
1. مقدمة

في المختبر السابق، جمعت سجلات الشحن المجزّأة وتتبّعت جهاز الإرسال والاستقبال الخاص بالشحن إلى نيويورك. ومع ذلك، تُظهر سجلات الوصول أنّه تمّت إعادة توجيه الحاوية على الفور لتجنُّب رصدها من قِبل الجمارك. وقد قادتك الآثار الآن إلى ميناء ريو دي جانيرو، وهو ميناء مترامي الأطراف يضمّ آلاف الحاويات. ويصعب العثور على الحاوية المطلوبة بين آلاف الحاويات الأخرى.
في هذا الدرس العملي، ستستخدم إمكانات الذكاء الاصطناعي المضمّنة في BigQuery "لقراءة" صور أمان المنافذ غير المنظَّمة ورصد الحالات الشاذة الحرارية في بيانات جهاز الاستشعار، وكل ذلك باستخدام لغة SQL العادية. بعد ذلك، ستصدِّر تضمينات المتّجهات إلى AlloyDB وتنفِّذ عملية بحث عن المتّجهات لمطابقة إشارة القياس عن بُعد المجزّأة مع الحاوية المفقودة.
الإجراءات التي ستنفذّها
- فحص صور أمان الحاويات المسروقة لتحديدها باستخدام BigQuery AI
- رصد قيمة حرارية شاذة باستخدام الذكاء الاصطناعي في BigQuery للتأكّد من أنّ الحاوية قد سُرقت ولم يتم وضعها في غير مكانها
- إنشاء عمليات تضمين متّجهة وتحميلها إلى AlloyDB للبحث في الوقت الفعلي
- مطابقة إشارة تجزئة من بيانات القياس عن بُعد لتحديد موقع الحاوية المسروقة باستخدام Vector Search
- استكشاف بيانات التحقيق باستخدام اللغة الطبيعية من خلال Conversational Analytics
المتطلبات
- متصفّح ويب، مثل Chrome
- مشروع Google Cloud تم تفعيل الفوترة فيه
- معرفة أساسية بلغة SQL وGoogle Cloud Console
هذا الدرس التطبيقي حول الترميز مخصّص للمطوّرين ذوي الخبرة المتوسطة.
يجب أن تكون تكلفة الموارد التي تم إنشاؤها في هذا الدرس التطبيقي حول الترميز أقل من 5 دولارات أمريكية.
2. قبل البدء
بدء Cloud Shell
ستستخدم Google Cloud Shell لتنزيل الرمز البرمجي وتشغيل نصوص الإعداد البرمجية ونشر التطبيق.
- في علامة تبويب جديدة في المتصفّح، افتح Cloud Shell: shell.cloud.google.com
- بعد الاتصال، اضبط رقم تعريف مشروعك وأكِّد بيئتك:
gcloud config set project <<YOUR_PROJECT_ID>>
export PROJECT_ID=$(gcloud config get-value project)
export REGION=us-central1
من المفترض أن تظهر لك رسالة مشابهة لما يلي:
Your active configuration is: [cloudshell-####] Updated property [core/project]
إنشاء نسخة طبق الأصل من المستودع
أنشئ نسخة طبق الأصل من مستودع الدرس التطبيقي حول الترميز إلى بيئة Cloud Shell:
cd ~/
git clone --filter=blob:none --no-checkout https://github.com/GoogleCloudPlatform/devrel-demos.git
cd ~/devrel-demos
git sparse-checkout init --cone
git sparse-checkout set codelabs/bigquery-alloydb-insights
git checkout main
cd codelabs/bigquery-alloydb-insights/
تفعيل واجهات برمجة التطبيقات
نفِّذ هذا الأمر في Cloud Shell لتفعيل جميع واجهات برمجة التطبيقات المطلوبة لهذا المختبر:
gcloud services enable \
aiplatform.googleapis.com \
bigquery.googleapis.com \
bigqueryconnection.googleapis.com \
alloydb.googleapis.com
عند التنفيذ بنجاح، من المفترض أن تظهر لك رسالة مشابهة لما يلي:
Operation "operations/..." finished successfully.
3- إعداد البيئة
قبل أن تتمكّن من تحليل الصور وبيانات القياس عن بُعد، عليك إعداد البنية الأساسية لهذا المختبر. ستنفّذ نصَّين برمجيَّين: أحدهما يبدأ عملية توفير AlloyDB في الخلفية، والآخر ينشئ جميع موارد BigQuery التي ستحتاج إليها.
الخطوة 1: بدء عملية نشر AlloyDB (في الخلفية)
تستغرق عملية توفير مجموعة AlloyDB حوالي 10 دقائق، لذا عليك البدء بها أولاً وتركها تعمل في الخلفية أثناء العمل على أقسام BigQuery. سيسجّل النص البرمجي تلقائيًا إعدادات مشروعك النشط في ملف .env محلي ليتم حفظ إعداداتك حتى إذا تم إغلاق أو إعادة تشغيل نافذة Cloud Shell.
chmod +x scripts/setup_alloydb.sh
nohup ./scripts/setup_alloydb.sh > /dev/null 2>&1 &
echo "AlloyDB deployment started in background (PID: $!)"
الخطوة 2: تنفيذ نص الإعداد
ينشئ هذا النص البرمجي مجموعة بيانات BigQuery وربط "موارد السحابة الإلكترونية" وأذونات إدارة الهوية وإمكانية الوصول وحزمة GCS، ويحمّل جميع بيانات جهاز الاستشعار التي ستُحلّلها في هذا المختبر. سيقرأ أيضًا متغيرات البيئة المحفوظة في ملف .env ويتأكّد منها.
chmod +x scripts/setup_lab.sh
./scripts/setup_lab.sh
يستغرق تنفيذ النص البرمجي دقيقة واحدة تقريبًا، وعند الانتهاء، سيظهر لك ملخّص لكل ما تم إنشاؤه.
📝 ملاحظة حول عمليات إعادة ضبط البيئة إذا انتهت مهلة جلسة Cloud Shell أو تمت إعادة تشغيلها في أي وقت خلال هذا المختبر، يمكنك استعادة متغيرات الوحدة الطرفية على الفور عن طريق تنفيذ ما يلي:
source scripts/setenv.sh
الخطوة 3: تشغيل Cloud Shell Editor
لقد كنت تستخدم وحدة Cloud Shell الطرفية حتى الآن. يمكنك الآن التبديل إلى "محرِّر Cloud Shell" الكامل الذي يوفّر لك مساحة عمل مشابهة لمساحة عمل VS Code مع إمكانية استخدام BigQuery المدمجة.
- في لوحة نافذة Cloud Shell الطرفية في أسفل الشاشة، انقر على الزر فتح المحرّر لتشغيل مساحة عمل Cloud Shell Editor.

الخطوة 4: تثبيت إضافة "حزمة Data Agent"
توفّر إضافة "مجموعة أدوات وكيل بيانات Google Cloud" إمكانية الدمج العميق مع خدمات بيانات Google Cloud مباشرةً في المحرّر، ما يتيح لك التفاعل مع BigQuery وAlloyDB وCloud Storage وغير ذلك بدون تبديل السياقات.
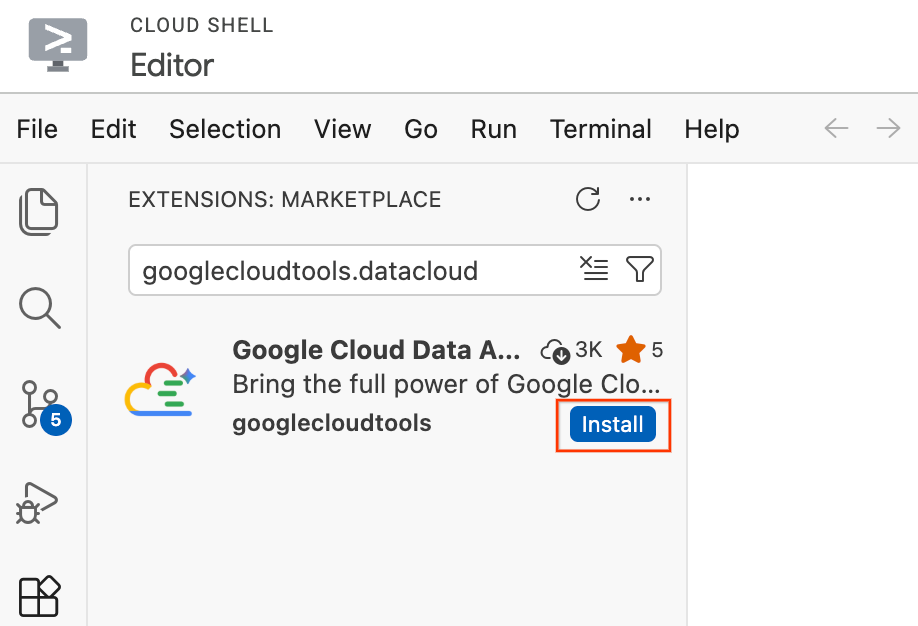
- في "محرّر Cloud Shell"، انقر على رمز الإضافات في "شريط الأنشطة" في أقصى يمين الشاشة (يبدو الرمز على شكل أربعة مربّعات).
- في شريط البحث أعلى لوحة "الإضافات"، اكتب
googlecloudtools.datacloud. - ابحث عن الإضافة المسماة Google Cloud Data Agent Kit التي نشرتها Google Cloud.
- انقر على الزر تثبيت.
- ستظهر رسالة تسألك: "هل تثق في الناشر googlecloudtools وإضافاته؟". انقر على الوثوق بالناشرين والتثبيت للمتابعة.
الخطوة 5: المصادقة على الإضافة وضبطها
بعد التثبيت، اربط الإضافة بمشروعك على Google Cloud.
- من المفترض أن تفتح تلقائيًا صفحة إعداد بعنوان "إعداد حزمة Google Cloud Data Agent". انقر على تسجيل الدخول إلى Google Cloud. اتّبِع أي طلبات تظهر في المتصفّح للسماح بالوصول.
- سيظهر نموذج "الإعداد قيد التقدّم". ستتحقّق الإضافة تلقائيًا من التبعيات المطلوبة، مثل Google Cloud CLI.
- في قسم ملخّص الإعداد، ابحث عن حقل المشروع. انقر على القائمة المنسدلة واختَر مشروعك على Google Cloud. اضبط منطقتك على
us-central1. - انتظِر إلى أن تنتهي عمليات التحقّق من الإعداد. بعد ظهور الرسالة "اكتمل الإعداد"، انقر على ضبط خوادم MCP.
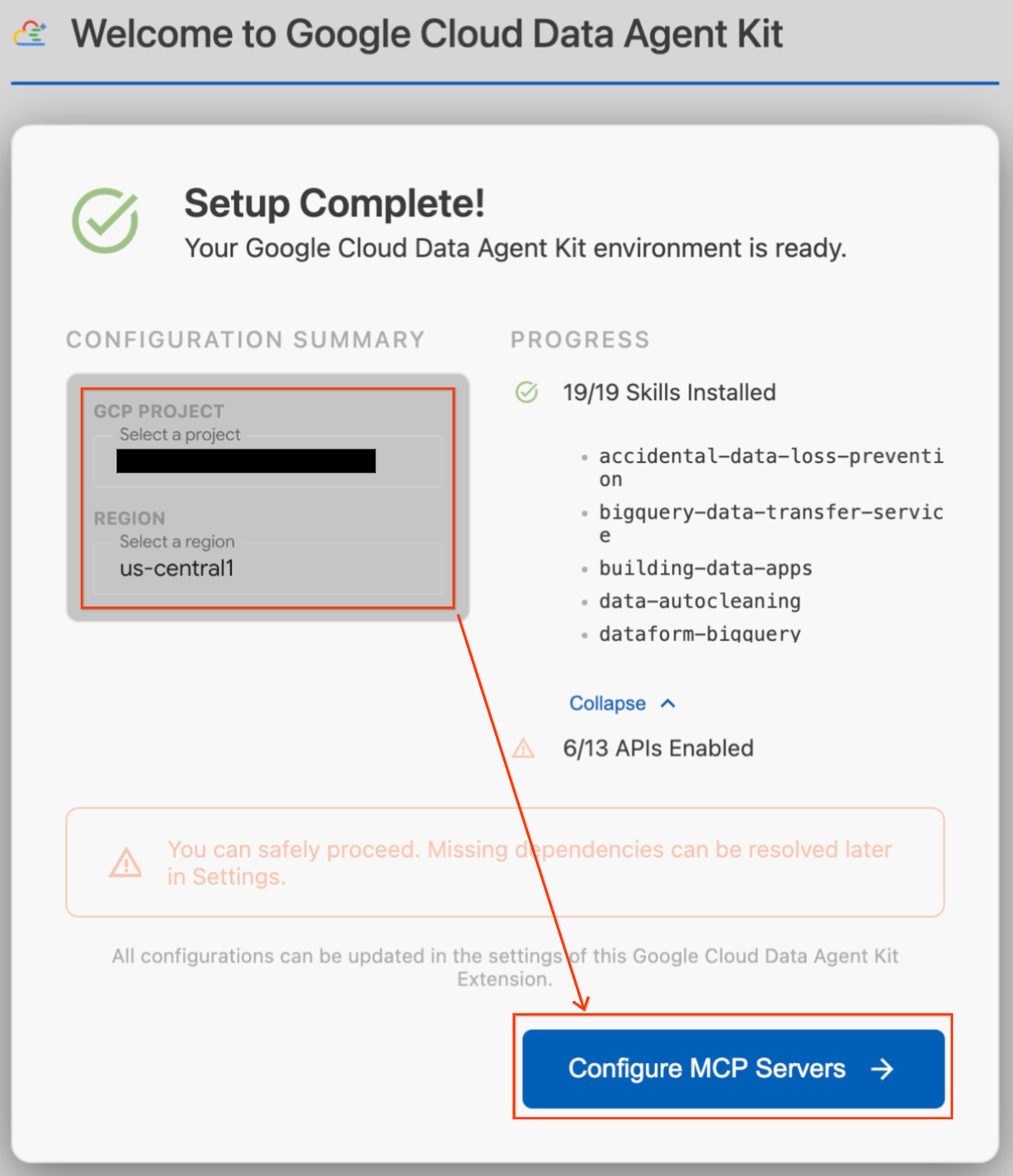
- اختَر BigQuery وAlloyDB ضمن "إعدادات MCP"، ثم انقر على البدء.
الخطوة 6: استكشاف خيارات الإعداد
بعد اكتمال عملية الإعداد، ستنتقل إلى لوحة بيانات "البدء باستخدام حزمة Google Cloud Data Agent".
- ضمن "الإعداد والتكوين"، انقر على البدء.
- سيؤدي ذلك إلى فتح لوحة إعدادات وكيل البيانات. استكشِف علامات التبويب التالية:
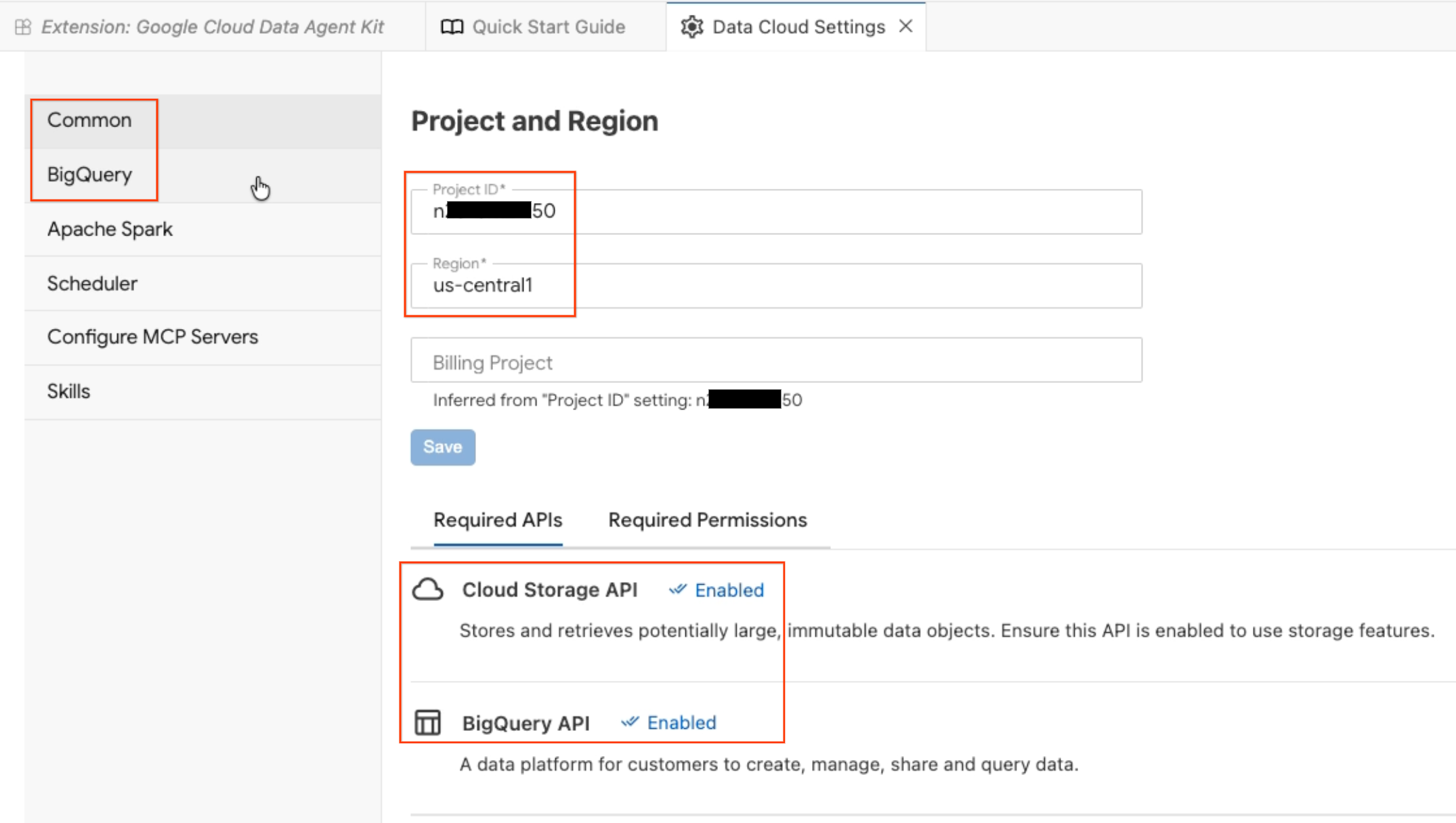
- المشروع والمنطقة: تحقَّق من رقم تعريف المشروع الذي اخترته وتأكَّد من تفعيل واجهات برمجة التطبيقات المطلوبة (Cloud Storage API وBigQuery API وCatalog API وAlloyDB API).
- BigQuery: اضبط الموقع الجغرافي التلقائي لطلبات بحث BigQuery. استخدِم المنطقة
us-central1. - إعداد خوادم MCP: يمكنك الاطّلاع على خوادم MCP المفعّلة (مثل BigQuery وNotebooks وAlloyDB وما إلى ذلك) التي تتيح لوكلاء الذكاء الاصطناعي التفاعل بأمان مع بياناتك.
- المهارات: استكشِف المهارات المُعدّة مسبقًا التي تزوّد الوكلاء بقدرات متخصّصة لإنجاز مهام البيانات المعقّدة.
الخطوة 7: التحقّق باستخدام BigQuery
تأكَّد من أنّ كل شيء يعمل بشكل صحيح من خلال تنفيذ طلب بحث سريع مقابل مجموعة بيانات عامة.
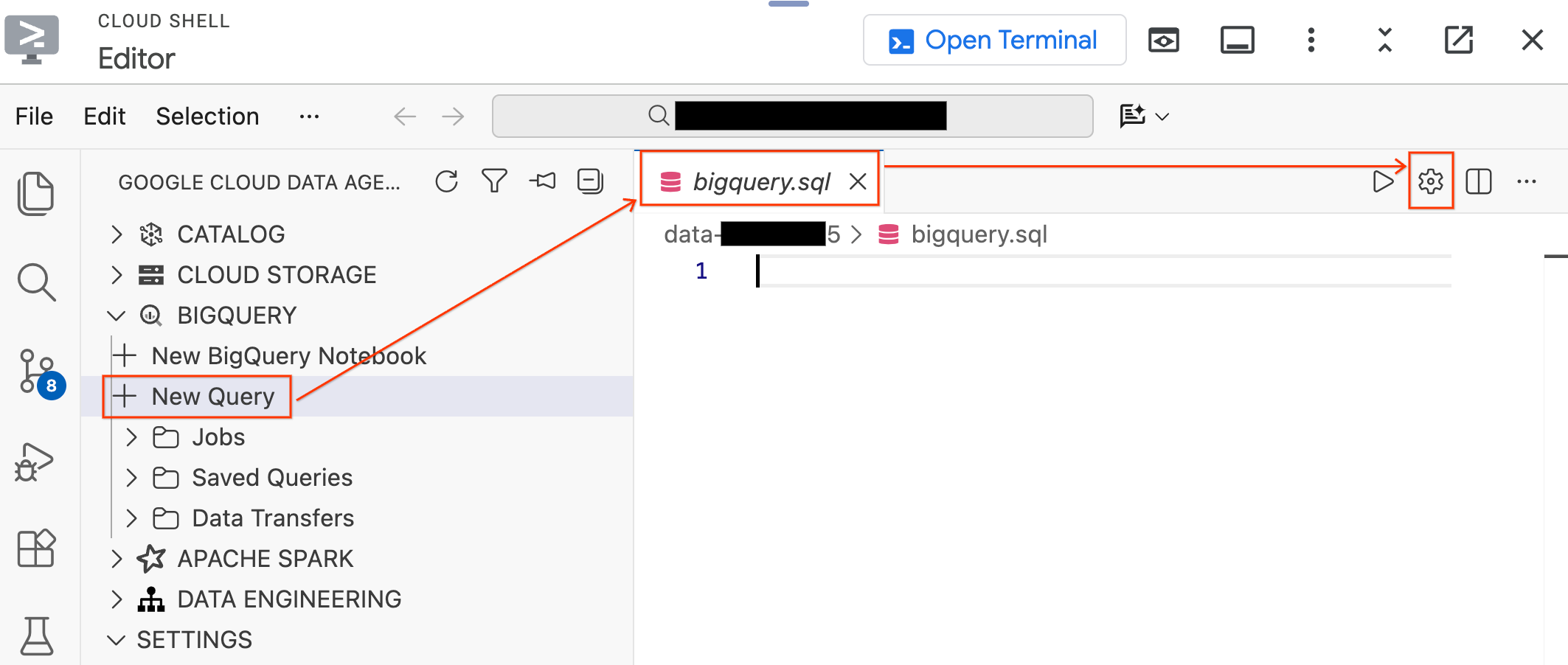
- في لوحة "حزمة أدوات وكيل البيانات" على يمين الصفحة، وسِّع قسم BigQuery وانقر على طلب بحث جديد لفتح علامة تبويب جديدة لأداة تعديل طلبات البحث.
- احفظ الملف بالضغط على
Ctrl+S(في نظام التشغيل Windows أو Linux) أوCmd+S(في نظام التشغيل macOS) وأطلِق عليه اسمbigquery. سيتم استخدام علامة التبويب هذه لإجراء جميع عمليات BigQuery. - انقر على إعدادات الطلب مع تفعيل علامة التبويب
bigquery.sql، واختَر BigQuery كـ مصدر البيانات، ثم انقر على حفظ.
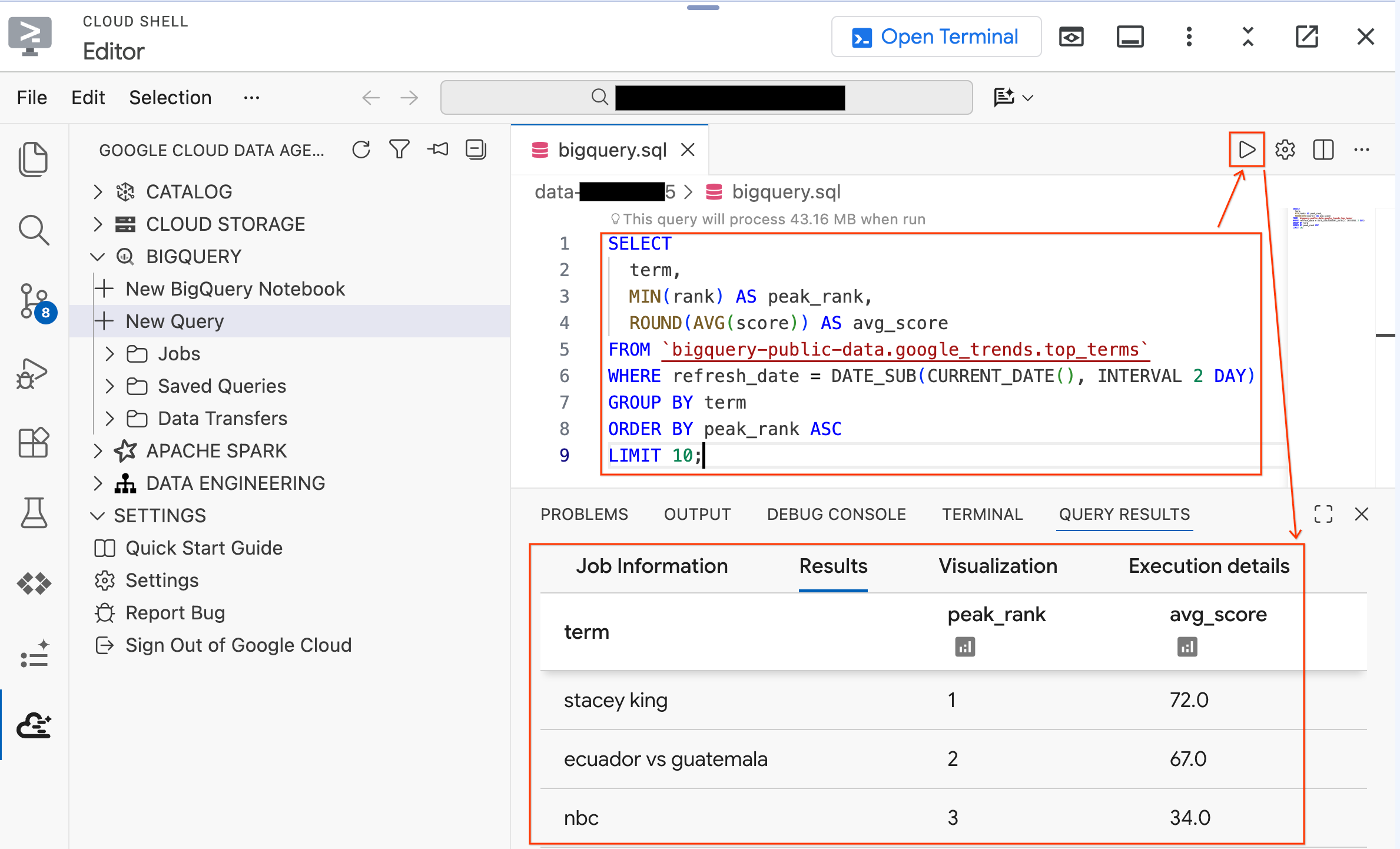
- نفِّذ الاستعلام التالي على مجموعة بيانات عامة:
SELECT
term,
MIN(rank) AS peak_rank,
ROUND(AVG(score)) AS avg_score
FROM `bigquery-public-data.google_trends.top_terms`
WHERE refresh_date = DATE_SUB(CURRENT_DATE(), INTERVAL 2 DAY)
GROUP BY term
ORDER BY peak_rank ASC
LIMIT 10;
- من المفترض أن تظهر لك أهم 10 عبارات بحث رائجة على Google من الأيام القليلة الماضية. إذا ظهرت النتائج، يعني ذلك أنّ الإضافة مرتبطة وجاهزة.
الآن، جرِّب تنفيذ طلب بحث على بيانات المختبر التي أنشأها نص التهيئة البرمجي. استبدِل طلب البحث الحالي بطلب البحث التالي:
SELECT * FROM `lost_cargo_dataset.telemetry_data` LIMIT 5;
من المفترض أن تظهر لك إدخالات سجلّ بيانات القياس عن بُعد مع العمودَين shipment_id وtelemetry_string. هذه هي البيانات التي ستعمل على تحليلها طوال التمرين.
ملخّص القسم: بدأت عملية نشر AlloyDB في الخلفية، وشغّلت نص التهيئة البرمجي، وأعددت Cloud Shell Editor باستخدام إضافة Data Agent Kit.
4. فحص لقطات الفيديو الأمنية
تمكّن فريق التحقيق من استرداد لقطات من كاميرا مراقبة في ميناء ريو دي جانيرو تُظهر صفوفًا من حاويات الشحن. من التجربة العملية 1، تعرف أنّ الحاوية المستهدَفة هي الحاوية الحمراء. عليك الآن تحديد أي حاوية حمراء هي.
ستنشئ "جدول كائنات" يتيح لـ BigQuery "الاطّلاع" على صور الأمان في Cloud Storage، ثم تستخدم الدالة AI.GENERATE لطلب استخراج بيانات منظَّمة من كل صورة من Gemini.
الخطوة 1: إنشاء "جدول العناصر"
جدول الكائنات هو جدول خاص في BigQuery يعمل كفهرس للملفات غير المنظَّمة (الصور وملفات PDF والصوت) المخزَّنة في Cloud Storage. ولا ينسخ الملفات إلى BigQuery، بل ينشئ مرجعًا يمكن الاستعلام عنه حتى تتمكّن دوال الذكاء الاصطناعي من "رؤيتها".
في علامة التبويب bigquery.sql في المحرّر، نفِّذ العبارة التالية لإنشاء "جدول الكائنات" الذي يشير إلى صور أمان المنفذ في حزمة مشروعك:
SET @@location = 'us-central1';
EXECUTE IMMEDIATE CONCAT("""
CREATE OR REPLACE EXTERNAL TABLE `lost_cargo_dataset.port_security_images`
WITH CONNECTION `us-central1.lost_cargo_conn`
OPTIONS (
object_metadata = 'SIMPLE',
uris = ['gs://""", @@project_id, """-lab2/images/*']
);
""");
في ما يلي نظرة سريعة على البيانات التي يمكن أن تراها BigQuery الآن:
SELECT uri, content_type FROM `lost_cargo_dataset.port_security_images` LIMIT 5;
يمثّل كل صف ملف صورة واحدًا في Cloud Storage، ويمكن لـ BigQuery الآن تمرير هذه الصور مباشرةً إلى نماذج الذكاء الاصطناعي.
الخطوة 2: تحليل صور الأمان
الآن، استخدِم دالة AI.GENERATE في BigQuery لتحليل كل صورة أمان. يطلب استعلام SQL الفردي هذا من Gemini فحص كل صورة وعرض بيانات منظَّمة:
SELECT
uri,
AI.GENERATE(
(
'Examine this port security image. Identify any shipping container IDs visible on the container and provide a one-word color of the container.',
ref
),
output_schema => 'detected_container_id STRING, color STRING'
).* EXCEPT (full_response, status)
FROM `lost_cargo_dataset.port_security_images`;
الخطوة 3: تحديد الحاوية المستهدَفة
فحص النتائج ابحث عن الصف الذي يعرض فيه عمود color "أحمر" (أو درجة من درجات اللون الأحمر). دوِّن detected_container_id. هذا هو هدفك: MV-CAPYBARA-003.
الخطوة 4: التحقّق من "المطابقة المرئية"
للاطّلاع على الصورة الفعلية التي تم تحليلها بدون مغادرة المحرِّر، اتّبِع الخطوات التالية:
- انقر على Cloud Storage في لوحة "مجموعة أدوات وكيل البيانات" على يمين الصفحة.
- وسِّع الحزمة (
YOUR_PROJECT_ID-lab2/images/) وانقر على ملف الصورة المتوافق مع الحاوية الحمراء لعرضه مباشرةً في المحرّر.
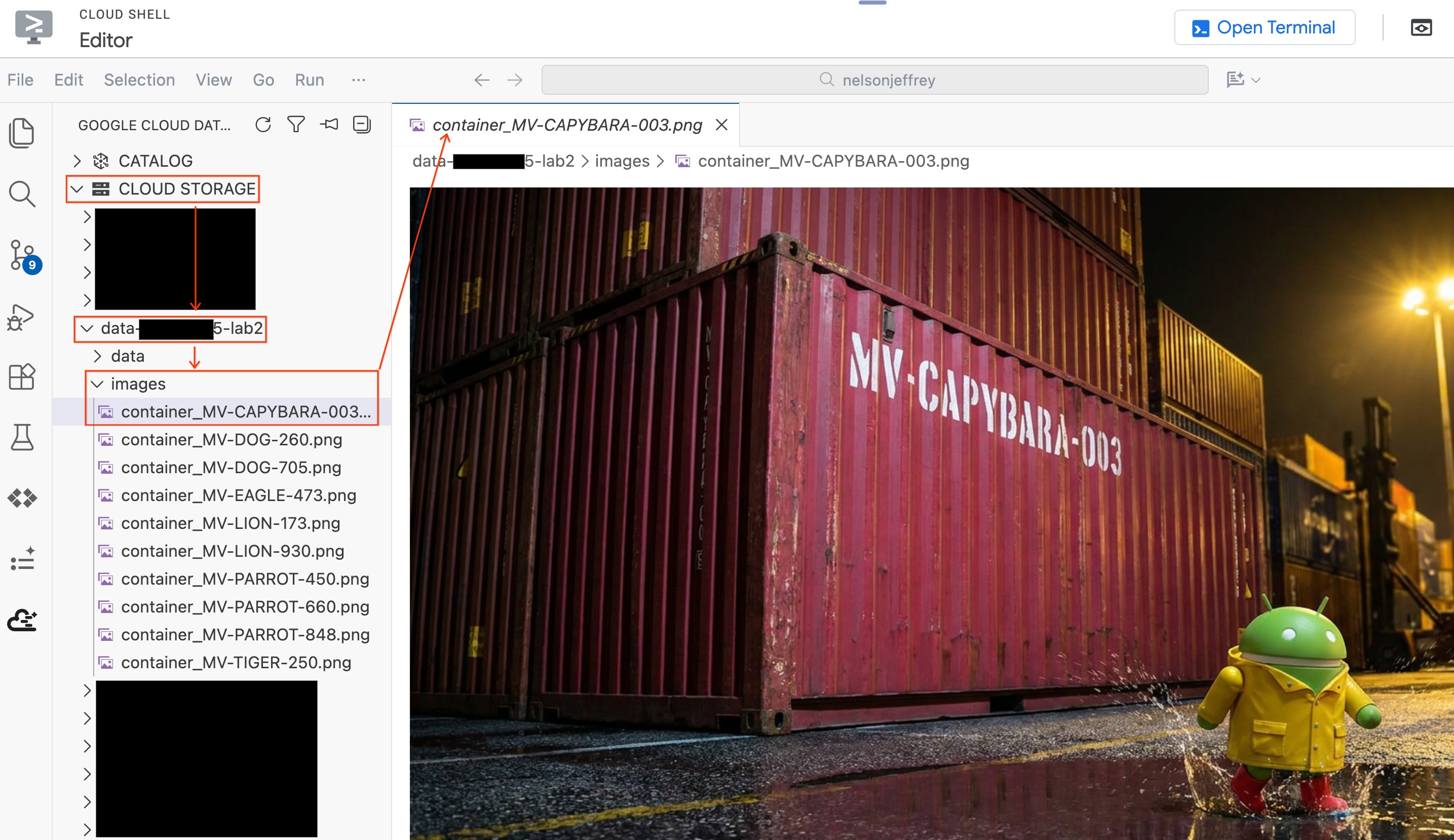
ملخّص القسم: أنشأت "جدول كائنات" لمنح BigQuery إذن الوصول إلى صور أمان الموانئ، ثمّ استخدمت AI.GENERATE لاستخراج بيانات الحاويات المنظَّمة من كلّ صورة. تمّ تحديد الحاوية الحمراء على أنّها MV-CAPYBARA-003.
5- تأكيد السرقة
لقد حدّدت الحاوية المفقودة على أنّها MV-CAPYBARA-003، ولكن هل تمّت سرقتها أو فقدانها؟ تشير سجلّات البيان إلى أنّ هذه الحاوية المحدّدة كانت متوقّفة بجوار جهاز استشعار بيئي SENS-99. إذا أوقف اللصوص وحدة التبريد المدمجة في الحاوية عمدًا قبل نقلها، من المحتمل أنّ SENS-99 سجّل ارتفاعًا مفاجئًا في العادم الحراري.
لنستخدم ميزة رصد القيم الشاذة لإثبات أنّه تم التلاعب بالحاوية.
- أولاً، استكشِف خط الأساس السابق، وهو عبارة عن القراءات العادية من
SENS-99خلال الساعات العديدة الماضية:
SELECT * FROM `lost_cargo_dataset.thermal_history`
ORDER BY reading_time DESC
LIMIT 50;
لاحظ أنّ درجات الحرارة تتراوح ضمن نطاق ضيق يتراوح بين 75 و78 درجة فهرنهايت، وهذا هو المعدّل الطبيعي.
- اطّلِع الآن على مجموعة القراءات الحالية من أداة الاستشعار نفسها:
SELECT * FROM `lost_cargo_dataset.thermal_current`
ORDER BY thermal_reading DESC
LIMIT 50;
هل ترى القراءة 148.4 درجة فهرنهايت بالقرب من أعلى الشاشة؟ يبدو كل شيء آخر طبيعيًا. يشير هذا الارتفاع إلى تعطُّل وحدة التبريد أو التلاعب المتعمد. هيا نطّلع على الإجابة.
- تشغيل ميزة رصد القيم الشاذة تستخدم ميزة
AI.DETECT_ANOMALIESفي BigQuery نموذج TimesFM الأساسي المُدرَّب مسبقًا لتحليل أنماط السلاسل الزمنية والإبلاغ عن القيم الشاذة تلقائيًا، بدون الحاجة إلى تدريب النموذج:
SELECT *
FROM AI.DETECT_ANOMALIES(
TABLE `lost_cargo_dataset.thermal_history`,
TABLE `lost_cargo_dataset.thermal_current`,
data_col => 'thermal_reading',
timestamp_col => 'reading_time',
id_cols => ['sensor_id']
)
WHERE is_anomaly = TRUE;
- فحص النتائج يجب وضع علامة على القراءة البالغة 148.4 درجة فهرنهايت باعتبارها حالة غير طبيعية مع احتمال كبير لحدوثها، ما يؤكّد حدوث شيء غير عادي بالقرب من منطقة الحاوية.
ملخّص القسم: استخدمت الدالة AI.DETECT_ANOMALIES في BigQuery للاستفادة من نموذج TimesFM المُدرَّب مسبقًا. من خلال تنفيذ طلب بحث واحد بلغة SQL، تمكّنت تلقائيًا من تحديد القيم الشاذة وعزل حدث التلاعب غير الطبيعي بدون كتابة أي رمز معقّد لتعلُّم الآلة أو تدريب النماذج من البداية.
6. إعداد نظام التتبُّع
تم التأكّد من سرقة الحاوية ولم تعُد في ريو دي جانيرو. تبثّ كل حاوية في الأسطول إشارات منارة القياس عن بُعد: قراءات المستشعرات وأجزاء نظام تحديد المواقع العالمي (GPS) وسجلات الحالة. إذا كان جهاز الإرسال في الحاوية المسروقة لا يزال يبث إشارات، يمكنك مطابقة هذه الإشارات مع التوقيعات المعروفة للعثور على الحاوية.
يتفوّق BigQuery في العمل التحليلي الذي أجريته حتى الآن، ولكن تحديد موقع حاوية في الوقت الفعلي يتطلّب طلبات بحث تشغيلية بزمن استجابة منخفض. تم تصميم AlloyDB، وهي قاعدة بيانات مُدارة بالكامل ومتوافقة مع PostgreSQL، لهذا الغرض تحديدًا: طلبات البحث المستندة إلى المتجهات بسرعة كافية لنظام تتبُّع مباشر. ستحمّل عمليات التضمين الخاصة بقياس الإحصاءات إلى AlloyDB وتستخدمها لمطابقة إشارة أداة القياس.
من المفترض أن يكون قد تم إعداد مجموعة AlloyDB التي بدأت تشغيلها في الخلفية في وقت سابق. لنعدّل إعداداتها مباشرةً من المحرّر.
الخطوة 1: الربط بـ AlloyDB من "المحرّر"
بدلاً من التبديل إلى Cloud Console، يمكنك الاتصال بـ AlloyDB مباشرةً باستخدام إضافة Data Agent Kit.
- في جزء "مجموعة أدوات وكيل البيانات" على يمين الصفحة ضِمن قسم BigQuery، انقر على طلب بحث جديد لفتح علامة تبويب جديدة لمحرّر طلبات البحث.
- احفظ الملف بالضغط على
Ctrl+S(في نظام التشغيل Windows أو Linux) أوCmd+S(في نظام التشغيل macOS) وأطلِق عليه الاسمalloydb. سيتم استخدام علامة التبويب هذه لجميع طلبات البحث في AlloyDB. - انقر على رمز الترس لفتح النافذة المنبثقة إعدادات طلب البحث.
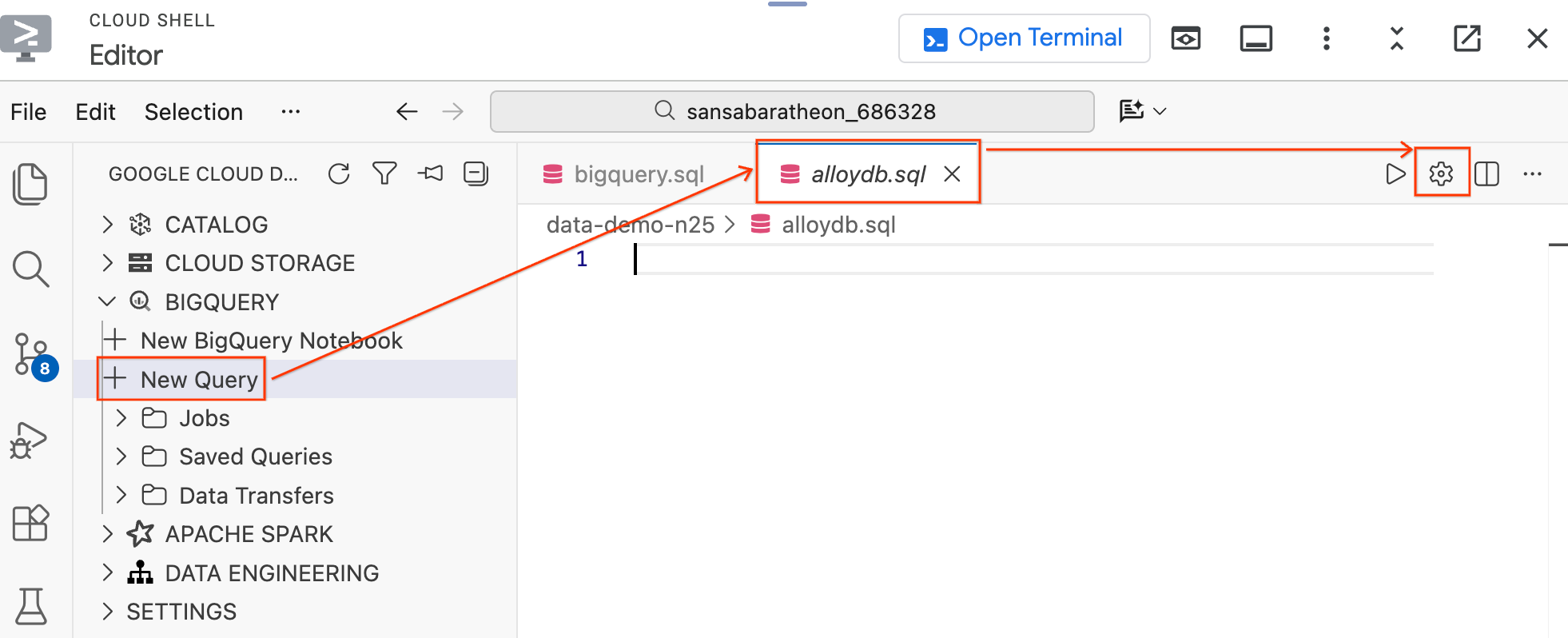
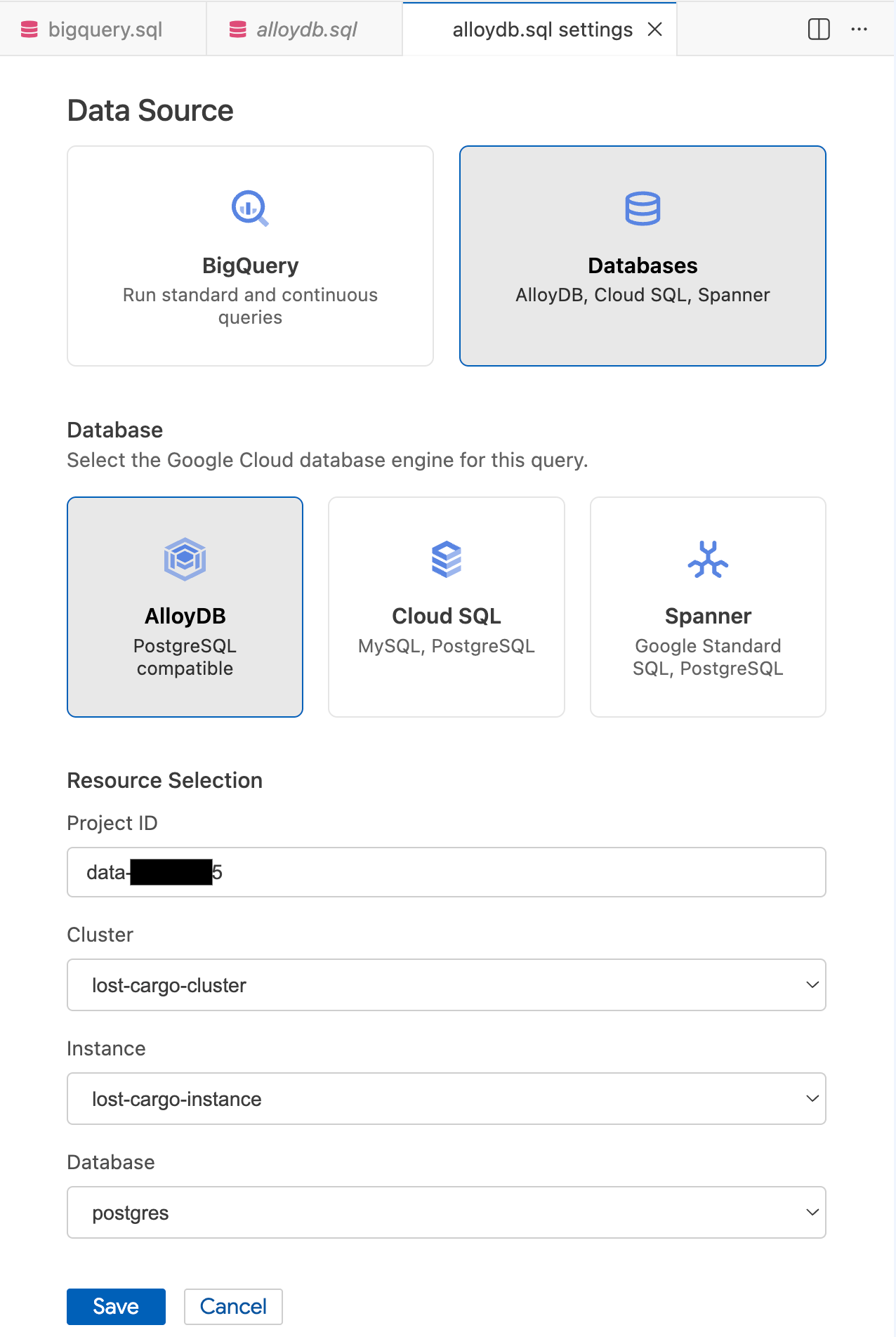
- في النافذة المنبثقة إعدادات طلب البحث، ضِمن مصدر البيانات، انقر على قواعد البيانات.
- ضمن قاعدة البيانات، اختَر AlloyDB.
- املأ تفاصيل اختيار الموارد:
- رقم تعريف المشروع: أدخِل رقم تعريف مشروع Google Cloud.
- تجميع: انقر على
lost-cargo-cluster. - المثيل: انقر على
lost-cargo-instance. - قاعدة البيانات: اختَر
postgres.
- انقر على حفظ.
الخطوة 2: تفعيل إضافة Vector وإنشاء الجدول
بعد الربط بـ AlloyDB، عليك تفعيل إضافات الذكاء الاصطناعي اللازمة وإنشاء الجدول الذي سيتلقّى بيانات القياس عن بُعد المضمّنة.
- في علامة التبويب النشطة
.sql، الصِق الأوامر التالية لتفعيل الإضافات المطلوبة:
CREATE EXTENSION IF NOT EXISTS vector;
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
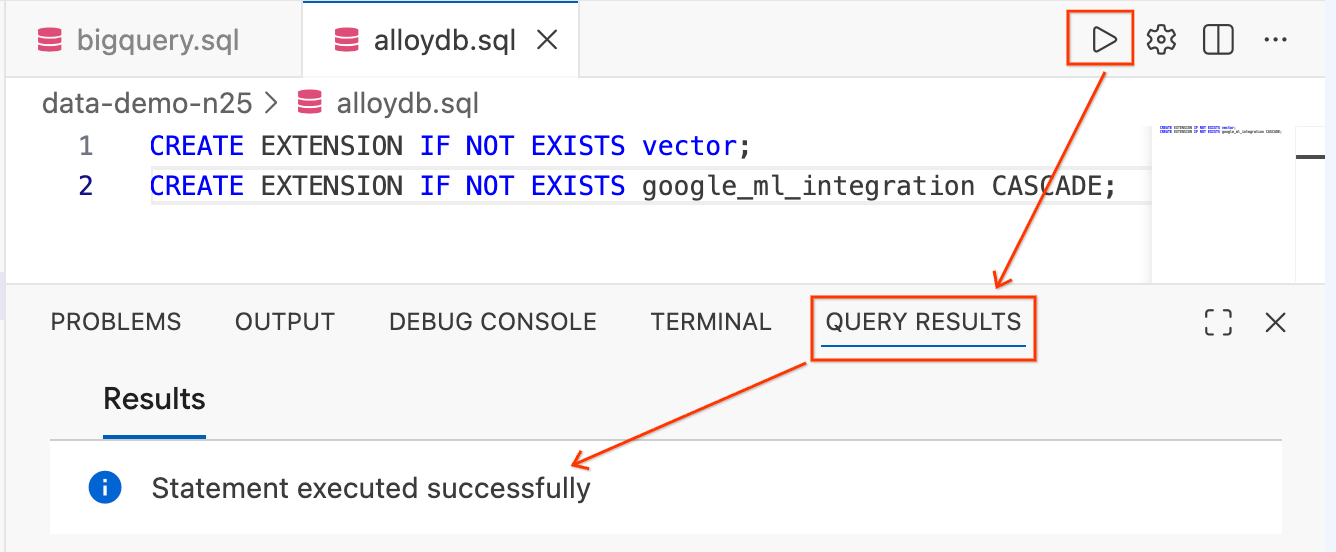
- ظلِّل النص وانقر على الزر تنفيذ طلب البحث (رمز التشغيل) في أعلى يسار المحرّر.
- تحقَّق من لوحة نتائج طلب البحث في أسفل الشاشة. يجب أن يظهر
Statement executed successfully.
- بعد ذلك، استبدِل النص في المحرّر بالعبارة التالية لإنشاء جدول بيانات القياس عن بُعد:
CREATE TABLE IF NOT EXISTS vessel_telemetry (
entry_id SERIAL PRIMARY KEY,
shipment_id VARCHAR(50),
telemetry_string TEXT,
embedding_vector vector(768)
);
- نفِّذ هذا الاستعلام كما فعلت مع الاستعلام السابق، وتأكَّد من تنفيذه بنجاح في اللوحة السفلية.
يأتي النوع vector(768) من الإضافة pgvector التي فعّلتها للتو. تتطابق الأبعاد الـ 768 مع ناتج نموذج text-embedding-005 من Google، والذي ستستخدمه في BigQuery لإنشاء التضمينات.
ملخّص القسم: ربطتَ بـ AlloyDB مباشرةً من "محرّر Cloud Shell"، وفعّلتَ الإضافتين pgvector وgoogle_ml_integration، وأنشأتَ الجدول المستهدَف. أصبحت خدمة AlloyDB جاهزة الآن للعمل كخادم خلفي تشغيلي لمطابقة بيانات القياس عن بُعد في الوقت الفعلي.
7. إنشاء فهرس "بحث Google"
عليك الآن نقل بيانات القياس عن بُعد إلى AlloyDB حتى تتمكّن من تشغيل ميزة مطابقة الإشارات في الوقت الفعلي. إنّ سجلّات القياس عن بُعد الأولية غير منظَّمة ومتغيرة الطول، ما يجعلها غير مناسبة للبحث عن التشابه. ستستخدم دوال الذكاء الاصطناعي من BigQuery لتلخيص كل سجلّ باستخدام Gemini وتحويل كل ملخّص إلى تضمين متّجه ذي 768 بُعدًا. بعد ذلك، ستصدّر البيانات المحسّنة إلى Cloud Storage وتستوردها إلى AlloyDB.
الخطوة 1: إنشاء تضمينات في BigQuery
بدِّل علامة تبويب المحرِّر مرة أخرى إلى bigquery.sql (التي تظل مرتبطة بـ BigQuery).
الآن، نفِّذ طلب البحث التالي لتلخيص كل سجلّ بيانات قياس عن بُعد باستخدام Gemini وإنشاء تضمينات متجهة:
CREATE OR REPLACE TABLE `lost_cargo_dataset.telemetry_embeddings_export` AS
WITH summarized_telemetry AS (
SELECT
shipment_id,
telemetry_string,
AI.GENERATE(
CONCAT('Summarize this telemetry log for vector search: ', telemetry_string)
).result AS summary
FROM `lost_cargo_dataset.telemetry_data`
),
telemetry_embeddings AS (
SELECT
shipment_id,
telemetry_string,
AI.EMBED(summary, endpoint => 'text-embedding-005').result AS embedding
FROM summarized_telemetry
)
SELECT
shipment_id,
telemetry_string,
TO_JSON_STRING(embedding) AS embedding_vector
FROM telemetry_embeddings;
الخطوة 2: معاينة "البيانات المحسّنة"
قبل التصدير، ألقِ نظرة على ما أنشأته. يعرض هذا الاستعلام أرقام تعريف الشحنات والأحرف الـ 80 الأولى من كل ملخّص وتضمين:
SELECT
shipment_id,
SUBSTR(telemetry_string, 1, 80) AS telemetry_preview,
SUBSTR(embedding_vector, 1, 80) AS embedding_preview
FROM `lost_cargo_dataset.telemetry_embeddings_export`
LIMIT 5;
يحتوي كل صف الآن على معرّف شحنة وسجلّ بيانات القياس عن بُعد الأصلي ومتّجه تضمين بـ 768 بُعدًا. هذه هي البيانات التي ستنقلها إلى AlloyDB.
الخطوة 3: تصدير التضمينات إلى Cloud Storage
استخدِم عبارة EXPORT DATA في BigQuery لكتابة جدول التضمينات في حزمة GCS الخاصة بمختبرك كملف CSV.
EXECUTE IMMEDIATE CONCAT("""
EXPORT DATA OPTIONS (
uri = 'gs://""", @@project_id, """-lab2/data/embeddings_export/*.csv',
format = 'CSV',
overwrite = true,
header = false
) AS
SELECT
shipment_id,
telemetry_string,
embedding_vector
FROM `lost_cargo_dataset.telemetry_embeddings_export`;
""");
الخطوة 4: استيراد البيانات إلى AlloyDB من Cloud Storage
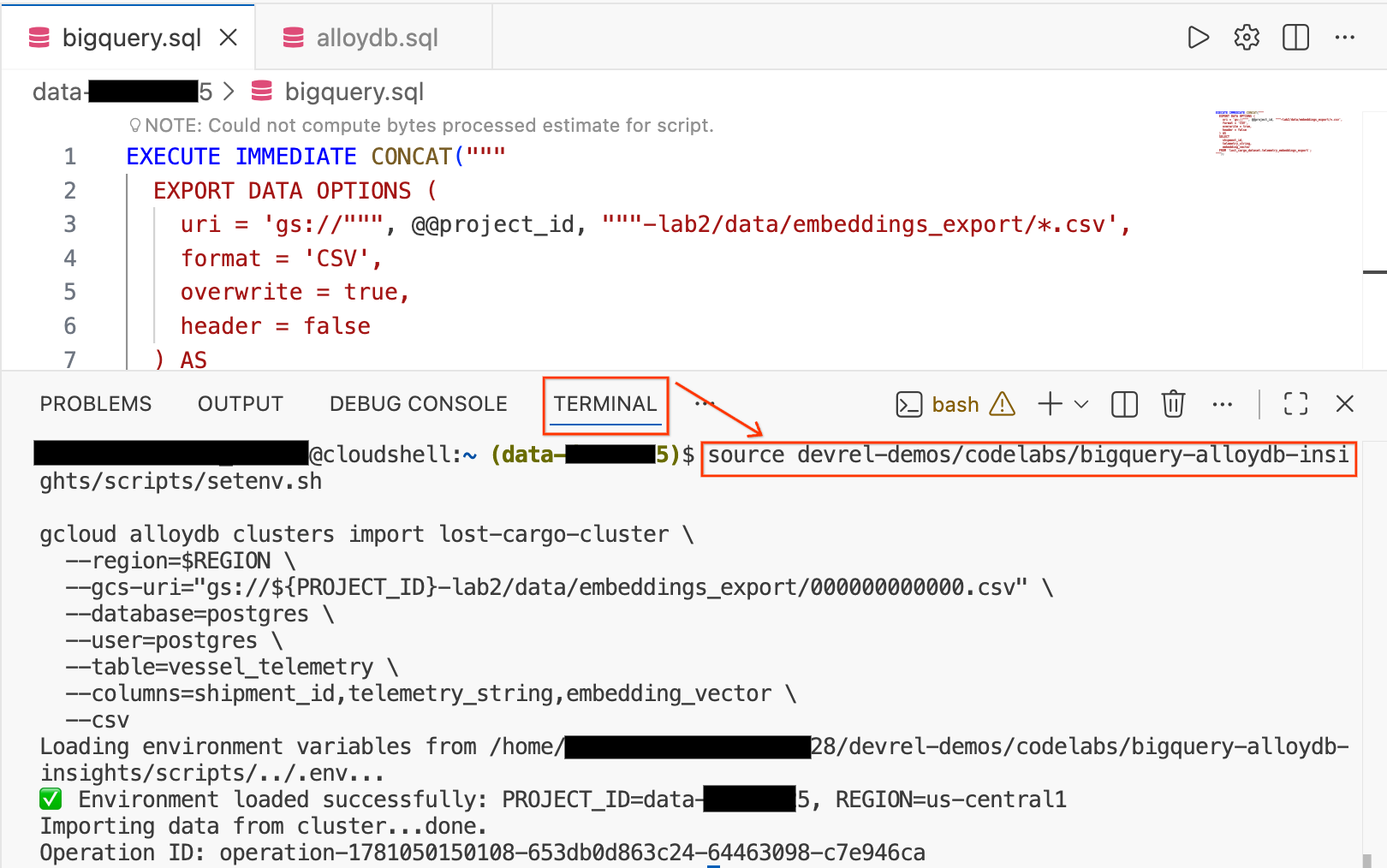
- في "محرِّر Cloud Shell"، انقر على علامة التبويب Terminal في أسفل الشاشة لفتح جلسة طرفية.
- نفِّذ الأوامر التالية لتحميل بيئتك واستيراد ملف CSV مباشرةً إلى جدول
vessel_telemetryفي AlloyDB:
source devrel-demos/codelabs/bigquery-alloydb-insights/scripts/setenv.sh
gcloud alloydb clusters import lost-cargo-cluster \
--region=$REGION \
--gcs-uri="gs://${PROJECT_ID}-lab2/data/embeddings_export/000000000000.csv" \
--database=postgres \
--user=postgres \
--table=vessel_telemetry \
--columns=shipment_id,telemetry_string,embedding_vector \
--csv
ملخّص القسم: استخدمت دوال الذكاء الاصطناعي في BigQuery لتلخيص بيانات القياس عن بُعد وتضمينها، ثم صدّرت النتائج إلى Cloud Storage بتنسيق CSV، ثم استوردتها إلى AlloyDB باستخدام gcloud. تم الآن تحميل قاعدة بيانات التتبُّع التشغيلية وأصبحت جاهزة.
8. مطابقة إشارة Beacon
اعترض فريق ميداني بالقرب من سيدني إشارة مجزّأة من جهاز إرسال بيانات عن بُعد. يظهر في السجلّ الجزئي ما يلي:
"وحدة التبريد غير متصلة بالإنترنت. الإلغاء اليدوي".
إذا كان هذا المحتوى من الحاوية المسروقة، من المفترض أن تتمكّن ميزة "البحث المتّجه" في AlloyDB من مطابقة المحتوى حتى إذا كانت الإشارة غير مكتملة. هذا هو بالضبط نوع طلب البحث التشغيلي في الوقت الفعلي الذي تم تصميم AlloyDB من أجله.
الخطوة 1: التحقّق من البيانات المستورَدة
بدِّل علامة تبويب المحرّر مرة أخرى إلى alloydb.sql (التي تظل مرتبطة بـ AlloyDB).
تأكَّد من تحميل بيانات القياس عن بُعد بنجاح من خلال تنفيذ ما يلي:
SELECT shipment_id, LEFT(telemetry_string, 80) AS telemetry_preview
FROM vessel_telemetry
LIMIT 10;
من المفترض أن تظهر لك صفوف تتضمّن قيم shipment_id ونص بيانات القياس عن بُعد. هذه هي توقيعات بيانات القياس عن بُعد للمجموعة، وهي الآن جاهزة للمطابقة في الوقت الفعلي.
الخطوة 2: البحث عن الحاوية المفقودة
الآن، استخدِم إضافة google_ml_integration في AlloyDB للبحث عن تطابق باستخدام جزء الإشارة الذي تم اعتراضه:
SELECT
shipment_id,
telemetry_string,
1 - (embedding_vector <=> embedding('text-embedding-005', 'Refrigeration unit offline. Manual override.')::vector) AS search_relevance_score
FROM vessel_telemetry
ORDER BY embedding_vector <=> embedding('text-embedding-005', 'Refrigeration unit offline. Manual override.')::vector
LIMIT 5;
تستدعي الدالة embedding()، التي توفّرها الإضافة google_ml_integration في AlloyDB، منصة Agent Platform مباشرةً من SQL لإنشاء تضمين متّجه مضمّن. يحسب عامل التشغيل <=> مسافة جيب التمام بين متجهَين (كلما اقتربت المسافة من 0، كان المتجهان أكثر تطابقًا). نطرح من 1 للتعبير عن النتائج على شكل نتيجة ملاءمة، وكلما كانت النتيجة أعلى، كانت الملاءمة أفضل.
الخطوة 3: تأكيد المطابقة
فحص النتائج يجب أن تكون النتيجة الأولى MV-CAPYBARA-003، مع أعلى درجة ملاءمة.
وهو الحاوية نفسها التي كنت تتتبّعها في كل خطوة من خطوات التحقيق هذه:
- 📷 رصدت لقطات من كاميرا مراقبة السفينة وهي تغادر ميناء ريو دي جانيرو ليلاً.
- 🌡️ أكّدت عملية رصد القيم الشاذة الحرارية أنّه تم إيقاف وحدة التبريد عمدًا.
- 📡 تمكّنت مطابقة إشارات Beacon من تحديد توقيع القياس عن بُعد بالقرب من سيدني.
ثلاثة أنواع مستقلة من الأدلة ثلاث إمكانات مختلفة للذكاء الاصطناعي في Google Cloud حاوية واحدة مسروقة
🎯 تم العثور على MV-CAPYBARA-003 بالقرب من سيدني.

ملخّص القسم: استخدمت ميزة دمج الذكاء الاصطناعي المضمّنة في AlloyDB لإنشاء تضمين بحث وإجراء بحث عن التشابه الجيب التمامي في طلب SQL واحد. أكّد تطابق إشارة جهاز التتبّع الموقع الجغرافي للحاوية المسروقة، ما أدّى إلى إكمال التحقيق.
9- استكشاف الأدلة
بعد تحديد الحاوية من خلال تحليل الصور المتعدد الوسائط والبحث المتّجه، يمكنك استخدام التحليلات الحوارية مباشرةً داخل المحرّر لاستكشاف بيانات التحقيق باستخدام اللغة الطبيعية، بدون كتابة أي استعلام SQL.
الخطوة 1: تحديد موقع البيانات في كتالوج المعرفة
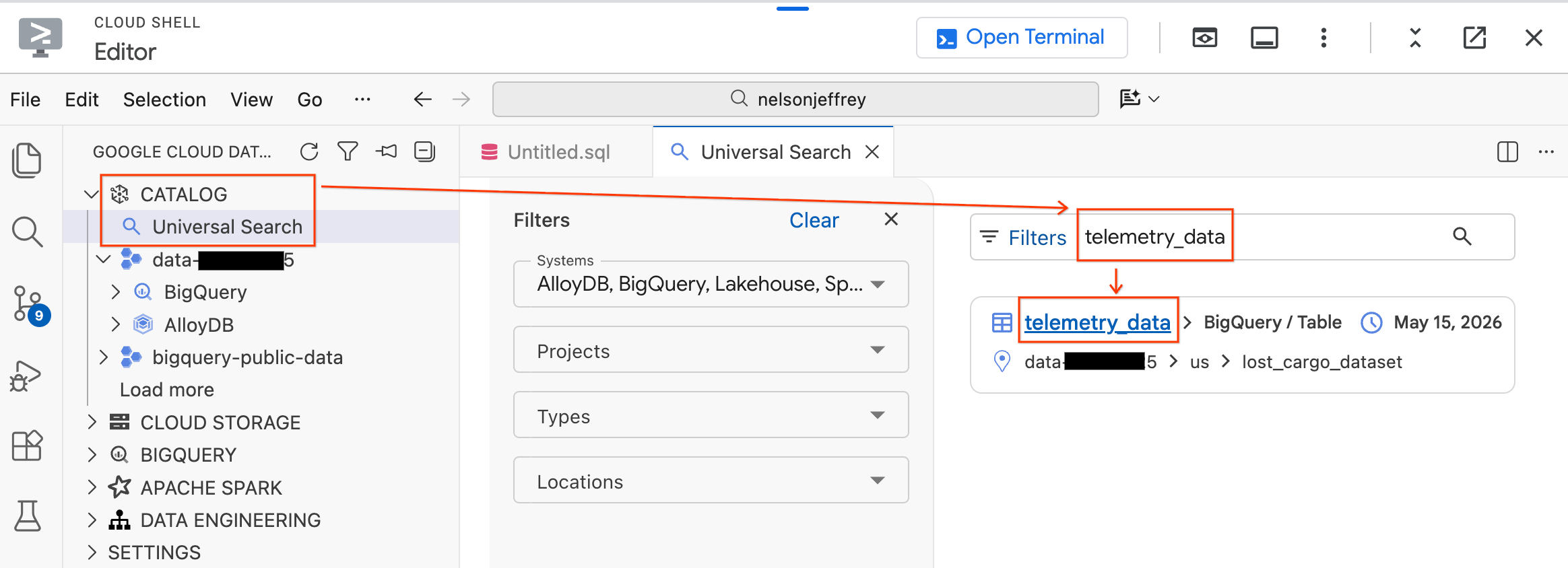
تتضمّن "حزمة أدوات وكيل البيانات" ميزة "البحث الشامل" التي تتيح لك العثور على أصول البيانات واستكشافها في بيئة Google Cloud.
- في لوحة "مجموعة أدوات وكيل البيانات" على يمين الصفحة، وسِّع قسم الفهرس.
- انقر على البحث الشامل.
- في شريط البحث، اكتب
telemetry_data. - انقر على جدول
telemetry_data(ضمنlost_cargo_dataset) من نتائج البحث.
الخطوة 2: إطلاق "تحليلات المحادثات"
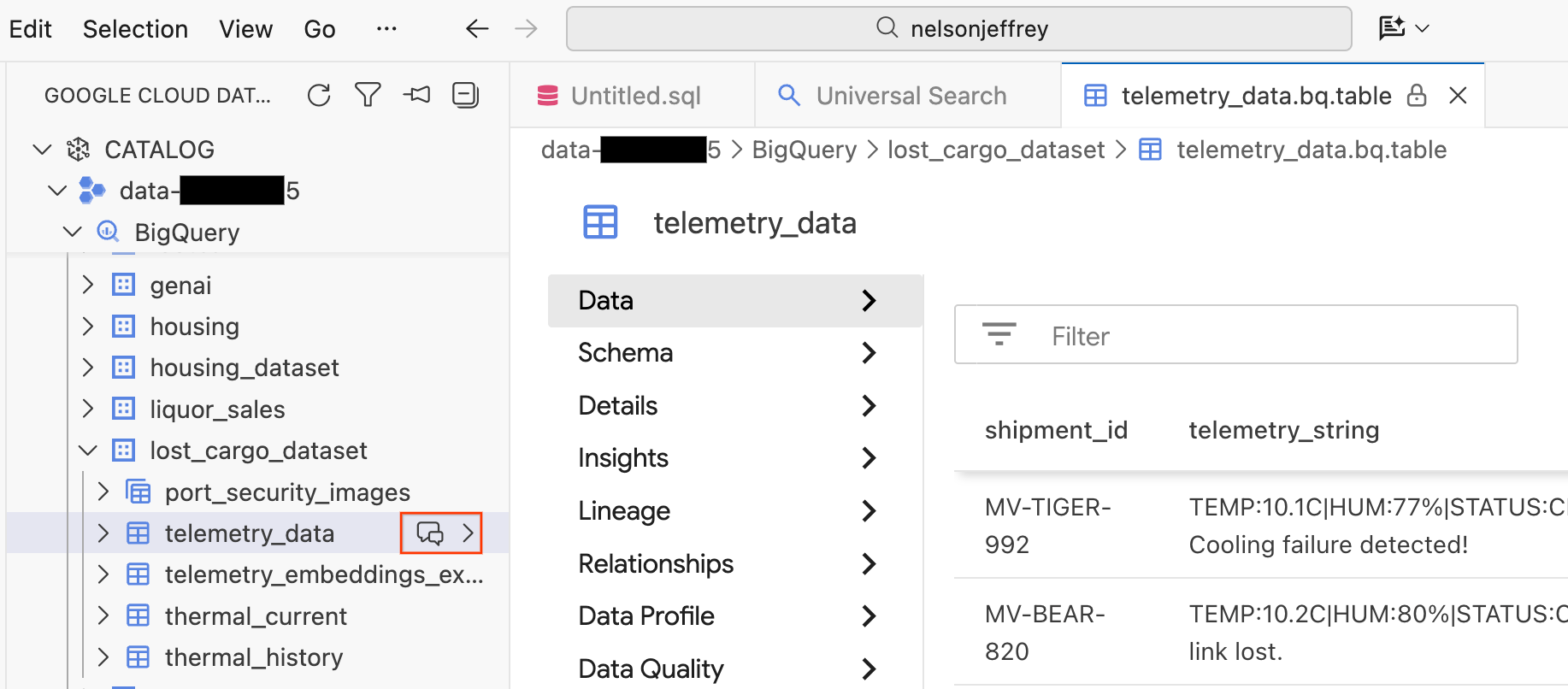
يؤدي النقر على نتيجة البحث إلى فتح علامة تبويب "عارض البيانات" حيث يمكنك معاينة البيانات الأولية وعرض المخطط والتحقّق من جودة البيانات.
- في اللوحة اليمنى، تظهر مجموعات بيانات وجداول BigQuery. انقر على الزر المحادثة لفتح نافذة محادثة جديدة.
الخطوة 3: طرح الأسئلة باللغة الطبيعية
يتم فتح علامة تبويب محادثة جديدة بعنوان "مرحبًا بك في Conversational Analytics". يتوفّر لدى الموظّف السياق حول مخطط جدولك ومحتوياته.
- في نافذة المحادثة، اكتب:"Show me the telemetry status and log for the Capybara shipment."
- اضغط على Enter.
يحوّل الوكيل سؤالك إلى لغة الاستعلامات البنيوية (SQL) في BigQuery، وينفّذ طلب البحث، ويعرض النتائج، بما في ذلك جدول بيانات وإحصاءات تلخّص النتائج. يمكنك التبديل بين وضع التفكير (تحليل أعمق، استجابة أبطأ) ووضع الاستجابة السريعة (استجابة أسرع) استنادًا إلى مدى تعقيد سؤالك. بما أنّ هذه الردود من إنشاء الذكاء الاصطناعي، قد تبدو نتائجك مختلفة قليلاً عن لقطات الشاشة أدناه.
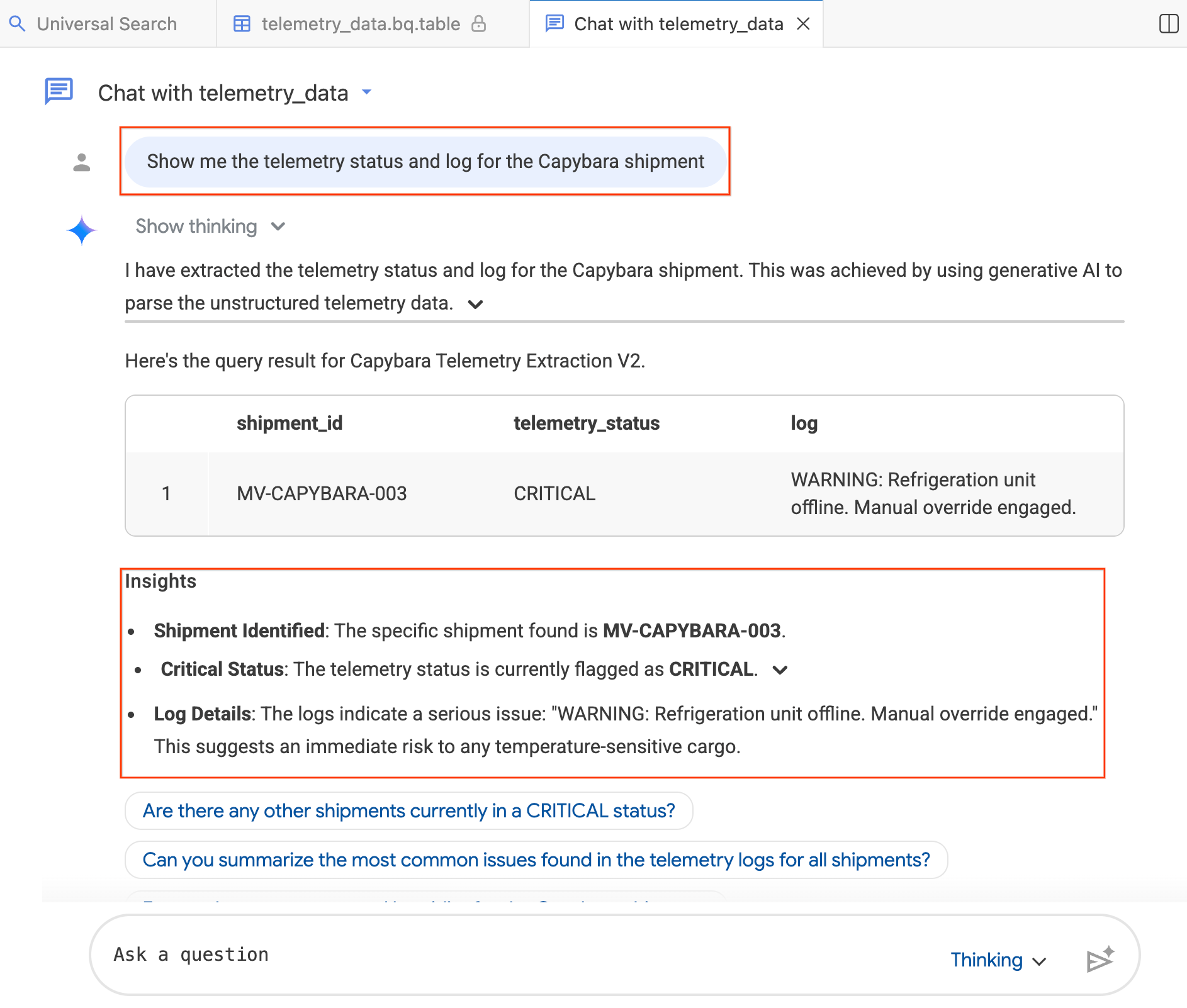
الخطوة 4: طرح أسئلة متابعة
يتذكّر الوكيل سياق محادثتك، لذا جرِّب طرح سؤال متابعة:
- "كم عدد الشحنات الفريدة في بيانات القياس عن بُعد؟"
- "كم عدد الشحنات الأخرى في الأسطول التي تحمل حاليًا الحالة "مهمة"؟"
ملخّص القسم: استخدمت ميزة "البحث الشامل" في "كتالوج المعرفة" لتحديد موقع مجموعة البيانات، وشغّلت "الإحصاءات الحوارية" لطلب بيانات التحقيق بلغة طبيعية. ترجم وكيل الذكاء الاصطناعي أسئلتك إلى SQL وقدّم إحصاءات تؤكّد النتائج التي توصّلت إليها.
10. تنظيف
لتجنُّب تكبُّد رسوم مستمرة على حسابك على Google Cloud، احذف الموارد التي أنشأتها في هذا الدرس التطبيقي. يمكنك تنفيذ هذه الأوامر في الوحدة الطرفية المدمجة داخل "محرّر Cloud Shell" (حيث كنت تستخدم "حزمة أدوات Data Agent") لتنظيف بيئتك.
أولاً، حمِّل متغيّرات البيئة:
source scripts/setenv.sh
- حذف موارد BigQuery (فقط إذا كنت لن تتابع إلى المختبر 3):
إذا كنت تخطّط لمواصلة التدرّب في المختبر 3، يمكنك تخطّي هذه الخطوة. تستخدم التجربة العملية 3 مجموعة بيانات BigQuery وعمليات الربط نفسها لإجراء إحصاءات حول الرسومات البيانية للمواقع.
لحذف مجموعة بيانات BigQuery وعمليات الربط:
# Drop the dataset
bq rm -r -f $PROJECT_ID:lost_cargo_dataset
# Delete the connections
bq rm --connection --location=us-central1 $PROJECT_ID.us-central1.lost_cargo_conn
bq rm --connection --location=us-central1 $PROJECT_ID.us-central1.lost_cargo_alloydb_conn
- حذف حزمة Cloud Storage:
gcloud storage rm --recursive gs://${PROJECT_ID}-lab2
- حذف مثيل AlloyDB ومجموعته:
لا يتم استخدام AlloyDB في الدرس العملي 3، لذا يمكنك إيقافه الآن.
gcloud alloydb instances delete lost-cargo-instance \
--region=$REGION \
--cluster=lost-cargo-cluster \
--quiet
gcloud alloydb clusters delete lost-cargo-cluster \
--region=$REGION \
--force \
--quiet
- حذف إعدادات البيئة المحلية:
أخيرًا، احذف ملف إعدادات البيئة المحلية من مساحة العمل:
rm -f .env
11. تهانينا!
لقد أكملت بنجاح المختبر 2: تحليل البيانات والإحصاءات المتعددة الوسائط. لقد اتّبعت المسار من ميناء مليء بآلاف الحاويات إلى عملية سرقة مؤكّدة وموقع جغرافي محدّد.
إنجازاتك
- فحص اللقطات: استخدمت
AI.GENERATEفي BigQuery لتحليل صور أمن الميناء وتحديد الحاوية MV-CAPYBARA-003 باللون الأحمر القرمزي. - تأكيد السرقة: استكشفت بيانات جهاز الاستشعار الحراري، ورصدت ارتفاعًا مشبوهًا في درجة الحرارة بلغ 148.4 درجة فهرنهايت، واستخدمت
AI.DETECT_ANOMALIESلإثبات أنّه تم التلاعب بالجهاز عمدًا. - إعداد نظام التتبُّع: تم إعداد AlloyDB باستخدام pgvector و
google_ml_integrationلمطابقة الإشارات في الوقت الفعلي. - إنشاء فهرس البحث: استخدمت
AI.GENERATEوAI.EMBEDفي BigQuery لإنشاء تضمينات، ثم صدّرتها إلى Cloud Storage واستوردتها إلى AlloyDB. - مطابقة إشارة جهاز التتبُّع: استخدمت ميزة "البحث المتّجه" في AlloyDB لمطابقة إشارة قياس عن بُعد مجزّأة، ما أدّى إلى تحديد موقع الحاوية المسروقة بالقرب من سيدني.
- استكشاف الأدلة: استخدمت التحليلات الحوارية مباشرةً من المحرّر لطلب البحث عن بيانات التحقيق باللغة الطبيعية.

الخطوات التالية
لقد عرفت مكان الحاوية، والآن عليك معرفة الجهة المسؤولة عنها.
في التمرين العملي 3: استهلاك البيانات وسير العمل المستند إلى الوكلاء، ستنشئ رسمًا بيانيًا للممتلكات خاصًا بشبكة الخدمات اللوجستية لتحديد العلاقات بين الشركات الوهمية، واستخدام "التحليلات الحوارية" للدردشة مع الرسم البياني، والبحث في "كتالوج المعرفة" للعثور على رمز التصريح الآمن اللازم لاسترداد الحاوية.