
1. 簡介
在本實驗室中,您將扮演全球物流公司的資料調查主管。裝有珍貴 Android 公仔收藏品的高價值貨櫃不翼而飛!如要找出最後已知位置並追蹤路線,您必須彙整區域物流合作夥伴提供的零碎貨運清單,以及非結構化應答器記錄檔。為此,您將設定現代 Google Cloud 開放資料湖倉。

學習內容
- 在 Cloud Shell 編輯器中設定 Google Cloud Data Agent Kit 擴充功能。
- 建立 Cloud Storage 值區,並佈建 Lakehouse Apache Iceberg REST 目錄和命名空間。
- 將 BigLake 外部資料表對應至 Cloud Storage 中的原始 JSON 合作夥伴資訊清單,找出船隻出發線索。
- 使用 Managed Service for Apache Spark 無伺服器服務,載入及處理非結構化應答器文字記錄。執行正規運算式正規化和動態線索擷取作業,找出遺失的酬載目的地。
- 透過 REST 目錄,將剖析的記錄指標寫入 Apache Iceberg 資料表。
- 使用對話式數據分析與 AI 代理對話,瞭解 Apache Iceberg 資料,找出遺失貨物的隱藏線索。
- 運用 Knowledge Catalog 的自動資料洞察功能,產生資料中繼資料。
- 建立安全分類,並使用 Knowledge Catalog 遮蓋機密保管人 ID,以實施精細的存取控管,建立資料擷取防護機制。
軟硬體需求
- 網路瀏覽器,例如 Chrome。
- 已啟用計費功能的 Google Cloud 專案。
- 熟悉基本的 SQL 查詢和終端機指令。
預計費用和時間長度
- 完成時間:約 45 分鐘。
- 預估費用:不到 $5.00 美元。
2. 事前準備
建立或選取 Google Cloud 專案
- 在 Google Cloud 控制台中,選取或建立 Google Cloud 專案。
- 確認 Cloud 專案已啟用計費功能。瞭解如何確認專案已啟用計費功能。
設定環境
您將透過 Cloud Shell 編輯器的整合式終端機執行大部分指令。這個雲端開發環境已預先載入開發人員工具和標準 Google Cloud SDK。
- 在新分頁中開啟 Cloud Shell 編輯器。
- 在終端機中執行下列指令,複製存放區:
cd ~/ git clone --filter=blob:none --no-checkout https://github.com/GoogleCloudPlatform/devrel-demos.git cd ~/devrel-demos git sparse-checkout init --cone git sparse-checkout set data-analytics/data-cloud-roadshow/lab1 git checkout main cd data-analytics/data-cloud-roadshow/lab1 - 設定專案 ID。您也可以在 Windows/Linux 上按
Ctrl+Shift+V,或在 macOS 上按Cmd+V,將專案 ID 貼到終端機:export PROJECT_ID="<YOUR_PROJECT_ID>" - 現在請在環境中設定。
gcloud config set project $PROJECT_ID - 選取區域。
export REGION="<YOUR_REGION>" # Replace with the region you chose, such as "us-central1" - 啟用必要的 API。
gcloud services enable \ bigquery.googleapis.com \ biglake.googleapis.com \ storage.googleapis.com \ dataplex.googleapis.com \ datacatalog.googleapis.com \ dataproc.googleapis.com \ aiplatform.googleapis.com \ cloudresourcemanager.googleapis.com \ serviceusage.googleapis.com \ cloudaicompanion.googleapis.com \ geminidataanalytics.googleapis.com
安裝擴充功能
現在要設定 Google Data Agent Kit 擴充功能,這個工具可直接在 IDE 中與 Google Cloud 的資料工具互動。
- 在編輯器的左側活動列中,按一下「擴充功能」圖示 (或在 Windows/Linux 上按
Ctrl+Shift+X,在 macOS 上按Cmd+X)。 - 在擴充功能搜尋框中輸入:
Google Cloud Data Agent Kit - 從結果中選取官方擴充功能,然後按一下「安裝」。如果系統提示,請選取「是,我信任作者」。
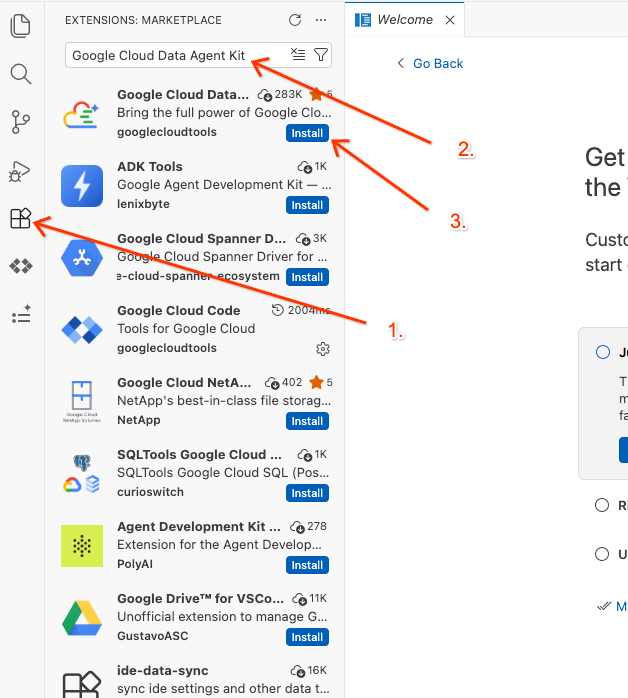
- 成功安裝後,活動列中會顯示 Google Cloud Data Agent Kit 圖示。請點選該服務。
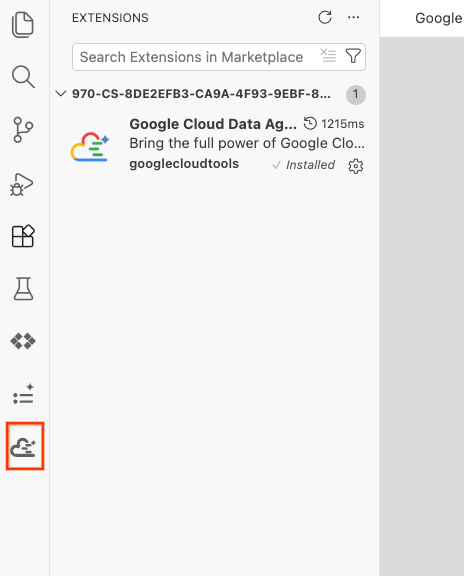
- 按一下「登入雲端」。
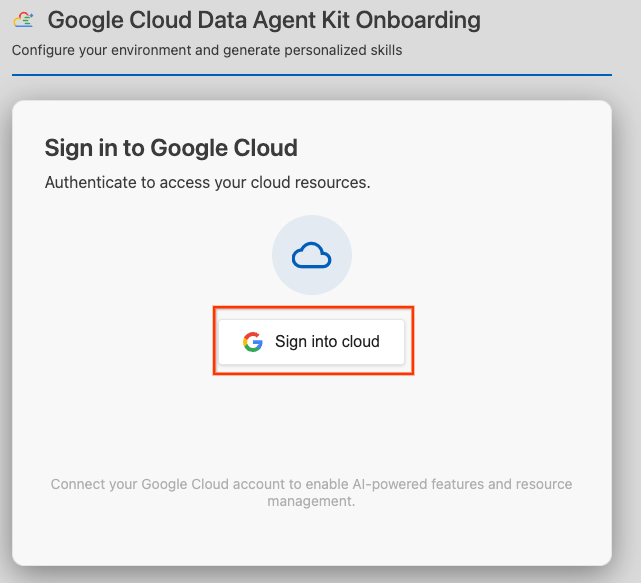
- 按一下「設定 MCP 伺服器」。
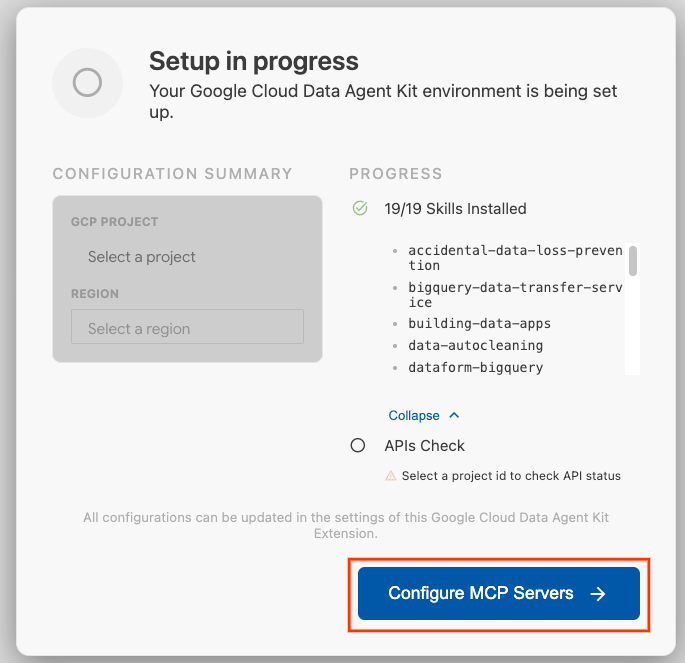
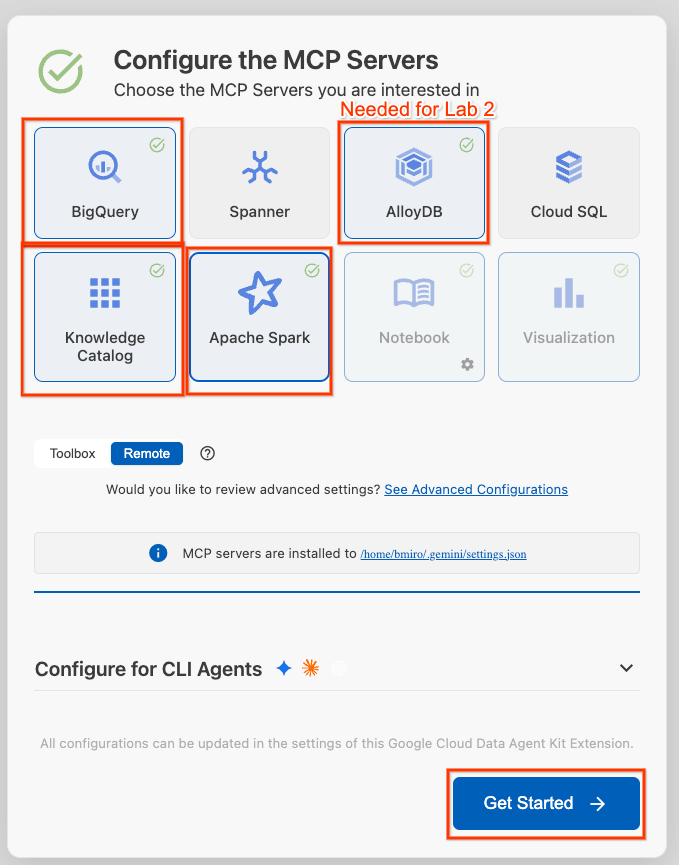
- 選取 BigQuery、Knowledge Catalog、Apache Spark 和 AlloyDB。您會在實驗室 2 中使用 AlloyDB。然後按一下「開始使用」。
- 按一下底部狀態列中的「專案 ID」選取器,然後選擇有效的 Google Cloud 專案。
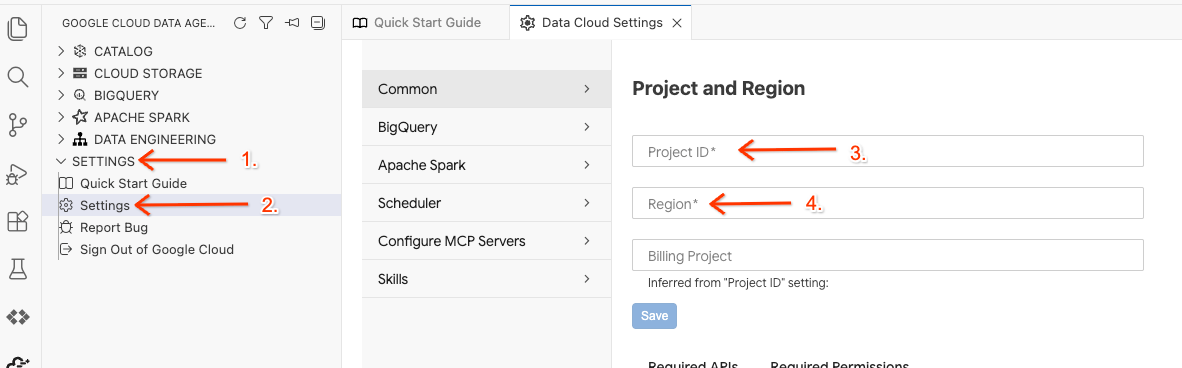
- 在 Data Agent Kit 中,依序點選「SETTINGS」(設定) 和「Settings」(設定),然後在「Common」(通用) 分頁中選取「Project ID」(專案 ID) 和「Region」(區域) (例如「us-central1」),即可執行實驗室。
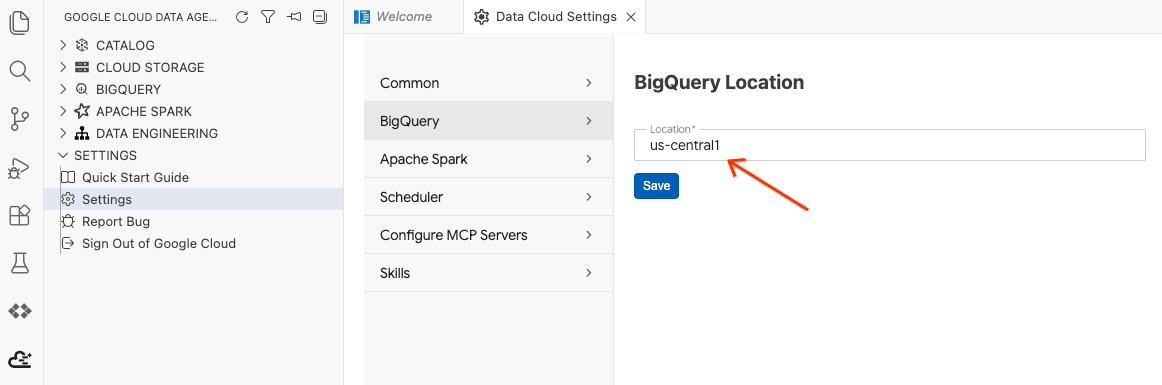
- 按一下「BigQuery 設定」,然後將「區域」替換為先前選取的區域。按一下 [儲存]。
現在可以使用 Data Agent Kit 了!
執行環境設定指令碼
在終端機中執行設定指令碼,為本實驗室建立必要的背景資源,並設定 IAM 權限:
chmod +x setup_lab1.sh
./setup_lab1.sh
source .env
您應該會看到一系列輸出步驟,顯示正在佈建的資源。我們會在實驗室中說明這些資源。
看到完成訊息後,即可繼續:
==================================================== Environment Setup Complete! ====================================================
現在就開始搜尋吧!
3. 擷取合作夥伴出貨清單
合作夥伴船隻的貨運艙單資料會以標準 JSON Lines (JSONL) 格式儲存在 bucket 中:gs://${PROJECT_ID}-lost-cargo-lake/shipping_manifests/manifests.jsonl。
執行深入分析前,您需要為這項非結構化資料建立受管理 BigLake 資料表。這樣一來,您就能立即使用標準 SQL 探索合作夥伴的物流資料,不必重複支付匯入費用。
在編輯器中開啟 Workspace 並執行查詢
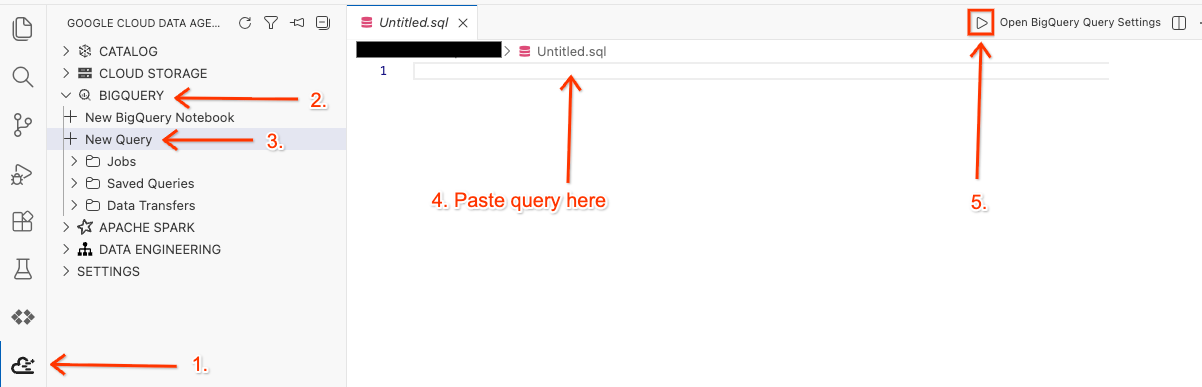
- 在 Cloud Shell 編輯器中,按一下側邊面板的「Google Cloud Data Agent Kit 擴充功能」圖示。
- 前往 BigQuery 並選取「+ New Query」(+ 新查詢)。
- 將下列查詢複製到查詢視窗。
SET @@location = "<YOUR_REGION>"; --Update to your resource region, such as "us-central1". Make sure it is in quotes.
EXECUTE IMMEDIATE ("""
CREATE OR REPLACE EXTERNAL TABLE `lost_cargo_dataset.shipping_manifests`
(
shipment_id STRING,
timestamp TIMESTAMP,
last_ping_lat FLOAT64,
last_ping_long FLOAT64,
seal_integrity_status INT64,
custodian_id STRING OPTIONS(description='Masked identification token for official cargo custodian personnel.')
)
WITH CONNECTION `""" || @@location || """.conn`
OPTIONS (
format = 'NEWLINE_DELIMITED_JSON',
uris = ['gs://""" || @@project_id || """-lost-cargo-lake/shipping_manifests/*.jsonl']
)
""");
- 按一下「執行」。
- 如要確認資料表是否已建立,請查看自動在底部開啟的「查詢結果」面板,當中會顯示成功訊息。
查詢外部資料表,找出遭入侵的應答器
讓我們找出受影響的應答器,方法是找出 seal_integrity_status 設為 0 時發生的故障。在先前開啟的查詢視窗中,複製並執行下列查詢:
SELECT shipment_id, last_ping_lat, last_ping_long, custodian_id
FROM `lost_cargo_dataset.shipping_manifests`
WHERE seal_integrity_status = 0;
「查詢結果」面板應會顯示類似以下的輸出內容:
shipment_id | last_ping_lat | last_ping_long | custodian_id |
MV-CAT-001 | 51.5074 | -0.1278 | usr_999_shadow |
4. 使用 Managed Service for Apache Spark 處理非結構化記錄
您已從結構化資訊清單中找到起始位置,但遺失的應答器完全停止運作。最後一次應答器 Ping 傳送的訊息是加密的非結構化訊息,位於 GCS 路徑 gs://${BUCKET_NAME}/raw_logs/maritime_logs.txt 中的原始文字記錄檔內。
如要處理及對應這份文字記錄、擷取時間戳記、隱藏身分,以及找出貨物的下游路線,您需要將無伺服器 Apache Spark (PySpark) 工作提交至 Managed Service for Apache Spark。
有了 Managed Service for Apache Spark,您不必佈建或管理叢集,就能執行 Spark 工作負載。這項服務會處理底層運算資源,並動態自動調度資源,您只需支付執行時間的費用。
指令碼會執行下列動作:
- 擷取原始的非結構化應答器文字 (以半形方括號括住)。
- 套用 PySpark SQL 正則運算式擷取篩選器,將時間戳記、保管人中繼資料和原始內容分開。
- 將雜亂的記錄分割為乾淨的句子層級記錄。
- 擷取遺失酬載的動態目的地座標目標。
- 將處理後的記錄資料架構連線並寫回 Lakehouse Apache Iceberg REST 目錄,做為可直接在 BigQuery 中查看的新分析資料表。
修正 PySpark 分析指令碼
據報,海上的 Python 海盜造成各種問題。
- 執行下列指令,在 Cloud Shell 編輯器中開啟
process_maritime_logs檔案。cd ~/devrel-demos/data-analytics/data-cloud-roadshow/lab1 cloudshell open ./process_maritime_logs.py - 請花點時間閱讀程式碼,瞭解其作用。
- 請確認程式碼中沒有任何可疑內容!如需刪除任何內容,請務必使用
Ctrl + S(Windows/Linux) 或Cmd + S(Mac) 儲存檔案。
提交無伺服器 Spark 工作
使用 gcloud SDK 提交工作。這項設定會自動設定 PySpark 工作,以存取 Lakehouse 目錄。
在整合式編輯器終端機中執行下列指令。
cd ~/devrel-demos/data-analytics/data-cloud-roadshow/lab1
source .env
gcloud dataproc batches submit pyspark process_maritime_logs.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--version=2.3 \
--deps-bucket=${BUCKET_NAME} \
--properties="\
spark.sql.defaultCatalog=cargo_catalog,\
spark.sql.catalog.${CATALOG_NAME}=org.apache.iceberg.spark.SparkCatalog,\
spark.sql.catalog.${CATALOG_NAME}.type=rest,\
spark.sql.catalog.${CATALOG_NAME}.uri=https://biglake.googleapis.com/iceberg/v1/restcatalog,\
spark.sql.catalog.${CATALOG_NAME}.warehouse=gs://${BUCKET_NAME},\
spark.sql.catalog.${CATALOG_NAME}.header.x-goog-user-project=${PROJECT_ID},\
spark.sql.catalog.${CATALOG_NAME}.rest.auth.type=org.apache.iceberg.gcp.auth.GoogleAuthManager,\
spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions,\
spark.sql.catalog.${CATALOG_NAME}.gcs.oauth2.refresh-credentials-endpoint=https://oauth2.googleapis.com/token, \
spark.sql.catalog.${CATALOG_NAME}.header.X-Iceberg-Access-Delegation=vended-credentials" \
-- ${BUCKET_NAME}
請稍候幾分鐘,等待無伺服器環境啟動、上傳指令碼,並執行處理邏輯。
看到類似以下的輸出內容後,處理過的資料表就會儲存至 Lakehouse 目錄,做為 Apache Iceberg 受管理資料表!
Batch [1fae0b4b42c045a084dd67917bd0c332] finished.
metadata:
'@type': type.googleapis.com/google.cloud.dataproc.v1.BatchOperationMetadata
batch: projects/<YOUR_PROJECT>/locations/us-central1/batches/1fae0b4b42c045a084dd67917bd0c332
batchUuid: 611b4465-fdac-4974-bc47-5f10adaf2a08
createTime: '2026-06-11T21:35:01.868157Z'
description: Batch
labels:
goog-dataproc-batch-id: 1fae0b4b42c045a084dd67917bd0c332
goog-dataproc-batch-uuid: 611b4465-fdac-4974-bc47-5f10adaf2a08
goog-dataproc-drz-resource-uuid: batch-611b4465-fdac-4974-bc47-5f10adaf2a08
goog-dataproc-location: us-central1
operationType: BATCH
name: projects/<YOUR_PROJECT/regions/us-central1/operations/7e2044db-dd97-3270-b368-4dc4ba417574
預覽已處理的記錄
在 Data Agent Kit 擴充功能的查詢編輯器中,複製下列查詢來預覽資料:
SET @@location = "<YOUR_REGION>"; -- e.g. "us-central1"
EXECUTE IMMEDIATE FORMAT("""
select log_timestamp, custodian_id, sentence from
`%s.%s-lost-cargo-lake.lost_cargo_namespace.processed_maritime_logs`
limit 5
""", @@project_id, @@project_id);
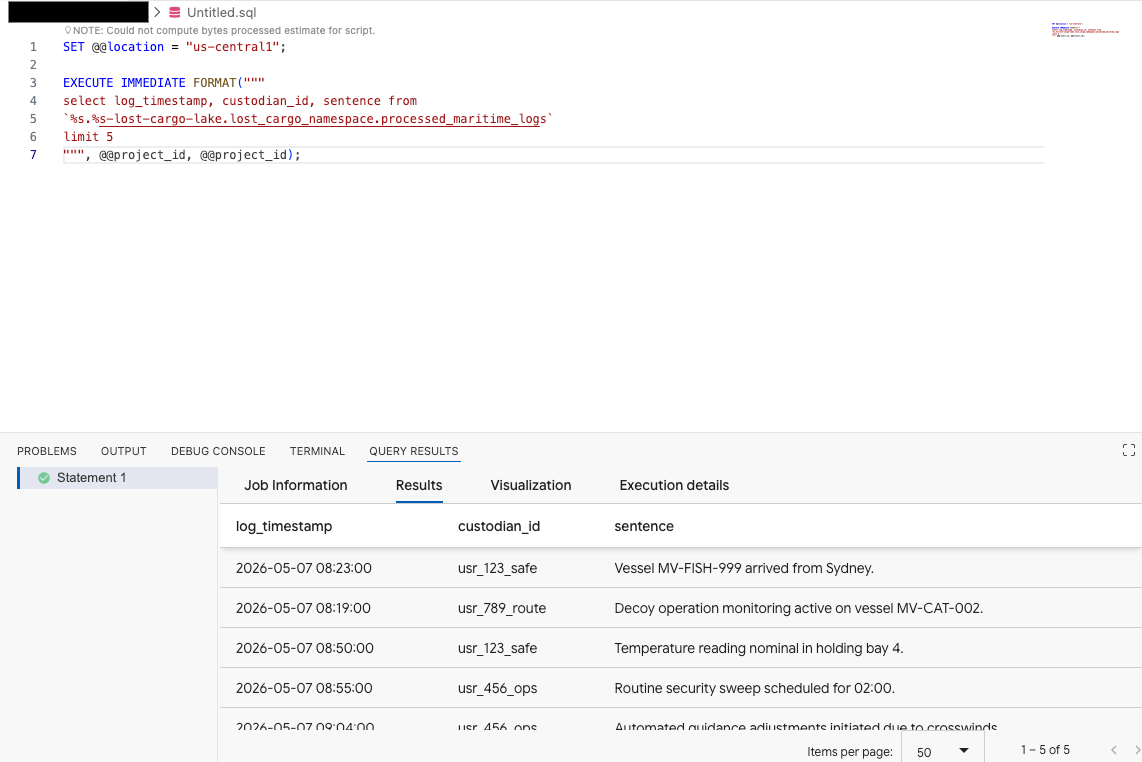
這表示您已成功從 BigQuery 存取目錄中註冊的 Iceberg 資料表!
擷取目的地線索
現在我們已取得處理過的記錄,接下來要搜尋包含目的地目標的記錄。然後,我們可以搜尋包含來源城市提及內容的記錄。
在查詢編輯器中執行下列查詢,並將 <YOUR_REGION> 替換為您的區域,以及將 <ORIGIN_CITY> 替換為您先前發現的原始城市。
SET @@location = "<YOUR_REGION>"; --e.g. "us-central1"
DECLARE origin_city STRING;
SET origin_city = "<ORIGIN_CITY>"; --e.g. "Boston". (It's not Boston)
EXECUTE IMMEDIATE FORMAT(r"""
SELECT
log_timestamp AS event_time,
custodian_id,
REGEXP_EXTRACT(raw_message, r'Destination:\s*([^.]+)') AS destination_target
FROM
`%s.%s-lost-cargo-lake.lost_cargo_namespace.processed_maritime_logs`
WHERE
-- STRPOS is highly optimized in BigQuery for a simple .contains() substring check
STRPOS(sentence, '%s') > 0;
""", @@project_id, @@project_id, origin_city);
在 BigQuery 控制台中,使用對話式數據分析功能與資料對話
您不必編寫複雜的 SQL 查詢來探索資料,只要使用對話式數據分析,就能以自然語言與資料表對話!
- 前往 BigQuery 控制台。
- 在左側的「Explorer」面板中,展開專案和資料集
-lost-cargo-lake.lost_cargo_namespace processed_maritime_logs」資料表,開啟詳細資料分頁。 - 按一下「查詢」旁邊的「即時通訊」。
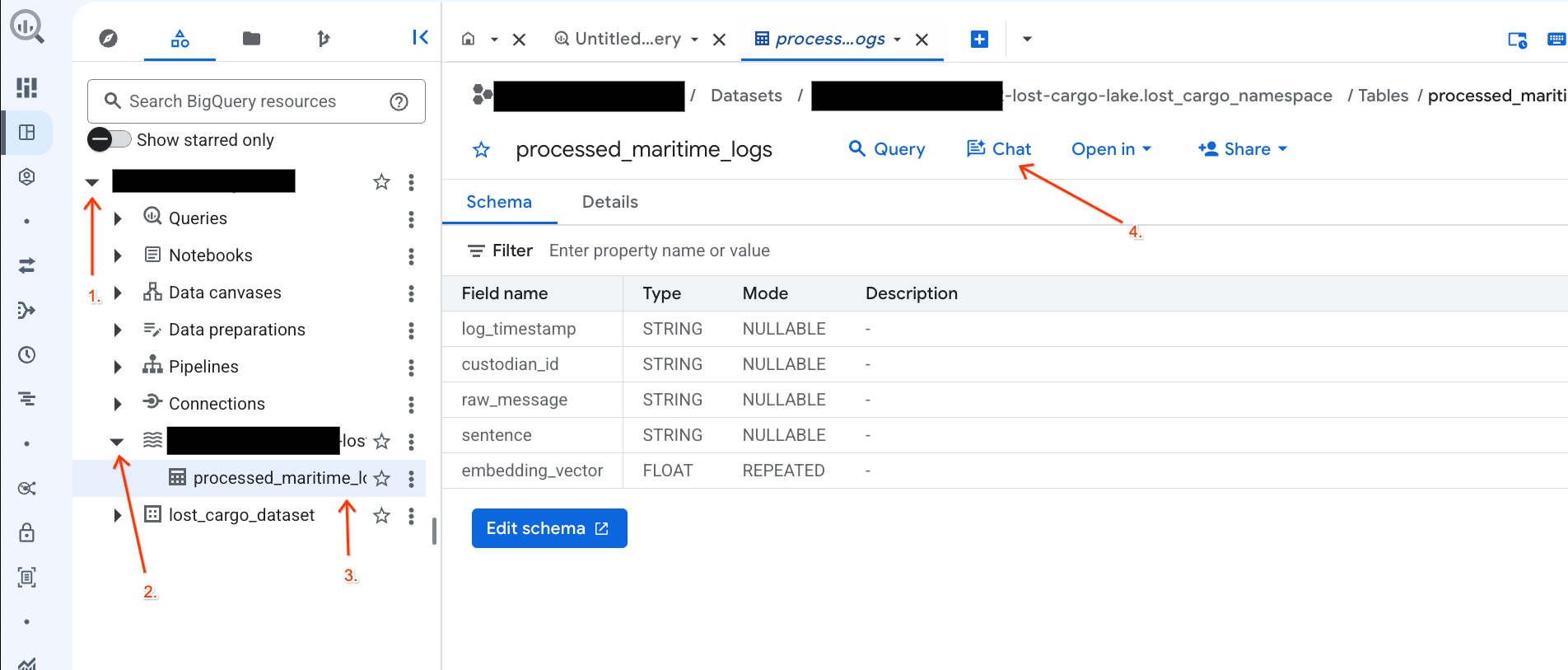
- 在對話面板中輸入下列問題,然後按下鍵盤上的 Enter 鍵傳送:
Based on this table, what color is the shipping container MV-CAT-001?
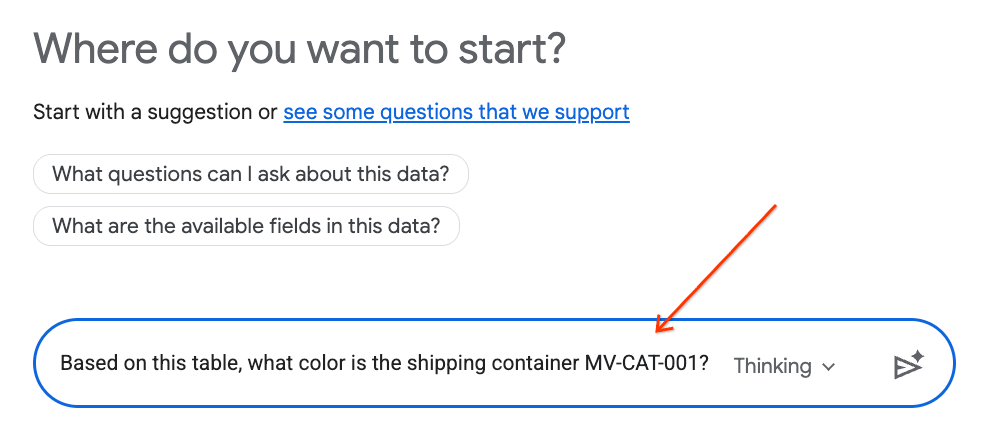
- 對話式數據分析 (由 Gemini 支援) 會分析有效表格的資料,並以顏色回覆。
5. 查看集中式 Lakehouse 目錄
如要將開放原始碼處理引擎 (例如 Apache Spark) 與企業資料引擎 (例如 BigQuery) 安全無縫整合,設定指令碼會設定 Lakehouse Iceberg REST 目錄。
Apache Iceberg REST 目錄是無伺服器「單一資料來源」,可管理結構定義和動態分割資料表,同時將實際的 Parquet 資料檔案儲存在 Cloud Storage 中。
讓我們直接在 Google Cloud 控制台中檢查這個目錄:
- 開啟 Lakehouse 控制台。
- 在「目錄」分頁中,找出並按一下有效的 Iceberg REST 目錄:
-lost-cargo-lake
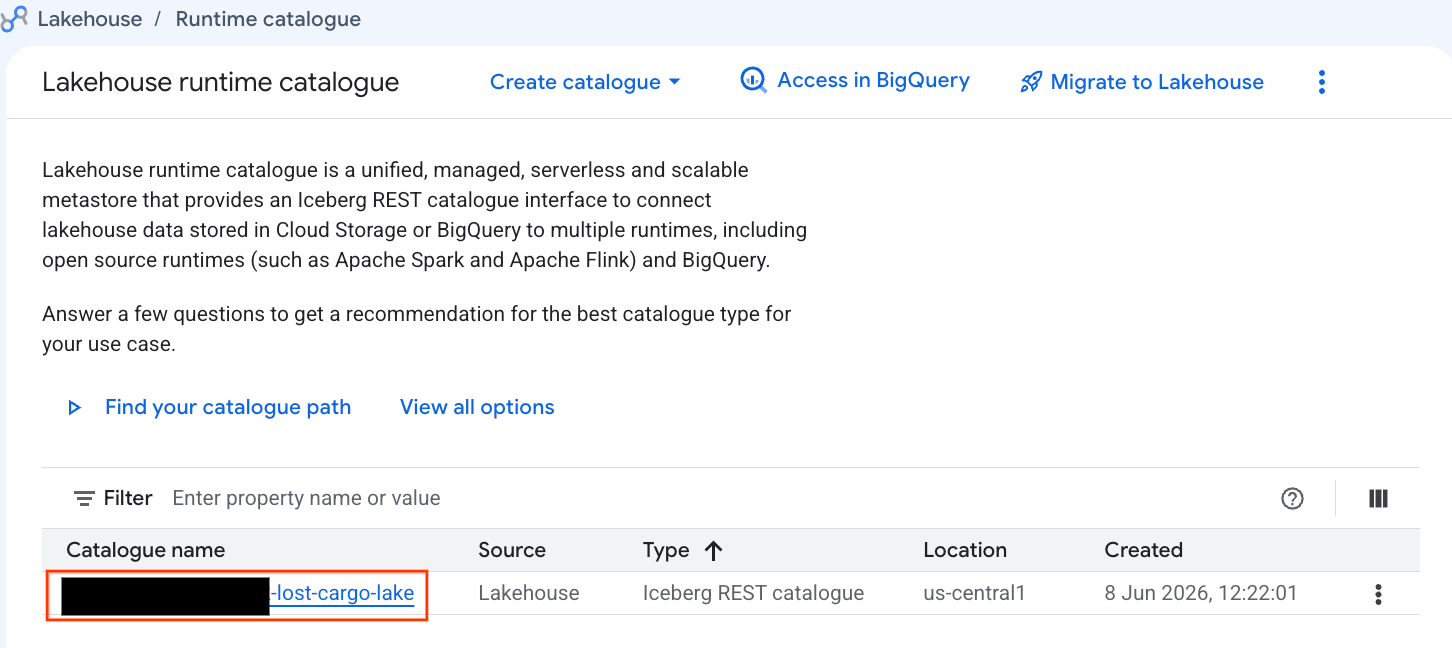
- 在目錄詳細資料檢視畫面中,您應該會在「命名空間」下方看到
lost_cargo_namespace。請點按分頁標籤。
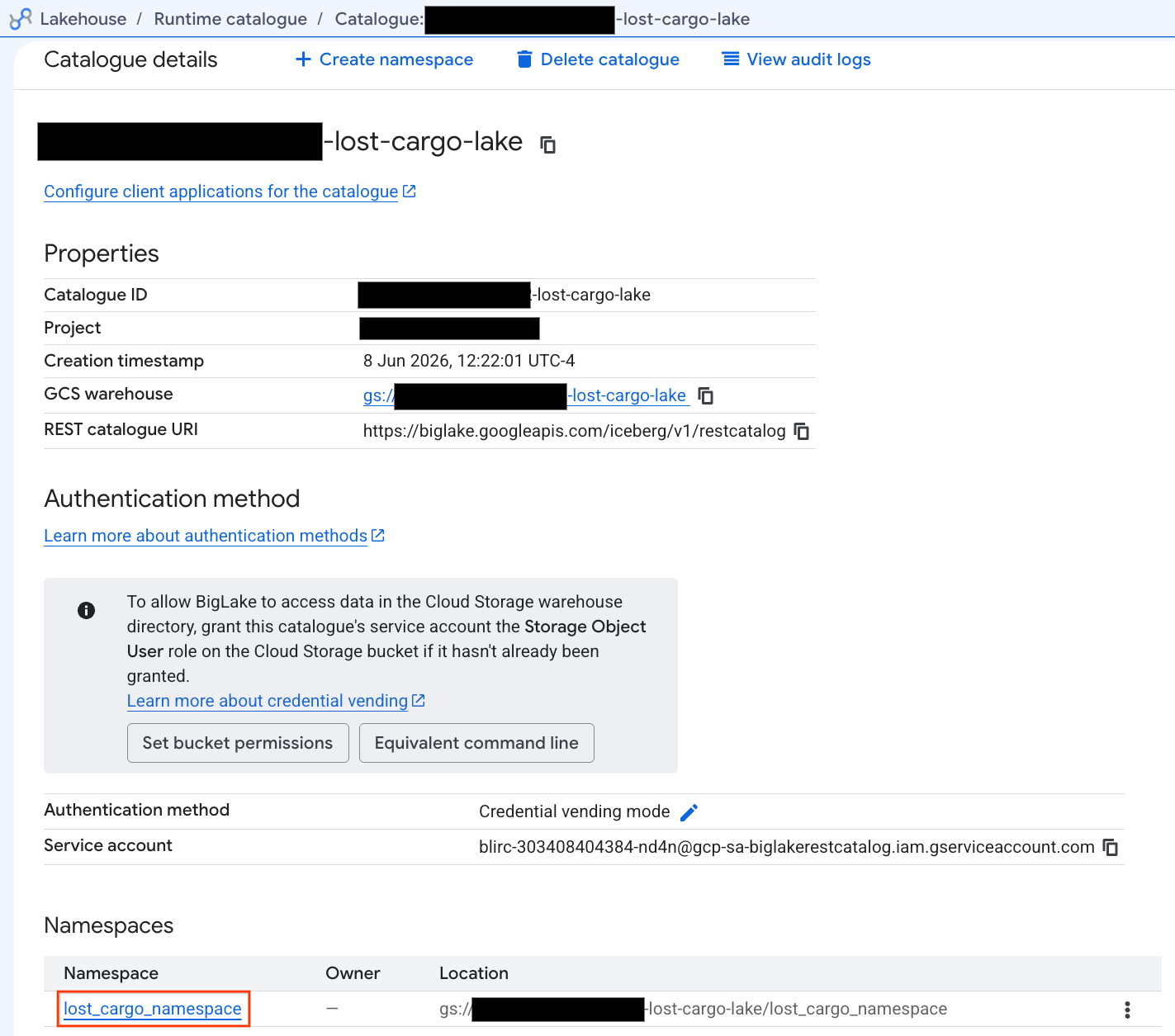
- PySpark 產生的新 Apache Iceberg 資料表會自動登錄在這個 metastore 命名空間下,並立即在 BigQuery 中可供查詢!
6. 生成貨運清單表格的洞察資料
讓我們返回並分析 shipping_manifests 資料表,使用 Knowledge Catalog 資料洞察瞭解資料表結構和內容。豐富中繼資料後,其他探索者就能更瞭解資料表,以利日後分析。
在 BigQuery Studio 中產生表格洞察
- 前往 Google Cloud 控制台的「BigQuery Studio」。
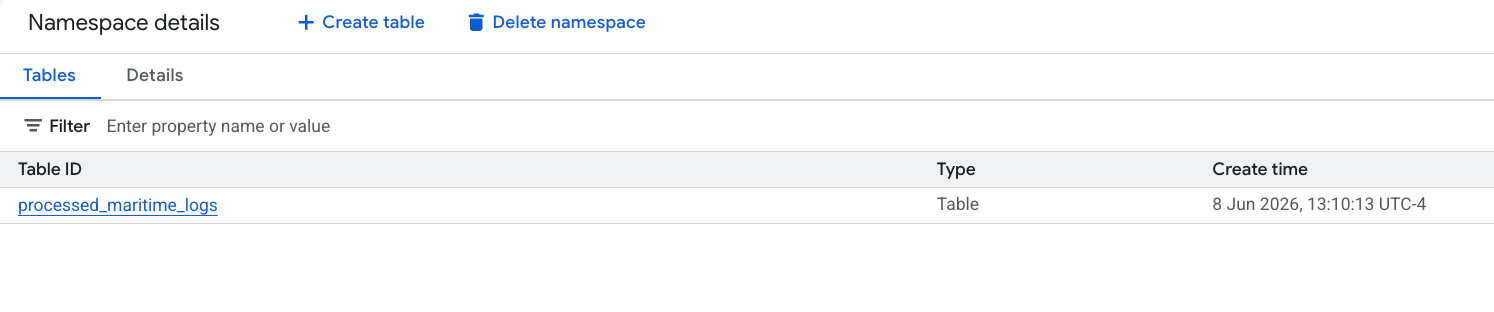
- 在「Explorer」面板中展開專案,展開
lost_cargo_dataset資料集,然後按一下shipping_manifests資料表。 - 在右側的詳細資料面板中,按一下「洞察」分頁標籤。
- 使用下拉式選單選取「產生並發布」。
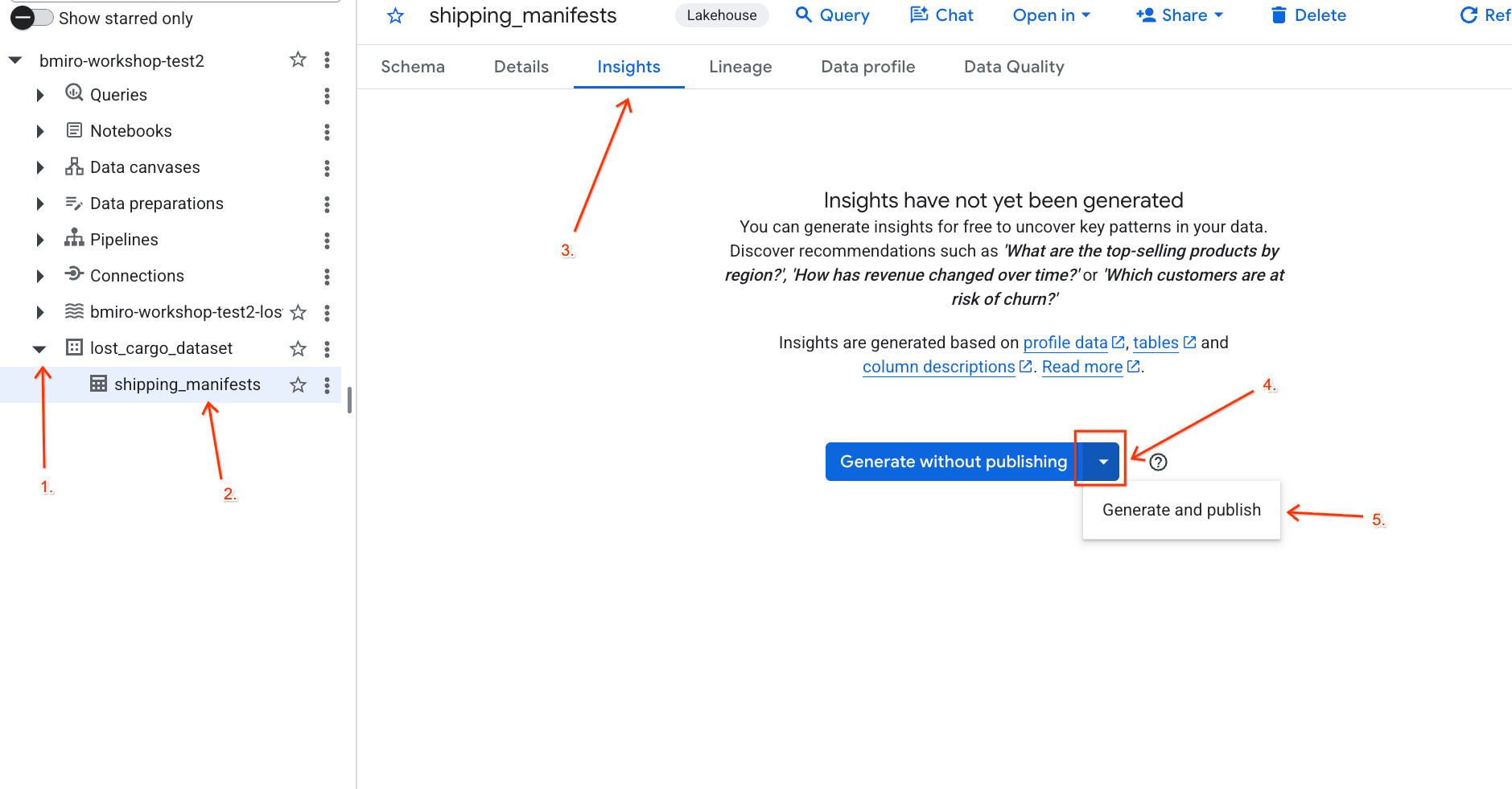
- 請等待約 3 分鐘,讓系統生成洞察資料。Gemini 會分析資料表的中繼資料,然後生成自然語言問題和對應的 SQL 查詢。
- 完成後,您會看到表格說明,其中以自然語言說明表格內容。
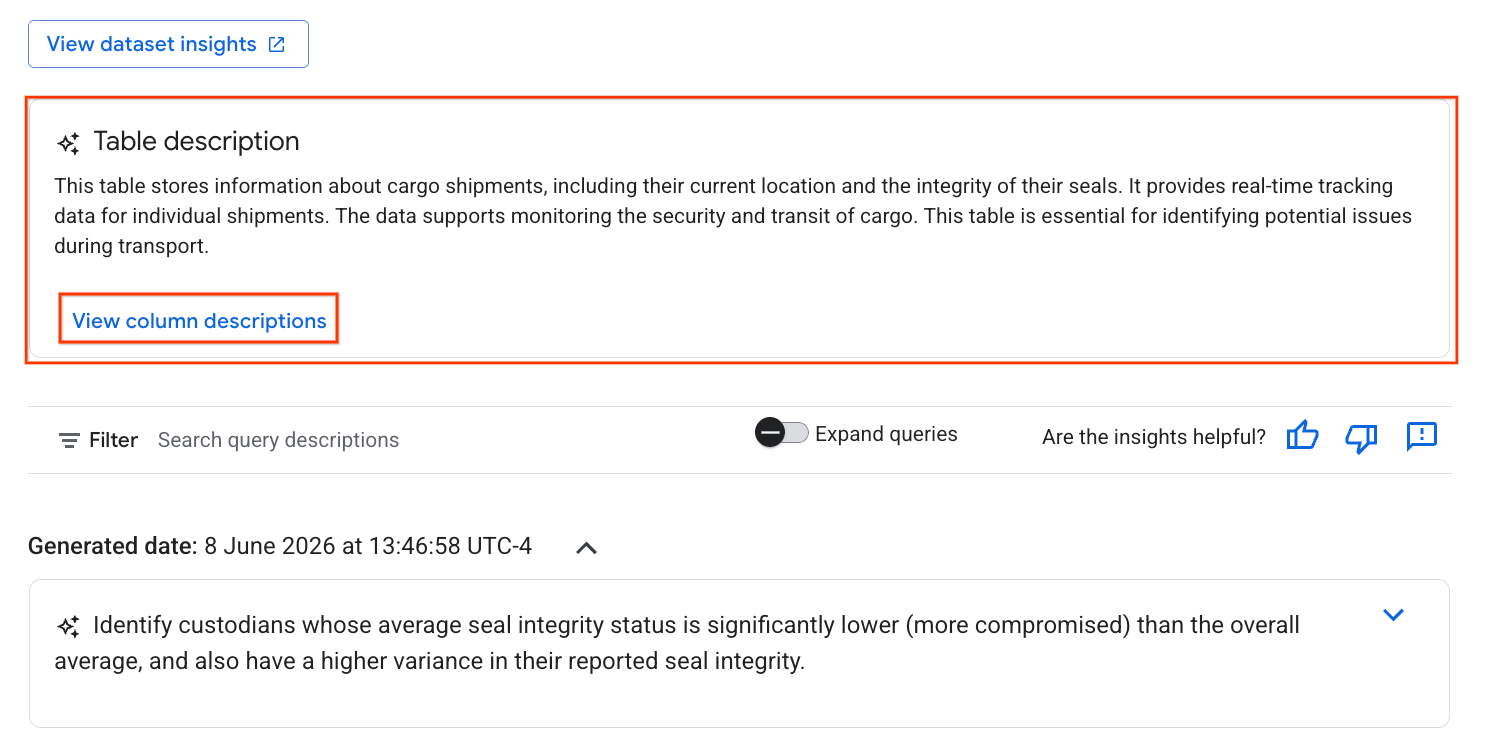
- 按一下「查看資料欄說明」,即可查看個別資料欄的相關資訊。
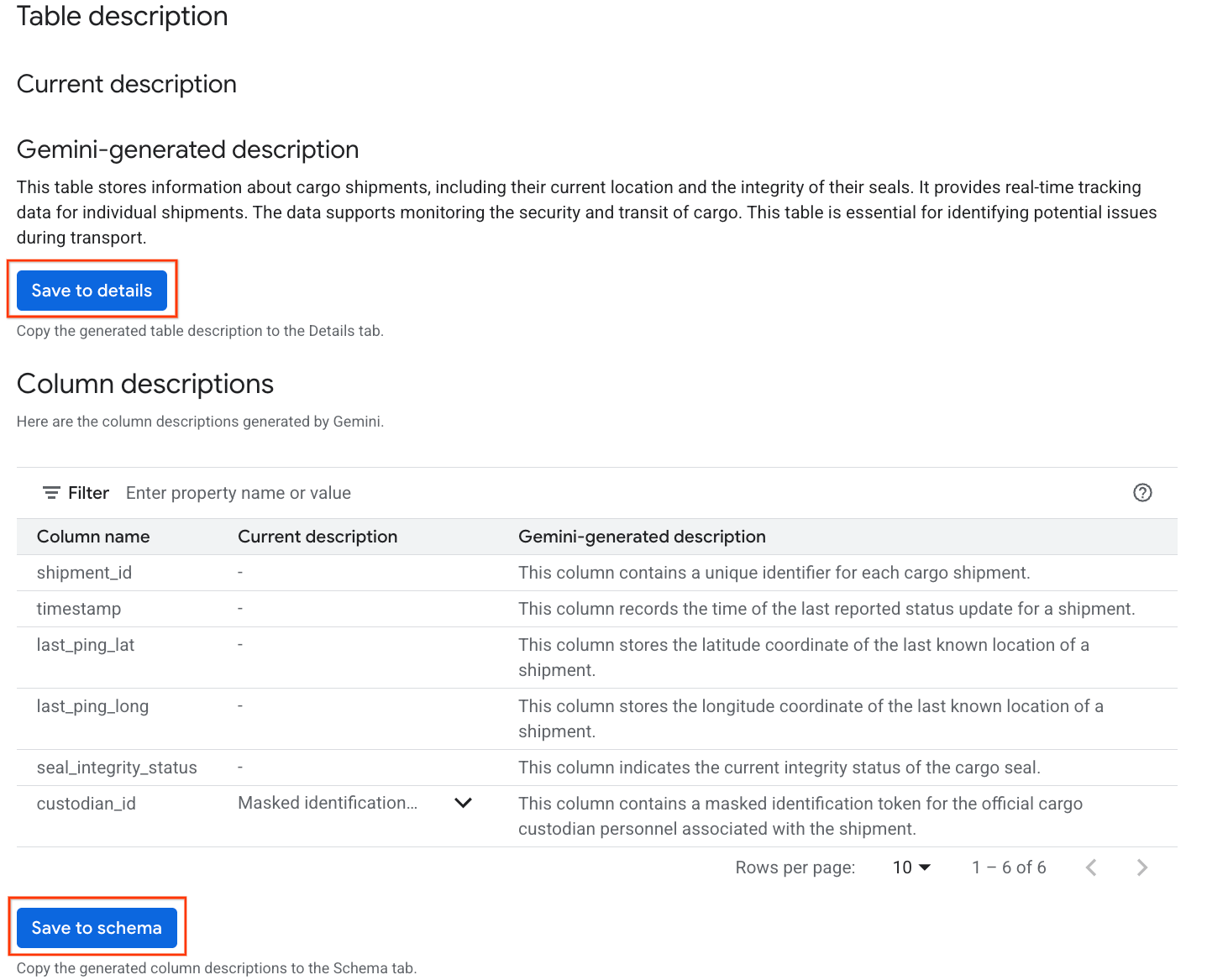
- 按一下
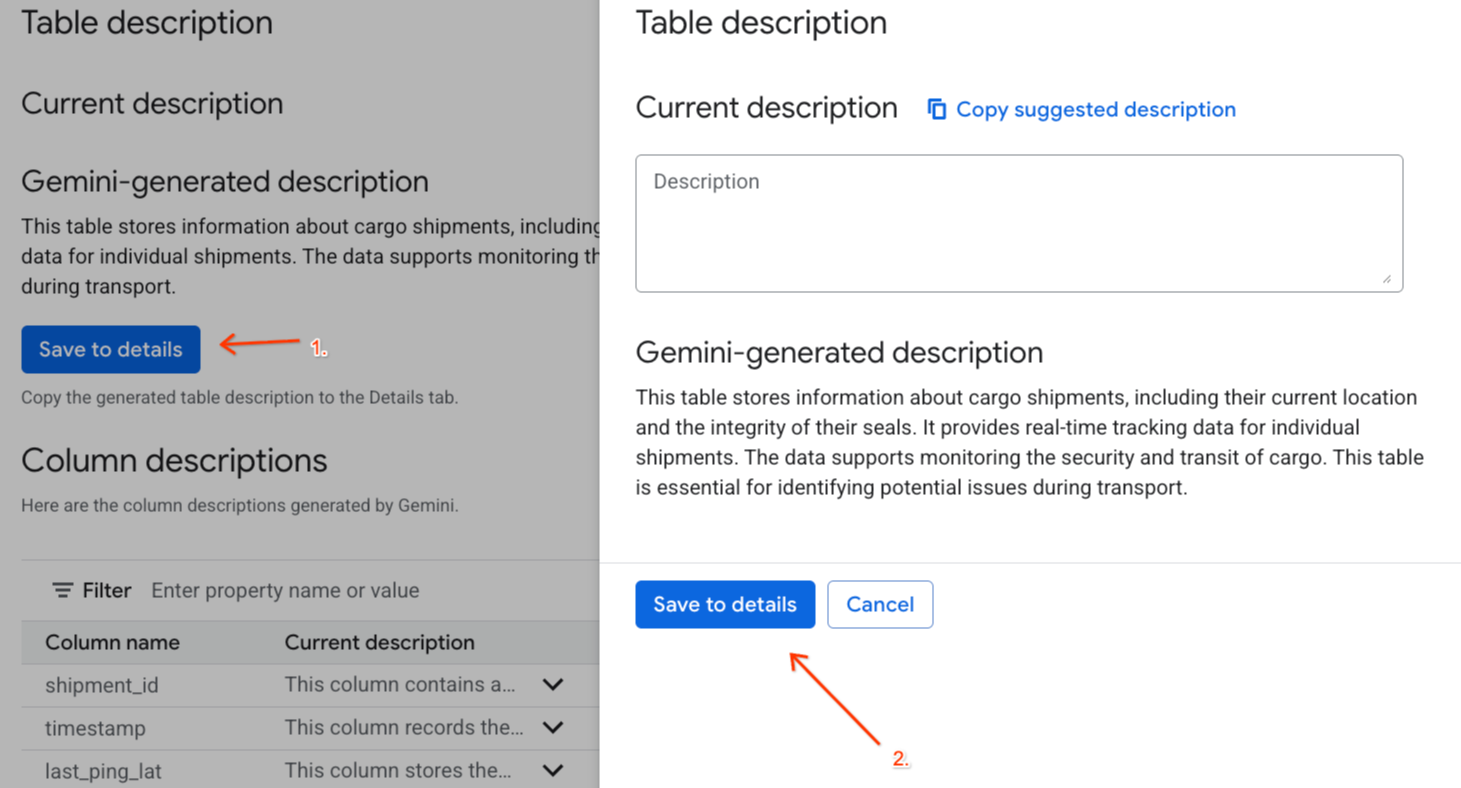
Gemini generated description下方的「儲存至詳細資料」,然後在彈出式視窗中按一下「儲存至詳細資料」。
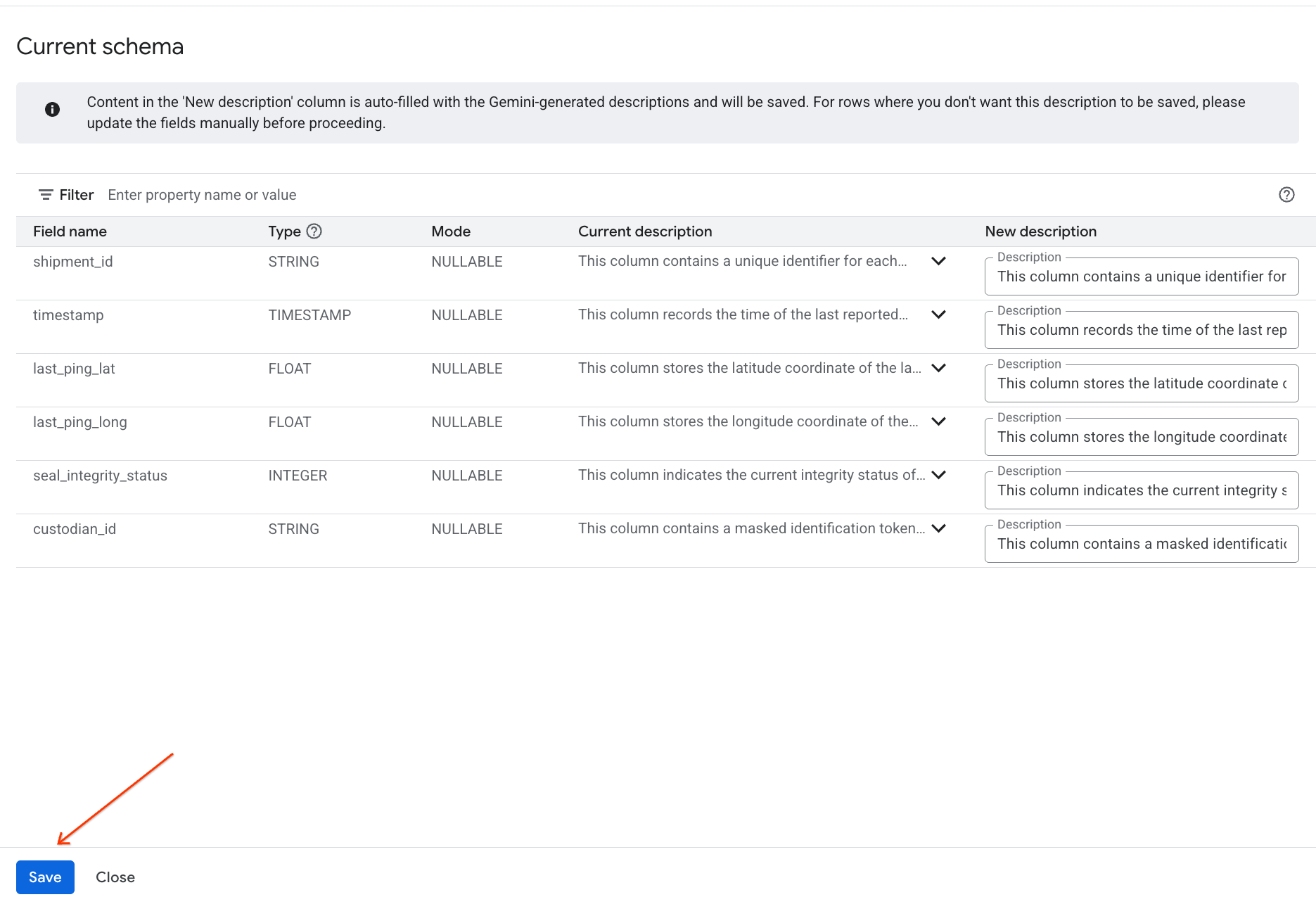
- 同樣地,按一下「儲存至結構定義」,即可將資料欄說明新增至資料表中繼資料。
查看生成的洞察資料
系統也會顯示建議問題清單,您可以點選任一問題,查看產生的 SQL 查詢並運作執行,藉此探索資料。舉例來說,您可能會看到以下問題:
- 「總出貨量是多少?」
- 「列出不重複的保管人 ID。」
執行這些查詢有助於瞭解資料。
7. 導入資料遮蓋和治理
為確保在進行中的貨物調查期間,不會洩漏有效的研究帳戶和使用者名稱,您必須強制執行標準安全通訊協定。您將建立安全政策標記分類,並在機密 custodian_id 資料欄上設定 Knowledge Catalog 資料遮蓋,以驗證資料隱私權。
根據預設,BigQuery 會拒絕存取受政策標記保護的資料欄。如要查詢資料表及驗證有效資料遮蓋,使用者帳戶必須具備 BigQuery 資料政策遮蓋讀取者角色。
在您首次執行 setup_lab1.sh! 時,這個角色會自動繫結至您的有效使用者帳戶。
建立分類和政策標記
建立資料分類和相關聯的政策標記,以便管理資料存取權。
- 前往「政策標記分類」頁面。
- 按一下「+ 建立分類」。
- 設定參數:
- 分類名稱:輸入
lost-cargo-,並將其替換為您的專案 ID。 - 「Region」(區域):選取區域。
- 政策標記「Name」:輸入
MaskCustodianID - 政策標記「Description」(說明):
Restricts visibility into cargo custodian usernames
- 分類名稱:輸入
- 按一下「建立」,註冊新的分類和政策標記。

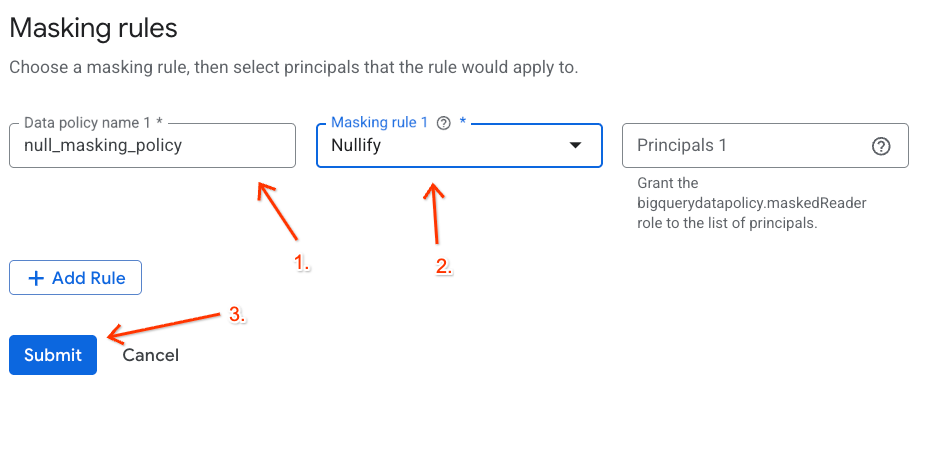
建立資料遮蓋政策
接著,設定資料政策,定義在 MaskCustodianID 分類標記下,資料如何受到遮蓋。您將使用「一律為空值」遮蓋規則 (將所有非具備權限的參與者相符值替換為空白/空值傳回)。
- 在「政策標記分類」頁面中,從分類清單點選新建立的分類。
- 在階層清單中,按一下
MaskCustodianID標記選取標記,然後選取「管理資料政策」。
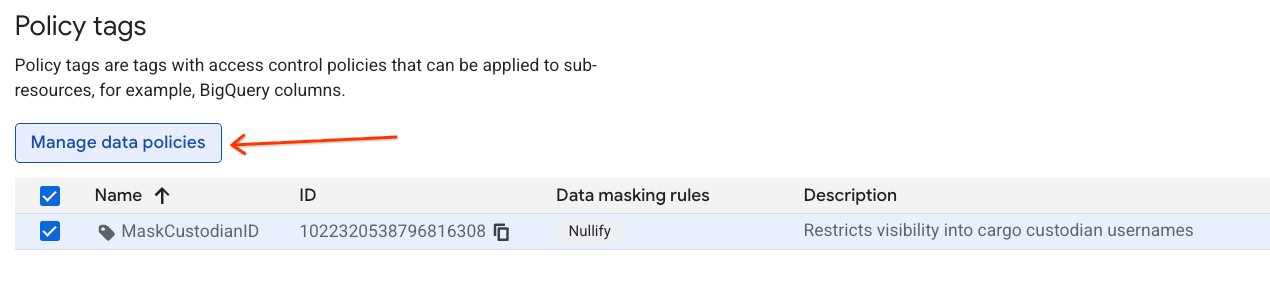
- 在右側面板中,按一下「+ 新增規則」按鈕。
- 在顯示的面板中設定政策詳細資料:
- 資料政策名稱:輸入
null_masking_policy(請勿使用自動產生的名稱,因為我們會在後續步驟中依名稱參照)。 - 遮蓋規則:從下拉式選單中選取
Nullify。
- 資料政策名稱:輸入
- 按一下「提交」。
將政策標記指派給 BigQuery 資料欄
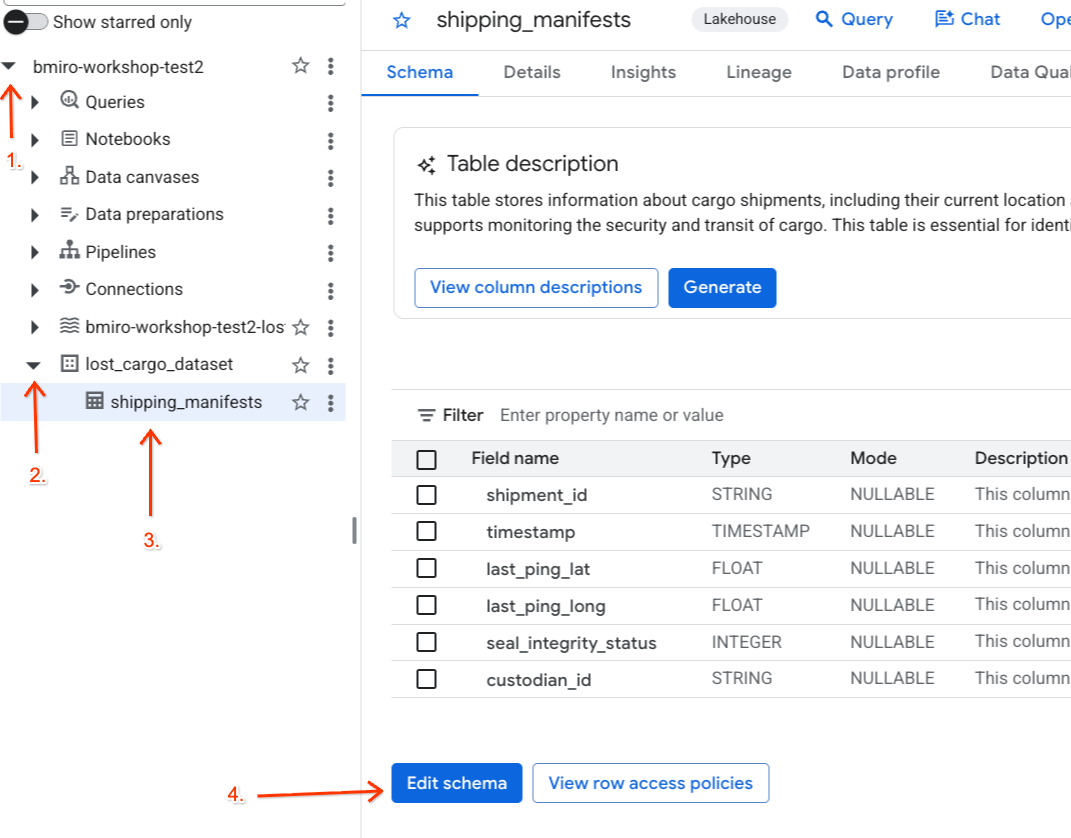
啟用政策標記和資料遮蓋規則後,請將分類標記直接對應至 BigQuery 合作夥伴出貨清單資料表中的 custodian_id 資料欄。
- 前往 BigQuery 控制台。
- 在左側的「Explorer」面板中,展開有效專案和「
lost_cargo_dataset」資料集,然後點選「shipping_manifests」資料表,開啟詳細檢視畫面。 - 點選「編輯結構定義」。
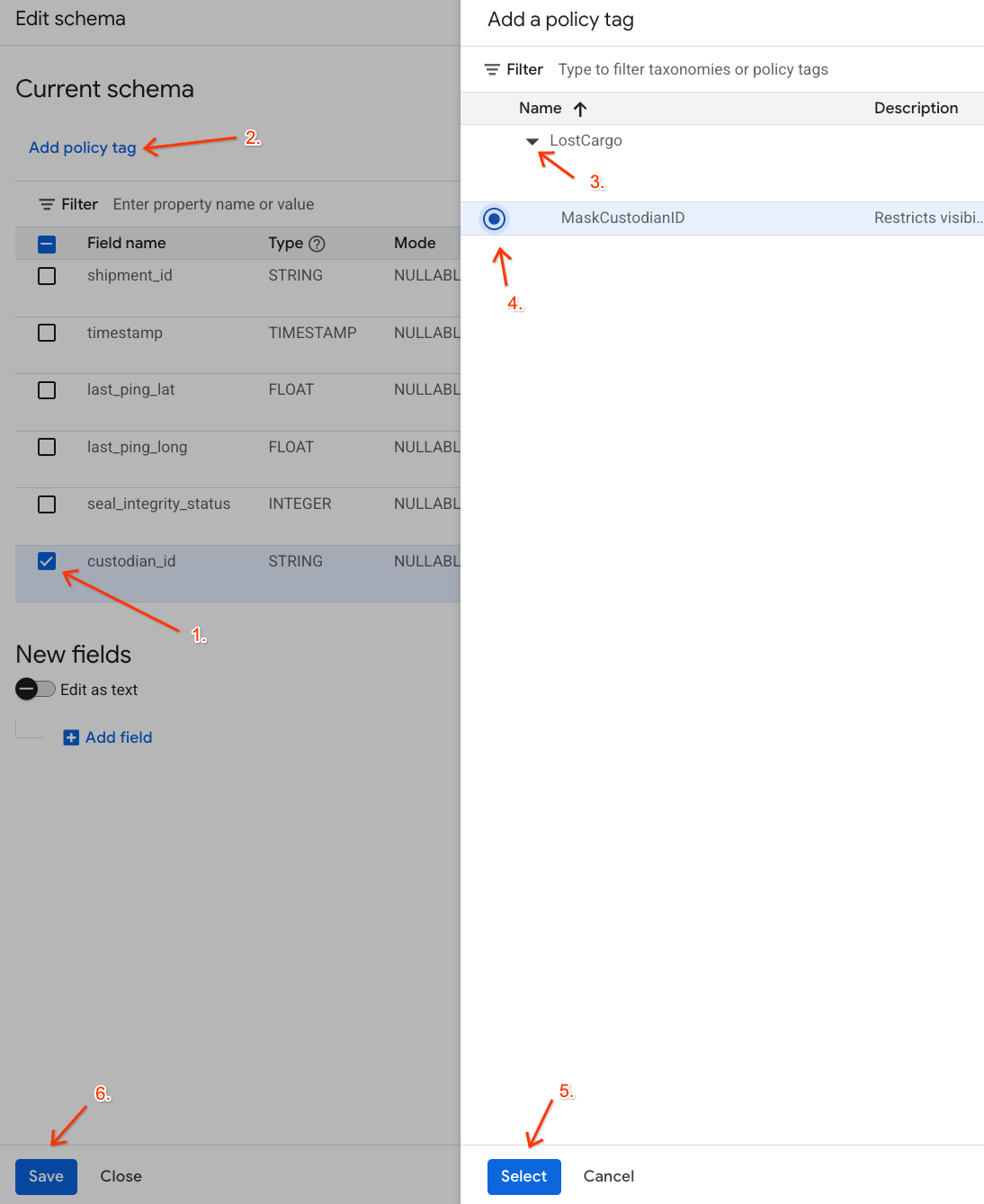
- 在資料欄清單中,勾選「
custodian_id」旁邊的方塊。 - 按一下結構化資料編輯器頂端工具列中的「新增政策標記」按鈕。
- 在「新增政策標記」面板中:
- 找出並展開
LostCargo分類。 - 選取「
MaskCustodianID」旁邊的泡泡。 - 按一下「選取」。
- 找出並展開
- 確認代表
custodian_id的資料列中,「政策標記」欄下方現在會顯示MaskCustodianID標記。 - 按一下 [儲存]。
確認政策限制
您現在擁有專案層級的「遮蓋讀取者」角色,可以查詢資料表,確認遮蓋政策是否已啟用。
返回 Data Agent Kit,然後執行下列查詢:
SELECT shipment_id, custodian_id
FROM lost_cargo_dataset.shipping_manifests
LIMIT 5;
輸出結果應該會類似下列內容:
shipment_id | custodian_id |
NORMAL-001 | 空值 |
NORMAL-002 | 空值 |
MV-CAT-001 | 空值 |
太棒了,即使您可以查看 shipment_id 記錄,敏感的 custodian_id 欄位也會傳回安全 null 遮罩,防止洩漏!
8. 清理
如要避免系統持續向您的 Google Cloud 帳戶收取本程式碼研究室所建立資源的費用,請在 Cloud Shell 終端機中執行下列指令,捨棄資料集和 bucket:
# Verify active variables
export PROJECT_ID=$(gcloud config get-value project)
export BUCKET_NAME="${PROJECT_ID}-lost-cargo-lake"
# Delete Knowledge Catalog security taxonomies
export TAXONOMY_NAME=$(gcloud data-catalog taxonomies list --location=us-central1 --filter="displayName:LostCargo" --format="value(name)")
if [[ -n "$TAXONOMY_NAME" ]]; then
curl -X DELETE \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
"https://datacatalog.googleapis.com/v1/${TAXONOMY_NAME}" || true
fi
# Delete Lakehouse Iceberg REST Catalog tables and namespaces
gcloud biglake iceberg tables delete processed_maritime_logs \
--catalog=${BUCKET_NAME} \
--namespace=lost_cargo_namespace \
--quiet || true
gcloud biglake iceberg namespaces delete lost_cargo_namespace \
--catalog=${BUCKET_NAME} \
--quiet || true
# Delete Lakehouse Iceberg REST Catalog
gcloud biglake iceberg catalogs delete ${BUCKET_NAME} --quiet || true
# Delete dependencies bucket
gcloud storage rm -r gs://${BUCKET_NAME} || true
# Delete BigQuery dataset and tables
bq rm -r -f -d ${PROJECT_ID}:lost_cargo_dataset || true
9. 恭喜
恭喜!您已順利完成「遺失貨物」調查的第一個重要單元。您已使用 Lakehouse Iceberg REST 目錄、PySpark 記錄正規化和細微的資料遮蓋,建立受控搜尋區域。
目前所學內容
- 在 IDE 工作區中安裝、設定及設定 Data Agent Kit 擴充功能。
- 建立無伺服器 Lakehouse Iceberg REST 目錄,並使用供應的憑證和階層式命名空間。
- 擷取跨格式區域動態饋給,並透過 Cloud Storage bucket 建立 BigQuery 外部資料表。
- 啟動無伺服器 Apache Spark 工作,剖析、正規化、區隔及將非結構化應答器記錄寫回 BigQuery,做為已註冊的 Iceberg 目錄資料表。
- 建立安全分類並對應Knowledge Catalog 資料遮蓋政策,防止機密記錄索引洩漏身分資訊。
- 使用 BigQuery 資料洞察產生及分析資料表的中繼資料洞察,加快資料探索速度。
收集到的線索驗證
確認您已記錄下列明確線索,以便進入下一個實驗室階段:
- 遺失的運送 ID:
MV-CAT-001(最後一次連線偵測位置:倫敦) - 預計目標目的地:
New York(和應答器真實別名:MV-DOG-002) - 容器顏色:
Crimson RED - 治理存取權標記:
MaskCustodianID
準備好進入下一個階段了嗎?
現在,應答器「出發地 / 目的地」路線已安全無虞,調查工作可以繼續進行!直接啟動實驗室 2,使用多模態 Gemini 模型檢查監視器、以視覺方式識別船隻,並在 AlloyDB 中執行向量搜尋,驗證竄改異常狀況!