
1. Crea una canalización de ETL inversa de Databricks a Spanner con Google Cloud Storage y BigQuery
Introducción
En este codelab, compilarás una canalización de ETL inverso de Databricks a Spanner. Tradicionalmente, las canalizaciones de ETL (extracción, transformación y carga) estándar mueven los datos de las bases de datos operativas a un almacén de datos como Databricks para el análisis. Una canalización de ETL inversa hace lo contrario: mueve datos procesados y seleccionados desde el almacén de datos de vuelta a las bases de datos operativas, como Spanner, una base de datos relacional distribuida a nivel global ideal para aplicaciones de alta disponibilidad, en la que puede potenciar aplicaciones, ofrecer funciones orientadas al usuario o usarse para la toma de decisiones en tiempo real.
El objetivo es transferir un conjunto de datos agregados de las tablas de Iceberg de Databricks a las tablas de Spanner.
Para lograrlo, se usan Google Cloud Storage (GCS) y BigQuery como pasos intermedios. A continuación, se muestra un desglose del flujo de datos y la lógica detrás de esta arquitectura:

- Databricks a Google Cloud Storage (GCS) en formato Iceberg:
- El primer paso es extraer los datos de Databricks en un formato abierto y bien definido. La tabla se exporta en formato Apache Iceberg. En este proceso, se escriben los datos subyacentes como un conjunto de archivos Parquet y los metadatos de la tabla (esquema, particiones, ubicaciones de archivos) como archivos JSON y Avro. Al organizar esta estructura de tabla completa en GCS, los datos se vuelven portátiles y accesibles para cualquier sistema que comprenda el formato de Iceberg.
- Convierte las tablas de Iceberg de GCS en tablas externas de BigLake de BigQuery:
- En lugar de cargar los datos directamente desde GCS a Spanner, se usa BigQuery como un potente intermediario. Se crea una tabla externa de BigLake en BigQuery que apunta directamente al archivo de metadatos de Iceberg en GCS. Este enfoque tiene varias ventajas:
- Sin duplicación de datos: BigQuery lee la estructura de la tabla de los metadatos y consulta los archivos de datos de Parquet in situ sin transferirlos, lo que ahorra una cantidad significativa de tiempo y costos de almacenamiento.
- Consultas federadas: Permiten ejecutar consultas en SQL complejas sobre los datos de GCS como si fueran una tabla nativa de BigQuery.
- Tabla externa de BigLake de ReverseETL en Spanner:
- El último paso es transferir los datos de BigQuery a Spanner. Esto se logra con una potente función de BigQuery llamada consulta
EXPORT DATA, que es el paso de "ETL inversa". - Preparación operativa: Spanner está diseñado para cargas de trabajo transaccionales, lo que proporciona coherencia sólida y alta disponibilidad para las aplicaciones. Al trasladar los datos a Spanner, se los hace accesibles para las aplicaciones orientadas al usuario, las APIs y otros sistemas operativos que requieren búsquedas puntuales de baja latencia.
- Escalabilidad: Este patrón permite aprovechar la potencia analítica de BigQuery para procesar grandes conjuntos de datos y, luego, entregar los resultados de manera eficiente a través de la infraestructura escalable a nivel global de Spanner.
Servicios y terminología
- DataBricks: Es una plataforma de datos basada en la nube y creada en torno a Apache Spark.
- Spanner: Es una base de datos relacional distribuida a nivel mundial y completamente administrada por Google.
- Google Cloud Storage: Es la oferta de almacenamiento de BLOB de Google Cloud.
- BigQuery: Es un almacén de datos sin servidores para estadísticas que Google administra por completo.
- Iceberg: Es un formato de tabla abierta definido por Apache que proporciona abstracción sobre los formatos de archivo de datos de código abierto comunes.
- Parquet: Es un formato de archivo de datos binarios columnar de código abierto de Apache.
Qué aprenderás
- Cómo cargar datos en Databricks como tablas de Iceberg
- Cómo crear un bucket de GCS
- Cómo exportar una tabla de Databricks a GCS en formato Iceberg
- Cómo crear una tabla externa de BigLake en BigQuery a partir de la tabla de Iceberg en GCS
- Cómo configurar una instancia de Spanner
- Cómo cargar tablas externas de BigLake en BigQuery a Spanner
2. Configuración, requisitos y limitaciones
Requisitos previos
- Una cuenta de Databricks, de preferencia en GCP
- Se requiere una cuenta de Google Cloud con una reserva de nivel Enterprise o superior de BigQuery para exportar datos de BigQuery a Spanner.
- Acceso a la consola de Google Cloud a través de un navegador web
- Una terminal para ejecutar comandos de Google Cloud CLI
Si tu organización de Google Cloud tiene habilitada la política iam.allowedPolicyMemberDomains, es posible que un administrador deba otorgar una excepción para permitir cuentas de servicio de dominios externos. Esto se abordará en un paso posterior, cuando corresponda.
Requisitos
- Un proyecto de Google Cloud con facturación habilitada.
- Un navegador web, como Chrome
- Una cuenta de Databricks (en este lab, se supone que hay un espacio de trabajo alojado en GCP)
- La instancia de BigQuery debe estar en la edición Enterprise o superior para usar la función EXPORT DATA.
- Si tu organización de Google Cloud tiene habilitada la política
iam.allowedPolicyMemberDomains, es posible que un administrador deba otorgar una excepción para permitir cuentas de servicio de dominios externos. Esto se abordará en un paso posterior, cuando corresponda.
Permisos de IAM de Google Cloud Platform
La Cuenta de Google necesitará los siguientes permisos para ejecutar todos los pasos de este codelab.
Cuentas de servicio | ||
| Permite la creación de cuentas de servicio. | |
Spanner | ||
| Permite crear una instancia de Spanner nueva. | |
| Permite ejecutar sentencias DDL para crear | |
| Permite ejecutar sentencias DDL para crear tablas en la base de datos. | |
Google Cloud Storage | ||
| Permite crear un bucket de GCS nuevo para almacenar los archivos Parquet exportados. | |
| Permite escribir los archivos Parquet exportados en el bucket de GCS. | |
| Permite que BigQuery lea los archivos Parquet del bucket de GCS. | |
| Permite que BigQuery cree una lista de los archivos Parquet en el bucket de GCS. | |
Dataflow | ||
| Permite reclamar elementos de trabajo de Dataflow. | |
| Permite que el trabajador de Dataflow envíe mensajes al servicio de Dataflow. | |
| Permite que los trabajadores de Dataflow escriban entradas de registro en Cloud Logging de Google Cloud. | |
Para mayor comodidad, se pueden usar roles predefinidos que contengan estos permisos.
|
|
|
|
|
|
|
|
Proyecto de Google Cloud
Un proyecto es una unidad básica de organización en Google Cloud. Si un administrador proporcionó una para usar, se puede omitir este paso.
Puedes crear un proyecto con la CLI de la siguiente manera:
gcloud projects create <your-project-name>
Obtén más información para crear y administrar proyectos aquí.
Limitaciones
Es importante tener en cuenta ciertas limitaciones e incompatibilidades de tipos de datos que pueden surgir en esta canalización.
Databricks Iceberg a BigQuery
Cuando uses BigQuery para consultar tablas de Iceberg administradas por Databricks (a través de UniForm), ten en cuenta lo siguiente:
- Evolución del esquema: Si bien UniForm hace un buen trabajo traduciendo los cambios de esquema de Delta Lake a Iceberg, es posible que los cambios complejos no siempre se propaguen como se espera. Por ejemplo, cambiar el nombre de las columnas en Delta Lake no se traduce a Iceberg, que lo ve como un
dropy unadd. Siempre prueba los cambios de esquema a fondo. - Viaje en el tiempo: BigQuery no puede usar las capacidades de viaje en el tiempo de Delta Lake. Solo consultará la instantánea más reciente de la tabla de Iceberg.
- Funciones de Delta Lake no admitidas: Las funciones como los vectores de eliminación y la asignación de columnas con el modo
iden Delta Lake no son compatibles con UniForm para Iceberg. El lab usa el modonamepara la asignación de columnas, que es compatible.
BigQuery a Spanner
El comando EXPORT DATA de BigQuery a Spanner no admite todos los tipos de datos de BigQuery. Si exportas una tabla con los siguientes tipos, se producirá un error:
STRUCTGEOGRAPHYDATETIMERANGETIME
Además, si el proyecto de BigQuery usa el dialecto GoogleSQL, los siguientes tipos numéricos tampoco se admiten para la exportación a Spanner:
BIGNUMERIC
Para obtener una lista completa y actualizada de las limitaciones, consulta la documentación oficial: Limitaciones de la exportación a Spanner.
Solución de problemas y posibles inconvenientes
- Si no se encuentra en una instancia de Databricks de GCP, es posible que no se pueda definir una ubicación de datos externa en GCS. En esos casos, los archivos deberán almacenarse de forma intermedia en la solución de almacenamiento del proveedor de servicios en la nube del espacio de trabajo de Databricks y, luego, migrarse a GCS por separado.
- Cuando lo hagas, deberás ajustar los metadatos, ya que la información tendrá rutas codificadas de forma rígida a los archivos transferidos.
3. Configura Google Cloud Storage (GCS)
Google Cloud Storage (GCS) se usará para almacenar los archivos de datos de Parquet que genera Databricks. Para ello, primero se deberá crear un bucket nuevo que se usará como destino del archivo.
Google Cloud Storage
Crea un bucket nuevo
- Navega a la página Google Cloud Storage en la consola de Cloud.
- En el panel izquierdo, selecciona Buckets:
- Haga clic en el botón Create:

- Completa los detalles del bucket:
- Elige un nombre de bucket para usar. Para este lab, se usará el nombre
codelabs_retl_databricks. - Selecciona una región para almacenar el bucket o usa los valores predeterminados.
- Mantener la clase de almacenamiento como
standard - Mantén los valores predeterminados para control access.
- Mantén los valores predeterminados para proteger los datos de objeto
- Cuando termines, haz clic en el botón
Create. Es posible que aparezca un mensaje para confirmar que se impedirá el acceso público. Confirma la operación. - ¡Felicitaciones! Se creó correctamente un bucket nuevo. Se producirá un redireccionamiento a la página del bucket.
- Copia el nombre del bucket nuevo en algún lugar, ya que lo necesitarás más adelante.
Preparación para los próximos pasos
Asegúrate de anotar los siguientes detalles, ya que los necesitarás en los próximos pasos:
- ID del proyecto de Google
- Nombre del bucket de Google Storage
4. Configura Databricks
Datos de TPC-H
En este lab, se usará el conjunto de datos TPC-H, que es una comparativa estándar de la industria para los sistemas de asistencia para decisiones. Su esquema modela un entorno empresarial realista con clientes, pedidos, proveedores y piezas, lo que lo hace perfecto para demostrar una situación real de análisis y movimiento de datos.
En lugar de usar las tablas sin procesar y normalizadas de TPC-H, se creará una tabla nueva y agregada. Esta nueva tabla combinará datos de las tablas orders, customer y nation para generar una vista desnormalizada y resumida de las ventas regionales. Este paso de preagregación es una práctica común en el análisis, ya que prepara los datos para un caso de uso específico, en este caso, para el consumo por parte de una aplicación operativa.
El esquema final de la tabla agregada será el siguiente:
Col | Tipo |
nation_name | string |
market_segment | string |
order_year | int |
order_priority | string |
total_order_count | bigint |
total_revenue | decimal(29,2) |
unique_customer_count | bigint |
Compatibilidad con Iceberg con el formato universal de Delta Lake (UniForm)
Para este lab, la tabla dentro de Databricks será una tabla de Delta Lake. Sin embargo, para que los sistemas externos, como BigQuery, puedan leerlo, se habilitará una potente función llamada Formato universal (UniForm).
UniForm genera automáticamente metadatos de Iceberg junto con los metadatos de Delta Lake para una sola copia compartida de los datos de la tabla. Esto proporciona lo mejor de ambos mundos:
- Dentro de Databricks: Se obtienen todos los beneficios de rendimiento y administración de Delta Lake.
- Fuera de Databricks: Cualquier motor de consultas compatible con Iceberg, como BigQuery, puede leer la tabla como si fuera una tabla de Iceberg nativa.
Esto elimina la necesidad de mantener copias separadas de los datos o ejecutar trabajos de conversión manuales. UniForm se habilitará estableciendo propiedades de tabla específicas cuando se cree la tabla.
Catálogos de Databricks
Un catálogo de Databricks es el contenedor de nivel superior para los datos en Unity Catalog, la solución de administración unificada de Databricks. Unity Catalog proporciona una forma centralizada de administrar los recursos de datos, controlar el acceso y hacer un seguimiento del linaje, lo que es fundamental para una plataforma de datos bien administrada.
Utiliza un espacio de nombres de tres niveles para organizar los datos: catalog.schema.table.
- Catálogo: Es el nivel más alto y se usa para agrupar los datos por entorno, unidad de negocios o proyecto.
- Esquema (o base de datos): Es una agrupación lógica de tablas, vistas y funciones dentro de un catálogo.
- Tabla: Es el objeto que contiene tus datos.
Antes de que se pueda crear la tabla agregada de TPC-H, primero se deben configurar un catálogo y un esquema dedicados para alojarla. Esto garantiza que el proyecto esté bien organizado y aislado de otros datos del espacio de trabajo.
Crea un catálogo y un esquema nuevos
En Databricks Unity Catalog, un catálogo sirve como el nivel más alto de organización para los recursos de datos, y actúa como un contenedor seguro que puede abarcar varios espacios de trabajo de Databricks. Te permite organizar y aislar datos según las unidades de negocios, los proyectos o los entornos, con permisos y controles de acceso claramente definidos.
Dentro de un catálogo, un esquema (también conocido como base de datos) organiza aún más las tablas, las vistas y las funciones. Esta estructura jerárquica permite un control detallado y una agrupación lógica de los objetos de datos relacionados. Para este lab, se crearán un catálogo y un esquema dedicados para alojar los datos de TPC-H, lo que garantizará un aislamiento y una administración adecuados.
Cómo crear un catálogo
- Ve a

- Haz clic en + y, luego, selecciona Crear un catálogo en el menú desplegable.
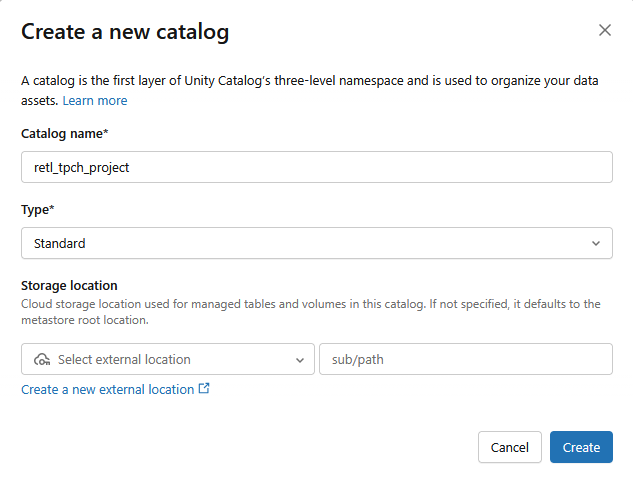
- Se creará un nuevo catálogo Estándar con la siguiente configuración:
- Nombre del catálogo:
retl_tpch_project - Ubicación de almacenamiento: Usa la predeterminada si se configuró una en el espacio de trabajo o crea una nueva.
Cómo crear un esquema
- Ve a
- Selecciona el catálogo nuevo que se creó en el panel izquierdo.
- Haz clic en
 .
. - Se creará un esquema nuevo con el Nombre del esquema como
tpch_data.
Configura datos externos
Para poder exportar datos de Databricks a Google Cloud Storage (GCS), se deben configurar credenciales de datos externos en Databricks. Esto permite que Databricks acceda y escriba en el bucket de GCS de forma segura.
- En la pantalla Catálogo, haz clic en
 .
.
- Si no ves la opción
External Data, es posible que encuentresExternal Locationsen un menú desplegableConnect.
- Haz clic en
 .
. - En la nueva ventana de diálogo, configura los valores requeridos para las credenciales:
- Tipo de credencial:
GCP Service Account - Nombre de la credencial:
retl-gcs-credential
- Haz clic en Create.
- A continuación, haz clic en la pestaña Ubicaciones externas.
- Haz clic en Crear ubicación.
- En la nueva ventana de diálogo, configura los valores necesarios para la ubicación externa:
- Nombre de la ubicación externa:
retl-gcs-location - Tipo de almacenamiento:
GCP - URL: Es la URL del bucket de GCS, en el formato
gs://YOUR_BUCKET_NAME. - Credencial de almacenamiento: Selecciona el objeto
retl-gcs-credentialque acabas de crear.
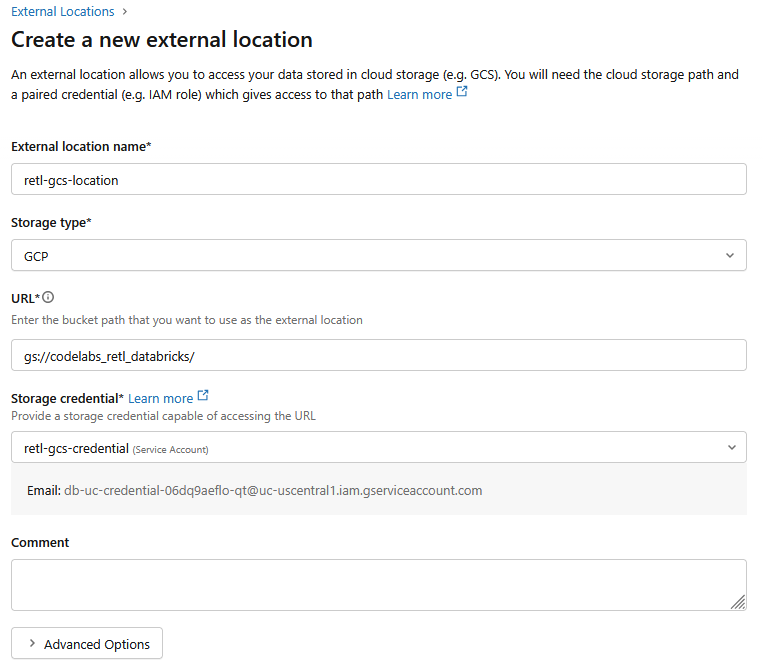
- Anota el correo electrónico de la cuenta de servicio que se completa automáticamente cuando seleccionas la credencial de almacenamiento, ya que lo necesitarás en el siguiente paso.
- Haz clic en Create.
5. Configurar permisos de la cuenta de servicio
Una cuenta de servicio es un tipo especial de cuenta que usan las aplicaciones o los servicios para realizar llamadas autorizadas a la API de los recursos de Google Cloud.
Ahora, se deberán agregar permisos a la cuenta de servicio creada para el bucket nuevo en GCS.
- En la página del bucket de GCS, selecciona la pestaña Permisos.
- Haz clic en Otorgar acceso en la página de principales.
- En el panel Grant Access que se desliza desde la derecha, ingresa el ID de la cuenta de servicio en el campo Principales nuevas.
- En Asignar roles, agrega
Storage Object AdminyStorage Legacy Bucket Reader. Estos roles permiten que la cuenta de servicio lea, escriba y enumere objetos en el bucket de almacenamiento.
Carga datos de TPC-H
Ahora que se crearon el catálogo y el esquema, los datos de TPCH se pueden cargar desde la tabla samples.tpch existente que se almacena de forma interna en Databricks y se manipula en una tabla nueva en el esquema recién definido.
Crea una tabla con compatibilidad con Iceberg
Compatibilidad de Iceberg con UniForm
En segundo plano, Databricks administra internamente esta tabla como una tabla de Delta Lake, lo que brinda todos los beneficios de las optimizaciones de rendimiento y las funciones de administración de Delta dentro del ecosistema de Databricks. Sin embargo, si habilitas UniForm (abreviatura de Universal Format), se le indica a Databricks que haga algo especial: cada vez que se actualiza la tabla, Databricks genera y mantiene automáticamente los metadatos de Iceberg correspondientes además de los metadatos de Delta Lake.
Esto significa que un solo conjunto compartido de archivos de datos (los archivos Parquet) ahora se describe con dos conjuntos diferentes de metadatos.
- Para Databricks: Usa
_delta_logpara leer la tabla. - Para lectores externos (como BigQuery): Usan el archivo de metadatos de Iceberg (
.metadata.json) para comprender el esquema, la partición y las ubicaciones de los archivos de la tabla.
El resultado es una tabla que es totalmente compatible y transparente con cualquier herramienta compatible con Iceberg. No hay duplicación de datos ni necesidad de conversión o sincronización manual. Es una única fuente de información a la que pueden acceder sin problemas tanto el mundo analítico de Databricks como el ecosistema más amplio de herramientas que admiten el estándar abierto de Iceberg.
- Haz clic en Nuevo y, luego, en Consulta.
- En el campo de texto de la página de consultas, ejecuta el siguiente comando en SQL:
CREATE TABLE retl_tpch_project.tpch_data.regional_sales_iceberg
USING DELTA
LOCATION 'gs://<Your bucket name>/regional_sales_iceberg'
TBLPROPERTIES (
'delta.columnMapping.mode' = 'name',
'delta.enableIcebergCompatV2' = 'true',
'delta.universalFormat.enabledFormats' = 'iceberg'
)
AS
SELECT
n.n_name AS nation_name,
c.c_mktsegment AS market_segment,
YEAR(o.o_orderdate) AS order_year,
o.o_orderpriority AS order_priority,
COUNT(o.o_orderkey) AS total_order_count,
ROUND(SUM(o.o_totalprice), 2) AS total_revenue,
COUNT(DISTINCT c.c_custkey) AS unique_customer_count
FROM samples.tpch.orders AS o
INNER JOIN samples.tpch.customer AS c
ON o.o_custkey = c.c_custkey
INNER JOIN samples.tpch.nation AS n
ON c.c_nationkey = n.n_nationkey
GROUP BY
n.n_name,
c.c_mktsegment,
YEAR(o.o_orderdate),
o.o_orderpriority;
OPTIMIZE retl_tpch_project.tpch_data.regional_sales_iceberg;
DESCRIBE EXTENDED retl_tpch_project.tpch_data.regional_sales_iceberg;
Notas:
- Using Delta: Especifica que estamos usando una tabla de Delta Lake. Solo las tablas de Delta Lake en Databricks se pueden almacenar como tablas externas.
- Ubicación: Especifica dónde se almacenará la tabla, si es externa.
- TablePropertoes:
delta.universalFormat.enabledFormats = ‘iceberg'crea los metadatos de Iceberg compatibles junto con los archivos de Delta Lake. - Optimize: Activa de forma forzada la generación de metadatos de UniForm, ya que, por lo general, se realiza de forma asíncrona.
- El resultado de la consulta debe mostrar detalles sobre la tabla recién creada.

Verifica los datos de la tabla de GCS
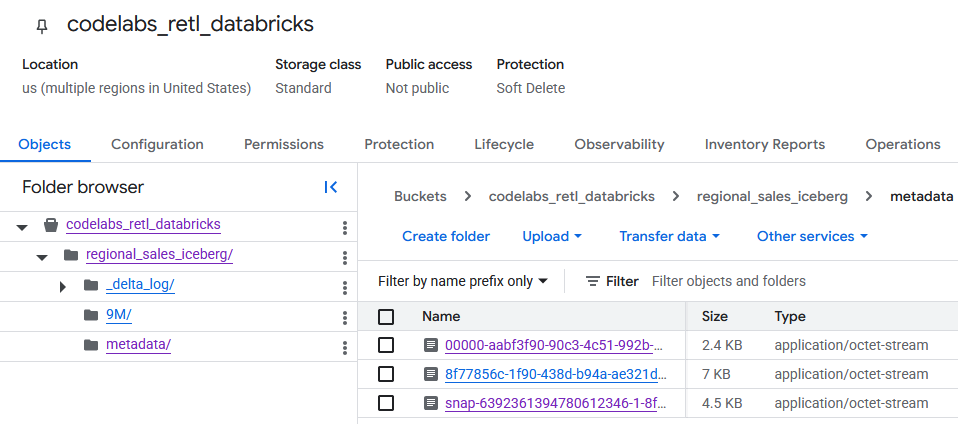
Cuando navegues al bucket de GCS, podrás encontrar los datos de la tabla recién creada.
Encontrarás los metadatos de Iceberg en la carpeta metadata, que utilizan los lectores externos (como BigQuery). Los metadatos de Delta Lake, que Databricks usa de forma interna, se registran en la carpeta _delta_log.
Los datos reales de la tabla se almacenan como archivos Parquet dentro de otra carpeta, que Databricks suele nombrar con una cadena generada de forma aleatoria. Por ejemplo, en la siguiente captura de pantalla, los archivos de datos se encuentran en la carpeta 9M.
6. Configura BigQuery y BigLake
Ahora que la tabla de Iceberg está en Google Cloud Storage, el siguiente paso es hacer que sea accesible para BigQuery. Para ello, se creará una tabla externa de BigLake.
BigLake es un motor de almacenamiento que permite crear tablas en BigQuery que leen datos directamente de fuentes externas, como Google Cloud Storage. En este lab, es la tecnología clave que permite que BigQuery comprenda la tabla de Iceberg que se acaba de exportar sin necesidad de transferir los datos.
Para que esto funcione, se necesitan dos componentes:
- Una conexión de recursos de Cloud: Es un vínculo seguro entre BigQuery y GCS. Utiliza una cuenta de servicio especial para controlar la autenticación, lo que garantiza que BigQuery tenga los permisos necesarios para leer los archivos del bucket de GCS.
- Una definición de tabla externa: Indica a BigQuery dónde encontrar el archivo de metadatos de la tabla de Iceberg en GCS y cómo se debe interpretar.
Crea una conexión de recursos de Cloud
Primero, se creará la conexión que le permite a BigQuery acceder a GCS.
Aquí puedes encontrar más información para crear conexiones de recursos de Cloud.
- Ir a BigQuery
- Haz clic en Conexiones en Explorador.
- Si el plano Explorer no está visible, haz clic en
 .
.
- En la página Conexiones, haz clic en
 .
. - En Tipo de conexión, elige
Vertex AI remote models, remote functions, BigLake and Spanner (Cloud Resource). - Establece el ID de conexión en
databricks_retly crea la conexión.

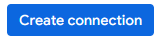
- Ahora debería aparecer una entrada en la tabla Connections de la conexión recién creada. Haz clic en esa entrada para ver los detalles de la conexión.

- En la página de detalles de la conexión, anota el ID de la cuenta de servicio, ya que lo necesitarás más adelante.
Otorga acceso a la cuenta de servicio de conexión
- Ve a IAM y administración.
- Haz clic en Otorgar acceso.
- En el campo Principales nuevas, ingresa el ID de la cuenta de servicio del recurso de conexión que creaste anteriormente.
- En Rol, selecciona
Storage Object Usery, luego, haz clic en .
.
Una vez establecida la conexión y otorgados los permisos necesarios a su cuenta de servicio, se puede crear la tabla externa de BigLake. Primero, se necesita un conjunto de datos en BigQuery para que actúe como contenedor de la tabla nueva. Luego, se creará la tabla y se dirigirá al archivo de metadatos de Iceberg en el bucket de GCS.
- Ir a BigQuery
- En el panel Explorador, haz clic en el ID del proyecto, luego en los tres puntos y, por último, selecciona Crear conjunto de datos.
- El conjunto de datos se llamará
databricks_retl. Deja las otras opciones con sus valores predeterminados y haz clic en el botón Crear conjunto de datos.
- Ahora, busca el nuevo conjunto de datos
databricks_retlen el panel Explorador. Haz clic en los tres puntos junto a él y selecciona Crear tabla.
- Completa la siguiente configuración para la creación de la tabla:
- Crear tabla desde:
Google Cloud Storage - Selecciona un archivo del bucket de GCS o usa un patrón de URI: Busca el bucket de GCS y localiza el archivo JSON de metadatos que se generó durante la exportación de Databricks. La ruta debería verse de la siguiente manera:
regional_sales/metadata/v1.metadata.json. - Formato de archivo:
Iceberg - Tabla:
regional_sales - Tipo de tabla:
External table - ID de conexión: Selecciona la conexión
databricks_retlque creaste antes. - Deja el resto de los valores como predeterminados y, luego, haz clic en Crear tabla.
- Una vez creada, la nueva tabla
regional_salesdebería estar visible en el conjunto de datosdatabricks_retl. Ahora se puede consultar esta tabla con SQL estándar, al igual que con cualquier otra tabla de BigQuery.
7. Carga en Spanner
Llegamos a la parte final y más importante de la canalización: mover los datos de las tablas externas de BigLake a Spanner. Este es el paso de "ETL inversa", en el que los datos, después de procesarse y organizarse en el almacén de datos, se cargan en un sistema operativo para que los usen las aplicaciones.
Spanner es una base de datos relacional completamente administrada y distribuida a nivel global. Ofrece la coherencia transaccional de una base de datos relacional tradicional, pero con la escalabilidad horizontal de una base de datos NoSQL. Esto la convierte en una opción ideal para compilar aplicaciones escalables y con alta disponibilidad.
El proceso será el siguiente:
- Crea una instancia de Spanner, que es la asignación física de recursos.
- Crea una base de datos dentro de esa instancia.
- Define un esquema de tabla en la base de datos que coincida con la estructura de los datos de
regional_sales. - Ejecuta una consulta
EXPORT DATAde BigQuery para cargar los datos de la tabla de BigLake directamente en la tabla de Spanner.
Crea una instancia, una base de datos y una tabla de Spanner
- Ir a Spanner
- Haz clic en
 . Si hay una instancia disponible, puedes usarla. Configura los requisitos de la instancia según sea necesario. Para este lab, se usaron los siguientes elementos:
. Si hay una instancia disponible, puedes usarla. Configura los requisitos de la instancia según sea necesario. Para este lab, se usaron los siguientes elementos:
Edición | Enterprise |
Nombre de la instancia | databricks-retl |
Configuración de la región | La región que elijas |
Unidad de procesamiento | Unidades de procesamiento (PU) |
Asignación manual | 100 |
- Una vez creada, ve a la página de la instancia de Spanner y selecciona
 . Si hay una base de datos disponible, puedes usarla.
. Si hay una base de datos disponible, puedes usarla.
- En este lab, se creará una base de datos con
- Nombre:
databricks-retl - Dialecto de la base de datos:
Google Standard SQL
- Una vez que se cree la base de datos, selecciónala en la página Instancia de Spanner para ingresar a la página Base de datos de Spanner.
- En la página Base de datos de Spanner, haz clic en
 .
. - En la nueva página de consultas, se creará la definición de la tabla que se importará a Spanner. Para ello, ejecuta la siguiente consulta en SQL.
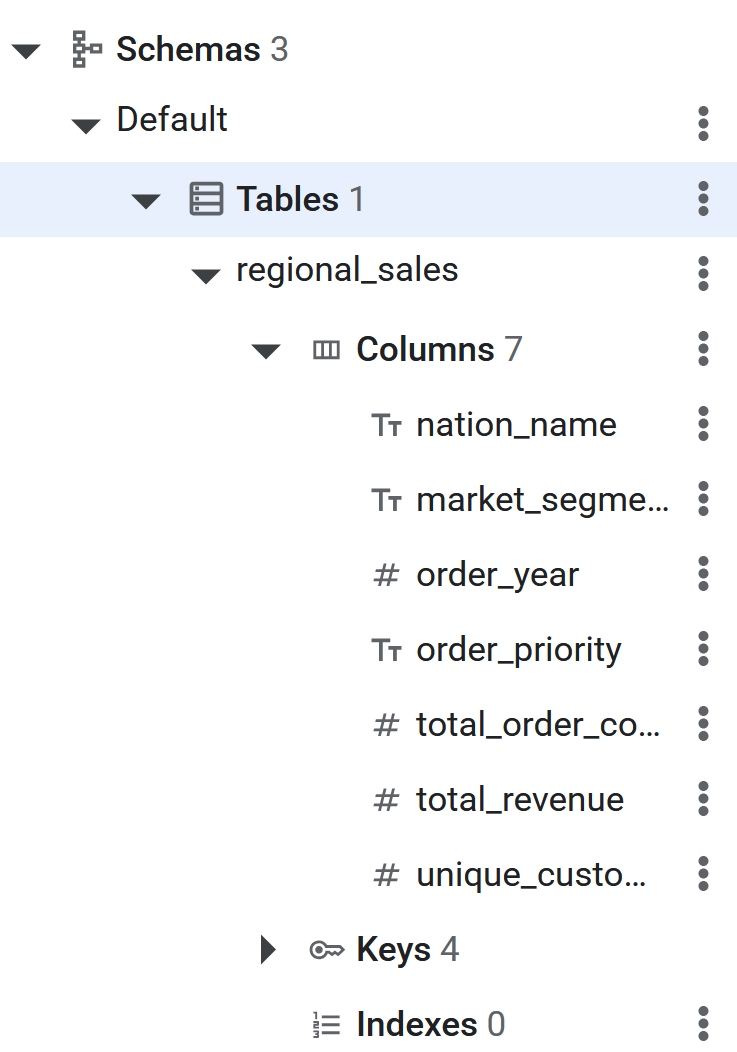
CREATE TABLE regional_sales (
nation_name STRING(MAX),
market_segment STRING(MAX),
order_year INT64,
order_priority STRING(MAX),
total_order_count INT64,
total_revenue NUMERIC,
unique_customer_count INT64
) PRIMARY KEY (nation_name, market_segment, order_year, order_priority);
- Una vez que se ejecute el comando SQL, la tabla de Spanner estará lista para que BigQuery realice la ETL inversa de los datos. Puedes verificar la creación de la tabla viendo que aparece en el panel izquierdo de la base de datos de Spanner.
ETL inverso a Spanner con EXPORT DATA
Este es el paso final. Con los datos de origen listos en una tabla de BigLake de BigQuery y la tabla de destino creada en Spanner, el movimiento de datos real es sorprendentemente simple. Se usará una sola consulta de BigQuery SQL: EXPORT DATA.
Esta consulta está diseñada específicamente para situaciones como esta. Exporta datos de manera eficiente desde una tabla de BigQuery (incluidas las externas, como la tabla de BigLake) a un destino externo. En este caso, el destino es la tabla de Spanner. Obtén más información sobre la función de exportación aquí.
Aquí puedes encontrar más información para configurar la ETL inversa de BigQuery a Spanner.
- Ir a BigQuery
- Abre una nueva pestaña del editor de consultas.
- En la página Query, ingresa el siguiente código SQL. Recuerda reemplazar el ID del proyecto en la **
uri** **y la ruta de la tabla por el ID del proyecto correcto.**
EXPORT DATA OPTIONS(
uri='https://spanner.googleapis.com/projects/YOUR_PROJECT_ID/instances/databricks-retl/databases/databricks-retl',
format='CLOUD_SPANNER',
spanner_options="""{
"table": "regional_sales",
"priority": "MEDIUM"
}"""
) AS
SELECT * FROM `YOUR_PROJECT_ID.databricks_retl.regional_sales`;
- Una vez que se complete el comando, los datos se habrán exportado correctamente a Spanner.
8. Verifica los datos en Spanner
¡Felicitaciones! Se compiló y ejecutó correctamente una canalización de ETL inversa completa, que trasladó datos de un almacén de datos de Databricks a una base de datos operativa de Spanner.
El paso final es verificar que los datos hayan llegado a Spanner según lo previsto.
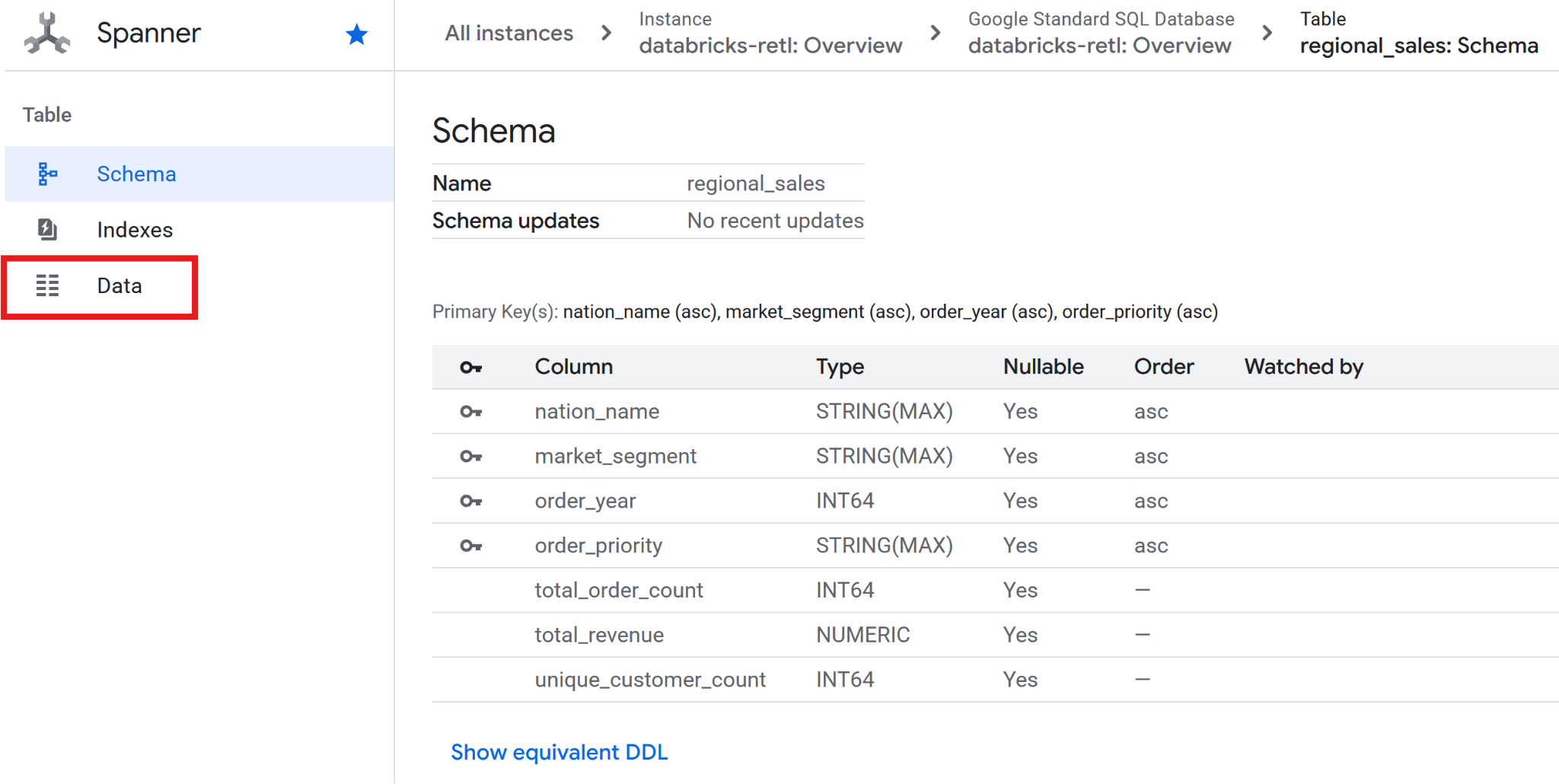
- Ve a Spanner.
- Navega a tu instancia de
databricks-retly, luego, a la base de datos dedatabricks-retl. - En la lista de tablas, haz clic en la tabla
regional_sales. - En el menú de navegación de la izquierda de la tabla, haz clic en la pestaña Datos.
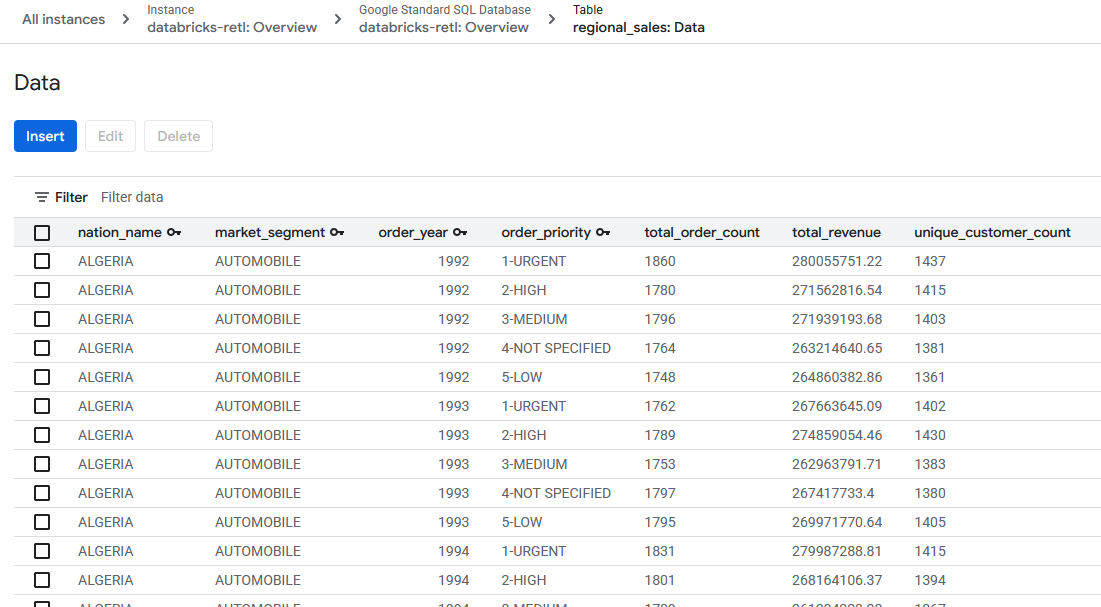
- Los datos de ventas agregados, que originalmente provienen de Databricks, ahora deberían estar cargados y listos para usarse en la tabla de Spanner. Ahora, estos datos se encuentran en un sistema operativo, listos para potenciar una aplicación en vivo, mostrar un panel o ser consultados por una API.
Se cerró con éxito la brecha entre los mundos de los datos operativos y analíticos.
9. Corrección
Cuando termines este lab, quita todas las tablas agregadas y los datos almacenados.
Borra las tablas de Spanner
- Ir a Spanner
- Haz clic en la instancia que se usó para este lab en la lista llamada
databricks-retl.

- En la página de la instancia, haz clic en
 .
. - Ingresa
databricks-retlen el diálogo de confirmación que aparece y haz clic en .
.
Limpia GCS
- Ir a GCS
- Selecciona
 en el menú lateral izquierdo.
en el menú lateral izquierdo. - Selecciona el bucket ``codelabs_retl_databricks``.
- Una vez que lo selecciones, haz clic en el botón
 que aparece en el banner superior.
que aparece en el banner superior.

- Ingresa
DELETEen el diálogo de confirmación que aparece y haz clic en.
Limpia Databricks
Borrar catálogo, esquema o tabla
- Accede a tu instancia de Databricks
- Haz clic en
 en el menú lateral izquierdo.
en el menú lateral izquierdo. - Selecciona el
 creado anteriormente en la lista del catálogo.
creado anteriormente en la lista del catálogo. - En la lista Esquema, selecciona
 que se creó.
que se creó. - Selecciona el
 creado anteriormente en la lista de la tabla.
creado anteriormente en la lista de la tabla. - Haz clic en
 para expandir las opciones de la tabla y selecciona
para expandir las opciones de la tabla y selecciona Delete. - Haz clic en
 en el diálogo de confirmación para borrar la tabla.
en el diálogo de confirmación para borrar la tabla. - Una vez que se borre la tabla, volverás a la página del esquema.
- Haz clic en para expandir las opciones de esquema y selecciona
Delete. - Haz clic en en el diálogo de confirmación para borrar el esquema.
- Una vez que se borre el esquema, volverás a la página del catálogo.
- Vuelve a seguir los pasos del 4 al 11 para borrar el esquema
defaultsi existe. - En la página del catálogo, haz clic en para expandir las opciones del catálogo y selecciona
Delete. - Haz clic en en el diálogo de confirmación para borrar el catálogo.
Borra la ubicación o las credenciales de datos externos
- En la pantalla Catálogo, haz clic en .
- Si no ves la opción
External Data, es posible que encuentresExternal Locationen un menú desplegableConnect. - Haz clic en la ubicación de datos externos
retl-gcs-locationque creaste anteriormente. - En la página de ubicación externa, haz clic en para expandir las opciones de ubicación y selecciona
Delete. - Haz clic en en el diálogo de confirmación para borrar la ubicación externa.
- Haz clic en .
- Haz clic en el elemento
retl-gcs-credentialque se creó anteriormente. - En la página de credenciales, expande las opciones de credenciales haciendo clic en y selecciona
Delete. - Haz clic en en el diálogo de confirmación para borrar las credenciales.
10. Felicitaciones
Felicitaciones por completar el codelab.
Temas abordados
- Cómo cargar datos en Databricks como tablas de Iceberg
- Cómo crear un bucket de GCS
- Cómo exportar una tabla de Databricks a GCS en formato Iceberg
- Cómo crear una tabla externa de BigLake en BigQuery a partir de la tabla de Iceberg en GCS
- Cómo configurar una instancia de Spanner
- Cómo cargar tablas externas de BigLake en BigQuery a Spanner