
1. Giới thiệu

Trong phòng thí nghiệm trước, bạn đã tổng hợp các nhật ký vận chuyển rời rạc và truy tìm thiết bị phản hồi của hàng hoá đến New York. Tuy nhiên, hồ sơ đến cho thấy vùng chứa đã được chuyển hướng ngay lập tức để tránh bị hải quan phát hiện. Dấu vết hiện đã dẫn bạn đến Cảng Rio de Janeiro, một cảng rộng lớn với hàng nghìn vùng chứa. Việc tìm ra vùng chứa phù hợp trong số hàng nghìn vùng chứa khác là một nhiệm vụ khó khăn.
Trong phòng thí nghiệm này, bạn sẽ sử dụng các chức năng AI tích hợp của BigQuery để "đọc" hình ảnh bảo mật cổng không có cấu trúc và phát hiện các điểm bất thường về nhiệt trong dữ liệu cảm biến, tất cả đều sử dụng SQL chuẩn. Sau đó, bạn sẽ xuất các giá trị nhúng vectơ sang AlloyDB và chạy một tìm kiếm vectơ để so khớp tín hiệu đo từ xa bị phân mảnh với vùng chứa bị thiếu.
Bạn sẽ thực hiện
- Quét hình ảnh bảo mật của cổng để xác định vùng chứa bị đánh cắp bằng BigQuery AI
- Phát hiện điểm bất thường về nhiệt bằng AI của BigQuery để xác nhận rằng thùng chứa đã bị đánh cắp chứ không phải bị thất lạc
- Tạo vectơ nhúng và tải các vectơ đó vào AlloyDB để tìm kiếm theo thời gian thực
- So khớp tín hiệu đèn hiệu đo từ xa bị phân mảnh để xác định vị trí của vùng chứa bị đánh cắp bằng tính năng Tìm kiếm vectơ
- Khám phá dữ liệu điều tra bằng ngôn ngữ tự nhiên thông qua tính năng Phân tích đàm thoại
Bạn cần có
- Một trình duyệt web như Chrome
- Một dự án trên Google Cloud đã bật tính năng thanh toán
- Hiểu biết cơ bản về SQL và Google Cloud Console
Lớp học lập trình này dành cho các nhà phát triển có trình độ trung cấp.
Các tài nguyên được tạo trong lớp học lập trình này sẽ có chi phí dưới 5 USD.
2. Trước khi bắt đầu
Khởi động Cloud Shell
Bạn sẽ sử dụng Google Cloud Shell để tải mã xuống, chạy tập lệnh thiết lập và triển khai ứng dụng.
- Trong một thẻ trình duyệt mới, hãy mở Cloud Shell: shell.cloud.google.com
- Sau khi kết nối, hãy đặt mã dự án và xác nhận môi trường của bạn:
gcloud config set project <<YOUR_PROJECT_ID>>
export PROJECT_ID=$(gcloud config get-value project)
export REGION=us-central1
Bạn sẽ thấy một thông báo tương tự như sau:
Your active configuration is: [cloudshell-####] Updated property [core/project]
Sao chép Kho lưu trữ
Sao chép kho lưu trữ lớp học lập trình vào môi trường Cloud Shell:
cd ~/
git clone --filter=blob:none --no-checkout https://github.com/GoogleCloudPlatform/devrel-demos.git
cd ~/devrel-demos
git sparse-checkout init --cone
git sparse-checkout set codelabs/bigquery-alloydb-insights
git checkout main
cd codelabs/bigquery-alloydb-insights/
Bật API
Chạy lệnh này trong Cloud Shell để bật tất cả các API bắt buộc cho bài thực hành này:
gcloud services enable \
aiplatform.googleapis.com \
bigquery.googleapis.com \
bigqueryconnection.googleapis.com \
alloydb.googleapis.com
Khi thực thi thành công, bạn sẽ thấy một thông báo tương tự như sau:
Operation "operations/..." finished successfully.
3. Thiết lập môi trường
Trước khi có thể phân tích hình ảnh và dữ liệu đo từ xa, bạn cần thiết lập cơ sở hạ tầng cho phòng thí nghiệm này. Bạn sẽ chạy 2 tập lệnh: một tập lệnh khởi động quy trình cấp phép AlloyDB ở chế độ nền và tập lệnh còn lại tạo tất cả tài nguyên BigQuery mà bạn cần.
Bước 1: Bắt đầu triển khai AlloyDB (Nền)
Việc cung cấp cụm AlloyDB mất khoảng 10 phút, vì vậy, trước tiên bạn sẽ bắt đầu và để cụm chạy ở chế độ nền trong khi bạn thực hiện các phần BigQuery. Tập lệnh sẽ tự động ghi lại các chế độ cài đặt dự án đang hoạt động vào tệp .env cục bộ để cấu hình của bạn được lưu ngay cả khi thiết bị đầu cuối Cloud Shell đóng hoặc khởi động lại.
chmod +x scripts/setup_alloydb.sh
nohup ./scripts/setup_alloydb.sh > /dev/null 2>&1 &
echo "AlloyDB deployment started in background (PID: $!)"
Bước 2: Chạy tập lệnh thiết lập
Tập lệnh này sẽ tạo tập dữ liệu BigQuery, kết nối Tài nguyên trên đám mây, cấp quyền IAM, tạo vùng chứa GCS và tải tất cả dữ liệu cảm biến mà bạn sẽ phân tích trong phòng thí nghiệm này. Công cụ này cũng sẽ đọc và xác minh các biến môi trường được lưu trong tệp .env.
chmod +x scripts/setup_lab.sh
./scripts/setup_lab.sh
Tập lệnh này mất khoảng một phút để chạy. Sau khi quá trình này kết thúc, bạn sẽ thấy thông tin tóm tắt về mọi nội dung mà AI tạo sinh đã tạo.
📝 Lưu ý về việc đặt lại môi trường Nếu phiên Cloud Shell của bạn hết thời gian chờ hoặc khởi động lại bất cứ lúc nào trong quá trình thực hành này, bạn có thể khôi phục ngay các biến của cửa sổ dòng lệnh bằng cách chạy:
source scripts/setenv.sh
Bước 3: Chạy Cloud Shell Editor
Cho đến nay, bạn đã sử dụng thiết bị đầu cuối Cloud Shell. Giờ đây, hãy chuyển sang Cloud Shell Editor đầy đủ. Công cụ này cung cấp cho bạn một không gian làm việc tương tự như VS Code với khả năng hỗ trợ BigQuery tích hợp.
- Trong ngăn cửa sổ dòng lệnh Cloud Shell ở cuối màn hình, hãy nhấp vào nút Open Editor (Mở trình chỉnh sửa) để chạy không gian làm việc Cloud Shell Editor.

Bước 4: Cài đặt Tiện ích Data Agent Kit
Tiện ích Google Cloud Data Agent Kit cung cấp khả năng tích hợp sâu với các dịch vụ dữ liệu của Google Cloud ngay trong trình chỉnh sửa, cho phép bạn tương tác với BigQuery, AlloyDB, Cloud Storage và nhiều dịch vụ khác mà không cần chuyển đổi ngữ cảnh.
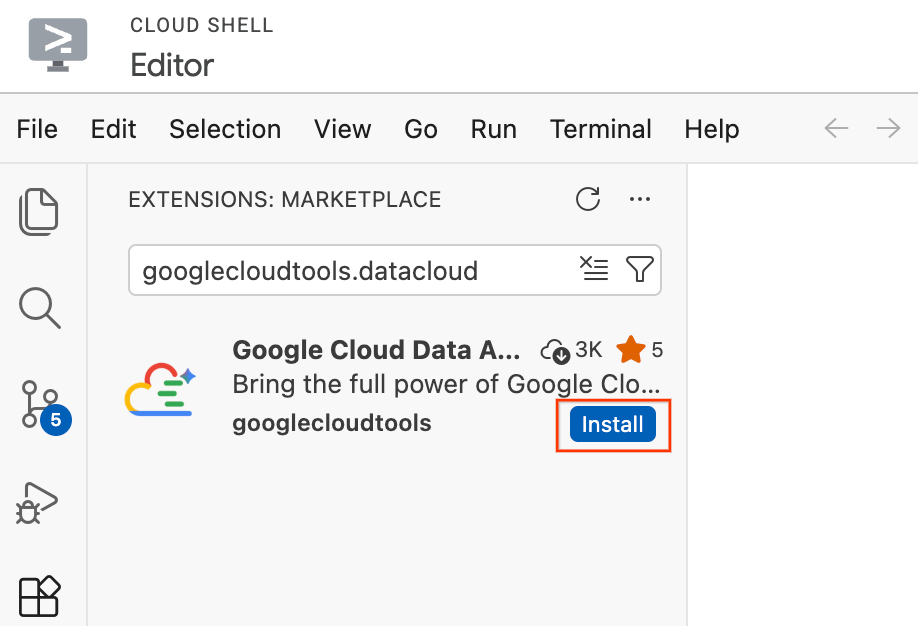
- Trong Cloud Shell Editor, hãy nhấp vào biểu tượng Tiện ích trong Thanh hoạt động ở ngoài cùng bên trái màn hình (biểu tượng này trông giống như 4 hình vuông).
- Trong thanh tìm kiếm ở đầu ngăn Tiện ích, hãy nhập
googlecloudtools.datacloud. - Tìm tiện ích có tên Google Cloud Data Agent Kit do Google Cloud xuất bản.
- Nhấp vào nút Install (Cài đặt).
- Một lời nhắc sẽ xuất hiện để hỏi "Bạn có tin tưởng nhà xuất bản "googlecloudtools" và các tiện ích của họ không?". Nhấp vào Tin tưởng nhà xuất bản và cài đặt để tiếp tục.
Bước 5: Xác thực và định cấu hình tiện ích
Sau khi cài đặt, hãy kết nối tiện ích này với dự án trên đám mây của Google.
- Một trang giới thiệu có tiêu đề "Giới thiệu về Google Cloud Data Agent Kit" sẽ tự động mở ra. Nhấp vào Đăng nhập vào Google Cloud. Làm theo mọi lời nhắc của trình duyệt để cho phép truy cập.
- Một cửa sổ phương thức "Đang thiết lập" sẽ xuất hiện. Tiện ích này sẽ tự động kiểm tra các phần phụ thuộc bắt buộc, chẳng hạn như Google Cloud CLI.
- Trong phần Configuration Summary (Tóm tắt cấu hình), hãy tìm trường dự án. Nhấp vào trình đơn thả xuống rồi chọn dự án trên đám mây của bạn trên Google Cloud. Đặt khu vực của bạn là
us-central1. - Chờ quá trình kiểm tra thiết lập hoàn tất. Sau khi bạn thấy thông báo "Thiết lập hoàn tất!", hãy nhấp vào Định cấu hình máy chủ MCP.
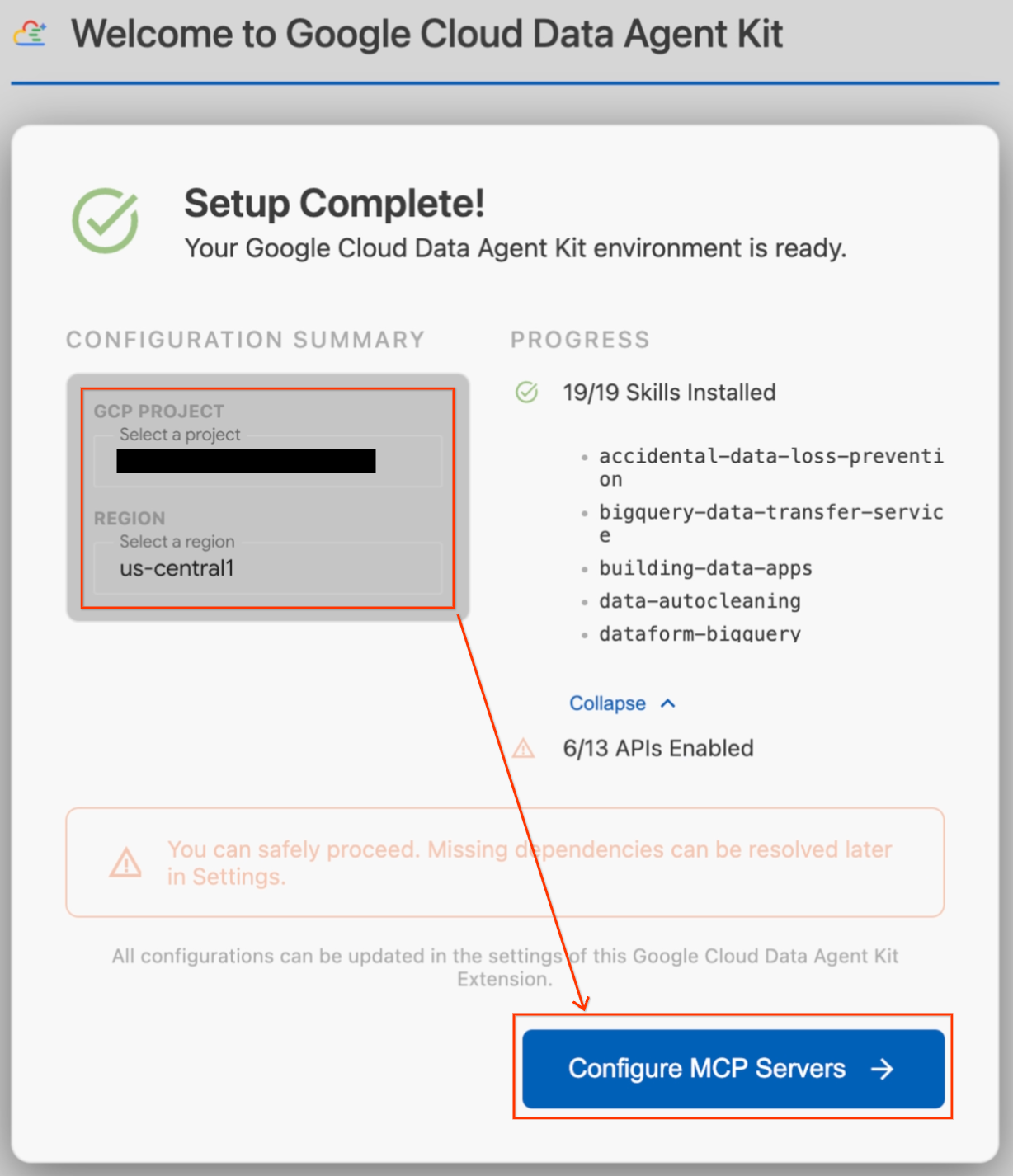
- Chọn BigQuery và AlloyDB trong phần Cấu hình MCP, rồi nhấp vào Bắt đầu.
Bước 6: Khám phá các lựa chọn về cấu hình
Sau khi hoàn tất quá trình thiết lập, bạn sẽ được chuyển đến trang tổng quan "Bắt đầu sử dụng Bộ công cụ đại lý dữ liệu Google Cloud".
- Trong mục "Thiết lập và cấu hình", hãy nhấp vào Bắt đầu.
- Thao tác này sẽ mở bảng điều khiển Cấu hình tác nhân dữ liệu. Khám phá các thẻ:
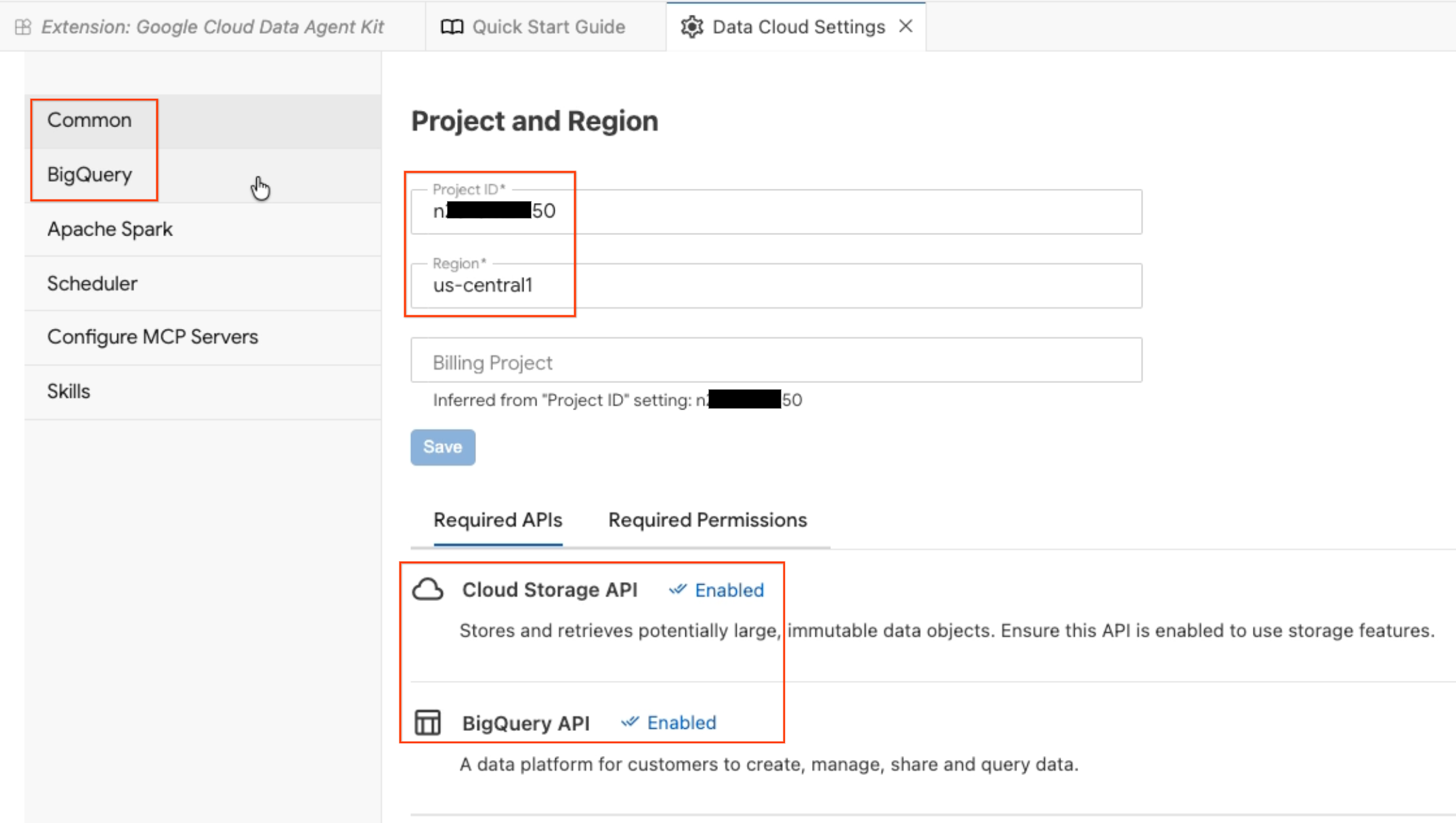
- Dự án và khu vực: Xác minh mã dự án bạn đã chọn và kiểm tra để đảm bảo rằng các API bắt buộc (Cloud Storage API, BigQuery API, Catalog API và AlloyDB API) đã được bật.
- BigQuery: Định cấu hình vị trí mặc định cho các truy vấn BigQuery. Sử dụng khu vực
us-central1. - Định cấu hình máy chủ MCP: Xem các máy chủ MCP đã bật (BigQuery, Notebooks, AlloyDB, v.v.) cho phép các tác nhân AI tương tác an toàn với dữ liệu của bạn.
- Kỹ năng: Khám phá các kỹ năng được tạo sẵn giúp các tác nhân có khả năng chuyên biệt để thực hiện các tác vụ dữ liệu phức tạp.
Bước 7: Xác minh bằng BigQuery
Xác nhận rằng mọi thứ đều hoạt động bằng cách chạy một truy vấn nhanh đối với một tập dữ liệu công khai.
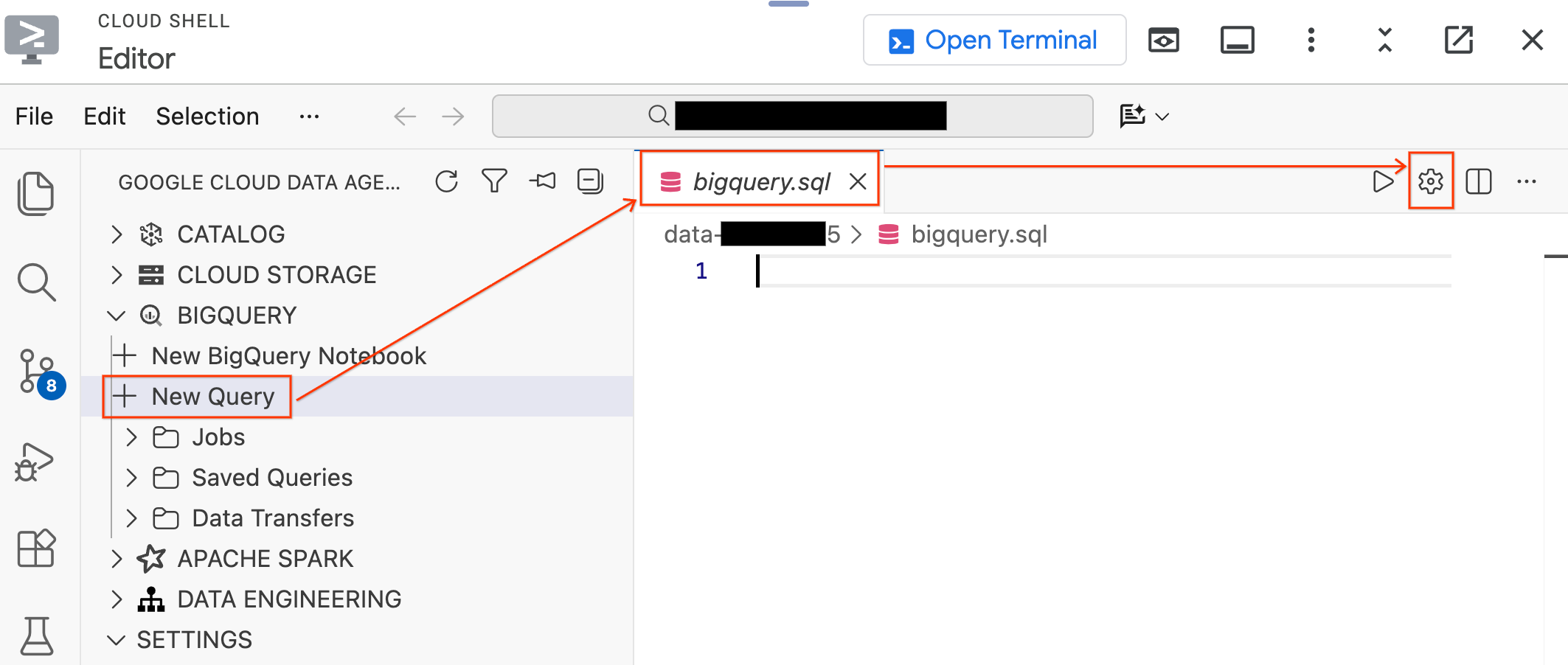
- Trong ngăn Data Agent Kit (Bộ công cụ tác nhân dữ liệu) ở bên trái, hãy mở rộng mục BigQuery rồi nhấp vào New Query (Truy vấn mới) để mở một thẻ trình chỉnh sửa truy vấn mới.
- Lưu tệp bằng cách nhấn
Ctrl+S(Windows/Linux) hoặcCmd+S(macOS) rồi đặt tên làbigquery. Thẻ này sẽ được dùng cho mọi thao tác của bạn trên BigQuery. - Nhấp vào Cài đặt truy vấn khi thẻ
bigquery.sqlđang hoạt động, chọn BigQuery làm Nguồn dữ liệu rồi nhấp vào Lưu.
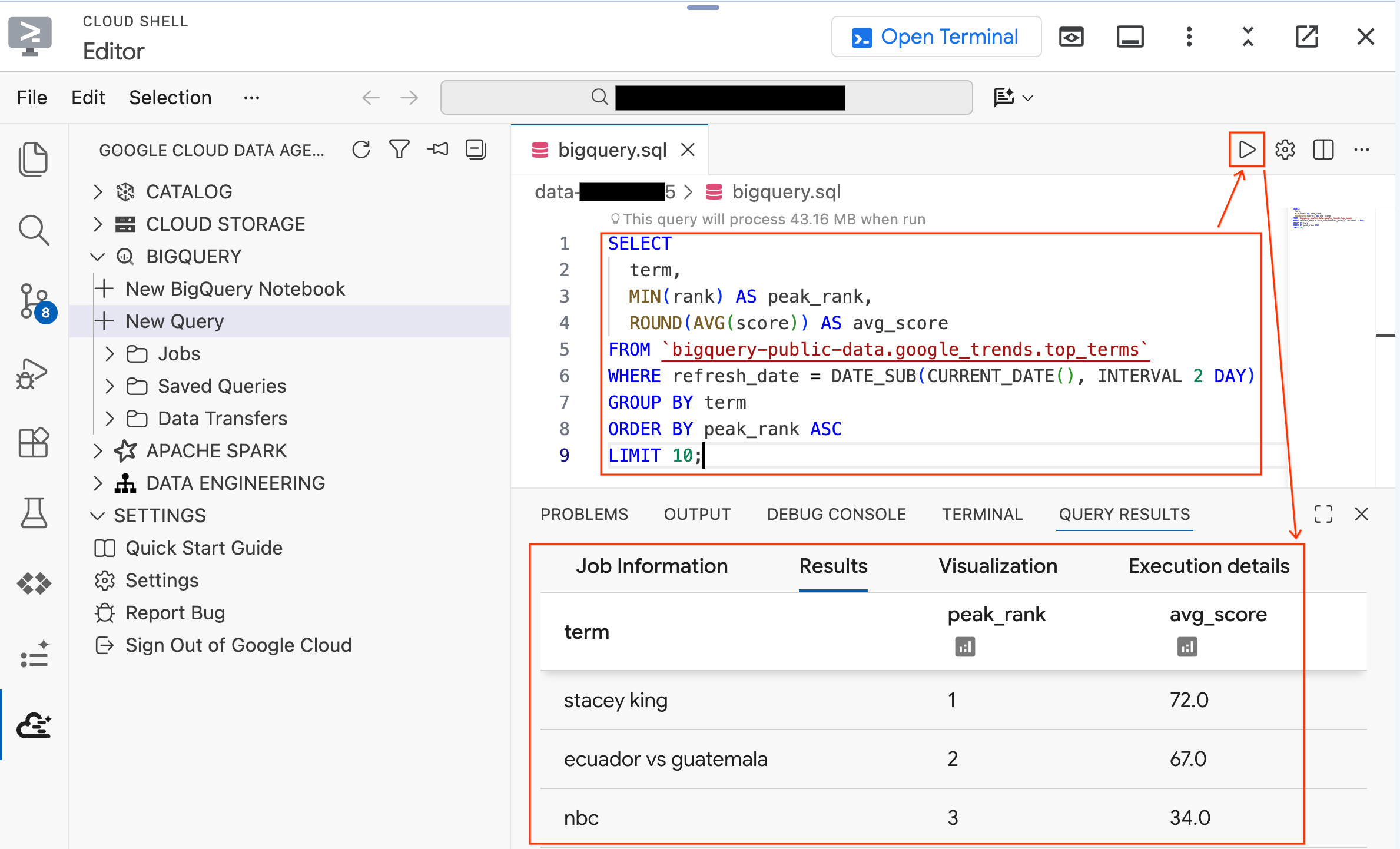
- Chạy truy vấn sau trên một tập dữ liệu công khai:
SELECT
term,
MIN(rank) AS peak_rank,
ROUND(AVG(score)) AS avg_score
FROM `bigquery-public-data.google_trends.top_terms`
WHERE refresh_date = DATE_SUB(CURRENT_DATE(), INTERVAL 2 DAY)
GROUP BY term
ORDER BY peak_rank ASC
LIMIT 10;
- Bạn sẽ thấy 10 cụm từ tìm kiếm thịnh hành nhất trên Google trong vài ngày qua. Nếu kết quả xuất hiện, tức là tiện ích của bạn đã được kết nối và sẵn sàng hoạt động.
Bây giờ, hãy thử truy vấn đối với dữ liệu trong phòng thí nghiệm mà tập lệnh thiết lập vừa tạo. Thay thế truy vấn hiện có bằng truy vấn sau:
SELECT * FROM `lost_cargo_dataset.telemetry_data` LIMIT 5;
Bạn sẽ thấy các mục nhật ký đo từ xa có cột shipment_id và telemetry_string. Đây là dữ liệu bạn sẽ phân tích trong suốt lớp học lập trình.
Tóm tắt phần: Bạn đã bắt đầu triển khai AlloyDB ở chế độ nền, chạy tập lệnh thiết lập và định cấu hình Cloud Shell Editor bằng tiện ích Data Agent Kit.
4. Quét cảnh quay từ camera an ninh
Nhóm điều tra đã thu thập được đoạn video an ninh tại Cảng Rio de Janeiro cho thấy các hàng container vận chuyển. Từ Lab 1, bạn biết rằng vùng chứa đích là red. Bây giờ, bạn cần xác định chính xác đó là thùng chứa màu đỏ nào.
Bạn sẽ tạo một Bảng đối tượng cho phép BigQuery "xem" các hình ảnh bảo mật trong Cloud Storage, sau đó sử dụng hàm AI.GENERATE để yêu cầu Gemini trích xuất dữ liệu có cấu trúc từ mỗi hình ảnh.
Bước 1: Tạo Bảng đối tượng
Bảng đối tượng là một bảng BigQuery đặc biệt, đóng vai trò là chỉ mục cho các tệp không có cấu trúc (hình ảnh, PDF, âm thanh) được lưu trữ trong Cloud Storage. Thao tác này không sao chép các tệp vào BigQuery mà tạo một thông tin tham chiếu có thể truy vấn để các hàm AI có thể "xem" các tệp đó.
Trong thẻ bigquery.sql trong trình chỉnh sửa, hãy chạy câu lệnh sau để tạo Bảng đối tượng trỏ đến hình ảnh bảo mật cổng trong nhóm của dự án:
SET @@location = 'us-central1';
EXECUTE IMMEDIATE CONCAT("""
CREATE OR REPLACE EXTERNAL TABLE `lost_cargo_dataset.port_security_images`
WITH CONNECTION `us-central1.lost_cargo_conn`
OPTIONS (
object_metadata = 'SIMPLE',
uris = ['gs://""", @@project_id, """-lab2/images/*']
);
""");
Hãy xem nhanh những gì BigQuery có thể thấy ngay bây giờ:
SELECT uri, content_type FROM `lost_cargo_dataset.port_security_images` LIMIT 5;
Mỗi hàng đại diện cho một tệp hình ảnh trong Cloud Storage. Giờ đây, BigQuery có thể chuyển trực tiếp những hình ảnh này đến các mô hình AI.
Bước 2: Phân tích hình ảnh bảo mật
Giờ đây, hãy sử dụng hàm AI.GENERATE của BigQuery để phân tích từng hình ảnh bảo mật. Câu lệnh truy vấn SQL duy nhất này sẽ nhắc Gemini kiểm tra từng hình ảnh và trả về dữ liệu có cấu trúc:
SELECT
uri,
AI.GENERATE(
(
'Examine this port security image. Identify any shipping container IDs visible on the container and provide a one-word color of the container.',
ref
),
output_schema => 'detected_container_id STRING, color STRING'
).* EXCEPT (full_response, status)
FROM `lost_cargo_dataset.port_security_images`;
Bước 3: Xác định vùng chứa đích
Kiểm tra kết quả. Tìm hàng mà cột color cho thấy "Đỏ" (hoặc một biến thể màu đỏ). Ghi lại detected_container_id. Đây là mục tiêu của bạn: MV-CAPYBARA-003.
Bước 4: Xác minh kết quả so khớp trực quan
Để xem hình ảnh thực tế đã được phân tích mà không cần rời khỏi trình chỉnh sửa, hãy làm như sau:
- Nhấp vào Cloud Storage (Bộ nhớ đám mây) trong ngăn Data Agent Kit (Bộ công cụ tác nhân dữ liệu) ở bên trái.
- Mở rộng nhóm của bạn (
YOUR_PROJECT_ID-lab2/images/) rồi nhấp vào tệp hình ảnh tương ứng với vùng chứa màu đỏ để xem trực tiếp trong trình chỉnh sửa.
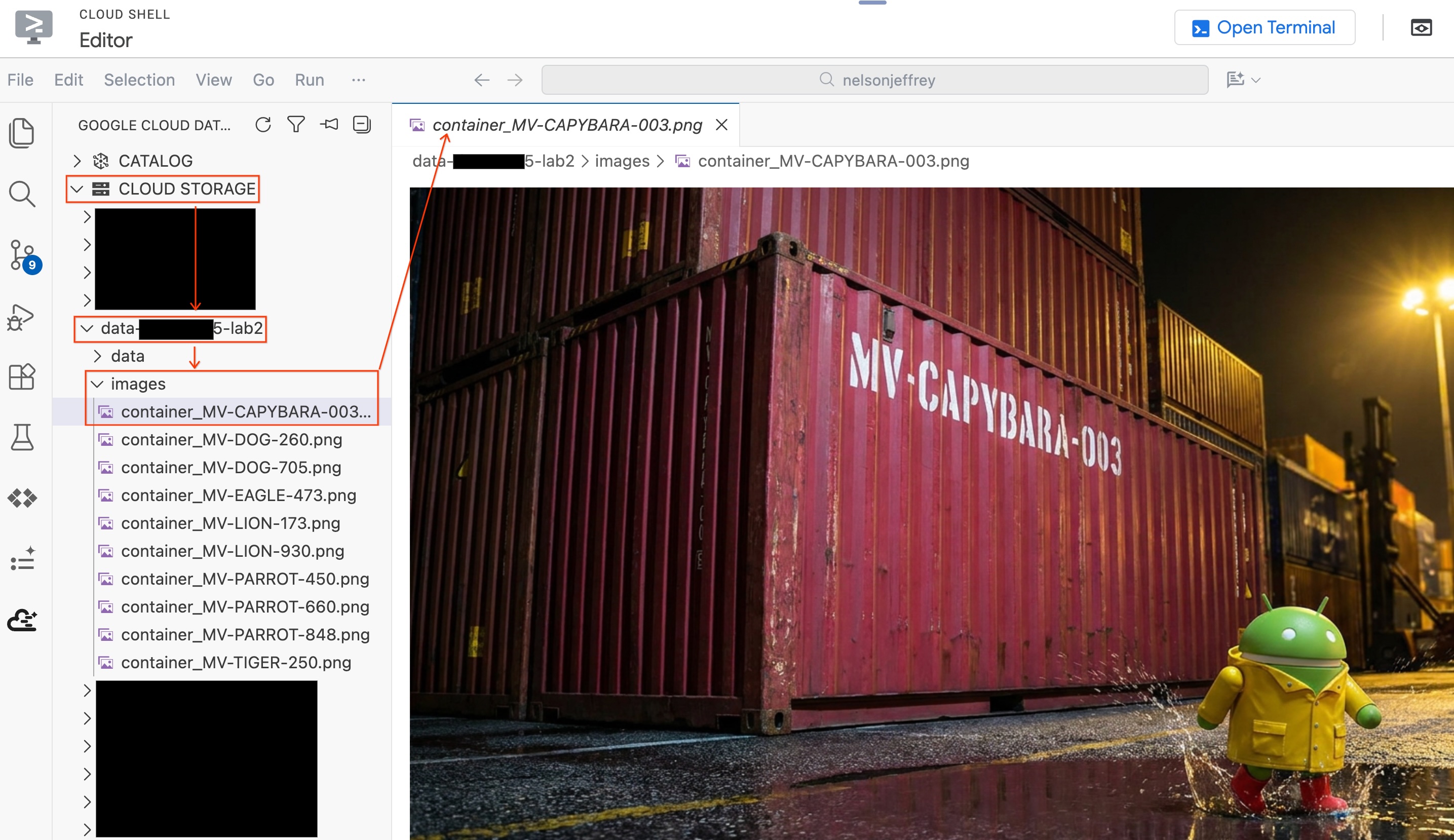
Tóm tắt phần: Bạn đã tạo một Bảng đối tượng để cấp cho BigQuery quyền truy cập vào hình ảnh bảo mật của cảng, sau đó sử dụng AI.GENERATE để trích xuất dữ liệu có cấu trúc của vùng chứa từ mỗi hình ảnh. Vùng chứa màu đỏ được xác định là MV-CAPYBARA-003.
5. Xác nhận hành vi trộm cắp
Bạn xác định thùng chứa bị thiếu là MV-CAPYBARA-003, nhưng thùng chứa này bị đánh cắp hay chỉ bị thất lạc? Nhật ký kê khai cho thấy thùng chứa cụ thể này được đặt bên cạnh cảm biến môi trường SENS-99. Nếu những tên trộm cố ý tắt thiết bị làm lạnh trên thùng chứa trước khi di chuyển, thì SENS-99 có thể đã ghi lại một đợt tăng đột ngột về khí thải nhiệt.
Hãy sử dụng tính năng phát hiện điểm bất thường để chứng minh rằng vùng chứa đã bị giả mạo.
- Trước tiên, hãy khám phá đường cơ sở trong quá khứ. Đây là các chỉ số bình thường của
SENS-99trong vài giờ qua:
SELECT * FROM `lost_cargo_dataset.thermal_history`
ORDER BY reading_time DESC
LIMIT 50;
Lưu ý rằng nhiệt độ dao động trong khoảng từ 24 đến 26°C. Đây là nhiệt độ bình thường.
- Bây giờ, hãy xem lô chỉ số hiện tại của cùng một cảm biến:
SELECT * FROM `lost_cargo_dataset.thermal_current`
ORDER BY thermal_reading DESC
LIMIT 50;
Bạn có thấy chỉ số 148,4°F ở gần phía trên cùng không? Mọi thứ khác đều có vẻ bình thường. Sự tăng đột biến đó có thể cho thấy thiết bị làm lạnh bị lỗi hoặc có hành vi cố ý giả mạo. Hãy cùng tìm hiểu.
- Chạy tính năng phát hiện điểm bất thường.
AI.DETECT_ANOMALIEScủa BigQuery sử dụng mô hình cơ sở TimesFM được huấn luyện trước để phân tích các mẫu chuỗi thời gian và tự động gắn cờ các giá trị ngoại lệ mà không cần huấn luyện mô hình:
SELECT *
FROM AI.DETECT_ANOMALIES(
TABLE `lost_cargo_dataset.thermal_history`,
TABLE `lost_cargo_dataset.thermal_current`,
data_col => 'thermal_reading',
timestamp_col => 'reading_time',
id_cols => ['sensor_id']
)
WHERE is_anomaly = TRUE;
- Kiểm tra kết quả. Số đọc 148,4°F sẽ được gắn cờ là điểm bất thường với xác suất bất thường cao, xác nhận rằng đã xảy ra điều gì đó bất thường gần khu vực vùng chứa.
Tóm tắt phần: Bạn đã sử dụng hàm AI.DETECT_ANOMALIES của BigQuery để tận dụng mô hình TimesFM được huấn luyện trước. Bằng cách chạy một truy vấn SQL duy nhất, bạn đã tự động xác định các giá trị ngoại lệ và tách biệt sự kiện giả mạo bất thường mà không cần viết bất kỳ mã học máy phức tạp nào hoặc huấn luyện mô hình từ đầu.
6. Chuẩn bị Hệ thống theo dõi
Vùng chứa này đã được xác nhận là bị đánh cắp và không còn ở Rio de Janeiro nữa. Mỗi vùng chứa trong đội tàu đều phát tín hiệu đèn hiệu đo từ xa: số đọc của cảm biến, đoạn GPS và nhật ký trạng thái. Nếu đèn hiệu của vùng chứa bị đánh cắp vẫn đang truyền tín hiệu, bạn có thể so khớp tín hiệu đó với các chữ ký đã biết để tìm ra vùng chứa.
BigQuery có khả năng vượt trội trong công việc phân tích mà bạn đã thực hiện cho đến nay, nhưng việc xác định vị trí của một vùng chứa theo thời gian thực đòi hỏi các truy vấn hoạt động có độ trễ thấp. AlloyDB, một cơ sở dữ liệu tương thích với PostgreSQL được quản lý hoàn toàn, được xây dựng chính xác cho mục đích này: các truy vấn tìm kiếm vectơ đủ nhanh cho một hệ thống theo dõi trực tiếp. Bạn sẽ tải các mục nhúng đo từ xa vào AlloyDB và sử dụng mục nhúng đó để so khớp tín hiệu beacon.
Nhóm AlloyDB mà bạn đã khởi động trong nền trước đó sẽ sẵn sàng vào thời điểm này. Hãy định cấu hình trực tiếp từ trình chỉnh sửa.
Bước 1: Kết nối với AlloyDB từ Trình chỉnh sửa
Thay vì chuyển sang Cloud Console, bạn có thể kết nối trực tiếp với AlloyDB bằng tiện ích Data Agent Kit.
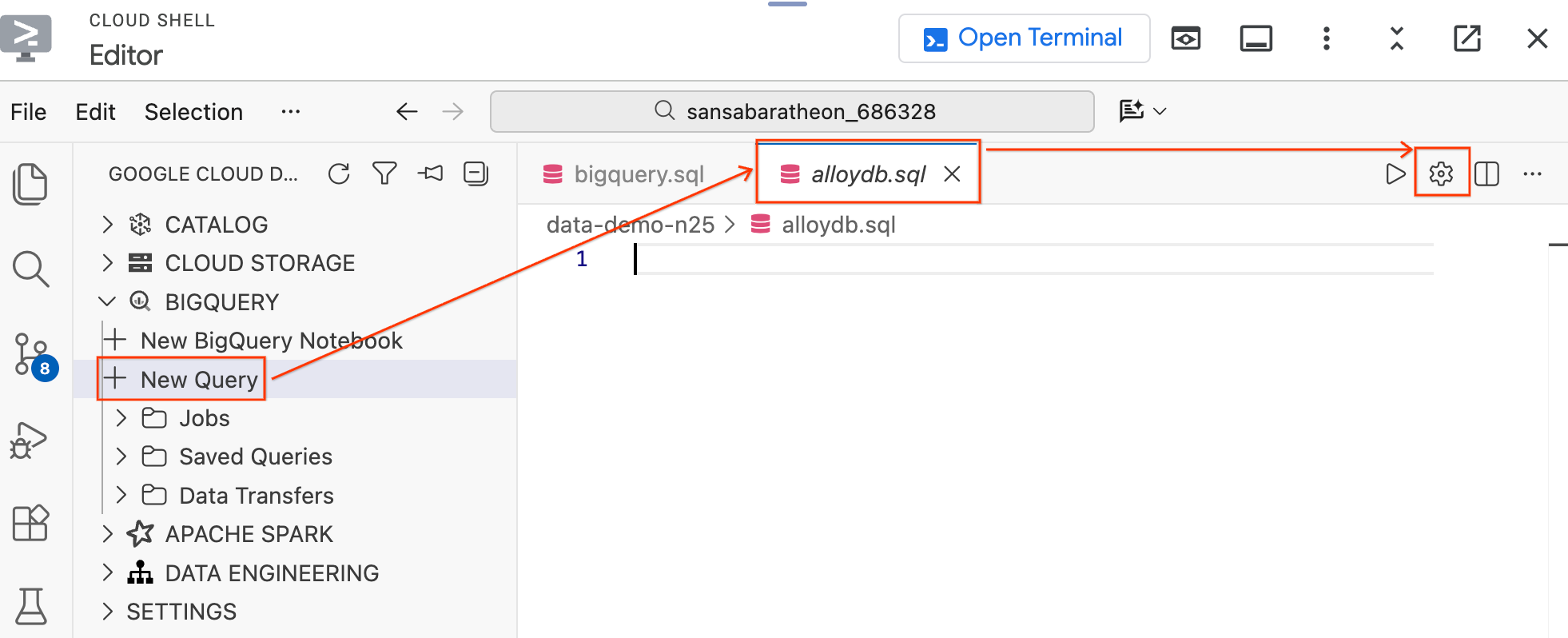
- Trong ngăn Data Agent Kit (Bộ công cụ đại lý dữ liệu) ở bên trái trong mục BigQuery, hãy nhấp vào New Query (Truy vấn mới) để mở một thẻ trình chỉnh sửa truy vấn mới.
- Lưu tệp bằng cách nhấn
Ctrl+S(Windows/Linux) hoặcCmd+S(macOS) rồi đặt tên làalloydb. Thẻ này sẽ được dùng cho tất cả các truy vấn AlloyDB. - Nhấp vào biểu tượng bánh răng để mở phương thức Query Settings (Cài đặt truy vấn).
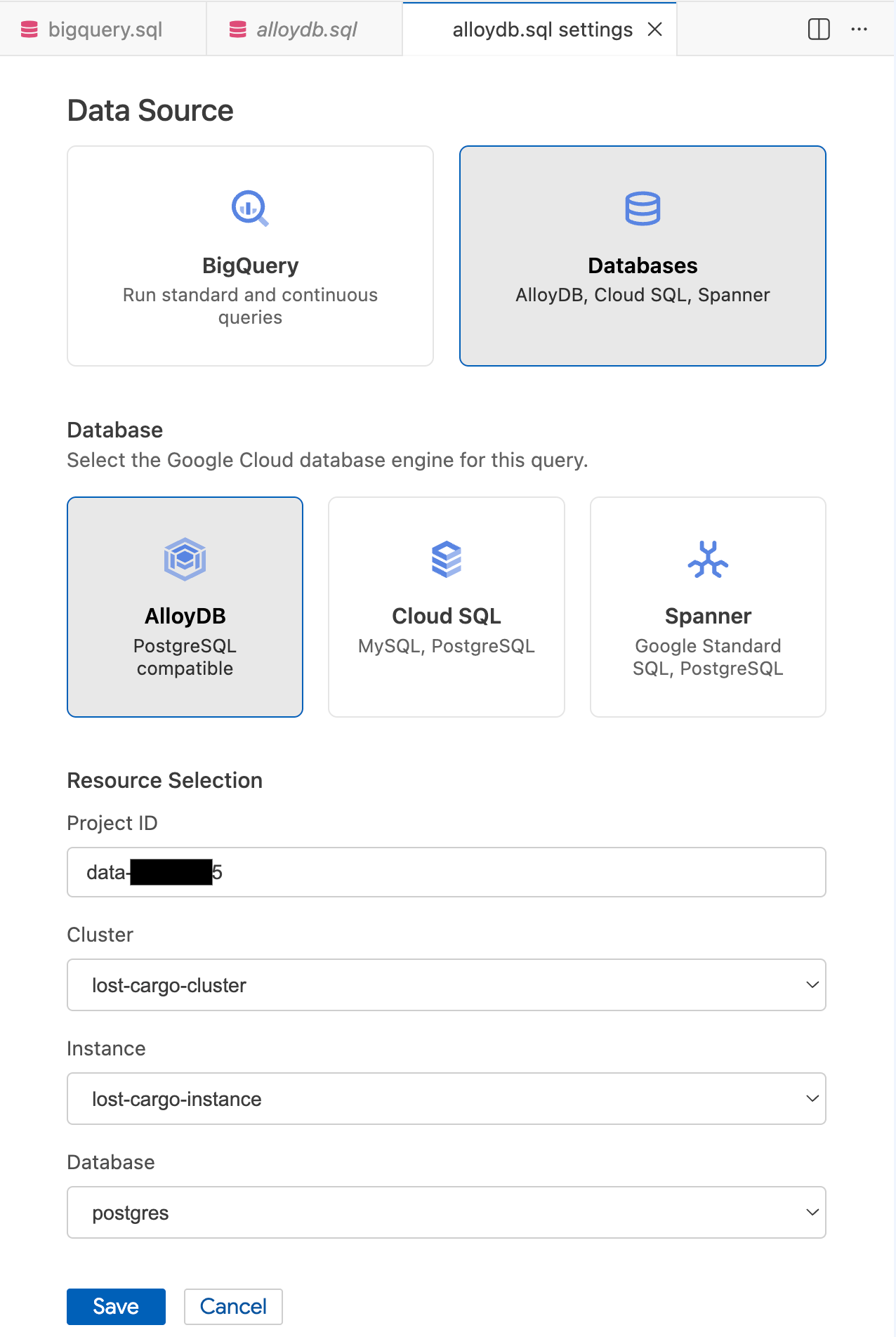
- Trong phương thức Cài đặt truy vấn, trong mục Nguồn dữ liệu, hãy chọn Cơ sở dữ liệu.
- Trong phần Cơ sở dữ liệu, hãy chọn AlloyDB.
- Điền thông tin chi tiết về Lựa chọn tài nguyên:
- Mã dự án: Nhập mã dự án trên Google Cloud.
- Cụm: Chọn
lost-cargo-cluster. - Phiên bản: Chọn
lost-cargo-instance. - Cơ sở dữ liệu: Chọn
postgres.
- Nhấp vào Lưu.
Bước 2: Bật Tiện ích vectơ và tạo bảng
Bây giờ, sau khi kết nối với AlloyDB, bạn cần bật các tiện ích AI cần thiết và tạo bảng sẽ nhận dữ liệu đo từ xa được nhúng.
- Trong thẻ
.sqlđang hoạt động, hãy dán các lệnh sau để bật các tiện ích bắt buộc:
CREATE EXTENSION IF NOT EXISTS vector;
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
- Đánh dấu văn bản rồi nhấp vào nút Run Query (Chạy truy vấn) (biểu tượng phát) ở trên cùng bên phải của trình chỉnh sửa.
- Kiểm tra bảng điều khiển Query Results (Kết quả truy vấn) ở cuối màn hình. Nội dung sẽ là
Statement executed successfully.
- Tiếp theo, hãy thay thế văn bản trong trình chỉnh sửa bằng câu lệnh sau để tạo bảng đo từ xa:
CREATE TABLE IF NOT EXISTS vessel_telemetry (
entry_id SERIAL PRIMARY KEY,
shipment_id VARCHAR(50),
telemetry_string TEXT,
embedding_vector vector(768)
);
- Chạy truy vấn này giống như truy vấn gần đây nhất. Xác nhận rằng truy vấn này thực thi thành công trong bảng điều khiển dưới cùng.
Loại vector(768) đến từ tiện ích pgvector mà bạn vừa bật. 768 phương diện này khớp với đầu ra của mô hình text-embedding-005 của Google. Bạn sẽ sử dụng mô hình này trong BigQuery để tạo vectơ nhúng.
Tóm tắt phần: Bạn đã kết nối với AlloyDB ngay từ Cloud Shell Editor, bật các tiện ích pgvector và google_ml_integration, đồng thời tạo bảng đích. AlloyDB hiện đã sẵn sàng đóng vai trò là phần phụ trợ hoạt động để so khớp dữ liệu đo từ xa theo thời gian thực.
7. Tạo chỉ mục tìm kiếm
Giờ đây, bạn cần đưa dữ liệu đo từ xa vào AlloyDB để có thể hỗ trợ tính năng so khớp tín hiệu theo thời gian thực. Nhật ký đo từ xa thô có độ dài thay đổi và lộn xộn, không phù hợp với tính năng tìm kiếm tương tự. Bạn sẽ sử dụng các hàm AI của BigQuery để tóm tắt từng nhật ký bằng Gemini và chuyển đổi từng bản tóm tắt thành một vectơ nhúng 768 chiều. Sau đó, bạn sẽ xuất dữ liệu đã làm phong phú sang Cloud Storage và nhập dữ liệu đó vào AlloyDB.
Bước 1: Tạo các vectơ nhúng trong BigQuery
Chuyển thẻ trình chỉnh sửa về bigquery.sql (vẫn được kết nối với BigQuery).
Bây giờ, hãy chạy truy vấn sau để tóm tắt từng nhật ký đo từ xa bằng Gemini và tạo các vectơ nhúng:
CREATE OR REPLACE TABLE `lost_cargo_dataset.telemetry_embeddings_export` AS
WITH summarized_telemetry AS (
SELECT
shipment_id,
telemetry_string,
AI.GENERATE(
CONCAT('Summarize this telemetry log for vector search: ', telemetry_string)
).result AS summary
FROM `lost_cargo_dataset.telemetry_data`
),
telemetry_embeddings AS (
SELECT
shipment_id,
telemetry_string,
AI.EMBED(summary, endpoint => 'text-embedding-005').result AS embedding
FROM summarized_telemetry
)
SELECT
shipment_id,
telemetry_string,
TO_JSON_STRING(embedding) AS embedding_vector
FROM telemetry_embeddings;
Bước 2: Xem trước Dữ liệu được làm phong phú
Trước khi xuất, hãy xem những gì bạn đã tạo. Truy vấn này cho thấy mã vận chuyển và 80 ký tự đầu tiên của từng bản tóm tắt và thông tin nhúng:
SELECT
shipment_id,
SUBSTR(telemetry_string, 1, 80) AS telemetry_preview,
SUBSTR(embedding_vector, 1, 80) AS embedding_preview
FROM `lost_cargo_dataset.telemetry_embeddings_export`
LIMIT 5;
Mỗi hàng hiện chứa một mã vận chuyển, nhật ký đo từ xa ban đầu và một vectơ nhúng 768 chiều. Đây là dữ liệu bạn sẽ chuyển vào AlloyDB.
Bước 3: Xuất các vectơ nhúng sang Cloud Storage
Sử dụng câu lệnh EXPORT DATA của BigQuery để ghi bảng nhúng vào bộ chứa GCS của phòng thí nghiệm dưới dạng tệp CSV.
EXECUTE IMMEDIATE CONCAT("""
EXPORT DATA OPTIONS (
uri = 'gs://""", @@project_id, """-lab2/data/embeddings_export/*.csv',
format = 'CSV',
overwrite = true,
header = false
) AS
SELECT
shipment_id,
telemetry_string,
embedding_vector
FROM `lost_cargo_dataset.telemetry_embeddings_export`;
""");
Bước 4: Nhập vào AlloyDB từ Cloud Storage
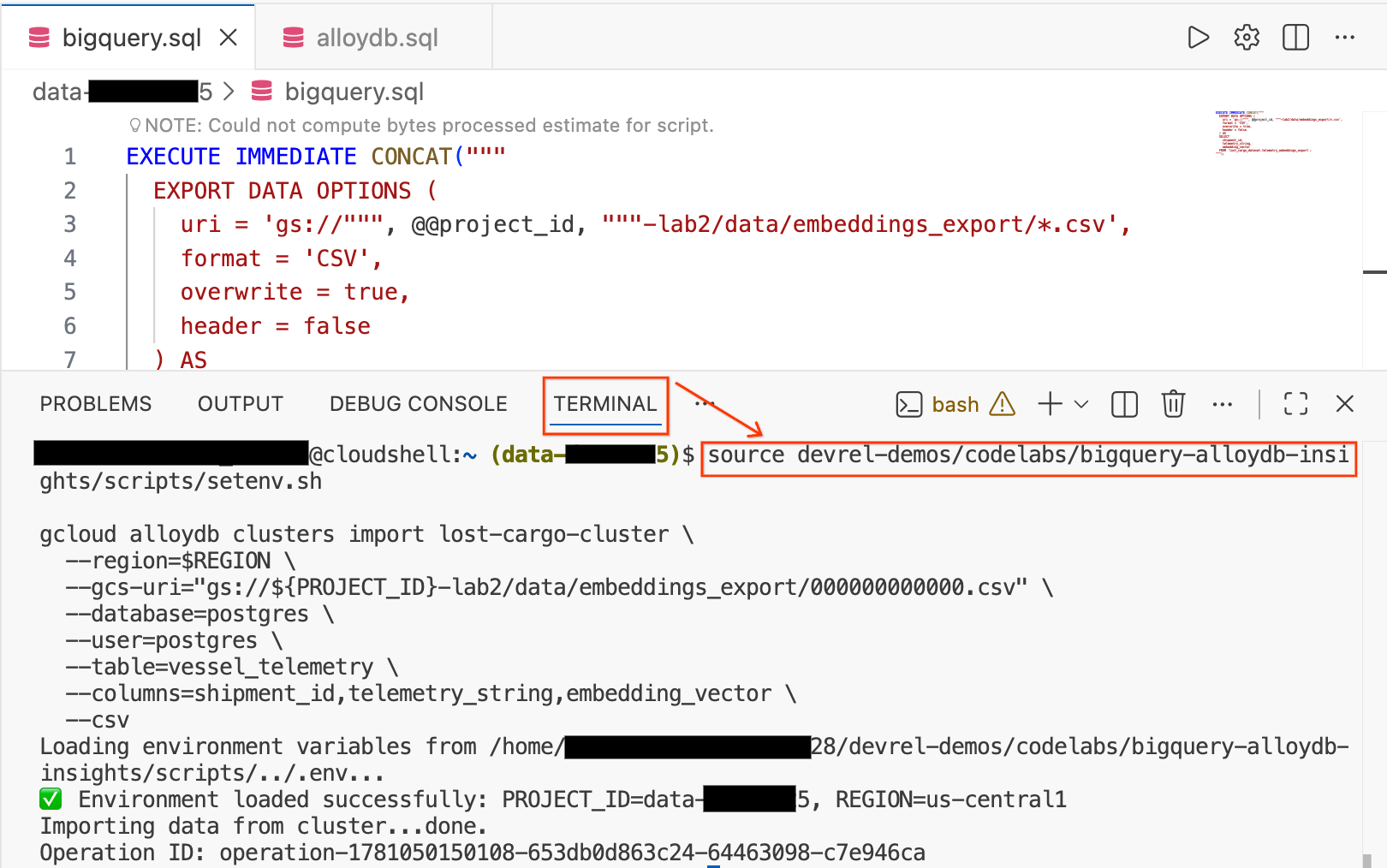
- Trong Cloud Shell Editor, hãy nhấp vào thẻ Terminal (Thiết bị đầu cuối) ở cuối màn hình để mở một phiên thiết bị đầu cuối.
- Chạy các lệnh sau để tải môi trường và nhập tệp CSV trực tiếp vào bảng
vessel_telemetrytrong AlloyDB:
source devrel-demos/codelabs/bigquery-alloydb-insights/scripts/setenv.sh
gcloud alloydb clusters import lost-cargo-cluster \
--region=$REGION \
--gcs-uri="gs://${PROJECT_ID}-lab2/data/embeddings_export/000000000000.csv" \
--database=postgres \
--user=postgres \
--table=vessel_telemetry \
--columns=shipment_id,telemetry_string,embedding_vector \
--csv
Tóm tắt phần: Bạn đã sử dụng các hàm AI của BigQuery để tóm tắt và nhúng dữ liệu đo từ xa, xuất kết quả sang Cloud Storage dưới dạng CSV, sau đó nhập kết quả vào AlloyDB bằng gcloud. Cơ sở dữ liệu theo dõi hoạt động hiện đã được tải và sẵn sàng.
8. Khớp tín hiệu báo hiệu
Một nhóm nhân viên thực địa gần Sydney đã chặn được tín hiệu của một thiết bị đo từ xa bị hỏng. Nhật ký một phần có nội dung như sau:
"Thiết bị làm lạnh đang ở chế độ ngoại tuyến. Ghi đè theo cách thủ công".
Nếu dữ liệu này đến từ vùng chứa bị đánh cắp, thì tính năng tìm kiếm vectơ của AlloyDB sẽ có thể so khớp dữ liệu đó ngay cả khi tín hiệu không đầy đủ. Đây chính xác là loại truy vấn hoạt động theo thời gian thực mà AlloyDB được thiết kế để xử lý.
Bước 1: Xác minh dữ liệu đã nhập
Chuyển thẻ trình chỉnh sửa về alloydb.sql (vẫn được kết nối với AlloyDB).
Xác nhận rằng dữ liệu đo từ xa đã được tải thành công bằng cách chạy:
SELECT shipment_id, LEFT(telemetry_string, 80) AS telemetry_preview
FROM vessel_telemetry
LIMIT 10;
Bạn sẽ thấy các hàng có giá trị shipment_id và văn bản đo từ xa. Đây là các chữ ký đo từ xa của đội xe, hiện đã sẵn sàng để so khớp theo thời gian thực.
Bước 2: Tìm vùng chứa bị thiếu
Giờ đây, hãy dùng tiện ích google_ml_integration của AlloyDB để tìm kết quả khớp bằng cách sử dụng đoạn tín hiệu bị chặn:
SELECT
shipment_id,
telemetry_string,
1 - (embedding_vector <=> embedding('text-embedding-005', 'Refrigeration unit offline. Manual override.')::vector) AS search_relevance_score
FROM vessel_telemetry
ORDER BY embedding_vector <=> embedding('text-embedding-005', 'Refrigeration unit offline. Manual override.')::vector
LIMIT 5;
Hàm embedding() do tiện ích google_ml_integration của AlloyDB cung cấp sẽ gọi Nền tảng tác nhân trực tiếp từ SQL để tạo một vectơ nhúng nội tuyến. Toán tử <=> tính khoảng cách cosin giữa hai vectơ (càng gần 0 thì hai vectơ càng giống nhau). Chúng tôi trừ đi 1 để thể hiện kết quả dưới dạng điểm số mức độ liên quan, trong đó điểm số càng cao thì càng tốt.
Bước 3: Xác nhận lượt khớp
Kiểm tra kết quả. Kết quả hàng đầu phải là MV-CAPYBARA-003, có điểm số mức độ liên quan cao nhất.
Đó là vùng chứa mà bạn đã theo dõi trong từng bước của quá trình điều tra này:
- 📷 Cảnh quay trích từ camera an ninh cho thấy chiếc tàu này rời cảng Rio de Janeiro vào ban đêm.
- 🌡️ Phát hiện bất thường về nhiệt xác nhận rằng thiết bị làm lạnh đã bị vô hiệu hoá một cách có chủ ý.
- 📡 Tính năng so khớp tín hiệu báo hiệu vừa xác định chính xác chữ ký đo từ xa của thiết bị gần Sydney.
Ba bằng chứng độc lập. Ba tính năng AI khác nhau của Google Cloud. Một vùng chứa bị đánh cắp.
🎯 Đã tìm thấy MV-CAPYBARA-003 gần Sydney!

Tóm tắt phần: Bạn đã sử dụng tính năng tích hợp AI tích hợp của AlloyDB để tạo một giá trị nhúng tìm kiếm và thực hiện tìm kiếm dựa trên độ tương đồng cosine trong một truy vấn SQL duy nhất. Thông tin khớp với thiết bị báo hiệu đã xác nhận vị trí của chiếc hộp bị đánh cắp, nhờ đó hoàn tất quá trình điều tra.
9. Khám phá bằng chứng
Giờ đây, sau khi xác định được vùng chứa thông qua tính năng phân tích hình ảnh đa phương thức và tìm kiếm vectơ, bạn có thể sử dụng Phân tích dựa trên cuộc trò chuyện ngay trong trình chỉnh sửa để khám phá dữ liệu điều tra bằng ngôn ngữ tự nhiên mà không cần viết bất kỳ câu lệnh SQL nào.
Bước 1: Tìm dữ liệu trong Danh mục kiến thức
Data Agent Kit có tính năng Tìm kiếm chung, cho phép bạn tìm và khám phá các tài sản dữ liệu trên môi trường Google Cloud.
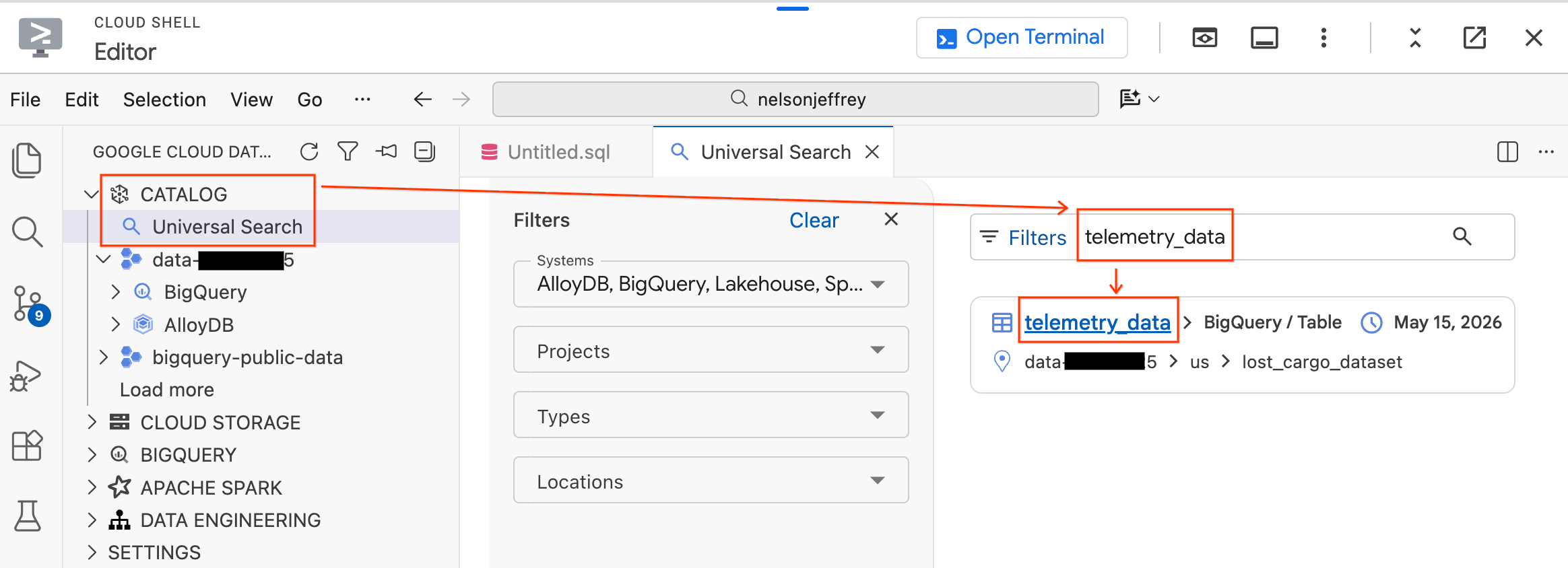
- Trong bảng điều khiển Data Agent Kit (Bộ công cụ của Data Agent) ở bên trái, hãy mở rộng mục Catalog (Danh mục).
- Nhấp vào Tìm kiếm chung.
- Trong thanh tìm kiếm, hãy nhập
telemetry_data. - Nhấp vào bảng
telemetry_data(trong phầnlost_cargo_dataset) trong kết quả tìm kiếm.
Bước 2: Chạy tính năng Phân tích cuộc trò chuyện
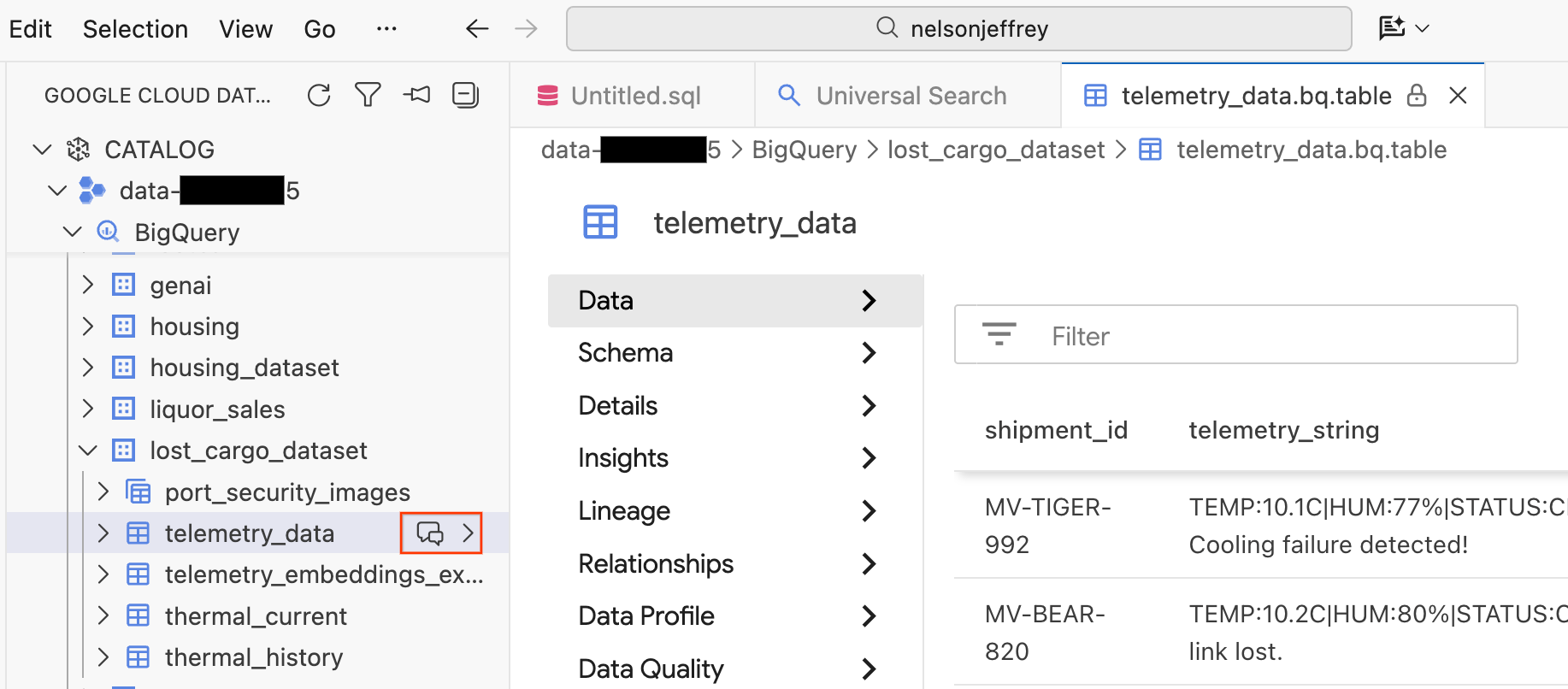
Khi nhấp vào kết quả tìm kiếm, một thẻ trình xem dữ liệu sẽ mở ra. Tại đây, bạn có thể xem trước dữ liệu thô, xem giản đồ và kiểm tra chất lượng dữ liệu.
- Trên ngăn bên trái, bạn sẽ thấy các tập dữ liệu và bảng BigQuery. Nhấp vào nút Trò chuyện để mở một cửa sổ trò chuyện mới.
Bước 3: Đặt câu hỏi bằng ngôn ngữ tự nhiên
Một thẻ trò chuyện mới "Chào mừng bạn đến với tính năng Phân tích cuộc trò chuyện!" sẽ mở ra. Trợ lý có thông tin về giản đồ và nội dung của bảng.
- Trong cửa sổ trò chuyện, hãy nhập:"Show me the telemetry status and log for the Capybara shipment." (Cho tôi xem trạng thái đo từ xa và nhật ký của lô hàng Capybara.)
- Nhấn Enter.
Tác nhân sẽ dịch câu hỏi của bạn sang SQL BigQuery, thực thi truy vấn và trả về kết quả, bao gồm cả bảng dữ liệu và Thông tin chi tiết tóm tắt các phát hiện. Bạn có thể chuyển đổi giữa chế độ Đang suy nghĩ (phân tích sâu hơn, chậm hơn) và Nhanh (phản hồi nhanh hơn) tuỳ thuộc vào độ phức tạp của câu hỏi. Vì đây là các câu trả lời do AI tạo, nên kết quả của bạn có thể hơi khác so với ảnh chụp màn hình bên dưới.
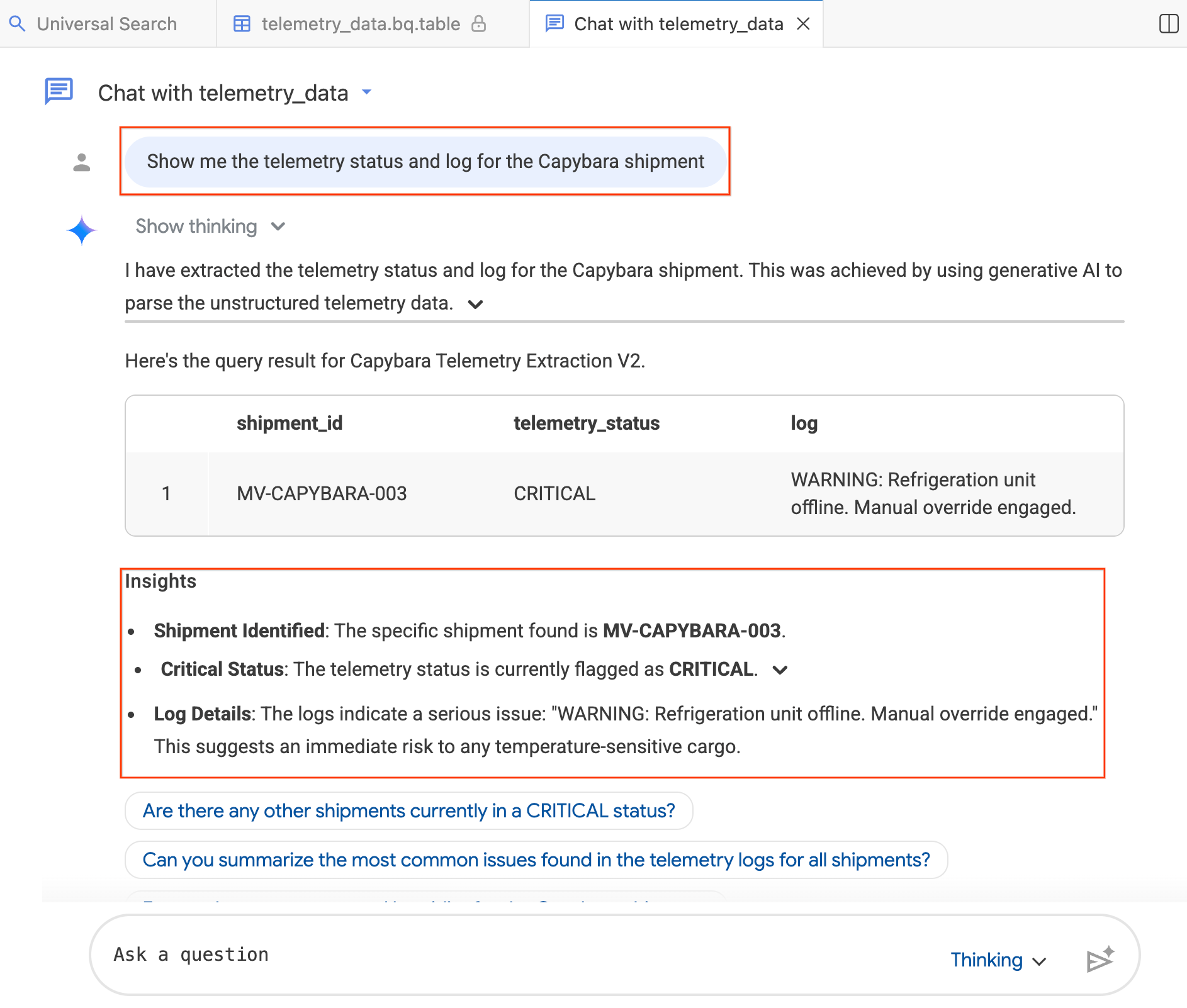
Bước 4: Đặt câu hỏi nối tiếp
Trợ lý sẽ ghi nhớ ngữ cảnh của cuộc trò chuyện. Hãy thử đặt một câu hỏi nối tiếp:
- "Có bao nhiêu lô hàng riêng biệt trong dữ liệu đo từ xa?"
- "Hiện có bao nhiêu lô hàng khác trong đội xe có trạng thái CRITICAL (NGHIÊM TRỌNG)?"
Tóm tắt phần: Bạn đã sử dụng tính năng Tìm kiếm chung của Danh mục kiến thức để xác định vị trí tập dữ liệu và khởi chạy Conversational Analytics để truy vấn dữ liệu điều tra bằng ngôn ngữ tự nhiên. Tác nhân AI đã dịch các câu hỏi của bạn sang SQL và cung cấp thông tin chi tiết xác nhận những phát hiện của bạn.
10. Dọn dẹp
Để tránh phát sinh các khoản phí liên tục cho tài khoản Google Cloud của mình, hãy xoá các tài nguyên mà bạn đã tạo trong phòng thí nghiệm này. Bạn có thể chạy các lệnh này trong thiết bị đầu cuối tích hợp bên trong Trình chỉnh sửa Cloud Shell (nơi bạn đã sử dụng Bộ công cụ Data Agent) để dọn dẹp môi trường của mình.
Trước tiên, hãy tải các biến môi trường của bạn:
source scripts/setenv.sh
- Xoá tài nguyên BigQuery (chỉ khi bạn không tiếp tục thực hiện Bài tập 3):
Nếu bạn dự định tiếp tục đến Phòng thí nghiệm 3, hãy bỏ qua bước này! Phòng thí nghiệm 3 sử dụng cùng một tập dữ liệu và các mối kết nối BigQuery để phân tích biểu đồ tài sản.
Cách xoá tập dữ liệu và các mối kết nối BigQuery:
# Drop the dataset
bq rm -r -f $PROJECT_ID:lost_cargo_dataset
# Delete the connections
bq rm --connection --location=us-central1 $PROJECT_ID.us-central1.lost_cargo_conn
bq rm --connection --location=us-central1 $PROJECT_ID.us-central1.lost_cargo_alloydb_conn
- Xoá bộ chứa Cloud Storage:
gcloud storage rm --recursive gs://${PROJECT_ID}-lab2
- Xoá phiên bản và cụm AlloyDB:
AlloyDB không được dùng trong Lab 3, vì vậy bạn có thể yên tâm xoá nó ngay bây giờ.
gcloud alloydb instances delete lost-cargo-instance \
--region=$REGION \
--cluster=lost-cargo-cluster \
--quiet
gcloud alloydb clusters delete lost-cargo-cluster \
--region=$REGION \
--force \
--quiet
- Xoá chế độ cài đặt môi trường cục bộ:
Cuối cùng, hãy dọn dẹp tệp chế độ cài đặt môi trường cục bộ khỏi không gian làm việc của bạn:
rm -f .env
11. Xin chúc mừng!
Bạn đã hoàn tất Phòng thí nghiệm 2: Phân tích dữ liệu và thông tin chi tiết đa phương thức! Bạn đã lần theo dấu vết từ một cảng có hàng nghìn container đến một vụ trộm đã được xác nhận và một vị trí được xác định chính xác.
Thành tích bạn đạt được
- Quét cảnh quay: Bạn đã sử dụng
AI.GENERATEcủa BigQuery để phân tích hình ảnh về an ninh cảng và xác định thùng chứa MV-CAPYBARA-003 có màu Đỏ thẫm. - Xác nhận hành vi trộm cắp: Bạn đã khám phá dữ liệu cảm biến nhiệt, phát hiện thấy một mức tăng đáng ngờ là 148, 4°F và dùng
AI.DETECT_ANOMALIESđể chứng minh đó là hành vi giả mạo có chủ ý. - Chuẩn bị hệ thống theo dõi: Bạn đã định cấu hình AlloyDB bằng pgvector và
google_ml_integrationđể so khớp tín hiệu theo thời gian thực. - Tạo chỉ mục tìm kiếm: Bạn đã sử dụng
AI.GENERATEvàAI.EMBEDtrong BigQuery để tạo các mục nhúng, sau đó xuất các mục nhúng đó sang Cloud Storage và nhập vào AlloyDB. - Khớp tín hiệu beacon: Bạn đã sử dụng tính năng tìm kiếm vectơ của AlloyDB để khớp một tín hiệu đo từ xa bị phân mảnh, xác định vị trí của thùng chứa bị đánh cắp gần Sydney.
- Khám phá bằng chứng: Bạn đã sử dụng Conversational Analytics ngay trong trình chỉnh sửa để truy vấn dữ liệu điều tra bằng ngôn ngữ tự nhiên.

Các bước tiếp theo
Bạn đã tìm thấy vị trí của vùng chứa. Giờ bạn cần tìm hiểu ai đứng sau vùng chứa đó.
Trong Phòng thí nghiệm 3: Mức tiêu thụ dữ liệu và quy trình làm việc dựa trên tác nhân, bạn sẽ tạo một biểu đồ tài sản của mạng lưới hậu cần để lập sơ đồ mối quan hệ giữa các công ty vỏ bọc, sử dụng Conversational Analytics để trò chuyện với biểu đồ và tìm kiếm trong Danh mục tri thức để tìm mã thông quan bảo mật cần thiết để khôi phục vùng chứa.