
1. 소개

이전 실습에서는 조각화된 배송 로그를 집계하고 화물 트랜스폰더를 뉴욕으로 추적했습니다. 하지만 도착 기록에 따르면 세관 탐지를 피하기 위해 컨테이너가 즉시 경로가 변경되었습니다. 이제 수천 개의 컨테이너가 있는 광활한 항구인 리우데자네이루 항구에 도착했습니다. 수천 개의 컨테이너 중에서 적절한 컨테이너를 찾는 것은 어려운 일입니다.
이 실습에서는 BigQuery의 기본 제공 AI 기능을 사용하여 비정형 항만 보안 이미지를 '읽고' 센서 데이터의 열 이상을 감지합니다. 이 모든 작업은 표준 SQL을 사용하여 수행합니다. 그런 다음 벡터 임베딩을 AlloyDB로 내보내고 벡터 검색을 실행하여 조각화된 원격 분석 신호를 누락된 컨테이너와 일치시킵니다.
실습할 내용
- BigQuery AI를 사용하여 항만 보안 이미지를 스캔하여 도난당한 컨테이너 식별
- BigQuery AI를 사용하여 열 이상을 감지하여 컨테이너가 잘못 배치된 것이 아니라 도난당했음을 확인
- 벡터 임베딩을 생성하고 실시간 검색을 위해 AlloyDB에 로드
- 벡터 검색을 사용하여 도난당한 컨테이너를 찾기 위해 조각화된 원격 분석 비콘 신호와 일치시킵니다.
- 대화형 분석을 사용하여 자연어로 조사 데이터 탐색
필요한 항목
- 웹브라우저(예: Chrome)
- 결제가 사용 설정된 Google Cloud 프로젝트
- SQL 및 Google Cloud 콘솔에 대한 기본 지식
이 Codelab은 중급 개발자를 위한 것입니다.
이 Codelab에서 만든 리소스의 비용은 5달러 미만이어야 합니다.
2. 시작하기 전에
Cloud Shell 시작
Google Cloud Shell을 사용하여 코드를 다운로드하고, 설정 스크립트를 실행하고, 애플리케이션을 배포합니다.
- 새 브라우저 탭에서 Cloud Shell(shell.cloud.google.com)을 엽니다.
- 연결되면 프로젝트 ID를 설정하고 환경을 확인합니다.
gcloud config set project <<YOUR_PROJECT_ID>>
export PROJECT_ID=$(gcloud config get-value project)
export REGION=us-central1
다음과 비슷한 메시지가 표시됩니다.
Your active configuration is: [cloudshell-####] Updated property [core/project]
저장소 클론
코드랩 저장소를 Cloud Shell 환경에 클론합니다.
cd ~/
git clone --filter=blob:none --no-checkout https://github.com/GoogleCloudPlatform/devrel-demos.git
cd ~/devrel-demos
git sparse-checkout init --cone
git sparse-checkout set codelabs/bigquery-alloydb-insights
git checkout main
cd codelabs/bigquery-alloydb-insights/
API 사용 설정
Cloud Shell에서 다음 명령어를 실행하여 이 실습에 필요한 모든 API를 사용 설정합니다.
gcloud services enable \
aiplatform.googleapis.com \
bigquery.googleapis.com \
bigqueryconnection.googleapis.com \
alloydb.googleapis.com
성공적으로 실행되면 다음과 유사한 메시지가 표시됩니다.
Operation "operations/..." finished successfully.
3. 환경 설정
이미지와 원격 분석 데이터를 분석하려면 이 실습의 인프라를 설정해야 합니다. 백그라운드에서 AlloyDB 프로비저닝을 시작하는 스크립트와 필요한 모든 BigQuery 리소스를 만드는 스크립트 두 개를 실행합니다.
1단계: AlloyDB 배포 시작 (백그라운드)
AlloyDB 클러스터 프로비저닝에는 약 10분이 걸리므로 먼저 시작하고 BigQuery 섹션을 진행하는 동안 백그라운드에서 실행되도록 합니다. 스크립트는 활성 프로젝트 설정을 로컬 .env 파일에 자동으로 기록하므로 Cloud Shell 터미널이 닫히거나 다시 시작되더라도 구성이 저장됩니다.
chmod +x scripts/setup_alloydb.sh
nohup ./scripts/setup_alloydb.sh > /dev/null 2>&1 &
echo "AlloyDB deployment started in background (PID: $!)"
2단계: 설정 스크립트 실행
이 스크립트는 BigQuery 데이터 세트, Cloud 리소스 연결, IAM 권한, GCS 버킷을 만들고 이 실습에서 분석할 모든 센서 데이터를 로드합니다. 또한 .env 파일에 저장된 환경 변수를 읽고 확인합니다.
chmod +x scripts/setup_lab.sh
./scripts/setup_lab.sh
스크립트를 실행하는 데 약 1분이 걸립니다. 완료되면 생성된 모든 항목의 요약이 표시됩니다.
📝 환경 재설정에 관한 참고사항 이 실습 중에 언제든지 Cloud Shell 세션이 타임아웃되거나 다시 시작되는 경우 다음을 실행하여 터미널 변수를 즉시 복원할 수 있습니다.
source scripts/setenv.sh
3단계: Cloud Shell 편집기 실행
지금까지 Cloud Shell 터미널을 사용했습니다. 이제 통합된 BigQuery 지원이 포함된 VS Code와 유사한 작업공간을 제공하는 전체 Cloud Shell 편집기로 전환합니다.
- 화면 하단의 Cloud Shell 터미널 창에서 편집기 열기 버튼을 클릭하여 Cloud Shell 편집기 작업공간을 실행합니다.

4단계: 데이터 에이전트 키트 확장 프로그램 설치
Google Cloud Data Agent Kit 확장 프로그램은 편집기 내에서 직접 Google Cloud 데이터 서비스와 긴밀하게 통합되므로 컨텍스트를 전환하지 않고도 BigQuery, AlloyDB, Cloud Storage 등과 상호작용할 수 있습니다.
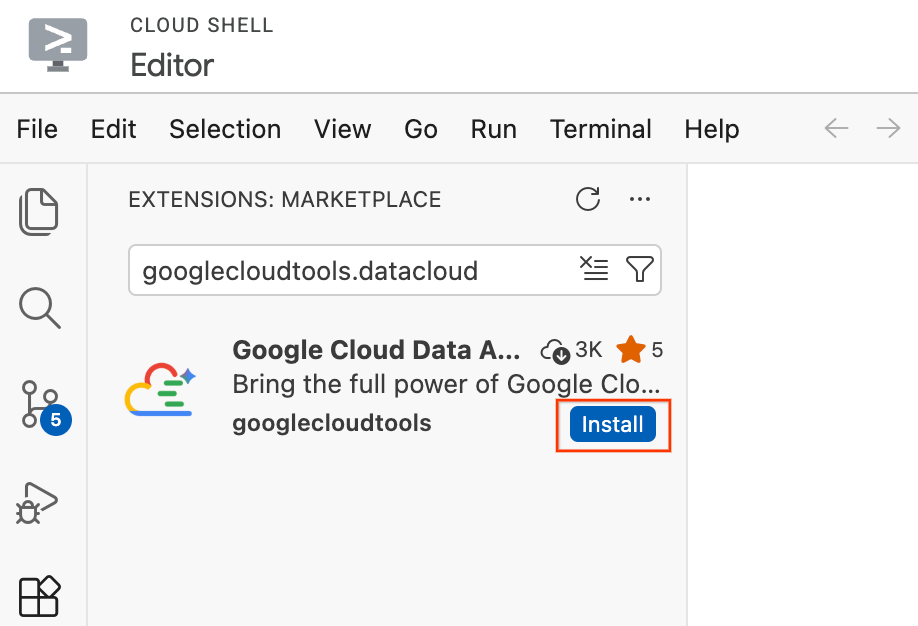
- Cloud Shell 편집기에서 화면 왼쪽 끝에 있는 작업 표시줄의 확장 프로그램 아이콘을 클릭합니다 (네 개의 정사각형 모양).
- 확장 프로그램 창 상단의 검색창에
googlecloudtools.datacloud를 입력합니다. - Google Cloud에서 게시한 Google Cloud Data Agent Kit이라는 확장 프로그램을 찾습니다.
- Install 버튼을 클릭합니다.
- '게시자'googlecloudtools' 및 확장 프로그램을 신뢰하시겠습니까?'라는 메시지가 표시됩니다. 게시자 신뢰 및 설치를 클릭하여 계속 진행합니다.
5단계: 확장 프로그램 인증 및 구성
설치 후 확장 프로그램을 Google Cloud 프로젝트에 연결합니다.
- 'Google Cloud 데이터 에이전트 키트 온보딩'이라는 제목의 온보딩 페이지가 자동으로 열립니다. Google Cloud에 로그인을 클릭합니다. 브라우저 메시지에 따라 액세스를 허용합니다.
- '설정 진행 중' 모달이 표시됩니다. 확장 프로그램은 Google Cloud CLI와 같은 필수 종속 항목을 자동으로 확인합니다.
- 구성 요약 섹션에서 프로젝트 필드를 찾습니다. 드롭다운을 클릭하고 Google Cloud 프로젝트를 선택합니다. 리전을
us-central1으로 설정합니다. - 설정 확인이 완료될 때까지 기다립니다. '설정 완료'가 표시되면 MCP 서버 구성을 클릭합니다.
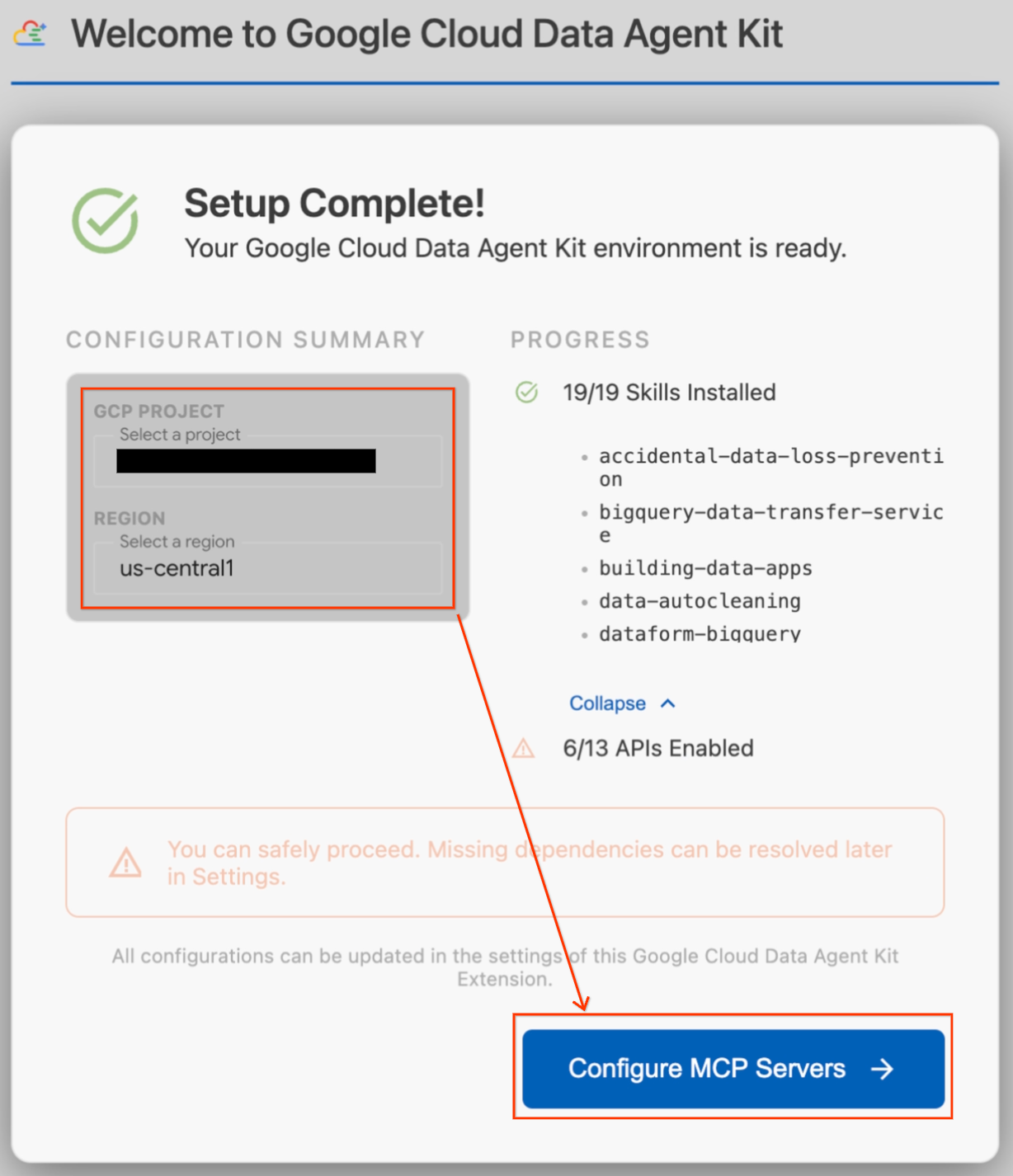
- MCP 구성에서 BigQuery 및 AlloyDB를 선택한 다음 시작하기를 클릭합니다.
6단계: 구성 옵션 살펴보기
설정이 완료되면 'Google Cloud 데이터 에이전트 키트 시작하기' 대시보드로 이동합니다.
- '설정 및 구성'에서 시작하기를 클릭합니다.
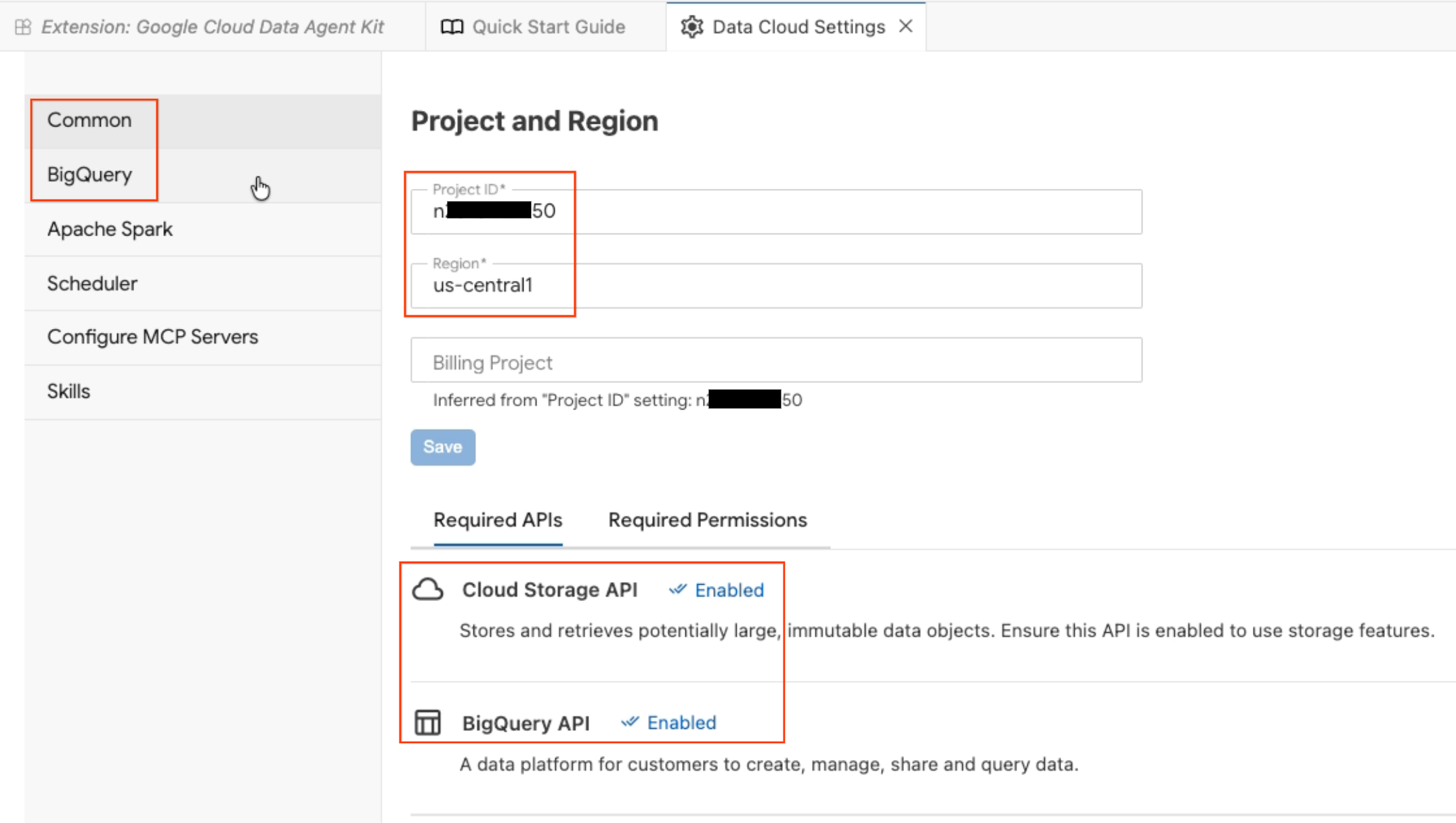
- 그러면 데이터 에이전트 구성 패널이 열립니다. 탭을 살펴봅니다.
- 프로젝트 및 리전: 선택한 프로젝트 ID를 확인하고 필수 API (Cloud Storage API, BigQuery API, Catalog API, AlloyDB API)가 사용 설정되어 있는지 확인합니다.
- BigQuery: BigQuery 쿼리의 기본 위치를 구성합니다.
us-central1리전을 사용합니다. - MCP 서버 구성: AI 에이전트가 데이터와 안전하게 상호작용할 수 있도록 지원하는 사용 설정된 MCP 서버 (BigQuery, Notebooks, AlloyDB 등)를 확인합니다.
- 기술: 에이전트에게 복잡한 데이터 작업을 위한 전문 기능을 제공하는 사전 빌드된 기술을 살펴봅니다.
7단계: BigQuery로 확인
공개 데이터 세트에 대해 간단한 쿼리를 실행하여 모든 것이 작동하는지 확인합니다.
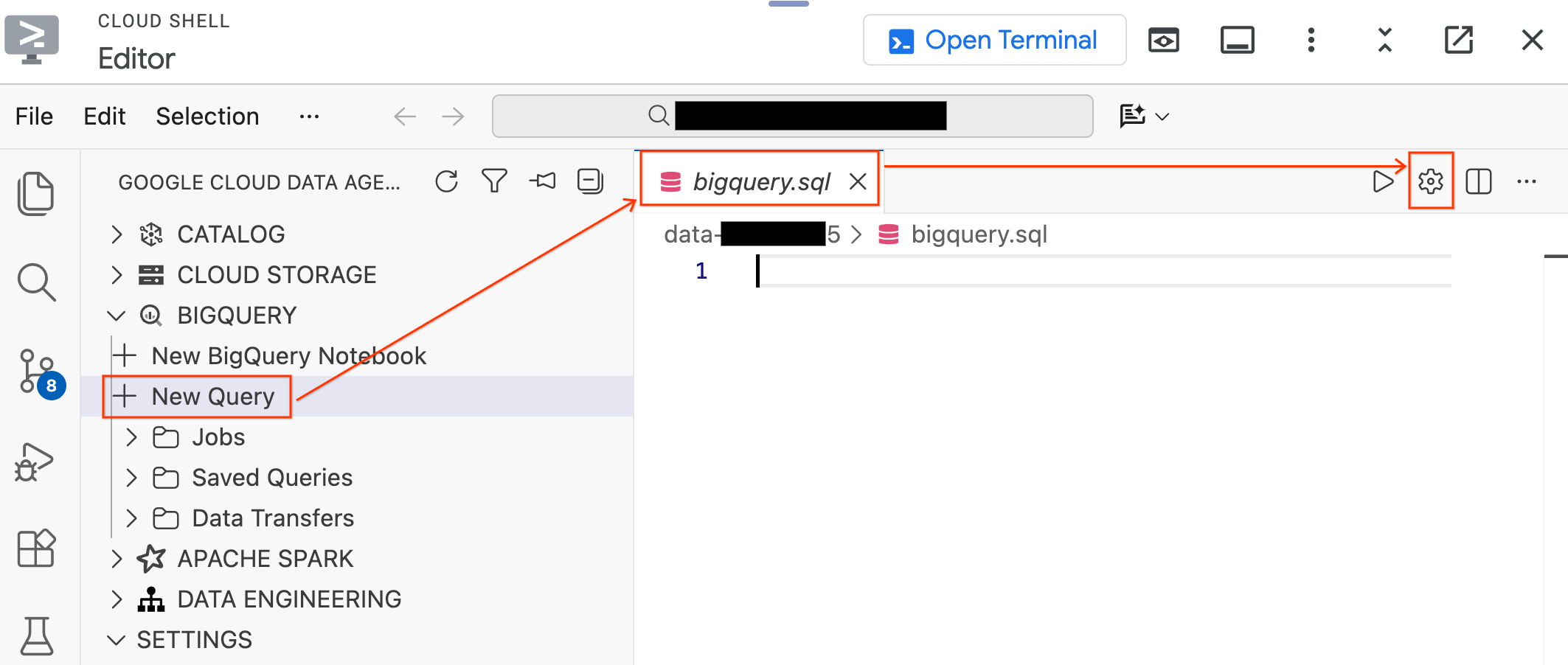
- 왼쪽의 데이터 에이전트 키트 창에서 BigQuery 섹션을 펼치고 새 쿼리를 클릭하여 새 쿼리 편집기 탭을 엽니다.
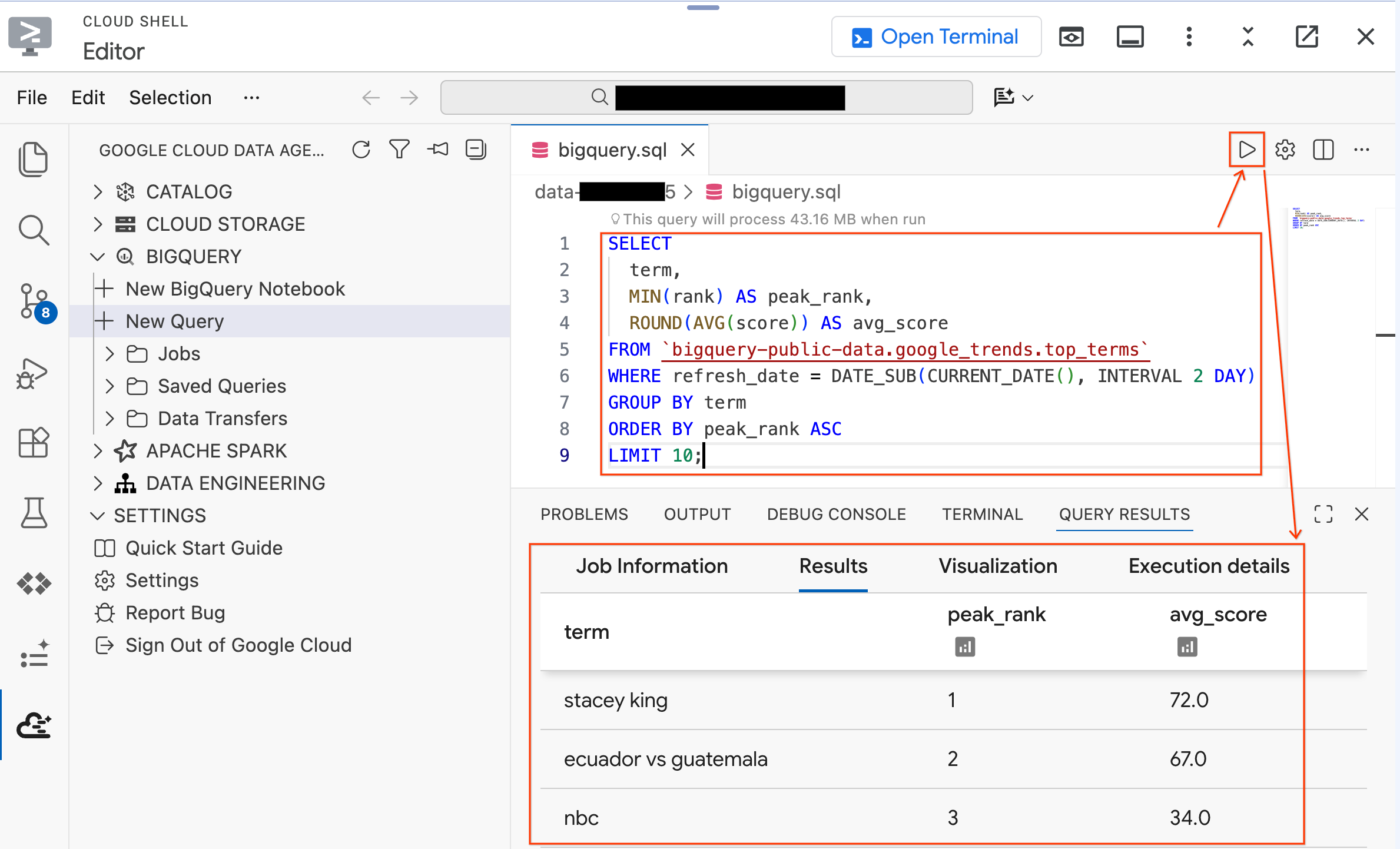
Ctrl+S(Windows/Linux) 또는Cmd+S(macOS)를 눌러 파일을 저장하고bigquery로 이름을 지정합니다. 이 탭은 모든 BigQuery 작업에 사용됩니다.bigquery.sql탭이 활성화된 상태에서 쿼리 설정을 클릭하고 데이터 소스로 BigQuery를 선택한 후 저장을 클릭합니다.
- 공개 데이터 세트에 대해 다음 쿼리를 실행합니다.
SELECT
term,
MIN(rank) AS peak_rank,
ROUND(AVG(score)) AS avg_score
FROM `bigquery-public-data.google_trends.top_terms`
WHERE refresh_date = DATE_SUB(CURRENT_DATE(), INTERVAL 2 DAY)
GROUP BY term
ORDER BY peak_rank ASC
LIMIT 10;
- 지난 며칠 동안의 인기 급상승 Google 검색어 상위 10개가 표시됩니다. 결과가 표시되면 확장 프로그램이 연결되어 사용할 준비가 된 것입니다.
이제 설정 스크립트에서 방금 만든 실습 데이터를 대상으로 쿼리를 실행해 보세요. 기존 쿼리를 다음으로 바꿉니다.
SELECT * FROM `lost_cargo_dataset.telemetry_data` LIMIT 5;
shipment_id 및 telemetry_string 열이 있는 텔레메트리 로그 항목이 표시됩니다. 이 데이터는 실습 전반에서 분석할 데이터입니다.
섹션 요약: 백그라운드에서 AlloyDB 배포를 시작하고, 설정 스크립트를 실행하고, 데이터 에이전트 키트 확장 프로그램으로 Cloud Shell 편집기를 구성했습니다.
4. 보안 영상 스캔
조사팀은 리우데자네이루 항구에서 선박 컨테이너가 줄지어 있는 보안 영상을 복구했습니다. 실습 1에서 타겟 컨테이너가 red임을 알 수 있습니다. 이제 어떤 빨간색 컨테이너인지 정확히 파악해야 합니다.
BigQuery가 Cloud Storage의 보안 이미지를 '볼' 수 있도록 객체 테이블을 만든 다음 AI.GENERATE 함수를 사용하여 Gemini에게 각 이미지에서 구조화된 데이터를 추출하도록 프롬프트를 표시합니다.
1단계: 객체 테이블 만들기
객체 테이블은 Cloud Storage에 저장된 비정형 파일 (이미지, PDF, 오디오)의 색인 역할을 하는 특수한 BigQuery 테이블입니다. 파일을 BigQuery에 복사하지 않고 AI 함수가 파일을 '볼' 수 있도록 쿼리 가능한 참조를 만듭니다.
편집기의 bigquery.sql 탭에서 다음 문을 실행하여 프로젝트 버킷의 포트 보안 이미지를 가리키는 객체 테이블을 만듭니다.
SET @@location = 'us-central1';
EXECUTE IMMEDIATE CONCAT("""
CREATE OR REPLACE EXTERNAL TABLE `lost_cargo_dataset.port_security_images`
WITH CONNECTION `us-central1.lost_cargo_conn`
OPTIONS (
object_metadata = 'SIMPLE',
uris = ['gs://""", @@project_id, """-lab2/images/*']
);
""");
이제 BigQuery에서 볼 수 있는 항목을 간단히 살펴보세요.
SELECT uri, content_type FROM `lost_cargo_dataset.port_security_images` LIMIT 5;
각 행은 Cloud Storage의 이미지 파일을 나타냅니다. 이제 BigQuery에서 이러한 이미지를 AI 모델에 직접 전달할 수 있습니다.
2단계: 보안 이미지 분석
이제 BigQuery의 AI.GENERATE 함수를 사용하여 각 보안 이미지를 분석합니다. 이 단일 SQL 쿼리는 Gemini에 모든 이미지를 검사하고 구조화된 데이터를 반환하도록 요청합니다.
SELECT
uri,
AI.GENERATE(
(
'Examine this port security image. Identify any shipping container IDs visible on the container and provide a one-word color of the container.',
ref
),
output_schema => 'detected_container_id STRING, color STRING'
).* EXCEPT (full_response, status)
FROM `lost_cargo_dataset.port_security_images`;
3단계: 타겟 컨테이너 식별
결과를 살펴봅니다. color 열에 'Red' (또는 빨간색 변형)이 표시된 행을 찾습니다. detected_container_id을 기록합니다. 타겟은 MV-CAPYBARA-003입니다.
4단계: 시각적 일치 확인
편집기를 종료하지 않고 분석된 실제 이미지를 보려면 다음 단계를 따르세요.
- 왼쪽의 데이터 에이전트 키트 창에서 Cloud Storage를 클릭합니다.
- 버킷 (
YOUR_PROJECT_ID-lab2/images/)을 펼치고 빨간색 컨테이너에 해당하는 이미지 파일을 클릭하여 편집기에서 직접 확인합니다.
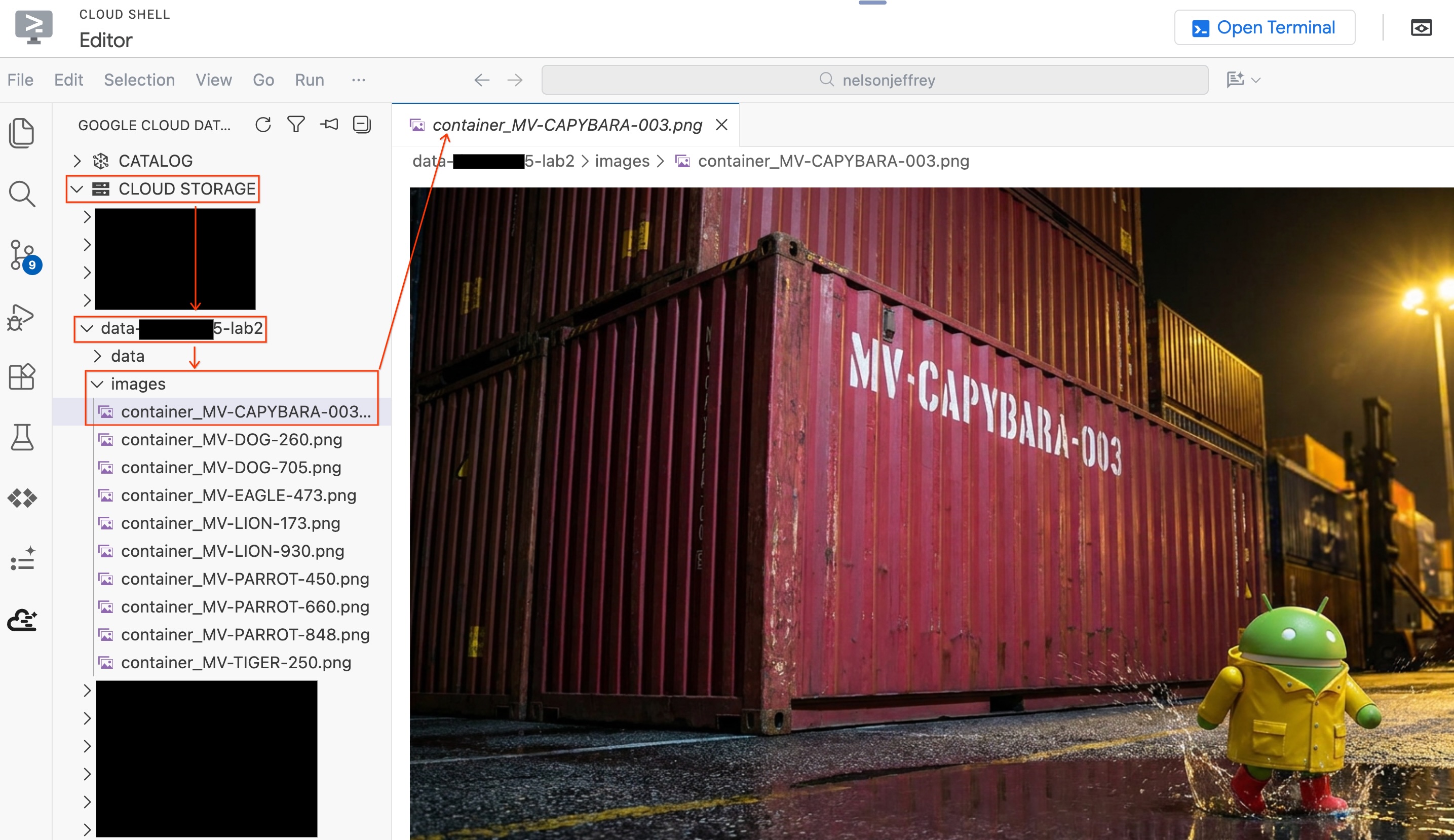
섹션 요약: BigQuery에서 항만 보안 이미지에 액세스할 수 있도록 객체 테이블을 만든 다음 AI.GENERATE를 사용하여 각 이미지에서 구조화된 컨테이너 데이터를 추출했습니다. 빨간색 컨테이너는 MV-CAPYBARA-003으로 식별되었습니다.
5. 도난 확인
누락된 컨테이너를 MV-CAPYBARA-003으로 확인했지만 도난당한 것인가요 아니면 단순히 잘못 놓은 것인가요? 매니페스트 로그는 이 특정 컨테이너가 환경 센서 SENS-99 옆에 주차되었음을 나타냅니다. 도둑이 컨테이너를 이동하기 전에 컨테이너의 온보드 냉장 장치를 고의로 사용 중지한 경우 SENS-99에서 갑작스러운 열 배출 스파이크를 기록했을 수 있습니다.
이상치 감지를 사용하여 컨테이너가 조작되었음을 증명해 보겠습니다.
- 먼저 과거 기준을 살펴봅니다. 지난 몇 시간 동안
SENS-99의 정상 수치는 다음과 같습니다.
SELECT * FROM `lost_cargo_dataset.thermal_history`
ORDER BY reading_time DESC
LIMIT 50;
온도가 75~78°F의 좁은 범위에서 유지됩니다. 정상적인 모습은 다음과 같습니다.
- 이제 동일한 센서에서 현재 배치된 판독값을 살펴보세요.
SELECT * FROM `lost_cargo_dataset.thermal_current`
ORDER BY thermal_reading DESC
LIMIT 50;
상단에 148.4°F라고 표시되어 있나요? 나머지는 모두 정상으로 표시됩니다. 이러한 급격한 증가는 냉장 장치 고장 또는 의도적인 조작을 나타냅니다. 지금부터 알아보겠습니다.
- 이상 감지를 실행합니다. BigQuery의
AI.DETECT_ANOMALIES는 사전 학습된 TimesFM 파운데이션 모델을 사용하여 시계열 패턴을 분석하고 이상치를 자동으로 표시하므로 모델 학습이 필요하지 않습니다.
SELECT *
FROM AI.DETECT_ANOMALIES(
TABLE `lost_cargo_dataset.thermal_history`,
TABLE `lost_cargo_dataset.thermal_current`,
data_col => 'thermal_reading',
timestamp_col => 'reading_time',
id_cols => ['sensor_id']
)
WHERE is_anomaly = TRUE;
- 결과를 살펴봅니다. 148.4°F 판독값은 이상치 확률이 높은 이상치로 표시되어야 하며, 컨테이너 영역 근처에서 비정상적인 일이 발생했음을 확인합니다.
섹션 요약: BigQuery의 AI.DETECT_ANOMALIES 함수를 사용하여 사전 학습된 TimesFM 모델을 활용했습니다. 단일 SQL 쿼리를 실행하여 복잡한 머신러닝 코드를 작성하거나 모델을 처음부터 학습시키지 않고도 이상치를 자동으로 식별하고 비정상적인 조작 이벤트를 격리했습니다.
6. 추적 시스템 준비
컨테이너가 도난된 것으로 확인되었으며 더 이상 리우데자네이루에 없습니다. 플릿의 각 컨테이너는 센서 수치, GPS 프래그먼트, 상태 로그인 원격 분석 비콘 신호를 브로드캐스트합니다. 도난당한 컨테이너의 비콘이 계속 전송되는 경우 알려진 서명과 일치시켜 컨테이너를 찾을 수 있습니다.
BigQuery는 지금까지 수행한 분석 작업에 탁월하지만 컨테이너를 실시간으로 찾으려면 지연 시간이 짧은 운영 쿼리가 필요합니다. 완전 관리형 PostgreSQL 호환 데이터베이스인 AlloyDB는 실시간 추적 시스템에 충분히 빠른 벡터 검색 쿼리를 위해 빌드되었습니다. 원격 분석 삽입을 AlloyDB에 로드하고 이를 사용하여 비콘 신호를 일치시킵니다.
이전에 백그라운드에서 시작한 AlloyDB 클러스터가 이제 준비되었을 것입니다. 편집기에서 직접 구성해 보겠습니다.
1단계: 편집기에서 AlloyDB에 연결
Cloud Console로 전환하는 대신 데이터 에이전트 키트 확장 프로그램을 사용하여 AlloyDB에 직접 연결할 수 있습니다.
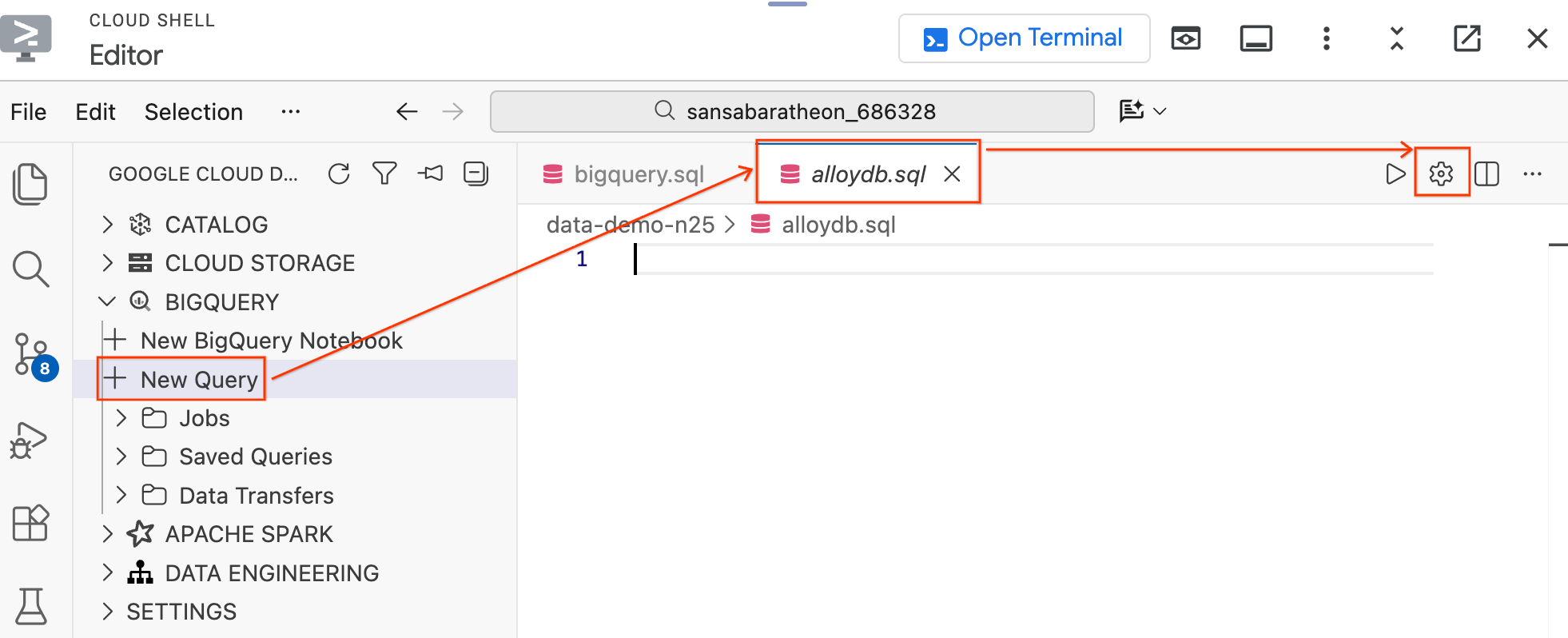
- 왼쪽의 데이터 에이전트 키트 창에 있는 BigQuery 섹션에서 새 쿼리를 클릭하여 새 쿼리 편집기 탭을 엽니다.
Ctrl+S(Windows/Linux) 또는Cmd+S(macOS)를 눌러 파일을 저장하고alloydb로 이름을 지정합니다. 이 탭은 모든 AlloyDB 쿼리에 사용됩니다.- 톱니바퀴 아이콘을 클릭하여 쿼리 설정 모달을 엽니다.
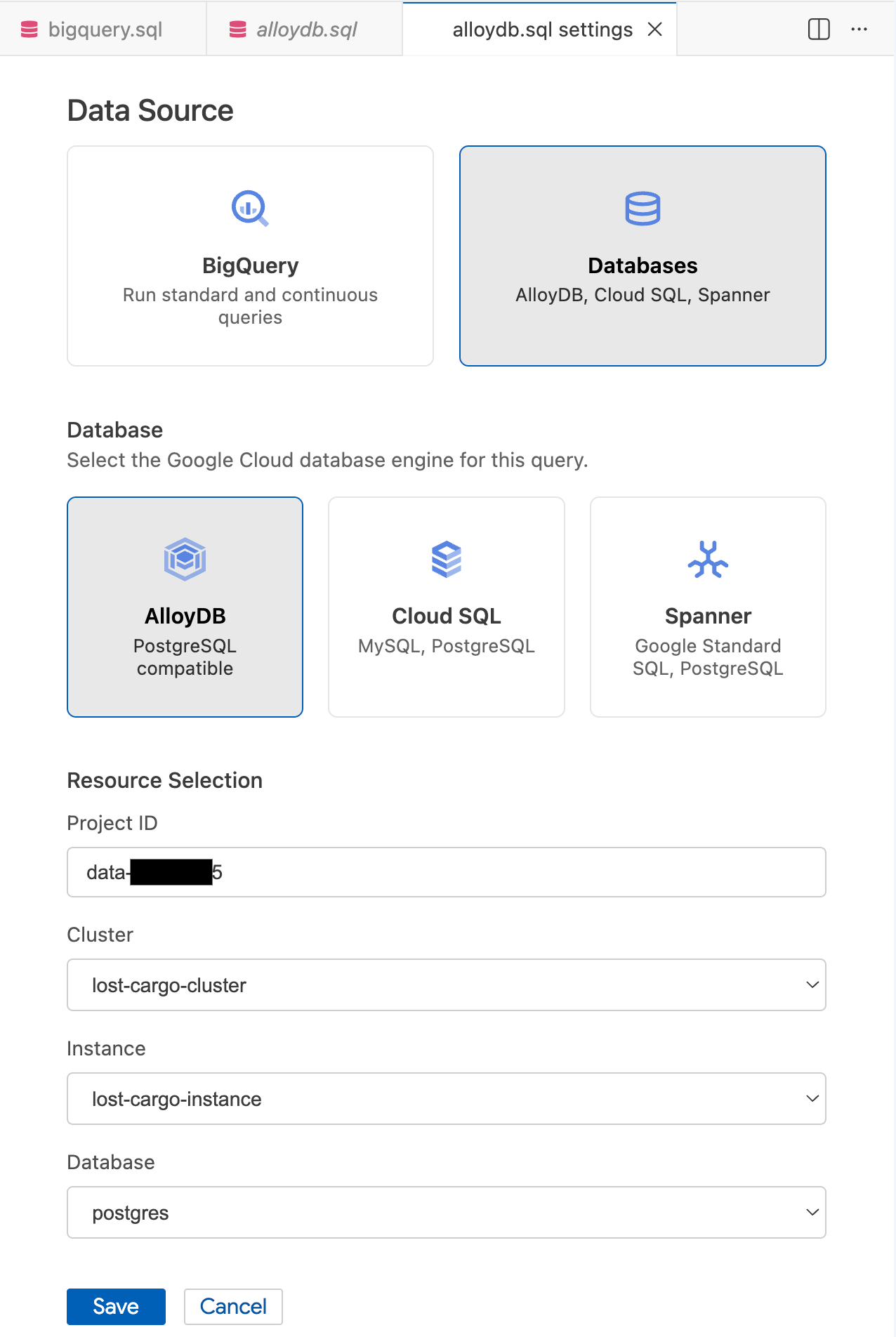
- 쿼리 설정 모달의 데이터 소스에서 데이터베이스를 선택합니다.
- 데이터베이스에서 AlloyDB를 선택합니다.
- 리소스 선택 세부정보를 입력합니다.
- 프로젝트 ID: Google Cloud 프로젝트 ID를 입력합니다.
- 클러스터:
lost-cargo-cluster를 선택합니다. - 인스턴스:
lost-cargo-instance를 선택합니다. - 데이터베이스:
postgres를 선택합니다.
- 저장을 클릭합니다.
2단계: 벡터 확장 프로그램 사용 설정 및 테이블 만들기
이제 AlloyDB에 연결되었으므로 필요한 AI 확장 프로그램을 사용 설정하고 삽입된 원격 분석 데이터를 수신할 테이블을 만들어야 합니다.
- 활성
.sql탭에서 다음 명령어를 붙여넣어 필요한 확장 프로그램을 사용 설정합니다.
CREATE EXTENSION IF NOT EXISTS vector;
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
- 텍스트를 강조 표시하고 편집기의 오른쪽 상단에 있는 쿼리 실행 버튼 (재생 아이콘)을 클릭합니다.
- 화면 하단의 쿼리 결과 터미널 패널을 확인합니다.
Statement executed successfully라고 표시되어야 합니다.
- 다음으로, 편집기의 텍스트를 다음 문으로 바꿔 원격 분석 테이블을 만듭니다.
CREATE TABLE IF NOT EXISTS vessel_telemetry (
entry_id SERIAL PRIMARY KEY,
shipment_id VARCHAR(50),
telemetry_string TEXT,
embedding_vector vector(768)
);
- 이 쿼리를 마지막 쿼리와 마찬가지로 실행합니다. 하단 패널에서 성공적으로 실행되는지 확인합니다.
vector(768) 유형은 방금 사용 설정한 pgvector 확장 프로그램에서 가져옵니다. 768개의 차원은 BigQuery에서 임베딩을 생성하는 데 사용할 Google의 text-embedding-005 모델의 출력과 일치합니다.
섹션 요약: Cloud Shell 편집기에서 AlloyDB에 직접 연결하고, pgvector 및 google_ml_integration 확장 프로그램을 사용 설정하고, 타겟 테이블을 만들었습니다. 이제 AlloyDB가 실시간 원격 분석 매칭을 위한 운영 백엔드로 사용될 수 있습니다.
7. 검색 색인 빌드
이제 실시간 비콘 매칭을 지원할 수 있도록 원격 분석 데이터를 AlloyDB로 가져와야 합니다. 원시 원격 분석 로그는 지저분하고 길이가 가변적이므로 유사성 검색에 적합하지 않습니다. BigQuery의 AI 함수를 사용하여 Gemini로 각 로그를 요약하고 각 요약을 768차원 벡터 임베딩으로 변환합니다. 그런 다음 보강된 데이터를 Cloud Storage로 내보내고 AlloyDB로 가져옵니다.
1단계: BigQuery에서 임베딩 생성
편집기 탭을 bigquery.sql (BigQuery에 연결된 상태로 유지됨)로 다시 전환합니다.
이제 다음 쿼리를 실행하여 Gemini로 각 원격 분석 로그를 요약하고 벡터 임베딩을 생성합니다.
CREATE OR REPLACE TABLE `lost_cargo_dataset.telemetry_embeddings_export` AS
WITH summarized_telemetry AS (
SELECT
shipment_id,
telemetry_string,
AI.GENERATE(
CONCAT('Summarize this telemetry log for vector search: ', telemetry_string)
).result AS summary
FROM `lost_cargo_dataset.telemetry_data`
),
telemetry_embeddings AS (
SELECT
shipment_id,
telemetry_string,
AI.EMBED(summary, endpoint => 'text-embedding-005').result AS embedding
FROM summarized_telemetry
)
SELECT
shipment_id,
telemetry_string,
TO_JSON_STRING(embedding) AS embedding_vector
FROM telemetry_embeddings;
2단계: 풍부한 데이터 미리보기
내보내기 전에 만든 항목을 확인하세요. 이 쿼리는 배송 ID와 각 요약 및 삽입의 처음 80자를 표시합니다.
SELECT
shipment_id,
SUBSTR(telemetry_string, 1, 80) AS telemetry_preview,
SUBSTR(embedding_vector, 1, 80) AS embedding_preview
FROM `lost_cargo_dataset.telemetry_embeddings_export`
LIMIT 5;
이제 각 행에는 배송 ID, 원래 원격 분석 로그, 768차원 임베딩 벡터가 포함됩니다. AlloyDB로 푸시할 데이터입니다.
3단계: Cloud Storage로 삽입 내보내기
BigQuery의 EXPORT DATA 문을 사용하여 삽입 테이블을 실습의 GCS 버킷에 CSV 파일로 작성합니다.
EXECUTE IMMEDIATE CONCAT("""
EXPORT DATA OPTIONS (
uri = 'gs://""", @@project_id, """-lab2/data/embeddings_export/*.csv',
format = 'CSV',
overwrite = true,
header = false
) AS
SELECT
shipment_id,
telemetry_string,
embedding_vector
FROM `lost_cargo_dataset.telemetry_embeddings_export`;
""");
4단계: Cloud Storage에서 AlloyDB로 가져오기
- Cloud Shell 편집기에서 화면 하단의 터미널 탭을 클릭하여 터미널 세션을 엽니다.
- 다음 명령어를 실행하여 환경을 로드하고 CSV 파일을 AlloyDB의
vessel_telemetry테이블로 직접 가져옵니다.
source devrel-demos/codelabs/bigquery-alloydb-insights/scripts/setenv.sh
gcloud alloydb clusters import lost-cargo-cluster \
--region=$REGION \
--gcs-uri="gs://${PROJECT_ID}-lab2/data/embeddings_export/000000000000.csv" \
--database=postgres \
--user=postgres \
--table=vessel_telemetry \
--columns=shipment_id,telemetry_string,embedding_vector \
--csv
섹션 요약: BigQuery의 AI 함수를 사용하여 원격 분석 데이터를 요약하고 삽입한 후 결과를 CSV로 Cloud Storage에 내보내고 gcloud를 사용하여 AlloyDB로 가져왔습니다. 이제 운영 추적 데이터베이스가 로드되어 준비되었습니다.
8. 표지 신호 일치
시드니 근처의 현장팀이 조각화된 텔레메트리 비콘 신호를 가로챘습니다. 부분 로그는 다음과 같습니다.
'냉장 장치가 오프라인입니다. 수동 재정의'를 선택합니다.
이 정보가 도난된 컨테이너에서 가져온 경우 신호가 불완전하더라도 AlloyDB의 벡터 검색이 이를 일치시킬 수 있습니다. 이는 AlloyDB가 설계된 실시간 운영 쿼리와 정확히 일치합니다.
1단계: 가져온 데이터 확인
편집기 탭을 alloydb.sql (AlloyDB에 연결된 상태로 유지됨)로 다시 전환합니다.
다음을 실행하여 텔레메트리 데이터가 성공적으로 로드되었는지 확인합니다.
SELECT shipment_id, LEFT(telemetry_string, 80) AS telemetry_preview
FROM vessel_telemetry
LIMIT 10;
shipment_id 값과 원격 분석 텍스트가 포함된 행이 표시됩니다. 이제 실시간 매칭을 위해 준비된 차량의 원격 분석 서명입니다.
2단계: 누락된 컨테이너 검색
이제 AlloyDB의 google_ml_integration 확장 프로그램을 사용하여 가로채진 신호 프래그먼트를 사용하여 일치하는 항목을 검색합니다.
SELECT
shipment_id,
telemetry_string,
1 - (embedding_vector <=> embedding('text-embedding-005', 'Refrigeration unit offline. Manual override.')::vector) AS search_relevance_score
FROM vessel_telemetry
ORDER BY embedding_vector <=> embedding('text-embedding-005', 'Refrigeration unit offline. Manual override.')::vector
LIMIT 5;
AlloyDB의 google_ml_integration 확장 프로그램에서 제공하는 embedding() 함수는 SQL에서 직접 에이전트 플랫폼을 호출하여 인라인으로 벡터 임베딩을 생성합니다. <=> 연산자는 두 벡터 간의 코사인 거리를 계산합니다(0에 가까울수록 두 벡터가 더 동일함). 1에서 빼서 결과를 관련성 점수로 표현합니다(높을수록 좋음).
3단계: 일치 확인
결과를 살펴봅니다. 상위 결과는 관련성 점수가 가장 높은 MV-CAPYBARA-003이어야 합니다.
이것은 이 조사의 모든 단계에서 추적해 온 동일한 컨테이너입니다.
- 📷 보안 영상에서 밤에 리우데자네이루 항구를 떠나는 것을 확인했습니다.
- 🌡️ 열 이상 감지를 통해 냉장 장치가 의도적으로 사용 중지되었음을 확인했습니다.
- 📡 비콘 신호 일치가 시드니 근처에서 텔레메트리 서명을 정확히 찾아냈습니다.
세 가지 독립적인 증거 세 가지 다른 Google Cloud AI 기능 도난된 컨테이너 1개
🎯 케이스 종료: MV-CAPYBARA-003이 시드니 근처에서 발견되었습니다.

섹션 요약: AlloyDB의 내장 AI 통합을 사용하여 검색 임베딩을 생성하고 단일 SQL 쿼리에서 코사인 유사도 검색을 실행했습니다. 비콘 일치로 도난된 컨테이너의 위치가 확인되어 조사가 완료되었습니다.
9. 증거 살펴보기
멀티모달 이미지 분석과 벡터 검색을 통해 컨테이너를 식별했으므로 이제 편집기 내에서 바로 대화형 분석을 사용하여 SQL을 작성하지 않고도 자연어로 조사 데이터를 탐색할 수 있습니다.
1단계: Knowledge Catalog에서 데이터 찾기
데이터 에이전트 키트에는 Google Cloud 환경 전반에서 데이터 애셋을 찾고 탐색할 수 있는 범용 검색 기능이 포함되어 있습니다.
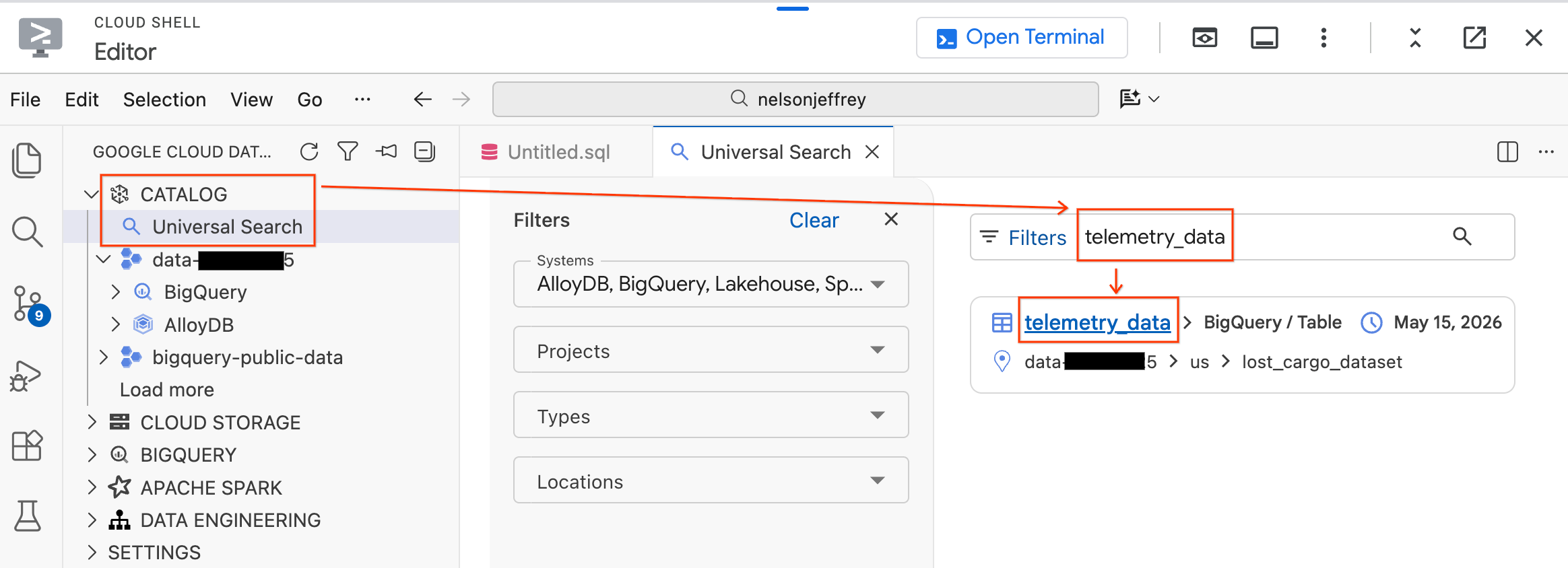
- 왼쪽의 데이터 에이전트 키트 패널에서 카탈로그 섹션을 펼칩니다.
- 유니버설 검색을 클릭합니다.
- 검색창에
telemetry_data를 입력합니다. - 검색 결과에서
telemetry_data표 (lost_cargo_dataset아래)를 클릭합니다.
2단계: 대화형 분석 실행하기
검색 결과를 클릭하면 원시 데이터를 미리 보고, 스키마를 확인하고, 데이터 품질을 확인할 수 있는 데이터 뷰어 탭이 열립니다.
- 왼쪽 창에 BigQuery 데이터 세트와 테이블이 표시됩니다. 채팅 버튼을 클릭하여 새 채팅 창을 엽니다.
3단계: 자연어로 질문하기
'대화형 분석에 오신 것을 환영합니다'라는 새 채팅 탭이 열립니다. 에이전트에는 표의 스키마와 콘텐츠에 관한 컨텍스트가 있습니다.
- 채팅 창에 '카피바라 배송의 원격 분석 상태와 로그를 보여 줘'라고 입력합니다.
- Enter를 누릅니다.
에이전트는 질문을 BigQuery SQL로 변환하고, 쿼리를 실행하고, 데이터 표와 결과를 요약하는 통계를 포함한 결과를 반환합니다. 질문의 복잡성에 따라 사고 (심층 분석, 느림) 모드와 빠름 (빠른 응답) 모드 간에 전환할 수 있습니다. AI 생성 대답이므로 결과가 아래 스크린샷과 약간 다를 수 있습니다.
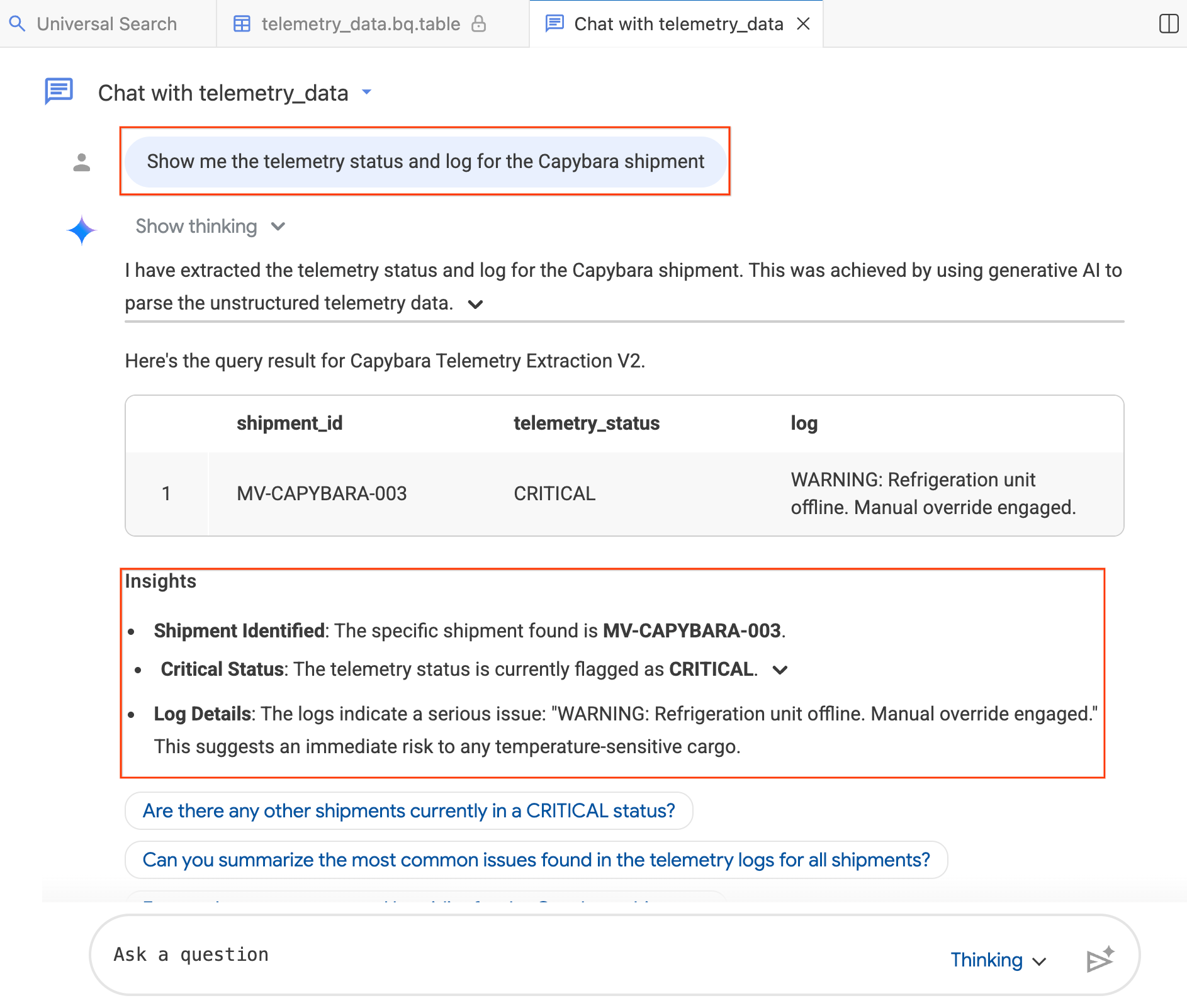
4단계: 후속 질문하기
에이전트는 대화의 맥락을 기억합니다. 후속 질문을 해 보세요.
- '원격 분석 데이터에 고유한 배송이 몇 개 있나요?'
- '현재 차량의 다른 배송 중 '심각' 상태인 배송이 몇 건 있나요?'
섹션 요약: Knowledge Catalog의 범용 검색 기능을 사용하여 데이터 세트를 찾고 대화형 분석을 실행하여 자연어로 조사 데이터를 쿼리했습니다. AI 에이전트가 질문을 SQL로 변환하고 발견한 내용을 뒷받침하는 통계를 제공했습니다.
10. 삭제
Google Cloud 계정에 지속적으로 요금이 청구되지 않도록 이 실습에서 만든 리소스를 삭제하세요. Cloud Shell 편집기 (데이터 에이전트 키트를 사용한 곳) 내의 통합 터미널에서 다음 명령어를 실행하여 환경을 정리할 수 있습니다.
먼저 환경 변수를 로드합니다.
source scripts/setenv.sh
- BigQuery 리소스 삭제 (실습 3을 계속하지 않는 경우에만 해당):
실습 3을 계속 진행할 계획이라면 이 단계를 건너뛰세요. 실습 3에서는 속성 그래프 분석에 동일한 BigQuery 데이터 세트와 연결을 사용합니다.
BigQuery 데이터 세트 및 연결을 삭제하려면 다음 단계를 따르세요.
# Drop the dataset
bq rm -r -f $PROJECT_ID:lost_cargo_dataset
# Delete the connections
bq rm --connection --location=us-central1 $PROJECT_ID.us-central1.lost_cargo_conn
bq rm --connection --location=us-central1 $PROJECT_ID.us-central1.lost_cargo_alloydb_conn
- Cloud Storage 버킷을 삭제합니다.
gcloud storage rm --recursive gs://${PROJECT_ID}-lab2
- AlloyDB 인스턴스 및 클러스터 삭제:
AlloyDB는 실습 3에서 사용되지 않으므로 지금 해체해도 됩니다.
gcloud alloydb instances delete lost-cargo-instance \
--region=$REGION \
--cluster=lost-cargo-cluster \
--quiet
gcloud alloydb clusters delete lost-cargo-cluster \
--region=$REGION \
--force \
--quiet
- 로컬 환경 설정 삭제:
마지막으로 작업공간에서 로컬 환경 설정 파일을 정리합니다.
rm -f .env
11. 축하합니다.
실습 2: 데이터 분석 및 멀티모달 통계를 성공적으로 완료했습니다. 수천 개의 컨테이너가 있는 항구에서 도난이 확인되고 위치가 정확히 파악될 때까지 추적했습니다.
학습한 내용
- 영상 스캔: BigQuery의
AI.GENERATE를 사용하여 항만 보안 이미지를 분석하고 Crimson Red 색상의 컨테이너 MV-CAPYBARA-003을 식별했습니다. - 도난 확인: 열 센서 데이터를 살펴보고 의심스러운 64.7°C 급증을 발견했으며
AI.DETECT_ANOMALIES를 사용하여 고의적인 조작임을 증명했습니다. - 추적 시스템 준비: 실시간 비콘 매칭을 위해 pgvector 및
google_ml_integration로 AlloyDB를 구성했습니다. - 검색 색인 빌드: BigQuery에서
AI.GENERATE및AI.EMBED를 사용하여 임베딩을 만든 다음 Cloud Storage로 내보내고 AlloyDB로 가져왔습니다. - 비콘 신호 일치: AlloyDB의 벡터 검색을 사용하여 조각화된 원격 분석 신호를 일치시켜 시드니 근처에서 도난당한 컨테이너를 찾았습니다.
- 증거 탐색: 편집기에서 직접 대화형 분석을 사용하여 자연어로 조사 데이터를 쿼리했습니다.

다음 단계
컨테이너가 어디에 있는지 확인했습니다. 이제 컨테이너를 만든 사람을 찾아야 합니다.
실습 3: 데이터 소비 및 에이전트 워크플로에서는 물류 네트워크의 속성 그래프를 빌드하여 페이퍼 컴퍼니 간의 관계를 매핑하고, Conversational Analytics를 사용하여 그래프와 채팅하고, Knowledge Catalog를 검색하여 컨테이너를 복구하는 데 필요한 보안 통관 코드를 찾습니다.