
1. Введение

В предыдущей лабораторной работе вы собрали разрозненные данные о грузе и отследили грузовой транспондер до Нью-Йорка. Однако записи о прибытии показывают, что контейнер был немедленно перенаправлен, чтобы избежать обнаружения таможней. Теперь след привел вас в порт Рио-де-Жанейро , огромный порт с тысячами контейнеров. Найти нужный контейнер среди тысяч других — непростая задача.
В этой лабораторной работе вы будете использовать встроенные в BigQuery возможности искусственного интеллекта для «чтения» неструктурированных изображений безопасности портов и обнаружения тепловых аномалий в данных датчиков, используя стандартный SQL. Затем вы экспортируете векторные представления в AlloyDB и выполните векторный поиск, чтобы сопоставить фрагментированный телеметрический сигнал с отсутствующим контейнером.
Что вы будете делать
- Сканирование изображений с камер видеонаблюдения порта для идентификации украденного контейнера с помощью искусственного интеллекта BigQuery.
- Обнаружение тепловой аномалии с помощью BigQuery AI позволяет подтвердить, что контейнер был украден, а не потерян.
- Сгенерируйте векторные представления и загрузите их в AlloyDB для поиска в реальном времени.
- Для определения местоположения украденного контейнера с помощью векторного поиска сопоставьте фрагментированный сигнал телеметрического маяка.
- Анализируйте данные расследований с помощью естественного языка, используя разговорную аналитику.
Что вам понадобится
- Веб-браузер, например Chrome.
- Проект Google Cloud с включенной функцией выставления счетов.
- Базовые знания SQL и Google Cloud Console.
Данный практический семинар предназначен для разработчиков среднего уровня.
Стоимость ресурсов, созданных в рамках этого практического занятия, должна составлять менее 5 долларов.
2. Перед началом работы
Запустить Cloud Shell
Для загрузки кода, запуска скриптов настройки и развертывания приложения вы будете использовать Google Cloud Shell .
- Откройте Cloud Shell в новой вкладке браузера : shell.cloud.google.com
- После подключения укажите идентификатор проекта и подтвердите свою среду:
gcloud config set project <<YOUR_PROJECT_ID>>
export PROJECT_ID=$(gcloud config get-value project)
export REGION=us-central1
Вы должны увидеть сообщение, похожее на следующее:
Your active configuration is: [cloudshell-####] Updated property [core/project]
Клонируйте репозиторий
Клонируйте репозиторий codelab в свою среду Cloud Shell:
cd ~/
git clone --filter=blob:none --no-checkout https://github.com/GoogleCloudPlatform/devrel-demos.git
cd ~/devrel-demos
git sparse-checkout init --cone
git sparse-checkout set codelabs/bigquery-alloydb-insights
git checkout main
cd codelabs/bigquery-alloydb-insights/
Включить API
Выполните эту команду в Cloud Shell, чтобы включить все необходимые API для этой лабораторной работы:
gcloud services enable \
aiplatform.googleapis.com \
bigquery.googleapis.com \
bigqueryconnection.googleapis.com \
alloydb.googleapis.com
После успешного выполнения вы должны увидеть сообщение, похожее на следующее:
Operation "operations/..." finished successfully.
3. Настройте свою среду.
Прежде чем приступить к анализу изображений и телеметрических данных, необходимо настроить инфраструктуру для этой лабораторной работы. Вам потребуется запустить два скрипта: один запускает процесс подготовки AlloyDB в фоновом режиме, а другой создает все необходимые ресурсы BigQuery.
Шаг 1: Запуск развертывания AlloyDB (в фоновом режиме)
Подготовка кластера AlloyDB занимает около 10 минут, поэтому запустите его первым и позвольте ему работать в фоновом режиме, пока вы занимаетесь разделами BigQuery. Скрипт автоматически сохранит активные настройки проекта в локальный файл .env , чтобы ваша конфигурация сохранялась даже при закрытии или перезапуске терминала Cloud Shell.
chmod +x scripts/setup_alloydb.sh
nohup ./scripts/setup_alloydb.sh > /dev/null 2>&1 &
echo "AlloyDB deployment started in background (PID: $!)"
Шаг 2: Запустите скрипт установки.
Этот скрипт создает набор данных BigQuery, устанавливает соединение с облачным ресурсом, предоставляет права доступа IAM, создает хранилище GCS и загружает все данные с датчиков, которые вы будете анализировать в этой лабораторной работе. Он также считывает и проверяет переменные среды, сохраненные в файле .env .
chmod +x scripts/setup_lab.sh
./scripts/setup_lab.sh
Выполнение скрипта занимает около минуты. После завершения вы увидите сводку всего созданного.
📝 Примечание о сбросе среды. Если ваша сессия Cloud Shell прервется или перезапустится в любой момент во время выполнения этой лабораторной работы, вы можете немедленно восстановить переменные терминала, выполнив команду:
source scripts/setenv.sh
Шаг 3: Запустите редактор Cloud Shell.
До сих пор вы использовали терминал Cloud Shell. Теперь переключитесь на полнофункциональный редактор Cloud Shell, который предоставляет вам рабочее пространство, похожее на VS Code, со встроенной поддержкой BigQuery.
- В нижней части экрана в панели терминала Cloud Shell нажмите кнопку «Открыть редактор» , чтобы запустить рабочую область редактора Cloud Shell.

Шаг 4: Установите расширение Data Agent Kit.
Расширение Google Cloud Data Agent Kit обеспечивает глубокую интеграцию с сервисами данных Google Cloud непосредственно в вашем редакторе, позволяя взаимодействовать с BigQuery, AlloyDB, Cloud Storage и другими сервисами без переключения контекста.
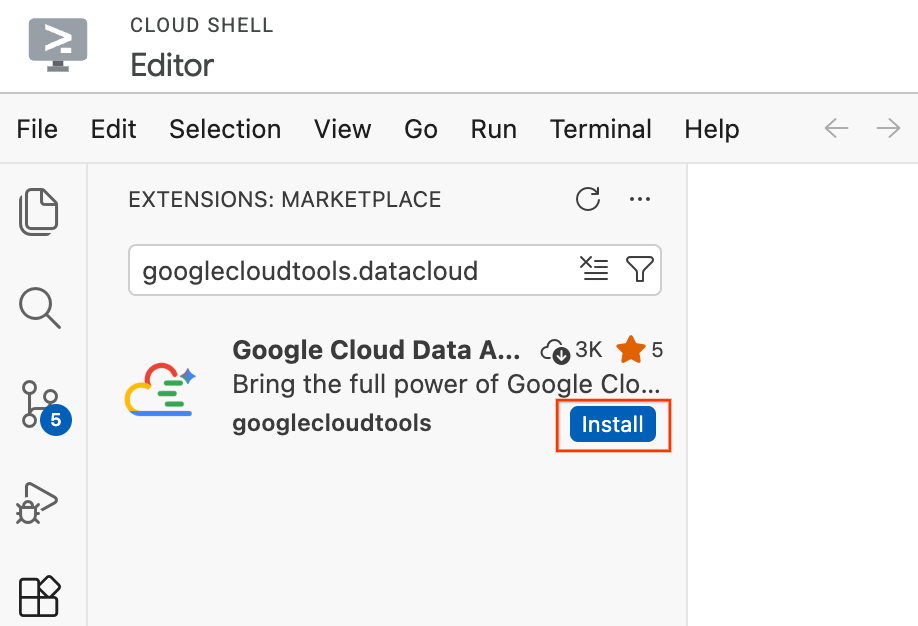
- В редакторе Cloud Shell нажмите на значок «Расширения» на панели действий в левой части экрана (он выглядит как четыре квадрата).
- В строке поиска в верхней части панели расширений введите
googlecloudtools.datacloud. - Найдите расширение под названием Google Cloud Data Agent Kit, опубликованное компанией Google Cloud.
- Нажмите кнопку «Установить» .
- Появится запрос: «Доверяете ли вы издателю 'googlecloudtools' и его расширениям?». Нажмите «Доверять издателям и установить» , чтобы продолжить.
Шаг 5: Аутентификация и настройка расширения
После установки подключите расширение к своему проекту в Google Cloud.
- Автоматически должна открыться страница регистрации под названием «Регистрация в Google Cloud Data Agent Kit». Нажмите «Войти в Google Cloud» . Следуйте инструкциям браузера для предоставления доступа.
- Появится модальное окно «Выполняется настройка». Расширение автоматически проверит наличие необходимых зависимостей, таких как Google Cloud CLI.
- В разделе «Сводка конфигурации» найдите поле «Проект». Щелкните раскрывающийся список и выберите свой проект Google Cloud. Установите регион как
us-central1. - Дождитесь завершения проверок настройки. Как только появится сообщение «Настройка завершена!», нажмите «Настроить серверы MCP ».
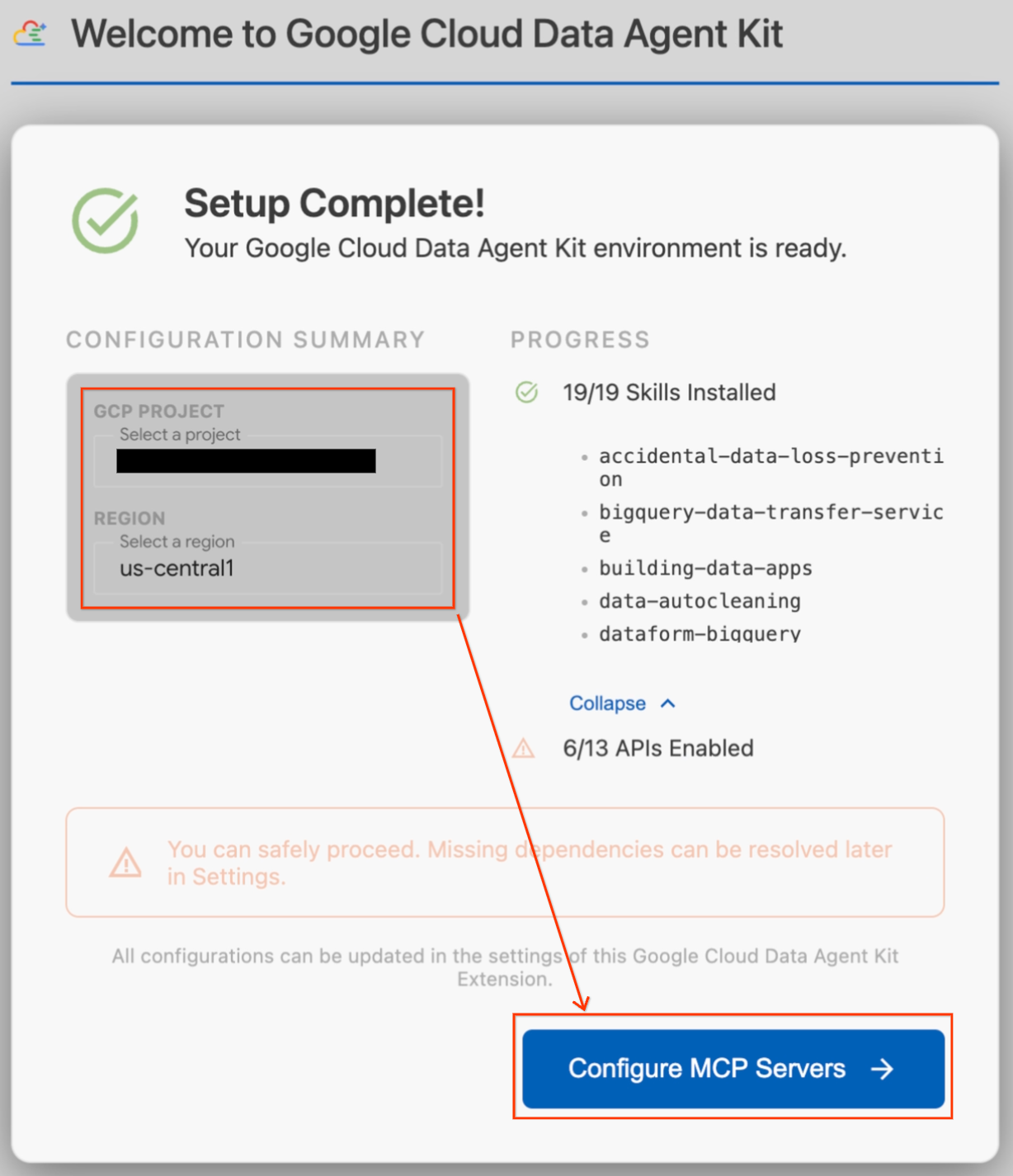
- В разделе «Конфигурация MCP» выберите BigQuery и AlloyDB, а затем нажмите «Начать» .
Шаг 6: Изучение параметров конфигурации
После завершения настройки вы попадете на панель управления "Начало работы с Google Cloud Data Agent Kit".
- В разделе «Настройка и конфигурация» нажмите «Начать» .
- Откроется панель конфигурации агента данных . Изучите вкладки:
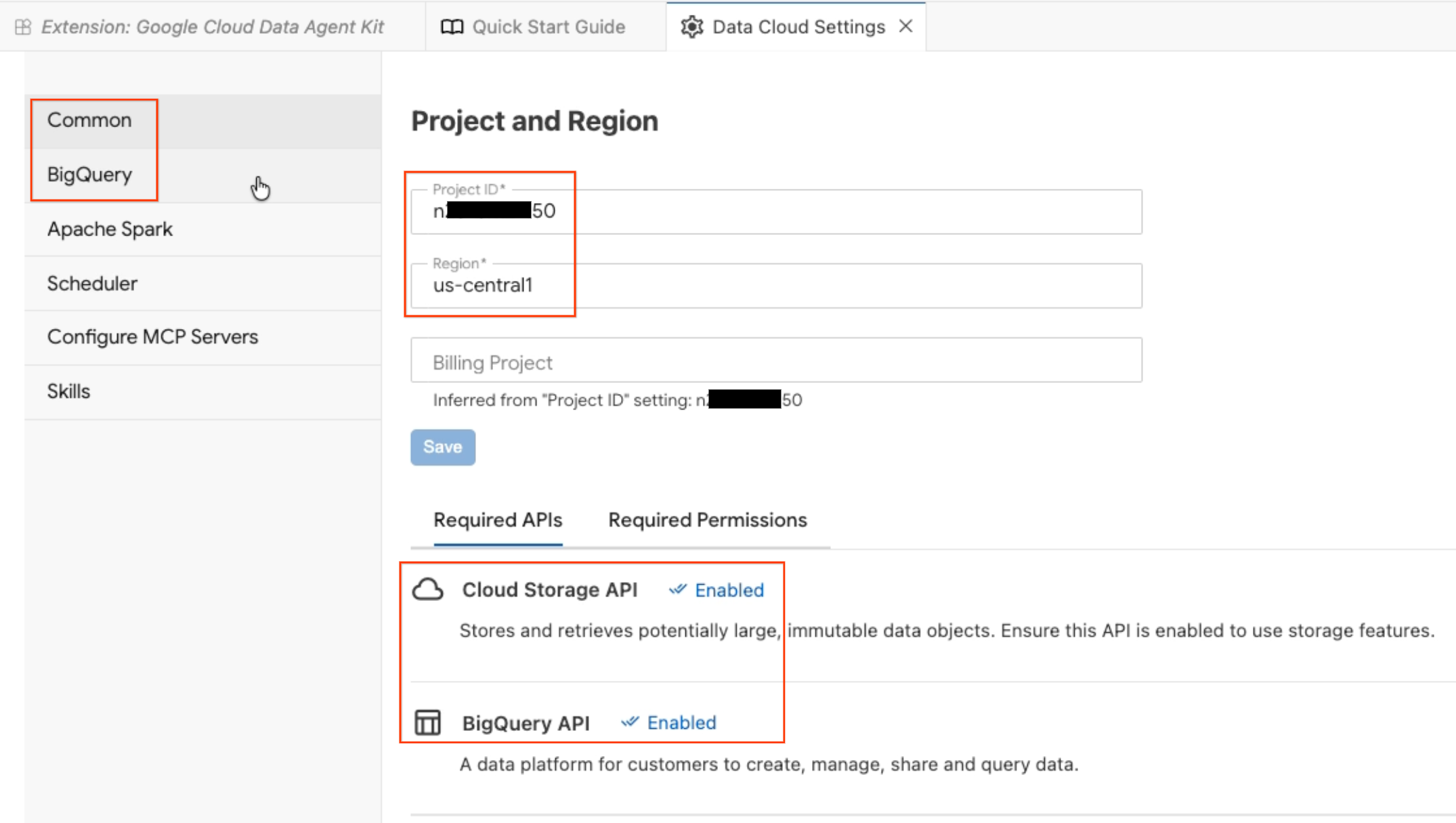
- Проект и регион: Проверьте выбранный идентификатор проекта и убедитесь, что необходимые API (API облачного хранилища, API BigQuery, API каталога и API AlloyDB) включены.
- BigQuery: Настройте местоположение по умолчанию для ваших запросов BigQuery. Используйте регион
us-central1. - Настройка серверов MCP: Просмотрите список включенных серверов MCP (BigQuery, Notebooks, AlloyDB и т. д.), которые позволяют агентам ИИ безопасно взаимодействовать с вашими данными.
- Навыки: Изучите встроенные навыки , которые предоставляют агентам специализированные возможности для решения сложных задач обработки данных.
Шаг 7: Проверка с помощью BigQuery
Убедитесь, что всё работает, выполнив быстрый запрос к общедоступному набору данных.
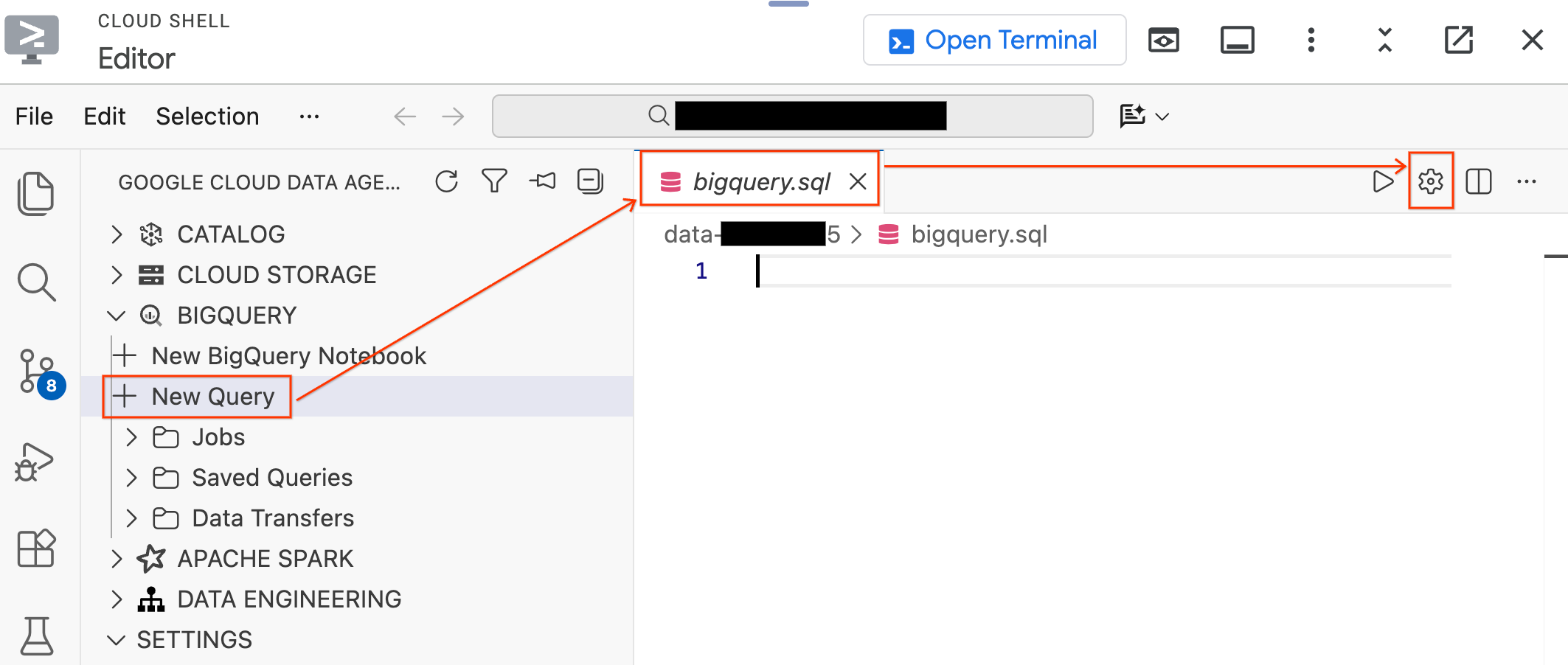
- В левой панели Data Agent Kit разверните раздел BigQuery и нажмите «Новый запрос» , чтобы открыть новую вкладку редактора запросов.
- Сохраните файл, нажав
Ctrl+S(Windows/Linux) илиCmd+S(macOS), и назовите егоbigquery. Эта вкладка будет использоваться для всех ваших операций BigQuery. - При активной вкладке
bigquery.sqlнажмите «Настройки запроса» , выберите BigQuery в качестве источника данных и нажмите «Сохранить» .
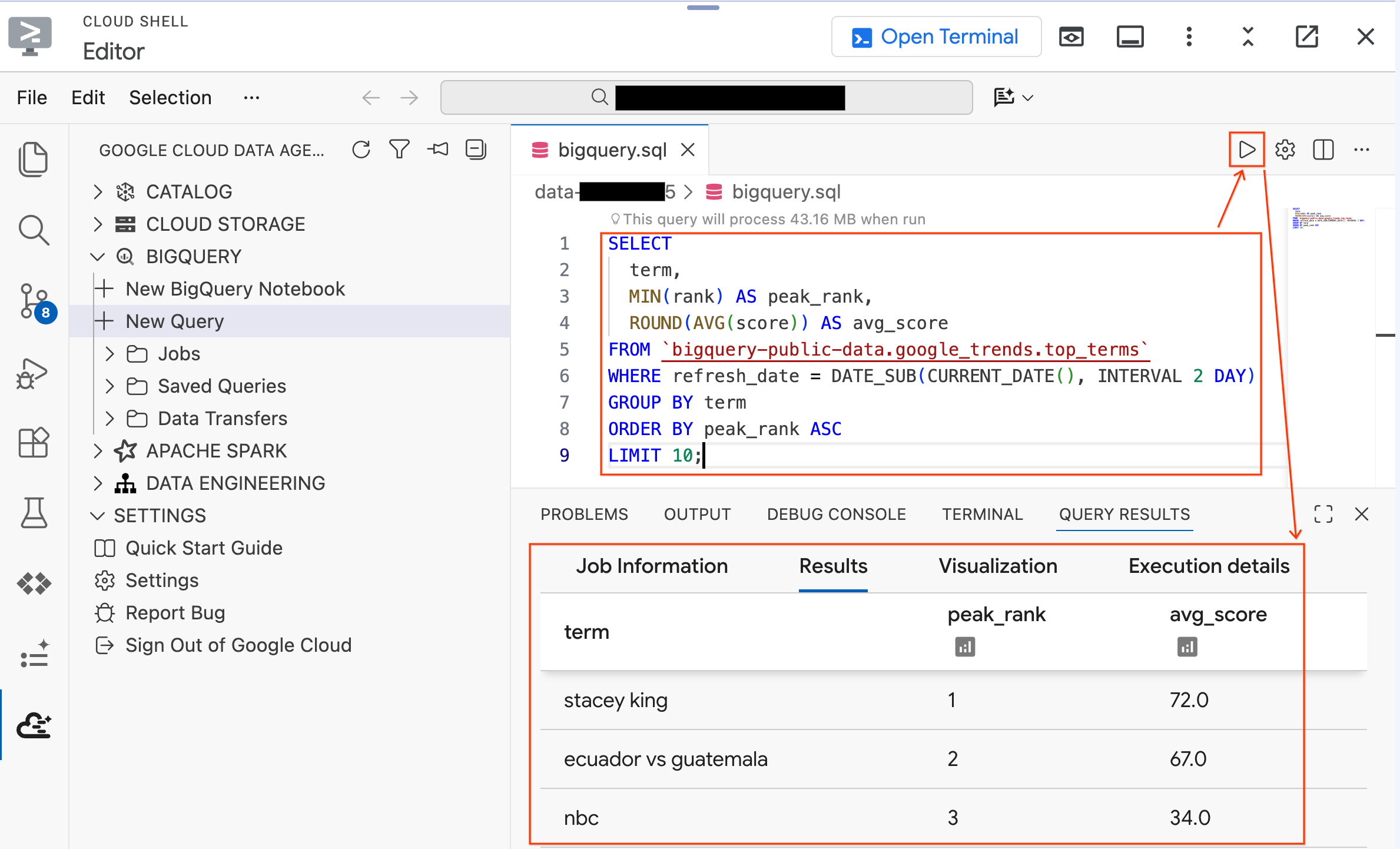
- Выполните следующий запрос к общедоступному набору данных:
SELECT
term,
MIN(rank) AS peak_rank,
ROUND(AVG(score)) AS avg_score
FROM `bigquery-public-data.google_trends.top_terms`
WHERE refresh_date = DATE_SUB(CURRENT_DATE(), INTERVAL 2 DAY)
GROUP BY term
ORDER BY peak_rank ASC
LIMIT 10;
- Вы должны увидеть 10 самых популярных поисковых запросов Google за последние несколько дней. Если результаты отображаются, значит, ваше расширение подключено и готово к работе.
Теперь попробуйте выполнить запрос к лабораторным данным, созданным вашим скриптом настройки. Замените существующий запрос следующим:
SELECT * FROM `lost_cargo_dataset.telemetry_data` LIMIT 5;
Вы должны увидеть записи телеметрии со столбцами shipment_id и telemetry_string . Именно эти данные вы будете анализировать на протяжении всей лабораторной работы.
Краткое содержание раздела: Вы запустили развертывание AlloyDB в фоновом режиме, выполнили скрипт настройки и сконфигурировали редактор Cloud Shell с расширением Data Agent Kit.
4. Просмотр записей с камер видеонаблюдения
Следственная группа получила записи с камер видеонаблюдения порта Рио-де-Жанейро, на которых видны ряды морских контейнеров. Из лабораторной работы 1 вы знаете, что целевой контейнер красный . Теперь вам нужно точно определить, какой именно это красный контейнер.
Вы создадите объектную таблицу, которая позволит BigQuery «видеть» изображения безопасности в Cloud Storage, а затем используете функцию AI.GENERATE , чтобы заставить Gemini извлечь структурированные данные из каждого изображения.
Шаг 1: Создайте таблицу объектов.
Объектная таблица — это специальная таблица BigQuery, которая выступает в качестве индекса для неструктурированных файлов (изображений, PDF-файлов, аудиофайлов), хранящихся в облачном хранилище. Она не копирует файлы в BigQuery; она создает доступную для запросов ссылку, чтобы функции искусственного интеллекта могли их «видеть».
В редакторе, на вкладке bigquery.sql , выполните следующее выражение, чтобы создать таблицу объектов, указывающую на образы безопасности портов в хранилище вашего проекта:
SET @@location = 'us-central1';
EXECUTE IMMEDIATE CONCAT("""
CREATE OR REPLACE EXTERNAL TABLE `lost_cargo_dataset.port_security_images`
WITH CONNECTION `us-central1.lost_cargo_conn`
OPTIONS (
object_metadata = 'SIMPLE',
uris = ['gs://""", @@project_id, """-lab2/images/*']
);
""");
Взгляните, что теперь может видеть BigQuery:
SELECT uri, content_type FROM `lost_cargo_dataset.port_security_images` LIMIT 5;
Каждая строка представляет собой один файл изображения в облачном хранилище. Теперь BigQuery может передавать эти изображения непосредственно моделям искусственного интеллекта.
Шаг 2: Анализ изображений с камер видеонаблюдения
Теперь используйте функцию AI.GENERATE из BigQuery для анализа каждого изображения с защитой. Этот единственный SQL-запрос заставляет Gemini изучить каждое изображение и вернуть структурированные данные:
SELECT
uri,
AI.GENERATE(
(
'Examine this port security image. Identify any shipping container IDs visible on the container and provide a one-word color of the container.',
ref
),
output_schema => 'detected_container_id STRING, color STRING'
).* EXCEPT (full_response, status)
FROM `lost_cargo_dataset.port_security_images`;
Шаг 3: Определите целевой контейнер
Изучите результаты. Найдите строку, где в столбце color » указано «Красный» (или какой-либо оттенок красного). Запишите detected_container_id . Это ваша цель: MV-CAPYBARA-003 .
Шаг 4: Проверка визуального соответствия
Чтобы увидеть проанализированное изображение, не выходя из редактора:
- В левой панели Data Agent Kit щелкните «Облачное хранилище» .
- Разверните свой контейнер (
YOUR_PROJECT_ID-lab2/images/) и щелкните по файлу изображения, соответствующему красному контейнеру, чтобы просмотреть его непосредственно в редакторе.
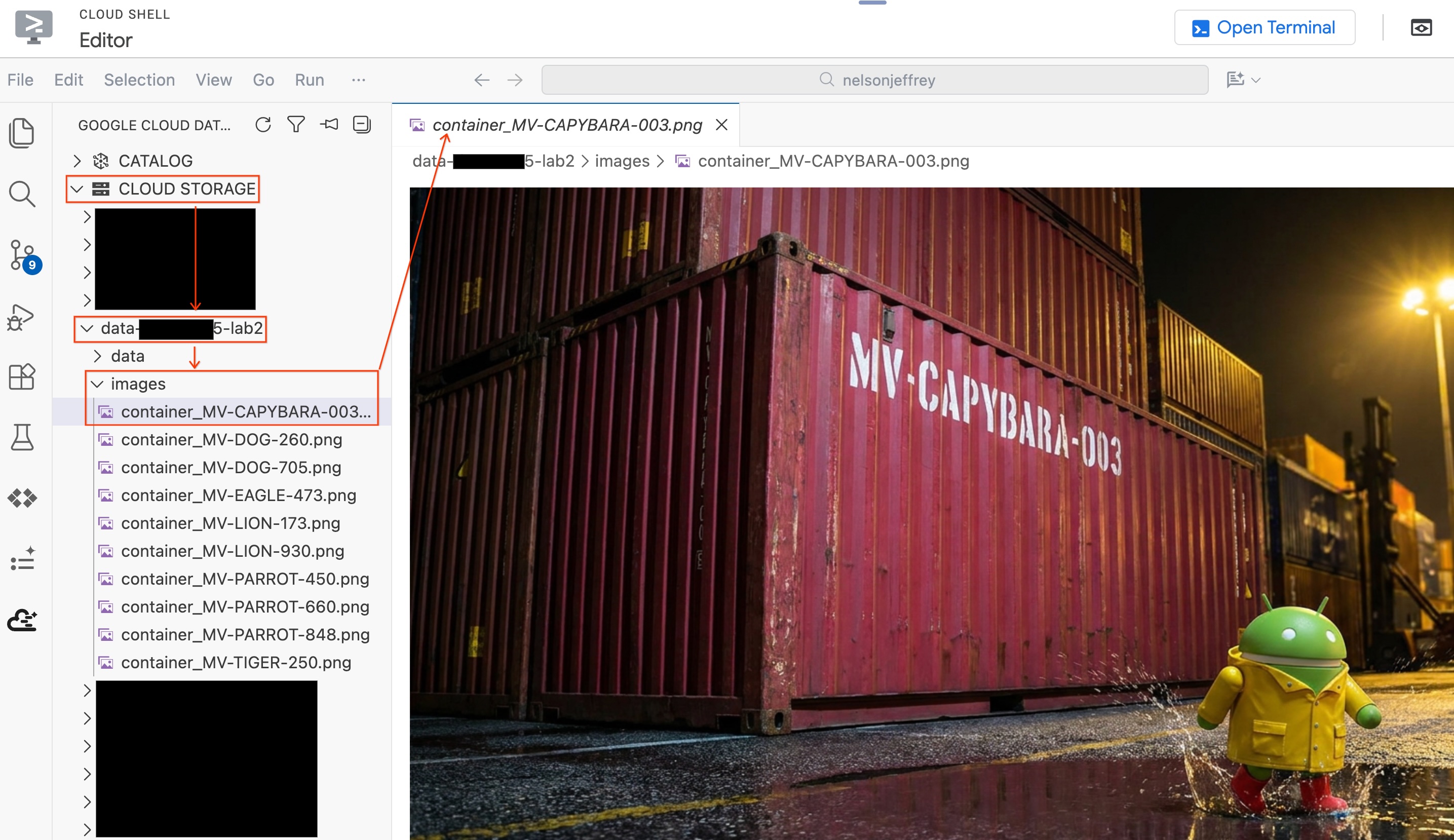
Краткое содержание раздела: Вы создали объектную таблицу, чтобы предоставить BigQuery доступ к образам с защитой портов, а затем использовали AI.GENERATE для извлечения структурированных данных контейнера из каждого образа. Красный контейнер идентифицирован как MV-CAPYBARA-003 .
5. Подтверждение кражи
Вы определили пропавший контейнер как MV-CAPYBARA-003 , но был ли он украден или просто потерян? Журналы учета показывают, что этот конкретный контейнер был припаркован рядом с датчиком окружающей среды SENS-99 . Если воры намеренно отключили встроенный холодильный агрегат контейнера перед его перемещением, SENS-99 мог зафиксировать внезапный скачок температуры выхлопных газов.
Давайте воспользуемся обнаружением аномалий, чтобы доказать, что контейнер был взломан.
- Для начала изучим исторические данные. Вот нормальные показания
SENS-99за последние несколько часов:
SELECT * FROM `lost_cargo_dataset.thermal_history`
ORDER BY reading_time DESC
LIMIT 50;
Обратите внимание, что температура колеблется в узком диапазоне 75-78°F. Так выглядит нормальная температура.
- Теперь взгляните на текущую серию показаний с того же датчика:
SELECT * FROM `lost_cargo_dataset.thermal_current`
ORDER BY thermal_reading DESC
LIMIT 50;
Видите показание 148,4°F в верхней части графика? Всё остальное выглядит нормально. Такой скачок может указывать либо на неисправность холодильной установки, либо на преднамеренное вмешательство. Давайте выясним.
- Запустите обнаружение аномалий.
AI.DETECT_ANOMALIESв BigQuery использует предварительно обученную базовую модель TimesFM для анализа закономерностей временных рядов и автоматического выявления выбросов, при этом обучение модели не требуется.
SELECT *
FROM AI.DETECT_ANOMALIES(
TABLE `lost_cargo_dataset.thermal_history`,
TABLE `lost_cargo_dataset.thermal_current`,
data_col => 'thermal_reading',
timestamp_col => 'reading_time',
id_cols => ['sensor_id']
)
WHERE is_anomaly = TRUE;
- Изучите результаты. Показатель 148,4°F следует отметить как аномалию с высокой вероятностью аномалии, подтверждающую, что вблизи зоны контейнера произошло что-то необычное.
Краткое содержание раздела: Вы использовали функцию AI.DETECT_ANOMALIES из BigQuery для работы с предварительно обученной моделью TimesFM. Выполнив всего один SQL-запрос, вы автоматически выявили выбросы и изолировали аномальное событие фальсификации данных, не написав сложного кода машинного обучения и не обучая модели с нуля.
6. Подготовка системы отслеживания
Подтверждено, что контейнер украден, и он больше не находится в Рио-де-Жанейро. Каждый контейнер в флоте передает сигналы телеметрического маяка : показания датчиков, фрагменты GPS и журналы состояния. Если маяк украденного контейнера все еще передает сигнал, его можно сопоставить с известными сигнатурами, чтобы найти его.
BigQuery отлично справляется с аналитической работой, которую вы проделали до сих пор, но для определения местоположения контейнера в реальном времени требуются оперативные запросы с низкой задержкой. AlloyDB , полностью управляемая база данных, совместимая с PostgreSQL, создана именно для этого: для выполнения векторных поисковых запросов, достаточно быстрых для системы отслеживания в реальном времени. Вы будете загружать свои телеметрические данные в AlloyDB и использовать их для сопоставления с сигналом маяка.
Кластер AlloyDB, который вы запустили в фоновом режиме ранее, должен быть готов. Давайте настроим его прямо из вашего редактора.
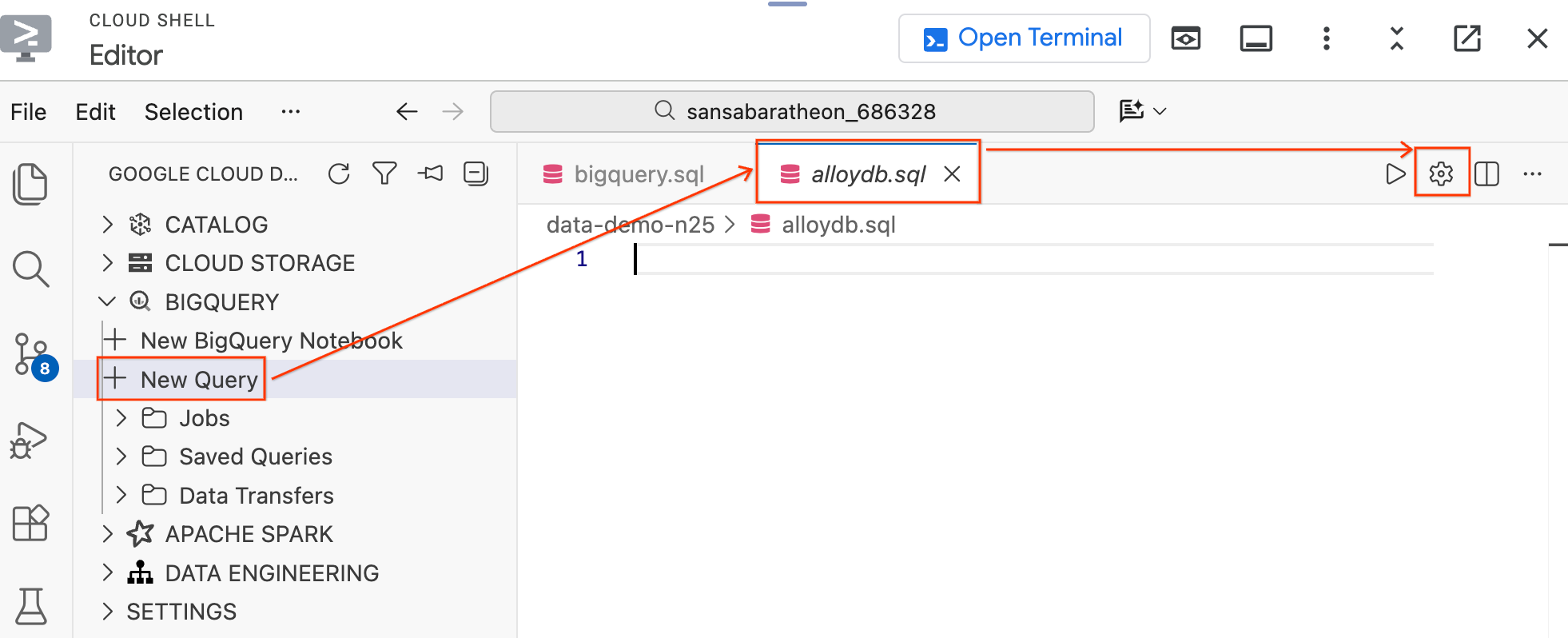
Шаг 1: Подключитесь к AlloyDB из редактора.
Вместо переключения на облачную консоль вы можете подключиться к AlloyDB напрямую, используя расширение Data Agent Kit.
- В левой панели Data Agent Kit в разделе BigQuery нажмите «Новый запрос» , чтобы открыть новую вкладку редактора запросов.
- Сохраните файл, нажав
Ctrl+S(Windows/Linux) илиCmd+S(macOS), и назовите егоalloydb. Эта вкладка будет использоваться для всех запросов AlloyDB. - Нажмите на значок шестеренки, чтобы открыть модальное окно « Настройки запроса» .
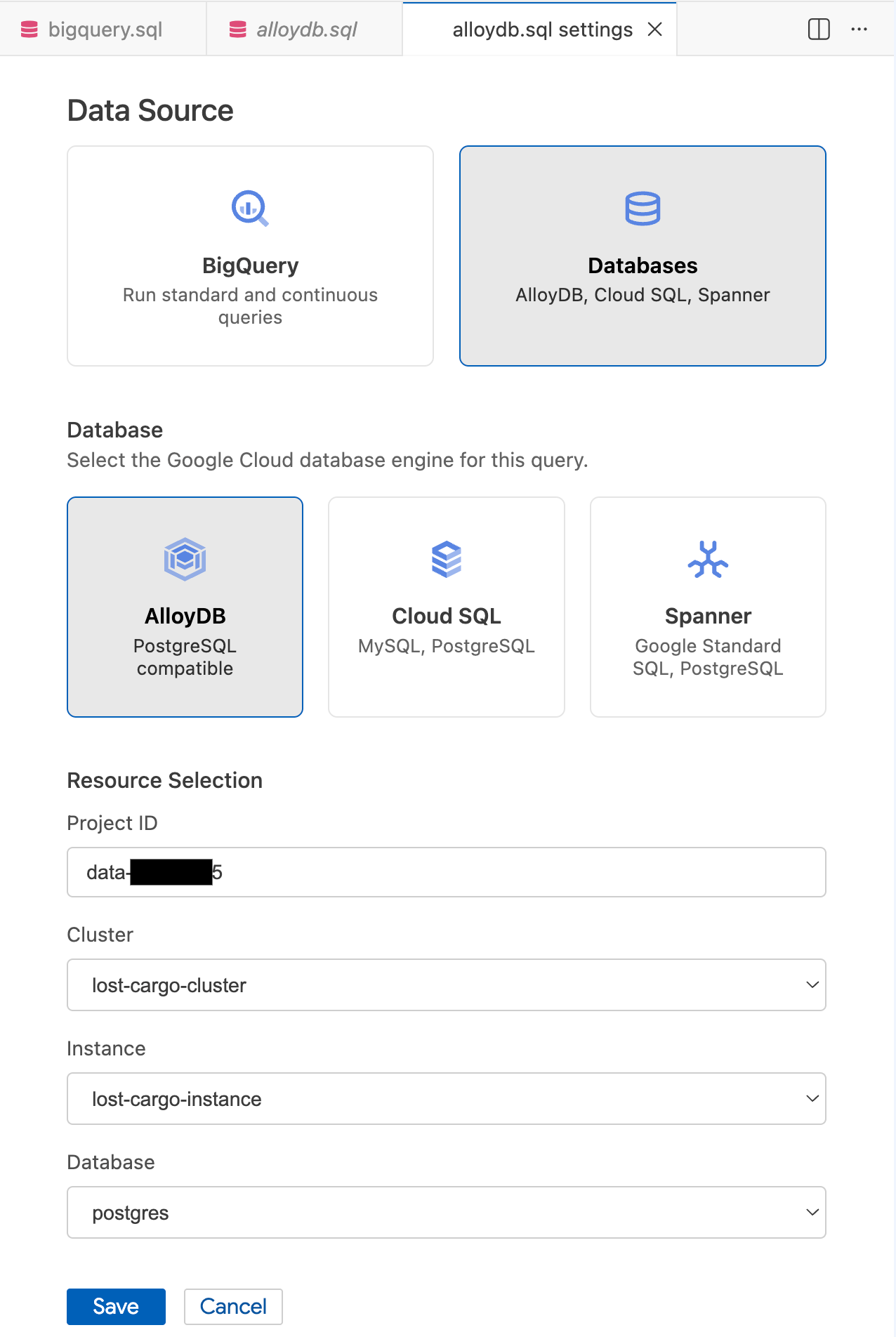
- В модальном окне «Настройки запроса» в разделе «Источник данных» выберите «Базы данных» .
- В разделе «База данных» выберите AlloyDB .
- Заполните поля выбора ресурсов :
- Идентификатор проекта : Введите идентификатор вашего проекта Google Cloud.
- Кластер : Выберите
lost-cargo-cluster. - Экземпляр : Выберите
lost-cargo-instance. - База данных : Select
postgres.
- Нажмите « Сохранить ».
Шаг 2: Включите расширение Vector и создайте таблицу.
Теперь, когда вы подключились к AlloyDB, вам необходимо включить необходимые расширения для искусственного интеллекта и создать таблицу, которая будет получать встроенные телеметрические данные.
- На активной вкладке
.sqlвставьте следующие команды, чтобы включить необходимые расширения:
CREATE EXTENSION IF NOT EXISTS vector;
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
- Выделите текст и нажмите кнопку «Выполнить запрос » (значок воспроизведения) в правом верхнем углу редактора.
- Проверьте панель результатов запроса в нижней части экрана. Там должно быть написано
Statement executed successfully.
- Далее замените текст в редакторе следующим выражением, чтобы создать таблицу телеметрии:
CREATE TABLE IF NOT EXISTS vessel_telemetry (
entry_id SERIAL PRIMARY KEY,
shipment_id VARCHAR(50),
telemetry_string TEXT,
embedding_vector vector(768)
);
- Выполните этот запрос так же, как и предыдущий. Убедитесь, что он успешно выполнен, на нижней панели.
Тип vector(768) берется из расширения pgvector которое вы только что включили. Размеры 768 соответствуют выходным данным модели text-embedding-005 от Google, которую вы будете использовать в BigQuery для генерации эмбеддингов.
Краткое содержание раздела: Вы подключились к AlloyDB напрямую из редактора Cloud Shell, включили расширения pgvector и google_ml_integration и создали целевую таблицу. Теперь AlloyDB готова служить в качестве операционной базы данных для сопоставления телеметрии в реальном времени.
7. Создание поискового индекса
Теперь вам нужно загрузить телеметрические данные в AlloyDB, чтобы она могла обеспечивать сопоставление маяков в реальном времени. Необработанные телеметрические журналы неструктурированы и имеют переменную длину, что не идеально для поиска сходства. Вы будете использовать функции искусственного интеллекта BigQuery для обобщения каждого журнала с помощью Gemini и преобразования каждого обобщения в 768-мерное векторное представление. Затем вы экспортируете обогащенные данные в Cloud Storage и импортируете их в AlloyDB.
Шаг 1: Создание эмбеддингов в BigQuery
Переключитесь обратно на вкладку редактора bigquery.sql (которая по-прежнему подключена к BigQuery).
Теперь выполните следующий запрос, чтобы обобщить каждый телеметрический журнал с помощью Gemini и сгенерировать векторные представления:
CREATE OR REPLACE TABLE `lost_cargo_dataset.telemetry_embeddings_export` AS
WITH summarized_telemetry AS (
SELECT
shipment_id,
telemetry_string,
AI.GENERATE(
CONCAT('Summarize this telemetry log for vector search: ', telemetry_string)
).result AS summary
FROM `lost_cargo_dataset.telemetry_data`
),
telemetry_embeddings AS (
SELECT
shipment_id,
telemetry_string,
AI.EMBED(summary, endpoint => 'text-embedding-005').result AS embedding
FROM summarized_telemetry
)
SELECT
shipment_id,
telemetry_string,
TO_JSON_STRING(embedding) AS embedding_vector
FROM telemetry_embeddings;
Шаг 2: Предварительный просмотр обогащенных данных
Перед экспортом ознакомьтесь с созданным файлом. Этот запрос показывает идентификаторы отправлений и первые 80 символов каждого сводного документа и его встраивания:
SELECT
shipment_id,
SUBSTR(telemetry_string, 1, 80) AS telemetry_preview,
SUBSTR(embedding_vector, 1, 80) AS embedding_preview
FROM `lost_cargo_dataset.telemetry_embeddings_export`
LIMIT 5;
Теперь каждая строка содержит идентификатор отправления, исходный журнал телеметрии и 768-мерный вектор встраивания. Именно эти данные вы будете загружать в AlloyDB.
Шаг 3: Экспорт встраиваний в облачное хранилище
Используйте оператор EXPORT DATA в BigQuery, чтобы записать таблицу эмбеддингов в хранилище GCS вашей лаборатории в виде CSV-файла.
EXECUTE IMMEDIATE CONCAT("""
EXPORT DATA OPTIONS (
uri = 'gs://""", @@project_id, """-lab2/data/embeddings_export/*.csv',
format = 'CSV',
overwrite = true,
header = false
) AS
SELECT
shipment_id,
telemetry_string,
embedding_vector
FROM `lost_cargo_dataset.telemetry_embeddings_export`;
""");
Шаг 4: Импорт в AlloyDB из облачного хранилища.
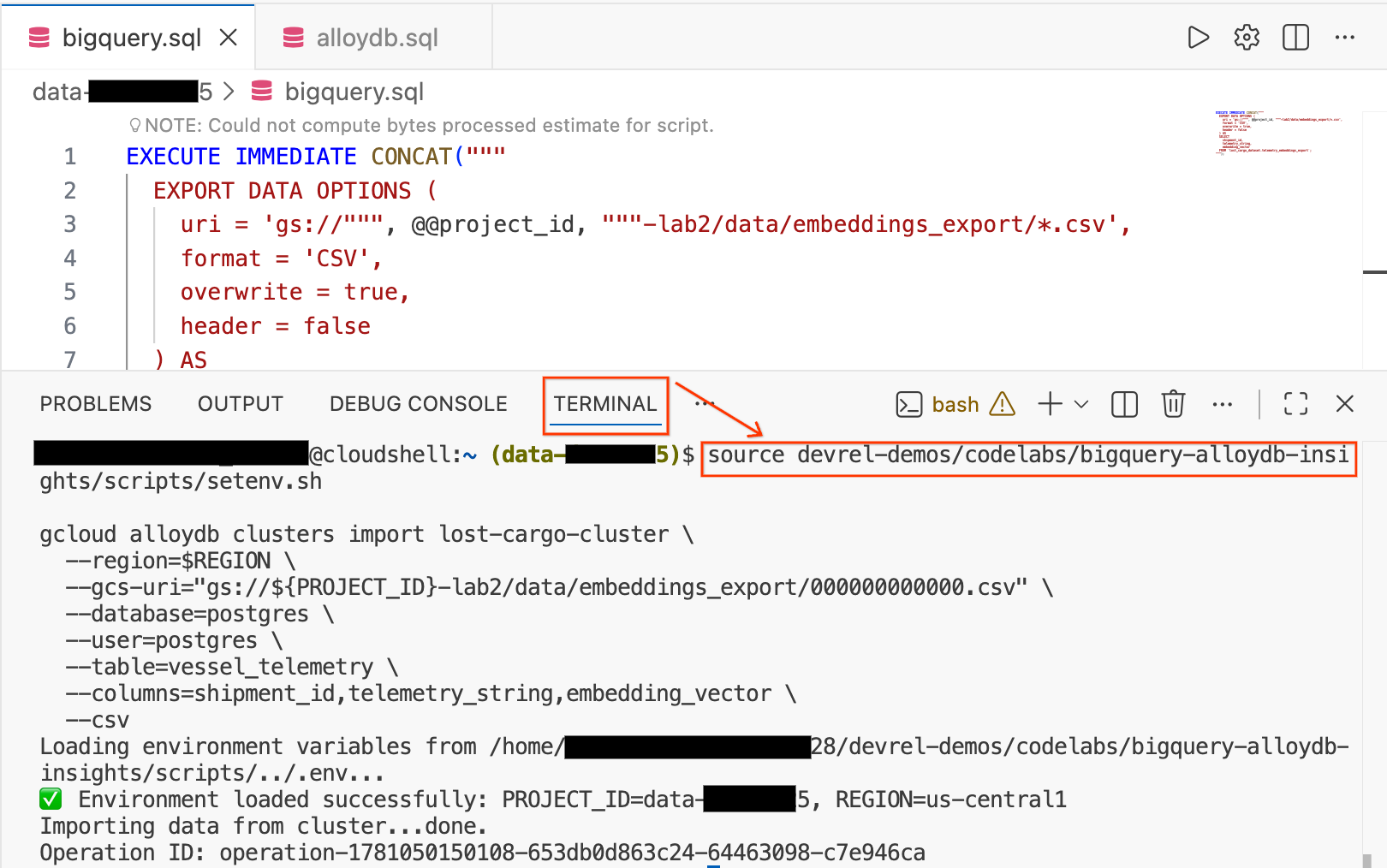
- В редакторе Cloud Shell нажмите вкладку «Терминал» в нижней части экрана, чтобы открыть сеанс терминала.
- Выполните следующие команды, чтобы загрузить вашу среду и импортировать CSV-файл непосредственно в таблицу
vessel_telemetryв AlloyDB:
source devrel-demos/codelabs/bigquery-alloydb-insights/scripts/setenv.sh
gcloud alloydb clusters import lost-cargo-cluster \
--region=$REGION \
--gcs-uri="gs://${PROJECT_ID}-lab2/data/embeddings_export/000000000000.csv" \
--database=postgres \
--user=postgres \
--table=vessel_telemetry \
--columns=shipment_id,telemetry_string,embedding_vector \
--csv
Краткое содержание раздела: Вы использовали функции искусственного интеллекта BigQuery для обобщения и встраивания телеметрических данных, экспортировали результаты в Cloud Storage в формате CSV, а затем импортировали их в AlloyDB с помощью gcloud . Оперативная база данных отслеживания теперь загружена и готова к использованию.
8. Согласование сигнала маяка
Группа исследователей, работающая в полевых условиях недалеко от Сиднея, перехватила фрагментированный сигнал телеметрического маяка. Частичный лог содержит следующую информацию:
"Холодильная установка отключена. Требуется ручное управление."
Если сигнал поступил из украденного контейнера, векторный поиск AlloyDB должен суметь его сопоставить, даже если сигнал неполный. Это именно тот тип оперативных запросов в реальном времени, для которых и создан AlloyDB.
Шаг 1: Проверка импортированных данных
Переключитесь обратно на вкладку редактора alloydb.sql (которая по-прежнему подключена к AlloyDB).
Убедитесь в успешной загрузке телеметрических данных, выполнив следующую команду:
SELECT shipment_id, LEFT(telemetry_string, 80) AS telemetry_preview
FROM vessel_telemetry
LIMIT 10;
Вы должны увидеть строки со значениями shipment_id и текстом телеметрии. Это телеметрические сигнатуры автопарка, готовые к сопоставлению в реальном времени.
Шаг 2: Найдите пропавший контейнер.
Теперь воспользуйтесь расширением google_ml_integration от AlloyDB для поиска совпадений по перехваченному фрагменту сигнала:
SELECT
shipment_id,
telemetry_string,
1 - (embedding_vector <=> embedding('text-embedding-005', 'Refrigeration unit offline. Manual override.')::vector) AS search_relevance_score
FROM vessel_telemetry
ORDER BY embedding_vector <=> embedding('text-embedding-005', 'Refrigeration unit offline. Manual override.')::vector
LIMIT 5;
Функция embedding() , предоставляемая расширением google_ml_integration от AlloyDB, напрямую вызывает Agent Platform из SQL для генерации векторного представления непосредственно в коде. Оператор <=> вычисляет косинусное расстояние между двумя векторами (чем ближе к 0, тем больше сходство между двумя векторами). Мы вычитаем из 1, чтобы выразить результат в виде показателя релевантности, где чем выше значение, тем лучше.
Шаг 3: Подтвердите матч
Проанализируйте результаты. Лучшим результатом должен быть MV-CAPYBARA-003 , имеющий наивысший показатель релевантности.
Это тот самый контейнер, который вы отслеживали на каждом этапе этого расследования:
- 📷 На записях с камер видеонаблюдения видно, что судно покидает порт Рио-де-Жанейро ночью.
- 🌡️ Система обнаружения тепловых аномалий подтвердила, что холодильная установка была преднамеренно выведена из строя.
- 📡 Система сопоставления сигналов маяка точно определила местоположение его телеметрической сигнатуры вблизи Сиднея.
Три независимых линии доказательств. Три различных возможности Google Cloud AI. Один украденный контейнер.
🎯 Дело закрыто: MV-CAPYBARA-003 найден недалеко от Сиднея!

Краткое содержание раздела: Вы использовали встроенную интеграцию ИИ в AlloyDB для генерации поискового шаблона и выполнения поиска по косинусному сходству в одном SQL-запросе. Совпадение с маяком подтвердило местоположение украденного контейнера, завершив расследование.
9. Изучение доказательств
Теперь, когда вы определили контейнер с помощью мультимодального анализа изображений и векторного поиска, вы можете использовать аналитику разговоров непосредственно в редакторе для изучения данных исследования с помощью естественного языка, не написав ни одного SQL-запроса.
Шаг 1: Найдите данные в каталоге знаний.
В состав Data Agent Kit входит функция универсального поиска, позволяющая находить и исследовать информационные ресурсы в вашей среде Google Cloud.
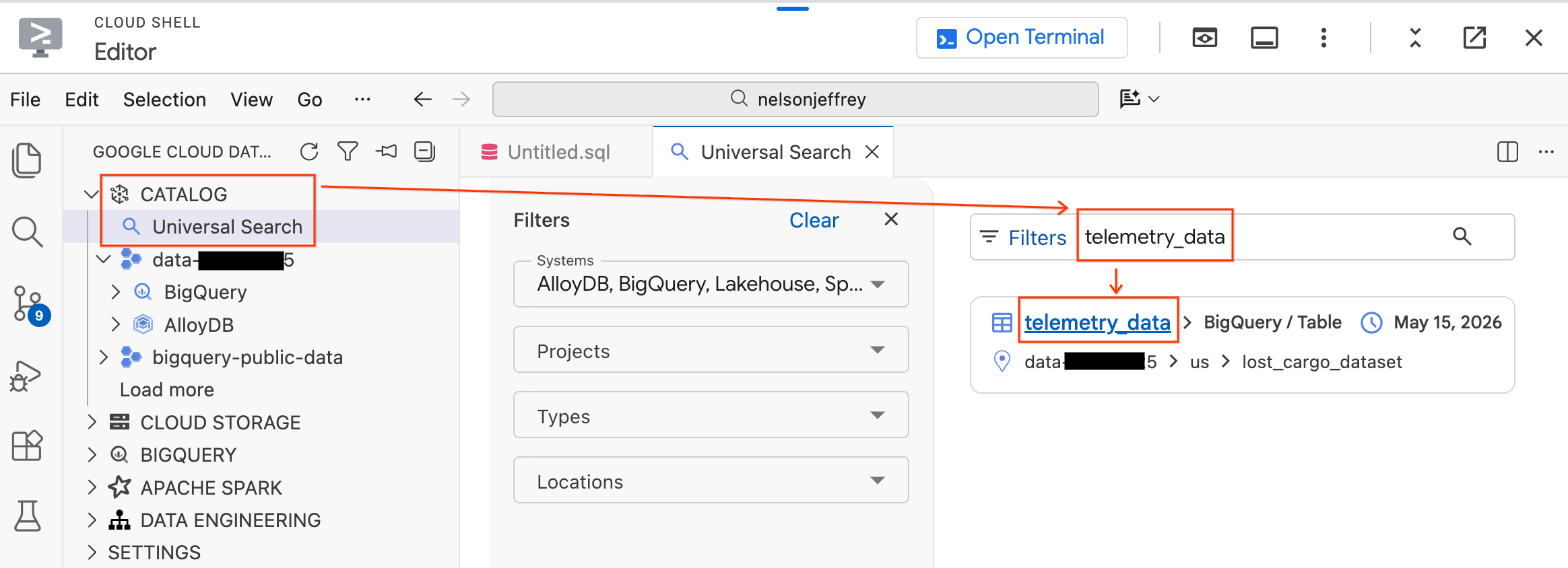
- В левой панели Data Agent Kit разверните раздел «Каталог» .
- Нажмите «Универсальный поиск» .
- В строке поиска введите
telemetry_data. - В результатах поиска щелкните по таблице
telemetry_data(в разделеlost_cargo_dataset).
Шаг 2: Запуск анализа диалогов
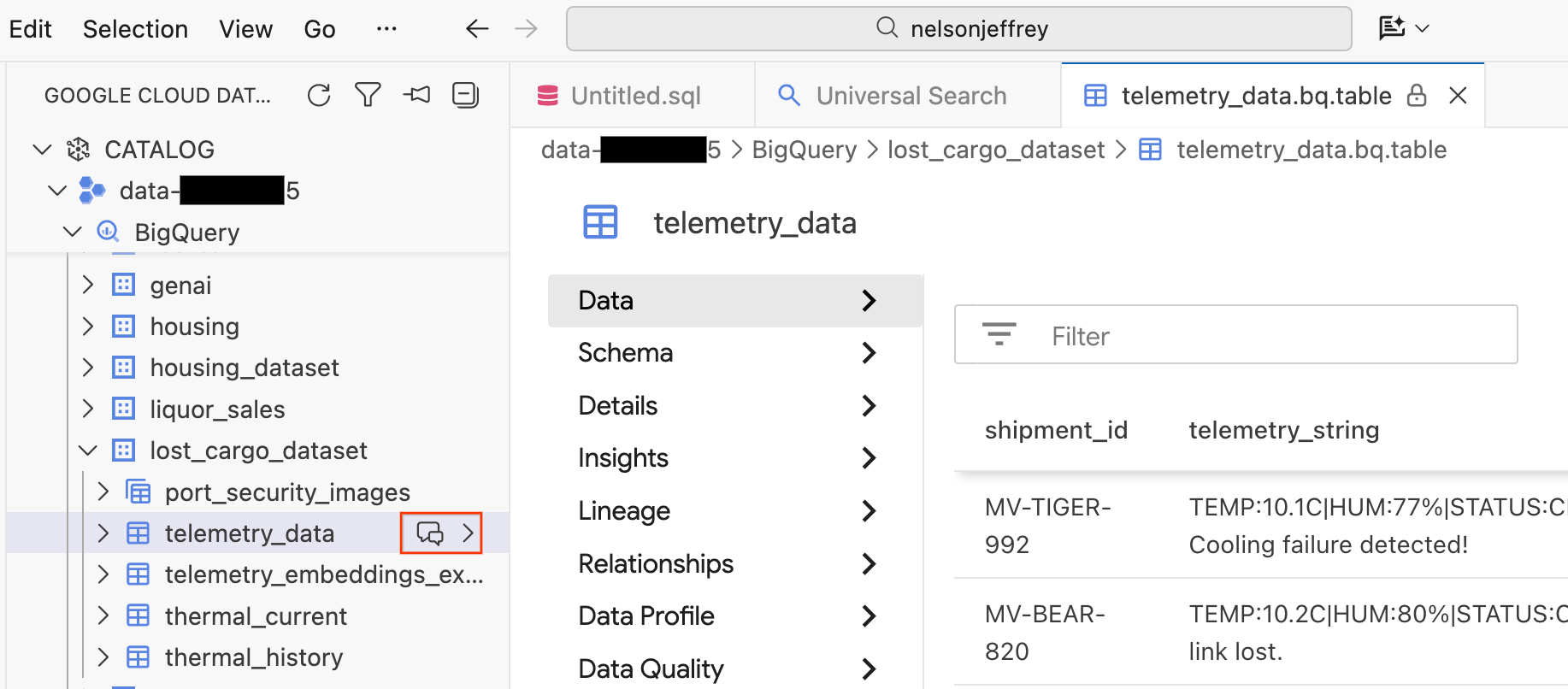
При нажатии на результат поиска открывается вкладка просмотра данных, где можно предварительно просмотреть исходные данные, просмотреть схему и проверить качество данных.
- В левой панели отображаются ваши наборы данных и таблицы BigQuery. Нажмите кнопку «Чат» , чтобы открыть новое окно чата.
Шаг 3: Задавайте вопросы на естественном языке.
Открывается новая вкладка чата «Добро пожаловать в аналитику разговоров!». Агент получает информацию о схеме и содержимом вашей таблицы.
- В окне чата введите: "Покажите мне состояние телеметрии и журнал для отправки "Капибары"".
- Нажмите Enter .
Агент переводит ваш вопрос в SQL-код BigQuery, выполняет запрос и возвращает результаты, включая таблицу данных и сводную информацию о полученных результатах. В зависимости от сложности вашего вопроса вы можете переключаться между режимами «Размышление» (более глубокий анализ, медленный) и «Быстрый» (более быстрые ответы). Поскольку это ответы, сгенерированные ИИ, ваши результаты могут немного отличаться от скриншотов ниже.
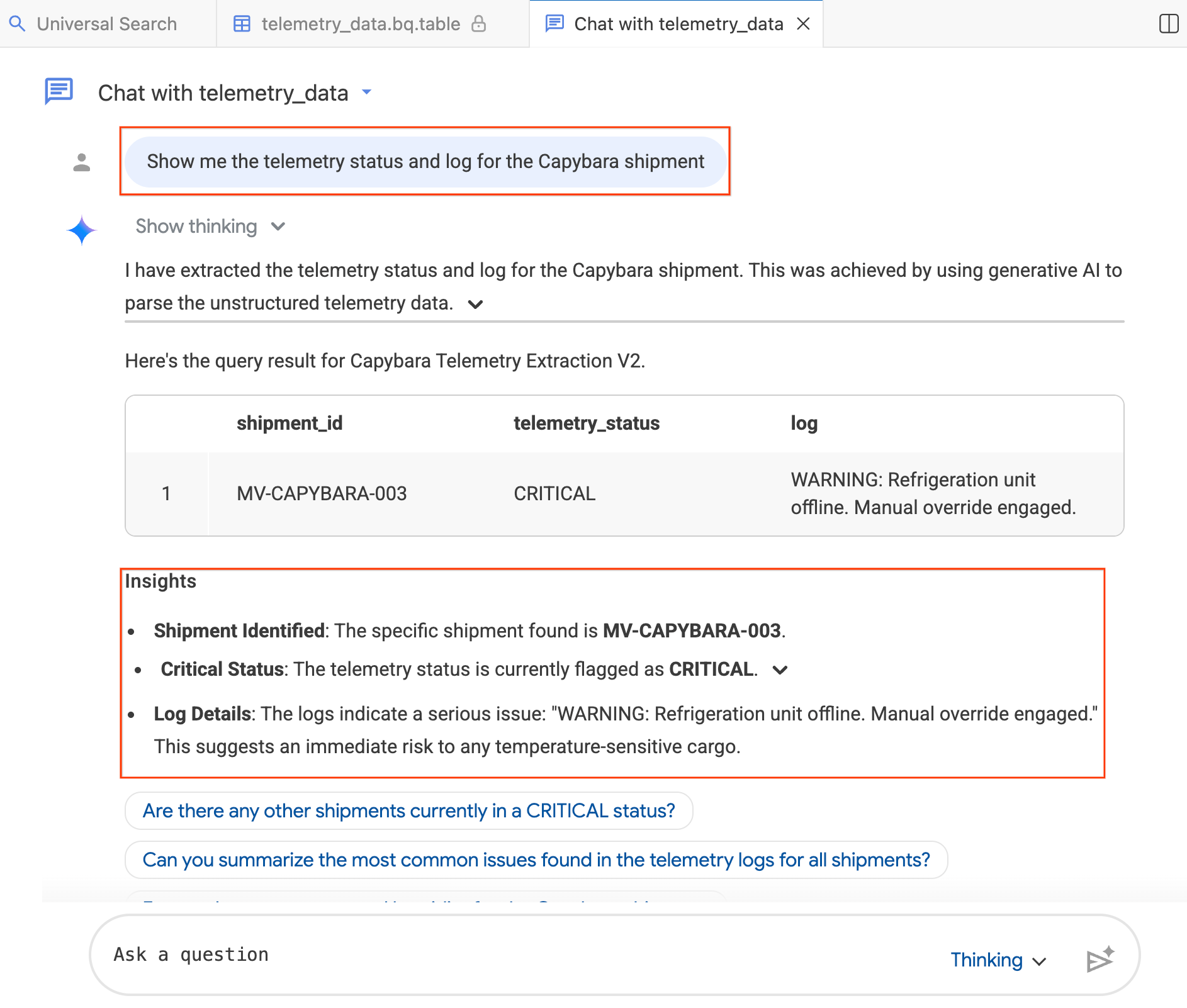
Шаг 4: Задайте уточняющие вопросы
Оператор помнит контекст вашего разговора. Попробуйте задать уточняющий вопрос:
- «Сколько уникальных отправлений содержится в телеметрических данных?»
- «Сколько ещё грузов в составе флота в настоящее время имеют КРИТИЧЕСКИЙ статус?»
Краткое содержание раздела: Вы использовали функцию универсального поиска в Knowledge Catalog для поиска вашего набора данных и запустили разговорную аналитику для запроса данных расследования с использованием естественного языка. Агент ИИ перевел ваши вопросы в SQL и предоставил информацию, которая подтвердила ваши выводы.
10. Уборка
Чтобы избежать постоянных списаний средств с вашего аккаунта Google Cloud, удалите ресурсы, созданные в этой лабораторной работе. Вы можете выполнить эти команды во встроенном терминале внутри редактора Cloud Shell (где вы использовали Data Agent Kit), чтобы очистить свою среду.
Сначала загрузите переменные окружения:
source scripts/setenv.sh
- Удалите ресурсы BigQuery (только если вы не продолжаете работу над лабораторной работой 3):
Если вы планируете перейти к лабораторной работе №3 , пропустите этот шаг! В лабораторной работе №3 используется тот же набор данных BigQuery и те же подключения для анализа графа недвижимости.
Чтобы удалить набор данных и подключения BigQuery:
# Drop the dataset
bq rm -r -f $PROJECT_ID:lost_cargo_dataset
# Delete the connections
bq rm --connection --location=us-central1 $PROJECT_ID.us-central1.lost_cargo_conn
bq rm --connection --location=us-central1 $PROJECT_ID.us-central1.lost_cargo_alloydb_conn
- Удалите сегмент облачного хранилища:
gcloud storage rm --recursive gs://${PROJECT_ID}-lab2
- Удалите экземпляр AlloyDB и кластер :
В лабораторной работе №3 AlloyDB не используется, поэтому его можно смело удалить.
gcloud alloydb instances delete lost-cargo-instance \
--region=$REGION \
--cluster=lost-cargo-cluster \
--quiet
gcloud alloydb clusters delete lost-cargo-cluster \
--region=$REGION \
--force \
--quiet
- Удалите локальные настройки среды :
Наконец, удалите локальный файл настроек среды из вашей рабочей области:
rm -f .env
11. Поздравляем!
Вы успешно завершили лабораторную работу 2: Анализ данных и мультимодальные выводы ! Вы проследили путь от порта, заполненного тысячами контейнеров, до подтвержденной кражи и точно определенного места.
Чего вы достигли
- Проведено сканирование видеоматериала : Вы использовали
AI.GENERATEиз BigQuery для анализа изображений с камер видеонаблюдения портов и идентификации контейнера MV-CAPYBARA-003 , выделенного ярко-красным цветом. - Подтверждено хищение : вы изучили данные теплового датчика, обнаружили подозрительный скачок температуры на 148,4°F и использовали
AI.DETECT_ANOMALIESчтобы доказать, что это было преднамеренное вмешательство. - Система отслеживания подготовлена : вы настроили AlloyDB с pgvector и
google_ml_integrationдля сопоставления маяков в реальном времени. - Создание поискового индекса : Вы использовали
AI.GENERATEиAI.EMBEDв BigQuery для создания эмбеддингов, затем экспортировали их в Cloud Storage и импортировали в AlloyDB. - Сопоставление с сигналом маяка : Вы использовали векторный поиск AlloyDB для сопоставления фрагментированного телеметрического сигнала, что позволило определить местоположение украденного контейнера недалеко от Сиднея.
- Проанализированы доказательства : Вы использовали аналитику разговоров непосредственно из редактора для запроса данных расследования с помощью естественного языка.

Следующие шаги
Вы нашли контейнер . Теперь вам нужно выяснить, кто за ним стоит.
В лабораторной работе № 3: «Использование данных и агентские рабочие процессы » вы построите граф свойств логистической сети, чтобы отобразить взаимосвязи между компаниями-подставными лицами, используете аналитику разговоров для общения с графом и выполните поиск в каталоге знаний, чтобы найти код доступа, необходимый для возврата контейнера.