
1. 簡介

在先前的實驗室中,您彙整了零碎的貨運記錄,並追蹤貨物應答器到紐約。不過,抵達記錄顯示,為避免海關偵測,貨櫃隨即改道。現在,追蹤結果顯示貨櫃位於里約熱內盧港,這個港口規模龐大,有數千個貨櫃。要在數千個貨櫃中找到正確的貨櫃並不容易。
在本實驗室中,您將使用 BigQuery 的內建 AI 功能「讀取」非結構化港口安全圖片,並偵測感應器資料中的熱異常,所有作業都使用標準 SQL。接著,您會將向量嵌入匯出至 AlloyDB,並執行向量搜尋,將片段遙測訊號與遺失的貨櫃相符。
學習內容
- 使用 BigQuery AI 掃描港口安全影像,找出遭竊貨櫃
- 使用 BigQuery AI 偵測熱異常,確認貨櫃遭竊而非放錯位置
- 生成向量嵌入,並載入 AlloyDB 以進行即時搜尋
- 比對零碎的遙測信號,使用向量搜尋找出遭竊的貨櫃
- 使用對話式數據分析,以自然語言探索調查資料
軟硬體需求
- 網路瀏覽器,例如 Chrome
- 已啟用計費功能的 Google Cloud 雲端專案
- 對 SQL 和 Google Cloud 控制台有基本瞭解
本程式碼研究室適合中階開發人員。
本程式碼研究室建立的資源費用應低於 $5 美元。
2. 事前準備
啟動 Cloud Shell
您將使用 Google Cloud Shell 下載程式碼、執行設定指令碼,以及部署應用程式。
- 在新的瀏覽器分頁中開啟 Cloud Shell:shell.cloud.google.com
- 連線後,請設定專案 ID 並確認環境:
gcloud config set project <<YOUR_PROJECT_ID>>
export PROJECT_ID=$(gcloud config get-value project)
export REGION=us-central1
您應會看見類似以下的訊息:
Your active configuration is: [cloudshell-####] Updated property [core/project]
複製存放區
將程式碼研究室存放區複製到 Cloud Shell 殼層環境:
cd ~/
git clone --filter=blob:none --no-checkout https://github.com/GoogleCloudPlatform/devrel-demos.git
cd ~/devrel-demos
git sparse-checkout init --cone
git sparse-checkout set codelabs/bigquery-alloydb-insights
git checkout main
cd codelabs/bigquery-alloydb-insights/
啟用 API
在 Cloud Shell 中執行下列指令,啟用本實驗室的所有必要 API:
gcloud services enable \
aiplatform.googleapis.com \
bigquery.googleapis.com \
bigqueryconnection.googleapis.com \
alloydb.googleapis.com
執行成功後,您應該會看到類似以下的訊息:
Operation "operations/..." finished successfully.
3. 設定環境
您必須先設定本實驗室的基礎架構,才能分析圖片和遙測資料。您將執行兩項指令碼:一項會在背景啟動 AlloyDB 佈建作業,另一項則會建立您需要的所有 BigQuery 資源。
步驟 1:啟動 AlloyDB 部署作業 (背景)
AlloyDB 叢集佈建作業約需 10 分鐘,因此請先啟動這項作業,讓它在背景執行,同時處理 BigQuery 相關部分。指令碼會自動將有效專案設定記錄到本機 .env 檔案,即使 Cloud Shell 終端機關閉或重新啟動,設定也會儲存。
chmod +x scripts/setup_alloydb.sh
nohup ./scripts/setup_alloydb.sh > /dev/null 2>&1 &
echo "AlloyDB deployment started in background (PID: $!)"
步驟 2:執行設定指令碼
這項指令碼會建立 BigQuery 資料集、Cloud 資源連結、IAM 授權、GCS bucket,並載入您將在本實驗室中分析的所有感應器資料。此外,系統也會讀取並驗證儲存在 .env 檔案中的環境變數。
chmod +x scripts/setup_lab.sh
./scripts/setup_lab.sh
指令碼大約需要一分鐘才能執行完畢。完成後,您會看到所有建立項目的摘要。
📝 環境重設注意事項:如果 Cloud Shell 工作階段在實驗室期間逾時或重新啟動,請執行下列指令,立即還原終端機變數:
source scripts/setenv.sh
步驟 3:啟動 Cloud Shell 編輯器
您目前使用的是 Cloud Shell 終端機。現在請切換至完整的 Cloud Shell 編輯器,這個編輯器提供類似 VS Code 的工作區,並整合了 BigQuery 支援。
- 在畫面底部的 Cloud Shell 終端機窗格中,點選「開啟編輯器」按鈕,啟動 Cloud Shell 編輯器工作區。

步驟 4:安裝 Data Agent Kit 擴充功能
Google Cloud Data Agent Kit 擴充功能可直接在編輯器中與 Google Cloud 資料服務深度整合,讓您與 BigQuery、AlloyDB、Cloud Storage 等服務互動時,不必切換環境。
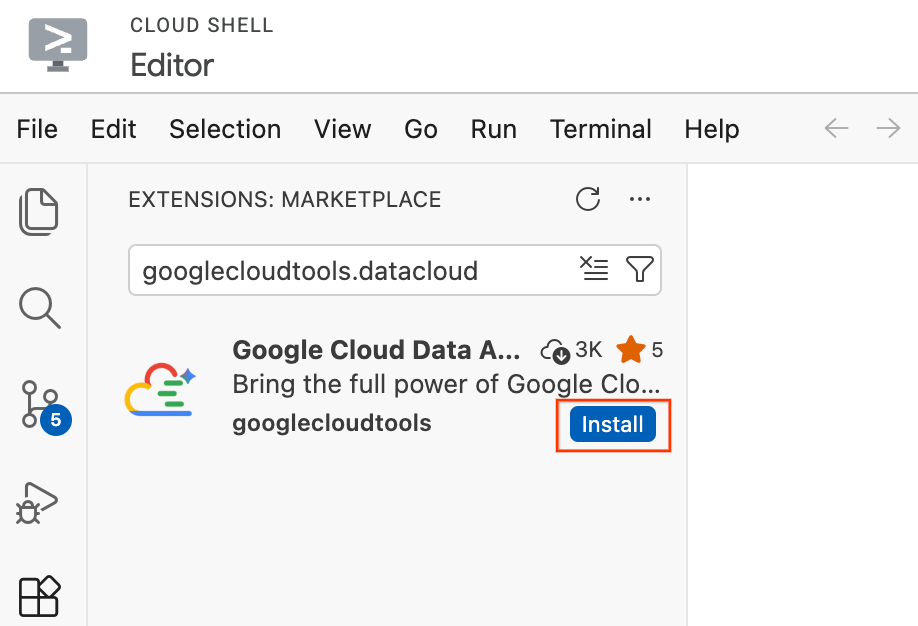
- 在 Cloud Shell 編輯器中,按一下畫面最左側活動列中的「擴充功能」圖示 (看起來像四個正方形)。
- 在「擴充功能」窗格頂端的搜尋列中,輸入
googlecloudtools.datacloud。 - 找出 Google Cloud 發布的「Google Cloud Data Agent Kit」擴充功能。
- 按一下「Install」按鈕。
- 系統會顯示提示,詢問「您是否信任發布者『googlecloudtools』及其擴充功能?」。按一下「信任發布者並安裝」繼續操作。
步驟 5:驗證及設定擴充功能
安裝完成後,請將擴充功能連結至 Google Cloud 專案。
- 系統應會自動開啟名為「Google Cloud Data Agent Kit Onboarding」的入門頁面。按一下「登入 Google Cloud」。按照瀏覽器提示允許存取。
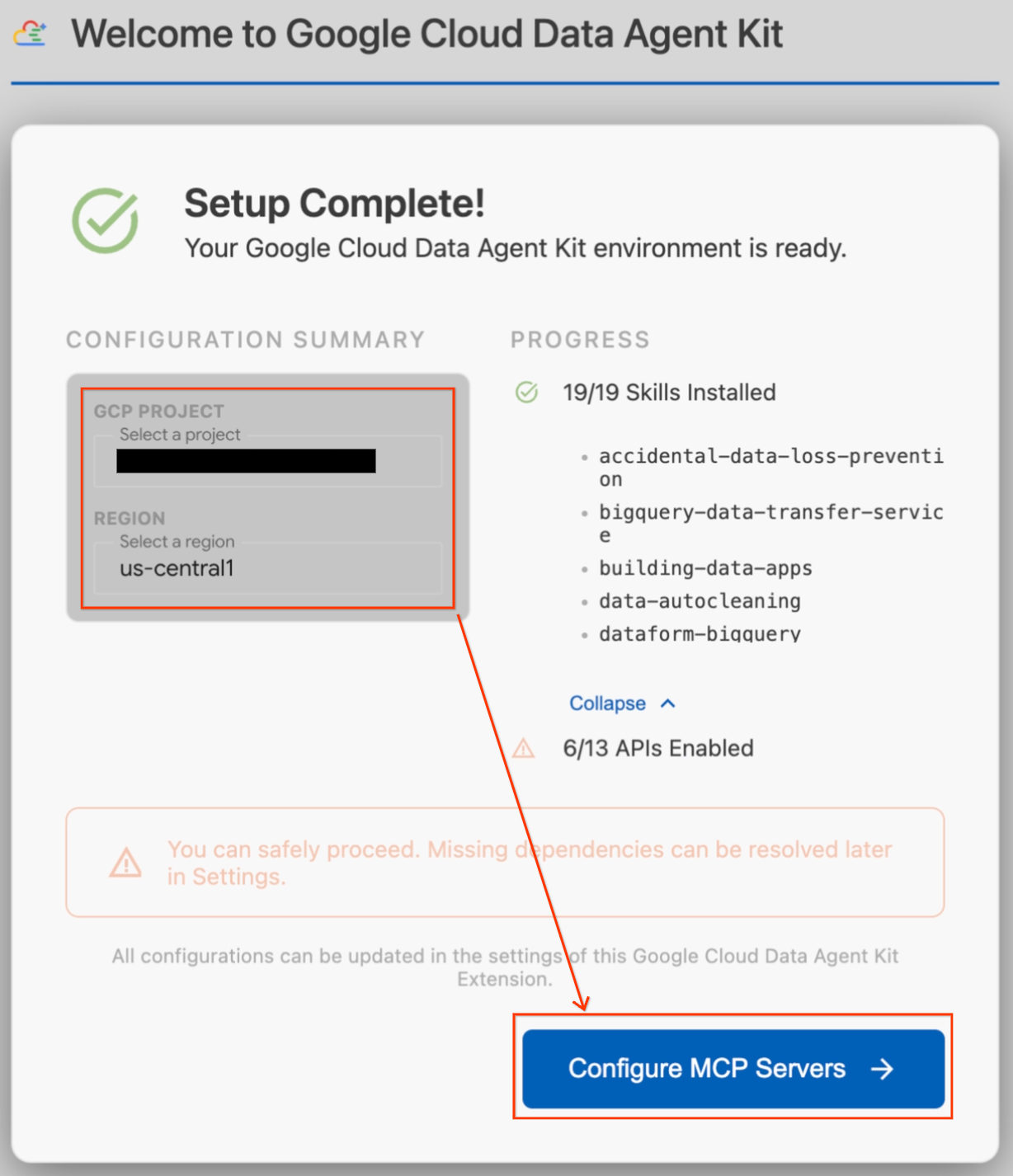
- 系統會顯示「設定進行中」強制回應。擴充功能會自動檢查 Google Cloud CLI 等必要依附元件。
- 在「設定摘要」部分,找到專案欄位。按一下下拉式選單,然後選取 Google Cloud 專案。將區域設為
us-central1。 - 等待設定檢查完成。看到「設定完成!」後,請按一下「設定 MCP 伺服器」。
- 在 MCP 設定下方選取 BigQuery 和 AlloyDB,然後按一下「開始使用」。
步驟 6:探索設定選項
設定完成後,系統會將您導向至「開始使用 Google Cloud Data Agent Kit」資訊主頁。
- 在「設定與配置」下方,按一下「開始使用」。
- 系統會開啟「資料代理程式設定」面板。請瀏覽下列分頁:
步驟 7:使用 BigQuery 驗證
對公開資料集執行快速查詢,確認一切運作正常。
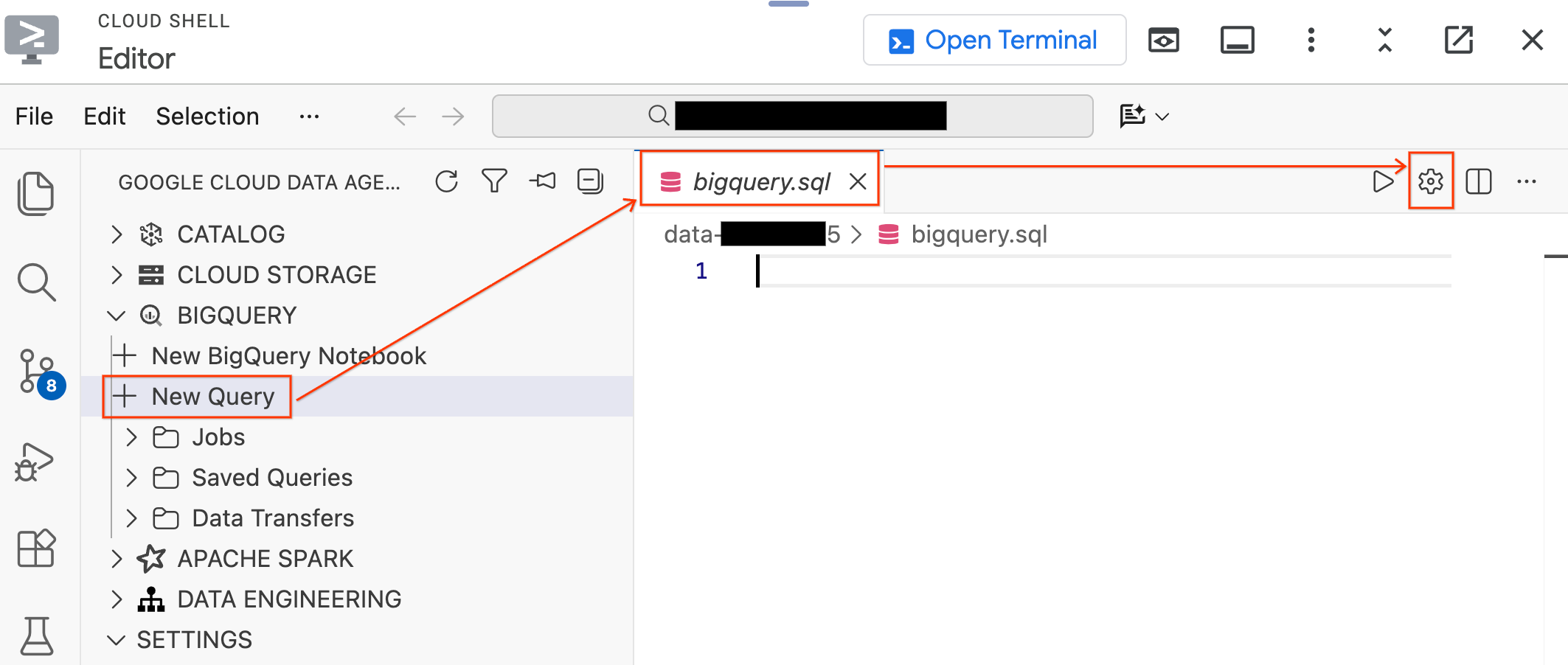
- 在左側的「Data Agent Kit」窗格中,展開「BigQuery」部分,然後按一下「New Query」,開啟新的查詢編輯器分頁。
- 按下
Ctrl+S鍵 (Windows/Linux) 或Cmd+S鍵 (macOS) 儲存檔案,並將檔案命名為bigquery。這個分頁將用於所有 BigQuery 作業。 - 按一下「Query Settings」(查詢設定),並啟用
bigquery.sql分頁,選取「BigQuery」做為「Data Source」(資料來源),然後按一下「Save」(儲存)。
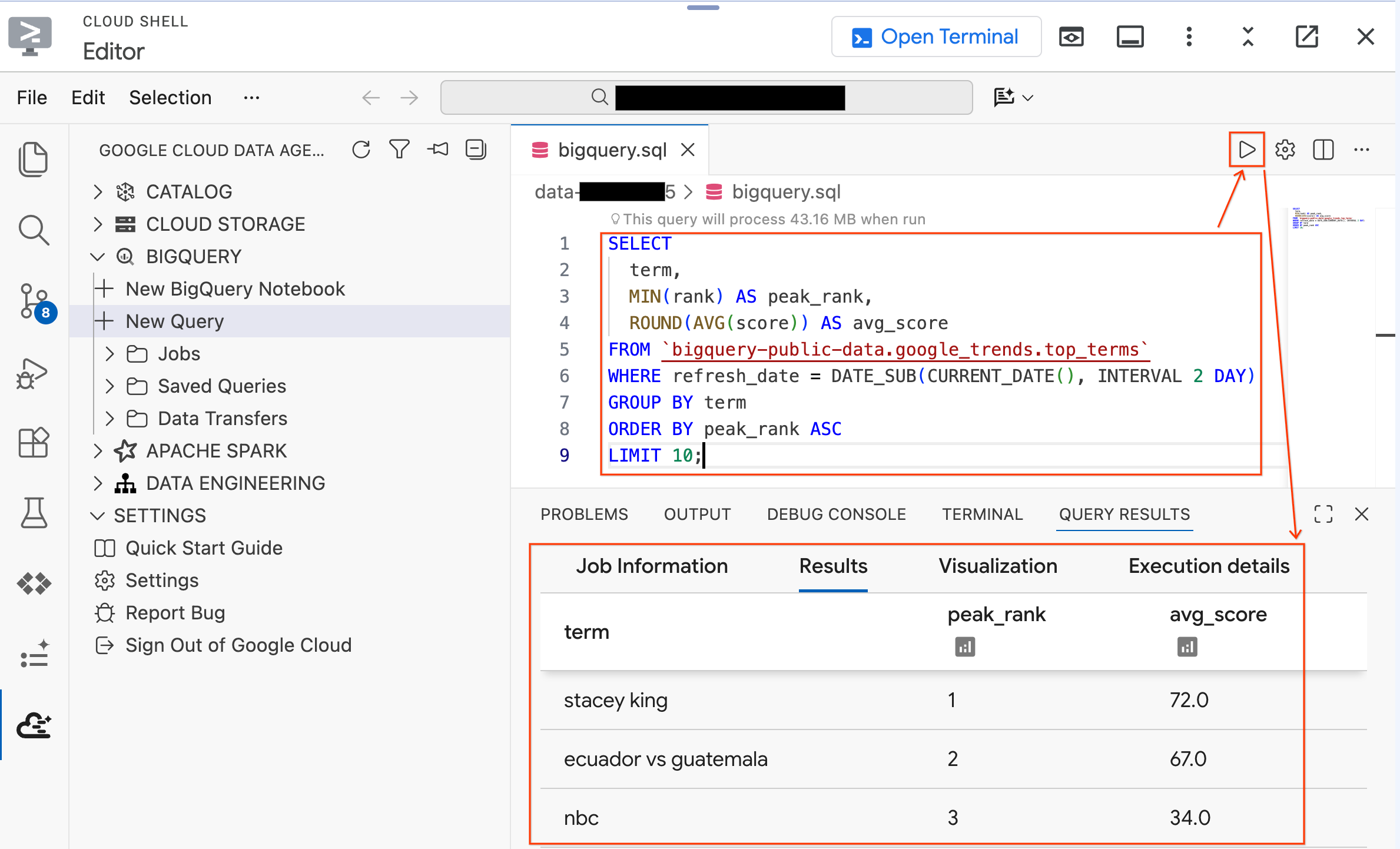
- 針對公開資料集執行下列查詢:
SELECT
term,
MIN(rank) AS peak_rank,
ROUND(AVG(score)) AS avg_score
FROM `bigquery-public-data.google_trends.top_terms`
WHERE refresh_date = DATE_SUB(CURRENT_DATE(), INTERVAL 2 DAY)
GROUP BY term
ORDER BY peak_rank ASC
LIMIT 10;
- 您應該會看到過去幾天內,前 10 大熱門 Google 搜尋字詞。如果顯示結果,表示擴充功能已連線並可供使用。
現在,請對設定指令碼剛建立的實驗室資料執行查詢。將現有查詢替換為以下查詢:
SELECT * FROM `lost_cargo_dataset.telemetry_data` LIMIT 5;
您應該會看到含有 shipment_id 和 telemetry_string 欄的遙測記錄項目。您將在本實驗室中分析這些資料。
本節重點:您已在背景啟動 AlloyDB 部署作業、執行設定指令碼,並透過 Data Agent Kit 擴充功能設定 Cloud Shell 編輯器。
4. 掃描安全影片片段
調查團隊已從里約熱內盧港口取得監視器畫面,顯示一排排的貨櫃。從實驗室 1 中,您知道目標容器是 red。現在您需要找出「哪個」紅色容器。
您將建立物件資料表,讓 BigQuery「查看」Cloud Storage 中的安全影像,然後使用 AI.GENERATE 函式提示 Gemini 從每張圖片擷取結構化資料。
步驟 1:建立物件資料表
物件資料表是特殊的 BigQuery 資料表,可做為 Cloud Storage 中儲存的非結構化檔案 (圖片、PDF、音訊) 的索引。這項功能不會將檔案複製到 BigQuery,而是建立可查詢的參照,讓 AI 函式「看到」這些檔案。
在編輯器的 bigquery.sql 分頁中,執行下列陳述式,建立指向專案 bucket 中連接埠安全圖片的物件資料表:
SET @@location = 'us-central1';
EXECUTE IMMEDIATE CONCAT("""
CREATE OR REPLACE EXTERNAL TABLE `lost_cargo_dataset.port_security_images`
WITH CONNECTION `us-central1.lost_cargo_conn`
OPTIONS (
object_metadata = 'SIMPLE',
uris = ['gs://""", @@project_id, """-lab2/images/*']
);
""");
快速瞭解 BigQuery 現在可以看到的內容:
SELECT uri, content_type FROM `lost_cargo_dataset.port_security_images` LIMIT 5;
每一列代表 Cloud Storage 中的一個圖片檔案。BigQuery 現在可以直接將這些圖片傳遞至 AI 模型。
步驟 2:分析安全圖片
現在使用 BigQuery 的 AI.GENERATE 函式分析每張安全影像。這項單一 SQL 查詢會提示 Gemini 檢查每張圖片,並傳回結構化資料:
SELECT
uri,
AI.GENERATE(
(
'Examine this port security image. Identify any shipping container IDs visible on the container and provide a one-word color of the container.',
ref
),
output_schema => 'detected_container_id STRING, color STRING'
).* EXCEPT (full_response, status)
FROM `lost_cargo_dataset.port_security_images`;
步驟 3:找出目標容器
檢查結果。找出「color」欄顯示「紅色」 (或某種紅色變體) 的列,並記下「detected_container_id」。這就是目標:MV-CAPYBARA-003。
步驟 4:驗證視覺比對結果
如要在不離開編輯器的情況下查看實際分析的圖片,請按照下列步驟操作:
- 按一下左側「Data Agent Kit」窗格中的「Cloud Storage」。
- 展開 bucket (
YOUR_PROJECT_ID-lab2/images/),然後按一下與紅色容器對應的圖片檔案,直接在編輯器中查看。
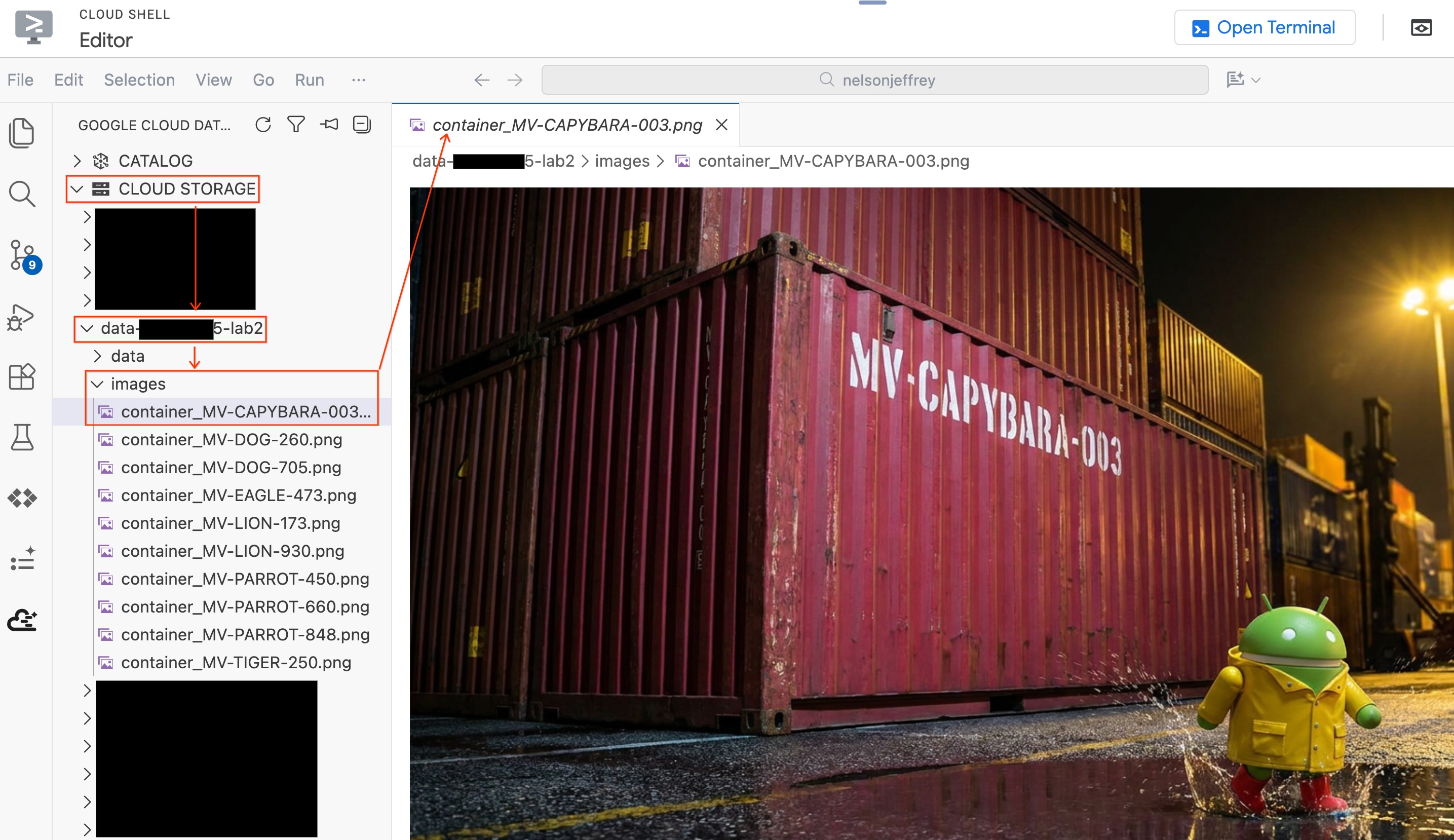
本節重點:您建立了物件資料表,讓 BigQuery 能夠存取港口安全圖片,然後使用 AI.GENERATE 從每張圖片中擷取結構化貨櫃資料。紅色貨櫃已識別為 MV-CAPYBARA-003。
5. 確認失竊
您已確認遺失的容器為 MV-CAPYBARA-003,但該容器是遭竊還是只是放錯地方?資訊清單記錄指出,這個特定貨櫃停放在環境感應器 SENS-99 旁。如果竊賊在移動貨櫃前,刻意停用貨櫃的內建冷凍裝置,SENS-99 可能會記錄到突然的排熱尖峰。
我們來使用異常偵測功能,證明容器遭到竄改。
- 首先,請查看歷史基準。這些是過去幾小時內
SENS-99的正常讀數:
SELECT * FROM `lost_cargo_dataset.thermal_history`
ORDER BY reading_time DESC
LIMIT 50;
請注意,溫度會維持在華氏 75 到 78 度之間。這是正常情況。
- 現在,請查看同一感應器目前批次的讀數:
SELECT * FROM `lost_cargo_dataset.thermal_current`
ORDER BY thermal_reading DESC
LIMIT 50;
您是否看到頂端附近的 148.4°F 讀數?其他一切正常。如果出現這種尖峰,表示冷藏裝置故障或有人蓄意干擾。讓我們一起來看看。
- 執行異常偵測。BigQuery 的
AI.DETECT_ANOMALIES會使用預先訓練的 TimesFM 基礎模型分析時間序列模式,並自動標記離群值,完全不需要模型訓練:
SELECT *
FROM AI.DETECT_ANOMALIES(
TABLE `lost_cargo_dataset.thermal_history`,
TABLE `lost_cargo_dataset.thermal_current`,
data_col => 'thermal_reading',
timestamp_col => 'reading_time',
id_cols => ['sensor_id']
)
WHERE is_anomaly = TRUE;
- 檢查結果。148.4°F 的讀數應會標示為異常,且異常機率很高,確認容器區域附近發生異常狀況。
本節重點:您使用 BigQuery 的 AI.DETECT_ANOMALIES 函式,運用預先訓練的 TimesFM 模型。只要執行單一 SQL 查詢,即可自動找出離群值,並隔離異常竄改事件,不必編寫任何複雜的機器學習程式碼,也不必從頭訓練模型。
6. 準備追蹤系統
該貨櫃已確認遭竊,且不在里約熱內盧。車隊中的每個貨櫃都會廣播遙測信號:感應器讀數、GPS 片段和狀態記錄。如果遭竊容器的信標仍在傳輸,您可以比對已知簽章來尋找。
BigQuery 非常適合您目前執行的分析工作,但要即時找出貨櫃,需要低延遲的作業查詢。AlloyDB 是與 PostgreSQL 相容的全代管資料庫,專為這類用途而生,可快速執行向量搜尋查詢,適用於即時追蹤系統。您會將遙測嵌入內容載入 AlloyDB,並用來比對信號。
您稍早啟動的 AlloyDB 叢集現在應該已準備就緒。讓我們直接從編輯器設定叢集。
步驟 1:從編輯器連線至 AlloyDB
您不必切換至 Cloud Console,直接使用 Data Agent Kit 擴充功能即可連線至 AlloyDB。
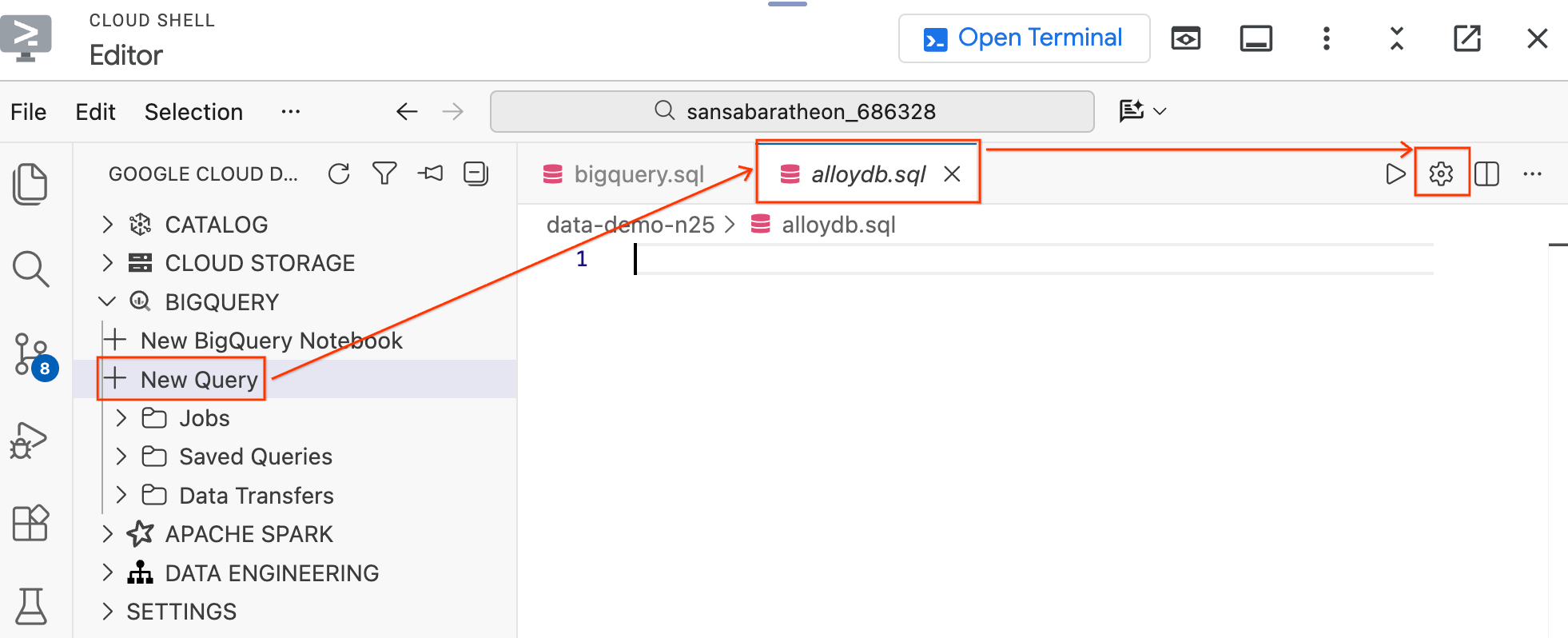
- 在左側「BigQuery」區段下方的「Data Agent Kit」窗格中,按一下「New Query」,開啟新的查詢編輯器分頁。
- 按下
Ctrl+S鍵 (Windows/Linux) 或Cmd+S鍵 (macOS) 儲存檔案,並將檔案命名為alloydb。這個分頁將用於所有 AlloyDB 查詢。 - 按一下齒輪圖示,開啟「查詢設定」模式。
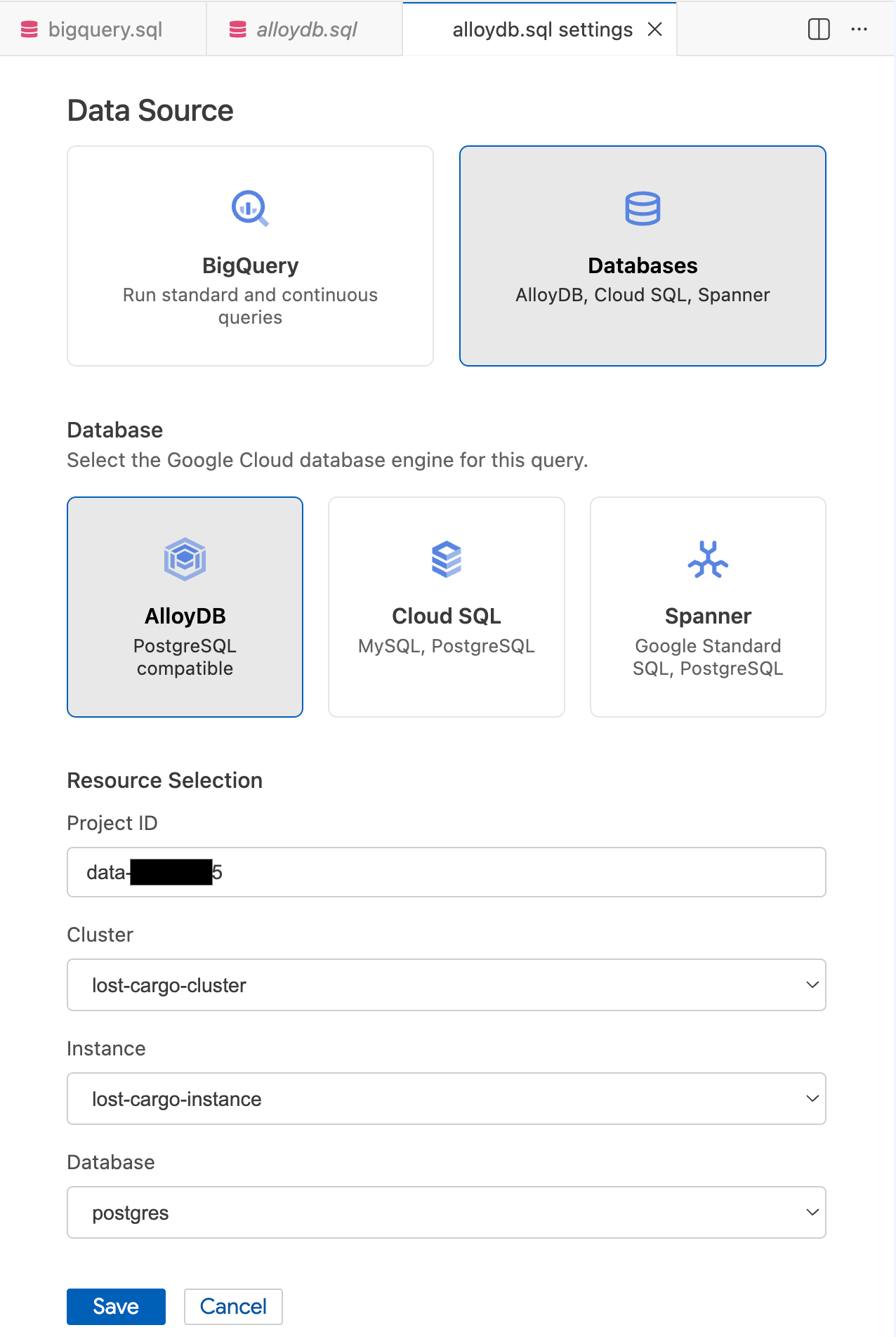
- 在「查詢設定」模式中,選取「資料來源」下方的「資料庫」。
- 在「資料庫」下方,選取「AlloyDB」。
- 填寫「資源選取」詳細資料:
- 專案 ID:輸入 Google Cloud 專案 ID。
- 叢集:選取
lost-cargo-cluster。 - 「執行個體」:選取
lost-cargo-instance。 - 「資料庫」:選取
postgres。
- 按一下 [儲存]。
步驟 2:啟用向量擴充功能並建立資料表
連線至 AlloyDB 後,您需要啟用必要的 AI 擴充功能,並建立接收內嵌遙測資料的資料表。
- 在現用
.sql分頁中貼上下列指令,啟用必要擴充功能:
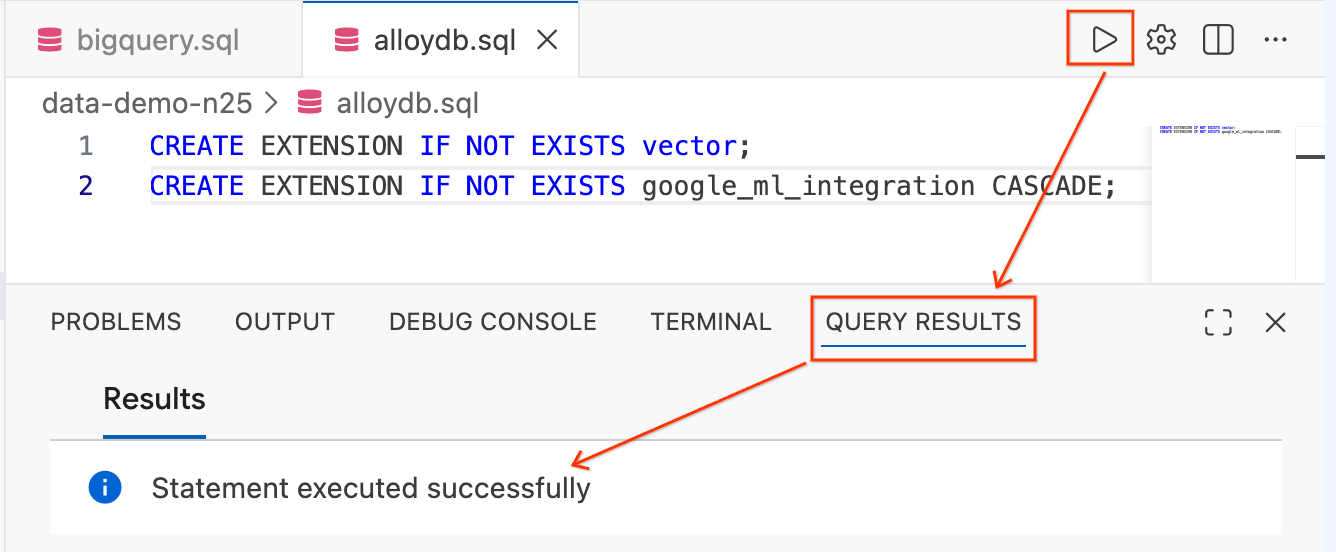
CREATE EXTENSION IF NOT EXISTS vector;
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
- 醒目顯示文字,然後按一下編輯器右上方的「執行查詢」按鈕 (播放圖示)。
- 查看畫面底部的「查詢結果」終端機面板,應該會顯示
Statement executed successfully。
- 接著,將編輯器中的文字替換為下列陳述式,建立遙測資料表:
CREATE TABLE IF NOT EXISTS vessel_telemetry (
entry_id SERIAL PRIMARY KEY,
shipment_id VARCHAR(50),
telemetry_string TEXT,
embedding_vector vector(768)
);
- 執行這項查詢,就像上次一樣。確認底部面板是否顯示執行成功。
vector(768) 類型來自您剛啟用的 pgvector 擴充功能。768 個維度與 Google 的 text-embedding-005 模型輸出內容相符,您將在 BigQuery 中使用該模型生成嵌入。
本節重點:您已直接從 Cloud Shell 編輯器連線至 AlloyDB,並啟用 pgvector 和 google_ml_integration 擴充功能,以及建立目標資料表。AlloyDB 現在已準備就緒,可做為即時遙測資料比對的作業後端。
7. 建構搜尋索引
現在您需要將遙測資料匯入 AlloyDB,才能進行即時信標比對。原始遙測記錄雜亂無章,長度也不固定,不適合用於相似度搜尋。您將使用 BigQuery 的 AI 函式,透過 Gemini 摘要說明每則記錄,並將每則摘要轉換為 768 維度的向量嵌入。接著,您會將經過擴增的資料匯出至 Cloud Storage,並匯入 AlloyDB。
步驟 1:在 BigQuery 中生成嵌入
將編輯器分頁切換回 bigquery.sql (仍連結至 BigQuery)。
現在,請執行下列查詢,使用 Gemini 摘要說明每筆遙測記錄,並生成向量嵌入:
CREATE OR REPLACE TABLE `lost_cargo_dataset.telemetry_embeddings_export` AS
WITH summarized_telemetry AS (
SELECT
shipment_id,
telemetry_string,
AI.GENERATE(
CONCAT('Summarize this telemetry log for vector search: ', telemetry_string)
).result AS summary
FROM `lost_cargo_dataset.telemetry_data`
),
telemetry_embeddings AS (
SELECT
shipment_id,
telemetry_string,
AI.EMBED(summary, endpoint => 'text-embedding-005').result AS embedding
FROM summarized_telemetry
)
SELECT
shipment_id,
telemetry_string,
TO_JSON_STRING(embedding) AS embedding_vector
FROM telemetry_embeddings;
步驟 2:預覽強化資料
匯出前,請先查看您建立的內容。這項查詢會顯示貨運 ID,以及每個摘要和嵌入內容的前 80 個字元:
SELECT
shipment_id,
SUBSTR(telemetry_string, 1, 80) AS telemetry_preview,
SUBSTR(embedding_vector, 1, 80) AS embedding_preview
FROM `lost_cargo_dataset.telemetry_embeddings_export`
LIMIT 5;
現在每列都包含貨運 ID、原始遙測記錄和 768 維度的嵌入向量。這是您要推送至 AlloyDB 的資料。
步驟 3:將嵌入內容匯出至 Cloud Storage
使用 BigQuery 的 EXPORT DATA 陳述式,將嵌入資料表寫入實驗室的 GCS bucket,做為 CSV 檔案。
EXECUTE IMMEDIATE CONCAT("""
EXPORT DATA OPTIONS (
uri = 'gs://""", @@project_id, """-lab2/data/embeddings_export/*.csv',
format = 'CSV',
overwrite = true,
header = false
) AS
SELECT
shipment_id,
telemetry_string,
embedding_vector
FROM `lost_cargo_dataset.telemetry_embeddings_export`;
""");
步驟 4:從 Cloud Storage 匯入 AlloyDB
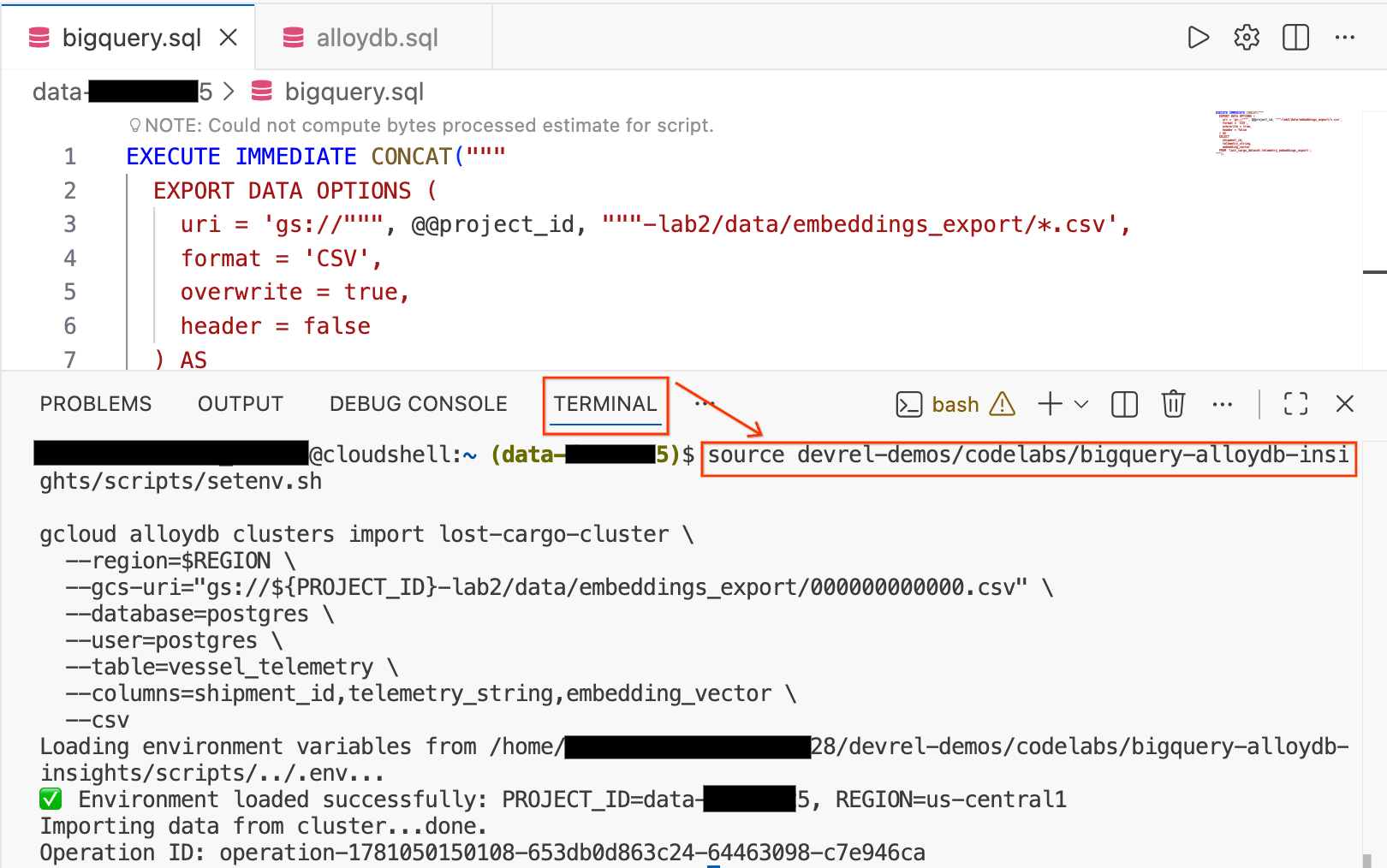
- 在 Cloud Shell 編輯器中,按一下畫面底部的「Terminal」分頁標籤,開啟終端機工作階段。
- 執行下列指令,載入環境並將 CSV 檔案直接匯入 AlloyDB 的
vessel_telemetry資料表:
source devrel-demos/codelabs/bigquery-alloydb-insights/scripts/setenv.sh
gcloud alloydb clusters import lost-cargo-cluster \
--region=$REGION \
--gcs-uri="gs://${PROJECT_ID}-lab2/data/embeddings_export/000000000000.csv" \
--database=postgres \
--user=postgres \
--table=vessel_telemetry \
--columns=shipment_id,telemetry_string,embedding_vector \
--csv
本節重點:您已使用 BigQuery 的 AI 函式匯總及嵌入遙測資料,將結果匯出至 Cloud Storage 做為 CSV 檔案,然後使用 gcloud 將結果匯入 AlloyDB。現在,營運追蹤資料庫已載入完畢,可供使用。
8. 比對 Beacon 信號
雪梨附近的外勤團隊攔截到片段的遙測信號。部分記錄如下:
「冷藏裝置離線。手動覆寫。」
如果這是從遭竊的容器傳送,即使信號不完整,AlloyDB 的向量搜尋功能也應能比對。這正是 AlloyDB 擅長的即時作業查詢。
步驟 1:驗證匯入的資料
將編輯器分頁切換回 alloydb.sql (仍連線至 AlloyDB)。
執行下列指令,確認遙測資料是否已順利載入:
SELECT shipment_id, LEFT(telemetry_string, 80) AS telemetry_preview
FROM vessel_telemetry
LIMIT 10;
您應該會看到含有 shipment_id 值和遙測文字的資料列。這些是車隊的遙測簽章,現在已可進行即時比對。
步驟 2:搜尋遺失的容器
現在,請使用 AlloyDB 的 google_ml_integration 擴充功能,透過攔截的信號片段搜尋相符項目:
SELECT
shipment_id,
telemetry_string,
1 - (embedding_vector <=> embedding('text-embedding-005', 'Refrigeration unit offline. Manual override.')::vector) AS search_relevance_score
FROM vessel_telemetry
ORDER BY embedding_vector <=> embedding('text-embedding-005', 'Refrigeration unit offline. Manual override.')::vector
LIMIT 5;
AlloyDB 的 google_ml_integration 擴充功能提供的 embedding() 函式會直接從 SQL 呼叫 Agent Platform,以內嵌方式產生向量嵌入。<=> 運算子會計算兩個向量之間的餘弦距離 (越接近 0,兩個向量就越相同)。我們從 1 減去餘弦距離,將結果表示為相關分數,分數越高越好。
步驟 3:確認比對結果
檢查結果。最相關的結果應為 MV-CAPYBARA-003,且相關性分數最高。
這與您在調查的每個步驟中追蹤的容器相同:
- 📷 監視器畫面顯示該船在夜間離開里約熱內盧港。
- 🌡️ 熱異常偵測確認冷藏設備遭到刻意停用。
- 📡 信標信號比對剛才在雪梨附近精確找出遙測簽章。
三條獨立的證據線索、三種不同的 Google Cloud AI 功能,以及一個遭竊的貨櫃。
🎯 案件已結案:MV-CAPYBARA-003 已在雪梨附近找到!

章節回顧:您已使用 AlloyDB 內建的 AI 整合功能,在單一 SQL 查詢中生成搜尋嵌入,並執行餘弦相似度搜尋。信號比對結果確認了遭竊貨櫃的位置,因此調查完成。
9. 探索證據
現在您已透過多模態圖片分析和向量搜尋功能找出容器,可以直接在編輯器中使用 Conversational Analytics,以自然語言探索調查資料,完全不需編寫任何 SQL。
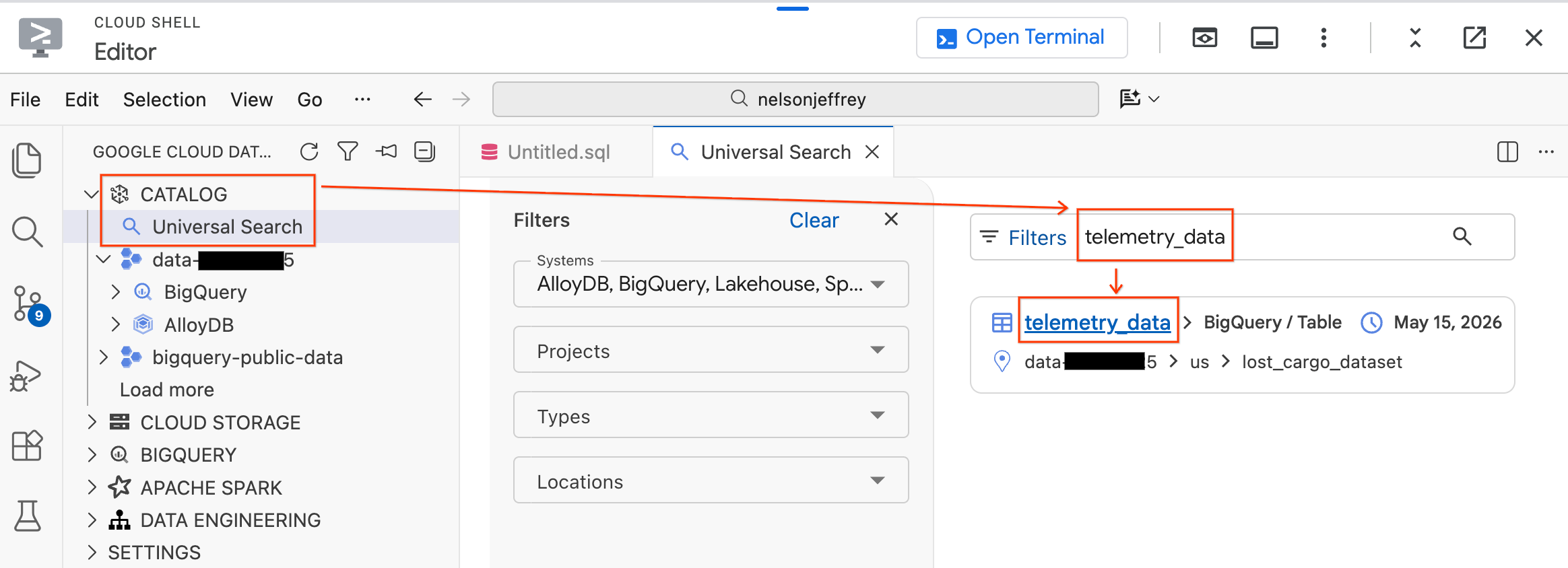
步驟 1:在 Knowledge Catalog 中找出資料
資料代理程式套件內含通用搜尋功能,可讓您在 Google Cloud 環境中尋找及探索資料資產。
- 在左側的「Data Agent Kit」面板中,展開「Catalog」部分。
- 按一下「通用搜尋」。
- 在搜尋列中輸入
telemetry_data。 - 按一下搜尋結果中的
telemetry_data資料表 (位於lost_cargo_dataset下方)。
步驟 2:啟動對話式數據分析
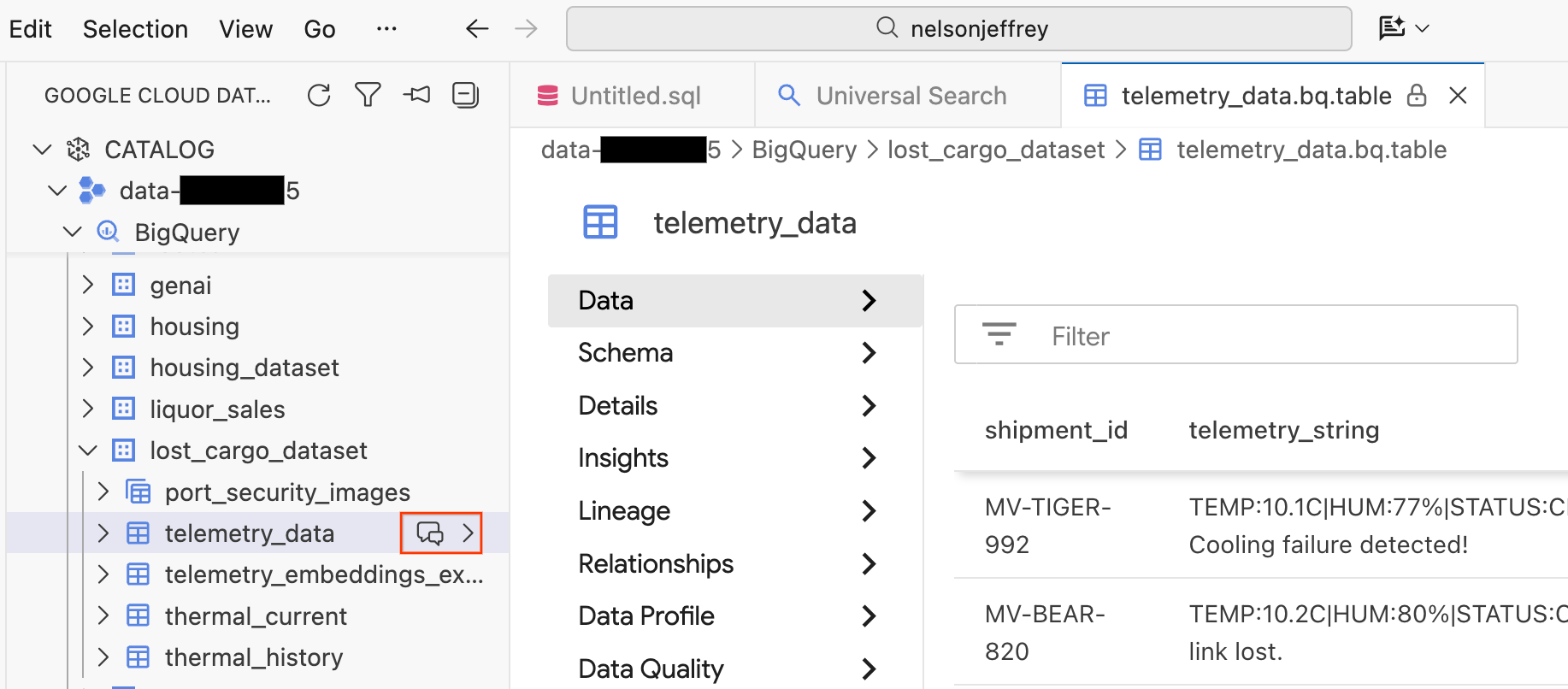
點選搜尋結果會開啟資料檢視器分頁,您可以在其中預覽原始資料、查看結構定義,以及檢查資料品質。
- 左側窗格會顯示 BigQuery 資料集和資料表。按一下「即時通訊」按鈕,開啟新的即時通訊視窗。
步驟 3:以自然語言提問
系統會開啟新的「歡迎使用對話式數據分析!」即時通訊分頁。代理程式會取得表格結構和內容的相關資訊。
- 在即時通訊視窗中輸入:「Show me the telemetry status and log for the Capybara shipment.」
- 按下 Enter 鍵。
代理程式會將您的問題翻譯成 BigQuery SQL,執行查詢並傳回結果,包括資料表和洞察結果,總結發現。您可以根據問題的複雜程度,在「思考型」 (深入分析,速度較慢) 和「快速型」 (快速回覆) 模式之間切換。由於這些是 AI 生成的回覆,您的結果可能與下方的螢幕截圖略有不同。
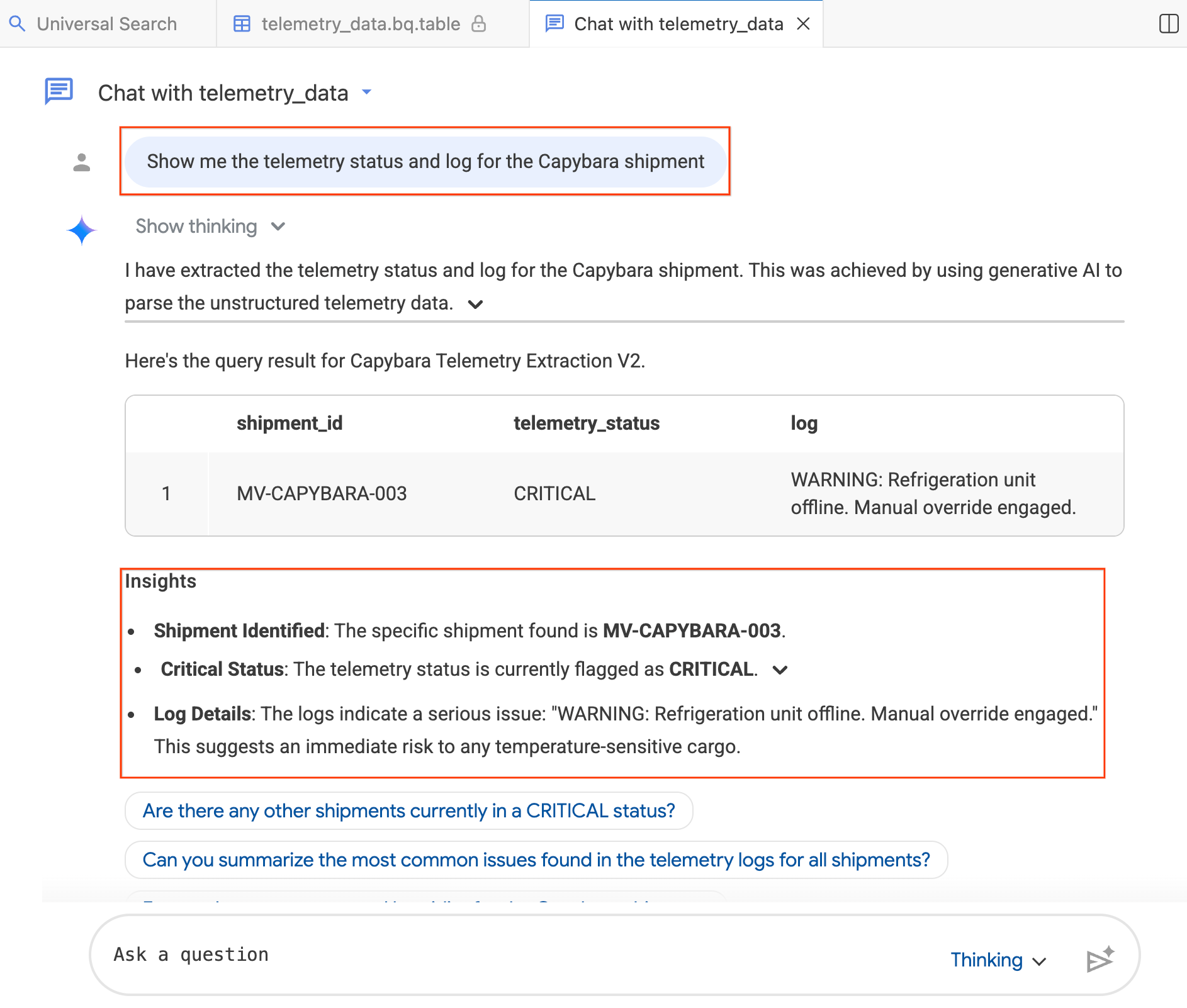
步驟 4:提出後續問題
代理程式會記住對話脈絡。請嘗試提出後續問題:
- 「遙測資料中有多少筆不重複的出貨記錄?」
- 「目前機群中有多少其他貨運處於『緊急』狀態?」
本節重點:您已使用 Knowledge Catalog 的通用搜尋功能找出資料集,並啟動對話式數據分析功能,以自然語言查詢調查資料。AI 代理程式將您的問題翻譯成 SQL,並提供與您發現結果一致的洞察資訊。
10. 清除
如要避免系統持續向您的 Google Cloud 帳戶收費,請刪除在本實驗室中建立的資源。您可以在 Cloud Shell 編輯器 (您使用 Data Agent Kit 的位置) 內的整合式終端機中執行這些指令,清理環境。
首先,載入環境變數:
source scripts/setenv.sh
- 刪除 BigQuery 資源 (僅限不繼續進行實驗室 3 的情況):
如果打算繼續進行實驗室 3,請略過這個步驟!實驗室 3 會使用相同的 BigQuery 資料集和連結,進行資源圖表分析。
如要刪除 BigQuery 資料集和連結,請按照下列步驟操作:
# Drop the dataset
bq rm -r -f $PROJECT_ID:lost_cargo_dataset
# Delete the connections
bq rm --connection --location=us-central1 $PROJECT_ID.us-central1.lost_cargo_conn
bq rm --connection --location=us-central1 $PROJECT_ID.us-central1.lost_cargo_alloydb_conn
- 刪除 Cloud Storage bucket:
gcloud storage rm --recursive gs://${PROJECT_ID}-lab2
- 刪除 AlloyDB 執行個體和叢集:
實驗室 3 不會使用 AlloyDB,因此現在可以放心拆除。
gcloud alloydb instances delete lost-cargo-instance \
--region=$REGION \
--cluster=lost-cargo-cluster \
--quiet
gcloud alloydb clusters delete lost-cargo-cluster \
--region=$REGION \
--force \
--quiet
- 刪除本機環境設定:
最後,請從工作區中清理本機環境設定檔:
rm -f .env
11. 恭喜!
您已順利完成實驗室 2:資料分析與多模態洞察!您從數千個貨櫃的港口追蹤到確認的竊盜事件和確切位置。
你的成就
- 掃描影像:您使用 BigQuery 的
AI.GENERATE分析港口安全影像,並在深紅色中找出 MV-CAPYBARA-003 貨櫃。 - 確認竊盜行為:您查看熱感應器資料,發現可疑的 148.4°F 尖峰,並使用
AI.DETECT_ANOMALIES證明這是蓄意竄改。 - 準備追蹤系統:您已使用 pgvector 和
google_ml_integration設定 AlloyDB,以便即時比對信標。 - 建立搜尋索引:您在 BigQuery 中使用
AI.GENERATE和AI.EMBED建立嵌入內容,然後將其匯出至 Cloud Storage 並匯入 AlloyDB。 - 比對信標信號:您使用 AlloyDB 的向量搜尋功能比對片段遙測信號,在雪梨附近找到遭竊的貨櫃。
- 探索證據:您直接在編輯器中使用對話式數據分析,以自然語言查詢調查資料。

後續步驟
您已找出容器所在位置,現在需要找出容器背後的擁有者。
在實驗室 3:資料消耗與代理工作流程中,您將建構物流網路的屬性圖,以便對應空殼公司之間的關係、使用對話式數據分析與圖表對話,並搜尋知識目錄,找出復原貨櫃所需的安全通關代碼。