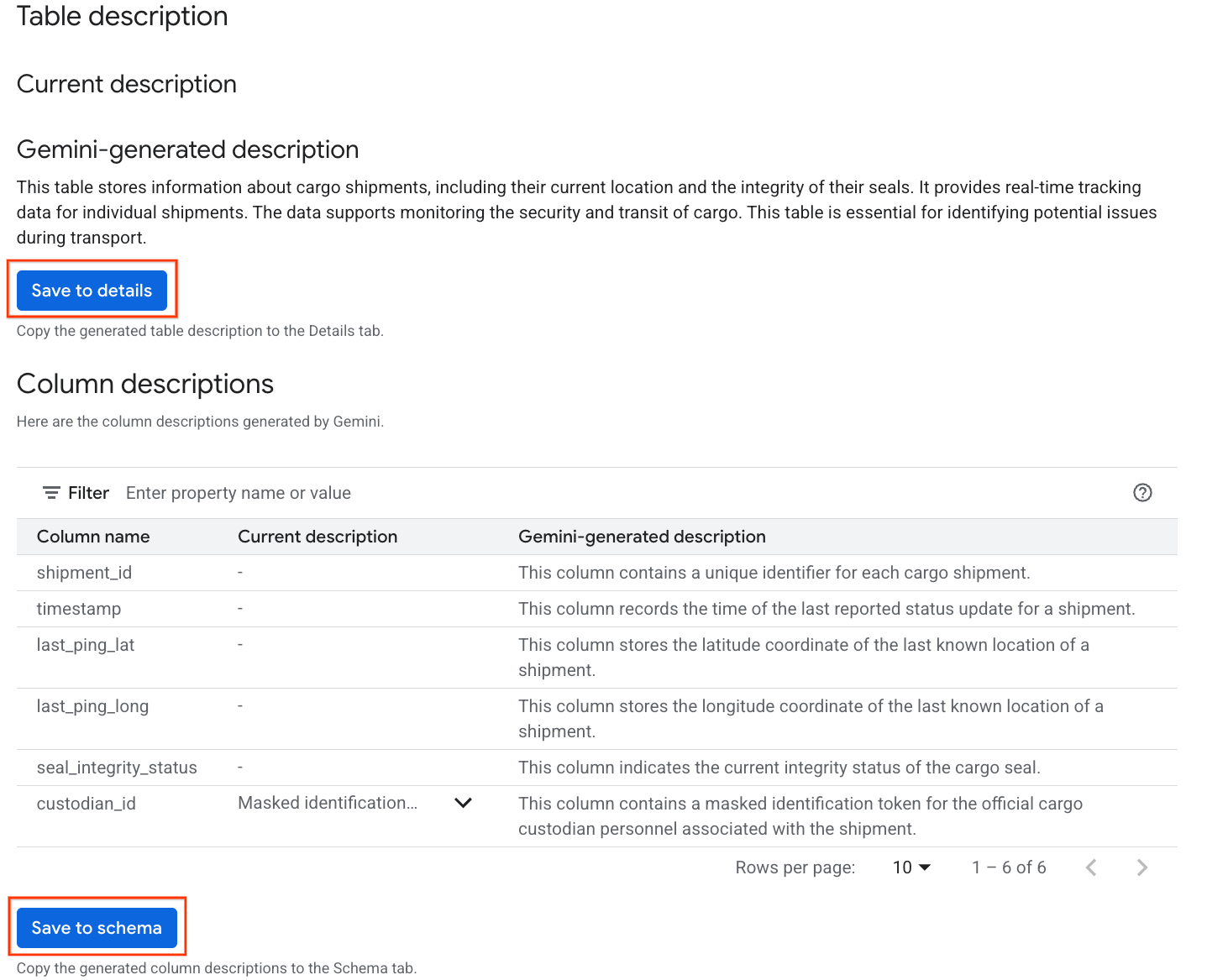
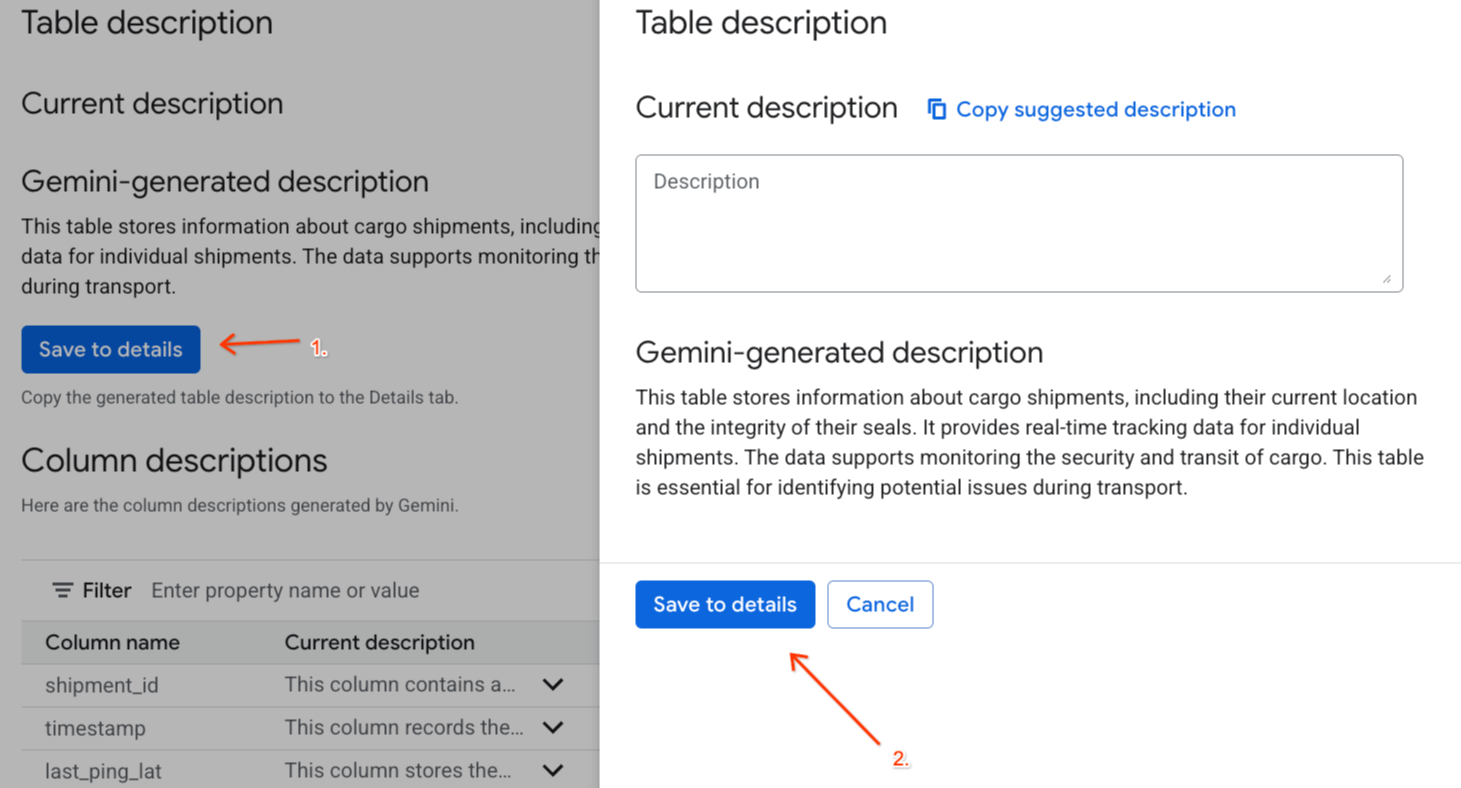
- Clique em Salvar em detalhes em
Gemini generated descriptione clique em Salvar em detalhes na janela que aparece.
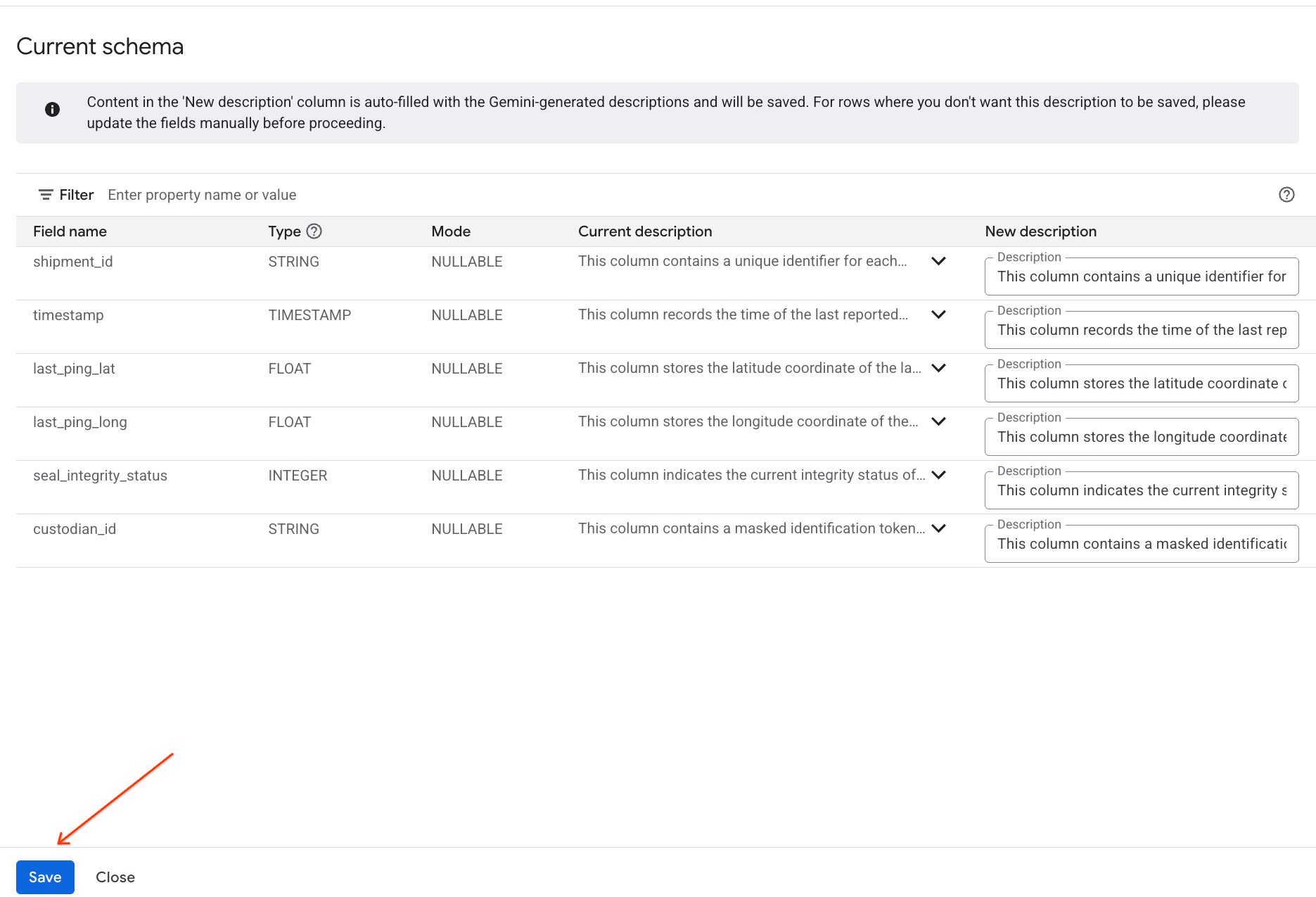
- Da mesma forma, clique em Salvar no esquema para adicionar as descrições de colunas aos metadados da tabela.
Analisar insights gerados
Você também vai encontrar uma lista de perguntas sugeridas. Clique em qualquer pergunta para conferir a consulta SQL gerada e execute-a para analisar os dados. Por exemplo, você pode ver perguntas como:
- "Qual é o número total de remessas?"
- "Liste os IDs exclusivos de custodiante."
Executar essas consultas ajuda você a entender os dados.
7. Implementar mascaramento e governança de dados
Para garantir que contas e nomes de usuários de pesquisa ativos não sejam vazados durante essa investigação de carga em andamento, você precisa aplicar protocolos de segurança padrão. Você vai criar uma taxonomia de tags de política de segurança e configurar o mascaramento de dados do catálogo de dados na coluna sensível custodian_id para verificar a privacidade dos dados.
Por padrão, o BigQuery nega o acesso a colunas protegidas por tags de política. Para consultar a tabela e verificar as máscaras de dados ativas, sua conta de usuário precisa ter o papel Leitor mascarado de política de dados do BigQuery.
Essa função foi vinculada automaticamente à sua conta de usuário ativa durante a execução inicial do setup_lab1.sh.
Criar a taxonomia e a tag de política
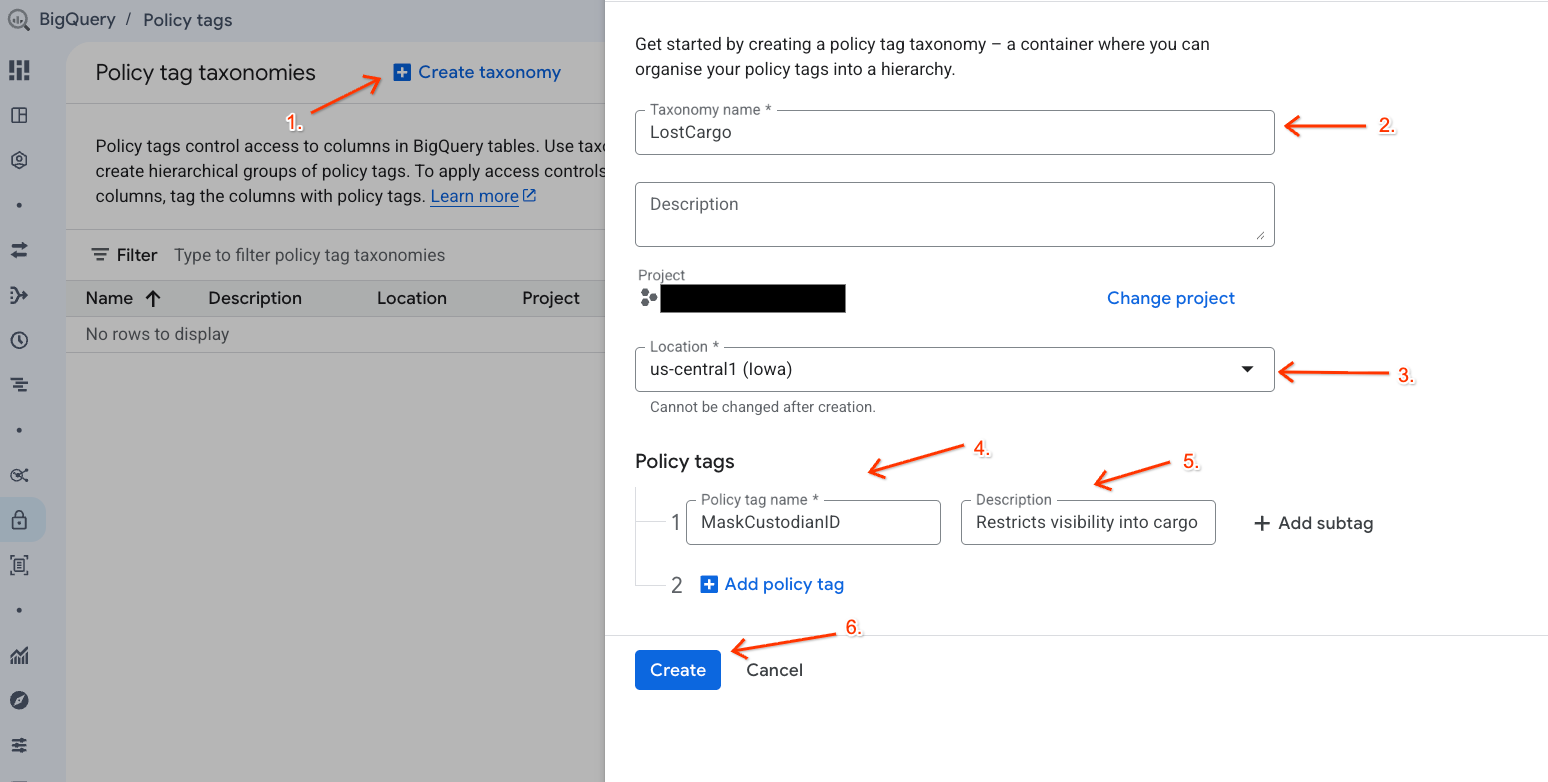
Crie uma taxonomia de dados e uma tag de política associada para gerenciar o acesso aos seus dados.
- Acesse a página Taxonomias de tags de política.
- Clique em + Criar taxonomia.
- Configure os parâmetros:
- Nome da taxonomia: insira
lost-cargo-, substituindo pelo ID do projeto. - Região: selecione sua região.
- Em Nome da tag de política, insira
MaskCustodianID. - Para a Descrição da tag de política:
Restricts visibility into cargo custodian usernames
- Nome da taxonomia: insira
- Clique em Criar para registrar a nova taxonomia e a tag de política.
Criar a política de mascaramento de dados
Em seguida, configure uma política de dados para definir como os dados são mascarados na tag de classificação MaskCustodianID. Você vai usar a regra de mascaramento Sempre nulo, substituindo os valores correspondentes por retornos vazios/nulos para todos os atores não privilegiados.
- Na página Taxonomias das tags de política, clique na taxonomia recém-criada na lista.
- Na lista de hierarquias, clique na tag
MaskCustodianIDpara selecioná-la e escolha Gerenciar políticas de dados.
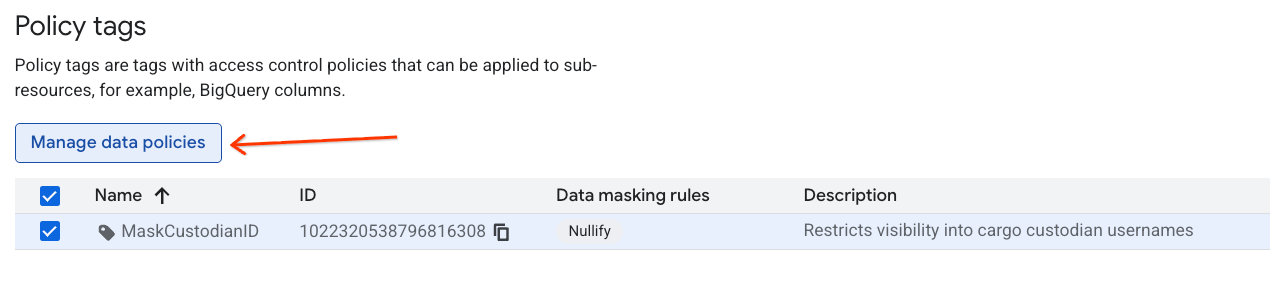
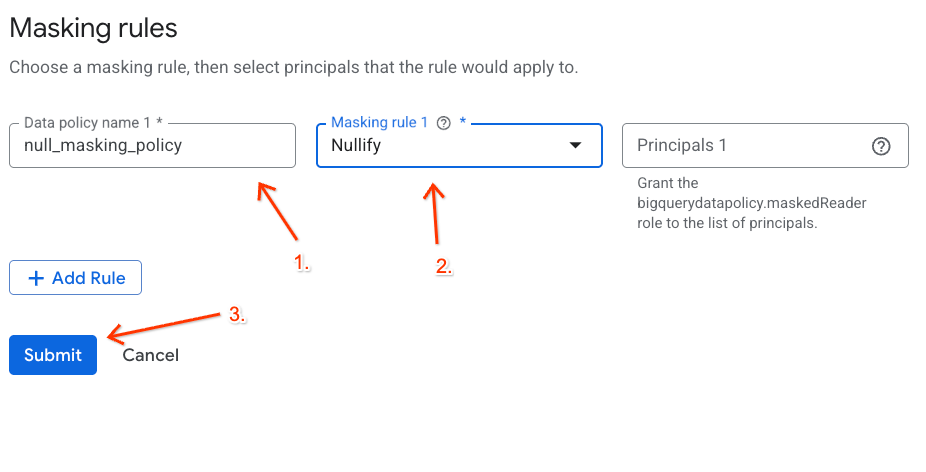
- No painel à direita, clique no botão + Adicionar regra.
- Configure os detalhes da política no painel que aparece:
- Nome da política de dados: insira
null_masking_policy. Não deixe que ele seja gerado automaticamente, porque vamos fazer referência a ele pelo nome nas próximas etapas. - Regra de mascaramento: selecione
Nullifyno menu suspenso.
- Nome da política de dados: insira
- Clique em Enviar.
Atribuir a tag de política à coluna do BigQuery
Com a tag de política e a regra de mascaramento de dados ativas, mapeie a tag de classificação diretamente para a coluna custodian_id na tabela de manifesto de envio do parceiro do BigQuery.
- Acesse o console do BigQuery.
- No painel Explorer à esquerda, expanda seu projeto ativo, o conjunto de dados
lost_cargo_datasete clique na tabelashipping_manifestspara abrir a visualização detalhada. - Clique em Editar esquema.
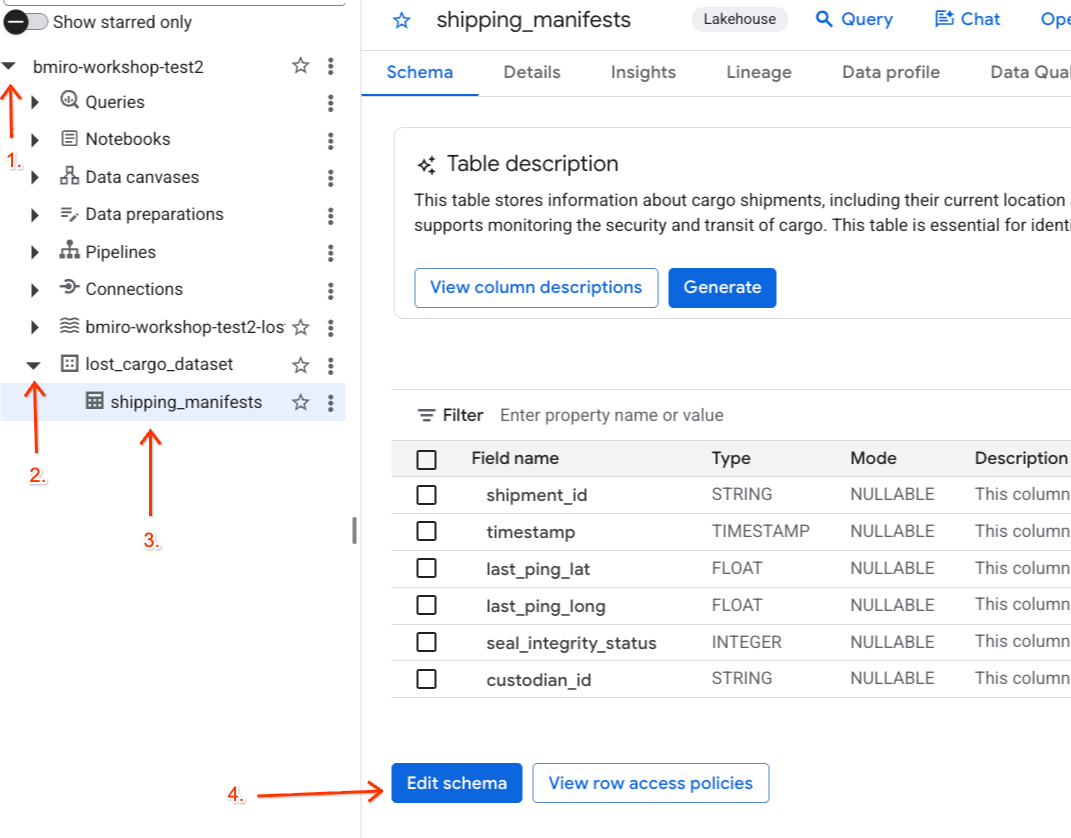
- Na lista de colunas, marque a caixa ao lado de
custodian_id. - Clique no botão Adicionar tag de política na barra de ferramentas superior do editor de esquema.
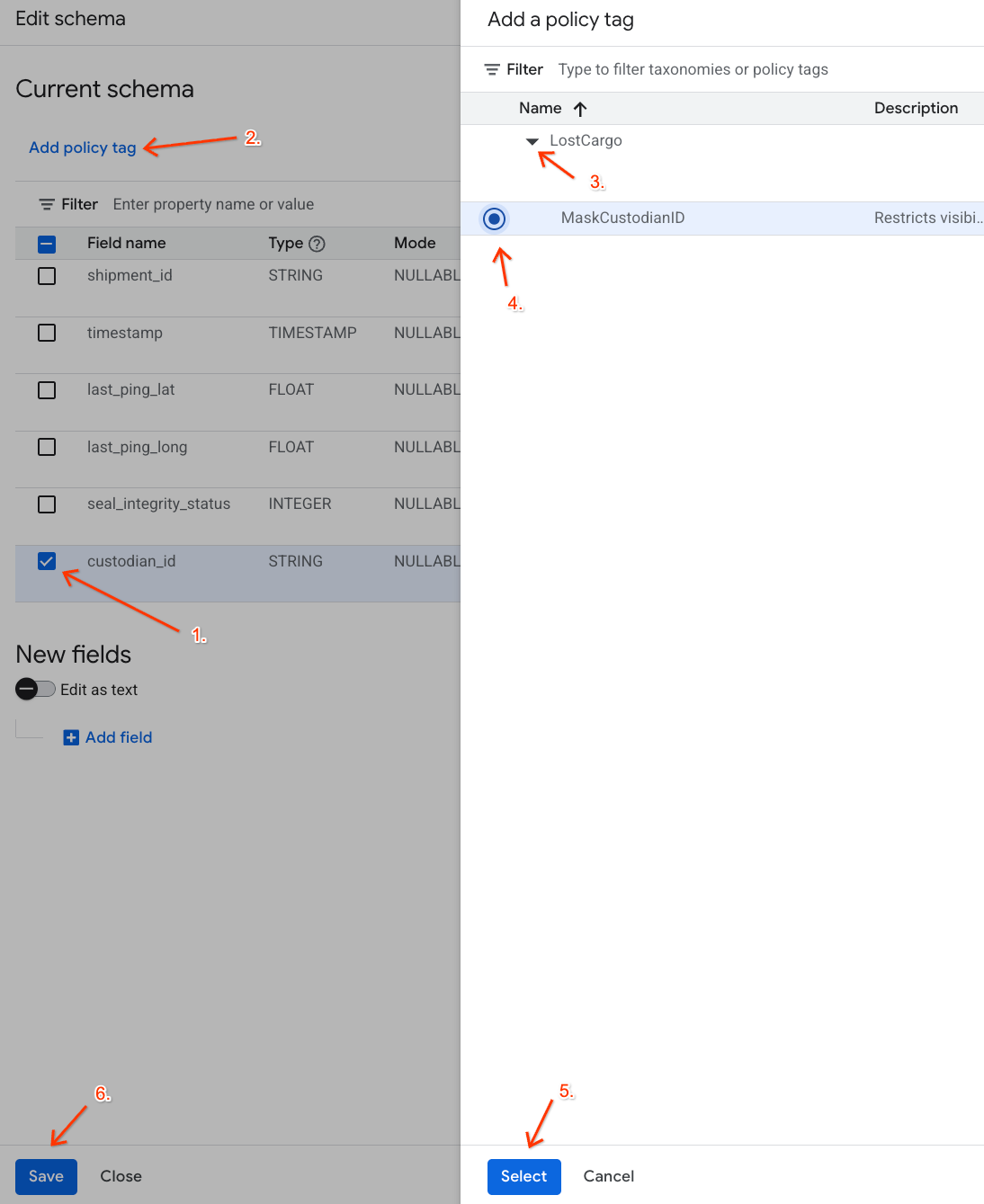
- No painel Adicionar uma tag de política:
- Localize e abra sua taxonomia
LostCargo. - Selecione a bolha ao lado de
MaskCustodianID. - Clique em Selecionar.
- Localize e abra sua taxonomia
- Verifique se a tag
MaskCustodianIDagora está visível na coluna Tag de política da linha que representacustodian_id. - Clique em Salvar.
Verificar as restrições de política
Agora que você tem o papel de leitor mascarado no nível do projeto, é possível consultar a tabela para verificar se a política de mascaramento está ativa.
Volte para o Data Agent Kit e execute a seguinte consulta:
SELECT shipment_id, custodian_id
FROM lost_cargo_dataset.shipping_manifests
LIMIT 5;
A resposta será semelhante a esta:
shipment_id | custodian_id |
NORMAL-001 | null |
NORMAL-002 | null |
MV-CAT-001 | null |
Pronto. Embora seja possível ver os registros de shipment_id, o campo sensível custodian_id retorna máscaras seguras de null para evitar vazamentos.
8. Limpar
Para evitar cobranças contínuas na sua conta do Google Cloud pelos recursos criados durante este codelab, execute estes comandos no terminal do Cloud Shell para excluir seus conjuntos de dados e buckets:
# Verify active variables
export PROJECT_ID=$(gcloud config get-value project)
export BUCKET_NAME="${PROJECT_ID}-lost-cargo-lake"
# Delete Knowledge Catalog security taxonomies
export TAXONOMY_NAME=$(gcloud data-catalog taxonomies list --location=us-central1 --filter="displayName:LostCargo" --format="value(name)")
if [[ -n "$TAXONOMY_NAME" ]]; then
curl -X DELETE \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
"https://datacatalog.googleapis.com/v1/${TAXONOMY_NAME}" || true
fi
# Delete Lakehouse Iceberg REST Catalog tables and namespaces
gcloud biglake iceberg tables delete processed_maritime_logs \
--catalog=${BUCKET_NAME} \
--namespace=lost_cargo_namespace \
--quiet || true
gcloud biglake iceberg namespaces delete lost_cargo_namespace \
--catalog=${BUCKET_NAME} \
--quiet || true
# Delete Lakehouse Iceberg REST Catalog
gcloud biglake iceberg catalogs delete ${BUCKET_NAME} --quiet || true
# Delete dependencies bucket
gcloud storage rm -r gs://${BUCKET_NAME} || true
# Delete BigQuery dataset and tables
bq rm -r -f -d ${PROJECT_ID}:lost_cargo_dataset || true
9. Parabéns
Parabéns! Você concluiu o primeiro módulo crucial da investigação Carga perdida. Você estabeleceu uma zona de pesquisa governada usando catálogos REST do Lakehouse Iceberg, normalização de registros do PySpark e mascaramento de dados refinado.
O que você aprendeu
- Instalar, configurar e configurar a extensão do Data Agent Kit no espaço de trabalho do ambiente de desenvolvimento integrado.
- Estabelecer um catálogo REST do Lakehouse Iceberg sem servidor usando credenciais vendidas e namespaces hierárquicos.
- Ingerir feeds regionais multiformato e criar tabelas externas do BigQuery em buckets do Cloud Storage.
- Execução de jobs do Apache Spark sem servidor para analisar, normalizar, segmentar e gravar registros não estruturados de transponders de volta no BigQuery como tabelas de catálogo do Iceberg registradas.
- Criar taxionomias de segurança e mapear políticas de mascaramento de dados do Knowledge Catalog para evitar vazamentos de identidade em índices de registros sensíveis.
- Gerar e analisar insights de metadados de tabelas usando os insights de dados do BigQuery para acelerar a análise de dados.
Verificação de pistas coletadas
Verifique se você registrou as seguintes pistas definitivas necessárias para iniciar a próxima fase do laboratório:
- ID do frete perdido:
MV-CAT-001(último local de ping: Londres) - Destino de destino planejado:
New York(e alias verdadeiro do transponder:MV-DOG-002) - Cor do contêiner:
Crimson RED - Tag de acesso à governança:
MaskCustodianID
Tudo pronto para a próxima fase?
Agora que as rotas de partida / destino do transponder estão seguras, a investigação continua. Vá direto para o Laboratório 2 para examinar câmeras de segurança usando modelos multimodais do Gemini, identificar a embarcação visualmente e realizar pesquisas vetoriais no AlloyDB para verificar anomalias de adulteração.
➡️ Continue com a etapa 2: análise de dados e insights multimodais