
1. إنشاء مسار عكسي لاستخراج البيانات وتحويلها وتحميلها من Databricks إلى Spanner باستخدام Google Cloud Storage وBigQuery
مقدمة
في هذا الدرس التطبيقي حول الترميز، ستنشئ مسار عملية عكسية لاستخراج البيانات وتحويلها وتحميلها من Databricks إلى Spanner. في السابق، كانت عمليات نقل البيانات القياسية من خلال مسارات ETL (الاستخراج والتحويل والتحميل) تنقل البيانات من قواعد البيانات التشغيلية إلى مستودع بيانات، مثل Databricks، لإجراء الإحصاءات. تنفّذ عملية Reverse ETL العكس من خلال نقل البيانات المنسّقة والمعالَجة من مستودع البيانات إلى قواعد البيانات التشغيلية، مثل Spanner، وهي قاعدة بيانات ارتباطية موزّعة على مستوى العالم ومثالية للتطبيقات العالية التوفّر، حيث يمكنها تشغيل التطبيقات أو تقديم ميزات للمستخدمين أو استخدامها لاتخاذ القرارات في الوقت الفعلي.
الهدف هو نقل مجموعة بيانات مجمّعة من جداول Databricks Iceberg إلى جداول Spanner.
لتحقيق ذلك، يتم استخدام Google Cloud Storage (GCS) وBigQuery كخطوات وسيطة. في ما يلي تفصيل لتدفّق البيانات وسبب اختيار هذه البنية:

- نقل البيانات من Databricks إلى Google Cloud Storage (GCS) بتنسيق Iceberg:
- الخطوة الأولى هي استخراج البيانات من Databricks بتنسيق مفتوح ومحدّد جيدًا. يتم تصدير الجدول بتنسيق Apache Iceberg. تؤدي هذه العملية إلى كتابة البيانات الأساسية كمجموعة من ملفات Parquet والبيانات الوصفية للجدول (المخطط والأقسام ومواقع الملفات) كـ ملفات JSON وAvro. يؤدي إعداد بنية الجدول الكاملة هذه في GCS إلى إتاحة نقل البيانات والوصول إليها من أي نظام يمكنه فهم تنسيق Iceberg.
- تحويل جداول Iceberg في "خدمة التخزين السحابي من Google" إلى جدول خارجي في BigLake ضمن BigQuery:
- بدلاً من تحميل البيانات مباشرةً من GCS إلى Spanner، يتم استخدام BigQuery كوسيط قوي. يتم إنشاء جدول خارجي في BigLake في BigQuery يشير مباشرةً إلى ملف بيانات Iceberg الوصفية في GCS. لهذا الأسلوب عدة مزايا:
- عدم تكرار البيانات: تقرأ BigQuery بنية الجدول من البيانات الوصفية وتطلب ملفات بيانات Parquet في مكانها بدون نقلها، ما يؤدي إلى توفير الكثير من الوقت وتكاليف التخزين.
- الطلبات الموحّدة: تتيح تنفيذ طلبات SQL معقّدة على بيانات GCS كما لو كانت جدول BigQuery أصليًا.
- عملية عكسية لاستخراج البيانات وتحويلها وتحميلها من جدول BigLake خارجي إلى Spanner:
- الخطوة الأخيرة هي نقل البيانات من BigQuery إلى Spanner. يتم تحقيق ذلك باستخدام ميزة فعّالة في BigQuery تُعرف باسم طلب بحث
EXPORT DATA، وهي خطوة "استخراج البيانات وتحويلها وتحميلها بشكل عكسي". - الاستعداد التشغيلي: تم تصميم Spanner لأحمال العمل المتعلقة بالمعاملات، ما يوفّر اتساقًا قويًا وتوفّرًا عاليًا للتطبيقات. من خلال نقل البيانات إلى Spanner، تصبح متاحة للتطبيقات التي تواجه المستخدمين وواجهات برمجة التطبيقات والأنظمة التشغيلية الأخرى التي تتطلّب عمليات بحث سريعة.
- قابلية التوسّع: يتيح هذا النمط الاستفادة من قدرة BigQuery التحليلية لمعالجة مجموعات البيانات الكبيرة ثم عرض النتائج بكفاءة من خلال البنية الأساسية القابلة للتوسّع عالميًا في Spanner.
الخدمات والمصطلحات
- DataBricks: منصة بيانات مستندة إلى السحابة الإلكترونية ومصمَّمة حول Apache Spark
- Spanner: قاعدة بيانات ارتباطية موزّعة عالميًا وتديرها Google بالكامل.
- Google Cloud Storage: خدمة تخزين البيانات الثنائية الكبيرة (BLOB) من Google Cloud.
- BigQuery: مستودع بيانات بدون خادم مخصّص للتحليلات، وتديره Google بالكامل.
- Iceberg: هو تنسيق جدول مفتوح محدّد من قِبل Apache، ويوفر تجريدًا لتنسيقات ملفات البيانات الشائعة مفتوحة المصدر.
- Parquet: هو تنسيق ملف بيانات ثنائي عمودي مفتوح المصدر من Apache.
أهداف الدورة التعليمية
- كيفية تحميل البيانات إلى Databricks كجداول Iceberg
- كيفية إنشاء حزمة GCS
- كيفية تصدير جدول Databricks إلى GCS بتنسيق Iceberg
- كيفية إنشاء جدول خارجي في BigLake من جدول Iceberg في BigQuery من جدول Iceberg في GCS
- كيفية إعداد مثيل Spanner
- كيفية تحميل جداول BigLake الخارجية في BigQuery إلى Spanner
2. الإعداد والمتطلبات والقيود
المتطلبات الأساسية
- حساب Databricks، يُفضَّل أن يكون على Google Cloud Platform
- يجب توفّر حساب على Google Cloud يتضمّن حجزًا من فئة Enterprise أو أعلى لتصدير البيانات من BigQuery إلى Spanner.
- الوصول إلى "وحدة تحكّم Google Cloud" من خلال متصفّح ويب
- وحدة طرفية لتنفيذ أوامر Google Cloud CLI
إذا كانت مؤسستك على Google Cloud مفعَّلة فيها سياسة iam.allowedPolicyMemberDomains، قد يحتاج المشرف إلى منح استثناء للسماح بحسابات الخدمة من نطاقات خارجية. سيتم تناول هذا الموضوع في خطوة لاحقة عند الاقتضاء.
المتطلبات
- مشروع Google Cloud تم تفعيل الفوترة فيه
- متصفّح ويب، مثل Chrome
- حساب Databricks (يفترض هذا المختبر مساحة عمل مستضافة في "منصة Google Cloud")
- يجب أن يكون مثيل BigQuery في إصدار Enterprise أو إصدار أحدث لاستخدام ميزة EXPORT DATA.
- إذا كانت مؤسستك على Google Cloud مفعَّلة فيها سياسة
iam.allowedPolicyMemberDomains، قد يحتاج المشرف إلى منح استثناء للسماح بحسابات الخدمة من نطاقات خارجية. سيتم تناول هذا الموضوع في خطوة لاحقة عند الاقتضاء.
أذونات "إدارة الهوية وإمكانية الوصول" في Google Cloud Platform
يجب أن يتضمّن حساب Google الأذونات التالية لتنفيذ جميع الخطوات الواردة في هذا الدرس العملي.
حسابات الخدمة | ||
| يسمح بإنشاء حسابات الخدمة. | |
Spanner | ||
| يسمح بإنشاء مثيل Spanner جديد. | |
| تسمح بتنفيذ عبارات DDL لإنشاء | |
| يسمح بتنفيذ عبارات DDL لإنشاء جداول في قاعدة البيانات. | |
Google Cloud Storage | ||
| تتيح إنشاء حزمة GCS جديدة لتخزين ملفات Parquet التي تم تصديرها. | |
| يسمح بكتابة ملفات Parquet التي تم تصديرها إلى حزمة GCS. | |
| يسمح هذا الإذن لأداة BigQuery بقراءة ملفات Parquet من حزمة GCS. | |
| يسمح لـ BigQuery بإدراج ملفات Parquet في حزمة GCS. | |
Dataflow | ||
| يسمح هذا الإذن بطلب عناصر العمل من Dataflow. | |
| يسمح هذا الإذن للعامل في Dataflow بإرسال رسائل إلى خدمة Dataflow. | |
| يسمح هذا الإذن لبرامج Dataflow العاملة بكتابة إدخالات السجلّ في Google Cloud Logging. | |
لتسهيل الأمر، يمكن استخدام الأدوار المحدّدة مسبقًا التي تتضمّن هذه الأذونات.
|
|
|
|
|
|
|
|
مشروع Google Cloud
المشروع هو وحدة تنظيم أساسية في Google Cloud. إذا قدّم المشرف رمزًا لاستخدامه، يمكن تخطّي هذه الخطوة.
يمكن إنشاء مشروع باستخدام واجهة سطر الأوامر على النحو التالي:
gcloud projects create <your-project-name>
مزيد من المعلومات عن إنشاء المشاريع وإدارتها
القيود
من المهم أن تكون على دراية ببعض القيود وحالات عدم التوافق بين أنواع البيانات التي يمكن أن تنشأ في مسار التعلّم هذا.
Databricks Iceberg إلى BigQuery
عند استخدام BigQuery لطلب بيانات من جداول Iceberg التي تديرها Databricks (من خلال UniForm)، يجب مراعاة ما يلي:
- تطوّر المخطط: على الرغم من أنّ UniForm يؤدي وظيفة جيدة في ترجمة تغييرات مخطط Delta Lake إلى Iceberg، قد لا تنتشر التغييرات المعقّدة دائمًا على النحو المتوقّع. على سبيل المثال، لا تتم ترجمة إعادة تسمية الأعمدة في Delta Lake إلى Iceberg، الذي يراها على أنّها
dropوadd. يجب اختبار تغييرات المخطط بدقة دائمًا. - السفر عبر الزمن: لا يمكن أن تستخدم BigQuery إمكانات السفر عبر الزمن في Delta Lake. سيتم طلب أحدث لقطة من جدول Iceberg فقط.
- ميزات Delta Lake غير المتوافقة: لا تتوافق ميزات مثل "متجهات الحذف" و"ربط الأعمدة" مع وضع
idفي Delta Lake مع UniForm for Iceberg. يستخدم المختبر الوضعnameلربط الأعمدة، وهو وضع متاح.
نقل البيانات من BigQuery إلى Spanner
لا يتوافق الأمر EXPORT DATA من BigQuery إلى Spanner مع جميع أنواع بيانات BigQuery. سيؤدي تصدير جدول يتضمّن الأنواع التالية إلى حدوث خطأ:
STRUCTGEOGRAPHYDATETIMERANGETIME
بالإضافة إلى ذلك، إذا كان مشروع BigQuery يستخدم لغة GoogleSQL، لا تتوفّر أيضًا الأنواع الرقمية التالية للتصدير إلى Spanner:
BIGNUMERIC
للحصول على قائمة كاملة وحديثة بالقيود، يُرجى الرجوع إلى المستندات الرسمية: قيود التصدير إلى Spanner.
تحديد المشاكل وحلّها والأخطاء الشائعة
- إذا لم تكن تستخدم مثيلاً من Databricks على Google Cloud Platform، قد لا يكون من الممكن تحديد موقع بيانات خارجي في GCS. في مثل هذه الحالات، يجب تخزين الملفات في حل التخزين الخاص بمزوّد الخدمات السحابية في مساحة عمل Databricks، ثم نقلها إلى GCS بشكل منفصل.
- عند إجراء ذلك، يجب إجراء تعديلات على البيانات الوصفية لأنّ المعلومات ستتضمّن مسارات مبرمَجة ثابتة إلى الملفات التي تمّت إضافتها.
3- إعداد Google Cloud Storage (GCS)
سيتم استخدام Google Cloud Storage (GCS) لتخزين ملفات بيانات Parquet التي تم إنشاؤها بواسطة Databricks. لإجراء ذلك، يجب أولاً إنشاء حزمة جديدة لاستخدامها كوجهة للملف.
Google Cloud Storage
إنشاء حزمة جديدة
- انتقِل إلى صفحة Google Cloud Storage في وحدة التحكّم السحابية.
- في اللوحة اليمنى، انقر على الحِزم:
- انقر على الزر إنشاء:

- أدخِل تفاصيل المجموعة:
- اختَر اسمًا للمجموعة لاستخدامه. في هذا التمرين العملي، سيتم استخدام الاسم
codelabs_retl_databricks - اختَر منطقة لتخزين الحزمة، أو استخدِم القيم التلقائية.
- إبقاء فئة التخزين على
standard - احتفِظ بالقيم التلقائية لإذن الوصول
- احتفِظ بالقيم التلقائية لحماية بيانات العناصر
- انقر على الزر
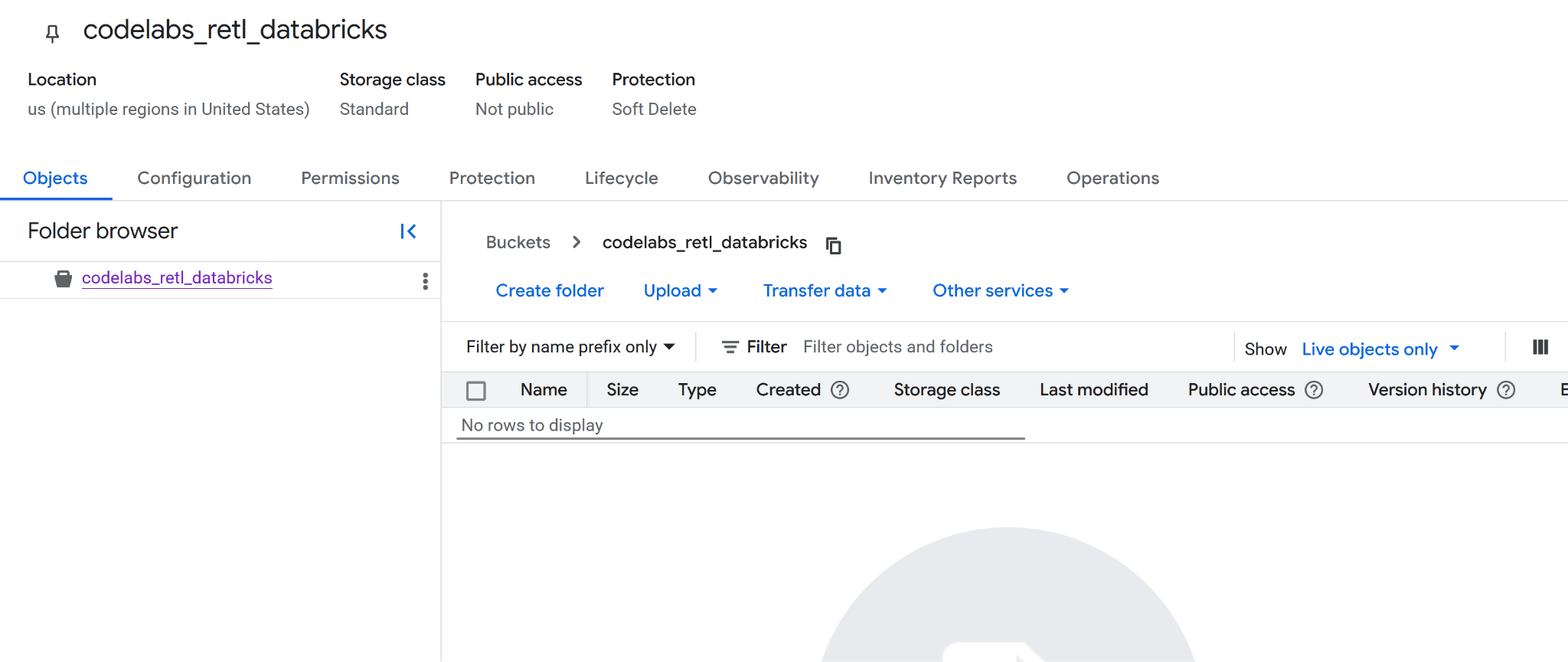
Createعند الانتهاء. قد تظهر رسالة لتأكيد أنّه سيتم منع الوصول للجميع. يمكنك المتابعة وتأكيد ذلك. - تهانينا، تم إنشاء مجموعة جديدة بنجاح. ستتم إعادة التوجيه إلى صفحة الحزمة.
- انسخ اسم الحزمة الجديدة واحتفِظ به لأنّك ستحتاج إليه لاحقًا.
الاستعداد للخطوات التالية
احرص على تدوين التفاصيل التالية لأنّك ستحتاج إليها في الخطوات التالية:
- معرّف مشروع Google
- اسم حزمة Google Storage
4. إعداد Databricks
بيانات TPC-H
في هذا المختبر، سيتم استخدام مجموعة بيانات TPC-H، وهي معيار متّبَع في المجال لأنظمة دعم اتخاذ القرار. يصمّم المخطط البياني بيئة نشاط تجاري واقعية تتضمّن عملاء وطلبات ومورّدين وأجزاء، ما يجعله مثاليًا لعرض سيناريو واقعي للتحليلات ونقل البيانات.
بدلاً من استخدام جداول TPC-H الأولية والموحّدة، سيتم إنشاء جدول جديد مجمّع. سيجمع هذا الجدول الجديد البيانات من الجداول orders وcustomer وnation لإنشاء عرض موجز وغير طبيعي للمبيعات الإقليمية. تُعدّ خطوة التجميع المُسبَق هذه من الممارسات الشائعة في الإحصاءات، لأنّها تُجهّز البيانات لحالة استخدام محدّدة، وهي في هذا السيناريو، للاستهلاك من خلال تطبيق تشغيلي.
سيكون المخطط النهائي للجدول المجمَّع على النحو التالي:
Col | النوع |
nation_name | سلسلة |
market_segment | سلسلة |
order_year | int |
order_priority | سلسلة |
total_order_count | bigint |
total_revenue | decimal(29,2) |
unique_customer_count | bigint |
إتاحة Iceberg مع تنسيق Delta Lake العالمي (UniForm)
في هذا الدرس التطبيقي، سيكون الجدول داخل Databricks جدول Delta Lake. ومع ذلك، لتسهيل قراءتها من خلال الأنظمة الخارجية، مثل BigQuery، سيتم تفعيل ميزة قوية تُعرف باسم التنسيق العام (UniForm).
تنشئ UniForm تلقائيًا بيانات Iceberg الوصفية إلى جانب بيانات Delta Lake الوصفية لنسخة واحدة مشترَكة من بيانات الجدول. يوفّر ذلك أفضل ما في العالمين:
- داخل Databricks: يمكنك الاستفادة من جميع مزايا الأداء والحوكمة التي يوفّرها Delta Lake.
- خارج Databricks: يمكن لأي محرك طلبات متوافق مع Iceberg قراءة الجدول، مثل BigQuery، كما لو كان جدول Iceberg أصليًا.
يُغنيك ذلك عن الاحتفاظ بنُسخ منفصلة من البيانات أو تنفيذ مهام التحويل يدويًا. سيتم تفعيل UniForm من خلال ضبط خصائص جدول معيّنة عند إنشاء الجدول.
كتالوجات Databricks
كتالوج Databricks هو الحاوية ذات المستوى الأعلى للبيانات في Unity Catalog، وهو حلّ موحّد لإدارة البيانات من Databricks. توفّر Unity Catalog طريقة مركزية لإدارة أصول البيانات والتحكّم في إمكانية الوصول إليها وتتبُّع مصدرها، وهو أمر بالغ الأهمية لمنصة بيانات مُدارة بشكل جيد.
تستخدم مساحة اسم بثلاثة مستويات لتنظيم البيانات: catalog.schema.table.
- الفهرس: هو المستوى الأعلى، ويُستخدم لتجميع البيانات حسب البيئة أو وحدة النشاط التجاري أو المشروع.
- المخطط (أو قاعدة البيانات): هو تجميع منطقي للجداول وطرق العرض والدوال ضمن فهرس.
- الجدول: العنصر الذي يحتوي على بياناتك.
قبل إنشاء جدول TPC-H المجمّع، يجب أولاً إعداد فهرس ومخطط مخصّصَين لاستضافته. يضمن ذلك تنظيم المشروع بشكلٍ جيد وعزله عن البيانات الأخرى في مساحة العمل.
إنشاء كتالوج ومخطط جديدَين
في Databricks Unity Catalog، يعمل "الكتالوج" كأعلى مستوى من التنظيم لأصول البيانات، ويعمل كحاوية آمنة يمكن أن تمتد على مساحات عمل متعددة في Databricks. يتيح لك تنظيم البيانات وعزلها استنادًا إلى وحدات الأعمال أو المشاريع أو البيئات، مع تحديد الأذونات وعناصر التحكّم في الوصول بشكل واضح.
ضمن "الكتالوج"، يعمل "المخطط" (المعروف أيضًا باسم قاعدة البيانات) على تنظيم الجداول وطرق العرض والدوال بشكل أكبر. يتيح هذا الهيكل الهرمي التحكّم الدقيق والتجميع المنطقي لعناصر البيانات ذات الصلة. في هذا الدرس التطبيقي، سيتم إنشاء "فهرس" و"مخطط" مخصّصَين لتخزين بيانات TPC-H، ما يضمن العزل والإدارة المناسبَين.
إنشاء كتالوج
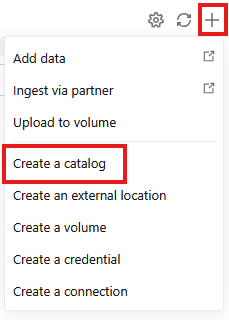
- انتقِل إلى

- انقر على + ثمّ اختَر إنشاء كتالوج من القائمة المنسدلة.
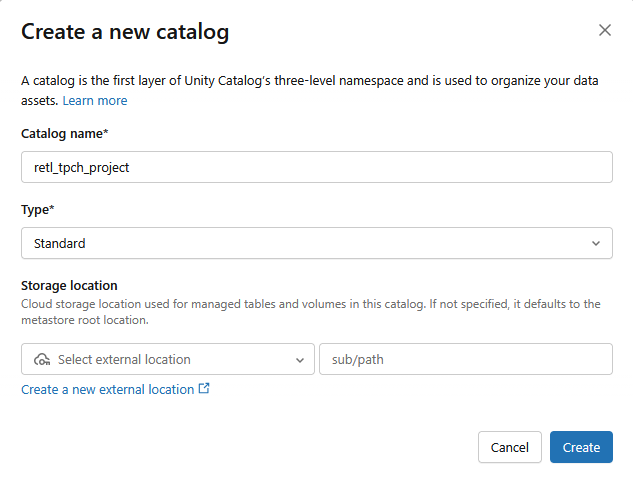
- سيتم إنشاء فهرس عادي جديد باستخدام الإعدادات التالية:
- اسم الكتالوج:
retl_tpch_project - موقع التخزين: استخدِم الموقع التلقائي إذا تم إعداده في مساحة العمل، أو أنشئ موقعًا جديدًا.
إنشاء مخطط
- انتقِل إلى
- اختَر الفهرس الجديد الذي تم إنشاؤه من اللوحة اليمنى
- انقر على
- سيتم إنشاء مخطط جديد باسم اسم المخطط على النحو التالي:
tpch_data
إعداد البيانات الخارجية
لتتمكّن من تصدير البيانات من Databricks إلى Google Cloud Storage (GCS)، يجب إعداد بيانات اعتماد البيانات الخارجية في Databricks. يتيح ذلك لخدمة Databricks الوصول إلى حزمة GCS وتعديلها بأمان.
- من شاشة الفهرس، انقر على

- إذا لم يظهر لك الخيار
External Data، قد تجدExternal Locationsمُدرَجًا ضمن القائمة المنسدلةConnectبدلاً من ذلك.
- انقر على

- في نافذة مربّع الحوار الجديدة، اضبط القيم المطلوبة لبيانات الاعتماد:
- نوع بيانات الاعتماد:
GCP Service Account - اسم بيانات الاعتماد:
retl-gcs-credential
- انقر على إنشاء
- بعد ذلك، انقر على علامة التبويب المواقع الجغرافية الخارجية.
- انقر على إنشاء موقع جغرافي.
- في نافذة مربّع الحوار الجديدة، اضبط القيم المطلوبة للموقع الجغرافي الخارجي:
- اسم الموقع الجغرافي الخارجي:
retl-gcs-location - نوع مساحة التخزين:
GCP - عنوان URL: عنوان URL لحزمة GCS، بالتنسيق
gs://YOUR_BUCKET_NAME - بيانات اعتماد مساحة التخزين: اختَر
retl-gcs-credentialالذي تم إنشاؤه للتو.
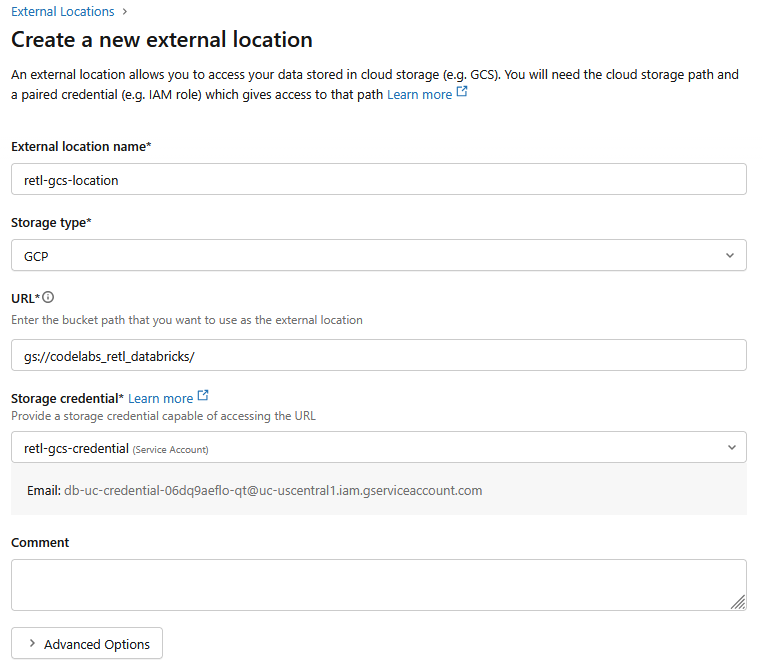
- دوِّن عنوان البريد الإلكتروني لحساب الخدمة الذي يتم ملؤه تلقائيًا عند اختيار بيانات اعتماد التخزين، لأنّك ستحتاج إليه في الخطوة التالية.
- انقر على إنشاء
5- ضبط أذونات حساب الخدمة
حساب الخدمة هو نوع خاص من الحسابات تستخدمه التطبيقات أو الخدمات لإجراء طلبات بيانات من واجهة برمجة التطبيقات معتمَدة إلى موارد Google Cloud.
يجب الآن إضافة الأذونات إلى حساب الخدمة الذي تم إنشاؤه للحزمة الجديدة في GCS.
- من صفحة حزمة GCS، انقر على علامة التبويب الأذونات.
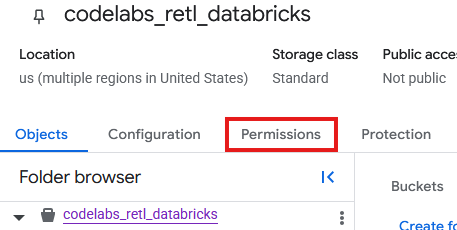
- انقر على منح إذن الوصول في صفحة المستخدمين الرئيسيين.
- في لوحة منح الإذن بالوصول التي تظهر من اليسار، أدخِل معرّف حساب الخدمة في حقل الأعضاء الجدد.
- ضمن إسناد الأدوار، أضِف
Storage Object AdminوStorage Legacy Bucket Reader. تتيح هذه الأدوار لحساب الخدمة قراءة العناصر وكتابتها وإدراجها في حزمة التخزين.
تحميل بيانات TPC-H
بعد إنشاء "الفهرس" و"المخطط"، يمكن تحميل بيانات TPCH من الجدول الحالي samples.tpch المخزَّن داخليًا في Databricks، ثم تعديلها في جدول جديد في المخطط الذي تم تحديده حديثًا.
إنشاء جدول متوافق مع Iceberg
توافق Iceberg مع UniForm
وراء الكواليس، تدير Databricks هذا الجدول داخليًا كجدول Delta Lake، ما يمنح جميع مزايا تحسين الأداء وميزات الحوكمة في Delta ضمن منظومة Databricks المتكاملة. ومع ذلك، من خلال تفعيل UniForm (اختصارًا لـ Universal Format)، يتم توجيه Databricks للقيام بشيء خاص: في كل مرة يتم فيها تعديل الجدول، تنشئ Databricks تلقائيًا بيانات وصفية متوافقة مع Iceberg وتحتفظ بها بالإضافة إلى البيانات الوصفية لـ Delta Lake.
وهذا يعني أنّه يتم الآن وصف مجموعة واحدة مشترَكة من ملفات البيانات (ملفات Parquet) من خلال مجموعتَين مختلفتَين من البيانات الوصفية.
- بالنسبة إلى Databricks: تستخدم
_delta_logلقراءة الجدول. - بالنسبة إلى القارئات الخارجية (مثل BigQuery): تستخدم هذه القارئات ملف البيانات الوصفية Iceberg (
.metadata.json) لفهم مخطط الجدول والتقسيم ومواقع الملفات.
والنتيجة هي جدول متوافق تمامًا وبشفافية مع أي أداة متوافقة مع Iceberg. لا يتم تكرار البيانات، ولا حاجة إلى التحويل أو المزامنة يدويًا. وهو مصدر واحد للحقيقة يمكن الوصول إليه بسلاسة من خلال كلّ من عالم التحليلات في Databricks ومنظومة الأدوات المتكاملة الأوسع التي تتوافق مع معيار Iceberg المفتوح.
- انقر على جديد ثم على طلب بحث.
- في حقل النص الخاص بصفحة طلب البحث، نفِّذ أمر SQL التالي:
CREATE TABLE retl_tpch_project.tpch_data.regional_sales_iceberg
USING DELTA
LOCATION 'gs://<Your bucket name>/regional_sales_iceberg'
TBLPROPERTIES (
'delta.columnMapping.mode' = 'name',
'delta.enableIcebergCompatV2' = 'true',
'delta.universalFormat.enabledFormats' = 'iceberg'
)
AS
SELECT
n.n_name AS nation_name,
c.c_mktsegment AS market_segment,
YEAR(o.o_orderdate) AS order_year,
o.o_orderpriority AS order_priority,
COUNT(o.o_orderkey) AS total_order_count,
ROUND(SUM(o.o_totalprice), 2) AS total_revenue,
COUNT(DISTINCT c.c_custkey) AS unique_customer_count
FROM samples.tpch.orders AS o
INNER JOIN samples.tpch.customer AS c
ON o.o_custkey = c.c_custkey
INNER JOIN samples.tpch.nation AS n
ON c.c_nationkey = n.n_nationkey
GROUP BY
n.n_name,
c.c_mktsegment,
YEAR(o.o_orderdate),
o.o_orderpriority;
OPTIMIZE retl_tpch_project.tpch_data.regional_sales_iceberg;
DESCRIBE EXTENDED retl_tpch_project.tpch_data.regional_sales_iceberg;
ملاحظات:
- استخدام Delta: يحدّد أنّنا نستخدم جدول Delta Lake. يمكن تخزين جداول Delta Lake في Databricks كجدول خارجي فقط.
- الموقع الجغرافي: يحدّد هذا الحقل مكان تخزين الجدول، إذا كان خارجيًا.
- TablePropertoes: ينشئ
delta.universalFormat.enabledFormats = ‘iceberg'بيانات وصفية متوافقة مع Iceberg إلى جانب ملفات Delta Lake. - تحسين: يؤدي إلى تشغيل عملية إنشاء البيانات الوصفية في UniForm بشكل إجباري، لأنّ هذه العملية تتم عادةً بشكل غير متزامن.
- يجب أن تعرض نتيجة طلب البحث تفاصيل حول الجدول الذي تم إنشاؤه حديثًا

التحقّق من بيانات جدول GCS
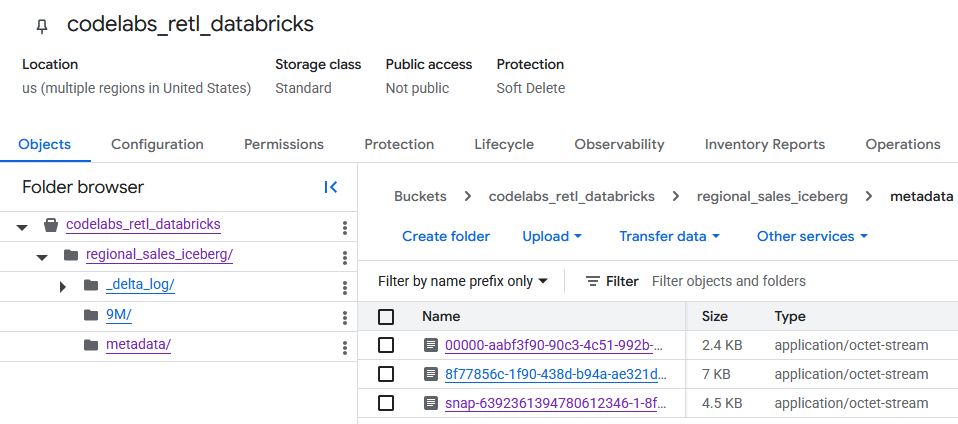
بعد الانتقال إلى حزمة GCS، يمكن الآن العثور على بيانات الجدول التي تم إنشاؤها حديثًا.
يمكنك العثور على البيانات الوصفية لـ Iceberg في المجلد metadata الذي تستخدمه أدوات القراءة الخارجية (مثل BigQuery). يتم تتبُّع البيانات الوصفية لـ Delta Lake، التي تستخدمها Databricks داخليًا، في المجلد _delta_log.
يتم تخزين بيانات الجدول الفعلية كـ ملفات Parquet ضِمن مجلد آخر، وعادةً ما يتم تسميته بسلسلة تم إنشاؤها عشوائيًا بواسطة Databricks. على سبيل المثال، في لقطة الشاشة أدناه، تقع ملفات البيانات في المجلد 9M.
6. إعداد BigQuery وBigLake
بعد أن أصبح جدول Iceberg في Google Cloud Storage، الخطوة التالية هي إتاحته في BigQuery. سيتم ذلك من خلال إنشاء جدول خارجي في BigLake.
BigLake هو محرّك تخزين يتيح إنشاء جداول في BigQuery تقرأ البيانات مباشرةً من مصادر خارجية، مثل Google Cloud Storage. في هذا المختبر، هذه هي التكنولوجيا الأساسية التي تتيح لأداة BigQuery فهم جدول Iceberg الذي تم تصديره للتو بدون الحاجة إلى استيعاب البيانات.
لإنجاح هذه العملية، يجب توفُّر عنصرَين:
- اتصال بمورد على السحابة الإلكترونية: هو رابط آمن بين BigQuery وGCS. يستخدم حساب خدمة خاصًا للتعامل مع المصادقة، ما يضمن حصول BigQuery على الأذونات اللازمة لقراءة الملفات من حزمة GCS.
- تعريف جدول خارجي: يخبر هذا التعريف BigQuery بمكان العثور على ملف البيانات الوصفية لجدول Iceberg في GCS وكيفية تفسيره.
إنشاء عملية ربط بمورد على السحابة الإلكترونية
أولاً، سيتم إنشاء عملية الربط التي تسمح لأداة BigQuery بالوصول إلى GCS.
يمكنك الاطّلاع على مزيد من المعلومات حول إنشاء Cloud Resource Connections هنا.
- الانتقال إلى BigQuery
- انقر على عمليات الربط ضمن المستكشف
- إذا لم تظهر طائرة المستكشف، انقر على

- في صفحة عمليات الربط، انقر على
 .
. - بالنسبة إلى نوع الاتصال، اختَر
Vertex AI remote models, remote functions, BigLake and Spanner (Cloud Resource) - اضبط معرّف الاتصال على
databricks_retlوأنشئ الاتصال

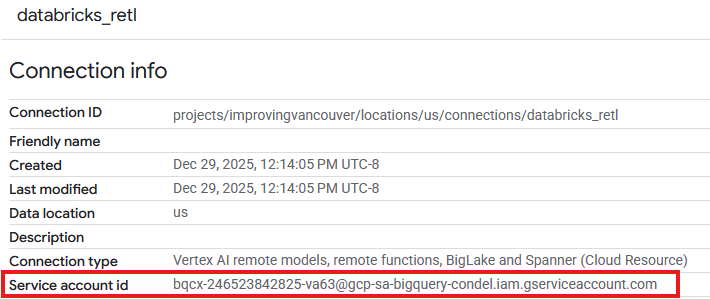
- من المفترض أن يظهر إدخال الآن في جدول عمليات الربط لعملية الربط التي تم إنشاؤها حديثًا. انقر على هذا الإدخال للاطّلاع على تفاصيل عملية الربط.

- في صفحة تفاصيل الربط، دوِّن رقم تعريف حساب الخدمة لأنّك ستحتاج إليه لاحقًا.
منح إذن الوصول إلى حساب خدمة الربط
- انتقِل إلى إدارة الهوية وإمكانية الوصول والمشرف.
- انقر على منح إذن الوصول.
- في حقل المشرفون الجدد، أدخِل معرّف حساب الخدمة الخاص بـ "مصدر الربط" الذي تم إنشاؤه أعلاه.
- بالنسبة إلى "الدور"، اختَر
Storage Object User، ثم انقر على .
.
بعد إنشاء عملية الربط ومنح حساب الخدمة الأذونات اللازمة، يمكن الآن إنشاء الجدول الخارجي BigLake. أولاً، يجب إنشاء مجموعة بيانات في BigQuery لتكون بمثابة حاوية للجدول الجديد. بعد ذلك، سيتم إنشاء الجدول نفسه، مع توجيهه إلى ملف البيانات الوصفية Iceberg في حزمة GCS.
- الانتقال إلى BigQuery
- في لوحة المستكشف، انقر على رقم تعريف المشروع، ثم انقر على النقاط الثلاث واختَر إنشاء مجموعة بيانات.
- ستتم تسمية مجموعة البيانات
databricks_retl. اترك الخيارات الأخرى على الإعدادات التلقائية وانقر على الزر إنشاء مجموعة بيانات.
- ابحث الآن عن مجموعة البيانات الجديدة
databricks_retlفي لوحة المستكشف. انقر على النقاط الثلاث بجانبه واختَر إنشاء جدول.
- املأ الإعدادات التالية لإنشاء الجدول:
- إنشاء جدول من:
Google Cloud Storage - اختيار ملف من حزمة GCS أو استخدام نمط معرّف الموارد المنتظم (URI): انتقِل إلى حزمة GCS وابحث عن ملف JSON الخاص بالبيانات الوصفية الذي تم إنشاؤه أثناء عملية التصدير من Databricks. يجب أن يبدو المسار على النحو التالي:
regional_sales/metadata/v1.metadata.json. - تنسيق الملف:
Iceberg - الجدول:
regional_sales - نوع الجدول:
External table - رقم تعريف الاتصال: اختَر اتصال
databricks_retlالذي تم إنشاؤه سابقًا. - اترك بقية القيم على الإعدادات التلقائية، ثم انقر على إنشاء جدول.
- بعد الإنشاء، من المفترض أن يظهر جدول
regional_salesالجديد ضمن مجموعة بياناتdatabricks_retl. يمكن الآن إجراء طلبات بحث في هذا الجدول باستخدام لغة SQL العادية، تمامًا كما هو الحال مع أي جدول آخر في BigQuery.
7. تحميل البيانات إلى Spanner
تم الوصول إلى الجزء الأخير والأكثر أهمية من مسار نقل البيانات، وهو نقل البيانات من الجداول الخارجية في BigLake إلى Spanner. هذه هي خطوة "استخراج البيانات وتحويلها وتحميلها بشكل عكسي"، حيث يتم تحميل البيانات، بعد معالجتها وتنظيمها في مستودع البيانات، إلى نظام تشغيلي لتستخدمه التطبيقات.
Spanner هي قاعدة بيانات ارتباطية مُدارة بالكامل وموزّعة على مستوى العالم. وتوفّر اتساق المعاملات لقاعدة بيانات ارتباطية تقليدية، ولكن مع قابلية التوسّع الأفقي لقاعدة بيانات NoSQL. وهذا يجعلها خيارًا مثاليًا لإنشاء تطبيقات قابلة للتوسّع ومتوفّرة بشكل كبير.
ستكون العملية على النحو التالي:
- أنشئ مثيل Spanner، وهو التخصيص الفعلي للموارد.
- أنشئ قاعدة بيانات ضمن هذا المثيل.
- حدِّد مخطط جدول في قاعدة البيانات يتطابق مع بنية بيانات
regional_sales. - نفِّذ طلب بحث
EXPORT DATAفي BigQuery لتحميل البيانات من جدول BigLake مباشرةً إلى جدول Spanner.
إنشاء مثيل وقاعدة بيانات وجدول في Spanner
- انتقِل إلى Spanner
- انقر على
 . يمكنك استخدام مثيل حالي إذا كان متاحًا. اضبط متطلبات المثيل حسب الحاجة. تم استخدام ما يلي في هذا الدرس التطبيقي:
. يمكنك استخدام مثيل حالي إذا كان متاحًا. اضبط متطلبات المثيل حسب الحاجة. تم استخدام ما يلي في هذا الدرس التطبيقي:
الإصدار | للمؤسسات |
اسم المثيل | databricks-retl |
إعدادات المنطقة | المنطقة التي تختارها |
وحدة الحوسبة | وحدات المعالجة (PU) |
التخصيص اليدوي | 100 |
- بعد إنشاء النسخة، انتقِل إلى صفحة مثيل Spanner، وانقر على
 . يمكنك استخدام قاعدة بيانات حالية إذا كانت متاحة.
. يمكنك استخدام قاعدة بيانات حالية إذا كانت متاحة.
- في هذا التمرين العملي، سيتم إنشاء قاعدة بيانات باستخدام
- الاسم:
databricks-retl - لغة قاعدة البيانات:
Google Standard SQL
- بعد إنشاء قاعدة البيانات، اختَرها من صفحة "مثيل Spanner" (Spanner Instance) للانتقال إلى صفحة "قاعدة بيانات Spanner" (Spanner Database).
- من صفحة "قاعدة بيانات Spanner"، انقر على
 .
. - في صفحة طلب البحث الجديدة، سيتم إنشاء تعريف الجدول الذي سيتم استيراده إلى Spanner. لإجراء ذلك، نفِّذ طلب SQL التالي.
CREATE TABLE regional_sales (
nation_name STRING(MAX),
market_segment STRING(MAX),
order_year INT64,
order_priority STRING(MAX),
total_order_count INT64,
total_revenue NUMERIC,
unique_customer_count INT64
) PRIMARY KEY (nation_name, market_segment, order_year, order_priority);
- بعد تنفيذ أمر SQL، سيصبح جدول Spanner جاهزًا الآن لكي تنقل BigQuery البيانات باستخدام Reverse ETL. يمكن التحقّق من إنشاء الجدول من خلال الاطّلاع عليه في اللوحة اليمنى في قاعدة بيانات Spanner.
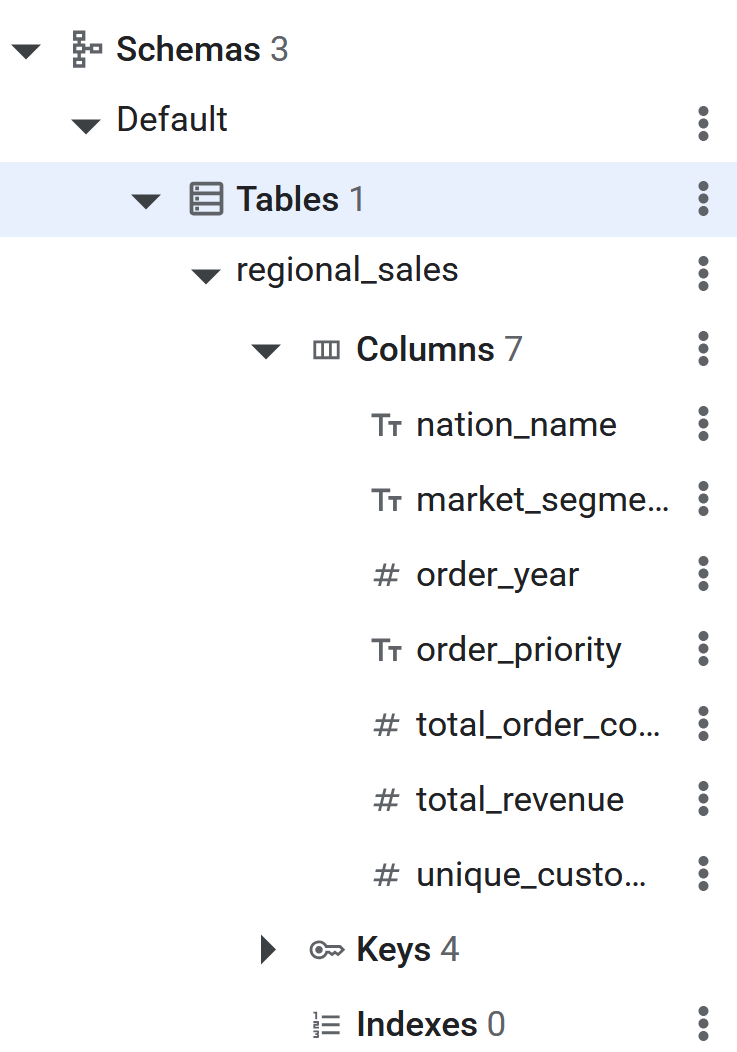
عملية عكسية لاستخراج البيانات وتحويلها وتحميلها إلى Spanner باستخدام EXPORT DATA
هذه هي الخطوة الأخيرة. بعد أن تصبح البيانات المصدر جاهزة في جدول BigLake في BigQuery وإنشاء جدول الوجهة في Spanner، تصبح عملية نقل البيانات الفعلية بسيطة بشكل مدهش. سيتم استخدام طلب بحث SQL واحد في BigQuery: EXPORT DATA.
تم تصميم هذا الاستعلام خصيصًا لحالات مثل هذه. تصدّر هذه الأداة البيانات بكفاءة من جدول BigQuery (بما في ذلك الجداول الخارجية مثل جدول BigLake) إلى وجهة خارجية. في هذه الحالة، تكون الوجهة هي جدول Spanner. يمكنك الاطّلاع على مزيد من المعلومات حول ميزة التصدير هنا.
يمكنك الاطّلاع على مزيد من المعلومات حول إعداد BigQuery لخدمة Spanner Reverse ETL هنا.
- الانتقال إلى BigQuery
- افتح علامة تبويب جديدة لمحرّر طلبات البحث.
- في صفحة "طلب البحث"، أدخِل عبارة SQL التالية. تذكَّر استبدال رقم تعريف المشروع في **
uri** **ومسار الجدول برقم تعريف المشروع الصحيح.**
EXPORT DATA OPTIONS(
uri='https://spanner.googleapis.com/projects/YOUR_PROJECT_ID/instances/databricks-retl/databases/databricks-retl',
format='CLOUD_SPANNER',
spanner_options="""{
"table": "regional_sales",
"priority": "MEDIUM"
}"""
) AS
SELECT * FROM `YOUR_PROJECT_ID.databricks_retl.regional_sales`;
- بعد اكتمال الأمر، تكون البيانات قد تم تصديرها بنجاح إلى Spanner.
8. التحقّق من البيانات في Spanner
تهانينا! تم إنشاء مسار كامل لعملية عكسية لاستخراج البيانات وتحويلها وتحميلها وتنفيذه بنجاح، ما أدّى إلى نقل البيانات من مستودع بيانات Databricks إلى قاعدة بيانات Spanner تشغيلية.
الخطوة الأخيرة هي التأكّد من وصول البيانات إلى Spanner على النحو المتوقّع.
- انتقِل إلى Spanner.
- انتقِل إلى مثيل
databricks-retlثم إلى قاعدة بياناتdatabricks-retl. - في قائمة الجداول، انقر على الجدول
regional_sales. - في قائمة التنقّل اليمنى للجدول، انقر على علامة التبويب البيانات.
- من المفترض الآن أن يتم تحميل بيانات المبيعات المجمّعة، التي تم استخراجها في الأصل من Databricks، وأن تكون جاهزة للاستخدام في جدول Spanner. تتوفّر هذه البيانات الآن في نظام تشغيلي، وهي جاهزة لتشغيل تطبيق مباشر أو عرض لوحة بيانات أو الاستعلام عنها من خلال واجهة برمجة تطبيقات.
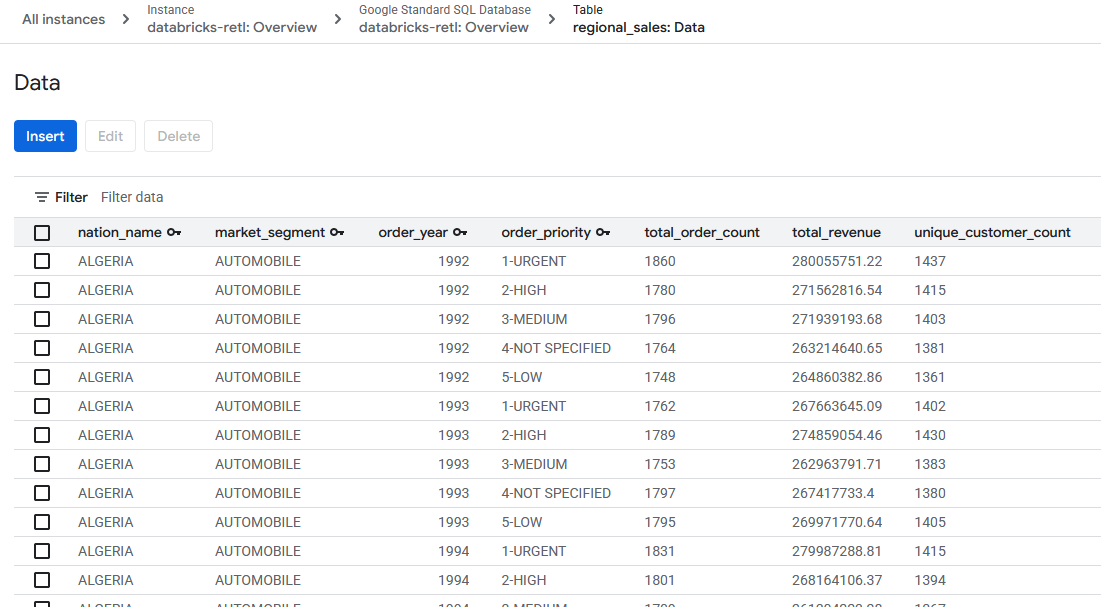
تم بنجاح سدّ الفجوة بين عالمَي البيانات التحليلية والتشغيلية.
9- الإزالة
أزِل جميع الجداول المضافة والبيانات المخزّنة عند الانتهاء من هذه التجربة.
تنظيف جداول Spanner
- الانتقال إلى Spanner
- انقر على الجهاز الظاهري الذي تم استخدامه في هذا المختبر من القائمة المسماة
databricks-retl

- في صفحة الجهاز الافتراضي، انقر على
 .
. - أدخِل
databricks-retlفي مربّع حوار التأكيد الذي يظهر، ثم انقر على .
.
إخلاء مساحة في GCS
- انتقِل إلى GCS
- انقر على
 من قائمة الجانب الأيمن
من قائمة الجانب الأيمن - اختَر الحزمة ``codelabs_retl_databricks
- بعد اختيار الملف، انقر على الزر
 الذي يظهر في البانر العلوي.
الذي يظهر في البانر العلوي.

- أدخِل
DELETEفي مربّع حوار التأكيد الذي يظهر، ثم انقر على.
تنظيف Databricks
حذف كتالوج/مخطط/جدول
- تسجيل الدخول إلى نسخة Databricks
- انقروا على
 من القائمة الجانبية اليمنى
من القائمة الجانبية اليمنى - اختَر
 الذي تم إنشاؤه سابقًا من قائمة الكتالوج
الذي تم إنشاؤه سابقًا من قائمة الكتالوج - في قائمة "المخطط"، اختَر
 الذي تم إنشاؤه
الذي تم إنشاؤه - اختَر
 الذي تم إنشاؤه سابقًا من قائمة الجدول.
الذي تم إنشاؤه سابقًا من قائمة الجدول. - وسِّع خيارات الجدول من خلال النقر على
 واختَر
واختَر Delete. - انقر على
 في مربّع حوار التأكيد لحذف الجدول.
في مربّع حوار التأكيد لحذف الجدول. - بعد حذف الجدول، ستتم إعادتك إلى صفحة المخطط.
- وسِّع خيارات المخطّط من خلال النقر على واختَر
Delete. - انقر على في مربّع حوار التأكيد لحذف المخطط.
- بعد حذف المخطط، ستتم إعادتك إلى صفحة الكتالوج.
- اتّبِع الخطوات من 4 إلى 11 مرة أخرى لحذف مخطط
defaultإذا كان متوفّرًا. - من صفحة الكتالوج، وسِّع خيارات الكتالوج بالنقر على واختَر
Delete. - انقر على في مربّع حوار التأكيد لحذف الفهرس
حذف بيانات اعتماد أو موقع البيانات الخارجية
- من شاشة "الفهرس"، انقر على
- إذا لم يظهر لك الخيار
External Data، قد تجدExternal Locationمُدرَجًا ضمن القائمة المنسدلةConnectبدلاً من ذلك. - انقر على موقع البيانات الخارجية
retl-gcs-locationالذي تم إنشاؤه سابقًا. - من صفحة الموقع الجغرافي الخارجي، وسِّع خيارات الموقع الجغرافي بالنقر على واختَر
Delete. - انقر على في مربّع حوار التأكيد لحذف الموقع الجغرافي الخارجي.
- انقر على
- انقر على
retl-gcs-credentialالذي تم إنشاؤه سابقًا - من صفحة بيانات الاعتماد، وسِّع خيارات بيانات الاعتماد من خلال النقر على واختَر
Delete. - انقر على في مربّع حوار التأكيد لحذف بيانات الاعتماد.
10. تهانينا
تهانينا على إكمال تجربة البرمجة.
المواضيع التي تناولناها
- كيفية تحميل البيانات إلى Databricks كجداول Iceberg
- كيفية إنشاء حزمة GCS
- كيفية تصدير جدول Databricks إلى GCS بتنسيق Iceberg
- كيفية إنشاء جدول خارجي في BigLake من جدول Iceberg في BigQuery من جدول Iceberg في GCS
- كيفية إعداد مثيل Spanner
- كيفية تحميل جداول BigLake الخارجية في BigQuery إلى Spanner