
1. Introdução

No laboratório anterior, você agregou registros de envio fragmentados e rastreou o transponder de carga até Nova York. No entanto, os registros de chegada mostram que o contêiner foi imediatamente redirecionado para evitar a detecção da alfândega. A trilha agora leva você ao Porto do Rio de Janeiro, um porto extenso com milhares de contêineres. Encontrar o contêiner certo entre milhares de outros é uma tarefa difícil.
Neste laboratório, você vai usar os recursos de IA integrados do BigQuery para "ler" imagens não estruturadas de segurança portuária e detectar anomalias térmicas em dados do sensor, tudo usando SQL padrão. Em seguida, você vai exportar embeddings de vetor para o AlloyDB e executar uma pesquisa vetorial para corresponder um sinal de telemetria fragmentado ao contêiner ausente.
Atividades deste laboratório
- Verificar imagens de segurança do porto para identificar o contêiner roubado usando a IA do BigQuery
- Detectar uma anomalia térmica usando a IA do BigQuery para confirmar que o contêiner foi roubado, não perdido
- Gerar embeddings vetoriais e carregá-los no AlloyDB para pesquisa em tempo real
- Corresponder um sinal de beacon de telemetria fragmentado para localizar o contêiner roubado usando a pesquisa vetorial
- Analise dados de investigação com linguagem natural usando a Análise de conversação
O que é necessário
- Um navegador da web, como o Chrome
- Tenha um projeto do Google Cloud com o faturamento ativado.
- Conhecimento básico de SQL e do console do Google Cloud
Este codelab é para desenvolvedores de nível intermediário.
Os recursos criados neste codelab custam menos de US $5.
2. Antes de começar
Iniciar o Cloud Shell
Você vai usar o Google Cloud Shell para baixar o código, executar scripts de configuração e implantar o aplicativo.
- Em uma nova guia do navegador, abra o Cloud Shell: shell.cloud.google.com
- Depois de se conectar, defina o ID do projeto e confirme o ambiente:
gcloud config set project <<YOUR_PROJECT_ID>>
export PROJECT_ID=$(gcloud config get-value project)
export REGION=us-central1
Você verá uma mensagem semelhante a:
Your active configuration is: [cloudshell-####] Updated property [core/project]
Clone o repositório
Clone o repositório do codelab no ambiente do Cloud Shell:
cd ~/
git clone --filter=blob:none --no-checkout https://github.com/GoogleCloudPlatform/devrel-demos.git
cd ~/devrel-demos
git sparse-checkout init --cone
git sparse-checkout set codelabs/bigquery-alloydb-insights
git checkout main
cd codelabs/bigquery-alloydb-insights/
Ativar APIs
Execute este comando no Cloud Shell para ativar todas as APIs necessárias para este laboratório:
gcloud services enable \
aiplatform.googleapis.com \
bigquery.googleapis.com \
bigqueryconnection.googleapis.com \
alloydb.googleapis.com
Se a execução for bem-sucedida, você vai receber uma mensagem semelhante a esta:
Operation "operations/..." finished successfully.
3. Configuração de seu ambiente
Antes de analisar imagens e dados de telemetria, você precisa configurar a infraestrutura para este laboratório. Você vai executar dois scripts: um inicia o provisionamento do AlloyDB em segundo plano, e o outro cria todos os recursos do BigQuery necessários.
Etapa 1: iniciar a implantação do AlloyDB (em segundo plano)
O provisionamento do cluster do AlloyDB leva cerca de 10 minutos. Portanto, inicie o processo primeiro e deixe-o em execução em segundo plano enquanto você trabalha nas seções do BigQuery. O script vai gravar automaticamente as configurações do projeto ativo em um arquivo .env local para que sua configuração seja salva mesmo que o terminal do Cloud Shell seja fechado ou reiniciado.
chmod +x scripts/setup_alloydb.sh
nohup ./scripts/setup_alloydb.sh > /dev/null 2>&1 &
echo "AlloyDB deployment started in background (PID: $!)"
Etapa 2: executar o script de configuração
Esse script cria o conjunto de dados do BigQuery, a conexão a recursos do Cloud, as concessões do IAM, o bucket do GCS e carrega todos os dados do sensor que você vai analisar neste laboratório. Ele também vai ler e verificar as variáveis de ambiente salvas no arquivo .env.
chmod +x scripts/setup_lab.sh
./scripts/setup_lab.sh
O script leva cerca de um minuto para ser executado. Quando terminar, você vai ver um resumo de tudo que foi criado.
📝 Observação sobre redefinições de ambiente: se a sessão do Cloud Shell expirar ou reiniciar a qualquer momento durante este laboratório, restaure as variáveis do terminal imediatamente executando:
source scripts/setenv.sh
Etapa 3: iniciar o editor do Cloud Shell
Você usou o terminal do Cloud Shell até agora. Agora mude para o editor completo do Cloud Shell, que oferece um espaço de trabalho semelhante ao VS Code com suporte integrado ao BigQuery.
- No painel do terminal do Cloud Shell na parte de baixo da tela, clique no botão Abrir editor para iniciar o espaço de trabalho do editor do Cloud Shell.

Etapa 4: instalar a extensão do Data Agent Kit
A extensão do Google Cloud Data Agent Kit oferece integração completa com os serviços de dados do Google Cloud diretamente no seu editor. Assim, é possível interagir com o BigQuery, o AlloyDB, o Cloud Storage e muito mais sem mudar de contexto.
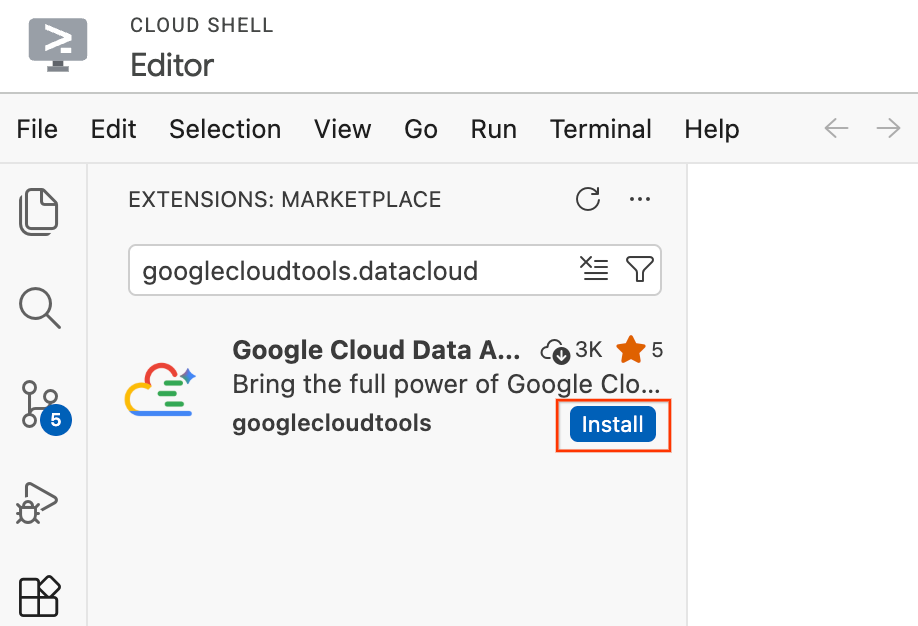
- No editor do Cloud Shell, clique no ícone Extensões na barra de atividades, no lado esquerdo da tela (parece quatro quadrados).
- Na barra de pesquisa na parte de cima do painel "Extensões", digite
googlecloudtools.datacloud. - Localize a extensão chamada Kit do agente de dados do Google Cloud publicada pelo Google Cloud.
- Clique no botão Install.
- Uma mensagem vai aparecer perguntando: "Você confia no publisher ‘googlecloudtools’ e nas extensões dele?". Clique em Confiar nos publishers e instalar para continuar.
Etapa 5: autenticar e configurar a extensão
Após a instalação, conecte a extensão ao seu projeto do Google Cloud.
- Uma página de integração intitulada "Google Cloud Data Agent Kit Onboarding" será aberta automaticamente. Clique em Fazer login no Google Cloud. Siga as instruções do navegador para permitir o acesso.
- Uma caixa de diálogo "Configuração em andamento" vai aparecer. A extensão vai verificar automaticamente as dependências necessárias, como a CLI do Google Cloud.
- Na seção Resumo da configuração, localize o campo do projeto. Clique no menu suspenso e selecione seu projeto do Google Cloud. Defina sua região como
us-central1. - Aguarde a conclusão das verificações de configuração. Quando aparecer a mensagem "Configuração concluída", clique em Configurar servidores MCP.
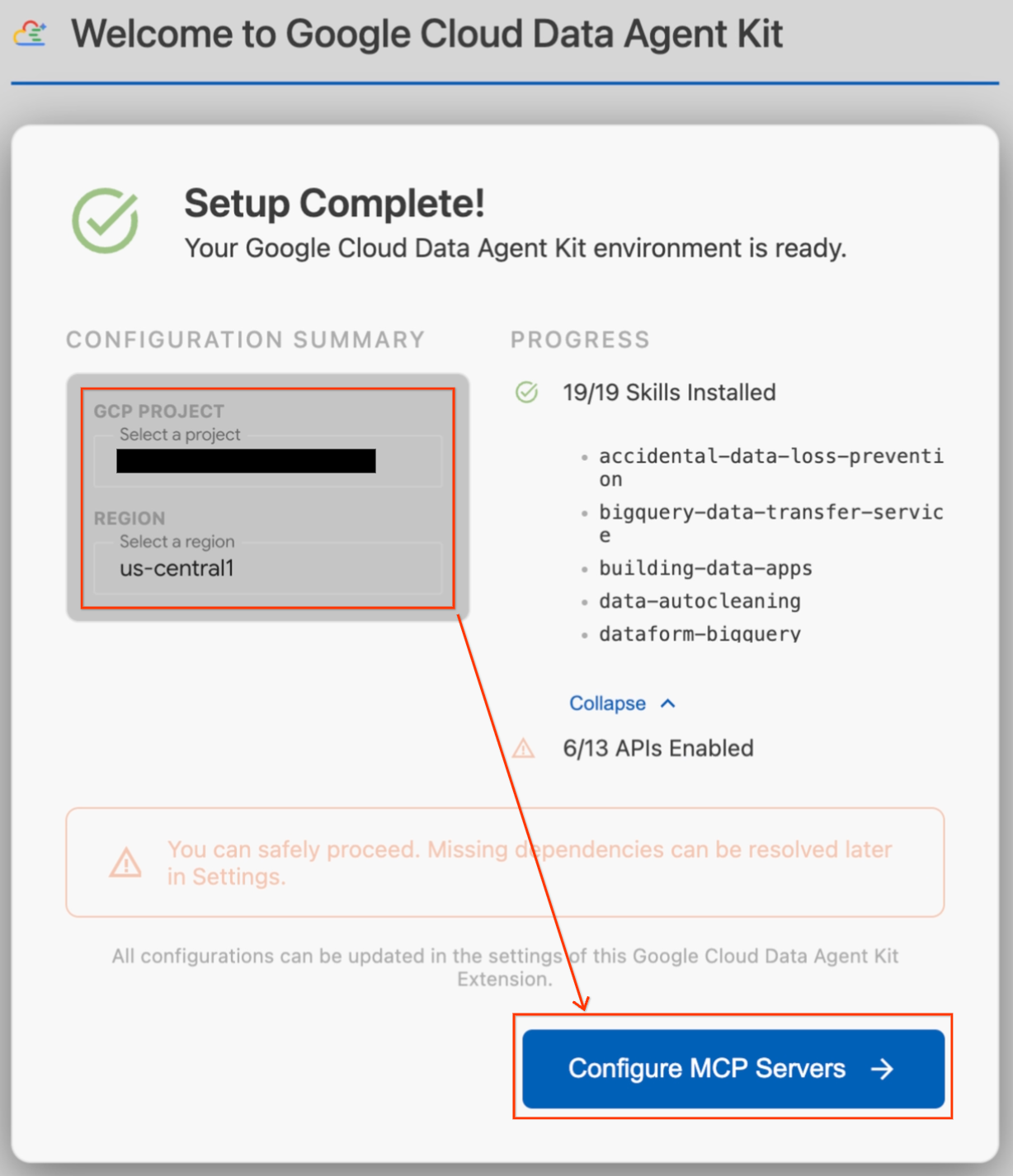
- Selecione BigQuery e AlloyDB em "Configuração da MCP" e clique em Começar.
Etapa 6: conhecer as opções de configuração
Quando a configuração for concluída, você vai acessar o painel "Começar a usar o Google Cloud Data Agent Kit".
- Em "Configuração", clique em Começar.
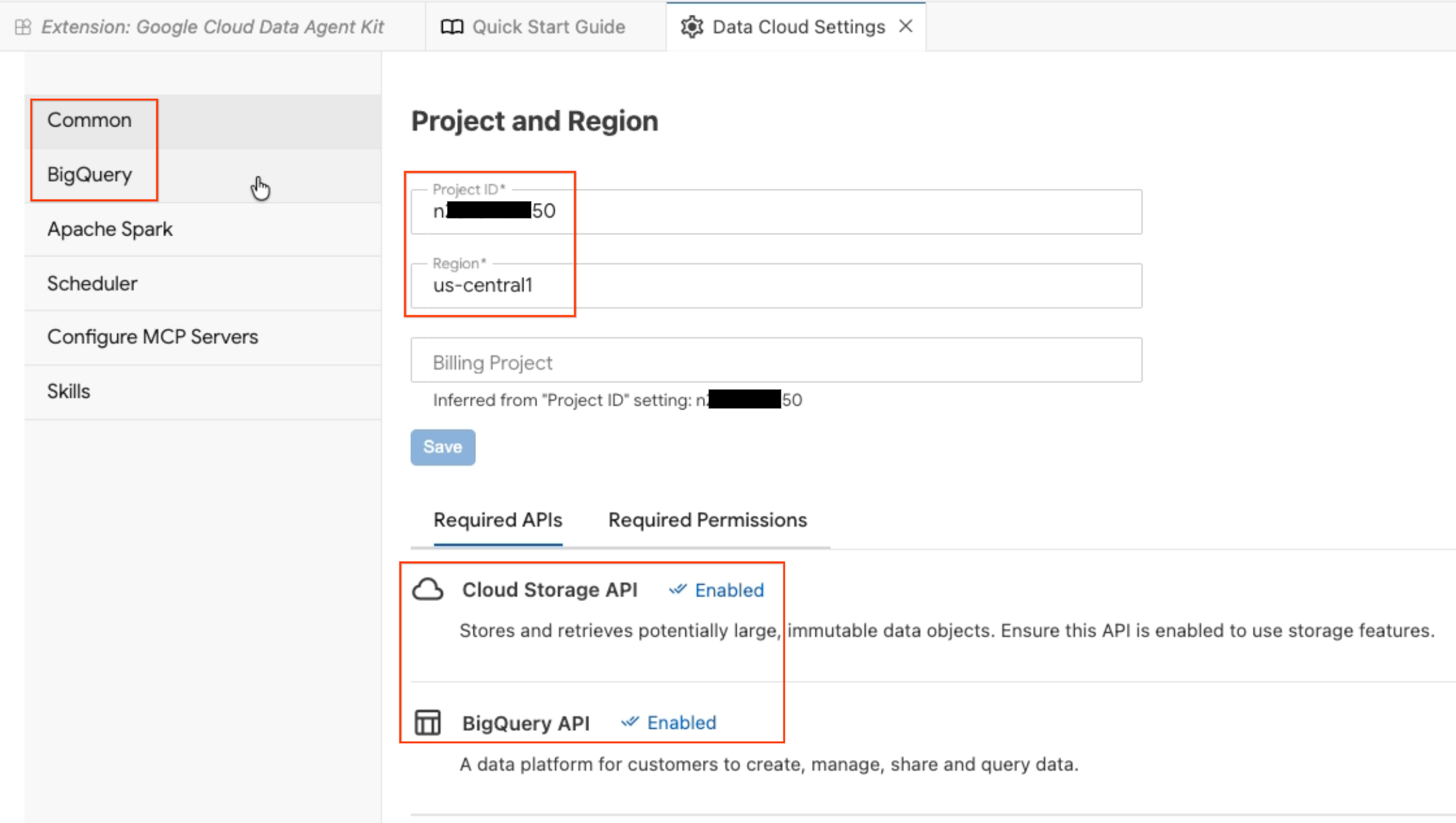
- O painel Configuração do agente de dados será aberto. Confira as guias:
- Projeto e região:verifique o ID do projeto selecionado e se as APIs necessárias (Cloud Storage, BigQuery, Catalog e AlloyDB) estão ativadas.
- BigQuery:configure o local padrão para suas consultas do BigQuery. Use a região
us-central1. - Configurar servidores MCP:veja os servidores MCP ativados (BigQuery, Notebooks, AlloyDB etc.) que permitem que agentes de IA interajam com seus dados de forma segura.
- Habilidades:conheça as habilidades pré-criadas que oferecem aos agentes recursos especializados para tarefas complexas de dados.
Etapa 7: verificar com o BigQuery
Confirme se tudo está funcionando executando uma consulta rápida em um conjunto de dados público.
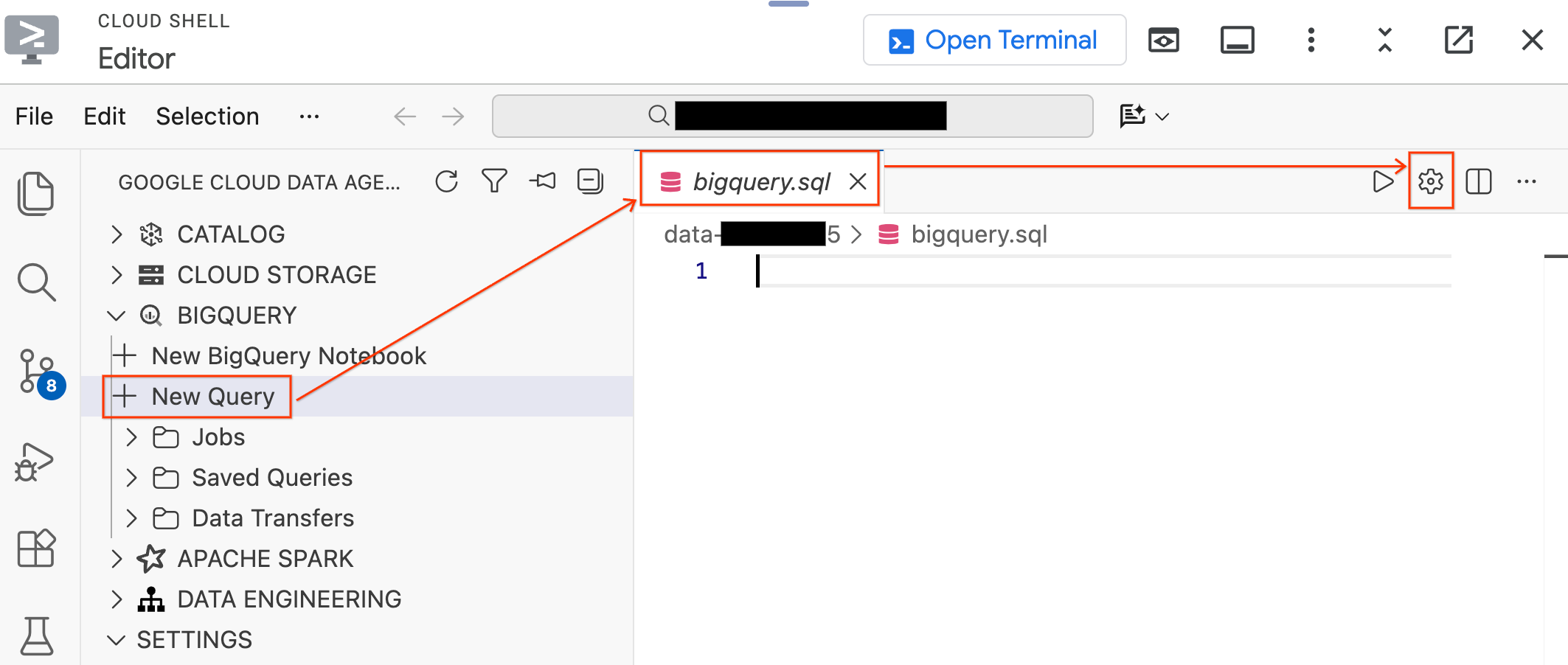
- No painel Data Agent Kit à esquerda, expanda a seção BigQuery e clique em Nova consulta para abrir uma nova guia do editor de consultas.
- Salve o arquivo pressionando
Ctrl+S(Windows/Linux) ouCmd+S(macOS) e nomeie-o comobigquery. Essa guia será usada para todas as suas operações do BigQuery. - Clique em Configurações de consulta com a guia
bigquery.sqlativa, selecione BigQuery como a Fonte de dados e clique em Salvar.
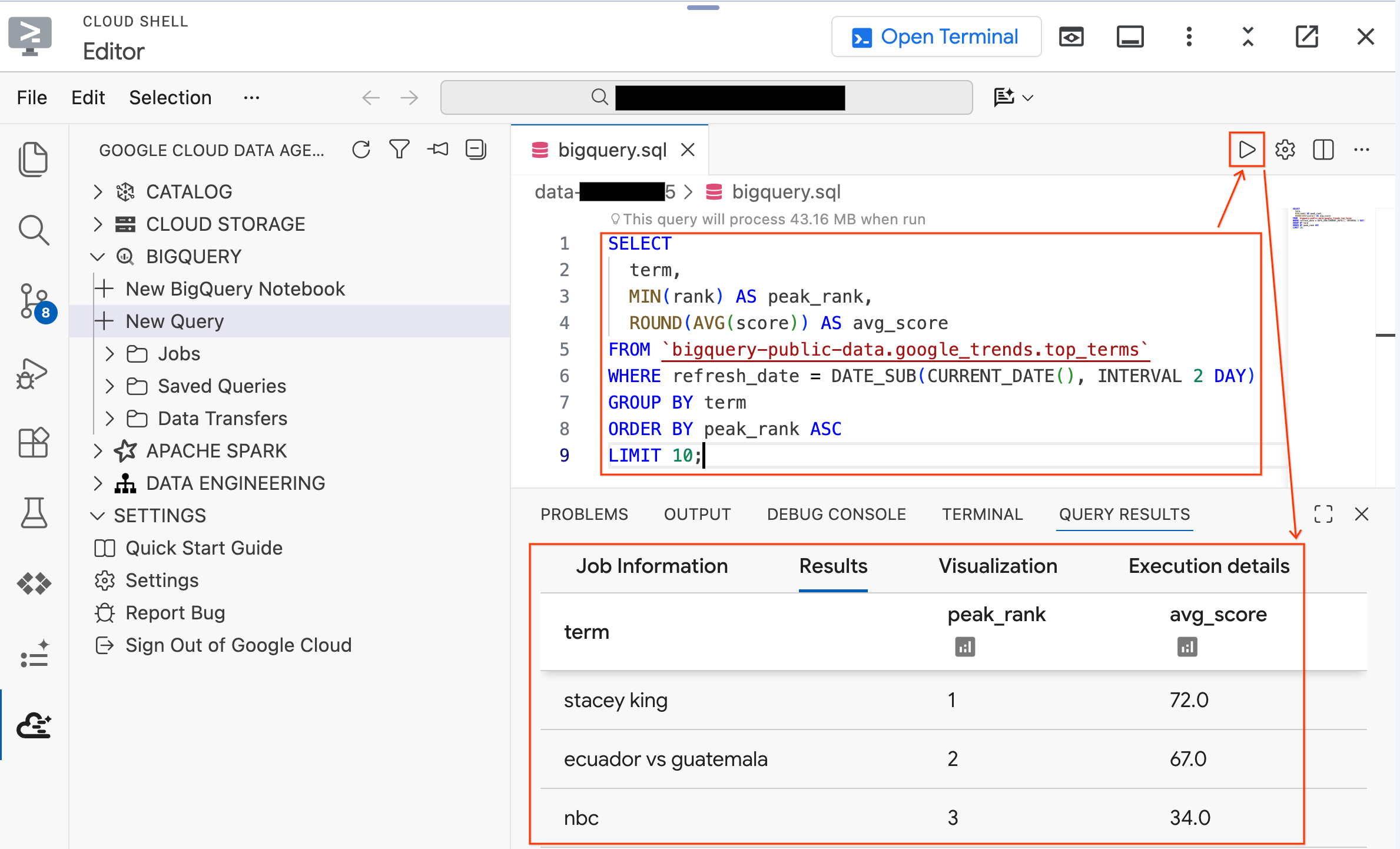
- Execute a seguinte consulta em um conjunto de dados público:
SELECT
term,
MIN(rank) AS peak_rank,
ROUND(AVG(score)) AS avg_score
FROM `bigquery-public-data.google_trends.top_terms`
WHERE refresh_date = DATE_SUB(CURRENT_DATE(), INTERVAL 2 DAY)
GROUP BY term
ORDER BY peak_rank ASC
LIMIT 10;
- Você vai encontrar os 10 principais termos de pesquisa do Google em alta nos últimos dias. Se os resultados aparecerem, a extensão estará conectada e pronta.
Agora, tente uma consulta nos dados do laboratório que o script de configuração acabou de criar. Substitua a consulta atual por esta:
SELECT * FROM `lost_cargo_dataset.telemetry_data` LIMIT 5;
Você vai ver entradas de registro de telemetria com as colunas shipment_id e telemetry_string. São esses dados que você vai analisar ao longo do laboratório.
Resumo da seção:você iniciou a implantação do AlloyDB em segundo plano, executou o script de configuração e configurou o editor do Cloud Shell com a extensão do Data Agent Kit.
4. Verificar as imagens de segurança
A equipe de investigação recuperou imagens de segurança do Porto do Rio de Janeiro mostrando fileiras de contêineres. No laboratório 1, você aprendeu que o contêiner de destino é vermelho. Agora você precisa identificar exatamente qual contêiner vermelho é.
Você vai criar uma tabela de objetos que permite ao BigQuery "ver" as imagens de segurança no Cloud Storage e usar a função AI.GENERATE para pedir ao Gemini que extraia dados estruturados de cada imagem.
Etapa 1: criar a tabela de objetos
Uma tabela de objetos é uma tabela especial do BigQuery que funciona como um índice de arquivos não estruturados (imagens, PDFs, áudio) armazenados no Cloud Storage. Ele não copia os arquivos para o BigQuery, mas cria uma referência consultável para que as funções de IA possam "enxergar" os arquivos.
Na guia bigquery.sql do editor, execute a seguinte instrução para criar a tabela de objetos que aponta para as imagens de segurança de porta no bucket do seu projeto:
SET @@location = 'us-central1';
EXECUTE IMMEDIATE CONCAT("""
CREATE OR REPLACE EXTERNAL TABLE `lost_cargo_dataset.port_security_images`
WITH CONNECTION `us-central1.lost_cargo_conn`
OPTIONS (
object_metadata = 'SIMPLE',
uris = ['gs://""", @@project_id, """-lab2/images/*']
);
""");
Confira o que o BigQuery pode ver agora:
SELECT uri, content_type FROM `lost_cargo_dataset.port_security_images` LIMIT 5;
Cada linha representa um arquivo de imagem no Cloud Storage. Agora, o BigQuery pode transmitir essas imagens diretamente para modelos de IA.
Etapa 2: analisar as imagens de segurança
Agora, use a função AI.GENERATE do BigQuery para analisar cada imagem de segurança. Essa única consulta SQL pede ao Gemini para examinar todas as imagens e retornar dados estruturados:
SELECT
uri,
AI.GENERATE(
(
'Examine this port security image. Identify any shipping container IDs visible on the container and provide a one-word color of the container.',
ref
),
output_schema => 'detected_container_id STRING, color STRING'
).* EXCEPT (full_response, status)
FROM `lost_cargo_dataset.port_security_images`;
Etapa 3: identificar o contêiner de destino
Confira os resultados. Procure a linha em que a coluna color mostra "Vermelho" (ou alguma variação de vermelho). Anote o detected_container_id. Este é o destino: MV-CAPYBARA-003.
Etapa 4: verificar a correspondência visual
Para ver a imagem real que foi analisada sem sair do editor:
- Clique em Cloud Storage no painel do Data Agent Kit à esquerda.
- Expanda seu bucket (
YOUR_PROJECT_ID-lab2/images/) e clique no arquivo de imagem correspondente ao contêiner vermelho para visualizá-lo diretamente no editor.
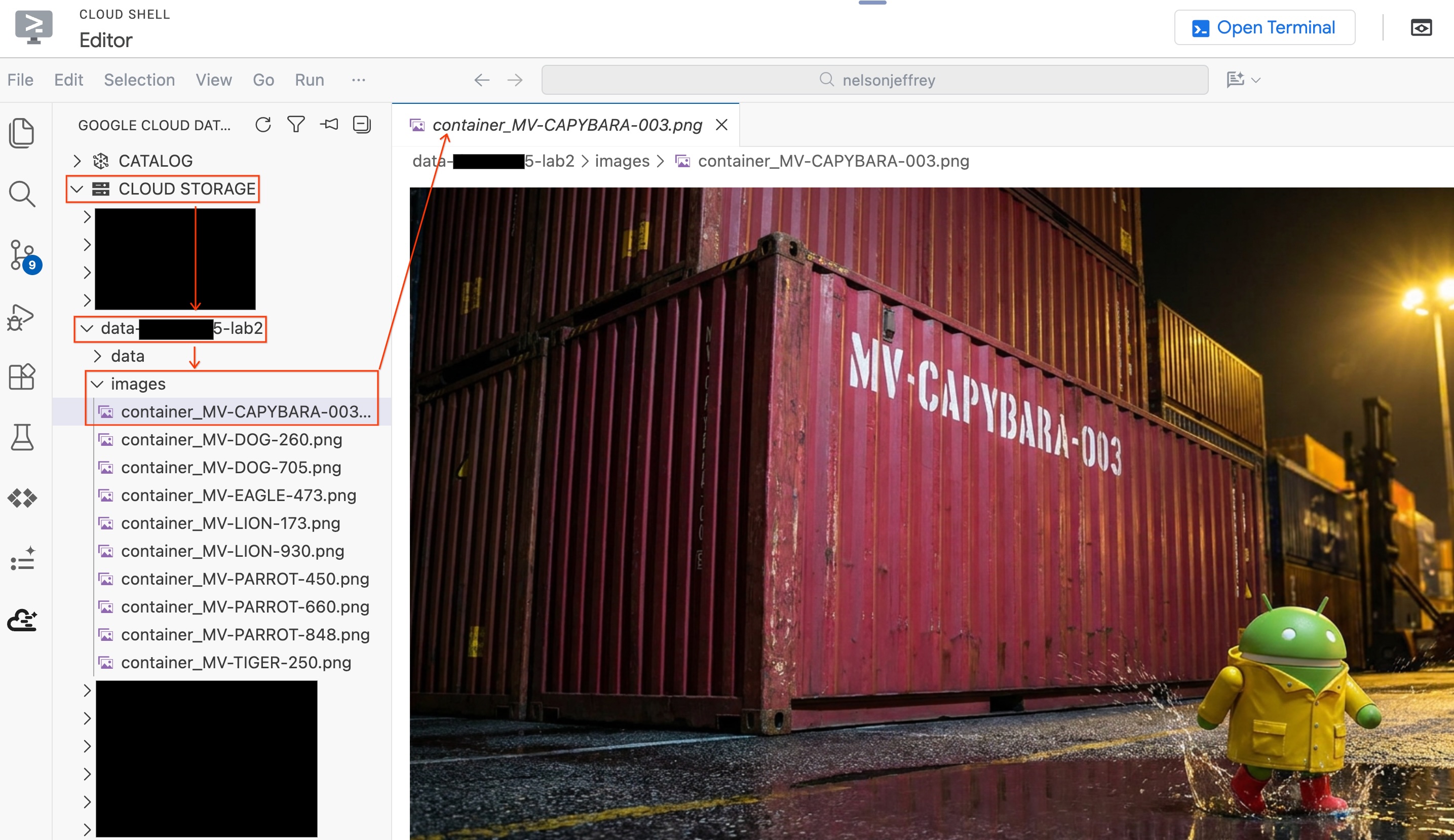
Resumo da seção:você criou uma tabela de objetos para dar ao BigQuery acesso a imagens de segurança de portos e usou AI.GENERATE para extrair dados estruturados de contêineres de cada imagem. O contêiner vermelho foi identificado como MV-CAPYBARA-003.
5. Confirmar o roubo
Você identificou o contêiner perdido como MV-CAPYBARA-003, mas ele foi roubado ou apenas perdido? Os registros do manifesto indicam que esse contêiner específico estava estacionado ao lado do sensor ambiental SENS-99. Se os ladrões desativaram deliberadamente a unidade de refrigeração integrada do contêiner antes de movê-lo, o SENS-99 pode ter registrado um aumento repentino no escape térmico.
Vamos usar a detecção de anomalias para provar que o contêiner foi adulterado.
- Primeiro, analise o valor de referência histórico. Estas são as leituras normais de
SENS-99nas últimas horas:
SELECT * FROM `lost_cargo_dataset.thermal_history`
ORDER BY reading_time DESC
LIMIT 50;
Observe que as temperaturas ficam em uma faixa estreita, entre 75 e 78 °F. É assim que a situação normal se parece.
- Agora confira o lote atual de leituras do mesmo sensor:
SELECT * FROM `lost_cargo_dataset.thermal_current`
ORDER BY thermal_reading DESC
LIMIT 50;
Está vendo a leitura 148,4 °F na parte de cima? Todo o resto parece normal. Esse pico indicaria uma falha na unidade de refrigeração ou adulteração proposital. Vamos descobrir.
- Execute a detecção de anomalias. O
AI.DETECT_ANOMALIESdo BigQuery usa o modelo de fundação TimesFM pré-treinado para analisar padrões de séries temporais e sinalizar outliers automaticamente, sem precisar de treinamento de modelo:
SELECT *
FROM AI.DETECT_ANOMALIES(
TABLE `lost_cargo_dataset.thermal_history`,
TABLE `lost_cargo_dataset.thermal_current`,
data_col => 'thermal_reading',
timestamp_col => 'reading_time',
id_cols => ['sensor_id']
)
WHERE is_anomaly = TRUE;
- Confira os resultados. A leitura de 64,7 °C precisa ser sinalizada como uma anomalia com alta probabilidade, confirmando que algo incomum aconteceu perto da área do contêiner.
Resumo da seção:você usou a função AI.DETECT_ANOMALIES do BigQuery para aproveitar o modelo TimesFM pré-treinado. Ao executar uma única consulta SQL, você identificou automaticamente os outliers e isolou o evento de adulteração anômala sem escrever nenhum código complexo de machine learning ou treinar modelos do zero.
6. Como preparar o sistema de rastreamento
O contêiner foi confirmado como roubado e não está mais no Rio de Janeiro. Cada contêiner da frota transmite sinais de beacon de telemetria: leituras de sensores, fragmentos de GPS e registros de status. Se o beacon do contêiner roubado ainda estiver transmitindo, você poderá compará-lo com assinaturas conhecidas para encontrá-lo.
O BigQuery é excelente para o trabalho analítico que você fez até agora, mas localizar um contêiner em tempo real exige consultas operacionais de baixa latência. O AlloyDB, um banco de dados totalmente gerenciado e compatível com PostgreSQL, foi criado exatamente para isso: consultas de pesquisa vetorial rápidas o suficiente para um sistema de rastreamento em tempo real. Você vai carregar os encodings de telemetria no AlloyDB e usá-los para corresponder ao indicador de beacon.
O cluster do AlloyDB que você iniciou em segundo plano já deve estar pronto. Vamos configurar diretamente no editor.
Etapa 1: conectar-se ao AlloyDB no Editor
Em vez de mudar para o Console do Cloud, você pode se conectar ao AlloyDB diretamente usando a extensão Data Agent Kit.
- No painel "Data Agent Kit" à esquerda, na seção BigQuery, clique em Nova consulta para abrir uma nova guia do editor de consultas.
- Salve o arquivo pressionando
Ctrl+S(Windows/Linux) ouCmd+S(macOS) e nomeie-o comoalloydb. Essa guia será usada para todas as consultas do AlloyDB. - Clique no ícone de engrenagem para abrir o modal Configurações de consulta.
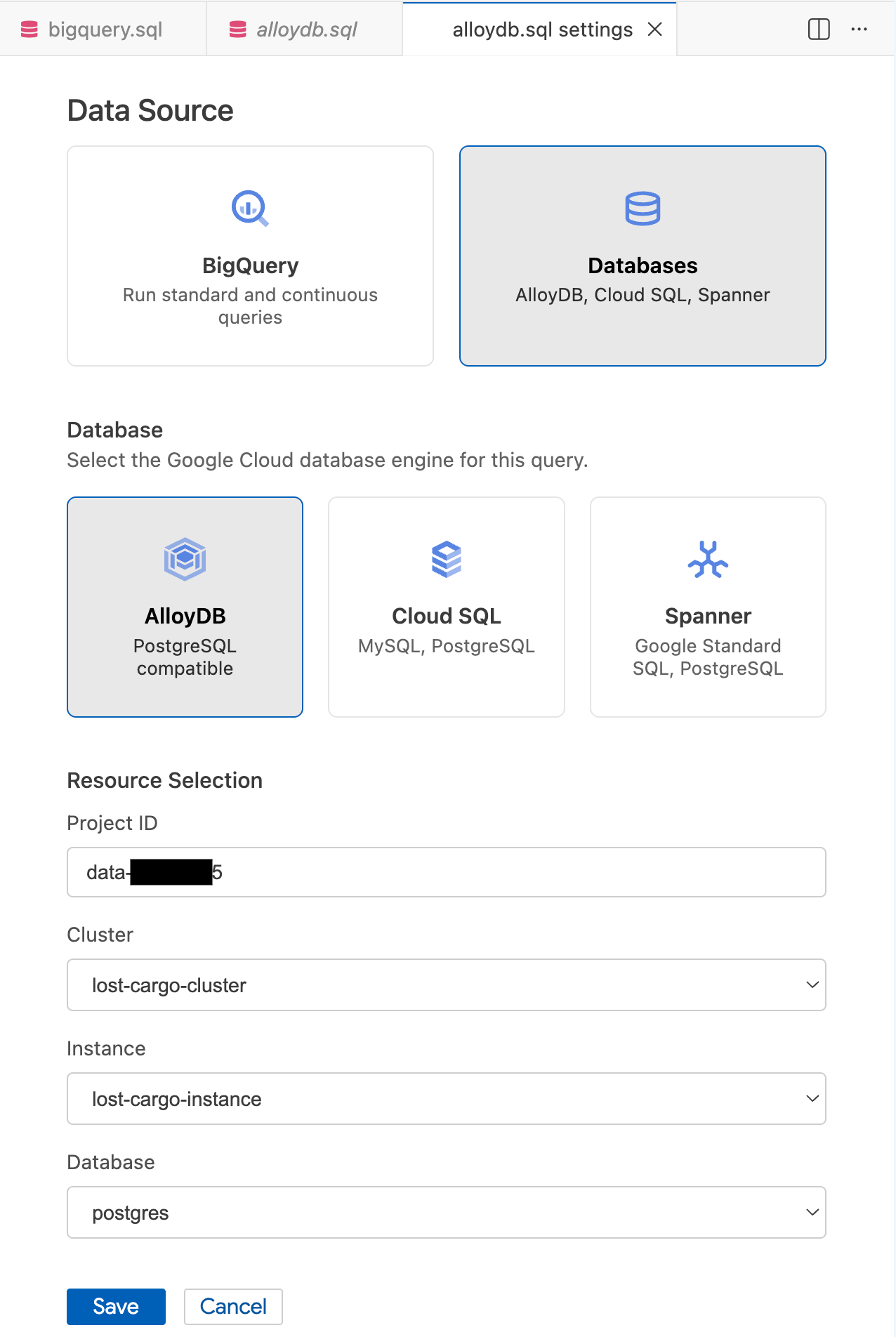
- No modal Configurações de consulta, em Fonte de dados, selecione Bancos de dados.
- Em Banco de dados, selecione AlloyDB.
- Preencha os detalhes da Seleção de recursos:
- ID do projeto: insira o ID do projeto do Google Cloud.
- Cluster: selecione
lost-cargo-cluster. - Instância: selecione
lost-cargo-instance. - Banco de dados: selecione
postgres.
- Clique em Salvar.
Etapa 2: ativar a extensão de vetor e criar a tabela
Agora que você está conectado ao AlloyDB, é necessário ativar as extensões de IA necessárias e criar a tabela que vai receber os dados de telemetria incorporados.
- Na guia
.sqlativa, cole os comandos a seguir para ativar as extensões necessárias:
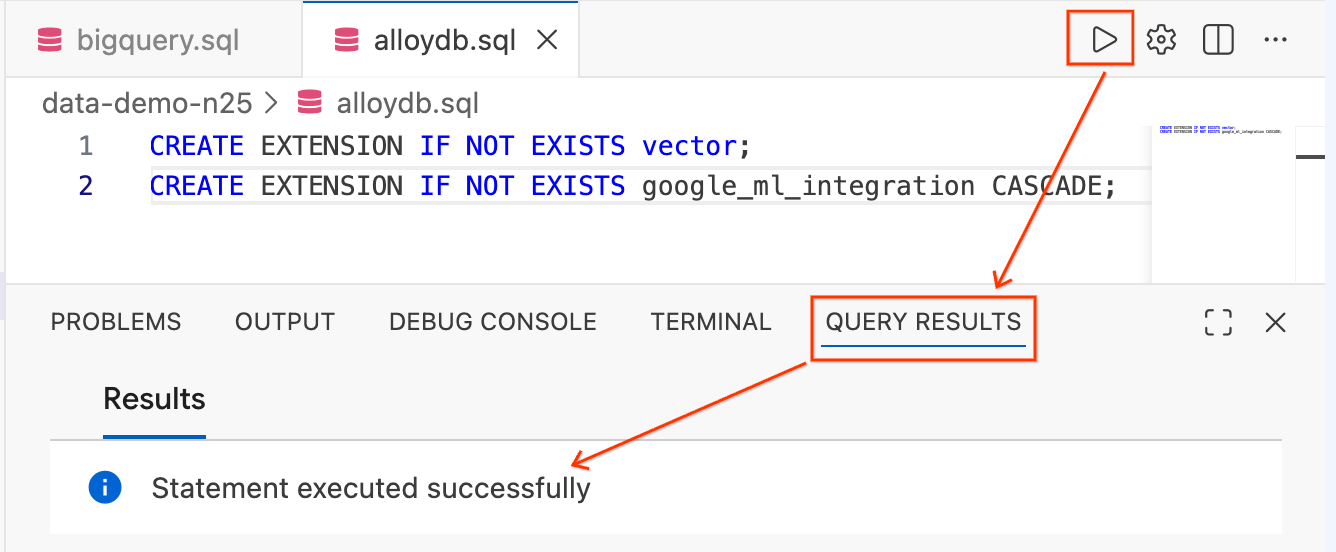
CREATE EXTENSION IF NOT EXISTS vector;
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
- Destaque o texto e clique no botão Executar consulta (ícone de reprodução) no canto superior direito do editor.
- Confira o painel do terminal Resultados da consulta na parte de baixo da tela. Ele deve dizer
Statement executed successfully.
- Em seguida, substitua o texto no editor pela seguinte instrução para criar a tabela de telemetria:
CREATE TABLE IF NOT EXISTS vessel_telemetry (
entry_id SERIAL PRIMARY KEY,
shipment_id VARCHAR(50),
telemetry_string TEXT,
embedding_vector vector(768)
);
- Execute esta consulta da mesma forma que a última. Confirme se a execução foi bem-sucedida no painel da parte de baixo.
O tipo vector(768) vem da extensão pgvector que você acabou de ativar. As 768 dimensões correspondem à saída do modelo text-embedding-005 do Google, que você vai usar no BigQuery para gerar os embeddings.
Resumo da seção:você se conectou ao AlloyDB diretamente do editor do Cloud Shell, ativou as extensões pgvector e google_ml_integration e criou a tabela de destino. O AlloyDB agora está pronto para servir como o back-end operacional para correspondência de telemetria em tempo real.
7. Como criar o índice de pesquisa
Agora você precisa transferir os dados de telemetria para o AlloyDB para que ele possa ativar a correspondência de beacons em tempo real. Os registros de telemetria brutos são confusos e de comprimento variável, o que não é ideal para a pesquisa de similaridade. Você vai usar as funções de IA do BigQuery para resumir cada registro com o Gemini e converter cada resumo em um embedding de vetor de 768 dimensões. Em seguida, exporte os dados enriquecidos para o Cloud Storage e importe-os para o AlloyDB.
Etapa 1: gerar embeddings no BigQuery
Volte para a guia do editor bigquery.sql, que continua conectada ao BigQuery.
Agora, execute a consulta a seguir para resumir cada registro de telemetria com o Gemini e gerar embeddings de vetor:
CREATE OR REPLACE TABLE `lost_cargo_dataset.telemetry_embeddings_export` AS
WITH summarized_telemetry AS (
SELECT
shipment_id,
telemetry_string,
AI.GENERATE(
CONCAT('Summarize this telemetry log for vector search: ', telemetry_string)
).result AS summary
FROM `lost_cargo_dataset.telemetry_data`
),
telemetry_embeddings AS (
SELECT
shipment_id,
telemetry_string,
AI.EMBED(summary, endpoint => 'text-embedding-005').result AS embedding
FROM summarized_telemetry
)
SELECT
shipment_id,
telemetry_string,
TO_JSON_STRING(embedding) AS embedding_vector
FROM telemetry_embeddings;
Etapa 2: visualizar os dados enriquecidos
Antes de exportar, confira o que você criou. Esta consulta mostra os IDs de envio e os 80 primeiros caracteres de cada resumo e incorporação:
SELECT
shipment_id,
SUBSTR(telemetry_string, 1, 80) AS telemetry_preview,
SUBSTR(embedding_vector, 1, 80) AS embedding_preview
FROM `lost_cargo_dataset.telemetry_embeddings_export`
LIMIT 5;
Cada linha agora contém um ID de remessa, o registro de telemetria original e um vetor de embedding de 768 dimensões. Esses são os dados que você vai enviar para o AlloyDB.
Etapa 3: exportar incorporações para o Cloud Storage
Use a instrução EXPORT DATA do BigQuery para gravar a tabela de incorporações no bucket do GCS do laboratório como um arquivo CSV.
EXECUTE IMMEDIATE CONCAT("""
EXPORT DATA OPTIONS (
uri = 'gs://""", @@project_id, """-lab2/data/embeddings_export/*.csv',
format = 'CSV',
overwrite = true,
header = false
) AS
SELECT
shipment_id,
telemetry_string,
embedding_vector
FROM `lost_cargo_dataset.telemetry_embeddings_export`;
""");
Etapa 4: importar para o AlloyDB do Cloud Storage
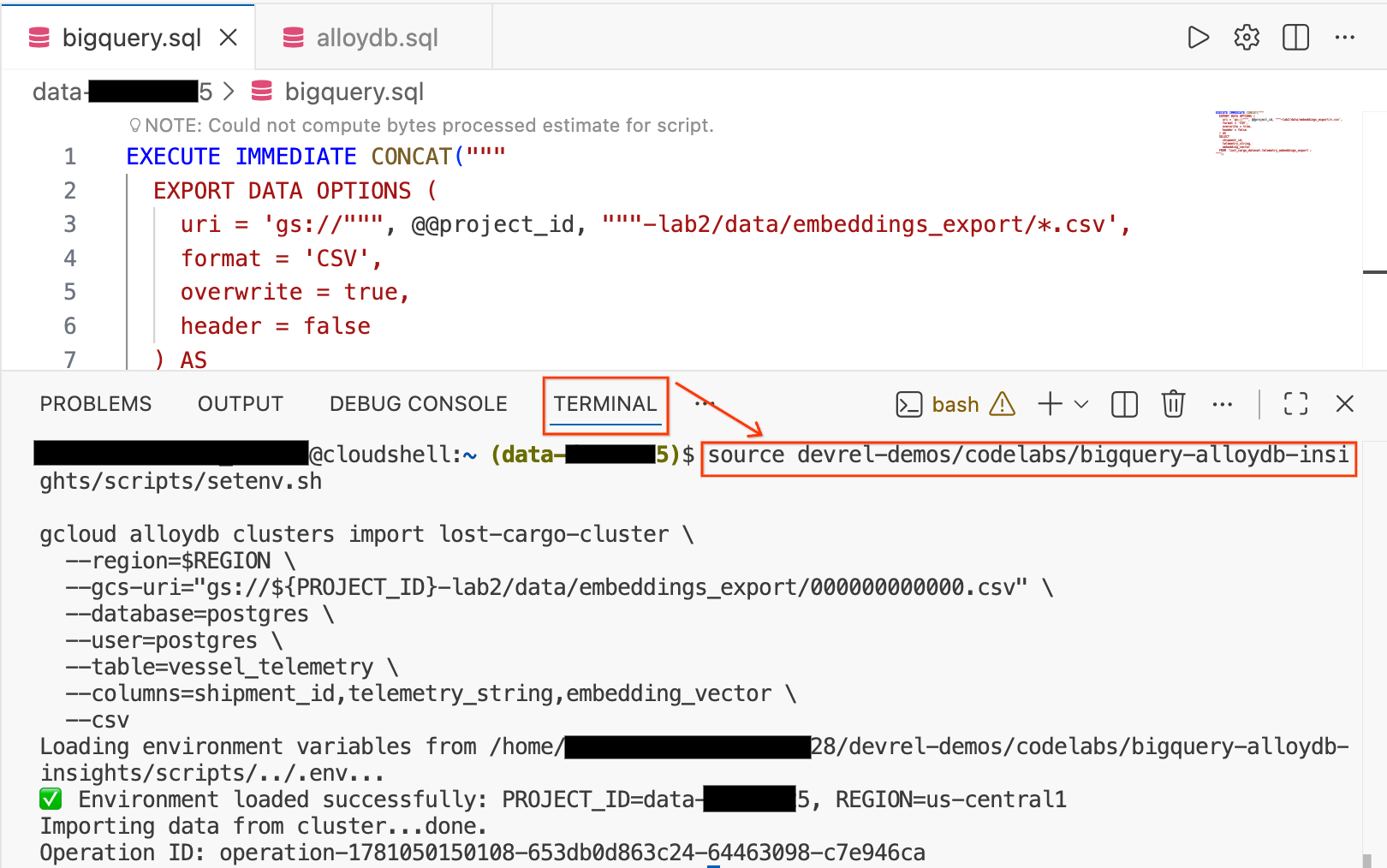
- No editor do Cloud Shell, clique na guia Terminal na parte de baixo da tela para abrir uma sessão de terminal.
- Execute os comandos a seguir para carregar seu ambiente e importar o arquivo CSV diretamente para a tabela
vessel_telemetryno AlloyDB:
source devrel-demos/codelabs/bigquery-alloydb-insights/scripts/setenv.sh
gcloud alloydb clusters import lost-cargo-cluster \
--region=$REGION \
--gcs-uri="gs://${PROJECT_ID}-lab2/data/embeddings_export/000000000000.csv" \
--database=postgres \
--user=postgres \
--table=vessel_telemetry \
--columns=shipment_id,telemetry_string,embedding_vector \
--csv
Resumo da seção:você usou as funções de IA do BigQuery para resumir e incorporar os dados de telemetria, exportou os resultados para o Cloud Storage como CSV e os importou para o AlloyDB usando gcloud. O banco de dados de rastreamento operacional agora está carregado e pronto.
8. Correspondência com o indicador de beacon
Uma equipe de campo perto de Sydney interceptou um sinal fragmentado de beacon de telemetria. O registro parcial mostra:
"Unidade de refrigeração off-line. Substituição manual."
Se isso vier do contêiner roubado, a pesquisa vetorial do AlloyDB poderá corresponder a ele, mesmo que o indicador esteja incompleto. Esse é exatamente o tipo de consulta operacional em tempo real para que o AlloyDB foi criado.
Etapa 1: verificar os dados importados
Mude a guia do editor de volta para alloydb.sql, que permanece conectada ao AlloyDB.
Confirme se os dados de telemetria foram carregados executando:
SELECT shipment_id, LEFT(telemetry_string, 80) AS telemetry_preview
FROM vessel_telemetry
LIMIT 10;
Você vai ver linhas com valores shipment_id e texto de telemetria. Essas são as assinaturas de telemetria da frota, agora prontas para correspondência em tempo real.
Etapa 2: pesquisar o contêiner ausente
Agora, use a extensão google_ml_integration do AlloyDB para pesquisar uma correspondência usando o fragmento de indicador interceptado:
SELECT
shipment_id,
telemetry_string,
1 - (embedding_vector <=> embedding('text-embedding-005', 'Refrigeration unit offline. Manual override.')::vector) AS search_relevance_score
FROM vessel_telemetry
ORDER BY embedding_vector <=> embedding('text-embedding-005', 'Refrigeration unit offline. Manual override.')::vector
LIMIT 5;
A função embedding(), fornecida pela extensão google_ml_integration do AlloyDB, chama a Agent Platform diretamente do SQL para gerar um embedding de vetor inline. O operador <=> calcula a distância do cosseno entre dois vetores. Quanto mais próximo de 0, mais idênticos são os vetores. Subtraímos de 1 para expressar os resultados como uma pontuação de relevância em que quanto maior, melhor.
Etapa 3: confirmar a correspondência
Confira os resultados. O primeiro resultado deve ser MV-CAPYBARA-003, com a maior pontuação de relevância.
É o mesmo contêiner que você rastreou em todas as etapas desta investigação:
- 📷 Imagens de segurança identificaram o navio saindo do Porto do Rio de Janeiro à noite.
- 🌡️ A detecção de anomalias térmicas confirmou que a unidade de refrigeração foi desativada propositalmente.
- 📡 A correspondência de indicadores de beacon acabou de identificar a assinatura de telemetria perto de Sydney.
Três linhas de evidências independentes. Três recursos diferentes de IA do Google Cloud. Um contêiner roubado.
🎯 Caso encerrado: o MV-CAPYBARA-003 foi localizado perto de Sydney!

Resumo da seção:você usou a integração de IA integrada do AlloyDB para gerar um embedding de pesquisa e realizar uma pesquisa de similaridade de cosseno em uma única consulta SQL. A correspondência do beacon confirmou a localização do contêiner roubado, concluindo a investigação.
9. Analisando as evidências
Agora que você identificou o contêiner usando a análise de imagens multimodal e a pesquisa vetorial, pode usar a análise de conversas diretamente no editor para analisar os dados da investigação usando linguagem natural, sem escrever SQL.
Etapa 1: localizar os dados no Knowledge Catalog
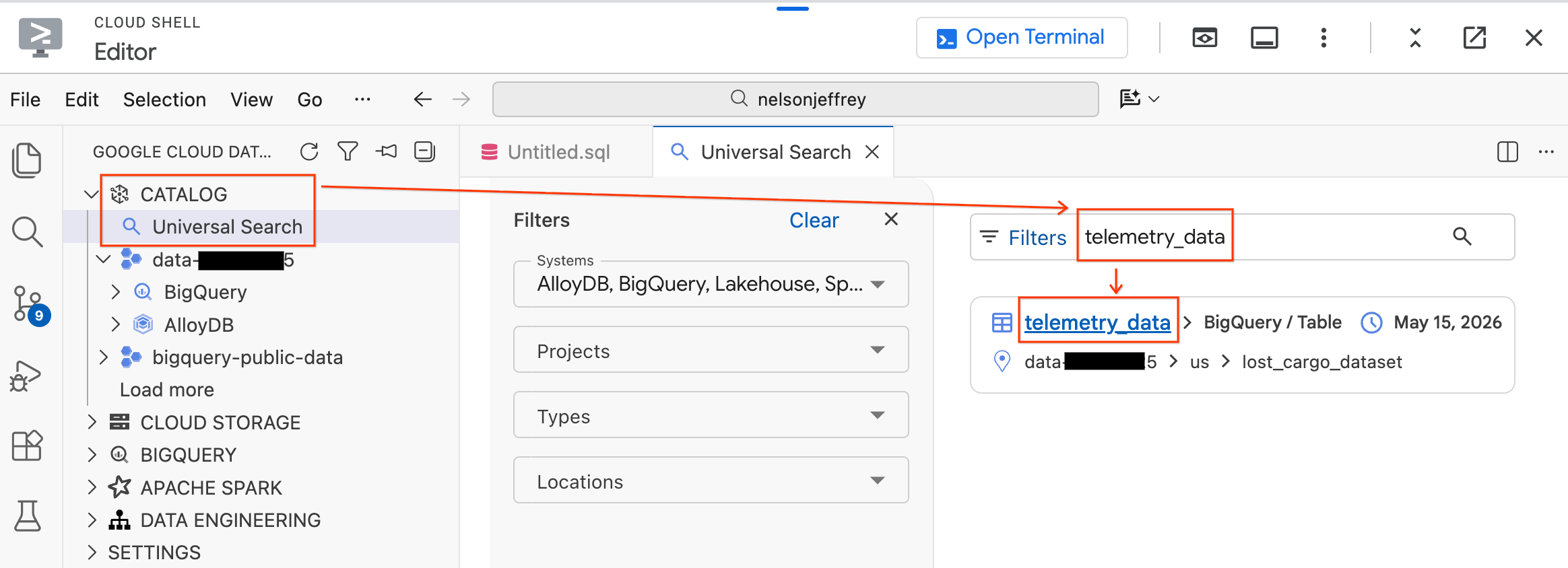
O Data Agent Kit inclui um recurso de pesquisa universal que permite encontrar e analisar recursos de dados em todo o ambiente do Google Cloud.
- No painel do Data Agent Kit à esquerda, expanda a seção Catálogo.
- Clique em Pesquisa universal.
- Na barra de pesquisa, digite
telemetry_data. - Clique na tabela
telemetry_data(emlost_cargo_dataset) nos resultados da pesquisa.
Etapa 2: iniciar o Conversational Analytics
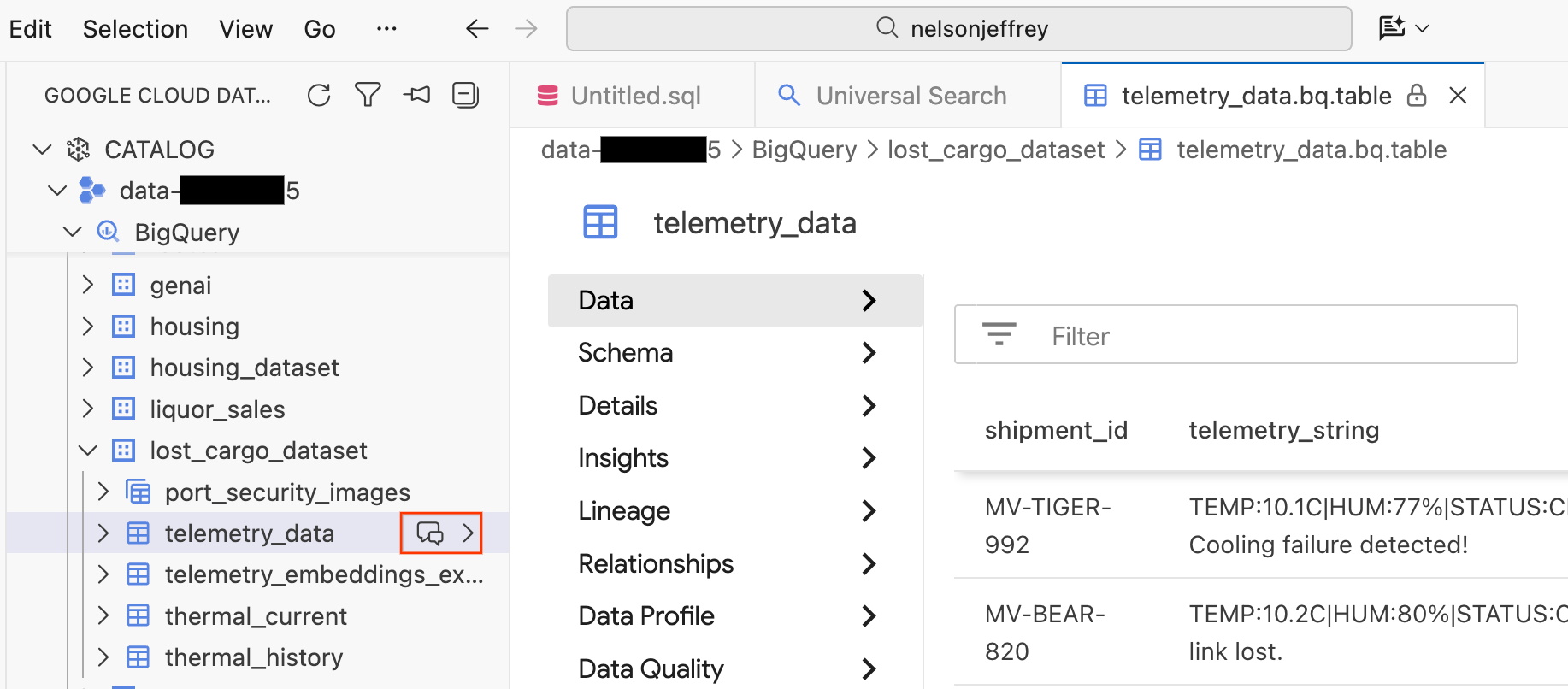
Ao clicar no resultado da pesquisa, uma guia do visualizador de dados é aberta. Nela, é possível conferir uma prévia dos dados brutos, ver o esquema e verificar a qualidade dos dados.
- No painel à esquerda, seus conjuntos de dados e tabelas do BigQuery ficam visíveis. Clique no botão Chat para abrir uma nova janela de chat.
Etapa 3: fazer perguntas em linguagem natural
Uma nova guia de chat "Olá! Este é o recurso Análise Conversacional" será aberta. O agente tem contexto sobre o esquema e o conteúdo da sua tabela.
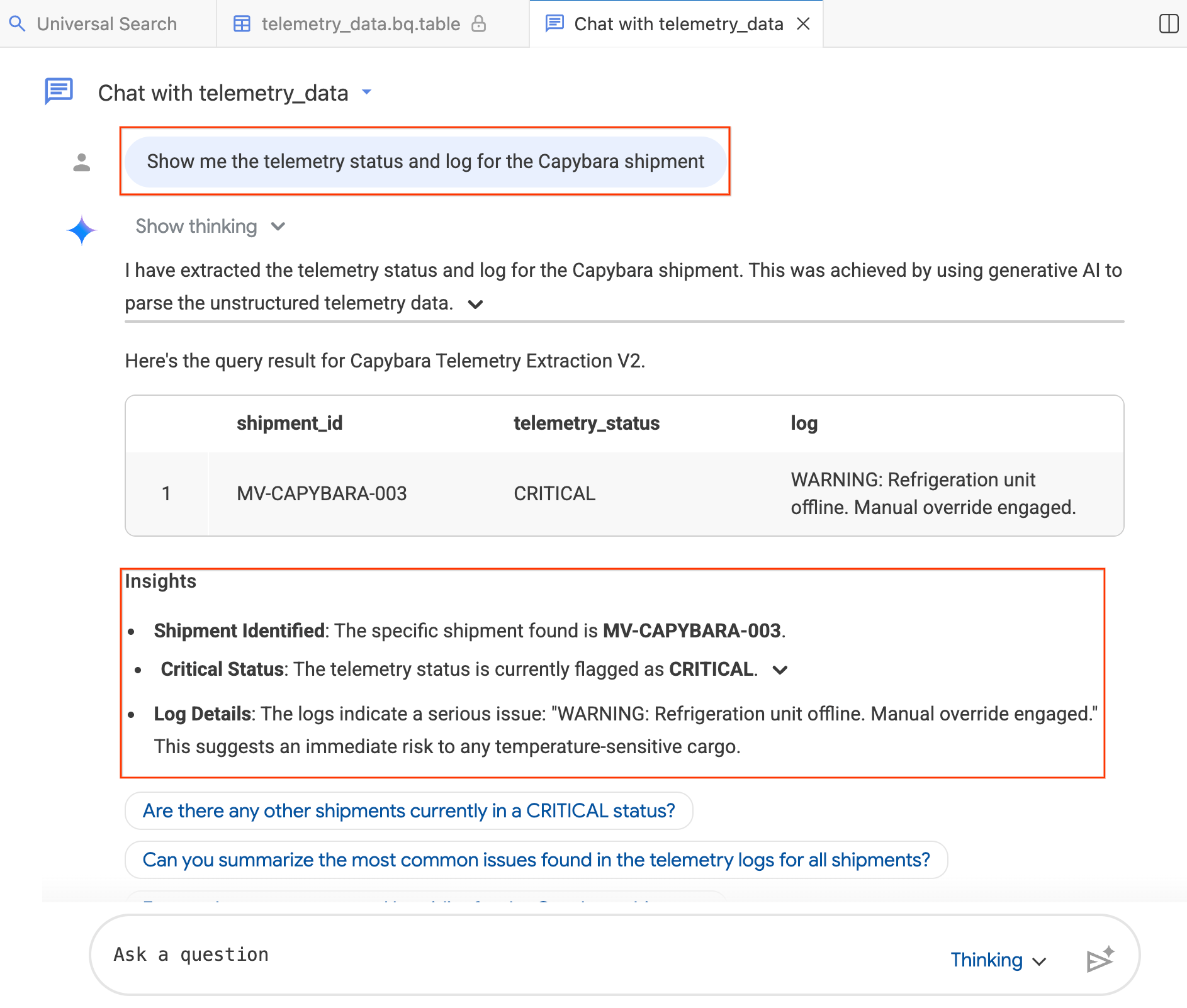
- Na janela de chat, digite:"Mostre o status da telemetria e o registro do envio de capivara".
- Pressione Enter.
O agente traduz sua pergunta para SQL do BigQuery, executa a consulta e retorna os resultados, incluindo uma tabela de dados e Insights que resumem as descobertas. Você pode alternar entre o modo Pensando (análise mais profunda, mais lenta) e Rápido (respostas mais rápidas), dependendo da complexidade da sua pergunta. Como essas são respostas geradas por IA, seus resultados podem ser um pouco diferentes das capturas de tela abaixo.
Etapa 4: faça perguntas complementares
O agente lembra o contexto da sua conversa. Faça uma pergunta complementar:
- "Quantos envios únicos há nos dados de telemetria?"
- "Quantos outros envios na frota têm um status CRÍTICO no momento?"
Resumo da seção:você usou o recurso de pesquisa universal do Knowledge Catalog para localizar seu conjunto de dados e iniciou o Conversational Analytics para consultar dados de investigação com linguagem natural. O agente de IA traduziu suas perguntas para SQL e forneceu insights que corroboraram suas descobertas.
10. Limpeza
Para evitar cobranças contínuas na sua conta do Google Cloud, exclua os recursos criados neste laboratório. É possível executar esses comandos no terminal integrado do editor Cloud Shell (onde você usou o Data Agent Kit) para limpar seu ambiente.
Primeiro, carregue as variáveis de ambiente:
source scripts/setenv.sh
- Exclua os recursos do BigQuery (somente se você não for continuar para o laboratório 3):
Se você planeja continuar no Laboratório 3, pule esta etapa. O Laboratório 3 usa o mesmo conjunto de dados e as mesmas conexões do BigQuery para análise de gráficos de propriedades.
Para excluir seu conjunto de dados e conexões do BigQuery:
# Drop the dataset
bq rm -r -f $PROJECT_ID:lost_cargo_dataset
# Delete the connections
bq rm --connection --location=us-central1 $PROJECT_ID.us-central1.lost_cargo_conn
bq rm --connection --location=us-central1 $PROJECT_ID.us-central1.lost_cargo_alloydb_conn
- Exclua o bucket do Cloud Storage:
gcloud storage rm --recursive gs://${PROJECT_ID}-lab2
- Exclua a instância e o cluster do AlloyDB:
O AlloyDB não é usado no laboratório 3, então você pode encerrá-lo agora.
gcloud alloydb instances delete lost-cargo-instance \
--region=$REGION \
--cluster=lost-cargo-cluster \
--quiet
gcloud alloydb clusters delete lost-cargo-cluster \
--region=$REGION \
--force \
--quiet
- Exclua as configurações do ambiente local:
Por fim, limpe o arquivo de configurações do ambiente local do seu espaço de trabalho:
rm -f .env
11. Parabéns!
Você concluiu o Laboratório 2: análise de dados e insights multimodais. Você seguiu a trilha de um porto cheio de milhares de contêineres até um roubo confirmado e um local exato.
O que você realizou
- Analisou as imagens: você usou o
AI.GENERATEdo BigQuery para analisar imagens de segurança portuária e identificar o contêiner MV-CAPYBARA-003 em vermelho carmim. - Confirmou o roubo: você analisou os dados do sensor térmico, identificou um pico suspeito de 64, 7 °C e usou o
AI.DETECT_ANOMALIESpara provar que foi uma violação proposital. - Preparação do sistema de rastreamento: você configurou o AlloyDB com pgvector e
google_ml_integrationpara correspondência de beacons em tempo real. - Criou o índice de pesquisa: você usou
AI.GENERATEeAI.EMBEDno BigQuery para criar embeddings, exportou para o Cloud Storage e importou para o AlloyDB. - Correspondência com o sinal do beacon: você usou a pesquisa vetorial do AlloyDB para corresponder a um sinal de telemetria fragmentado, localizando o contêiner roubado perto de Sydney.
- Analisou as evidências: você usou as Análises de Conversação diretamente do editor para consultar dados de investigação com linguagem natural.

Próximas etapas
Você já descobriu onde está o contêiner. Agora, é preciso saber quem está por trás dele.
No Laboratório 3: consumo de dados e fluxos de trabalho de agentes, você vai criar um gráfico de propriedades da rede logística para mapear as relações entre empresas de fachada, usar a análise de conversas para conversar com o gráfico e pesquisar no catálogo do Knowledge para encontrar o código de autorização seguro necessário para recuperar o contêiner.