
1. Giới thiệu
Trong phòng thí nghiệm này, bạn sẽ đóng vai trò là một điều tra viên dữ liệu chính cho một công ty logistics toàn cầu. Một thùng hàng có giá trị cao chở các bức tượng nhỏ Android quý giá đã bị mất tích! Để tìm vị trí đã biết gần đây nhất và theo dõi tuyến đường của lô hàng, bạn phải tổng hợp các bản kê khai vận chuyển rời rạc từ các đối tác hậu cần khu vực và các tệp nhật ký bộ phát đáp không có cấu trúc. Để làm như vậy, bạn sẽ định cấu hình một Google Cloud Open Data Lakehouse hiện đại.

Bạn sẽ thực hiện
- Định cấu hình tiện ích Google Cloud Data Agent Kit trong Cloud Shell Editor.
- Tạo một bộ chứa Cloud Storage và cung cấp Danh mục REST Lakehouse Apache Iceberg và không gian tên.
- Liên kết một bảng bên ngoài BigLake với tệp kê khai JSON thô của đối tác trong Cloud Storage để khám phá manh mối về thời gian khởi hành của con tàu.
- Tải và xử lý nhật ký văn bản của bộ phát đáp không có cấu trúc bằng cách sử dụng dịch vụ Managed Service for Apache Spark không máy chủ. Thực hiện chuẩn hoá biểu thức chính quy và trích xuất manh mối động để nhắm đến đích đến của tải trọng bị mất.
- Ghi các chỉ số nhật ký đã phân tích cú pháp dưới dạng bảng Apache Iceberg thông qua danh mục REST.
- Trò chuyện với một tác nhân AI về dữ liệu Apache Iceberg của bạn bằng Conversational Analytics để khám phá những manh mối ẩn về lô hàng bị thất lạc.
- Khai thác thông tin chi tiết tự động về dữ liệu bằng Danh mục tri thức để tạo siêu dữ liệu về dữ liệu của bạn.
- Thiết lập các biện pháp bảo vệ việc truyền dữ liệu bằng cách tạo một hệ thống phân loại bảo mật và sử dụng Danh mục kiến thức để áp dụng chế độ kiểm soát quyền truy cập chi tiết thông qua việc che giấu mã nhận dạng người giám hộ nhạy cảm.
Bạn cần có
- Một trình duyệt web như Chrome.
- Một dự án trên Google Cloud đã bật tính năng thanh toán.
- Làm quen với các truy vấn SQL cơ bản và lệnh trên thiết bị đầu cuối.
Chi phí và thời lượng dự kiến
- Thời gian hoàn thành: Khoảng 45 phút.
- Chi phí ước tính: Dưới 5 USD.
2. Trước khi bắt đầu
Tạo hoặc chọn một dự án trên Google Cloud
- Trong Google Cloud Console, hãy chọn hoặc tạo một dự án trên Google Cloud.
- Đảm bảo bạn đã bật tính năng thanh toán cho dự án trên đám mây. Tìm hiểu cách xác nhận rằng tính năng thanh toán đã được bật cho một dự án.
Định cấu hình môi trường
Bạn sẽ chạy hầu hết các lệnh từ cửa sổ dòng lệnh tích hợp trong Cloud Shell Editor, một môi trường phát triển dựa trên đám mây được tải sẵn các công cụ dành cho nhà phát triển và Google Cloud SDK tiêu chuẩn.
- Mở Trình chỉnh sửa Cloud Shell trong một thẻ mới.
- Chạy lệnh sau trong dòng lệnh để sao chép kho lưu trữ:
cd ~/ git clone --filter=blob:none --no-checkout https://github.com/GoogleCloudPlatform/devrel-demos.git cd ~/devrel-demos git sparse-checkout init --cone git sparse-checkout set data-analytics/data-cloud-roadshow/lab1 git checkout main cd data-analytics/data-cloud-roadshow/lab1 - Đặt mã dự án. Bạn cũng có thể nhấn
Ctrl+Shift+Vtrên Windows/Linux hoặcCmd+Vtrên macOS để dán nội dung này vào thiết bị đầu cuối:export PROJECT_ID="<YOUR_PROJECT_ID>" - Bây giờ, hãy định cấu hình nó trong môi trường của bạn.
gcloud config set project $PROJECT_ID - Chọn một vùng.
export REGION="<YOUR_REGION>" # Replace with the region you chose, such as "us-central1" - Bật các API bắt buộc.
gcloud services enable \ bigquery.googleapis.com \ biglake.googleapis.com \ storage.googleapis.com \ dataplex.googleapis.com \ datacatalog.googleapis.com \ dataproc.googleapis.com \ aiplatform.googleapis.com \ cloudresourcemanager.googleapis.com \ serviceusage.googleapis.com \ cloudaicompanion.googleapis.com \ geminidataanalytics.googleapis.com
Cài đặt tiện ích mở rộng
Bây giờ, bạn sẽ định cấu hình tiện ích Bộ công cụ đại lý dữ liệu của Google, một công cụ để tương tác trực tiếp với các công cụ dữ liệu của Google Cloud trong IDE.
- Trong thanh hoạt động bên trái của trình chỉnh sửa, hãy nhấp vào biểu tượng Tiện ích (hoặc nhấn
Ctrl+Shift+Xtrên Windows/Linux hoặcCmd+Xtrên macOS). - Trong hộp tìm kiếm tiện ích, hãy nhập:
Google Cloud Data Agent Kit - Chọn tiện ích chính thức trong số các kết quả rồi nhấp vào Cài đặt. Nếu được nhắc, hãy chọn "Có, tôi tin tưởng các tác giả".
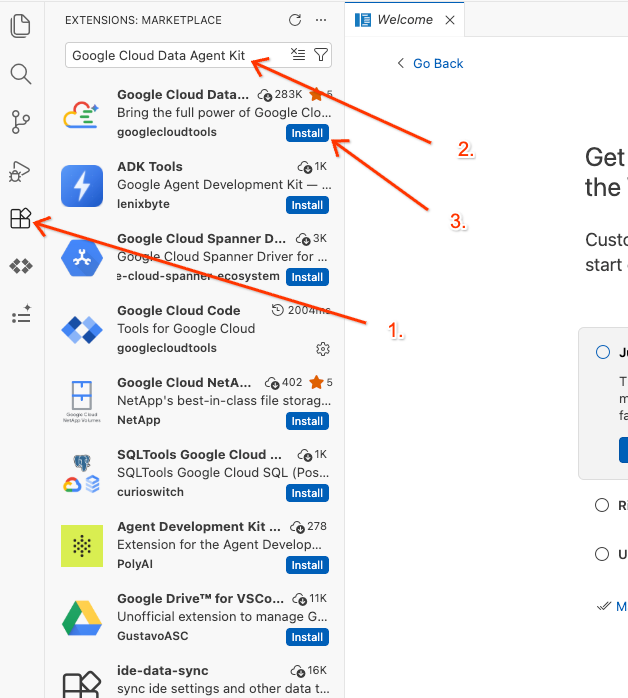
- Sau khi cài đặt thành công, bạn sẽ thấy biểu tượng Google Cloud Data Agent Kit xuất hiện trong thanh hoạt động! Nhấp vào biểu tượng đó.
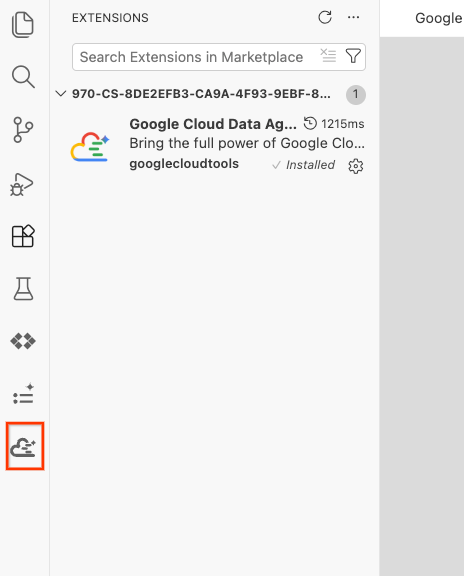
- Nhấp vào Đăng nhập vào đám mây.
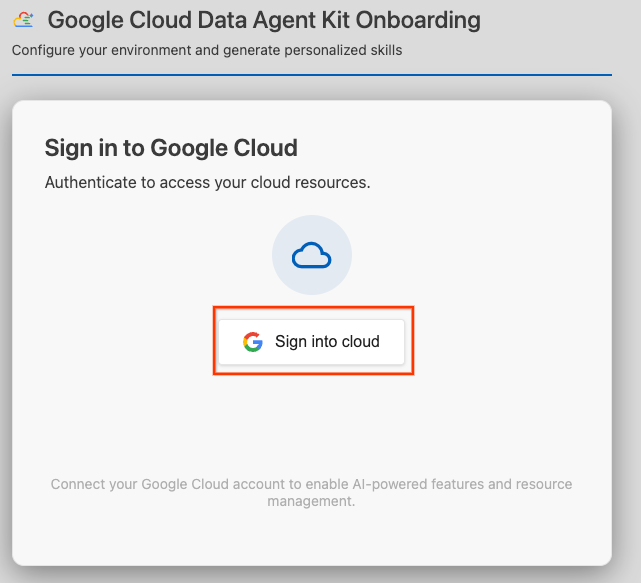
- Nhấp vào Định cấu hình máy chủ MCP.
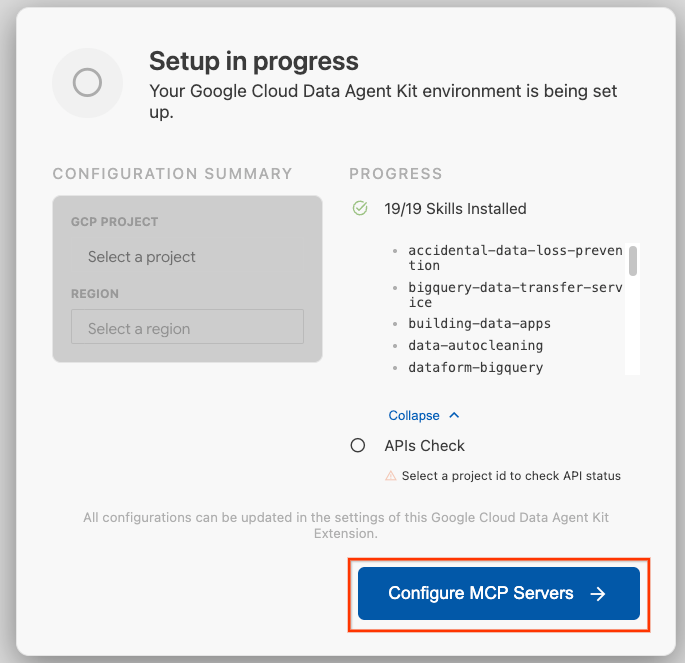
- Chọn BigQuery, Danh mục tri thức, Apache Spark và AlloyDB. Bạn sẽ sử dụng AlloyDB trong Bài thực hành 2. Sau đó, hãy nhấp vào Bắt đầu.
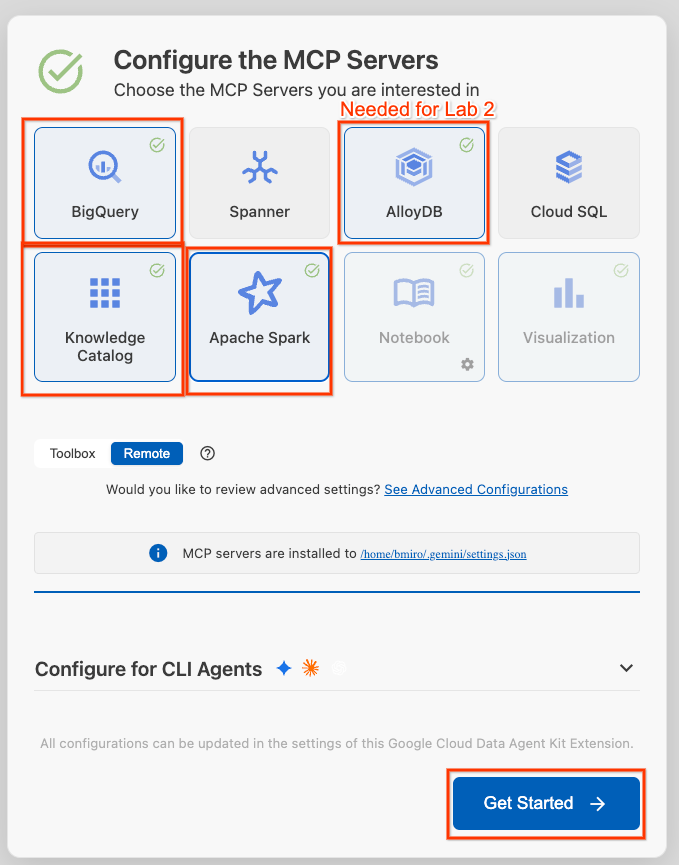
- Nhấp vào bộ chọn Mã dự án trong thanh trạng thái ở dưới cùng rồi chọn dự án trên đám mây đang hoạt động của bạn trên Google Cloud.
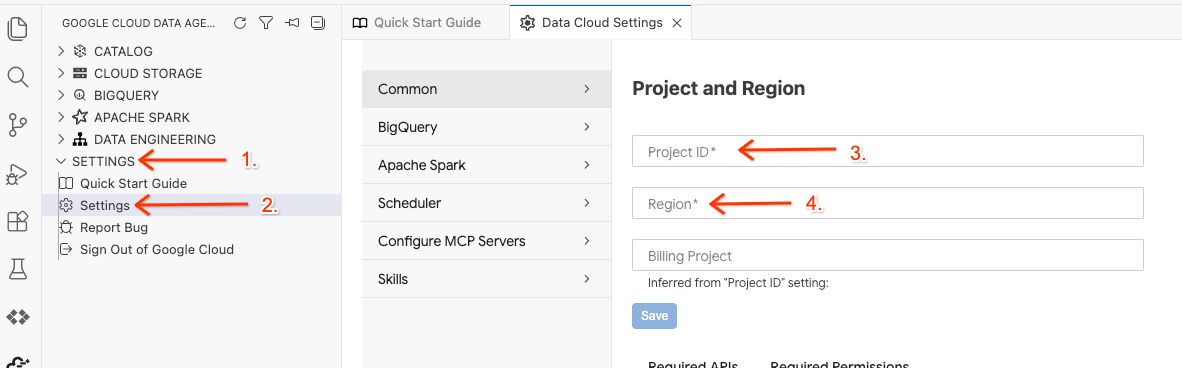
- Trong Data Agent Kit, hãy nhấp vào SETTINGS (CÀI ĐẶT), sau đó nhấp vào Settings (Cài đặt) rồi chọn Project ID (Mã dự án) và Region (Khu vực) trong thẻ Common (Chung) để chạy phòng thí nghiệm, chẳng hạn như us-central1.
- Nhấp vào Cài đặt BigQuery rồi thay thế Khu vực bằng khu vực mà bạn đã chọn trước đó. Nhấp vào Lưu.
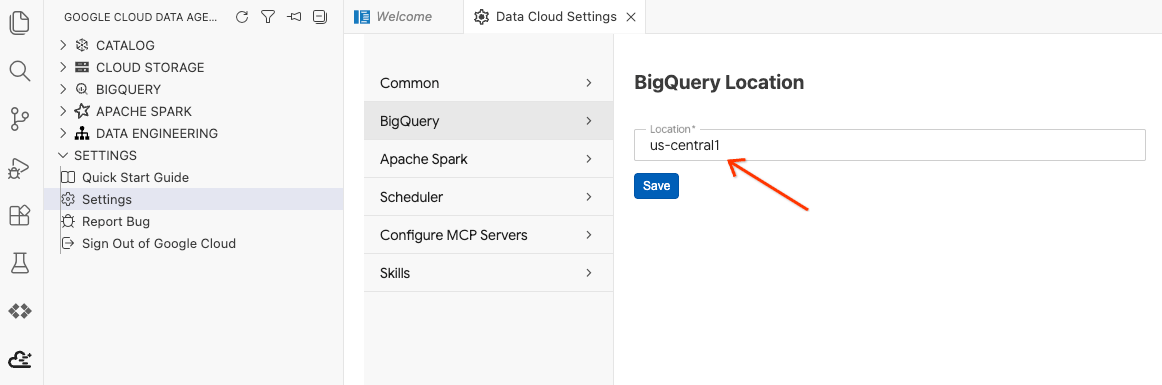
Giờ đây, bạn đã có thể sử dụng Bộ công cụ Data Agent!
Thực thi tập lệnh thiết lập môi trường
Trong thiết bị đầu cuối, hãy chạy tập lệnh thiết lập để tạo các tài nguyên cần thiết ở chế độ nền cho phòng thí nghiệm này và định cấu hình quyền IAM:
chmod +x setup_lab1.sh
./setup_lab1.sh
source .env
Bạn sẽ thấy một loạt các bước đầu ra cho biết những tài nguyên đang được cung cấp. Chúng ta sẽ tìm hiểu về những nội dung này trong suốt lớp học.
Sau khi thấy thông báo hoàn tất, bạn đã sẵn sàng:
==================================================== Environment Setup Complete! ====================================================
Giờ thì chúng ta hãy bắt đầu tìm kiếm!
3. Nhập tệp kê khai thông tin vận chuyển của đối tác
Dữ liệu bản kê khai vận chuyển của các tàu đối tác được lưu trữ ở định dạng JSON Lines (JSONL) tiêu chuẩn trong nhóm của bạn: gs://${PROJECT_ID}-lost-cargo-lake/shipping_manifests/manifests.jsonl.
Trước khi thực hiện phân tích chuyên sâu, bạn sẽ tạo một bảng BigLake được quản lý cho dữ liệu không có cấu trúc này. Điều này cho phép bạn khám phá ngay dữ liệu hậu cần của đối tác bằng cách sử dụng SQL tiêu chuẩn mà không phải nhập trùng lặp chi phí.
Mở Không gian làm việc trong Trình chỉnh sửa và chạy truy vấn
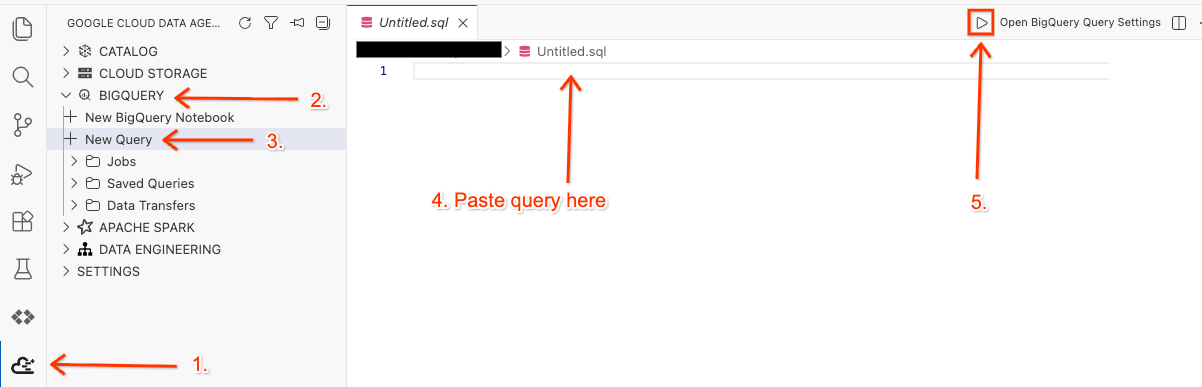
- Trong Trình chỉnh sửa Cloud Shell, hãy nhấp vào biểu tượng tiện ích Google Cloud Data Agent Kit trên bảng điều khiển bên.
- Chuyển đến BigQuery rồi chọn + Truy vấn mới.
- Sao chép truy vấn sau vào cửa sổ truy vấn.
SET @@location = "<YOUR_REGION>"; --Update to your resource region, such as "us-central1". Make sure it is in quotes.
EXECUTE IMMEDIATE ("""
CREATE OR REPLACE EXTERNAL TABLE `lost_cargo_dataset.shipping_manifests`
(
shipment_id STRING,
timestamp TIMESTAMP,
last_ping_lat FLOAT64,
last_ping_long FLOAT64,
seal_integrity_status INT64,
custodian_id STRING OPTIONS(description='Masked identification token for official cargo custodian personnel.')
)
WITH CONNECTION `""" || @@location || """.conn`
OPTIONS (
format = 'NEWLINE_DELIMITED_JSON',
uris = ['gs://""" || @@project_id || """-lost-cargo-lake/shipping_manifests/*.jsonl']
)
""");
- Nhấp vào Chạy.
- Để xác minh rằng bảng đã được tạo, bạn sẽ thấy một thông báo thành công trong bảng Kết quả truy vấn tự động mở ở dưới cùng.
Truy vấn bảng bên ngoài để cô lập các bộ phát đáp bị xâm nhập
Hãy xác định các bộ phát đáp bị xâm nhập bằng cách xác định các lỗi khi seal_integrity_status được đặt thành 0. Sao chép và chạy truy vấn sau trong cửa sổ truy vấn mà bạn đã mở trước đó:
SELECT shipment_id, last_ping_lat, last_ping_long, custodian_id
FROM `lost_cargo_dataset.shipping_manifests`
WHERE seal_integrity_status = 0;
Trong bảng điều khiển Query Results (Kết quả truy vấn), bạn sẽ thấy kết quả đầu ra tương tự như sau:
shipment_id | last_ping_lat | last_ping_long | custodian_id |
MV-CAT-001 | 51.5074 | -0,1278 | usr_999_shadow |
4. Xử lý nhật ký không có cấu trúc bằng Dịch vụ được quản lý cho Apache Spark
Bạn đã tìm thấy vị trí bắt đầu từ các tệp kê khai có cấu trúc, nhưng bộ tiếp sóng bị mất đã hoàn toàn ngừng hoạt động. Lần ping cuối cùng của bộ tiếp sóng đã để lại một thông báo khó hiểu, không có cấu trúc bên trong một tệp nhật ký văn bản thô trong đường dẫn GCS gs://${BUCKET_NAME}/raw_logs/maritime_logs.txt.
Để xử lý và lập bản đồ nhật ký văn bản này, hãy trích xuất dấu thời gian, ngụy trang danh tính và xác định vị trí tuyến đường xuôi dòng của hàng hoá, bạn sẽ gửi một công việc Apache Spark (PySpark) không máy chủ đến Dịch vụ được quản lý cho Apache Spark.
Dịch vụ được quản lý cho Apache Spark cho phép bạn chạy các khối lượng công việc Spark mà không cần cấp phép hoặc quản lý một cụm. Dịch vụ này xử lý các tài nguyên điện toán cơ bản, tự động mở rộng quy mô một cách linh hoạt và bạn chỉ phải trả tiền cho thời gian thực thi.
Tập lệnh sẽ:
- Tiếp nhận văn bản thô, có dấu ngoặc vuông và không có cấu trúc của bộ phát đáp.
- Áp dụng bộ lọc trích xuất biểu thức chính quy PySpark SQL để tách dấu thời gian, siêu dữ liệu của người giám hộ và nội dung thô.
- Chia nhật ký lộn xộn thành các bản ghi sạch sẽ ở cấp câu.
- Trích xuất mục tiêu toạ độ đích đến động nơi chuyến bay chở hàng bị mất kết thúc.
- Kết nối và ghi khung dữ liệu nhật ký đã xử lý trở lại Danh mục REST Apache Iceberg Lakehouse dưới dạng một bảng phân tích mới có thể xem trực tiếp trong BigQuery.
Chỉnh sửa tập lệnh phân tích PySpark
Có thông tin về việc nhóm cướp biển Python gây ra đủ loại vấn đề trên biển.
- Chạy lệnh sau để mở tệp
process_maritime_logstrong Cloud Shell Editor.cd ~/devrel-demos/data-analytics/data-cloud-roadshow/lab1 cloudshell open ./process_maritime_logs.py - Dành chút thời gian để đọc mã và tìm hiểu chức năng của mã.
- Đảm bảo không có gì đáng ngờ trong mã! Nếu bạn cần xoá nội dung nào đó, hãy nhớ lưu tệp bằng cách nhấn tổ hợp phím
Ctrl + S(Windows/Linux) hoặcCmd + S(máy Mac).
Gửi công việc Spark không máy chủ
Gửi công việc bằng cách sử dụng SDK gcloud. Cấu hình này tự động định cấu hình công việc PySpark để truy cập vào danh mục Lakehouse.
Chạy lệnh sau trong cửa sổ dòng lệnh của trình chỉnh sửa tích hợp.
cd ~/devrel-demos/data-analytics/data-cloud-roadshow/lab1
source .env
gcloud dataproc batches submit pyspark process_maritime_logs.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--version=2.3 \
--deps-bucket=${BUCKET_NAME} \
--properties="\
spark.sql.defaultCatalog=cargo_catalog,\
spark.sql.catalog.${CATALOG_NAME}=org.apache.iceberg.spark.SparkCatalog,\
spark.sql.catalog.${CATALOG_NAME}.type=rest,\
spark.sql.catalog.${CATALOG_NAME}.uri=https://biglake.googleapis.com/iceberg/v1/restcatalog,\
spark.sql.catalog.${CATALOG_NAME}.warehouse=gs://${BUCKET_NAME},\
spark.sql.catalog.${CATALOG_NAME}.header.x-goog-user-project=${PROJECT_ID},\
spark.sql.catalog.${CATALOG_NAME}.rest.auth.type=org.apache.iceberg.gcp.auth.GoogleAuthManager,\
spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions,\
spark.sql.catalog.${CATALOG_NAME}.gcs.oauth2.refresh-credentials-endpoint=https://oauth2.googleapis.com/token, \
spark.sql.catalog.${CATALOG_NAME}.header.X-Iceberg-Access-Delegation=vended-credentials" \
-- ${BUCKET_NAME}
Chờ vài phút để môi trường phi máy chủ khởi động, tải tập lệnh lên và thực thi logic xử lý.
Sau khi bạn thấy kết quả tương tự như sau, bảng đã xử lý của bạn sẽ được lưu vào danh mục Lakehouse dưới dạng bảng được quản lý Apache Iceberg!
Batch [1fae0b4b42c045a084dd67917bd0c332] finished.
metadata:
'@type': type.googleapis.com/google.cloud.dataproc.v1.BatchOperationMetadata
batch: projects/<YOUR_PROJECT>/locations/us-central1/batches/1fae0b4b42c045a084dd67917bd0c332
batchUuid: 611b4465-fdac-4974-bc47-5f10adaf2a08
createTime: '2026-06-11T21:35:01.868157Z'
description: Batch
labels:
goog-dataproc-batch-id: 1fae0b4b42c045a084dd67917bd0c332
goog-dataproc-batch-uuid: 611b4465-fdac-4974-bc47-5f10adaf2a08
goog-dataproc-drz-resource-uuid: batch-611b4465-fdac-4974-bc47-5f10adaf2a08
goog-dataproc-location: us-central1
operationType: BATCH
name: projects/<YOUR_PROJECT/regions/us-central1/operations/7e2044db-dd97-3270-b368-4dc4ba417574
Xem trước nhật ký đã xử lý
Trong trình chỉnh sửa Truy vấn của tiện ích Bộ công cụ tác nhân dữ liệu, hãy sao chép truy vấn sau để xem trước dữ liệu:
SET @@location = "<YOUR_REGION>"; -- e.g. "us-central1"
EXECUTE IMMEDIATE FORMAT("""
select log_timestamp, custodian_id, sentence from
`%s.%s-lost-cargo-lake.lost_cargo_namespace.processed_maritime_logs`
limit 5
""", @@project_id, @@project_id);
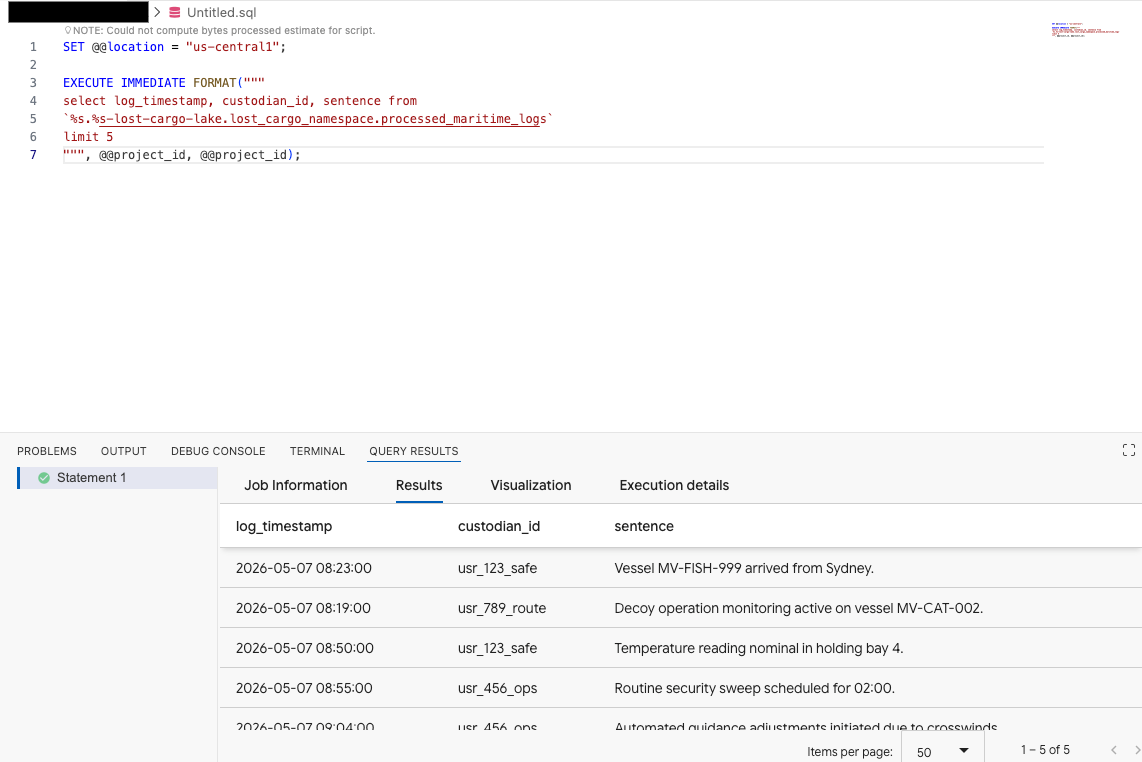
Điều này cho thấy bạn có thể truy cập thành công vào bảng Iceberg đã đăng ký trong danh mục từ BigQuery!
Trích xuất Gợi ý về điểm đến
Giờ đây, khi đã có nhật ký được xử lý, hãy tìm nhật ký có chứa đích đến mục tiêu. Từ đó, chúng ta có thể tìm nhật ký có chứa thông tin về thành phố xuất phát.
Trong trình chỉnh sửa truy vấn, hãy chạy truy vấn sau, thay thế <YOUR_REGION> bằng khu vực của bạn và thay thế <ORIGIN_CITY> bằng thành phố xuất phát mà bạn đã khám phá trước đó.
SET @@location = "<YOUR_REGION>"; --e.g. "us-central1"
DECLARE origin_city STRING;
SET origin_city = "<ORIGIN_CITY>"; --e.g. "Boston". (It's not Boston)
EXECUTE IMMEDIATE FORMAT(r"""
SELECT
log_timestamp AS event_time,
custodian_id,
REGEXP_EXTRACT(raw_message, r'Destination:\s*([^.]+)') AS destination_target
FROM
`%s.%s-lost-cargo-lake.lost_cargo_namespace.processed_maritime_logs`
WHERE
-- STRPOS is highly optimized in BigQuery for a simple .contains() substring check
STRPOS(sentence, '%s') > 0;
""", @@project_id, @@project_id, origin_city);
Trò chuyện với dữ liệu của bạn trong Bảng điều khiển BigQuery bằng tính năng Phân tích đàm thoại
Thay vì viết các truy vấn SQL phức tạp để khám phá dữ liệu, bạn có thể sử dụng tính năng Phân tích dựa trên cuộc trò chuyện để trò chuyện với các bảng bằng ngôn ngữ tự nhiên!
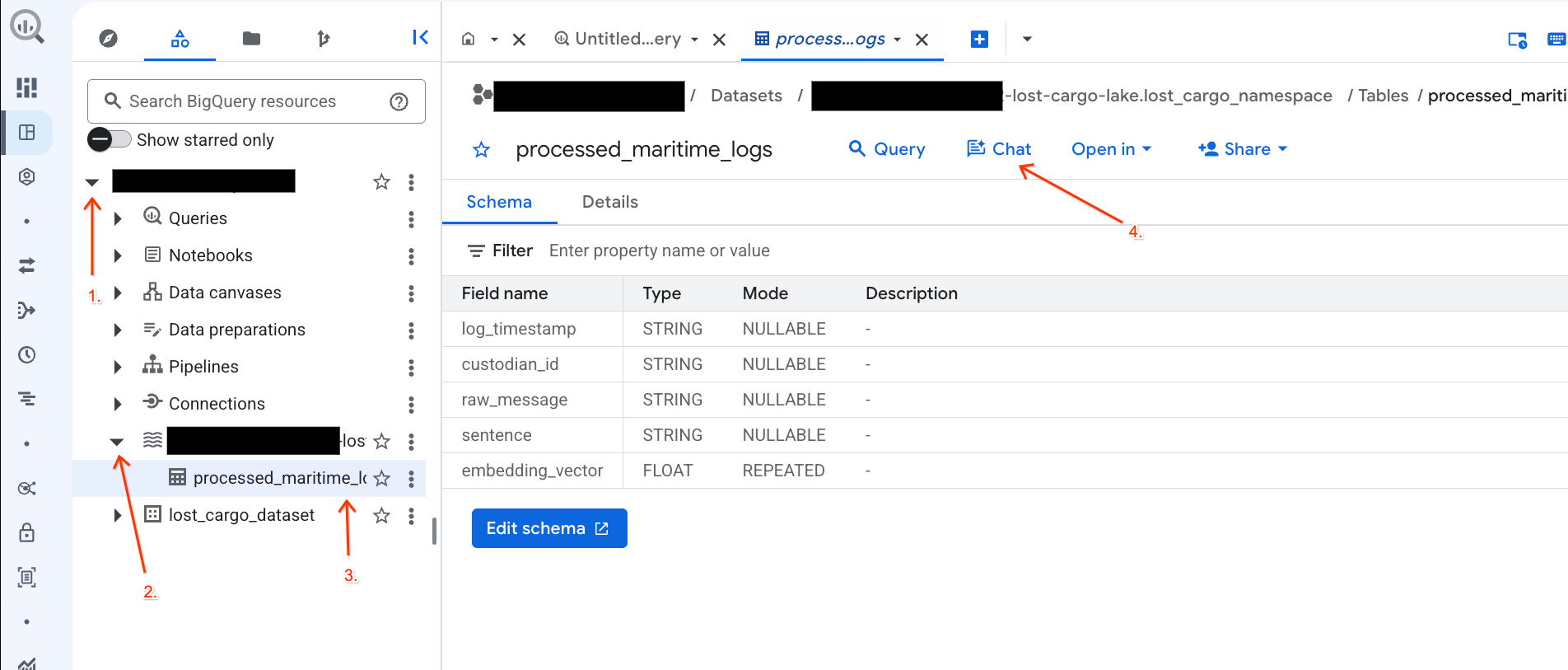
- Chuyển đến Bảng điều khiển BigQuery.
- Trong bảng điều khiển Explorer (Trình khám phá) ở bên trái, hãy mở rộng dự án và tập dữ liệu
-lost-cargo-lake.lost_cargo_namespace processed_maritime_logsđể mở thẻ chi tiết của bảng đó. - Bên cạnh Câu hỏi, hãy nhấp vào Trò chuyện.
- Trong bảng trò chuyện, hãy nhập câu hỏi sau rồi nhấn phím Enter trên bàn phím để gửi:
Based on this table, what color is the shipping container MV-CAT-001?
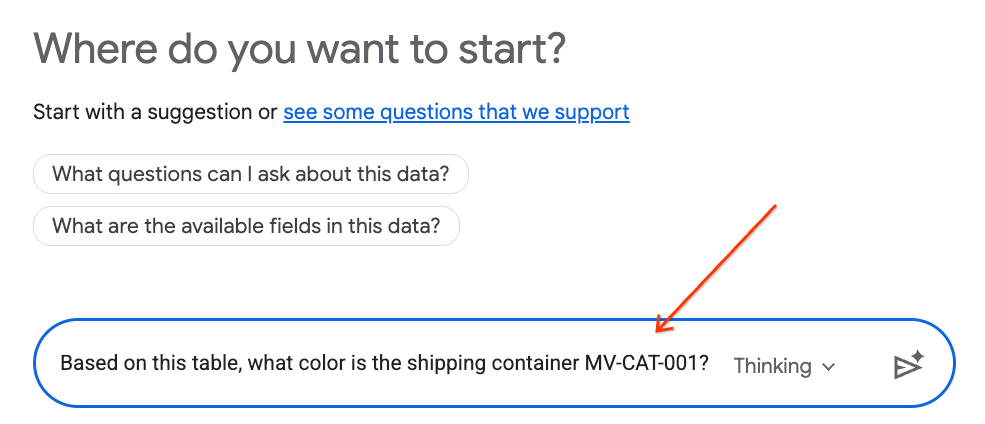
- Tính năng Conversational Analytics (do Gemini hỗ trợ) sẽ phân tích dữ liệu của bảng đang hoạt động và trả lời bằng màu sắc.
5. Xem danh mục Lakehouse tập trung
Để tích hợp các công cụ xử lý nguồn mở (như Apache Spark) một cách an toàn và liền mạch với các công cụ dữ liệu doanh nghiệp (như BigQuery), tập lệnh thiết lập của bạn đã định cấu hình một Danh mục REST Lakehouse Iceberg.
Danh mục REST của Apache Iceberg đóng vai trò là "nguồn đáng tin cậy duy nhất" không máy chủ cho siêu dữ liệu bảng, quản lý giản đồ và phân vùng bảng một cách linh hoạt trong khi lưu trữ các tệp dữ liệu Parquet thực tế trong Cloud Storage.
Hãy xem xét danh mục này ngay trong Bảng điều khiển Google Cloud:
- Mở Lakehouse Console.
- Trong thẻ Danh mục, hãy tìm và nhấp vào Danh mục REST Iceberg đang hoạt động của bạn:
-lost-cargo-lake
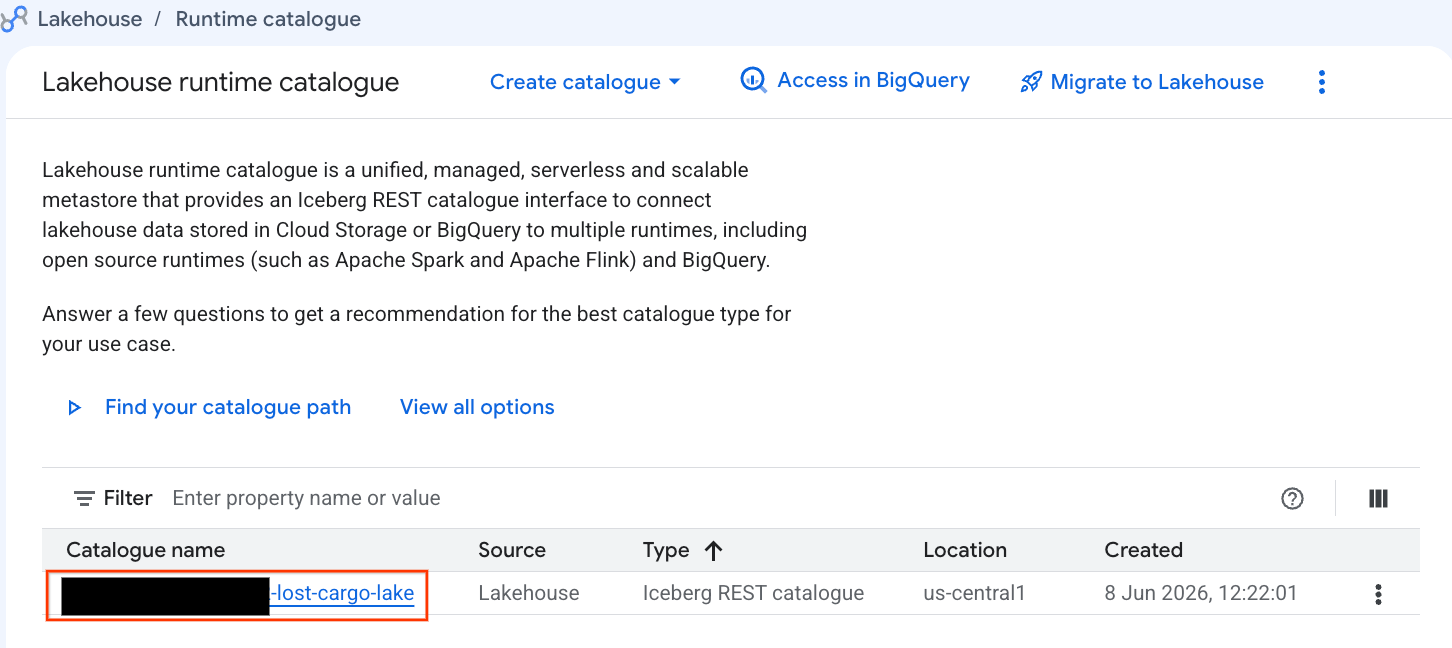
- Trong chế độ xem chi tiết danh mục, bạn sẽ thấy
lost_cargo_namespacetrong phần Không gian tên. Hãy nhấp vào thẻ đó.
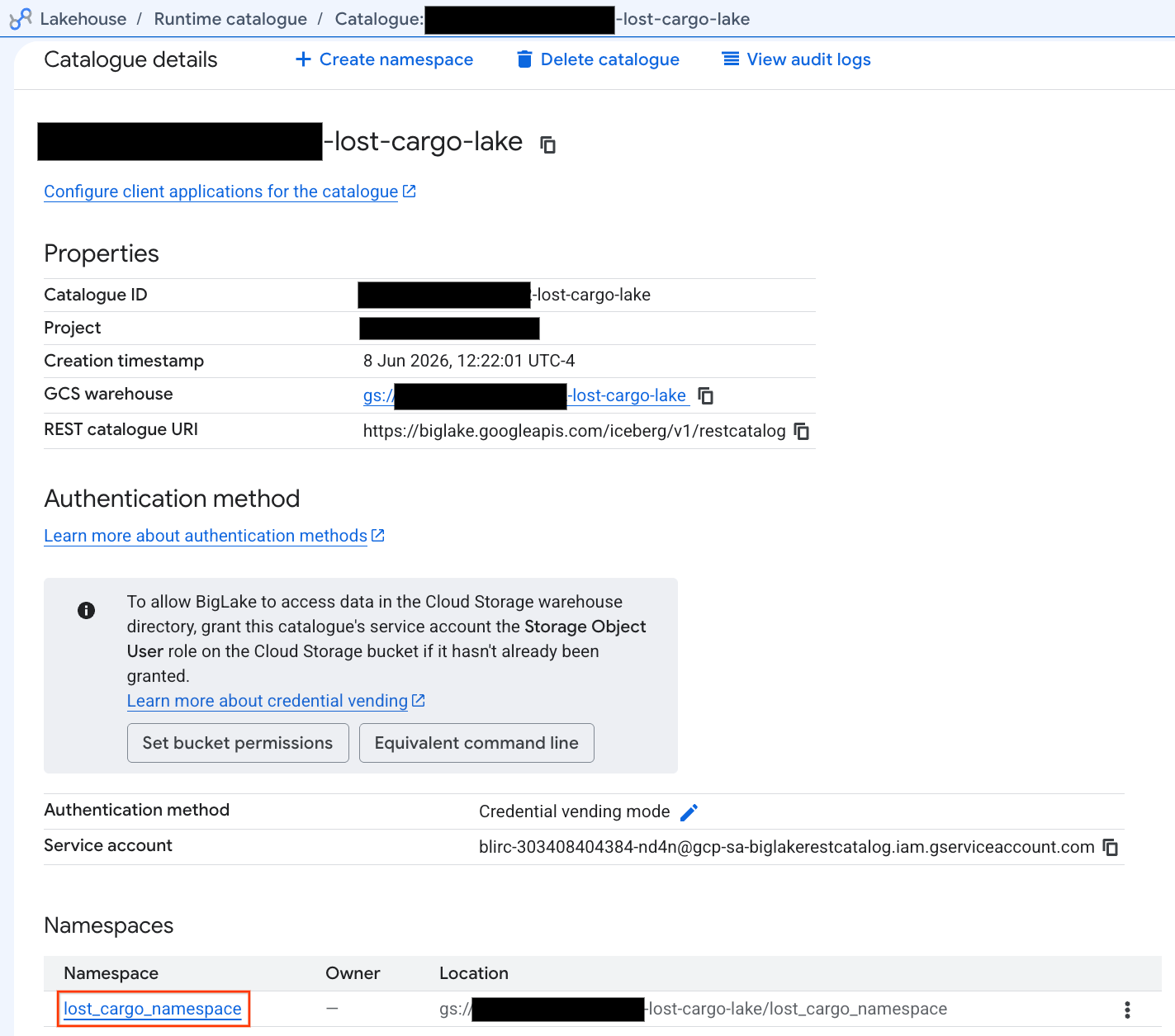
- Bảng Apache Iceberg mới do PySpark tạo sẽ tự động được đăng ký trong không gian tên metastore này và có thể truy vấn ngay trên BigQuery!
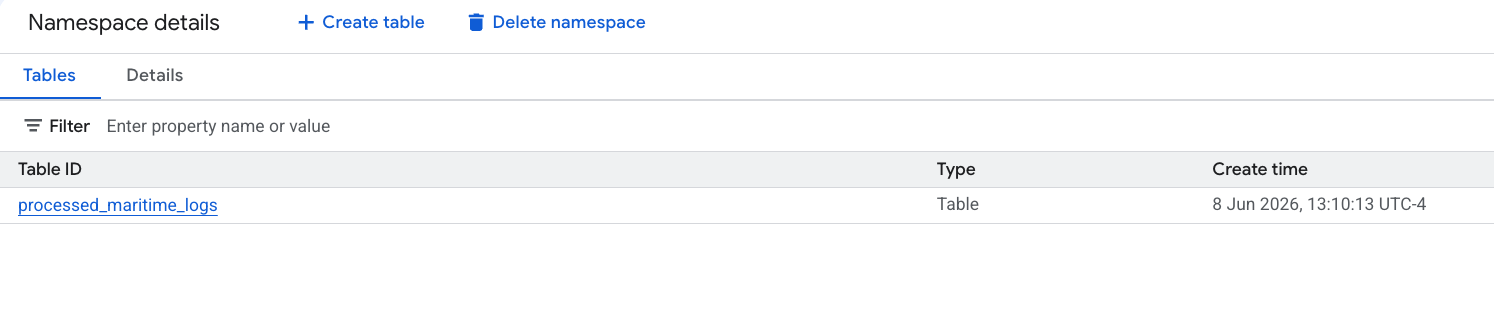
6. Tạo thông tin chi tiết trên bảng Tờ khai vận chuyển
Hãy quay lại và phân tích bảng shipping_manifests để hiểu cấu trúc và nội dung của bảng này bằng cách sử dụng Thông tin chi tiết về dữ liệu trong danh mục kiến thức. Bằng cách làm phong phú siêu dữ liệu, những người khám phá khác có thể hiểu rõ hơn về bảng để phân tích trong tương lai.
Tạo thông tin chi tiết về bảng trong BigQuery Studio
- Trong Google Cloud Console, hãy chuyển đến BigQuery Studio.
- Trong bảng điều khiển Explorer (Trình khám phá), hãy mở rộng dự án, mở rộng tập dữ liệu
lost_cargo_datasetrồi nhấp vào bảngshipping_manifests. - Trong bảng chi tiết ở bên phải, hãy nhấp vào thẻ Thông tin chi tiết.
- Sử dụng trình đơn thả xuống để chọn Tạo và xuất bản.
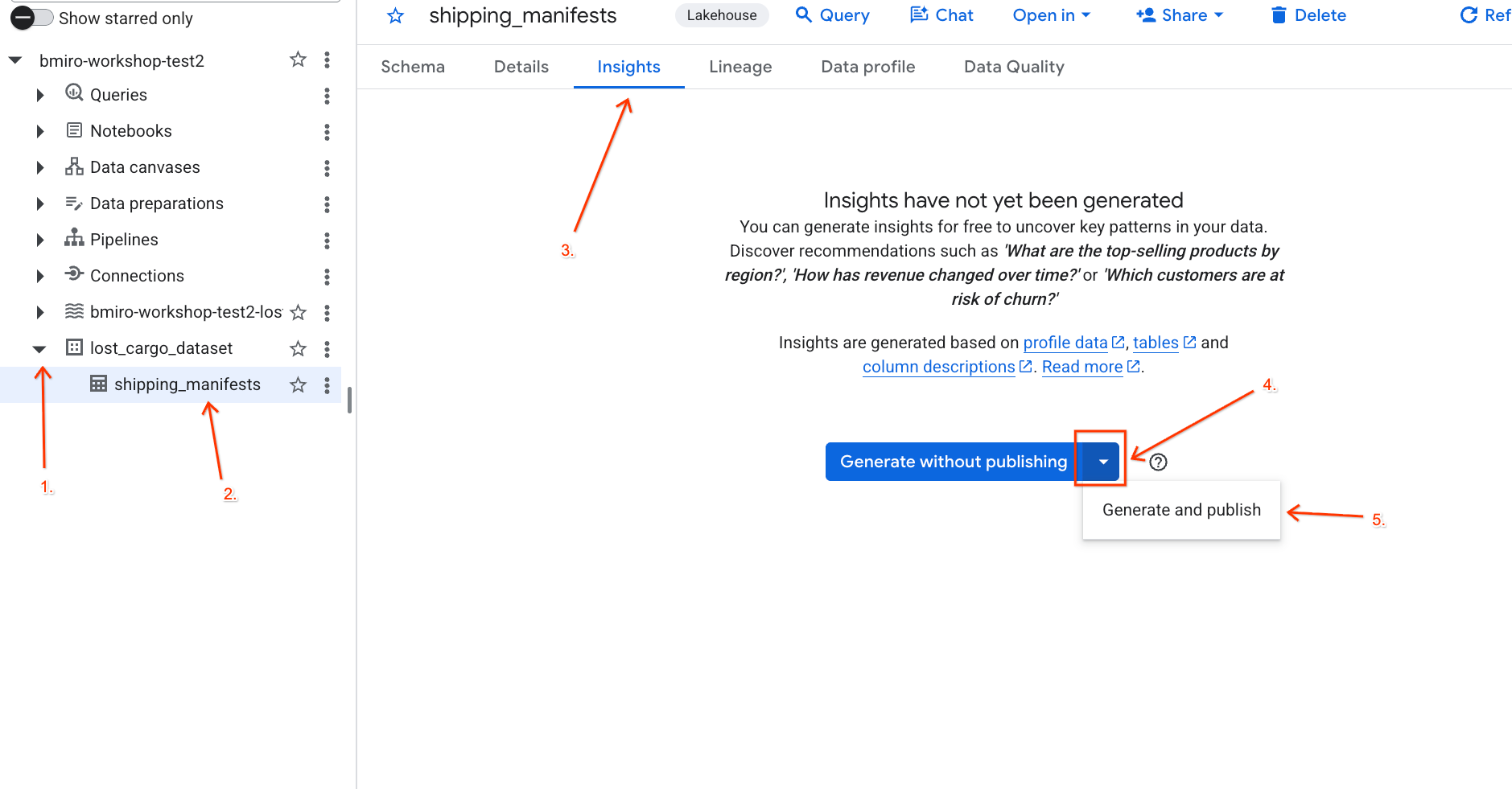
- Đợi khoảng 3 phút để quá trình tạo thông tin chi tiết hoàn tất. Gemini sẽ phân tích siêu dữ liệu của bảng và tạo câu hỏi bằng ngôn ngữ tự nhiên cũng như các truy vấn SQL tương ứng.
- Sau khi hoàn tất, bạn sẽ thấy Nội dung mô tả bảng kèm theo nội dung giải thích bằng ngôn ngữ tự nhiên về bảng.
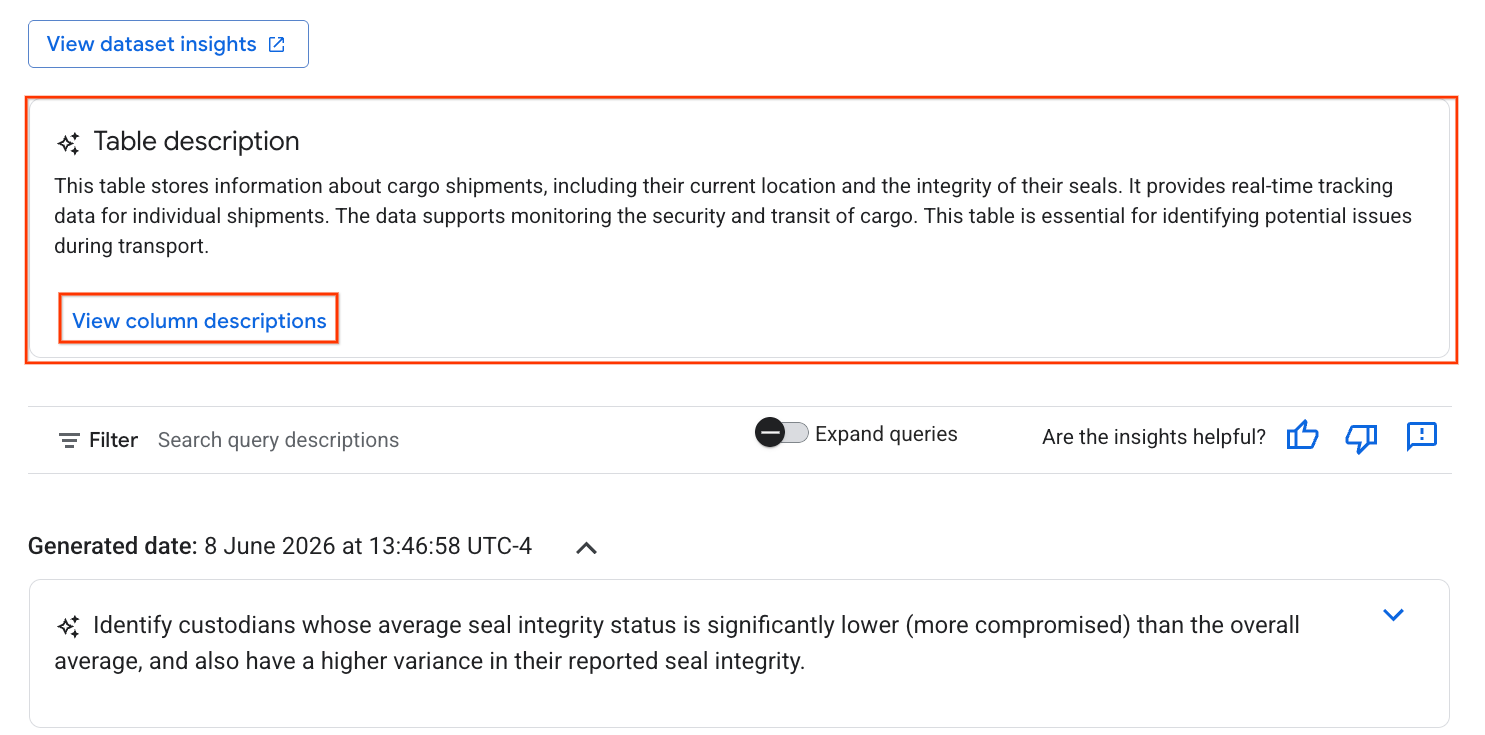
- Nhấp vào Xem nội dung mô tả cột để xem thông tin về từng cột.
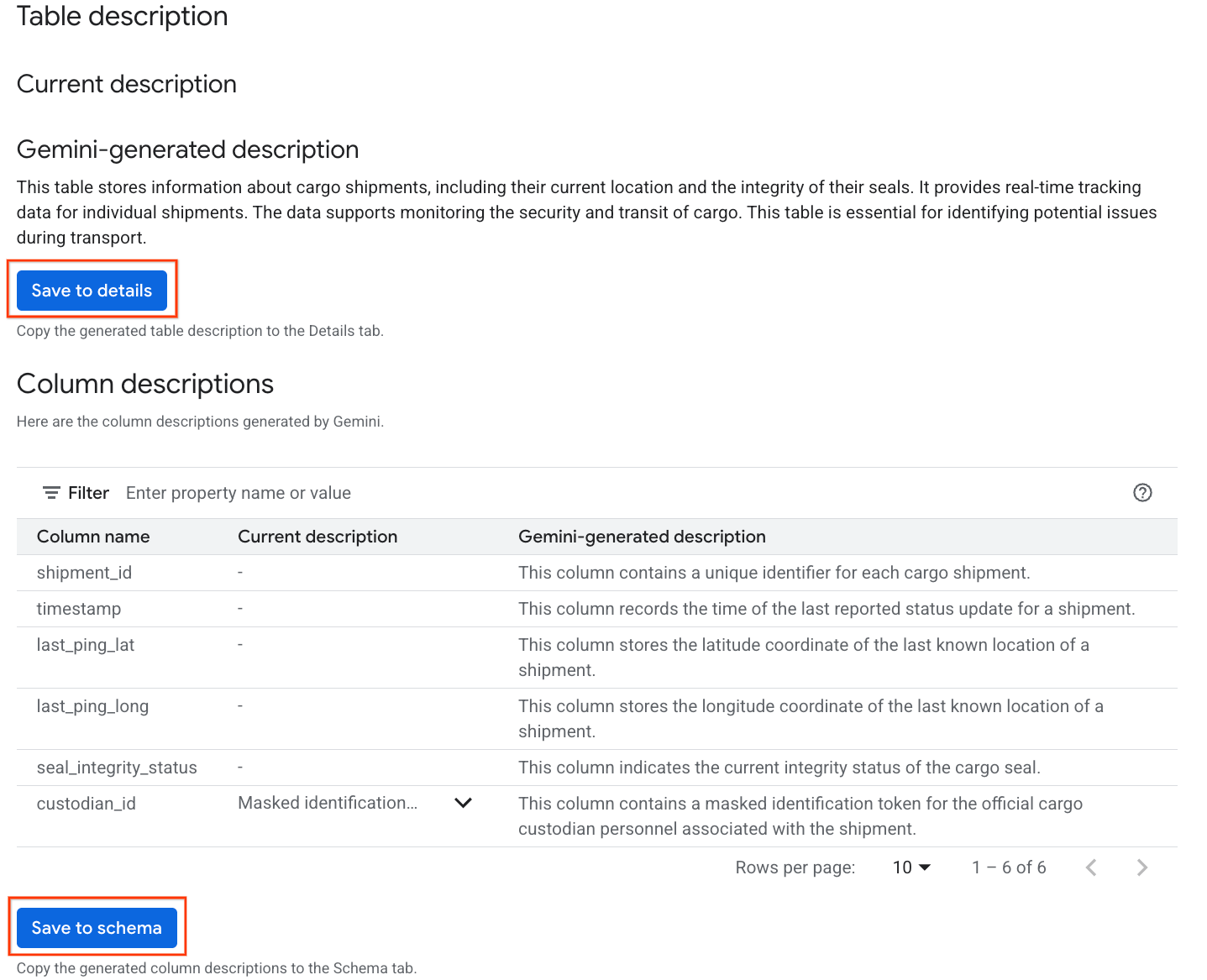
- Nhấp vào Lưu vào phần chi tiết trong mục
Gemini generated descriptionrồi nhấp vào Lưu vào phần chi tiết trong cửa sổ bật lên.
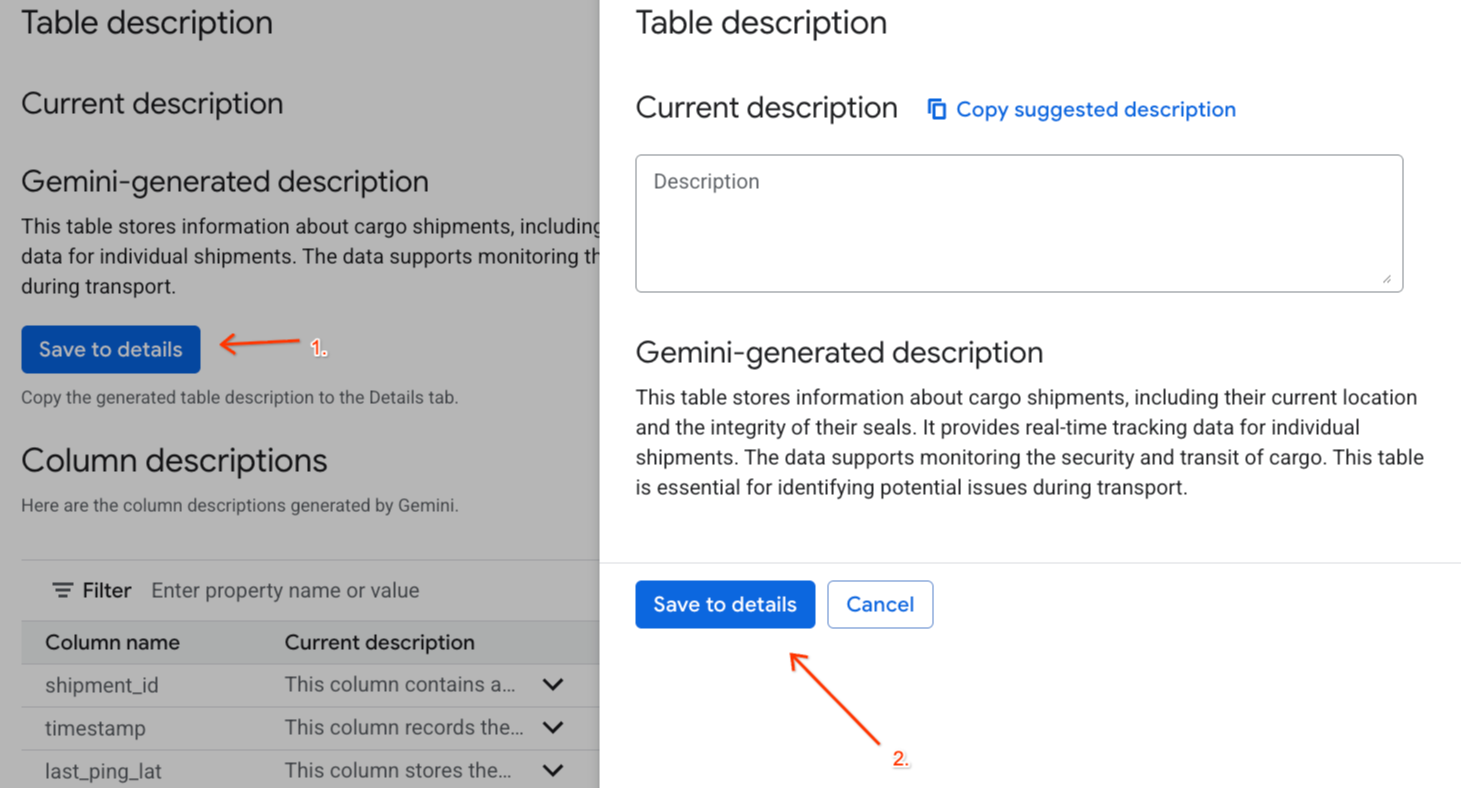
- Tương tự, hãy nhấp vào Lưu vào giản đồ để thêm nội dung mô tả cột vào siêu dữ liệu của bảng.
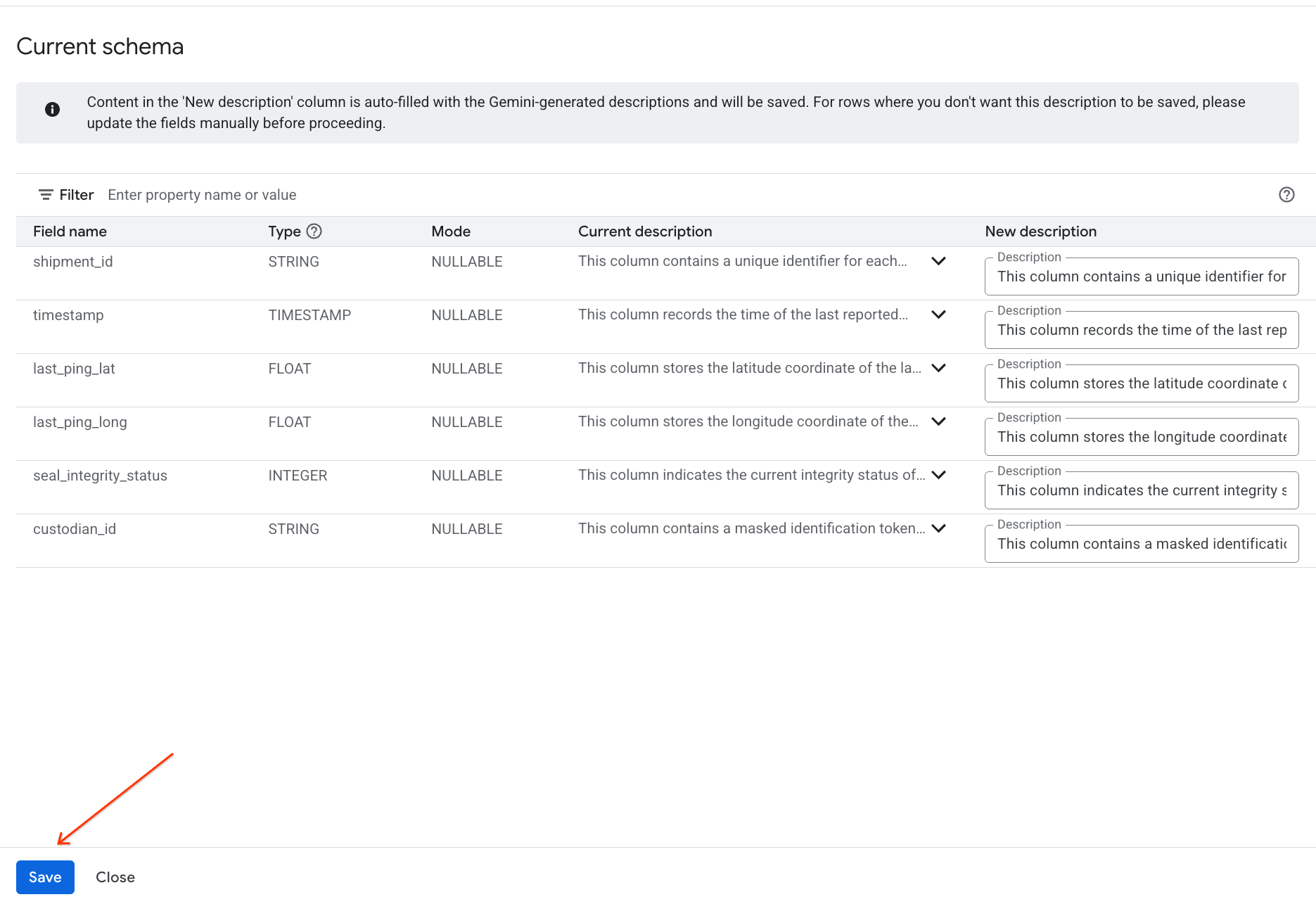
Xem thông tin chi tiết được tạo
Bạn cũng sẽ thấy danh sách các câu hỏi được đề xuất. Bạn có thể nhấp vào bất kỳ câu hỏi nào để xem truy vấn SQL được tạo và kích hoạt truy vấn đó để khám phá dữ liệu. Ví dụ: bạn có thể thấy những câu hỏi như:
- "Tổng số lô hàng là bao nhiêu?"
- "Liệt kê các mã nhận dạng người giám hộ duy nhất."
Việc chạy các truy vấn này giúp bạn hiểu rõ dữ liệu.
7. Triển khai tính năng che giấu và quản trị dữ liệu
Để đảm bảo rằng các tài khoản và tên người dùng nghiên cứu đang hoạt động không bị rò rỉ trong quá trình điều tra hàng hoá đang diễn ra này, bạn phải thực thi các giao thức bảo mật tiêu chuẩn. Bạn sẽ tạo Phân loại thẻ chính sách bảo mật và định cấu hình Mặt nạ dữ liệu danh mục kiến thức trên cột custodian_id nhạy cảm để xác minh quyền riêng tư đối với dữ liệu.
Theo mặc định, BigQuery từ chối quyền truy cập vào các cột được bảo vệ bằng thẻ chính sách. Để truy vấn bảng và xác minh các mặt nạ dữ liệu đang hoạt động, tài khoản người dùng của bạn phải có vai trò Người đọc được che mặt nạ theo chính sách dữ liệu BigQuery.
Vai trò này được tự động liên kết với tài khoản người dùng đang hoạt động của bạn trong lần thực thi setup_lab1.sh đầu tiên!
Tạo thẻ phân loại và thẻ chính sách
Tạo một hệ thống phân loại dữ liệu và thẻ chính sách liên kết để quản lý quyền truy cập vào dữ liệu của bạn.
- Chuyển đến trang Phân loại thẻ chính sách.
- Nhấp vào + Tạo phân loại.
- Định cấu hình các thông số:
- Tên phân loại: Nhập
lost-cargo-, thay thế bằng mã dự án của bạn. - Khu vực: Chọn khu vực của bạn.
- Đối với Tên thẻ Chính sách: Nhập
MaskCustodianID - Đối với Nội dung mô tả của thẻ Chính sách:
Restricts visibility into cargo custodian usernames
- Tên phân loại: Nhập
- Nhấp vào Tạo để đăng ký hệ thống phân loại và thẻ chính sách mới.
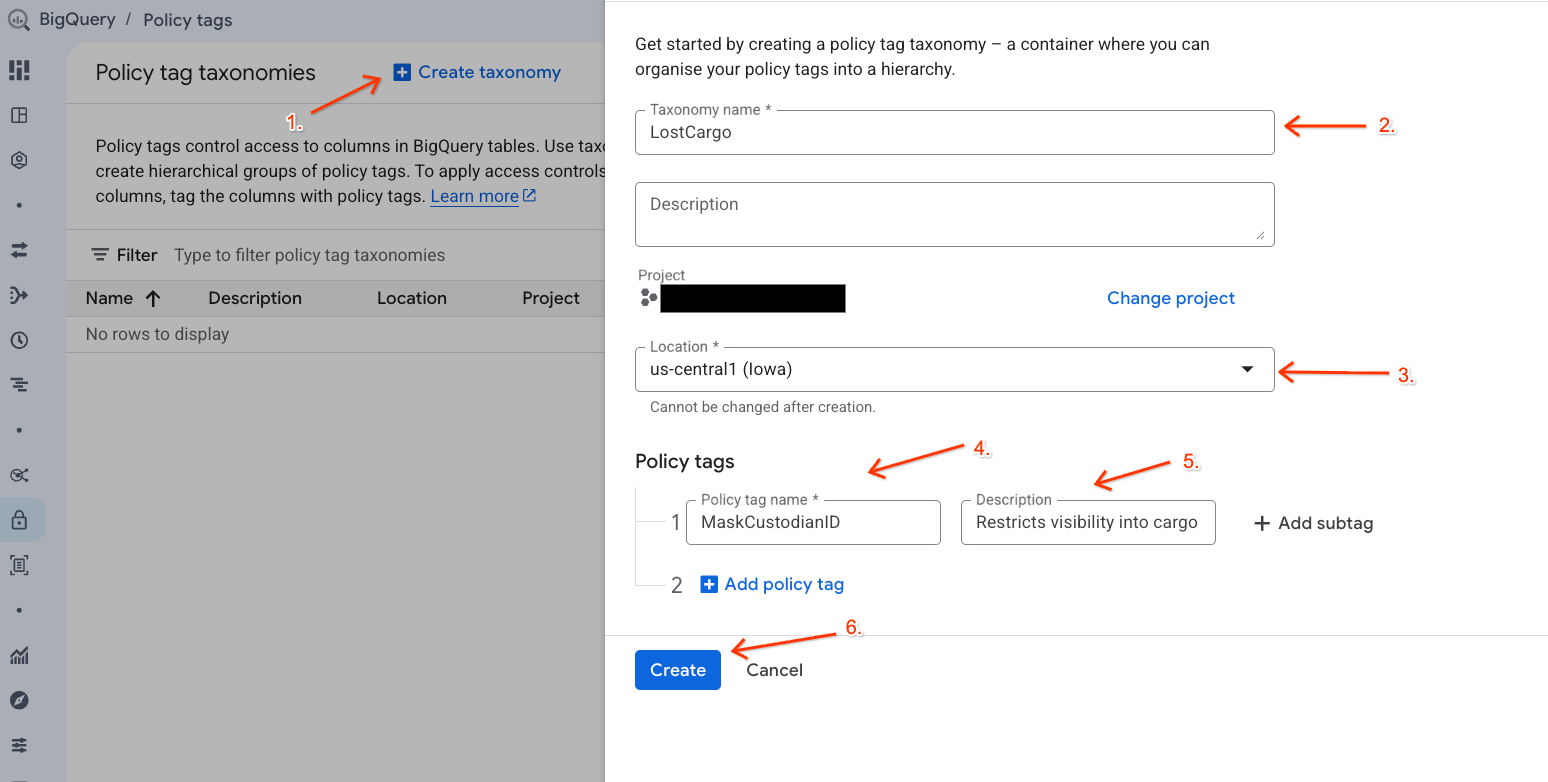
Tạo chính sách che giấu dữ liệu
Tiếp theo, hãy định cấu hình một chính sách dữ liệu để xác định cách dữ liệu được che giấu theo thẻ phân loại MaskCustodianID. Bạn sẽ sử dụng quy tắc che giấu Luôn có giá trị rỗng (thay thế các giá trị trùng khớp bằng giá trị trả về trống/rỗng cho tất cả các tác nhân không có đặc quyền).
- Trên trang Phân loại thẻ chính sách, hãy nhấp vào phân loại mới tạo trong danh sách phân loại.
- Trong danh sách phân cấp, hãy nhấp vào thẻ
MaskCustodianIDđể chọn thẻ đó, rồi chọn Quản lý chính sách dữ liệu.
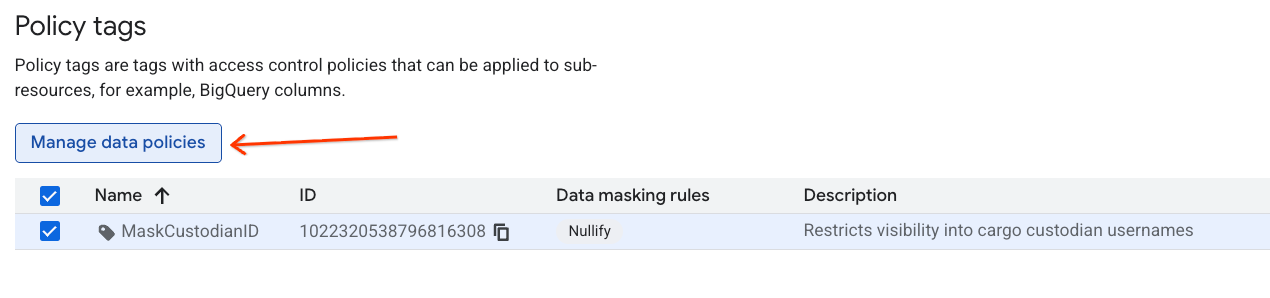
- Trên bảng điều khiển bên phải, hãy nhấp vào nút + Thêm quy tắc.
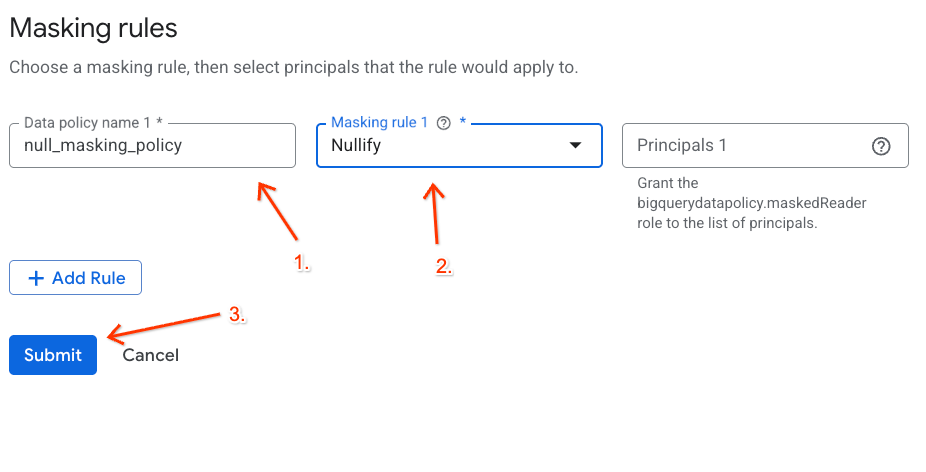
- Định cấu hình thông tin chi tiết về chính sách trong bảng điều khiển xuất hiện:
- Tên chính sách dữ liệu: Nhập
null_masking_policy(đừng để tên này tự động tạo vì chúng ta sẽ tham chiếu tên này trong các bước tiếp theo). - Quy tắc che giấu: Chọn biểu tượng
Nullifytrong trình đơn thả xuống.
- Tên chính sách dữ liệu: Nhập
- Nhấp vào Gửi.
Chỉ định Thẻ chính sách cho Cột BigQuery
Khi thẻ chính sách và quy tắc che dữ liệu của thẻ đó đang hoạt động, hãy liên kết trực tiếp thẻ phân loại với cột custodian_id trong bảng kê khai thông tin vận chuyển của đối tác trên BigQuery.
- Chuyển đến BigQuery.
- Trong bảng điều khiển Trình khám phá ở bên trái, hãy mở rộng dự án đang hoạt động, mở rộng tập dữ liệu
lost_cargo_datasetrồi nhấp vào bảngshipping_manifestsđể mở chế độ xem chi tiết của bảng đó. - Nhấp vào Chỉnh sửa giản đồ.
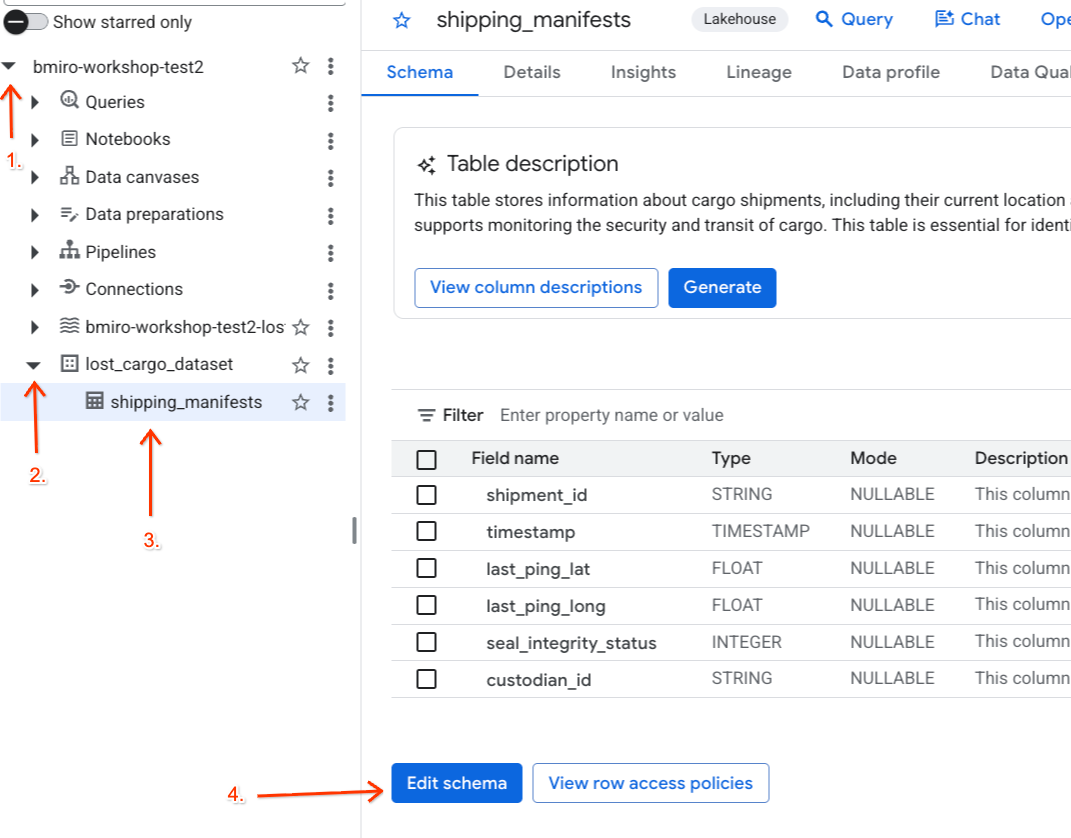
- Trong danh sách cột, hãy đánh dấu vào hộp bên cạnh biểu tượng
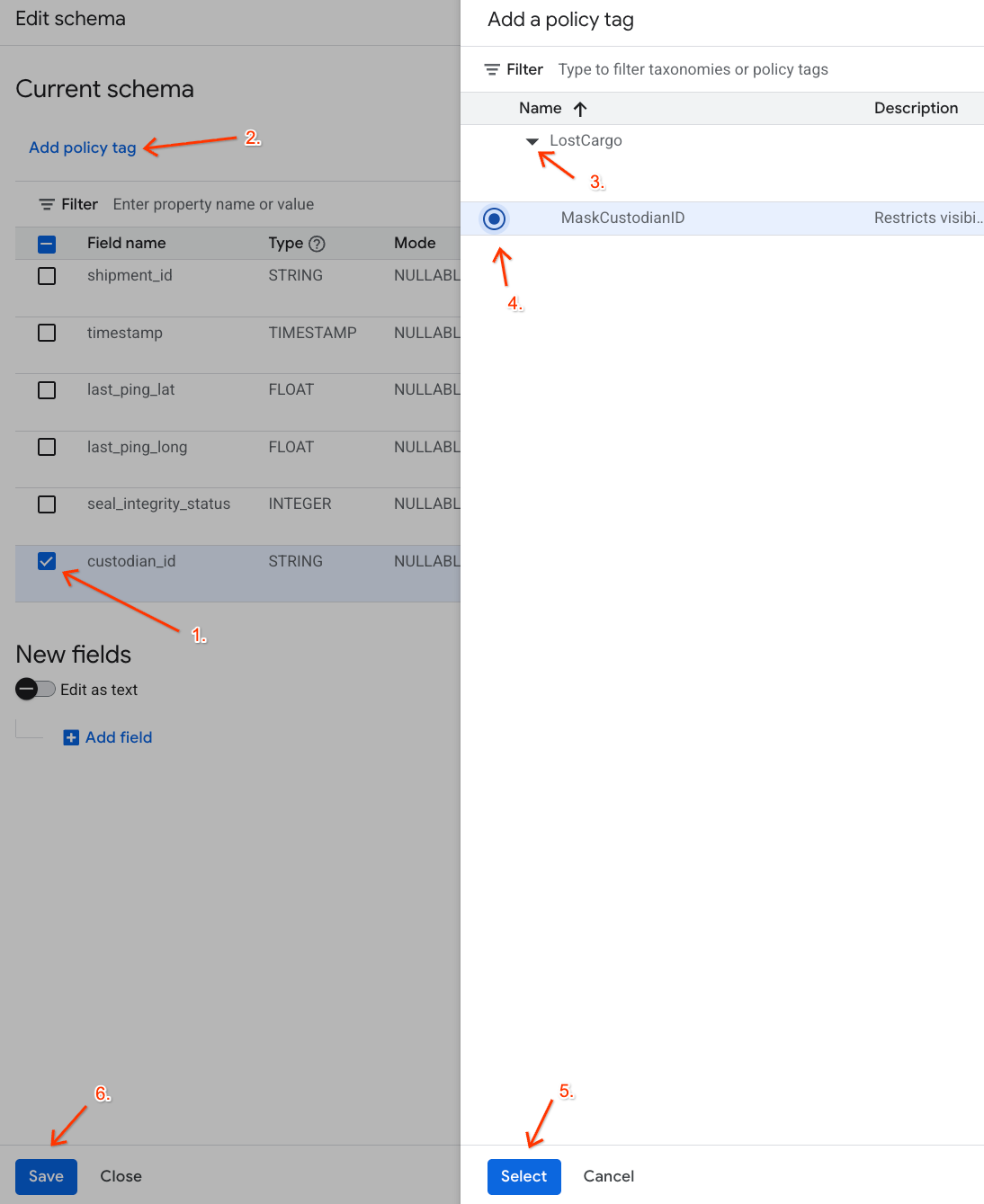
custodian_id. - Nhấp vào nút Thêm thẻ chính sách trên thanh công cụ trên cùng của trình chỉnh sửa giản đồ.
- Trong bảng điều khiển Thêm thẻ chính sách:
- Tìm và mở rộng hệ thống phân loại
LostCargo. - Chọn biểu tượng
MaskCustodianID. - Nhấp vào Chọn.
- Tìm và mở rộng hệ thống phân loại
- Xác minh rằng thẻ
MaskCustodianIDhiện đã xuất hiện trong cột Thẻ chính sách trong hàng đại diện chocustodian_id. - Nhấp vào Lưu.
Xác minh các quy định hạn chế theo chính sách
Giờ đây, khi có vai trò Masked Reader ở cấp dự án, bạn có thể truy vấn bảng để xác minh rằng chính sách che dữ liệu đang hoạt động.
Quay lại Data Agent Kit rồi chạy truy vấn sau:
SELECT shipment_id, custodian_id
FROM lost_cargo_dataset.shipping_manifests
LIMIT 5;
Bạn sẽ thấy kết quả tương tự như dưới đây:
shipment_id | custodian_id |
NORMAL-001 | null |
NORMAL-002 | null |
MV-CAT-001 | null |
Thành công! Mặc dù bạn có thể xem các bản ghi shipment_id, nhưng trường custodian_id nhạy cảm sẽ trả về các mặt nạ null bảo mật để ngăn chặn rò rỉ!
8. Dọn dẹp
Để tránh bị tính phí liên tục cho tài khoản Google Cloud của bạn đối với các tài nguyên được tạo trong lớp học lập trình này, hãy chạy các lệnh sau trong thiết bị đầu cuối Cloud Shell để thả các tập dữ liệu và bộ chứa của bạn:
# Verify active variables
export PROJECT_ID=$(gcloud config get-value project)
export BUCKET_NAME="${PROJECT_ID}-lost-cargo-lake"
# Delete Knowledge Catalog security taxonomies
export TAXONOMY_NAME=$(gcloud data-catalog taxonomies list --location=us-central1 --filter="displayName:LostCargo" --format="value(name)")
if [[ -n "$TAXONOMY_NAME" ]]; then
curl -X DELETE \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
"https://datacatalog.googleapis.com/v1/${TAXONOMY_NAME}" || true
fi
# Delete Lakehouse Iceberg REST Catalog tables and namespaces
gcloud biglake iceberg tables delete processed_maritime_logs \
--catalog=${BUCKET_NAME} \
--namespace=lost_cargo_namespace \
--quiet || true
gcloud biglake iceberg namespaces delete lost_cargo_namespace \
--catalog=${BUCKET_NAME} \
--quiet || true
# Delete Lakehouse Iceberg REST Catalog
gcloud biglake iceberg catalogs delete ${BUCKET_NAME} --quiet || true
# Delete dependencies bucket
gcloud storage rm -r gs://${BUCKET_NAME} || true
# Delete BigQuery dataset and tables
bq rm -r -f -d ${PROJECT_ID}:lost_cargo_dataset || true
9. Xin chúc mừng
Xin chúc mừng! Bạn đã hoàn tất thành công mô-đun quan trọng đầu tiên của cuộc điều tra về Hàng hoá bị thất lạc. Bạn đã thiết lập một vùng tìm kiếm được quản trị bằng cách sử dụng Danh mục REST của Lakehouse Iceberg, chuẩn hoá nhật ký PySpark và che dữ liệu chi tiết.
Kiến thức bạn học được
- Cài đặt, thiết lập và định cấu hình tiện ích Data Agent Kit trong không gian làm việc IDE của bạn.
- Thiết lập một danh mục REST Iceberg Lakehouse không máy chủ bằng cách sử dụng thông tin đăng nhập được cung cấp và không gian tên phân cấp.
- Tiếp nhận nguồn cấp dữ liệu theo khu vực có nhiều định dạng và tạo bảng bên ngoài BigQuery trên các vùng chứa Cloud Storage.
- Khởi chạy các công việc Apache Spark không máy chủ để phân tích cú pháp, chuẩn hoá, phân đoạn và ghi nhật ký bộ tiếp sóng không có cấu trúc trở lại BigQuery dưới dạng các bảng danh mục Iceberg đã đăng ký.
- Xây dựng hệ thống phân loại bảo mật và lập bản đồ các chính sách che giấu dữ liệu trong Danh mục kiến thức để ngăn chặn tình trạng rò rỉ danh tính trên các chỉ mục nhật ký nhạy cảm.
- Tạo và phân tích thông tin chi tiết về siêu dữ liệu của bảng bằng thông tin chi tiết về dữ liệu BigQuery để đẩy nhanh quá trình khám phá dữ liệu.
Xác minh thông tin thu thập được
Kiểm tra để đảm bảo bạn đã ghi lại những manh mối rõ ràng sau đây cần thiết để chuyển sang giai đoạn tiếp theo của phòng thí nghiệm:
- Mã lô hàng bị mất:
MV-CAT-001(vị trí ping gần đây nhất: London) - Đích đến dự kiến:
New York(và bí danh thực của bộ tiếp sóng:MV-DOG-002) - Màu vùng chứa:
Crimson RED - Thẻ quyền truy cập quản trị:
MaskCustodianID
Bạn đã sẵn sàng cho giai đoạn tiếp theo chưa?
Giờ đây, khi các tuyến đường Đi / Đến của bộ tiếp sóng đã an toàn, cuộc điều tra sẽ tiếp tục! Hãy bắt đầu ngay Phòng thí nghiệm 2 để kiểm tra camera an ninh bằng các mô hình Gemini đa phương thức, xác định tàu bằng hình ảnh và thực hiện tìm kiếm vectơ trong AlloyDB để xác minh các điểm bất thường do giả mạo!
➡️ Tiếp tục với Bước 2: Phân tích dữ liệu và thông tin chi tiết đa phương thức