
1. Giriş
Bu laboratuvarda, küresel bir lojistik firmasında baş veri araştırmacısı rolünü üstleneceksiniz. Değerli Android figür koleksiyonlarını taşıyan yüksek değerli bir kargo konteyneri kayboldu. Bilinen son konumunu bulmak ve rotasını izlemek için bölgesel lojistik iş ortaklarından gelen parçalanmış kargo manifestolarını ve yapılandırılmamış transponder günlük dosyalarını toplamanız gerekir. Bunu yapmak için modern bir Google Cloud Open Data Lakehouse yapılandıracaksınız.

Yapacaklarınız
- Cloud Shell Düzenleyici'de Google Cloud Data Agent Kit uzantısını yapılandırın.
- Cloud Storage paketi oluşturun ve Lakehouse Apache Iceberg REST Kataloğu ile ad alanı sağlayın.
- Geminin kalkış ipucunu bulmak için Cloud Storage'daki ham JSON iş ortağı manifestlerini BigLake harici tablosuyla eşleyin.
- Managed Service for Apache Spark sunucusuz hizmetini kullanarak yapılandırılmamış transponder metin günlüklerini yükleyin ve işleyin. Kayıp yük hedefini hedeflemek için normalleştirme ve dinamik ipucu çıkarma işlemleri gerçekleştirin.
- REST kataloğu aracılığıyla ayrıştırılmış günlük metriklerini Apache Iceberg tablosu olarak yazın.
- Kayıp gönderinizle ilgili gizli ipuçlarını keşfetmek için Etkileşimli Analytics'i kullanarak Apache Iceberg verileriniz hakkında bir yapay zeka ajanıyla sohbet edin.
- Verileriniz hakkında meta veri oluşturmak için Knowledge Catalog ile otomatik veri analizlerinden yararlanın.
- Güvenlik sınıflandırması oluşturarak ve hassas gözetimci kimliklerini maskeleyerek ayrıntılı erişim denetimi uygulamak için Knowledge Catalog'u kullanarak alım sınırları belirleyin.
İhtiyacınız olanlar
- Chrome gibi bir web tarayıcısı
- Faturalandırmanın etkin olduğu bir Google Cloud projesi.
- Temel SQL sorguları ve terminal komutları hakkında bilgi sahibi olma.
Beklenen Maliyet ve Süre
- Tamamlama süresi: yaklaşık 45 dakika.
- Tahmini maliyet: 5,00 TRY'den az.
2. Başlamadan önce
Google Cloud projesi oluşturma veya seçme
- Google Cloud Console'da bir Google Cloud projesi seçin veya oluşturun.
- Cloud projeniz için faturalandırmanın etkinleştirildiğinden emin olun. Projede faturalandırmanın etkinleştirildiğini onaylamayı öğrenin.
Ortamı yapılandırma
Komutlarınızın çoğunu, geliştirici araçları ve standart Google Cloud SDK'sı önceden yüklenmiş olarak gelen bulut tabanlı bir geliştirme ortamı olan Cloud Shell Düzenleyici'deki entegre terminalden çalıştıracaksınız.
- Cloud Shell Düzenleyici'yi yeni bir sekmede açın.
- Depoyu klonlamak için terminalde aşağıdaki komutu çalıştırın:
cd ~/ git clone --filter=blob:none --no-checkout https://github.com/GoogleCloudPlatform/devrel-demos.git cd ~/devrel-demos git sparse-checkout init --cone git sparse-checkout set data-analytics/data-cloud-roadshow/lab1 git checkout main cd data-analytics/data-cloud-roadshow/lab1 - Proje kimliğinizi ayarlayın. Ayrıca, Windows/Linux'ta
Ctrl+Shift+Vveya macOS'teCmd+Vtuşlarına basarak bunu terminale yapıştırabilirsiniz:export PROJECT_ID="<YOUR_PROJECT_ID>" - Şimdi ortamınızda yapılandırın.
gcloud config set project $PROJECT_ID - Bir bölge seçin.
export REGION="<YOUR_REGION>" # Replace with the region you chose, such as "us-central1" - Gerekli API'leri etkinleştirin.
gcloud services enable \ bigquery.googleapis.com \ biglake.googleapis.com \ storage.googleapis.com \ dataplex.googleapis.com \ datacatalog.googleapis.com \ dataproc.googleapis.com \ aiplatform.googleapis.com \ cloudresourcemanager.googleapis.com \ serviceusage.googleapis.com \ cloudaicompanion.googleapis.com \ geminidataanalytics.googleapis.com
Uzantıyı Yükleyin
Şimdi Google Cloud'un veri araçlarıyla doğrudan IDE'nizde etkileşim kurmanızı sağlayan bir araç olan Google Data Agent Kit uzantısını yapılandıracaksınız.
- Düzenleyicinin sol etkinlik çubuğunda Uzantılar simgesini tıklayın (veya Windows/Linux'ta
Ctrl+Shift+X, macOS'teCmd+Xtuşuna basın). - Uzantı arama kutusuna şunu yazın:
Google Cloud Data Agent Kit - Sonuçlardan resmi uzantıyı seçip Yükle'yi tıklayın. İstenirse "Evet, yazarlara güveniyorum"u seçin.
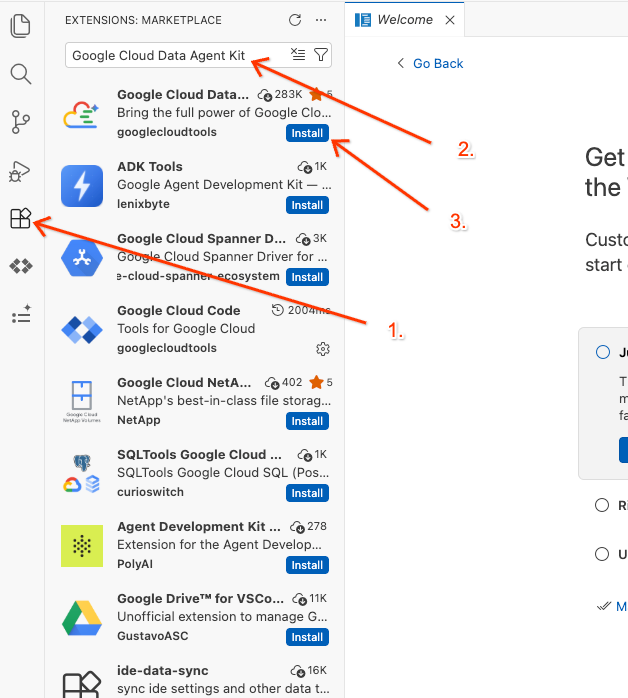
- Başarıyla yüklendikten sonra etkinlik çubuğunda Google Cloud Data Agent Kit simgesini görürsünüz. Bu düğmeyi tıklayın.
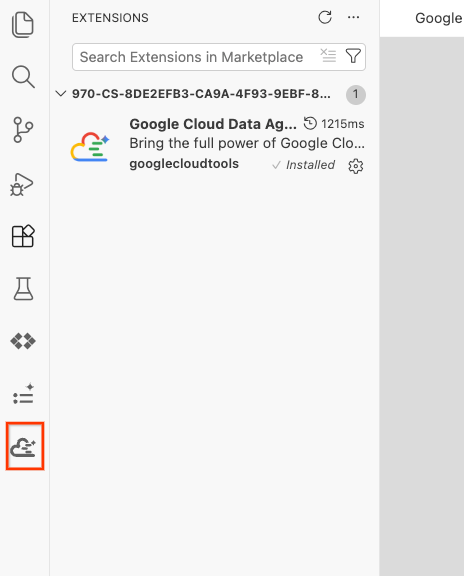
- Bulutta oturum aç'ı tıklayın.
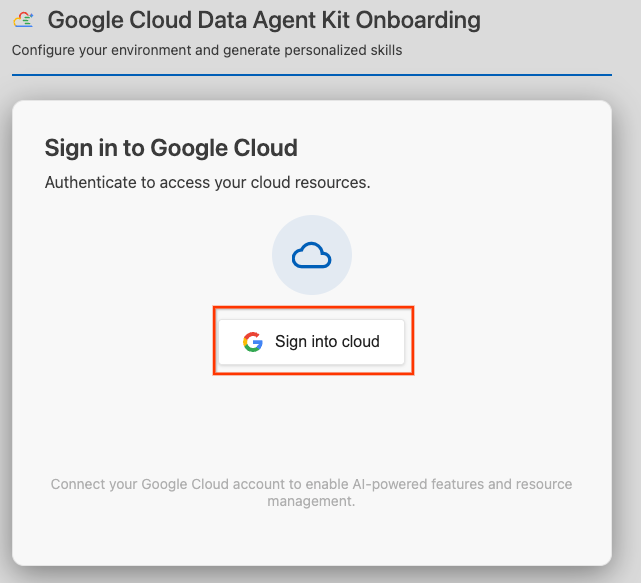
- MCP Sunucularını Yapılandır'ı tıklayın.
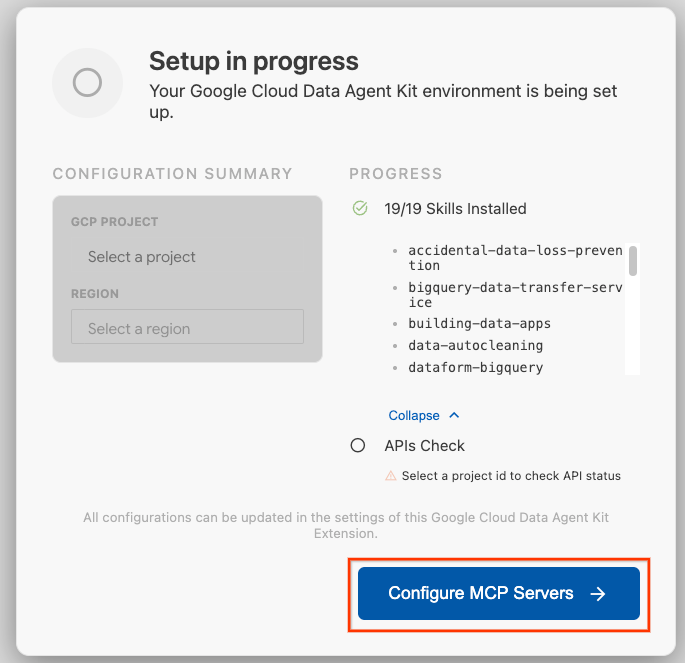
- BigQuery, Knowledge Catalog, Apache Spark ve AlloyDB'yi seçin. AlloyDB'yi 2. laboratuvarda kullanacaksınız. Ardından Başlayın'ı tıklayın.
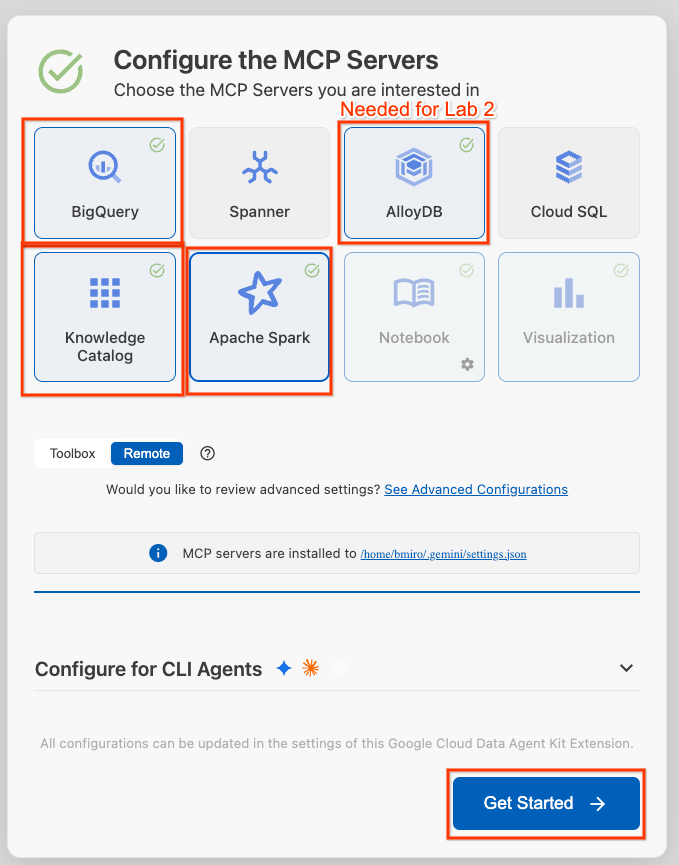
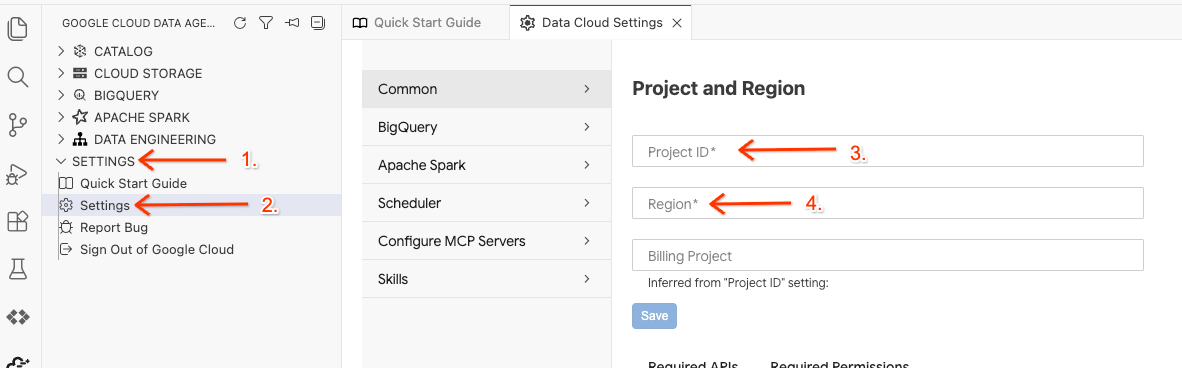
- Alt durum çubuğunda Proje Kimliği seçiciyi tıklayın ve etkin Google Cloud projenizi seçin.
- Veri Aracısı Kit'inde AYARLAR'ı, ardından Ayarlar'ı tıklayın ve Ortak sekmesinde laboratuvarınızı çalıştırmak için Proje Kimliği'nizi ve Bölge'nizi (ör. us-central1) seçin.
- BigQuery Ayarları'nı tıklayın ve Bölge'yi daha önce seçtiğiniz bölgeyle değiştirin. Kaydet'i tıklayın.
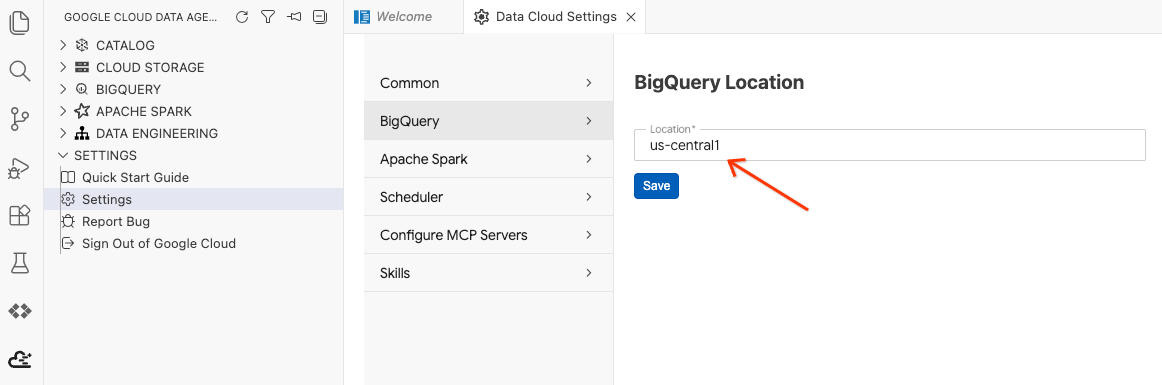
Artık Veri Temsilcisi Kitinizi kullanmaya hazırsınız.
Ortam kurulumu komut dosyasını yürütme
Terminalde, bu laboratuvar için gerekli arka plan kaynaklarını oluşturmak ve IAM izinlerini yapılandırmak üzere kurulum komut dosyasını çalıştırın:
chmod +x setup_lab1.sh
./setup_lab1.sh
source .env
Hangi kaynakların sağlandığını gösteren bir dizi çıkış adımı görürsünüz. Bunları laboratuvar boyunca ele alacağız.
Tamamlama mesajını gördüğünüzde kullanmaya başlayabilirsiniz:
==================================================== Environment Setup Complete! ====================================================
Şimdi aramaya başlayalım.
3. İş Ortağı Kargo Manifestlerini Alma
İş ortağı gemilerinden gelen kargo manifestosu verileri, paketinizde standart JSON Lines (JSONL) biçiminde depolanır: gs://${PROJECT_ID}-lost-cargo-lake/shipping_manifests/manifests.jsonl.
Derin analiz yapmadan önce bu yapılandırılmamış veriler için yönetilen bir BigLake tablosu oluşturursunuz. Bu sayede, standart SQL kullanarak iş ortağı lojistik verilerini anında ve yinelenen içe aktarma maliyetleri olmadan keşfedebilirsiniz.
Çalışma alanını düzenleyicide açın ve sorguyu çalıştırın.
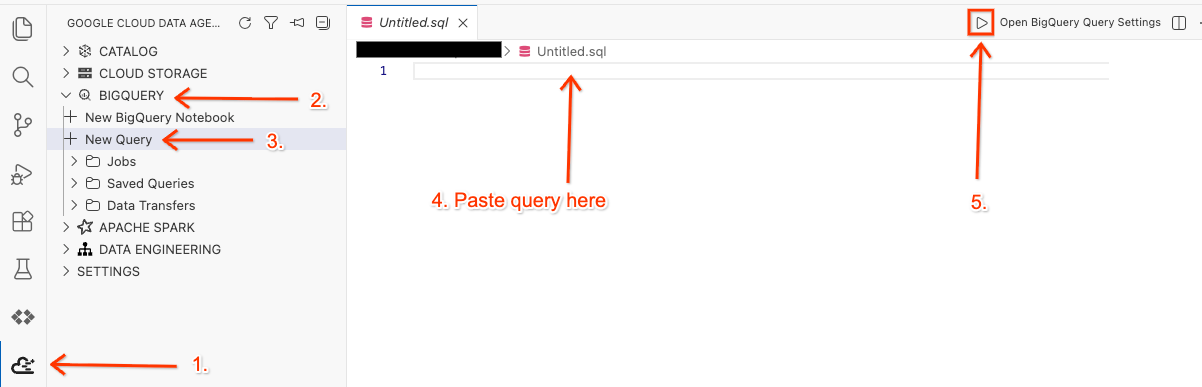
- Cloud Shell Düzenleyicinizde, yan paneldeki Google Cloud Data Agent Kit uzantısı simgesini tıklayın.
- BigQuery'ye gidip + Yeni Sorgu'yu seçin.
- Aşağıdaki sorguyu sorgu penceresine kopyalayın.
SET @@location = "<YOUR_REGION>"; --Update to your resource region, such as "us-central1". Make sure it is in quotes.
EXECUTE IMMEDIATE ("""
CREATE OR REPLACE EXTERNAL TABLE `lost_cargo_dataset.shipping_manifests`
(
shipment_id STRING,
timestamp TIMESTAMP,
last_ping_lat FLOAT64,
last_ping_long FLOAT64,
seal_integrity_status INT64,
custodian_id STRING OPTIONS(description='Masked identification token for official cargo custodian personnel.')
)
WITH CONNECTION `""" || @@location || """.conn`
OPTIONS (
format = 'NEWLINE_DELIMITED_JSON',
uris = ['gs://""" || @@project_id || """-lost-cargo-lake/shipping_manifests/*.jsonl']
)
""");
- Çalıştır'ı tıklayın.
- Tablonun oluşturulduğunu doğrulamak için Sorgu Sonuçları panelinde başarı mesajı görürsünüz. Bu panel, otomatik olarak en altta açılır.
Güvenliği ihlal edilmiş transponderleri belirlemek için harici tabloyu sorgulayın.
seal_integrity_status 0 olarak ayarlandığında hataları bularak güvenliği ihlal edilmiş transponderleri belirleyelim. Aşağıdaki sorguyu kopyalayıp daha önce açtığınız sorgu penceresinde çalıştırın:
SELECT shipment_id, last_ping_lat, last_ping_long, custodian_id
FROM `lost_cargo_dataset.shipping_manifests`
WHERE seal_integrity_status = 0;
Sorgu Sonuçları panelinde şuna benzer bir çıkış görürsünüz:
shipment_id | last_ping_lat | last_ping_long | custodian_id |
MV-CAT-001 | 51,5074 | -0,1278 | usr_999_shadow |
4. Managed Service for Apache Spark ile Yapılandırılmamış Günlükleri İşleme
Yapılandırılmış manifestlerden başlangıç konumunu buldunuz ancak kayıp transponder tamamen karardı. Son transponder ping'i, GCS yolundaki gs://${BUCKET_NAME}/raw_logs/maritime_logs.txt ham metin günlük dosyasında şifreli ve yapılandırılmamış bir mesaj bıraktı.
Bu metin günlüğünü işlemek ve eşlemek, zaman damgalarını ayıklamak, kimlikleri gizlemek ve kargonun aşağı akış rotasını bulmak için Managed Service for Apache Spark'a sunucusuz bir Apache Spark (PySpark) işi göndereceksiniz.
Managed Service for Apache Spark, küme sağlama veya yönetme işlemi yapmadan Spark iş yüklerini çalıştırmanıza olanak tanır. Hizmet, temel bilgi işlem kaynaklarını yönetir ve bunları dinamik olarak otomatik ölçeklendirir. Siz yalnızca yürütme süresi için ödeme yaparsınız.
Komut dosyası:
- Ham, köşeli parantezli, yapılandırılmamış transponder metnini alın.
- Zaman damgalarını, saklama görevlisi meta verilerini ve ham içeriği ayırmak için PySpark SQL normal ifade ayıklama filtreleri uygulayın.
- Dağınık günlükleri temiz ve cümle düzeyinde kayıtlara ayırın.
- Kayıp yükün kalkışının sona erdiği dinamik hedef koordinatını ayıklayın.
- İşlenmiş günlük veri çerçevesini, doğrudan BigQuery'de görünen yeni bir analiz tablosu olarak Lakehouse Apache Iceberg REST Kataloğunuza bağlayın ve geri yazın.
PySpark analiz komut dosyasını düzeltme
Denizlerde her türlü soruna yol açan Python Korsanları olduğu bildiriliyor.
process_maritime_logsdosyasını Cloud Shell Düzenleyicinizde açmak için aşağıdaki komutu çalıştırın.cd ~/devrel-demos/data-analytics/data-cloud-roadshow/lab1 cloudshell open ./process_maritime_logs.py- Kodu okumak ve ne yaptığını anlamak için biraz zaman ayırın.
- Koddaki hiçbir şeyin şüpheli görünmediğinden emin olun. Silmeniz gereken bir şey varsa dosyayı
Ctrl + S(Windows/Linux) veyaCmd + S(Mac) kullanarak kaydettiğinizden emin olun.
Sunucusuz Spark işini gönderme
gcloud SDK'sını kullanarak işi gönderin. Yapılandırma, PySpark işini Lakehouse kataloğuna erişecek şekilde otomatik olarak yapılandırır.
Entegre düzenleyici terminalinizde aşağıdaki komutu çalıştırın.
cd ~/devrel-demos/data-analytics/data-cloud-roadshow/lab1
source .env
gcloud dataproc batches submit pyspark process_maritime_logs.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--version=2.3 \
--deps-bucket=${BUCKET_NAME} \
--properties="\
spark.sql.defaultCatalog=cargo_catalog,\
spark.sql.catalog.${CATALOG_NAME}=org.apache.iceberg.spark.SparkCatalog,\
spark.sql.catalog.${CATALOG_NAME}.type=rest,\
spark.sql.catalog.${CATALOG_NAME}.uri=https://biglake.googleapis.com/iceberg/v1/restcatalog,\
spark.sql.catalog.${CATALOG_NAME}.warehouse=gs://${BUCKET_NAME},\
spark.sql.catalog.${CATALOG_NAME}.header.x-goog-user-project=${PROJECT_ID},\
spark.sql.catalog.${CATALOG_NAME}.rest.auth.type=org.apache.iceberg.gcp.auth.GoogleAuthManager,\
spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions,\
spark.sql.catalog.${CATALOG_NAME}.gcs.oauth2.refresh-credentials-endpoint=https://oauth2.googleapis.com/token, \
spark.sql.catalog.${CATALOG_NAME}.header.X-Iceberg-Access-Delegation=vended-credentials" \
-- ${BUCKET_NAME}
Sunucusuz ortamın başlatılması, komut dosyanızın yüklenmesi ve işleme mantığının yürütülmesi için birkaç dakika bekleyin.
Aşağıdakine benzer bir çıkış gördüğünüzde, işlenmiş tablonuz Apache Iceberg tarafından yönetilen bir tablo olarak Lakehouse kataloğuna kaydedilir.
Batch [1fae0b4b42c045a084dd67917bd0c332] finished.
metadata:
'@type': type.googleapis.com/google.cloud.dataproc.v1.BatchOperationMetadata
batch: projects/<YOUR_PROJECT>/locations/us-central1/batches/1fae0b4b42c045a084dd67917bd0c332
batchUuid: 611b4465-fdac-4974-bc47-5f10adaf2a08
createTime: '2026-06-11T21:35:01.868157Z'
description: Batch
labels:
goog-dataproc-batch-id: 1fae0b4b42c045a084dd67917bd0c332
goog-dataproc-batch-uuid: 611b4465-fdac-4974-bc47-5f10adaf2a08
goog-dataproc-drz-resource-uuid: batch-611b4465-fdac-4974-bc47-5f10adaf2a08
goog-dataproc-location: us-central1
operationType: BATCH
name: projects/<YOUR_PROJECT/regions/us-central1/operations/7e2044db-dd97-3270-b368-4dc4ba417574
İşlenmiş günlükleri önizleme
Veri Aracısı Kiti uzantısı Sorgu Düzenleyici'de, verilerin önizlemesini görmek için aşağıdaki sorguyu kopyalayın:
SET @@location = "<YOUR_REGION>"; -- e.g. "us-central1"
EXECUTE IMMEDIATE FORMAT("""
select log_timestamp, custodian_id, sentence from
`%s.%s-lost-cargo-lake.lost_cargo_namespace.processed_maritime_logs`
limit 5
""", @@project_id, @@project_id);
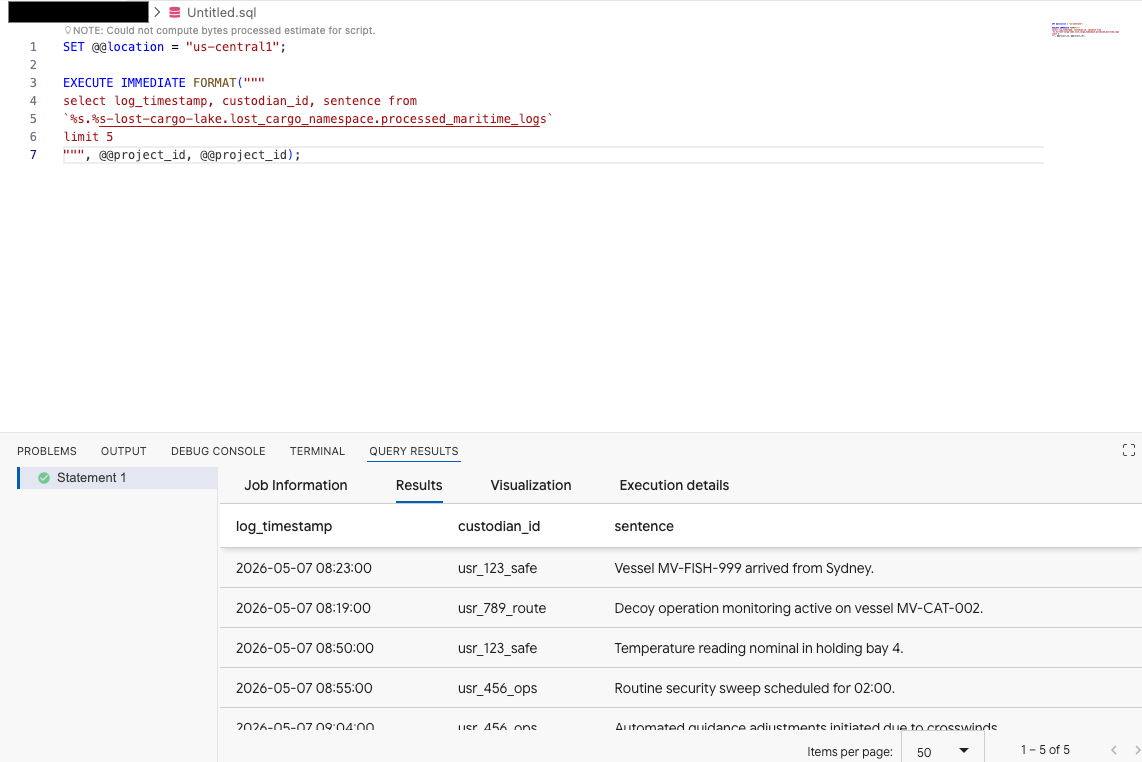
Bu, katalogda kayıtlı Iceberg tablosuna BigQuery'den başarıyla erişilebildiğini gösterir.
Hedef ipucunu çıkarma
İşlenmiş günlükleri aldığımıza göre, şimdi hedef hedefi içeren günlükleri arayalım. Buradan, günlüklerde kalkış şehrimizden bahsedilenleri arayabiliriz.
Sorgu düzenleyicinizde aşağıdaki sorguyu çalıştırın. <YOUR_REGION> kısmını bölgenizle, <ORIGIN_CITY> kısmını ise daha önce keşfettiğiniz başlangıç şehriyle değiştirin.
SET @@location = "<YOUR_REGION>"; --e.g. "us-central1"
DECLARE origin_city STRING;
SET origin_city = "<ORIGIN_CITY>"; --e.g. "Boston". (It's not Boston)
EXECUTE IMMEDIATE FORMAT(r"""
SELECT
log_timestamp AS event_time,
custodian_id,
REGEXP_EXTRACT(raw_message, r'Destination:\s*([^.]+)') AS destination_target
FROM
`%s.%s-lost-cargo-lake.lost_cargo_namespace.processed_maritime_logs`
WHERE
-- STRPOS is highly optimized in BigQuery for a simple .contains() substring check
STRPOS(sentence, '%s') > 0;
""", @@project_id, @@project_id, origin_city);
Etkileşimli Analytics'i kullanarak BigQuery Konsolu'nda verilerinizle sohbet etme
Verilerinizi keşfetmek için karmaşık SQL sorguları yazmak yerine Etkileşimli Analiz'i kullanarak tablolarınızla doğal dilde sohbet edebilirsiniz.
- BigQuery Konsolu'na gidin.
- Soldaki Gezgin panelinde projenizi ve veri kümesini
-lost-cargo-lake.lost_cargo_namespace processed_maritime_logstablosunu tıklayın. - Sorgu'nun yanında Sohbet'i tıklayın.
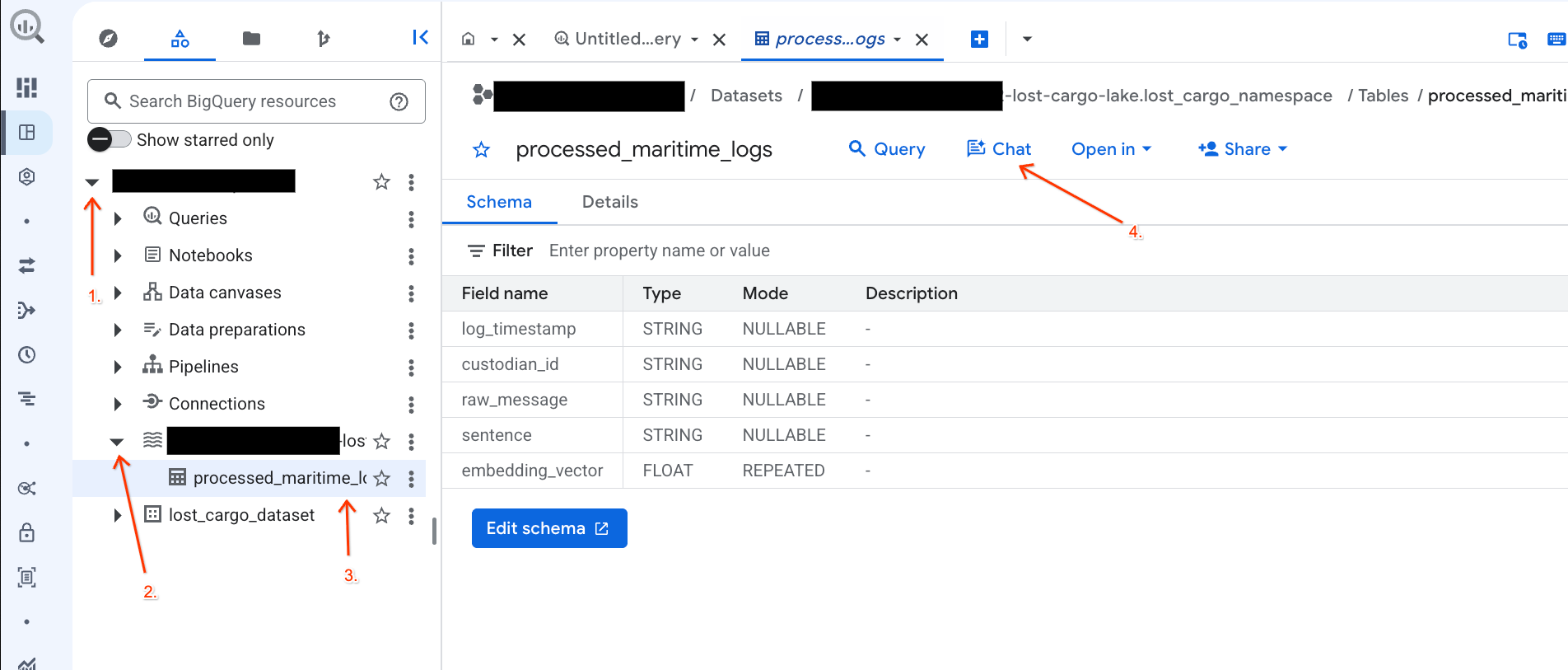
- Sohbet panelinde aşağıdaki soruyu yazın ve göndermek için klavyenizde Enter tuşuna basın:
Based on this table, what color is the shipping container MV-CAT-001?
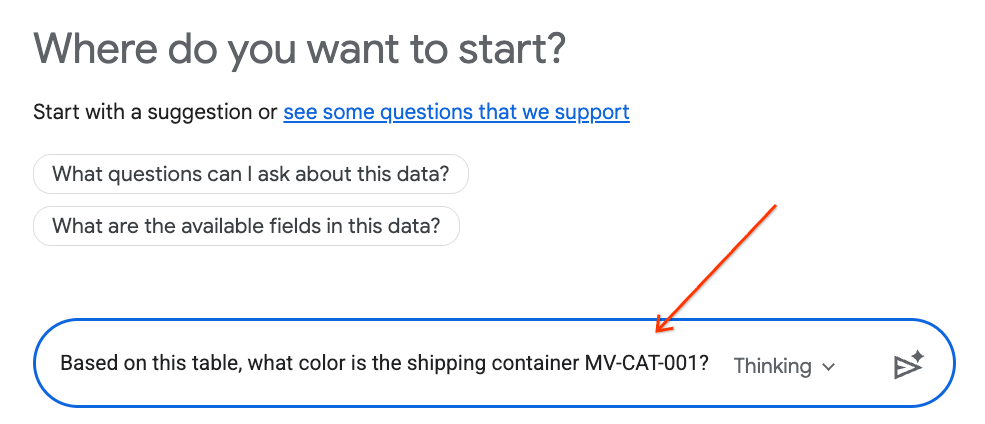
- Etkileşimli Analytics (Gemini tarafından desteklenir), etkin tablonun verilerini analiz eder ve renkle yanıt verir.
5. Merkezi Lakehouse Kataloğu'nu görüntüleme
Açık kaynaklı işleme motorlarını (ör. Apache Spark) kurumsal veri motorlarıyla (ör. BigQuery) güvenli ve sorunsuz bir şekilde entegre etmek için kurulum komut dosyanız bir Lakehouse Iceberg REST Kataloğu yapılandırdı.
Apache Iceberg REST Kataloğu, tablo meta verileri için sunucusuz "tek doğruluk kaynağı" olarak işlev görür. Şemaları ve bölümleme tablolarını dinamik olarak yönetirken fiziksel Parquet veri dosyalarını Cloud Storage'da depolar.
Bu kataloğu doğrudan Google Cloud Console'da inceleyelim:
- Lakehouse Console'u açın.
- Kataloglar sekmesinde etkin Iceberg REST kataloğunuzu bulun ve tıklayın:
-lost-cargo-lake
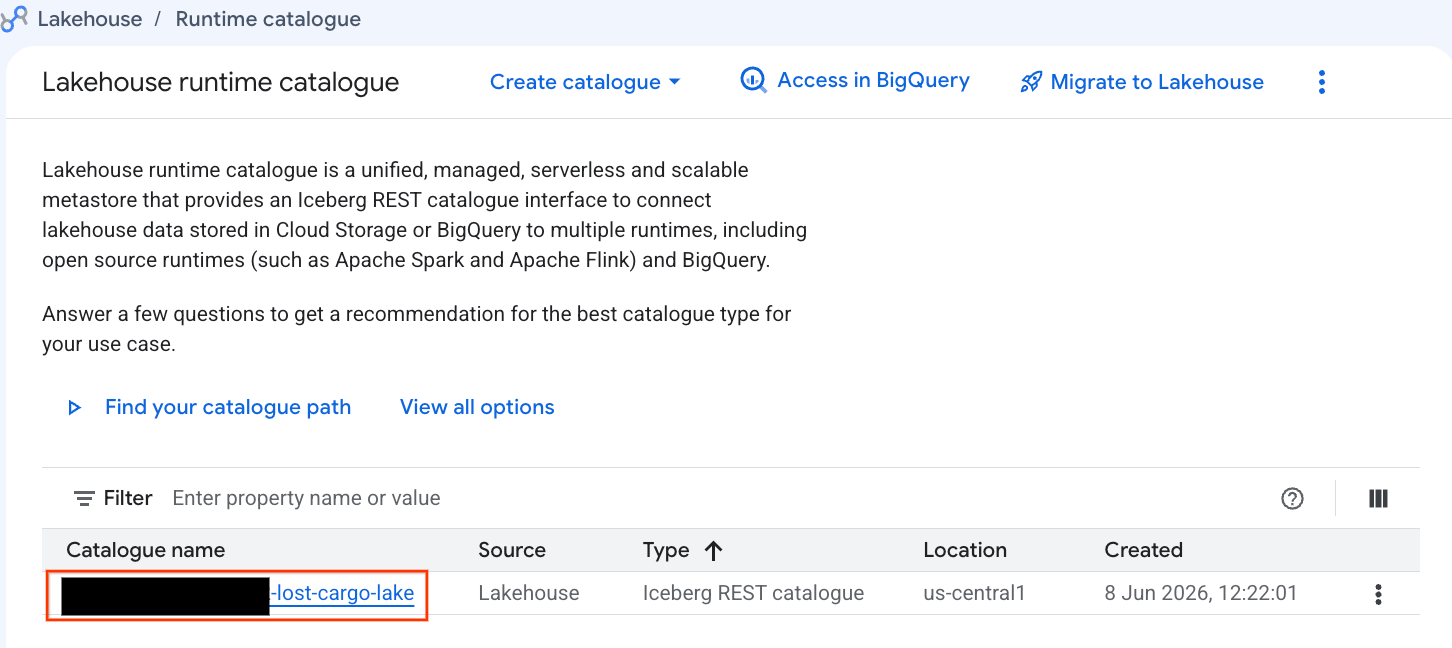
- Katalog ayrıntıları görünümünde, Ad alanları bölümünde
lost_cargo_namespacesimgesini görmeniz gerekir. Bu sekmeyi tıklayın.
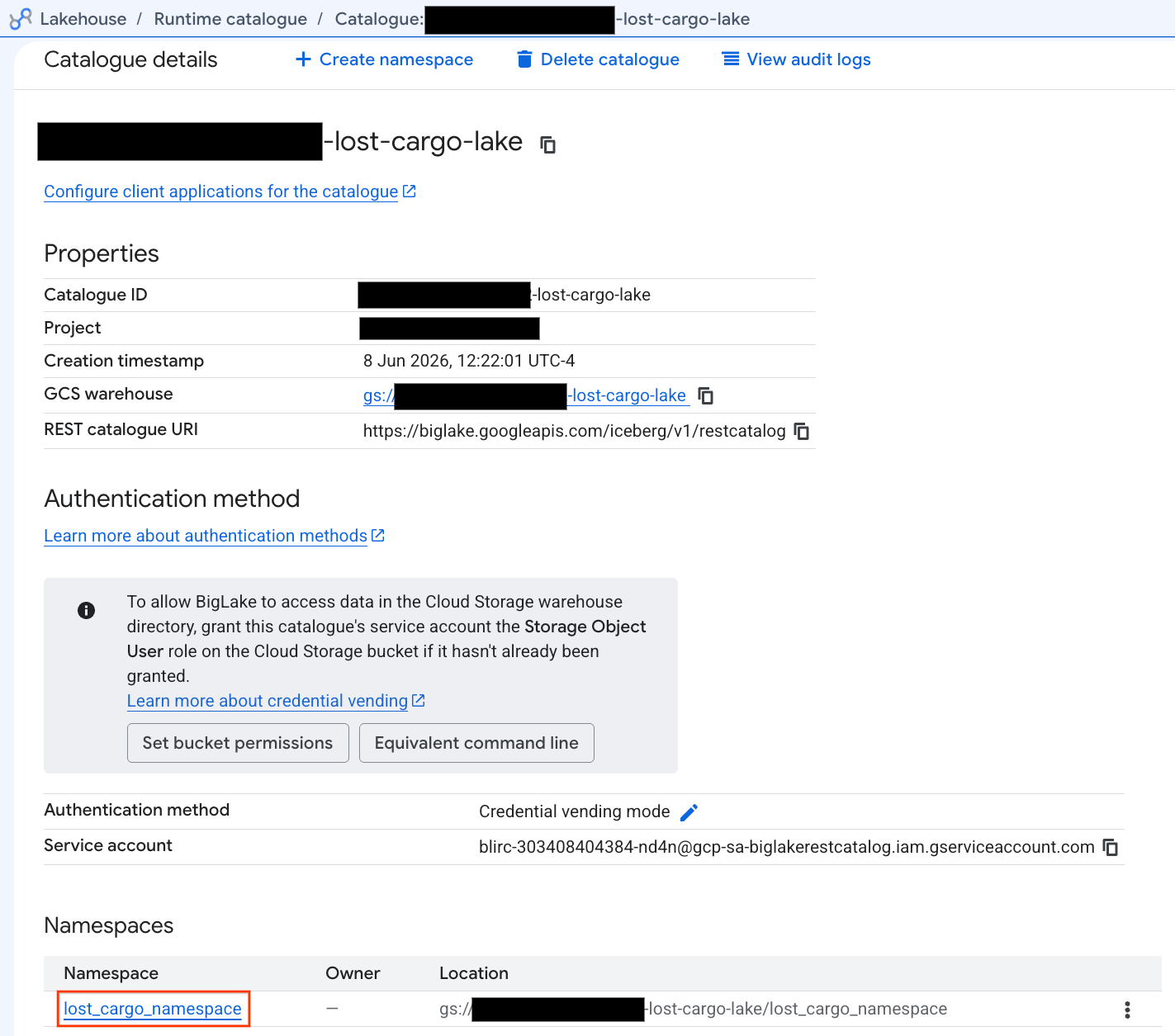
- PySpark tarafından oluşturulan yeni Apache Iceberg tablonuz, bu metastore ad alanı altında otomatik olarak kaydedildi ve BigQuery'de anında sorgulanabilir hale geldi.
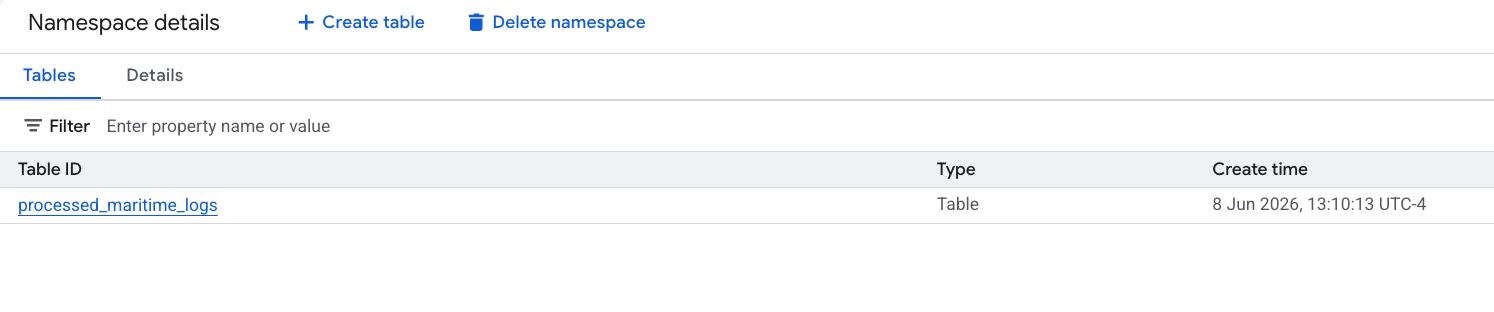
6. Kargo manifestleri tablosunda analiz oluşturma
Knowledge Catalog Data Insights'ı kullanarak yapısını ve içeriğini anlamak için shipping_manifests tablosunu analiz edelim. Meta verileri zenginleştirerek diğer kaşiflerin gelecekteki analizler için tabloyu daha iyi anlamasını sağlayabilirsiniz.
BigQuery Studio'da Tablo Analizleri Oluşturma
- Google Cloud Console'da BigQuery Studio'ya gidin.
- Gezgin panelinde projenizi,
lost_cargo_datasetveri kümesini genişletin veshipping_manifeststablosunu tıklayın. - Sağdaki ayrıntılar panelinde Analizler sekmesini tıklayın.
- Açılır listeyi kullanarak Oluştur ve yayınla'yı seçin.
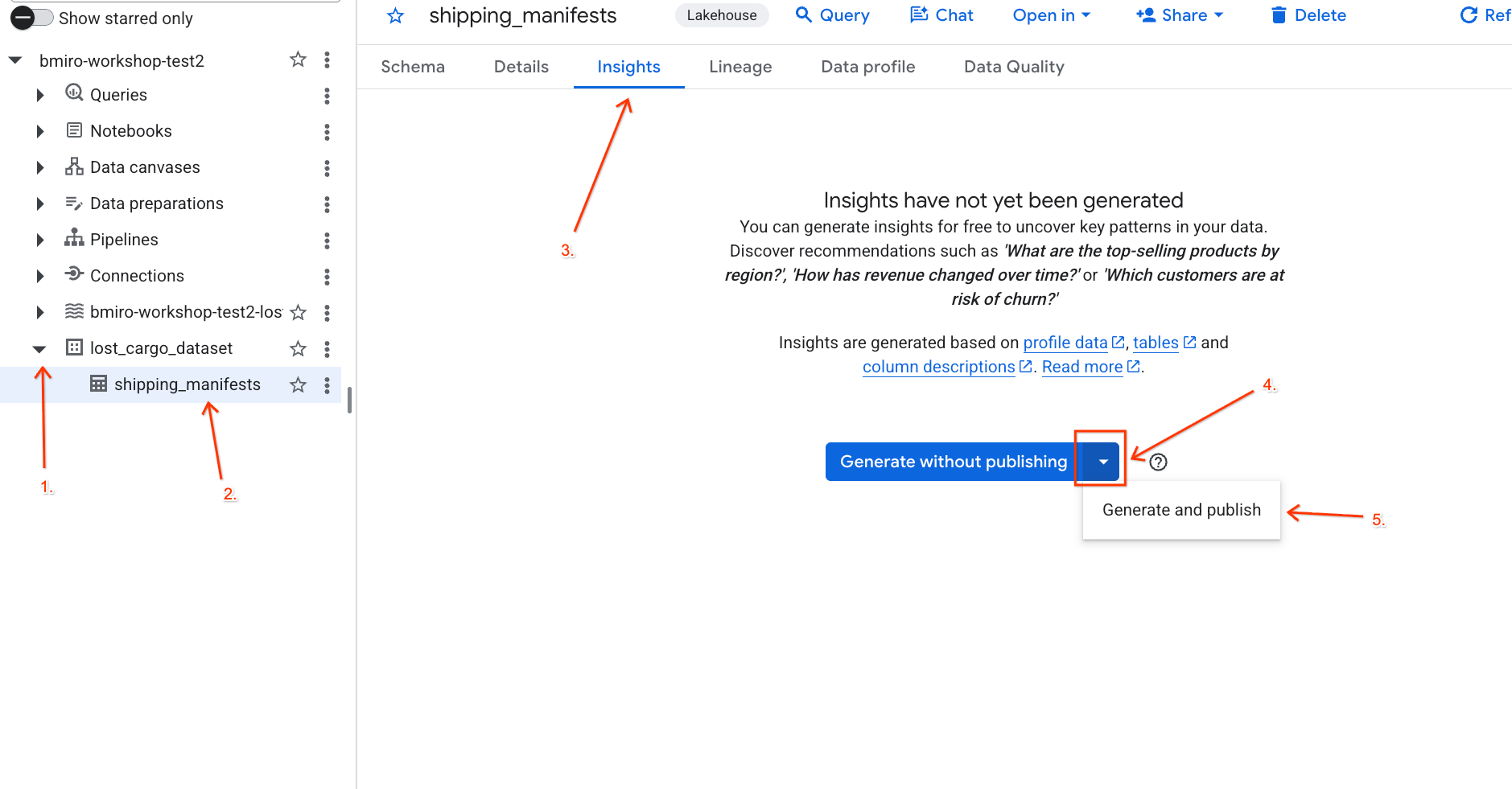
- Analiz oluşturma işleminin tamamlanması için yaklaşık 3 dakika bekleyin. Gemini, tablo meta verilerini analiz eder ve doğal dil soruları ile ilgili SQL sorguları oluşturur.
- İşlem tamamlandığında, tablonun doğal dilde açıklamasını içeren bir Tablo açıklaması görürsünüz.
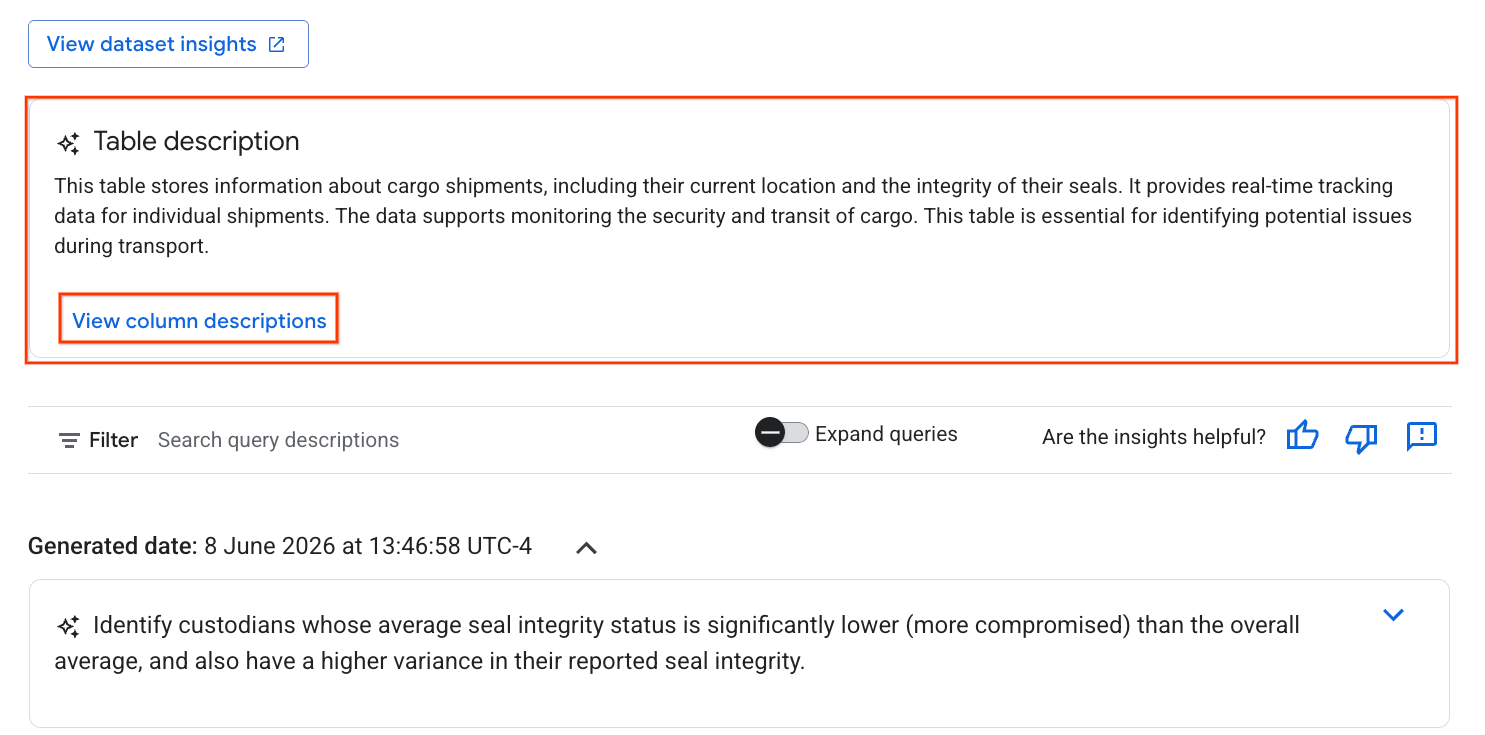
- Sütunlar hakkında bilgi edinmek için Sütun açıklamalarını görüntüle'yi tıklayın.
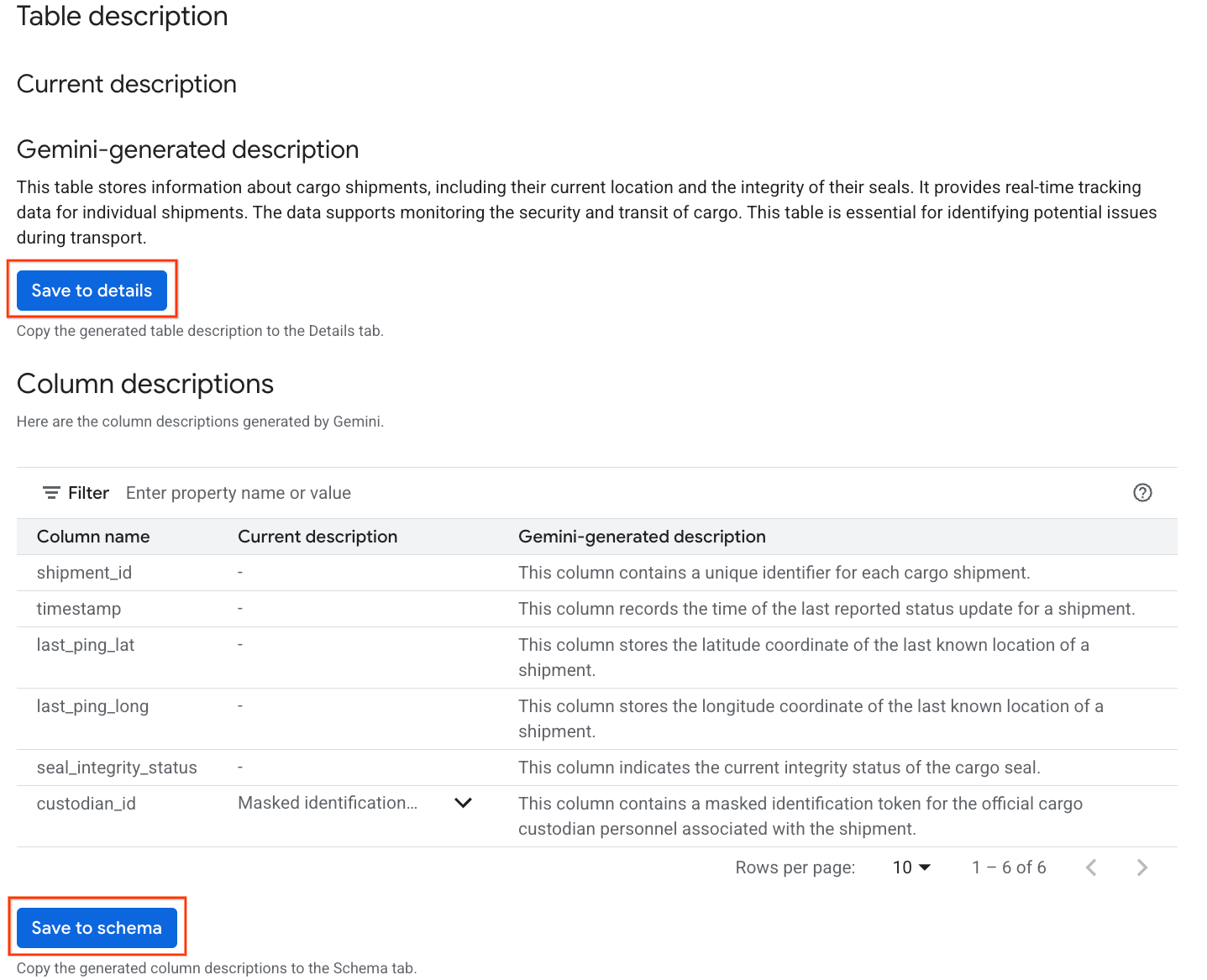
Gemini generated descriptionbölümünde Ayrıntılara kaydet'i, açılan pencerede ise Ayrıntılara kaydet'i tıklayın.
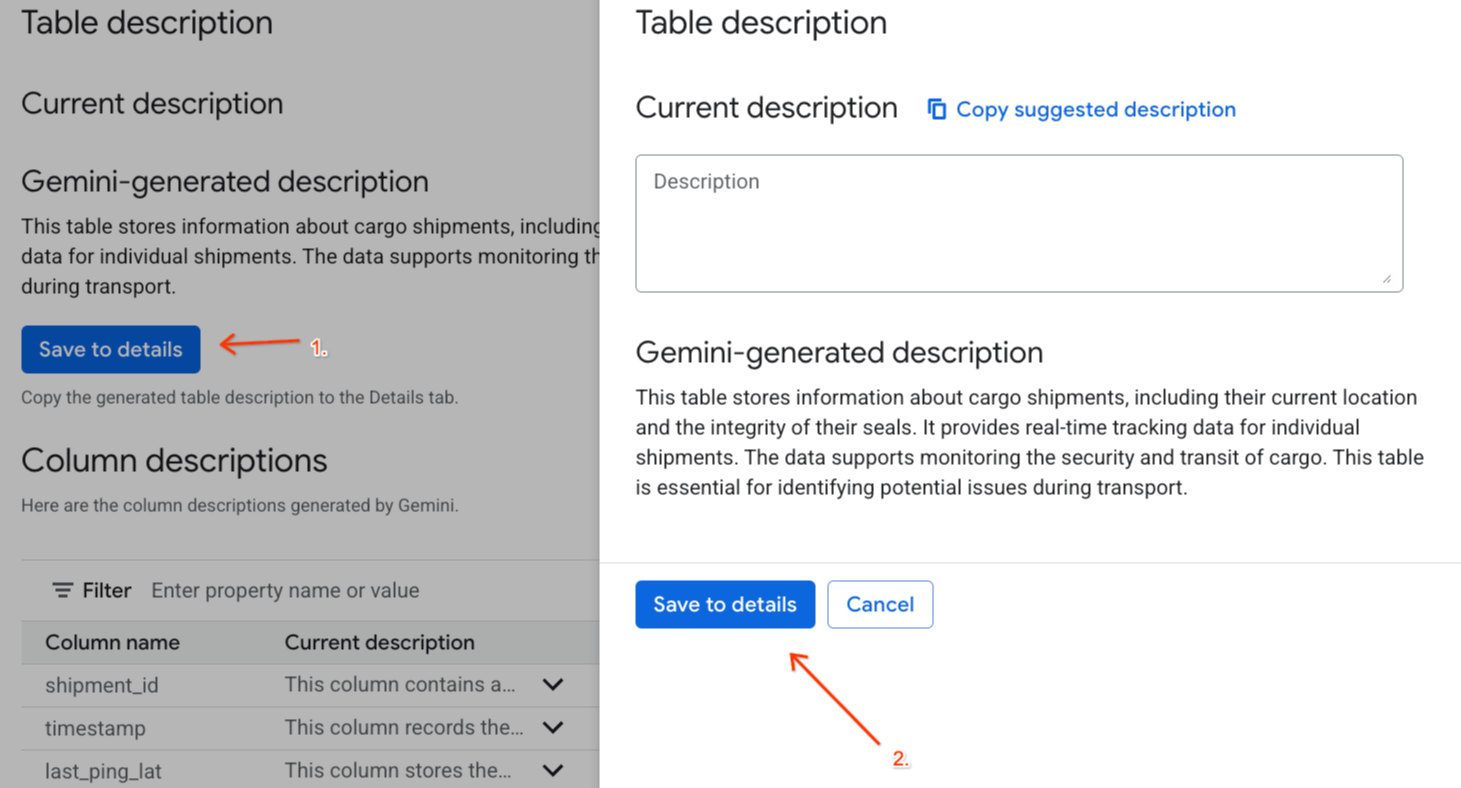
- Benzer şekilde, sütun açıklamalarını tablo meta verilerine eklemek için Şemaya kaydet'i tıklayın.
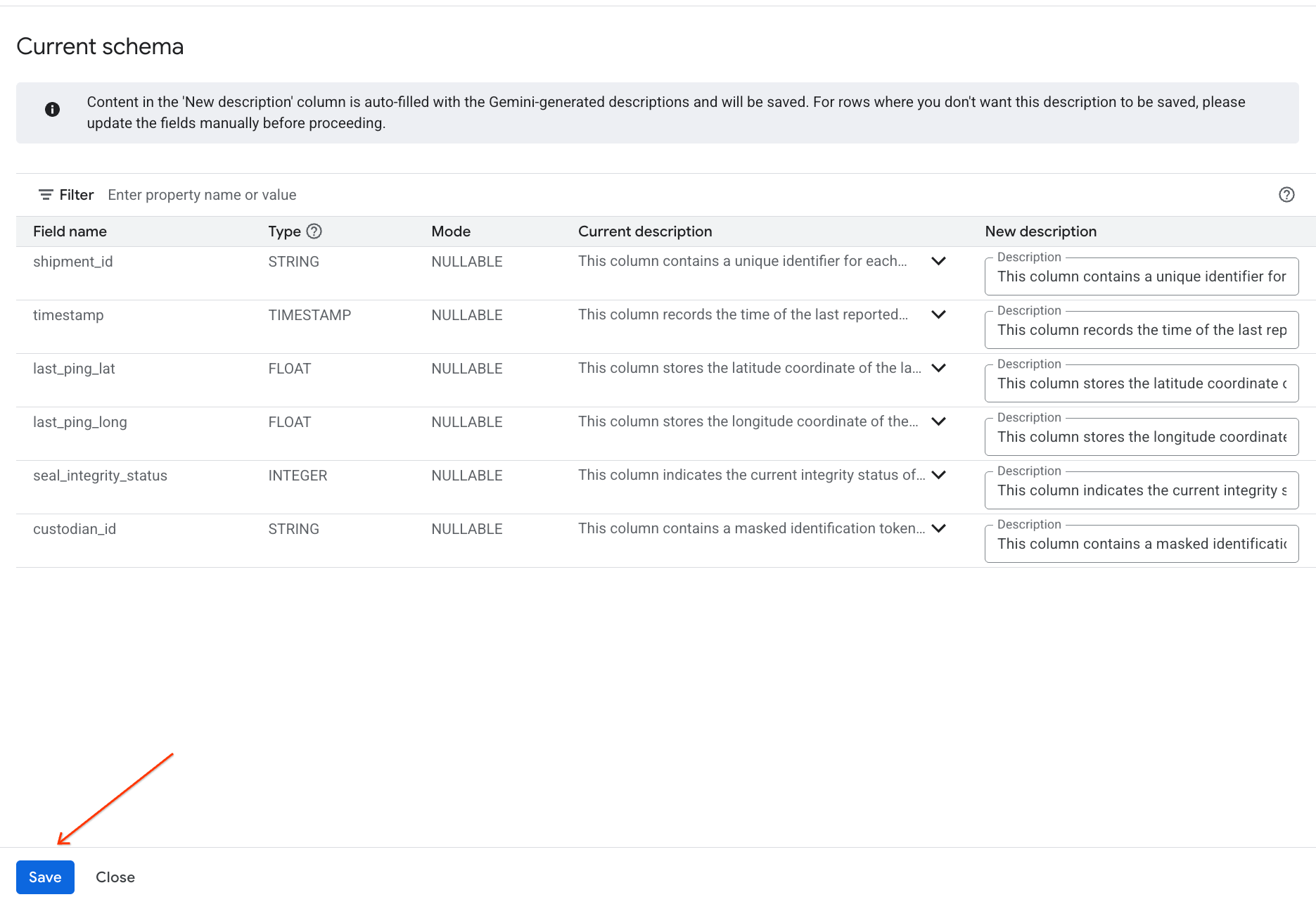
Oluşturulan analizleri inceleme
Önerilen soruların bir listesini de görürsünüz. Oluşturulan SQL sorgusunu görmek ve verileri keşfetmek için herhangi bir soruyu tıklayabilirsiniz. Örneğin, şu gibi sorular görebilirsiniz:
- "Toplam gönderi sayısı kaç?"
- "Benzersiz gözetimci kimliklerini listeleyin."
Bu sorguları çalıştırmak verileri anlamanıza yardımcı olur.
7. Veri Maskeleme ve Yönetimi Uygulama
Devam eden kargo incelemesi sırasında etkin araştırma hesaplarının ve kullanıcı adlarının sızdırılmaması için standart güvenlik protokollerini zorunlu kılmanız gerekir. Veri gizliliğini doğrulamak için Güvenlik Politikası Etiketi Taksonomisi oluşturacak ve hassas custodian_id sütununda Bilgi Kataloğu Veri Maskeleme'yi yapılandıracaksınız.
BigQuery, varsayılan olarak politika etiketleriyle korunan sütunlara erişimi reddeder. Tabloyu sorgulamak ve etkin veri maskelerini doğrulamak için kullanıcı hesabınızın BigQuery Veri Politikası Maskeli Okuyucu rolüne sahip olması gerekir.
Bu rol, setup_lab1.sh'yı ilk kez çalıştırdığınızda etkin kullanıcı hesabınıza otomatik olarak bağlanmıştır.
Sınıflandırma ve politika etiketi oluşturma
Verilerinize erişimi yönetmek için bir veri sınıflandırması ve ilişkili politika etiketi oluşturun.
- Politika etiketi sınıflandırmaları sayfasına gidin.
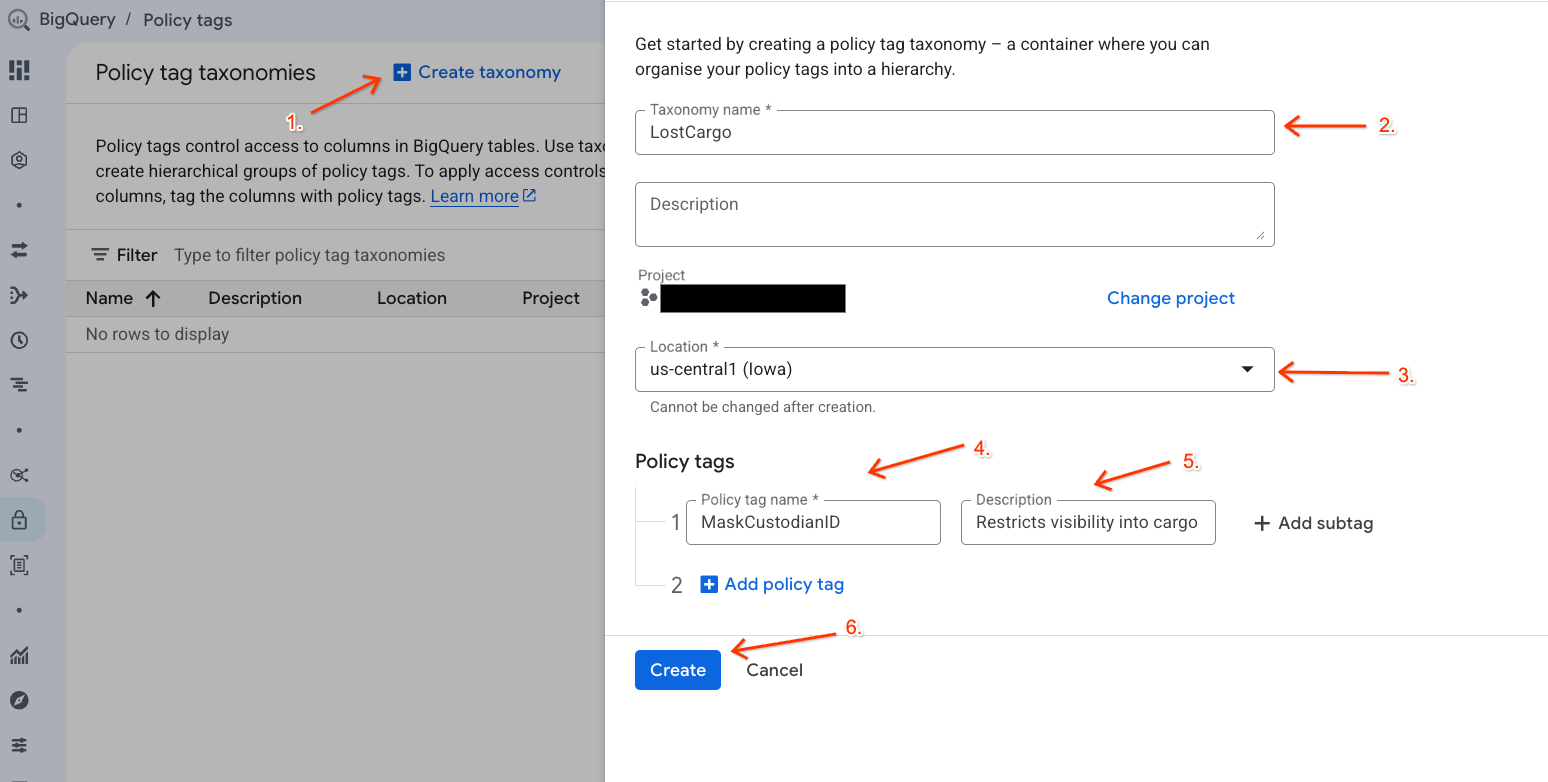
- + Create Taxonomy'yi (+ Taksonomi Oluştur) tıklayın.
- Parametreleri yapılandırın:
- Taxonomy name (Taksonomi adı):
lost-cargo-değerini girin ve proje kimliğinizle değiştirin. - Bölge: Bölgenizi seçin.
- Politika etiketi Adı için:
MaskCustodianIDgirin. - Politika etiketi Açıklaması için:
Restricts visibility into cargo custodian usernames
- Taxonomy name (Taksonomi adı):
- Yeni sınıflandırmanızı ve politika etiketini kaydetmek için Oluştur'u tıklayın.
Veri maskeleme politikasını oluşturma
Ardından, MaskCustodianID sınıflandırma etiketi altında verilerin nasıl maskeleneceğini tanımlamak için bir veri politikası yapılandırın. Her Zaman Boş maskeleme kuralını (eşleşen değerleri, ayrıcalıklı olmayan tüm aktörler için boş/Null döndüren değerlerle değiştirme) kullanırsınız.
- Politika etiketi sınıflandırmaları sayfasında, sınıflandırma listenizden yeni oluşturulan sınıflandırmayı tıklayın.
- Hiyerarşi listesinde
MaskCustodianIDetiketini tıklayarak seçin ve ardından Veri politikalarını yönet'i seçin.
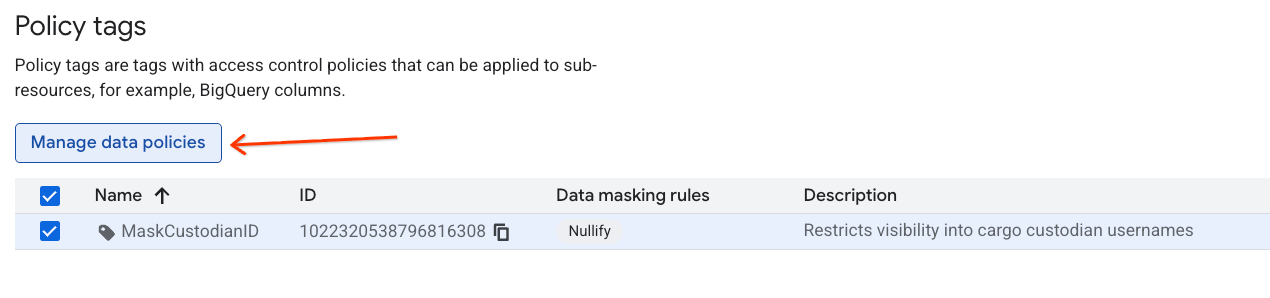
- Sağdaki panelde + Kural Ekle düğmesini tıklayın.
- Açılan panelde politika ayrıntılarını yapılandırın:
- Veri politikası adı:
null_masking_policygirin (sonraki adımlarda ada göre referans vereceğimiz için otomatik olarak oluşturulmuş şekilde bırakmayın). - Maskeleme kuralı: Açılır menüden
Nullifysimgesini seçin.
- Veri politikası adı:
- Gönder'i tıklayın.
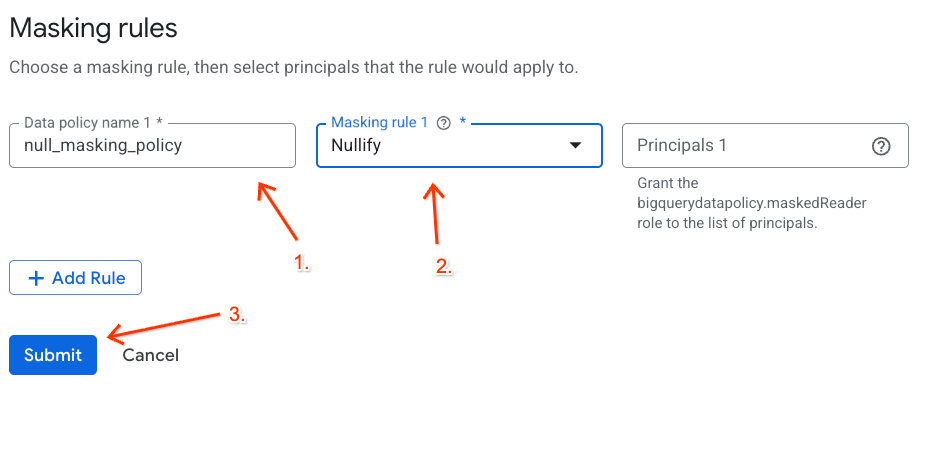
Politika etiketini BigQuery sütununuza atama
Politika etiketi ve veri maskeleme kuralı etkin durumdayken sınıflandırma etiketini doğrudan BigQuery iş ortağı kargo manifestosu tablonuzdaki custodian_id sütununa eşleyin.
- BigQuery konsoluna gidin.
- Soldaki Gezgin panelinde etkin projenizi,
lost_cargo_datasetveri kümesini genişletin ve ayrıntılı görünümünü açmak içinshipping_manifeststablosunu tıklayın. - Şemayı Düzenle'yi tıklayın.
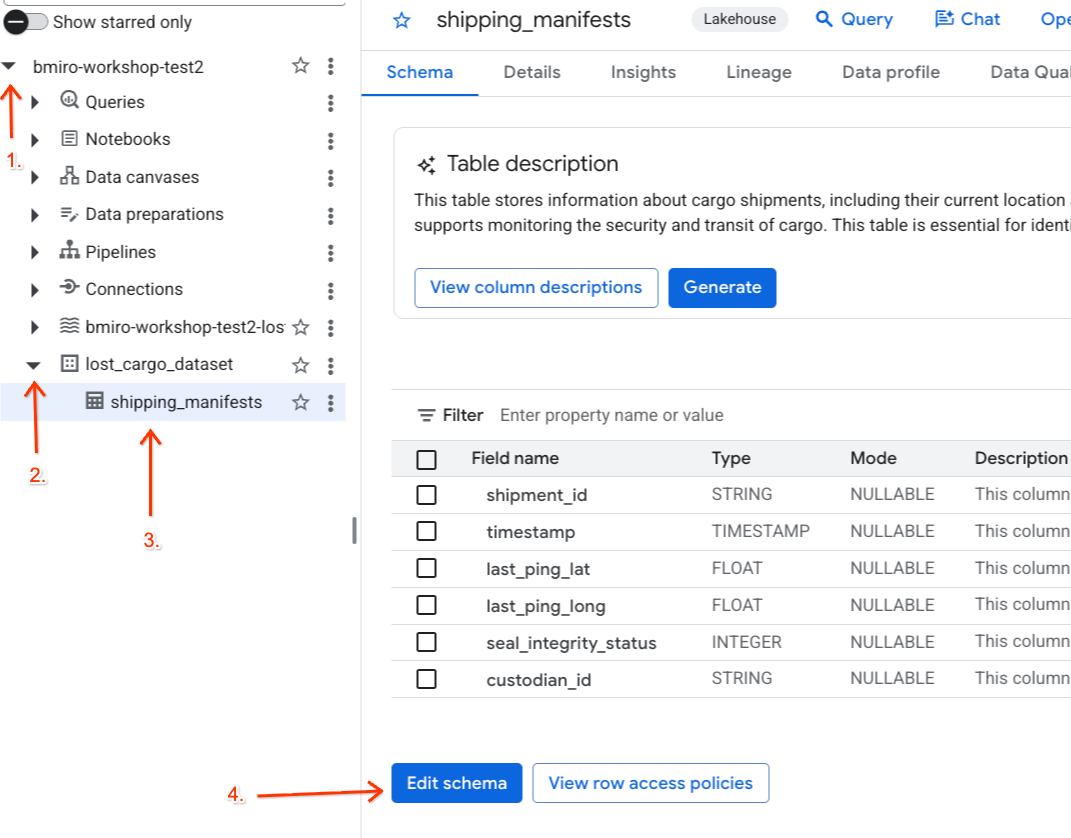
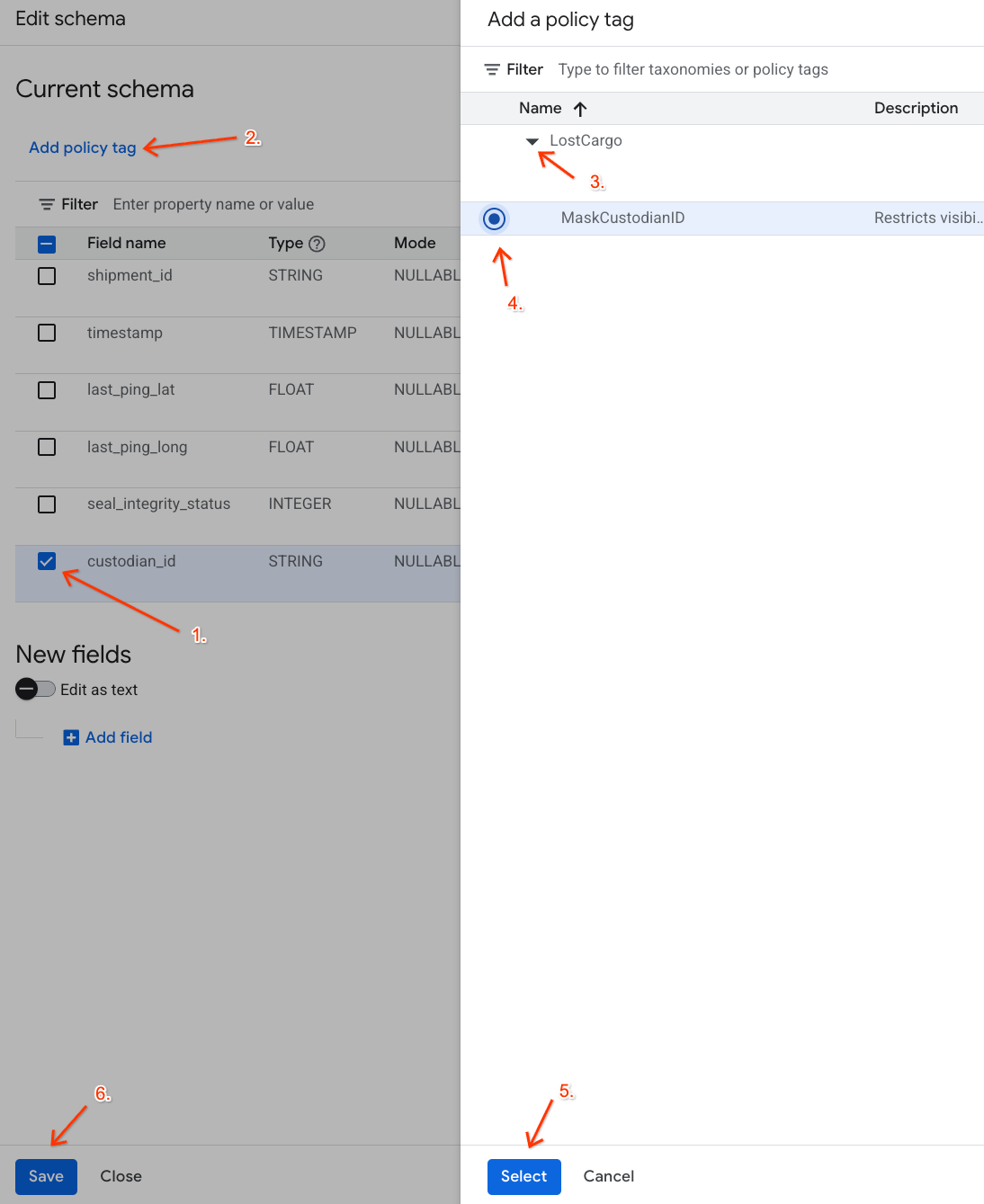
- Sütun listesinde,
custodian_idsimgesinin yanındaki kutuyu işaretleyin. - Şema düzenleyicinin üst araç çubuğundaki Politika etiketi ekle düğmesini tıklayın.
- Politika etiketi ekle panelinde:
LostCargotaksonominizi bulup genişletin.MaskCustodianIDsimgesinin yanındaki balonu seçin.- Seç'i tıklayın.
custodian_id'ü temsil eden satırda Politika etiketi sütununun altındaMaskCustodianIDetiketinin görünür olduğunu doğrulayın.- Kaydet'i tıklayın.
Politika kısıtlamalarını doğrulama
Artık proje düzeyinde Maskelenmiş Okuyucu rolüne sahip olduğunuz için maskeleme politikasının etkin olduğunu doğrulamak üzere tabloyu sorgulayabilirsiniz.
Veri Temsilcisi Kiti'ne geri dönün ve aşağıdaki sorguyu çalıştırın:
SELECT shipment_id, custodian_id
FROM lost_cargo_dataset.shipping_manifests
LIMIT 5;
Şuna benzer bir çıkış alırsınız:
shipment_id | custodian_id |
NORMAL-001 | null |
NORMAL-002 | null |
MV-CAT-001 | null |
Başarılı aktarım shipment_id kayıtlarını görüntüleyebilseniz de hassas custodian_id alanı, sızıntıları önlemek için güvenli null maskeler döndürür.
8. Temizleme
Bu codelab sırasında oluşturulan kaynaklar için Google Cloud hesabınızın sürekli olarak ücretlendirilmesini önlemek amacıyla, veri kümelerinizi ve paketlerinizi bırakmak için Cloud Shell terminalinizde aşağıdaki komutları çalıştırın:
# Verify active variables
export PROJECT_ID=$(gcloud config get-value project)
export BUCKET_NAME="${PROJECT_ID}-lost-cargo-lake"
# Delete Knowledge Catalog security taxonomies
export TAXONOMY_NAME=$(gcloud data-catalog taxonomies list --location=us-central1 --filter="displayName:LostCargo" --format="value(name)")
if [[ -n "$TAXONOMY_NAME" ]]; then
curl -X DELETE \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
"https://datacatalog.googleapis.com/v1/${TAXONOMY_NAME}" || true
fi
# Delete Lakehouse Iceberg REST Catalog tables and namespaces
gcloud biglake iceberg tables delete processed_maritime_logs \
--catalog=${BUCKET_NAME} \
--namespace=lost_cargo_namespace \
--quiet || true
gcloud biglake iceberg namespaces delete lost_cargo_namespace \
--catalog=${BUCKET_NAME} \
--quiet || true
# Delete Lakehouse Iceberg REST Catalog
gcloud biglake iceberg catalogs delete ${BUCKET_NAME} --quiet || true
# Delete dependencies bucket
gcloud storage rm -r gs://${BUCKET_NAME} || true
# Delete BigQuery dataset and tables
bq rm -r -f -d ${PROJECT_ID}:lost_cargo_dataset || true
9. Tebrikler
Tebrikler! Kayıp Kargo soruşturmasının ilk önemli modülünü başarıyla tamamladınız. Lakehouse Iceberg REST kataloglarını, PySpark günlük normalleştirmesini ve ayrıntılı veri maskeleme özelliğini kullanarak yönetilen bir arama bölgesi oluşturmuş olmanız gerekir.
Öğrendikleriniz
- IDE çalışma alanınıza Data Agent Kit uzantısını yükleme, ayarlama ve yapılandırma
- Sağlanan kimlik bilgilerini ve hiyerarşik ad alanlarını kullanarak sunucusuz bir Lakehouse Iceberg REST kataloğu oluşturma.
- Çok formatlı bölgesel feed'leri alma ve Cloud Storage paketleri üzerinde BigQuery harici tabloları oluşturma.
- Yapılandırılmamış transponder günlüklerini ayrıştırmak, normalleştirmek, segmentlere ayırmak ve kayıtlı Iceberg katalog tabloları olarak BigQuery'ye geri yazmak için sunucusuz Apache Spark işlerini başlatma.
- Hassas günlük dizinlerinde kimlik sızıntılarını önlemek için güvenlik taksonomileri oluşturma ve Knowledge Catalog veri maskeleme politikalarını eşleme.
- Veri keşfini hızlandırmak için BigQuery veri analizlerini kullanarak tablo meta verileri analizleri oluşturma ve analiz etme.
Toplanan İpuçlarının Doğrulanması
Bir sonraki laboratuvar aşamasına geçmek için gereken aşağıdaki kesin ipuçlarını kaydettiğinizi doğrulayın:
- Kayıp kargo kimliği:
MV-CAT-001(son ping konumu: Londra) - Planlanan Hedef Varış Noktası:
New York(ve transponder gerçek takma adı:MV-DOG-002) - Kapsayıcı Rengi:
Crimson RED - Yönetim erişim etiketi:
MaskCustodianID
Bir sonraki aşamaya hazır mısınız?
Transponder Kalkış / Varış rotaları artık güvenli olduğundan soruşturma devam ediyor. Çok formatlı Gemini modellerini kullanarak güvenlik kameralarını incelemek, gemiyi görsel olarak tanımlamak ve kurcalama anormalliklerini doğrulamak için AlloyDB'de vektör aramaları yapmak üzere doğrudan 2. laboratuvara geçin.
➡️ İkinci Adım: Veri Analizi ve Çok Formatlı İçgörüler ile devam edin