
1. 简介
在本实验中,您将扮演一家全球物流公司首席数据调查员的角色。一个装有珍贵 Android 小雕像收藏品的高价值货运集装箱不见了!若要查找其最近一次已知位置并追踪其路线,您必须汇总来自区域物流合作伙伴的零散货运清单和非结构化应答器日志文件。为此,您将配置现代 Google Cloud 开放式数据湖仓一体架构。

您将执行的操作
- 在 Cloud Shell 编辑器中配置 Google Cloud Data Agent Kit 扩展程序。
- 创建 Cloud Storage 存储分区,并预配 Lakehouse Apache Iceberg REST Catalog 和命名空间。
- 将 BigLake 外部表映射到 Cloud Storage 中的原始 JSON 合作伙伴清单,以发现船只的出发线索。
- 使用托管式 Apache Spark 无服务器加载和处理非结构化应答器文本日志。执行正则表达式归一化和动态线索提取,以确定丢失的载荷目的地。
- 通过 REST Catalog 将已解析的日志指标写入为 Apache Iceberg 表。
- 使用对话式分析与 AI 智能体就 Apache Iceberg 数据进行对话,发现有关丢失货件的隐藏线索。
- 利用 Knowledge Catalog 自动生成有关数据的元数据,从而获得数据分析洞见。
- 通过创建安全分类法并使用 Knowledge Catalog,通过遮盖敏感的保管人 ID 来应用精细的访问权限控制,从而建立数据提取防护措施。
所需条件
- 网络浏览器,例如 Chrome。
- 启用了结算功能的 Google Cloud 项目。
- 熟悉基本的 SQL 查询和终端命令。
预期费用和时长
- 完成所需时间:约 45 分钟。
- 预计费用:不到 5.00 美元。
2. 准备工作
创建或选择 Google Cloud 项目
- 在 Google Cloud 控制台中,选择或创建 Google Cloud 项目。
- 确保您的 Cloud 项目已启用结算功能。了解如何确认项目已启用结算功能。
配置环境
您将通过 Cloud Shell 编辑器(一种基于云的开发环境,预加载了开发者工具和标准 Google Cloud SDK)中的集成式终端运行大部分命令。
- 在新标签页中打开 Cloud Shell 编辑器。
- 在终端中运行以下命令以克隆代码库:
cd ~/ git clone --filter=blob:none --no-checkout https://github.com/GoogleCloudPlatform/devrel-demos.git cd ~/devrel-demos git sparse-checkout init --cone git sparse-checkout set data-analytics/data-cloud-roadshow/lab1 git checkout main cd data-analytics/data-cloud-roadshow/lab1 - 设置项目 ID。您还可以按
Ctrl+Shift+V(在 Windows/Linux 上)或Cmd+V(在 macOS 上)将此内容粘贴到终端中:export PROJECT_ID="<YOUR_PROJECT_ID>" - 现在,在您的环境中配置该功能。
gcloud config set project $PROJECT_ID - 选择区域。
export REGION="<YOUR_REGION>" # Replace with the region you chose, such as "us-central1" - 启用所需的 API。
gcloud services enable \ bigquery.googleapis.com \ biglake.googleapis.com \ storage.googleapis.com \ dataplex.googleapis.com \ datacatalog.googleapis.com \ dataproc.googleapis.com \ aiplatform.googleapis.com \ cloudresourcemanager.googleapis.com \ serviceusage.googleapis.com \ cloudaicompanion.googleapis.com \ geminidataanalytics.googleapis.com
安装扩展程序
您现在将配置 Google Data Agent Kit 扩展程序,该工具可让您直接在 IDE 中与 Google Cloud 的数据工具进行交互。
- 在编辑器的左侧活动栏中,点击扩展程序图标(或在 Windows/Linux 上按
Ctrl+Shift+X,在 macOS 上按Cmd+X)。 - 在扩展程序搜索框中,输入:
Google Cloud Data Agent Kit - 从结果中选择官方扩展程序,然后点击安装。如果系统提示,请选择“是,我信任此作者”。
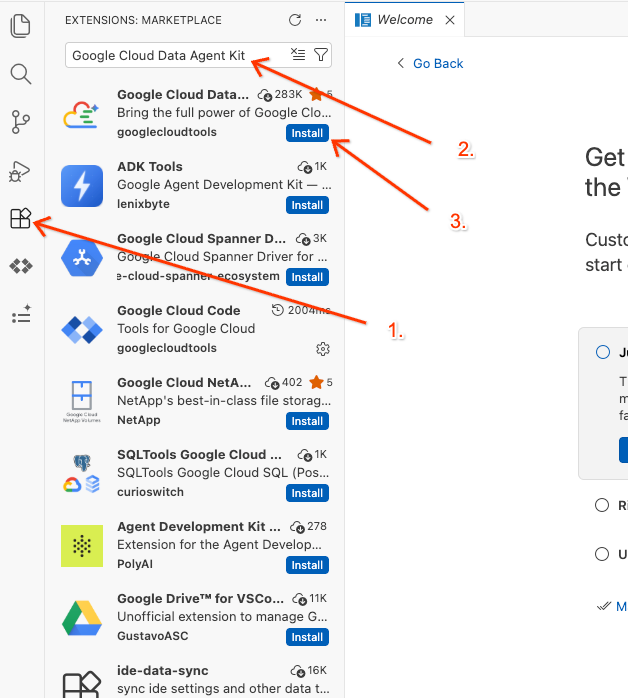
- 成功安装后,您应该会在活动栏中看到 Google Cloud Data Agent Kit 图标!点击该服务。
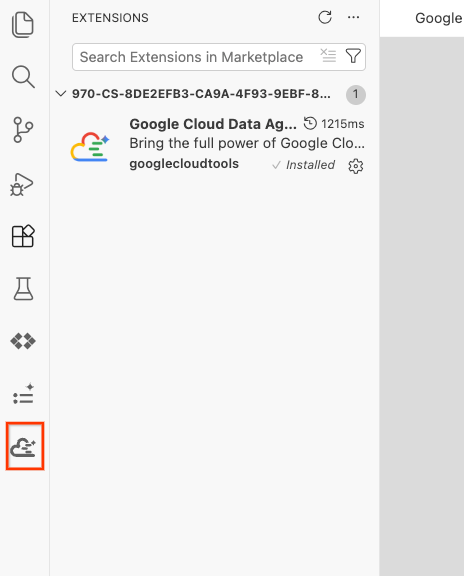
- 点击登录云端。
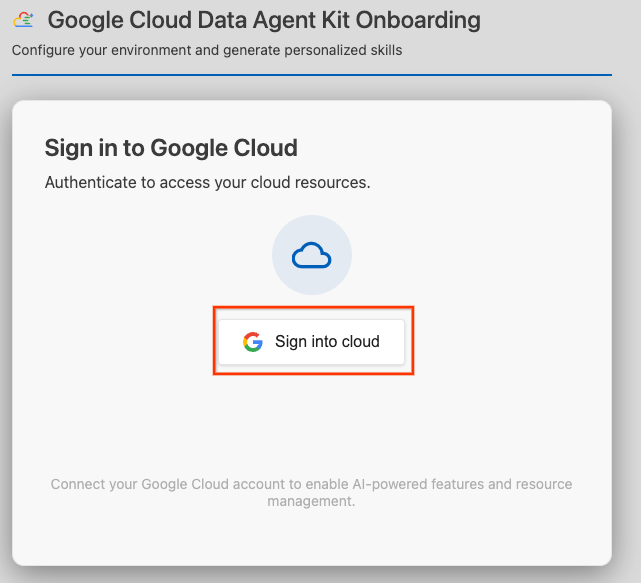
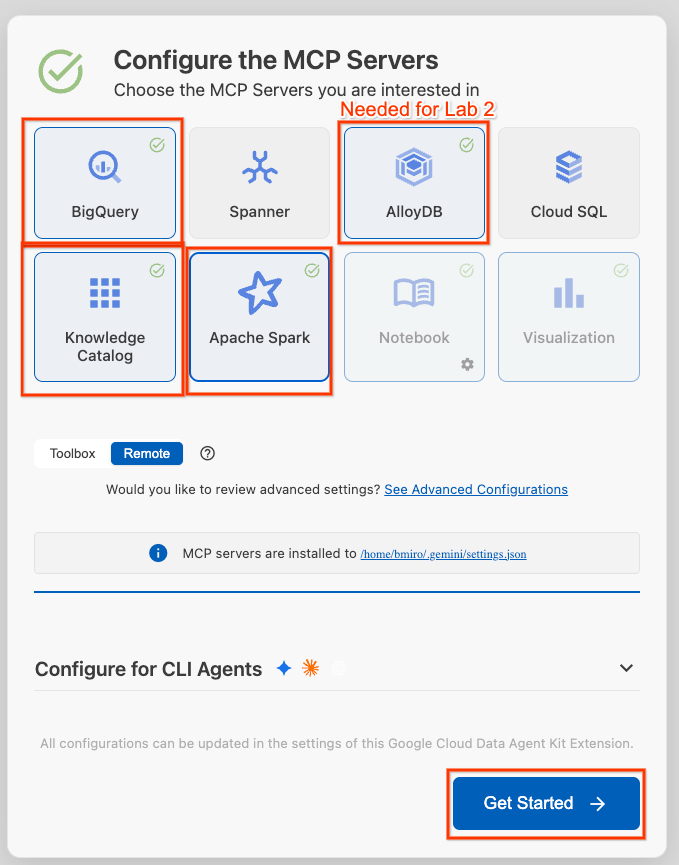
- 点击配置 MCP 服务器。
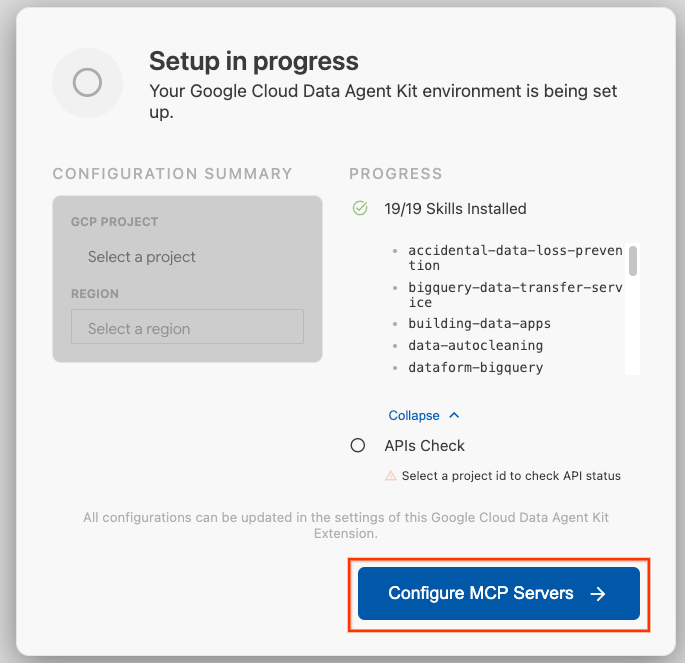
- 选择 BigQuery、Knowledge Catalog、Apache Spark 和 AlloyDB。您将在实验 2 中使用 AlloyDB。然后点击开始。
- 点击底部状态栏中的项目 ID 选择器,然后选择您的有效 Google Cloud 项目。
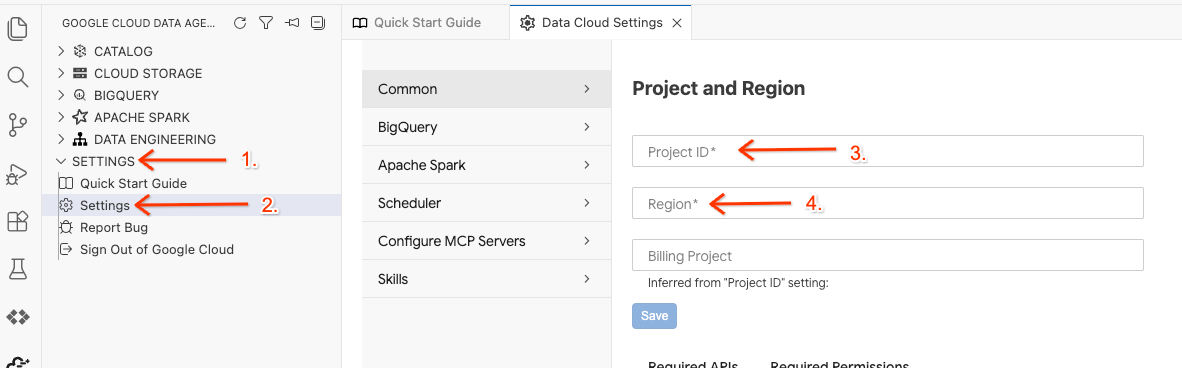
- 在 Data Agent Kit 中,依次点击 SETTINGS 和 Settings,然后在 Common 标签页中选择用于运行实验的项目 ID 和区域,例如 us-central1。
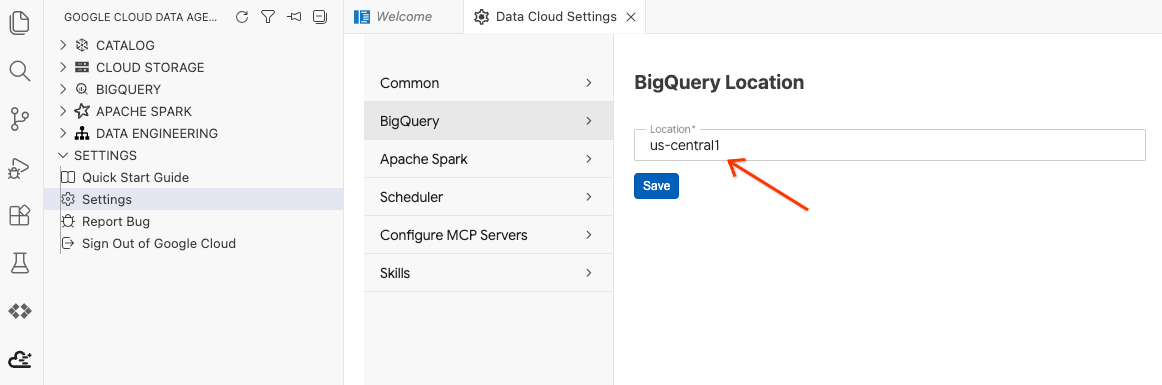
- 点击 BigQuery 设置,然后将区域替换为您之前选择的区域。点击保存。
您现在可以使用 Data Agent Kit 了!
执行环境设置脚本
在终端中,运行设置脚本,为本实验创建必要的后台资源并配置 IAM 权限:
chmod +x setup_lab1.sh
./setup_lab1.sh
source .env
您应该会看到一系列输出步骤,显示正在配置哪些资源。我们将在整个实验中介绍这些资源。
看到完成消息后,您就可以开始使用新账号了:
==================================================== Environment Setup Complete! ====================================================
现在,让我们开始搜索吧!
3. 提取合作伙伴运输清单
合作伙伴船只的运输清单数据以标准 JSON Lines (JSONL) 格式存储在您的存储分区中:gs://${PROJECT_ID}-lost-cargo-lake/shipping_manifests/manifests.jsonl。
在进行深入分析之前,您将为此非结构化数据创建一个受管控的 BigLake 表。这样一来,您就可以立即使用标准 SQL 探索合作伙伴的物流数据,而无需支付重复的导入费用。
在编辑器中打开工作区并运行查询
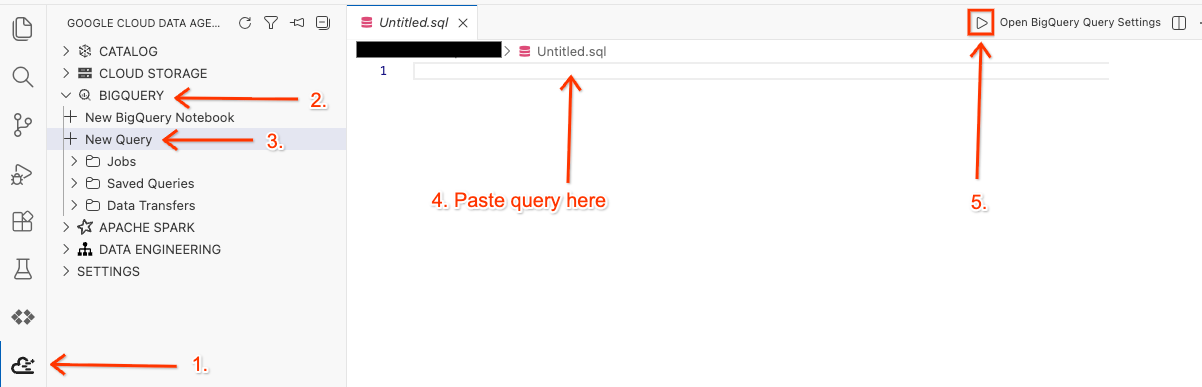
- 在 Cloud Shell 编辑器中,点击侧边栏上的 Google Cloud Data Agent Kit 扩展程序图标。
- 前往 BigQuery 并选择 + 新查询。
- 将以下查询复制到查询窗口中。
SET @@location = "<YOUR_REGION>"; --Update to your resource region, such as "us-central1". Make sure it is in quotes.
EXECUTE IMMEDIATE ("""
CREATE OR REPLACE EXTERNAL TABLE `lost_cargo_dataset.shipping_manifests`
(
shipment_id STRING,
timestamp TIMESTAMP,
last_ping_lat FLOAT64,
last_ping_long FLOAT64,
seal_integrity_status INT64,
custodian_id STRING OPTIONS(description='Masked identification token for official cargo custodian personnel.')
)
WITH CONNECTION `""" || @@location || """.conn`
OPTIONS (
format = 'NEWLINE_DELIMITED_JSON',
uris = ['gs://""" || @@project_id || """-lost-cargo-lake/shipping_manifests/*.jsonl']
)
""");
- 点击运行。
- 如需验证表是否已创建,您会在底部自动滑出的查询结果面板中看到一条成功消息。
查询外部表以隔离受入侵的应答器
我们来确定受损的应答器,方法是找到当 seal_integrity_status 设置为 0 时出现的故障。在之前打开的查询窗口中复制并运行以下查询:
SELECT shipment_id, last_ping_lat, last_ping_long, custodian_id
FROM `lost_cargo_dataset.shipping_manifests`
WHERE seal_integrity_status = 0;
在查询结果面板中,您应该会看到如下所示的输出:
shipment_id | last_ping_lat | last_ping_long | custodian_id |
MV-CAT-001 | 51.5074 | -0.1278 | usr_999_shadow |
4. 使用 Managed Service for Apache Spark 处理非结构化日志
您已从结构化清单中找到起始位置,但丢失的转发器已完全停止工作。最后一个转发器 ping 在 GCS 路径 gs://${BUCKET_NAME}/raw_logs/maritime_logs.txt 中的原始文本日志文件中留下了一条神秘的非结构化消息。
为了处理和映射此文本日志,提取时间戳,伪装身份,并找到货物的下游路线,您将向 Managed Service for Apache Spark 提交无服务器 Apache Spark (PySpark) 作业。
借助 Managed Service for Apache Spark,您可以运行 Spark 工作负载,而无需预配或管理集群。该服务会处理底层计算资源,动态自动扩缩这些资源,而您只需为执行时长付费。
该脚本将:
- 提取原始的带方括号的非结构化应答器文本。
- 应用 PySpark SQL 正则表达式提取过滤条件,以分离时间戳、保管人元数据和原始内容。
- 将杂乱的日志拆分为清晰的句子级记录。
- 提取丢失的载荷出发地所对应的动态目的地坐标目标。
- 连接并以新分析表的形式将处理后的日志 DataFrame 写回 Lakehouse Apache Iceberg REST 目录,该表可直接在 BigQuery 中查看。
修复 PySpark 分析脚本
有报告称,海上的 Python 海盗造成了各种各样的问题。
- 运行以下命令,在 Cloud Shell 编辑器中打开文件
process_maritime_logs。cd ~/devrel-demos/data-analytics/data-cloud-roadshow/lab1 cloudshell open ./process_maritime_logs.py - 花些时间阅读代码,了解其功能。
- 确保代码中没有任何可疑内容!如果您需要删除任何内容,请务必使用
Ctrl + S(Windows/Linux) 或Cmd + S(Mac) 保存文件。
提交无服务器 Spark 作业
使用 gcloud SDK 提交作业。该配置会自动配置 PySpark 作业以访问 Lakehouse 目录。
在集成编辑器终端中运行以下命令。
cd ~/devrel-demos/data-analytics/data-cloud-roadshow/lab1
source .env
gcloud dataproc batches submit pyspark process_maritime_logs.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--version=2.3 \
--deps-bucket=${BUCKET_NAME} \
--properties="\
spark.sql.defaultCatalog=cargo_catalog,\
spark.sql.catalog.${CATALOG_NAME}=org.apache.iceberg.spark.SparkCatalog,\
spark.sql.catalog.${CATALOG_NAME}.type=rest,\
spark.sql.catalog.${CATALOG_NAME}.uri=https://biglake.googleapis.com/iceberg/v1/restcatalog,\
spark.sql.catalog.${CATALOG_NAME}.warehouse=gs://${BUCKET_NAME},\
spark.sql.catalog.${CATALOG_NAME}.header.x-goog-user-project=${PROJECT_ID},\
spark.sql.catalog.${CATALOG_NAME}.rest.auth.type=org.apache.iceberg.gcp.auth.GoogleAuthManager,\
spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions,\
spark.sql.catalog.${CATALOG_NAME}.gcs.oauth2.refresh-credentials-endpoint=https://oauth2.googleapis.com/token, \
spark.sql.catalog.${CATALOG_NAME}.header.X-Iceberg-Access-Delegation=vended-credentials" \
-- ${BUCKET_NAME}
等待几分钟,让无服务器环境启动、上传脚本并执行处理逻辑。
看到类似如下所示的输出后,您处理过的表就会作为 Apache Iceberg 受管表保存到 Lakehouse 目录中!
Batch [1fae0b4b42c045a084dd67917bd0c332] finished.
metadata:
'@type': type.googleapis.com/google.cloud.dataproc.v1.BatchOperationMetadata
batch: projects/<YOUR_PROJECT>/locations/us-central1/batches/1fae0b4b42c045a084dd67917bd0c332
batchUuid: 611b4465-fdac-4974-bc47-5f10adaf2a08
createTime: '2026-06-11T21:35:01.868157Z'
description: Batch
labels:
goog-dataproc-batch-id: 1fae0b4b42c045a084dd67917bd0c332
goog-dataproc-batch-uuid: 611b4465-fdac-4974-bc47-5f10adaf2a08
goog-dataproc-drz-resource-uuid: batch-611b4465-fdac-4974-bc47-5f10adaf2a08
goog-dataproc-location: us-central1
operationType: BATCH
name: projects/<YOUR_PROJECT/regions/us-central1/operations/7e2044db-dd97-3270-b368-4dc4ba417574
预览已处理的日志
在 Data Agent Kit 扩展程序的查询编辑器中,复制以下查询以预览数据:
SET @@location = "<YOUR_REGION>"; -- e.g. "us-central1"
EXECUTE IMMEDIATE FORMAT("""
select log_timestamp, custodian_id, sentence from
`%s.%s-lost-cargo-lake.lost_cargo_namespace.processed_maritime_logs`
limit 5
""", @@project_id, @@project_id);
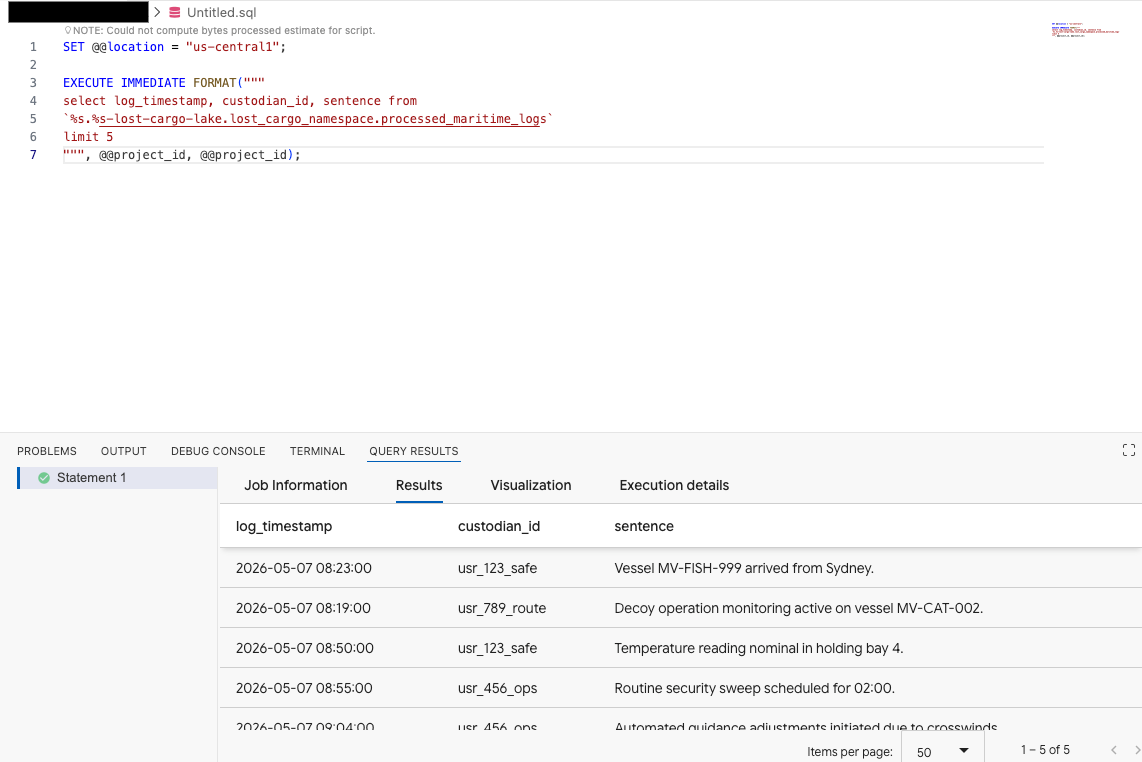
这表明,在目录中注册的 Iceberg 表可以成功从 BigQuery 访问!
提取目的地线索
现在,我们已经有了处理后的日志,接下来搜索包含目标位置的日志。然后,我们可以搜索包含我们出发城市信息的日志。
在查询编辑器中,运行以下查询,将 <YOUR_REGION> 替换为您的区域,并将 <ORIGIN_CITY> 替换为您之前发现的出发城市。
SET @@location = "<YOUR_REGION>"; --e.g. "us-central1"
DECLARE origin_city STRING;
SET origin_city = "<ORIGIN_CITY>"; --e.g. "Boston". (It's not Boston)
EXECUTE IMMEDIATE FORMAT(r"""
SELECT
log_timestamp AS event_time,
custodian_id,
REGEXP_EXTRACT(raw_message, r'Destination:\s*([^.]+)') AS destination_target
FROM
`%s.%s-lost-cargo-lake.lost_cargo_namespace.processed_maritime_logs`
WHERE
-- STRPOS is highly optimized in BigQuery for a simple .contains() substring check
STRPOS(sentence, '%s') > 0;
""", @@project_id, @@project_id, origin_city);
使用对话式分析在 BigQuery 控制台中与您的数据对话
您无需编写复杂的 SQL 查询来探索数据,而是可以使用对话式分析,通过自然语言与表进行对话!
- 前往 BigQuery 控制台。
- 在左侧的探索器面板中,展开您的项目和数据集
-lost-cargo-lake.lost_cargo_namespace processed_maritime_logs表以打开其详情标签页。 - 点击查询旁边的聊天。
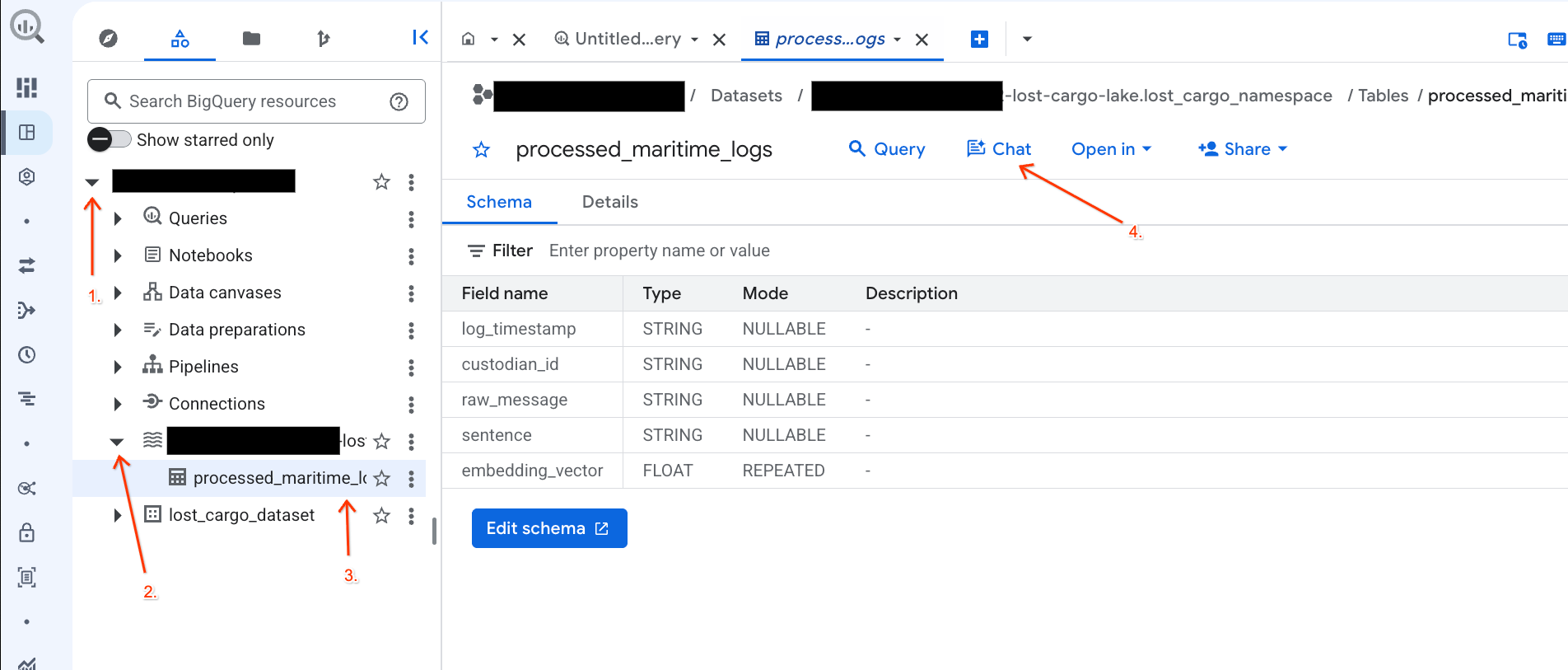
- 在聊天面板中,输入以下问题,然后按键盘上的 Enter 键发送:
Based on this table, what color is the shipping container MV-CAT-001?
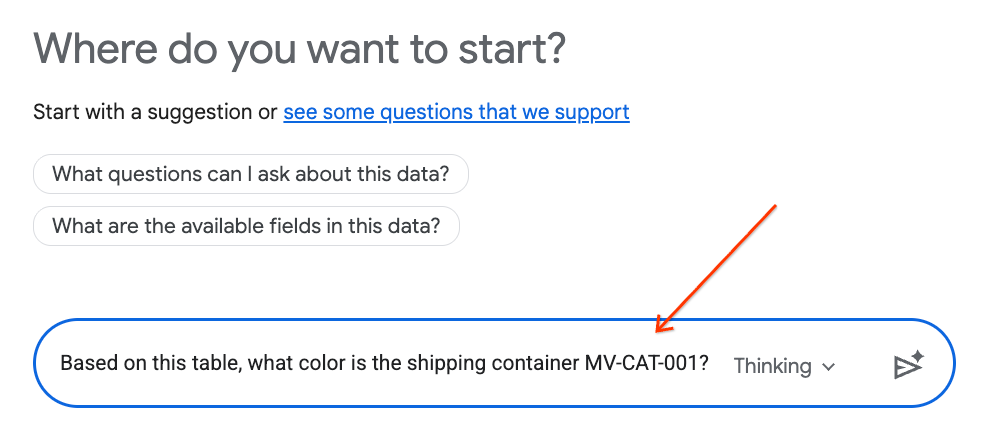
- 对话式分析(由 Gemini 提供支持)将分析有效表格的数据,并以颜色作为回答。
5. 查看集中式 Lakehouse 目录
为了将开源处理引擎(如 Apache Spark)与企业数据引擎(如 BigQuery)安全无缝地集成,您的设置脚本配置了 Lakehouse Iceberg REST 目录。
Apache Iceberg REST 目录充当无服务器的表元数据“单一可信来源”,可动态管理架构和分区表,同时将 Parquet 物理数据文件存储在 Cloud Storage 中。
我们直接在 Google Cloud 控制台中检查此目录:
- 打开 Lakehouse 控制台。
- 在目录标签页中,找到并点击有效的 Iceberg REST 目录:
-lost-cargo-lake
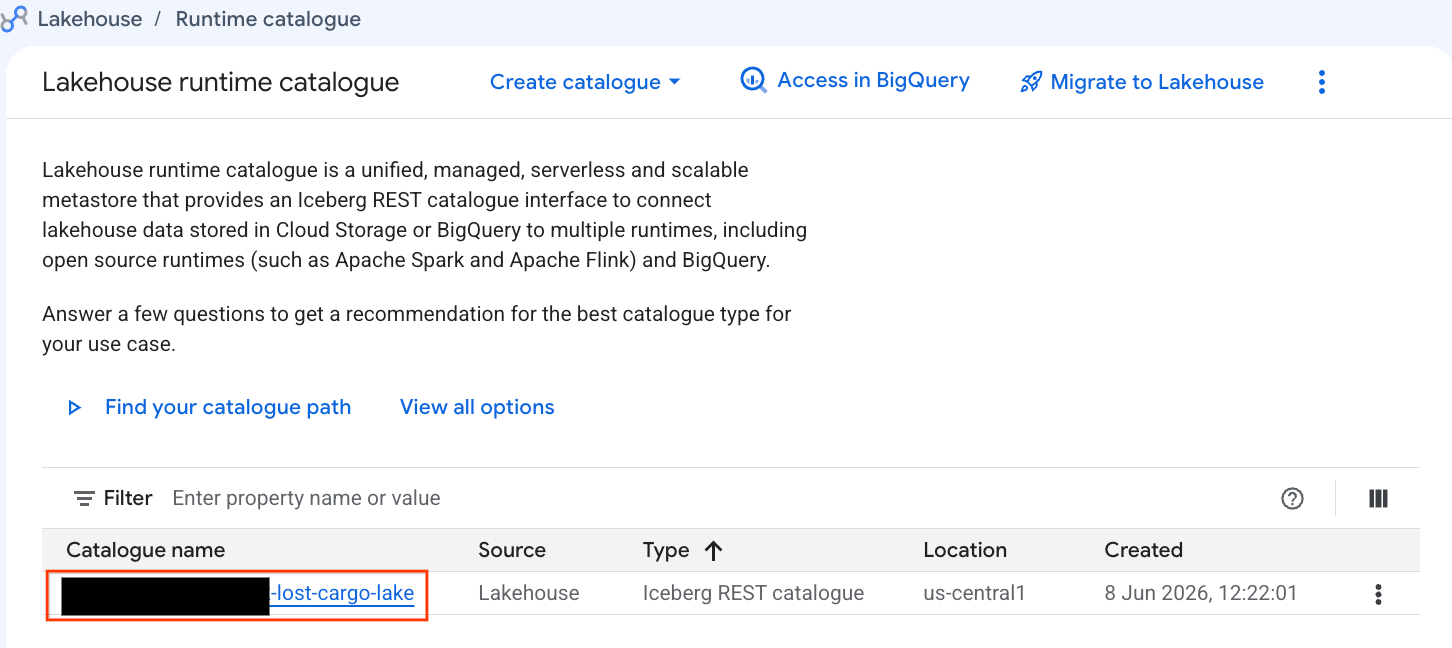
- 在目录详情视图中,您应该会在命名空间下看到
lost_cargo_namespace。点击此标签页。
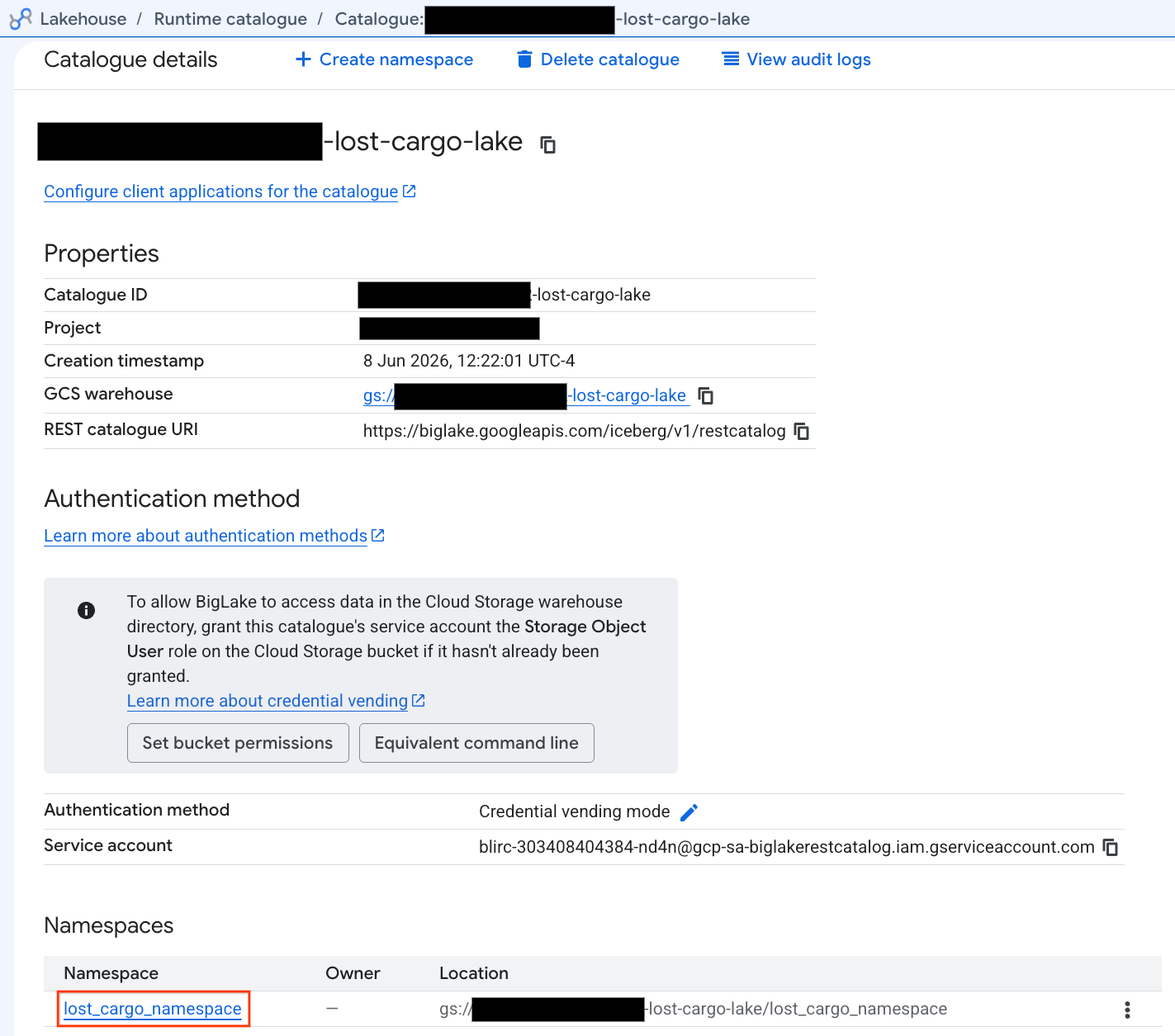
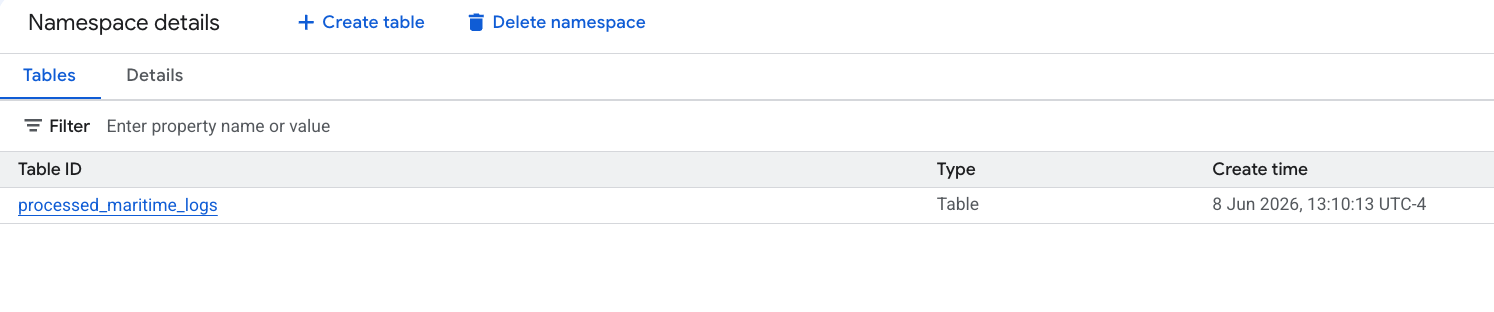
- 由 PySpark 生成的新 Apache Iceberg 表会自动在此 metastore 命名空间下注册,并可在 BigQuery 中立即查询!
6. 根据运输清单表生成数据分析
让我们返回并分析 shipping_manifests 表,使用 Knowledge Catalog 数据分析洞见了解其结构和内容。通过丰富元数据,其他探索者可以更好地了解该表,以便日后进行分析。
在 BigQuery Studio 中生成表格分析
- 在 Google Cloud 控制台中,前往 BigQuery Studio。
- 在探索器面板中,展开您的项目,展开
lost_cargo_dataset数据集,然后点击shipping_manifests表。 - 在右侧的详细信息面板中,点击数据洞见标签页。
- 使用下拉菜单选择生成并发布。
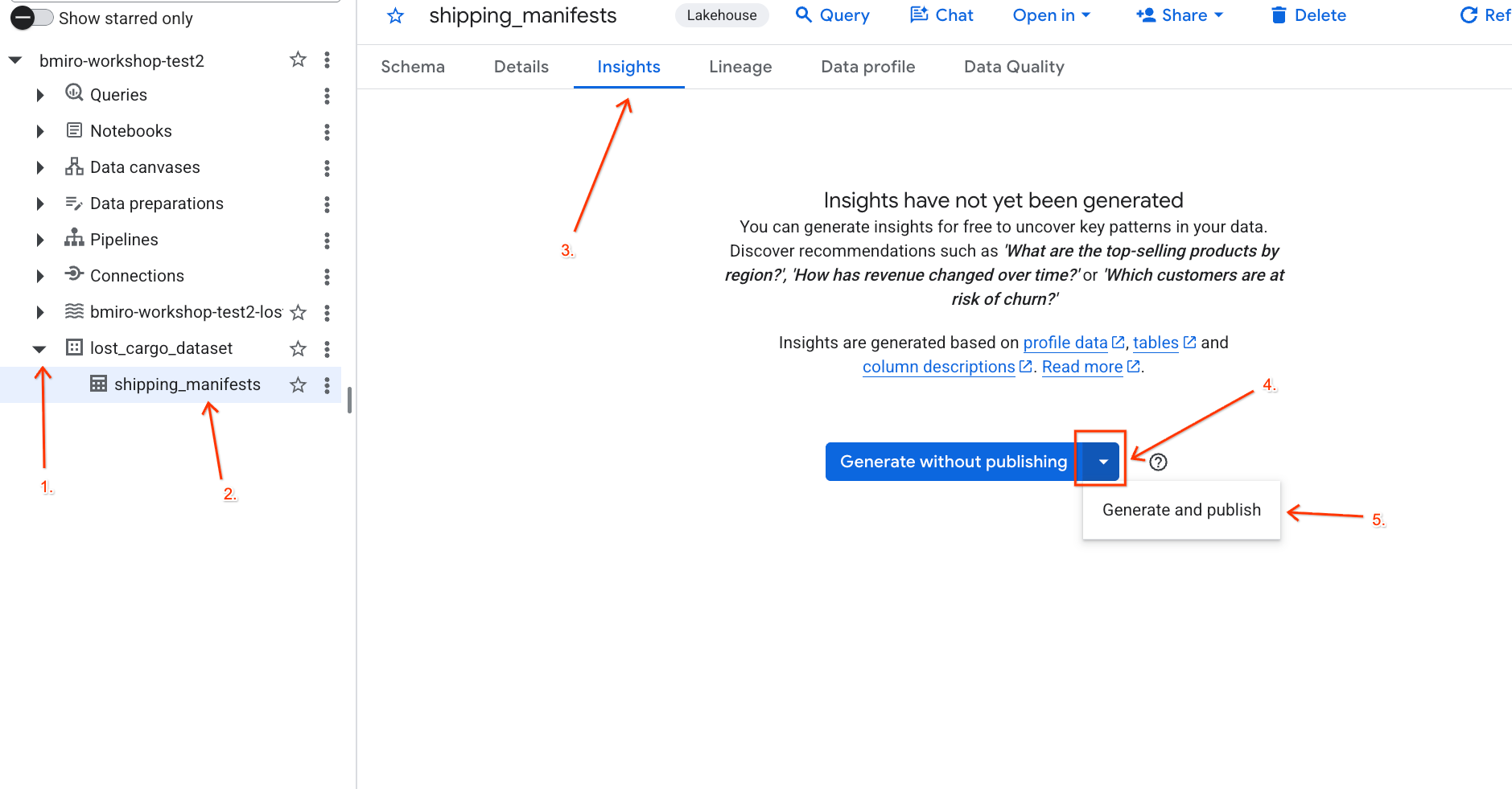
- 等待大约 3 分钟,直到数据分析生成完毕。Gemini 将分析表元数据,并生成自然语言问题和相应的 SQL 查询。
- 完成后,您会看到一个表格说明,其中包含表格的自然语言说明。
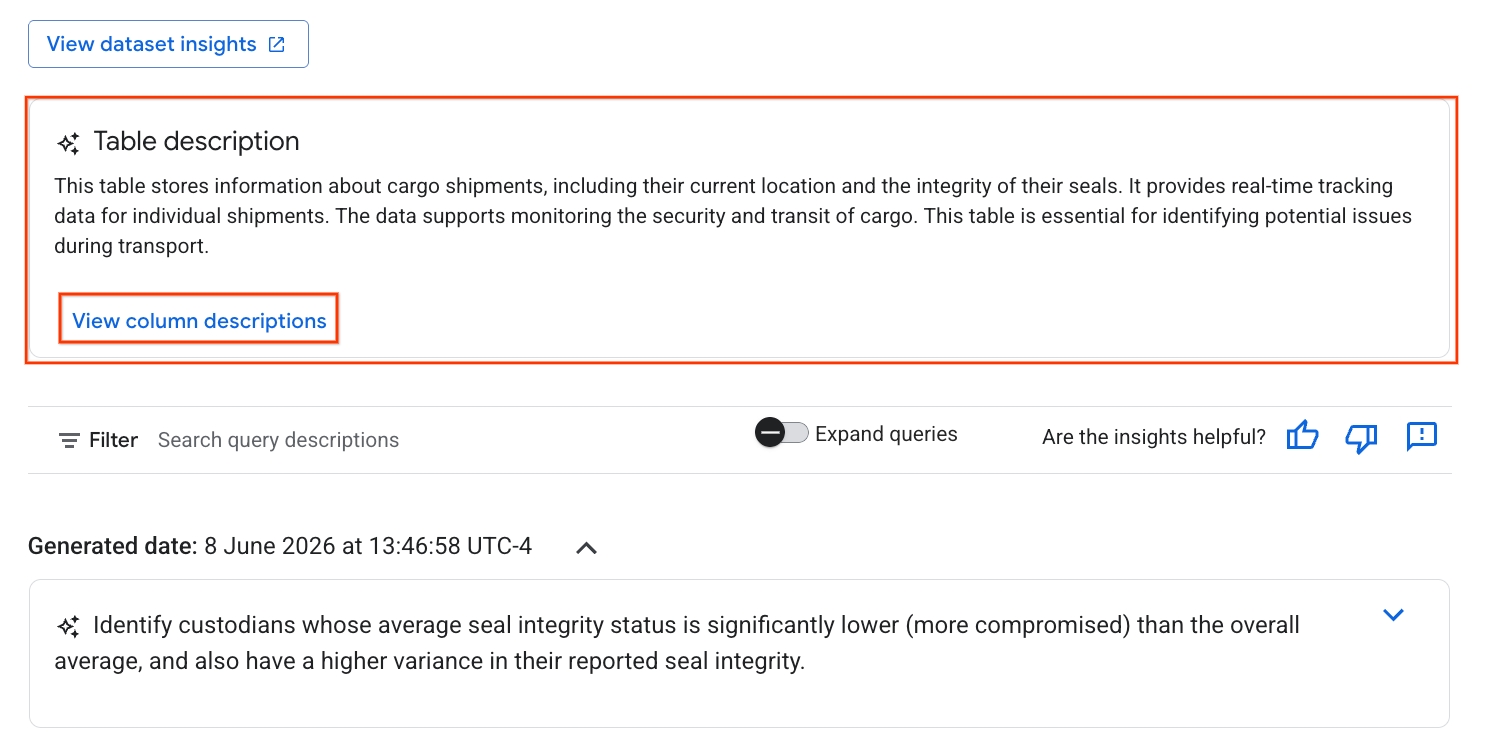
- 点击查看列说明,即可查看各个列的相关信息。
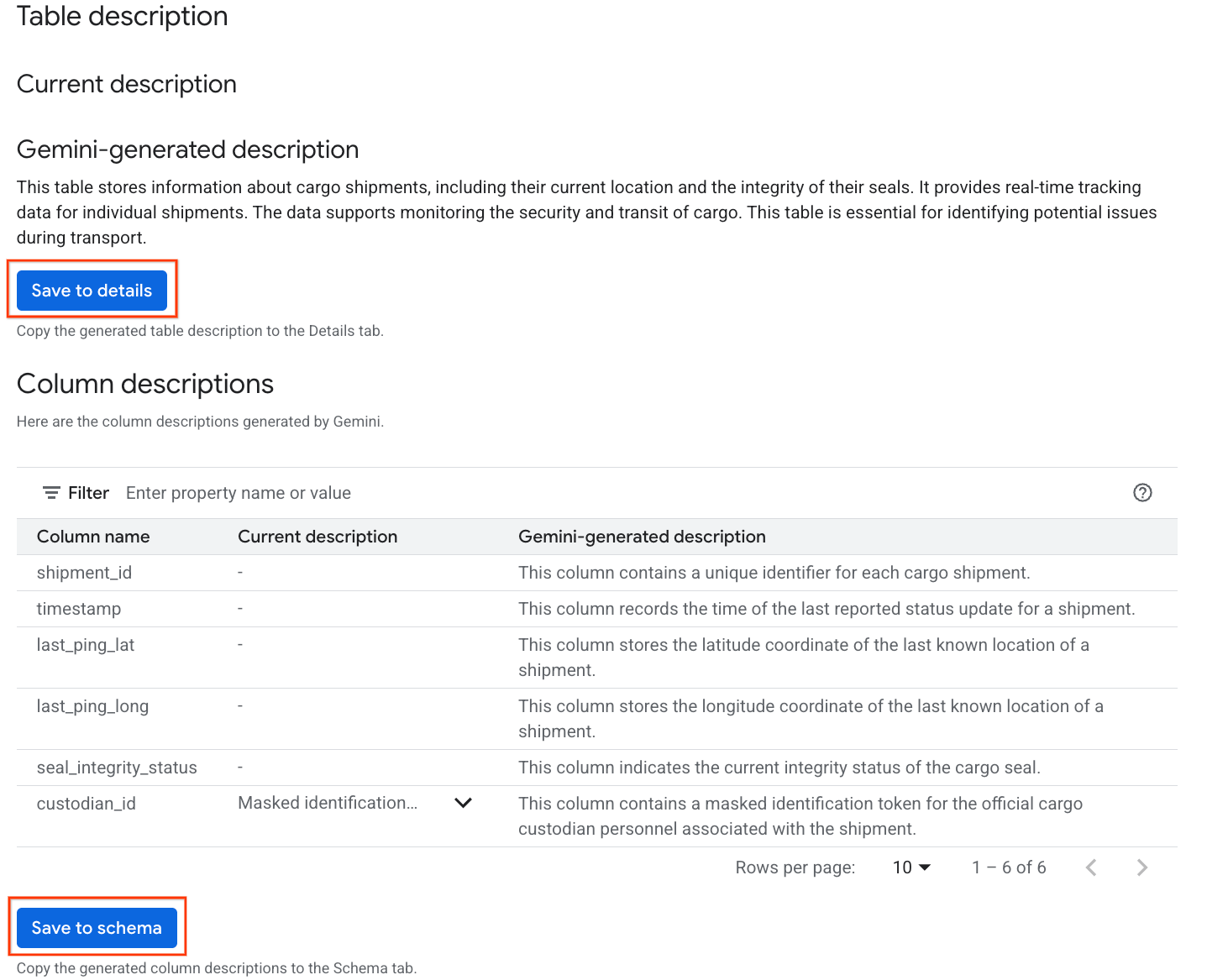
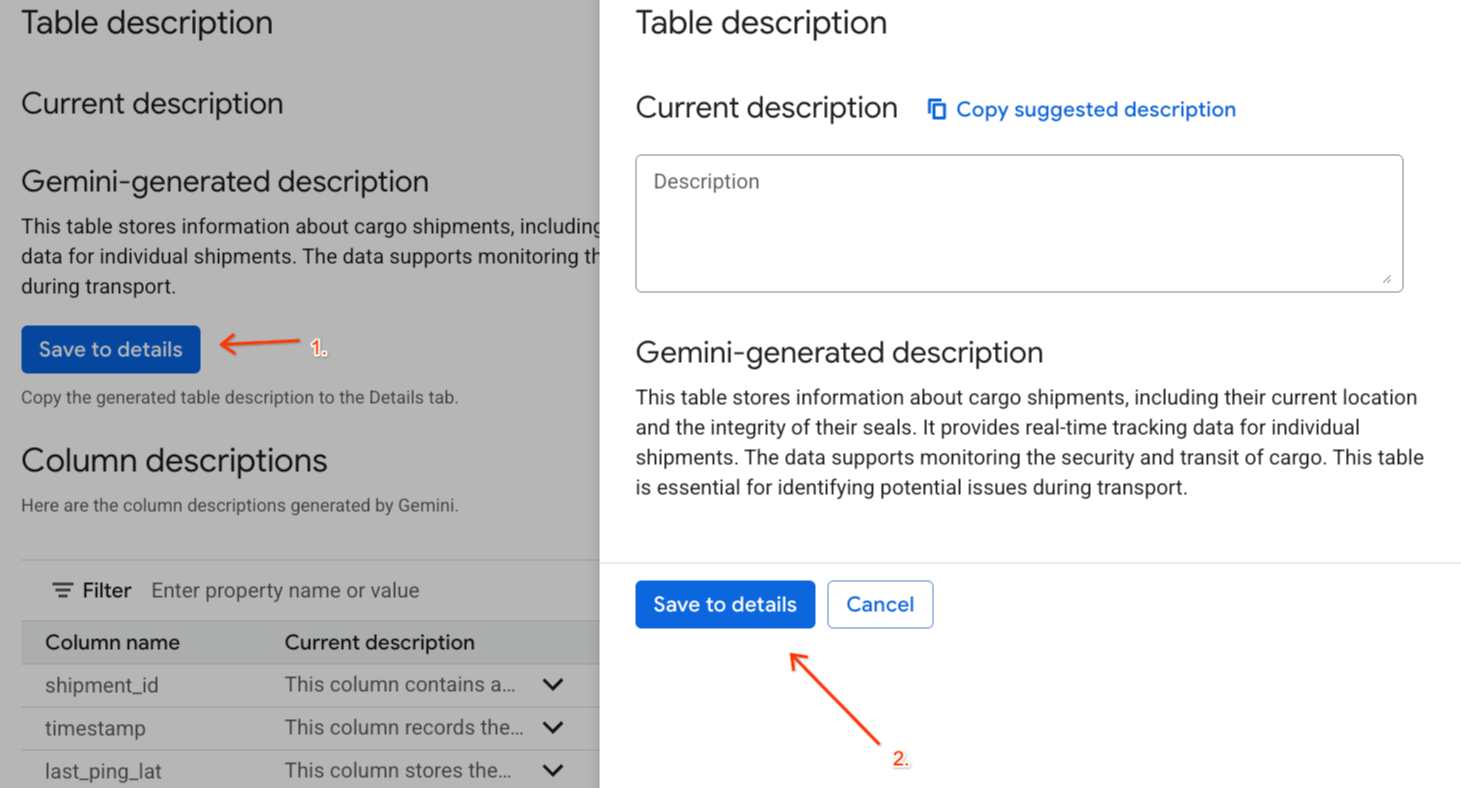
- 点击
Gemini generated description下方的保存到详细信息,然后在随即显示的窗口中点击保存到详细信息。
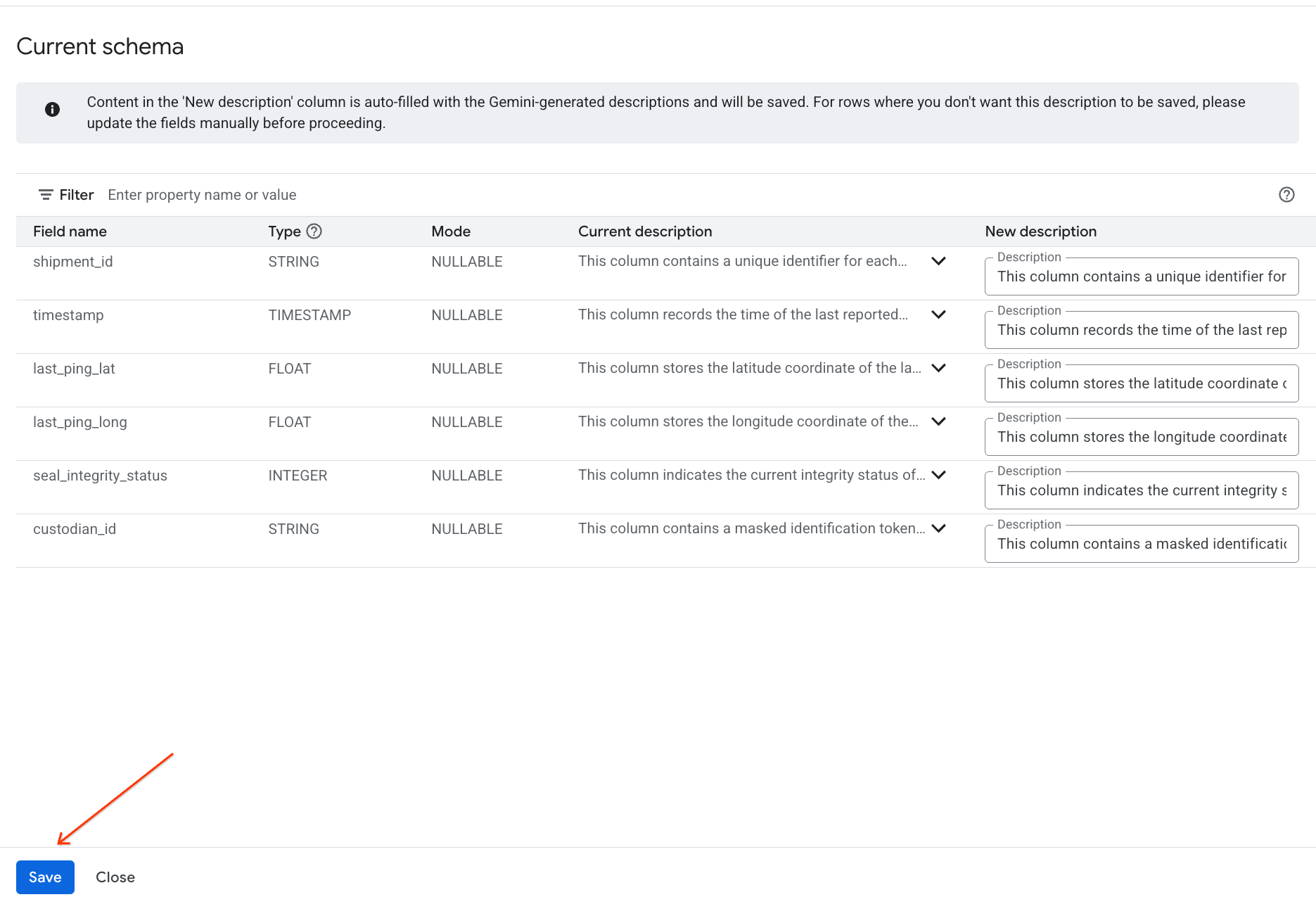
- 同样,点击保存到架构,将列说明添加到表格元数据中。
查看生成的分析洞见
您还会看到建议的问题列表。您可以点击任意问题,查看生成的 SQL 查询并运行该查询来探索数据。例如,您可能会看到以下问题:
- “总货件数是多少?”
- “列出唯一的保管人 ID。”
运行这些查询有助于您了解数据。
7. 实现数据遮盖和治理
为确保在当前进行的货物调查期间,活跃的研究账号和用户名不会泄露,您必须强制执行标准安全协议。您将创建一个安全政策标记分类,并针对敏感的 custodian_id 列配置 Knowledge Catalog 数据遮盖,以验证数据隐私权。
默认情况下,BigQuery 会拒绝访问受政策标记保护的列。如需查询表并验证有效的数据遮盖,您的用户账号必须拥有 BigQuery Data Policy Masked Reader 角色。
在您首次执行 setup_lab1.sh 时,此角色会自动绑定到您的有效用户账号!
创建分类和政策标记
创建数据分类和关联的政策标记,以便管理对数据的访问权限。
- 前往政策标记分类页面。
- 点击 + 创建分类。
- 配置参数:
- 分类群名称:输入
lost-cargo-,并将 替换为您的项目 ID。 - 区域:选择您所在的地区。
- 对于政策标记名称:输入
MaskCustodianID - 对于政策标记说明:
Restricts visibility into cargo custodian usernames
- 分类群名称:输入
- 点击创建以注册新的分类和政策标记。

创建数据遮盖政策
接下来,配置数据政策,以定义在 MaskCustodianID 分类标记下如何遮盖数据。您将使用始终为 Null 遮盖规则(将匹配的值替换为空/Null 返回值,适用于所有非特权行为者)。
- 在政策标记分类页面上,点击分类列表中的新创建的分类。
- 在层次结构列表中,点击
MaskCustodianID标记以选择它,然后选择管理数据政策。
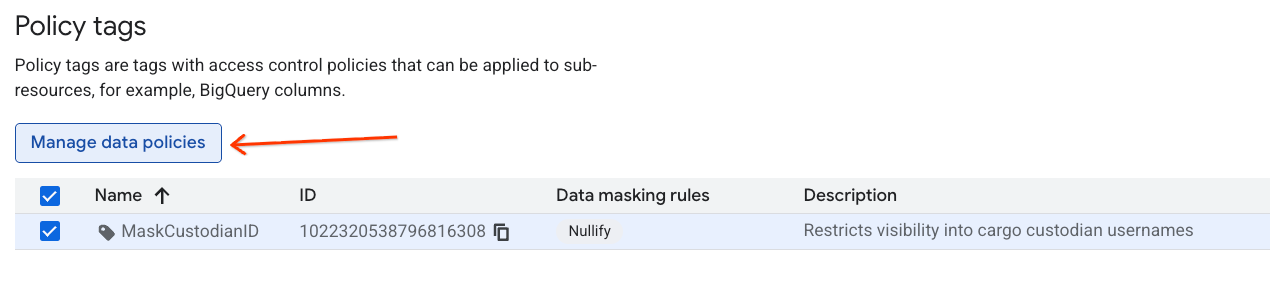
- 在右侧面板中,点击 + 添加规则按钮。
- 在显示的面板中配置政策详细信息:
- 数据政策名称:输入
null_masking_policy(请勿保留自动生成的名称,因为我们会在后续步骤中按名称引用它)。 - 遮盖规则:从下拉菜单中选择
Nullify。
- 数据政策名称:输入
- 点击提交。
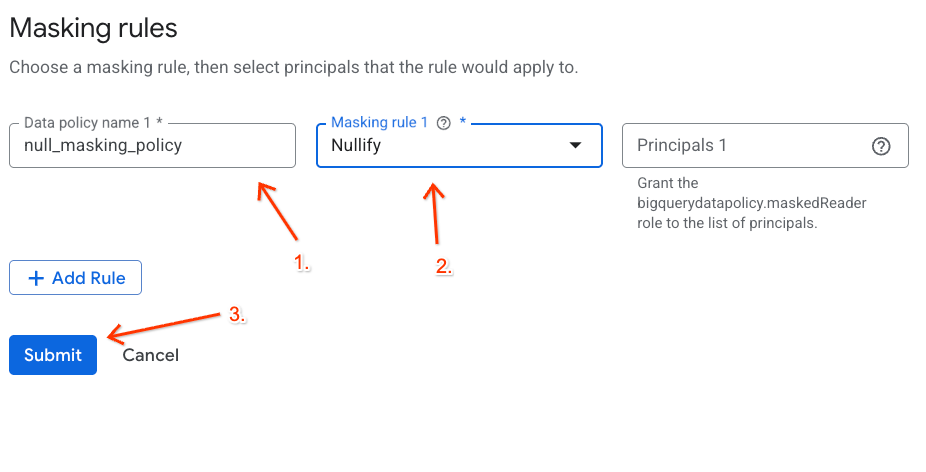
将政策标记分配给 BigQuery 列
在政策标记及其数据遮盖规则处于有效状态时,将分类标记直接映射到 BigQuery 合作伙伴配送清单表中的 custodian_id 列。
- 前往 BigQuery 控制台。
- 在左侧的探索器面板中,展开您的有效项目,展开
lost_cargo_dataset数据集,然后点击shipping_manifests表以打开其详细视图。 - 点击修改架构。
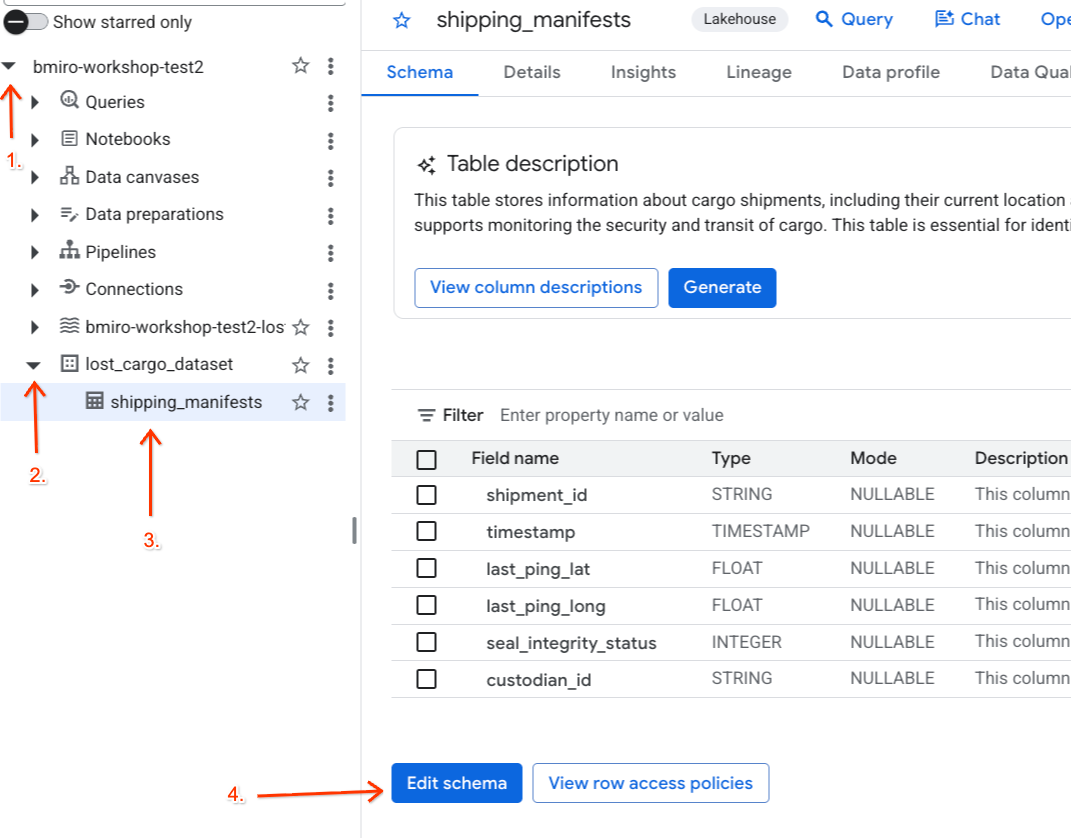
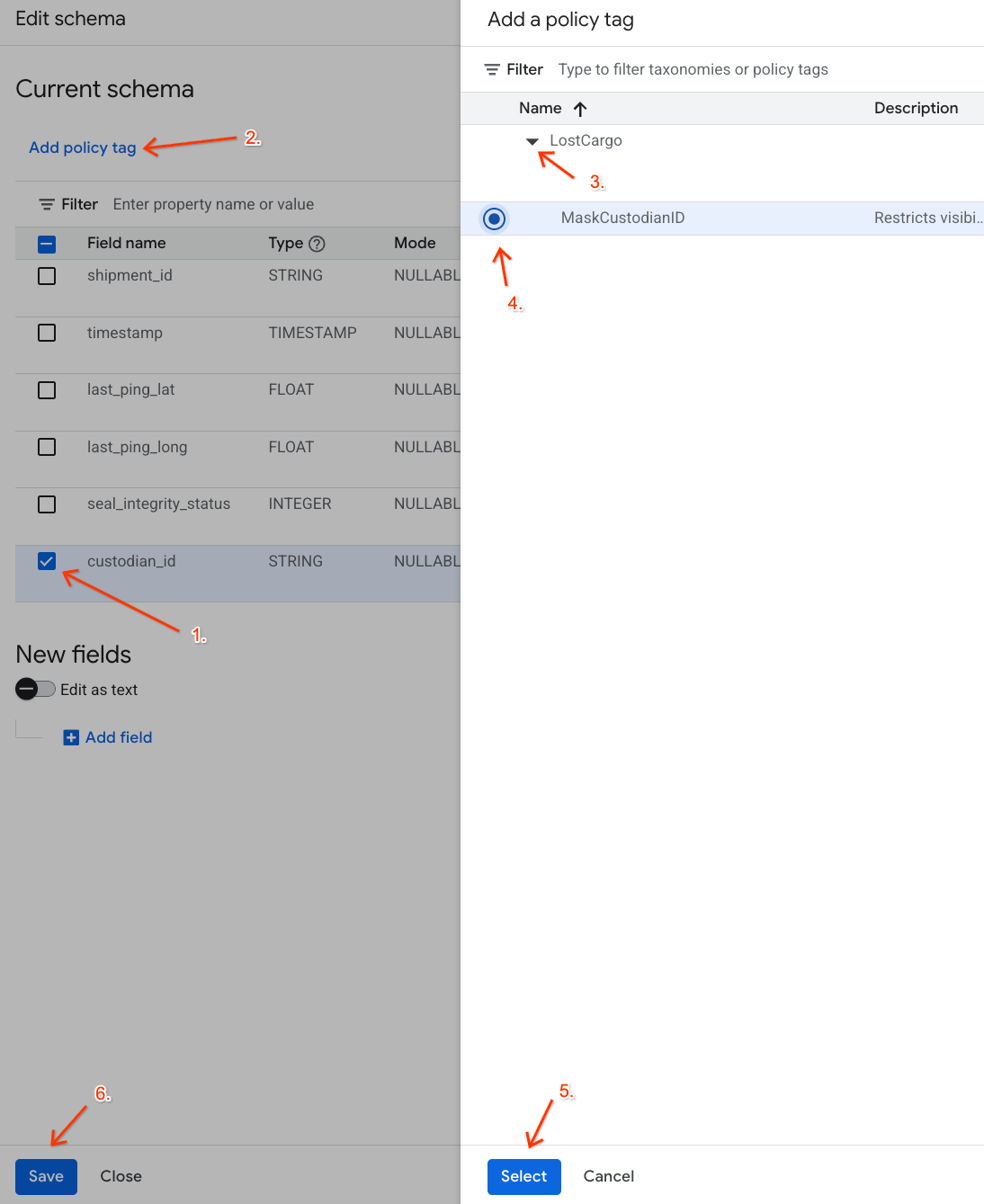
- 在列列表中,选中
custodian_id旁边的复选框。 - 点击架构编辑器顶部工具栏中的添加政策标记按钮。
- 在添加政策标记面板中:
- 找到并展开
LostCargo分类体系。 - 选择
MaskCustodianID旁边的圆圈。 - 点击选择。
- 找到并展开
- 验证代表
custodian_id的行中的政策标记列下现在是否显示MaskCustodianID标记。 - 点击保存。
验证政策限制
现在,您已在项目级层拥有 Masked Reader 角色,可以查询该表以验证遮盖政策是否处于有效状态。
返回到 Data Agent Kit 并运行以下查询:
SELECT shipment_id, custodian_id
FROM lost_cargo_dataset.shipping_manifests
LIMIT 5;
您应看到类似于以下内容的输出:
shipment_id | custodian_id |
NORMAL-001 | null |
NORMAL-002 | null |
MV-CAT-001 | null |
大功告成!即使您可以查看 shipment_id 记录,敏感的 custodian_id 字段也会返回安全的 null 遮盖,以防止泄露!
8. 清理
为避免系统因本 Codelab 中创建的资源向您的 Google Cloud 账号持续收取费用,请在 Cloud Shell 终端中运行以下命令,以删除您的数据集和存储分区:
# Verify active variables
export PROJECT_ID=$(gcloud config get-value project)
export BUCKET_NAME="${PROJECT_ID}-lost-cargo-lake"
# Delete Knowledge Catalog security taxonomies
export TAXONOMY_NAME=$(gcloud data-catalog taxonomies list --location=us-central1 --filter="displayName:LostCargo" --format="value(name)")
if [[ -n "$TAXONOMY_NAME" ]]; then
curl -X DELETE \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
"https://datacatalog.googleapis.com/v1/${TAXONOMY_NAME}" || true
fi
# Delete Lakehouse Iceberg REST Catalog tables and namespaces
gcloud biglake iceberg tables delete processed_maritime_logs \
--catalog=${BUCKET_NAME} \
--namespace=lost_cargo_namespace \
--quiet || true
gcloud biglake iceberg namespaces delete lost_cargo_namespace \
--catalog=${BUCKET_NAME} \
--quiet || true
# Delete Lakehouse Iceberg REST Catalog
gcloud biglake iceberg catalogs delete ${BUCKET_NAME} --quiet || true
# Delete dependencies bucket
gcloud storage rm -r gs://${BUCKET_NAME} || true
# Delete BigQuery dataset and tables
bq rm -r -f -d ${PROJECT_ID}:lost_cargo_dataset || true
9. 恭喜
恭喜!您已成功完成丢失的货物调查的第一个关键模块。您已使用 Lakehouse Iceberg REST 目录、PySpark 日志规范化和精细的数据遮盖功能建立受治理的搜索区。
您学到的内容
- 在 IDE 工作区中安装、设置和配置 Data Agent Kit 扩展程序。
- 建立利用供应商提供的凭据和分层命名空间的无服务器 Lakehouse Iceberg REST 目录。
- 提取多种形式的区域性 Feed,并在 Cloud Storage 存储分区中构建 BigQuery 外部表。
- 启动无服务器 Apache Spark 作业,以解析、规范化、分段和将非结构化应答器日志写回 BigQuery,作为已注册的 Iceberg 目录表。
- 构建安全分类法并映射 Knowledge Catalog 数据遮盖政策,以防止敏感日志索引中的身份信息泄露。
- 使用 BigQuery 数据洞察生成和分析表元数据洞见,以加快数据探索速度。
收集线索验证
验证您是否已记录以下明确的线索,以便进入下一个实验阶段:
- 丢失的运单 ID:
MV-CAT-001(上次 ping 的位置:伦敦) - 计划目标目的地:
New York(以及转发器真实别名:MV-DOG-002) - 容器颜色:
Crimson RED - 治理访问权限标记:
MaskCustodianID
准备好进入下一阶段了吗?
现在,应答器的出发地 / 目的地路线已安全,调查可以继续进行!直接进入实验 2,使用多模态 Gemini 模型检查安全摄像头,直观地识别船只,并在 AlloyDB 中执行向量搜索,以验证篡改异常!