
1. परिचय

पिछले लैब में, आपने शिपिंग के फ़्रैगमेंट किए गए लॉग को इकट्ठा किया था. साथ ही, कार्गो ट्रांसपॉन्डर को न्यूयॉर्क तक ट्रैक किया था. हालांकि, पहुंचने के रिकॉर्ड से पता चलता है कि कंटेनर को तुरंत दूसरे रास्ते पर भेज दिया गया था, ताकि कस्टम विभाग को इसकी जानकारी न मिले. अब यह ट्रेल आपको रियो डि जेनेरो के बंदरगाह तक ले गई है. यह एक विशाल बंदरगाह है, जहां हज़ारों कंटेनर मौजूद हैं. हज़ारों कंटेनर में से सही कंटेनर ढूंढना मुश्किल होता है.
इस लैब में, BigQuery में पहले से मौजूद एआई की सुविधाओं का इस्तेमाल करके, पोर्ट की सुरक्षा से जुड़ी अनस्ट्रक्चर्ड इमेज को "पढ़ने" के साथ-साथ सेंसर डेटा में थर्मल असामान्यताएं पता लगाई जाएंगी. यह सब स्टैंडर्ड एसक्यूएल का इस्तेमाल करके किया जाएगा. इसके बाद, वेक्टर एम्बेडिंग को AlloyDB में एक्सपोर्ट करें. साथ ही, वेक्टर खोज चलाकर, फ़्रैगमेंट किए गए टेलीमेट्री सिग्नल को उस कंटेनर से मैच करें जो मौजूद नहीं है.
आपको क्या करना होगा
- BigQuery AI का इस्तेमाल करके, पोर्ट की सुरक्षा से जुड़ी इमेज स्कैन करें, ताकि चोरी किए गए कंटेनर का पता लगाया जा सके
- BigQuery AI का इस्तेमाल करके, तापमान में हुई गड़बड़ी का पता लगाना. इससे यह पुष्टि की जा सकेगी कि कंटेनर चोरी हुआ है, न कि गलत जगह पर रखा गया है
- वेक्टर एंबेडिंग जनरेट करना और उन्हें रीयल-टाइम में खोजने के लिए, AlloyDB में लोड करना
- टेलीमेट्री बीकन के फ़्रैगमेंट किए गए सिग्नल को मैच करके, वेक्टर सर्च का इस्तेमाल करके चुराए गए कंटेनर का पता लगाना
- कन्वर्सेशनल ऐनलिटिक्स का इस्तेमाल करके, आसान भाषा में जांच से जुड़े डेटा को एक्सप्लोर करना
आपको किन चीज़ों की ज़रूरत होगी
- कोई वेब ब्राउज़र, जैसे कि Chrome
- बिलिंग की सुविधा वाला Google Cloud प्रोजेक्ट
- SQL और Google Cloud Console के बारे में बुनियादी जानकारी
यह कोडलैब, इंटरमीडिएट डेवलपर के लिए है.
इस कोडलैब में बनाए गए संसाधनों की लागत 5 डॉलर से कम होनी चाहिए.
2. शुरू करने से पहले
Cloud Shell शुरू करना
कोड डाउनलोड करने, सेटअप स्क्रिप्ट चलाने, और ऐप्लिकेशन को डिप्लॉय करने के लिए, Google Cloud Shell का इस्तेमाल किया जाएगा.
- नए ब्राउज़र टैब में, Cloud Shell खोलें: shell.cloud.google.com
- कनेक्ट होने के बाद, अपना प्रोजेक्ट आईडी सेट करें और अपने एनवायरमेंट की पुष्टि करें:
gcloud config set project <<YOUR_PROJECT_ID>>
export PROJECT_ID=$(gcloud config get-value project)
export REGION=us-central1
आपको इस तरह का मैसेज दिखेगा:
Your active configuration is: [cloudshell-####] Updated property [core/project]
डेटा स्टोर करने की जगह का क्लोन बनाना
कोडलैब की रिपॉज़िटरी को अपने Cloud Shell एनवायरमेंट में क्लोन करें:
cd ~/
git clone --filter=blob:none --no-checkout https://github.com/GoogleCloudPlatform/devrel-demos.git
cd ~/devrel-demos
git sparse-checkout init --cone
git sparse-checkout set codelabs/bigquery-alloydb-insights
git checkout main
cd codelabs/bigquery-alloydb-insights/
एपीआई चालू करें
इस लैब के लिए ज़रूरी सभी एपीआई चालू करने के लिए, Cloud Shell में यह कमांड चलाएं:
gcloud services enable \
aiplatform.googleapis.com \
bigquery.googleapis.com \
bigqueryconnection.googleapis.com \
alloydb.googleapis.com
सफल तरीके से लागू होने पर, आपको इस तरह का मैसेज दिखेगा:
Operation "operations/..." finished successfully.
3. अपना एनवायरमेंट सेट अप करना
इमेज और टेलीमेट्री डेटा का विश्लेषण करने से पहले, आपको इस लैब के लिए इन्फ़्रास्ट्रक्चर सेट अप करना होगा. आपको दो स्क्रिप्ट चलानी होंगी: एक स्क्रिप्ट, बैकग्राउंड में AlloyDB प्रोविज़निंग शुरू करती है. वहीं, दूसरी स्क्रिप्ट, BigQuery के वे सभी संसाधन बनाती है जिनकी आपको ज़रूरत होगी.
पहला चरण: AlloyDB डिप्लॉयमेंट शुरू करना (बैकग्राउंड में)
AlloyDB क्लस्टर को चालू होने में करीब 10 मिनट लगते हैं. इसलिए, इसे सबसे पहले चालू करें और BigQuery सेक्शन पर काम करते समय इसे बैकग्राउंड में चलने दें. यह स्क्रिप्ट, आपके चालू प्रोजेक्ट की सेटिंग को अपने-आप लोकल .env फ़ाइल में रिकॉर्ड करेगी. इससे, Cloud Shell टर्मिनल बंद होने या फिर से चालू होने पर भी आपका कॉन्फ़िगरेशन सेव रहेगा.
chmod +x scripts/setup_alloydb.sh
nohup ./scripts/setup_alloydb.sh > /dev/null 2>&1 &
echo "AlloyDB deployment started in background (PID: $!)"
दूसरा चरण: सेटअप स्क्रिप्ट चलाना
यह स्क्रिप्ट, BigQuery डेटासेट, Cloud Resource कनेक्शन, IAM ग्रांट, और GCS बकेट बनाती है. साथ ही, उन सभी सेंसर डेटा को लोड करती है जिनका विश्लेषण आपको इस लैब में करना है. यह .env फ़ाइल में सेव किए गए एनवायरमेंट वैरिएबल को भी पढ़ेगा और उनकी पुष्टि करेगा.
chmod +x scripts/setup_lab.sh
./scripts/setup_lab.sh
स्क्रिप्ट को चलने में करीब एक मिनट लगता है. इसके खत्म होने पर, आपको इसकी खास जानकारी दिखेगी.
📝 एनवायरमेंट रीसेट करने के बारे में जानकारी अगर इस लैब के दौरान आपका Cloud Shell सेशन बंद हो जाता है या किसी भी समय रीस्टार्ट हो जाता है, तो टर्मिनल वैरिएबल को तुरंत वापस लाने के लिए, यह कमांड चलाएं:
source scripts/setenv.sh
तीसरा चरण: Cloud Shell Editor लॉन्च करना
अब तक, Cloud Shell टर्मिनल का इस्तेमाल किया जा रहा था. अब Cloud Shell Editor के फ़ुल वर्शन पर स्विच करें. इसमें आपको VS Code जैसा वर्कस्पेस मिलता है. साथ ही, इसमें BigQuery के साथ इंटिग्रेट करने की सुविधा भी मिलती है.
- Cloud Shell Editor वर्कस्पेस लॉन्च करने के लिए, स्क्रीन पर सबसे नीचे मौजूद Cloud Shell टर्मिनल पैन में, Open Editor बटन पर क्लिक करें.

चौथा चरण: Data Agent Kit एक्सटेंशन इंस्टॉल करना
Google Cloud Data Agent Kit एक्सटेंशन, Google Cloud की डेटा सेवाओं के साथ सीधे तौर पर इंटिग्रेट होता है. इससे आपको अपने एडिटर में ही BigQuery, AlloyDB, Cloud Storage वगैरह के साथ इंटरैक्ट करने की सुविधा मिलती है. इसके लिए, आपको कॉन्टेक्स्ट स्विच करने की ज़रूरत नहीं होती.
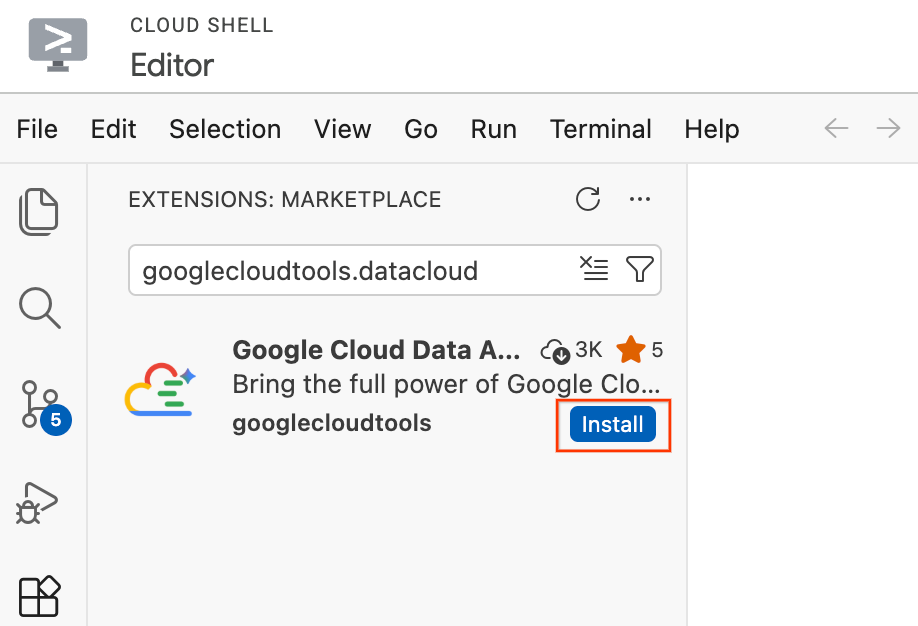
- Cloud Shell Editor में, स्क्रीन की बाईं ओर मौजूद गतिविधि बार में, एक्सटेंशन आइकॉन पर क्लिक करें. यह आइकॉन, चार स्क्वेयर की तरह दिखता है.
- एक्सटेंशन पैनल में सबसे ऊपर मौजूद खोज बार में,
googlecloudtools.datacloudटाइप करें. - Google Cloud के पब्लिश किए गए Google Cloud Data Agent Kit नाम के एक्सटेंशन को ढूंढें.
- इंस्टॉल करें बटन पर क्लिक करें.
- आपको एक मैसेज दिखेगा. इसमें पूछा जाएगा, "क्या आपको पब्लिशर ‘googlecloudtools' और उसके एक्सटेंशन पर भरोसा है?". आगे बढ़ने के लिए, भरोसेमंद पब्लिशर और इंस्टॉल करें पर क्लिक करें.
पांचवां चरण: पुष्टि करना और एक्सटेंशन कॉन्फ़िगर करना
एक्सटेंशन इंस्टॉल करने के बाद, इसे अपने Google Cloud प्रोजेक्ट से कनेक्ट करें.
- "Google Cloud Data Agent Kit Onboarding" नाम का एक पेज अपने-आप खुल जाएगा. Google Cloud में साइन इन करें पर क्लिक करें. ऐक्सेस की अनुमति देने के लिए, ब्राउज़र के किसी भी प्रॉम्प्ट का पालन करें.
- आपको "सेटअप किया जा रहा है" मोडल दिखेगा. एक्सटेंशन, Google Cloud CLI जैसी ज़रूरी डिपेंडेंसी की जांच अपने-आप करेगा.
- कॉन्फ़िगरेशन की खास जानकारी सेक्शन में, प्रोजेक्ट फ़ील्ड ढूंढें. ड्रॉपडाउन पर क्लिक करें और अपना Google Cloud प्रोजेक्ट चुनें. अपने देश/इलाके को
us-central1के तौर पर सेट करें. - सेटअप की जांच पूरी होने तक इंतज़ार करें. "सेटअप पूरा हुआ!" दिखने के बाद, एमसीपी सर्वर कॉन्फ़िगर करें पर क्लिक करें.
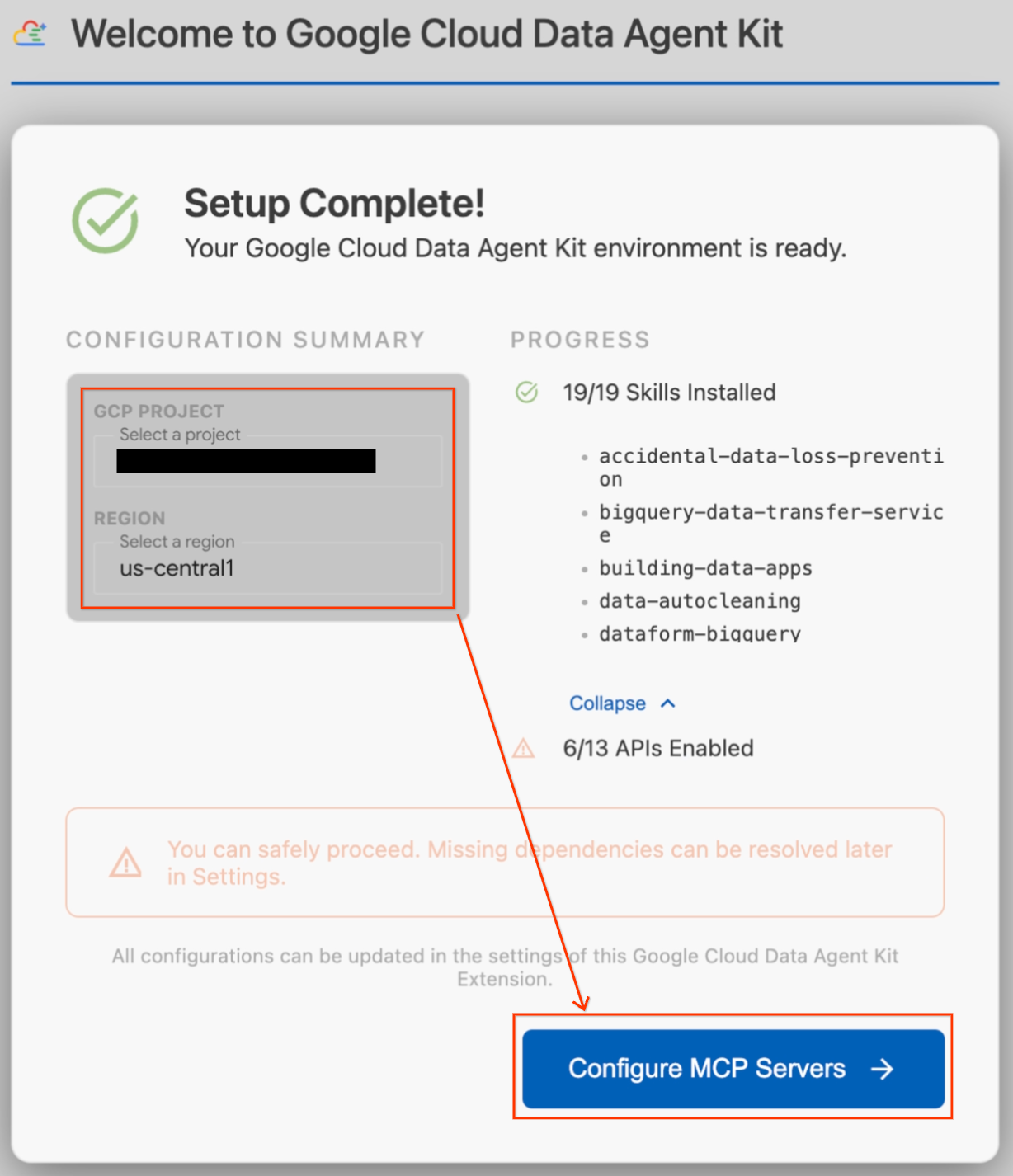
- एमसीपी कॉन्फ़िगरेशन में जाकर, BigQuery और AlloyDB को चुनें. इसके बाद, शुरू करें पर क्लिक करें.
छठा चरण: कॉन्फ़िगरेशन के विकल्पों के बारे में जानें
सेटअप पूरा होने के बाद, आपको "Google Cloud Data Agent Kit का इस्तेमाल शुरू करें" डैशबोर्ड पर रीडायरेक्ट कर दिया जाएगा.
- "सेटअप और कॉन्फ़िगरेशन" में जाकर, शुरू करें पर क्लिक करें.
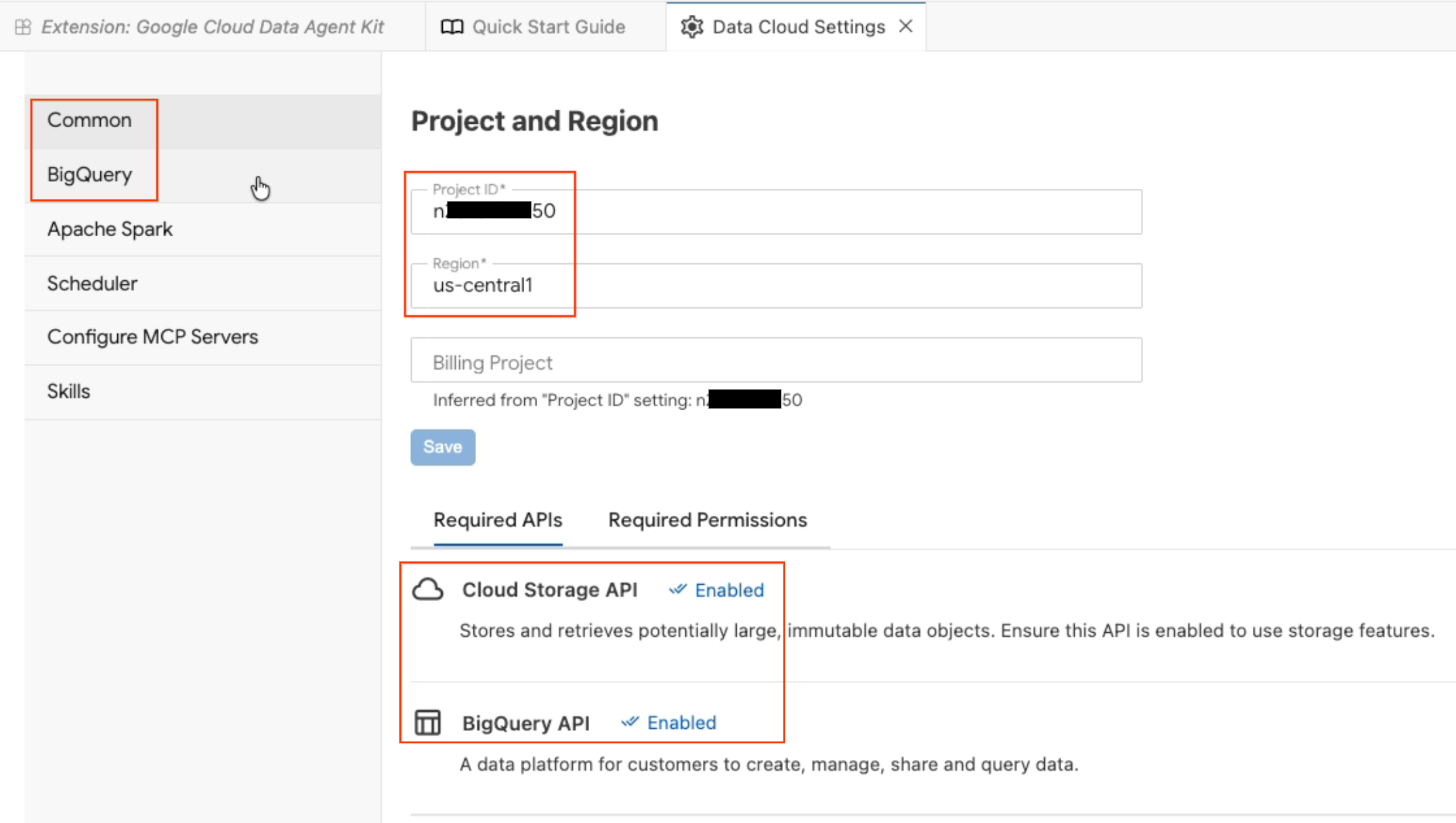
- इससे डेटा एजेंट कॉन्फ़िगरेशन पैनल खुलता है. टैब एक्सप्लोर करें:
- प्रोजेक्ट और क्षेत्र: चुने गए प्रोजेक्ट आईडी की पुष्टि करें. साथ ही, यह देखें कि ज़रूरी एपीआई (Cloud Storage API, BigQuery API, Catalog API, और AlloyDB API) चालू हों.
- BigQuery: अपनी BigQuery क्वेरी के लिए डिफ़ॉल्ट जगह कॉन्फ़िगर करें. इसके लिए,
us-central1क्षेत्र का इस्तेमाल करें. - एमसीपी सर्वर कॉन्फ़िगर करें: चालू किए गए एमसीपी सर्वर (BigQuery, Notebooks, AlloyDB वगैरह) देखें. इनकी मदद से, एआई एजेंट आपके डेटा के साथ सुरक्षित तरीके से इंटरैक्ट कर सकते हैं.
- स्किल: पहले से बनी हुई स्किल एक्सप्लोर करें. ये स्किल, एजेंट को मुश्किल डेटा टास्क के लिए खास सुविधाएं देती हैं.
सातवां चरण: BigQuery की मदद से पुष्टि करना
पुष्टि करें कि सब कुछ काम कर रहा है. इसके लिए, सार्वजनिक डेटासेट के ख़िलाफ़ एक क्वेरी चलाएं.
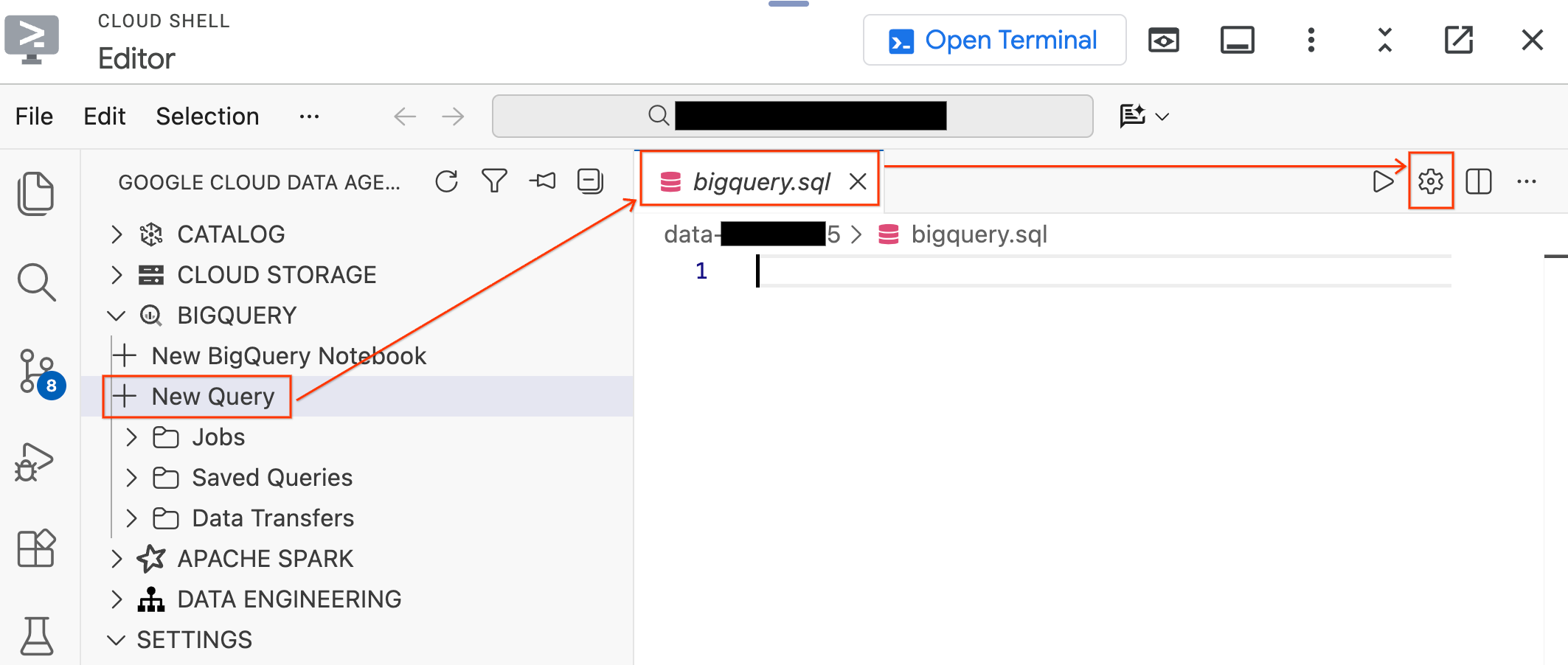
- बाईं ओर मौजूद डेटा एजेंट किट पैनल में, BigQuery सेक्शन को बड़ा करें. इसके बाद, नया क्वेरी एडिटर टैब खोलने के लिए, नई क्वेरी पर क्लिक करें.
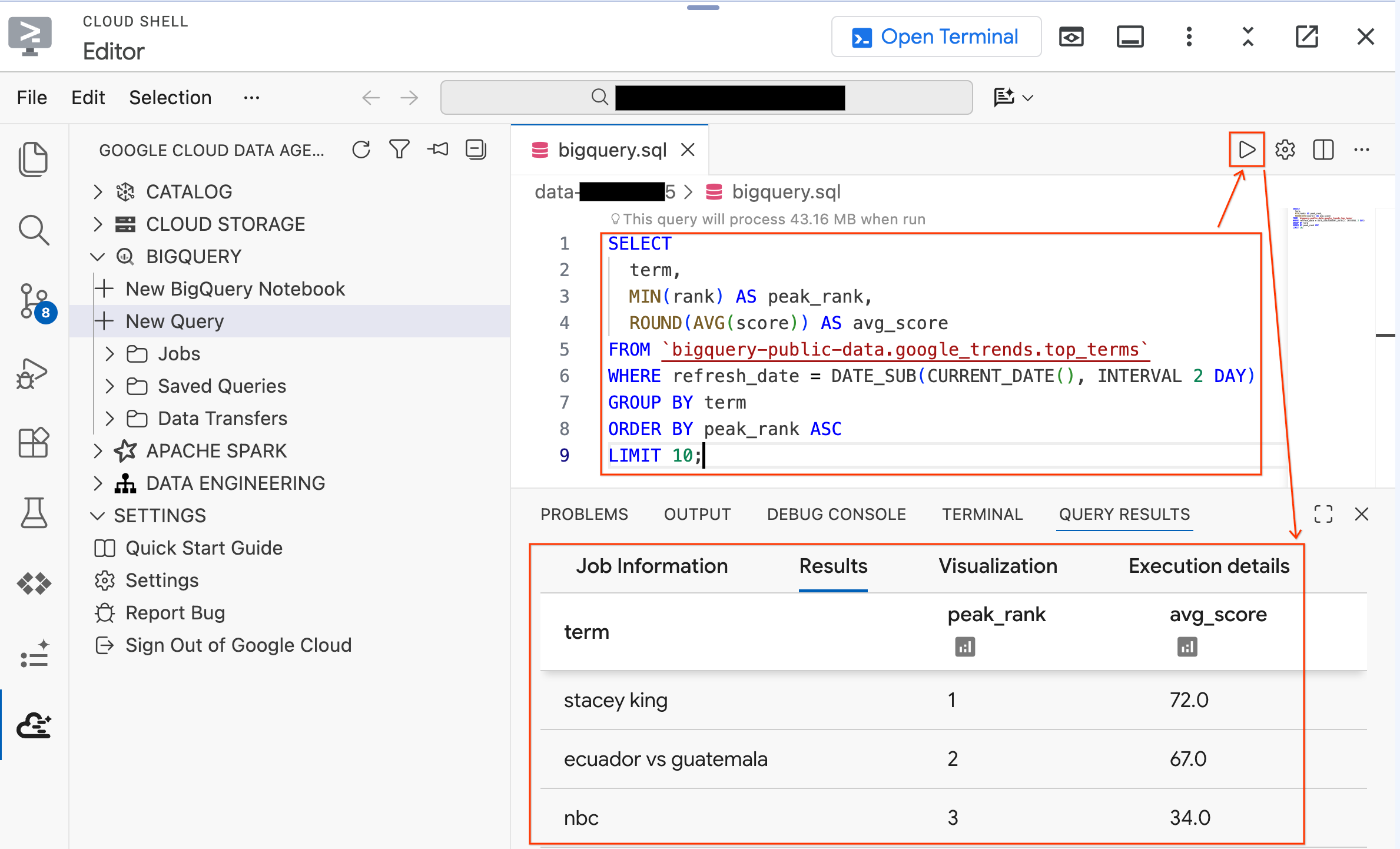
Ctrl+S(Windows/Linux) याCmd+S(macOS) दबाकर फ़ाइल को सेव करें और उसका नामbigqueryरखें. इस टैब का इस्तेमाल, BigQuery से जुड़ी सभी कार्रवाइयों के लिए किया जाएगा.bigquery.sqlटैब चालू होने पर, क्वेरी सेटिंग पर क्लिक करें. इसके बाद, डेटा सोर्स के तौर पर BigQuery को चुनें और सेव करें पर क्लिक करें.
- सार्वजनिक डेटासेट के ख़िलाफ़ यह क्वेरी चलाएं:
SELECT
term,
MIN(rank) AS peak_rank,
ROUND(AVG(score)) AS avg_score
FROM `bigquery-public-data.google_trends.top_terms`
WHERE refresh_date = DATE_SUB(CURRENT_DATE(), INTERVAL 2 DAY)
GROUP BY term
ORDER BY peak_rank ASC
LIMIT 10;
- आपको पिछले कुछ दिनों के सबसे ज़्यादा खोजे गए 10 Google सर्च टर्म दिखेंगे. अगर नतीजे दिखते हैं, तो इसका मतलब है कि आपका एक्सटेंशन कनेक्ट हो गया है और इस्तेमाल के लिए तैयार है.
अब लैब के उस डेटा के लिए क्वेरी चलाएं जिसे आपकी सेटअप स्क्रिप्ट ने अभी बनाया है. मौजूदा क्वेरी को इस क्वेरी से बदलें:
SELECT * FROM `lost_cargo_dataset.telemetry_data` LIMIT 5;
आपको shipment_id और telemetry_string कॉलम के साथ टेलीमेट्री लॉग एंट्री दिखनी चाहिए. इस लैब में, आपको इसी डेटा का विश्लेषण करना होगा.
सेक्शन की खास जानकारी: आपने बैकग्राउंड में AlloyDB डिप्लॉयमेंट शुरू किया, सेटअप स्क्रिप्ट चलाई, और Cloud Shell Editor को Data Agent Kit एक्सटेंशन के साथ कॉन्फ़िगर किया.
4. सुरक्षा कैमरे के फ़ुटेज को स्कैन करना
जांच टीम को रियो डि जेनेरो के पोर्ट से सुरक्षा फ़ुटेज मिला है. इसमें शिपिंग कंटेनर की लाइनें दिख रही हैं. लैब 1 से आपको पता है कि टारगेट कंटेनर लाल रंग का है. अब आपको यह पता लगाना है कि वह कौनसा लाल कंटेनर है.
आपको एक ऑब्जेक्ट टेबल बनानी होगी, ताकि BigQuery, Cloud Storage में मौजूद सुरक्षा से जुड़ी इमेज को "देख" सके. इसके बाद, AI.GENERATE फ़ंक्शन का इस्तेमाल करके, Gemini को हर इमेज से स्ट्रक्चर्ड डेटा निकालने के लिए कहा जा सकता है.
पहला चरण: ऑब्जेक्ट टेबल बनाना
ऑब्जेक्ट टेबल, BigQuery की एक खास टेबल होती है. यह Cloud Storage में सेव की गई बिना स्ट्रक्चर वाली फ़ाइलों (इमेज, PDF, ऑडियो) के इंडेक्स के तौर पर काम करती है. यह फ़ाइलों को BigQuery में कॉपी नहीं करता है. यह एक ऐसा रेफ़रंस बनाता है जिसे क्वेरी किया जा सकता है, ताकि एआई फ़ंक्शन उन्हें "देख" सकें.
एडिटर में मौजूद bigquery.sql टैब में, नीचे दिया गया स्टेटमेंट चलाएं. इससे, आपके प्रोजेक्ट के बकेट में मौजूद पोर्ट की सुरक्षा से जुड़ी इमेज की ओर इशारा करने वाली ऑब्जेक्ट टेबल बन जाएगी:
SET @@location = 'us-central1';
EXECUTE IMMEDIATE CONCAT("""
CREATE OR REPLACE EXTERNAL TABLE `lost_cargo_dataset.port_security_images`
WITH CONNECTION `us-central1.lost_cargo_conn`
OPTIONS (
object_metadata = 'SIMPLE',
uris = ['gs://""", @@project_id, """-lab2/images/*']
);
""");
यहां देखें कि BigQuery अब क्या-क्या देख सकता है:
SELECT uri, content_type FROM `lost_cargo_dataset.port_security_images` LIMIT 5;
हर लाइन, Cloud Storage में मौजूद किसी इमेज फ़ाइल के बारे में बताती है. अब BigQuery, इन इमेज को सीधे तौर पर एआई मॉडल को पास कर सकता है.
दूसरा चरण: सुरक्षा के लिए इस्तेमाल की गई इमेज का विश्लेषण करना
अब BigQuery के AI.GENERATE फ़ंक्शन का इस्तेमाल करके, हर सुरक्षा इमेज का विश्लेषण करें. इस एक एसक्यूएल क्वेरी से, Gemini को हर इमेज की जांच करने और स्ट्रक्चर्ड डेटा दिखाने के लिए कहा जाता है:
SELECT
uri,
AI.GENERATE(
(
'Examine this port security image. Identify any shipping container IDs visible on the container and provide a one-word color of the container.',
ref
),
output_schema => 'detected_container_id STRING, color STRING'
).* EXCEPT (full_response, status)
FROM `lost_cargo_dataset.port_security_images`;
तीसरा चरण: टारगेट कंटेनर का पता लगाना
नतीजों की जांच करें. उस लाइन को ढूंढें जहां color कॉलम में "लाल" (या लाल रंग का कोई अन्य शेड) दिखता हो. detected_container_id को नोट कर लें. यह आपका टारगेट है: MV-CAPYBARA-003.
चौथा चरण: विज़ुअल मैच की पुष्टि करना
एडिटर को बंद किए बिना, विश्लेषण की गई ओरिजनल इमेज देखने के लिए:
- बाईं ओर मौजूद डेटा एजेंट किट पैनल में, Cloud Storage पर क्लिक करें.
- अपने बकेट (
YOUR_PROJECT_ID-lab2/images/) को बड़ा करें और लाल कंटेनर से जुड़ी इमेज फ़ाइल पर क्लिक करें, ताकि उसे सीधे एडिटर में देखा जा सके.
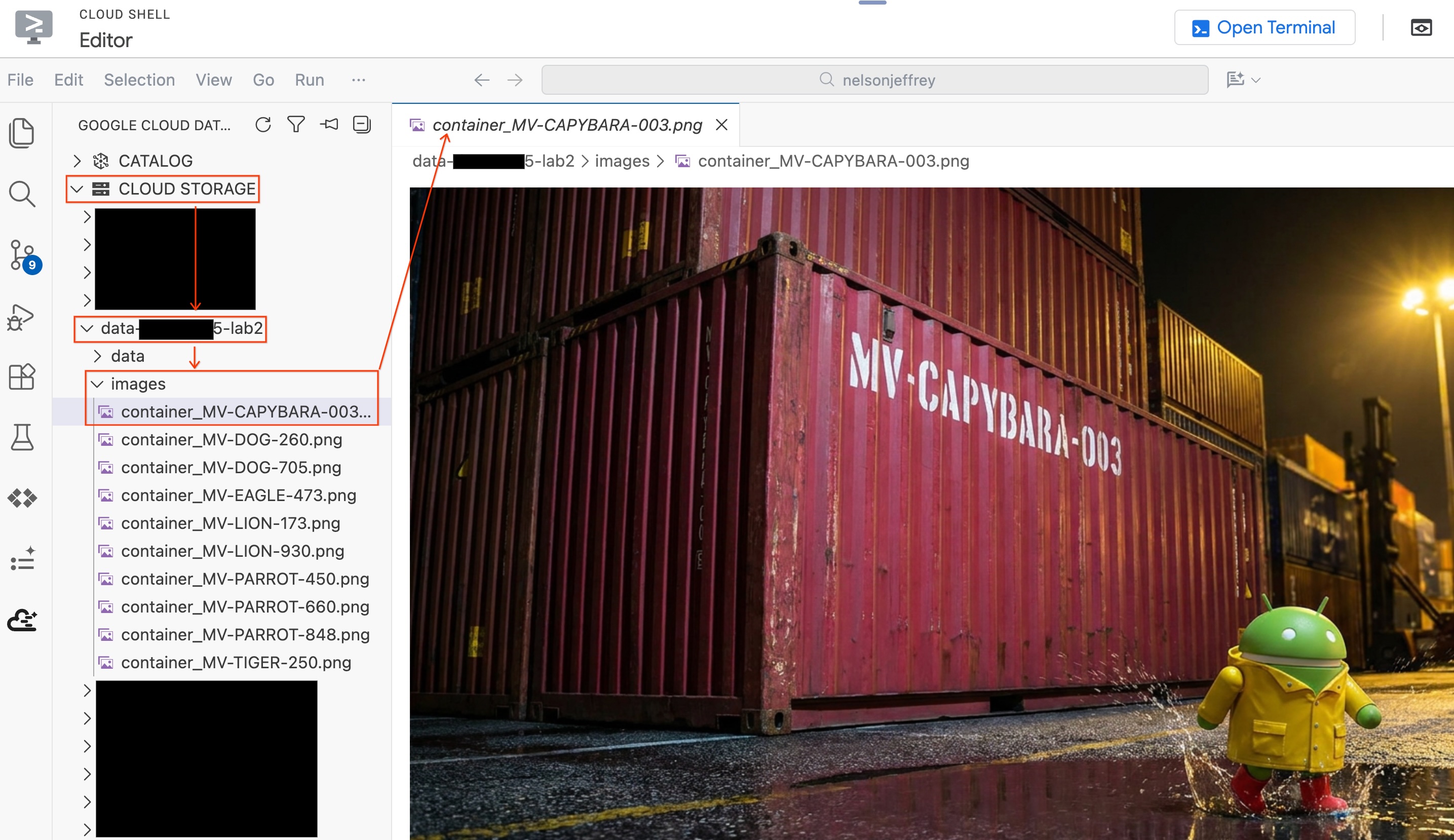
सेक्शन की खास जानकारी: आपने पोर्ट की सुरक्षा से जुड़ी इमेज का ऐक्सेस BigQuery को देने के लिए, ऑब्जेक्ट टेबल बनाई. इसके बाद, हर इमेज से स्ट्रक्चर्ड कंटेनर डेटा निकालने के लिए, AI.GENERATE का इस्तेमाल किया. लाल रंग के कंटेनर की पहचान MV-CAPYBARA-003 के तौर पर की गई है.
5. चोरी की पुष्टि करना
आपने MV-CAPYBARA-003 को लापता कंटेनर के तौर पर मार्क किया है. हालांकि, क्या यह चोरी हो गया था या सिर्फ़ अपनी जगह से हट गया था? मेनिफ़ेस्ट लॉग से पता चलता है कि इस कंटेनर को एनवायरमेंटल सेंसर SENS-99 के बगल में रखा गया था. अगर चोरों ने कंटेनर को ले जाने से पहले, जान-बूझकर उसके रेफ़्रिजरेटर को बंद कर दिया था, तो SENS-99 ने अचानक तापमान बढ़ने की जानकारी रिकॉर्ड की होगी.
आइए, गड़बड़ी की पहचान करने की सुविधा का इस्तेमाल करके यह साबित करें कि कंटेनर में छेड़छाड़ की गई है.
- सबसे पहले, पुरानी बेसलाइन देखें. ये
SENS-99से मिली सामान्य रीडिंग हैं, जो पिछले कुछ घंटों में मिली हैं:
SELECT * FROM `lost_cargo_dataset.thermal_history`
ORDER BY reading_time DESC
LIMIT 50;
ध्यान दें कि तापमान 75 से 78°F के बीच है. सामान्य तौर पर ऐसा दिखता है.
- अब उसी सेंसर से मिली रीडिंग के मौजूदा बैच को देखें:
SELECT * FROM `lost_cargo_dataset.thermal_current`
ORDER BY thermal_reading DESC
LIMIT 50;
क्या आपको सबसे ऊपर 148.4°F दिख रहा है? बाकी सब कुछ सामान्य है. इस तरह की अचानक हुई बढ़ोतरी से पता चलता है कि रेफ़्रिजरेटर यूनिट में कोई गड़बड़ी हुई है या जान-बूझकर छेड़छाड़ की गई है. Let's find out.
- गड़बड़ी की पहचान करने की सुविधा चालू करें. BigQuery का
AI.DETECT_ANOMALIES, पहले से ट्रेन किए गए TimesFM फ़ाउंडेशन मॉडल का इस्तेमाल करता है. इससे टाइम-सीरीज़ के पैटर्न का विश्लेषण किया जाता है और आउटलायर अपने-आप फ़्लैग हो जाते हैं. इसके लिए, मॉडल को ट्रेनिंग देने की ज़रूरत नहीं होती:
SELECT *
FROM AI.DETECT_ANOMALIES(
TABLE `lost_cargo_dataset.thermal_history`,
TABLE `lost_cargo_dataset.thermal_current`,
data_col => 'thermal_reading',
timestamp_col => 'reading_time',
id_cols => ['sensor_id']
)
WHERE is_anomaly = TRUE;
- नतीजों की जांच करें. 148.4°F तापमान को गड़बड़ी के तौर पर फ़्लैग किया जाना चाहिए. साथ ही, गड़बड़ी होने की ज़्यादा संभावना के बारे में भी बताया जाना चाहिए. इससे पुष्टि होती है कि कंटेनर के आस-पास कुछ असामान्य हुआ है.
सेक्शन की खास जानकारी: आपने पहले से ट्रेन किए गए TimesFM मॉडल का फ़ायदा पाने के लिए, BigQuery के AI.DETECT_ANOMALIES फ़ंक्शन का इस्तेमाल किया. आपने एक एसक्यूएल क्वेरी चलाकर, आउटलायर का पता अपने-आप लगा लिया. साथ ही, आपने मशीन लर्निंग का कोई मुश्किल कोड लिखे बिना या मॉडल को शुरू से ट्रेन किए बिना, डेटा में छेड़छाड़ करने वाले असामान्य इवेंट को अलग कर दिया.
6. ट्रैकिंग सिस्टम तैयार किया जा रहा है
कंटेनर के चोरी होने की पुष्टि हो गई है और अब वह रियो डि जेनेरो में नहीं है. फ़्लीट में मौजूद हर कंटेनर, टेलीमेट्री बीकन सिग्नल ब्रॉडकास्ट करता है: सेंसर रीडिंग, जीपीएस फ़्रैगमेंट, और स्टेटस लॉग. अगर चोरी किए गए कंटेनर का बीकन अब भी डेटा ट्रांसमिट कर रहा है, तो उसे ढूंढने के लिए, जाने-पहचाने सिग्नेचर से मैच किया जा सकता है.
BigQuery, अब तक किए गए आपके विश्लेषण के काम में बेहतर है. हालांकि, रीयल टाइम में कंटेनर का पता लगाने के लिए, कम समय में जवाब देने वाली क्वेरी की ज़रूरत होती है. AlloyDB, PostgreSQL के साथ काम करने वाला एक पूरी तरह से मैनेज किया गया डेटाबेस है. इसे खास तौर पर इसी काम के लिए बनाया गया है: वेक्टर सर्च क्वेरी इतनी तेज़ी से की जा सकती हैं कि लाइव ट्रैकिंग सिस्टम के लिए काफ़ी हों. टेलीमेट्री एम्बेडिंग को AlloyDB में लोड किया जाएगा. इसके बाद, इसका इस्तेमाल बीकन सिग्नल से मैच करने के लिए किया जाएगा.
आपने बैकग्राउंड में जो AlloyDB क्लस्टर शुरू किया था वह अब तैयार हो जाना चाहिए. आइए, इसे सीधे अपने एडिटर से कॉन्फ़िगर करें.
पहला चरण: Editor से AlloyDB से कनेक्ट करना
Cloud Console पर स्विच करने के बजाय, Data Agent Kit एक्सटेंशन का इस्तेमाल करके सीधे AlloyDB से कनेक्ट किया जा सकता है.
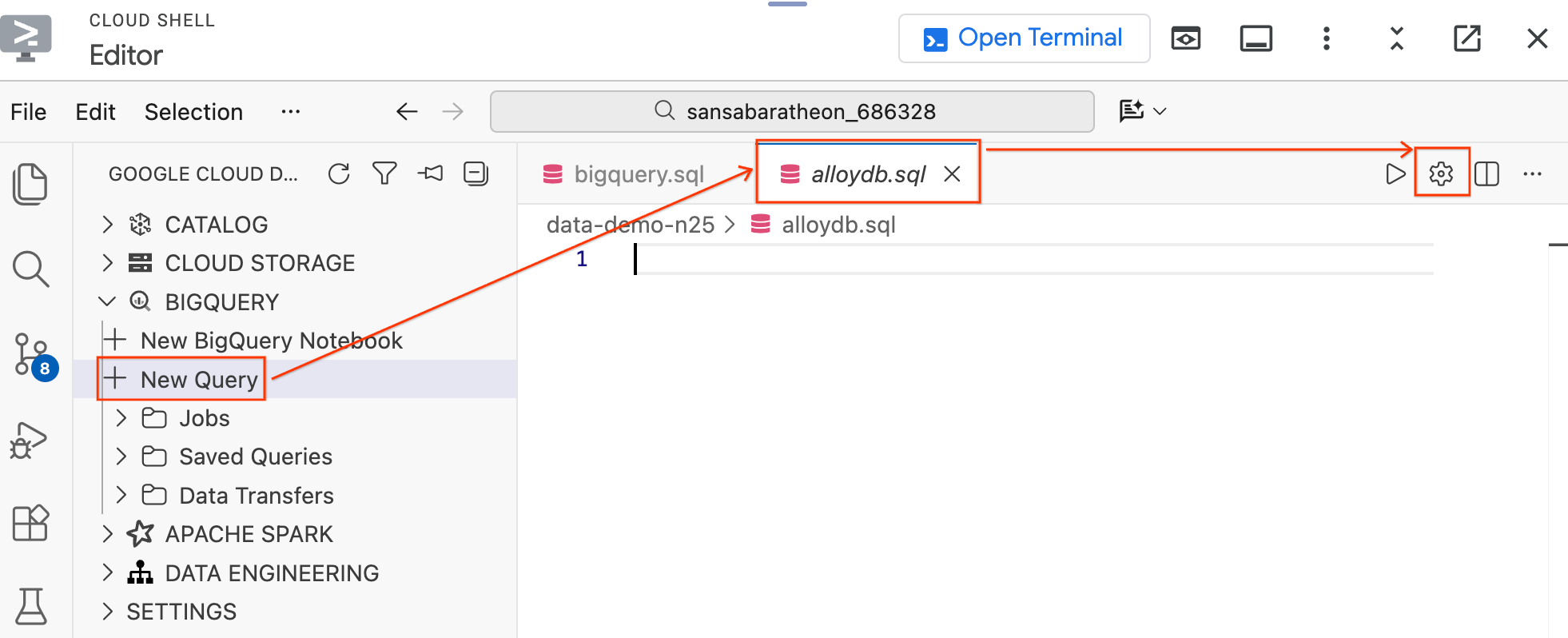
- बाईं ओर मौजूद डेटा एजेंट किट पैनल में, BigQuery सेक्शन में जाकर, नई क्वेरी पर क्लिक करें. इससे नया क्वेरी एडिटर टैब खुल जाएगा.
Ctrl+S(Windows/Linux) याCmd+S(macOS) दबाकर फ़ाइल को सेव करें और उसका नामalloydbरखें. इस टैब का इस्तेमाल, सभी AlloyDB क्वेरी के लिए किया जाएगा.- क्वेरी सेटिंग मॉडल खोलने के लिए, गियर आइकॉन पर क्लिक करें.
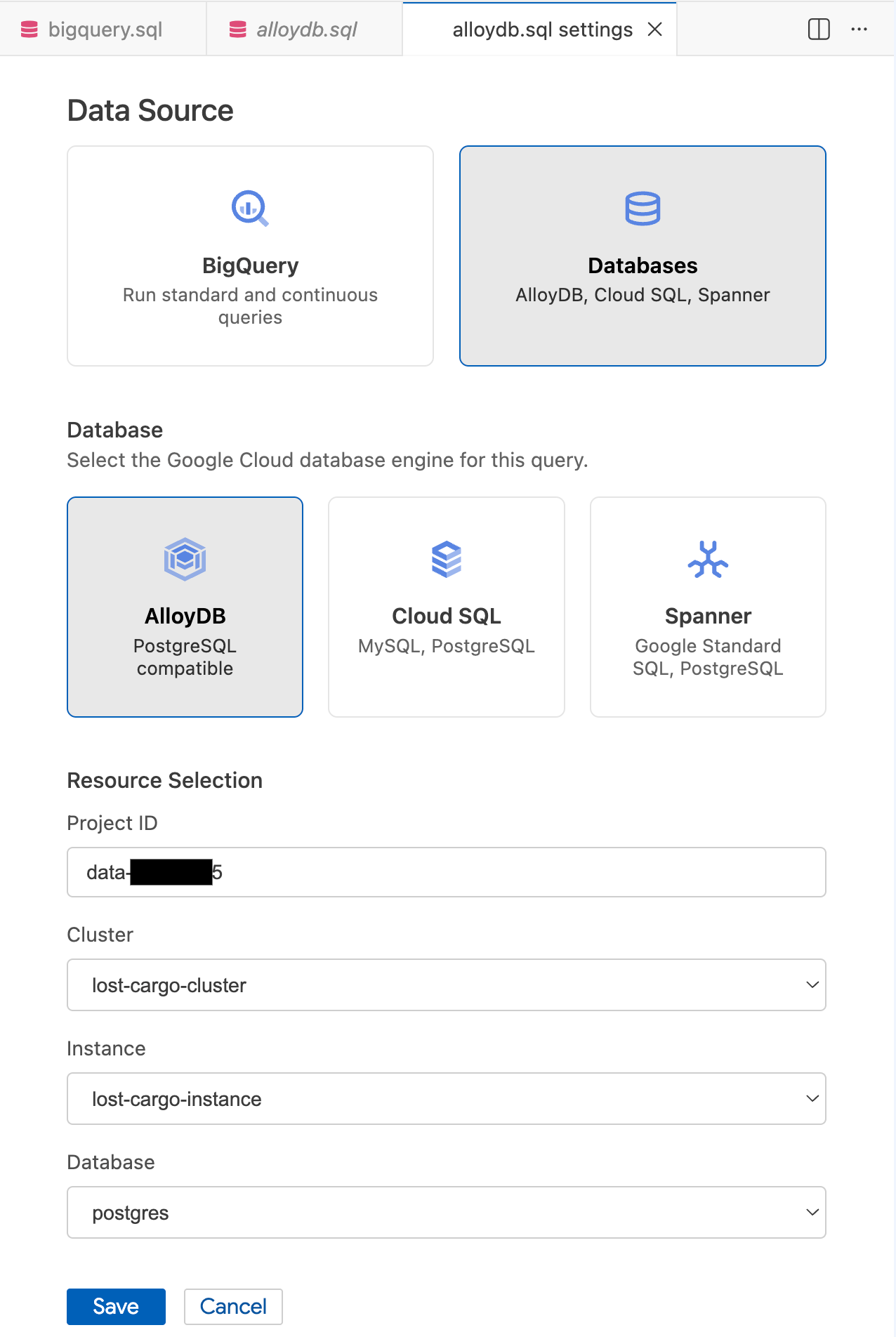
- क्वेरी सेटिंग मोडल में, डेटा सोर्स में जाकर, डेटाबेस को चुनें.
- डेटाबेस में जाकर, AlloyDB चुनें.
- संसाधन चुनने से जुड़ी जानकारी भरें:
- प्रोजेक्ट आईडी: अपना Google Cloud प्रोजेक्ट आईडी डालें.
- क्लस्टर:
lost-cargo-clusterको चुनें. - इंस्टेंस:
lost-cargo-instanceको चुनें. - डेटाबेस:
postgresको चुनें.
- सेव करें पर क्लिक करें.
दूसरा चरण: Vector Extension को चालू करना और टेबल बनाना
AlloyDB से कनेक्ट होने के बाद, आपको ज़रूरी एआई एक्सटेंशन चालू करने होंगे. साथ ही, वह टेबल बनानी होगी जिसमें एम्बेड किया गया टेलीमेट्री डेटा मिलेगा.
- ज़रूरी एक्सटेंशन चालू करने के लिए, अपनी चालू
.sqlटैब में ये कमांड चिपकाएं:
CREATE EXTENSION IF NOT EXISTS vector;
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
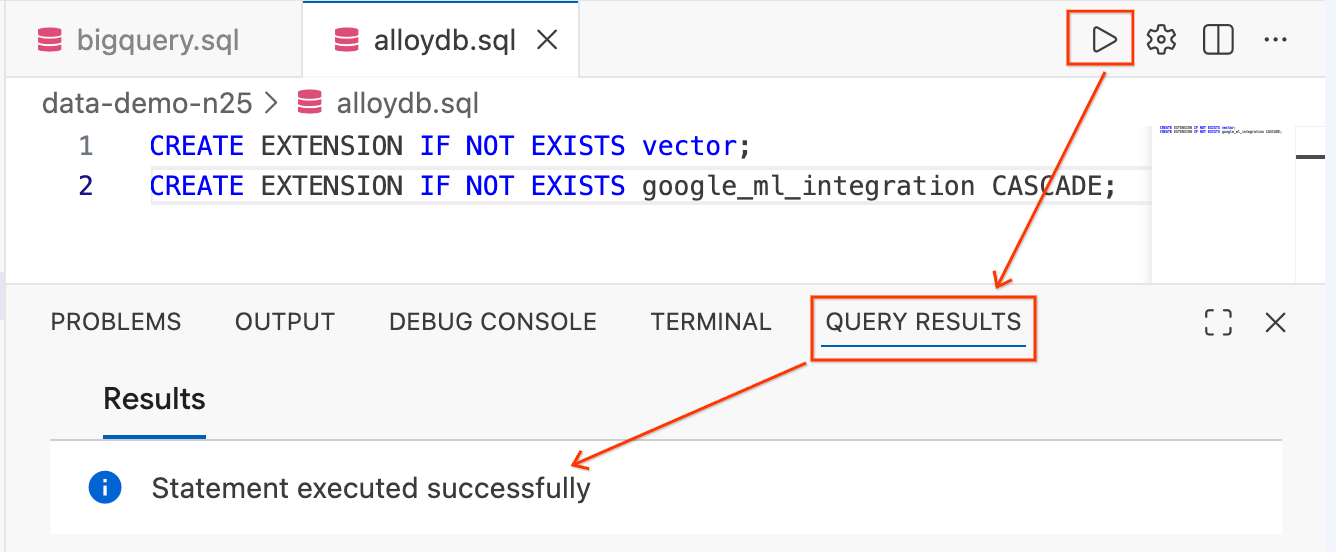
- टेक्स्ट को हाइलाइट करें. इसके बाद, एडिटर में सबसे ऊपर दाईं ओर मौजूद, क्वेरी चलाएं बटन (प्ले आइकॉन) पर क्लिक करें.
- स्क्रीन पर सबसे नीचे मौजूद क्वेरी के नतीजे टर्मिनल पैनल देखें. इसमें
Statement executed successfullyलिखा होना चाहिए.
- इसके बाद, टेलीमेट्री टेबल बनाने के लिए, अपने एडिटर में मौजूद टेक्स्ट को इस स्टेटमेंट से बदलें:
CREATE TABLE IF NOT EXISTS vessel_telemetry (
entry_id SERIAL PRIMARY KEY,
shipment_id VARCHAR(50),
telemetry_string TEXT,
embedding_vector vector(768)
);
- इस क्वेरी को पिछली क्वेरी की तरह ही चलाओ. पुष्टि करें कि यह बॉटम पैनल में सही तरीके से काम कर रहा है.
vector(768) टाइप, अभी चालू किए गए pgvector एक्सटेंशन से मिलता है. 768 डाइमेंशन, Google के text-embedding-005 मॉडल के आउटपुट से मेल खाते हैं. इस मॉडल का इस्तेमाल, BigQuery में एम्बेडिंग जनरेट करने के लिए किया जाएगा.
सेक्शन की खास जानकारी: आपने Cloud Shell Editor से सीधे तौर पर AlloyDB से कनेक्ट किया, pgvector और google_ml_integration एक्सटेंशन चालू किए, और टारगेट टेबल बनाई. AlloyDB अब रीयल-टाइम में टेलीमेट्री मैचिंग के लिए, ऑपरेशनल बैकएंड के तौर पर काम करने के लिए तैयार है.
7. Search इंडेक्स बनाना
अब आपको टेलीमेट्री डेटा को AlloyDB में डालना होगा, ताकि रीयल-टाइम बीकन मैचिंग की सुविधा काम कर सके. रॉ टेलीमेट्री लॉग, गड़बड़ और अलग-अलग लंबाई के होते हैं. इसलिए, ये मिलते-जुलते आइटम खोजने के लिए सही नहीं होते. Gemini की मदद से हर लॉग का सारांश बनाने के लिए, BigQuery के एआई फ़ंक्शन का इस्तेमाल किया जाएगा. साथ ही, हर सारांश को 768 डाइमेंशन वाली वेक्टर एम्बेडिंग में बदला जाएगा. इसके बाद, बेहतर बनाए गए डेटा को Cloud Storage में एक्सपोर्ट करें और उसे AlloyDB में इंपोर्ट करें.
पहला चरण: BigQuery में एम्बेडिंग जनरेट करना
एडिटर टैब को वापस bigquery.sql पर स्विच करें. यह टैब, BigQuery से कनेक्ट रहता है.
अब, Gemini की मदद से हर टेलीमेट्री लॉग की खास जानकारी पाने और वेक्टर एम्बेडिंग जनरेट करने के लिए, यह क्वेरी चलाएं:
CREATE OR REPLACE TABLE `lost_cargo_dataset.telemetry_embeddings_export` AS
WITH summarized_telemetry AS (
SELECT
shipment_id,
telemetry_string,
AI.GENERATE(
CONCAT('Summarize this telemetry log for vector search: ', telemetry_string)
).result AS summary
FROM `lost_cargo_dataset.telemetry_data`
),
telemetry_embeddings AS (
SELECT
shipment_id,
telemetry_string,
AI.EMBED(summary, endpoint => 'text-embedding-005').result AS embedding
FROM summarized_telemetry
)
SELECT
shipment_id,
telemetry_string,
TO_JSON_STRING(embedding) AS embedding_vector
FROM telemetry_embeddings;
दूसरा चरण: बेहतर बनाए गए डेटा की झलक देखना
एक्सपोर्ट करने से पहले, देखें कि आपने क्या बनाया है. इस क्वेरी में शिपमेंट आईडी और हर खास जानकारी और एम्बेडिंग के पहले 80 वर्ण दिखाए गए हैं:
SELECT
shipment_id,
SUBSTR(telemetry_string, 1, 80) AS telemetry_preview,
SUBSTR(embedding_vector, 1, 80) AS embedding_preview
FROM `lost_cargo_dataset.telemetry_embeddings_export`
LIMIT 5;
हर लाइन में अब शिपमेंट आईडी, ओरिजनल टेलीमेट्री लॉग, और 768 डाइमेंशन वाला एम्बेडिंग वेक्टर शामिल है. यह वह डेटा है जिसे आपको AlloyDB में पुश करना है.
तीसरा चरण: Cloud Storage में एम्बेडिंग एक्सपोर्ट करना
BigQuery के EXPORT DATA स्टेटमेंट का इस्तेमाल करके, एम्बेडिंग टेबल को अपने लैब के GCS बकेट में CSV फ़ाइल के तौर पर लिखें.
EXECUTE IMMEDIATE CONCAT("""
EXPORT DATA OPTIONS (
uri = 'gs://""", @@project_id, """-lab2/data/embeddings_export/*.csv',
format = 'CSV',
overwrite = true,
header = false
) AS
SELECT
shipment_id,
telemetry_string,
embedding_vector
FROM `lost_cargo_dataset.telemetry_embeddings_export`;
""");
चौथा चरण: Cloud Storage से AlloyDB में इंपोर्ट करना
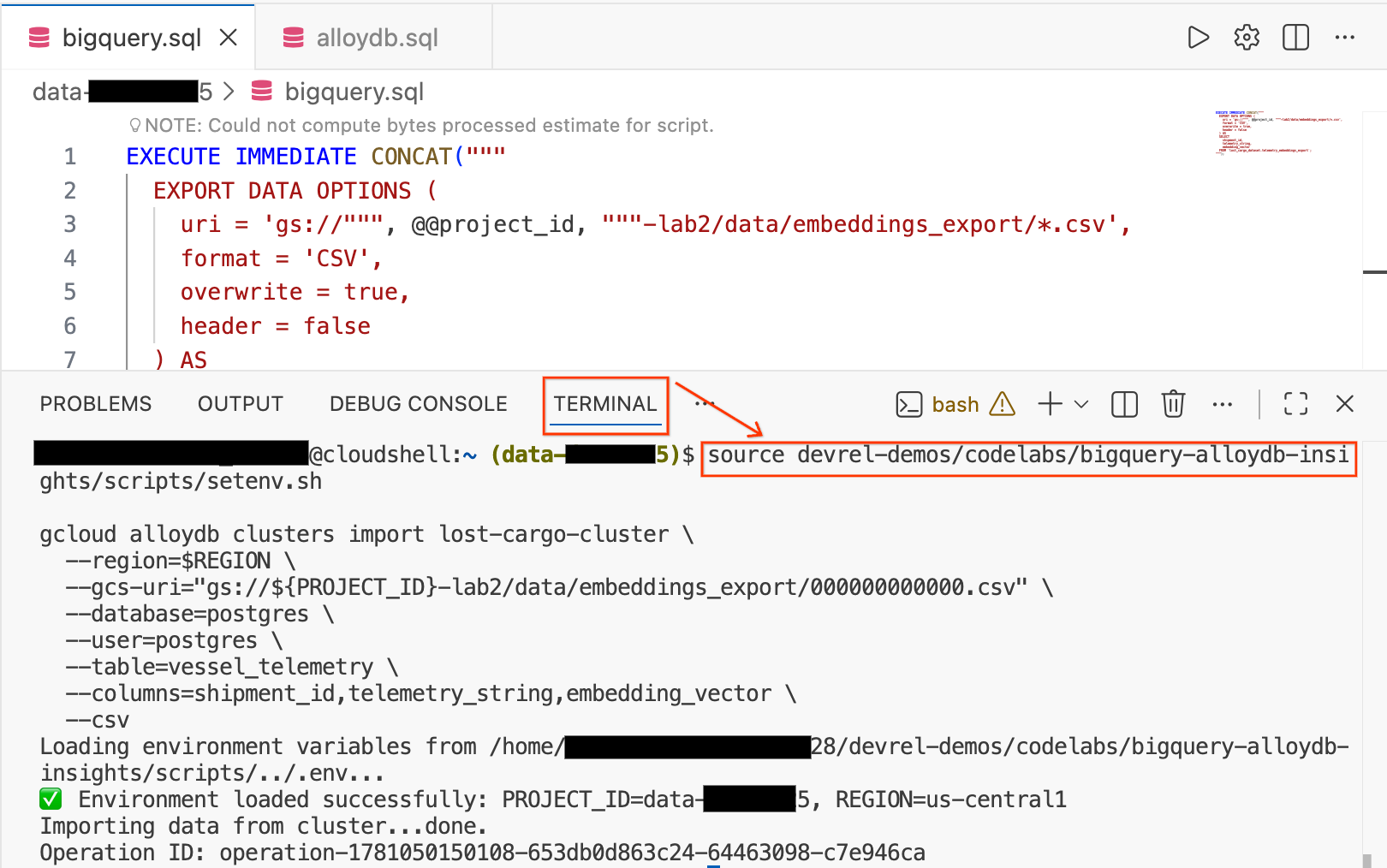
- टर्मिनल सेशन खोलने के लिए, Cloud Shell Editor में स्क्रीन पर सबसे नीचे मौजूद टर्मिनल टैब पर क्लिक करें.
- अपने एनवायरमेंट को लोड करने और CSV फ़ाइल को सीधे AlloyDB में मौजूद
vessel_telemetryटेबल में इंपोर्ट करने के लिए, ये कमांड चलाएं:
source devrel-demos/codelabs/bigquery-alloydb-insights/scripts/setenv.sh
gcloud alloydb clusters import lost-cargo-cluster \
--region=$REGION \
--gcs-uri="gs://${PROJECT_ID}-lab2/data/embeddings_export/000000000000.csv" \
--database=postgres \
--user=postgres \
--table=vessel_telemetry \
--columns=shipment_id,telemetry_string,embedding_vector \
--csv
सेक्शन की खास जानकारी: आपने टेलीमेट्री डेटा की खास जानकारी देने और उसे एम्बेड करने के लिए, BigQuery के एआई फ़ंक्शन इस्तेमाल किए. इसके बाद, नतीजों को CSV फ़ाइल के तौर पर Cloud Storage में एक्सपोर्ट किया. फिर, उन्हें gcloud का इस्तेमाल करके AlloyDB में इंपोर्ट किया. अब ऑपरेशनल ट्रैकिंग डेटाबेस लोड हो गया है और इस्तेमाल के लिए तैयार है.
8. बीकन सिग्नल मैच करना
सिडनी के पास मौजूद फ़ील्ड टीम ने, टेलीमेट्री बीकन के सिग्नल को इंटरसेप्ट किया है. आंशिक लॉग में यह जानकारी होती है:
"रेफ़्रिजरेशन यूनिट ऑफ़लाइन है. मैन्युअल तरीके से बदलाव किया गया है."
अगर यह डेटा चुराए गए कंटेनर से आया है, तो AlloyDB की वेक्टर सर्च सुविधा को इससे मैच करना चाहिए. भले ही, सिग्नल अधूरा हो. AlloyDB को ठीक इसी तरह की रीयल-टाइम, ऑपरेशनल क्वेरी के लिए बनाया गया है.
पहला चरण: इंपोर्ट किए गए डेटा की पुष्टि करना
अपने एडिटर टैब को वापस alloydb.sql पर स्विच करें. यह AlloyDB से कनेक्ट रहता है.
पुष्टि करें कि टेलीमेट्री डेटा सही तरीके से लोड हो गया है. इसके लिए, यह कमांड चलाएं:
SELECT shipment_id, LEFT(telemetry_string, 80) AS telemetry_preview
FROM vessel_telemetry
LIMIT 10;
आपको shipment_id वैल्यू और टेलीमेट्री टेक्स्ट वाली लाइनें दिखेंगी. ये फ्लीट के टेलीमेट्री सिग्नेचर हैं. अब इन्हें रीयल-टाइम में मैच किया जा सकता है.
दूसरा चरण: 'लापता' कंटेनर ढूंढना
अब इंटरसेप्ट किए गए सिग्नल फ़्रैगमेंट का इस्तेमाल करके, मैच खोजने के लिए AlloyDB के google_ml_integration एक्सटेंशन का इस्तेमाल करें:
SELECT
shipment_id,
telemetry_string,
1 - (embedding_vector <=> embedding('text-embedding-005', 'Refrigeration unit offline. Manual override.')::vector) AS search_relevance_score
FROM vessel_telemetry
ORDER BY embedding_vector <=> embedding('text-embedding-005', 'Refrigeration unit offline. Manual override.')::vector
LIMIT 5;
AlloyDB के google_ml_integration एक्सटेंशन से मिला embedding() फ़ंक्शन, एसक्यूएल से सीधे तौर पर Agent Platform को कॉल करता है, ताकि वेक्टर एम्बेडिंग इनलाइन जनरेट की जा सके. <=> ऑपरेटर, दो वेक्टर के बीच कोसाइन दूरी का हिसाब लगाता है. यह दूरी जितनी कम होगी, दोनों वेक्टर उतने ही मिलते-जुलते होंगे. हम 1 में से दूरी को घटाकर, नतीजों को काम के स्कोर के तौर पर दिखाते हैं. स्कोर जितना ज़्यादा होगा, नतीजे उतने ही काम के होंगे.
तीसरा चरण: मैच की पुष्टि करना
नतीजों की जांच करें. सबसे ऊपर दिखने वाला नतीजा MV-CAPYBARA-003 होना चाहिए. साथ ही, इसका रिलेवंस स्कोर सबसे ज़्यादा होना चाहिए.
यह वही कंटेनर है जिसे इस जांच के हर चरण में ट्रैक किया गया है:
- 📷 सुरक्षा कैमरे के फ़ुटेज में, उसे रात में रियो डि जेनेरो के पोर्ट से जाते हुए देखा गया.
- 🌡️ थर्मल गड़बड़ी का पता लगाने वाली सुविधा से पुष्टि हुई है कि रेफ़्रिजरेशन यूनिट को जान-बूझकर बंद किया गया था.
- 📡 बीकन सिग्नल मैचिंग ने अभी-अभी सिडनी के पास टेलीमेट्री सिग्नेचर का पता लगाया है.
सबूत के तौर पर तीन अलग-अलग तरह के दस्तावेज़. Google Cloud में एआई की तीन अलग-अलग सुविधाएं. एक चोरी किया गया कंटेनर.
🎯 केस बंद हुआ: MV-CAPYBARA-003 को सिडनी के पास देखा गया है!

सेक्शन की खास जानकारी: आपने AlloyDB में पहले से मौजूद एआई इंटिग्रेशन का इस्तेमाल करके, एक सर्च एम्बेडिंग जनरेट की. साथ ही, एक ही एसक्यूएल क्वेरी में कोसाइन सिमिलैरिटी सर्च की. बीकन मैच से, चुराए गए कंटेनर की जगह की पुष्टि हुई. इससे जांच पूरी हो गई.
9. सबूतों की जांच करना
मल्टीमॉडल इमेज विश्लेषण और वेक्टर सर्च की मदद से कंटेनर की पहचान करने के बाद, अब सीधे तौर पर अपने एडिटर में बातचीत वाली Analytics का इस्तेमाल किया जा सकता है. इससे, एसक्यूएल लिखे बिना, सामान्य भाषा का इस्तेमाल करके जांच के डेटा को एक्सप्लोर किया जा सकता है.
पहला चरण: नॉलेज कैटलॉग में डेटा ढूंढना
डेटा एजेंट किट में, यूनिवर्सल सर्च की सुविधा शामिल होती है. इसकी मदद से, Google Cloud एनवायरमेंट में मौजूद डेटा ऐसेट को ढूंढा और एक्सप्लोर किया जा सकता है.
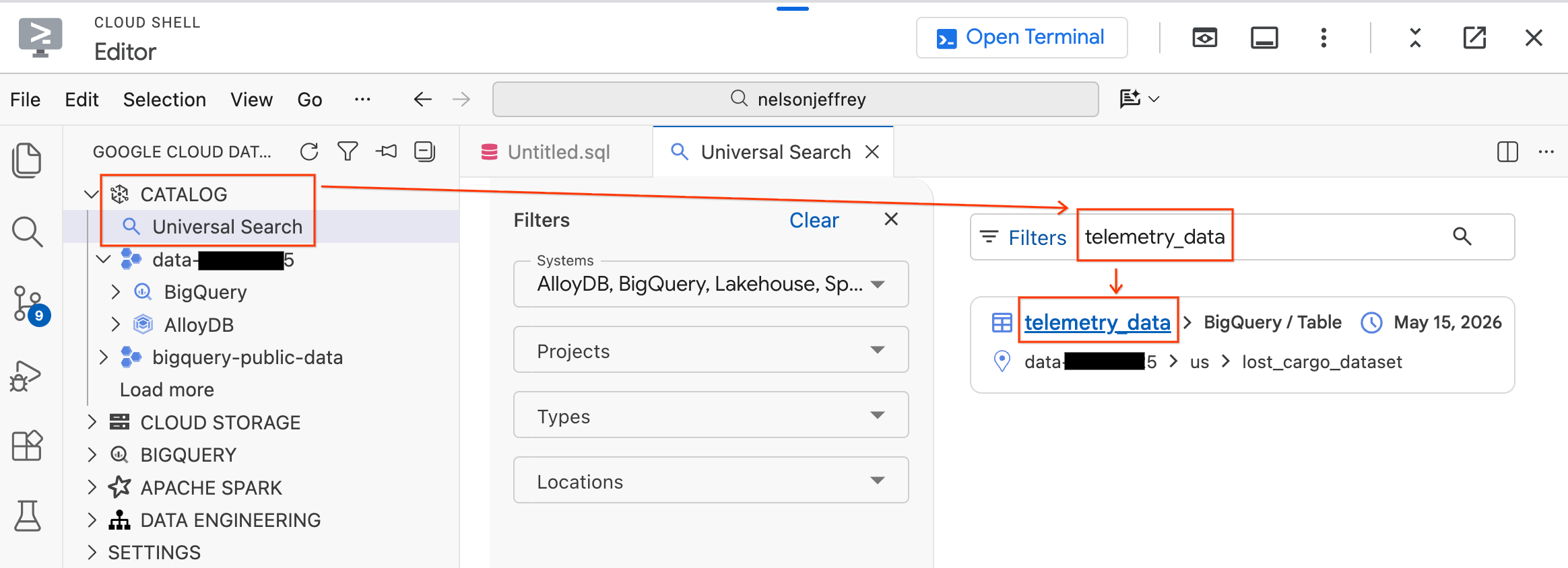
- बाईं ओर मौजूद डेटा एजेंट किट पैनल में, कैटलॉग सेक्शन को बड़ा करें.
- यूनिवर्सल सर्च पर क्लिक करें.
- खोज बार में,
telemetry_dataटाइप करें. - खोज के नतीजों में,
telemetry_dataटेबल (lost_cargo_datasetमें) पर क्लिक करें.
दूसरा चरण: Conversational Analytics लॉन्च करना
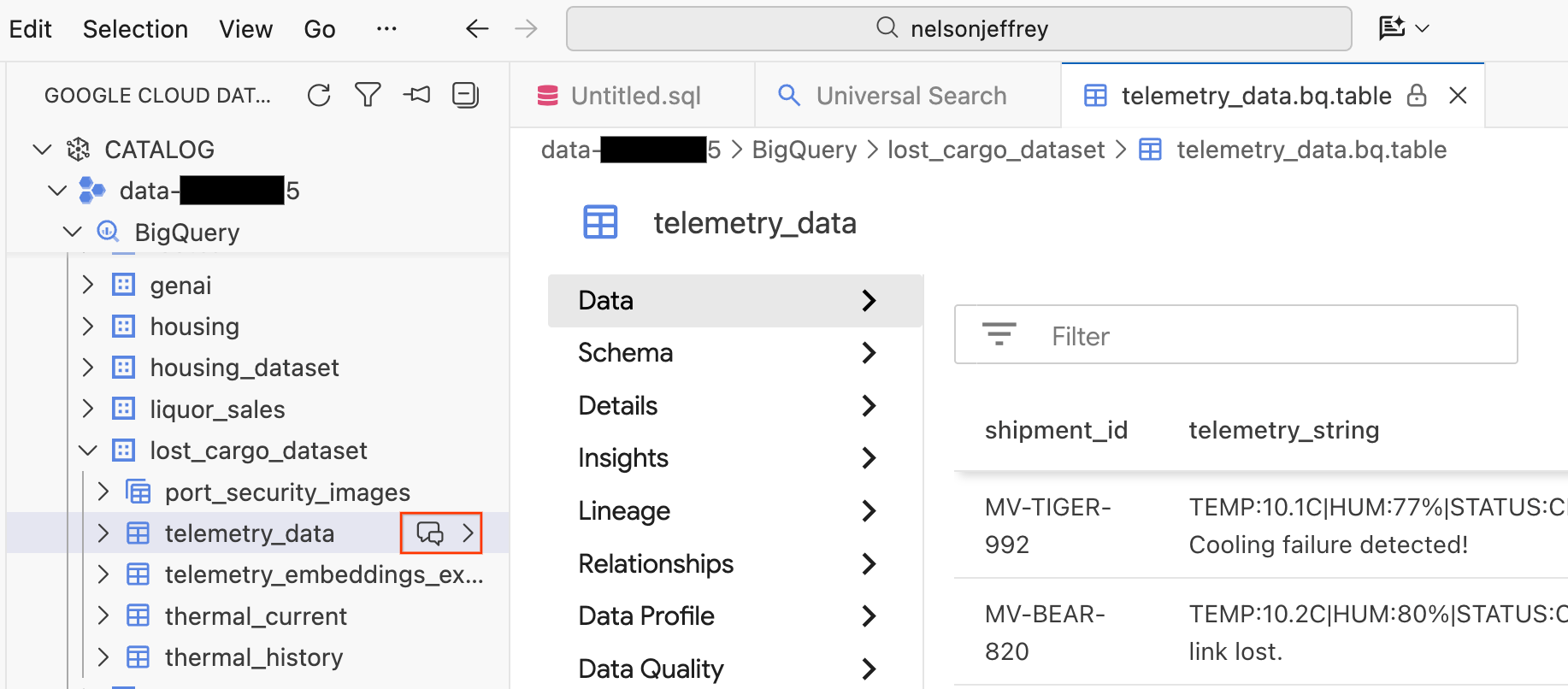
खोज के नतीजे पर क्लिक करने से, डेटा व्यूअर टैब खुलता है. यहां रॉ डेटा की झलक देखी जा सकती है, स्कीमा देखा जा सकता है, और डेटा क्वालिटी की जांच की जा सकती है.
- बाएं पैनल में, आपके BigQuery डेटासेट और टेबल दिखती हैं. नई चैट विंडो खोलने के लिए, चैट करें बटन पर क्लिक करें.
तीसरा चरण: नैचुरल लैंग्वेज में सवाल पूछना
"बातचीत वाली Analytics की सुविधा में आपका स्वागत है!" नाम का नया चैट टैब खुलता है. एजेंट के पास आपकी टेबल के स्कीमा और कॉन्टेंट के बारे में जानकारी होती है.
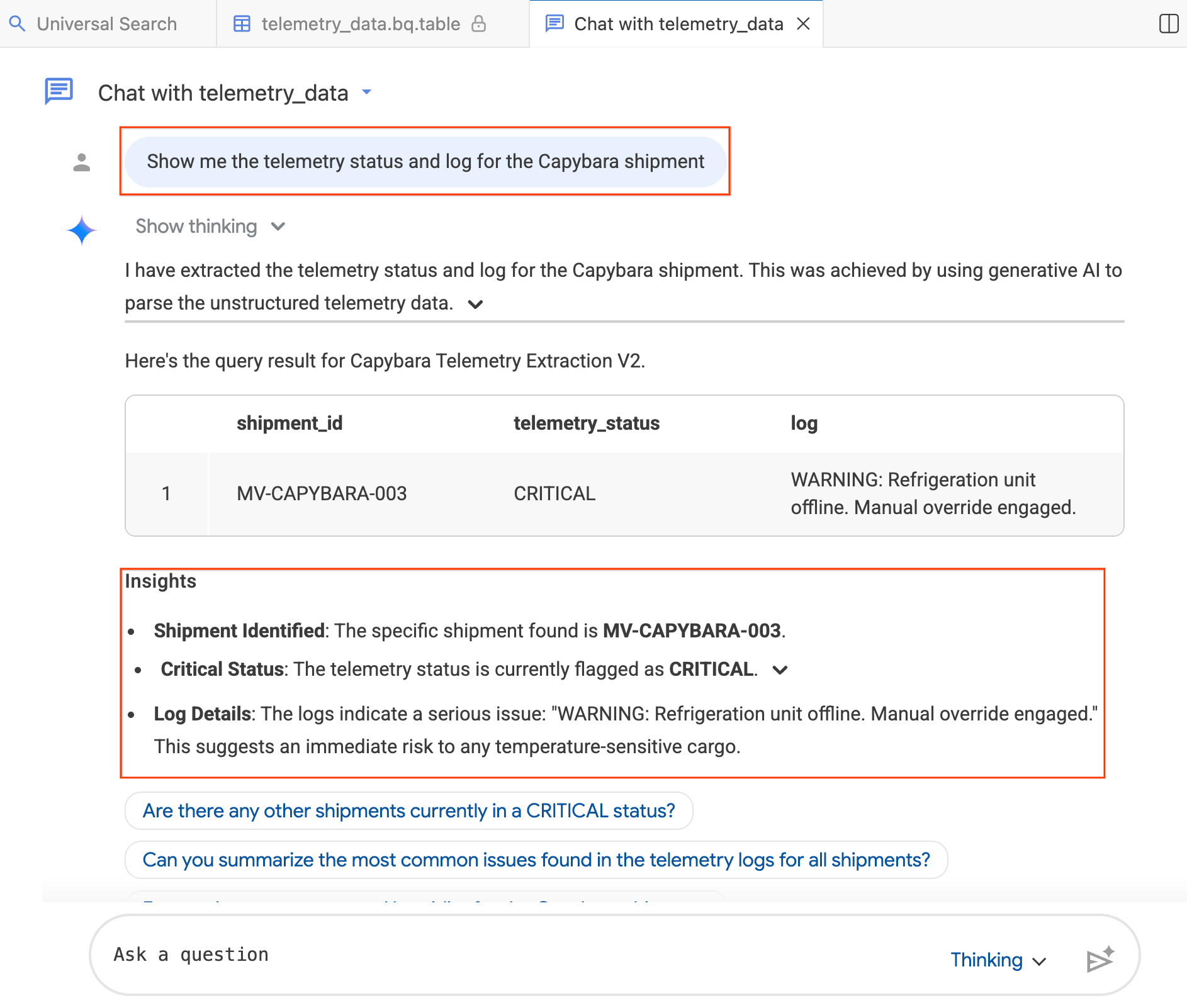
- चैट विंडो में, यह टाइप करें:"मुझे Capybara शिपमेंट के लिए टेलीमेट्री का स्टेटस और लॉग दिखाओ."
- Enter दबाएं.
यह एजेंट आपके सवाल को BigQuery SQL में बदलता है, क्वेरी को लागू करता है, और नतीजे दिखाता है. इन नतीजों में, डेटा टेबल और खास जानकारी, दोनों शामिल होती हैं. आपके पास अपने सवाल की जटिलता के हिसाब से, सोच-विचार करना (ज़्यादा विश्लेषण, ज़्यादा समय लगता है) और तेज़ (जल्दी जवाब मिलते हैं) मोड के बीच टॉगल करने का विकल्प होता है. ये जवाब एआई से जनरेट किए जाते हैं. इसलिए, हो सकता है कि आपके नतीजे यहां दिए गए स्क्रीनशॉट से थोड़े अलग दिखें.
चौथा चरण: फ़ॉलो-अप वाले सवाल पूछना
एजेंट को आपकी बातचीत का कॉन्टेक्स्ट याद रहता है. फ़ॉलो-अप सवाल पूछकर देखें:
- "टेलीमेट्री डेटा में कितने यूनीक शिपमेंट हैं?"
- "फ़्लीट में मौजूद अन्य शिपमेंट में से कितने शिपमेंट की स्थिति फ़िलहाल CRITICAL है?"
सेक्शन की खास जानकारी: आपने अपने डेटासेट का पता लगाने के लिए, नॉलेज कैटलॉग की यूनिवर्सल सर्च सुविधा का इस्तेमाल किया. साथ ही, आम भाषा में जांच के डेटा के बारे में क्वेरी करने के लिए, Conversational Analytics को लॉन्च किया. एआई एजेंट ने आपके सवालों को एसक्यूएल में बदला और ऐसी अहम जानकारी दी जिससे आपके नतीजों की पुष्टि हुई.
10. क्लीन अप करें
अपने Google Cloud खाते से शुल्क लिए जाने से रोकने के लिए, इस लैब में बनाई गई संसाधन मिटाएं. अपने एनवायरमेंट को क्लीन अप करने के लिए, इन कमांड को Cloud Shell Editor में इंटिग्रेट किए गए टर्मिनल में चलाएं. Cloud Shell Editor में, Data Agent Kit का इस्तेमाल किया जा रहा था.
सबसे पहले, अपने एनवायरमेंट वैरिएबल लोड करें:
source scripts/setenv.sh
- BigQuery के संसाधन मिटाएं (सिर्फ़ तब, जब आपको लैब 3 जारी नहीं रखनी है):
अगर आपको लैब 3 का इस्तेमाल जारी रखना है, तो इस चरण को छोड़ दें! लैब 3 में, प्रॉपर्टी ग्राफ़ के विश्लेषण के लिए एक ही BigQuery डेटासेट और कनेक्शन का इस्तेमाल किया जाता है.
अपने BigQuery डेटासेट और कनेक्शन मिटाने के लिए:
# Drop the dataset
bq rm -r -f $PROJECT_ID:lost_cargo_dataset
# Delete the connections
bq rm --connection --location=us-central1 $PROJECT_ID.us-central1.lost_cargo_conn
bq rm --connection --location=us-central1 $PROJECT_ID.us-central1.lost_cargo_alloydb_conn
- Cloud Storage बकेट मिटाएं:
gcloud storage rm --recursive gs://${PROJECT_ID}-lab2
- AlloyDB इंस्टेंस और क्लस्टर मिटाएं:
AlloyDB का इस्तेमाल Lab 3 में नहीं किया जाता है. इसलिए, अब इसे बंद किया जा सकता है.
gcloud alloydb instances delete lost-cargo-instance \
--region=$REGION \
--cluster=lost-cargo-cluster \
--quiet
gcloud alloydb clusters delete lost-cargo-cluster \
--region=$REGION \
--force \
--quiet
- लोकल एनवायरमेंट की सेटिंग मिटाएं:
आखिर में, अपने फ़ाइल फ़ोल्डर से लोकल एनवायरमेंट की सेटिंग वाली फ़ाइल मिटाएं:
rm -f .env
11. बधाई हो!
आपने Lab 2: डेटा का विश्लेषण करना और मल्टीमॉडल इनसाइट पाना को पूरा कर लिया है! आपने हज़ारों कंटेनर वाले पोर्ट से लेकर चोरी की पुष्टि होने और जगह की सटीक जानकारी तक का पता लगाया.
आपने क्या-क्या हासिल किया
- फुटेज स्कैन किया गया: आपने पोर्ट की सुरक्षा से जुड़ी इमेज का विश्लेषण करने के लिए, BigQuery के
AI.GENERATEका इस्तेमाल किया. साथ ही, आपने क्रिमसन रेड रंग के कंटेनर MV-CAPYBARA-003 की पहचान की. - चोरी की पुष्टि की गई: आपने थर्मल सेंसर के डेटा की जांच की. इसमें आपको 64.6°C का संदिग्ध स्पाइक दिखा. आपने
AI.DETECT_ANOMALIESका इस्तेमाल करके यह साबित किया कि जान-बूझकर छेड़छाड़ की गई है. - ट्रैकिंग सिस्टम तैयार किया गया: आपने रीयल-टाइम बीकन मैचिंग के लिए, AlloyDB को pgvector और
google_ml_integrationके साथ कॉन्फ़िगर किया है. - सर्च इंडेक्स बनाया गया: आपने BigQuery में
AI.GENERATEऔरAI.EMBEDका इस्तेमाल करके एम्बेडिंग बनाईं. इसके बाद, उन्हें Cloud Storage में एक्सपोर्ट किया और AlloyDB में इंपोर्ट किया. - बीकन सिग्नल से मैच किया गया: आपने AlloyDB की वेक्टर सर्च सुविधा का इस्तेमाल करके, टेलीमेट्री के फ़्रैगमेंट किए गए सिग्नल को मैच किया. इससे, सिडनी के पास चोरी किए गए कंटेनर का पता चला.
- सबूत की जांच की गई: आपने एडिटर से सीधे तौर पर कन्वर्सेशनल ऐनलिटिक्स का इस्तेमाल करके, आसान भाषा में जांच के डेटा के बारे में क्वेरी की.

अगले चरण
आपको यह पता चल गया है कि कंटेनर कहां है. अब आपको यह पता लगाना है कि इसे किसने बनाया है.
लैब 3: डेटा का इस्तेमाल और एजेंटिक वर्कफ़्लो में, लॉजिस्टिक्स नेटवर्क का प्रॉपर्टी ग्राफ़ बनाया जाएगा. इससे शेल कंपनियों के बीच के संबंधों को मैप किया जा सकेगा. साथ ही, ग्राफ़ से चैट करने के लिए, बातचीत वाली Analytics का इस्तेमाल किया जा सकेगा. इसके अलावा, कंटेनर को वापस पाने के लिए ज़रूरी सुरक्षित क्लीयरेंस कोड ढूंढने के लिए, नॉलेज कैटलॉग को खोजा जा सकेगा.