
1. Введение
В этой лабораторной работе вы примерите на себя роль ведущего специалиста по анализу данных в глобальной логистической компании. Пропал ценный грузовой контейнер с коллекционными фигурками андроидов! Чтобы определить его последнее известное местоположение и отследить маршрут, вам необходимо собрать разрозненные накладные от региональных логистических партнеров и неструктурированные файлы журналов транспондеров. Для этого вам потребуется настроить современную среду Google Cloud Open Data Lakehouse .

Что вы будете делать
- Настройте расширение Google Cloud Data Agent Kit в редакторе Cloud Shell.
- Создайте сегмент Cloud Storage и подготовьте каталог REST и пространство имен Apache Iceberg для Lakehouse.
- Сопоставьте внешнюю таблицу BigLake с необработанными JSON-манифестами партнеров в Cloud Storage, чтобы найти подсказку о месте отплытия корабля.
- Загрузка и обработка неструктурированных текстовых логов транспондеров с использованием управляемого сервиса для бессерверной архитектуры Apache Spark . Выполнение нормализации с помощью регулярных выражений и динамического извлечения подсказок для определения места назначения потерянной полезной нагрузки.
- Записывайте проанализированные метрики логов в таблицу Apache Iceberg через REST-каталог.
- Пообщайтесь с агентом искусственного интеллекта, используя аналитику разговоров, чтобы узнать о ваших данных Apache Iceberg и обнаружить скрытые подсказки о потерянной посылке.
- Используйте автоматизированный анализ данных с помощью Knowledge Catalog для генерации метаданных о ваших данных.
- Установите ограничения на доступ к данным, создав таксономию безопасности и используя каталог знаний для применения детального контроля доступа путем маскировки идентификаторов ответственных лиц, содержащих конфиденциальную информацию.
Что вам понадобится
- Веб-браузер, например Chrome .
- Проект Google Cloud с включенной функцией выставления счетов.
- Знание основных SQL-запросов и команд терминала.
Ожидаемая стоимость и продолжительность
- Время выполнения : ~45 минут.
- Ориентировочная стоимость : менее 5,00 долларов США .
2. Прежде чем начать
Создайте или выберите проект Google Cloud.
- В консоли Google Cloud выберите или создайте проект Google Cloud .
- Убедитесь, что для вашего облачного проекта включена функция выставления счетов. Узнайте, как подтвердить включение выставления счетов для проекта .
Настройка среды
Большинство команд вы будете выполнять из встроенного терминала в Cloud Shell Editor — облачной среде разработки, которая поставляется с предустановленными инструментами разработчика и стандартным SDK Google Cloud.
- Откройте редактор Cloud Shell в новой вкладке.
- Для клонирования репозитория выполните следующую команду в терминале:
cd ~/ git clone --filter=blob:none --no-checkout https://github.com/GoogleCloudPlatform/devrel-demos.git cd ~/devrel-demos git sparse-checkout init --cone git sparse-checkout set data-analytics/data-cloud-roadshow/lab1 git checkout main cd data-analytics/data-cloud-roadshow/lab1 - Укажите идентификатор вашего проекта. Вы также можете
Ctrl+Shift+Vв Windows/Linux илиCmd+Vв macOS, чтобы вставить это в терминал:export PROJECT_ID="<YOUR_PROJECT_ID>" - Теперь настройте это в своей среде.
gcloud config set project $PROJECT_ID - Выберите регион .
export REGION="<YOUR_REGION>" # Replace with the region you chose, such as "us-central1" - Включите необходимые API.
gcloud services enable \ bigquery.googleapis.com \ biglake.googleapis.com \ storage.googleapis.com \ dataplex.googleapis.com \ datacatalog.googleapis.com \ dataproc.googleapis.com \ aiplatform.googleapis.com \ cloudresourcemanager.googleapis.com \ serviceusage.googleapis.com \ cloudaicompanion.googleapis.com \ geminidataanalytics.googleapis.com
Установить расширение
Теперь вам предстоит настроить расширение Google Data Agent Kit — инструмент для непосредственного взаимодействия с инструментами работы с данными Google Cloud в вашей IDE.
- В левой панели действий редактора щелкните значок «Расширения» (или нажмите
Ctrl+Shift+Xв Windows/Linux илиCmd+Xв macOS). - В поле поиска расширений введите:
Google Cloud Data Agent Kit - Выберите официальное расширение из результатов поиска и нажмите «Установить» . Если появится запрос, выберите «Да, я доверяю авторам».
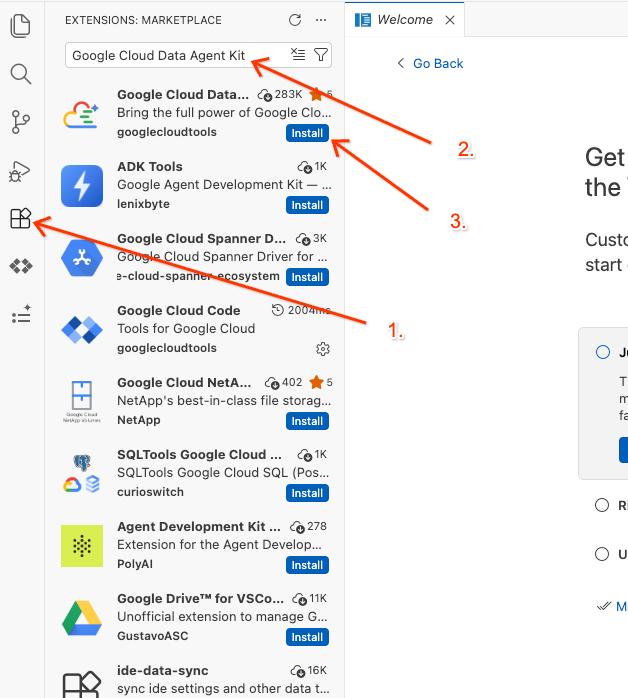
- После успешной установки вы должны увидеть значок Google Cloud Data Agent Kit на панели действий! Щелкните по нему.
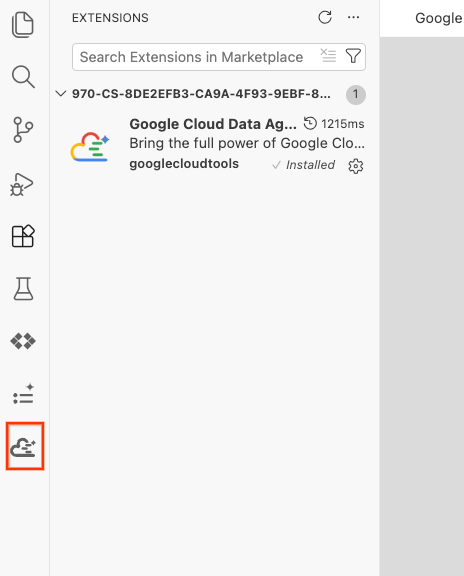
- Нажмите «Войти в облако» .
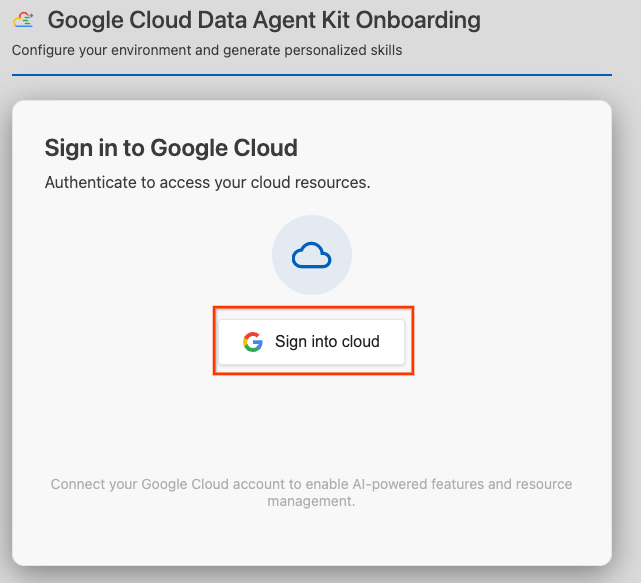
- Нажмите «Настроить серверы MCP» .
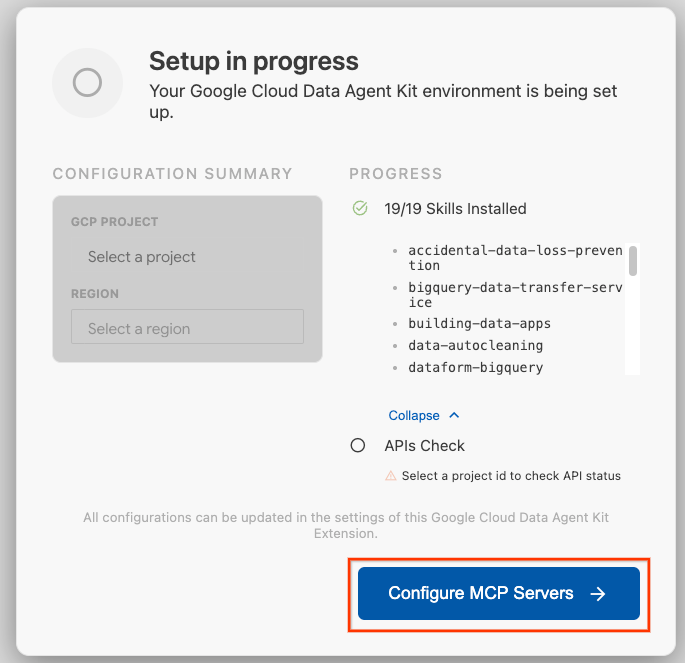
- Выберите BigQuery, Knowledge Catalog, Apache Spark и AlloyDB. AlloyDB вы будете использовать в лабораторной работе 2. Затем нажмите «Начать» .
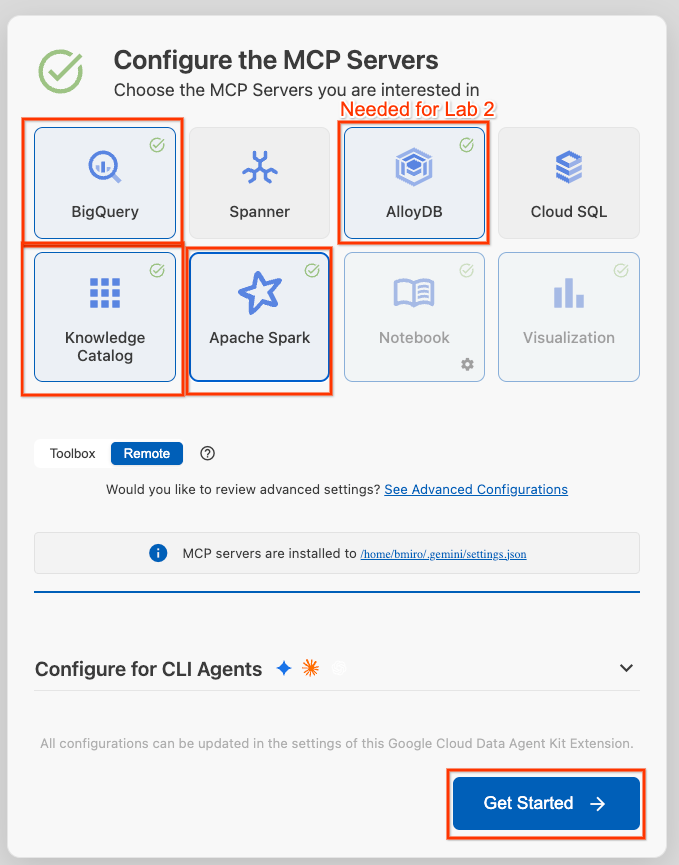
- В нижней строке состояния щелкните селектор идентификатора проекта и выберите свой активный проект Google Cloud.
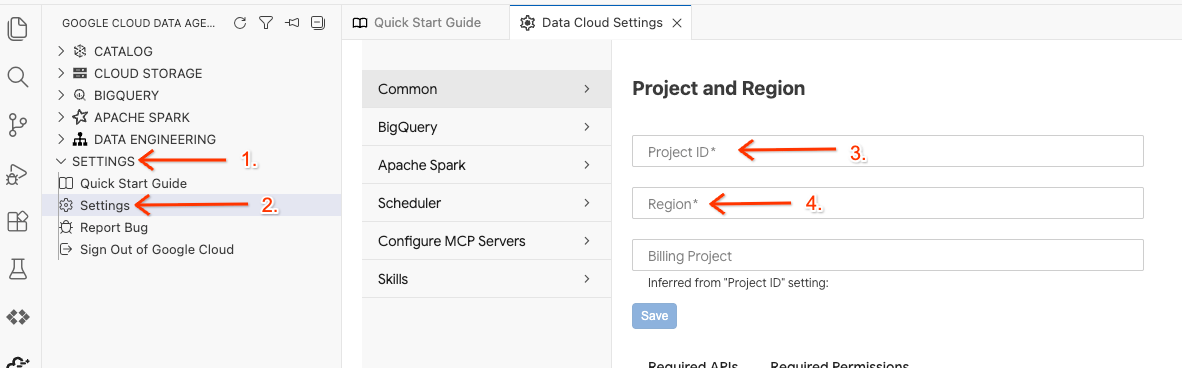
- В Data Agent Kit нажмите НАСТРОЙКИ , затем Настройки , и на вкладке Общие выберите идентификатор проекта и регион для запуска вашей лаборатории, например, us-central1 .
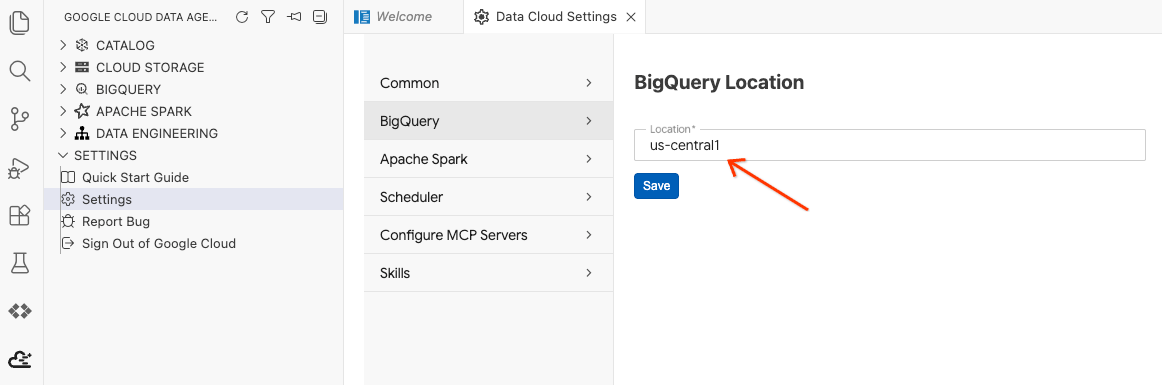
- Нажмите «Настройки BigQuery» и замените «Регион» на регион, который вы выбрали ранее. Нажмите «Сохранить» .
Теперь вы готовы использовать Data Agent Kit!
Выполнить скрипт настройки среды
В терминале запустите скрипт настройки, чтобы создать необходимые фоновые ресурсы для этой лабораторной работы и настроить разрешения IAM:
chmod +x setup_lab1.sh
./setup_lab1.sh
source .env
Вы должны увидеть серию шагов вывода, показывающих, какие ресурсы выделяются. Мы рассмотрим их на протяжении всей лабораторной работы.
Как только вы увидите сообщение о завершении, вы готовы продолжить:
==================================================== Environment Setup Complete! ====================================================
Итак, начнём поиски!
3. Прием грузовых накладных от партнеров.
Данные грузовых манифестов от судов-партнеров хранятся в вашем хранилище в стандартном формате JSON Lines (JSONL): gs://${PROJECT_ID}-lost-cargo-lake/shipping_manifests/manifests.jsonl .
Перед проведением углубленного анализа вам потребуется создать управляемую таблицу BigLake для этих неструктурированных данных. Это позволит вам немедленно изучать данные о логистике партнеров, используя стандартный SQL, без дополнительных затрат на импорт.
Откройте рабочую область в редакторе и выполните запрос.
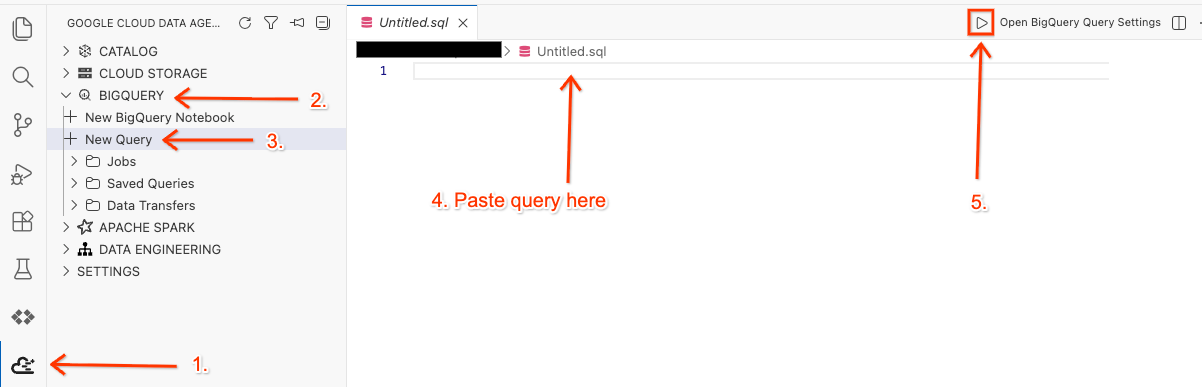
- В редакторе Cloud Shell Editor щелкните значок расширения Google Cloud Data Agent Kit на боковой панели.
- Перейдите в BigQuery и выберите + Новый запрос .
- Скопируйте следующий запрос в окно запросов.
SET @@location = "<YOUR_REGION>"; --Update to your resource region, such as "us-central1". Make sure it is in quotes.
EXECUTE IMMEDIATE ("""
CREATE OR REPLACE EXTERNAL TABLE `lost_cargo_dataset.shipping_manifests`
(
shipment_id STRING,
timestamp TIMESTAMP,
last_ping_lat FLOAT64,
last_ping_long FLOAT64,
seal_integrity_status INT64,
custodian_id STRING OPTIONS(description='Masked identification token for official cargo custodian personnel.')
)
WITH CONNECTION `""" || @@location || """.conn`
OPTIONS (
format = 'NEWLINE_DELIMITED_JSON',
uris = ['gs://""" || @@project_id || """-lost-cargo-lake/shipping_manifests/*.jsonl']
)
""");
- Нажмите «Выполнить» .
- Чтобы убедиться в создании таблицы, вы увидите сообщение об успешном выполнении в панели результатов запроса , которая автоматически откроется внизу.
Для выявления скомпрометированных транспондеров выполните запрос к внешней таблице.
Давайте определим скомпрометированные транспондеры, выявив сбои, когда параметр seal_integrity_status был установлен на 0 Скопируйте и выполните следующий запрос в открытом ранее окне запросов:
SELECT shipment_id, last_ping_lat, last_ping_long, custodian_id
FROM `lost_cargo_dataset.shipping_manifests`
WHERE seal_integrity_status = 0;
В панели «Результаты запроса» вы должны увидеть вывод, похожий на этот:
shipment_id | last_ping_lat | last_ping_long | custodian_id |
MV-CAT-001 | 51.5074 | -0.1278 | usr_999_shadow |
4. Обработка неструктурированных журналов с помощью управляемого сервиса для Apache Spark.
Вы определили начальное местоположение по структурированным манифестам, но потерянный транспондер полностью перестал работать. Последний пинг транспондера оставил загадочное, неструктурированное сообщение в файле журнала в формате raw text, расположенном по пути GCS gs://${BUCKET_NAME}/raw_logs/maritime_logs.txt .
Для обработки и сопоставления этого текстового журнала, извлечения временных меток, маскировки идентификаторов и определения маршрута следования груза вам потребуется отправить бессерверное задание Apache Spark (PySpark) в Managed Service for Apache Spark .
Управляемая служба для Apache Spark позволяет запускать рабочие нагрузки Spark без выделения или управления кластером. Служба обрабатывает базовые вычислительные ресурсы, динамически масштабируя их, и вы платите только за время выполнения.
Сценарий будет:
- Обработайте исходный, заключенный в скобки, неструктурированный текст транспондера.
- Примените фильтры извлечения данных из SQL-запросов PySpark с помощью регулярных выражений, чтобы разделить временные метки, метаданные хранителя и исходное содержимое.
- Разбейте неряшливые записи на более понятные, однострочные тексты.
- Извлеките динамические целевые координаты пункта назначения, где завершились вылеты потерянного груза.
- Подключитесь и запишите обработанный DataFrame логов обратно в ваш REST-каталог Lakehouse Apache Iceberg в виде новой аналитической таблицы, видимой непосредственно в BigQuery.
Исправьте скрипт анализа PySpark.
Поступали сообщения о том, что пираты-«питоны» в море создают всевозможные проблемы.
- Чтобы открыть файл
process_maritime_logsв редакторе Cloud Shell, выполните следующую команду.cd ~/devrel-demos/data-analytics/data-cloud-roadshow/lab1 cloudshell open ./process_maritime_logs.py - Уделите время изучению кода и пониманию того, что он делает.
- Убедитесь, что в коде нет ничего подозрительного! Если вам нужно что-то удалить, обязательно сохраните файл, используя
Ctrl + S(Windows/Linux) илиCmd + S(Mac).
Отправьте задание Serverless Spark.
Отправьте задание, используя SDK gcloud . Конфигурация автоматически настроит задание PySpark для доступа к каталогу Lakehouse.
Выполните следующую команду в терминале вашего встроенного редактора.
cd ~/devrel-demos/data-analytics/data-cloud-roadshow/lab1
source .env
gcloud dataproc batches submit pyspark process_maritime_logs.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--version=2.3 \
--deps-bucket=${BUCKET_NAME} \
--properties="\
spark.sql.defaultCatalog=cargo_catalog,\
spark.sql.catalog.${CATALOG_NAME}=org.apache.iceberg.spark.SparkCatalog,\
spark.sql.catalog.${CATALOG_NAME}.type=rest,\
spark.sql.catalog.${CATALOG_NAME}.uri=https://biglake.googleapis.com/iceberg/v1/restcatalog,\
spark.sql.catalog.${CATALOG_NAME}.warehouse=gs://${BUCKET_NAME},\
spark.sql.catalog.${CATALOG_NAME}.header.x-goog-user-project=${PROJECT_ID},\
spark.sql.catalog.${CATALOG_NAME}.rest.auth.type=org.apache.iceberg.gcp.auth.GoogleAuthManager,\
spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions,\
spark.sql.catalog.${CATALOG_NAME}.gcs.oauth2.refresh-credentials-endpoint=https://oauth2.googleapis.com/token, \
spark.sql.catalog.${CATALOG_NAME}.header.X-Iceberg-Access-Delegation=vended-credentials" \
-- ${BUCKET_NAME}
Подождите несколько минут, пока запустится бессерверная среда, загрузится ваш скрипт и выполнится логика обработки.
Как только вы увидите результат, похожий на приведенный ниже, обработанная таблица будет сохранена в каталоге Lakehouse как управляемая таблица Apache Iceberg!
Batch [1fae0b4b42c045a084dd67917bd0c332] finished.
metadata:
'@type': type.googleapis.com/google.cloud.dataproc.v1.BatchOperationMetadata
batch: projects/<YOUR_PROJECT>/locations/us-central1/batches/1fae0b4b42c045a084dd67917bd0c332
batchUuid: 611b4465-fdac-4974-bc47-5f10adaf2a08
createTime: '2026-06-11T21:35:01.868157Z'
description: Batch
labels:
goog-dataproc-batch-id: 1fae0b4b42c045a084dd67917bd0c332
goog-dataproc-batch-uuid: 611b4465-fdac-4974-bc47-5f10adaf2a08
goog-dataproc-drz-resource-uuid: batch-611b4465-fdac-4974-bc47-5f10adaf2a08
goog-dataproc-location: us-central1
operationType: BATCH
name: projects/<YOUR_PROJECT/regions/us-central1/operations/7e2044db-dd97-3270-b368-4dc4ba417574
Предварительный просмотр обработанных журналов
В редакторе запросов расширения Data Agent Kit скопируйте следующий запрос для предварительного просмотра данных:
SET @@location = "<YOUR_REGION>"; -- e.g. "us-central1"
EXECUTE IMMEDIATE FORMAT("""
select log_timestamp, custodian_id, sentence from
`%s.%s-lost-cargo-lake.lost_cargo_namespace.processed_maritime_logs`
limit 5
""", @@project_id, @@project_id);
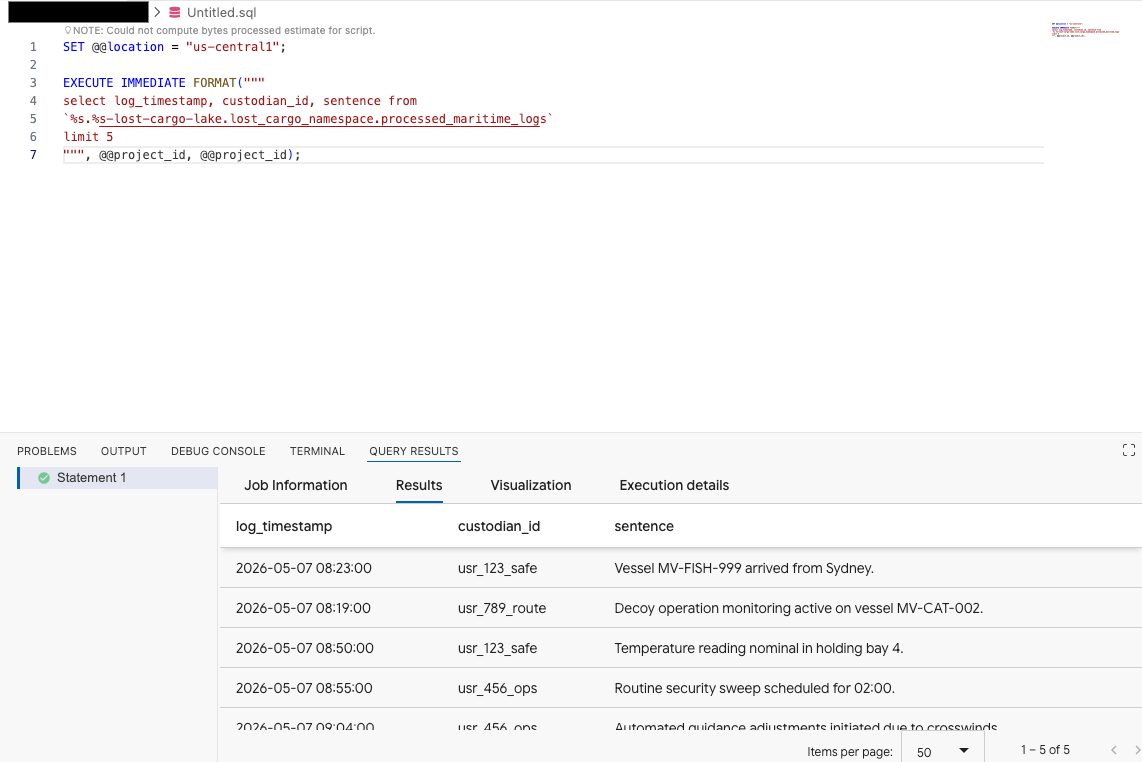
Это показывает, что к таблице Iceberg, зарегистрированной в каталоге, можно успешно получить доступ из BigQuery!
Извлеките подсказку о пункте назначения.
Теперь, когда у нас есть обработанные журналы, давайте найдем те из них, которые содержат указание на целевой объект. Оттуда мы можем выполнить поиск журналов, в которых упоминается наш город отправления.
В редакторе запросов выполните следующий запрос, заменив <YOUR_REGION> на ваш регион и <ORIGIN_CITY> на город происхождения, который вы определили ранее.
SET @@location = "<YOUR_REGION>"; --e.g. "us-central1"
DECLARE origin_city STRING;
SET origin_city = "<ORIGIN_CITY>"; --e.g. "Boston". (It's not Boston)
EXECUTE IMMEDIATE FORMAT(r"""
SELECT
log_timestamp AS event_time,
custodian_id,
REGEXP_EXTRACT(raw_message, r'Destination:\s*([^.]+)') AS destination_target
FROM
`%s.%s-lost-cargo-lake.lost_cargo_namespace.processed_maritime_logs`
WHERE
-- STRPOS is highly optimized in BigQuery for a simple .contains() substring check
STRPOS(sentence, '%s') > 0;
""", @@project_id, @@project_id, origin_city);
Общайтесь со своими данными в консоли BigQuery, используя аналитику диалогов.
Вместо написания сложных SQL-запросов для анализа данных вы можете использовать разговорную аналитику , чтобы общаться с таблицами на естественном языке!
- Перейдите в консоль BigQuery .
- В левой панели «Проводник» разверните свой проект и набор данных.
-lost-cargo-lake.lost_cargo_namespace processed_maritime_logs, чтобы открыть вкладку с подробными сведениями. - Рядом с кнопкой «Запрос» нажмите «Чат» .
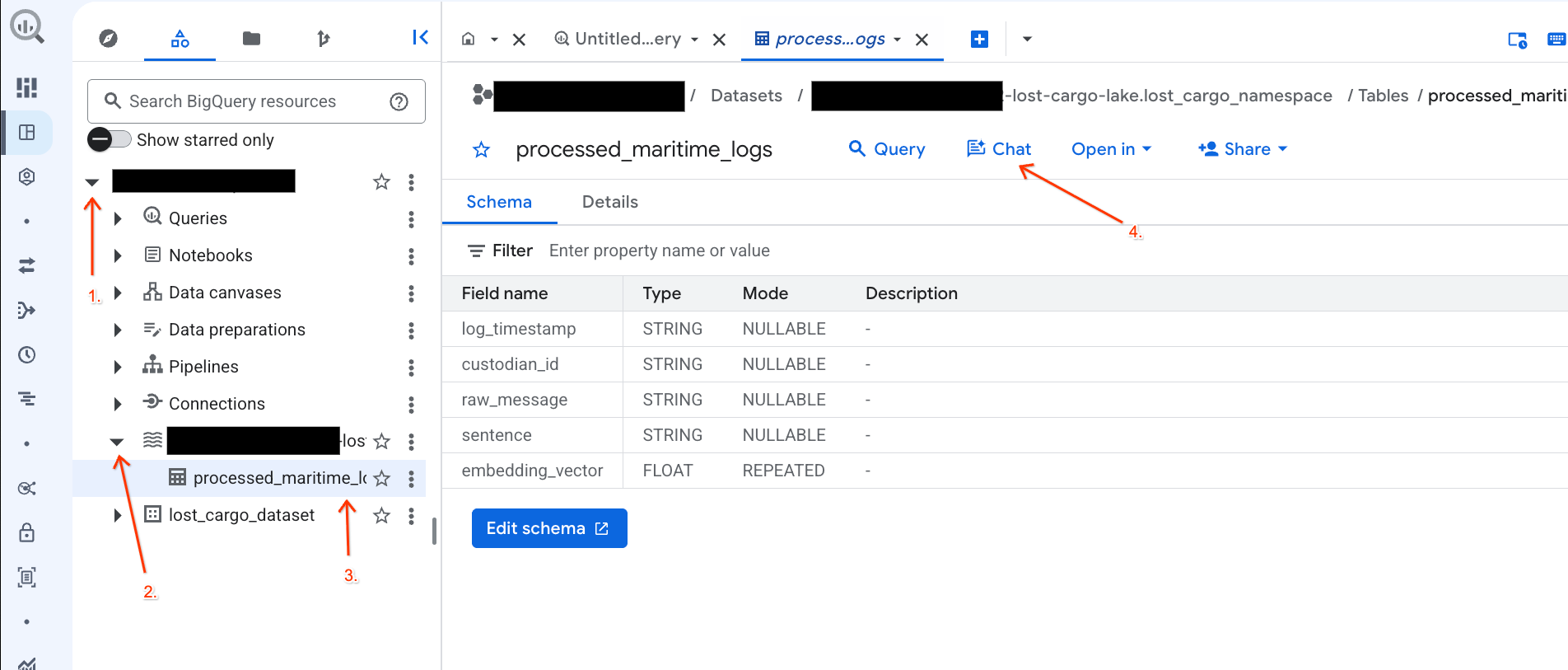
- В чате введите следующий вопрос и нажмите Enter на клавиатуре, чтобы отправить его:
Based on this table, what color is the shipping container MV-CAT-001?
- Система анализа разговорных ситуаций (на базе Gemini) проанализирует данные активной таблицы и отреагирует соответствующим цветом.
5. Просмотрите централизованный каталог домов на берегу озера.
Для безопасной и бесперебойной интеграции механизмов обработки данных с открытым исходным кодом (например, Apache Spark) с корпоративными системами обработки данных (например, BigQuery) ваш скрипт настройки создал REST-каталог Lakehouse Iceberg .
Каталог Apache Iceberg REST служит бессерверным «единым источником достоверной информации» для метаданных таблиц, динамически управляя схемами и разделяя таблицы, а также храня физические файлы данных Parquet в облачном хранилище.
Давайте рассмотрим этот каталог непосредственно в консоли Google Cloud:
- Откройте консоль Lakehouse .
- На вкладке «Каталоги» найдите и щелкните по активному каталогу Iceberg REST:
-lost-cargo-lake
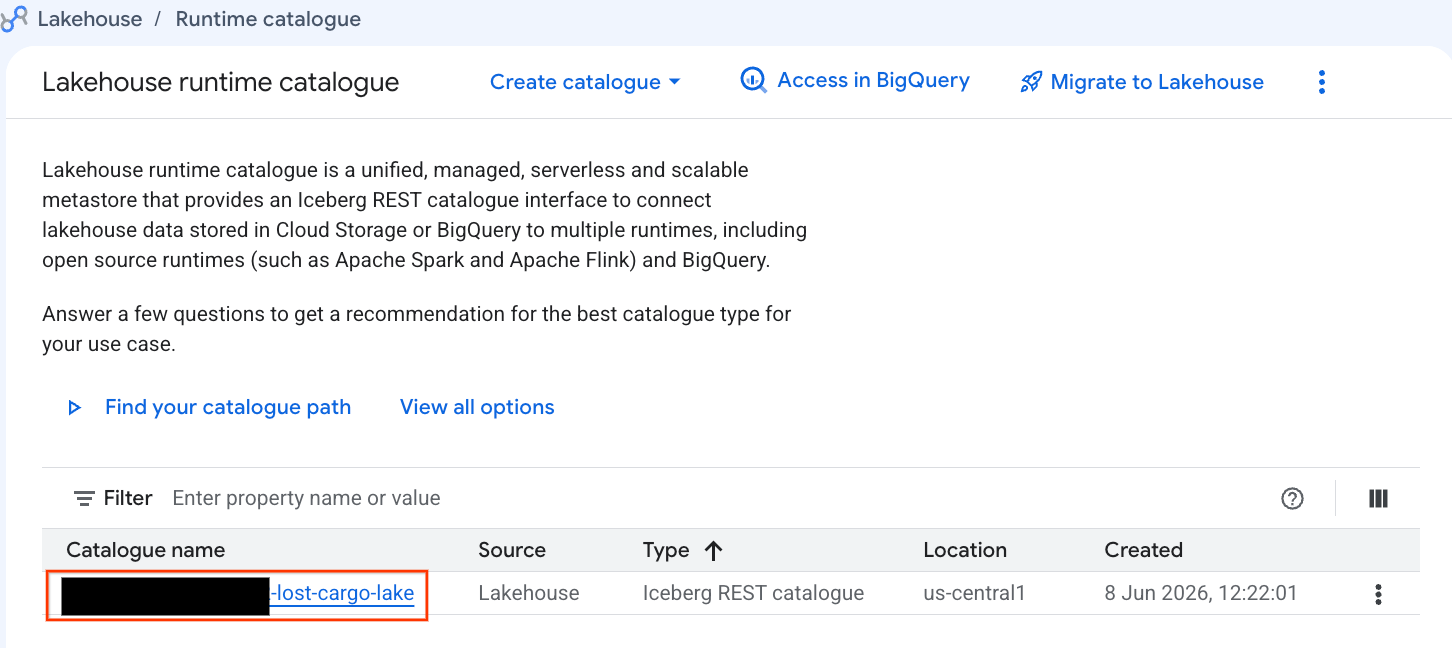
- В подробном представлении каталога в разделе «Пространства имен» вы должны увидеть
lost_cargo_namespace. Щелкните по нему.
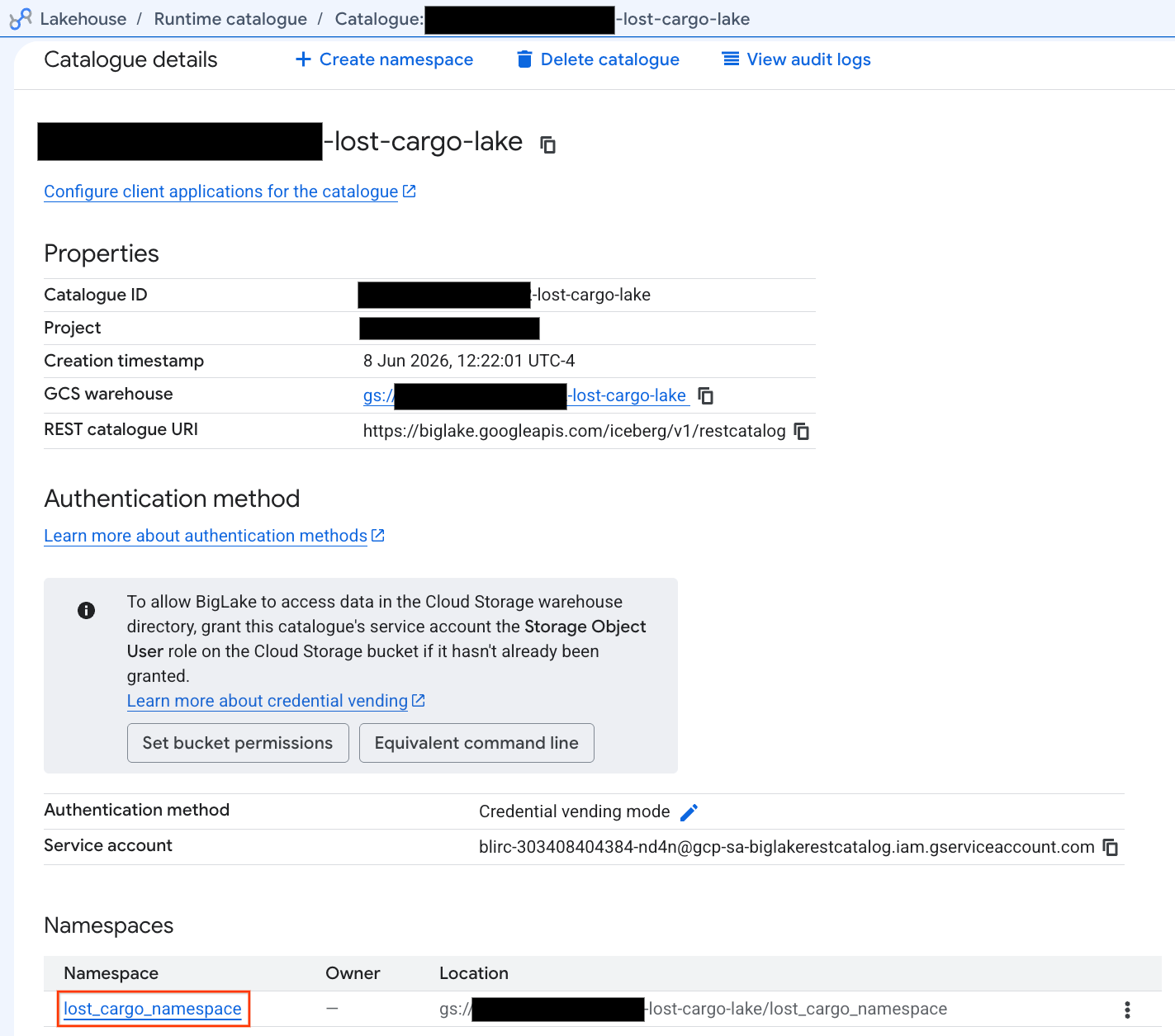
- Ваша новая таблица Apache Iceberg, сгенерированная PySpark, автоматически зарегистрировалась в этом пространстве имен метаданных и мгновенно стала доступна для запросов в BigQuery!
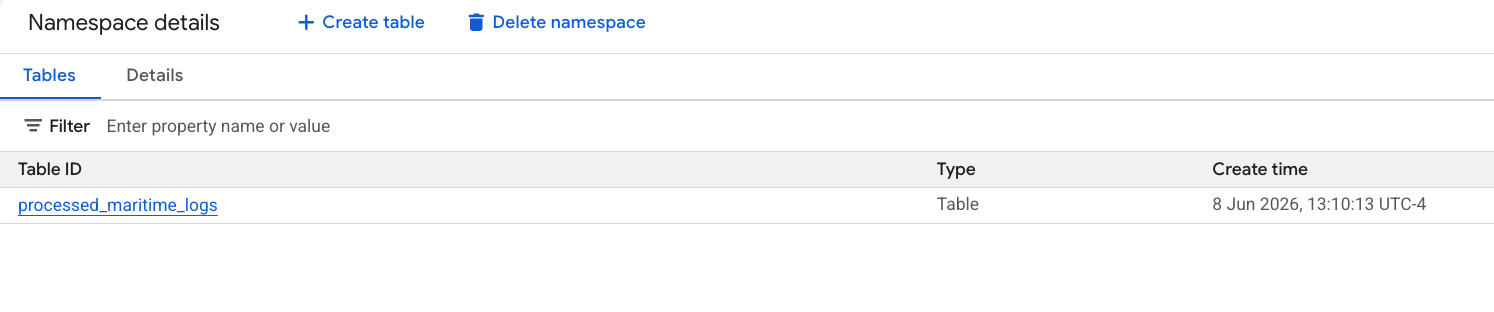
6. Получите аналитические данные из таблицы судовых манифестов.
Давайте вернемся к анализу таблицы shipping_manifests , чтобы понять ее структуру и содержимое, используя инструмент Knowledge Catalog Data Insights . Обогащение метаданных позволит другим исследователям лучше понять таблицу для дальнейшего анализа.
Создание аналитических данных для таблиц в BigQuery Studio
- В консоли Google Cloud перейдите в раздел BigQuery Studio .
- В панели «Проводник» разверните свой проект, разверните набор данных
lost_cargo_datasetи щелкните таблицуshipping_manifests. - В панели сведений справа нажмите вкладку «Аналитика» .
- Воспользуйтесь раскрывающимся списком, чтобы выбрать «Создать и опубликовать» .
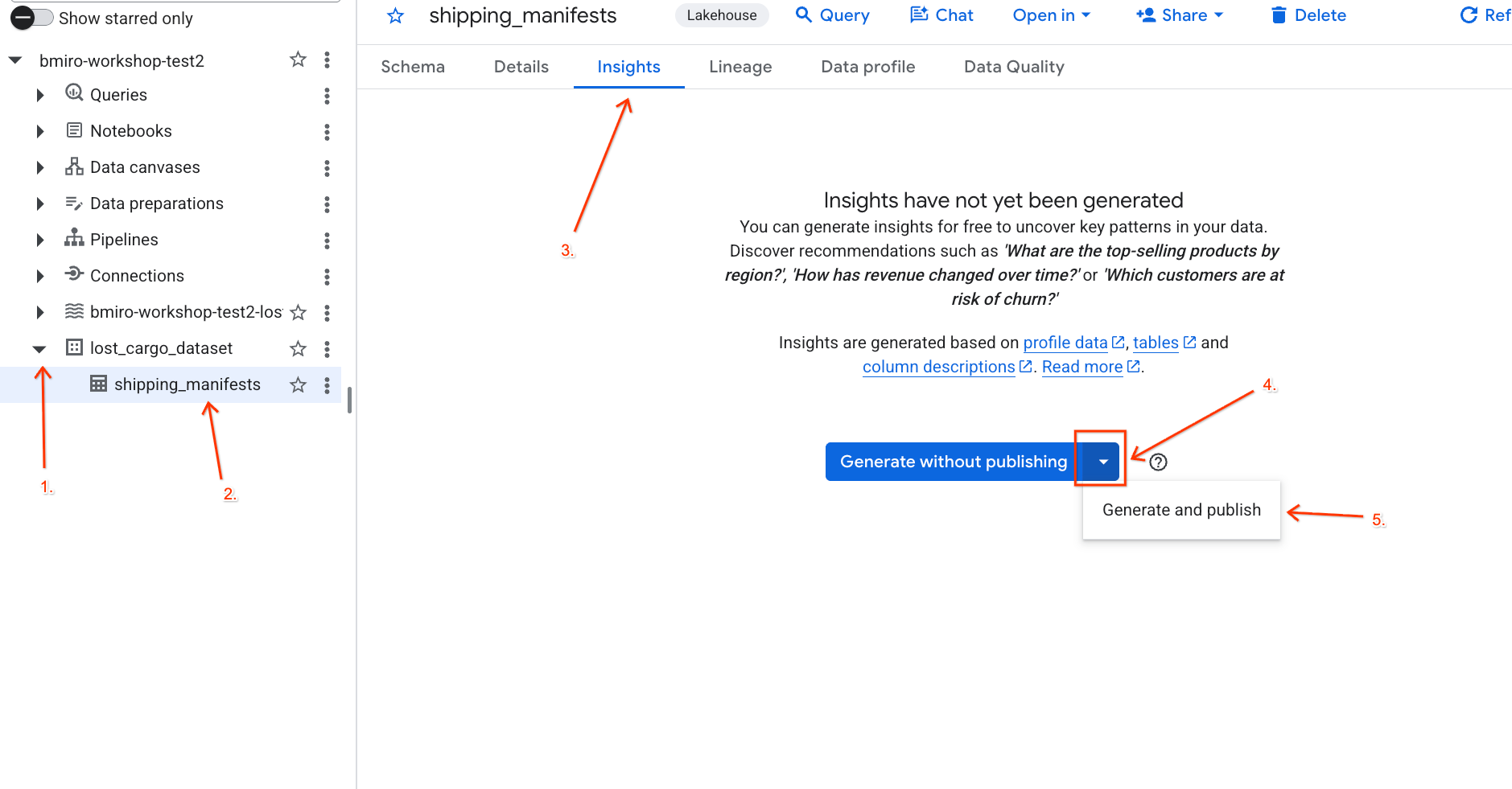
- Подождите около 3 минут, пока завершится генерация аналитических данных. Gemini проанализирует метаданные таблицы и сгенерирует вопросы на естественном языке, а также соответствующие SQL-запросы.
- После завершения вы увидите описание таблицы с пояснением ее содержимого на естественном языке.
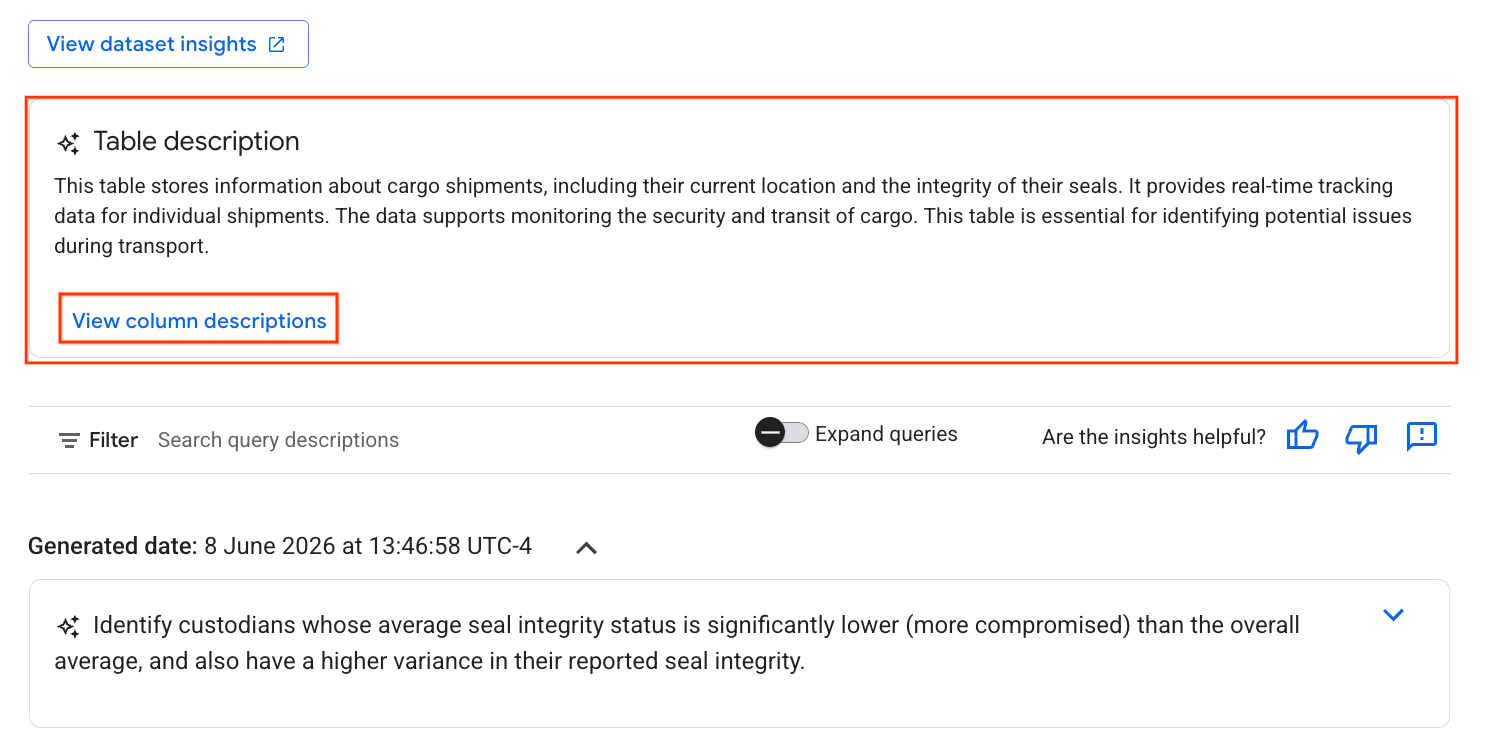
- Нажмите «Просмотреть описания столбцов» , чтобы увидеть информацию об отдельных столбцах.
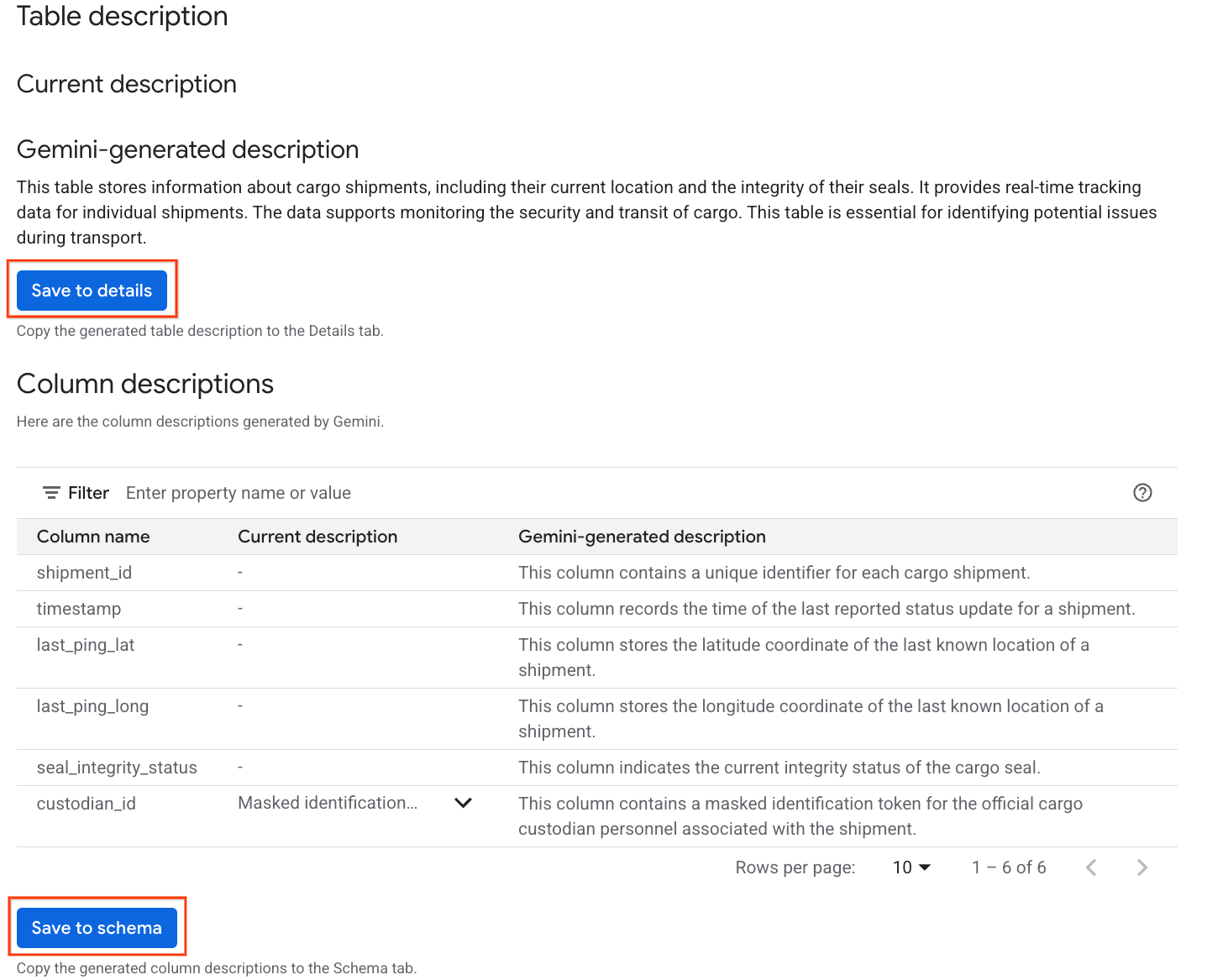
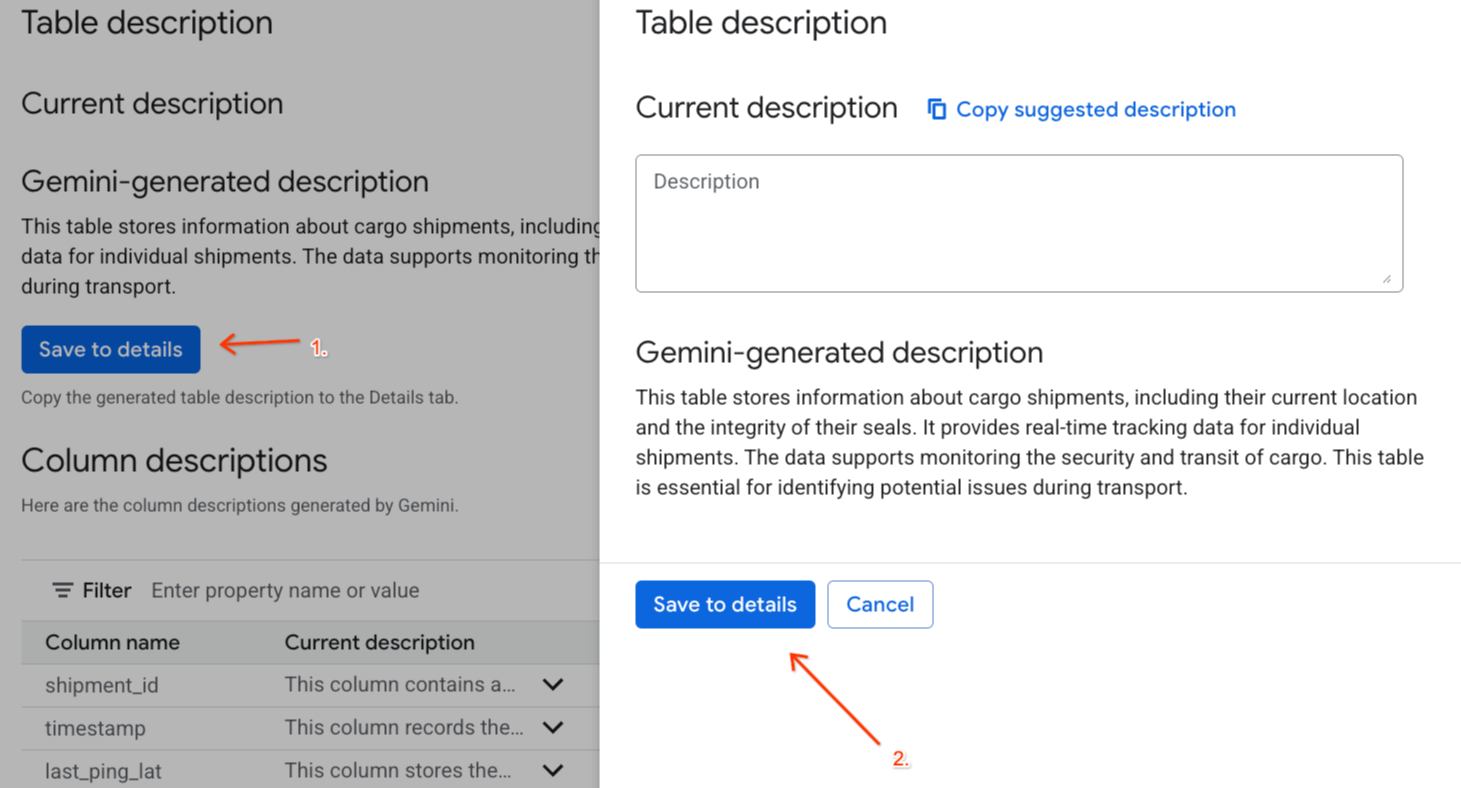
- Нажмите «Сохранить подробности» под
Gemini generated description, и нажмите «Сохранить подробности» во всплывающем окне.
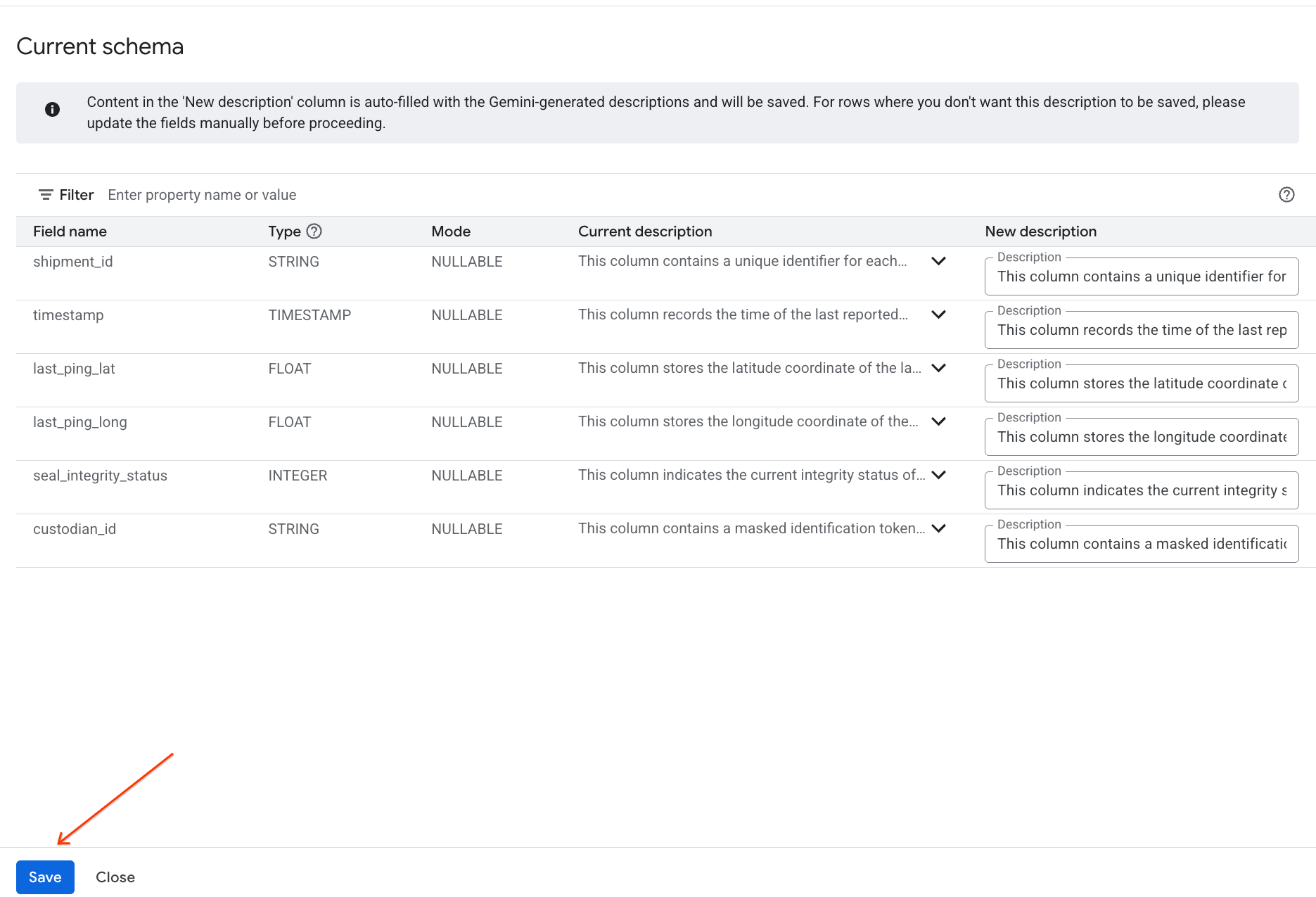
- Аналогичным образом, нажмите «Сохранить в схему» , чтобы добавить описания столбцов в метаданные таблицы.
Анализ полученных данных
Вы также увидите список предлагаемых вопросов. Вы можете щелкнуть по любому вопросу, чтобы увидеть сгенерированный SQL-запрос и запустить его для анализа данных. Например, вы можете увидеть вопросы типа:
- «Каково общее количество отгрузок?»
- "Перечислите уникальные идентификаторы хранителей."
Выполнение этих запросов поможет вам понять данные.
7. Внедрить маскирование данных и управление данными.
Чтобы гарантировать невозможность утечки активных исследовательских учетных записей и имен пользователей во время текущего расследования по поводу груза, необходимо внедрить стандартные протоколы безопасности. Вам потребуется создать таксономию тегов политики безопасности и настроить маскирование данных в каталоге знаний для конфиденциального столбца custodian_id , чтобы проверить конфиденциальность данных.
По умолчанию BigQuery запрещает доступ к столбцам, защищенным тегами политики. Для выполнения запросов к таблице и проверки активных масок данных ваша учетная запись пользователя должна иметь роль « Читатель с защитой масок данных в соответствии с политикой BigQuery» .
Эта роль была автоматически привязана к вашей активной учетной записи пользователя во время первого выполнения скрипта setup_lab1.sh !
Создайте тег таксономии и политики.
Создайте таксономию данных и соответствующий тег политики для управления доступом к вашим данным.
- Перейдите на страницу таксономий тегов политики .
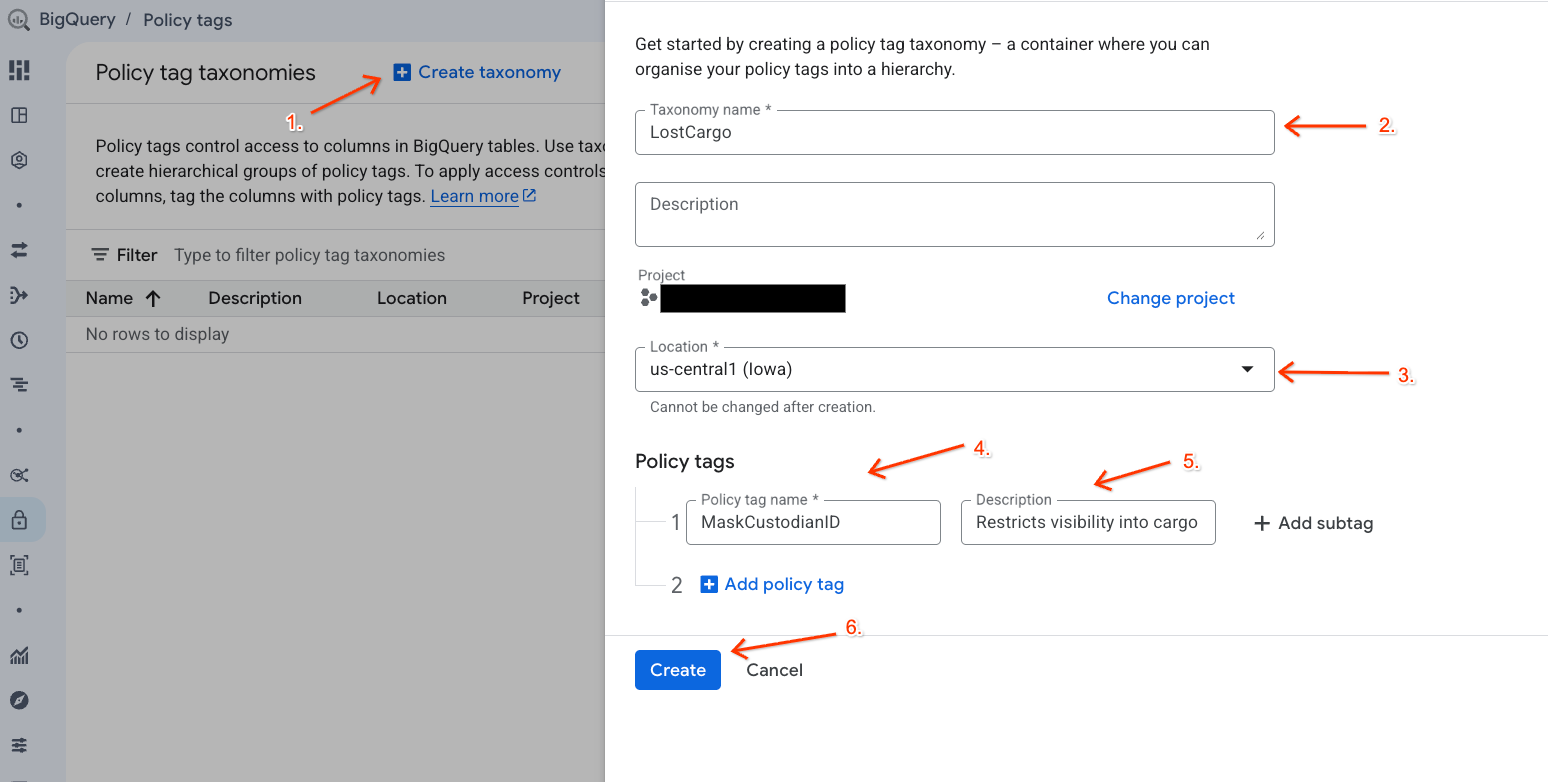
- Нажмите + Создать таксономию .
- Настройте параметры:
- Название таксономии : Введите
lost-cargo-, заменив на идентификатор вашего проекта. - Регион : Выберите свой регион.
- Для поля «Имя тега политики» введите
MaskCustodianID. - Описание тега политики:
Restricts visibility into cargo custodian usernames
- Название таксономии : Введите
- Нажмите «Создать» , чтобы зарегистрировать новую таксономию и тег политики.
Создайте политику маскирования данных.
Далее настройте политику данных, чтобы определить, как данные будут маскироваться в соответствии с классификационным тегом MaskCustodianID . Вы будете использовать правило маскирования Always Null (замена совпадающих значений пустыми/Null для всех непривилегированных участников).
- На странице «Таксономии тегов политики» щелкните по только что созданной таксономии из списка таксономий.
- В списке иерархии щелкните по тегу
MaskCustodianID, чтобы выбрать его, а затем выберите «Управление политиками данных» .
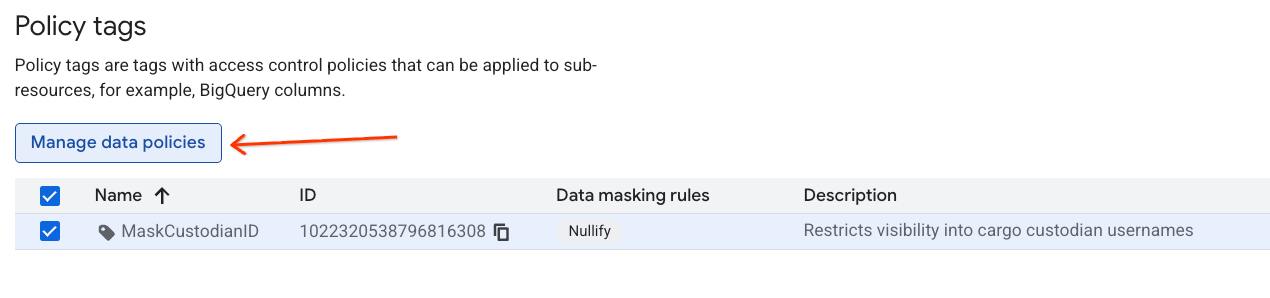
- На правой панели нажмите кнопку «+ Добавить правило» .
- Настройте параметры политики в появившейся панели:
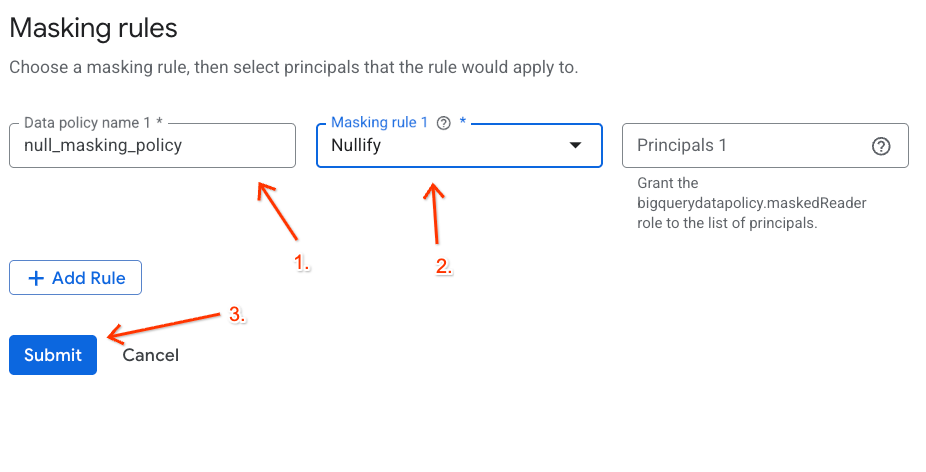
- Название политики данных : Введите
null_masking_policy(не оставляйте его автоматически сгенерированным, так как мы будем ссылаться на него по имени на следующих шагах). - Правило маскирования : выберите
Nullifyиз выпадающего меню.
- Название политики данных : Введите
- Нажмите «Отправить» .
Присвойте тег политики столбцу вашего запроса BigQuery.
При активном теге политики и соответствующем правиле маскирования данных сопоставьте тег классификации непосредственно со столбцом custodian_id в таблице манифестов доставки партнеров BigQuery.
- Перейдите в консоль BigQuery .
- В левой панели «Проводник» разверните активный проект, разверните набор данных
lost_cargo_datasetи щелкните таблицуshipping_manifests, чтобы открыть ее подробное представление. - Нажмите «Редактировать схему» .
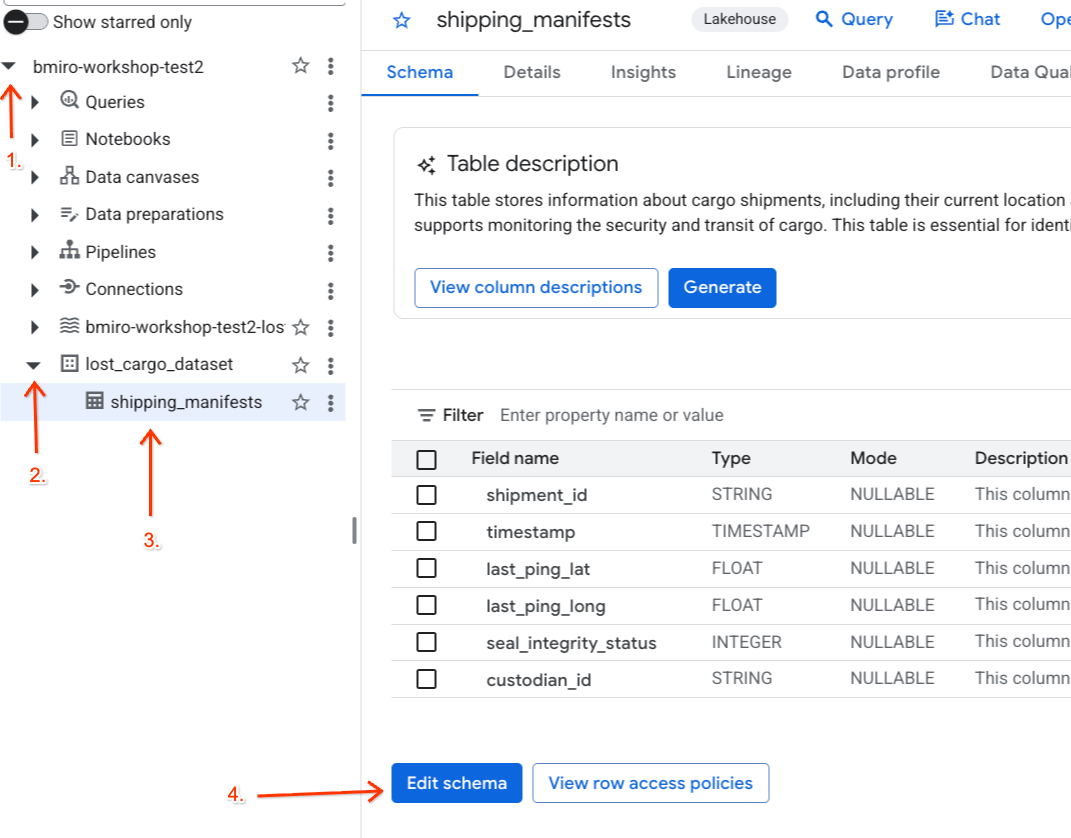
- В списке столбцов установите флажок рядом с
custodian_id. - Нажмите кнопку «Добавить тег политики» на верхней панели инструментов редактора схем.
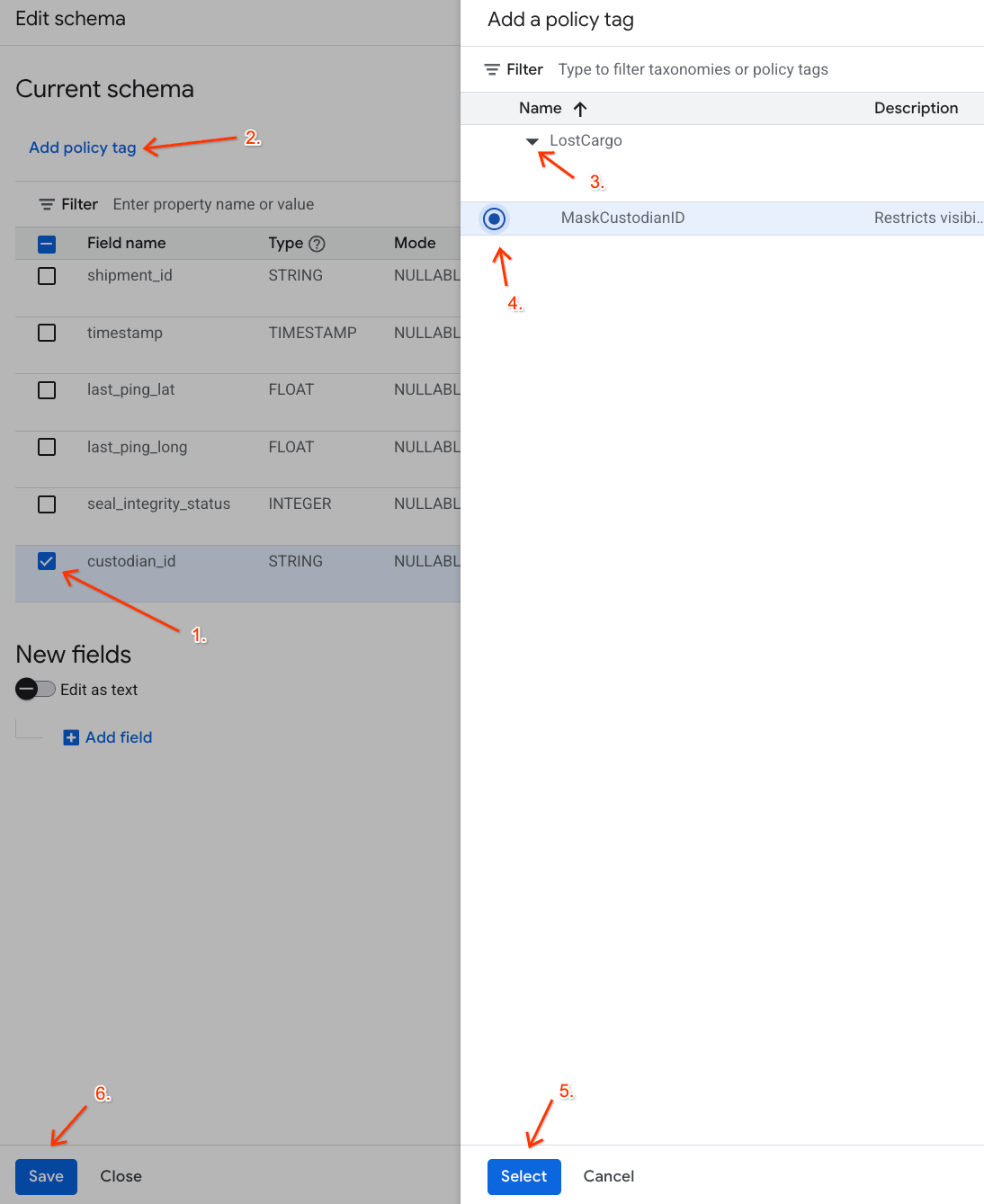
- В панели «Добавить тег политики» :
- Найдите и расширьте свою таксономию
LostCargo. - Выберите кружок рядом с
MaskCustodianID. - Нажмите «Выбрать» .
- Найдите и расширьте свою таксономию
- Убедитесь, что тег
MaskCustodianIDтеперь виден в столбце «Тег политики» в строке, представляющейcustodian_id. - Нажмите « Сохранить ».
Проверьте ограничения политики.
Теперь, когда у вас есть роль «Замаскированный читатель» на уровне проекта, вы можете запросить таблицу, чтобы убедиться, что политика маскирования активна.
Вернитесь в Data Agent Kit и выполните следующий запрос:
SELECT shipment_id, custodian_id
FROM lost_cargo_dataset.shipping_manifests
LIMIT 5;
В результате вы должны увидеть примерно следующий вывод:
shipment_id | custodian_id |
НОРМАЛ-001 | нулевой |
НОРМАЛ-002 | нулевой |
MV-CAT-001 | нулевой |
Успех! Несмотря на то, что вы можете просматривать записи shipment_id , конфиденциальное поле custodian_id возвращает защищенные null маски для предотвращения утечек!
8. Уборка
Чтобы избежать постоянного списания средств с вашего аккаунта Google Cloud за ресурсы, созданные в ходе этого практического занятия, выполните следующие команды в терминале Cloud Shell, чтобы удалить ваши наборы данных и хранилища:
# Verify active variables
export PROJECT_ID=$(gcloud config get-value project)
export BUCKET_NAME="${PROJECT_ID}-lost-cargo-lake"
# Delete Knowledge Catalog security taxonomies
export TAXONOMY_NAME=$(gcloud data-catalog taxonomies list --location=us-central1 --filter="displayName:LostCargo" --format="value(name)")
if [[ -n "$TAXONOMY_NAME" ]]; then
curl -X DELETE \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
"https://datacatalog.googleapis.com/v1/${TAXONOMY_NAME}" || true
fi
# Delete Lakehouse Iceberg REST Catalog tables and namespaces
gcloud biglake iceberg tables delete processed_maritime_logs \
--catalog=${BUCKET_NAME} \
--namespace=lost_cargo_namespace \
--quiet || true
gcloud biglake iceberg namespaces delete lost_cargo_namespace \
--catalog=${BUCKET_NAME} \
--quiet || true
# Delete Lakehouse Iceberg REST Catalog
gcloud biglake iceberg catalogs delete ${BUCKET_NAME} --quiet || true
# Delete dependencies bucket
gcloud storage rm -r gs://${BUCKET_NAME} || true
# Delete BigQuery dataset and tables
bq rm -r -f -d ${PROJECT_ID}:lost_cargo_dataset || true
9. Поздравляем!
Поздравляем! Вы успешно завершили первый важный модуль расследования «Потерянный груз» . Вы создали управляемую зону поиска, используя REST-каталоги Lakehouse Iceberg, нормализацию логов PySpark и детальное маскирование данных.
Что вы узнали
- Установка, настройка и конфигурирование расширения Data Agent Kit в рабочей области вашей IDE.
- Создание бессерверного REST-каталога Lakehouse Iceberg с использованием предоставленных учетных данных и иерархических пространств имен.
- Обработка региональных потоков данных в различных форматах и создание внешних таблиц BigQuery на основе данных из облачного хранилища.
- Запуск бессерверных заданий Apache Spark для анализа, нормализации, сегментации и записи неструктурированных логов транспондеров обратно в BigQuery в виде зарегистрированных таблиц каталога Iceberg.
- Создание таксономий безопасности и сопоставление политик маскирования данных в каталоге знаний для предотвращения утечек идентификационных данных в индексах конфиденциальных журналов.
- Генерация и анализ метаданных таблиц с использованием инструментов анализа данных BigQuery для ускорения исследования данных.
Проверка собранных улик
Убедитесь, что вы зафиксировали следующие ключевые данные, необходимые для перехода к следующему этапу лабораторной работы:
- Идентификатор утерянного груза :
MV-CAT-001(последнее местоположение по сигналу: Лондон ) - Планируемое место назначения :
New York(и настоящий псевдоним транспондера:MV-DOG-002) - Цвет контейнера :
Crimson RED - Метка доступа к управлению :
MaskCustodianID
Готовы к следующему этапу?
Теперь, когда маршруты отправления/назначения транспондера защищены, расследование продвигается вперед! Сразу же отправляйтесь в Лабораторию 2 , чтобы изучить камеры видеонаблюдения с помощью многомодальных моделей Gemini, визуально идентифицировать судно и выполнить векторный поиск в AlloyDB для проверки аномалий, связанных с несанкционированным доступом!
➡️ Переходим ко второму шагу: анализ данных и мультимодальные выводы