
1. מבוא

בשיעור ה-Lab הקודם, צירפתם יחד נתוני יומן משלוחים מפוצלים ועקבתם אחרי המשדר של המטען עד לניו יורק. עם זאת, רשומות ההגעה מראות שהמכולה הופנתה מחדש באופן מיידי כדי להימנע מזיהוי על ידי המכס. הגעתם לנמל ריו דה ז'ניירו, נמל עצום עם אלפי מכולות. קשה למצוא את הקונטיינר הנכון בין אלפים אחרים.
בשיעור ה-Lab הזה תשתמשו ביכולות ה-AI המובנות של BigQuery כדי "לקרוא" תמונות לא מובְנות של אבטחת יציאות ולזהות אנומליות תרמיות בנתוני חיישנים, והכול באמצעות SQL רגיל. לאחר מכן תייצאו הטמעות וקטוריות ל-AlloyDB ותריצו חיפוש וקטורי כדי להתאים אותות טלמטריה מקוטעים למאגר החסר.
הפעולות שתבצעו:
- סריקת תמונות אבטחה של נמל כדי לזהות את המכולה הגנובה באמצעות BigQuery AI
- זיהוי חריגה תרמית באמצעות AI ב-BigQuery כדי לוודא שהמכולה נגנבה ולא הלכה לאיבוד
- יצירת הטמעות וקטוריות וטעינתן ל-AlloyDB לחיפוש בזמן אמת
- התאמה של אות משובש של משואת טלמטריה כדי לאתר את המכולה הגנובה באמצעות Vector Search
- חקירת נתונים באמצעות שפה טבעית באמצעות ניתוח נתוני שיחות
הדרישות
- דפדפן אינטרנט כמו Chrome
- פרויקט ב-Google Cloud שהחיוב בו מופעל
- היכרות בסיסית עם SQL ועם מסוף Google Cloud
ה-Codelab הזה מיועד למפתחים ברמת ביניים.
העלות של המשאבים שנוצרו ב-codelab הזה צריכה להיות פחות מ-5$.
2. לפני שתתחיל
הפעלת Cloud Shell
תשתמשו ב-Google Cloud Shell כדי להוריד את הקוד, להריץ סקריפטים של הגדרה ולפרוס את האפליקציה.
- בכרטיסייה חדשה בדפדפן, פותחים את Cloud Shell: shell.cloud.google.com
- אחרי החיבור, מגדירים את מזהה הפרויקט ומאשרים את הסביבה:
gcloud config set project <<YOUR_PROJECT_ID>>
export PROJECT_ID=$(gcloud config get-value project)
export REGION=us-central1
אמורה להופיע הודעה דומה לזו:
Your active configuration is: [cloudshell-####] Updated property [core/project]
שכפול המאגר
משכפלים את מאגר ה-Codelab לסביבת Cloud Shell:
cd ~/
git clone --filter=blob:none --no-checkout https://github.com/GoogleCloudPlatform/devrel-demos.git
cd ~/devrel-demos
git sparse-checkout init --cone
git sparse-checkout set codelabs/bigquery-alloydb-insights
git checkout main
cd codelabs/bigquery-alloydb-insights/
הפעלת ממשקי ה-API
מריצים את הפקודה הזו ב-Cloud Shell כדי להפעיל את כל ממשקי ה-API הנדרשים למעבדה הזו:
gcloud services enable \
aiplatform.googleapis.com \
bigquery.googleapis.com \
bigqueryconnection.googleapis.com \
alloydb.googleapis.com
אם ההפעלה בוצעה בהצלחה, תוצג הודעה שדומה לזו:
Operation "operations/..." finished successfully.
3. הגדרת הסביבה
לפני שתוכלו לנתח תמונות ונתוני טלמטריה, תצטרכו להגדיר את התשתית לשיעור Lab הזה. תריצו שני סקריפטים: אחד יתחיל הקצאת משאבים של AlloyDB ברקע, והשני ייצור את כל משאבי BigQuery שתצטרכו.
שלב 1: הפעלת פריסה של AlloyDB (ברקע)
הקצאת משאבים של אשכול AlloyDB נמשכת כ-10 דקות, ולכן כדאי להתחיל בהקצאה ולתת לה לפעול ברקע בזמן שאתם עובדים על החלקים של BigQuery. הסקריפט יתעד אוטומטית את הגדרות הפרויקט הפעיל בקובץ .env מקומי, כך שההגדרה שלכם תישמר גם אם מסוף Cloud Shell ייסגר או יופעל מחדש.
chmod +x scripts/setup_alloydb.sh
nohup ./scripts/setup_alloydb.sh > /dev/null 2>&1 &
echo "AlloyDB deployment started in background (PID: $!)"
שלב 2: מריצים את סקריפט ההגדרה
הסקריפט הזה יוצר את מערך הנתונים ב-BigQuery, את החיבור למשאבי Cloud, את הרשאות ה-IAM, את קטגוריית ה-GCS ומטען את כל נתוני החיישנים שתנתחו בשיעור Lab הזה. הוא גם יקרא ויאמת את משתני הסביבה שנשמרו בקובץ .env.
chmod +x scripts/setup_lab.sh
./scripts/setup_lab.sh
הרצת הסקריפט נמשכת כדקה. בסיום התהליך יוצג סיכום של כל מה שהכלי יצר.
📝 הערה לגבי איפוס הסביבה אם פג הזמן של סשן Cloud Shell או שהוא מופעל מחדש בשלב כלשהו במהלך ה-Lab הזה, אפשר לשחזר את משתני הטרמינל באופן מיידי על ידי הפעלת הפקודה:
source scripts/setenv.sh
שלב 3: מפעילים את Cloud Shell Editor
עד עכשיו השתמשתם בטרמינל של Cloud Shell. עכשיו נעבור ל-Cloud Shell Editor המלא, שכולל סביבת עבודה כמו VS Code עם תמיכה משולבת ב-BigQuery.
- בחלונית הטרמינל של Cloud Shell בתחתית המסך, לוחצים על הלחצן Open Editor כדי להפעיל את סביבת העבודה של Cloud Shell Editor.

שלב 4: התקנת התוסף Data Agent Kit
התוסף Google Cloud Data Agent Kit מספק שילוב עמוק עם שירותי נתונים של Google Cloud ישירות בתוך העורך, ומאפשר לכם לקיים אינטראקציה עם BigQuery, AlloyDB, Cloud Storage ועוד בלי להחליף הקשרים.
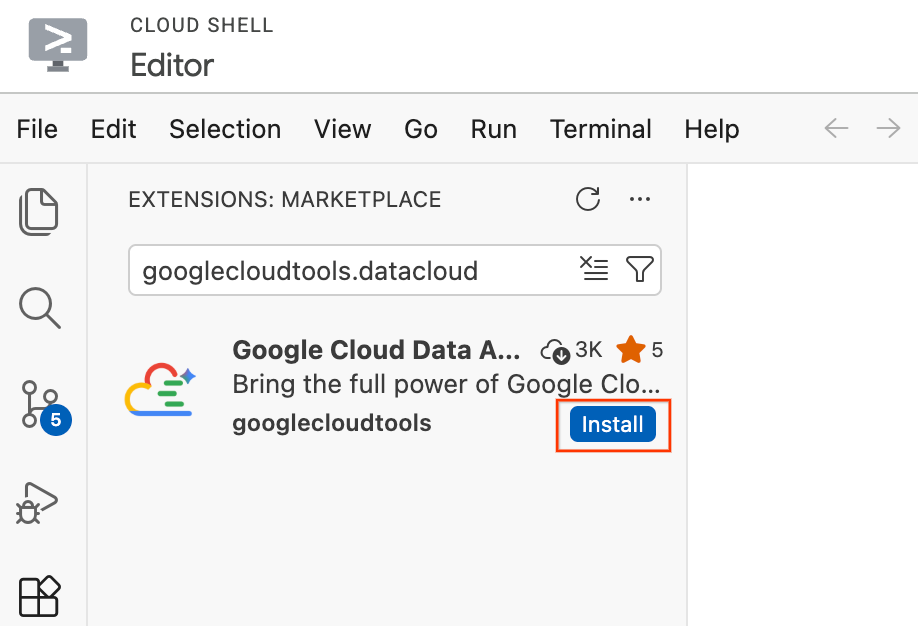
- ב-Cloud Shell Editor, לוחצים על סמל התוספים בסרגל הפעילות בצד ימין של המסך (הסמל נראה כמו ארבעה ריבועים).
- בסרגל החיפוש בחלק העליון של חלונית התוספים, מקלידים
googlecloudtools.datacloud. - מאתרים את התוסף Google Cloud Data Agent Kit שפורסם על ידי Google Cloud.
- לוחצים על הלחצן התקנה.
- תופיע הנחיה עם השאלה 'האם אתה בוטח במוציא לאור googlecloudtools ובתוספים שלו?'. לוחצים על Trust Publishers & Install (הבעת אמון בבעלי האתרים והתקנה) כדי להמשיך.
שלב 5: אימות והגדרת התוסף
אחרי ההתקנה, מקשרים את התוסף לפרויקט בענן ב-Google Cloud.
- דף ההצטרפות 'הצטרפות ל-Google Cloud Data Agent Kit' אמור להיפתח באופן אוטומטי. לוחצים על כניסה ל-Google Cloud ופועלים לפי ההנחיות בדפדפן כדי לאשר גישה.
- יופיע חלון קופץ עם הכיתוב 'ההגדרה מתבצעת'. התוסף יבדוק אוטומטית אם יש תלות נדרשת, כמו Google Cloud CLI.
- בקטע Configuration Summary, מאתרים את שדה הפרויקט. לוחצים על התפריט הנפתח ובוחרים את הפרויקט ב-Google Cloud. מגדירים את האזור כ-
us-central1. - מחכים עד שהבדיקות של ההגדרה יסתיימו. כשמופיעה ההודעה 'ההגדרה הושלמה!', לוחצים על הגדרת שרתי MCP.
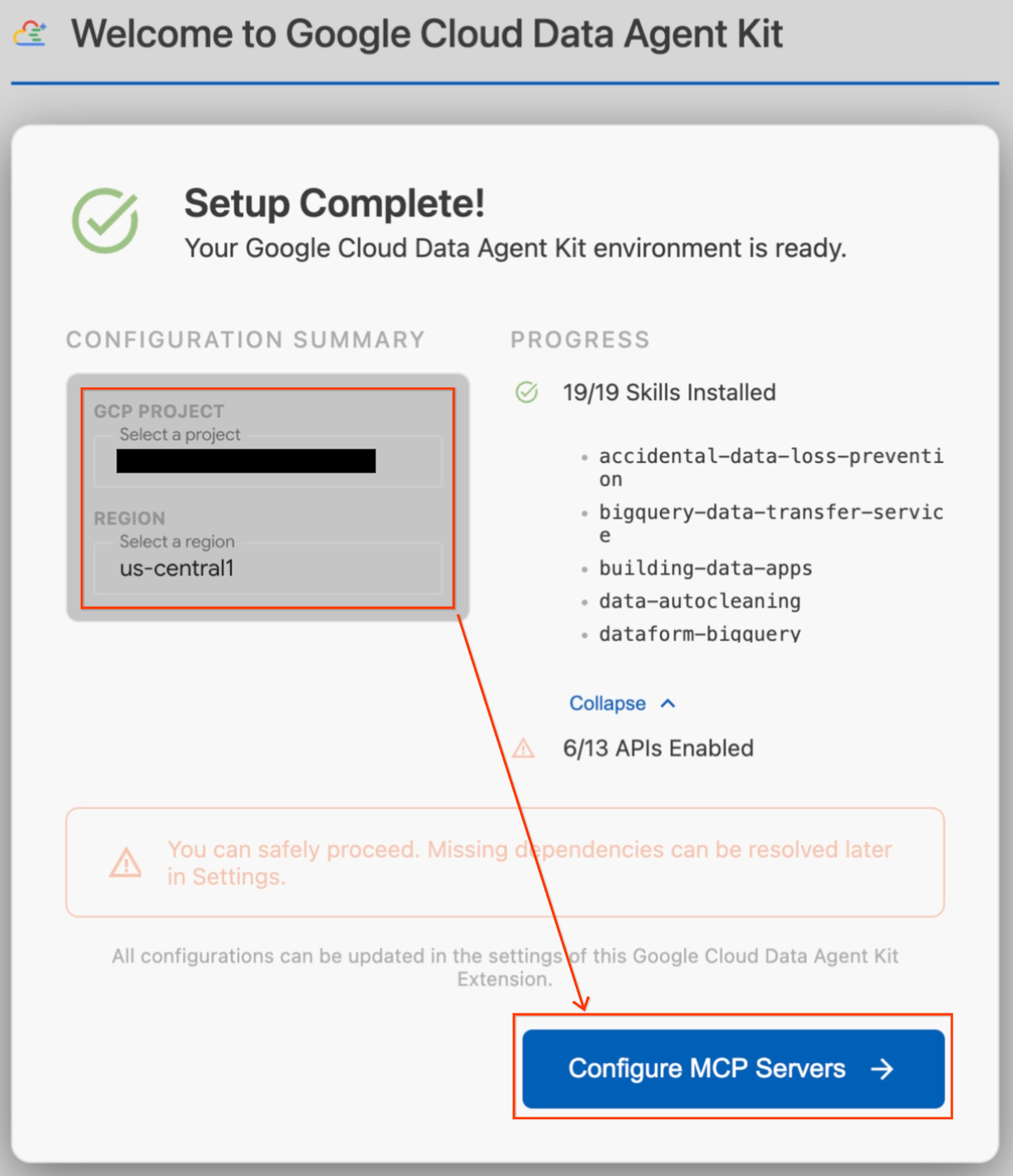
- בוחרים באפשרות BigQuery ובאפשרות AlloyDB בקטע MCP Configuration (הגדרת MCP) ולוחצים על Get Started (תחילת העבודה).
שלב 6: בודקים את אפשרויות ההגדרה
בסיום תהליך ההגדרה, תועברו אל מרכז הבקרה Get started with Google Cloud Data Agent Kit (תחילת העבודה עם ערכת כלי הסוכן של Google Cloud Data).
- בקטע 'הגדרה וקביעת תצורה', לוחצים על תחילת העבודה.
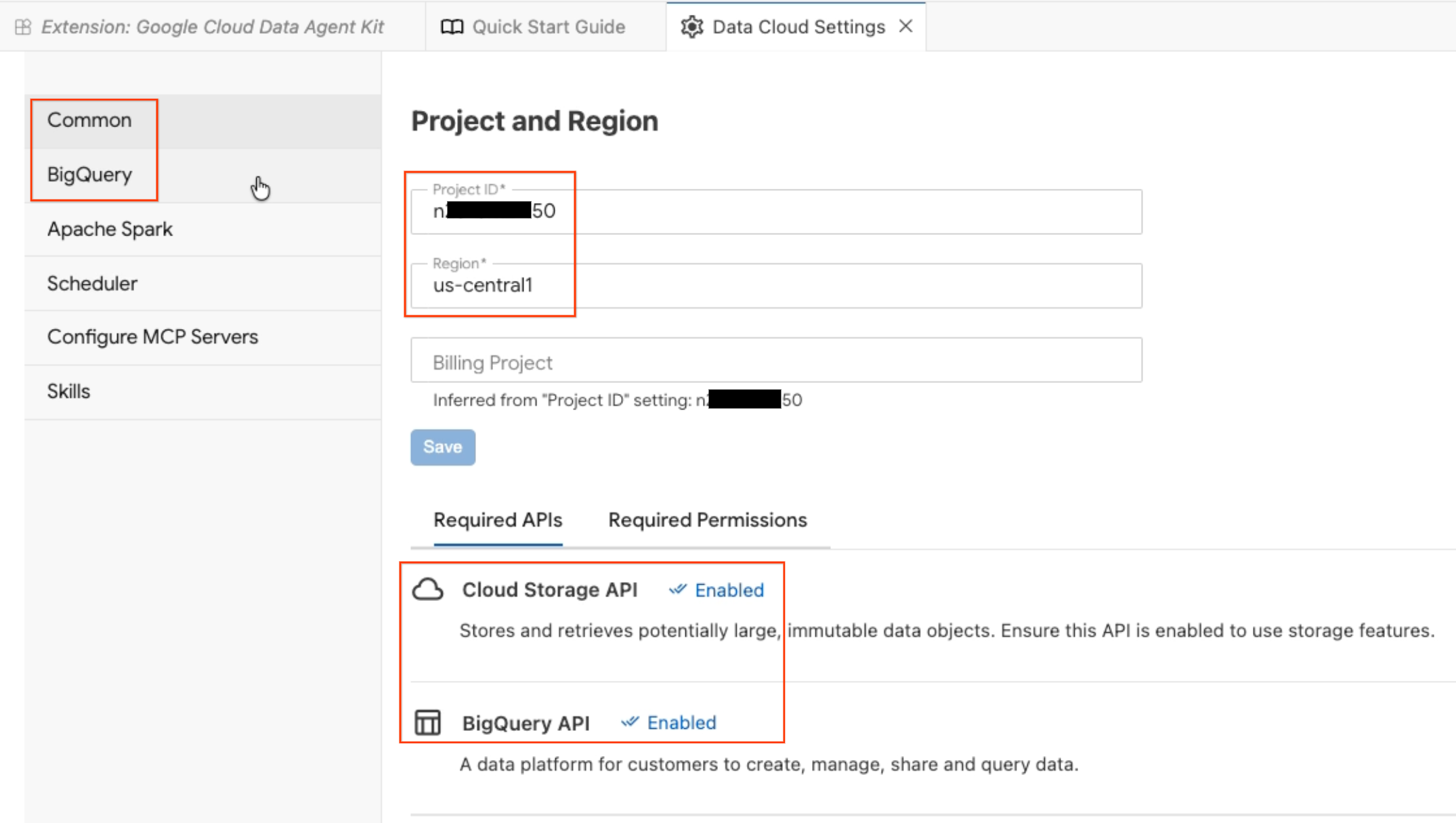
- תיפתח החלונית Data Agent Configuration (הגדרת סוכן נתונים). כדאי לעיין בכרטיסיות:
- פרויקט ואזור: מוודאים שמזהה הפרויקט שנבחר נכון, ושממשקי ה-API הנדרשים (Cloud Storage API, BigQuery API, Catalog API ו-AlloyDB API) מופעלים.
- BigQuery: מגדירים את מיקום ברירת המחדל לשאילתות BigQuery. משתמשים באזור
us-central1. - הגדרת שרתי MCP: אפשר לראות את שרתי ה-MCP המופעלים (BigQuery, Notebooks, AlloyDB וכו') שמאפשרים לסוכני AI ליצור אינטראקציה מאובטחת עם הנתונים שלכם.
- מיומנויות: אפשר לעיין במיומנויות מוגדרות מראש שמספקות לסוכנים יכולות ייעודיות למשימות מורכבות שקשורות לנתונים.
שלב 7: אימות באמצעות BigQuery
כדי לוודא שהכול פועל, מריצים שאילתה מהירה על מערך נתונים ציבורי.
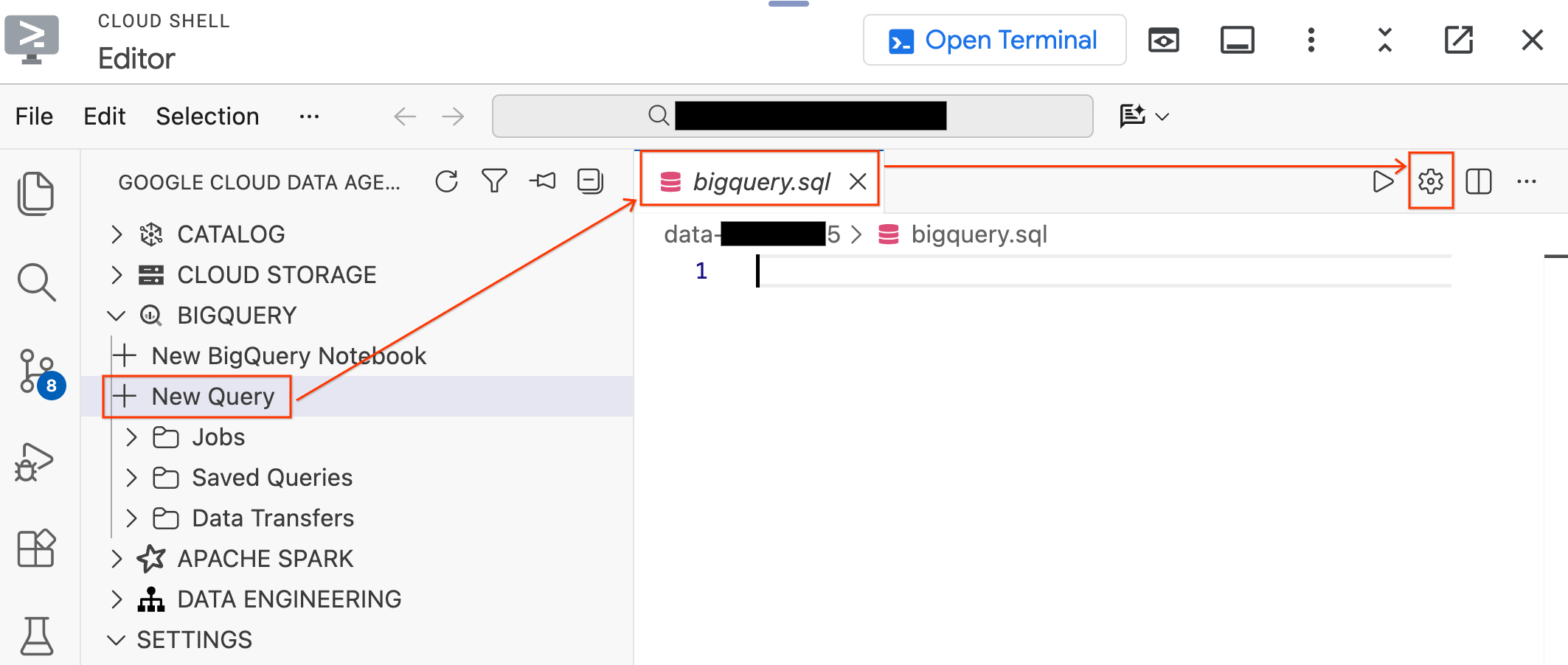
- בחלונית Data Agent Kit (ערכת כלי סוכן הנתונים) בצד ימין, מרחיבים את הקטע BigQuery ולוחצים על New Query (שאילתה חדשה) כדי לפתוח כרטיסייה חדשה של עורך השאילתות.
- שומרים את הקובץ על ידי הקשה על
Ctrl+S(Windows/Linux) או עלCmd+S(macOS) ונותנים לו את השםbigquery. הכרטיסייה הזו תשמש לכל הפעולות שלכם ב-BigQuery. - לוחצים על הגדרות שאילתה כשהכרטיסייה
bigquery.sqlפעילה, בוחרים באפשרות BigQuery בתור מקור הנתונים ולוחצים על שמירה.
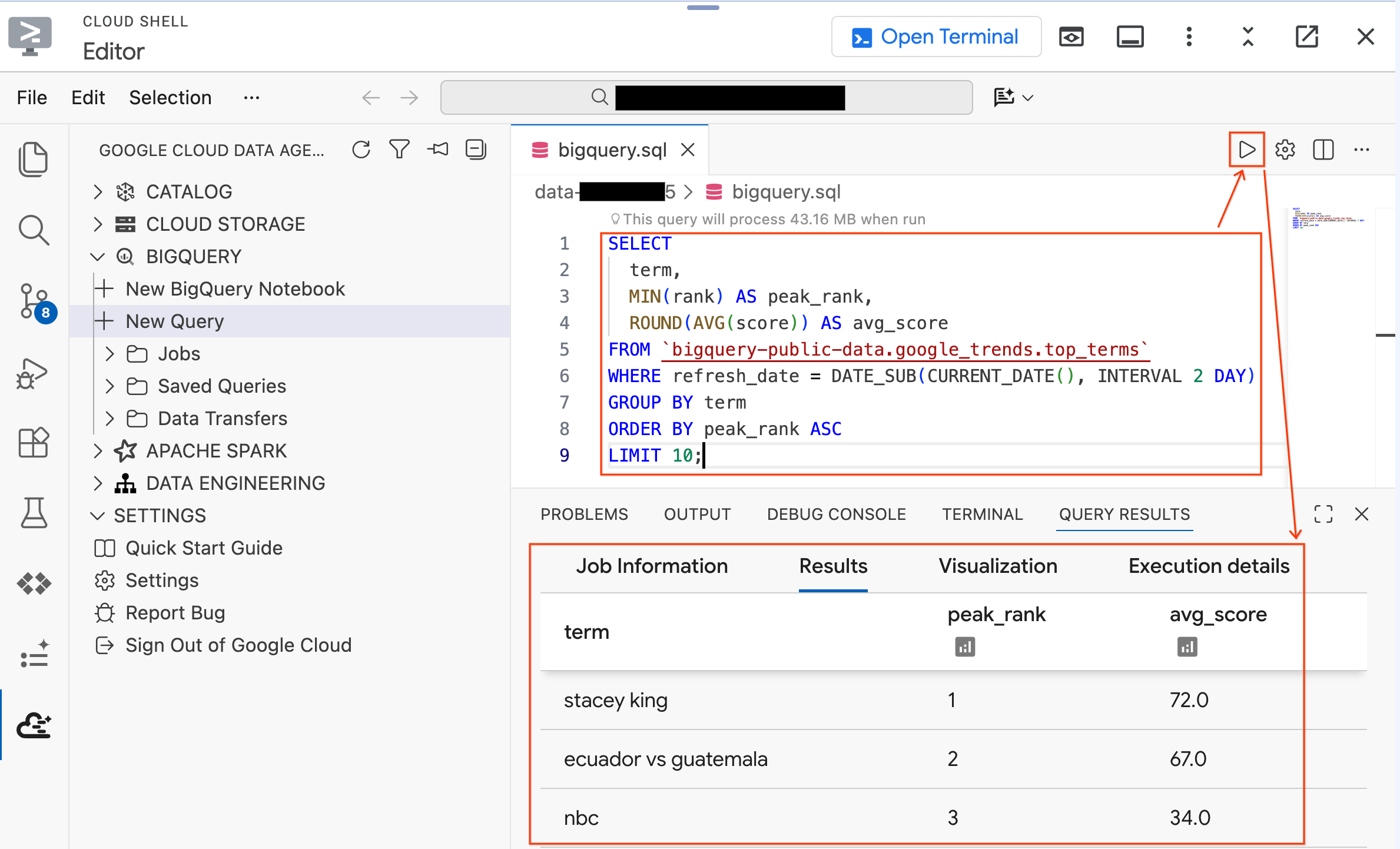
- מריצים את השאילתה הבאה על מערך נתונים ציבורי:
SELECT
term,
MIN(rank) AS peak_rank,
ROUND(AVG(score)) AS avg_score
FROM `bigquery-public-data.google_trends.top_terms`
WHERE refresh_date = DATE_SUB(CURRENT_DATE(), INTERVAL 2 DAY)
GROUP BY term
ORDER BY peak_rank ASC
LIMIT 10;
- יוצגו לכם 10 מונחי החיפוש המובילים ב-Google מהימים האחרונים. אם התוצאות מופיעות, התוסף מחובר ומוכן.
עכשיו מנסים להריץ שאילתה על נתוני המעבדה שנוצרו על ידי סקריפט ההגדרה. מחליפים את השאילתה הקיימת בשאילתה הבאה:
SELECT * FROM `lost_cargo_dataset.telemetry_data` LIMIT 5;
אמורות להופיע רשומות ביומן הטלמטריה עם העמודות shipment_id ו-telemetry_string. אלה הנתונים שתנתחו במהלך המעבדה.
סיכום הקטע: התחלתם את הפריסה של AlloyDB ברקע, הפעלתם את סקריפט ההגדרה והגדרתם את Cloud Shell Editor באמצעות התוסף Data Agent Kit.
4. סריקת צילומי האבטחה
צוות החקירה הצליח לשחזר צילומי אבטחה מנמל ריו דה ז'ניירו שבהם נראות שורות של מכולות משלוח. משיעור Lab 1, אתם יודעים שמאגר היעד הוא אדום. עכשיו צריך לזהות בדיוק איזה מאגר אדום זה.
תצרו טבלת אובייקטים שתאפשר ל-BigQuery 'לראות' את תמונות האבטחה ב-Cloud Storage, ואז תשתמשו בפונקציה AI.GENERATE כדי להנחות את Gemini לחלץ נתונים מובנים מכל תמונה.
שלב 1: יוצרים את טבלת האובייקטים
טבלת אובייקטים היא טבלה מיוחדת ב-BigQuery שמשמשת כאינדקס של קבצים לא מובְנים (תמונות, קובצי PDF, אודיו) שמאוחסנים ב-Cloud Storage. הקבצים לא מועתקים ל-BigQuery, אלא נוצרת הפניה שאפשר לשאול עליה שאילתות, כדי שפונקציות ה-AI יוכלו 'לראות' אותם.
בכרטיסייה bigquery.sql בעורך, מריצים את ההצהרה הבאה כדי ליצור את טבלת האובייקטים שמפנה לתמונות של אבטחת היציאות בדלי של הפרויקט:
SET @@location = 'us-central1';
EXECUTE IMMEDIATE CONCAT("""
CREATE OR REPLACE EXTERNAL TABLE `lost_cargo_dataset.port_security_images`
WITH CONNECTION `us-central1.lost_cargo_conn`
OPTIONS (
object_metadata = 'SIMPLE',
uris = ['gs://""", @@project_id, """-lab2/images/*']
);
""");
כדאי להסתכל במהירות על מה ש-BigQuery יכול לראות עכשיו:
SELECT uri, content_type FROM `lost_cargo_dataset.port_security_images` LIMIT 5;
כל שורה מייצגת קובץ תמונה אחד ב-Cloud Storage. עכשיו אפשר להעביר את התמונות האלה ישירות למודלים של AI ב-BigQuery.
שלב 2: ניתוח תמונות האבטחה
עכשיו משתמשים בפונקציה AI.GENERATE של BigQuery כדי לנתח כל תמונה של אבטחה. שאילתת ה-SQL היחידה הזו מנחה את Gemini לבדוק כל תמונה ולהחזיר נתונים מובְנים:
SELECT
uri,
AI.GENERATE(
(
'Examine this port security image. Identify any shipping container IDs visible on the container and provide a one-word color of the container.',
ref
),
output_schema => 'detected_container_id STRING, color STRING'
).* EXCEPT (full_response, status)
FROM `lost_cargo_dataset.port_security_images`;
שלב 3: זיהוי מאגר התגים של היעד
בודקים את התוצאות. מחפשים את השורה שבעמודה color מופיע בה Red (או וריאציה של אדום). רושמים את detected_container_id. זהו היעד שלכם: MV-CAPYBARA-003.
שלב 4: בדיקת ההתאמה החזותית
כדי לראות את התמונה בפועל שנותחה בלי לצאת מהעורך:
- בחלונית Data Agent Kit (ערכת כלי סוכן הנתונים) שמימין, לוחצים על Cloud Storage.
- מרחיבים את המאגר (
YOUR_PROJECT_ID-lab2/images/) ולוחצים על קובץ התמונה שמתאים למאגר האדום כדי לראות אותו ישירות בכלי העריכה.
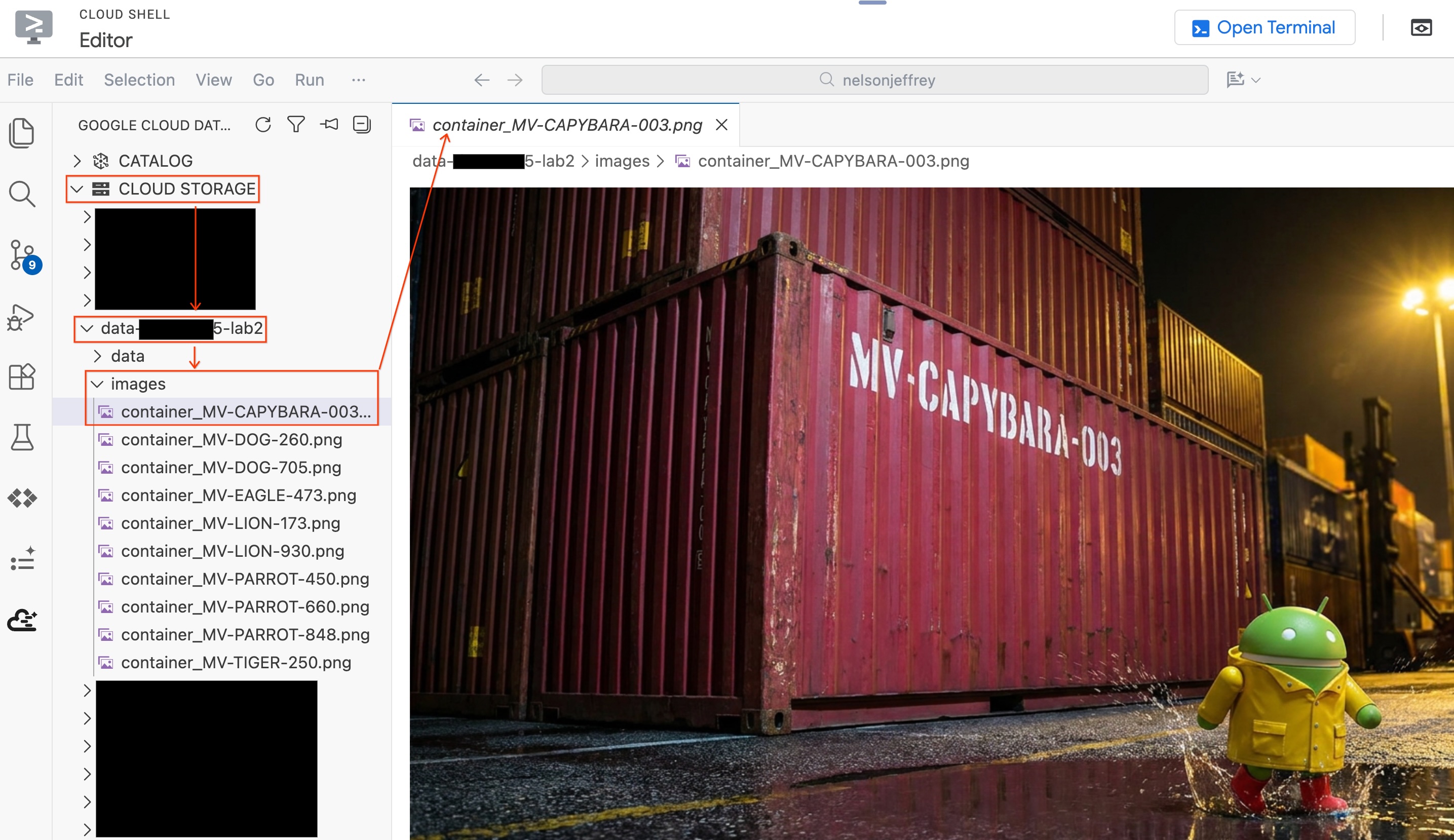
סיכום של הקטע: יצרתם טבלת אובייקטים כדי לתת ל-BigQuery גישה לתמונות של אבטחת יציאות, ואז השתמשתם ב-AI.GENERATE כדי לחלץ נתונים מובנים של קונטיינרים מכל תמונה. המאגר האדום זוהה כ-MV-CAPYBARA-003.
5. אישור הגניבה
זיהית שהקונטיינר החסר הוא MV-CAPYBARA-003, אבל האם הוא נגנב או פשוט הונח במקום לא נכון? ביומני המניפסט מצוין שהקונטיינר הספציפי הזה חנה ליד חיישן הסביבה SENS-99. אם הגנבים השביתו בכוונה את יחידת הקירור המובנית של הקונטיינר לפני שהזיזו אותו, יכול להיות ש-SENS-99 רשם עלייה פתאומית בטמפרטורת הפליטה.
נשתמש בזיהוי אנומליות כדי להוכיח שהיה ניסיון לחבל במאגר התגים.
- קודם כל, כדאי לעיין בנתוני הבסיס ההיסטוריים. אלה הקריאות הרגילות מ
SENS-99במהלך השעות האחרונות:
SELECT * FROM `lost_cargo_dataset.thermal_history`
ORDER BY reading_time DESC
LIMIT 50;
שימו לב שהטמפרטורות נעות בטווח מצומצם של 24-26°C. זהו טווח נורמלי.
- עכשיו בודקים את קבוצת הקריאות הנוכחית מאותו חיישן:
SELECT * FROM `lost_cargo_dataset.thermal_current`
ORDER BY thermal_reading DESC
LIMIT 50;
רואים את הקריאה 148.4°F ליד החלק העליון? כל השאר נראה תקין. העלייה החדה הזו תצביע על תקלה ביחידת הקירור או על שיבוש מכוון. בואו נגלה.
- מריצים את זיהוי האנומליות.
AI.DETECT_ANOMALIESב-BigQuery משתמש במודל בסיסי מאומן מראש של TimesFM כדי לנתח דפוסים של סדרות זמנים ולסמן חריגים באופן אוטומטי, ללא צורך באימון מודל:
SELECT *
FROM AI.DETECT_ANOMALIES(
TABLE `lost_cargo_dataset.thermal_history`,
TABLE `lost_cargo_dataset.thermal_current`,
data_col => 'thermal_reading',
timestamp_col => 'reading_time',
id_cols => ['sensor_id']
)
WHERE is_anomaly = TRUE;
- בודקים את התוצאות. הקריאה של 64.7°C צריכה להיות מסומנת כאנומליה עם סבירות גבוהה לאנומליה, כדי לאשר שמשהו חריג קרה ליד אזור המכולה.
סיכום הקטע: השתמשתם בפונקציה AI.DETECT_ANOMALIES של BigQuery כדי להשתמש במודל TimesFM שעבר אימון מראש. על ידי הפעלת שאילתת SQL אחת, זיהיתם באופן אוטומטי ערכים חריגים ובידדתם את אירוע החבלה החריג בלי לכתוב קוד מורכב של למידת מכונה או לאמן מודלים מאפס.
6. הכנת מערכת המעקב
התכולה של המכולה נגנבה והיא כבר לא נמצאת בריו דה ז'ניירו. כל קונטיינר ב-Fleet משדר אותות משואת טלמטריה: קריאות חיישנים, פרגמנטים של GPS ויומני סטטוס. אם המשואה של המכולה הגנובה עדיין משדרת, אפשר להשוות אותה לחתימות ידועות כדי למצוא אותה.
BigQuery מצטיין בעבודה האנליטית שביצעתם עד עכשיו, אבל כדי לאתר מאגר תגים בזמן אמת צריך שאילתות תפעוליות עם חביון נמוך. AlloyDB, מסד נתונים מנוהל שתואם ל-PostgreSQL, נועד בדיוק למטרה הזו: שאילתות של חיפוש וקטורי שמהירות מספיק למערכת מעקב בזמן אמת. תטעינו את ההטמעות של נתוני הטלמטריה ב-AlloyDB ותשתמשו בהן כדי להתאים את אות המשואה.
אשכול ה-AlloyDB שהפעלתם ברקע קודם אמור להיות מוכן עכשיו. נתחיל להגדיר אותו ישירות מהכלי לעריכה.
שלב 1: התחברות ל-AlloyDB מהעורך
במקום לעבור אל Cloud Console, אתם יכולים להתחבר ישירות אל AlloyDB באמצעות התוסף Data Agent Kit.
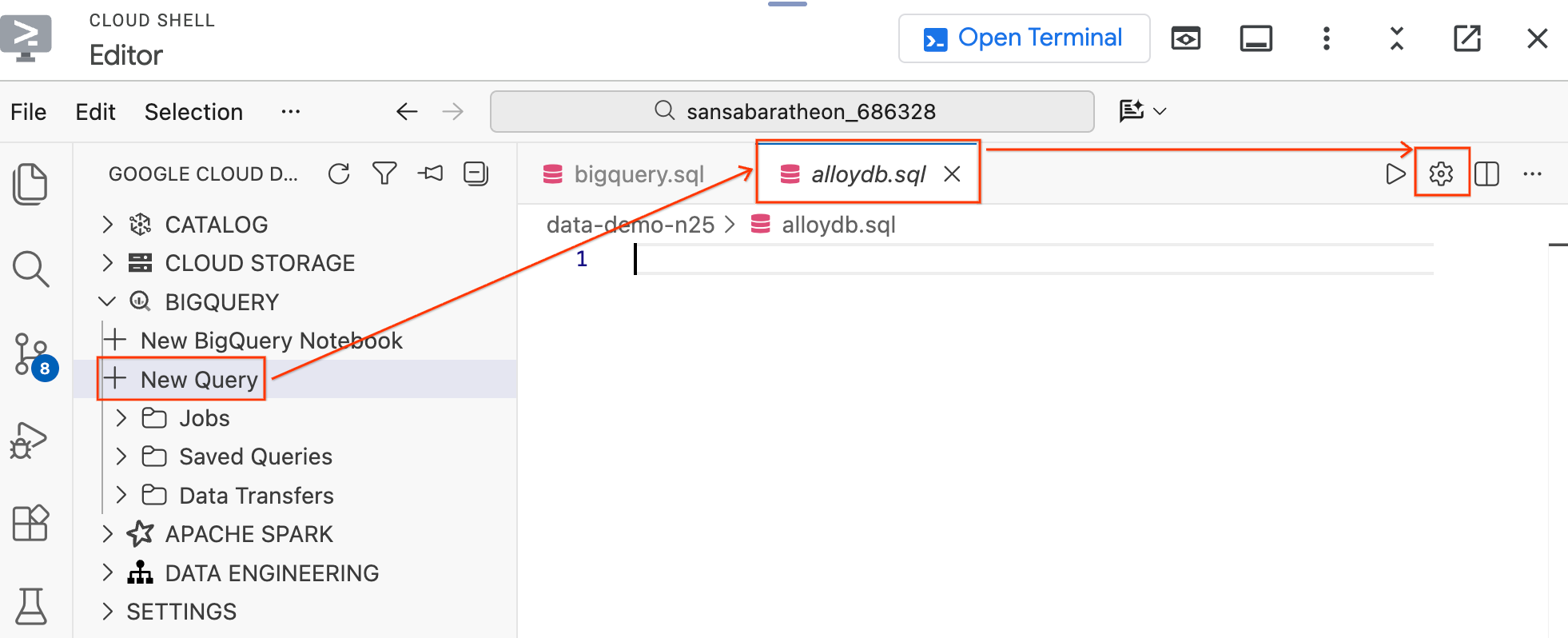
- בחלונית Data Agent Kit (ערכת כלי סוכן הנתונים) בצד ימין, בקטע BigQuery, לוחצים על New Query (שאילתה חדשה) כדי לפתוח כרטיסייה חדשה של עורך השאילתות.
- שומרים את הקובץ על ידי הקשה על
Ctrl+S(Windows/Linux) או עלCmd+S(macOS) ונותנים לו את השםalloydb. הכרטיסייה הזו תשמש לכל השאילתות ב-AlloyDB. - לוחצים על סמל גלגל השיניים כדי לפתוח את תיבת הדו-שיח הגדרות שאילתה.
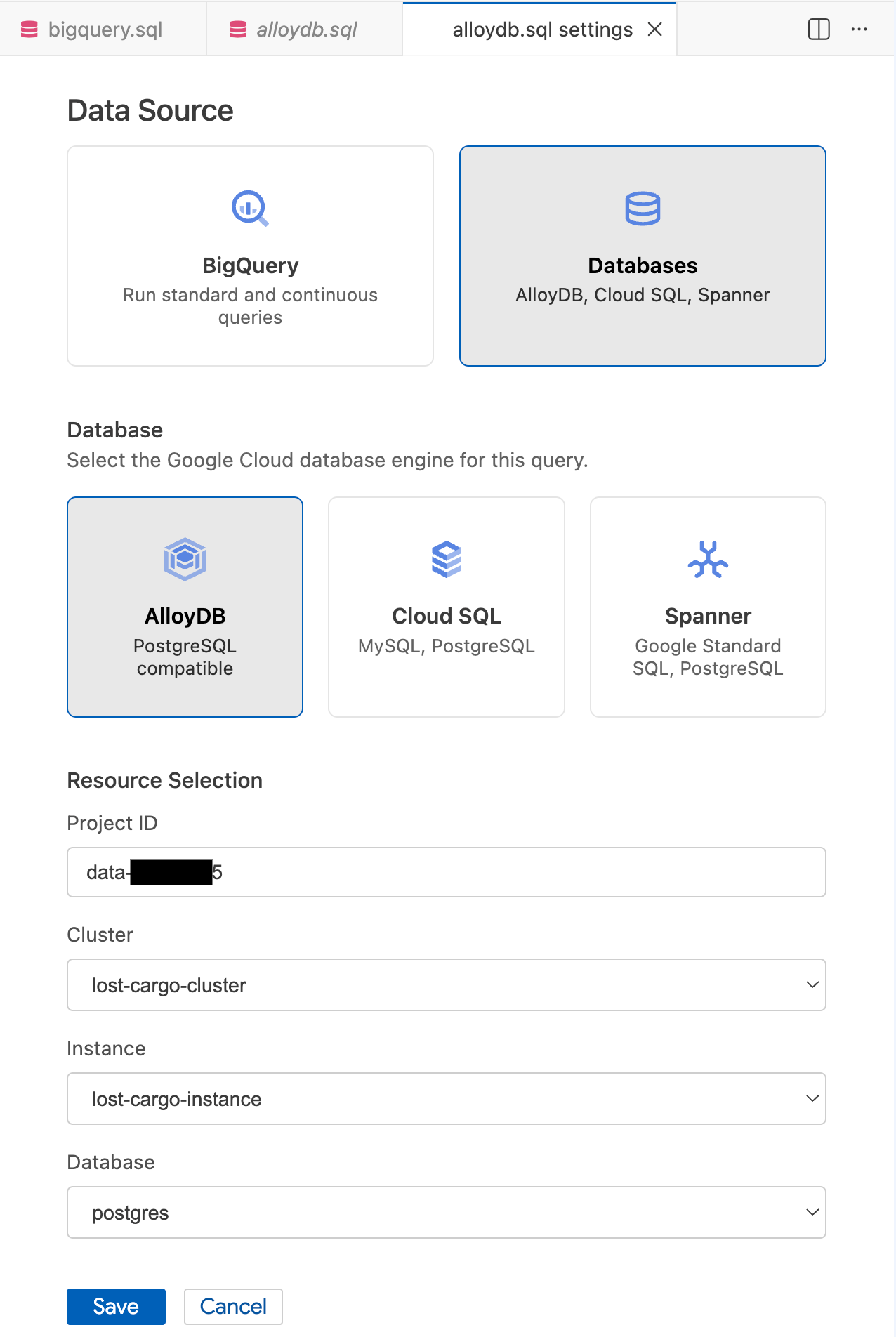
- בתיבת הדו-שיח הגדרות שאילתה, בקטע מקור נתונים, בוחרים באפשרות מסדי נתונים.
- בקטע מסד נתונים, בוחרים באפשרות AlloyDB.
- ממלאים את הפרטים בבחירת משאבים:
- מזהה הפרויקט: מזינים את מזהה הפרויקט ב-Google Cloud.
- אשכול: בוחרים באפשרות
lost-cargo-cluster. - Instance: בוחרים באפשרות
lost-cargo-instance. - מסד נתונים: בוחרים באפשרות
postgres.
- לוחצים על שמירה.
שלב 2: הפעלת התוסף Vector ויצירת הטבלה
אחרי שמתחברים ל-AlloyDB, צריך להפעיל את תוספי ה-AI הנדרשים וליצור את הטבלה שתקבל את נתוני הטלמטריה המוטמעים.
- בכרטיסייה הפעילה
.sql, מדביקים את הפקודות הבאות כדי להפעיל את התוספים הנדרשים:
CREATE EXTENSION IF NOT EXISTS vector;
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
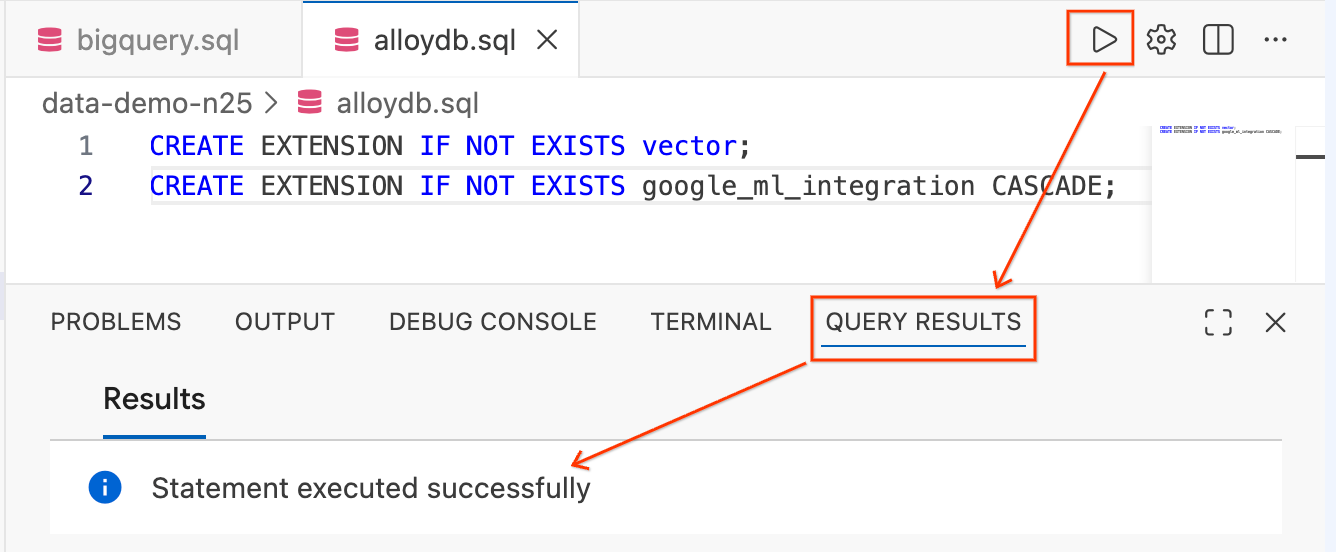
- מסמנים את הטקסט ולוחצים על הלחצן Run Query (הסמל של ההפעלה) בפינה השמאלית העליונה של כלי העריכה.
- בודקים את חלונית המסוף Query Results בתחתית המסך. אמור להופיע הכיתוב
Statement executed successfully.
- לאחר מכן, מחליפים את הטקסט בעורך בהצהרה הבאה כדי ליצור את טבלת הטלמטריה:
CREATE TABLE IF NOT EXISTS vessel_telemetry (
entry_id SERIAL PRIMARY KEY,
shipment_id VARCHAR(50),
telemetry_string TEXT,
embedding_vector vector(768)
);
- מריצים את השאילתה הזו בדיוק כמו השאילתה הקודמת. מוודאים שההפעלה בוצעה בהצלחה בחלונית התחתונה.
הסוג vector(768) מגיע מהתוסף pgvector שהפעלתם. 768 המאפיינים תואמים לפלט של מודל text-embedding-005 של Google, שבו תשתמשו ב-BigQuery כדי ליצור את ההטמעות.
סיכום הקטע: התחברתם ל-AlloyDB ישירות מ-Cloud Shell Editor, הפעלתם את התוספים pgvector ו-google_ml_integration ויצרתם את טבלת היעד. AlloyDB מוכן עכשיו לשמש כקצה העורפי התפעולי להתאמה של טלמטריה בזמן אמת.
7. יצירת אינדקס החיפוש
עכשיו צריך להעביר את נתוני הטלמטריה אל AlloyDB כדי שיוכלו להפעיל התאמה של אותות בזמן אמת. יומני טלמטריה גולמיים הם מבולגנים ואורכם משתנה, ולכן הם לא אידיאליים לחיפוש דמיון. תשתמשו בפונקציות ה-AI של BigQuery כדי לסכם כל יומן באמצעות Gemini ולהמיר כל סיכום להטמעה של וקטור עם 768 ממדים. לאחר מכן תייצאו את הנתונים המועשרים אל Cloud Storage ותייבאו אותם אל AlloyDB.
שלב 1: יצירת הטמעות ב-BigQuery
מחליפים את הכרטיסייה של העורך בחזרה ל-bigquery.sql (שנשאר מחובר ל-BigQuery).
עכשיו מריצים את השאילתה הבאה כדי לסכם כל יומן טלמטריה באמצעות Gemini וליצור הטמעות וקטוריות:
CREATE OR REPLACE TABLE `lost_cargo_dataset.telemetry_embeddings_export` AS
WITH summarized_telemetry AS (
SELECT
shipment_id,
telemetry_string,
AI.GENERATE(
CONCAT('Summarize this telemetry log for vector search: ', telemetry_string)
).result AS summary
FROM `lost_cargo_dataset.telemetry_data`
),
telemetry_embeddings AS (
SELECT
shipment_id,
telemetry_string,
AI.EMBED(summary, endpoint => 'text-embedding-005').result AS embedding
FROM summarized_telemetry
)
SELECT
shipment_id,
telemetry_string,
TO_JSON_STRING(embedding) AS embedding_vector
FROM telemetry_embeddings;
שלב 2: תצוגה מקדימה של הנתונים המועשרים
לפני שמייצאים, כדאי לבדוק את מה שיצרתם. השאילתה הזו מציגה את מזהי המשלוחים ואת 80 התווים הראשונים של כל סיכום וכל הטמעה:
SELECT
shipment_id,
SUBSTR(telemetry_string, 1, 80) AS telemetry_preview,
SUBSTR(embedding_vector, 1, 80) AS embedding_preview
FROM `lost_cargo_dataset.telemetry_embeddings_export`
LIMIT 5;
כל שורה מכילה עכשיו מזהה משלוח, את יומן הטלמטריה המקורי וקטור הטמעה עם 768 ממדים. אלה הנתונים שתדחפו ל-AlloyDB.
שלב 3: ייצוא הטמעות ל-Cloud Storage
משתמשים בהצהרת EXPORT DATA של BigQuery כדי לכתוב את טבלת ההטבעות לקטגוריית GCS של המעבדה כקובץ CSV.
EXECUTE IMMEDIATE CONCAT("""
EXPORT DATA OPTIONS (
uri = 'gs://""", @@project_id, """-lab2/data/embeddings_export/*.csv',
format = 'CSV',
overwrite = true,
header = false
) AS
SELECT
shipment_id,
telemetry_string,
embedding_vector
FROM `lost_cargo_dataset.telemetry_embeddings_export`;
""");
שלב 4: ייבוא ל-AlloyDB מ-Cloud Storage
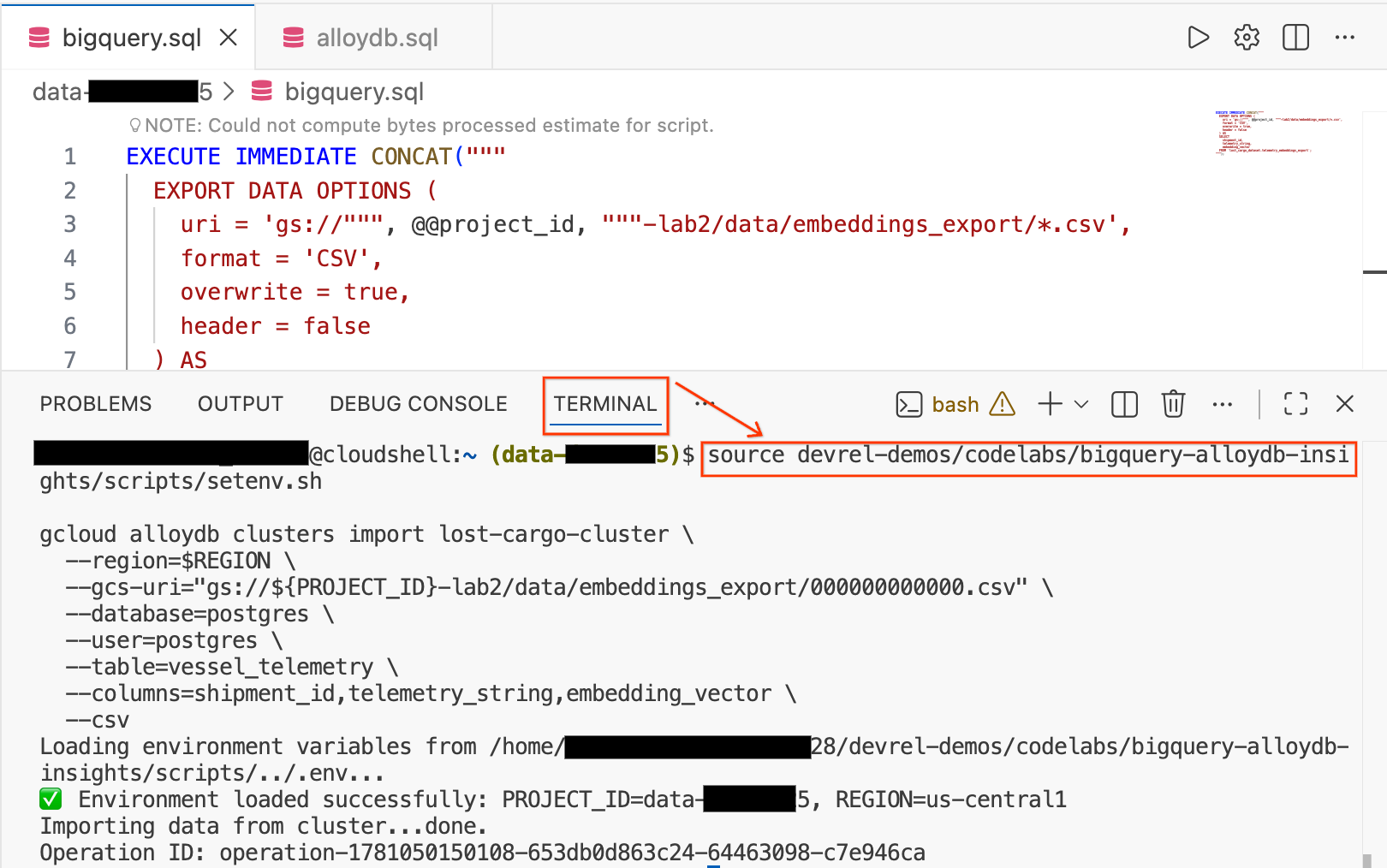
- ב-Cloud Shell Editor, לוחצים על הכרטיסייה Terminal בתחתית המסך כדי לפתוח סשן טרמינל.
- מריצים את הפקודות הבאות כדי לטעון את הסביבה ולייבא את קובץ ה-CSV ישירות לטבלה
vessel_telemetryב-AlloyDB:
source devrel-demos/codelabs/bigquery-alloydb-insights/scripts/setenv.sh
gcloud alloydb clusters import lost-cargo-cluster \
--region=$REGION \
--gcs-uri="gs://${PROJECT_ID}-lab2/data/embeddings_export/000000000000.csv" \
--database=postgres \
--user=postgres \
--table=vessel_telemetry \
--columns=shipment_id,telemetry_string,embedding_vector \
--csv
סיכום שלב: השתמשתם בפונקציות ה-AI של BigQuery כדי לסכם ולהטמיע את נתוני הטלמטריה, ייצאתם את התוצאות ל-Cloud Storage כקובץ CSV, ואז ייבאתם אותן ל-AlloyDB באמצעות gcloud. מסד הנתונים של מעקב התפעול נטען ועכשיו הוא מוכן.
8. התאמה של אות ה-Beacon
צוות שטח ליד סידני יירט אות טלמטריה מפוצל. היומן החלקי ייראה כך:
"יחידת הקירור לא מחוברת לאינטרנט. יש לבצע שינוי ידני."
אם ההודעה הזו הגיעה ממאגר התגים שנגנב, חיפוש הווקטורים ב-AlloyDB אמור להתאים אותה גם אם האות לא שלם. זה בדיוק סוג השאילתה התפעולית בזמן אמת ש-AlloyDB נועד לבצע.
שלב 1: אימות הנתונים המיובאים
מעבירים את כרטיסיית העריכה בחזרה אל alloydb.sql (שנשאר מחובר ל-AlloyDB).
כדי לוודא שנתוני הטלמטריה נטענו בהצלחה, מריצים את הפקודה:
SELECT shipment_id, LEFT(telemetry_string, 80) AS telemetry_preview
FROM vessel_telemetry
LIMIT 10;
אמורות להופיע שורות עם ערכים של shipment_id וטקסט טלמטריה. אלה חתימות הטלמטריה של הצי, שמוכנות עכשיו להתאמה בזמן אמת.
שלב 2: חיפוש המאגר החסר
עכשיו משתמשים בתוסף google_ml_integration של AlloyDB כדי לחפש התאמה באמצעות קטע האות שנקלט:
SELECT
shipment_id,
telemetry_string,
1 - (embedding_vector <=> embedding('text-embedding-005', 'Refrigeration unit offline. Manual override.')::vector) AS search_relevance_score
FROM vessel_telemetry
ORDER BY embedding_vector <=> embedding('text-embedding-005', 'Refrigeration unit offline. Manual override.')::vector
LIMIT 5;
הפונקציה embedding(), שסופקה על ידי התוסף google_ml_integration של AlloyDB, קוראת ל-Agent Platform ישירות מ-SQL כדי ליצור הטמעת וקטורים בשורה. האופרטור <=> מחשב את המרחק הקוסינוסי בין שני וקטורים (ככל שהערך קרוב יותר ל-0, כך שני הווקטורים זהים יותר). אנחנו מחסירים מ-1 כדי להציג את התוצאות כציון רלוונטיות, שבו ציון גבוה יותר מצביע על רלוונטיות גבוהה יותר.
שלב 3: אישור ההתאמה
בודקים את התוצאות. התוצאה הראשונה צריכה להיות MV-CAPYBARA-003, עם ציון הרלוונטיות הכי גבוה.
זהו אותו מאגר תגים שביצעתם בו מעקב בכל שלב של הבדיקה הזו:
- 📷 צילומים ממצלמת אבטחה שזיהו את הספינה יוצאת מנמל ריו דה ז'ניירו בלילה.
- 🌡️ זיהוי אנומליות תרמיות אישר שיחידת הקירור שלו הושבתה בכוונה.
- 📡 Beacon signal matching just pinpointed its telemetry signature near Sydney.
שלוש שורות נפרדות של ראיות. שלוש יכולות שונות של AI ב-Google Cloud. מאגר אחד נגנב.
🎯 התיק נסגר: איתרנו את MV-CAPYBARA-003 ליד סידני!

סיכום הקטע: השתמשתם בשילוב ה-AI המובנה של AlloyDB כדי ליצור הטמעה של חיפוש ולבצע חיפוש של דמיון קוסינוס בשאילתת SQL אחת. התאמת המשואה אישרה את המיקום של המכולה הגנובה, והחקירה הושלמה.
9. בדיקת ההוכחות
אחרי שזיהיתם את המכולה באמצעות ניתוח תמונות מולטי-מודאלי וחיפוש וקטורי, אתם יכולים להשתמש בניתוח נתונים שיחתי ישירות בתוך העורך כדי לחקור את נתוני החקירה באמצעות שפה טבעית, בלי לכתוב שאילתות SQL.
שלב 1: איתור הנתונים בKnowledge Catalog
חבילת Data Agent Kit כוללת תכונה של חיפוש אוניברסלי שמאפשרת לכם למצוא ולחקור נכסי נתונים בסביבת Google Cloud שלכם.
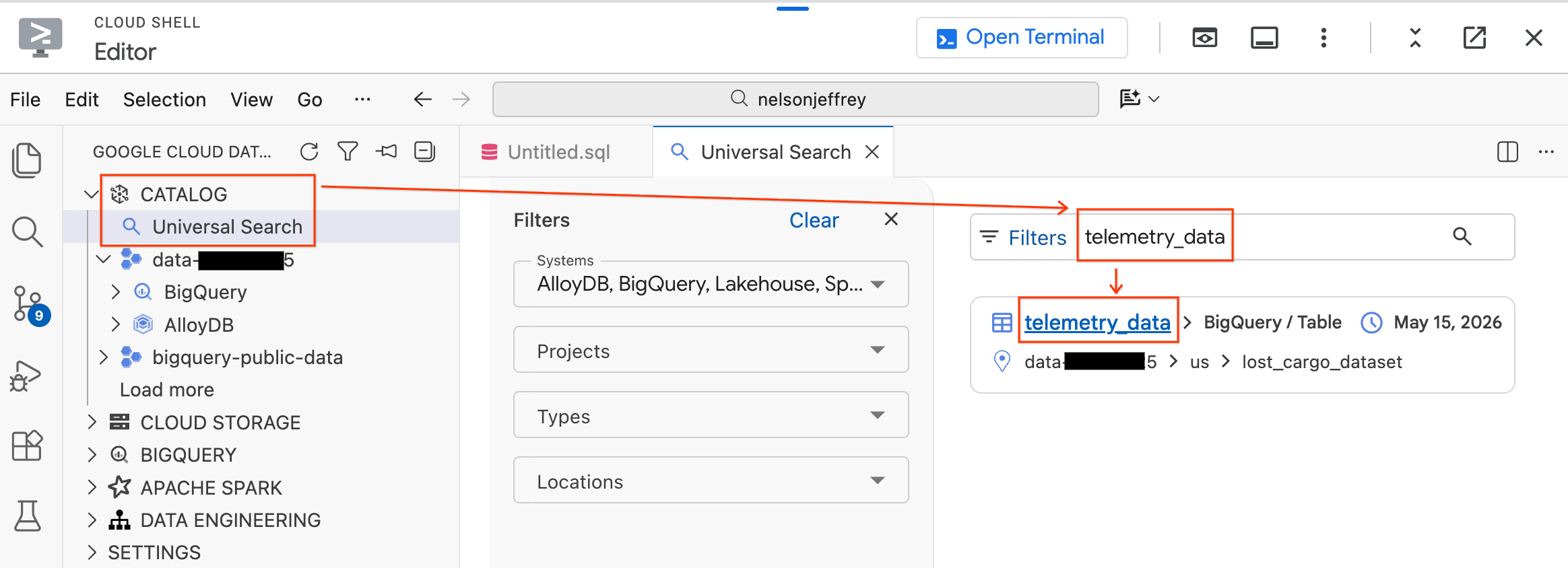
- בחלונית Data Agent Kit (ערכת כלים לסוכן נתונים) בצד ימין, מרחיבים את הקטע Catalog (קטלוג).
- לוחצים על חיפוש אוניברסלי.
- בסרגל החיפוש, מקלידים
telemetry_data. - בתוצאות החיפוש, לוחצים על הטבלה
telemetry_data(בקטעlost_cargo_dataset).
שלב 2: הפעלת ניתוח נתוני השיחות
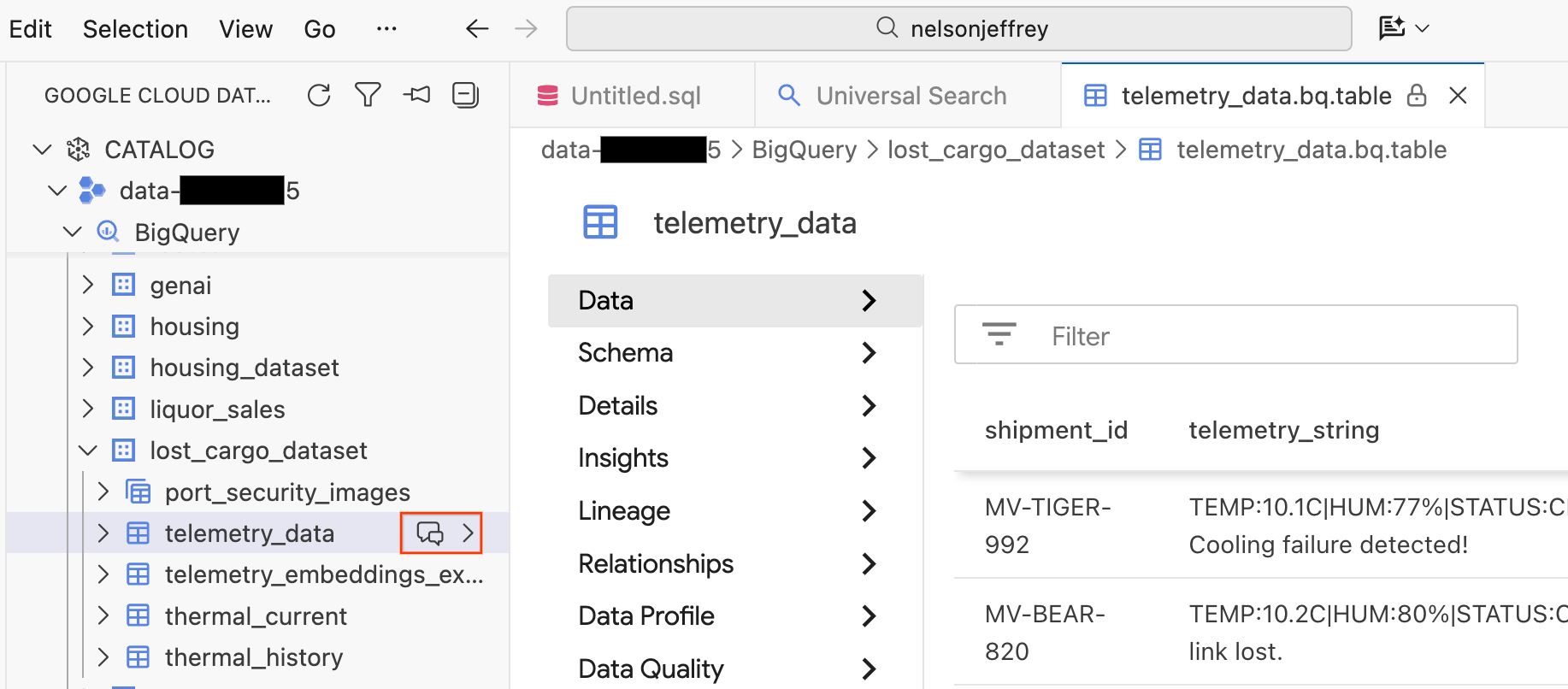
כשלוחצים על תוצאת החיפוש, נפתחת כרטיסייה של כלי לצפייה בנתונים, שבה אפשר לראות תצוגה מקדימה של הנתונים הגולמיים, להציג את הסכימה ולבדוק את איכות הנתונים.
- בחלונית הימנית, אפשר לראות את מערכי הנתונים והטבלאות של BigQuery. לוחצים על הלחצן צ'אט כדי לפתוח חלון צ'אט חדש.
שלב 3: שואלים שאלות בשפה טבעית
תיפתח כרטיסיית צ'אט חדשה עם ההודעה 'ברוכים הבאים לניתוח נתונים שימושי!'. לסוכן יש הקשר לגבי הסכימה והתוכן של הטבלה.
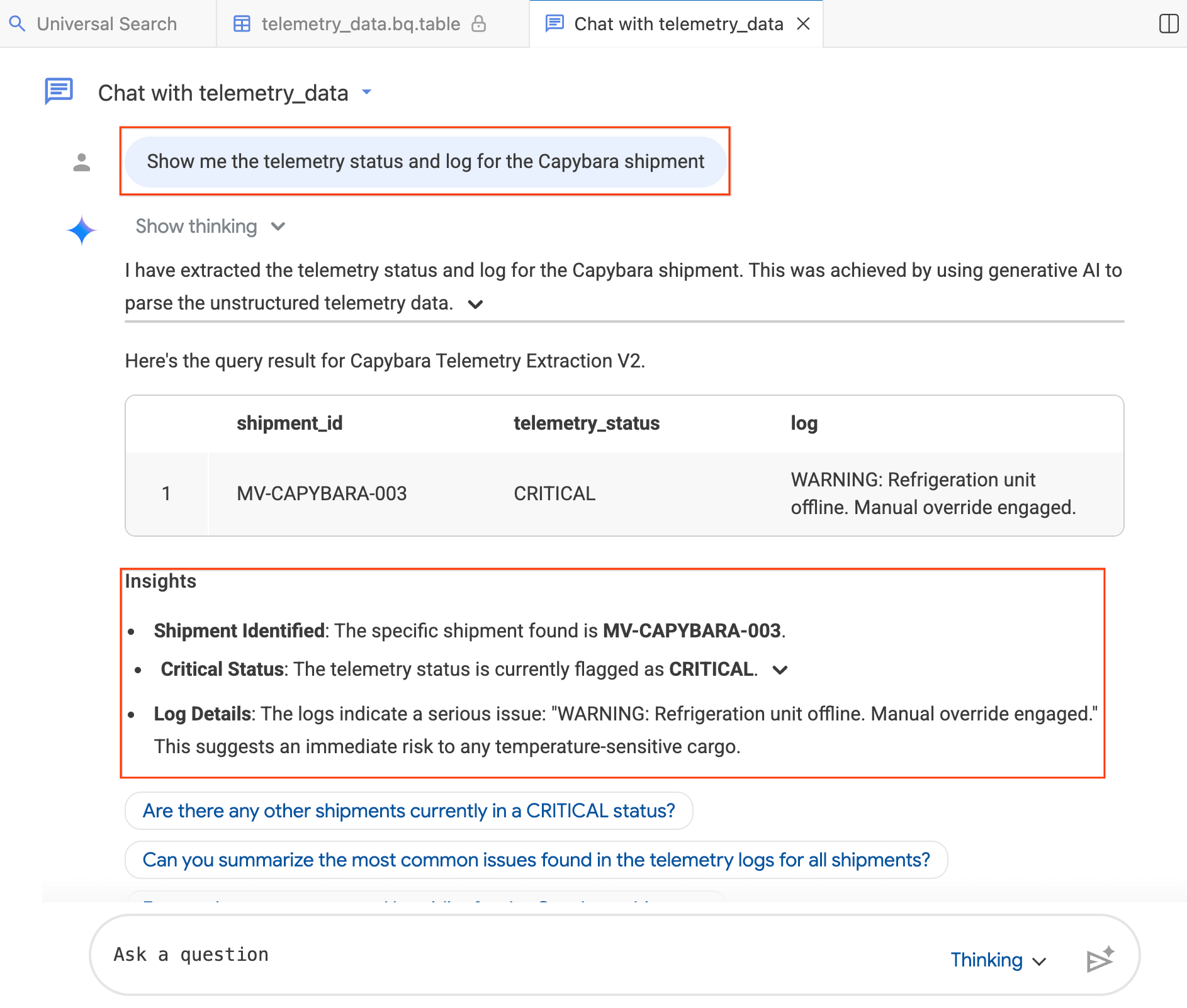
- בחלון הצ'אט, מקלידים:"Show me the telemetry status and log for the Capybara shipment."
- מקישים על Enter.
הסוכן מתרגם את השאלה שלכם ל-SQL של BigQuery, מריץ את השאילתה ומחזיר את התוצאות, כולל טבלת נתונים ותובנות שמסכמות את הממצאים. אתם יכולים לעבור בין מצב העמקה (ניתוח מעמיק יותר, איטי יותר) לבין מצב מהיר (תשובות מהירות יותר) בהתאם למורכבות השאלה. התשובות האלה נוצרות על ידי AI, ולכן יכול להיות שהתוצאות שיוצגו לכם יהיו שונות מעט מצילומי המסך שבהמשך.
שלב 4: שליחת שאלות המשך
הסוכן זוכר את ההקשר של השיחה. כדאי לנסות לשאול שאלת המשך:
- "כמה משלוחים ייחודיים יש בנתוני הטלמטריה?"
- "כמה משלוחים אחרים בצי נמצאים כרגע בסטטוס קריטי?"
סיכום הקטע: השתמשתם בתכונת החיפוש האוניברסלי של Knowledge Catalog כדי לאתר את מערך הנתונים, והפעלתם את Conversational Analytics כדי לשלוח שאילתות לגבי נתוני החקירה בשפה טבעית. סוכן ה-AI תרגם את השאלות שלכם ל-SQL וסיפק תובנות שאישרו את הממצאים שלכם.
10. הסרת המשאבים
כדי להימנע מחיובים שוטפים בחשבון Google Cloud, צריך למחוק את המשאבים שיצרתם בשיעור ה-Lab הזה. אפשר להריץ את הפקודות האלה בטרמינל המשולב בתוך Cloud Shell Editor (שבו השתמשתם ב-Data Agent Kit) כדי לנקות את הסביבה.
קודם כול, טוענים את משתני הסביבה:
source scripts/setenv.sh
- מחיקת משאבי BigQuery (רק אם לא ממשיכים למעבדה 3):
אם אתם מתכננים להמשיך לLab 3, דלגו על השלב הזה. בשיעור Lab 3 נעשה שימוש באותו מערך נתונים וחיבורים של BigQuery לניתוח גרף של נכס.
כדי למחוק את מערך הנתונים והחיבורים ב-BigQuery:
# Drop the dataset
bq rm -r -f $PROJECT_ID:lost_cargo_dataset
# Delete the connections
bq rm --connection --location=us-central1 $PROJECT_ID.us-central1.lost_cargo_conn
bq rm --connection --location=us-central1 $PROJECT_ID.us-central1.lost_cargo_alloydb_conn
- מחיקת הקטגוריה של Cloud Storage:
gcloud storage rm --recursive gs://${PROJECT_ID}-lab2
- מחיקת מופע וקלאסטר של AlloyDB:
לא נעשה שימוש ב-AlloyDB ב-Lab 3, ולכן אפשר להסיר אותו עכשיו.
gcloud alloydb instances delete lost-cargo-instance \
--region=$REGION \
--cluster=lost-cargo-cluster \
--quiet
gcloud alloydb clusters delete lost-cargo-cluster \
--region=$REGION \
--force \
--quiet
- מחיקת ההגדרות של הסביבה המקומית:
לבסוף, מנקים את קובץ ההגדרות של הסביבה המקומית מ-Workspace:
rm -f .env
11. מעולה!
סיימתם בהצלחה את שיעור Lab 2: ניתוח נתונים ותובנות מרובות-אופנים. עקבתם אחרי עקבות מנמל מלא באלפי מכולות ועד לגניבה מאומתת ולמיקום מדויק.
מה השגתם
- סריקת הצילומים: השתמשתם ב-
AI.GENERATEשל BigQuery כדי לנתח תמונות של אבטחת נמלים ולזהות את המכולה MV-CAPYBARA-003 בצבע אדום עז. - אישרת את הגניבה: בחנת נתוני חיישנים תרמיים, זיהית עלייה חשודה של 64.7°C והשתמשת ב-
AI.DETECT_ANOMALIESכדי להוכיח שמדובר בחבלה מכוונת. - הכנת מערכת המעקב: הגדרתם את AlloyDB עם pgvector ו-
google_ml_integrationלהתאמת משואות בזמן אמת. - יצירת אינדקס החיפוש: השתמשתם ב-
AI.GENERATEוב-AI.EMBEDב-BigQuery כדי ליצור הטבעות, ואז ייצאתם אותן ל-Cloud Storage וייבאתם אותן ל-AlloyDB. - התאמה לאות המשואה: השתמשתם בחיפוש וקטורי של AlloyDB כדי להתאים אות טלמטריה מקוטע, וכך לאתר את המכולה הגנובה ליד סידני.
- בדקת את הראיות: השתמשת בניתוח נתונים בשיחה ישירות מהעורך כדי לשלוח שאילתות לגבי נתוני החקירה בשפה טבעית.

השלבים הבאים
מצאתם איפה נמצא מאגר התגים. עכשיו צריך לגלות מי עומד מאחוריו.
בשיעור Lab 3: צריכת נתונים ותהליכי עבודה מבוססי-סוכנים, תיצרו גרף מאפיינים של רשת הלוגיסטיקה כדי למפות את הקשרים בין חברות קשב, תשתמשו ב-Conversational Analytics כדי לשוחח עם הגרף ותחפשו ב-Knowledge Catalog כדי למצוא את קוד האישור המאובטח שנדרש לשחזור המכולה.