
1. บทนำ
ใน Lab นี้ คุณจะได้สวมบทบาทเป็นหัวหน้าทีมตรวจสอบข้อมูลของบริษัทโลจิสติกส์ระดับโลก ตู้คอนเทนเนอร์บรรทุกสินค้าที่มีมูลค่าสูงซึ่งมีโมเดล Android อันล้ำค่าได้หายไป เพื่อค้นหาตำแหน่งล่าสุดและติดตามเส้นทาง คุณต้องรวบรวมใบกำกับการขนส่งที่กระจัดกระจายจากพาร์ทเนอร์ด้านโลจิสติกส์ในภูมิภาคและไฟล์บันทึกของทรานสปอนเดอร์ที่ไม่มีโครงสร้าง ในการดำเนินการดังกล่าว คุณจะต้องกำหนดค่า Google Cloud Open Data Lakehouse ที่ทันสมัย

สิ่งที่คุณต้องทำ
- กำหนดค่าส่วนขยาย Google Cloud Data Agent Kit ใน Cloud Shell Editor
- สร้าง Bucket ของ Cloud Storage และจัดสรรแคตตาล็อก REST ของ Apache Iceberg สำหรับ Lakehouse และเนมสเปซ
- แมปตารางภายนอก BigLake กับไฟล์ Manifest ของพาร์ทเนอร์ JSON ดิบใน Cloud Storage เพื่อค้นหาเบาะแสการออกเดินทางของเรือ
- โหลดและประมวลผลบันทึกข้อความของทรานสปอนเดอร์ที่ไม่มีโครงสร้างโดยใช้ Managed Service สำหรับ Apache Spark แบบ Serverless ดำเนินการทำให้นิพจน์ทั่วไปเป็นปกติและแยกคำใบ้แบบไดนามิกเพื่อกำหนดเป้าหมายปลายทางของเพย์โหลดที่สูญหาย
- เขียนเมตริกของบันทึกที่แยกวิเคราะห์แล้วเป็นตาราง Apache Iceberg ผ่านแคตตาล็อก REST
- แชทกับ AI Agent เกี่ยวกับข้อมูล Apache Iceberg โดยใช้ Conversational Analytics เพื่อค้นหาเบาะแสที่ซ่อนอยู่เกี่ยวกับการจัดส่งที่สูญหาย
- ใช้ประโยชน์จากข้อมูลเชิงลึกของข้อมูลอัตโนมัติด้วยแคตตาล็อกความรู้เพื่อสร้างข้อมูลเมตาเกี่ยวกับข้อมูล
- กำหนดแนวทางการนำเข้าโดยการสร้างอนุกรมวิธานด้านความปลอดภัยและใช้แคตตาล็อกความรู้เพื่อใช้การควบคุมการเข้าถึงแบบละเอียดผ่านการมาสก์รหัสผู้ดูแลระบบที่ละเอียดอ่อน
สิ่งที่คุณต้องมี
- เว็บเบราว์เซอร์ เช่น Chrome
- โปรเจ็กต์ Google Cloud ที่เปิดใช้การเรียกเก็บเงิน
- มีความคุ้นเคยกับคำค้นหา SQL พื้นฐานและคำสั่งเทอร์มินัล
ค่าใช้จ่ายและระยะเวลาที่คาดไว้
- เวลาที่ใช้โดยประมาณ: ~45 นาที
- ค่าใช้จ่ายโดยประมาณ: น้อยกว่า $5.00 USD
2. ก่อนเริ่มต้น
สร้างหรือเลือกโปรเจ็กต์ Google Cloud
- ในคอนโซล Google Cloud ให้เลือกหรือสร้างโปรเจ็กต์ Google Cloud
- ตรวจสอบว่าได้เปิดใช้การเรียกเก็บเงินสำหรับโปรเจ็กต์ที่อยู่ในระบบคลาวด์แล้ว ดูวิธียืนยันว่ามีการเปิดใช้การเรียกเก็บเงินในโปรเจ็กต์
กำหนดค่าสภาพแวดล้อม
คุณจะเรียกใช้คำสั่งส่วนใหญ่จากเทอร์มินัลแบบผสานรวมใน Cloud Shell Editor ซึ่งเป็นสภาพแวดล้อมในการพัฒนาซอฟต์แวร์บนระบบคลาวด์ที่โหลดไว้ล่วงหน้าด้วยเครื่องมือสำหรับนักพัฒนาซอฟต์แวร์และ Google Cloud SDK มาตรฐาน
- เปิด Cloud Shell Editor ในแท็บใหม่
- เรียกใช้คำสั่งต่อไปนี้ในเทอร์มินัลเพื่อโคลนที่เก็บ
cd ~/ git clone --filter=blob:none --no-checkout https://github.com/GoogleCloudPlatform/devrel-demos.git cd ~/devrel-demos git sparse-checkout init --cone git sparse-checkout set data-analytics/data-cloud-roadshow/lab1 git checkout main cd data-analytics/data-cloud-roadshow/lab1 - ตั้งค่ารหัสโปรเจ็กต์ นอกจากนี้ คุณยัง
Ctrl+Shift+Vใน Windows/Linux หรือCmd+Vใน macOS เพื่อวางลงในเทอร์มินัลได้ด้วยexport PROJECT_ID="<YOUR_PROJECT_ID>" - ตอนนี้ให้กำหนดค่าในสภาพแวดล้อมของคุณ
gcloud config set project $PROJECT_ID - เลือกภูมิภาค
export REGION="<YOUR_REGION>" # Replace with the region you chose, such as "us-central1" - เปิดใช้ API ที่จำเป็น
gcloud services enable \ bigquery.googleapis.com \ biglake.googleapis.com \ storage.googleapis.com \ dataplex.googleapis.com \ datacatalog.googleapis.com \ dataproc.googleapis.com \ aiplatform.googleapis.com \ cloudresourcemanager.googleapis.com \ serviceusage.googleapis.com \ cloudaicompanion.googleapis.com \ geminidataanalytics.googleapis.com
ติดตั้งส่วนขยาย
ตอนนี้คุณจะกำหนดค่าส่วนขยาย Google Data Agent Kit ซึ่งเป็นเครื่องมือสำหรับโต้ตอบกับเครื่องมือข้อมูลของ Google Cloud โดยตรงใน IDE
- ในแถบกิจกรรมด้านซ้ายของโปรแกรมแก้ไข ให้คลิกไอคอนส่วนขยาย (หรือกด
Ctrl+Shift+Xใน Windows/Linux หรือCmd+Xใน macOS) - ในช่องค้นหาส่วนขยาย ให้พิมพ์
Google Cloud Data Agent Kit - เลือกส่วนขยายอย่างเป็นทางการจากผลการค้นหา แล้วคลิกติดตั้ง หากได้รับข้อความแจ้ง ให้เลือก "ใช่ ฉันเชื่อถือผู้เขียน"
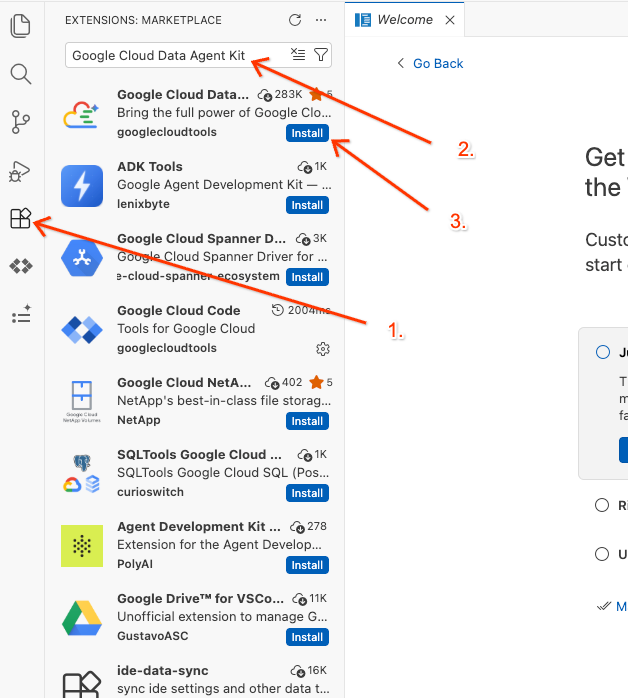
- เมื่อติดตั้งสำเร็จแล้ว คุณควรเห็นไอคอน Google Cloud Data Agent Kit แสดงในแถบกิจกรรม คลิก
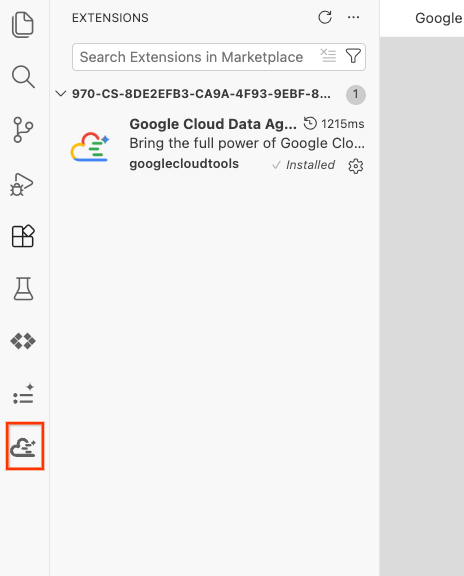
- คลิกลงชื่อเข้าใช้ระบบคลาวด์
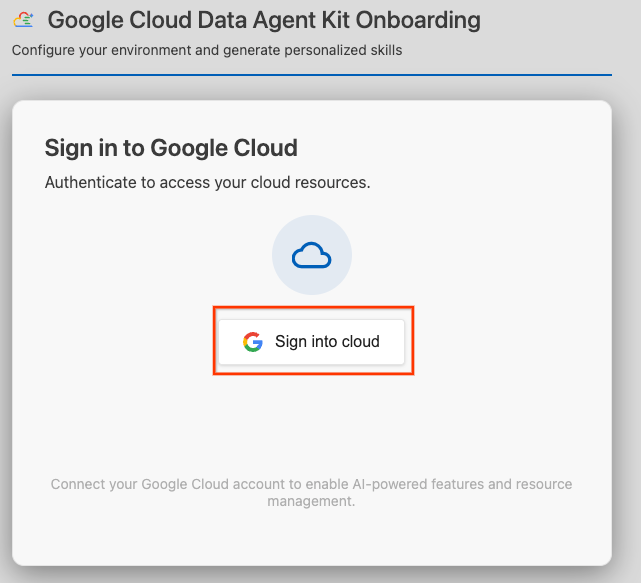
- คลิก Configure MCP Servers
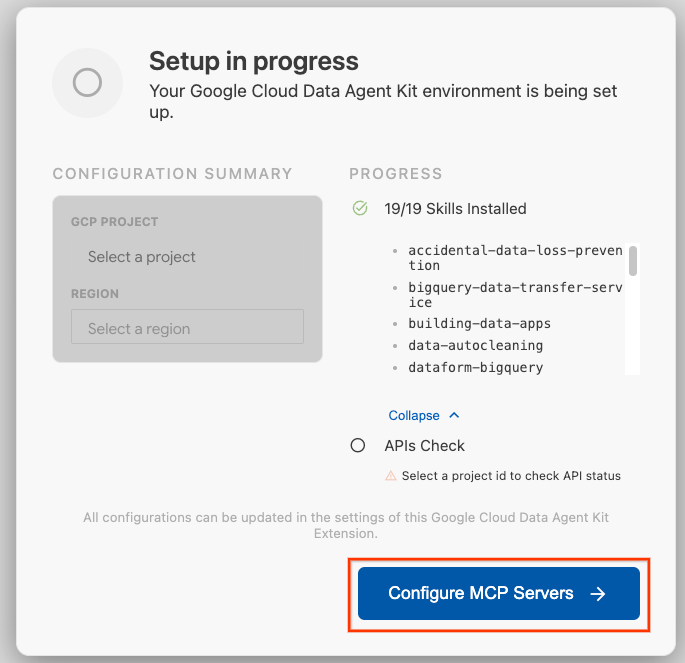
- เลือก BigQuery, Knowledge Catalog, Apache Spark และ AlloyDB คุณจะได้ใช้ AlloyDB ใน Lab 2 จากนั้นคลิกเริ่มต้นใช้งาน
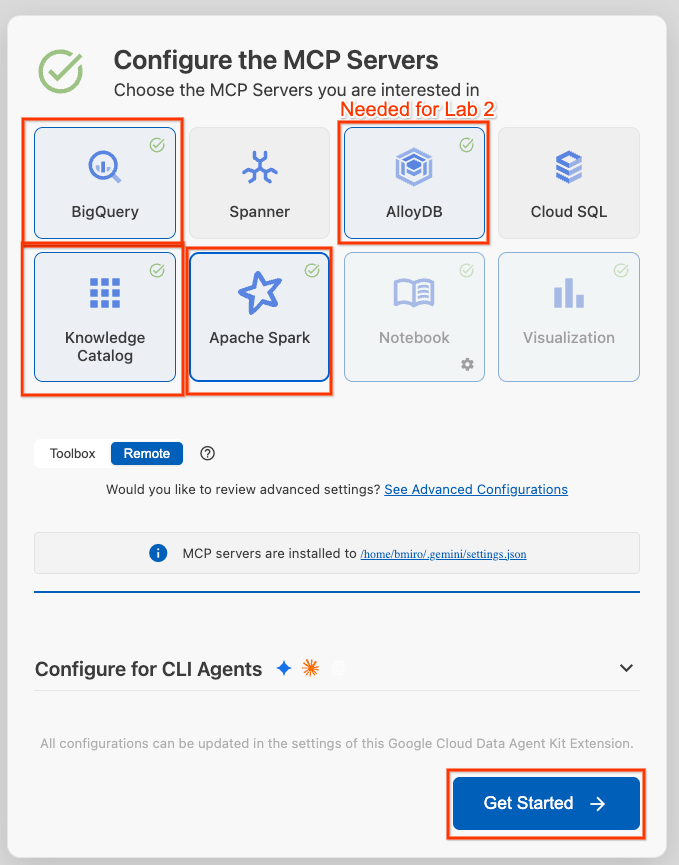
- คลิกตัวเลือกรหัสโปรเจ็กต์ในแถบสถานะด้านล่าง แล้วเลือกโปรเจ็กต์ที่อยู่ในระบบคลาวด์ Google ที่ใช้งานอยู่
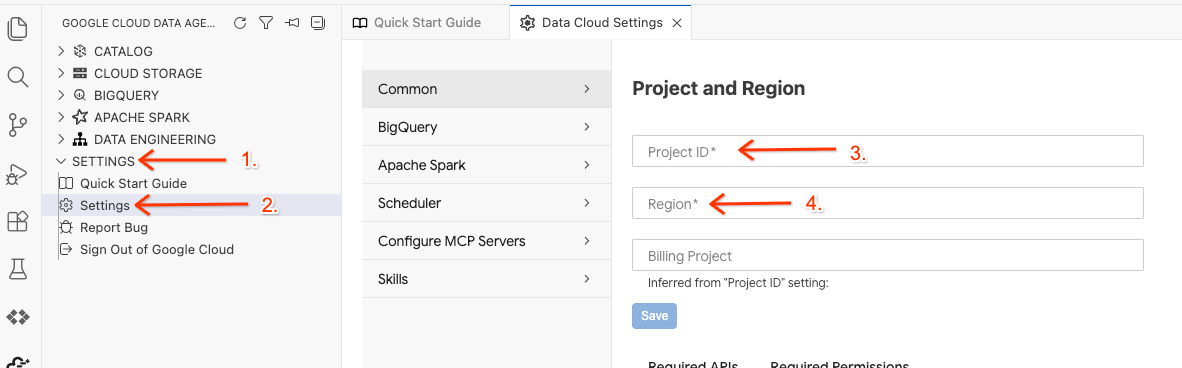
- ใน Data Agent Kit ให้คลิกการตั้งค่า จากนั้นคลิกการตั้งค่า แล้วเลือกรหัสโปรเจ็กต์และภูมิภาคในแท็บทั่วไปเพื่อเรียกใช้ Lab เช่น us-central1
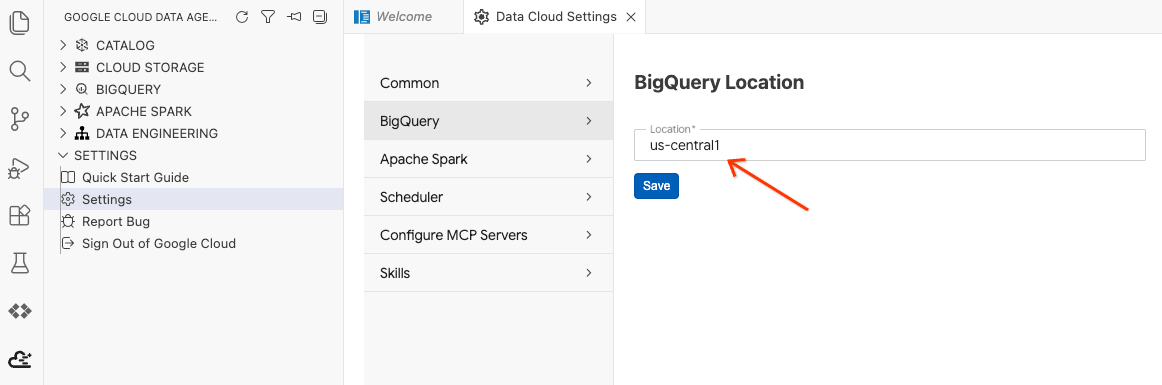
- คลิกการตั้งค่า BigQuery แล้วแทนที่ภูมิภาคด้วยภูมิภาคที่คุณเลือกไว้ก่อนหน้านี้ คลิกบันทึก
ตอนนี้คุณพร้อมที่จะใช้ชุดเครื่องมือ Data Agent แล้ว
เรียกใช้สคริปต์การตั้งค่าสภาพแวดล้อม
ในเทอร์มินัล ให้เรียกใช้สคริปต์การตั้งค่าเพื่อสร้างทรัพยากรเบื้องหลังที่จำเป็นสำหรับแล็บนี้และกำหนดค่าสิทธิ์ IAM ดังนี้
chmod +x setup_lab1.sh
./setup_lab1.sh
source .env
คุณควรเห็นชุดขั้นตอนเอาต์พุตที่แสดงทรัพยากรที่กำลังจัดสรร เราจะพูดถึงเรื่องเหล่านี้ตลอดทั้งแล็บ
เมื่อเห็นข้อความว่าเสร็จสมบูรณ์แล้ว คุณก็พร้อมใช้งาน
==================================================== Environment Setup Complete! ====================================================
มาเริ่มค้นหากันเลย
3. นำเข้าไฟล์ Manifest การจัดส่งของพาร์ทเนอร์
ระบบจะจัดเก็บข้อมูล Manifest การจัดส่งจากเรือของพาร์ทเนอร์ในรูปแบบ JSON Lines (JSONL) มาตรฐานใน Bucket gs://${PROJECT_ID}-lost-cargo-lake/shipping_manifests/manifests.jsonl
ก่อนที่จะทําการวิเคราะห์เชิงลึก คุณจะต้องสร้างตาราง BigLake ที่มีการควบคุมสําหรับข้อมูลที่ไม่มีโครงสร้างนี้ ซึ่งจะช่วยให้คุณสํารวจข้อมูลด้านลอจิสติกส์ของพาร์ทเนอร์ได้ทันทีโดยใช้ SQL มาตรฐานโดยไม่มีค่าใช้จ่ายในการนําเข้าที่ซ้ำกัน
เปิด Workspace ในเครื่องมือแก้ไขและเรียกใช้การค้นหา
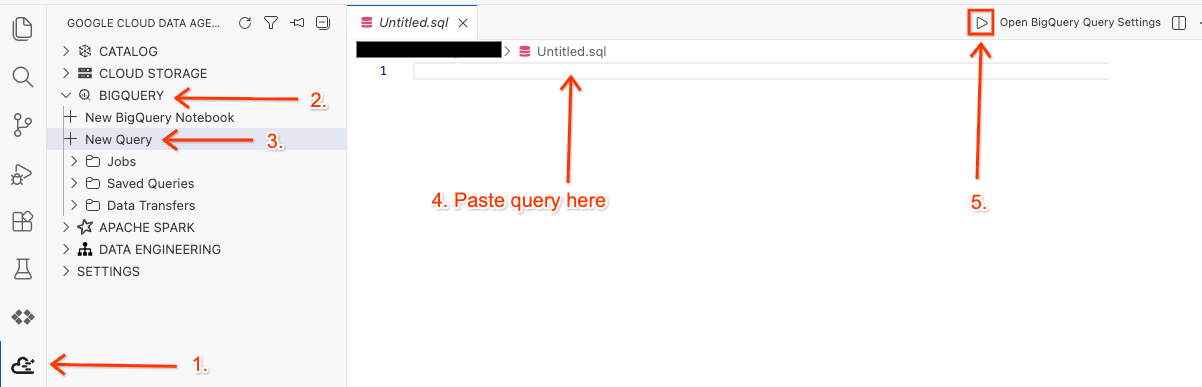
- ใน Cloud Shell Editor ให้คลิกไอคอนส่วนขยาย Google Cloud Data Agent Kit ในแผงด้านข้าง
- ไปที่ BigQuery แล้วเลือก + การค้นหาใหม่
- คัดลอกคำค้นหาต่อไปนี้ลงในหน้าต่างคำค้นหา
SET @@location = "<YOUR_REGION>"; --Update to your resource region, such as "us-central1". Make sure it is in quotes.
EXECUTE IMMEDIATE ("""
CREATE OR REPLACE EXTERNAL TABLE `lost_cargo_dataset.shipping_manifests`
(
shipment_id STRING,
timestamp TIMESTAMP,
last_ping_lat FLOAT64,
last_ping_long FLOAT64,
seal_integrity_status INT64,
custodian_id STRING OPTIONS(description='Masked identification token for official cargo custodian personnel.')
)
WITH CONNECTION `""" || @@location || """.conn`
OPTIONS (
format = 'NEWLINE_DELIMITED_JSON',
uris = ['gs://""" || @@project_id || """-lost-cargo-lake/shipping_manifests/*.jsonl']
)
""");
- คลิกเรียกใช้
- หากต้องการยืนยันว่าสร้างตารางแล้ว คุณจะเห็นข้อความว่าดำเนินการสำเร็จในแผงผลการค้นหาซึ่งจะเลื่อนเปิดโดยอัตโนมัติที่ด้านล่าง
ค้นหาตารางภายนอกเพื่อแยกทรานสปอนเดอร์ที่ถูกบุกรุก
มาดูว่าทรานสปอนเดอร์ที่ถูกบุกรุกคือตัวใดโดยดูจากความล้มเหลวเมื่อตั้งค่า seal_integrity_status เป็น 0 คัดลอกและเรียกใช้การค้นหาต่อไปนี้ในหน้าต่างการค้นหาที่คุณเปิดไว้ก่อนหน้านี้
SELECT shipment_id, last_ping_lat, last_ping_long, custodian_id
FROM `lost_cargo_dataset.shipping_manifests`
WHERE seal_integrity_status = 0;
ในแผงผลการค้นหา คุณควรเห็นเอาต์พุตที่คล้ายกับต่อไปนี้
shipment_id | last_ping_lat | last_ping_long | custodian_id |
MV-CAT-001 | 51.5074 | -0.1278 | usr_999_shadow |
4. ประมวลผลบันทึกที่ไม่มีโครงสร้างด้วยบริการที่มีการจัดการสำหรับ Apache Spark
คุณพบตำแหน่งเริ่มต้นจากไฟล์ Manifest ที่มีโครงสร้าง แต่ทรานสปอนเดอร์ที่สูญหายนั้นปิดสนิท การปิงทรานสปอนเดอร์ครั้งสุดท้ายทิ้งข้อความที่ซับซ้อนและไม่มีโครงสร้างไว้ในไฟล์บันทึกข้อความดิบในเส้นทาง GCS gs://${BUCKET_NAME}/raw_logs/maritime_logs.txt
หากต้องการประมวลผลและแมปบันทึกข้อความนี้ ให้ดึงข้อมูลการประทับเวลา ซ่อนตัวตน และค้นหาเส้นทางปลายทางของสินค้า คุณจะต้องส่งงาน Apache Spark (PySpark) แบบ Serverless ไปยัง Managed Service for Apache Spark
Managed Service สำหรับ Apache Spark ช่วยให้คุณเรียกใช้ภาระงาน Spark ได้โดยไม่ต้องจัดสรรหรือจัดการคลัสเตอร์ บริการจะจัดการทรัพยากรการประมวลผลพื้นฐาน ปรับขนาดอัตโนมัติแบบไดนามิก และคุณจะจ่ายเฉพาะระยะเวลาการดำเนินการเท่านั้น
สคริปต์จะทำสิ่งต่อไปนี้
- ส่งข้อความทรานสปอนเดอร์ดิบที่ไม่มีโครงสร้างและมีวงเล็บ
- ใช้ตัวกรองการแยกนิพจน์ทั่วไปของ PySpark SQL เพื่อแยกการประทับเวลา ข้อมูลเมตาของผู้ดูแล และเนื้อหาดิบ
- แยกบันทึกที่ยุ่งเหยิงออกเป็นระเบียนระดับประโยคที่อ่านง่าย
- ดึงเป้าหมายพิกัดปลายทางแบบไดนามิกที่เพย์โหลดที่สูญหายสิ้นสุดลง
- เชื่อมต่อและเขียน DataFrame ของบันทึกที่ประมวลผลแล้วกลับไปยัง Lakehouse Apache Iceberg REST Catalog เป็นตารางข้อมูลวิเคราะห์ใหม่ที่มองเห็นได้โดยตรงภายใน BigQuery
แก้ไขสคริปต์การวิเคราะห์ PySpark
มีรายงานว่ามีโจรสลัด Python อยู่ในทะเลซึ่งก่อให้เกิดปัญหาต่างๆ
- เรียกใช้คำสั่งต่อไปนี้เพื่อเปิดไฟล์
process_maritime_logsใน Cloud Shell Editorcd ~/devrel-demos/data-analytics/data-cloud-roadshow/lab1 cloudshell open ./process_maritime_logs.py - โปรดสละเวลาอ่านโค้ดและทำความเข้าใจสิ่งที่โค้ดทำ
- ตรวจสอบว่าไม่มีสิ่งใดในโค้ดที่ดูน่าสงสัย หากต้องการลบสิ่งใด ให้ตรวจสอบว่าคุณได้บันทึกไฟล์โดยใช้
Ctrl + S(Windows/Linux) หรือCmd + S(Mac)
ส่งงาน Spark แบบ Serverless
ส่งงานโดยใช้ gcloud SDK การกำหนดค่าจะกำหนดค่างาน PySpark โดยอัตโนมัติเพื่อให้เข้าถึงแคตตาล็อก Lakehouse ได้
เรียกใช้คำสั่งต่อไปนี้ในเทอร์มินัลของโปรแกรมแก้ไขแบบผสานรวม
cd ~/devrel-demos/data-analytics/data-cloud-roadshow/lab1
source .env
gcloud dataproc batches submit pyspark process_maritime_logs.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--version=2.3 \
--deps-bucket=${BUCKET_NAME} \
--properties="\
spark.sql.defaultCatalog=cargo_catalog,\
spark.sql.catalog.${CATALOG_NAME}=org.apache.iceberg.spark.SparkCatalog,\
spark.sql.catalog.${CATALOG_NAME}.type=rest,\
spark.sql.catalog.${CATALOG_NAME}.uri=https://biglake.googleapis.com/iceberg/v1/restcatalog,\
spark.sql.catalog.${CATALOG_NAME}.warehouse=gs://${BUCKET_NAME},\
spark.sql.catalog.${CATALOG_NAME}.header.x-goog-user-project=${PROJECT_ID},\
spark.sql.catalog.${CATALOG_NAME}.rest.auth.type=org.apache.iceberg.gcp.auth.GoogleAuthManager,\
spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions,\
spark.sql.catalog.${CATALOG_NAME}.gcs.oauth2.refresh-credentials-endpoint=https://oauth2.googleapis.com/token, \
spark.sql.catalog.${CATALOG_NAME}.header.X-Iceberg-Access-Delegation=vended-credentials" \
-- ${BUCKET_NAME}
รอสักครู่เพื่อให้สภาพแวดล้อมแบบไม่ใช้เซิร์ฟเวอร์เริ่มทำงาน อัปโหลดสคริปต์ และเรียกใช้ตรรกะการประมวลผล
เมื่อเห็นเอาต์พุตคล้ายกับเอาต์พุตต่อไปนี้ ระบบจะบันทึกตารางที่ประมวลผลแล้วลงในแคตตาล็อก Lakehouse เป็นตารางที่มีการจัดการ Apache Iceberg
Batch [1fae0b4b42c045a084dd67917bd0c332] finished.
metadata:
'@type': type.googleapis.com/google.cloud.dataproc.v1.BatchOperationMetadata
batch: projects/<YOUR_PROJECT>/locations/us-central1/batches/1fae0b4b42c045a084dd67917bd0c332
batchUuid: 611b4465-fdac-4974-bc47-5f10adaf2a08
createTime: '2026-06-11T21:35:01.868157Z'
description: Batch
labels:
goog-dataproc-batch-id: 1fae0b4b42c045a084dd67917bd0c332
goog-dataproc-batch-uuid: 611b4465-fdac-4974-bc47-5f10adaf2a08
goog-dataproc-drz-resource-uuid: batch-611b4465-fdac-4974-bc47-5f10adaf2a08
goog-dataproc-location: us-central1
operationType: BATCH
name: projects/<YOUR_PROJECT/regions/us-central1/operations/7e2044db-dd97-3270-b368-4dc4ba417574
ดูตัวอย่างบันทึกที่ประมวลผลแล้ว
ในตัวแก้ไขคำค้นหาของส่วนขยาย Data Agent Kit ให้คัดลอกคำค้นหาต่อไปนี้เพื่อแสดงตัวอย่างข้อมูล
SET @@location = "<YOUR_REGION>"; -- e.g. "us-central1"
EXECUTE IMMEDIATE FORMAT("""
select log_timestamp, custodian_id, sentence from
`%s.%s-lost-cargo-lake.lost_cargo_namespace.processed_maritime_logs`
limit 5
""", @@project_id, @@project_id);
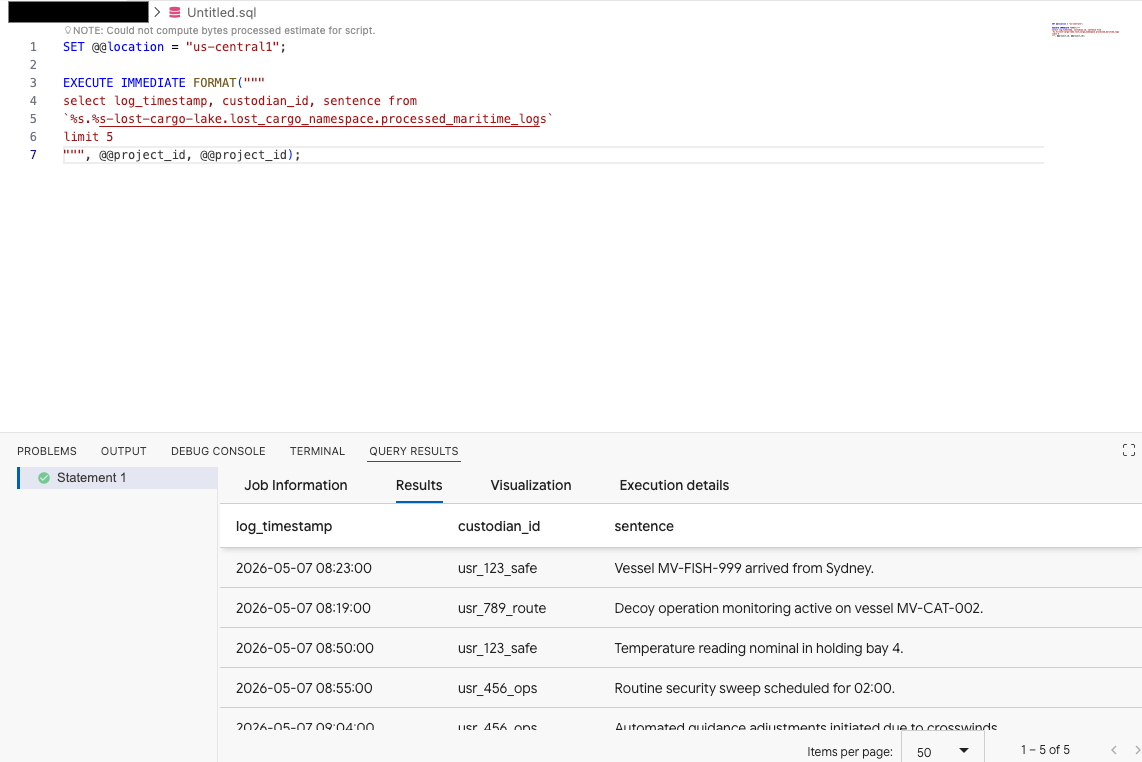
ซึ่งแสดงให้เห็นว่าตาราง Iceberg ที่ลงทะเบียนในแคตตาล็อกสามารถเข้าถึงได้จาก BigQuery
แยกคำใบ้ของจุดหมาย
ตอนนี้เรามีบันทึกที่ประมวลผลแล้ว มาค้นหาบันทึกที่มีเป้าหมายปลายทางกัน จากนั้นเราจะค้นหาบันทึกซึ่งมีการกล่าวถึงเมืองต้นทางของเรา
ในเครื่องมือแก้ไขคำค้นหา ให้เรียกใช้คำค้นหาต่อไปนี้ โดยแทนที่ <YOUR_REGION> ด้วยภูมิภาคของคุณ และแทนที่ <ORIGIN_CITY> ด้วยเมืองต้นทางที่คุณค้นพบก่อนหน้านี้
SET @@location = "<YOUR_REGION>"; --e.g. "us-central1"
DECLARE origin_city STRING;
SET origin_city = "<ORIGIN_CITY>"; --e.g. "Boston". (It's not Boston)
EXECUTE IMMEDIATE FORMAT(r"""
SELECT
log_timestamp AS event_time,
custodian_id,
REGEXP_EXTRACT(raw_message, r'Destination:\s*([^.]+)') AS destination_target
FROM
`%s.%s-lost-cargo-lake.lost_cargo_namespace.processed_maritime_logs`
WHERE
-- STRPOS is highly optimized in BigQuery for a simple .contains() substring check
STRPOS(sentence, '%s') > 0;
""", @@project_id, @@project_id, origin_city);
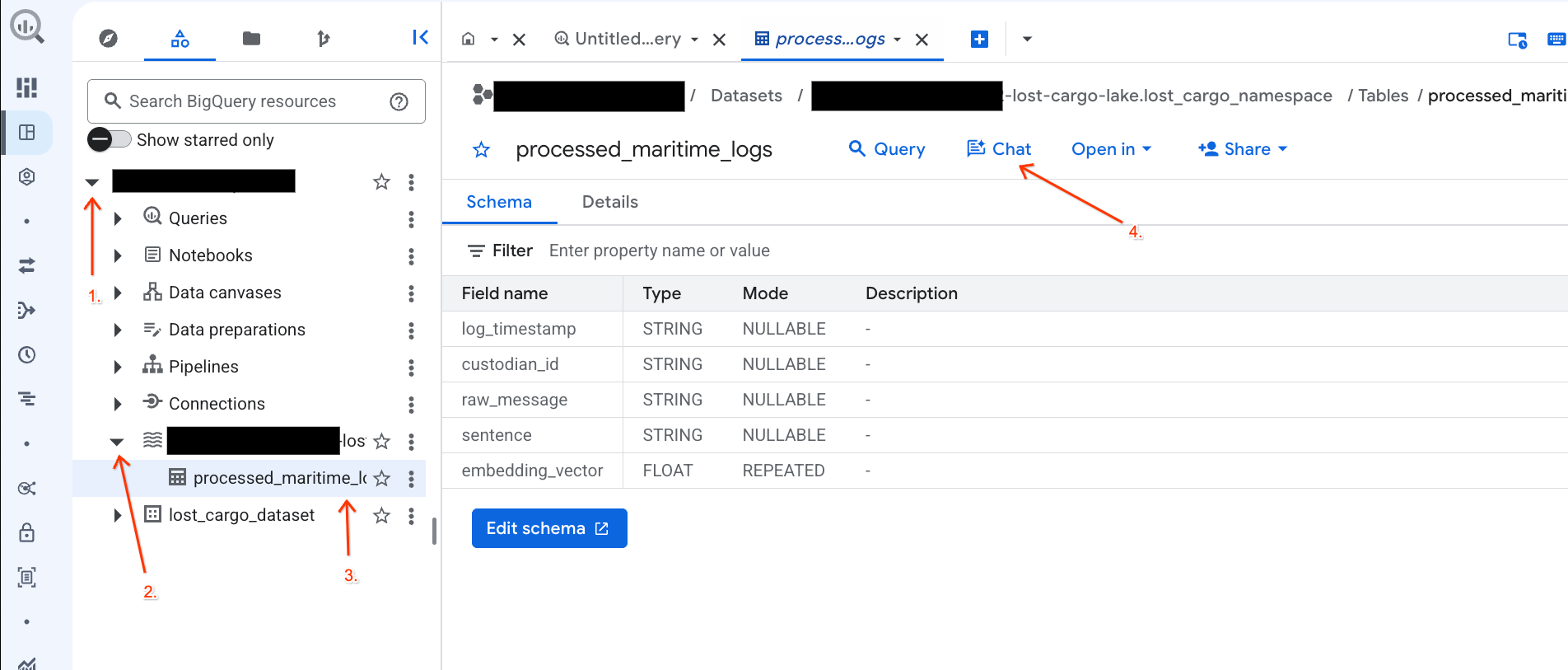
แชทกับข้อมูลในคอนโซล BigQuery โดยใช้ Conversational Analytics
แทนที่จะเขียนคําค้นหา SQL ที่ซับซ้อนเพื่อสํารวจข้อมูล คุณสามารถใช้ Conversational Analytics เพื่อแชทกับตารางโดยใช้ภาษาธรรมชาติได้
- ไปที่ BigQuery Console
- ในแผง Explorer ทางด้านซ้าย ให้ขยายโปรเจ็กต์และชุดข้อมูล
-lost-cargo-lake.lost_cargo_namespace processed_maritime_logsเพื่อเปิดแท็บรายละเอียด - คลิกแชทข้างคำค้นหา
- ในแผงแชท ให้พิมพ์คำถามต่อไปนี้ แล้วกด Enter บนแป้นพิมพ์เพื่อส่ง
Based on this table, what color is the shipping container MV-CAT-001?
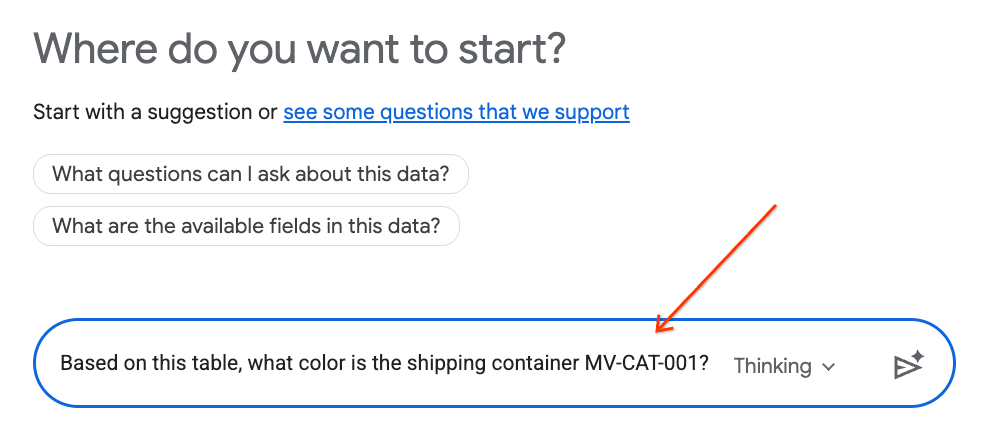
- Conversational Analytics (ขับเคลื่อนโดย Gemini) จะวิเคราะห์ข้อมูลของตารางที่ใช้งานอยู่และตอบกลับด้วยสี
5. ดูแคตตาล็อก Lakehouse แบบรวมศูนย์
สคริปต์การตั้งค่าได้กำหนดค่าแคตตาล็อก REST ของ Lakehouse Iceberg เพื่อผสานรวมเครื่องมือประมวลผลโอเพนซอร์ส (เช่น Apache Spark) อย่างปลอดภัยและราบรื่นกับเครื่องมือข้อมูลระดับองค์กร (เช่น BigQuery)
แคตตาล็อก REST ของ Apache Iceberg ทำหน้าที่เป็น "แหล่งข้อมูลที่เชื่อถือได้เพียงแหล่งเดียว" แบบ Serverless สำหรับข้อมูลเมตาของตาราง โดยจะจัดการสคีมาและตารางที่แบ่งพาร์ติชันแล้วแบบไดนามิกขณะจัดเก็บไฟล์ข้อมูล Parquet จริงใน Cloud Storage
มาดูแคตตาล็อกนี้โดยตรงในคอนโซล Google Cloud กัน
- เปิด Lakehouse Console
- ในแท็บแคตตาล็อก ให้ค้นหาและคลิกแคตตาล็อก Iceberg REST ที่ใช้งานอยู่:
-lost-cargo-lake
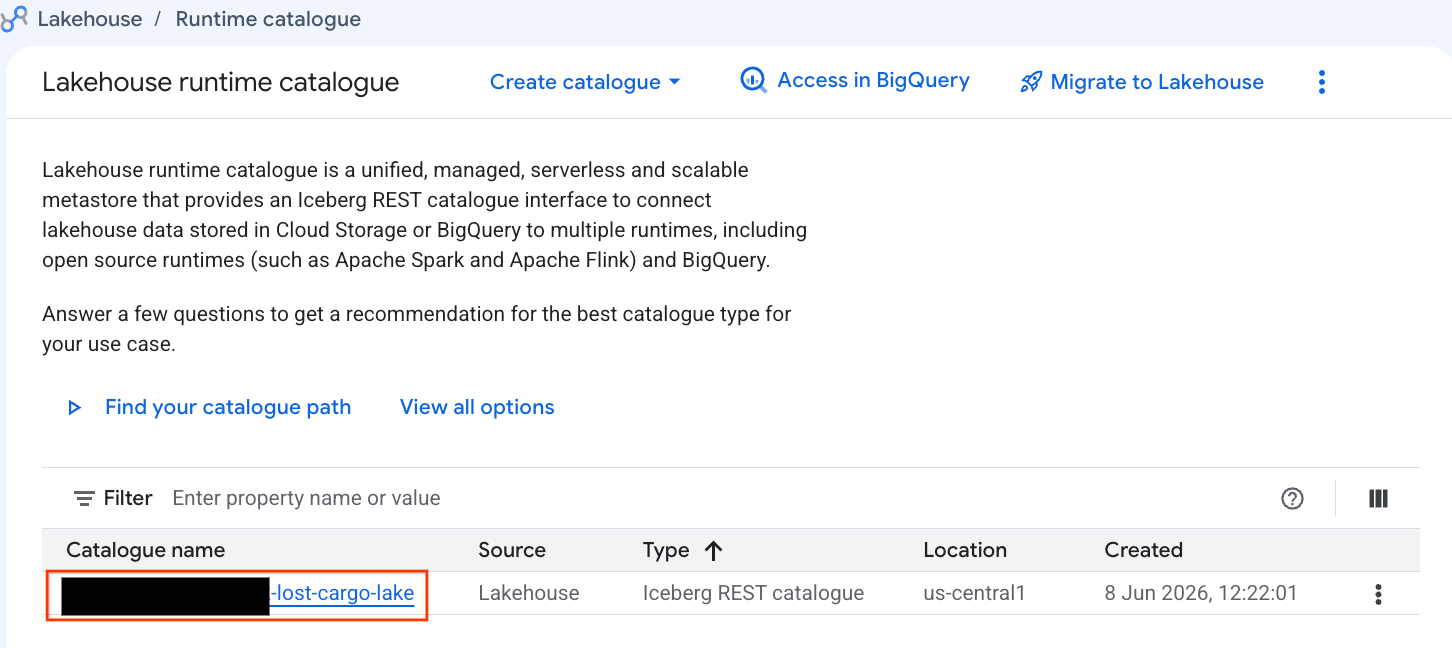
- ในมุมมองรายละเอียดแคตตาล็อก คุณควรเห็น
lost_cargo_namespaceในส่วนเนมสเปซ ให้คลิกไอคอนนั้น
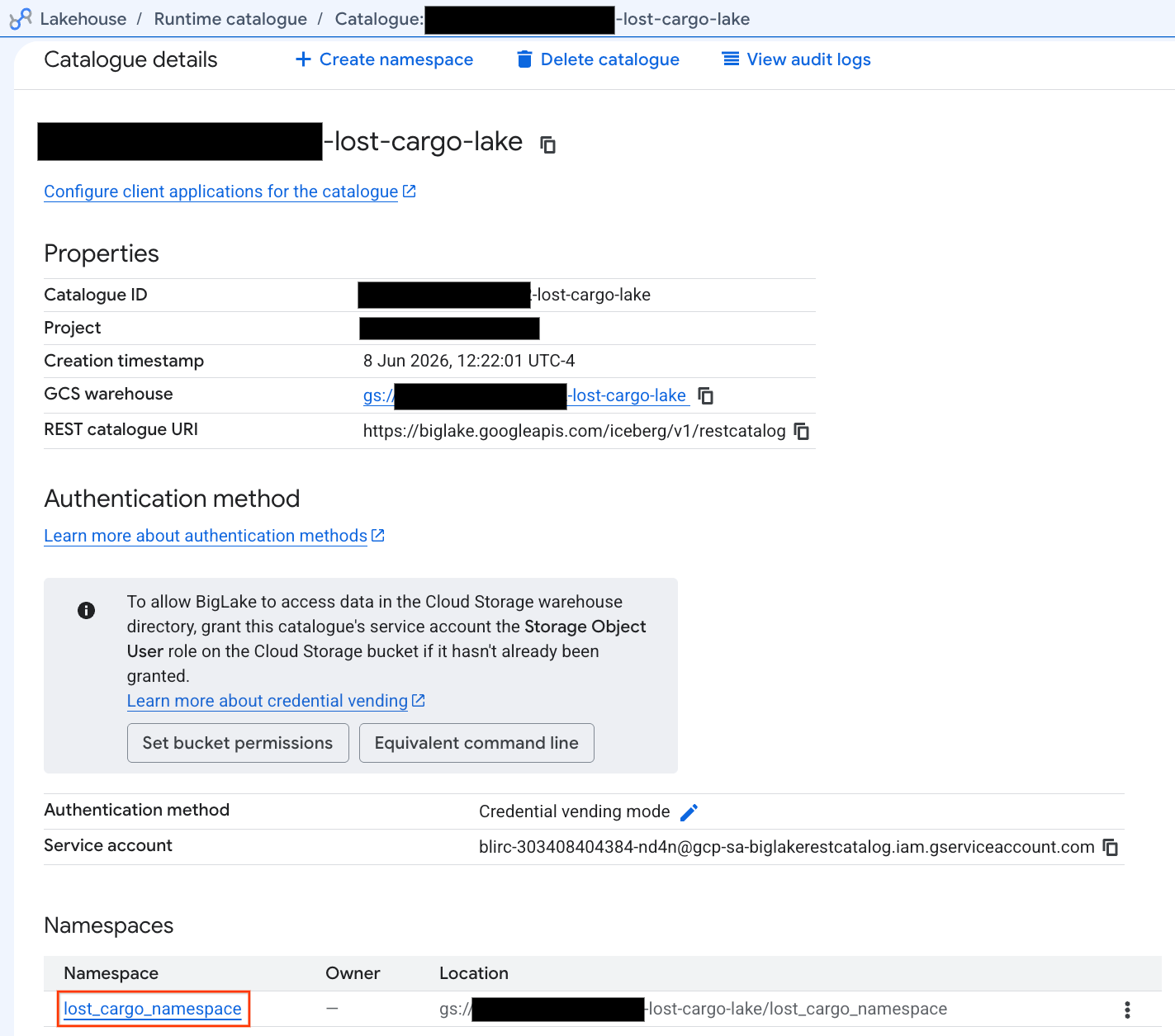
- ตาราง Apache Iceberg ใหม่ที่สร้างโดย PySpark จะลงทะเบียนโดยอัตโนมัติภายใต้เนมสเปซของ Metastore นี้ และพร้อมให้ค้นหาใน BigQuery ได้ทันที
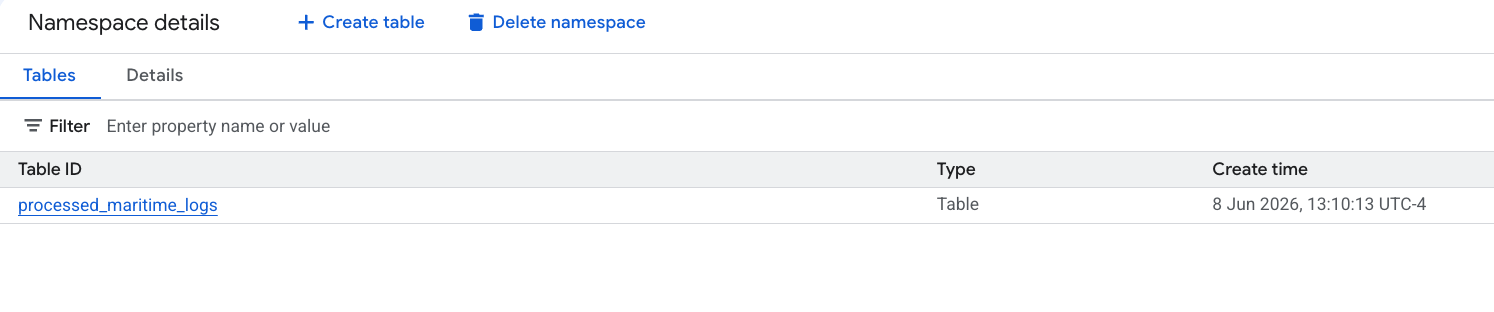
6. สร้างข้อมูลเชิงลึกในตารางใบกำกับการขนส่ง
กลับไปวิเคราะห์shipping_manifestsตารางเพื่อทําความเข้าใจโครงสร้างและเนื้อหาโดยใช้ข้อมูลเชิงลึกของแคตตาล็อกความรู้กัน การเพิ่มข้อมูลเมตาจะช่วยให้ผู้สำรวจคนอื่นๆ เข้าใจตารางได้ดียิ่งขึ้นสำหรับการวิเคราะห์ในอนาคต
สร้างข้อมูลเชิงลึกของตารางใน BigQuery Studio
- ในคอนโซล Google Cloud ให้ไปที่ BigQuery Studio
- ในแผง Explorer ให้ขยายโปรเจ็กต์ ขยายชุดข้อมูล
lost_cargo_datasetแล้วคลิกตารางshipping_manifests - คลิกแท็บข้อมูลเชิงลึกในแผงรายละเอียดทางด้านขวา
- ใช้เมนูแบบเลื่อนลงเพื่อเลือกสร้างและเผยแพร่
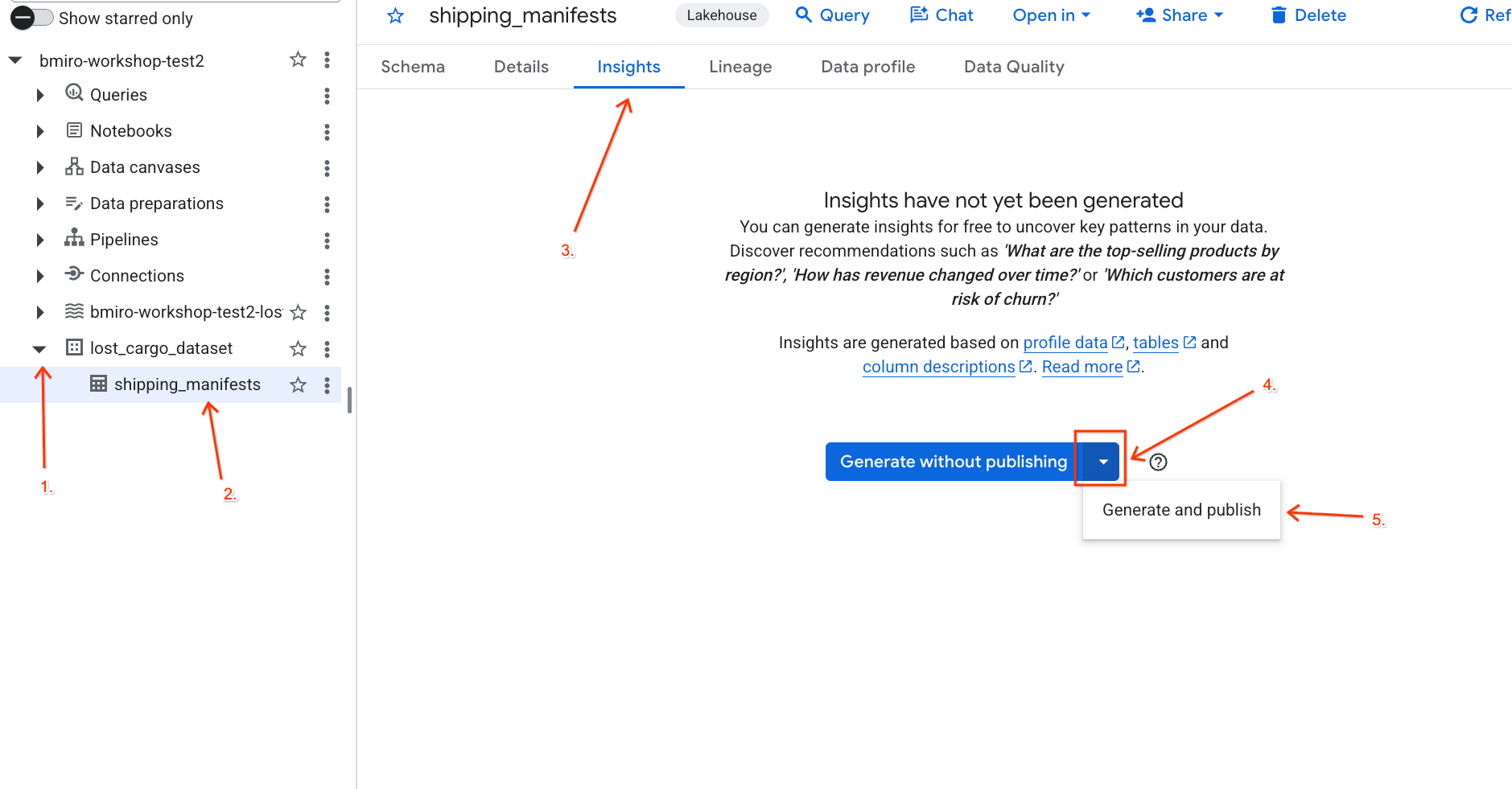
- รอประมาณ 3 นาทีเพื่อให้ระบบสร้างข้อมูลเชิงลึกเสร็จสมบูรณ์ Gemini จะวิเคราะห์ข้อมูลเมตาของตารางและสร้างคำถามในภาษาธรรมชาติและคำค้นหา SQL ที่เกี่ยวข้อง
- เมื่อเสร็จสมบูรณ์แล้ว คุณจะเห็นคำอธิบายตารางพร้อมคำอธิบายตารางในภาษาธรรมชาติ
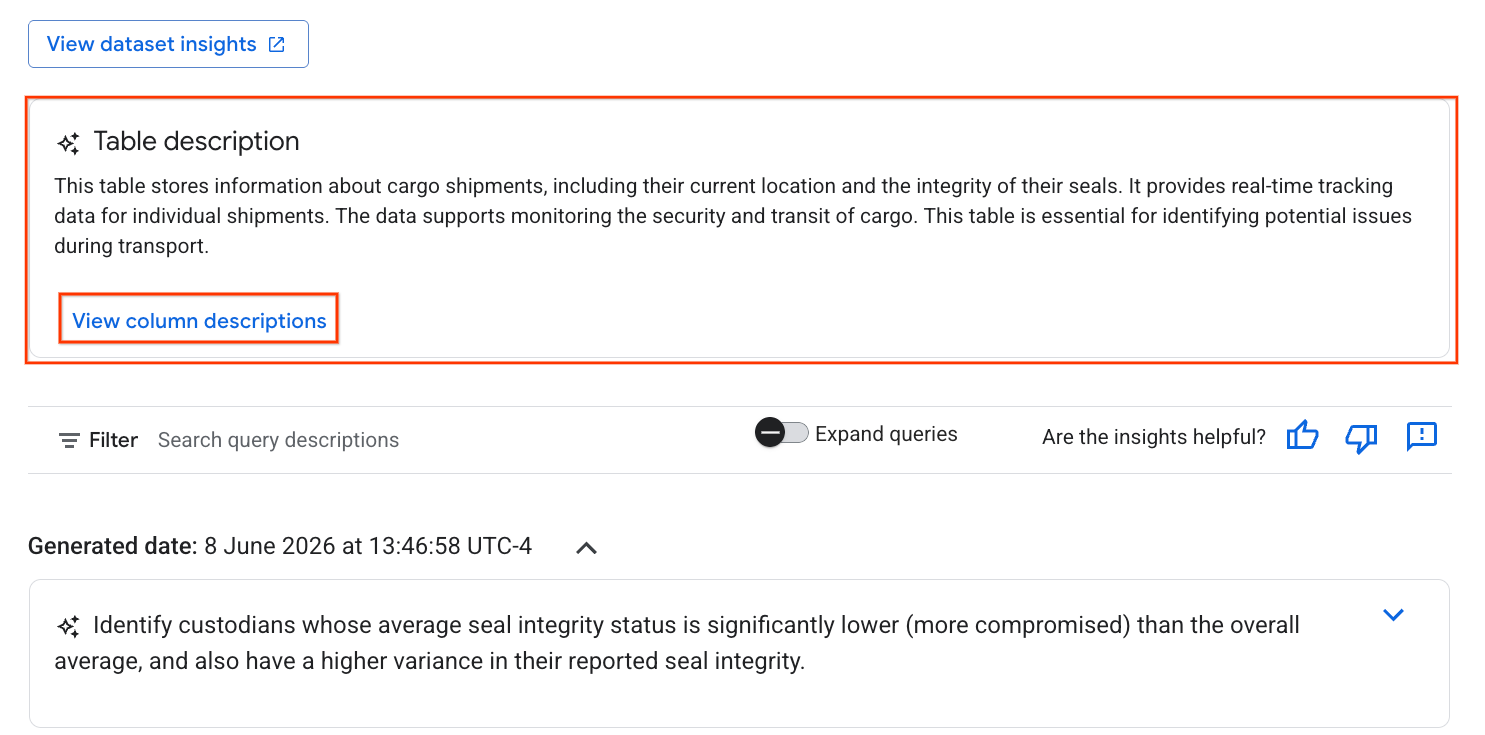
- คลิกดูคำอธิบายคอลัมน์เพื่อดูข้อมูลเกี่ยวกับแต่ละคอลัมน์
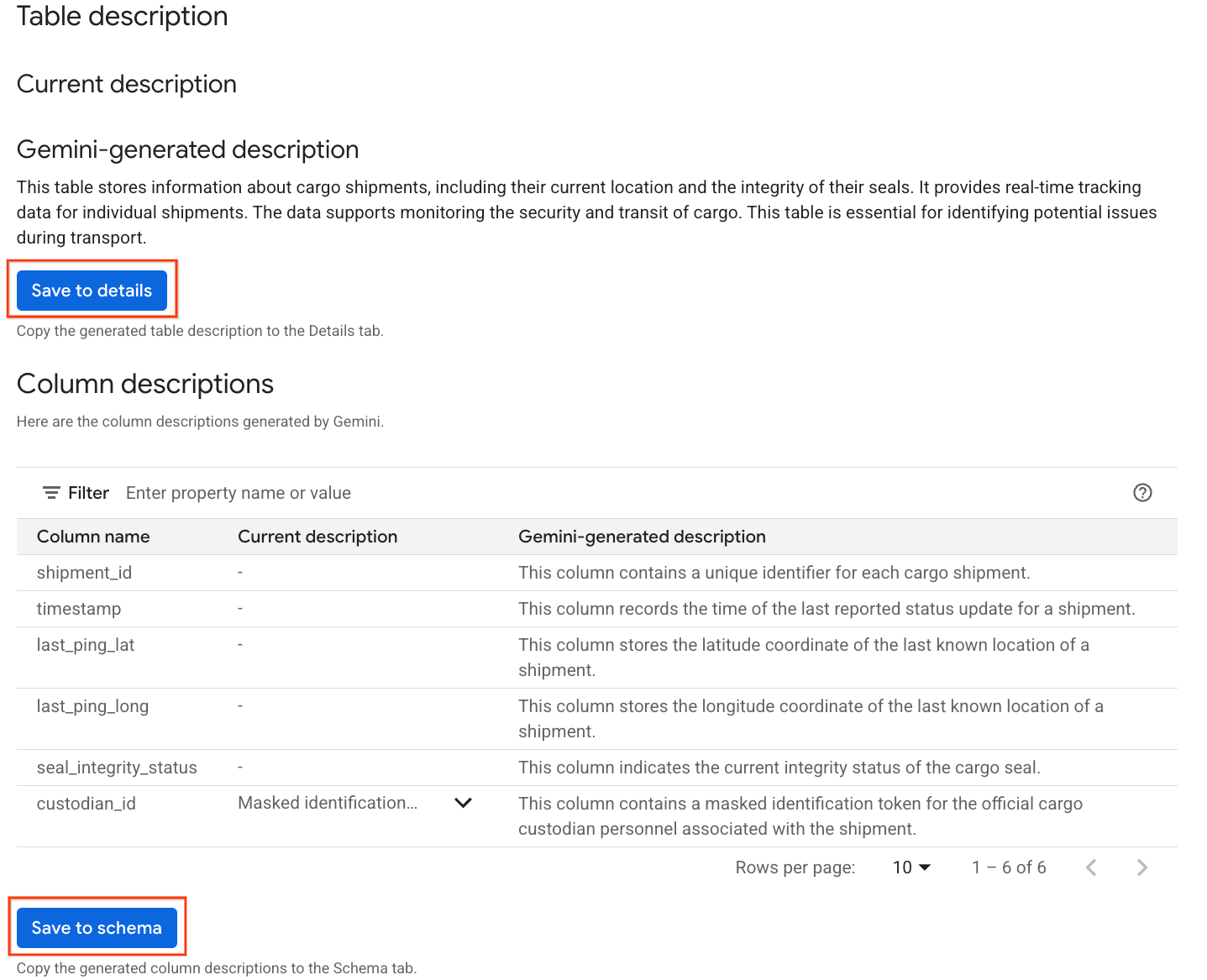
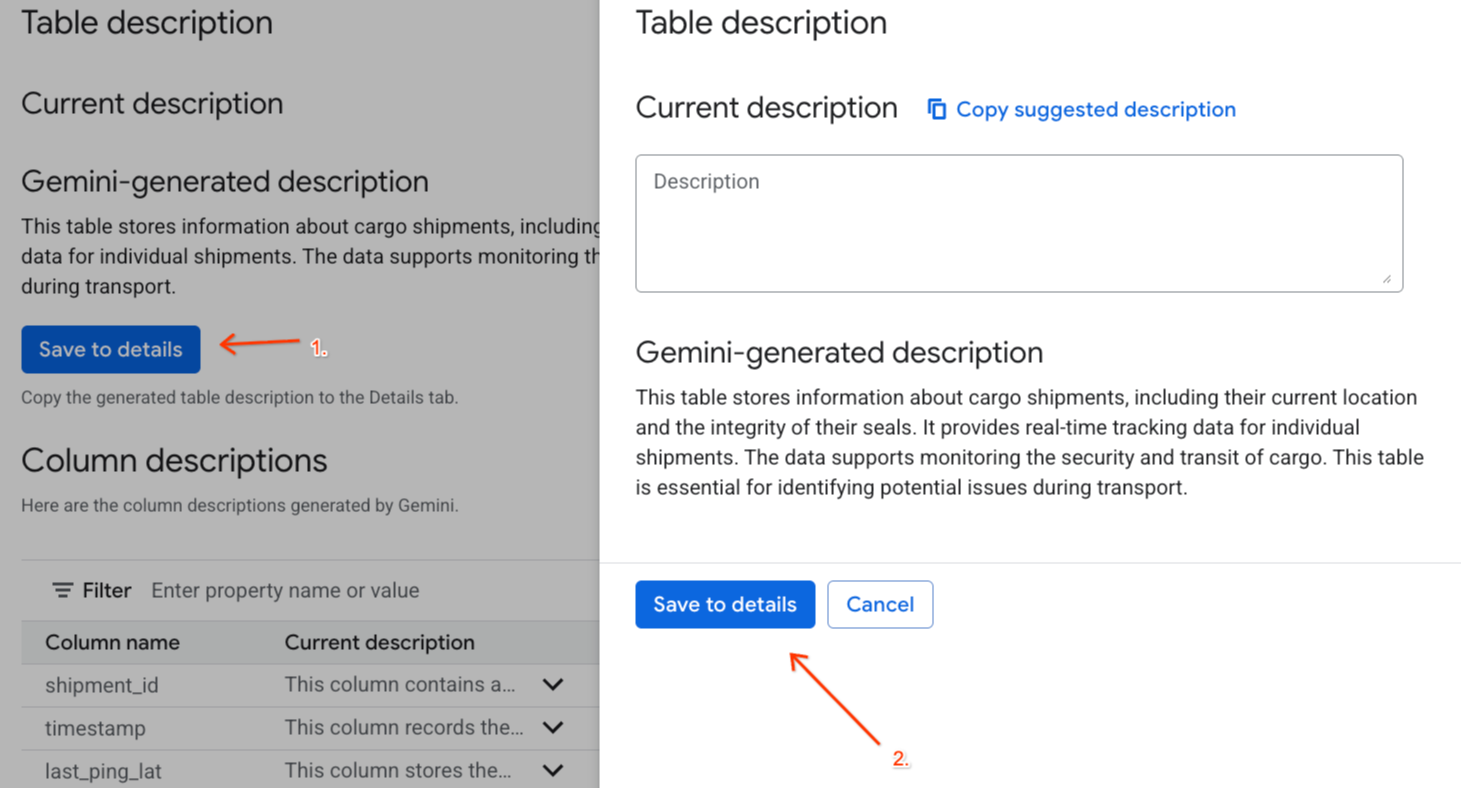
- คลิกบันทึกไปยังรายละเอียดในส่วน
Gemini generated descriptionแล้วคลิกบันทึกไปยังรายละเอียดในหน้าต่างที่ปรากฏขึ้น
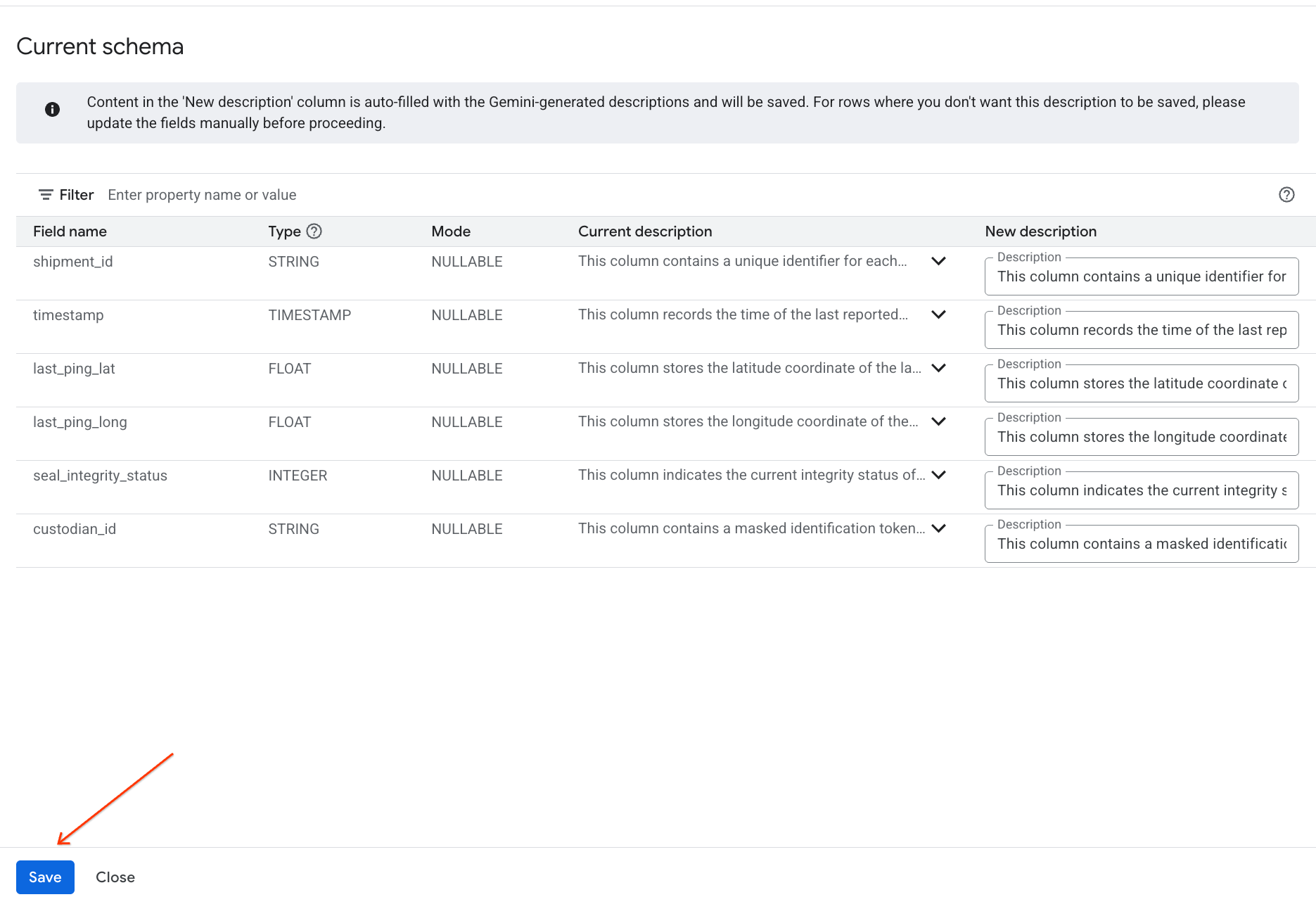
- ในทำนองเดียวกัน ให้คลิกบันทึกลงในสคีมาเพื่อเพิ่มคำอธิบายคอลัมน์ลงในข้อมูลเมตาของตาราง
ตรวจสอบข้อมูลเชิงลึกที่สร้างขึ้น
นอกจากนี้ คุณยังเห็นรายการคำถามที่แนะนำได้ด้วย โดยคลิกคำถามใดก็ได้เพื่อดูการค้นหาด้วย SQL ที่สร้างขึ้น แล้วดำเนินการเพื่อสำรวจข้อมูล เช่น คุณอาจเห็นคำถามต่อไปนี้
- "มีการจัดส่งทั้งหมดกี่ครั้ง"
- "แสดงรหัสผู้ดูแลที่ไม่ซ้ำกัน"
การเรียกใช้การค้นหาเหล่านี้จะช่วยให้คุณเข้าใจข้อมูล
7. ใช้การปกปิดข้อมูลบางส่วนและการกำกับดูแล
คุณต้องบังคับใช้โปรโตคอลความปลอดภัยมาตรฐานเพื่อให้มั่นใจว่าจะไม่มีการรั่วไหลของบัญชีและชื่อผู้ใช้ที่ใช้ในการวิจัยซึ่งยังใช้งานอยู่ระหว่างการตรวจสอบสินค้าที่กำลังดำเนินการอยู่ คุณจะสร้างอนุกรมวิธานแท็กนโยบายความปลอดภัยและกำหนดค่าการมาสก์ข้อมูลแคตตาล็อกความรู้ในคอลัมน์custodian_idที่มีความละเอียดอ่อนเพื่อยืนยันความเป็นส่วนตัวของข้อมูล
โดยค่าเริ่มต้น BigQuery จะปฏิเสธการเข้าถึงคอลัมน์ที่ได้รับการปกป้องโดยแท็กนโยบาย หากต้องการค้นหาตารางและยืนยันการมาสก์ข้อมูลที่ใช้งานอยู่ บัญชีผู้ใช้ของคุณต้องมีบทบาทผู้อ่านที่มาสก์นโยบายข้อมูล BigQuery
ระบบจะเชื่อมโยงบทบาทนี้กับบัญชีผู้ใช้ที่ใช้งานอยู่โดยอัตโนมัติในระหว่างการเรียกใช้ setup_lab1.sh ครั้งแรก
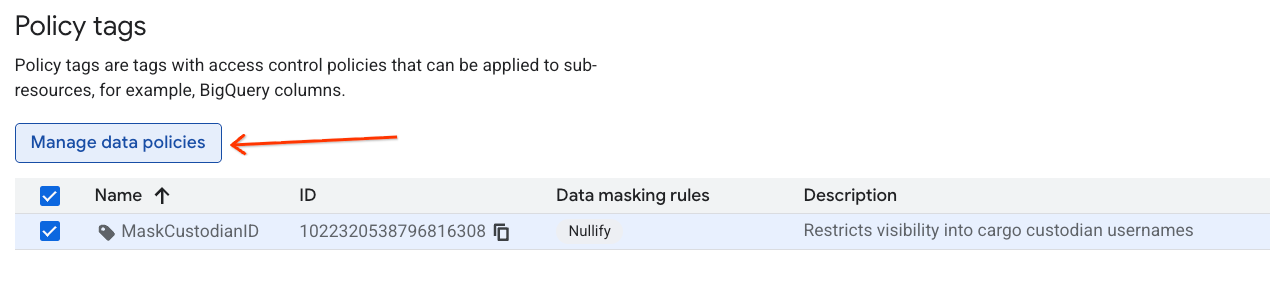
สร้างการจัดหมวดหมู่และแท็กนโยบาย
สร้างการจัดหมวดหมู่ข้อมูลและแท็กนโยบายที่เชื่อมโยงเพื่อจัดการการเข้าถึงข้อมูล
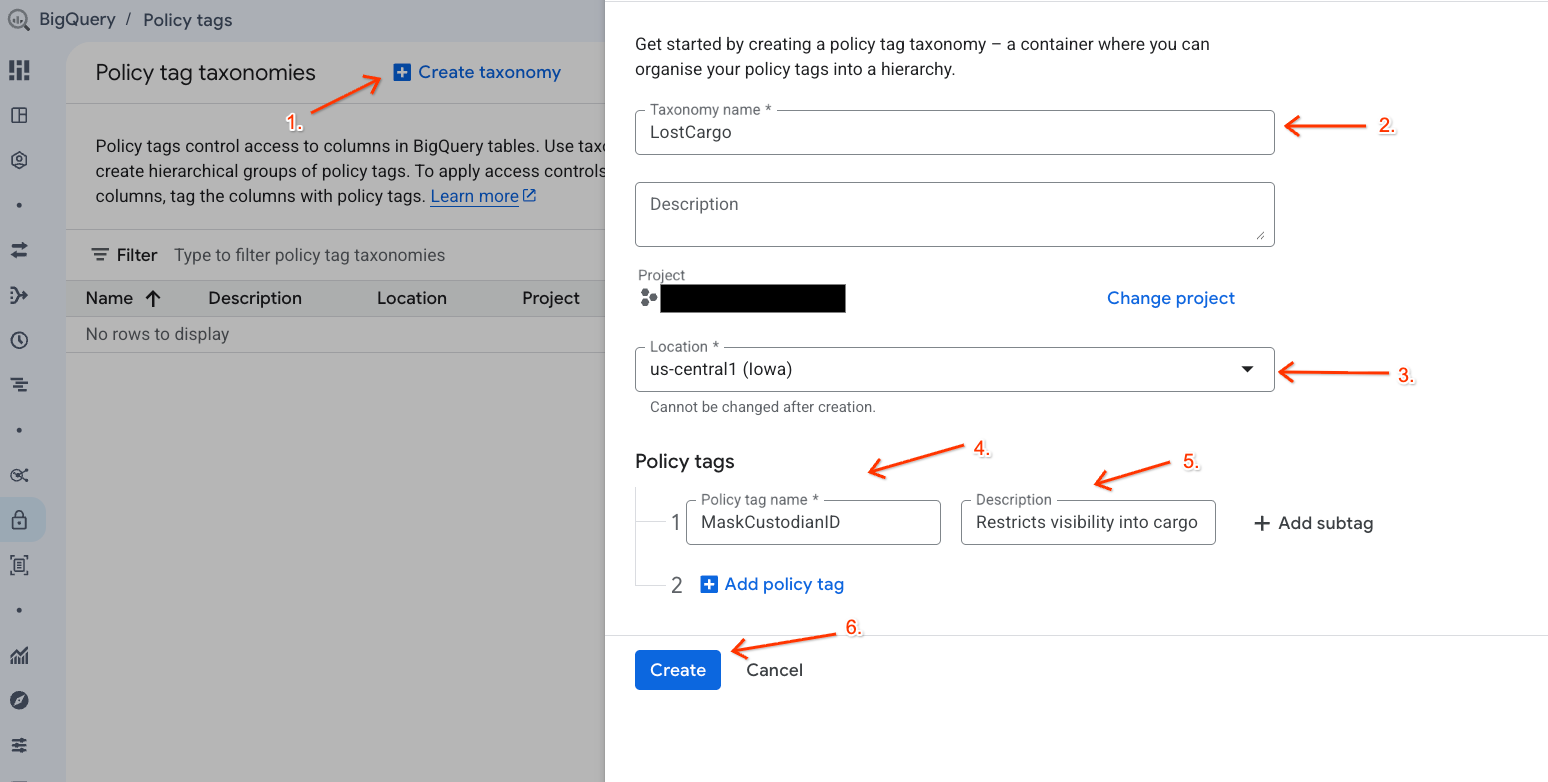
- ไปที่หน้าการจัดหมวดหมู่แท็กนโยบาย
- คลิก + สร้างการจัดหมวดหมู่
- กำหนดค่าพารามิเตอร์
- ชื่อการจัดหมวดหมู่: ป้อน
lost-cargo-โดยแทนที่ด้วยรหัสโปรเจ็กต์ของคุณ - ภูมิภาค: เลือกภูมิภาคของคุณ
- สำหรับชื่อแท็กนโยบาย ให้ป้อน
MaskCustodianID - สำหรับคำอธิบายแท็กนโยบาย ให้ทำดังนี้
Restricts visibility into cargo custodian usernames
- ชื่อการจัดหมวดหมู่: ป้อน
- คลิกสร้างเพื่อลงทะเบียนการจัดหมวดหมู่และแท็กนโยบายใหม่
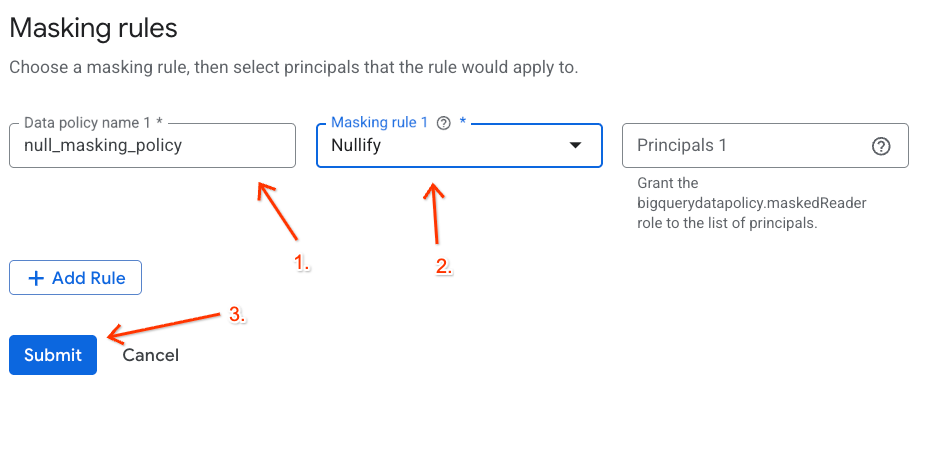
สร้างนโยบายการปกปิดข้อมูล
จากนั้นกำหนดค่านโยบายข้อมูลเพื่อระบุวิธีการมาสก์ข้อมูลภายใต้แท็กการจัดประเภท MaskCustodianID คุณจะใช้กฎการมาสก์ Always Null (แทนที่ค่าที่ตรงกันด้วยค่าว่าง/Null สำหรับผู้ใช้ที่ไม่ได้รับสิทธิ์ทั้งหมด)
- ในหน้าการจัดหมวดหมู่แท็กนโยบาย ให้คลิกการจัดหมวดหมู่ที่สร้างขึ้นใหม่จากรายการการจัดหมวดหมู่
- ในรายการลำดับชั้น ให้คลิกแท็ก
MaskCustodianIDเพื่อเลือก แล้วเลือกจัดการนโยบายข้อมูล
- คลิกปุ่ม + เพิ่มกฎในแผงด้านขวา
- กำหนดรายละเอียดนโยบายในแผงที่ปรากฏขึ้น
- ชื่อนโยบายข้อมูล: ป้อน
null_masking_policy(อย่าปล่อยให้ระบบสร้างชื่อโดยอัตโนมัติ เนื่องจากเราจะอ้างอิงชื่อนี้ในขั้นตอนถัดไป) - กฎการมาสก์: เลือก
Nullifyจากเมนูแบบเลื่อนลง
- ชื่อนโยบายข้อมูล: ป้อน
- คลิกส่ง
กำหนดแท็กนโยบายให้กับคอลัมน์ BigQuery
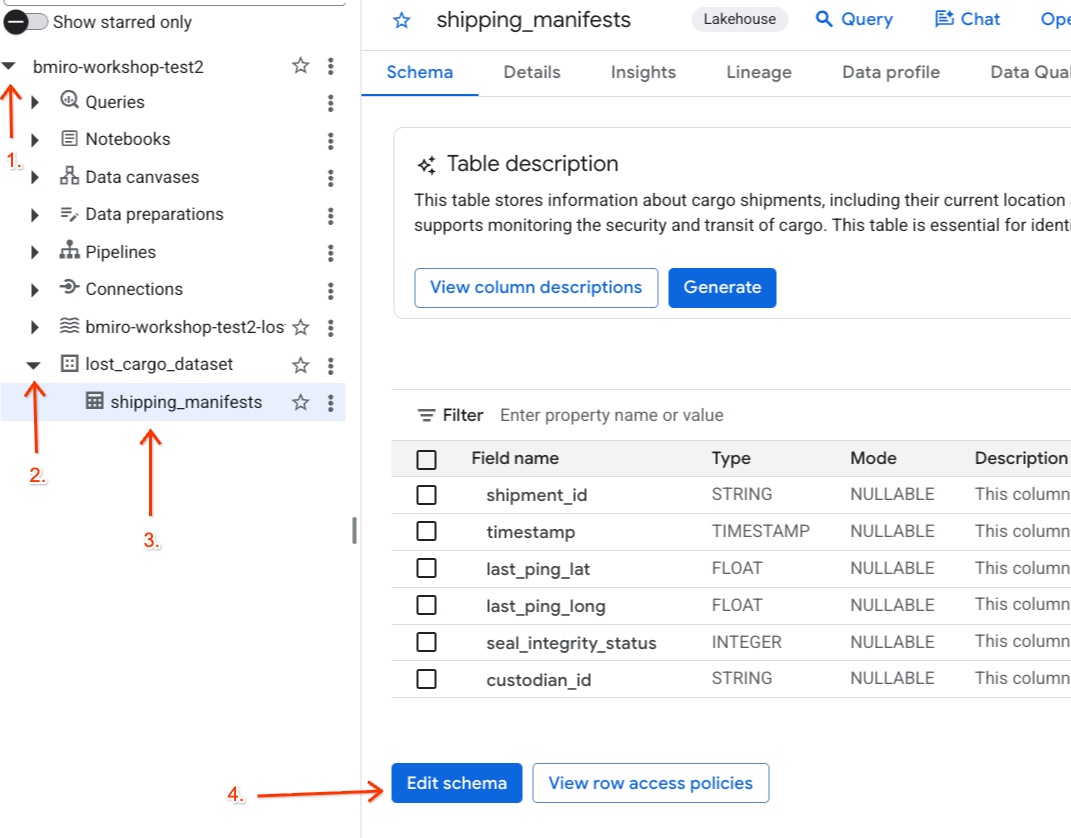
เมื่อแท็กนโยบายและกฎการมาสก์ข้อมูลของแท็กนั้นทำงานอยู่ ให้แมปแท็กการแยกประเภทกับคอลัมน์ custodian_id โดยตรงในตารางใบแจ้งการจัดส่งของพาร์ทเนอร์ BigQuery
- ไปที่BigQuery
- ในแผง Explorer ทางด้านซ้าย ให้ขยายโปรเจ็กต์ที่ใช้งานอยู่ ขยายชุดข้อมูล
lost_cargo_datasetแล้วคลิกตารางshipping_manifestsเพื่อเปิดมุมมองแบบละเอียด - คลิกแก้ไขสคีมา
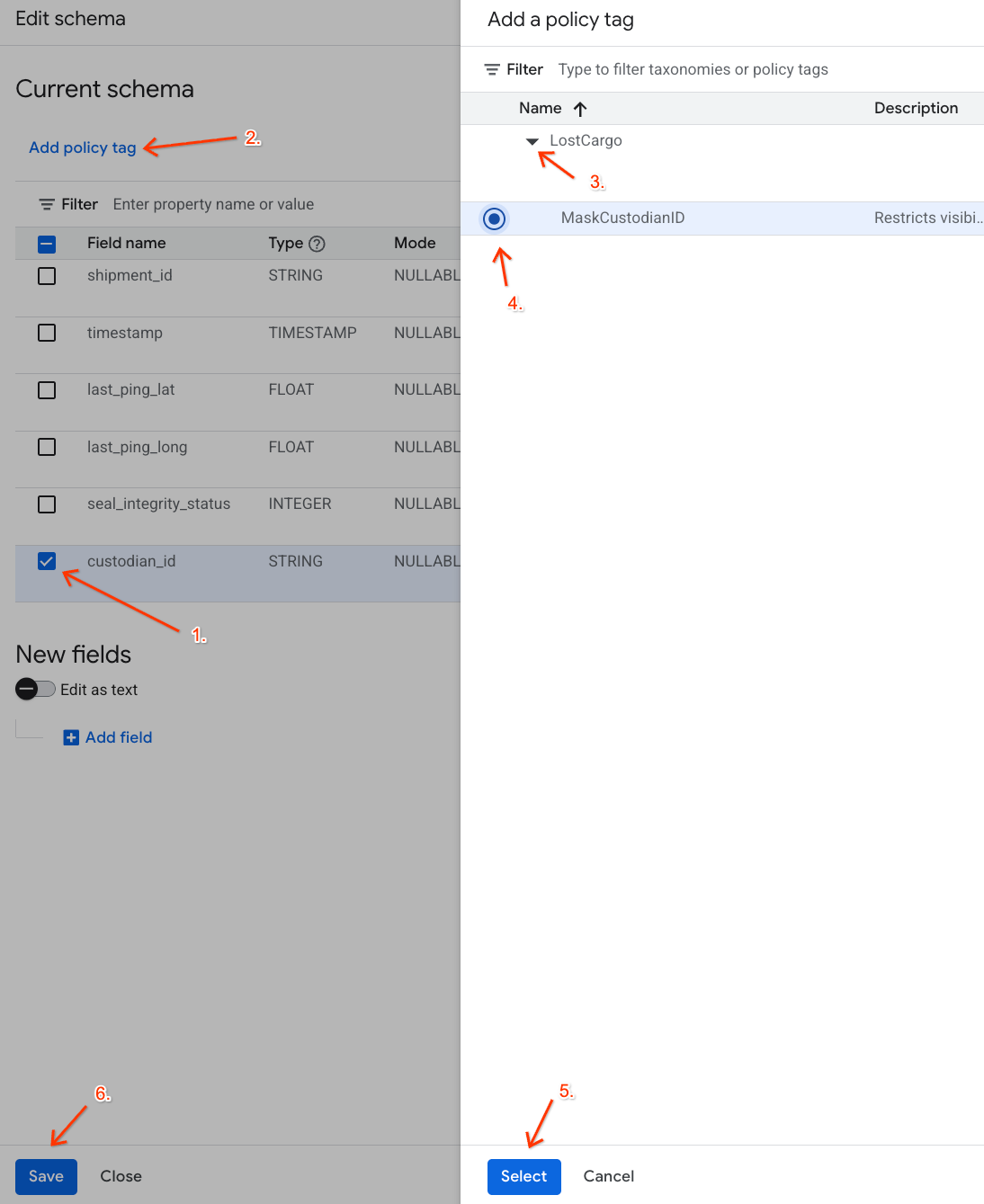
- ในรายการคอลัมน์ ให้เลือกช่องข้าง
custodian_id - คลิกปุ่มเพิ่มแท็กนโยบายในแถบเครื่องมือด้านบนของเครื่องมือแก้ไขสคีมา
- ในแผงเพิ่มแท็กนโยบาย ให้ทำดังนี้
- ค้นหาและขยายการจัดหมวดหมู่
LostCargo - เลือกบับเบิลข้าง
MaskCustodianID - คลิกเลือก
- ค้นหาและขยายการจัดหมวดหมู่
- ตรวจสอบว่าแท็ก
MaskCustodianIDปรากฏในคอลัมน์แท็กนโยบายในแถวที่แสดงcustodian_idแล้ว - คลิกบันทึก
ยืนยันข้อจำกัดด้านนโยบาย
ตอนนี้คุณมีบทบาท Masked Reader ที่ระดับโปรเจ็กต์แล้ว คุณจึงสามารถค้นหาตารางเพื่อยืนยันว่านโยบายการมาสก์ทำงานอยู่
กลับไปที่ Data Agent Kit แล้วเรียกใช้การค้นหาต่อไปนี้
SELECT shipment_id, custodian_id
FROM lost_cargo_dataset.shipping_manifests
LIMIT 5;
คุณควรเห็นเอาต์พุตคล้ายกับตัวอย่างต่อไปนี้
shipment_id | custodian_id |
NORMAL-001 | null |
NORMAL-002 | null |
MV-CAT-001 | null |
สำเร็จ! แม้ว่าคุณจะดูระเบียน shipment_id ได้ แต่ช่อง custodian_id ที่ละเอียดอ่อนจะแสดงมาสก์ null ที่ปลอดภัยเพื่อป้องกันการรั่วไหล
8. ล้างข้อมูล
หากต้องการหลีกเลี่ยงการเรียกเก็บเงินอย่างต่อเนื่องในบัญชี Google Cloud สำหรับทรัพยากรที่สร้างขึ้นระหว่าง Codelab นี้ ให้เรียกใช้คำสั่งต่อไปนี้ในเทอร์มินัล Cloud Shell เพื่อทิ้งชุดข้อมูลและที่เก็บ
# Verify active variables
export PROJECT_ID=$(gcloud config get-value project)
export BUCKET_NAME="${PROJECT_ID}-lost-cargo-lake"
# Delete Knowledge Catalog security taxonomies
export TAXONOMY_NAME=$(gcloud data-catalog taxonomies list --location=us-central1 --filter="displayName:LostCargo" --format="value(name)")
if [[ -n "$TAXONOMY_NAME" ]]; then
curl -X DELETE \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
"https://datacatalog.googleapis.com/v1/${TAXONOMY_NAME}" || true
fi
# Delete Lakehouse Iceberg REST Catalog tables and namespaces
gcloud biglake iceberg tables delete processed_maritime_logs \
--catalog=${BUCKET_NAME} \
--namespace=lost_cargo_namespace \
--quiet || true
gcloud biglake iceberg namespaces delete lost_cargo_namespace \
--catalog=${BUCKET_NAME} \
--quiet || true
# Delete Lakehouse Iceberg REST Catalog
gcloud biglake iceberg catalogs delete ${BUCKET_NAME} --quiet || true
# Delete dependencies bucket
gcloud storage rm -r gs://${BUCKET_NAME} || true
# Delete BigQuery dataset and tables
bq rm -r -f -d ${PROJECT_ID}:lost_cargo_dataset || true
9. ขอแสดงความยินดี
ยินดีด้วย คุณได้เรียนรู้โมดูลแรกที่สำคัญที่สุดของการสืบสวนสินค้าที่สูญหายเรียบร้อยแล้ว คุณได้สร้างโซนการค้นหาที่มีการควบคุมโดยใช้แคตตาล็อก REST ของ Lakehouse Iceberg, การทำให้บันทึก PySpark เป็นมาตรฐาน และการมาสก์ข้อมูลแบบละเอียด
สิ่งที่คุณได้เรียนรู้
- การติดตั้ง ตั้งค่า และกำหนดค่าส่วนขยาย Data Agent Kit ภายในพื้นที่ทำงาน IDE
- การสร้างแคตตาล็อก Iceberg REST ของ Lakehouse แบบไร้เซิร์ฟเวอร์โดยใช้ข้อมูลเข้าสู่ระบบที่จำหน่ายและเนมสเปซแบบลำดับชั้น
- การนำเข้าฟีดระดับภูมิภาค Multi-Format และการสร้างตารางภายนอก BigQuery ในที่เก็บข้อมูล Cloud Storage
- เปิดใช้งาน Apache Spark แบบไร้เซิร์ฟเวอร์เพื่อแยกวิเคราะห์ ทำให้เป็นมาตรฐาน แบ่งกลุ่ม และเขียนบันทึกทรานสปอนเดอร์ที่ไม่มีโครงสร้างกลับลงใน BigQuery เป็นตารางแคตตาล็อก Iceberg ที่ลงทะเบียน
- การสร้างอนุกรมวิธานด้านความปลอดภัยและการแมปนโยบายการมาสก์ข้อมูลแคตตาล็อกความรู้เพื่อป้องกันการรั่วไหลของข้อมูลประจำตัวในดัชนีบันทึกที่ละเอียดอ่อน
- สร้างและวิเคราะห์ข้อมูลเชิงลึกของข้อมูลเมตาของตารางโดยใช้ข้อมูลเชิงลึกของข้อมูล BigQuery เพื่อเร่งการสํารวจข้อมูล
การยืนยันเบาะแสที่รวบรวม
ตรวจสอบว่าคุณได้บันทึกเบาะแสที่ชัดเจนต่อไปนี้ซึ่งจำเป็นต่อการเข้าสู่ระยะที่ 2 ของ Lab แล้ว
- รหัสการจัดส่งที่สูญหาย:
MV-CAT-001(ตำแหน่งที่ปิงล่าสุด: ลอนดอน) - ปลายทางเป้าหมายที่วางแผนไว้:
New York(และนามแฝงจริงของทรานสปอนเดอร์:MV-DOG-002) - สีคอนเทนเนอร์:
Crimson RED - แท็กการเข้าถึงเพื่อการกำกับดูแล:
MaskCustodianID
พร้อมสำหรับเฟสถัดไปหรือยัง
ตอนนี้เส้นทางออกเดินทาง / จุดหมายของทรานสปอนเดอร์ปลอดภัยแล้ว การตรวจสอบจึงดำเนินต่อไปได้ เปิดห้องทดลอง 2 โดยตรงเพื่อตรวจสอบกล้องรักษาความปลอดภัยโดยใช้โมเดล Gemini แบบมัลติโมดัล ระบุเรือด้วยภาพ และทำการค้นหาเวกเตอร์ใน AlloyDB เพื่อยืนยันความผิดปกติของการดัดแปลง
➡️ ดำเนินการต่อในขั้นตอนที่ 2: การวิเคราะห์ข้อมูลและข้อมูลเชิงลึกแบบมัลติโมดัล