
1. はじめに

前のラボでは、断片化された配送ログを集計し、貨物トランスポンダをニューヨークまで追跡しました。しかし、到着記録には、税関の検出を避けるためにコンテナが直ちに再ルーティングされたことが示されています。トレイルは、数千ものコンテナが並ぶ広大なリオデジャネイロ港へと続いています。数千ものコンテナの中から適切なコンテナを見つけるのは難しい作業です。
このラボでは、BigQuery の組み込み AI 機能を使用して、標準の SQL を使用して非構造化ポート セキュリティ画像を「読み取り」、センサーデータの熱異常を検出します。次に、ベクトル エンベディングを AlloyDB にエクスポートし、ベクトル検索を実行して、断片化されたテレメトリー信号を欠落しているコンテナに照合します。
演習内容
- BigQuery AI を使用してポートのセキュリティ画像をスキャンし、盗まれたコンテナを特定する
- BigQuery AI を使用して温度異常を検出し、コンテナが紛失したのではなく盗まれたことを確認する
- ベクトル エンベディングを生成して AlloyDB に読み込み、リアルタイム検索を行う
- 断片化されたテレメトリー ビーコン信号を照合して、ベクトル検索を使用して盗まれたコンテナを特定する
- 会話分析を使用して、自然言語で調査データを探索する
必要なもの
- ウェブブラウザ(Chrome など)
- 課金を有効にした Google Cloud プロジェクト
- SQL と Google Cloud コンソールに関する基本的な知識
この Codelab は中級レベルのデベロッパーを対象としています。
この Codelab で作成するリソースの費用は 5 ドル未満です。
2. 始める前に
Cloud Shell の起動
Google Cloud Shell を使用して、コードのダウンロード、設定スクリプトの実行、アプリケーションのデプロイを行います。
- 新しいブラウザタブで、Cloud Shell(shell.cloud.google.com)を開きます。
- 接続したら、プロジェクト ID を設定して環境を確認します。
gcloud config set project <<YOUR_PROJECT_ID>>
export PROJECT_ID=$(gcloud config get-value project)
export REGION=us-central1
次のようなメッセージが表示されます。
Your active configuration is: [cloudshell-####] Updated property [core/project]
リポジトリのクローンを作成する
Cloud Shell 環境に Codelab リポジトリのクローンを作成します。
cd ~/
git clone --filter=blob:none --no-checkout https://github.com/GoogleCloudPlatform/devrel-demos.git
cd ~/devrel-demos
git sparse-checkout init --cone
git sparse-checkout set codelabs/bigquery-alloydb-insights
git checkout main
cd codelabs/bigquery-alloydb-insights/
API を有効にする
Cloud Shell で次のコマンドを実行して、このラボに必要なすべての API を有効にします。
gcloud services enable \
aiplatform.googleapis.com \
bigquery.googleapis.com \
bigqueryconnection.googleapis.com \
alloydb.googleapis.com
実行が成功すると、次のようなメッセージが表示されます。
Operation "operations/..." finished successfully.
3. 環境をセットアップする
画像とテレメトリー データを分析する前に、このラボのインフラストラクチャを設定する必要があります。2 つのスクリプトを実行します。1 つは AlloyDB のプロビジョニングをバックグラウンドで開始し、もう 1 つは必要なすべての BigQuery リソースを作成します。
ステップ 1: AlloyDB のデプロイを開始する(バックグラウンド)
AlloyDB クラスタのプロビジョニングには約 10 分かかるため、最初に開始して、BigQuery のセクションを進めている間、バックグラウンドで実行します。スクリプトは、アクティブなプロジェクト設定をローカルの .env ファイルに自動的に記録します。これにより、Cloud Shell ターミナルが閉じたり再起動したりしても、構成が保存されます。
chmod +x scripts/setup_alloydb.sh
nohup ./scripts/setup_alloydb.sh > /dev/null 2>&1 &
echo "AlloyDB deployment started in background (PID: $!)"
ステップ 2: 設定スクリプトを実行する
このスクリプトは、BigQuery データセット、Cloud リソース接続、IAM 権限付与、GCS バケットを作成し、このラボで分析するすべてのセンサーデータを読み込みます。また、.env ファイルに保存されている環境変数を読み取って検証します。
chmod +x scripts/setup_lab.sh
./scripts/setup_lab.sh
スクリプトの実行には約 1 分かかります。完了すると、作成されたすべての概要が表示されます。
📝 環境のリセットに関する注 このラボの途中で Cloud Shell セッションがタイムアウトまたは再起動した場合は、次のコマンドを実行してターミナル変数をすぐに復元できます。
source scripts/setenv.sh
ステップ 3: Cloud Shell エディタを起動する
これまでは Cloud Shell ターミナルを使用していましたが、ここで Cloud Shell エディタに切り替えます。Cloud Shell エディタは、BigQuery のサポートが統合された VS Code のようなワークスペースを提供します。
- 画面下部の Cloud Shell ターミナル ペインで、[エディタを開く] ボタンをクリックして、Cloud Shell エディタ ワークスペースを起動します。

ステップ 4: Data Agent Kit 拡張機能をインストールする
Google Cloud Data Agent Kit 拡張機能は、エディタ内で Google Cloud データ サービスと深く統合されており、コンテキストを切り替えることなく BigQuery、AlloyDB、Cloud Storage などを操作できます。
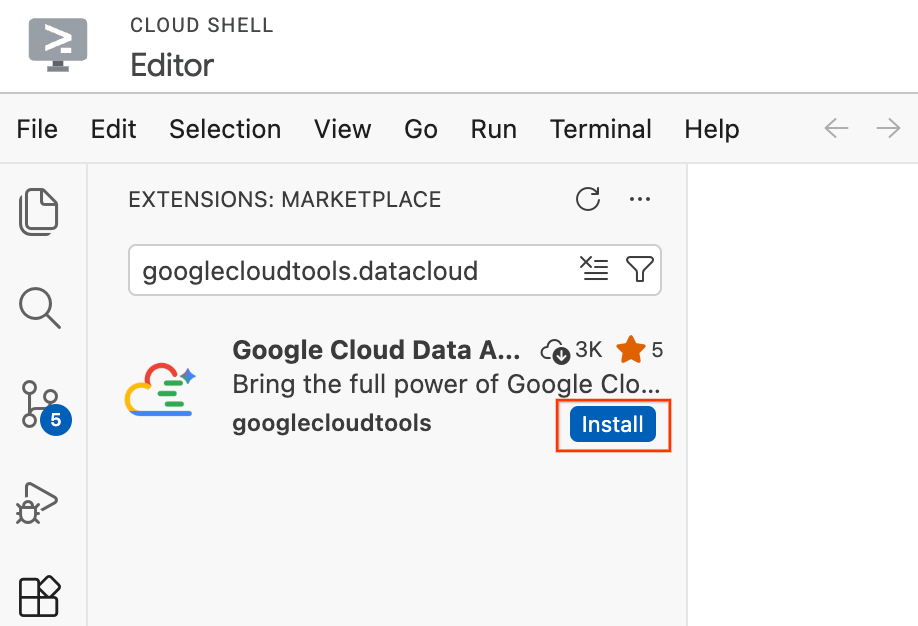
- Cloud Shell エディタで、画面の左端にあるアクティビティ バーの [拡張機能] アイコン(4 つの正方形のようなアイコン)をクリックします。
- [拡張機能] ペインの上部にある検索バーに「
googlecloudtools.datacloud」と入力します。 - Google Cloud が公開した Google Cloud Data Agent Kit という名前の拡張機能を見つけます。
- [Install] ボタンをクリックします。
- 「発行元「googlecloudtools」とその拡張機能を信頼しますか?」というメッセージが表示されます。[発行元を信頼してインストール] をクリックして続行します。
ステップ 5: 拡張機能を認証して構成する
インストール後、拡張機能を Google Cloud プロジェクトに接続します。
- 「Google Cloud Data Agent Kit Onboarding」というタイトルのオンボーディング ページが自動的に開きます。[Sign in to Google Cloud] をクリックします。ブラウザのプロンプトに沿ってアクセスを許可します。
- [設定中] モーダルが表示されます。拡張機能は、Google Cloud CLI などの必要な依存関係を自動的に確認します。
- [構成の概要] セクションで、プロジェクト フィールドを見つけます。プルダウンをクリックして、Google Cloud プロジェクトを選択します。リージョンを
us-central1に設定します。 - セットアップ チェックが完了するまで待ちます。[Setup Complete!](セットアップ完了)と表示されたら、[Configure MCP Servers](MCP サーバーを構成)をクリックします。
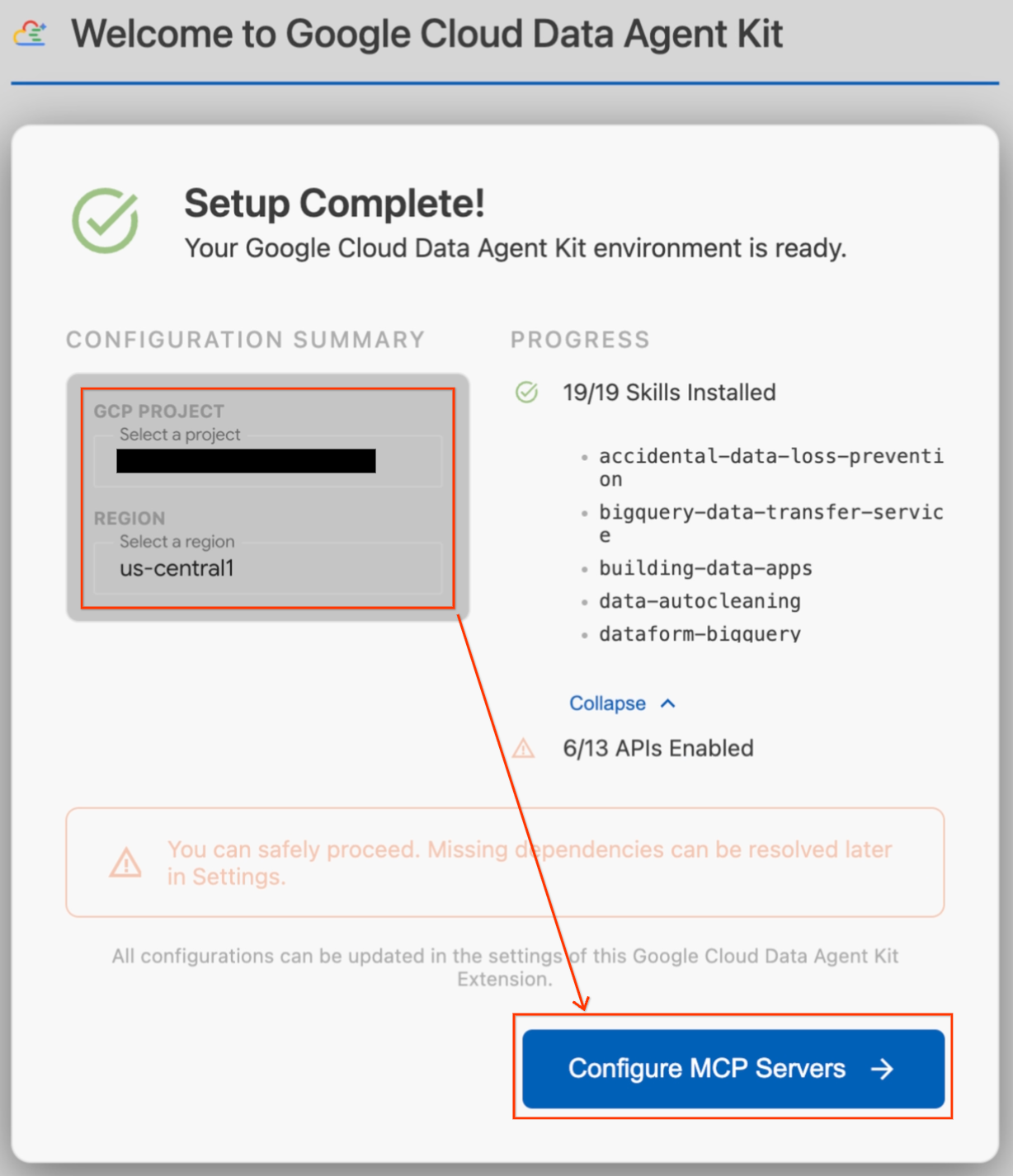
- [MCP 構成] で [BigQuery] と [AlloyDB] を選択し、[始める] をクリックします。
ステップ 6: 構成オプションを確認する
設定が完了すると、[Google Cloud Data Agent Kit を使ってみる] ダッシュボードが表示されます。
- [設定と構成] で、[開始] をクリックします。
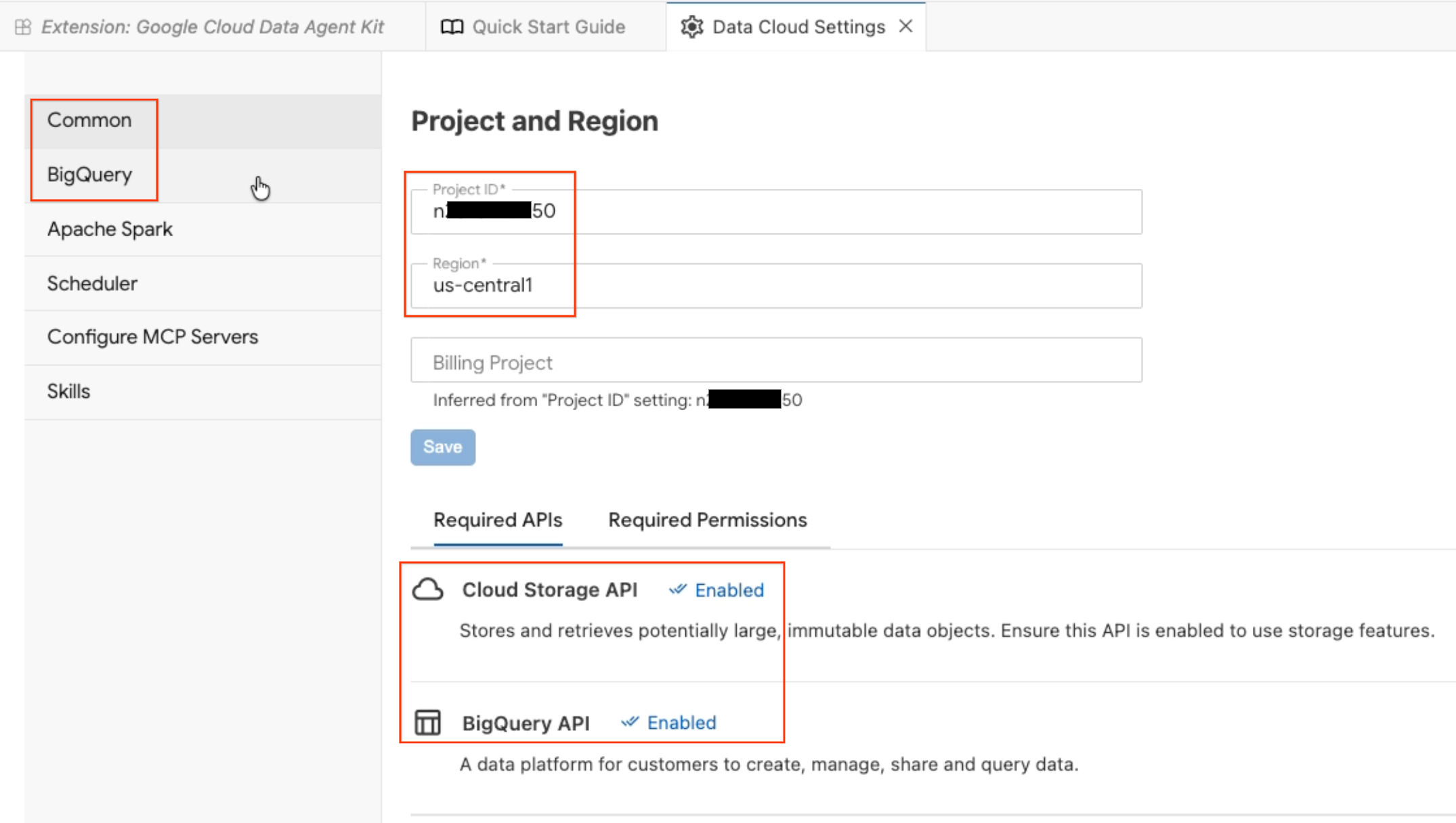
- [データ エージェントの構成] パネルが開きます。次のタブを確認します。
- プロジェクトとリージョン: 選択したプロジェクト ID を確認し、必要な API(Cloud Storage API、BigQuery API、Catalog API、AlloyDB API)が有効になっていることを確認します。
- BigQuery: BigQuery クエリのデフォルトの場所を構成します。リージョン
us-central1を使用します。 - MCP サーバーを構成する: AI エージェントがデータを安全に操作できるようにする有効な MCP サーバー(BigQuery、Notebooks、AlloyDB など)を表示します。
- スキル: エージェントに複雑なデータタスク用の特殊な機能を提供する事前構築済みのスキルをご覧ください。
ステップ 7: BigQuery で検証する
一般公開データセットに対して簡単なクエリを実行して、すべてが機能していることを確認します。
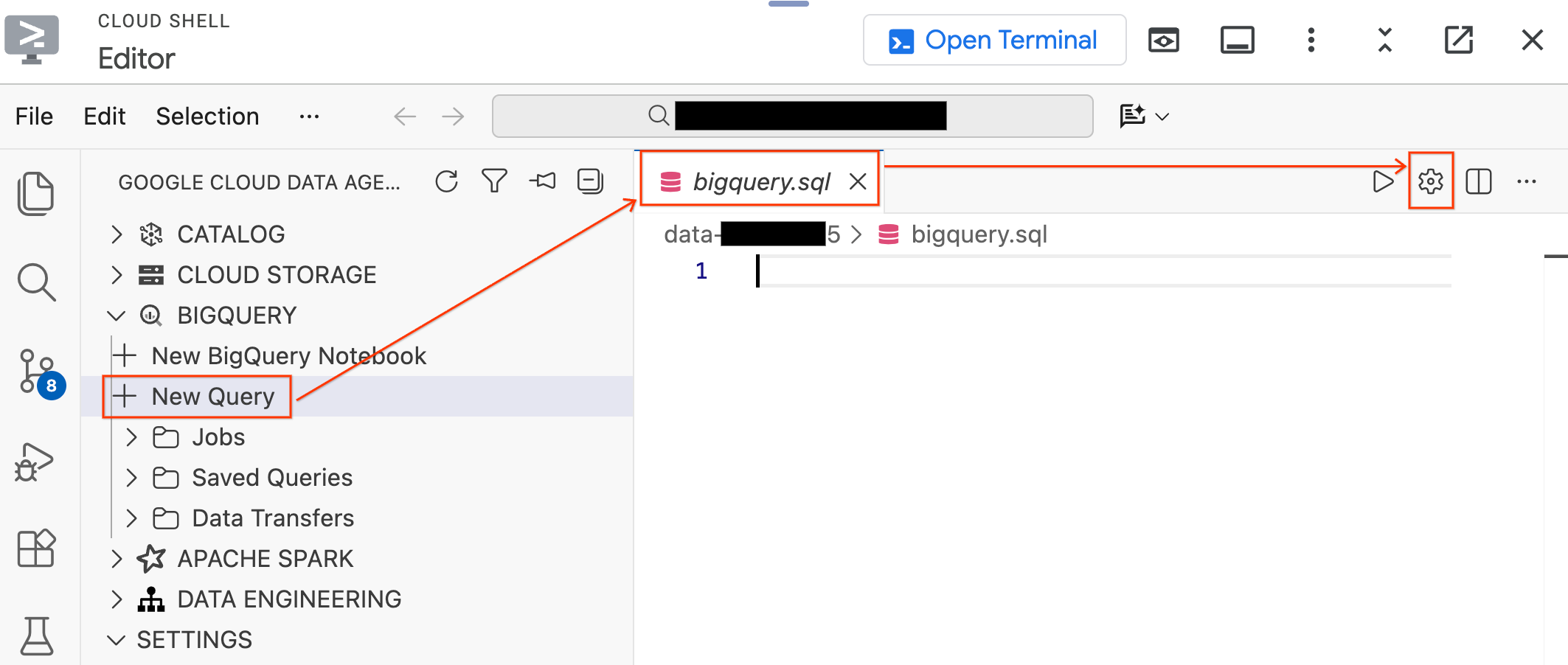
- 左側の [Data Agent Kit] ペインで、[BigQuery] セクションを開き、[新しいクエリ] をクリックして新しいクエリエディタ タブを開きます。
Ctrl+S(Windows/Linux)またはCmd+S(macOS)を押してファイルを保存し、bigqueryという名前を付けます。このタブは、すべての BigQuery オペレーションで使用されます。bigquery.sqlタブがアクティブな状態で [クエリ設定] をクリックし、[データソース] として [BigQuery] を選択して、[保存] をクリックします。
- 一般公開データセットに対して次のクエリを実行します。
SELECT
term,
MIN(rank) AS peak_rank,
ROUND(AVG(score)) AS avg_score
FROM `bigquery-public-data.google_trends.top_terms`
WHERE refresh_date = DATE_SUB(CURRENT_DATE(), INTERVAL 2 DAY)
GROUP BY term
ORDER BY peak_rank ASC
LIMIT 10;
- 過去数日間の Google 検索トレンドの上位 10 件が表示されます。結果が表示されれば、拡張機能が接続され、使用できる状態になっています。
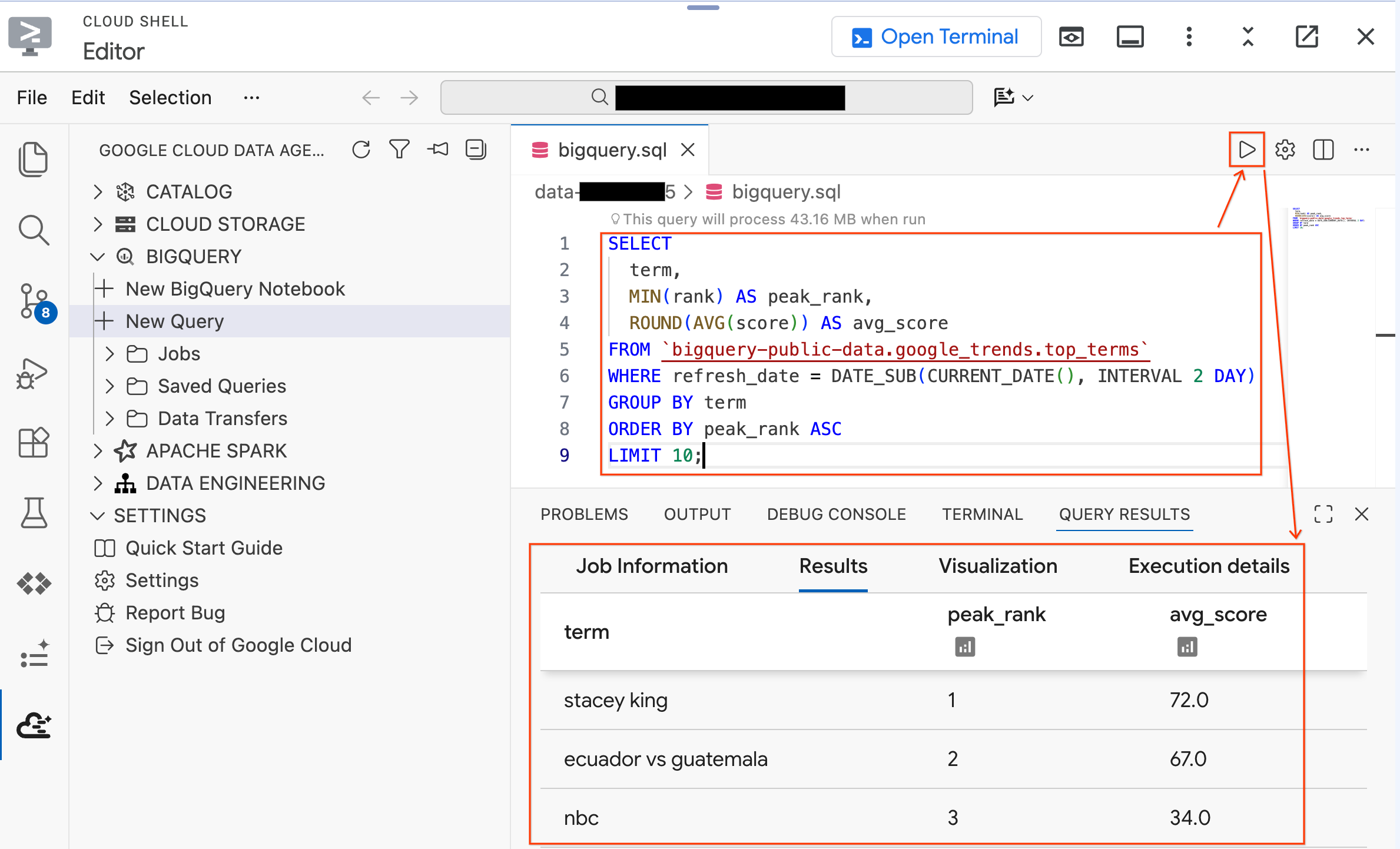
次に、設定スクリプトで作成したラボデータに対してクエリを試します。既存のクエリを次のクエリに置き換えます。
SELECT * FROM `lost_cargo_dataset.telemetry_data` LIMIT 5;
shipment_id 列と telemetry_string 列を含むテレメトリー ログエントリが表示されます。これは、ラボ全体で分析するデータです。
セクションのまとめ: バックグラウンドで AlloyDB のデプロイを開始し、設定スクリプトを実行して、Data Agent Kit 拡張機能で Cloud Shell エディタを構成しました。
4. セキュリティ映像のスキャン
調査チームは、リオデジャネイロ港の防犯カメラの映像を復元しました。映像には、コンテナが並んでいる様子が映っています。ラボ 1 で、ターゲットのコンテナが赤色であることがわかっています。どの赤色のコンテナがターゲットなのかを特定する必要があります。
BigQuery が Cloud Storage のセキュリティ画像を「認識」できるようにするオブジェクト テーブルを作成し、AI.GENERATE 関数を使用して、各画像から構造化データを抽出するように Gemini に指示します。
ステップ 1: オブジェクト テーブルを作成する
オブジェクト テーブルは、Cloud Storage に保存されている非構造化ファイル(画像、PDF、音声)のインデックスとして機能する特別な BigQuery テーブルです。ファイルが BigQuery にコピーされるのではなく、クエリ可能な参照が作成され、AI 関数がファイルを参照できるようになります。
エディタの [bigquery.sql] タブで、次のステートメントを実行して、プロジェクトのバケットにあるポート セキュリティ イメージを指すオブジェクト テーブルを作成します。
SET @@location = 'us-central1';
EXECUTE IMMEDIATE CONCAT("""
CREATE OR REPLACE EXTERNAL TABLE `lost_cargo_dataset.port_security_images`
WITH CONNECTION `us-central1.lost_cargo_conn`
OPTIONS (
object_metadata = 'SIMPLE',
uris = ['gs://""", @@project_id, """-lab2/images/*']
);
""");
BigQuery で確認できる内容を簡単に見てみましょう。
SELECT uri, content_type FROM `lost_cargo_dataset.port_security_images` LIMIT 5;
各行は、Cloud Storage 内の 1 つの画像ファイルを表します。BigQuery は、これらの画像を AI モデルに直接渡すことができるようになりました。
ステップ 2: セキュリティ画像を分析する
次に、BigQuery の AI.GENERATE 関数を使用して、各セキュリティ画像を分析します。この単一の SQL クエリは、Gemini にすべての画像を調べて構造化データを返すよう指示します。
SELECT
uri,
AI.GENERATE(
(
'Examine this port security image. Identify any shipping container IDs visible on the container and provide a one-word color of the container.',
ref
),
output_schema => 'detected_container_id STRING, color STRING'
).* EXCEPT (full_response, status)
FROM `lost_cargo_dataset.port_security_images`;
ステップ 3: ターゲット コンテナを特定する
結果を確認します。color 列に 「赤」(または赤のバリエーション)が表示されている行を探します。detected_container_id をメモします。ターゲットは MV-CAPYBARA-003 です。
ステップ 4: ビジュアル マッチを確認する
エディタを離れることなく、分析された実際の画像を表示するには:
- 左側の [Data Agent Kit] ペインで [Cloud Storage] をクリックします。
- バケット(
YOUR_PROJECT_ID-lab2/images/)を開き、赤いコンテナに対応する画像ファイルをクリックして、エディタで直接表示します。
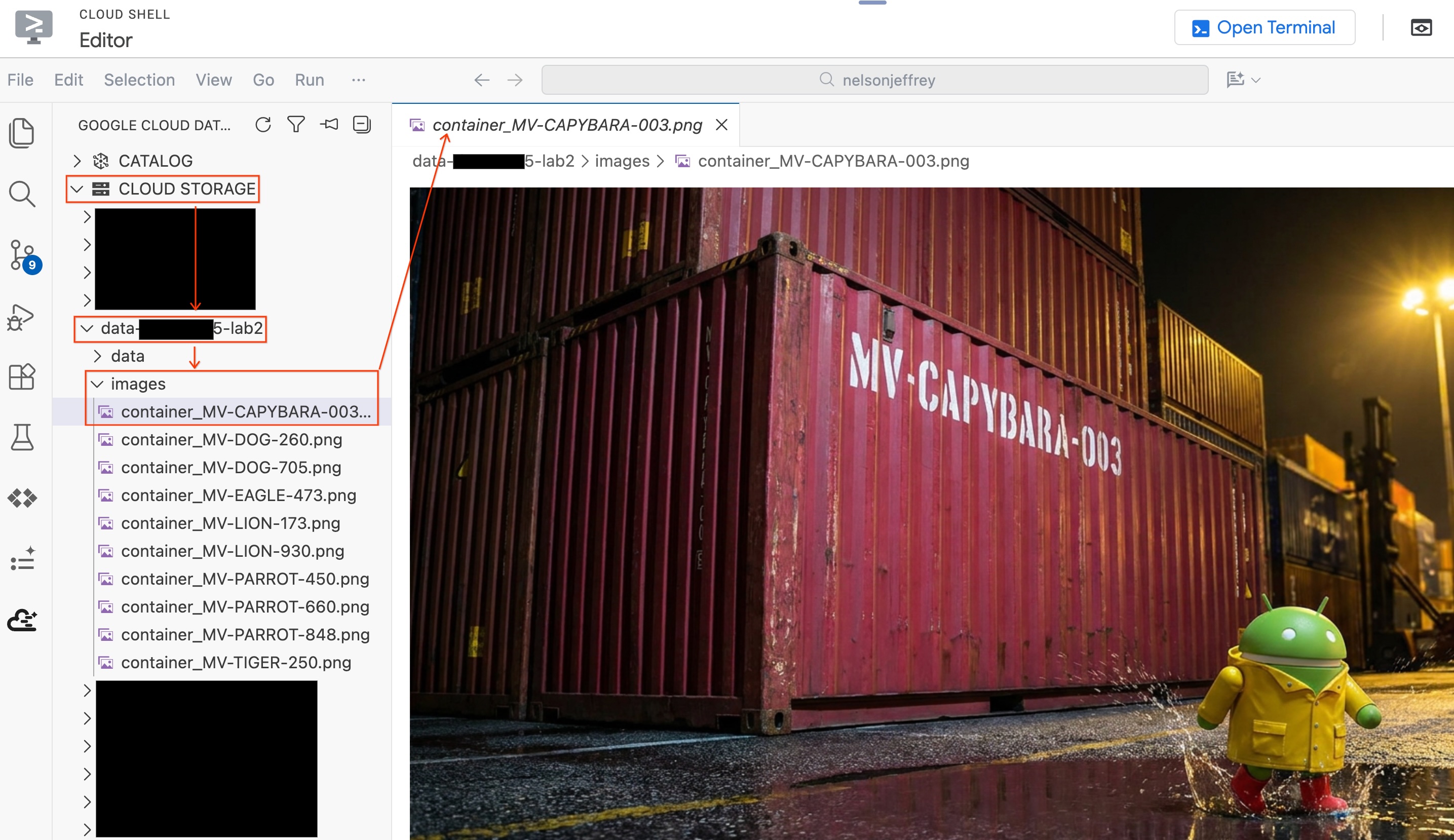
セクションのまとめ: オブジェクト テーブルを作成して、BigQuery にポート セキュリティ イメージへのアクセス権を付与し、AI.GENERATE を使用して各イメージから構造化されたコンテナデータを抽出しました。Red コンテナは MV-CAPYBARA-003 として識別されています。
5. 盗難の確認
紛失したコンテナは MV-CAPYBARA-003 と特定されていますが、盗難に遭ったのか、単に置き忘れたのかを教えてください。マニフェスト ログには、この特定のコンテナが環境センサー SENS-99 の隣に駐車されたことが示されています。窃盗犯がコンテナを移動する前にコンテナの冷蔵ユニットを意図的に無効にした場合、SENS-99 は急激な排熱の急上昇を記録している可能性があります。
異常検出を使用して、コンテナが改ざんされたことを証明します。
- まず、過去のベースラインを確認します。過去数時間の
SENS-99の通常の測定値は次のとおりです。
SELECT * FROM `lost_cargo_dataset.thermal_history`
ORDER BY reading_time DESC
LIMIT 50;
温度が 75 ~ 78°F の狭い範囲で推移していることに注目してください。これが正常な状態です。
- 同じセンサーから取得した現在のバッチの測定値を見てみましょう。
SELECT * FROM `lost_cargo_dataset.thermal_current`
ORDER BY thermal_reading DESC
LIMIT 50;
上部付近に 148.4°F と表示されています。それ以外は正常のようです。この急上昇は、冷蔵ユニットの故障または意図的な改ざんを示します。Let's find out.(HONEY の節約額を確認してみましょう。)
- 異常検出を実行します。BigQuery の
AI.DETECT_ANOMALIESは、事前トレーニング済みの TimesFM 基盤モデルを使用して時系列パターンを分析し、外れ値を自動的にフラグ設定します。モデルのトレーニングは必要ありません。
SELECT *
FROM AI.DETECT_ANOMALIES(
TABLE `lost_cargo_dataset.thermal_history`,
TABLE `lost_cargo_dataset.thermal_current`,
data_col => 'thermal_reading',
timestamp_col => 'reading_time',
id_cols => ['sensor_id']
)
WHERE is_anomaly = TRUE;
- 結果を確認します。148.4°F の測定値は、異常確率が高い異常としてフラグが設定され、コンテナ エリアの近くで異常な事象が発生したことが確認されます。
セクションのまとめ: BigQuery の AI.DETECT_ANOMALIES 関数を使用して、事前トレーニング済みの TimesFM モデルを活用しました。単一の SQL クエリを実行することで、複雑な ML コードを記述したり、モデルをゼロからトレーニングしたりすることなく、外れ値を自動的に特定し、異常な改ざんイベントを分離しました。
6. トラッキング システムの準備
コンテナが盗難されたことが確認され、リオデジャネイロにはありません。フリート内の各コンテナは、センサーの読み取り値、GPS フラグメント、ステータスログなどのテレメトリー ビーコン信号をブロードキャストします。盗難されたコンテナのビーコンがまだ送信されている場合は、既知のシグネチャと照合して見つけることができます。
BigQuery はこれまで行ってきた分析作業に優れていますが、コンテナをリアルタイムで特定するには、低レイテンシの運用クエリが必要です。AlloyDB は、フルマネージドの PostgreSQL 互換データベースであり、まさにこの目的のために構築されています。つまり、ライブ トラッキング システムに十分な速度でベクトル検索クエリを実行できます。テレメトリー エンベディングを AlloyDB に読み込み、ビーコン シグナルの照合に使用します。
先ほどバックグラウンドで開始した AlloyDB クラスタは、すでに準備が整っているはずです。エディタから直接構成しましょう。
ステップ 1: エディタから AlloyDB に接続する
Cloud コンソールに切り替える代わりに、Data Agent Kit 拡張機能を使用して AlloyDB に直接接続できます。
- 左側の [Data Agent Kit] ペインの [BigQuery] セクションで、[New Query] をクリックして新しいクエリエディタ タブを開きます。
Ctrl+S(Windows/Linux)またはCmd+S(macOS)を押してファイルを保存し、alloydbという名前を付けます。このタブは、すべての AlloyDB クエリに使用されます。- 歯車アイコンをクリックして、[クエリ設定] モーダルを開きます。
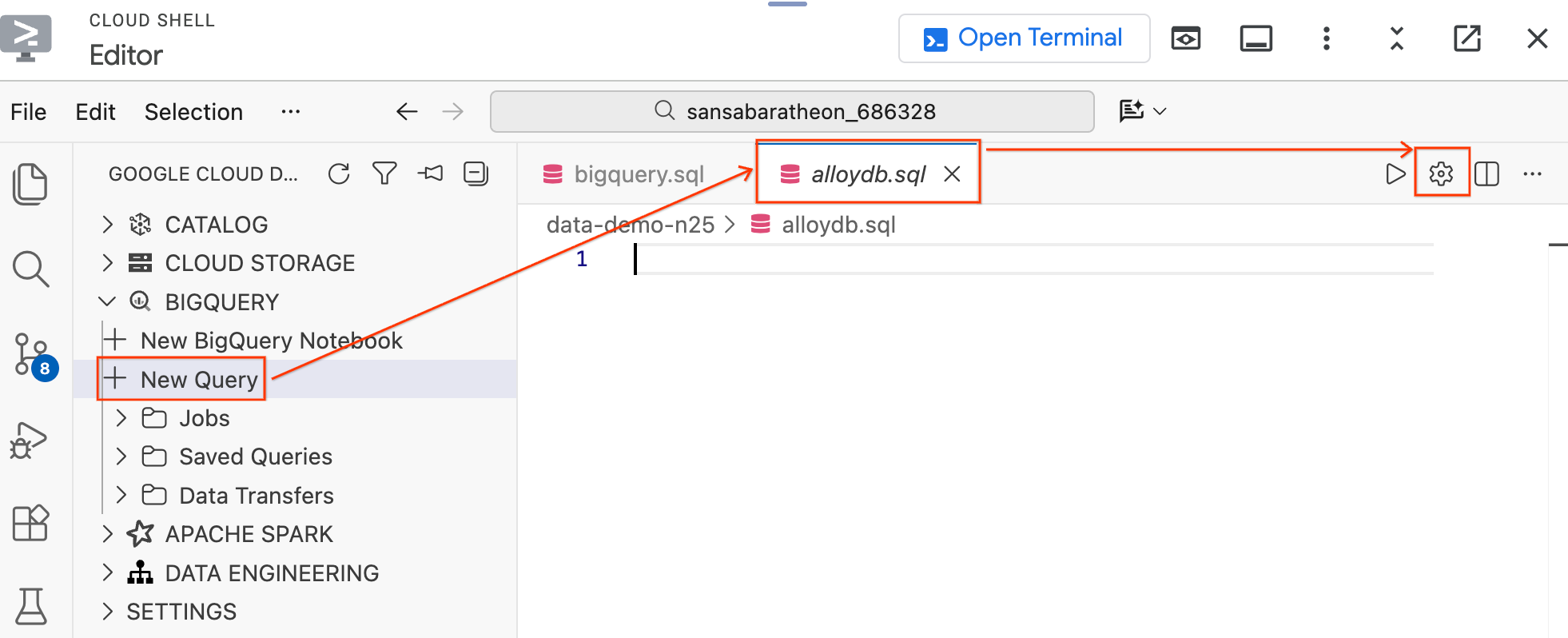
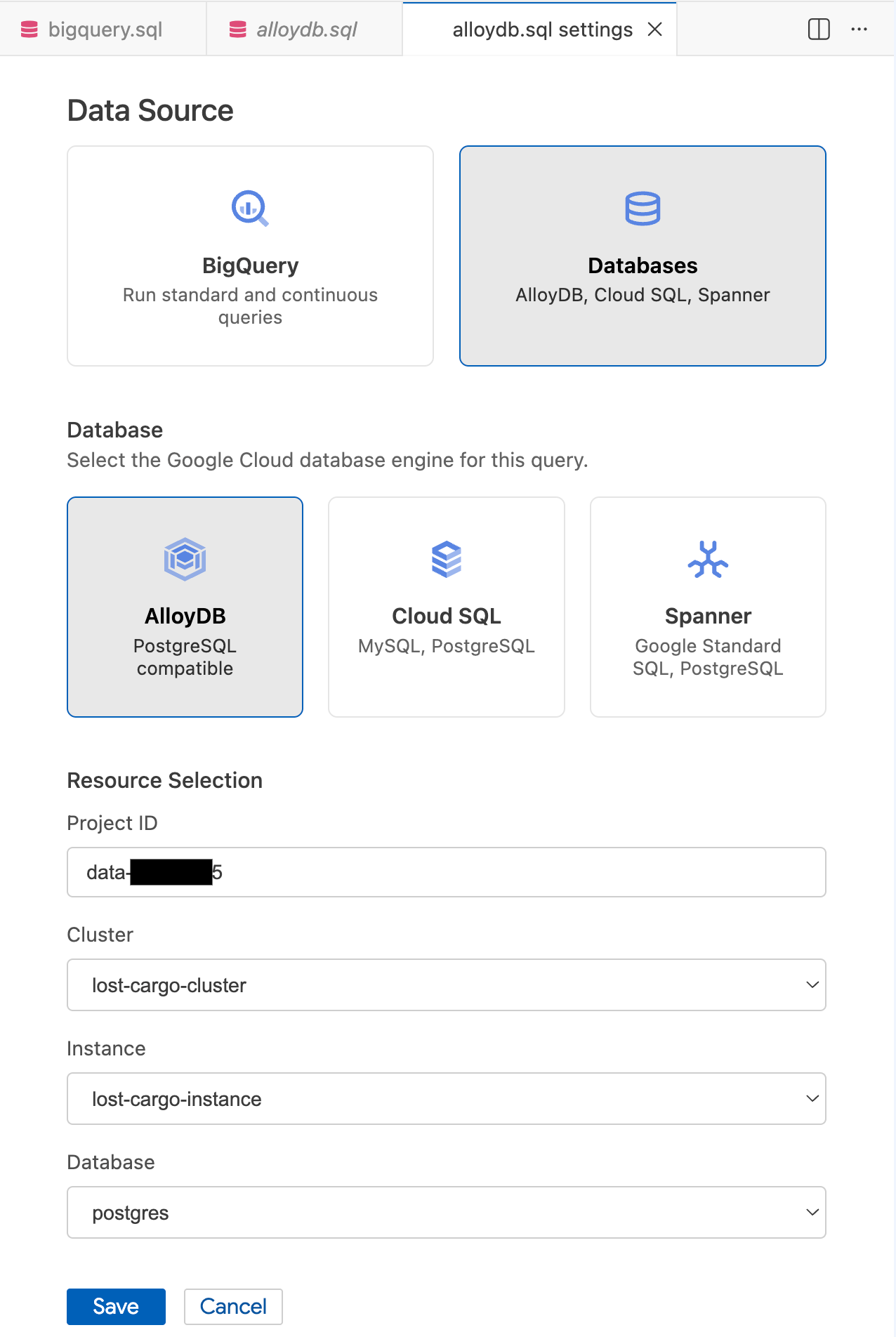
- [クエリの設定] モーダルの [データソース] で、[データベース] を選択します。
- [データベース] で [AlloyDB] を選択します。
- [リソースの選択] の詳細を入力します。
- Project ID: Google Cloud プロジェクト ID を入力します。
- クラスタ:
lost-cargo-clusterを選択します。 - インスタンス:
lost-cargo-instanceを選択します。 - データベース:
postgresを選択します。
- [保存] をクリックします。
ステップ 2: ベクトル拡張機能を有効にしてテーブルを作成する
AlloyDB に接続したので、必要な AI 拡張機能を有効にして、埋め込みテレメトリー データを受け取るテーブルを作成する必要があります。
- アクティブな
.sqlタブで、次のコマンドを貼り付けて、必要な拡張機能を有効にします。
CREATE EXTENSION IF NOT EXISTS vector;
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
- テキストをハイライト表示し、エディタの右上にある [クエリを実行] ボタン(再生アイコン)をクリックします。
- 画面下部の [クエリ結果] ターミナル パネルを確認します。
Statement executed successfullyと表示されているはずです。
- 次に、エディタのテキストを次のステートメントに置き換えて、テレメトリー テーブルを作成します。
CREATE TABLE IF NOT EXISTS vessel_telemetry (
entry_id SERIAL PRIMARY KEY,
shipment_id VARCHAR(50),
telemetry_string TEXT,
embedding_vector vector(768)
);
- このクエリを前回と同様に実行します。下部のパネルで、正常に実行されたことを確認します。
vector(768) 型は、有効にした pgvector 拡張機能から取得されます。768 ディメンションは、BigQuery でエンベディングの生成に使用する Google の text-embedding-005 モデルの出力と一致します。
セクションのまとめ: Cloud Shell エディタから AlloyDB に直接接続し、pgvector 拡張機能と google_ml_integration 拡張機能を有効にして、ターゲット テーブルを作成しました。これで、AlloyDB はリアルタイムのテレメトリー マッチングの運用バックエンドとして機能する準備が整いました。
7. 検索インデックスの構築
次に、テレメトリー データを AlloyDB に取り込んで、リアルタイムのビーコン マッチングを可能にする必要があります。未加工のテレメトリー ログは、整理されておらず、長さも一定ではないため、類似性検索には適していません。BigQuery の AI 関数を使用して、Gemini で各ログを要約し、各要約を 768 次元のベクトル エンベディングに変換します。次に、拡充されたデータを Cloud Storage にエクスポートし、AlloyDB にインポートします。
ステップ 1: BigQuery でエンベディングを生成する
エディタのタブを bigquery.sql に戻します(BigQuery への接続は維持されます)。
次に、次のクエリを実行して、Gemini で各テレメトリー ログを要約し、ベクトル エンベディングを生成します。
CREATE OR REPLACE TABLE `lost_cargo_dataset.telemetry_embeddings_export` AS
WITH summarized_telemetry AS (
SELECT
shipment_id,
telemetry_string,
AI.GENERATE(
CONCAT('Summarize this telemetry log for vector search: ', telemetry_string)
).result AS summary
FROM `lost_cargo_dataset.telemetry_data`
),
telemetry_embeddings AS (
SELECT
shipment_id,
telemetry_string,
AI.EMBED(summary, endpoint => 'text-embedding-005').result AS embedding
FROM summarized_telemetry
)
SELECT
shipment_id,
telemetry_string,
TO_JSON_STRING(embedding) AS embedding_vector
FROM telemetry_embeddings;
ステップ 2: 拡充されたデータをプレビューする
エクスポートする前に、作成した内容を確認します。次のクエリは、配送 ID と、各概要とエンベディングの最初の 80 文字を表示します。
SELECT
shipment_id,
SUBSTR(telemetry_string, 1, 80) AS telemetry_preview,
SUBSTR(embedding_vector, 1, 80) AS embedding_preview
FROM `lost_cargo_dataset.telemetry_embeddings_export`
LIMIT 5;
各行には、配送 ID、元のテレメトリー ログ、768 次元のエンベディング ベクトルが含まれています。これは、AlloyDB に push するデータです。
ステップ 3: エンベディングを Cloud Storage にエクスポートする
BigQuery の EXPORT DATA ステートメントを使用して、エンベディング テーブルを CSV ファイルとしてラボの GCS バケットに書き込みます。
EXECUTE IMMEDIATE CONCAT("""
EXPORT DATA OPTIONS (
uri = 'gs://""", @@project_id, """-lab2/data/embeddings_export/*.csv',
format = 'CSV',
overwrite = true,
header = false
) AS
SELECT
shipment_id,
telemetry_string,
embedding_vector
FROM `lost_cargo_dataset.telemetry_embeddings_export`;
""");
ステップ 4: Cloud Storage から AlloyDB にインポートする
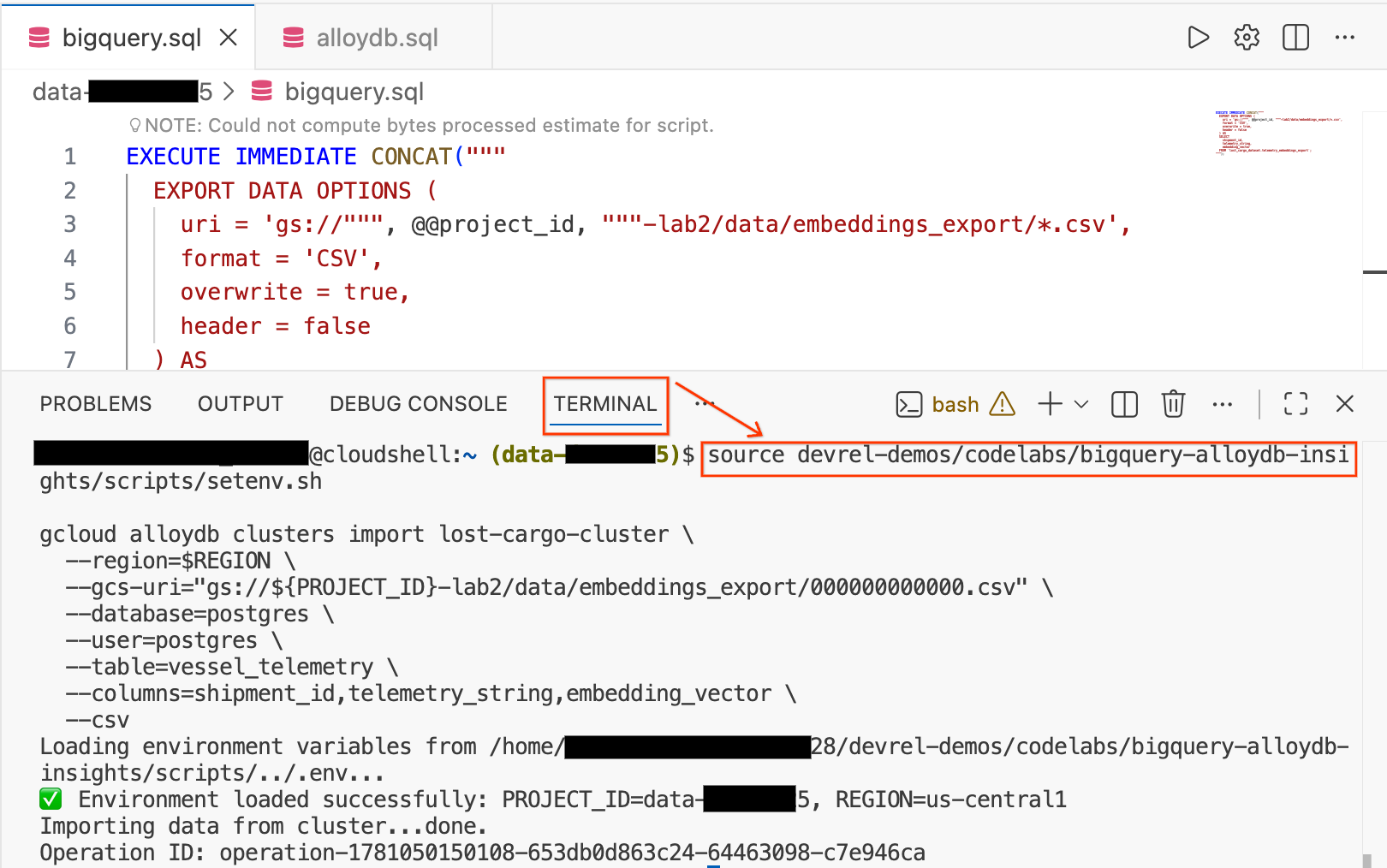
- Cloud Shell エディタで、画面下部の [ターミナル] タブをクリックして、ターミナル セッションを開きます。
- 次のコマンドを実行して、環境を読み込み、CSV ファイルを AlloyDB の
vessel_telemetryテーブルに直接インポートします。
source devrel-demos/codelabs/bigquery-alloydb-insights/scripts/setenv.sh
gcloud alloydb clusters import lost-cargo-cluster \
--region=$REGION \
--gcs-uri="gs://${PROJECT_ID}-lab2/data/embeddings_export/000000000000.csv" \
--database=postgres \
--user=postgres \
--table=vessel_telemetry \
--columns=shipment_id,telemetry_string,embedding_vector \
--csv
セクションのまとめ: BigQuery の AI 関数を使用してテレメトリー データを要約して埋め込み、結果を CSV として Cloud Storage にエクスポートしてから、gcloud を使用して AlloyDB にインポートしました。運用追跡データベースが読み込まれ、準備が整いました。
8. ビーコン シグナルの照合
シドニー近郊のフィールド チームが、断片化されたテレメトリー ビーコン信号を傍受しました。部分ログは次のようになります。
「冷蔵ユニットがオフラインです。手動でオーバーライドします。」
これが盗まれたコンテナから送信された場合、シグナルが不完全であっても、AlloyDB のベクトル検索で一致させることができます。これは、AlloyDB が構築されたまさにリアルタイムの運用クエリです。
ステップ 1: インポートされたデータを確認する
エディタのタブを alloydb.sql に戻します(AlloyDB に接続されたままになります)。
次のコマンドを実行して、テレメトリー データが正常に読み込まれたことを確認します。
SELECT shipment_id, LEFT(telemetry_string, 80) AS telemetry_preview
FROM vessel_telemetry
LIMIT 10;
shipment_id 値とテレメトリー テキストを含む行が表示されます。これらはフリートのテレメトリー シグネチャであり、リアルタイム マッチングの準備が整いました。
ステップ 2: 見つからないコンテナを検索する
次に、AlloyDB の google_ml_integration 拡張機能を使用して、インターセプトされたシグナル フラグメントを使用して一致するものを検索します。
SELECT
shipment_id,
telemetry_string,
1 - (embedding_vector <=> embedding('text-embedding-005', 'Refrigeration unit offline. Manual override.')::vector) AS search_relevance_score
FROM vessel_telemetry
ORDER BY embedding_vector <=> embedding('text-embedding-005', 'Refrigeration unit offline. Manual override.')::vector
LIMIT 5;
AlloyDB の google_ml_integration 拡張機能で提供される embedding() 関数は、SQL から Agent Platform を直接呼び出して、ベクトル エンベディングをインラインで生成します。<=> 演算子は、2 つのベクトル間のコサイン距離を計算します(0 に近いほど、2 つのベクトルが同一である可能性が高くなります)。1 から減算して、結果を関連性スコアとして表します。スコアが高いほど、関連性が高いことを示します。
ステップ 3: 一致を確認する
結果を確認します。上位の結果は、関連性スコアが最も高い MV-CAPYBARA-003 になります。
これは、この調査のすべての手順で追跡してきたコンテナと同じです。
- 📷 セキュリティ カメラの映像から、夜間にリオ デ ジャネイロ港を出港したことが確認されました。
- 🌡️ 温度異常の検出により、冷蔵ユニットが意図的に無効にされたことが確認されました。
- 📡 ビーコン信号のマッチングにより、シドニー付近のテレメトリー シグネチャが特定されました。
3 つの独立した証拠。3 つの異なる Google Cloud AI 機能。コンテナ 1 個が盗難された。
🎯 ケースをクローズ: MV-CAPYBARA-003 がシドニー付近で発見されました。

セクションのまとめ: AlloyDB の組み込み AI 統合を使用して、検索エンベディングを生成し、単一の SQL クエリでコサイン類似度検索を実行しました。ビーコンの一致により、盗難されたコンテナの位置が確認され、調査が完了しました。
9. 証拠を調べる
マルチモーダル画像分析とベクトル検索でコンテナを特定したら、エディタ内で 会話型分析を直接使用して、SQL を記述せずに自然言語で調査データを探索できます。
ステップ 1: Knowledge Catalog でデータを見つける
Data Agent Kit には、Google Cloud 環境全体でデータアセットを検索して探索できるユニバーサル検索機能が含まれています。
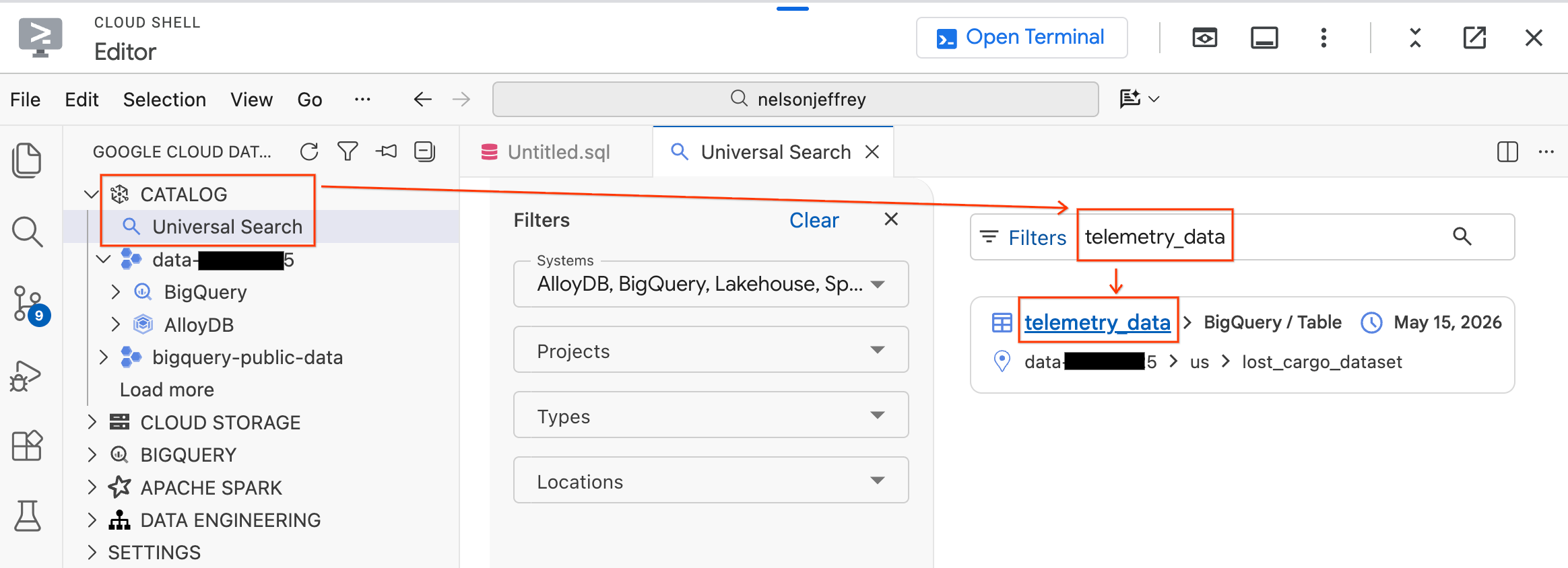
- 左側の [Data Agent Kit] パネルで、[カタログ] セクションを開きます。
- [ユニバーサル検索] をクリックします。
- 検索バーに「
telemetry_data」と入力します。 - 検索結果から
telemetry_dataテーブル(lost_cargo_datasetの下)をクリックします。
ステップ 2: 会話型分析を起動する
検索結果をクリックすると、データビューアのタブが開き、生データのプレビュー、スキーマの表示、データ品質の確認を行うことができます。
- 左側のペインに、BigQuery のデータセットとテーブルが表示されます。[チャット] ボタンをクリックして、新しいチャット ウィンドウを開きます。
![[チャット] ボタンをクリックします。](https://codelabs.developers.google.com/static/data-roadshow-26/lab2/img/evidence/chat_button.png?hl=ja)
ステップ 3: 自然言語で質問する
新しい [Welcome to Conversational Analytics!] チャットタブが開きます。エージェントは、テーブルのスキーマとコンテンツに関するコンテキストを把握しています。
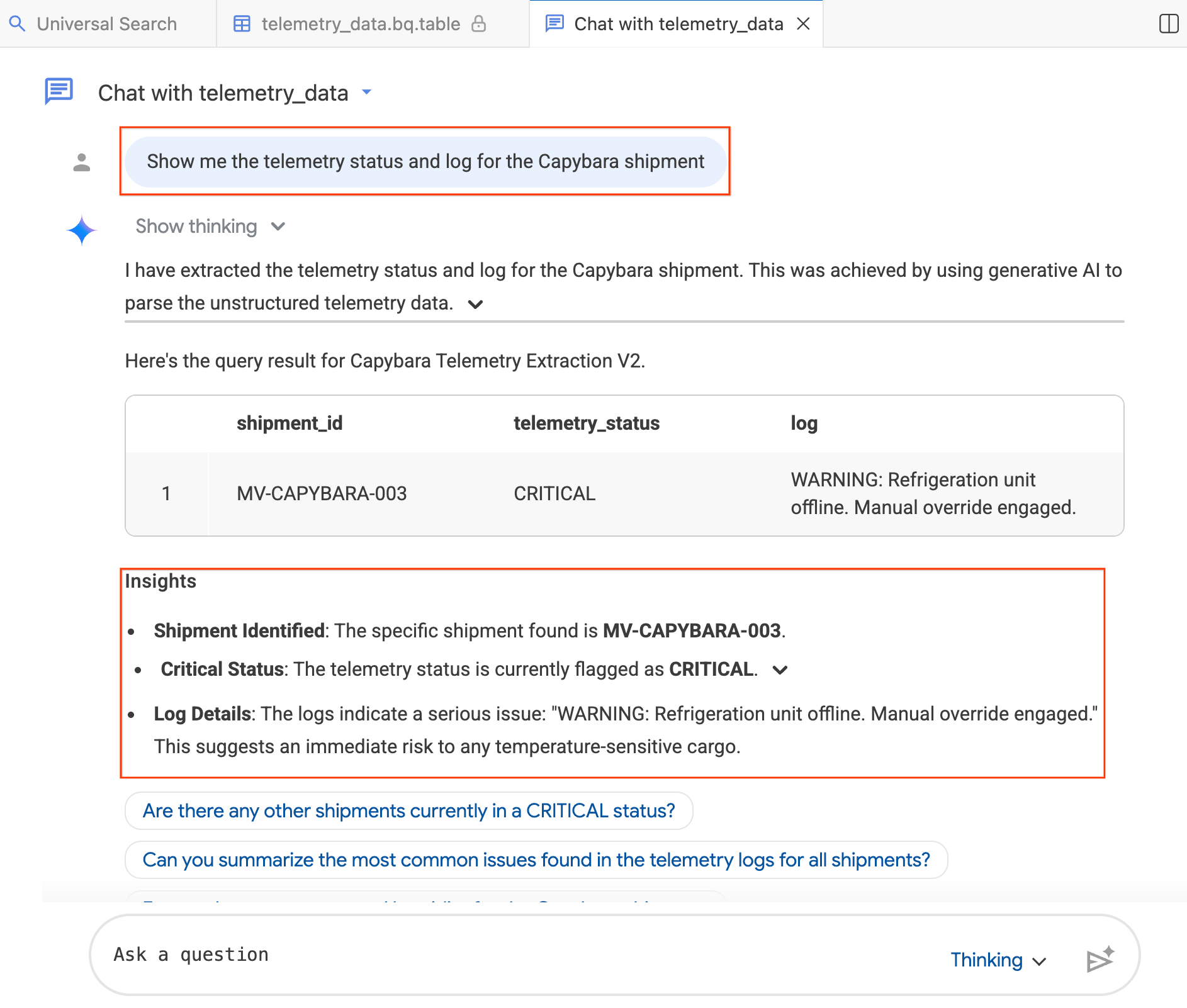
- チャット ウィンドウに「カピバラの出荷のテレメトリー ステータスとログを表示して」と入力します。
- Enter キーを押します。
エージェントは質問を BigQuery SQL に変換し、クエリを実行して、結果(データテーブルと調査結果をまとめた分析情報の両方)を返します。質問の複雑さに応じて、思考モード(より詳細な分析、処理に時間がかかる)と高速モード(より迅速な回答)を切り替えることができます。これらは AI によって生成された回答であるため、結果は以下のスクリーンショットと若干異なる場合があります。
ステップ 4: フォローアップの質問をする
エージェントは会話のコンテキストを記憶します。フォローアップの質問を試してみましょう。
- 「テレメトリー データに含まれる一意の配送の数はいくつですか?」
- 「フリート内の他の配送で現在 CRITICAL ステータスのものはいくつありますか?」
セクションのまとめ: Knowledge Catalog のユニバーサル検索機能を使用してデータセットを見つけ、会話型分析を起動して自然言語で調査データにクエリを実行しました。AI エージェントが質問を SQL に変換し、調査結果を裏付ける分析情報を提供しました。
10. クリーンアップ
Google Cloud アカウントに継続的に課金されないようにするには、このラボで作成したリソースを削除します。これらのコマンドは、Cloud Shell エディタ内の統合ターミナル(Data Agent Kit を使用していた場所)で実行して、環境をクリーンアップできます。
まず、環境変数を読み込みます。
source scripts/setenv.sh
- BigQuery リソースを削除する(ラボ 3 に進まない場合のみ):
ラボ 3 に進む場合は、この手順をスキップしてください。ラボ 3 では、プロパティ グラフ分析に同じ BigQuery データセットと接続を使用します。
BigQuery データセットと接続を削除するには:
# Drop the dataset
bq rm -r -f $PROJECT_ID:lost_cargo_dataset
# Delete the connections
bq rm --connection --location=us-central1 $PROJECT_ID.us-central1.lost_cargo_conn
bq rm --connection --location=us-central1 $PROJECT_ID.us-central1.lost_cargo_alloydb_conn
- Cloud Storage バケットを削除します。
gcloud storage rm --recursive gs://${PROJECT_ID}-lab2
- AlloyDB インスタンスとクラスタを削除します。
AlloyDB はラボ 3 で使用されないため、今すぐ削除しても問題ありません。
gcloud alloydb instances delete lost-cargo-instance \
--region=$REGION \
--cluster=lost-cargo-cluster \
--quiet
gcloud alloydb clusters delete lost-cargo-cluster \
--region=$REGION \
--force \
--quiet
- ローカル環境設定を削除します。
最後に、ワークスペースからローカル環境設定ファイルをクリーンアップします。
rm -f .env
11. 完了
これで、ラボ 2: データ分析とマルチモーダル分析情報が完了しました。数千個のコンテナが保管されている港から、盗難の確認と場所の特定まで、追跡を行いました。
学習した内容
- 映像をスキャンした: BigQuery の
AI.GENERATEを使用して、港湾セキュリティの画像を分析し、クリムゾン レッドのコンテナ MV-CAPYBARA-003 を特定しました。 - 盗難を確認した: 温度センサーのデータを調べ、不審な 148.4°F の急上昇を発見し、
AI.DETECT_ANOMALIESを使用して意図的な改ざんであることを証明しました。 - トラッキング システムを準備した: リアルタイム ビーコン マッチング用に pgvector と
google_ml_integrationを使用して AlloyDB を構成しました。 - 検索インデックスを構築した: BigQuery で
AI.GENERATEとAI.EMBEDを使用してエンベディングを作成し、Cloud Storage にエクスポートして AlloyDB にインポートしました。 - ビーコン信号を照合した: AlloyDB のベクトル検索を使用して、断片化されたテレメトリー信号を照合し、シドニー近郊で盗まれたコンテナを特定しました。
- 証拠を調査した: エディタから直接 会話型分析を使用して、自然言語で調査データにクエリを実行しました。

次のステップ
コンテナの場所は特定できました。次は、コンテナの背後にいる人物を特定する必要があります。
ラボ 3: データ消費とエージェント ワークフローでは、物流ネットワークのプロパティ グラフを構築して、ペーパー カンパニー間の関係をマッピングし、会話型分析を使用してグラフとチャットし、Knowledge Catalog を検索してコンテナの回収に必要なセキュリティ保護された通関コードを見つけます。