
1. Reverse-ETL-Pipeline von Databricks zu Cloud Spanner mit Google Cloud Storage und BigQuery erstellen
Einführung
In diesem Codelab erstellen Sie eine Reverse-ETL-Pipeline von Databricks nach Spanner. In der Regel werden Daten mit Standard-ETL-Pipelines (Extrahieren, Transformieren, Laden) aus operativen Datenbanken in ein Data Warehouse wie Databricks für Analysen verschoben. Eine Reverse-ETL-Pipeline macht das Gegenteil: Sie verschiebt kuratierte, verarbeitete Daten aus dem Data Warehouse zurück in operative Datenbanken wie Spanner, eine weltweit verteilte relationale Datenbank, die sich ideal für Anwendungen mit hoher Verfügbarkeit eignet. Dort können sie Anwendungen unterstützen, nutzerorientierte Funktionen bereitstellen oder für Echtzeitentscheidungen verwendet werden.
Ziel ist es, einen aggregierten Datensatz aus Databricks Iceberg-Tabellen in Spanner-Tabellen zu verschieben.
Dazu werden Google Cloud Storage (GCS) und BigQuery als Zwischenschritte verwendet. Hier sehen Sie eine Aufschlüsselung des Datenflusses und die Gründe für diese Architektur:

- Databricks in Google Cloud Storage (GCS) im Iceberg-Format:
- Der erste Schritt besteht darin, die Daten aus Databricks in einem offenen, genau definierten Format zu exportieren. Die Tabelle wird im Apache Iceberg-Format exportiert. Bei diesem Vorgang werden die zugrunde liegenden Daten als eine Reihe von Parquet-Dateien und die Metadaten der Tabelle (Schema, Partitionen, Dateispeicherorte) als JSON- und Avro-Dateien geschrieben. Durch das Bereitstellen dieser vollständigen Tabellenstruktur in GCS sind die Daten portierbar und für jedes System zugänglich, das das Iceberg-Format unterstützt.
- GCS-Iceberg-Tabellen in externe BigQuery BigLake-Tabellen konvertieren:
- Anstatt die Daten direkt aus GCS in Spanner zu laden, wird BigQuery als leistungsstarkes Zwischenmedium verwendet. In BigQuery wird eine externe BigLake-Tabelle erstellt, die direkt auf die Iceberg-Metadatendatei in GCS verweist. Dieser Ansatz bietet verschiedene Vorteile:
- Keine Datenduplizierung:BigQuery liest die Tabellenstruktur aus den Metadaten und fragt die Parquet-Datendateien direkt ab, ohne sie aufzunehmen. Das spart viel Zeit und Speicherkosten.
- Föderierte Abfragen:Damit können komplexe SQL-Abfragen für GCS-Daten ausgeführt werden, als wären sie eine native BigQuery-Tabelle.
- Reverse-ETL-BigLake-Tabelle in Spanner:
- Der letzte Schritt besteht darin, die Daten aus BigQuery in Spanner zu verschieben. Dies wird durch eine leistungsstarke Funktion in BigQuery erreicht, die als
EXPORT DATA-Abfrage bezeichnet wird. Dies ist der Schritt „Reverse-ETL“. - Betriebsbereitschaft:Spanner ist für transaktionale Arbeitslasten konzipiert und bietet Anwendungen eine hohe Konsistenz und Verfügbarkeit. Durch die Übertragung der Daten in Spanner werden sie für nutzerorientierte Anwendungen, APIs und andere Betriebssysteme zugänglich, die Punktabfragen mit niedriger Latenz erfordern.
- Skalierbarkeit:Mit diesem Muster lässt sich die Analyseleistung von BigQuery nutzen, um große Datasets zu verarbeiten und die Ergebnisse dann effizient über die global skalierbare Infrastruktur von Spanner bereitzustellen.
Dienste und Terminologie
- DataBricks: Cloudbasierte Datenplattform, die auf Apache Spark basiert.
- Spanner: Eine global verteilte relationale Datenbank, die vollständig von Google verwaltet wird.
- Google Cloud Storage: Das Blob-Speicherangebot von Google Cloud.
- BigQuery: Ein serverloses Data Warehouse für Analysen, das vollständig von Google verwaltet wird.
- Iceberg: Ein von Apache definiertes offenes Tabellenformat, das eine Abstraktion über gängige Open-Source-Datendateiformate bietet.
- Parquet: Ein spaltenorientiertes binäres Open-Source-Dateiformat von Apache.
Lerninhalte
- Daten als Iceberg-Tabellen in Databricks laden
- GCS-Bucket erstellen
- Databricks-Tabelle im Iceberg-Format in GCS exportieren
- BigLake-externe Tabelle in BigQuery aus der Iceberg-Tabelle in GCS erstellen
- Spanner-Instanz einrichten
- BigLake-Tabellen in BigQuery in Spanner laden
2. Einrichtung, Anforderungen und Einschränkungen
Vorbereitung
- Ein Databricks-Konto, vorzugsweise auf der GCP
- Für den Export von BigQuery nach Spanner ist ein Google Cloud-Konto mit einer Reservierung auf Enterprise-Ebene oder höher für BigQuery erforderlich.
- Zugriff auf die Google Cloud Console über einen Webbrowser
- Ein Terminal zum Ausführen von Google Cloud CLI-Befehlen
Wenn in Ihrer Google Cloud-Organisation die Richtlinie iam.allowedPolicyMemberDomains aktiviert ist, muss ein Administrator möglicherweise eine Ausnahme gewähren, damit Dienstkonten aus externen Domains verwendet werden können. Dies wird gegebenenfalls in einem späteren Schritt behandelt.
Voraussetzungen
- Google Cloud-Projekt mit aktivierter Abrechnungsfunktion.
- Ein Webbrowser wie Chrome
- Ein Databricks-Konto (in diesem Lab wird ein in GCP gehosteter Arbeitsbereich vorausgesetzt)
- Die BigQuery-Instanz muss mindestens die Enterprise-Version haben, damit die Funktion „EXPORT DATA“ verwendet werden kann.
- Wenn in Ihrer Google Cloud-Organisation die Richtlinie
iam.allowedPolicyMemberDomainsaktiviert ist, muss ein Administrator möglicherweise eine Ausnahme gewähren, damit Dienstkonten aus externen Domains verwendet werden können. Dies wird gegebenenfalls in einem späteren Schritt behandelt.
Google Cloud Platform-IAM-Berechtigungen
Das Google-Konto benötigt die folgenden Berechtigungen, um alle Schritte in diesem Codelab auszuführen.
Dienstkonten | ||
| Ermöglicht das Erstellen von Dienstkonten. | |
Spanner | ||
| Ermöglicht das Erstellen einer neuen Spanner-Instanz. | |
| Ermöglicht das Ausführen von DDL-Anweisungen zum Erstellen | |
| Ermöglicht das Ausführen von DDL-Anweisungen zum Erstellen von Tabellen in der Datenbank. | |
Google Cloud Storage | ||
| Ermöglicht das Erstellen eines neuen GCS-Buckets zum Speichern der exportierten Parquet-Dateien. | |
| Ermöglicht das Schreiben der exportierten Parquet-Dateien in den GCS-Bucket. | |
| Ermöglicht BigQuery, die Parquet-Dateien aus dem GCS-Bucket zu lesen. | |
| Ermöglicht BigQuery, die Parquet-Dateien im GCS-Bucket aufzulisten. | |
Dataflow | ||
| Ermöglicht das Beanspruchen von Arbeitselementen aus Dataflow. | |
| Ermöglicht dem Dataflow-Worker, Nachrichten an den Dataflow-Dienst zurückzusenden. | |
| Ermöglicht Dataflow-Workern, Logeinträge in Google Cloud Logging zu schreiben. | |
Sie können auch vordefinierte Rollen verwenden, die diese Berechtigungen enthalten.
|
|
|
|
|
|
|
|
Google Cloud-Projekt
Ein Projekt ist eine Grundeinheit für die Organisation in Google Cloud. Wenn ein Administrator einen solchen Schlüssel zur Verfügung gestellt hat, kann dieser Schritt übersprungen werden.
Ein Projekt kann mit der CLI so erstellt werden:
gcloud projects create <your-project-name>
Weitere Informationen zum Erstellen und Verwalten von Projekten
Beschränkungen
Es ist wichtig, sich über bestimmte Einschränkungen und Inkompatibilitäten von Datentypen im Klaren zu sein, die in dieser Pipeline auftreten können.
Databricks Iceberg zu BigQuery
Wenn Sie BigQuery verwenden, um von Databricks verwaltete Iceberg-Tabellen (über UniForm) abzufragen, beachten Sie Folgendes:
- Schemaentwicklung: UniForm übersetzt Delta Lake-Schemaänderungen zwar gut in Iceberg, aber komplexe Änderungen werden möglicherweise nicht immer wie erwartet weitergegeben. Das Umbenennen von Spalten in Delta Lake wird beispielsweise nicht in Iceberg übersetzt. Dort wird es als
dropundaddbetrachtet. Testen Sie Schemaänderungen immer gründlich. - Zeitreisen: BigQuery kann die Zeitreisefunktionen von Delta Lake nicht nutzen. Es wird nur der letzte Snapshot der Iceberg-Tabelle abgefragt.
- Nicht unterstützte Delta Lake-Funktionen: Funktionen wie Löschvektoren und Spaltenzuordnung mit dem Modus
idin Delta Lake sind nicht mit UniForm für Iceberg kompatibel. Im Lab wird der Modusnamefür die Spaltenzuordnung verwendet, der unterstützt wird.
BigQuery für Spanner
Der Befehl EXPORT DATA von BigQuery nach Spanner unterstützt nicht alle BigQuery-Datentypen. Wenn Sie eine Tabelle mit den folgenden Typen exportieren, tritt ein Fehler auf:
STRUCTGEOGRAPHYDATETIMERANGETIME
Wenn im BigQuery-Projekt der GoogleSQL-Dialekt verwendet wird, werden die folgenden numerischen Typen auch nicht für den Export nach Spanner unterstützt:
BIGNUMERIC
Eine vollständige und aktuelle Liste der Einschränkungen finden Sie in der offiziellen Dokumentation: Einschränkungen beim Exportieren nach Spanner.
Fehlerbehebung und Fallstricke
- Wenn Sie keine GCP Databricks-Instanz verwenden, ist es möglicherweise nicht möglich, einen External Data Location (externen Datenspeicherort) in GCS zu definieren. In solchen Fällen müssen die Dateien in der Speicherlösung des Cloud-Anbieters des Databricks-Arbeitsbereichs bereitgestellt und dann separat zu GCS migriert werden.
- Dabei müssen die Metadaten angepasst werden, da die Informationen fest codierte Pfade zu den bereitgestellten Dateien enthalten.
3. Google Cloud Storage (GCS) einrichten
Google Cloud Storage (GCS) wird zum Speichern der von Databricks generierten Parquet-Datendateien verwendet. Dazu muss zuerst ein neuer Bucket als Dateiziel erstellt werden.
Google Cloud Storage
Neuen Bucket erstellen
- Rufen Sie in Ihrer Cloud Console die Seite Google Cloud Storage auf.
- Wählen Sie im linken Bereich Buckets aus:
- Klicken Sie auf die Schaltfläche Erstellen:

- Geben Sie die Bucket-Details ein:
- Wählen Sie einen Bucket-Namen aus. In diesem Lab wird der Name
codelabs_retl_databricksverwendet. - Wählen Sie eine Region aus, in der der Bucket gespeichert werden soll, oder verwenden Sie die Standardwerte.
- Speicherklasse als
standardbeibehalten - Standardwerte für Zugriff steuern beibehalten
- Standardwerte für Objektdaten schützen beibehalten
- Klicken Sie auf die Schaltfläche
Create, wenn Sie fertig sind. Möglicherweise werden Sie aufgefordert, zu bestätigen, dass öffentlicher Zugriff verhindert wird. Bestätigen Sie die Änderung. - Ein neuer Bucket wurde erstellt. Sie werden zur Bucket-Seite weitergeleitet.
- Kopieren Sie den neuen Bucket-Namen und speichern Sie ihn, da Sie ihn später benötigen.
Vorbereitung auf die nächsten Schritte
Notieren Sie sich die folgenden Details, da sie in den nächsten Schritten benötigt werden:
- Google-Projekt-ID
- Name des Google Storage-Buckets
4. Databricks einrichten
TPC-H-Daten
In diesem Lab wird das TPC-H-Dataset verwendet, das ein Branchenstandard-Benchmark für Entscheidungsunterstützungssysteme ist. Das Schema bildet eine realistische Geschäftsumgebung mit Kunden, Bestellungen, Lieferanten und Teilen ab und eignet sich daher perfekt, um ein reales Analyse- und Datenmigrationsszenario zu demonstrieren.
Anstelle der Verwendung der Rohdaten der normalisierten TPC-H-Tabellen wird eine neue aggregierte Tabelle erstellt. In dieser neuen Tabelle werden Daten aus den Tabellen orders, customer und nation zusammengeführt, um eine denormalisierte, zusammengefasste Ansicht der regionalen Umsätze zu erstellen. Dieser Schritt der Vorabaggregation ist in der Analyse üblich, da er die Daten für einen bestimmten Anwendungsfall vorbereitet – in diesem Fall für die Nutzung durch eine operative Anwendung.
Das endgültige Schema für die aggregierte Tabelle sieht so aus:
Col | Typ |
nation_name | String |
market_segment | String |
order_year | int |
order_priority | String |
total_order_count | bigint |
total_revenue | decimal(29,2) |
unique_customer_count | bigint |
Iceberg-Unterstützung mit Delta Lake Universal Format (UniForm)
Für dieses Lab ist die Tabelle in Databricks eine Delta Lake-Tabelle. Damit sie jedoch von externen Systemen wie BigQuery gelesen werden können, wird eine leistungsstarke Funktion namens Universal Format (UniForm) aktiviert.
UniForm generiert automatisch Iceberg-Metadaten neben den Delta Lake-Metadaten für eine einzelne, gemeinsame Kopie der Tabellendaten. So erhalten Sie das Beste aus beiden Welten:
- Inside Databricks:Alle Leistungs- und Governance-Vorteile von Delta Lake werden genutzt.
- Außerhalb von Databricks:Die Tabelle kann von jeder Iceberg-kompatiblen Abfrage-Engine wie BigQuery gelesen werden, als wäre sie eine native Iceberg-Tabelle.
Dadurch entfällt die Notwendigkeit, separate Kopien der Daten zu verwalten oder manuelle Konvertierungsjobs auszuführen. UniForm wird aktiviert, indem beim Erstellen der Tabelle bestimmte Tabelleneigenschaften festgelegt werden.
Databricks-Kataloge
Ein Databricks-Katalog ist der Container der obersten Ebene für Daten in Unity Catalog, der einheitlichen Governance-Lösung von Databricks. Unity Catalog bietet eine zentrale Möglichkeit, Daten-Assets zu verwalten, den Zugriff zu steuern und die Herkunft zu verfolgen. Das ist entscheidend für eine gut verwaltete Datenplattform.
Die Daten werden in einem Namespace mit drei Ebenen organisiert: catalog.schema.table.
- Katalog:Die oberste Ebene, mit der Daten nach Umgebung, Geschäftseinheit oder Projekt gruppiert werden.
- Schema (oder Datenbank): Eine logische Gruppierung von Tabellen, Ansichten und Funktionen in einem Katalog.
- Tabelle:Das Objekt, das Ihre Daten enthält.
Bevor die aggregierte TPC-H-Tabelle erstellt werden kann, müssen ein dedizierter Katalog und ein dediziertes Schema eingerichtet werden, in denen sie gespeichert wird. So ist das Projekt gut organisiert und von anderen Daten im Arbeitsbereich isoliert.
Neuen Katalog und neues Schema erstellen
Im Databricks Unity Catalog ist ein Katalog die oberste Organisationsebene für Datenassets. Er fungiert als sicherer Container, der sich über mehrere Databricks-Arbeitsbereiche erstrecken kann. Damit können Sie Daten nach Geschäftsbereichen, Projekten oder Umgebungen organisieren und isolieren und dabei klar definierte Berechtigungen und Zugriffskontrollen festlegen.
In einem Katalog werden Tabellen, Ansichten und Funktionen in einem Schema (auch als Datenbank bezeichnet) weiter organisiert. Diese hierarchische Struktur ermöglicht eine detaillierte Steuerung und logische Gruppierung zugehöriger Datenobjekte. Für dieses Lab werden ein dedizierter Katalog und ein dediziertes Schema erstellt, um die TPC-H-Daten zu speichern und so eine ordnungsgemäße Isolation und Verwaltung zu gewährleisten.
Katalog erstellen
- Rufen Sie
 auf.
auf. - Klicken Sie auf das + und wählen Sie im Drop-down-Menü Katalog erstellen aus.
- Ein neuer Standard-Katalog wird mit den folgenden Einstellungen erstellt:
- Katalogname:
retl_tpch_project - Speicherort: Verwenden Sie den Standardspeicherort, falls einer im Arbeitsbereich eingerichtet wurde, oder erstellen Sie einen neuen.
Schema erstellen
- Rufen Sie auf.
- Wählen Sie im linken Bereich den neuen Katalog aus, der erstellt wurde.
- Klicken Sie auf
 .
. - Ein neues Schema wird mit dem Schemanamen als
tpch_dataerstellt.
Externe Daten einrichten
Damit Sie Daten aus Databricks in Google Cloud Storage (GCS) exportieren können, müssen in Databricks Anmeldedaten für externe Daten eingerichtet werden. Dadurch kann Databricks sicher auf den GCS-Bucket zugreifen und Daten hineinschreiben.
- Klicken Sie auf dem Bildschirm Katalog auf
 .
.
- Wenn Sie die Option
External Datanicht sehen, finden SieExternal Locationsmöglicherweise stattdessen in einem Drop-down-MenüConnect.
- Klicken Sie auf
 .
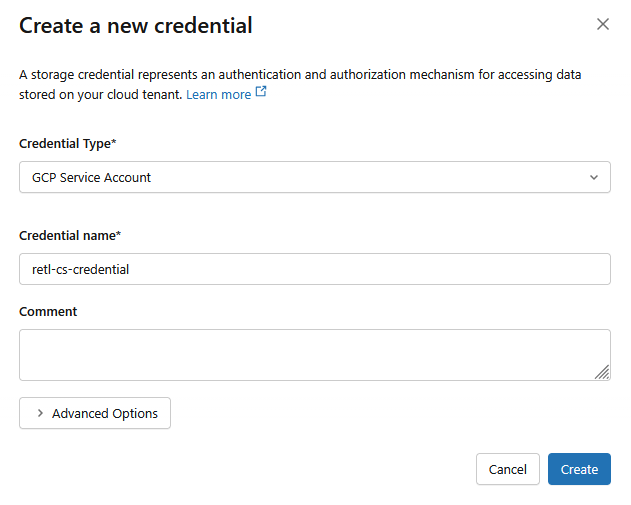
. - Legen Sie im neuen Dialogfeld die erforderlichen Werte für die Anmeldedaten fest:
- Berechtigungsnachweistyp:
GCP Service Account - Name des Berechtigungsnachweises:
retl-gcs-credential
- Klicken Sie auf Erstellen.
- Klicken Sie dann auf den Tab Externe Standorte.
- Klicken Sie auf Standort erstellen.
- Legen Sie im neuen Dialogfeld die erforderlichen Werte für den externen Speicherort fest:
- Name des externen Standorts:
retl-gcs-location - Speichertyp:
GCP - URL: Die URL des GCS-Buckets im Format
gs://YOUR_BUCKET_NAME - Speicheranmeldedaten: Wählen Sie die gerade erstellten
retl-gcs-credentialaus.
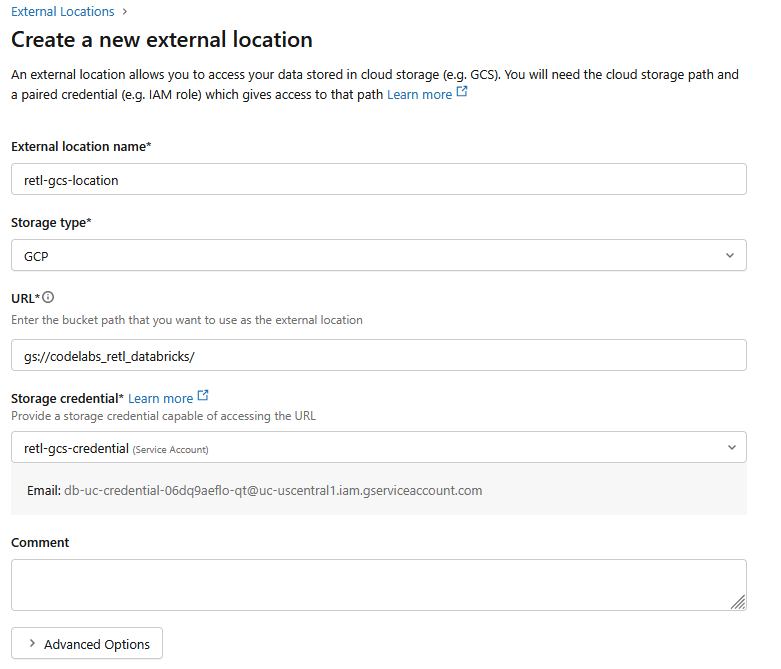
- Notieren Sie sich die E-Mail-Adresse des Dienstkontos, die automatisch ausgefüllt wird, wenn Sie die Speicheranmeldedaten auswählen, da sie im nächsten Schritt benötigt wird.
- Klicken Sie auf Erstellen.
5. Dienstkontoberechtigungen festlegen
Ein Dienstkonto ist ein spezieller Kontotyp, der von Anwendungen oder Diensten verwendet wird, um autorisierte API-Aufrufe an Google Cloud-Ressourcen zu senden.
Dem Dienstkonto, das für den neuen Bucket in GCS erstellt wurde, müssen jetzt Berechtigungen hinzugefügt werden.
- Wählen Sie auf der Seite des GCS-Buckets den Tab Berechtigungen aus.
- Klicken Sie auf der Seite „Hauptkonten“ auf Zugriff gewähren.
- Geben Sie im Bereich Zugriff gewähren, der von rechts eingeblendet wird, die Dienstkonto-ID in das Feld Neue Hauptkonten ein.
- Fügen Sie unter Rollen zuweisen die Rollen
Storage Object AdminundStorage Legacy Bucket Readerhinzu. Mit diesen Rollen kann das Dienstkonto Objekte im Storage-Bucket lesen, schreiben und auflisten.
TPC-H-Daten laden
Nachdem der Katalog und das Schema erstellt wurden, können die TPCH-Daten aus der vorhandenen Tabelle samples.tpch geladen werden, die intern in Databricks gespeichert ist, und in eine neue Tabelle im neu definierten Schema eingefügt werden.
Tabelle mit Iceberg-Unterstützung erstellen
Iceberg-Kompatibilität mit UniForm
Im Hintergrund verwaltet Databricks diese Tabelle intern als Delta Lake-Tabelle und bietet so alle Vorteile der Leistungsoptimierungen und Governance-Funktionen von Delta im Databricks-Ökosystem. Wenn Sie jedoch UniForm (kurz für Universal Format) aktivieren, wird Databricks angewiesen, etwas Besonderes zu tun: Jedes Mal, wenn die Tabelle aktualisiert wird, generiert und verwaltet Databricks automatisch die entsprechenden Iceberg-Metadaten zusätzlich zu den Delta Lake-Metadaten.
Das bedeutet, dass ein einzelner, gemeinsamer Satz von Datendateien (die Parquet-Dateien) jetzt durch zwei verschiedene Metadatensätze beschrieben wird.
- Für Databricks:Zum Lesen der Tabelle wird
_delta_logverwendet. - Für externe Leser (z. B. BigQuery): Sie verwenden die Iceberg-Metadatendatei (
.metadata.json), um das Schema, die Partitionierung und die Dateispeicherorte der Tabelle zu ermitteln.
Das Ergebnis ist eine Tabelle, die vollständig und transparent mit allen Iceberg-kompatiblen Tools kompatibel ist. Es gibt keine Datenduplizierung und keine manuelle Konvertierung oder Synchronisierung ist erforderlich. Es ist eine einzige Quelle der Wahrheit, auf die sowohl die analytische Welt von Databricks als auch das breitere Ökosystem von Tools, die den offenen Iceberg-Standard unterstützen, nahtlos zugreifen können.
- Klicken Sie auf Neu und dann auf Abfrage.
- Führen Sie im Textfeld der Abfrageseite den folgenden SQL-Befehl aus:
CREATE TABLE retl_tpch_project.tpch_data.regional_sales_iceberg
USING DELTA
LOCATION 'gs://<Your bucket name>/regional_sales_iceberg'
TBLPROPERTIES (
'delta.columnMapping.mode' = 'name',
'delta.enableIcebergCompatV2' = 'true',
'delta.universalFormat.enabledFormats' = 'iceberg'
)
AS
SELECT
n.n_name AS nation_name,
c.c_mktsegment AS market_segment,
YEAR(o.o_orderdate) AS order_year,
o.o_orderpriority AS order_priority,
COUNT(o.o_orderkey) AS total_order_count,
ROUND(SUM(o.o_totalprice), 2) AS total_revenue,
COUNT(DISTINCT c.c_custkey) AS unique_customer_count
FROM samples.tpch.orders AS o
INNER JOIN samples.tpch.customer AS c
ON o.o_custkey = c.c_custkey
INNER JOIN samples.tpch.nation AS n
ON c.c_nationkey = n.n_nationkey
GROUP BY
n.n_name,
c.c_mktsegment,
YEAR(o.o_orderdate),
o.o_orderpriority;
OPTIMIZE retl_tpch_project.tpch_data.regional_sales_iceberg;
DESCRIBE EXTENDED retl_tpch_project.tpch_data.regional_sales_iceberg;
Hinweise:
- Using Delta: Gibt an, dass wir eine Delta Lake-Tabelle verwenden. Nur Delta Lake-Tabellen in Databricks können als externe Tabelle gespeichert werden.
- Speicherort: Gibt an, wo die Tabelle gespeichert werden soll, wenn sie extern ist.
- TablePropertoes: Mit
delta.universalFormat.enabledFormats = ‘iceberg'werden die kompatiblen Iceberg-Metadaten neben den Delta Lake-Dateien erstellt. - Optimize: Löst die UniForm-Metadatengenerierung sofort aus, da sie normalerweise asynchron erfolgt.
- Die Ausgabe der Abfrage sollte Details zur neu erstellten Tabelle enthalten.

GCS-Tabellendaten prüfen
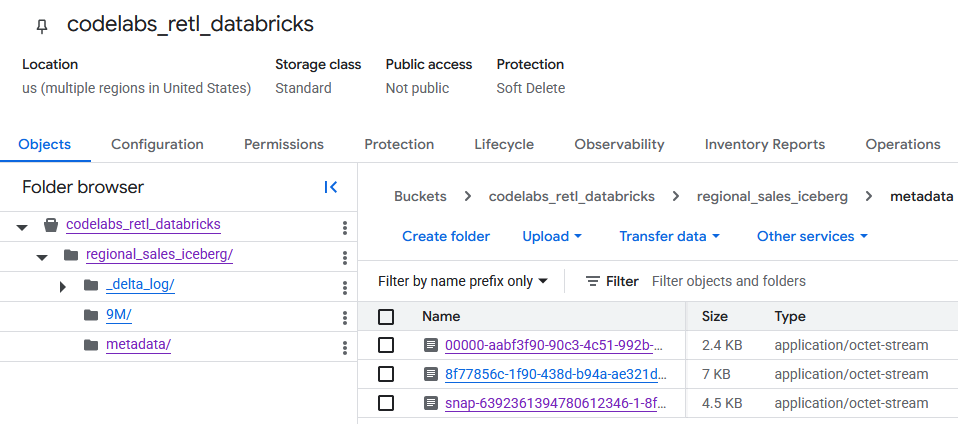
Wenn Sie zum GCS-Bucket navigieren, finden Sie dort die neu erstellten Tabellendaten.
Die Iceberg-Metadaten finden Sie im Ordner metadata, der von externen Lesern (z. B. BigQuery) verwendet wird. Die Delta Lake-Metadaten, die intern von Databricks verwendet werden, werden im Ordner _delta_log gespeichert.
Die eigentlichen Tabellendaten werden als Parquet-Dateien in einem anderen Ordner gespeichert, der in der Regel von Databricks mit einem zufällig generierten String benannt wird. Im Screenshot unten befinden sich die Datendateien beispielsweise im Ordner 9M.
6. BigQuery und BigLake einrichten
Nachdem sich die Iceberg-Tabelle in Google Cloud Storage befindet, muss sie für BigQuery zugänglich gemacht werden. Dazu wird eine externe BigLake-Tabelle erstellt.
BigLake ist eine Speicher-Engine, mit der Tabellen in BigQuery erstellt werden können, die Daten direkt aus externen Quellen wie Google Cloud Storage lesen. Für dieses Lab ist es die Schlüsseltechnologie, die es BigQuery ermöglicht, die gerade exportierte Iceberg-Tabelle zu verstehen, ohne die Daten aufnehmen zu müssen.
Dazu sind zwei Komponenten erforderlich:
- Cloud-Ressourcenverbindung:Dies ist eine sichere Verbindung zwischen BigQuery und GCS. Für die Authentifizierung wird ein spezielles Dienstkonto verwendet, damit BigQuery die erforderlichen Berechtigungen zum Lesen der Dateien aus dem GCS-Bucket hat.
- Definition einer externen Tabelle:Damit wird BigQuery mitgeteilt, wo die Metadatendatei der Iceberg-Tabelle in GCS zu finden ist und wie sie interpretiert werden soll.
Cloud-Ressourcenverbindung erstellen
Zuerst wird die Verbindung erstellt, über die BigQuery auf GCS zugreifen kann.
Weitere Informationen zum Erstellen von Cloud-Ressourcenverbindungen
- BigQuery
- Klicken Sie unter Explorer auf Verbindungen.
- Wenn die Ebene Explorer nicht sichtbar ist, klicken Sie auf
 .
.
- Klicken Sie auf der Seite Verbindungen auf
 .
. - Wählen Sie als Verbindungstyp
Vertex AI remote models, remote functions, BigLake and Spanner (Cloud Resource)aus. - Legen Sie die Verbindungs-ID auf
databricks_retlfest und erstellen Sie die Verbindung.

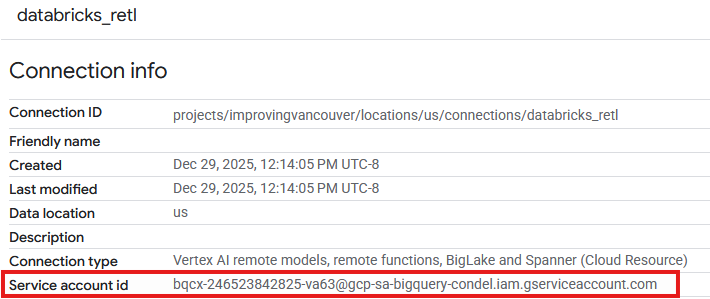
- In der Tabelle Verbindungen der neu erstellten Verbindung sollte jetzt ein Eintrag zu sehen sein. Klicken Sie auf diesen Eintrag, um die Verbindungsdetails aufzurufen.

- Notieren Sie sich auf der Seite mit den Verbindungsdetails die Dienstkonto-ID, da Sie sie später benötigen.
Zugriff auf das Dienstkonto für die Verbindung gewähren
- Rufen Sie IAM & Verwaltung auf.
- Klicken Sie auf Zugriff gewähren.
- Geben Sie im Feld Neue Hauptkonten die oben erstellte Dienstkonto-ID der Verbindungsressource ein.
- Wählen Sie als Rolle
Storage Object Useraus und klicken Sie dann auf .
.
Nachdem die Verbindung hergestellt und dem zugehörigen Dienstkonto die erforderlichen Berechtigungen erteilt wurden, kann die externe BigLake-Tabelle erstellt werden. Zuerst benötigen Sie ein Dataset in BigQuery, das als Container für die neue Tabelle dient. Anschließend wird die Tabelle selbst erstellt und auf die Iceberg-Metadatendatei im GCS-Bucket verwiesen.
- BigQuery
- Klicken Sie im Bereich Explorer auf die Projekt‑ID, dann auf das Dreipunkt-Menü und wählen Sie Dataset erstellen aus.
- Das Dataset wird
databricks_retlgenannt. Übernehmen Sie für die anderen Optionen die Standardwerte und klicken Sie auf die Schaltfläche Dataset erstellen.
- Suchen Sie nun im Bereich Explorer nach dem neuen Dataset
databricks_retl. Klicken Sie auf das Dreipunkt-Menü daneben und wählen Sie Tabelle erstellen aus.
- Nehmen Sie die folgenden Einstellungen für die Tabellenerstellung vor:
- Tabelle erstellen aus:
Google Cloud Storage - Datei aus GCS-Bucket auswählen oder URI-Muster verwenden: Suchen Sie nach dem GCS-Bucket und der JSON-Metadatendatei, die beim Databricks-Export generiert wurde. Der Pfad sollte etwa so aussehen:
regional_sales/metadata/v1.metadata.json. - Dateiformat:
Iceberg - Tabelle:
regional_sales - Tabellentyp:
External table - Verbindungs-ID: Wählen Sie die zuvor erstellte
databricks_retl-Verbindung aus. - Übernehmen Sie die Standardwerte für die übrigen Werte und klicken Sie auf Tabelle erstellen.
- Nachdem die neue
regional_sales-Tabelle erstellt wurde, sollte sie imdatabricks_retl-Dataset sichtbar sein. Diese Tabelle kann jetzt mit Standard-SQL abgefragt werden, genau wie jede andere BigQuery-Tabelle.
7. In Spanner laden
Der letzte und wichtigste Teil der Pipeline ist erreicht: die Daten aus BigLake-Tabellen in Spanner verschieben. Dies ist der Schritt „Reverse-ETL“, bei dem die Daten, die im Data Warehouse verarbeitet und kuratiert wurden, in ein Betriebssystem geladen werden, damit sie von Anwendungen verwendet werden können.
Spanner ist eine vollständig verwaltete, global verteilte relationale Datenbank. Sie bietet die Transaktionskonsistenz einer herkömmlichen relationalen Datenbank, aber mit der horizontalen Skalierbarkeit einer NoSQL-Datenbank. Daher ist es eine ideale Wahl für die Entwicklung skalierbarer, hochverfügbarer Anwendungen.
So läuft der Prozess ab:
- Erstellen Sie eine Spanner-Instanz, die die physische Zuweisung von Ressourcen darstellt.
- Erstellen Sie eine Datenbank in dieser Instanz.
- Definieren Sie in der Datenbank ein Tabellenschema, das der Struktur der
regional_sales-Daten entspricht. - Führen Sie eine BigQuery-
EXPORT DATA-Abfrage aus, um die Daten aus der BigLake-Tabelle direkt in die Spanner-Tabelle zu laden.
Spanner-Instanz, -Datenbank und -Tabelle erstellen
- Rufen Sie Spanner auf.
- Klicken Sie auf
 . Sie können eine vorhandene Instanz verwenden, falls eine verfügbar ist. Richten Sie die Instanzanforderungen nach Bedarf ein. Für dieses Lab wurde Folgendes verwendet:
. Sie können eine vorhandene Instanz verwenden, falls eine verfügbar ist. Richten Sie die Instanzanforderungen nach Bedarf ein. Für dieses Lab wurde Folgendes verwendet:
Edition | Unternehmen |
Instanzname | databricks-retl |
Region konfigurieren | Ihre bevorzugte Region |
Recheneinheit | Verarbeitungseinheiten |
Manuelle Zuweisung | 100 |
- Rufen Sie nach der Erstellung die Seite der Spanner-Instanz auf und wählen Sie
 aus. Sie können eine vorhandene Datenbank verwenden, falls eine verfügbar ist.
aus. Sie können eine vorhandene Datenbank verwenden, falls eine verfügbar ist.
- Für dieses Lab wird eine Datenbank mit folgenden Eigenschaften erstellt:
- Name:
databricks-retl - Datenbankdialekt:
Google Standard SQL
- Nachdem die Datenbank erstellt wurde, wählen Sie sie auf der Seite „Spanner-Instanz“ aus, um die Seite „Spanner-Datenbank“ aufzurufen.
- Klicken Sie auf der Seite „Spanner-Datenbank“ auf
 .
. - Auf der neuen Abfrageseite wird die Tabellendefinition für die Tabelle erstellt, die in Spanner importiert werden soll. Führen Sie dazu die folgende SQL-Abfrage aus.
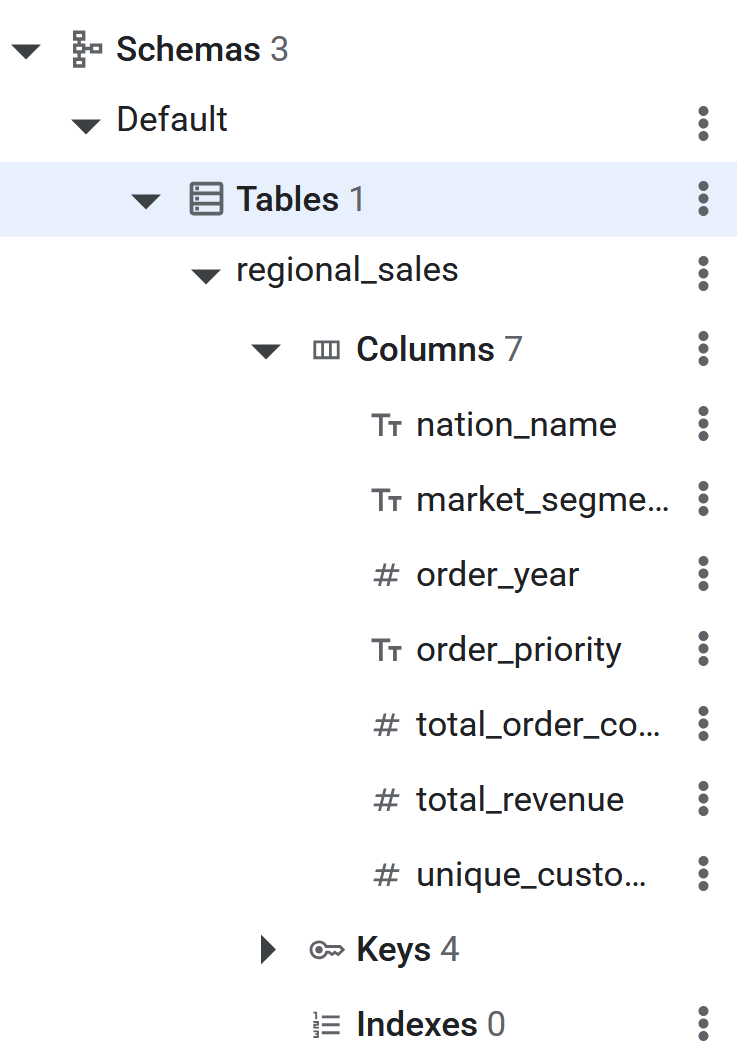
CREATE TABLE regional_sales (
nation_name STRING(MAX),
market_segment STRING(MAX),
order_year INT64,
order_priority STRING(MAX),
total_order_count INT64,
total_revenue NUMERIC,
unique_customer_count INT64
) PRIMARY KEY (nation_name, market_segment, order_year, order_priority);
- Nachdem der SQL-Befehl ausgeführt wurde, ist die Spanner-Tabelle bereit für das Reverse-ETL der Daten durch BigQuery. Sie können die Erstellung der Tabelle überprüfen, indem Sie sie in der Spanner-Datenbank im linken Bereich aufrufen.
Reverse-ETL zu Cloud Spanner mit EXPORT DATA
Das ist der letzte Schritt. Nachdem die Quelldaten in einer BigQuery BigLake-Tabelle verfügbar sind und die Zieltabelle in Spanner erstellt wurde, ist die eigentliche Datenübertragung überraschend einfach. Es wird eine einzelne BigQuery-SQL-Abfrage verwendet: EXPORT DATA.
Diese Abfrage wurde speziell für solche Szenarien entwickelt. Damit lassen sich Daten effizient aus einer BigQuery-Tabelle (einschließlich externer Tabellen wie der BigLake-Tabelle) an ein externes Ziel exportieren. In diesem Fall ist das Ziel die Spanner-Tabelle. Weitere Informationen zur Exportfunktion
Weitere Informationen zum Einrichten des umgekehrten ETL-Prozesses von BigQuery zu Cloud Spanner finden Sie hier.
- BigQuery
- Öffnen Sie einen neuen Tab für den Abfrageeditor.
- Geben Sie auf der Seite „Abfrage“ den folgenden SQL-Code ein. Denken Sie daran, die Projekt-ID im **
uri** **und den Tabellenpfad durch die richtige Projekt-ID zu ersetzen.**
EXPORT DATA OPTIONS(
uri='https://spanner.googleapis.com/projects/YOUR_PROJECT_ID/instances/databricks-retl/databases/databricks-retl',
format='CLOUD_SPANNER',
spanner_options="""{
"table": "regional_sales",
"priority": "MEDIUM"
}"""
) AS
SELECT * FROM `YOUR_PROJECT_ID.databricks_retl.regional_sales`;
- Sobald der Befehl abgeschlossen ist, wurden die Daten erfolgreich nach Spanner exportiert.
8. Daten in Spanner prüfen
Glückwunsch! Eine vollständige Reverse-ETL-Pipeline wurde erfolgreich erstellt und ausgeführt, um Daten aus einem Databricks-Data-Warehouse in eine operative Spanner-Datenbank zu übertragen.
Im letzten Schritt müssen Sie prüfen, ob die Daten wie erwartet in Spanner angekommen sind.
- Rufen Sie Spanner auf.
- Rufen Sie Ihre
databricks-retl-Instanz und dann diedatabricks-retl-Datenbank auf. - Klicken Sie in der Liste der Tabellen auf die Tabelle
regional_sales. - Klicken Sie im Navigationsmenü links für die Tabelle auf den Tab Daten.
- Die aggregierten Verkaufsdaten, die ursprünglich aus Databricks stammen, sollten jetzt geladen und für die Verwendung in der Spanner-Tabelle bereit sein. Diese Daten befinden sich jetzt in einem operativen System und können für eine Live-Anwendung, ein Dashboard oder API-Abfragen verwendet werden.
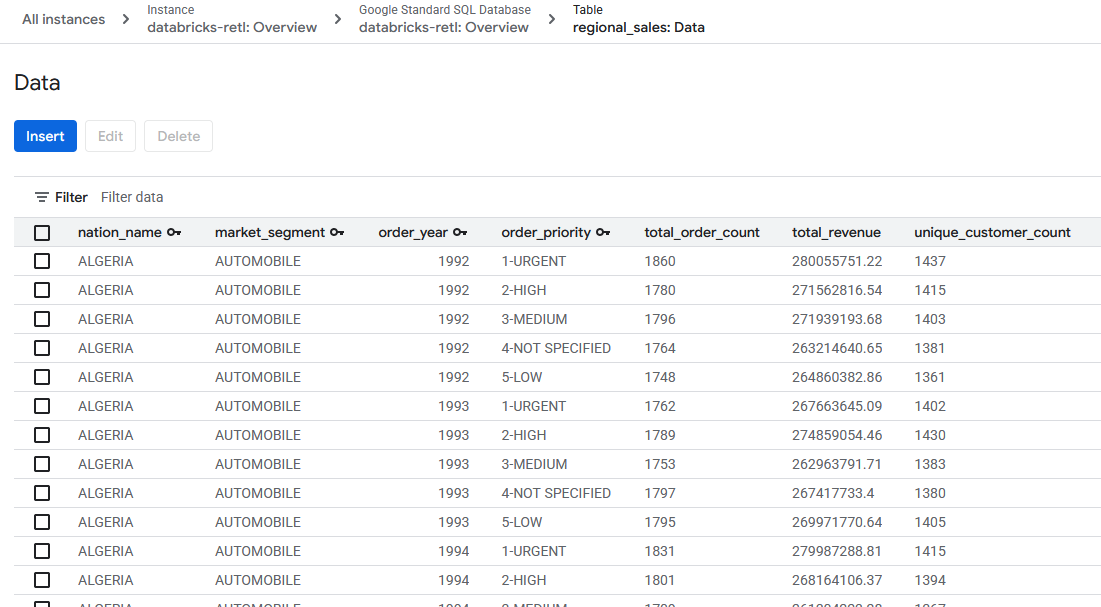
Die Lücke zwischen der Welt der Analyse- und Betriebsdaten wurde erfolgreich geschlossen.
9. Klären
Entfernen Sie alle hinzugefügten Tabellen und gespeicherten Daten, wenn Sie dieses Lab abgeschlossen haben.
Cloud Spanner-Tabellen bereinigen
- Gehen Sie zu Spanner.
- Klicken Sie in der Liste mit dem Namen
databricks-retlauf die Instanz, die für dieses Lab verwendet wurde.

- Klicken Sie auf der Instanzseite auf
 .
. - Geben Sie im angezeigten Bestätigungsdialog
databricks-retlein und klicken Sie auf .
.
GCS bereinigen
- GCS aufrufen
- Wählen Sie im Menü auf der linken Seite
 aus.
aus. - Wählen Sie den Bucket „codelabs_retl_databricks“ aus.
- Klicken Sie nach der Auswahl auf die Schaltfläche
 im oberen Banner.
im oberen Banner.

- Geben Sie im angezeigten Bestätigungsdialog
DELETEein und klicken Sie auf.
Databricks bereinigen
Katalog/Schema/Tabelle löschen
- Bei Ihrer Databricks-Instanz anmelden
- Klicken Sie im Menü auf der linken Seite auf
 .
. - Wählen Sie die zuvor erstellte
 aus der Katalogliste aus.
aus der Katalogliste aus. - Wählen Sie in der Schemaliste das Schema
 aus, das erstellt wurde.
aus, das erstellt wurde. - Wählen Sie die zuvor erstellte
 aus der Tabellenliste aus.
aus der Tabellenliste aus. - Maximieren Sie die Tabellenoptionen, indem Sie auf
 klicken, und wählen Sie
klicken, und wählen Sie Deleteaus. - Klicken Sie im Bestätigungsdialogfeld auf
 , um die Tabelle zu löschen.
, um die Tabelle zu löschen. - Nachdem die Tabelle gelöscht wurde, werden Sie zur Schemaseite zurückgeleitet.
- Maximieren Sie die Schemaoptionen, indem Sie auf klicken, und wählen Sie
Deleteaus. - Klicken Sie im Bestätigungsdialogfeld auf , um das Schema zu löschen.
- Nachdem das Schema gelöscht wurde, werden Sie zur Katalogseite zurückgeleitet.
- Wiederholen Sie die Schritte 4 bis 11, um das
default-Schema zu löschen, falls es vorhanden ist. - Maximieren Sie auf der Katalogseite die Katalogoptionen, indem Sie auf klicken, und wählen Sie
Deleteaus. - Klicken Sie im Bestätigungsdialogfeld auf , um den Katalog zu löschen.
Speicherort / Anmeldedaten für externe Daten löschen
- Klicken Sie auf dem Bildschirm „Katalog“ auf .
- Wenn Sie die Option
External Datanicht sehen, finden SieExternal Locationmöglicherweise stattdessen in einem Drop-down-MenüConnect. - Klicken Sie auf den zuvor erstellten externen Datenstandort
retl-gcs-location. - Erweitern Sie auf der Seite für den externen Standort die Standortoptionen, indem Sie auf klicken, und wählen Sie
Deleteaus. - Klicken Sie im Bestätigungsdialogfeld auf , um den externen Standort zu löschen.
- Klicken Sie auf .
- Klicken Sie auf das zuvor erstellte
retl-gcs-credential. - Klicken Sie auf der Seite „Anmeldedaten“ auf , um die Optionen für Anmeldedaten zu maximieren, und wählen Sie
Deleteaus. - Klicken Sie im Bestätigungsdialogfeld auf , um die Anmeldedaten zu löschen.
10. Glückwunsch
Herzlichen Glückwunsch zum Abschluss des Codelabs.
Behandelte Themen
- Daten als Iceberg-Tabellen in Databricks laden
- GCS-Bucket erstellen
- Databricks-Tabelle im Iceberg-Format in GCS exportieren
- BigLake-externe Tabelle in BigQuery aus der Iceberg-Tabelle in GCS erstellen
- Spanner-Instanz einrichten
- BigLake-Tabellen in BigQuery in Spanner laden