
1. Introduction

Dans l'atelier précédent, vous avez agrégé des journaux d'expédition fragmentés et suivi le transpondeur de la cargaison jusqu'à New York. Toutefois, les enregistrements d'arrivée montrent que le conteneur a été immédiatement réacheminé pour éviter la détection par les douanes. La piste vous a maintenant mené au port de Rio de Janeiro, un vaste port avec des milliers de conteneurs. Il est difficile de trouver le bon conteneur parmi des milliers d'autres.
Dans cet atelier, vous allez utiliser les fonctionnalités d'IA intégrées à BigQuery pour "lire" des images non structurées de sécurité portuaire et détecter des anomalies thermiques dans les données de capteurs, le tout à l'aide de SQL standard. Vous allez ensuite exporter les embeddings vectoriels vers AlloyDB et exécuter une recherche vectorielle pour faire correspondre un signal de télémétrie fragmenté au conteneur manquant.
Objectifs de l'atelier
- Analysez les images de sécurité du port pour identifier le conteneur volé à l'aide de BigQuery AI.
- Détecter une anomalie thermique à l'aide de BigQuery AI pour confirmer que le conteneur a été volé et non égaré
- Générer des embeddings vectoriels et les charger dans AlloyDB pour la recherche en temps réel
- Faire correspondre un signal de balise de télémétrie fragmenté pour localiser le conteneur volé à l'aide de Vector Search
- Explorer les données d'investigation en langage naturel à l'aide de Conversational Analytics
Prérequis
- Un navigateur Web (par exemple, Chrome)
- Un projet Google Cloud avec facturation activée
- Connaissances de base de SQL et de la console Google Cloud
Cet atelier de programmation s'adresse aux développeurs de niveau intermédiaire.
Les ressources créées dans cet atelier de programmation devraient coûter moins de 5 $.
2. Avant de commencer
Démarrer Cloud Shell
Vous utiliserez Google Cloud Shell pour télécharger le code, exécuter les scripts de configuration et déployer l'application.
- Dans un nouvel onglet de navigateur, ouvrez Cloud Shell : shell.cloud.google.com.
- Une fois connecté, définissez votre ID de projet et confirmez votre environnement :
gcloud config set project <<YOUR_PROJECT_ID>>
export PROJECT_ID=$(gcloud config get-value project)
export REGION=us-central1
Un message de ce type doit s'afficher :
Your active configuration is: [cloudshell-####] Updated property [core/project]
Cloner le dépôt
Clonez le dépôt de l'atelier de programmation dans votre environnement Cloud Shell :
cd ~/
git clone --filter=blob:none --no-checkout https://github.com/GoogleCloudPlatform/devrel-demos.git
cd ~/devrel-demos
git sparse-checkout init --cone
git sparse-checkout set codelabs/bigquery-alloydb-insights
git checkout main
cd codelabs/bigquery-alloydb-insights/
Activer les API
Exécutez cette commande dans Cloud Shell pour activer toutes les API requises pour cet atelier :
gcloud services enable \
aiplatform.googleapis.com \
bigquery.googleapis.com \
bigqueryconnection.googleapis.com \
alloydb.googleapis.com
Si l'exécution réussit, un message semblable à celui-ci s'affiche :
Operation "operations/..." finished successfully.
3. Configurer votre environnement
Avant de pouvoir analyser des images et des données de télémétrie, vous devez configurer l'infrastructure pour cet atelier. Vous exécuterez deux scripts : l'un lance le provisionnement d'AlloyDB en arrière-plan et l'autre crée toutes les ressources BigQuery dont vous aurez besoin.
Étape 1 : Démarrer le déploiement AlloyDB (en arrière-plan)
Le provisionnement du cluster AlloyDB prend environ 10 minutes. Vous allez donc le lancer en premier et le laisser s'exécuter en arrière-plan pendant que vous parcourez les sections BigQuery. Le script enregistre automatiquement les paramètres de votre projet actif dans un fichier .env local. Votre configuration est ainsi conservée même si votre terminal Cloud Shell se ferme ou redémarre.
chmod +x scripts/setup_alloydb.sh
nohup ./scripts/setup_alloydb.sh > /dev/null 2>&1 &
echo "AlloyDB deployment started in background (PID: $!)"
Étape 2 : Exécutez le script de configuration
Ce script crée l'ensemble de données BigQuery, la connexion à la ressource Cloud, les autorisations IAM et le bucket GCS, puis charge toutes les données de capteur que vous analyserez dans cet atelier. Il lira et vérifiera également les variables d'environnement enregistrées dans le fichier .env.
chmod +x scripts/setup_lab.sh
./scripts/setup_lab.sh
L'exécution du script prend environ une minute. Une fois l'opération terminée, un récapitulatif de tout ce qui a été créé s'affiche.
📝 Remarque sur la réinitialisation de l'environnement : Si votre session Cloud Shell expire ou redémarre à un moment donné de cet atelier, vous pouvez restaurer immédiatement vos variables de terminal en exécutant la commande suivante :
source scripts/setenv.sh
Étape 3 : Lancer l'éditeur Cloud Shell
Jusqu'à présent, vous avez utilisé le terminal Cloud Shell. Passez maintenant à l'éditeur Cloud Shell complet, qui vous offre un espace de travail semblable à VS Code avec une compatibilité BigQuery intégrée.
- Dans le volet du terminal Cloud Shell en bas de l'écran, cliquez sur le bouton Ouvrir l'éditeur pour lancer l'espace de travail de l'éditeur Cloud Shell.

Étape 4 : Installez l'extension Data Agent Kit
L'extension Google Cloud Data Agent Kit offre une intégration approfondie aux services de données Google Cloud directement dans votre éditeur. Vous pouvez ainsi interagir avec BigQuery, AlloyDB, Cloud Storage et d'autres services sans changer de contexte.
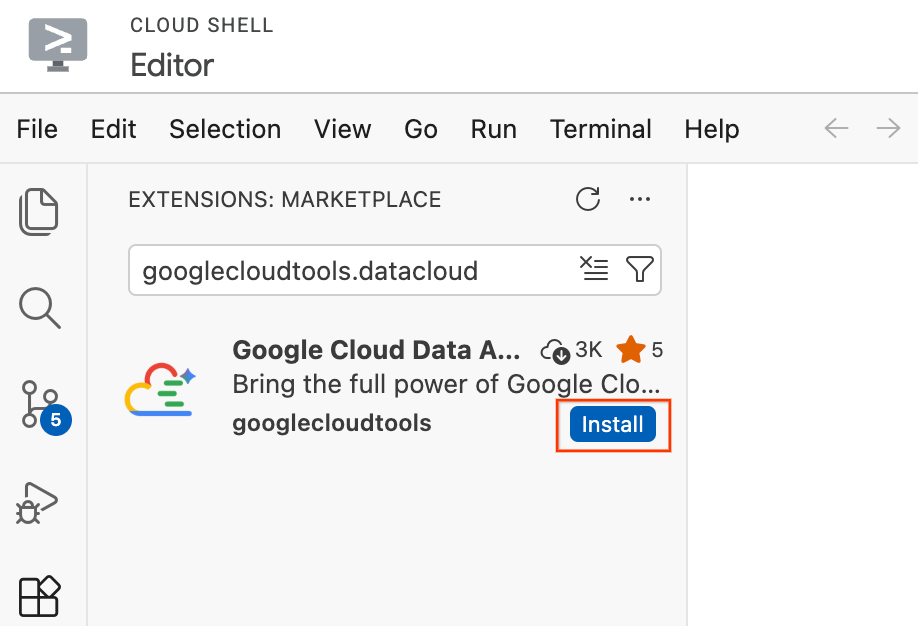
- Dans l'éditeur Cloud Shell, cliquez sur l'icône Extensions (Extensions) dans la barre d'activité, tout à gauche de l'écran (elle ressemble à quatre carrés).
- Dans la barre de recherche en haut du volet "Extensions", saisissez
googlecloudtools.datacloud. - Recherchez l'extension Google Cloud Data Agent Kit publiée par Google Cloud.
- Cliquez sur le bouton Install (installer).
- Une invite s'affiche pour vous demander si vous faites confiance à l'éditeur "googlecloudtools" et à ses extensions. Cliquez sur Faire confiance aux éditeurs et installer pour continuer.
Étape 5 : Authentifiez et configurez l'extension
Une fois l'extension installée, associez-la à votre projet Google Cloud.
- Une page d'intégration intitulée "Intégration du kit d'agent de données Google Cloud" devrait s'ouvrir automatiquement. Cliquez sur Se connecter à Google Cloud. Suivez les instructions du navigateur pour autoriser l'accès.
- Une fenêtre modale "Configuration en cours" s'affiche. L'extension recherche automatiquement les dépendances requises, comme Google Cloud CLI.
- Dans la section Résumé de la configuration, recherchez le champ "Projet". Cliquez sur le menu déroulant et sélectionnez votre projet Google Cloud. Définissez votre région sur
us-central1. - Attendez que les vérifications de la configuration soient terminées. Une fois le message "Configuration terminée" affiché, cliquez sur Configurer les serveurs MCP.
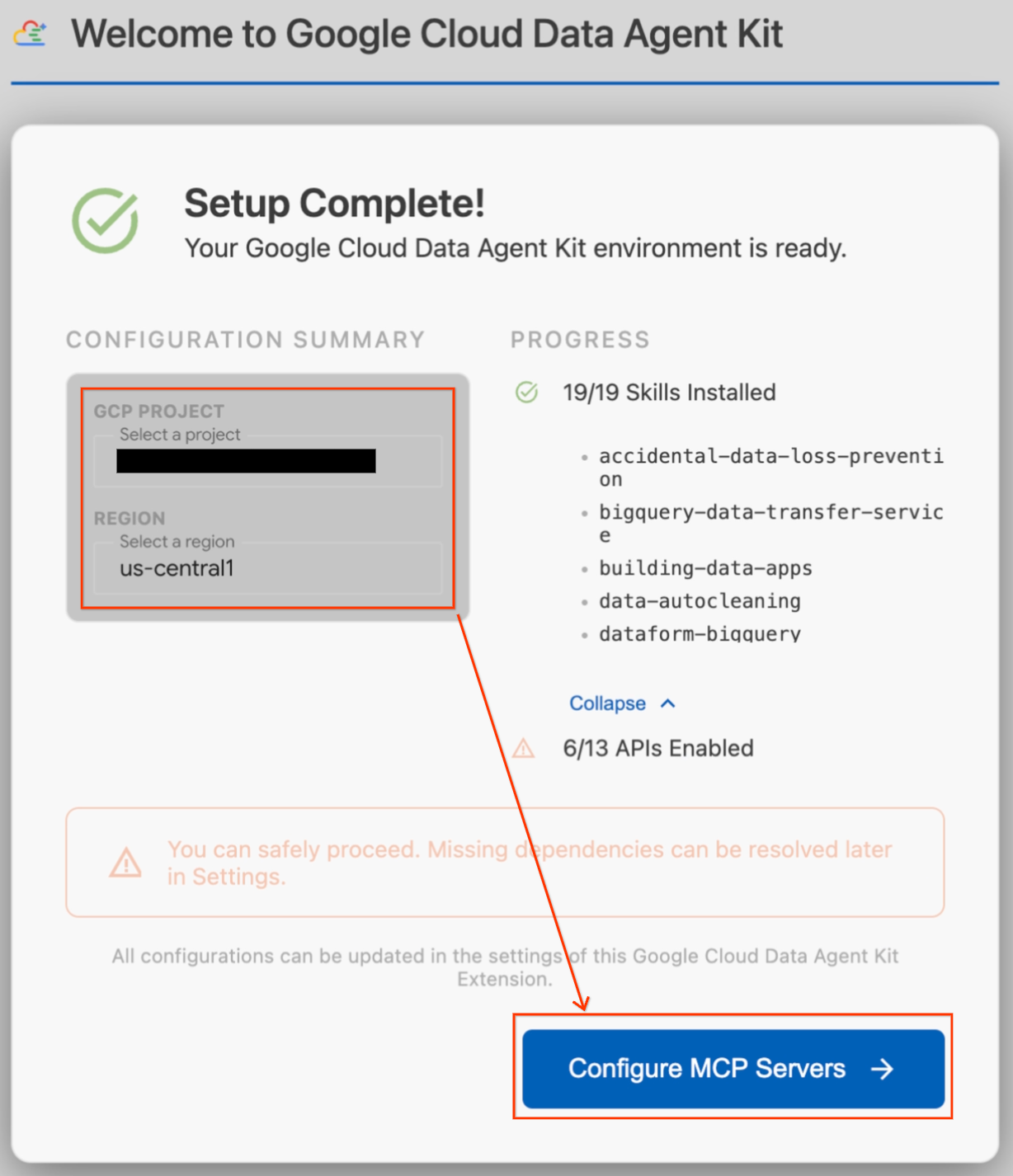
- Sélectionnez BigQuery et AlloyDB sous "Configuration MCP", puis cliquez sur Commencer.
Étape 6 : Explorer les options de configuration
Une fois la configuration terminée, vous serez redirigé vers le tableau de bord "Commencer à utiliser le kit d'agent de données Google Cloud".
- Sous "Configuration", cliquez sur Premiers pas.
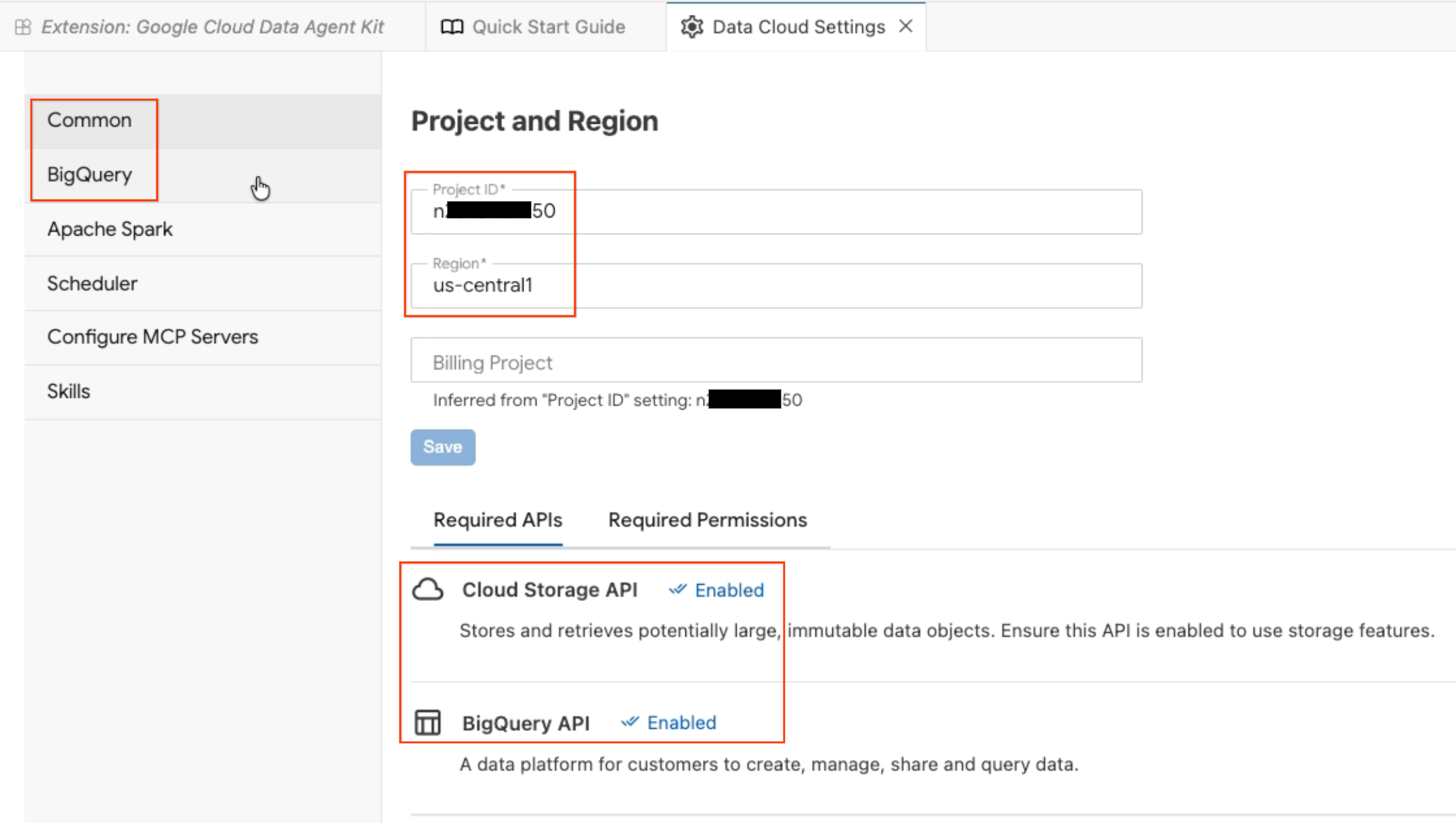
- Le panneau Configuration de l'agent de données s'ouvre. Explorez les onglets :
- Projet et région : vérifiez l'ID du projet sélectionné et assurez-vous que les API requises (API Cloud Storage, API BigQuery, API Catalog et API AlloyDB) sont activées.
- BigQuery : configurez l'emplacement par défaut de vos requêtes BigQuery. Utilisez la région
us-central1. - Configurer les serveurs MCP : affichez les serveurs MCP activés (BigQuery, Notebooks, AlloyDB, etc.) qui permettent aux agents IA d'interagir de manière sécurisée avec vos données.
- Compétences : explorez les compétences prédéfinies qui offrent aux agents des capacités spécialisées pour les tâches de données complexes.
Étape 7 : Vérifier avec BigQuery
Vérifiez que tout fonctionne en exécutant une requête rapide sur un ensemble de données public.
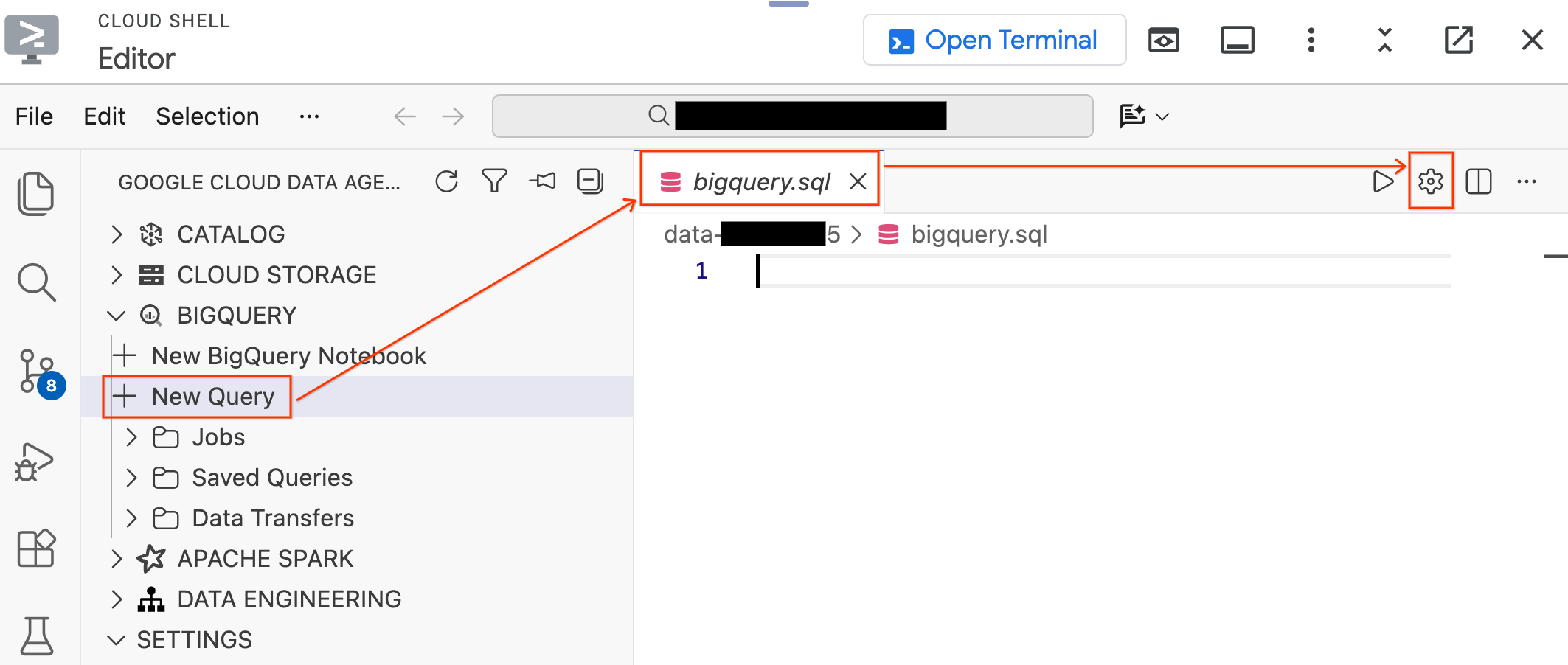
- Dans le volet "Data Agent Kit" (Kit d'agent de données) à gauche, développez la section BigQuery, puis cliquez sur New Query (Nouvelle requête) pour ouvrir un nouvel onglet de l'éditeur de requête.
- Enregistrez le fichier en appuyant sur
Ctrl+S(Windows/Linux) ouCmd+S(macOS), puis nommez-lebigquery. Cet onglet sera utilisé pour toutes vos opérations BigQuery. - Cliquez sur Paramètres de requête avec l'onglet
bigquery.sqlactif, sélectionnez BigQuery comme source de données, puis cliquez sur Enregistrer.
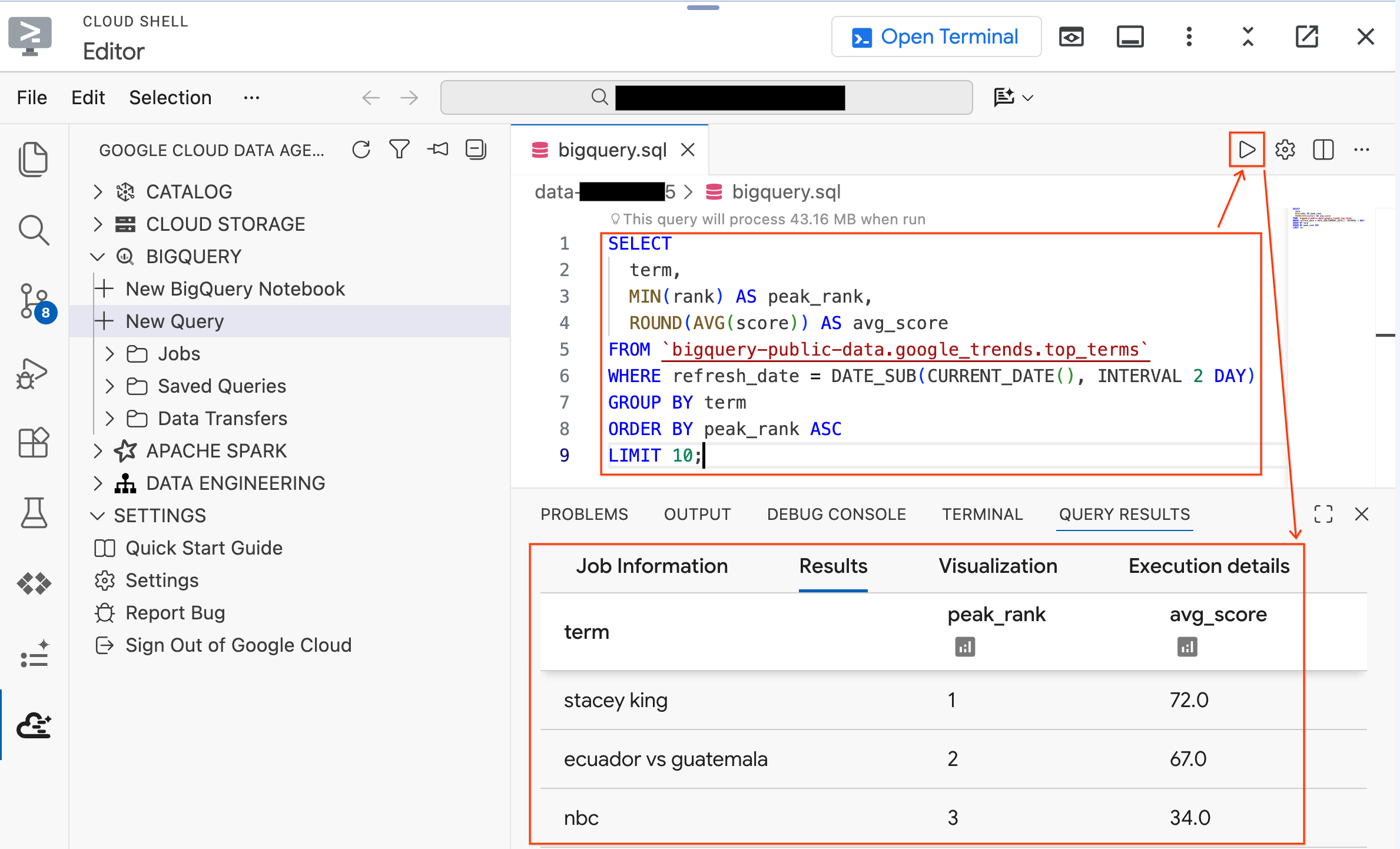
- Exécutez la requête suivante sur un ensemble de données public :
SELECT
term,
MIN(rank) AS peak_rank,
ROUND(AVG(score)) AS avg_score
FROM `bigquery-public-data.google_trends.top_terms`
WHERE refresh_date = DATE_SUB(CURRENT_DATE(), INTERVAL 2 DAY)
GROUP BY term
ORDER BY peak_rank ASC
LIMIT 10;
- Vous devriez voir les 10 termes les plus recherchés sur Google au cours des derniers jours. Si des résultats s'affichent, cela signifie que votre extension est connectée et prête à l'emploi.
Essayez maintenant d'exécuter une requête sur les données de l'atelier que votre script de configuration vient de créer. Remplacez la requête existante par celle-ci :
SELECT * FROM `lost_cargo_dataset.telemetry_data` LIMIT 5;
Vous devriez voir des entrées de journaux de télémétrie avec les colonnes shipment_id et telemetry_string. Il s'agit des données que vous analyserez tout au long de l'atelier.
Récapitulatif de la section : vous avez lancé le déploiement d'AlloyDB en arrière-plan, exécuté le script de configuration et configuré l'éditeur Cloud Shell avec l'extension Data Agent Kit.
4. Parcourir les images de sécurité
L'équipe d'enquête a récupéré des images de sécurité du port de Rio de Janeiro montrant des rangées de conteneurs maritimes. Dans l'atelier 1, vous avez appris que le conteneur cible est red. Vous devez maintenant identifier précisément lequel des conteneurs rouges il s'agit.
Vous allez créer une table d'objets qui permettra à BigQuery de "voir" les images de sécurité dans Cloud Storage, puis utiliser la fonction AI.GENERATE pour demander à Gemini d'extraire des données structurées de chaque image.
Étape 1 : Créer la table d'objets
Une table d'objets est une table BigQuery spéciale qui sert d'index pour les fichiers non structurés (images, PDF, fichiers audio) stockés dans Cloud Storage. Il ne copie pas les fichiers dans BigQuery, mais crée une référence interrogeable pour que les fonctions d'IA puissent les "voir".
Dans l'onglet bigquery.sql de l'éditeur, exécutez l'instruction suivante pour créer la table d'objets pointant vers les images de sécurité des ports dans le bucket de votre projet :
SET @@location = 'us-central1';
EXECUTE IMMEDIATE CONCAT("""
CREATE OR REPLACE EXTERNAL TABLE `lost_cargo_dataset.port_security_images`
WITH CONNECTION `us-central1.lost_cargo_conn`
OPTIONS (
object_metadata = 'SIMPLE',
uris = ['gs://""", @@project_id, """-lab2/images/*']
);
""");
Voici un aperçu de ce que BigQuery peut désormais voir :
SELECT uri, content_type FROM `lost_cargo_dataset.port_security_images` LIMIT 5;
Chaque ligne représente un fichier image dans Cloud Storage. BigQuery peut désormais transmettre ces images directement aux modèles d'IA.
Étape 2 : Analyser les images de sécurité
Utilisez maintenant la fonction AI.GENERATE de BigQuery pour analyser chaque image de sécurité. Cette requête SQL unique invite Gemini à examiner chaque image et à renvoyer des données structurées :
SELECT
uri,
AI.GENERATE(
(
'Examine this port security image. Identify any shipping container IDs visible on the container and provide a one-word color of the container.',
ref
),
output_schema => 'detected_container_id STRING, color STRING'
).* EXCEPT (full_response, status)
FROM `lost_cargo_dataset.port_security_images`;
Étape 3 : Identifiez le conteneur cible
Parcourez les résultats. Recherchez la ligne où la colonne color affiche Rouge (ou une variante de rouge). Notez la valeur de detected_container_id. Votre cible est la suivante : MV-CAPYBARA-003.
Étape 4 : Vérifiez la correspondance visuelle
Pour voir l'image analysée sans quitter votre éditeur :
- Cliquez sur Cloud Storage dans le volet "Kit d'agent de données" à gauche.
- Développez votre bucket (
YOUR_PROJECT_ID-lab2/images/), puis cliquez sur le fichier image correspondant au conteneur rouge pour l'afficher directement dans l'éditeur.
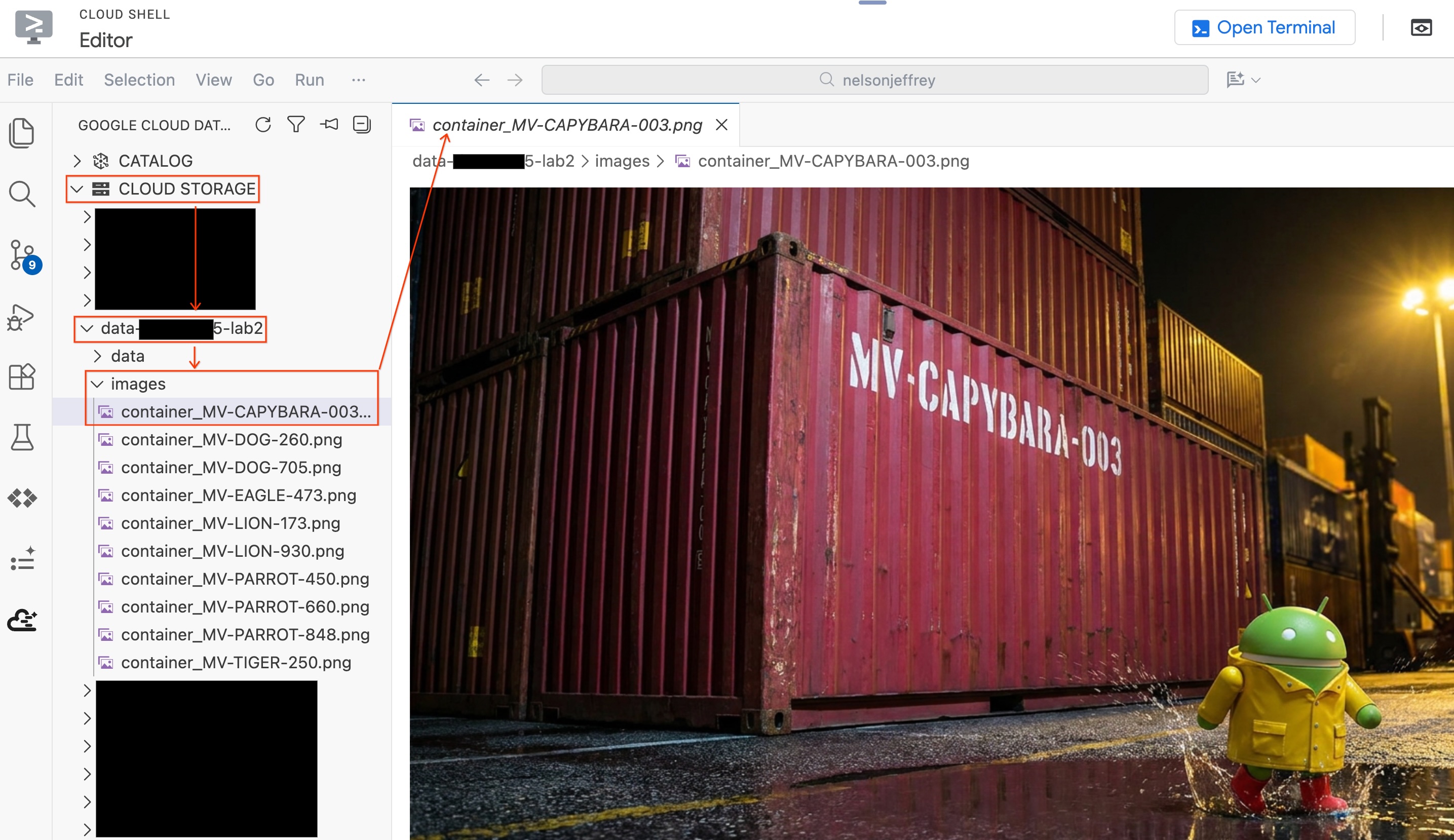
Récapitulatif de la section : vous avez créé une table d'objets pour permettre à BigQuery d'accéder aux images de sécurité du port, puis vous avez utilisé AI.GENERATE pour extraire les données structurées des conteneurs de chaque image. Le conteneur rouge a été identifié comme MV-CAPYBARA-003.
5. Confirmer le vol
Vous avez identifié le conteneur manquant comme MV-CAPYBARA-003, mais a-t-il été volé ou simplement égaré ? Les journaux du manifeste indiquent que ce conteneur spécifique était garé à côté du capteur environnemental SENS-99. Si les voleurs ont délibérément désactivé le groupe frigorifique embarqué du conteneur avant de le déplacer, SENS-99 a peut-être enregistré un pic soudain d'échappement thermique.
Utilisons la détection d'anomalies pour prouver que le conteneur a été falsifié.
- Commencez par explorer la référence historique. Voici les lectures normales de
SENS-99au cours des dernières heures :
SELECT * FROM `lost_cargo_dataset.thermal_history`
ORDER BY reading_time DESC
LIMIT 50;
Notez que les températures se situent dans une plage étroite autour de 24 à 26 °C. Voici à quoi ressemble une situation normale.
- Examinons maintenant le lot actuel de lectures du même capteur :
SELECT * FROM `lost_cargo_dataset.thermal_current`
ORDER BY thermal_reading DESC
LIMIT 50;
Vous voyez la température de 64,7 °C en haut de l'écran ? Tout le reste semble normal. Ce pic indiquerait une défaillance de l'unité de réfrigération ou une falsification délibérée. Vérifions-le dès maintenant.
- Exécutez la détection des anomalies. La fonction
AI.DETECT_ANOMALIESde BigQuery utilise le modèle de fondation TimesFM pré-entraîné pour analyser les tendances des séries temporelles et signaler automatiquement les valeurs aberrantes, sans nécessiter d'entraînement de modèle :
SELECT *
FROM AI.DETECT_ANOMALIES(
TABLE `lost_cargo_dataset.thermal_history`,
TABLE `lost_cargo_dataset.thermal_current`,
data_col => 'thermal_reading',
timestamp_col => 'reading_time',
id_cols => ['sensor_id']
)
WHERE is_anomaly = TRUE;
- Parcourez les résultats. La lecture de 64,7 °C doit être signalée comme une anomalie avec une probabilité d'anomalie élevée, ce qui confirme qu'un événement inhabituel s'est produit à proximité de la zone du conteneur.
Récapitulatif de la section : vous avez utilisé la fonction AI.DETECT_ANOMALIES de BigQuery pour exploiter le modèle TimesFM pré-entraîné. En exécutant une seule requête SQL, vous avez automatiquement identifié les valeurs aberrantes et isolé l'événement de falsification anormale sans écrire de code de machine learning complexe ni entraîner de modèles à partir de zéro.
6. Préparer le système de suivi
Le vol du conteneur a été confirmé. Il ne se trouve plus à Rio de Janeiro. Chaque conteneur de la flotte émet des signaux de balise de télémétrie : des relevés de capteurs, des fragments GPS et des journaux d'état. Si la balise du conteneur volé continue d'émettre, vous pouvez la comparer à des signatures connues pour le retrouver.
BigQuery excelle dans le travail analytique que vous avez effectué jusqu'à présent, mais la localisation d'un conteneur en temps réel nécessite des requêtes opérationnelles à faible latence. AlloyDB, une base de données entièrement gérée compatible avec PostgreSQL, est conçue exactement pour cela : des requêtes de recherche vectorielle suffisamment rapides pour un système de suivi en direct. Vous chargerez vos embeddings de télémétrie dans AlloyDB et les utiliserez pour faire correspondre le signal de balise.
Le cluster AlloyDB que vous avez lancé en arrière-plan devrait maintenant être prêt. Configurons-le directement depuis votre éditeur.
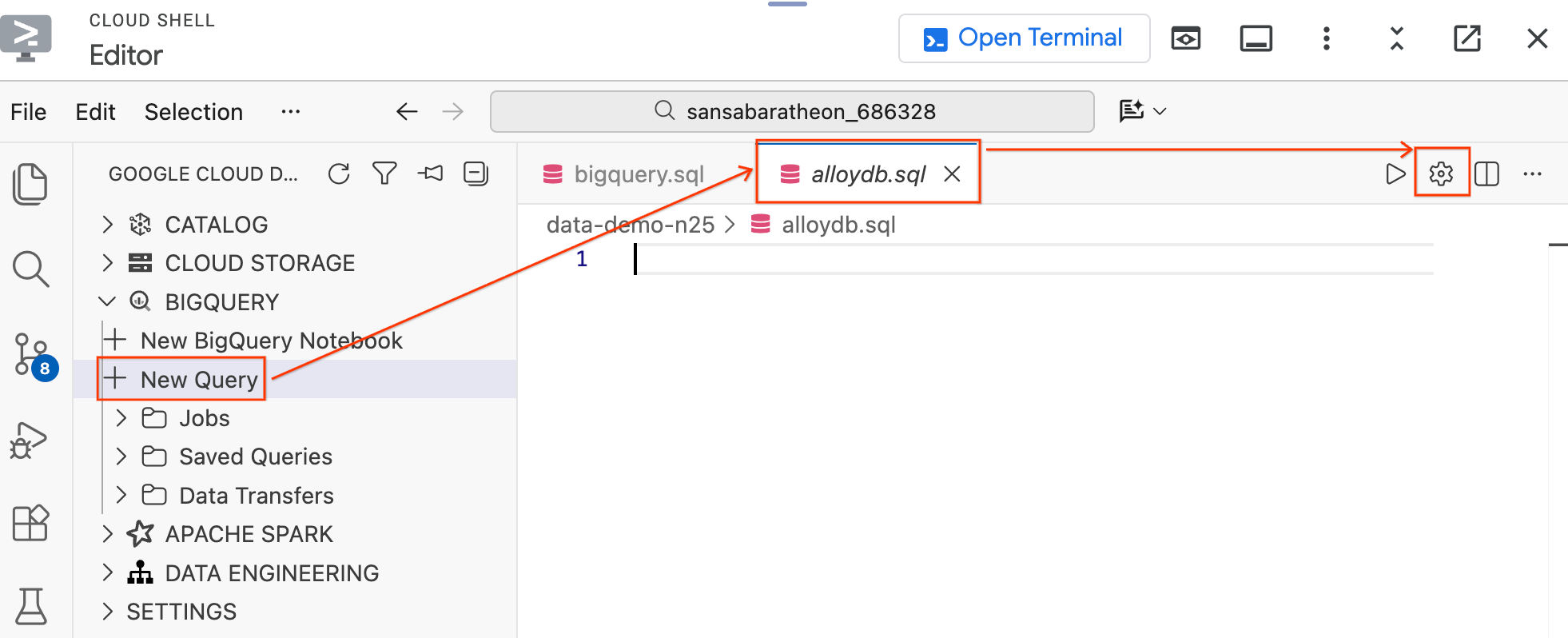
Étape 1 : Se connecter à AlloyDB depuis l'éditeur
Au lieu de passer à la console Cloud, vous pouvez vous connecter directement à AlloyDB à l'aide de l'extension Data Agent Kit.
- Dans le volet "Data Agent Kit" (Kit d'agent de données) à gauche, sous la section BigQuery, cliquez sur New Query (Nouvelle requête) pour ouvrir un nouvel onglet de l'éditeur de requête.
- Enregistrez le fichier en appuyant sur
Ctrl+S(Windows/Linux) ouCmd+S(macOS), puis nommez-lealloydb. Cet onglet sera utilisé pour toutes les requêtes AlloyDB. - Cliquez sur l'icône en forme de roue dentée pour ouvrir la fenêtre modale Paramètres de la requête.
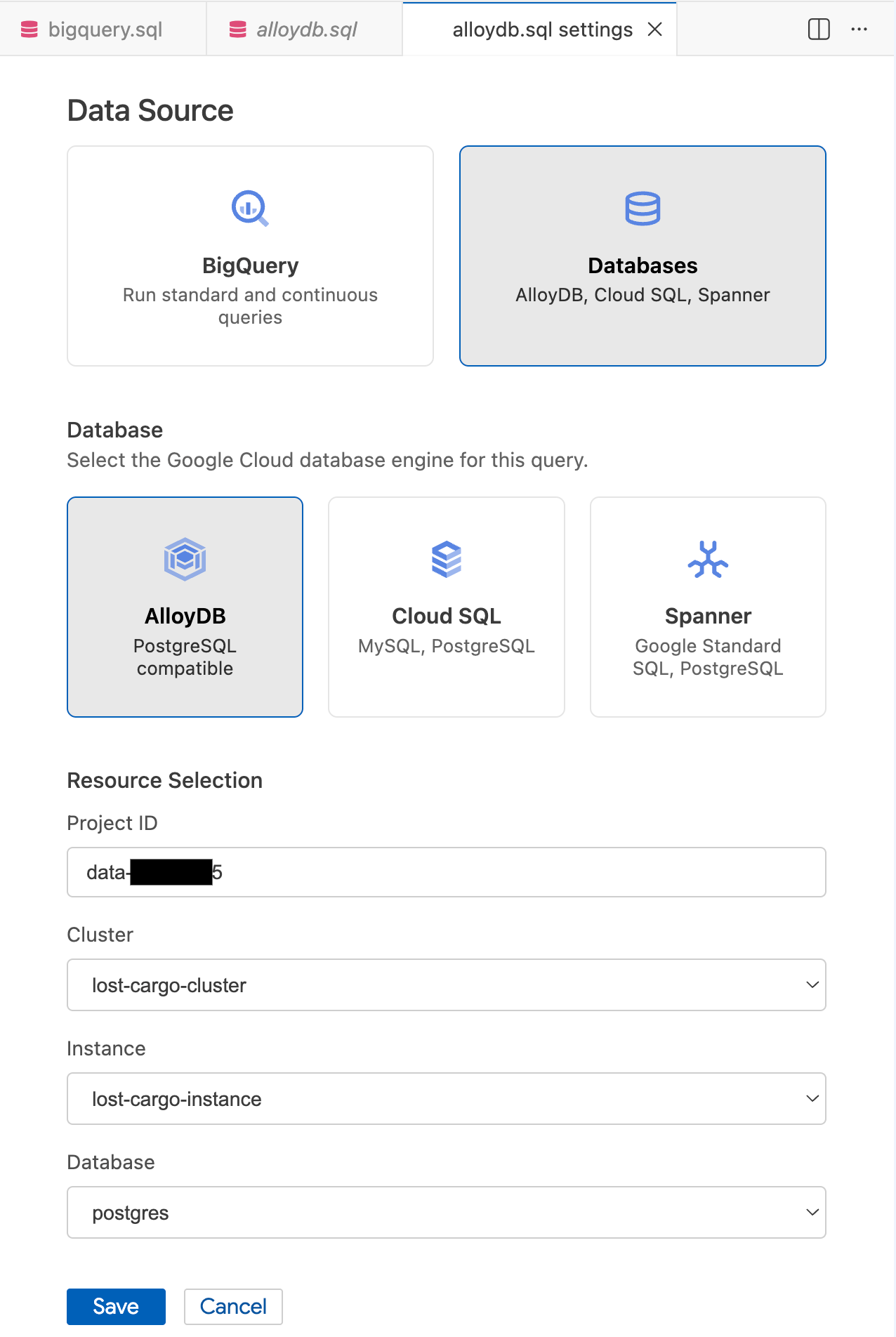
- Dans la fenêtre modale Paramètres de requête, sous Source de données, sélectionnez Bases de données.
- Sous Base de données, sélectionnez AlloyDB.
- Renseignez les détails de la sélection des ressources :
- ID du projet : saisissez l'ID de votre projet Google Cloud.
- Cluster : sélectionnez
lost-cargo-cluster. - Instance : sélectionnez
lost-cargo-instance. - Base de données : sélectionnez
postgres.
- Cliquez sur Enregistrer.
Étape 2 : Activez l'extension Vector et créez la table
Maintenant que vous êtes connecté à AlloyDB, vous devez activer les extensions d'IA nécessaires et créer la table qui recevra les données de télémétrie intégrées.
- Dans l'onglet
.sqlactif, collez les commandes suivantes pour activer les extensions requises :
CREATE EXTENSION IF NOT EXISTS vector;
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
- Mettez en surbrillance le texte, puis cliquez sur le bouton Exécuter la requête (icône de lecture) en haut à droite de l'éditeur.
- Consultez le panneau du terminal Résultats de la requête en bas de l'écran. Elle devrait afficher
Statement executed successfully.
- Ensuite, remplacez le texte de votre éditeur par l'instruction suivante pour créer la table de télémétrie :
CREATE TABLE IF NOT EXISTS vessel_telemetry (
entry_id SERIAL PRIMARY KEY,
shipment_id VARCHAR(50),
telemetry_string TEXT,
embedding_vector vector(768)
);
- Exécutez cette requête comme la précédente. Vérifiez qu'il s'exécute correctement dans le panneau inférieur.
Le type vector(768) provient de l'extension pgvector que vous venez d'activer. Les 768 dimensions correspondent à la sortie du modèle text-embedding-005 de Google, que vous utiliserez dans BigQuery pour générer les embeddings.
Récapitulatif de la section : vous vous êtes connecté à AlloyDB directement depuis l'éditeur Cloud Shell, vous avez activé les extensions pgvector et google_ml_integration, et vous avez créé la table cible. AlloyDB est désormais prêt à servir de backend opérationnel pour la mise en correspondance de la télémétrie en temps réel.
7. Créer l'index de recherche
Vous devez maintenant insérer les données de télémétrie dans AlloyDB pour qu'elles puissent alimenter la mise en correspondance des balises en temps réel. Les journaux de télémétrie bruts sont désordonnés et de longueur variable, ce qui n'est pas idéal pour la recherche par similarité. Vous utiliserez les fonctions d'IA de BigQuery pour résumer chaque journal avec Gemini et convertir chaque résumé en un embedding vectoriel de 768 dimensions. Vous exporterez ensuite les données enrichies vers Cloud Storage et les importerez dans AlloyDB.
Étape 1 : Générer des embeddings dans BigQuery
Revenez à l'onglet de l'éditeur bigquery.sql (qui reste connecté à BigQuery).
Exécutez maintenant la requête suivante pour résumer chaque journal de télémétrie avec Gemini et générer des embeddings vectoriels :
CREATE OR REPLACE TABLE `lost_cargo_dataset.telemetry_embeddings_export` AS
WITH summarized_telemetry AS (
SELECT
shipment_id,
telemetry_string,
AI.GENERATE(
CONCAT('Summarize this telemetry log for vector search: ', telemetry_string)
).result AS summary
FROM `lost_cargo_dataset.telemetry_data`
),
telemetry_embeddings AS (
SELECT
shipment_id,
telemetry_string,
AI.EMBED(summary, endpoint => 'text-embedding-005').result AS embedding
FROM summarized_telemetry
)
SELECT
shipment_id,
telemetry_string,
TO_JSON_STRING(embedding) AS embedding_vector
FROM telemetry_embeddings;
Étape 2 : Prévisualisez les données enrichies
Avant d'exporter, examinez ce que vous avez créé. Cette requête affiche les ID d'expédition ainsi que les 80 premiers caractères de chaque résumé et intégration :
SELECT
shipment_id,
SUBSTR(telemetry_string, 1, 80) AS telemetry_preview,
SUBSTR(embedding_vector, 1, 80) AS embedding_preview
FROM `lost_cargo_dataset.telemetry_embeddings_export`
LIMIT 5;
Chaque ligne contient désormais un ID d'expédition, le journal de télémétrie d'origine et un vecteur d'intégration à 768 dimensions. Il s'agit des données que vous allez transférer dans AlloyDB.
Étape 3 : Exporter les embeddings vers Cloud Storage
Utilisez l'instruction EXPORT DATA de BigQuery pour écrire la table d'embeddings dans le bucket GCS de votre atelier sous forme de fichier CSV.
EXECUTE IMMEDIATE CONCAT("""
EXPORT DATA OPTIONS (
uri = 'gs://""", @@project_id, """-lab2/data/embeddings_export/*.csv',
format = 'CSV',
overwrite = true,
header = false
) AS
SELECT
shipment_id,
telemetry_string,
embedding_vector
FROM `lost_cargo_dataset.telemetry_embeddings_export`;
""");
Étape 4 : Importer dans AlloyDB depuis Cloud Storage
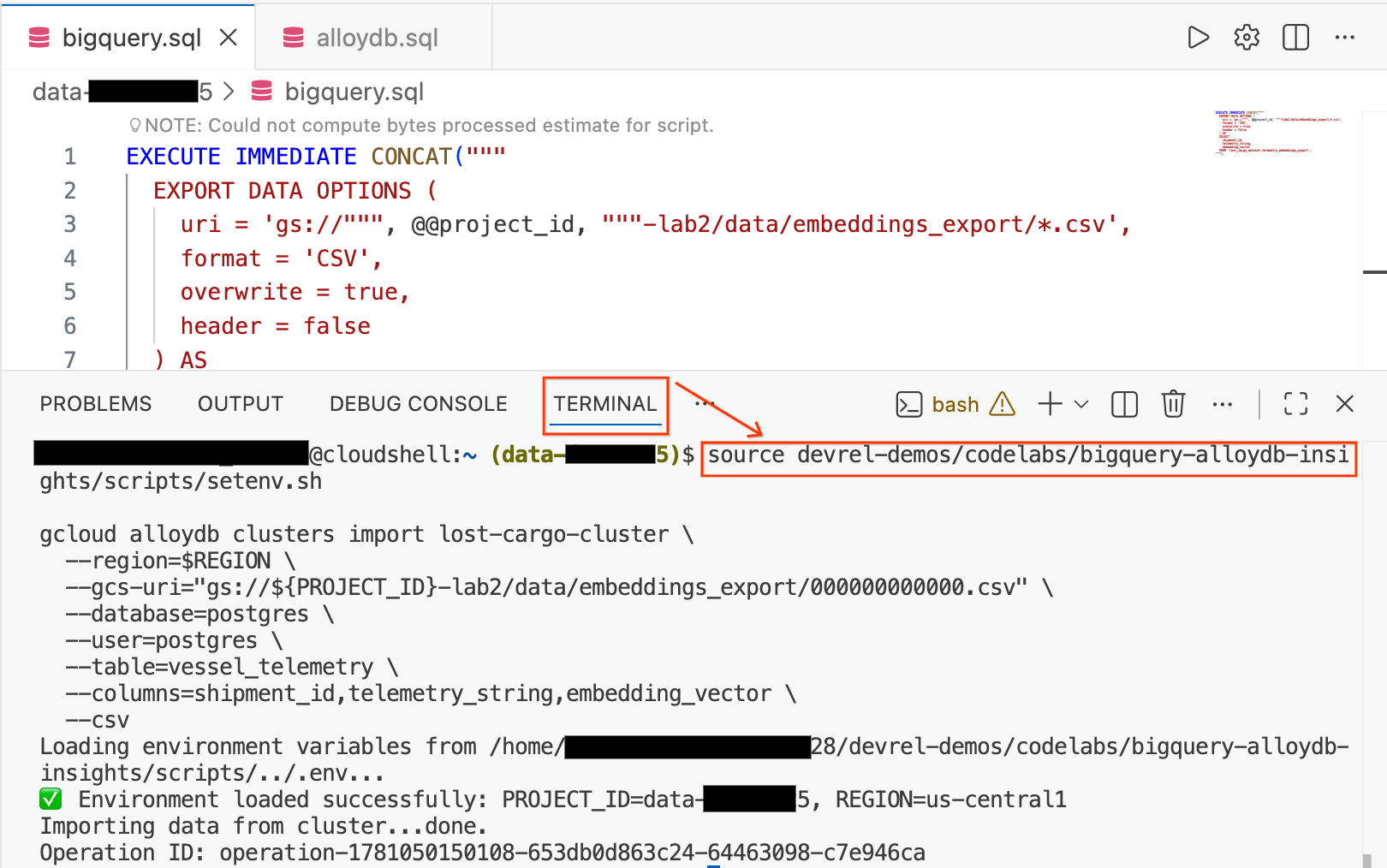
- Dans l'éditeur Cloud Shell, cliquez sur l'onglet Terminal en bas de l'écran pour ouvrir une session de terminal.
- Exécutez les commandes suivantes pour charger votre environnement et importer le fichier CSV directement dans la table
vessel_telemetryd'AlloyDB :
source devrel-demos/codelabs/bigquery-alloydb-insights/scripts/setenv.sh
gcloud alloydb clusters import lost-cargo-cluster \
--region=$REGION \
--gcs-uri="gs://${PROJECT_ID}-lab2/data/embeddings_export/000000000000.csv" \
--database=postgres \
--user=postgres \
--table=vessel_telemetry \
--columns=shipment_id,telemetry_string,embedding_vector \
--csv
Récapitulatif de la section : vous avez utilisé les fonctions d'IA de BigQuery pour résumer et intégrer les données de télémétrie, exporté les résultats vers Cloud Storage au format CSV, puis les avez importés dans AlloyDB à l'aide de gcloud. La base de données de suivi opérationnel est maintenant chargée et prête.
8. Correspondance avec le signal de la balise
Une équipe sur le terrain près de Sydney a intercepté un signal de balise de télémétrie fragmenté. Le journal partiel se lit comme suit :
"L'unité de réfrigération est hors connexion. Remplacement manuel."
Si cela provient du conteneur volé, la recherche vectorielle d'AlloyDB devrait pouvoir le faire correspondre même si le signal est incomplet. C'est exactement le type de requête opérationnelle en temps réel pour lequel AlloyDB a été conçu.
Étape 1 : Vérifiez les données importées
Revenez à l'onglet de l'éditeur alloydb.sql (qui reste connecté à AlloyDB).
Vérifiez que les données de télémétrie ont bien été chargées en exécutant la commande suivante :
SELECT shipment_id, LEFT(telemetry_string, 80) AS telemetry_preview
FROM vessel_telemetry
LIMIT 10;
Vous devriez voir des lignes avec des valeurs shipment_id et du texte de télémétrie. Il s'agit des signatures télémétriques de la flotte, désormais prêtes pour la mise en correspondance en temps réel.
Étape 2 : Recherchez le conteneur manquant
Utilisez maintenant l'extension google_ml_integration d'AlloyDB pour rechercher une correspondance à l'aide du fragment de signal intercepté :
SELECT
shipment_id,
telemetry_string,
1 - (embedding_vector <=> embedding('text-embedding-005', 'Refrigeration unit offline. Manual override.')::vector) AS search_relevance_score
FROM vessel_telemetry
ORDER BY embedding_vector <=> embedding('text-embedding-005', 'Refrigeration unit offline. Manual override.')::vector
LIMIT 5;
La fonction embedding(), fournie par l'extension google_ml_integration d'AlloyDB, appelle la plate-forme d'agents directement depuis SQL pour générer un embedding vectoriel intégré. L'opérateur <=> calcule la distance cosinus entre deux vecteurs (plus la valeur est proche de 0, plus les deux vecteurs sont identiques). Nous soustrayons 1 pour exprimer les résultats sous forme de score de pertinence, où une valeur plus élevée est préférable.
Étape 3 : Confirmez la correspondance
Parcourez les résultats. Le premier résultat doit être MV-CAPYBARA-003, avec le score de pertinence le plus élevé.
Il s'agit du même conteneur que celui que vous avez suivi à chaque étape de cette investigation :
- 📷 Les images de vidéosurveillance l'ont identifié quittant le port de Rio de Janeiro de nuit.
- 🌡️ La détection d'anomalies thermiques a confirmé que l'unité de réfrigération avait été délibérément désactivée.
- 📡 La correspondance des signaux de balise vient de localiser sa signature télémétrique près de Sydney.
Trois pistes indépendantes. Trois fonctionnalités d'IA Google Cloud différentes. Un conteneur volé.
🎯 Affaire classée : MV-CAPYBARA-003 a été localisé près de Sydney !

Récapitulatif de la section : vous avez utilisé l'intégration de l'IA intégrée à AlloyDB pour générer un embedding de recherche et effectuer une recherche par similarité cosinus dans une seule requête SQL. La balise a permis de confirmer l'emplacement du conteneur volé, ce qui a permis de clore l'enquête.
9. Explorer les preuves
Maintenant que vous avez identifié le conteneur grâce à l'analyse d'images multimodales et à la recherche vectorielle, vous pouvez utiliser l'analyse conversationnelle directement dans votre éditeur pour explorer les données d'investigation en langage naturel, sans écrire de code SQL.
Étape 1 : Localisez les données dans Knowledge Catalog
Le kit d'agent de données inclut une fonctionnalité de recherche universelle qui vous permet de trouver et d'explorer des éléments de données dans votre environnement Google Cloud.
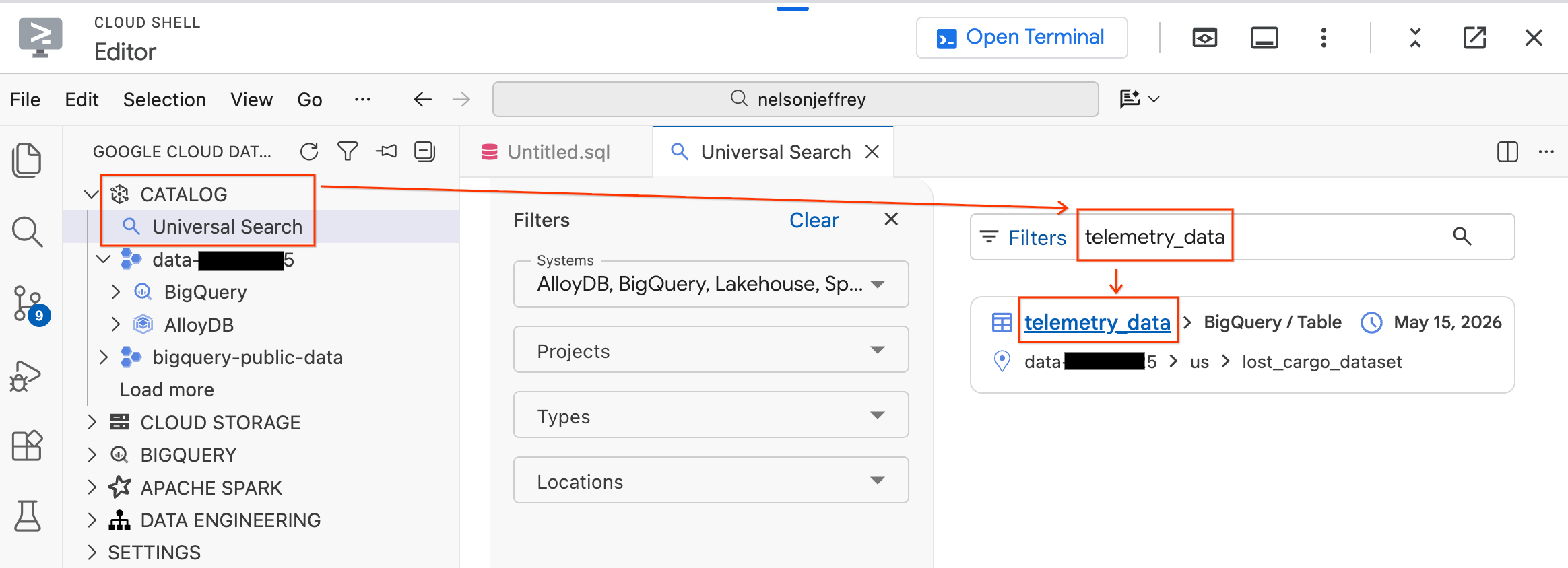
- Dans le panneau "Data Agent Kit" (Kit d'agent de données) à gauche, développez la section Catalog (Catalogue).
- Cliquez sur Recherche universelle.
- Dans la barre de recherche, saisissez
telemetry_data. - Dans les résultats de recherche, cliquez sur le tableau
telemetry_data(souslost_cargo_dataset).
Étape 2 : Lancez Conversational Analytics
Si vous cliquez sur un résultat de recherche, un onglet d'affichage des données s'ouvre. Vous pouvez y prévisualiser les données brutes, afficher le schéma et vérifier la qualité des données.
- Le volet de gauche affiche vos ensembles de données et tables BigQuery. Cliquez sur le bouton Chat pour ouvrir une nouvelle fenêtre de chat.
Étape 3 : Poser des questions en langage naturel
Un nouvel onglet de chat "Bienvenue dans Conversational Analytics !" s'ouvre. L'agent dispose d'un contexte sur le schéma et le contenu de votre tableau.
- Dans la fenêtre de chat, saisissez : "Show me the telemetry status and log for the Capybara shipment." (Affiche-moi l'état de la télémétrie et le journal de l'envoi Capybara.)
- Appuyez sur Entrée.
L'agent traduit votre question en SQL BigQuery, exécute la requête et renvoie les résultats, y compris un tableau de données et des insights résumant les résultats. Vous pouvez basculer entre le mode Raisonnement (analyse plus approfondie, réponse plus lente) et le mode Rapide (réponse plus rapide) en fonction de la complexité de votre question. Comme il s'agit de réponses générées par IA, vos résultats peuvent être légèrement différents de ceux des captures d'écran ci-dessous.
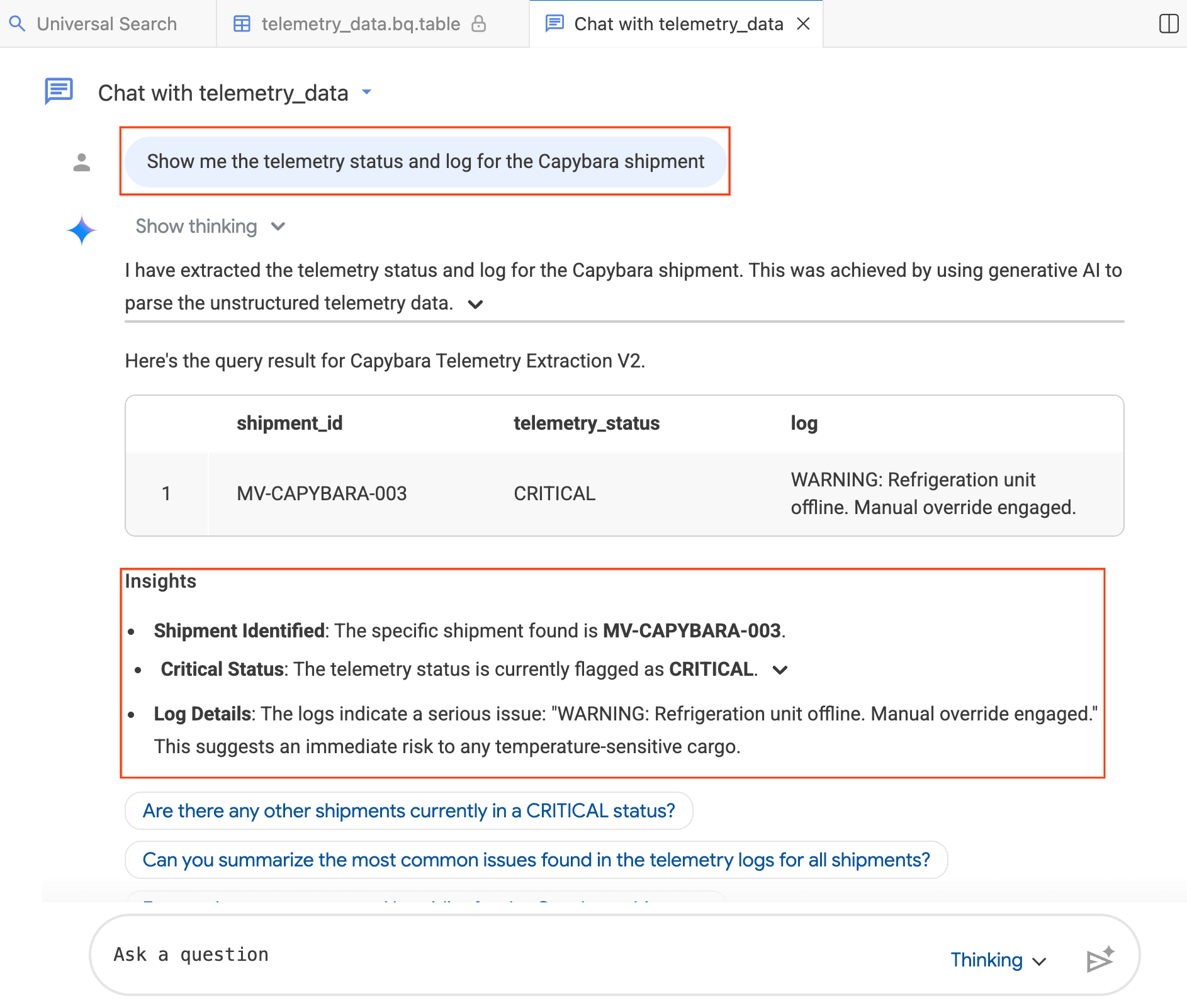
Étape 4 : Poser des questions complémentaires
L'agent se souvient du contexte de votre conversation. Essayez de poser une question complémentaire :
- "Combien d'envois uniques sont inclus dans les données de télémétrie ?"
- "Combien d'autres envois de la flotte ont actuellement un état CRITIQUE ?"
Récapitulatif de la section : vous avez utilisé la fonctionnalité de recherche universelle de Knowledge Catalog pour localiser votre ensemble de données et lancé Conversational Analytics pour interroger les données d'investigation en langage naturel. L'agent IA a traduit vos questions en SQL et vous a fourni des insights qui ont confirmé vos conclusions.
10. Effectuer un nettoyage
Pour éviter que les ressources créées dans cet atelier soient facturées en permanence sur votre compte Google Cloud, supprimez-les. Vous pouvez exécuter ces commandes dans votre terminal intégré de l'éditeur Cloud Shell (où vous avez utilisé le kit de l'agent de données) pour nettoyer votre environnement.
Tout d'abord, chargez vos variables d'environnement :
source scripts/setenv.sh
- Supprimez les ressources BigQuery (uniquement si vous ne passez pas à l'atelier 3) :
Si vous prévoyez de passer à l'atelier 3, ignorez cette étape. L'atelier 3 utilise les mêmes connexions et ensemble de données BigQuery pour l'analyse des graphiques de propriétés.
Pour supprimer votre ensemble de données et vos connexions BigQuery :
# Drop the dataset
bq rm -r -f $PROJECT_ID:lost_cargo_dataset
# Delete the connections
bq rm --connection --location=us-central1 $PROJECT_ID.us-central1.lost_cargo_conn
bq rm --connection --location=us-central1 $PROJECT_ID.us-central1.lost_cargo_alloydb_conn
- Supprimez le bucket Cloud Storage :
gcloud storage rm --recursive gs://${PROJECT_ID}-lab2
- Supprimez l'instance et le cluster AlloyDB :
AlloyDB n'étant pas utilisé dans l'atelier 3, vous pouvez l'arrêter maintenant.
gcloud alloydb instances delete lost-cargo-instance \
--region=$REGION \
--cluster=lost-cargo-cluster \
--quiet
gcloud alloydb clusters delete lost-cargo-cluster \
--region=$REGION \
--force \
--quiet
- Supprimez les paramètres de l'environnement local :
Enfin, supprimez le fichier de paramètres de l'environnement local de votre espace de travail :
rm -f .env
11. Félicitations !
Vous avez terminé l'atelier 2 : Analyse des données et insights multimodaux. Vous avez suivi la piste d'un port rempli de milliers de conteneurs jusqu'à un vol confirmé et un emplacement précis.
Ce que vous avez accompli
- Analyse des images : vous avez utilisé
AI.GENERATEde BigQuery pour analyser les images de sécurité du port et identifier le conteneur MV-CAPYBARA-003 en rouge carmin. - Vous avez confirmé le vol : vous avez exploré les données des capteurs thermiques, repéré un pic suspect de 64, 7 °C et utilisé
AI.DETECT_ANOMALIESpour prouver qu'il s'agissait d'une manipulation délibérée. - Préparation du système de suivi : vous avez configuré AlloyDB avec pgvector et
google_ml_integrationpour la mise en correspondance des balises en temps réel. - Créer l'index de recherche : vous avez utilisé
AI.GENERATEetAI.EMBEDdans BigQuery pour créer des embeddings, puis vous les avez exportés vers Cloud Storage et importés dans AlloyDB. - Signal de balise détecté : vous avez utilisé la recherche vectorielle d'AlloyDB pour faire correspondre un signal de télémétrie fragmenté et localiser le conteneur volé près de Sydney.
- Vous avez exploré les preuves : vous avez utilisé Conversational Analytics directement depuis l'éditeur pour interroger les données d'investigation en langage naturel.

Étapes suivantes
Vous avez trouvé où se trouve le conteneur. Vous devez maintenant découvrir qui se cache derrière.
Dans l'atelier 3 : Consommation de données et workflows agentiques, vous allez créer un graphique de propriétés du réseau logistique pour mapper les relations entre les sociétés écrans, utiliser Conversational Analytics pour discuter avec le graphique et parcourir le catalogue de connaissances pour trouver le code d'autorisation sécurisé nécessaire à la récupération du conteneur.