
1. Giriş

Önceki laboratuvarda, parçalanmış kargo günlüklerini toplamış ve kargo transponder'ını New York'a kadar takip etmiştiniz. Ancak varış kayıtları, gümrük tespitinden kaçınmak için konteynerin hemen yeniden yönlendirildiğini gösteriyor. Takip sizi şimdi binlerce konteynerin bulunduğu geniş bir liman olan Rio de Janeiro Limanı'na götürdü. Binlerce konteyner arasından doğru konteyneri bulmak zor bir görev.
Bu laboratuvarda, BigQuery'nin yerleşik yapay zeka özelliklerini kullanarak yapılandırılmamış bağlantı noktası güvenliği görüntülerini "okuyacak" ve sensör verisindeki termal anormallikleri tespit edeceksiniz. Tüm bu işlemleri standart SQL kullanarak yapacaksınız. Ardından, vektör yerleştirmelerini AlloyDB'ye aktarır ve parçalanmış bir telemetri sinyalini eksik kapsayıcıyla eşleştirmek için vektör araması yaparsınız.
Yapacaklarınız
- BigQuery Yapay Zeka'yı kullanarak çalınan konteyneri belirlemek için liman güvenliği görüntülerini tarama
- BigQuery Yapay Zeka'yı kullanarak termal anormallik algılama ve konteynerin kaybolmadığını, çalındığını doğrulama
- Vektör yerleştirmeleri oluşturma ve bunları gerçek zamanlı arama için AlloyDB'ye yükleme
- Vector Search'ü kullanarak çalınan konteyneri bulmak için parçalanmış bir telemetri işaret sinyalini eşleştirme
- Etkileşimli Analizler'i kullanarak doğal dilde inceleme verilerini keşfetme
İhtiyacınız olanlar
- Chrome gibi bir web tarayıcısı
- Faturalandırmanın etkin olduğu bir Google Cloud projesi
- SQL ve Google Cloud Console hakkında temel düzeyde bilgi sahibi olma
Bu codelab, orta düzeydeki geliştiriciler içindir.
Bu codelab'de oluşturulan kaynakların maliyeti 5 ABD dolarından az olmalıdır.
2. Başlamadan Önce
Cloud Shell'i Başlatma
Kodu indirmek, kurulum komut dosyalarını çalıştırmak ve uygulamayı dağıtmak için Google Cloud Shell'i kullanacaksınız.
- Yeni bir tarayıcı sekmesinde Cloud Shell'i açın: shell.cloud.google.com
- Bağlandıktan sonra proje kimliğinizi ayarlayın ve ortamınızı onaylayın:
gcloud config set project <<YOUR_PROJECT_ID>>
export PROJECT_ID=$(gcloud config get-value project)
export REGION=us-central1
Şuna benzer bir mesaj görürsünüz:
Your active configuration is: [cloudshell-####] Updated property [core/project]
Depoyu Klonlama
Codelab deposunu Cloud Shell kabuk ortamınıza klonlayın:
cd ~/
git clone --filter=blob:none --no-checkout https://github.com/GoogleCloudPlatform/devrel-demos.git
cd ~/devrel-demos
git sparse-checkout init --cone
git sparse-checkout set codelabs/bigquery-alloydb-insights
git checkout main
cd codelabs/bigquery-alloydb-insights/
API'leri etkinleştir
Bu laboratuvar için gerekli tüm API'leri etkinleştirmek üzere Cloud Shell'de şu komutu çalıştırın:
gcloud services enable \
aiplatform.googleapis.com \
bigquery.googleapis.com \
bigqueryconnection.googleapis.com \
alloydb.googleapis.com
Başarılı bir yürütmenin ardından şuna benzer bir mesaj görürsünüz:
Operation "operations/..." finished successfully.
3. Ortamınızı ayarlama
Resimleri ve telemetri verilerini analiz edebilmek için önce bu laboratuvarın altyapısını ayarlamanız gerekir. İki komut dosyası çalıştıracaksınız: Biri AlloyDB'nin arka planda sağlanmasını başlatır, diğeri ise ihtiyacınız olan tüm BigQuery kaynaklarını oluşturur.
1. adım: AlloyDB dağıtımını başlatın (arka plan)
AlloyDB kümesi sağlama işlemi yaklaşık 10 dakika sürer. Bu nedenle, önce bu işlemi başlatıp BigQuery bölümleriyle çalışırken arka planda çalışmasına izin vereceksiniz. Cloud Shell terminaliniz kapansa veya yeniden başlatılsa bile yapılandırmanızın kaydedilmesi için komut dosyası, etkin proje ayarlarınızı otomatik olarak yerel bir .env dosyasına kaydeder.
chmod +x scripts/setup_alloydb.sh
nohup ./scripts/setup_alloydb.sh > /dev/null 2>&1 &
echo "AlloyDB deployment started in background (PID: $!)"
2. adım: Kurulum komut dosyasını çalıştırın
Bu komut dosyası; BigQuery veri kümesini, Cloud Resource bağlantısını, IAM izinlerini, GCS paketini oluşturur ve bu laboratuvarda analiz edeceğiniz tüm sensör verilerini yükler. Ayrıca .env dosyasında kaydedilen ortam değişkenlerini okur ve doğrular.
chmod +x scripts/setup_lab.sh
./scripts/setup_lab.sh
Komut dosyasının çalışması yaklaşık bir dakika sürer. İşlem tamamlandığında oluşturulan her şeyin özetini görürsünüz.
📝 Ortam sıfırlamalarıyla ilgili not Cloud Shell oturumunuz bu laboratuvar sırasında herhangi bir noktada zaman aşımına uğrarsa veya yeniden başlatılırsa aşağıdaki komutu çalıştırarak terminal değişkenlerinizi hemen geri yükleyebilirsiniz:
source scripts/setenv.sh
3. adım: Cloud Shell Düzenleyici'yi başlatın
Şimdiye kadar Cloud Shell terminalini kullandınız. Şimdi, entegre BigQuery desteğiyle VS Code benzeri bir çalışma alanı sunan tam Cloud Shell Düzenleyici'ye geçin.
- Ekranınızın alt kısmındaki Cloud Shell terminal bölmesinde Open Editor (Düzenleyiciyi Aç) düğmesini tıklayarak Cloud Shell Editor çalışma alanını başlatın.

4. adım: Veri Aracısı Kiti Uzantısı'nı yükleyin
Google Cloud Data Agent Kit uzantısı, Google Cloud veri hizmetleriyle doğrudan düzenleyicinizde derin entegrasyon sağlayarak bağlam değiştirmenize gerek kalmadan BigQuery, AlloyDB ve Cloud Storage gibi hizmetlerle etkileşim kurmanıza olanak tanır.
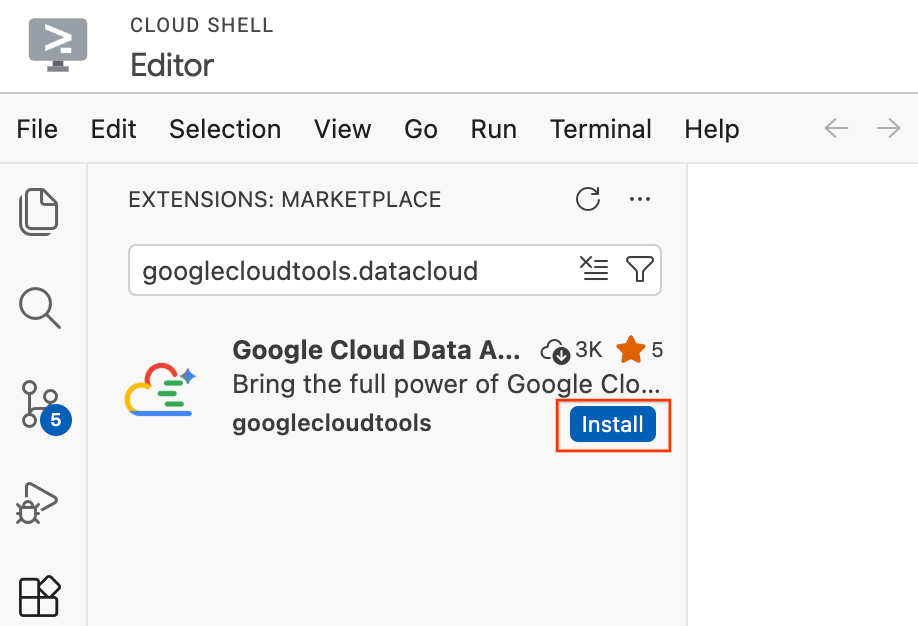
- Cloud Shell Düzenleyici'de, ekranın en sol tarafındaki etkinlik çubuğunda Uzantılar simgesini (dört kareye benzer) tıklayın.
- Uzantılar bölmesinin üst kısmındaki arama çubuğuna
googlecloudtools.datacloudyazın. - Google Cloud tarafından yayınlanan Google Cloud Data Agent Kit adlı uzantıyı bulun.
- Yükle düğmesini tıklayın.
- "googlecloudtools" yayıncısına ve uzantılarına güveniyor musunuz?" sorusunu içeren bir istem gösterilir. Devam etmek için Yayıncılara güven ve yükle'yi tıklayın.
5. adım: Uzantıyı doğrulayın ve yapılandırın
Yükleme işleminden sonra uzantıyı Google Cloud projenize bağlayın.
- "Google Cloud Data Agent Kit Onboarding" başlıklı bir ilk katılım sayfası otomatik olarak açılır. Google Cloud'da oturum aç'ı tıklayın. Erişime izin vermek için tarayıcı istemlerini uygulayın.
- "Kurulum devam ediyor" başlıklı bir modal görünür. Uzantı, Google Cloud KSA gibi gerekli bağımlılıkları otomatik olarak kontrol eder.
- Yapılandırma Özeti bölümünde proje alanını bulun. Açılır listeyi tıklayın ve Google Cloud projenizi seçin. Bölgenizi
us-central1olarak ayarlayın. - Kurulum kontrollerinin tamamlanmasını bekleyin. "Kurulum Tamamlandı!" mesajını gördüğünüzde MCP Sunucularını Yapılandır'ı tıklayın.
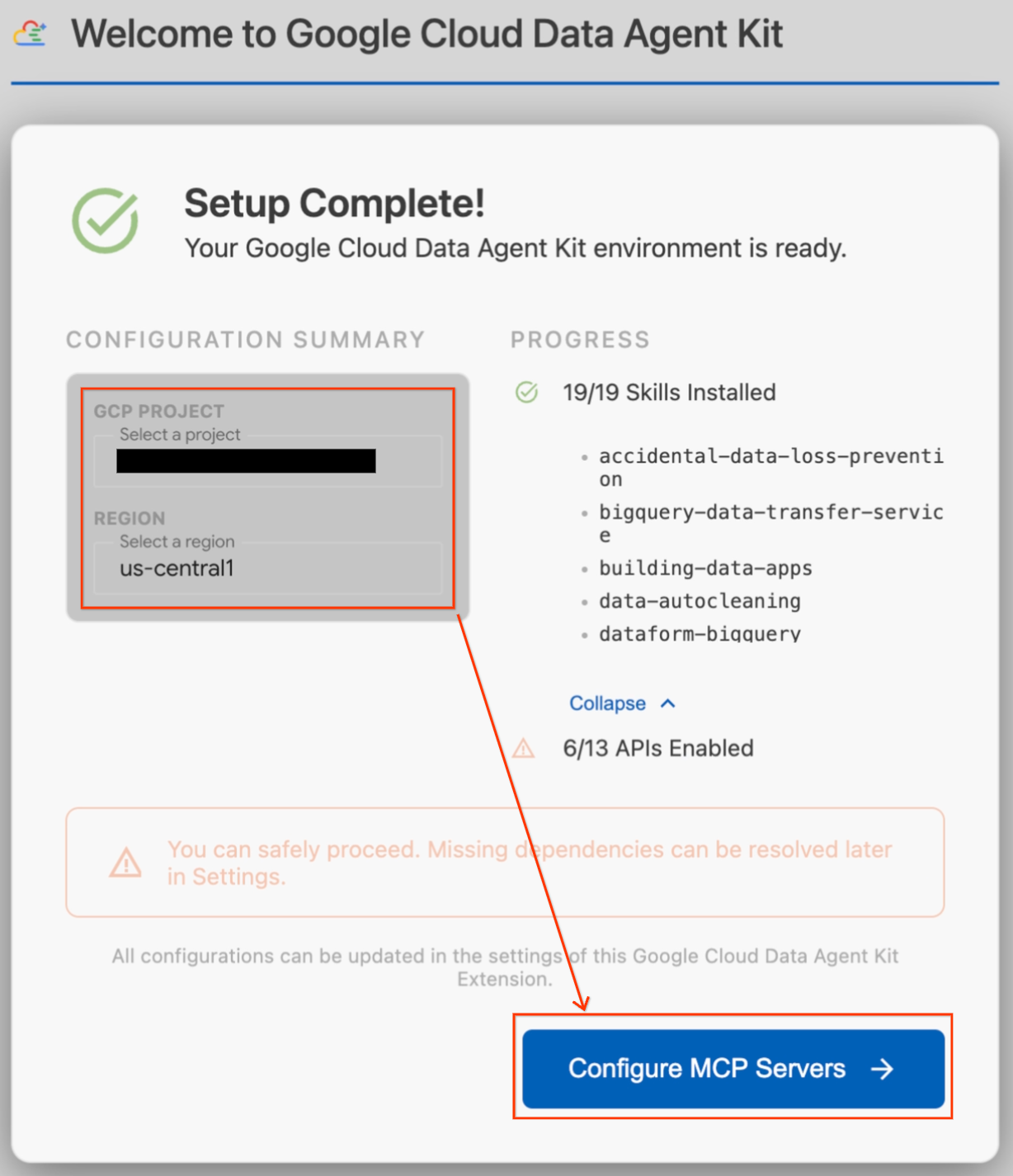
- MCP Yapılandırması altında BigQuery ve AlloyDB'yi seçip Başlayın'ı tıklayın.
6. adım: Yapılandırma seçeneklerini keşfedin
Kurulum tamamlandıktan sonra "Google Cloud Veri Aracısı Kiti'ni kullanmaya başlama" kontrol paneline yönlendirilirsiniz.
- "Kurulum ve Yapılandırma " bölümünde Başlayın'ı tıklayın.
- Bu işlem, Veri Aracısı Yapılandırması panelini açar. Sekmeleri keşfedin:
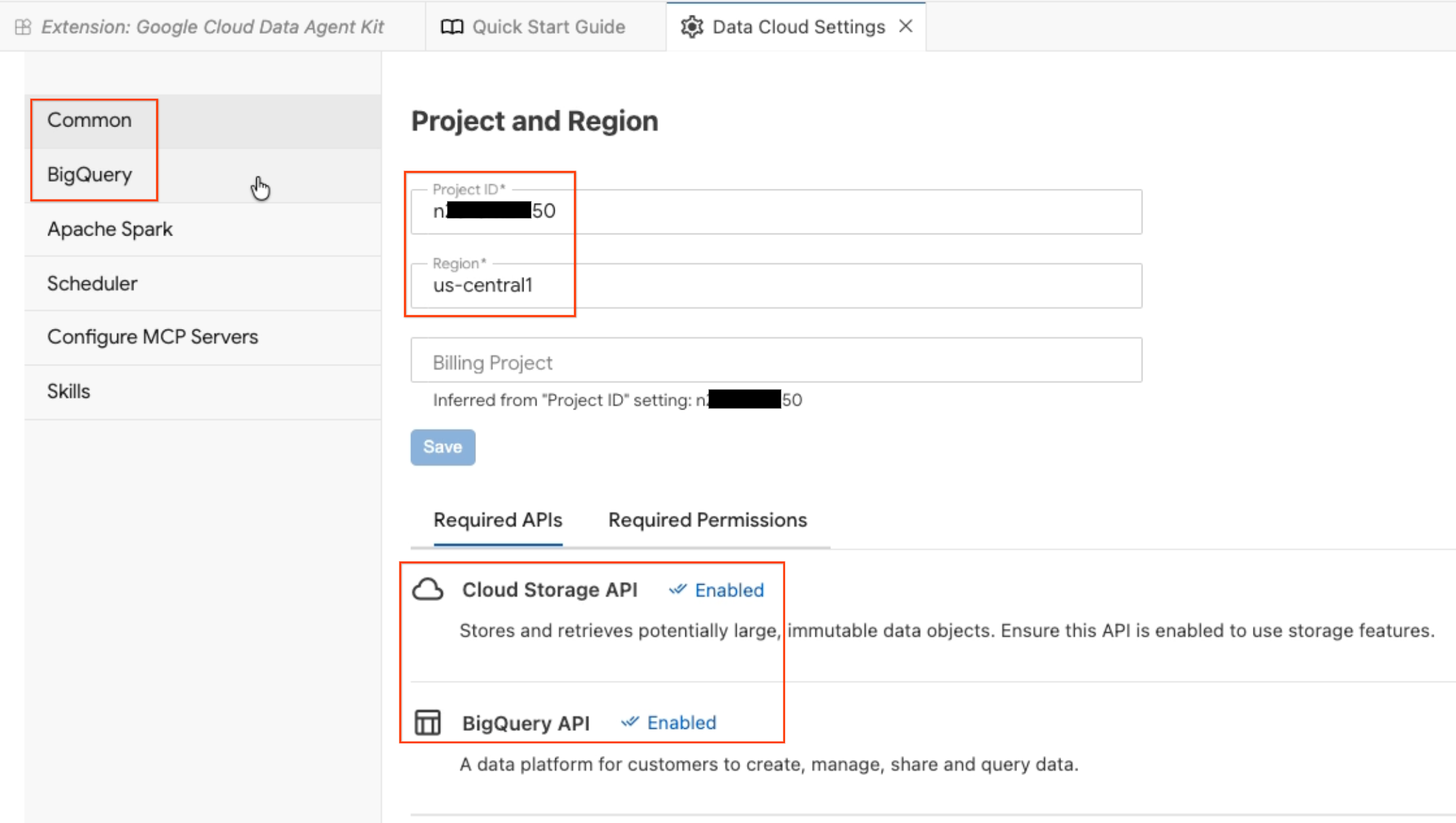
- Proje ve Bölge: Seçtiğiniz proje kimliğini doğrulayın ve gerekli API'lerin (Cloud Storage API, BigQuery API, Catalog API ve AlloyDB API) etkinleştirildiğini kontrol edin.
- BigQuery: BigQuery sorgularınız için varsayılan konumu yapılandırın. Bölgeyi
us-central1kullanın. - MCP sunucularını yapılandırma: Yapay zeka aracılarına verilerinizle güvenli bir şekilde etkileşim kurma olanağı tanıyan etkinleştirilmiş MCP sunucularını (BigQuery, Notebooks, AlloyDB vb.) görüntüleyin.
- Beceriler: Temsilcilere karmaşık veri görevleri için özel yetenekler sağlayan önceden oluşturulmuş becerileri keşfedin.
7. adım: BigQuery ile doğrulama
Herkese açık bir veri kümesinde hızlı bir sorgu çalıştırarak her şeyin çalıştığını doğrulayın.
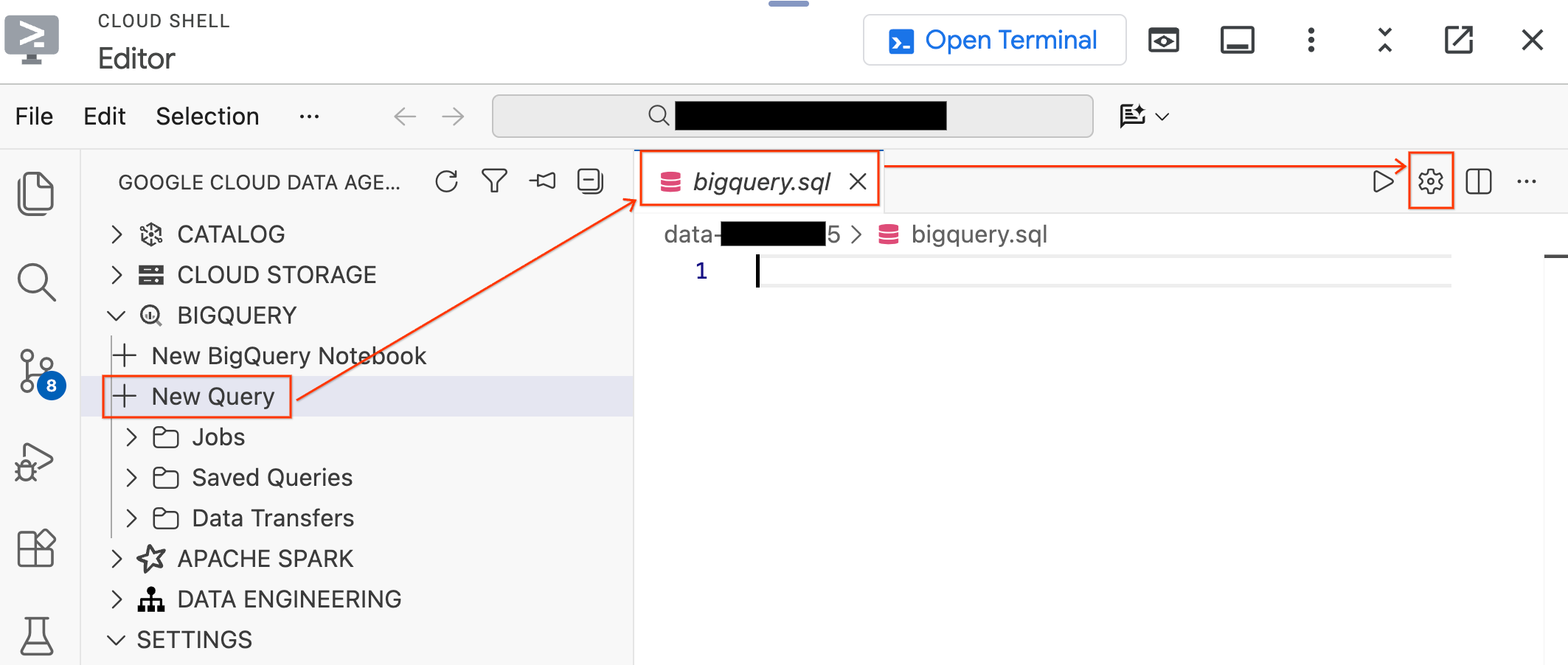
- Soldaki Veri Aracısı Kiti bölmesinde BigQuery bölümünü genişletin ve yeni bir sorgu düzenleyici sekmesi açmak için Yeni Sorgu'yu tıklayın.
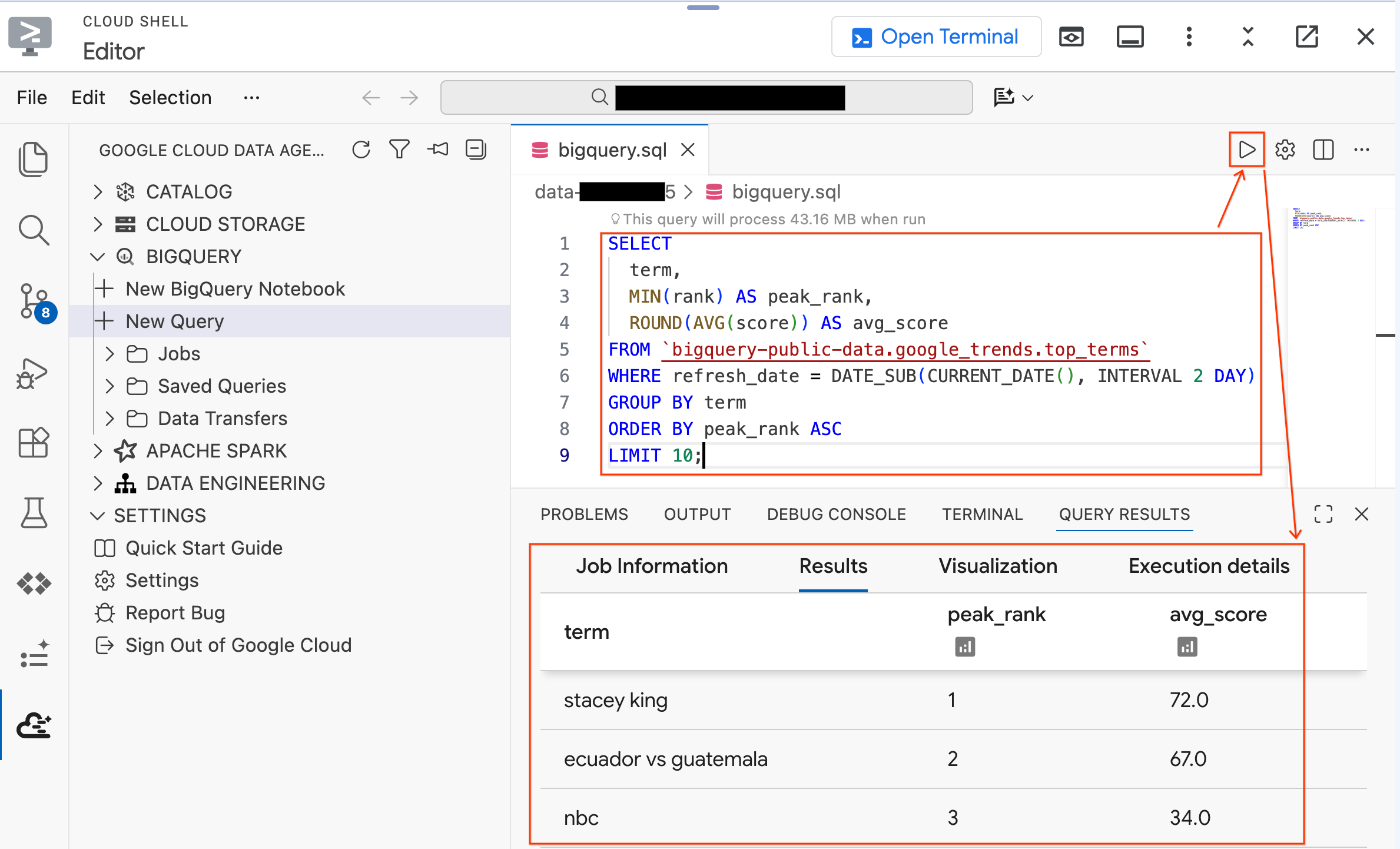
Ctrl+S(Windows/Linux) veyaCmd+S(macOS) tuşuna basarak dosyayı kaydedin vebigqueryolarak adlandırın. Bu sekme, tüm BigQuery işlemleriniz için kullanılır.bigquery.sqlsekmesi etkin durumdayken Sorgu Ayarları'nı tıklayın, Veri Kaynağı olarak BigQuery'yi seçin ve Kaydet'i tıklayın.
- Herkese açık bir veri kümesinde aşağıdaki sorguyu çalıştırın:
SELECT
term,
MIN(rank) AS peak_rank,
ROUND(AVG(score)) AS avg_score
FROM `bigquery-public-data.google_trends.top_terms`
WHERE refresh_date = DATE_SUB(CURRENT_DATE(), INTERVAL 2 DAY)
GROUP BY term
ORDER BY peak_rank ASC
LIMIT 10;
- Son birkaç günün en popüler 10 Google arama terimini görürsünüz. Sonuçlar görünüyorsa uzantınız bağlı ve hazır demektir.
Şimdi, kurulum komut dosyanızın yeni oluşturduğu laboratuvar verileriyle ilgili bir sorgu çalıştırmayı deneyin. Mevcut sorguyu aşağıdakilerle değiştirin:
SELECT * FROM `lost_cargo_dataset.telemetry_data` LIMIT 5;
shipment_id ve telemetry_string sütunlarını içeren telemetri günlüğü girişlerini görmeniz gerekir. Bu, laboratuvar boyunca analiz edeceğiniz verilerdir.
Bölüm Özeti: AlloyDB dağıtımını arka planda başlattınız, kurulum komut dosyasını çalıştırdınız ve Cloud Shell Düzenleyici'yi Veri Ajanı Kiti uzantısıyla yapılandırdınız.
4. Güvenlik Kamerası Görüntülerini Tarama
İnceleme ekibi, Rio de Janeiro Limanı'ndan nakliye konteynerlerinin sıralarını gösteren güvenlik kamerası görüntülerini kurtardı. 1. laboratuvardan hedef kapsayıcının kırmızı olduğunu biliyorsunuz. Şimdi tam olarak hangi kırmızı konteyner olduğunu belirlemeniz gerekiyor.
BigQuery'nin Cloud Storage'daki güvenlik görüntülerini "görmesini" sağlayan bir Nesne Tablosu oluşturacak, ardından Gemini'dan her görüntüden yapılandırılmış verileri çıkarmasını istemek için AI.GENERATE işlevini kullanacaksınız.
1. adım: Nesne tablosunu oluşturun
Nesne tablosu, Cloud Storage'da depolanan yapılandırılmamış dosyalar (resimler, PDF'ler, ses) üzerinde dizin görevi gören özel bir BigQuery tablosudur. Dosyaları BigQuery'ye kopyalamaz. Yapay zeka işlevlerinin dosyaları "görebilmesi" için sorgulanabilir bir referans oluşturur.
Düzenleyicideki bigquery.sql sekmenizde, projenizin paketindeki bağlantı noktası güvenlik resimlerini işaret eden Nesne Tablosu'nu oluşturmak için aşağıdaki ifadeyi çalıştırın:
SET @@location = 'us-central1';
EXECUTE IMMEDIATE CONCAT("""
CREATE OR REPLACE EXTERNAL TABLE `lost_cargo_dataset.port_security_images`
WITH CONNECTION `us-central1.lost_cargo_conn`
OPTIONS (
object_metadata = 'SIMPLE',
uris = ['gs://""", @@project_id, """-lab2/images/*']
);
""");
BigQuery'nin artık görebildiği verilere hızlıca göz atın:
SELECT uri, content_type FROM `lost_cargo_dataset.port_security_images` LIMIT 5;
Her satır, Cloud Storage'daki bir resim dosyasını temsil eder. BigQuery artık bu görüntüleri doğrudan yapay zeka modellerine iletebilir.
2. adım: Güvenlik resimlerini analiz edin
Şimdi her bir güvenlik görüntüsünü analiz etmek için BigQuery'nin AI.GENERATE işlevini kullanın. Bu tek SQL sorgusu, Gemini'ı her resmi incelemeye ve yapılandırılmış veriler döndürmeye yönlendirir:
SELECT
uri,
AI.GENERATE(
(
'Examine this port security image. Identify any shipping container IDs visible on the container and provide a one-word color of the container.',
ref
),
output_schema => 'detected_container_id STRING, color STRING'
).* EXCEPT (full_response, status)
FROM `lost_cargo_dataset.port_security_images`;
3. adım: Hedef kapsayıcıyı belirleyin
Sonuçları inceleyin. color sütununda "Kırmızı" (veya kırmızı bir varyasyon) yazan satırı bulun. detected_container_id değerini not edin. Hedefiniz: MV-CAPYBARA-003.
4. adım: Görsel eşleşmeyi doğrulayın
Düzenleyiciden ayrılmadan analiz edilen gerçek görüntüyü görmek için:
- Soldaki Veri Aracısı Kiti bölmesinde Cloud Storage'ı tıklayın.
- Paketinizi genişletin (
YOUR_PROJECT_ID-lab2/images/) ve doğrudan düzenleyicide görüntülemek için kırmızı kapsayıcıya karşılık gelen resim dosyasını tıklayın.
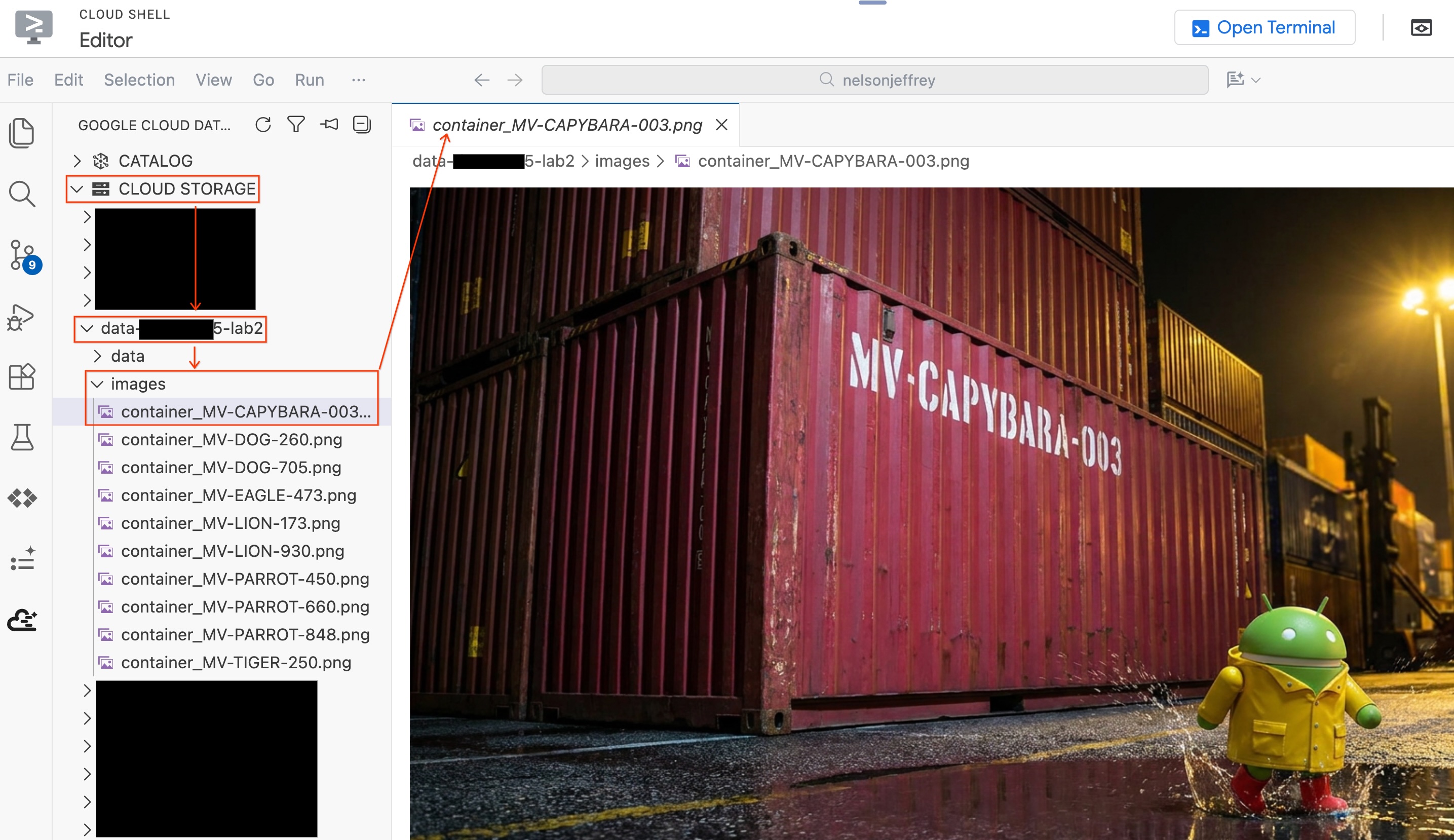
Bölüm Özeti: BigQuery'ye bağlantı noktası güvenlik görüntülerine erişim izni vermek için bir Nesne Tablosu oluşturdunuz, ardından her görüntüden yapılandırılmış kapsayıcı verilerini çıkarmak için AI.GENERATE kullandınız. Kırmızı kapsayıcı MV-CAPYBARA-003 olarak tanımlandı.
5. Hırsızlığı Onaylama
Eksik konteyneri MV-CAPYBARA-003 olarak tanımladınız ancak bu konteyner çalındı mı yoksa sadece yanlış yere mi yerleştirildi? Manifest günlükleri, bu konteynerin SENS-99 numaralı çevre sensörünün yanına park edildiğini gösteriyor. Hırsızlar, konteyneri taşımadan önce üzerindeki soğutma birimini kasıtlı olarak devre dışı bıraktıysa SENS-99, ani bir termal egzoz artışı kaydetmiş olabilir.
Container'ın kurcalandığını kanıtlamak için anormallik algılama özelliğini kullanalım.
- Öncelikle geçmişteki temel çizgiyi inceleyin.
SENS-99cihazının son birkaç saatteki normal ölçümleri:
SELECT * FROM `lost_cargo_dataset.thermal_history`
ORDER BY reading_time DESC
LIMIT 50;
Sıcaklıkların 24-26 °C civarında dar bir aralıkta seyrettiğini fark edin. Normal durum budur.
- Şimdi aynı sensörden alınan mevcut okuma grubuna bakın:
SELECT * FROM `lost_cargo_dataset.thermal_current`
ORDER BY thermal_reading DESC
LIMIT 50;
Üst kısımlarda 148,4 °F değerini görüyor musunuz? Diğer her şey normal görünüyor. Bu ani yükseliş, soğutma ünitesinde bir arıza olduğunu veya kasıtlı olarak kurcalandığını gösterir. Haydi öğrenelim.
- Anormallik algılamayı çalıştırın. BigQuery'nin
AI.DETECT_ANOMALIESözelliği, zaman serisi kalıplarını analiz etmek ve aykırı değerleri otomatik olarak işaretlemek için önceden eğitilmiş TimesFM temel modelini kullanır. Model eğitimi gerekmez:
SELECT *
FROM AI.DETECT_ANOMALIES(
TABLE `lost_cargo_dataset.thermal_history`,
TABLE `lost_cargo_dataset.thermal_current`,
data_col => 'thermal_reading',
timestamp_col => 'reading_time',
id_cols => ['sensor_id']
)
WHERE is_anomaly = TRUE;
- Sonuçları inceleyin. 148,4 °F değeri, yüksek anormallik olasılığına sahip bir anormallik olarak işaretlenmelidir.Bu, konteyner alanının yakınında olağan dışı bir durum yaşandığını doğrular.
Bölüm Özeti: Önceden eğitilmiş TimesFM modelinden yararlanmak için BigQuery'nin AI.DETECT_ANOMALIES işlevini kullandınız. Tek bir SQL sorgusu çalıştırarak, karmaşık makine öğrenimi kodu yazmadan veya modelleri sıfırdan eğitmeden aykırı değerleri otomatik olarak belirlediniz ve anormal kurcalama etkinliğini izole ettiniz.
6. Takip sistemini hazırlama
Çalındığı onaylanan konteyner artık Rio de Janeiro'da değil. Filodaki her konteyner telemetri işaret sinyalleri (sensör okumaları, GPS parçaları ve durum günlükleri) yayınlıyor. Çalınan konteynerin işaret sinyali hâlâ iletiliyorsa konteyneri bilinen imzalarla eşleştirerek bulabilirsiniz.
BigQuery, şu ana kadar yaptığınız analitik çalışmalarda mükemmeldir ancak bir konteyneri gerçek zamanlı olarak bulmak için düşük gecikmeli operasyonel sorgular gerekir. Tümüyle yönetilen ve PostgreSQL ile uyumlu bir veritabanı olan AlloyDB, tam olarak bu amaçla geliştirilmiştir: canlı izleme sistemi için yeterince hızlı olan vektör arama sorguları. Telemetri yerleştirmelerinizi AlloyDB'ye yükleyip işaret sinyaliyle eşleştirmek için kullanırsınız.
Daha önce arka planda başlattığınız AlloyDB kümesi şu anda hazır olmalıdır. Doğrudan düzenleyicinizden yapılandıralım.
1. adım: Düzenleyiciden AlloyDB'ye bağlanın
Cloud Console'a geçmek yerine Data Agent Kit uzantısını kullanarak doğrudan AlloyDB'ye bağlanabilirsiniz.
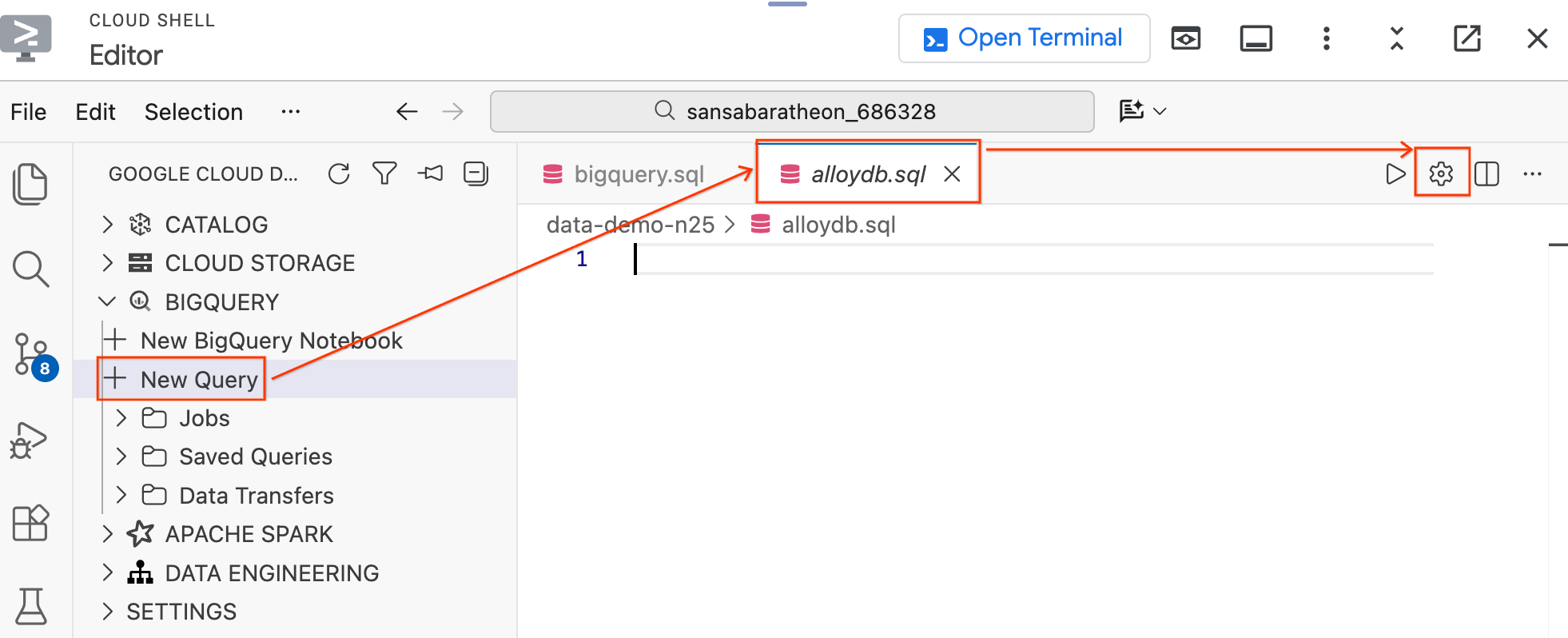
- Sol taraftaki Veri Aracısı Kiti bölmesinde, BigQuery bölümünün altında Yeni Sorgu'yu tıklayarak yeni bir sorgu düzenleyici sekmesi açın.
Ctrl+S(Windows/Linux) veyaCmd+S(macOS) tuşuna basarak dosyayı kaydedin vealloydbolarak adlandırın. Bu sekme, tüm AlloyDB sorguları için kullanılır.- Sorgu Ayarları kalıcı öğesini açmak için dişli simgesini tıklayın.
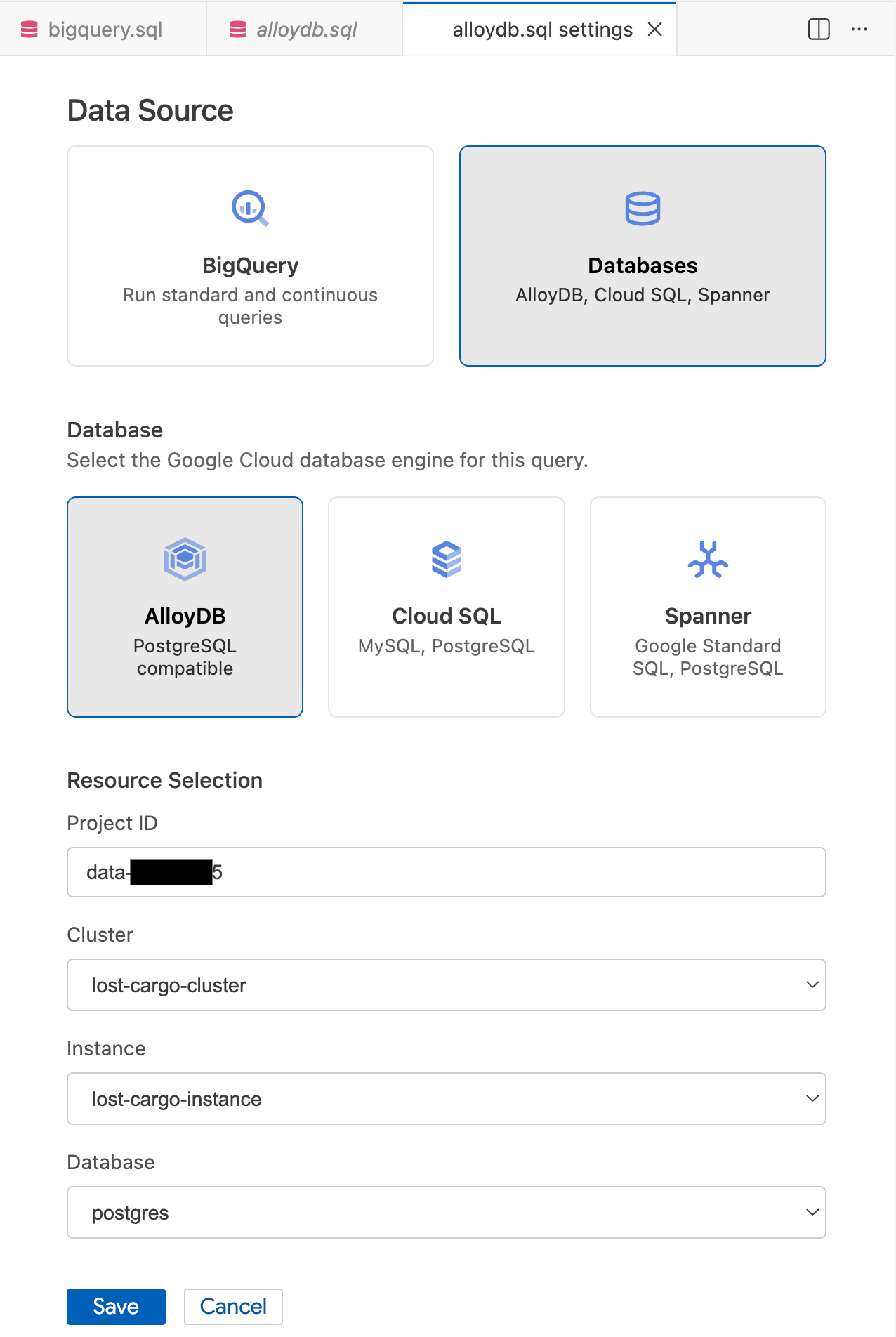
- Sorgu Ayarları kalıcı öğesinde, Veri Kaynağı bölümünde Veritabanları'nı seçin.
- Veritabanı bölümünde AlloyDB'yi seçin.
- Kaynak Seçimi ayrıntılarını doldurun:
- Proje kimliği: Google Cloud proje kimliğinizi girin.
- Küme:
lost-cargo-clustersimgesini seçin. - Örnek:
lost-cargo-instancesimgesini seçin. - Veritabanı:
postgressimgesini seçin.
- Kaydet'i tıklayın.
2. adım: Vector Extension'ı etkinleştirin ve tabloyu oluşturun
AlloyDB'ye bağlandığınıza göre, gerekli yapay zeka uzantılarını etkinleştirmeniz ve yerleştirilmiş telemetri verilerini alacak tabloyu oluşturmanız gerekir.
- Etkin
.sqlsekmenize, gerekli uzantıları etkinleştirmek için aşağıdaki komutları yapıştırın:
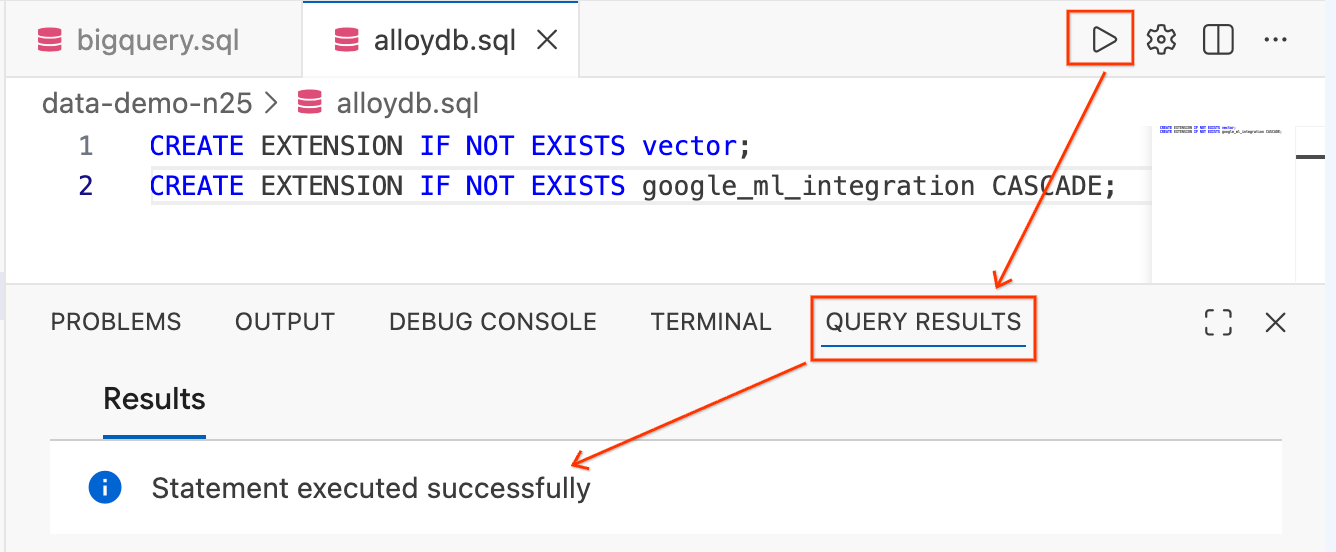
CREATE EXTENSION IF NOT EXISTS vector;
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
- Metni vurgulayın ve düzenleyicinin sağ üst kısmındaki Sorguyu Çalıştır düğmesini (oynat simgesi) tıklayın.
- Ekranınızın alt kısmındaki Sorgu Sonuçları terminal panelini kontrol edin.
Statement executed successfullyyazmalıdır.
- Ardından, telemetri tablosunu oluşturmak için düzenleyicinizdeki metni aşağıdaki ifadeyle değiştirin:
CREATE TABLE IF NOT EXISTS vessel_telemetry (
entry_id SERIAL PRIMARY KEY,
shipment_id VARCHAR(50),
telemetry_string TEXT,
embedding_vector vector(768)
);
- Bu sorguyu son sorgu gibi çalıştırın. Alt panelde sorgunun başarıyla yürütüldüğünü onaylayın.
vector(768) türü, yeni etkinleştirdiğiniz pgvector uzantısından gelir. 768 boyut, yerleştirmeleri oluşturmak için BigQuery'de kullanacağınız Google'ın text-embedding-005 modelinin çıkışıyla eşleşir.
Bölüm Özeti: Cloud Shell Editor'dan doğrudan AlloyDB'ye bağlandınız, pgvector ve google_ml_integration uzantılarını etkinleştirdiniz ve hedef tabloyu oluşturdunuz. AlloyDB artık gerçek zamanlı telemetri eşleştirme için operasyonel arka uç olarak hizmet vermeye hazır.
7. Arama dizinini oluşturma
Şimdi, telemetri verilerini AlloyDB'ye aktarmanız gerekiyor. Böylece bu veriler, gerçek zamanlı sinyal eşleştirme için kullanılabilir. Ham telemetri günlükleri düzensiz ve değişken uzunluktadır. Bu nedenle benzerlik araması için ideal değildir. Her günlüğü Gemini ile özetlemek ve her özeti 768 boyutlu bir vektör yerleştirmeye dönüştürmek için BigQuery'nin yapay zeka işlevlerini kullanacaksınız. Ardından, zenginleştirilmiş verileri Cloud Storage'a aktarıp AlloyDB'ye içe aktaracaksınız.
1. adım: BigQuery'de yerleştirmeler oluşturun
Düzenleyici sekmenizi tekrar bigquery.sql'a (BigQuery'ye bağlı kalır) geçirin.
Şimdi, her bir telemetri günlüğünü Gemini ile özetlemek ve vektör yerleştirmeleri oluşturmak için aşağıdaki sorguyu çalıştırın:
CREATE OR REPLACE TABLE `lost_cargo_dataset.telemetry_embeddings_export` AS
WITH summarized_telemetry AS (
SELECT
shipment_id,
telemetry_string,
AI.GENERATE(
CONCAT('Summarize this telemetry log for vector search: ', telemetry_string)
).result AS summary
FROM `lost_cargo_dataset.telemetry_data`
),
telemetry_embeddings AS (
SELECT
shipment_id,
telemetry_string,
AI.EMBED(summary, endpoint => 'text-embedding-005').result AS embedding
FROM summarized_telemetry
)
SELECT
shipment_id,
telemetry_string,
TO_JSON_STRING(embedding) AS embedding_vector
FROM telemetry_embeddings;
2. adım: Zenginleştirilmiş verileri önizleyin
Dışa aktarmadan önce oluşturduklarınıza göz atın. Bu sorgu, gönderim kimliklerini ve her özet ile yerleştirmenin ilk 80 karakterini gösterir:
SELECT
shipment_id,
SUBSTR(telemetry_string, 1, 80) AS telemetry_preview,
SUBSTR(embedding_vector, 1, 80) AS embedding_preview
FROM `lost_cargo_dataset.telemetry_embeddings_export`
LIMIT 5;
Her satırda artık bir kargo kimliği, orijinal telemetri günlüğü ve 768 boyutlu bir yerleştirme vektörü bulunuyor. Bu, AlloyDB'ye aktaracağınız verilerdir.
3. adım: Yerleştirmeleri Cloud Storage'a aktarın
Yerleştirme tablosunu laboratuvarınızın GCS paketine CSV dosyası olarak yazmak için BigQuery'nin EXPORT DATA ifadesini kullanın.
EXECUTE IMMEDIATE CONCAT("""
EXPORT DATA OPTIONS (
uri = 'gs://""", @@project_id, """-lab2/data/embeddings_export/*.csv',
format = 'CSV',
overwrite = true,
header = false
) AS
SELECT
shipment_id,
telemetry_string,
embedding_vector
FROM `lost_cargo_dataset.telemetry_embeddings_export`;
""");
4. adım: Cloud Storage'dan AlloyDB'ye içe aktarma
- Cloud Shell Düzenleyicinizde, terminal oturumu açmak için ekranın alt kısmındaki Terminal sekmesini tıklayın.
- Ortamınızı yüklemek ve CSV dosyasını doğrudan AlloyDB'deki
vessel_telemetrytablosuna aktarmak için aşağıdaki komutları çalıştırın:
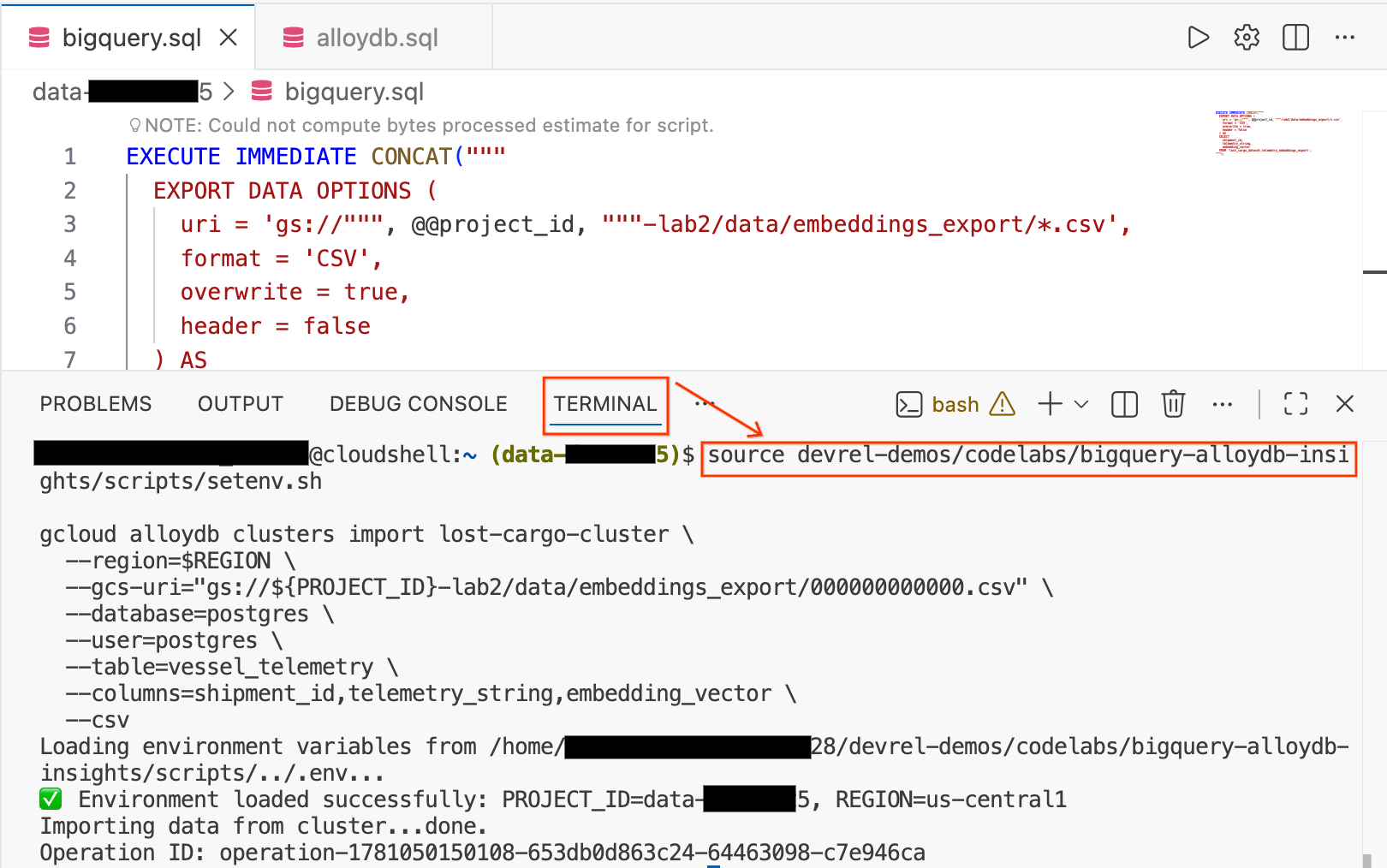
source devrel-demos/codelabs/bigquery-alloydb-insights/scripts/setenv.sh
gcloud alloydb clusters import lost-cargo-cluster \
--region=$REGION \
--gcs-uri="gs://${PROJECT_ID}-lab2/data/embeddings_export/000000000000.csv" \
--database=postgres \
--user=postgres \
--table=vessel_telemetry \
--columns=shipment_id,telemetry_string,embedding_vector \
--csv
Bölüm Özeti: Telemetri verilerini özetlemek ve yerleştirmek için BigQuery'nin yapay zeka işlevlerini kullandınız, sonuçları CSV olarak Cloud Storage'a aktardınız ve ardından gcloud kullanarak AlloyDB'ye içe aktardınız. Operasyonel izleme veritabanı artık yüklendi ve hazır.
8. İşaretçi Sinyalini Eşleştirme
Sidney yakınlarındaki bir saha ekibi, parçalanmış bir telemetri sinyalini engelledi. Kısmi günlükte şunlar yer alır:
"Soğutma ünitesi çevrimdışı. Manuel geçersiz kılma."
Bu, çalınan kapsayıcıdan geliyorsa AlloyDB'nin vektör araması, sinyal eksik olsa bile bunu eşleştirebilmelidir. AlloyDB tam olarak bu tür gerçek zamanlı, operasyonel sorgular için tasarlanmıştır.
1. adım: İçe aktarılan verileri doğrulayın
Düzenleyici sekmenizi tekrar alloydb.sql'a (AlloyDB'ye bağlı kalır) geçirin.
Aşağıdaki komutu çalıştırarak telemetri verilerinin başarıyla yüklendiğini onaylayın:
SELECT shipment_id, LEFT(telemetry_string, 80) AS telemetry_preview
FROM vessel_telemetry
LIMIT 10;
shipment_id değerleri ve telemetri metni içeren satırlar görürsünüz. Bunlar, filonun telemetri imzalarıdır ve artık gerçek zamanlı eşleşmeye hazırdır.
2. adım: Eksik kapsayıcıyı arayın
Şimdi, AlloyDB'nin google_ml_integration uzantısını kullanarak yakalanan sinyal parçasını kullanarak eşleşme arayın:
SELECT
shipment_id,
telemetry_string,
1 - (embedding_vector <=> embedding('text-embedding-005', 'Refrigeration unit offline. Manual override.')::vector) AS search_relevance_score
FROM vessel_telemetry
ORDER BY embedding_vector <=> embedding('text-embedding-005', 'Refrigeration unit offline. Manual override.')::vector
LIMIT 5;
AlloyDB'nin google_ml_integration uzantısı tarafından sağlanan embedding() işlevi, satır içi vektör yerleştirme oluşturmak için Agent Platform'u doğrudan SQL'den çağırır. <=> operatörü, iki vektör arasındaki kosinüs uzaklığını hesaplar (0'a ne kadar yakınsa iki vektör o kadar özdeştir). Sonuçları, yüksek değerin daha iyi olduğu bir alaka düzeyi puanı olarak ifade etmek için 1'den çıkarırız.
3. adım: Eşleşmeyi onaylayın
Sonuçları inceleyin. En üstteki sonuç, en yüksek alaka düzeyine sahip MV-CAPYBARA-003 olmalıdır.
Bu, bu incelemenin her adımında izlediğiniz kapsayıcıyla aynıdır:
- 📷 Güvenlik görüntülerinde, geminin gece Rio de Janeiro Limanı'ndan ayrıldığı görülüyor.
- 🌡️ Termal anormallik algılama, soğutma biriminin kasıtlı olarak devre dışı bırakıldığını doğruladı.
- 📡 İşaretçi sinyali eşleştirme, telemetri imzasını Sidney yakınlarında tam olarak belirledi.
Üç bağımsız kanıt. Üç farklı Google Cloud Yapay Zeka özelliği. Bir çalınan konteyner.
🎯 Case closed: MV-CAPYBARA-003 has been located near Sydney!

Bölüm Özeti: Arama yerleştirmesi oluşturmak ve tek bir SQL sorgusunda kosinüs benzerliği araması yapmak için AlloyDB'nin yerleşik yapay zeka entegrasyonunu kullandınız. Beacon eşleşmesi, çalınan konteynerin konumunu doğrulayarak soruşturmayı tamamladı.
9. Kanıtları İnceleme
Çok formatlı görüntü analizi ve vektör aramasıyla kapsayıcıyı belirlediğinize göre artık doğal dili kullanarak araştırma verilerini keşfetmek için doğrudan düzenleyicinizde Etkileşimli Analiz'i kullanabilirsiniz. Bunun için SQL yazmanız gerekmez.
1. adım: Verileri Bilgi Kataloğu'nda bulun
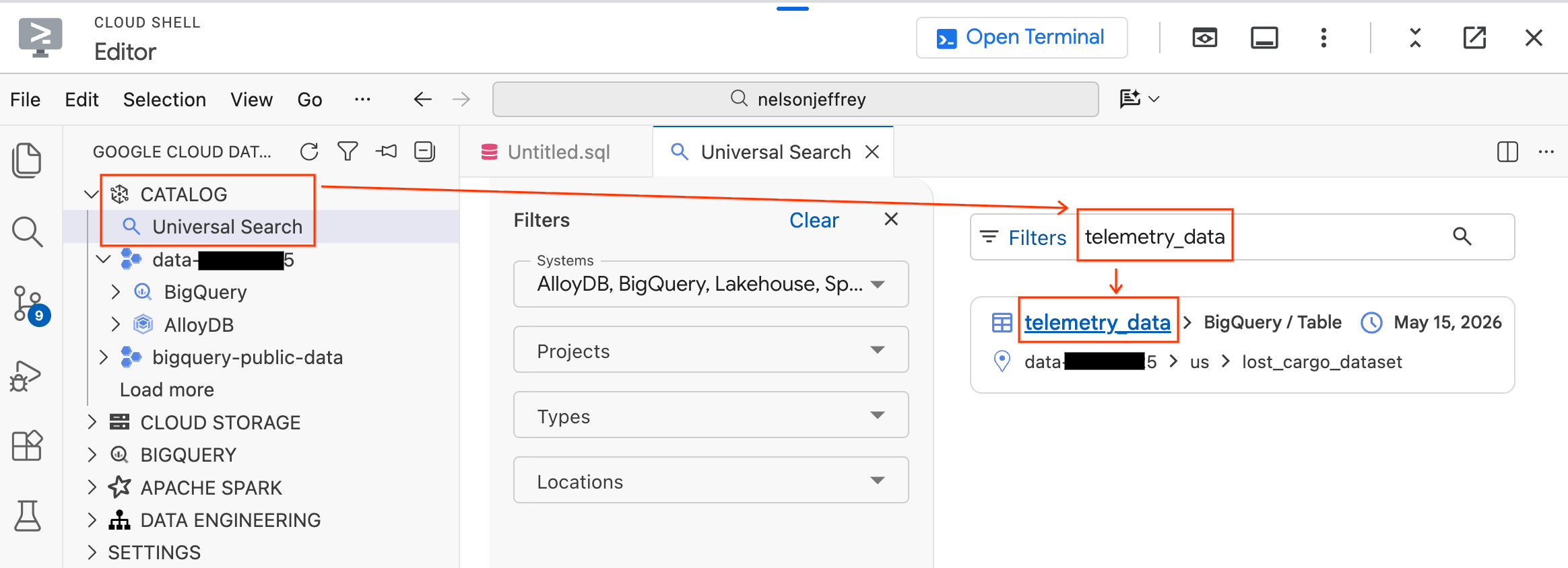
Veri Aracı Kiti, Google Cloud ortamınızdaki veri öğelerini bulup keşfetmenizi sağlayan bir Evrensel Arama özelliği içerir.
- Soldaki Veri Aracısı Kiti panelinde Katalog bölümünü genişletin.
- Evrensel Arama'yı tıklayın.
- Arama çubuğuna
telemetry_datayazın. - Arama sonuçlarından
telemetry_datatablosunu (lost_cargo_datasetaltında) tıklayın.
2. adım: Konuşma Analizi'ni başlatın
Arama sonucunu tıkladığınızda, ham verileri önizleyebileceğiniz, şemayı görüntüleyebileceğiniz ve veri kalitesini kontrol edebileceğiniz bir veri görüntüleyici sekmesi açılır.
- Sol bölmede BigQuery veri kümeleriniz ve tablolarınız görünür. Yeni bir sohbet penceresi açmak için Sohbet düğmesini tıklayın.
3. adım: Doğal dilde soru sorun
Yeni bir "Sohbet Analitiği'ne Hoş Geldiniz!" sohbet sekmesi açılır. Ajan, tablonuzun şeması ve içeriği hakkında bağlam bilgisine sahiptir.
- Sohbet penceresine "Show me the telemetry status and log for the Capybara shipment." (Kapibara sevkiyatının telemetri durumunu ve günlüğünü göster) yazın.
- Enter tuşuna basın.
Aracı, sorunuzu BigQuery SQL'e çevirir, sorguyu yürütür ve sonuçları (hem bir veri tablosu hem de bulguları özetleyen analizler dahil) döndürür. Sorunuzun karmaşıklığına bağlı olarak Düşünen (daha derinlemesine analiz, daha yavaş) ve Hızlı (daha hızlı yanıtlar) modları arasında geçiş yapabilirsiniz. Bunlar yapay zekayla üretilen yanıtlar olduğundan sonuçlarınız aşağıdaki ekran görüntülerinden biraz farklı görünebilir.
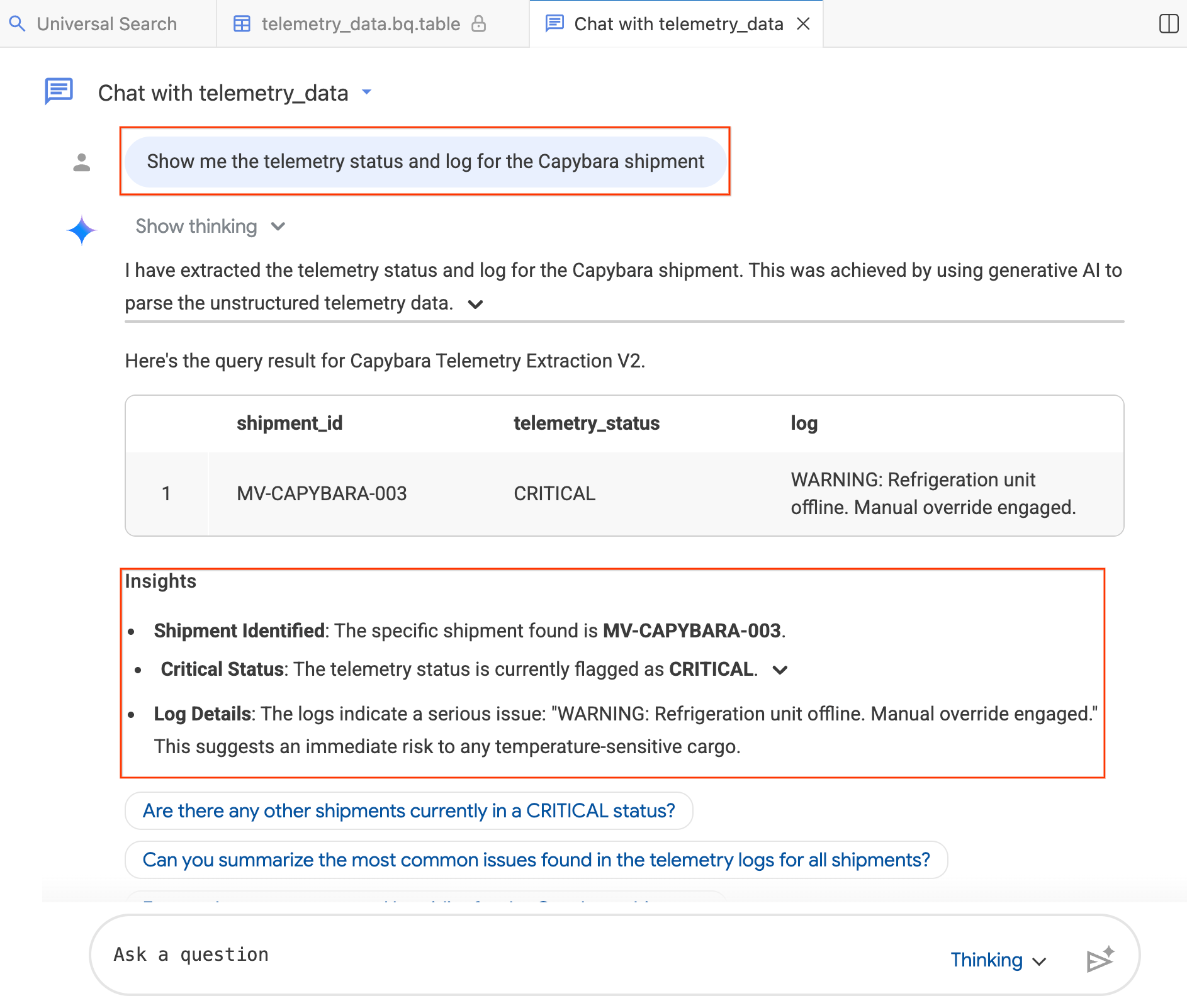
4. adım: Ek sorular sorun
Ajan, sohbetinizin bağlamını hatırlar. Ek soru sormayı deneyin:
- "Telemetri verilerinde kaç benzersiz gönderi var?"
- "Filodaki diğer kaç gönderinin durumu şu anda KRİTİK?"
Bölüm Özeti: Veri kümenizi bulmak için Knowledge Catalog'un Evrensel Arama özelliğini kullandınız ve soruşturma verilerini doğal dilde sorgulamak için Sohbet Ederek Analiz özelliğini başlattınız. Yapay zeka aracısı, sorularınızı SQL'e çevirip bulgularınızı doğrulayan analizler sağladı.
10. Temizleme
Google Cloud hesabınızın sürekli olarak ücretlendirilmesini önlemek için bu laboratuvarda oluşturduğunuz kaynakları silin. Ortamınızı temizlemek için bu komutları Cloud Shell Düzenleyici'deki (Data Agent Kit'i kullandığınız yer) entegre terminalinizde çalıştırabilirsiniz.
Öncelikle ortam değişkenlerinizi yükleyin:
source scripts/setenv.sh
- BigQuery Kaynaklarını Silme (yalnızca 3. laboratuvara devam etmiyorsanız):
3. laboratuvara devam etmeyi planlıyorsanız bu adımı atlayın. 3. laboratuvarda, mülk grafiği analizi için aynı BigQuery veri kümesi ve bağlantılar kullanılır.
BigQuery veri kümenizi ve bağlantılarınızı silmek için:
# Drop the dataset
bq rm -r -f $PROJECT_ID:lost_cargo_dataset
# Delete the connections
bq rm --connection --location=us-central1 $PROJECT_ID.us-central1.lost_cargo_conn
bq rm --connection --location=us-central1 $PROJECT_ID.us-central1.lost_cargo_alloydb_conn
- Cloud Storage paketini silin:
gcloud storage rm --recursive gs://${PROJECT_ID}-lab2
- AlloyDB örneğini ve kümesini silme:
AlloyDB, 3. laboratuvarda kullanılmadığından şu anda güvenle kaldırılabilir.
gcloud alloydb instances delete lost-cargo-instance \
--region=$REGION \
--cluster=lost-cargo-cluster \
--quiet
gcloud alloydb clusters delete lost-cargo-cluster \
--region=$REGION \
--force \
--quiet
- Yerel ortam ayarlarını silin:
Son olarak, çalışma alanınızdaki yerel ortam ayarları dosyasını temizleyin:
rm -f .env
11. Tebrikler!
Lab 2: Veri Analizi ve Çok Formatlı İçgörüler adlı laboratuvarı başarıyla tamamladınız. Binlerce konteynerle dolu bir limandan başlayan izi takip ederek hırsızlığın doğrulandığı ve yerinin tespit edildiği bir noktaya ulaştınız.
Başarılarınız
- Görüntüleri tarama: BigQuery'nin
AI.GENERATEözelliğini kullanarak liman güvenliği görüntülerini analiz ettiniz ve Crimson Red rengindeki MV-CAPYBARA-003 konteynerini belirlediniz. - Hırsızlığı doğruladınız: Termal sensör verilerini incelediniz, şüpheli bir 64, 7 °C artış tespit ettiniz ve bunun kasıtlı bir kurcalama olduğunu kanıtlamak için
AI.DETECT_ANOMALIESkullandınız. - İzleme sistemini hazırladınız: Anlık işaret eşleştirme için AlloyDB'yi pgvector ve
google_ml_integrationile yapılandırdınız. - Arama dizinini oluşturma: BigQuery'de yerleştirmeler oluşturmak için
AI.GENERATEveAI.EMBEDişlevlerini kullandınız, ardından bunları Cloud Storage'a aktarıp AlloyDB'ye içe aktardınız. - Beacon sinyaliyle eşleşti: AlloyDB'nin vektör arama özelliğini kullanarak parçalanmış bir telemetri sinyalini eşleştirdiniz ve çalınan konteyneri Sidney yakınlarında buldunuz.
- Kanıtları incelediyseniz: İnceleme verilerini doğal dilde sorgulamak için doğrudan düzenleyiciden Sohbet Analizi'ni kullandıysanız.

Sonraki Adımlar
Kapsayıcının nerede olduğunu buldunuz. Şimdi de kimin kapsayıcısı olduğunu bulmanız gerekiyor.
3. Laboratuvar: Veri Tüketimi ve Temsilci İş Akışları'nda, paravan şirketler arasındaki ilişkileri eşlemek için lojistik ağının bir özellik grafiğini oluşturacak, grafikle sohbet etmek için Sohbet Analizi'ni kullanacak ve konteyneri kurtarmak için gereken güvenli gümrükleme kodunu bulmak üzere Bilgi Kataloğu'nda arama yapacaksınız.