
1. Introducción

En el lab anterior, agregaste registros de envío fragmentados y rastreaste el transpondedor de carga hasta Nueva York. Sin embargo, los registros de llegada muestran que el contenedor se desvió de inmediato para evitar la detección de aduanas. El sendero te llevó al Puerto de Río de Janeiro, un puerto extenso con miles de contenedores. Encontrar el contenedor adecuado entre miles de otros es una tarea difícil.
En este lab, usarás las capacidades integradas de IA de BigQuery para "leer" imágenes no estructuradas de seguridad portuaria y detectar anomalías térmicas en los datos de sensores, todo con SQL estándar. Luego, exportarás embeddings de vectores a AlloyDB y ejecutarás una búsqueda de vectores para hacer coincidir un indicador de telemetría fragmentado con el contenedor faltante.
Actividades
- Analiza las imágenes de seguridad del puerto para identificar el contenedor robado con BigQuery AI
- Detectar una anomalía térmica con la IA de BigQuery para confirmar que el contenedor se robó y no se extravió
- Genera embeddings de vectores y cárgalos en AlloyDB para realizar búsquedas en tiempo real
- Usa la Búsqueda de Vectores para hacer coincidir un fragmento de la señal de baliza de telemetría y ubicar el contenedor robado
- Explora los datos de investigación con lenguaje natural usando Conversational Analytics
Requisitos
- Un navegador web, como Chrome
- Un proyecto de Google Cloud con la facturación habilitada.
- Conocimientos básicos de SQL y la consola de Google Cloud
Este codelab es para desarrolladores intermedios.
Los recursos creados en este codelab deberían costar menos de USD 5.
2. Antes de comenzar
Inicie Cloud Shell
Usarás Google Cloud Shell para descargar el código, ejecutar secuencias de comandos de configuración y, luego, implementar la aplicación.
- En una pestaña nueva del navegador, abre Cloud Shell: shell.cloud.google.com
- Una vez que te conectes, configura tu ID del proyecto y confirma tu entorno:
gcloud config set project <<YOUR_PROJECT_ID>>
export PROJECT_ID=$(gcloud config get-value project)
export REGION=us-central1
Deberías ver un mensaje similar a este:
Your active configuration is: [cloudshell-####] Updated property [core/project]
Clona el repositorio
Clona el repositorio del codelab en tu entorno de Cloud Shell:
cd ~/
git clone --filter=blob:none --no-checkout https://github.com/GoogleCloudPlatform/devrel-demos.git
cd ~/devrel-demos
git sparse-checkout init --cone
git sparse-checkout set codelabs/bigquery-alloydb-insights
git checkout main
cd codelabs/bigquery-alloydb-insights/
Habilita las APIs
Ejecuta este comando en Cloud Shell para habilitar todas las APIs requeridas para este lab:
gcloud services enable \
aiplatform.googleapis.com \
bigquery.googleapis.com \
bigqueryconnection.googleapis.com \
alloydb.googleapis.com
Si la ejecución se realiza correctamente, deberías ver un mensaje similar al siguiente:
Operation "operations/..." finished successfully.
3. Configura tu entorno
Antes de analizar imágenes y datos de telemetría, debes configurar la infraestructura para este lab. Ejecutarás dos secuencias de comandos: una iniciará el aprovisionamiento de AlloyDB en segundo plano y la otra creará todos los recursos de BigQuery que necesitarás.
Paso 1: Inicia la implementación de AlloyDB (en segundo plano)
El aprovisionamiento del clúster de AlloyDB tarda alrededor de 10 minutos, por lo que lo iniciarás primero y lo dejarás ejecutándose en segundo plano mientras trabajas en las secciones de BigQuery. La secuencia de comandos registrará automáticamente la configuración de tu proyecto activo en un archivo .env local para que se guarde tu configuración, incluso si se cierra o reinicia tu terminal de Cloud Shell.
chmod +x scripts/setup_alloydb.sh
nohup ./scripts/setup_alloydb.sh > /dev/null 2>&1 &
echo "AlloyDB deployment started in background (PID: $!)"
Paso 2: Ejecuta la secuencia de comandos de configuración
Esta secuencia de comandos crea el conjunto de datos de BigQuery, la conexión de recursos de Cloud, las concesiones de IAM y el bucket de GCS, y carga todos los datos del sensor que analizarás en este lab. También leerá y verificará las variables de entorno guardadas en el archivo .env.
chmod +x scripts/setup_lab.sh
./scripts/setup_lab.sh
La secuencia de comandos tarda aproximadamente un minuto en ejecutarse. Cuando finalice, verás un resumen de todo lo que creó.
📝 Nota sobre el restablecimiento del entorno Si se agota el tiempo de espera de tu sesión de Cloud Shell o se reinicia en cualquier momento durante este lab, puedes restablecer tus variables de terminal de inmediato ejecutando el siguiente comando:
source scripts/setenv.sh
Paso 3: Inicia el editor de Cloud Shell
Hasta ahora, usaste la terminal de Cloud Shell. Ahora, cambia al editor de Cloud Shell completo, que te brinda un espacio de trabajo similar a VS Code con compatibilidad integrada con BigQuery.
- En el panel de la terminal de Cloud Shell que se encuentra en la parte inferior de la pantalla, haz clic en el botón Abrir editor para iniciar el espacio de trabajo del editor de Cloud Shell.

Paso 4: Instala la extensión del kit del agente de datos
La extensión del kit de agentes de datos de Google Cloud proporciona una integración profunda con los servicios de datos de Google Cloud directamente en tu editor, lo que te permite interactuar con BigQuery, AlloyDB, Cloud Storage y muchos más sin cambiar de contexto.
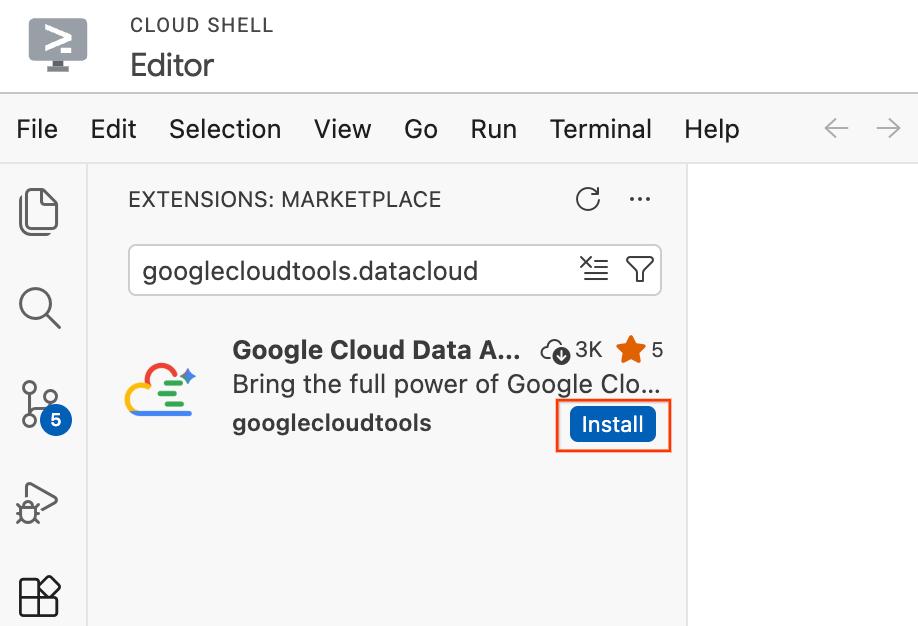
- En el editor de Cloud Shell, haz clic en el ícono Extensiones en la barra de actividad, en el extremo izquierdo de la pantalla (parece cuatro cuadrados).
- En la barra de búsqueda que se encuentra en la parte superior del panel Extensiones, escribe
googlecloudtools.datacloud. - Busca la extensión llamada Google Cloud Data Agent Kit publicada por Google Cloud.
- Haz clic en el botón Install.
- Aparecerá un mensaje que te preguntará si confías en el publicador "googlecloudtools" y sus extensiones. Haz clic en Confiar en los publicadores y, luego, en Instalar para continuar.
Paso 5: Autentica y configura la extensión
Después de la instalación, conecta la extensión a tu proyecto de Google Cloud.
- Se abrirá automáticamente una página de incorporación titulada "Incorporación del kit del agente de datos de Google Cloud". Haz clic en Acceder a Google Cloud. Sigue las indicaciones del navegador para permitir el acceso.
- Aparecerá una ventana modal con el mensaje "Configuración en curso". La extensión verificará automáticamente las dependencias requeridas, como Google Cloud CLI.
- En la sección Resumen de la configuración, busca el campo del proyecto. Haz clic en el menú desplegable y selecciona tu proyecto de Google Cloud. Establece tu región como
us-central1. - Espera a que finalicen las verificaciones de configuración. Cuando veas el mensaje "¡Configuración completa!", haz clic en Configurar servidores de MCP.
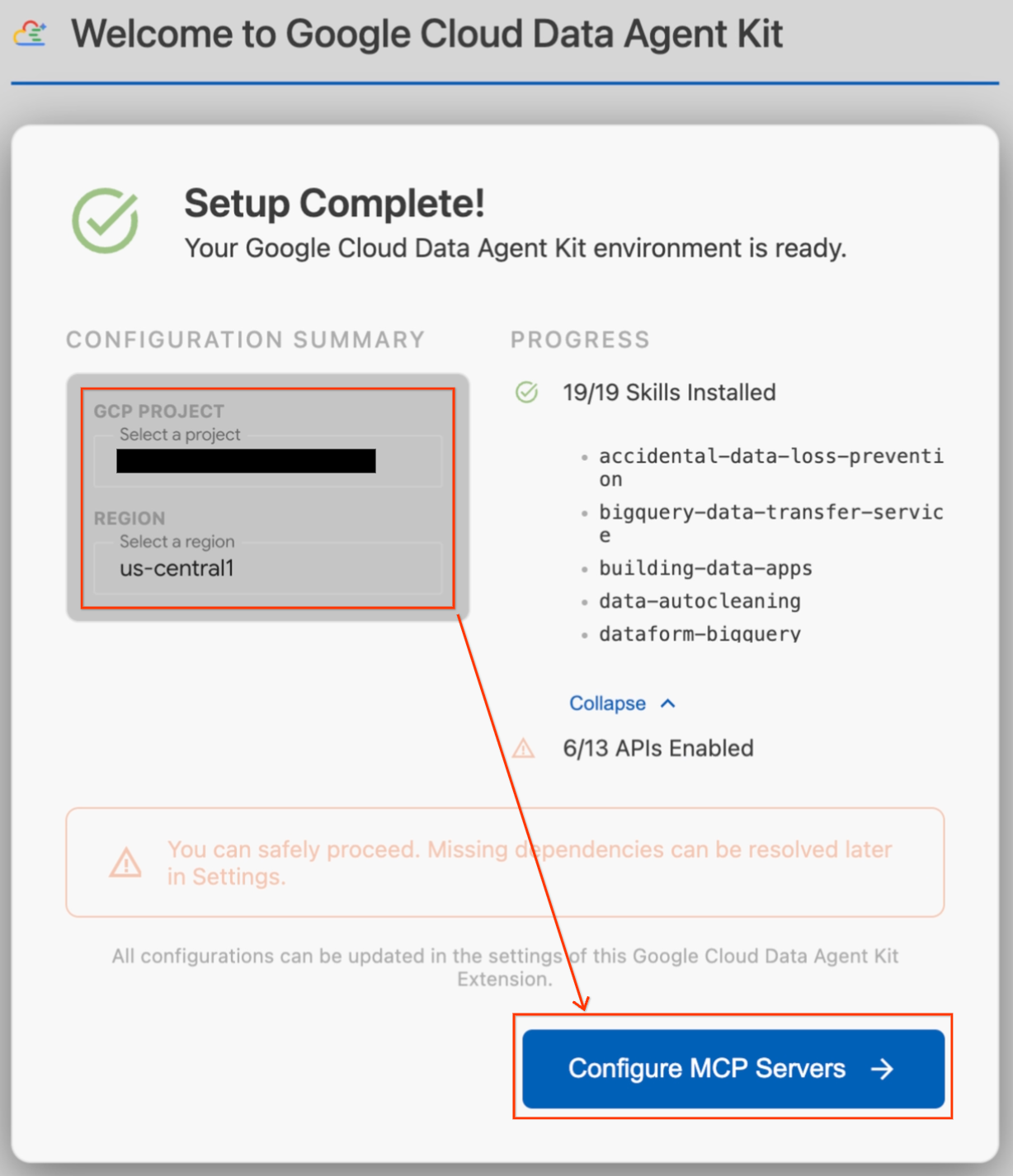
- Selecciona BigQuery y AlloyDB en Configuración del MCP y, luego, haz clic en Comenzar.
Paso 6: Explora las opciones de configuración
Una vez que se complete la configuración, llegarás al panel "Comienza a usar el kit de agentes de datos de Google Cloud".
- En "Configuración", haz clic en Comenzar.
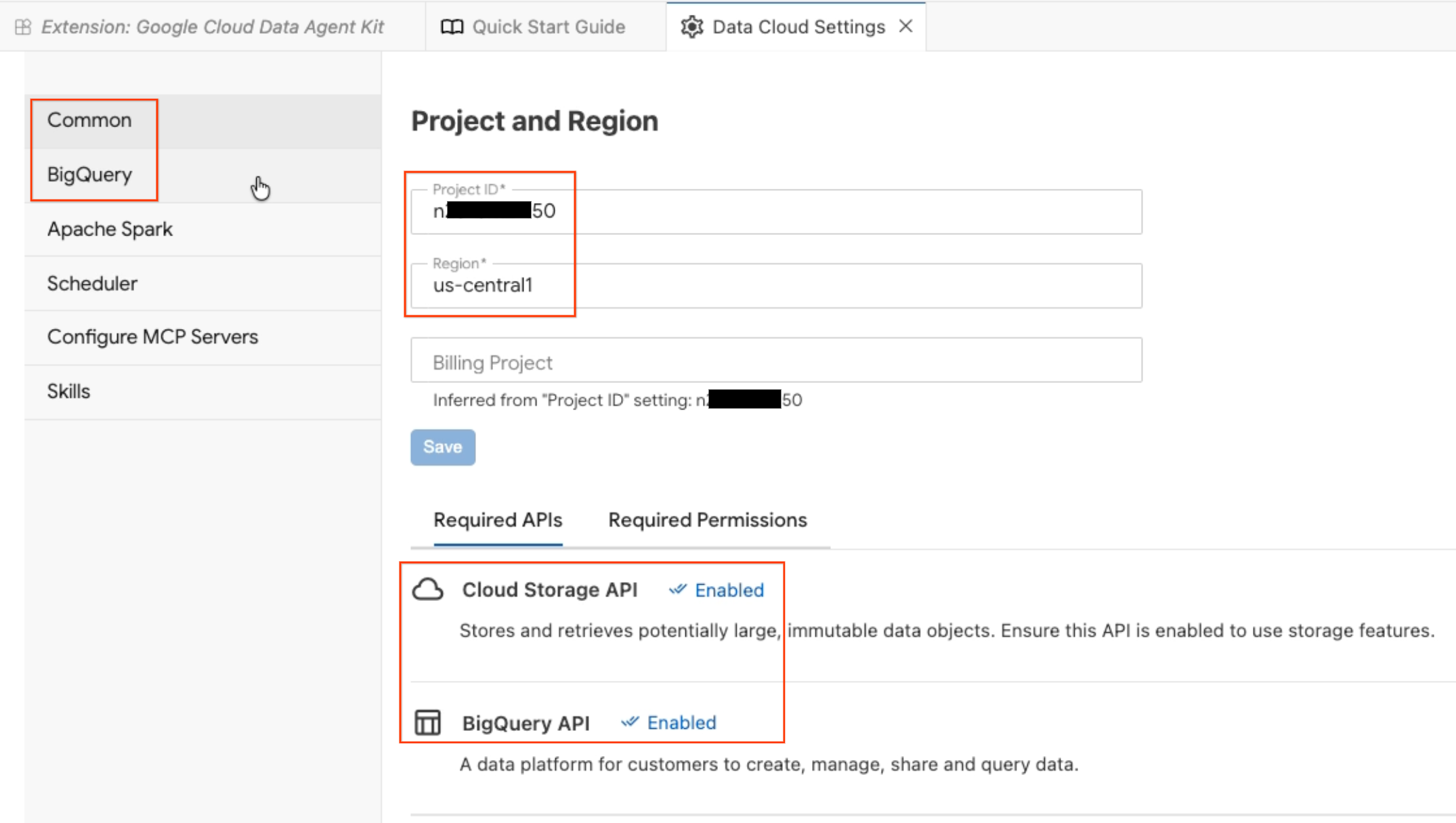
- Se abrirá el panel Configuración del agente de datos. Explora las pestañas:
- Proyecto y región: Verifica el ID del proyecto seleccionado y comprueba que las APIs requeridas (API de Cloud Storage, API de BigQuery, API de Catalog y API de AlloyDB) estén habilitadas.
- BigQuery: Configura la ubicación predeterminada para tus consultas de BigQuery. Usa la región
us-central1. - Configura servidores de MCP: Consulta los servidores de MCP habilitados (BigQuery, Notebooks, AlloyDB, etc.) que permiten que los agentes de IA interactúen de forma segura con tus datos.
- Habilidades: Explora las habilidades prediseñadas que proporcionan a los agentes capacidades especializadas para tareas de datos complejas.
Paso 7: Verifica con BigQuery
Para confirmar que todo funciona, ejecuta una consulta rápida en un conjunto de datos públicos.
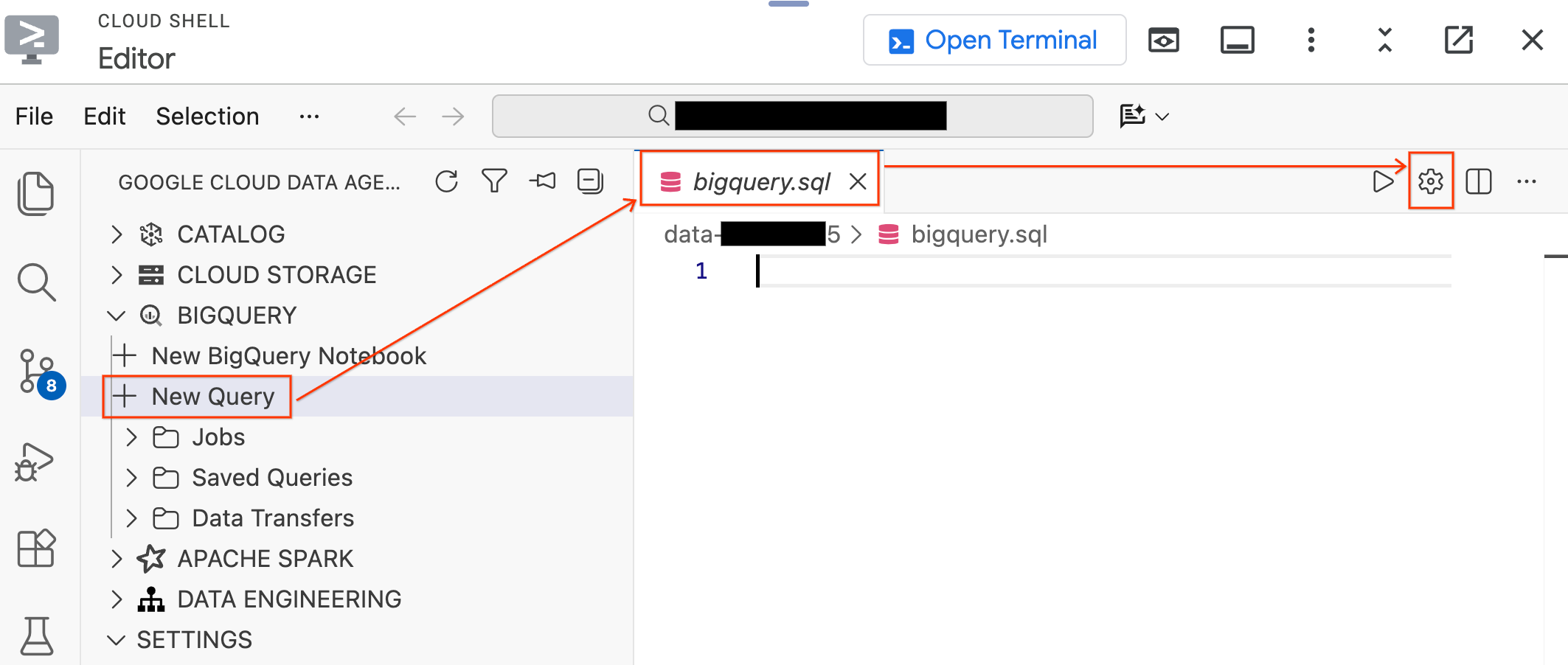
- En el panel Data Agent Kit de la izquierda, expande la sección BigQuery y haz clic en New Query para abrir una nueva pestaña del editor de consultas.
- Para guardar el archivo, presiona
Ctrl+S(Windows/Linux) oCmd+S(macOS) y asígnale el nombrebigquery. Esta pestaña se usará para todas tus operaciones de BigQuery. - Haz clic en Configuración de consulta con la pestaña
bigquery.sqlactiva, selecciona BigQuery como la fuente de datos y haz clic en Guardar.
- Ejecuta la siguiente consulta en un conjunto de datos públicos:
SELECT
term,
MIN(rank) AS peak_rank,
ROUND(AVG(score)) AS avg_score
FROM `bigquery-public-data.google_trends.top_terms`
WHERE refresh_date = DATE_SUB(CURRENT_DATE(), INTERVAL 2 DAY)
GROUP BY term
ORDER BY peak_rank ASC
LIMIT 10;
- Deberías ver los 10 términos de búsqueda más populares de Google de los últimos días. Si aparecen resultados, significa que la extensión está conectada y lista para usarse.
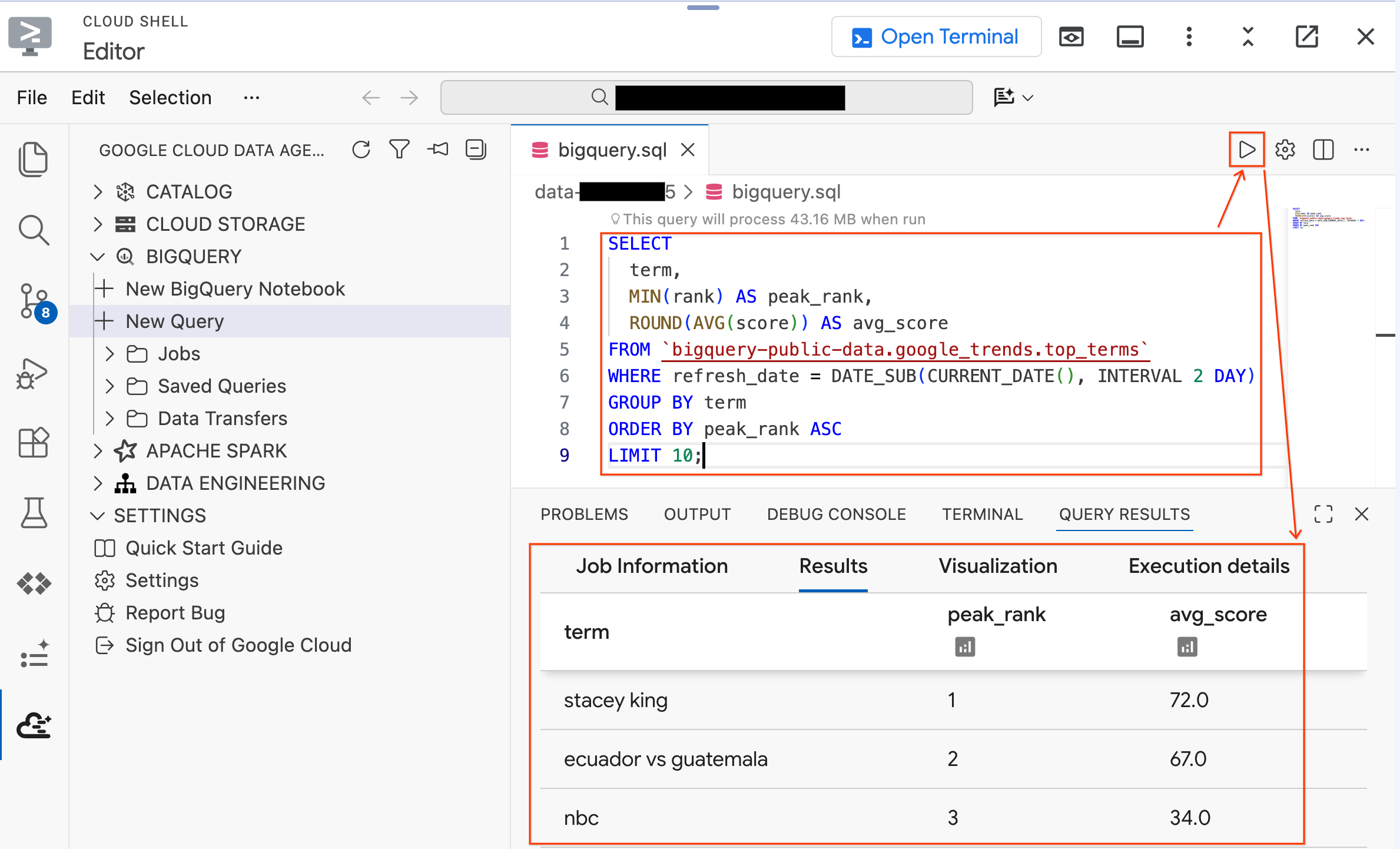
Ahora, prueba una consulta en los datos del lab que acaba de crear tu secuencia de comandos de configuración. Reemplaza la consulta existente por esta:
SELECT * FROM `lost_cargo_dataset.telemetry_data` LIMIT 5;
Deberías ver entradas de registro de telemetría con las columnas shipment_id y telemetry_string. Estos son los datos que analizarás a lo largo del lab.
Resumen de la sección: Iniciaste la implementación de AlloyDB en segundo plano, ejecutaste la secuencia de comandos de configuración y configuraste el Editor de Cloud Shell con la extensión Data Agent Kit.
4. Cómo analizar las grabaciones de seguridad
El equipo de investigación recuperó imágenes de seguridad del puerto de Río de Janeiro en las que se ven filas de contenedores de envío. En el lab 1, sabes que el contenedor objetivo es red. Ahora debes identificar exactamente cuál es el contenedor rojo.
Crearás una tabla de objetos que le permitirá a BigQuery "ver" las imágenes de seguridad en Cloud Storage y, luego, usarás la función AI.GENERATE para indicarle a Gemini que extraiga datos estructurados de cada imagen.
Paso 1: Crea la tabla de objetos
Una tabla de objetos es una tabla especial de BigQuery que actúa como un índice sobre los archivos no estructurados (imágenes, PDFs, audio) almacenados en Cloud Storage. No copia los archivos en BigQuery, sino que crea una referencia consultable para que las funciones de IA puedan "verlos".
En la pestaña bigquery.sql del editor, ejecuta la siguiente instrucción para crear la tabla de objetos que apunta a las imágenes de seguridad del puerto en el bucket de tu proyecto:
SET @@location = 'us-central1';
EXECUTE IMMEDIATE CONCAT("""
CREATE OR REPLACE EXTERNAL TABLE `lost_cargo_dataset.port_security_images`
WITH CONNECTION `us-central1.lost_cargo_conn`
OPTIONS (
object_metadata = 'SIMPLE',
uris = ['gs://""", @@project_id, """-lab2/images/*']
);
""");
Echa un vistazo rápido a lo que BigQuery ahora puede ver:
SELECT uri, content_type FROM `lost_cargo_dataset.port_security_images` LIMIT 5;
Cada fila representa un archivo de imagen en Cloud Storage. Ahora BigQuery puede pasar estas imágenes directamente a los modelos de IA.
Paso 2: Analiza las imágenes de seguridad
Ahora usa la función AI.GENERATE de BigQuery para analizar cada imagen de seguridad. Esta única consulta en SQL le indica a Gemini que examine cada imagen y devuelva datos estructurados:
SELECT
uri,
AI.GENERATE(
(
'Examine this port security image. Identify any shipping container IDs visible on the container and provide a one-word color of the container.',
ref
),
output_schema => 'detected_container_id STRING, color STRING'
).* EXCEPT (full_response, status)
FROM `lost_cargo_dataset.port_security_images`;
Paso 3: Identifica el contenedor de destino
Analiza los resultados. Busca la fila en la que la columna color muestre "Rojo" (o alguna variación de rojo). Anota el detected_container_id. Este es tu objetivo: MV-CAPYBARA-003.
Paso 4: Verifica la coincidencia visual
Para ver la imagen real que se analizó sin salir del editor, haz lo siguiente:
- Haz clic en Cloud Storage en el panel del kit del agente de datos a la izquierda.
- Expande tu bucket (
YOUR_PROJECT_ID-lab2/images/) y haz clic en el archivo de imagen correspondiente al contenedor rojo para verlo directamente en el editor.
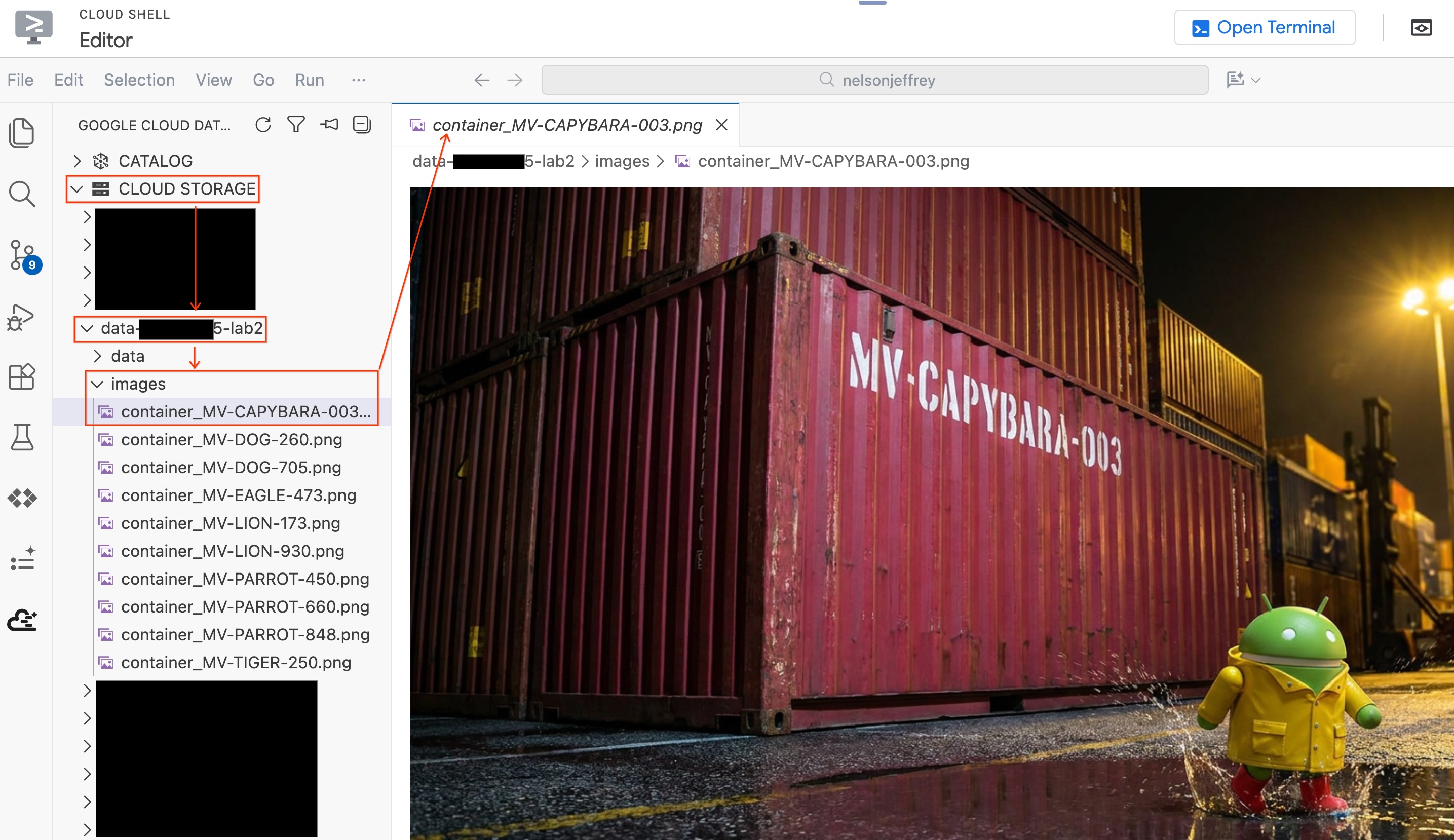
Resumen de la sección: Creaste una tabla de objetos para que BigQuery pueda acceder a las imágenes de seguridad del puerto y, luego, usaste AI.GENERATE para extraer datos estructurados de contenedores de cada imagen. El contenedor rojo se identificó como MV-CAPYBARA-003.
5. Confirmación del robo
Identificaste el contenedor faltante como MV-CAPYBARA-003, pero ¿se lo robaron o simplemente se extravió? Los registros del manifiesto indican que este contenedor específico se estacionó junto al sensor ambiental SENS-99. Si los ladrones inhabilitaron deliberadamente la unidad de refrigeración integrada del contenedor antes de moverlo, es posible que SENS-99 haya registrado un aumento repentino del escape térmico.
Usemos la detección de anomalías para demostrar que se manipuló el contenedor.
- Primero, explora el valor de referencia histórico. Estas son las lecturas normales del
SENS-99en las últimas horas:
SELECT * FROM `lost_cargo_dataset.thermal_history`
ORDER BY reading_time DESC
LIMIT 50;
Observa que las temperaturas se mantienen en un rango estrecho de entre 24 y 26 °C (75 y 78 °F). Así se ve la normalidad.
- Ahora, observa el lote actual de lecturas del mismo sensor:
SELECT * FROM `lost_cargo_dataset.thermal_current`
ORDER BY thermal_reading DESC
LIMIT 50;
¿Ves la lectura de 148.4 °F cerca de la parte superior? Todo lo demás se ve normal. Ese aumento indicaría una falla en la unidad de refrigeración o una manipulación deliberada. Averigüémoslo.
- Ejecuta la detección de anomalías. La función
AI.DETECT_ANOMALIESde BigQuery usa el modelo de base TimesFM entrenado previamente para analizar patrones de series temporales y marcar valores atípicos automáticamente, sin necesidad de entrenamiento de modelos:
SELECT *
FROM AI.DETECT_ANOMALIES(
TABLE `lost_cargo_dataset.thermal_history`,
TABLE `lost_cargo_dataset.thermal_current`,
data_col => 'thermal_reading',
timestamp_col => 'reading_time',
id_cols => ['sensor_id']
)
WHERE is_anomaly = TRUE;
- Analiza los resultados. La lectura de 64.7 °C debe marcarse como una anomalía con una probabilidad alta de anomalía, lo que confirma que sucedió algo inusual cerca del área del contenedor.
Resumen de la sección: Usaste la función AI.DETECT_ANOMALIES de BigQuery para aprovechar el modelo TimesFM entrenado previamente. Con una sola consulta en SQL, identificaste automáticamente los valores atípicos y aislaste el evento de manipulación anómalo sin escribir ningún código complejo de aprendizaje automático ni entrenar modelos desde cero.
6. Cómo preparar el sistema de seguimiento
Se confirmó que se robó el contenedor y ya no está en Río de Janeiro. Cada contenedor de la flota transmite señales de baliza de telemetría: lecturas de sensores, fragmentos de GPS y registros de estado. Si la baliza del contenedor robado sigue transmitiendo, puedes compararla con firmas conocidas para encontrarla.
BigQuery se destaca en el trabajo de análisis que realizaste hasta ahora, pero ubicar un contenedor en tiempo real requiere consultas operativas de baja latencia. AlloyDB, una base de datos completamente administrada y compatible con PostgreSQL, se creó exactamente para esto: consultas de búsqueda vectorial lo suficientemente rápidas para un sistema de seguimiento en vivo. Cargarás tus incorporaciones de telemetría en AlloyDB y las usarás para hacer coincidir el indicador de baliza.
El clúster de AlloyDB que iniciaste en segundo plano debería estar listo. Configurémoslo directamente desde el editor.
Paso 1: Conéctate a AlloyDB desde el editor
En lugar de cambiar a Cloud Console, puedes conectarte a AlloyDB directamente con la extensión Data Agent Kit.
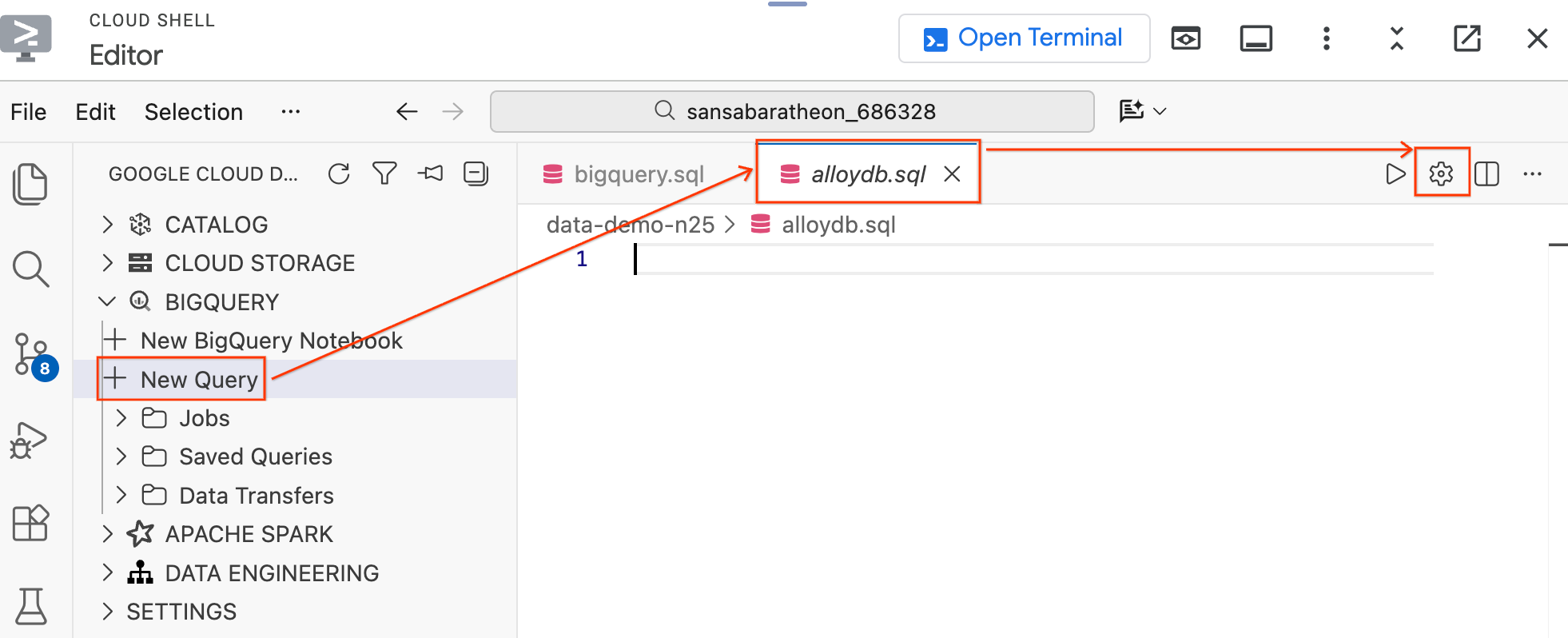
- En el panel Data Agent Kit, a la izquierda, en la sección BigQuery, haz clic en New Query para abrir una nueva pestaña del editor de consultas.
- Para guardar el archivo, presiona
Ctrl+S(Windows/Linux) oCmd+S(macOS) y asígnale el nombrealloydb. Esta pestaña se usará para todas las consultas de AlloyDB. - Haz clic en el ícono de ajustes para abrir la ventana modal Configuración de la consulta.
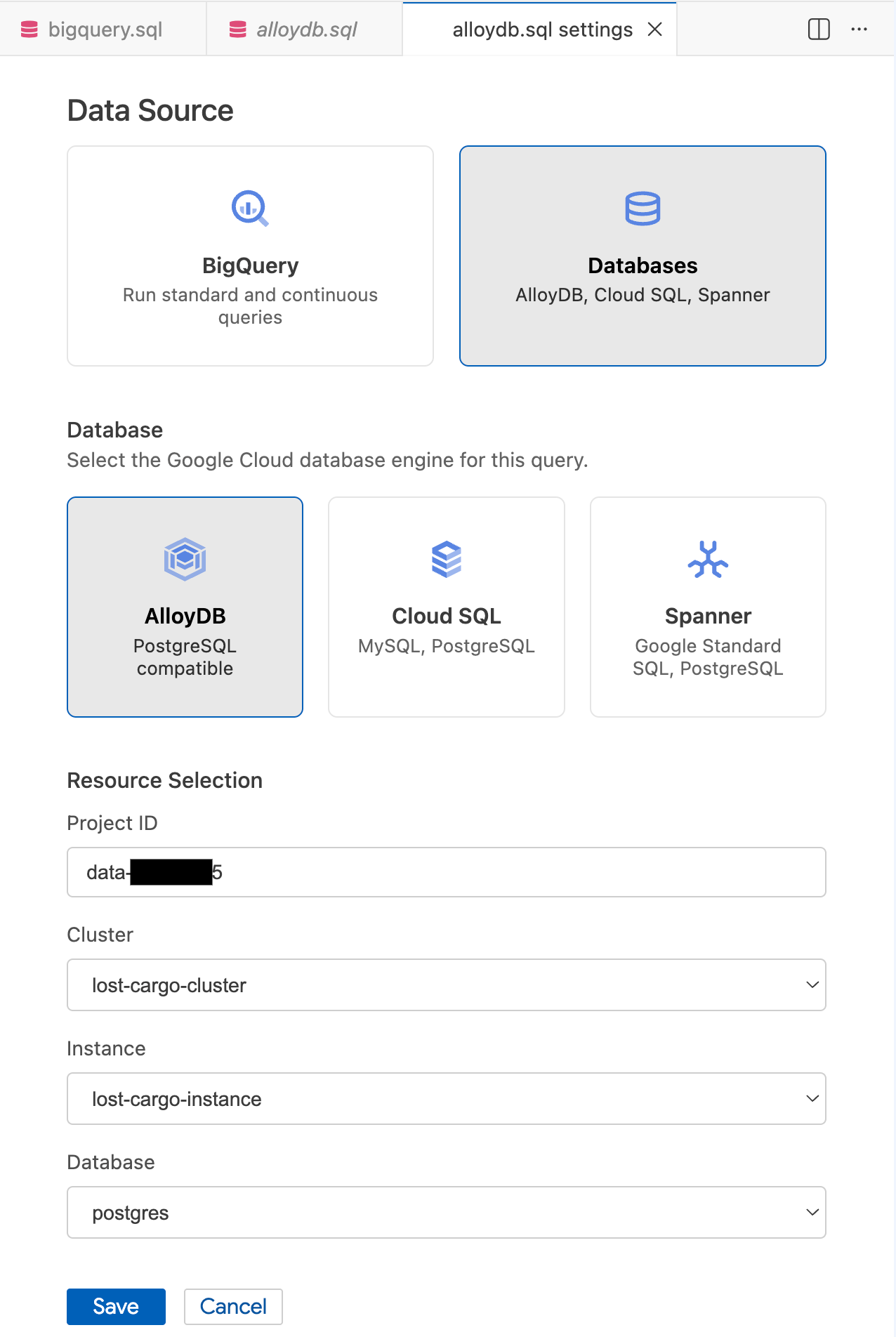
- En la ventana modal Configuración de consulta, en Fuente de datos, selecciona Bases de datos.
- En Base de datos, selecciona AlloyDB.
- Completa los detalles de Selección de recursos:
- ID del proyecto: Ingresa el ID de tu proyecto de Google Cloud.
- Clúster: Selecciona
lost-cargo-cluster. - Instancia: Selecciona
lost-cargo-instance. - Base de datos: Selecciona
postgres.
- Haz clic en Guardar.
Paso 2: Habilita la extensión de vectores y crea la tabla
Ahora que te conectaste a AlloyDB, debes habilitar las extensiones de IA necesarias y crear la tabla que recibirá los datos de telemetría incorporados.
- En la pestaña
.sqlactiva, pega los siguientes comandos para habilitar las extensiones requeridas:
CREATE EXTENSION IF NOT EXISTS vector;
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
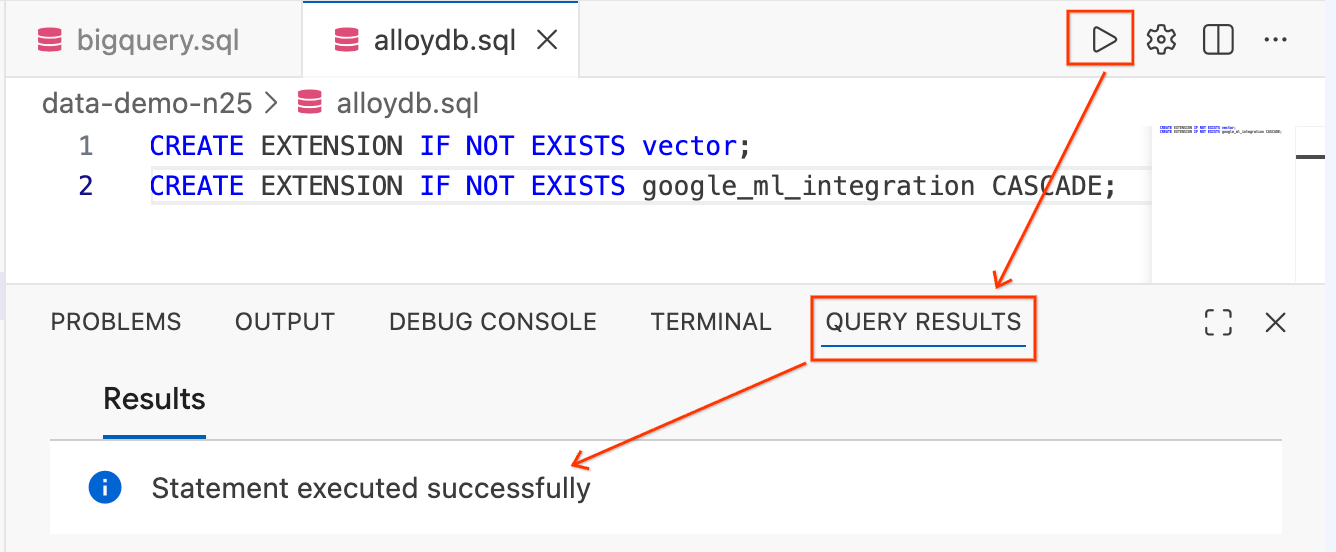
- Destaca el texto y haz clic en el botón Ejecutar consulta (el ícono de reproducción) en la parte superior derecha del editor.
- Revisa el panel de la terminal Resultados de la consulta en la parte inferior de la pantalla. Debería decir
Statement executed successfully.
- A continuación, reemplaza el texto del editor por la siguiente instrucción para crear la tabla de telemetría:
CREATE TABLE IF NOT EXISTS vessel_telemetry (
entry_id SERIAL PRIMARY KEY,
shipment_id VARCHAR(50),
telemetry_string TEXT,
embedding_vector vector(768)
);
- Ejecuta esta consulta de la misma manera que la anterior. Confirma que se ejecute correctamente en el panel inferior.
El tipo vector(768) proviene de la extensión pgvector que acabas de habilitar. Las 768 dimensiones coinciden con el resultado del modelo text-embedding-005 de Google, que usarás en BigQuery para generar los embeddings.
Resumen de la sección: Te conectaste a AlloyDB directamente desde el editor de Cloud Shell, habilitaste las extensiones pgvector y google_ml_integration, y creaste la tabla de destino. AlloyDB ahora está listo para funcionar como backend operativo para la correlación de telemetría en tiempo real.
7. Compilación del índice de búsqueda
Ahora debes transferir los datos de telemetría a AlloyDB para que pueda realizar la correlación de balizas en tiempo real. Los registros de telemetría sin procesar son desordenados y de longitud variable, lo que no es ideal para la búsqueda por similitud. Usarás las funciones IA de BigQuery para resumir cada registro con Gemini y convertir cada resumen en un embedding de vector de 768 dimensiones. Luego, exportarás los datos enriquecidos a Cloud Storage y los importarás a AlloyDB.
Paso 1: Genera embeddings en BigQuery
Vuelve a la pestaña del editor bigquery.sql (que permanece conectada a BigQuery).
Ahora, ejecuta la siguiente consulta para resumir cada registro de telemetría con Gemini y generar embeddings de vectores:
CREATE OR REPLACE TABLE `lost_cargo_dataset.telemetry_embeddings_export` AS
WITH summarized_telemetry AS (
SELECT
shipment_id,
telemetry_string,
AI.GENERATE(
CONCAT('Summarize this telemetry log for vector search: ', telemetry_string)
).result AS summary
FROM `lost_cargo_dataset.telemetry_data`
),
telemetry_embeddings AS (
SELECT
shipment_id,
telemetry_string,
AI.EMBED(summary, endpoint => 'text-embedding-005').result AS embedding
FROM summarized_telemetry
)
SELECT
shipment_id,
telemetry_string,
TO_JSON_STRING(embedding) AS embedding_vector
FROM telemetry_embeddings;
Paso 2: Obtén una vista previa de los datos enriquecidos
Antes de exportar, observa lo que creaste. En esta consulta, se muestran los IDs de los envíos y los primeros 80 caracteres de cada resumen y cada incorporación:
SELECT
shipment_id,
SUBSTR(telemetry_string, 1, 80) AS telemetry_preview,
SUBSTR(embedding_vector, 1, 80) AS embedding_preview
FROM `lost_cargo_dataset.telemetry_embeddings_export`
LIMIT 5;
Cada fila ahora contiene un ID de envío, el registro de telemetría original y un vector de incorporación de 768 dimensiones. Estos son los datos que insertarás en AlloyDB.
Paso 3: Exporta las incorporaciones a Cloud Storage
Usa la instrucción EXPORT DATA de BigQuery para escribir la tabla de incorporaciones en el bucket de GCS de tu lab como un archivo CSV.
EXECUTE IMMEDIATE CONCAT("""
EXPORT DATA OPTIONS (
uri = 'gs://""", @@project_id, """-lab2/data/embeddings_export/*.csv',
format = 'CSV',
overwrite = true,
header = false
) AS
SELECT
shipment_id,
telemetry_string,
embedding_vector
FROM `lost_cargo_dataset.telemetry_embeddings_export`;
""");
Paso 4: Importa datos a AlloyDB desde Cloud Storage
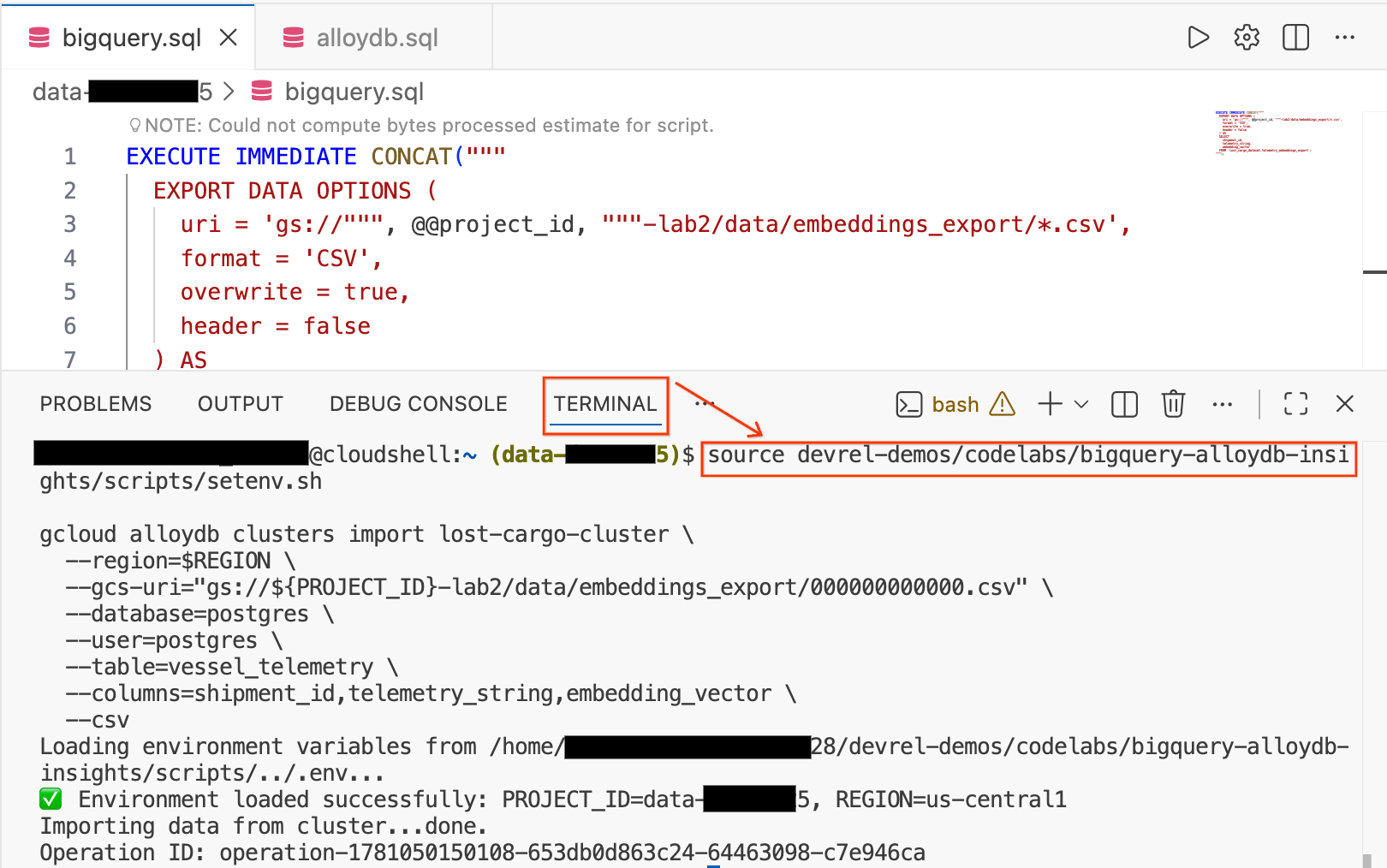
- En el editor de Cloud Shell, haz clic en la pestaña Terminal en la parte inferior de la pantalla para abrir una sesión de terminal.
- Ejecuta los siguientes comandos para cargar tu entorno y, luego, importar el archivo CSV directamente a la tabla
vessel_telemetryen AlloyDB:
source devrel-demos/codelabs/bigquery-alloydb-insights/scripts/setenv.sh
gcloud alloydb clusters import lost-cargo-cluster \
--region=$REGION \
--gcs-uri="gs://${PROJECT_ID}-lab2/data/embeddings_export/000000000000.csv" \
--database=postgres \
--user=postgres \
--table=vessel_telemetry \
--columns=shipment_id,telemetry_string,embedding_vector \
--csv
Resumen de la sección: Usaste las funciones basadas en IA de BigQuery para resumir y, luego, incorporar los datos de telemetría. Después, exportaste los resultados a Cloud Storage como archivos CSV y, por último, los importaste a AlloyDB con gcloud. La base de datos de seguimiento operativo ya está cargada y lista para usarse.
8. Cómo hacer coincidir el indicador de baliza
Un equipo de campo cerca de Sídney interceptó una señal fragmentada de baliza de telemetría. El registro parcial dice lo siguiente:
"La unidad de refrigeración está sin conexión. Anulación manual".
Si proviene del contenedor robado, la búsqueda de vectores de AlloyDB debería poder encontrar una coincidencia, aunque el indicador esté incompleto. Este es exactamente el tipo de consulta operativa en tiempo real para la que se creó AlloyDB.
Paso 1: Verifica los datos importados
Vuelve a cambiar la pestaña del editor a alloydb.sql (que permanece conectada a AlloyDB).
Para confirmar que los datos de telemetría se cargaron correctamente, ejecuta el siguiente comando:
SELECT shipment_id, LEFT(telemetry_string, 80) AS telemetry_preview
FROM vessel_telemetry
LIMIT 10;
Deberías ver filas con valores de shipment_id y texto de telemetría. Estas son las firmas de telemetría de la flota, que ahora están listas para la correlación en tiempo real.
Paso 2: Busca el contenedor faltante
Ahora, usa la extensión google_ml_integration de AlloyDB para buscar una coincidencia con el fragmento de señal interceptado:
SELECT
shipment_id,
telemetry_string,
1 - (embedding_vector <=> embedding('text-embedding-005', 'Refrigeration unit offline. Manual override.')::vector) AS search_relevance_score
FROM vessel_telemetry
ORDER BY embedding_vector <=> embedding('text-embedding-005', 'Refrigeration unit offline. Manual override.')::vector
LIMIT 5;
La función embedding(), proporcionada por la extensión google_ml_integration de AlloyDB, llama a Agent Platform directamente desde SQL para generar un embedding de vector intercalado. El operador <=> calcula la distancia del coseno entre dos vectores (cuanto más cerca de 0, más idénticos son los dos vectores). Restamos 1 para expresar los resultados como una puntuación de relevancia, en la que un valor más alto es mejor.
Paso 3: Confirma la coincidencia
Analiza los resultados. El primer resultado debería ser MV-CAPYBARA-003, con la puntuación de relevancia más alta.
Ese es el mismo contenedor que has estado rastreando en cada paso de esta investigación:
- 📷 Las cámaras de seguridad lo identificaron saliendo del puerto de Río de Janeiro por la noche.
- 🌡️ La detección de anomalías térmicas confirmó que la unidad de refrigeración se inhabilitó de forma deliberada.
- 📡 La coincidencia de señales de baliza acaba de identificar su firma de telemetría cerca de Sídney.
Tres líneas de evidencia independientes Tres capacidades diferentes de la IA de Google Cloud. Un contenedor robado.
🎯 Caso cerrado: Se encontró el MV-CAPYBARA-003 cerca de Sídney.

Resumen de la sección: Usaste la integración de IA integrada de AlloyDB para generar un embedding de búsqueda y realizar una búsqueda de similitud del coseno en una sola consulta en SQL. La coincidencia de baliza confirmó la ubicación del contenedor robado, lo que completó la investigación.
9. Exploración de la evidencia
Ahora que identificaste el contenedor a través del análisis de imágenes multimodales y la búsqueda vectorial, puedes usar Conversational Analytics directamente en tu editor para explorar los datos de la investigación con lenguaje natural, sin escribir código SQL.
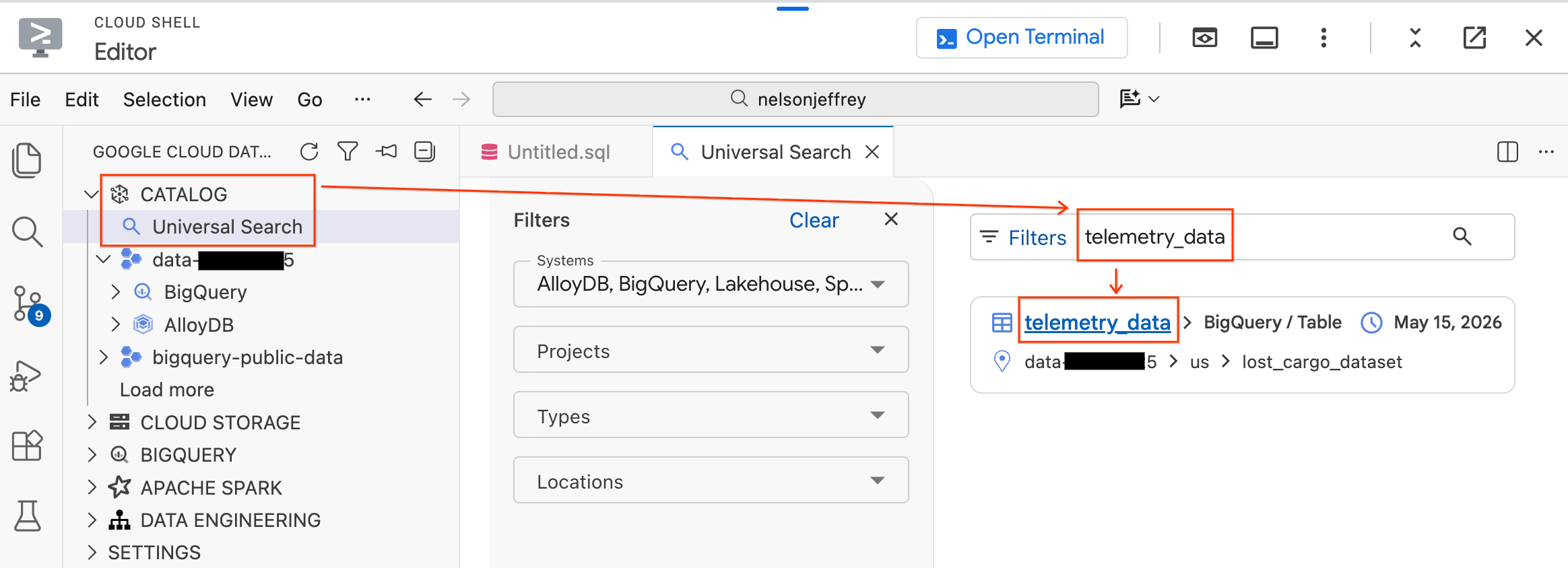
Paso 1: Busca los datos en Knowledge Catalog
El kit de Data Agent incluye una función de Búsqueda universal que te permite encontrar y explorar recursos de datos en todo tu entorno de Google Cloud.
- En el panel del kit del agente de datos que se encuentra a la izquierda, expande la sección Catálogo.
- Haz clic en Búsqueda universal.
- En la barra de búsqueda, escribe
telemetry_data. - En los resultados de la búsqueda, haz clic en la tabla
telemetry_data(enlost_cargo_dataset).
Paso 2: Inicia Conversational Analytics
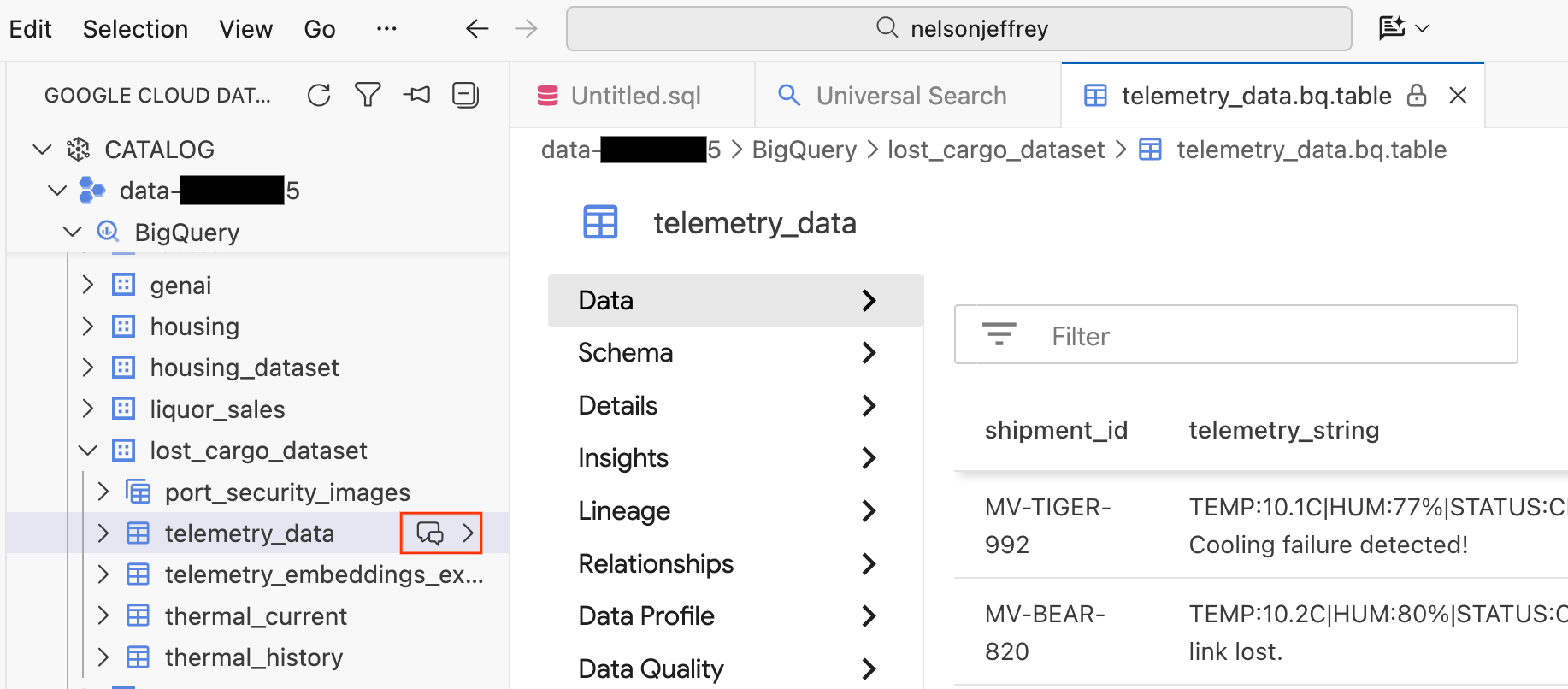
Si haces clic en el resultado de la búsqueda, se abrirá una pestaña del visualizador de datos en la que podrás obtener una vista previa de los datos sin procesar, ver el esquema y verificar la calidad de los datos.
- En el panel izquierdo, se muestran tus conjuntos de datos y tablas de BigQuery. Haz clic en el botón Chat para abrir una nueva ventana de chat.
Paso 3: Haz preguntas en lenguaje natural
Se abrirá una nueva pestaña de chat con el mensaje "¡Bienvenido a Conversational Analytics!". El agente tiene contexto sobre el esquema y el contenido de tu tabla.
- En la ventana de chat, escribe lo siguiente:"Muéstrame el estado de telemetría y el registro del envío de Capybara".
- Presiona Intro.
El agente traduce tu pregunta a SQL de BigQuery, ejecuta la consulta y muestra los resultados, que incluyen una tabla de datos y estadísticas que resumen los hallazgos. Puedes alternar entre el modo Pensando (análisis más profundo, más lento) y el modo Rápido (respuestas más rápidas) según la complejidad de tu pregunta. Dado que estas son respuestas generadas por IA, es posible que tus resultados se vean un poco diferentes a las capturas de pantalla que se muestran a continuación.
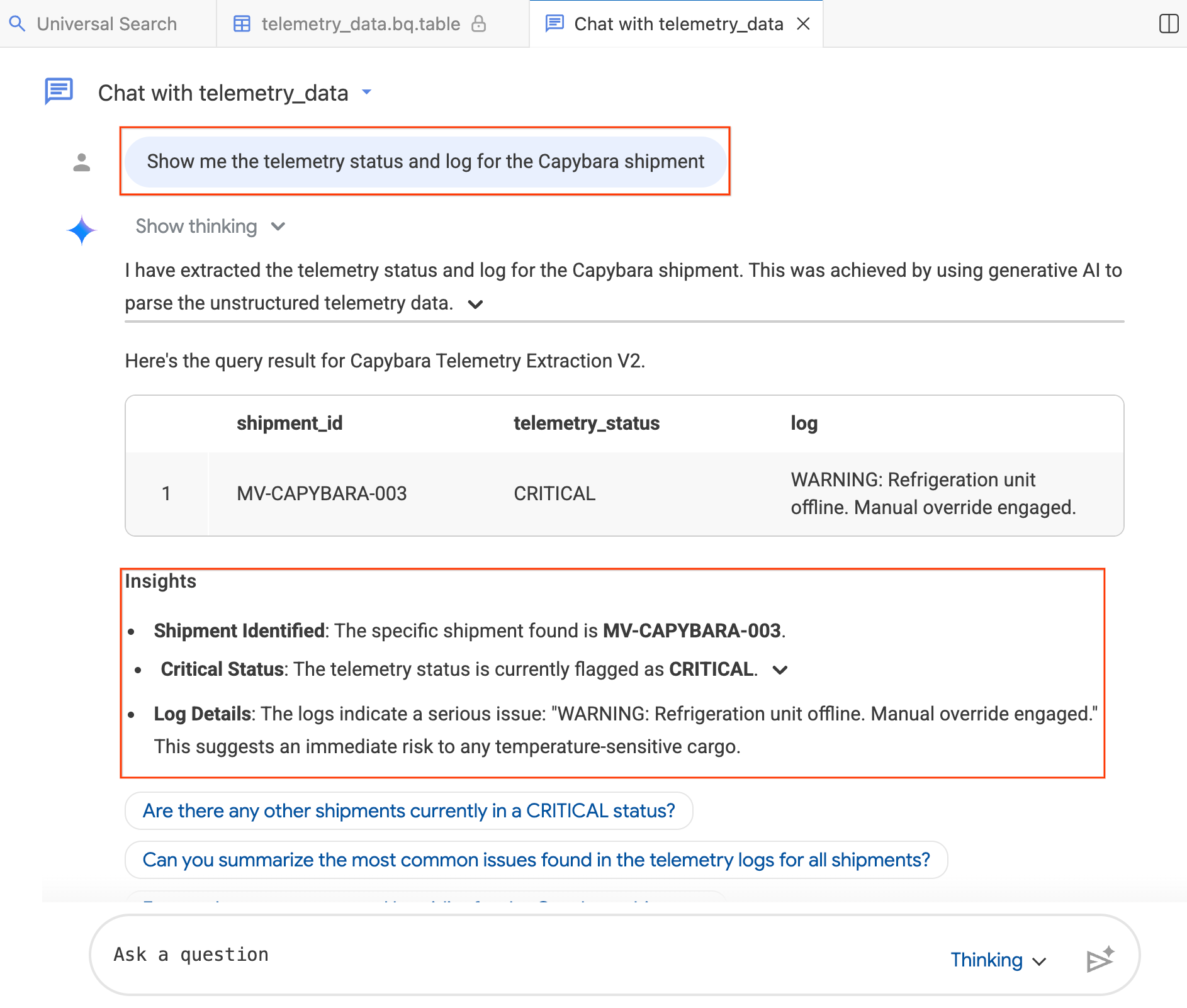
Paso 4: Haz preguntas de seguimiento
El agente recuerda el contexto de tu conversación. Prueba con una pregunta de seguimiento:
- "¿Cuántos envíos únicos hay en los datos de telemetría?"
- "¿Cuántos otros envíos de la flota tienen actualmente el estado CRÍTICO?"
Resumen de la sección: Usaste la función de búsqueda universal de Knowledge Catalog para ubicar tu conjunto de datos y, luego, iniciaste Conversational Analytics para consultar los datos de la investigación con lenguaje natural. El agente de IA tradujo tus preguntas a SQL y proporcionó estadísticas que corroboraron tus hallazgos.
10. Limpieza
Para evitar que se generen cargos continuos en tu cuenta de Google Cloud, borra los recursos que creaste en este lab. Puedes ejecutar estos comandos en la terminal integrada dentro del editor de Cloud Shell (donde usaste el kit de Data Agent) para limpiar tu entorno.
Primero, carga tus variables de entorno:
source scripts/setenv.sh
- Borra los recursos de BigQuery (solo si no continuarás con el lab 3):
Si planeas continuar con el lab 3, omite este paso. En el lab 3, se usan el mismo conjunto de datos y las mismas conexiones de BigQuery para el análisis de gráficos de propiedades.
Para borrar tu conjunto de datos y tus conexiones de BigQuery, haz lo siguiente:
# Drop the dataset
bq rm -r -f $PROJECT_ID:lost_cargo_dataset
# Delete the connections
bq rm --connection --location=us-central1 $PROJECT_ID.us-central1.lost_cargo_conn
bq rm --connection --location=us-central1 $PROJECT_ID.us-central1.lost_cargo_alloydb_conn
- Borra el bucket de Cloud Storage:
gcloud storage rm --recursive gs://${PROJECT_ID}-lab2
- Borra la instancia y el clúster de AlloyDB:
AlloyDB no se usa en el lab 3, por lo que puedes detenerlo ahora.
gcloud alloydb instances delete lost-cargo-instance \
--region=$REGION \
--cluster=lost-cargo-cluster \
--quiet
gcloud alloydb clusters delete lost-cargo-cluster \
--region=$REGION \
--force \
--quiet
- Borra la configuración del entorno local:
Por último, limpia el archivo de configuración del entorno local de tu espacio de trabajo:
rm -f .env
11. ¡Felicitaciones!
Completaste correctamente el lab 2: Análisis de datos y estadísticas multimodales. Seguiste el rastro desde un puerto lleno de miles de contenedores hasta un robo confirmado y una ubicación precisa.
Tus logros
- Se analizó el video: Usaste
AI.GENERATEde BigQuery para analizar imágenes de seguridad del puerto e identificar el contenedor MV-CAPYBARA-003 en rojo carmesí. - Confirmaste el robo: Exploraste los datos del sensor térmico, detectaste un aumento repentino sospechoso de 64.6 °C y usaste
AI.DETECT_ANOMALIESpara demostrar que se trató de una manipulación deliberada. - Preparaste el sistema de seguimiento: Configuraste AlloyDB con pgvector y
google_ml_integrationpara la coincidencia de balizas en tiempo real. - Creaste el índice de búsqueda: Usaste
AI.GENERATEyAI.EMBEDen BigQuery para crear embeddings, luego los exportaste a Cloud Storage y los importaste a AlloyDB. - Se encontró una coincidencia con el indicador de baliza: Usaste la búsqueda de vectores de AlloyDB para encontrar una coincidencia con un indicador de telemetría fragmentado y ubicar el contenedor robado cerca de Sídney.
- Exploraste la evidencia: Usaste Conversational Analytics directamente desde el editor para consultar datos de la investigación con lenguaje natural.

Próximos pasos
Ya encontraste dónde está el contenedor. Ahora debes averiguar quién está detrás de él.
En el lab 3: Agentic Workflows y consumo de datos, crearás un gráfico de propiedades de la red logística para asignar relaciones entre empresas fantasma, usarás Conversational Analytics para chatear con el gráfico y buscarás en el Knowledge Catalog para encontrar el código de autorización seguro necesario para recuperar el contenedor.