
۱. مقدمه

در آزمایش قبلی، شما گزارشهای تکهتکه شدهی حمل و نقل را جمعآوری کردید و فرستندهی محموله را تا نیویورک ردیابی کردید. با این حال، سوابق ورود نشان میدهد که کانتینر بلافاصله برای جلوگیری از شناسایی توسط گمرک تغییر مسیر داده شده است. این رد اکنون شما را به بندر ریودوژانیرو ، بندری وسیع با هزاران کانتینر، رسانده است. پیدا کردن کانتینر مناسب در میان هزاران کانتینر دیگر کار دشواری است.
در این آزمایش، شما از قابلیتهای هوش مصنوعی داخلی BigQuery برای «خواندن» تصاویر امنیتی بدون ساختار پورت و تشخیص ناهنجاریهای حرارتی در دادههای حسگر، با استفاده از SQL استاندارد، استفاده خواهید کرد. سپس جاسازیهای برداری را به AlloyDB صادر میکنید و یک جستجوی برداری را برای مطابقت یک سیگنال تلهمتری تکهتکه شده با کانتینر گمشده اجرا میکنید.
کاری که انجام خواهید داد
- اسکن تصاویر امنیتی پورت برای شناسایی کانتینر دزدیده شده با استفاده از هوش مصنوعی BigQuery
- با استفاده از هوش مصنوعی BigQuery، یک ناهنجاری حرارتی را تشخیص دهید تا تأیید کنید که کانتینر دزدیده شده است، نه اینکه گم شده باشد.
- ایجاد جاسازیهای برداری و بارگذاری آنها در AlloyDB برای جستجوی بلادرنگ
- با استفاده از جستجوی برداری، یک سیگنال بیکن تلهمتری تکهتکه شده را برای یافتن کانتینر دزدیده شده تطبیق دهید.
- کاوش دادههای تحقیقاتی با زبان طبیعی با استفاده از تحلیل مکالمهای
آنچه نیاز دارید
- یک مرورگر وب مانند کروم
- یک پروژه گوگل کلود با قابلیت پرداخت صورتحساب
- آشنایی اولیه با SQL و کنسول ابری گوگل
این codelab برای توسعهدهندگان سطح متوسط است.
منابع ایجاد شده در این آزمایشگاه کد باید کمتر از ۵ دلار هزینه داشته باشند.
۲. قبل از شروع
شروع پوسته ابری
شما از Google Cloud Shell برای دانلود کد، اجرای اسکریپتهای راهاندازی و استقرار برنامه استفاده خواهید کرد.
- در یک برگه مرورگر جدید ، Cloud Shell را باز کنید: shell.cloud.google.com
- پس از اتصال، شناسه پروژه خود را تنظیم کرده و محیط خود را تأیید کنید:
gcloud config set project <<YOUR_PROJECT_ID>>
export PROJECT_ID=$(gcloud config get-value project)
export REGION=us-central1
شما باید پیامی مشابه زیر را ببینید:
Your active configuration is: [cloudshell-####] Updated property [core/project]
مخزن را کلون کنید
مخزن codelab را در محیط Cloud Shell خود کلون کنید:
cd ~/
git clone --filter=blob:none --no-checkout https://github.com/GoogleCloudPlatform/devrel-demos.git
cd ~/devrel-demos
git sparse-checkout init --cone
git sparse-checkout set codelabs/bigquery-alloydb-insights
git checkout main
cd codelabs/bigquery-alloydb-insights/
فعال کردن APIها
برای فعال کردن تمام API های مورد نیاز برای این آزمایشگاه، این دستور را در Cloud Shell اجرا کنید:
gcloud services enable \
aiplatform.googleapis.com \
bigquery.googleapis.com \
bigqueryconnection.googleapis.com \
alloydb.googleapis.com
در صورت اجرای موفقیتآمیز، باید پیامی مشابه زیر را مشاهده کنید:
Operation "operations/..." finished successfully.
۳. محیط خود را آماده کنید
قبل از اینکه بتوانید تصاویر و دادههای تلهمتری را تجزیه و تحلیل کنید، باید زیرساخت این آزمایشگاه را راهاندازی کنید. شما دو اسکریپت اجرا خواهید کرد: یکی آمادهسازی AlloyDB را در پسزمینه آغاز میکند و دیگری تمام منابع BigQuery مورد نیاز شما را ایجاد میکند.
مرحله 1: شروع استقرار AlloyDB (پیشزمینه)
آمادهسازی کلاستر AlloyDB حدود ۱۰ دقیقه طول میکشد، بنابراین ابتدا آن را شروع میکنید و اجازه میدهید در پسزمینه اجرا شود تا شما روی بخشهای BigQuery کار کنید. این اسکریپت به طور خودکار تنظیمات فعال پروژه شما را در یک فایل .env محلی ثبت میکند تا پیکربندی شما حتی اگر ترمینال Cloud Shell شما بسته یا مجدداً راهاندازی شود، ذخیره شود.
chmod +x scripts/setup_alloydb.sh
nohup ./scripts/setup_alloydb.sh > /dev/null 2>&1 &
echo "AlloyDB deployment started in background (PID: $!)"
مرحله ۲: اجرای اسکریپت راهاندازی
این اسکریپت مجموعه داده BigQuery، اتصال Cloud Resource، مجوزهای IAM، سطل GCS را ایجاد میکند و تمام دادههای حسگری را که در این آزمایش تجزیه و تحلیل خواهید کرد، بارگذاری میکند. همچنین متغیرهای محیطی ذخیره شده در فایل .env را میخواند و تأیید میکند.
chmod +x scripts/setup_lab.sh
./scripts/setup_lab.sh
اجرای اسکریپت حدود یک دقیقه طول میکشد. وقتی تمام شد، خلاصهای از هر چیزی که ایجاد شده را خواهید دید.
📝 نکتهای در مورد بازنشانی محیط اگر در هر مرحله از این آزمایش، زمان جلسه Cloud Shell شما به پایان رسید یا مجدداً راهاندازی شد، میتوانید متغیرهای ترمینال خود را فوراً با اجرای دستور زیر بازیابی کنید:
source scripts/setenv.sh
مرحله ۳: ویرایشگر Cloud Shell را اجرا کنید
تا اینجا از ترمینال Cloud Shell استفاده میکردید. حالا به ویرایشگر کامل Cloud Shell بروید که یک فضای کاری شبیه به VS Code با پشتیبانی یکپارچه از BigQuery در اختیار شما قرار میدهد.
- در پنجره ترمینال Cloud Shell در پایین صفحه، روی دکمه Open Editor کلیک کنید تا فضای کاری Cloud Shell Editor اجرا شود.

مرحله ۴: افزونه Data Agent Kit را نصب کنید
افزونه Google Cloud Data Agent Kit ادغام عمیقی را با سرویسهای داده Google Cloud مستقیماً در ویرایشگر شما فراهم میکند و به شما امکان میدهد بدون تغییر زمینه، با BigQuery، AlloyDB، Cloud Storage و موارد دیگر تعامل داشته باشید.
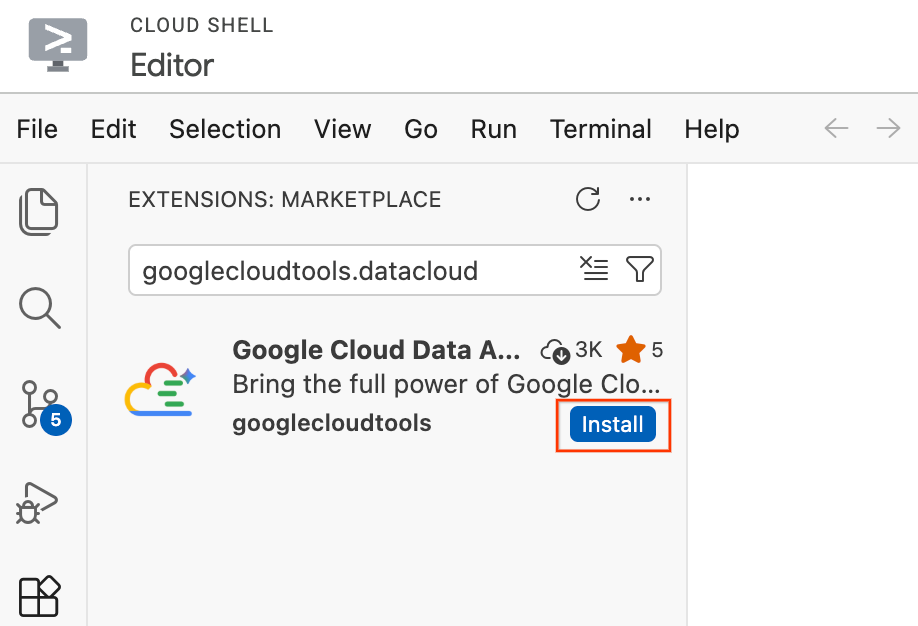
- در ویرایشگر Cloud Shell، روی آیکون Extensions در نوار فعالیت در سمت چپ صفحه کلیک کنید (شبیه چهار مربع است).
- در نوار جستجو در بالای صفحه افزونهها، عبارت
googlecloudtools.datacloudرا تایپ کنید. - افزونهای با نام Google Cloud Data Agent Kit که توسط Google Cloud منتشر شده است را پیدا کنید.
- روی دکمه نصب کلیک کنید.
- پیامی ظاهر میشود که میپرسد: «آیا به ناشر «googlecloudtools» و افزونههای آن اعتماد دارید؟». برای ادامه، روی «اعتماد به ناشران و نصب» کلیک کنید.
مرحله ۵: تأیید اعتبار و پیکربندی افزونه
پس از نصب، افزونه را به پروژه Google Cloud خود متصل کنید.
- یک صفحهی شروع با عنوان «شروع به کار کیت عامل دادههای ابری گوگل» باید بهطور خودکار باز شود. روی «ورود به سیستم ابری گوگل» کلیک کنید. برای اجازه دسترسی، هرگونه دستورالعمل مرورگر را دنبال کنید.
- یک پنجرهی «در حال راهاندازی» ظاهر میشود. افزونه بهطور خودکار وابستگیهای مورد نیاز مانند رابط خط فرمان گوگل کلود (Google Cloud CLI) را بررسی میکند.
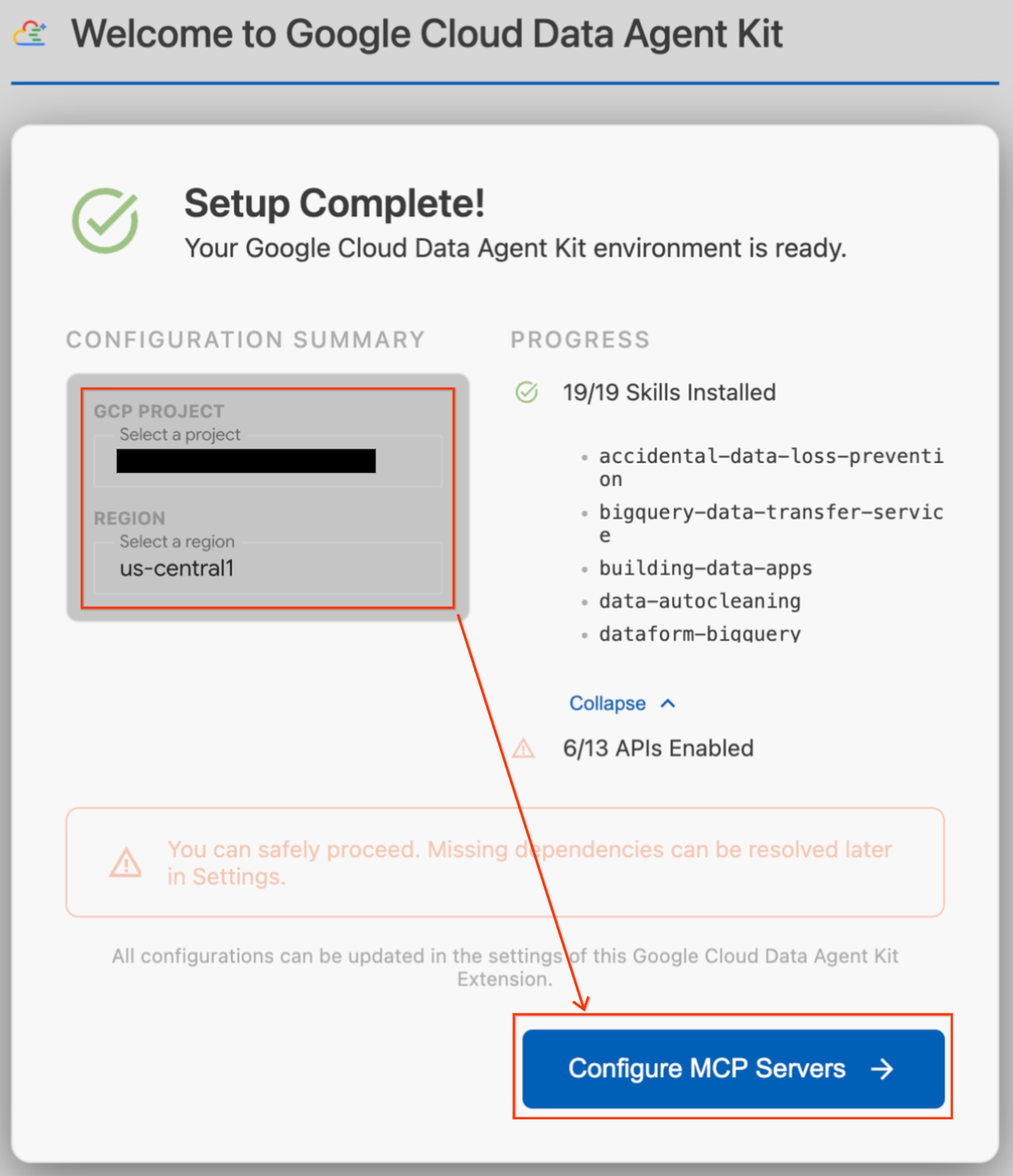
- در بخش خلاصه پیکربندی ، فیلد پروژه را پیدا کنید. روی منوی کشویی کلیک کنید و پروژه Google Cloud خود را انتخاب کنید. منطقه خود را به عنوان
us-central1تنظیم کنید. - صبر کنید تا بررسیهای راهاندازی تمام شود. وقتی عبارت «Setup Complete!» را دیدید، روی «Configure MCP Servers» کلیک کنید.
- در بخش پیکربندی MCP، BigQuery و AlloyDB را انتخاب کنید و سپس روی Get Started کلیک کنید.
مرحله 6: گزینههای پیکربندی را بررسی کنید
پس از اتمام راهاندازی، به داشبورد «شروع به کار با Google Cloud Data Agent Kit» خواهید رسید.
- در قسمت «تنظیمات و پیکربندی»، روی «شروع به کار » کلیک کنید.
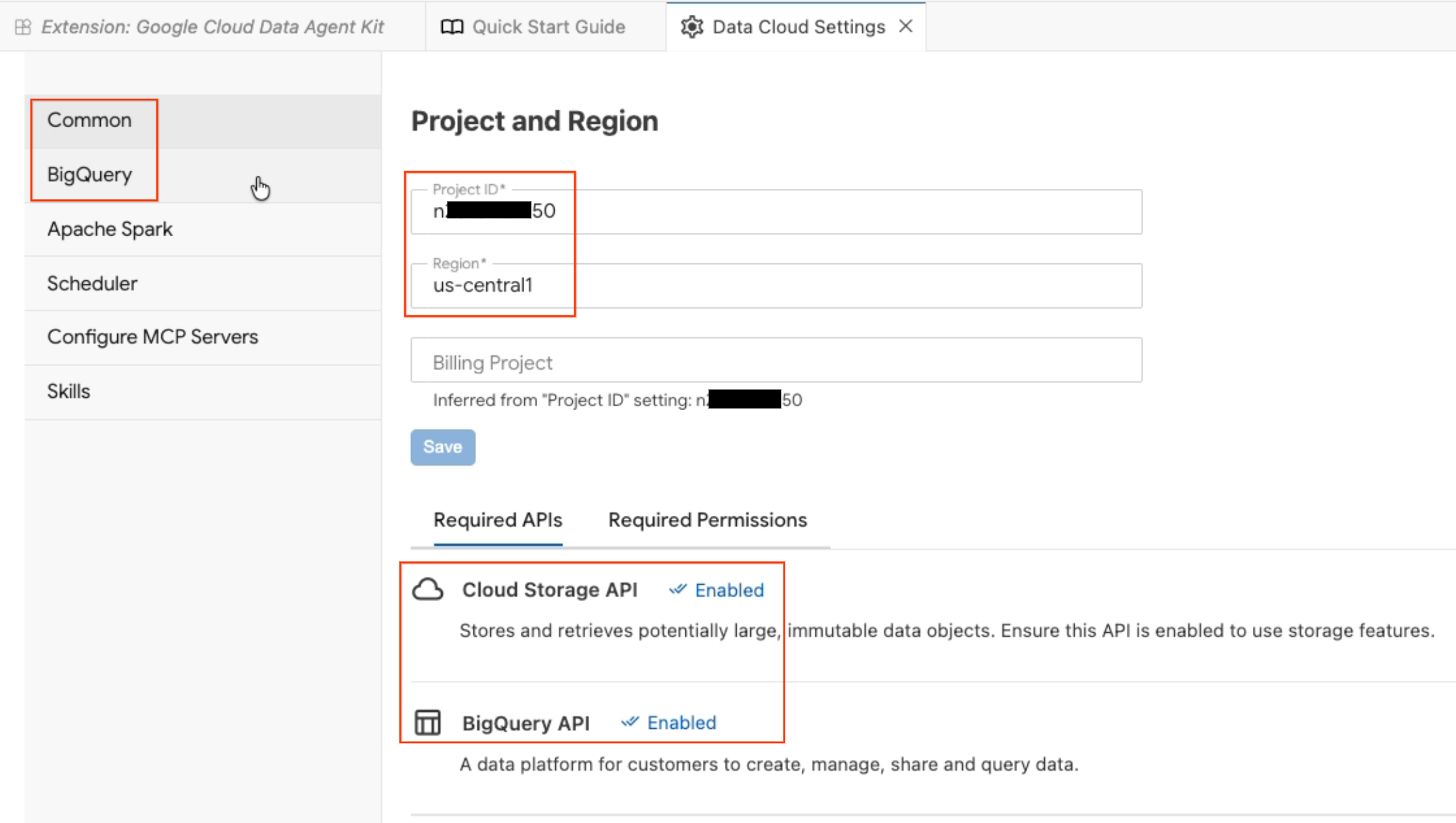
- این پنل پیکربندی عامل داده را باز میکند. تبها را بررسی کنید:
- پروژه و منطقه: شناسه پروژه انتخابی خود را تأیید کنید و بررسی کنید که APIهای مورد نیاز (Cloud Storage API، BigQuery API، Catalog API و AlloyDB API) فعال باشند.
- BigQuery: مکان پیشفرض برای کوئریهای BigQuery خود را پیکربندی کنید. از ناحیه
us-central1استفاده کنید. - پیکربندی سرورهای MCP: سرورهای MCP فعال (BigQuery، Notebooks، AlloyDB و غیره) را که به عوامل هوش مصنوعی اجازه میدهند تا به طور ایمن با دادههای شما تعامل داشته باشند، مشاهده کنید.
- مهارتها: مهارتهای از پیش ساخته شدهای را بررسی کنید که قابلیتهای تخصصی را برای وظایف پیچیده داده در اختیار عاملها قرار میدهند.
مرحله 7: تأیید با BigQuery
با اجرای یک کوئری سریع روی یک مجموعه داده عمومی، مطمئن شوید که همه چیز درست کار میکند.
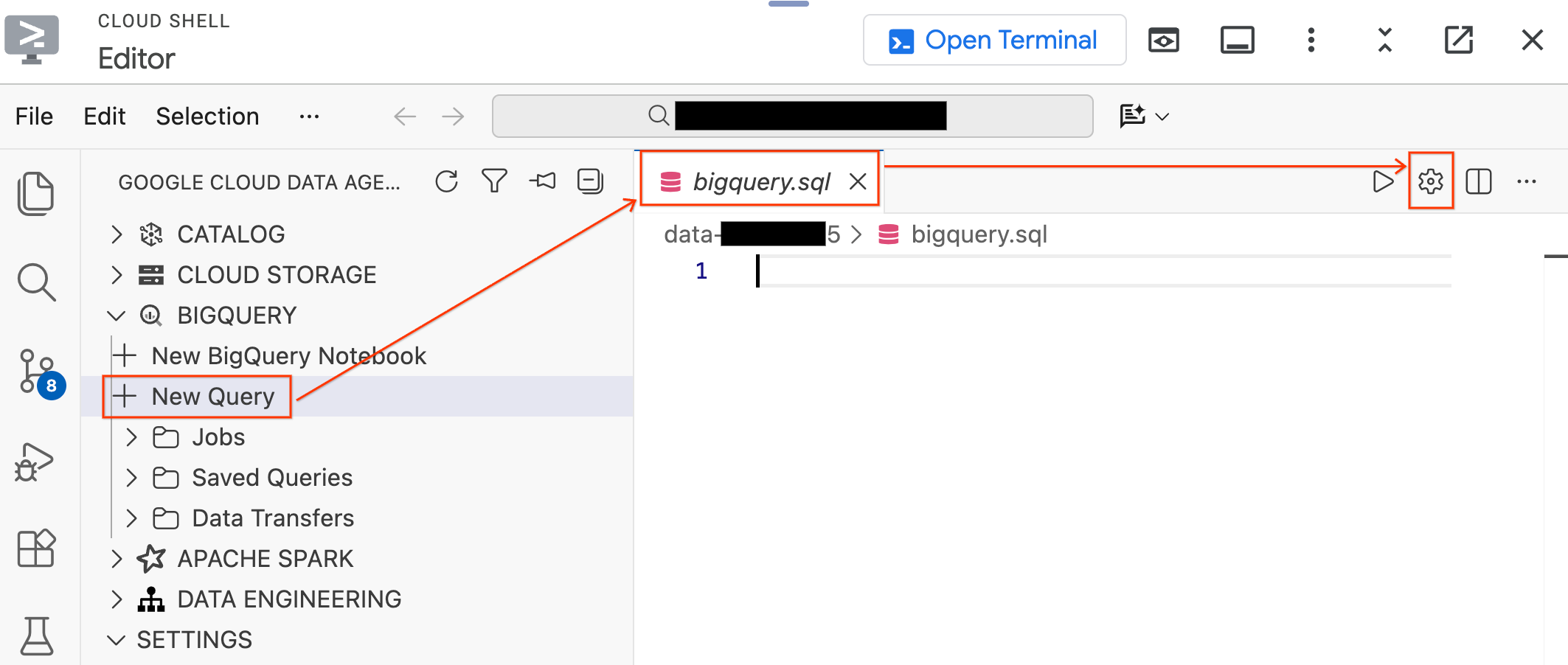
- در پنل Data Agent Kit در سمت چپ، بخش BigQuery را باز کنید و روی New Query کلیک کنید تا یک تب ویرایشگر کوئری جدید باز شود.
- فایل را با فشردن
Ctrl+S(ویندوز/لینوکس) یاCmd+S(مک) ذخیره کنید و نام آن راbigqueryبگذارید. این تب برای تمام عملیات BigQuery شما استفاده خواهد شد. - در حالی که تب
bigquery.sqlفعال است، روی تنظیمات پرسوجو (Query Settings) کلیک کنید، BigQuery را به عنوان منبع داده (Data Source ) انتخاب کنید و روی ذخیره (Save) کلیک کنید.
- کوئری زیر را روی یک مجموعه داده عمومی اجرا کنید:
SELECT
term,
MIN(rank) AS peak_rank,
ROUND(AVG(score)) AS avg_score
FROM `bigquery-public-data.google_trends.top_terms`
WHERE refresh_date = DATE_SUB(CURRENT_DATE(), INTERVAL 2 DAY)
GROUP BY term
ORDER BY peak_rank ASC
LIMIT 10;
- شما باید 10 عبارت جستجوی پرطرفدار گوگل در چند روز گذشته را ببینید. اگر نتایج ظاهر شدند، افزونه شما متصل و آماده است.
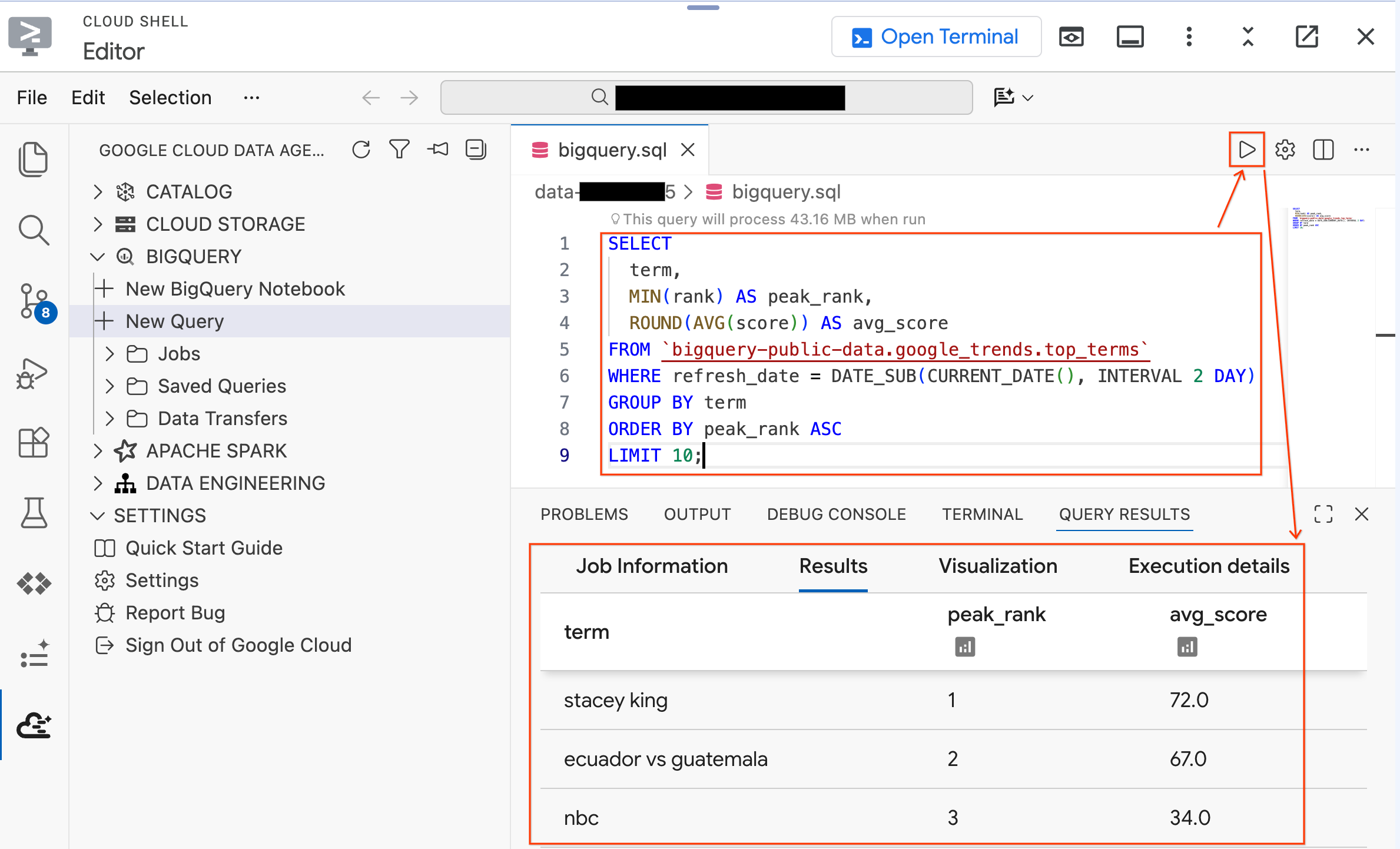
حالا یک کوئری روی دادههای آزمایشگاهی که اسکریپت راهاندازی شما ایجاد کرده است، امتحان کنید. کوئری موجود را با این یکی جایگزین کنید :
SELECT * FROM `lost_cargo_dataset.telemetry_data` LIMIT 5;
شما باید ورودیهای گزارش تلهمتری را با ستونهای shipment_id و telemetry_string ببینید. اینها دادههایی هستند که در طول آزمایش تجزیه و تحلیل خواهید کرد.
خلاصه بخش: شما استقرار AlloyDB را در پسزمینه آغاز کردید، اسکریپت راهاندازی را اجرا کردید و ویرایشگر Cloud Shell را با افزونه Data Agent Kit پیکربندی کردید.
۴. اسکن فیلم امنیتی
تیم تحقیق، فیلمهای امنیتی از بندر ریودوژانیرو را بازیابی کرده است که ردیفهایی از کانتینرهای حمل و نقل را نشان میدهد. از آزمایش ۱، میدانید که کانتینر هدف قرمز است. حالا باید دقیقاً مشخص کنید کدام کانتینر قرمز است.
شما یک جدول شیء (Object Table) ایجاد خواهید کرد که به BigQuery اجازه میدهد تصاویر امنیتی موجود در فضای ذخیرهسازی ابری را «ببیند»، سپس از تابع AI.GENERATE برای وادار کردن Gemini به استخراج دادههای ساختاریافته از هر تصویر استفاده خواهید کرد.
مرحله ۱: ایجاد جدول اشیاء
یک جدول شیء (Object Table ) یک جدول ویژه BigQuery است که به عنوان یک فهرست روی فایلهای بدون ساختار (تصاویر، PDFها، صدا) ذخیره شده در فضای ذخیرهسازی ابری عمل میکند. این جدول فایلها را در BigQuery کپی نمیکند؛ بلکه یک مرجع قابل پرسوجو ایجاد میکند تا توابع هوش مصنوعی بتوانند آنها را "ببینند".
در تب bigquery.sql در ویرایشگر، دستور زیر را اجرا کنید تا جدول اشیاء (Object Table) که به تصاویر امنیتی پورت در سطل پروژه شما اشاره میکند، ایجاد شود:
SET @@location = 'us-central1';
EXECUTE IMMEDIATE CONCAT("""
CREATE OR REPLACE EXTERNAL TABLE `lost_cargo_dataset.port_security_images`
WITH CONNECTION `us-central1.lost_cargo_conn`
OPTIONS (
object_metadata = 'SIMPLE',
uris = ['gs://""", @@project_id, """-lab2/images/*']
);
""");
نگاهی سریع به آنچه BigQuery اکنون میتواند ببیند، بیندازید:
SELECT uri, content_type FROM `lost_cargo_dataset.port_security_images` LIMIT 5;
هر ردیف نشاندهندهی یک فایل تصویری در فضای ذخیرهسازی ابری است. بیگکوئری اکنون میتواند این تصاویر را مستقیماً به مدلهای هوش مصنوعی منتقل کند.
مرحله ۲: تصاویر امنیتی را تجزیه و تحلیل کنید
حالا از تابع AI.GENERATE در BigQuery برای تحلیل هر تصویر امنیتی استفاده کنید. این کوئری SQL، Gemini را وادار میکند تا هر تصویر را بررسی کرده و دادههای ساختاریافته را برگرداند:
SELECT
uri,
AI.GENERATE(
(
'Examine this port security image. Identify any shipping container IDs visible on the container and provide a one-word color of the container.',
ref
),
output_schema => 'detected_container_id STRING, color STRING'
).* EXCEPT (full_response, status)
FROM `lost_cargo_dataset.port_security_images`;
مرحله ۳: شناسایی کانتینر هدف
نتایج را بررسی کنید. به دنبال ردیفی باشید که ستون color آن "قرمز" (یا مقداری تغییر رنگ قرمز) را نشان میدهد. شناسه detected_container_id را یادداشت کنید. این هدف شماست: MV-CAPYBARA-003 .
مرحله ۴: تأیید تطابق بصری
برای دیدن تصویر واقعی که بدون ترک ویرایشگر شما تجزیه و تحلیل شده است:
- در پنل Data Agent Kit در سمت چپ، روی Cloud Storage کلیک کنید.
- سطل خود (
YOUR_PROJECT_ID-lab2/images/) را باز کنید و روی فایل تصویری مربوط به ظرف قرمز کلیک کنید تا مستقیماً در ویرایشگر مشاهده شود.
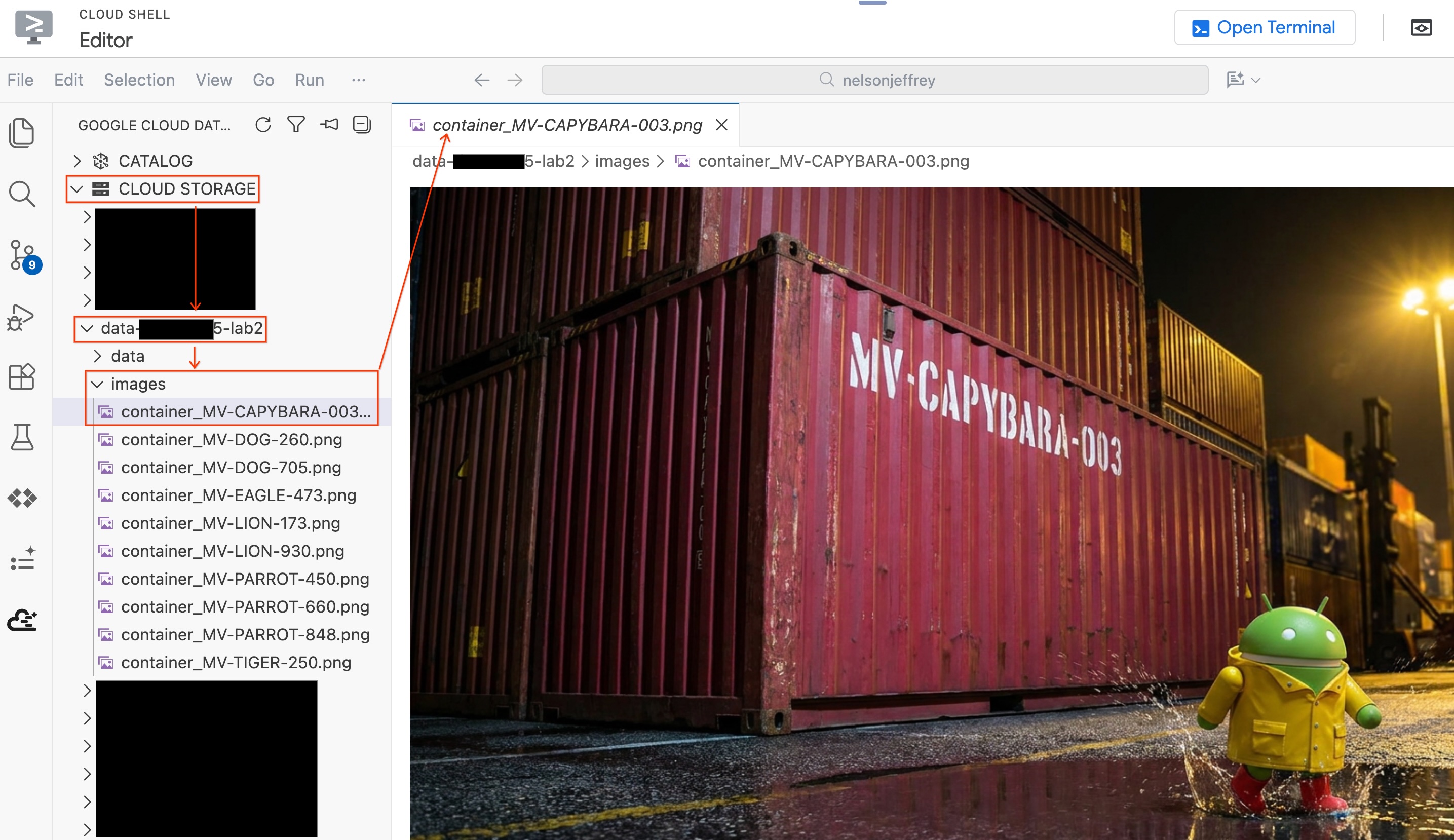
خلاصه بخش: شما یک جدول شیء (Object Table) ایجاد کردید تا به BigQuery اجازه دسترسی به تصاویر امنیتی پورت را بدهید، سپس از AI.GENERATE برای استخراج دادههای ساختاریافته کانتینر از هر تصویر استفاده کردید. کانتینر قرمز با عنوان MV-CAPYBARA-003 شناسایی شده است.
۵. تأیید سرقت
شما کانتینر گمشده را با نام MV-CAPYBARA-003 شناسایی کردهاید، اما آیا آن را دزدیدهاید یا صرفاً آن را گم کردهاید؟ گزارشهای آشکار نشان میدهد که این کانتینر خاص در مجاورت حسگر محیطی SENS-99 پارک شده بوده است. اگر سارقان عمداً واحد تبرید داخلی کانتینر را قبل از جابجایی آن غیرفعال کرده باشند، SENS-99 ممکن است یک افزایش ناگهانی دمای اگزوز را ثبت کرده باشد.
بیایید از تشخیص ناهنجاری برای اثبات دستکاری کانتینر استفاده کنیم.
- ابتدا، مقادیر پایه تاریخی را بررسی کنید. اینها مقادیر عادی
SENS-99در چند ساعت گذشته هستند:
SELECT * FROM `lost_cargo_dataset.thermal_history`
ORDER BY reading_time DESC
LIMIT 50;
توجه داشته باشید که دما در محدودهی محدودی بین ۷۵ تا ۷۸ درجه فارنهایت (۷۵ تا ۷۸ درجه فارنهایت) متغیر است. این دمای نرمال است.
- حالا به دسته فعلی مقادیر خوانده شده از همان سنسور نگاه کنید:
SELECT * FROM `lost_cargo_dataset.thermal_current`
ORDER BY thermal_reading DESC
LIMIT 50;
آن عدد ۱۴۸.۴ درجه فارنهایت را نزدیک به بالای صفحه میبینید؟ بقیه چیزها طبیعی به نظر میرسند. این افزایش ناگهانی دما یا نشان دهنده خرابی واحد تبرید است یا دستکاری عمدی. بیایید بفهمیم.
- تشخیص ناهنجاری را اجرا کنید.
AI.DETECT_ANOMALIESدر BigQuery از مدل پایه TimesFM که از قبل آموزش دیده است، برای تجزیه و تحلیل الگوهای سری زمانی و علامتگذاری خودکار دادههای پرت استفاده میکند، بدون اینکه نیازی به آموزش مدل باشد:
SELECT *
FROM AI.DETECT_ANOMALIES(
TABLE `lost_cargo_dataset.thermal_history`,
TABLE `lost_cargo_dataset.thermal_current`,
data_col => 'thermal_reading',
timestamp_col => 'reading_time',
id_cols => ['sensor_id']
)
WHERE is_anomaly = TRUE;
- نتایج را بررسی کنید. دمای ۱۴۸.۴ درجه فارنهایت باید به عنوان یک ناهنجاری با احتمال ناهنجاری بالا علامتگذاری شود و تأیید کند که اتفاق غیرمعمولی در نزدیکی محوطه کانتینر رخ داده است.
خلاصه بخش: شما از تابع AI.DETECT_ANOMALIES در BigQuery برای بهرهبرداری از مدل از پیش آموزشدیده TimesFM استفاده کردید. با اجرای یک کوئری SQL، شما بهطور خودکار دادههای پرت را شناسایی و رویداد دستکاری غیرعادی را بدون نوشتن هیچ کد پیچیده یادگیری ماشین یا مدلهای آموزشی از ابتدا، جداسازی کردید.
۶. آمادهسازی سیستم ردیابی
سرقت کانتینر تأیید شده است و دیگر در ریودوژانیرو نیست. هر کانتینر در ناوگان ، سیگنالهای بیکن تلهمتری را پخش میکند: اطلاعات حسگرها، قطعات GPS و گزارشهای وضعیت. اگر بیکن کانتینر سرقت شده هنوز در حال ارسال اطلاعات است، میتوانید آن را با امضاهای شناخته شده مطابقت دهید تا آن را پیدا کنید.
BigQuery در کارهای تحلیلی که تاکنون انجام دادهاید، عالی عمل میکند، اما یافتن یک کانتینر در زمان واقعی نیاز به پرسوجوهای عملیاتی با تأخیر کم دارد. AlloyDB ، یک پایگاه داده کاملاً مدیریتشده سازگار با PostgreSQL، دقیقاً برای همین منظور ساخته شده است: پرسوجوهای جستجوی برداری که به اندازه کافی سریع برای یک سیستم ردیابی زنده هستند. شما جاسازیهای تلهمتری خود را در AlloyDB بارگذاری میکنید و از آن برای مطابقت با سیگنال بیکن استفاده میکنید.
کلاستر AlloyDB که قبلاً در پسزمینه راهاندازی کردید، باید تا الان آماده باشد. بیایید آن را مستقیماً از ویرایشگر خود پیکربندی کنیم.
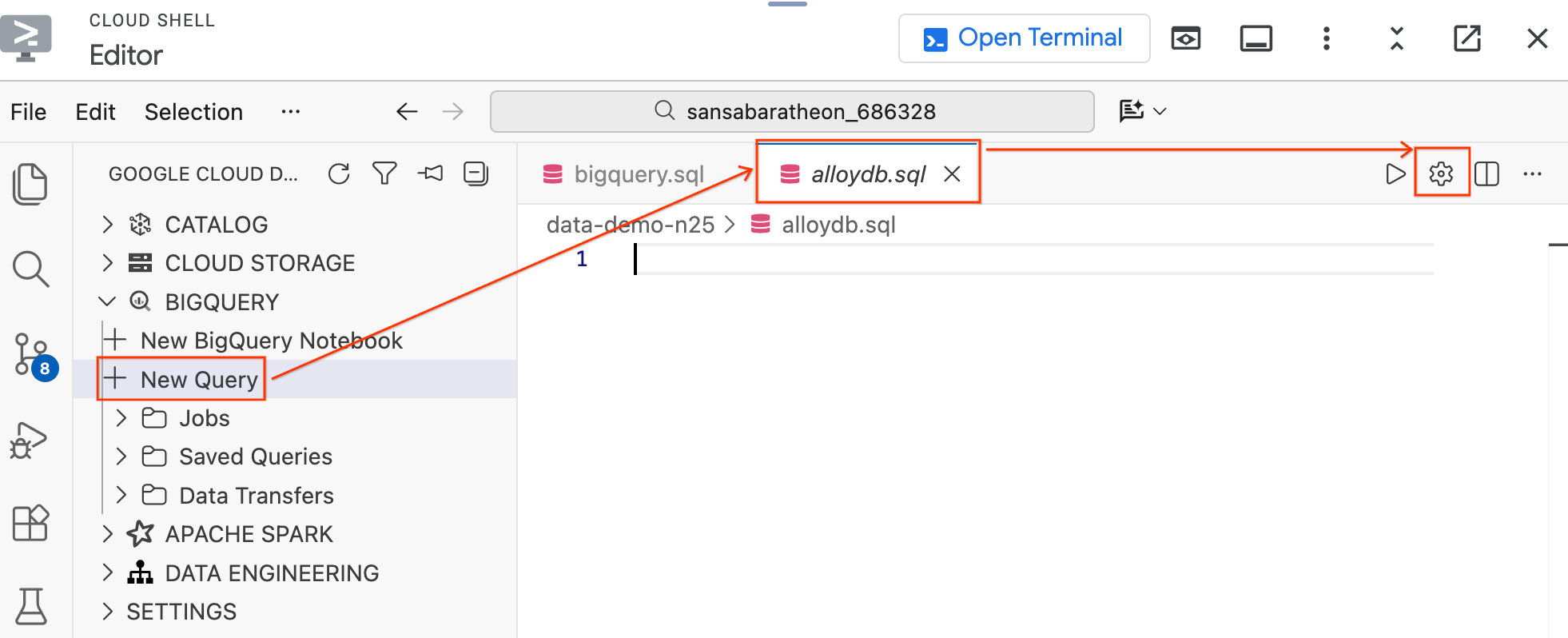
مرحله 1: اتصال به AlloyDB از طریق ویرایشگر
به جای رفتن به کنسول ابری، میتوانید مستقیماً با استفاده از افزونه Data Agent Kit به AlloyDB متصل شوید.
- در پنل Data Agent Kit در سمت چپ، زیر بخش BigQuery ، روی New Query کلیک کنید تا یک تب ویرایشگر کوئری جدید باز شود.
- فایل را با فشردن
Ctrl+S(ویندوز/لینوکس) یاCmd+S(مک) ذخیره کنید و نام آن راalloydbبگذارید. این تب برای همه کوئریهای AlloyDB استفاده خواهد شد. - برای باز کردن پنجره تنظیمات پرسوجو، روی نماد چرخدنده کلیک کنید.
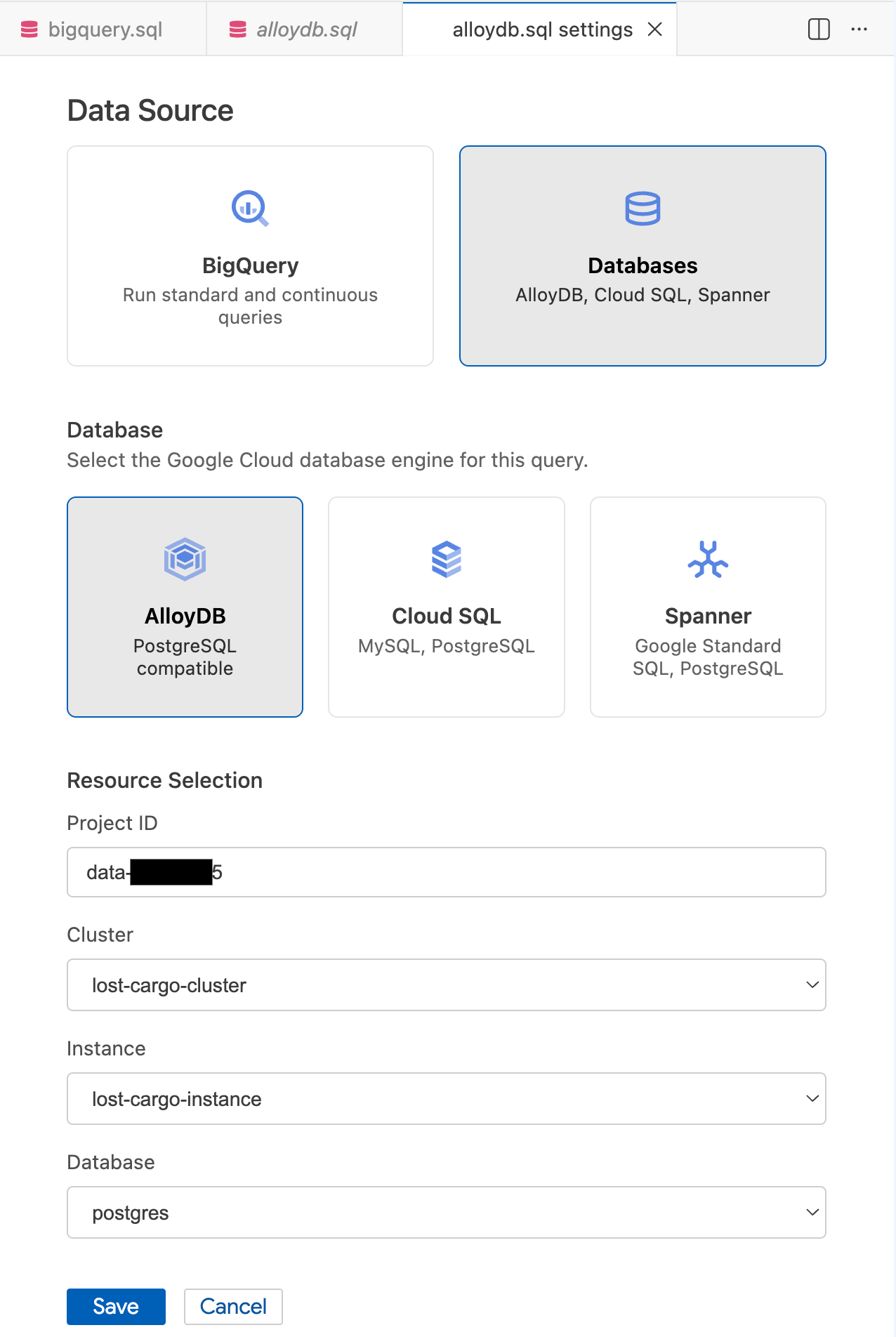
- در پنجره تنظیمات پرسوجو (Query Settings )، در قسمت منبع داده (Data Source )، گزینه پایگاههای داده (Databases) را انتخاب کنید.
- در قسمت Database ، گزینه AlloyDB را انتخاب کنید.
- جزئیات انتخاب منابع را پر کنید:
- شناسه پروژه : شناسه پروژه گوگل کلود خود را وارد کنید.
- خوشه :
lost-cargo-clusterرا انتخاب کنید. - نمونه :
lost-cargo-instanceرا انتخاب کنید. - پایگاه داده :
postgresرا انتخاب کنید.
- روی ذخیره کلیک کنید.
مرحله ۲: فعال کردن افزونه بردار و ایجاد جدول
اکنون که به AlloyDB متصل شدهاید، باید افزونههای هوش مصنوعی لازم را فعال کرده و جدولی را ایجاد کنید که دادههای تلهمتری تعبیهشده را دریافت کند.
- در تب فعال
.sqlخود، دستورات زیر را برای فعال کردن افزونههای مورد نیاز وارد کنید:
CREATE EXTENSION IF NOT EXISTS vector;
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
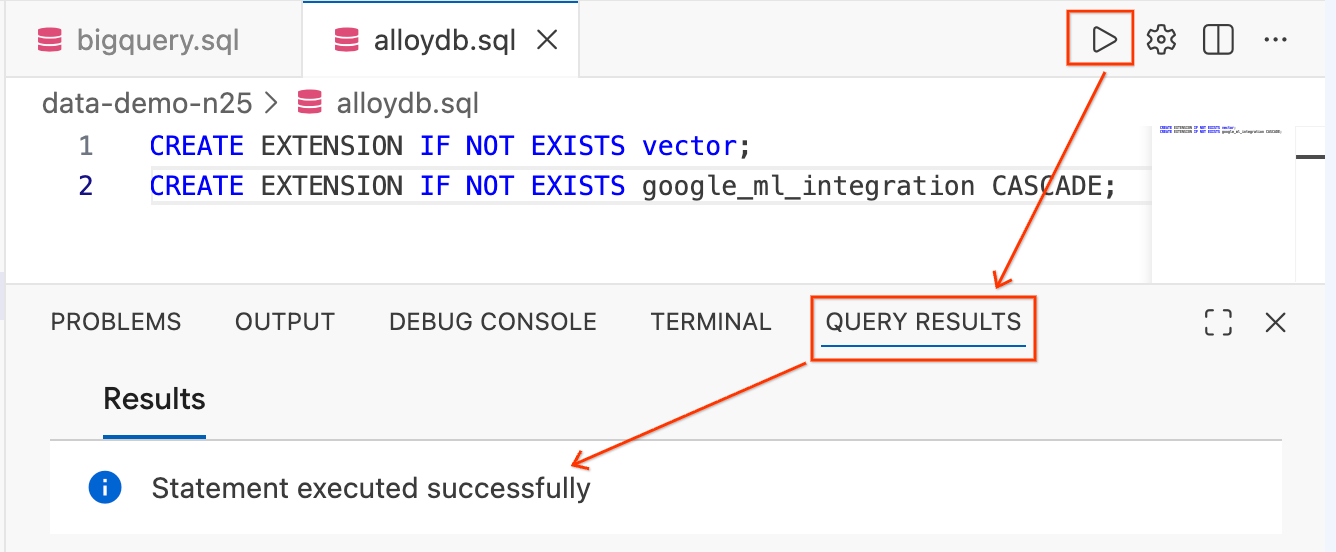
- متن را هایلایت کنید و روی دکمهی اجرای پرسوجو (آیکون پخش) در بالا سمت راست ویرایشگر کلیک کنید.
- پنل ترمینال نتایج جستجو (Query Results) را در پایین صفحه بررسی کنید. باید عبارت
Statement executed successfullyنمایش داده شود.
- در مرحله بعد، متن موجود در ویرایشگر خود را با عبارت زیر جایگزین کنید تا جدول تلهمتری ایجاد شود:
CREATE TABLE IF NOT EXISTS vessel_telemetry (
entry_id SERIAL PRIMARY KEY,
shipment_id VARCHAR(50),
telemetry_string TEXT,
embedding_vector vector(768)
);
- این کوئری را درست مانند کوئری قبلی اجرا کنید. در پنل پایین، اجرای موفقیتآمیز آن را تأیید کنید.
نوع vector(768) از افزونه pgvector که فعال کردید میآید. ابعاد 768 با خروجی مدل text-embedding-005 گوگل مطابقت دارد، که شما در BigQuery برای تولید جاسازیها از آن استفاده خواهید کرد.
خلاصه بخش: شما مستقیماً از ویرایشگر Cloud Shell خود به AlloyDB متصل شدید، افزونههای pgvector و google_ml_integration را فعال کردید و جدول هدف را ایجاد کردید. اکنون AlloyDB آماده است تا به عنوان پشتیبان عملیاتی برای تطبیق تلهمتری در زمان واقعی عمل کند.
۷. ساخت فهرست جستجو
حالا باید دادههای تلهمتری را به AlloyDB وارد کنید تا بتواند تطبیق بیکن را در لحظه انجام دهد. لاگهای خام تلهمتری، نامرتب و با طول متغیر هستند که برای جستجوی شباهت ایدهآل نیستند. شما از توابع هوش مصنوعی BigQuery برای خلاصه کردن هر لاگ با Gemini استفاده خواهید کرد و هر خلاصه را به یک جاسازی برداری ۷۶۸ بعدی تبدیل خواهید کرد. سپس دادههای غنیشده را به Cloud Storage صادر کرده و آن را به AlloyDB وارد خواهید کرد.
مرحله 1: ایجاد جاسازیها در BigQuery
تب ویرایشگر خود را به bigquery.sql برگردانید (که همچنان به BigQuery متصل است).
اکنون، کوئری زیر را برای خلاصه کردن هر گزارش تلهمتری با Gemini و تولید جاسازیهای برداری اجرا کنید:
CREATE OR REPLACE TABLE `lost_cargo_dataset.telemetry_embeddings_export` AS
WITH summarized_telemetry AS (
SELECT
shipment_id,
telemetry_string,
AI.GENERATE(
CONCAT('Summarize this telemetry log for vector search: ', telemetry_string)
).result AS summary
FROM `lost_cargo_dataset.telemetry_data`
),
telemetry_embeddings AS (
SELECT
shipment_id,
telemetry_string,
AI.EMBED(summary, endpoint => 'text-embedding-005').result AS embedding
FROM summarized_telemetry
)
SELECT
shipment_id,
telemetry_string,
TO_JSON_STRING(embedding) AS embedding_vector
FROM telemetry_embeddings;
مرحله ۲: پیشنمایش دادههای غنیشده
قبل از خروجی گرفتن، نگاهی به آنچه ایجاد کردهاید بیندازید. این کوئری شناسههای ارسال و ۸۰ کاراکتر اول هر خلاصه و جاسازی را نشان میدهد:
SELECT
shipment_id,
SUBSTR(telemetry_string, 1, 80) AS telemetry_preview,
SUBSTR(embedding_vector, 1, 80) AS embedding_preview
FROM `lost_cargo_dataset.telemetry_embeddings_export`
LIMIT 5;
اکنون هر ردیف شامل یک شناسه محموله، گزارش تلهمتری اصلی و یک بردار جاسازی ۷۶۸ بعدی است. این دادههایی است که به AlloyDB ارسال خواهید کرد.
مرحله 3: انتقال جاسازیها به فضای ذخیرهسازی ابری
از دستور EXPORT DATA در BigQuery برای نوشتن جدول جاسازیها در سطل GCS آزمایشگاه خود به عنوان یک فایل CSV استفاده کنید.
EXECUTE IMMEDIATE CONCAT("""
EXPORT DATA OPTIONS (
uri = 'gs://""", @@project_id, """-lab2/data/embeddings_export/*.csv',
format = 'CSV',
overwrite = true,
header = false
) AS
SELECT
shipment_id,
telemetry_string,
embedding_vector
FROM `lost_cargo_dataset.telemetry_embeddings_export`;
""");
مرحله ۴: وارد کردن دادهها از فضای ذخیرهسازی ابری به AlloyDB
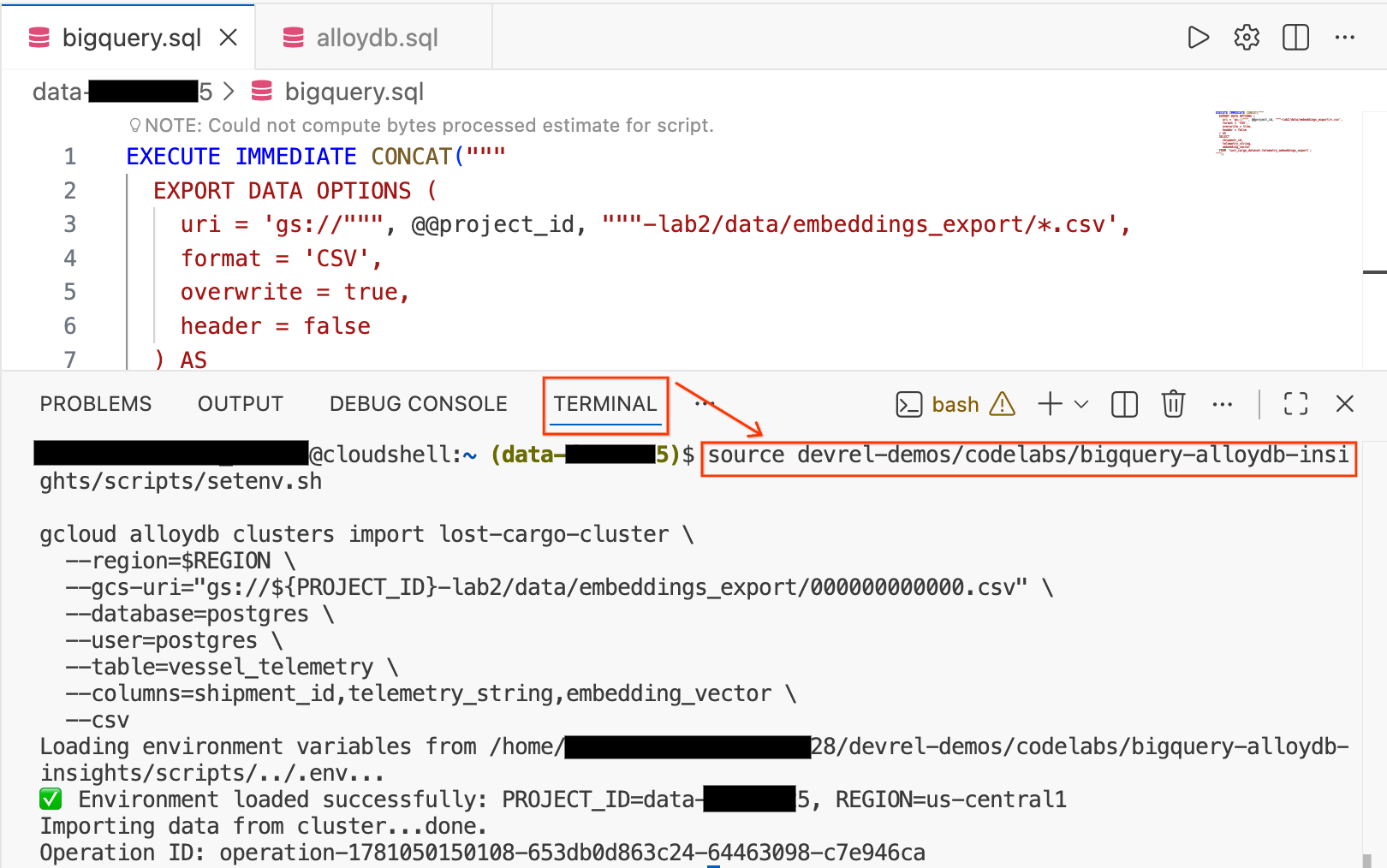
- در ویرایشگر Cloud Shell خود، روی تب Terminal در پایین صفحه کلیک کنید تا یک جلسه ترمینال باز شود.
- دستورات زیر را برای بارگذاری محیط خود و وارد کردن مستقیم فایل CSV به جدول
vessel_telemetryدر AlloyDB اجرا کنید:
source devrel-demos/codelabs/bigquery-alloydb-insights/scripts/setenv.sh
gcloud alloydb clusters import lost-cargo-cluster \
--region=$REGION \
--gcs-uri="gs://${PROJECT_ID}-lab2/data/embeddings_export/000000000000.csv" \
--database=postgres \
--user=postgres \
--table=vessel_telemetry \
--columns=shipment_id,telemetry_string,embedding_vector \
--csv
خلاصه بخش: شما از توابع هوش مصنوعی BigQuery برای خلاصهسازی و جاسازی دادههای تلهمتری استفاده کردید، نتایج را به صورت CSV به Cloud Storage صادر کردید، سپس آنها را با استفاده از gcloud به AlloyDB وارد کردید. پایگاه داده ردیابی عملیاتی اکنون بارگذاری و آماده است.
۸. تطبیق سیگنال بیکن
یک تیم میدانی در نزدیکی سیدنی یک سیگنال پراکنده از یک فرستنده تله متری را رهگیری کرده است. در گزارش ناقص آمده است:
"دستگاه تبرید آفلاین است. لغو دستی."
اگر این از کانتینر دزدیده شده آمده باشد، جستجوی برداری AlloyDB باید بتواند آن را مطابقت دهد، حتی اگر سیگنال ناقص باشد. این دقیقاً همان نوع پرسوجوی عملیاتی و بلادرنگ است که AlloyDB برای آن ساخته شده است.
مرحله ۱: تأیید دادههای وارد شده
تب ویرایشگر خود را به alloydb.sql برگردانید (که همچنان به AlloyDB متصل است).
با اجرای دستور زیر، تأیید کنید که دادههای تلهمتری با موفقیت بارگذاری شدهاند:
SELECT shipment_id, LEFT(telemetry_string, 80) AS telemetry_preview
FROM vessel_telemetry
LIMIT 10;
شما باید ردیفهایی با مقادیر shipment_id و متن telemetry ببینید. اینها امضاهای telemetry ناوگان هستند که اکنون برای تطبیق در لحظه آمادهاند.
مرحله ۲: جستجوی کانتینر گمشده
اکنون، از افزونه google_ml_integration در AlloyDB برای جستجوی تطابق با استفاده از قطعه سیگنال رهگیری شده استفاده کنید:
SELECT
shipment_id,
telemetry_string,
1 - (embedding_vector <=> embedding('text-embedding-005', 'Refrigeration unit offline. Manual override.')::vector) AS search_relevance_score
FROM vessel_telemetry
ORDER BY embedding_vector <=> embedding('text-embedding-005', 'Refrigeration unit offline. Manual override.')::vector
LIMIT 5;
تابع embedding() که توسط افزونه google_ml_integration از AlloyDB ارائه شده است، مستقیماً از SQL، پلتفرم عامل (Agent Platform) را فراخوانی میکند تا یک جاسازی بردار به صورت درونخطی (inline) ایجاد کند. عملگر <=> فاصله کسینوسی بین دو بردار را محاسبه میکند (هرچه به 0 نزدیکتر باشد، دو بردار بیشتر شبیه هم هستند). ما از 1 کم میکنیم تا نتایج را به عنوان یک امتیاز مرتبط بیان کنیم که در آن هر چه بالاتر باشد بهتر است.
مرحله ۳: تایید تطابق
نتایج را بررسی کنید. بالاترین نتیجه باید MV-CAPYBARA-003 باشد که بالاترین امتیاز مرتبط بودن را دارد.
این همان کانتینری است که شما در هر مرحله از این تحقیق ردیابی کردهاید:
- 📷 تصاویر دوربینهای امنیتی نشان داد که این کشتی شبانه از بندر ریودوژانیرو خارج شده است.
- 🌡️ تشخیص ناهنجاری حرارتی تأیید کرد که واحد تبرید آن عمداً از کار افتاده است.
- 📡 تطبیق سیگنال بیکن، ردپای تلهمتری آن را در نزدیکی سیدنی مشخص کرد.
سه مدرک مستقل. سه قابلیت مختلف هوش مصنوعی گوگل کلود. یک کانتینر دزدیده شده.
🎯 پرونده مختومه شد: MV-CAPYBARA-003 در نزدیکی سیدنی پیدا شده است!

خلاصه بخش: شما از یکپارچهسازی هوش مصنوعی داخلی AlloyDB برای ایجاد یک جاسازی جستجو و انجام جستجوی شباهت کسینوسی در یک پرسوجوی SQL واحد استفاده کردید. تطابق بیکن، مکان کانتینر دزدیده شده را تأیید کرد و تحقیقات را تکمیل نمود.
۹. بررسی شواهد
اکنون که کانتینر را از طریق تحلیل تصویر چندوجهی و جستجوی برداری شناسایی کردهاید، میتوانید مستقیماً درون ویرایشگر خود از تحلیل مکالمهای برای کاوش دادههای تحقیق با استفاده از زبان طبیعی و بدون نوشتن هیچ SQL استفاده کنید.
مرحله ۱: دادهها را در کاتالوگ دانش پیدا کنید
کیت عامل داده شامل یک ویژگی جستجوی جهانی است که به شما امکان میدهد داراییهای داده را در محیط Google Cloud خود پیدا و کاوش کنید.
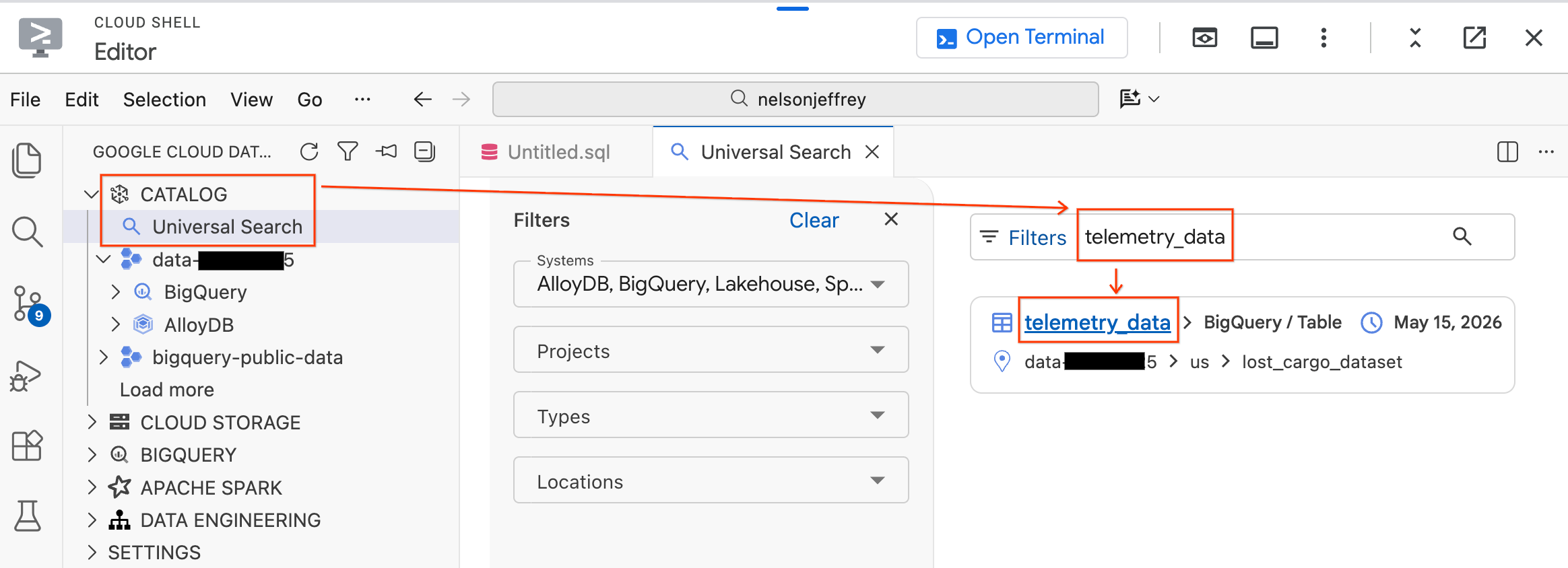
- در پنل Data Agent Kit در سمت چپ، بخش Catalog را باز کنید.
- روی جستجوی جهانی کلیک کنید.
- در نوار جستجو،
telemetry_dataرا تایپ کنید. - از نتایج جستجو، روی جدول
telemetry_data(زیرlost_cargo_dataset) کلیک کنید.
مرحله ۲: راهاندازی تحلیل مکالمهای
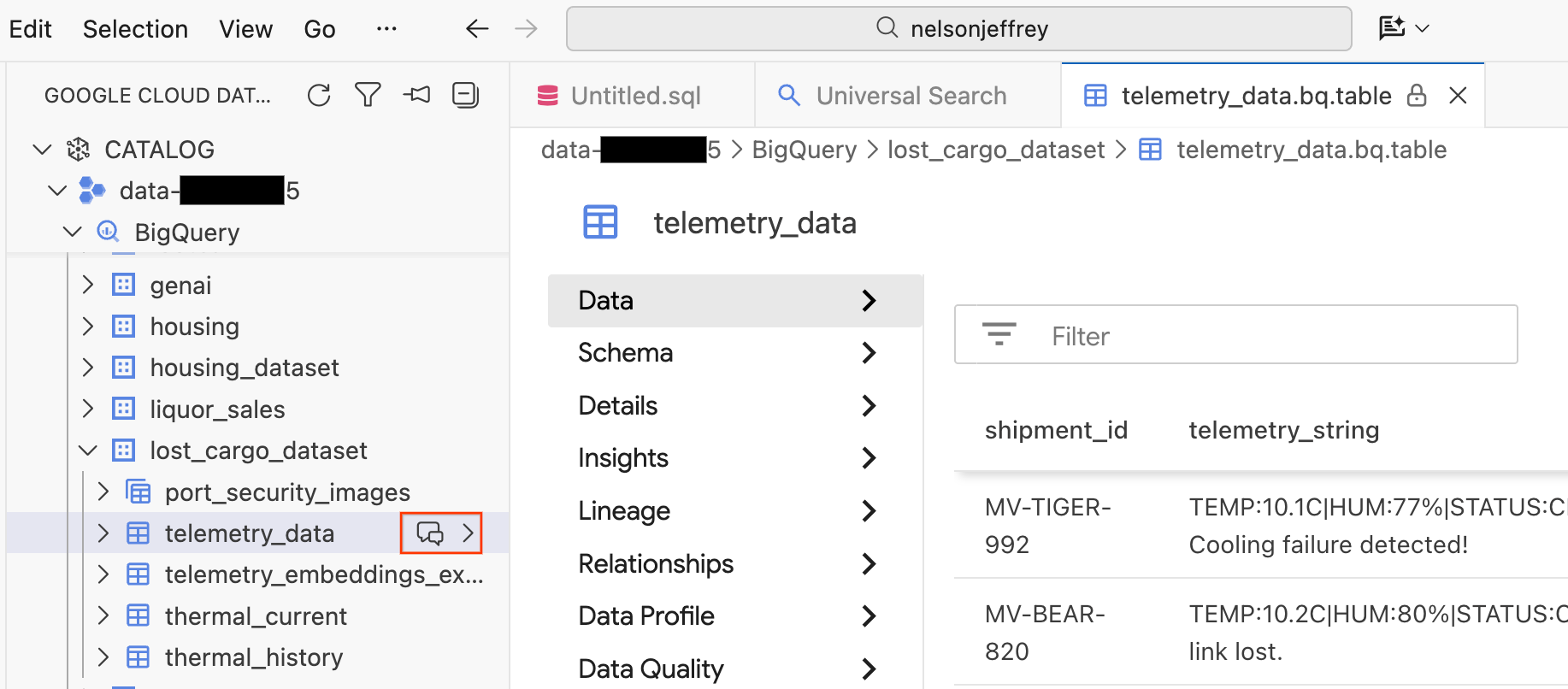
با کلیک بر روی نتیجه جستجو، یک برگه نمایش داده باز میشود که در آن میتوانید دادههای خام را پیشنمایش کنید، طرحواره را مشاهده کنید و کیفیت دادهها را بررسی کنید.
- در پنل سمت چپ، مجموعه دادهها و جداول BigQuery شما قابل مشاهده است. برای باز کردن یک پنجره چت جدید، روی دکمه Chat کلیک کنید.
مرحله ۳: پرسیدن سوال به زبان طبیعی
یک برگه گفتگوی جدید با عنوان «به تحلیل مکالمهای خوش آمدید!» باز میشود. عامل اطلاعاتی در مورد طرحواره و محتوای جدول شما دارد.
- در پنجره چت، تایپ کنید: «وضعیت تلهمتری و گزارش محموله کاپیبارا را به من نشان بده.»
- اینتر را فشار دهید.
این عامل، سوال شما را به BigQuery SQL ترجمه میکند، پرسوجو را اجرا میکند و نتایج را برمیگرداند، که شامل جدول دادهها و خلاصهای از یافتهها به صورت Insights است. بسته به پیچیدگی سوال خود، میتوانید بین حالت Thinking (تحلیل عمیقتر، کندتر) و Fast (پاسخهای سریعتر) یکی را انتخاب کنید. از آنجایی که این پاسخها توسط هوش مصنوعی تولید میشوند، نتایج شما ممکن است کمی با تصاویر زیر متفاوت باشد.
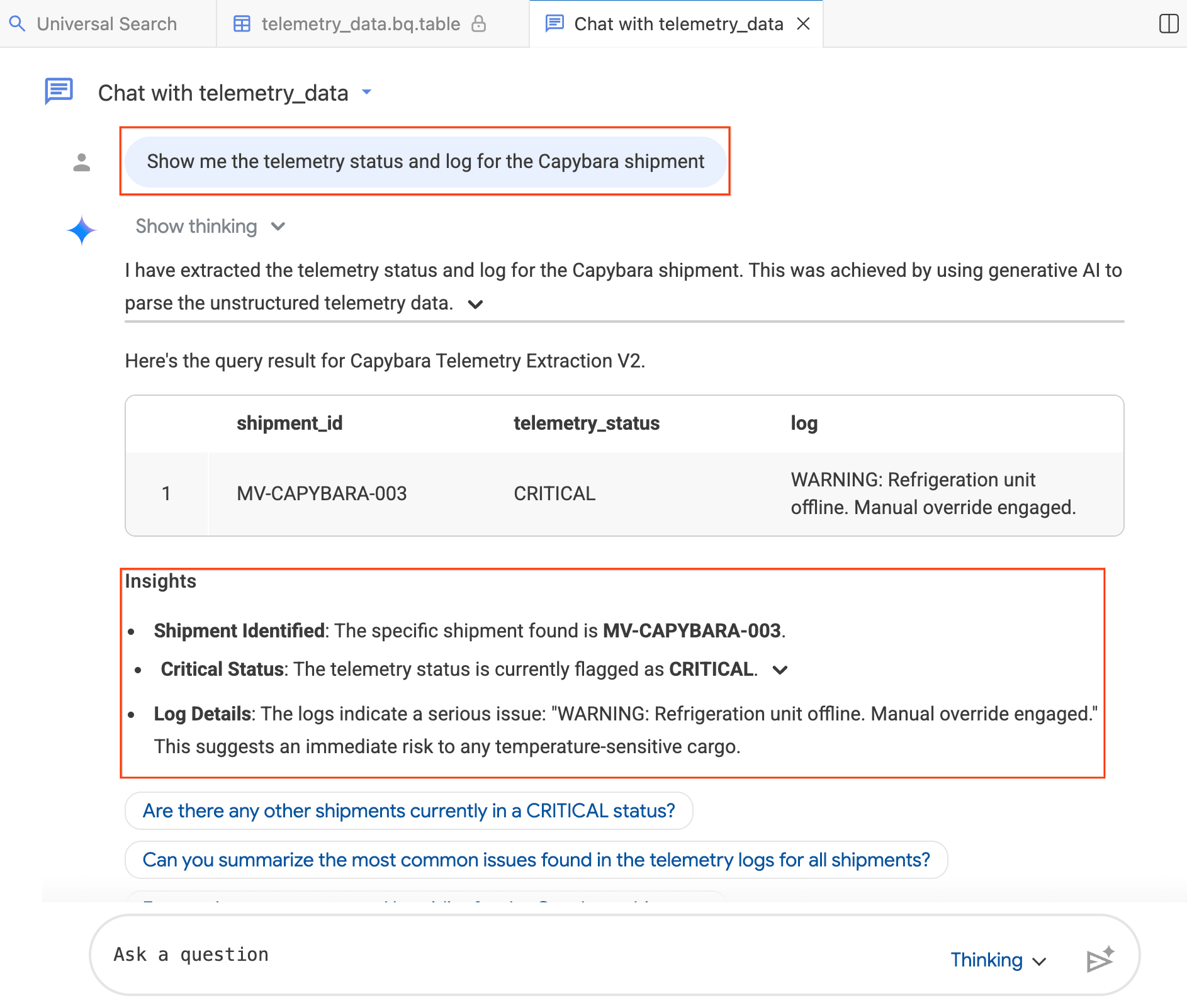
مرحله ۴: سوالات تکمیلی بپرسید
کارشناس، زمینه مکالمه شما را به خاطر میسپارد. یک سوال تکمیلی بپرسید:
- «چند محموله منحصر به فرد در دادههای تلهمتری وجود دارد؟»
- «در حال حاضر چند محموله دیگر در ناوگان وضعیت بحرانی دارند؟»
خلاصه بخش: شما از ویژگی جستجوی جهانی کاتالوگ دانش برای یافتن مجموعه دادههای خود استفاده کردید و تجزیه و تحلیل مکالمهای را برای جستجوی دادههای تحقیق با زبان طبیعی راهاندازی کردید. عامل هوش مصنوعی سوالات شما را به SQL ترجمه کرد و بینشهایی ارائه داد که یافتههای شما را تأیید میکرد.
۱۰. تمیز کردن
برای جلوگیری از هزینههای مداوم برای حساب Google Cloud خود، منابعی را که در این آزمایشگاه ایجاد کردهاید حذف کنید. میتوانید این دستورات را در ترمینال یکپارچه خود در داخل ویرایشگر Cloud Shell (جایی که از Data Agent Kit استفاده میکردید) اجرا کنید تا محیط خود را پاکسازی کنید.
ابتدا، متغیرهای محیطی خود را بارگذاری کنید:
source scripts/setenv.sh
- منابع BigQuery را حذف کنید (فقط در صورتی که قصد ادامه دادن به آزمایش ۳ را ندارید):
اگر قصد دارید به آزمایش ۳ ادامه دهید، از این مرحله صرف نظر کنید! آزمایش ۳ از همان مجموعه داده BigQuery و اتصالات برای تجزیه و تحلیل نمودار ویژگی استفاده میکند.
برای حذف مجموعه داده و اتصالات BigQuery خود:
# Drop the dataset
bq rm -r -f $PROJECT_ID:lost_cargo_dataset
# Delete the connections
bq rm --connection --location=us-central1 $PROJECT_ID.us-central1.lost_cargo_conn
bq rm --connection --location=us-central1 $PROJECT_ID.us-central1.lost_cargo_alloydb_conn
- حذف سطل ذخیرهسازی ابری:
gcloud storage rm --recursive gs://${PROJECT_ID}-lab2
- نمونه و کلاستر AlloyDB را حذف کنید :
AlloyDB در آزمایشگاه ۳ استفاده نشده است، بنابراین اکنون میتوان آن را با خیال راحت از بین برد.
gcloud alloydb instances delete lost-cargo-instance \
--region=$REGION \
--cluster=lost-cargo-cluster \
--quiet
gcloud alloydb clusters delete lost-cargo-cluster \
--region=$REGION \
--force \
--quiet
- تنظیمات محیط محلی را حذف کنید :
در نهایت، فایل تنظیمات محیط محلی را از فضای کاری خود پاک کنید:
rm -f .env
۱۱. تبریک میگویم!
شما با موفقیت آزمایشگاه ۲: تحلیل دادهها و بینشهای چندوجهی را به پایان رساندید! شما ردپا را از بندری پر از هزاران کانتینر تا یک سرقت تایید شده و یک مکان مشخص دنبال کردید.
کاری که شما انجام دادید
- فیلم را اسکن کردم : شما از
AI.GENERATEدر BigQuery برای تجزیه و تحلیل تصاویر امنیتی پورت و شناسایی کانتینر MV-CAPYBARA-003 به رنگ قرمز زرشکی استفاده کردید. - سرقت تایید شد : شما دادههای حسگر حرارتی را بررسی کردید، یک افزایش مشکوک ۱۴۸.۴ درجه فارنهایت را مشاهده کردید و
AI.DETECT_ANOMALIESبرای اثبات دستکاری عمدی آن استفاده کردید. - سیستم ردیابی را آماده کردید : شما AlloyDB را با pgvector و
google_ml_integrationبرای تطبیق بیکن در لحظه پیکربندی کردید. - ساخت فهرست جستجو : شما از
AI.GENERATEوAI.EMBEDدر BigQuery برای ایجاد جاسازیها استفاده کردید، سپس آنها را به Cloud Storage صادر و به AlloyDB وارد کردید. - تطبیق سیگنال بیکن : شما از جستجوی برداری AlloyDB برای تطبیق یک سیگنال تلهمتری تکهتکه شده استفاده کردید و کانتینر دزدیده شده را در نزدیکی سیدنی پیدا کردید.
- شواهد را بررسی کردید : شما مستقیماً از ویرایشگر برای جستجوی دادههای تحقیق با زبان طبیعی از تحلیل مکالمهای استفاده کردید.

مراحل بعدی
شما جای کانتینر را پیدا کردهاید. حالا باید بفهمید چه کسی پشت آن است.
در آزمایشگاه ۳: مصرف داده و گردشهای کاری عاملدار ، شما یک نمودار ویژگی از شبکه لجستیک برای ترسیم روابط بین شرکتهای پوششی ایجاد خواهید کرد، از تحلیلهای مکالمهای برای گفتگو با نمودار استفاده خواهید کرد و از طریق کاتالوگ دانش، کد ترخیص ایمن مورد نیاز برای بازیابی کانتینر را پیدا خواهید کرد.