
۱. ساخت یک خط لوله ETL معکوس از Databricks به Spanner با استفاده از Google Cloud Storage و BigQuery
مقدمه
در این آزمایشگاه کد، شما یک خط لوله ETL معکوس از Databricks به Spanner خواهید ساخت. به طور سنتی، خطوط لوله استاندارد ETL (استخراج، تبدیل، بارگذاری) دادهها را از پایگاههای داده عملیاتی به یک انبار داده مانند Databricks برای تجزیه و تحلیل منتقل میکنند. یک خط لوله ETL معکوس برعکس عمل میکند و دادههای پردازش شده و مرتب شده را از انبار داده به پایگاههای داده عملیاتی، مانند Spanner، که یک پایگاه داده رابطهای توزیع شده جهانی ایدهآل برای برنامههای کاربردی با دسترسی بالا است، منتقل میکند، جایی که میتواند برنامهها را تغذیه کند، ویژگیهای کاربرپسند را ارائه دهد یا برای تصمیمگیری در زمان واقعی استفاده شود.
هدف این است که یک مجموعه داده تجمیعشده از جداول Databricks Iceberg به جداول Spanner منتقل شود.
برای دستیابی به این هدف، از فضای ذخیرهسازی ابری گوگل (GCS) و BigQuery به عنوان مراحل میانی استفاده میشود. در اینجا خلاصهای از جریان دادهها و دلیل پشت این معماری آمده است:

- انتقال دیتابریکها به فضای ذخیرهسازی ابری گوگل (GCS) با فرمت آیسبرگ:
- اولین قدم، استخراج دادهها از Databricks در قالبی باز و خوشتعریف است. جدول در قالب Apache Iceberg صادر میشود. این فرآیند، دادههای زیربنایی را به صورت مجموعهای از فایلهای Parquet و فرادادههای جدول (طرحواره، پارتیشنها، مکان فایلها) را به صورت فایلهای JSON و Avro مینویسد. پیادهسازی این ساختار کامل جدول در GCS، دادهها را قابل حمل و در دسترس هر سیستمی که قالب Iceberg را درک میکند، قرار میدهد.
- تبدیل جداول GCS Iceberg به جدول خارجی BigQuery BigLake:
- به جای بارگذاری مستقیم دادهها از GCS به Spanner، از BigQuery به عنوان یک واسطه قدرتمند استفاده میشود. یک جدول خارجی BigLake در BigQuery ایجاد میشود که مستقیماً به فایل فراداده Iceberg در GCS اشاره میکند. این رویکرد چندین مزیت دارد:
- عدم تکرار دادهها: BigQuery ساختار جدول را از فرادادهها میخواند و فایلهای داده Parquet را بدون نیاز به پردازش، جستجو میکند که این امر باعث صرفهجویی قابل توجه در زمان و هزینههای ذخیرهسازی میشود.
- کوئریهای فدرال: این امکان را فراهم میکند تا کوئریهای پیچیده SQL را روی دادههای GCS اجرا کنید، گویی که یک جدول بومی BigQuery هستند.
- جدول خارجی ReverseETL BigLake را به Spanner منتقل کنید:
- مرحله آخر، انتقال دادهها از BigQuery به Spanner است. این کار با استفاده از یک ویژگی قدرتمند در BigQuery به نام
EXPORT DATAquery انجام میشود که همان مرحله "ETL معکوس" است. - آمادگی عملیاتی: Spanner برای بارهای کاری تراکنشی طراحی شده است و سازگاری قوی و دسترسیپذیری بالایی را برای برنامهها فراهم میکند. با انتقال دادهها به Spanner، این دادهها برای برنامههای کاربردی کاربرپسند، APIها و سایر سیستمهای عملیاتی که نیاز به جستجوی نقاط با تأخیر کم دارند، قابل دسترسی میشوند.
- مقیاسپذیری: این الگو امکان بهرهبرداری از قدرت تحلیلی BigQuery را برای پردازش مجموعه دادههای بزرگ و سپس ارائه نتایج به طور کارآمد از طریق زیرساخت مقیاسپذیر جهانی Spanner فراهم میکند.
خدمات و اصطلاحات
- DataBricks - پلتفرم داده مبتنی بر ابر که بر اساس Apache Spark ساخته شده است.
- Spanner - یک پایگاه داده رابطهای توزیعشده جهانی که بهطور کامل توسط گوگل مدیریت میشود.
- فضای ذخیرهسازی ابری گوگل - ارائه فضای ذخیرهسازی بلاب (blob storage) از گوگل کلود.
- BigQuery - یک انبار داده بدون سرور برای تجزیه و تحلیل، که به طور کامل توسط گوگل مدیریت میشود.
- آیسبرگ - یک قالب جدول باز که توسط آپاچی تعریف شده و نسبت به قالبهای رایج فایلهای داده متنباز، انتزاعیسازی ارائه میدهد.
- پارکت - یک فرمت فایل داده دودویی ستونی متنباز توسط آپاچی.
آنچه یاد خواهید گرفت
- نحوه بارگذاری دادهها در Databricks به عنوان جداول Iceberg
- نحوه ایجاد یک سطل GCS
- نحوه خروجی گرفتن از جدول Databricks به GCS با فرمت Iceberg
- نحوه ایجاد یک جدول خارجی BigLake در BigQuery از جدول Iceberg در GCS
- نحوه راهاندازی یک نمونه Spanner
- نحوه بارگذاری جداول خارجی BigLake در BigQuery به Spanner
۲. راهاندازی، الزامات و محدودیتها
پیشنیازها
- یک حساب کاربری Databricks، ترجیحاً روی GCP
- برای خروجی گرفتن از BigQuery به Spanner، یک حساب Google Cloud با رزرو BigQuery Enterprise-tier یا بالاتر مورد نیاز است.
- دسترسی به کنسول ابری گوگل از طریق مرورگر وب
- یک ترمینال برای اجرای دستورات Google Cloud CLI
اگر سیاست iam.allowedPolicyMemberDomains در سازمان Google Cloud شما فعال باشد، ممکن است لازم باشد مدیر سیستم برای مجاز کردن حسابهای سرویس از دامنههای خارجی، استثنا قائل شود. این موضوع در مرحله بعدی، در صورت لزوم، پوشش داده خواهد شد.
الزامات
- یک پروژه گوگل کلود با قابلیت پرداخت.
- یک مرورگر وب، مانند کروم
- یک حساب کاربری Databricks (این آزمایش فرض میکند که یک فضای کاری میزبانی شده در GCP وجود دارد)
- برای استفاده از ویژگی EXPORT DATA، نمونه BigQuery باید در نسخه Enterprise یا بالاتر باشد.
- اگر سیاست
iam.allowedPolicyMemberDomainsدر سازمان Google Cloud شما فعال باشد، ممکن است لازم باشد مدیر سیستم برای مجاز کردن حسابهای سرویس از دامنههای خارجی، استثنا قائل شود. این موضوع در مرحله بعدی، در صورت لزوم، پوشش داده خواهد شد.
مجوزهای IAM پلتفرم ابری گوگل
برای اجرای تمام مراحل این codelab، حساب گوگل به مجوزهای زیر نیاز دارد.
حسابهای خدماتی | ||
| امکان ایجاد حسابهای کاربری سرویس (Service Accounts) را فراهم میکند. | |
آچار | ||
| امکان ایجاد یک نمونه جدید از Spanner را فراهم میکند. | |
| به اجرای دستورات DDL اجازه ایجاد میدهد. | |
| به اجرای دستورات DDL اجازه میدهد تا جداولی در پایگاه داده ایجاد کنند. | |
فضای ذخیرهسازی ابری گوگل | ||
| امکان ایجاد یک سطل GCS جدید برای ذخیره فایلهای پارکت صادر شده را فراهم میکند. | |
| امکان نوشتن فایلهای پارکت صادر شده را در سطل GCS فراهم میکند. | |
| به BigQuery اجازه میدهد فایلهای Parquet را از سطل GCS بخواند. | |
| به BigQuery اجازه میدهد تا فایلهای Parquet را در سطل GCS فهرست کند. | |
جریان داده | ||
| امکان دریافت اقلام کاری از Dataflow را فراهم میکند. | |
| به کارگر Dataflow اجازه میدهد تا پیامها را به سرویس Dataflow ارسال کند. | |
| به کاربران Dataflow اجازه میدهد تا ورودیهای گزارش را در Google Cloud Logging بنویسند. | |
برای راحتی، میتوان از نقشهای از پیش تعریفشدهای که حاوی این مجوزها هستند استفاده کرد.
|
|
|
|
|
|
|
|
پروژه ابری گوگل
یک پروژه واحد اساسی سازماندهی در Google Cloud است. اگر مدیر پروژهای را برای استفاده ارائه کرده باشد، میتوان از این مرحله صرف نظر کرد.
یک پروژه میتواند با استفاده از CLI به صورت زیر ایجاد شود:
gcloud projects create <your-project-name>
درباره ایجاد و مدیریت پروژهها اینجا بیشتر بیاموزید.
محدودیتها
مهم است که از محدودیتهای خاص و ناسازگاریهای نوع دادهای که ممکن است در این خط لوله ایجاد شوند، آگاه باشید.
از Databricks Iceberg به BigQuery
هنگام استفاده از BigQuery برای پرسوجو از جداول Iceberg که توسط Databricks (از طریق UniForm) مدیریت میشوند، موارد زیر را در نظر داشته باشید:
- تکامل طرحواره : اگرچه UniForm کار خوبی در ترجمه تغییرات طرحواره Delta Lake به Iceberg انجام میدهد، اما تغییرات پیچیده ممکن است همیشه آنطور که انتظار میرود منتشر نشوند. به عنوان مثال، تغییر نام ستونها در Delta Lake به Iceberg ترجمه نمیشود، که آن را به عنوان یک
dropو یکaddمیبیند. همیشه تغییرات طرحواره را به طور کامل آزمایش کنید. - سفر در زمان : بیگکوئری نمیتواند از قابلیتهای سفر در زمان دلتا لیک استفاده کند. این ابزار فقط آخرین تصویر لحظهای از جدول آیسبرگ را جستجو میکند.
- ویژگیهای پشتیبانی نشدهی دلتا لیک : ویژگیهایی مانند بردارهای حذف و نگاشت ستون با حالت
idدر دلتا لیک با UniForm برای Iceberg سازگار نیستند. آزمایشگاه از حالتnameبرای نگاشت ستون استفاده میکند که پشتیبانی میشود.
BigQuery به آچار
دستور EXPORT DATA از BigQuery به Spanner از همه انواع داده BigQuery پشتیبانی نمیکند. خروجی گرفتن از جدولی با انواع داده زیر منجر به خطا خواهد شد:
-
STRUCT -
GEOGRAPHY -
DATETIME -
RANGE -
TIME
علاوه بر این، اگر پروژه BigQuery از گویش GoogleSQL استفاده میکند، انواع عددی زیر نیز برای صادرات به Spanner پشتیبانی نمیشوند:
-
BIGNUMERIC
برای فهرست کامل و بهروز محدودیتها، به مستندات رسمی مراجعه کنید: Exporting to Spanner Limitations .
عیبیابی و مشکلات
- اگر روی یک نمونه GCP Databricks نباشد، تعریف یک مکان داده خارجی در GCS ممکن است امکانپذیر نباشد. در چنین مواردی، فایلها باید در راهکار ذخیرهسازی ابری ارائهدهنده فضای کاری Databricks قرار داده شوند و سپس بهطور جداگانه به GCS منتقل شوند.
- هنگام انجام این کار، تنظیماتی در فرادادهها لازم خواهد بود زیرا اطلاعات دارای مسیرهای کدگذاری شدهی سخت به فایلهای مرحلهبندی شده خواهند بود.
۳. راهاندازی فضای ذخیرهسازی ابری گوگل (GCS)
از فضای ذخیرهسازی ابری گوگل (GCS) برای ذخیره فایلهای داده پارکت تولید شده توسط Databricks استفاده خواهد شد. برای انجام این کار، ابتدا باید یک سطل جدید ایجاد شود تا به عنوان مقصد فایل استفاده شود.
فضای ذخیرهسازی ابری گوگل
ایجاد یک سطل جدید
- به صفحه Google Cloud Storage در کنسول ابری خود بروید.
- در پنل سمت چپ، Buckets را انتخاب کنید:
- روی دکمه ایجاد کلیک کنید:

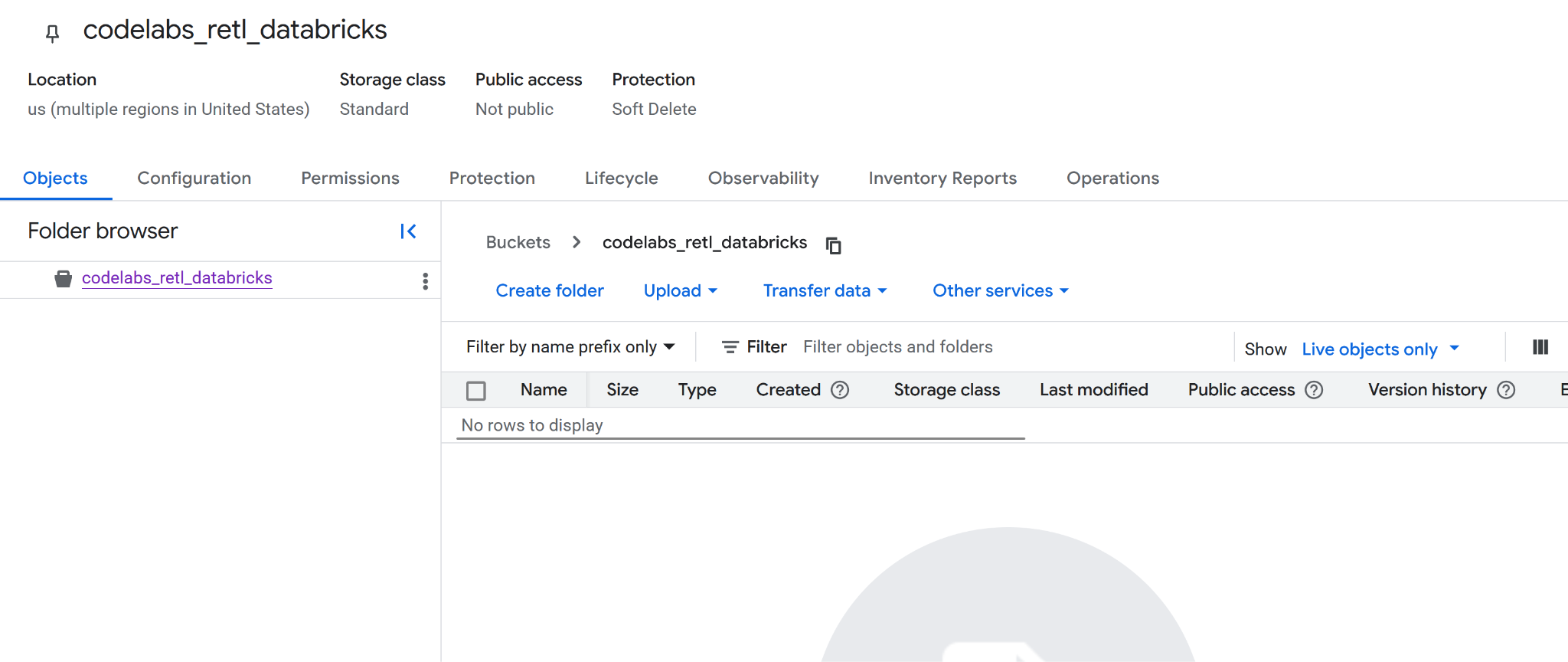
- جزئیات سطل خود را پر کنید:
- یک نام برای باکت انتخاب کنید. برای این آزمایش، از نام
codelabs_retl_databricksاستفاده خواهد شد. - منطقهای را برای ذخیره سطل انتخاب کنید یا از مقادیر پیشفرض استفاده کنید.
- کلاس ذخیرهسازی را به صورت
standardنگه دارید - مقادیر پیشفرض را برای دسترسی به کنترلها نگه دارید
- مقادیر پیشفرض را برای محافظت از دادههای شیء حفظ کنید
- پس از اتمام، روی دکمهی
Createکلیک کنید. ممکن است پیامی برای تأیید جلوگیری از دسترسی عمومی ظاهر شود. آن را تأیید کنید. - تبریک، یک سطل جدید با موفقیت ایجاد شد! به صفحه سطل هدایت خواهید شد.
- نام جدید سطل را جایی کپی کنید زیرا بعداً به آن نیاز خواهیم داشت.
آمادهسازی برای مراحل بعدی
مطمئن شوید که جزئیات زیر را یادداشت کردهاید زیرا در مراحل بعدی به آنها نیاز خواهید داشت:
- شناسه پروژه گوگل
- نام مخزن ذخیرهسازی گوگل
۴. راهاندازی دیتابریکها
دادههای TPC-H
برای این آزمایشگاه، از مجموعه داده TPC-H استفاده خواهد شد که یک معیار استاندارد صنعتی برای سیستمهای پشتیبانی تصمیمگیری است. طرحواره آن یک محیط تجاری واقعگرایانه با مشتریان، سفارشات، تأمینکنندگان و قطعات را مدلسازی میکند و آن را برای نشان دادن یک سناریوی تجزیه و تحلیل و انتقال داده در دنیای واقعی ایدهآل میسازد.
به جای استفاده از جداول خام و نرمالشدهی TPC-H، یک جدول جدید و تجمیعشده ایجاد خواهد شد. این جدول جدید، دادههای جداول orders ، customer و nation را به هم متصل میکند تا یک نمای غیر نرمالشده و خلاصهشده از فروش منطقهای ایجاد کند. این مرحلهی پیشتجمیع، یک روش رایج در تجزیه و تحلیل است، زیرا دادهها را برای یک مورد استفادهی خاص - در این سناریو، برای مصرف توسط یک برنامهی عملیاتی - آماده میکند.
طرح نهایی برای جدول تجمیع شده به صورت زیر خواهد بود:
ستون | نوع |
نام_ملت | رشته |
بخش_بازار | رشته |
سال_سفارش | عدد صحیح |
اولویت_ترتیب | رشته |
تعداد_سفارش_کل | بزرگ |
درآمد کل | اعشاری(29،2) |
تعداد_مشتری_منحصربهفرد | بزرگ |
پشتیبانی از آیسبرگ با قالب جهانی دلتا لیک (UniForm)
برای این آزمایش، جدول درون Databricks یک جدول Delta Lake خواهد بود. با این حال، برای اینکه توسط سیستمهای خارجی مانند BigQuery قابل خواندن باشد، یک ویژگی قدرتمند به نام Universal Format (UniForm) فعال خواهد شد.
UniForm به طور خودکار فرادادههای Iceberg را در کنار فرادادههای Delta Lake برای یک کپی مشترک از دادههای جدول تولید میکند. این روش بهترین مزایای هر دو را ارائه میدهد:
- درون Databricks: تمام مزایای عملکرد و مدیریت Delta Lake به دست میآید.
- خارج از Databricks: این جدول میتواند توسط هر موتور پرسوجوی سازگار با Iceberg، مانند BigQuery، خوانده شود، گویی یک جدول بومی Iceberg است.
این امر نیاز به نگهداری کپیهای جداگانه از دادهها یا اجرای کارهای تبدیل دستی را از بین میبرد. UniForm با تنظیم ویژگیهای خاص جدول هنگام ایجاد جدول فعال میشود.
کاتالوگهای دیتابریک
کاتالوگ Databricks، بالاترین سطح دادهها در Unity Catalog ، راهکار یکپارچه مدیریت Databricks، است. Unity Catalog روشی متمرکز برای مدیریت داراییهای داده، کنترل دسترسی و ردیابی دودمان دادهها ارائه میدهد که برای یک پلتفرم داده با مدیریت خوب بسیار مهم است.
از یک فضای نام سه سطحی برای سازماندهی دادهها استفاده میکند: catalog.schema.table .
- کاتالوگ: بالاترین سطح، که برای گروهبندی دادهها بر اساس محیط، واحد تجاری یا پروژه استفاده میشود.
- طرحواره (یا پایگاه داده): یک گروهبندی منطقی از جداول، نماها و توابع درون یک کاتالوگ.
- جدول: شیء حاوی دادههای شما.
قبل از اینکه جدول TPC-H تجمیعشده ایجاد شود، ابتدا باید یک کاتالوگ و طرحواره اختصاصی برای قرار دادن آن تنظیم شود. این امر تضمین میکند که پروژه به طور منظم سازماندهی شده و از سایر دادهها در فضای کاری جدا شده است.
ایجاد کاتالوگ و طرحواره جدید
در کاتالوگ یونیتی Databricks، یک کاتالوگ به عنوان بالاترین سطح سازماندهی برای داراییهای داده عمل میکند و به عنوان یک محفظه امن عمل میکند که میتواند در چندین فضای کاری Databricks گسترش یابد. این به شما امکان میدهد دادهها را بر اساس واحدهای تجاری، پروژهها یا محیطها، با مجوزها و کنترلهای دسترسی کاملاً تعریف شده، سازماندهی و جداسازی کنید.
در یک کاتالوگ، یک Schema (که به عنوان پایگاه داده نیز شناخته میشود) جداول، نماها و توابع را بیشتر سازماندهی میکند. این ساختار سلسله مراتبی امکان کنترل جزئی و گروهبندی منطقی اشیاء داده مرتبط را فراهم میکند. برای این آزمایش، یک کاتالوگ و Schema اختصاصی برای نگهداری دادههای TPC-H ایجاد خواهد شد که جداسازی و مدیریت مناسب را تضمین میکند.
ایجاد کاتالوگ
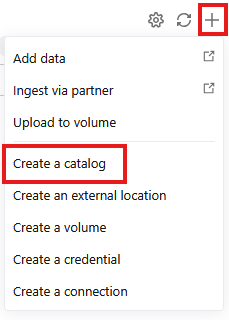
- رفتن به

- روی + کلیک کنید و سپس از منوی کشویی، گزینه ایجاد کاتالوگ (Create a catalog) را انتخاب کنید.
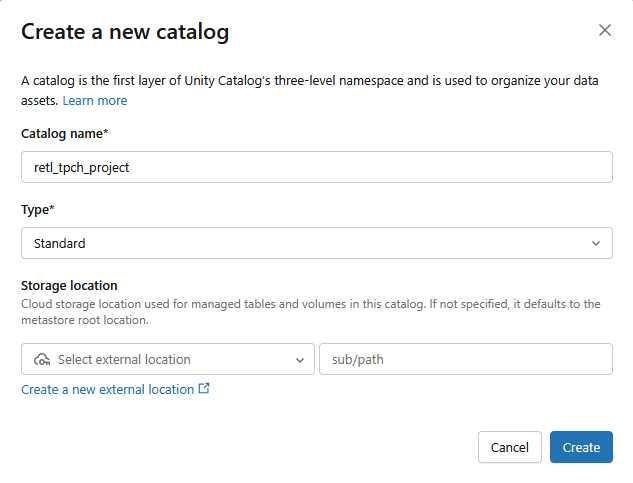
- یک کاتالوگ استاندارد جدید با تنظیمات زیر ایجاد خواهد شد:
- نام کاتالوگ :
retl_tpch_project - محل ذخیرهسازی : اگر در فضای کاری، مکانی پیشفرض تنظیم شده است، از آن استفاده کنید، یا یک مکان جدید ایجاد کنید.
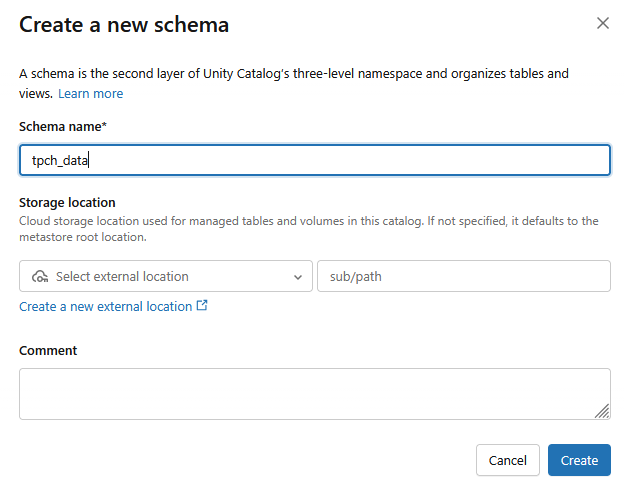
ایجاد یک طرحواره
- رفتن به
- کاتالوگ جدیدی که از پنل سمت چپ ایجاد شده است را انتخاب کنید
- کلیک کنید
- یک طرحواره جدید با نام طرحواره
tpch_dataایجاد خواهد شد.
تنظیم دادههای خارجی
برای اینکه بتوانید دادهها را از Databricks به Google Cloud Storage (GCS) صادر کنید، باید اعتبارنامههای دادههای خارجی را در Databricks تنظیم کنید. این به Databricks اجازه میدهد تا به طور ایمن به سطل GCS دسترسی داشته باشد و در آن بنویسد.
- از صفحه کاتالوگ ، روی کلیک کنید

- اگر گزینهی
External Dataرا نمیبینید، میتوانید به جای آن،External Locationsرا در زیر منوی کشوییConnectمشاهده کنید.
- کلیک کنید

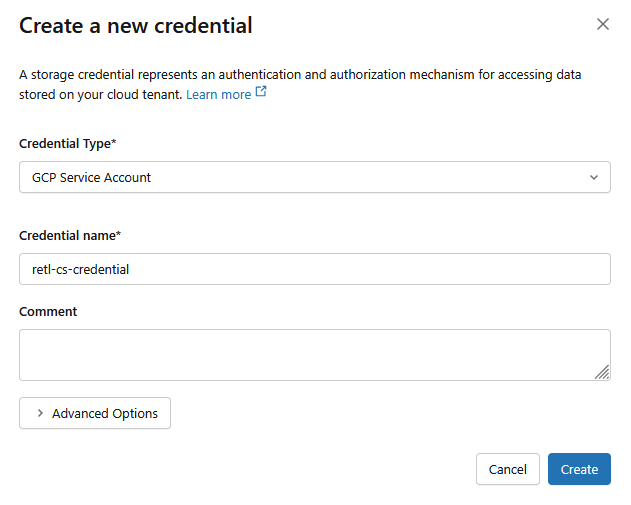
- در پنجره جدید، مقادیر مورد نیاز برای اعتبارنامهها را تنظیم کنید:
- نوع اعتبارنامه :
GCP Service Account - نام اعتبارنامه :
retl-gcs-credential
- روی ایجاد کلیک کنید
- سپس، روی برگه «مکانهای خارجی» کلیک کنید.
- روی ایجاد مکان کلیک کنید.
- در پنجره محاورهای جدید، مقادیر مورد نیاز برای مکان خارجی را تنظیم کنید:
- نام مکان خارجی :
retl-gcs-location - نوع ذخیره سازی :
GCP - URL : آدرس اینترنتی سطل GCS، با فرمت
gs://YOUR_BUCKET_NAME - اعتبارنامه ذخیرهسازی :
retl-gcs-credentialکه تازه ایجاد شده است را انتخاب کنید.
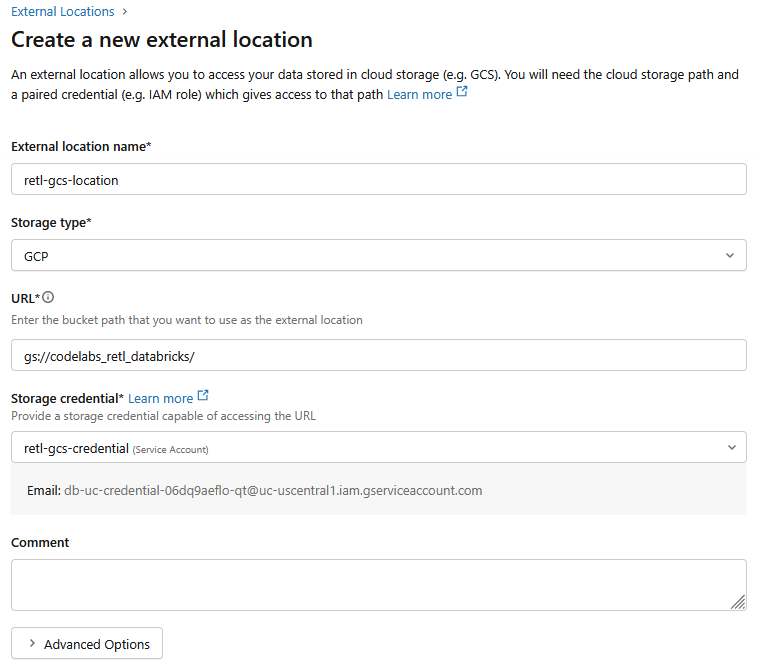
- ایمیل حساب سرویس را که به طور خودکار با انتخاب اعتبارنامه ذخیرهسازی پر میشود، یادداشت کنید زیرا در مرحله بعدی مورد نیاز خواهد بود.
- روی ایجاد کلیک کنید
۵. تنظیم مجوزهای حساب سرویس
حساب کاربری سرویس ، نوع خاصی از حساب کاربری است که توسط برنامهها یا سرویسها برای برقراری تماسهای API مجاز به منابع Google Cloud استفاده میشود.
اکنون باید مجوزها به حساب سرویس ایجاد شده برای سطل جدید در GCS اضافه شوند.
- از صفحهی GCS bucket، تب Permissions را انتخاب کنید.
- در صفحه مدیران، روی اعطای دسترسی کلیک کنید.
- در پنل اعطای دسترسی که از سمت راست به صورت کشویی نمایش داده میشود، شناسه حساب کاربری سرویس (Service Account ID) را در فیلد New principals وارد کنید.
- در قسمت «اختصاص نقشها» ،
Storage Object AdminوStorage Legacy Bucket Readerرا اضافه کنید. این نقشها به حساب سرویس اجازه میدهند اشیاء موجود در سطل ذخیرهسازی را بخواند، بنویسد و فهرست کند.
بارگذاری دادههای TPC-H
اکنون که کاتالوگ و طرحواره ایجاد شدهاند، دادههای TPCH میتوانند از جدول samples.tpch موجود که به صورت داخلی در Databricks ذخیره شده است، بارگذاری شده و در یک جدول جدید در طرحواره تازه تعریف شده، دستکاری شوند.
ایجاد جدول با پشتیبانی Iceberg
سازگاری Iceberg با UniForm
در پشت صحنه، Databricks این جدول را به صورت داخلی به عنوان یک جدول Delta Lake مدیریت میکند و تمام مزایای بهینهسازی عملکرد و ویژگیهای مدیریتی Delta را در اکوسیستم Databricks ارائه میدهد. با این حال، با فعال کردن UniForm (مخفف Universal Format)، به Databricks دستور داده میشود که کار خاصی انجام دهد: هر بار که جدول بهروزرسانی میشود، Databricks علاوه بر متاداده Delta Lake، متاداده Iceberg مربوطه را نیز به طور خودکار تولید و نگهداری میکند.
این بدان معناست که یک مجموعه مشترک از فایلهای داده (فایلهای پارکت) اکنون توسط دو مجموعه فراداده متفاوت توصیف میشود.
- برای Databricks: از
_delta_logبرای خواندن جدول استفاده میکند. - برای خوانندگان خارجی (مانند BigQuery): آنها از فایل ابرداده Iceberg (
.metadata.json) برای درک طرحواره جدول، پارتیشنبندی و مکانهای فایل استفاده میکنند.
نتیجه، جدولی است که به طور کامل و شفاف با هر ابزار آگاه از Iceberg سازگار است. هیچ تکراری از دادهها وجود ندارد و نیازی به تبدیل یا همگامسازی دستی نیست. این یک منبع واحد از حقیقت است که میتواند به طور یکپارچه توسط دنیای تحلیلی Databricks و اکوسیستم وسیعتر ابزارهایی که از استاندارد باز Iceberg پشتیبانی میکنند، قابل دسترسی باشد.
- روی «جدید» و سپس «پرسوجو» کلیک کنید
- در فیلد متنی صفحه پرس و جو، دستور SQL زیر را اجرا کنید:
CREATE TABLE retl_tpch_project.tpch_data.regional_sales_iceberg
USING DELTA
LOCATION 'gs://<Your bucket name>/regional_sales_iceberg'
TBLPROPERTIES (
'delta.columnMapping.mode' = 'name',
'delta.enableIcebergCompatV2' = 'true',
'delta.universalFormat.enabledFormats' = 'iceberg'
)
AS
SELECT
n.n_name AS nation_name,
c.c_mktsegment AS market_segment,
YEAR(o.o_orderdate) AS order_year,
o.o_orderpriority AS order_priority,
COUNT(o.o_orderkey) AS total_order_count,
ROUND(SUM(o.o_totalprice), 2) AS total_revenue,
COUNT(DISTINCT c.c_custkey) AS unique_customer_count
FROM samples.tpch.orders AS o
INNER JOIN samples.tpch.customer AS c
ON o.o_custkey = c.c_custkey
INNER JOIN samples.tpch.nation AS n
ON c.c_nationkey = n.n_nationkey
GROUP BY
n.n_name,
c.c_mktsegment,
YEAR(o.o_orderdate),
o.o_orderpriority;
OPTIMIZE retl_tpch_project.tpch_data.regional_sales_iceberg;
DESCRIBE EXTENDED retl_tpch_project.tpch_data.regional_sales_iceberg;
یادداشتها:
- استفاده از دلتا - مشخص میکند که ما از جدول دلتا لیک استفاده میکنیم. فقط جداول دلتا لیک در Databricks میتوانند به عنوان یک جدول خارجی ذخیره شوند.
- مکان - در صورت خارجی بودن، مشخص میکند که جدول کجا ذخیره شود.
- TablePropertoes - دستور
delta.universalFormat.enabledFormats = 'iceberg'متادیتای سازگار با کوه یخ را در کنار فایلهای Delta Lake ایجاد میکند. - Optimize - به طور اجباری تولید متادیتای UniForm را آغاز میکند، زیرا این کار معمولاً به صورت غیرهمزمان انجام میشود.
- خروجی پرس و جو باید جزئیات مربوط به جدول تازه ایجاد شده را نشان دهد.

دادههای جدول GCS را تأیید کنید
با رفتن به سطل GCS، دادههای جدول تازه ایجاد شده اکنون قابل دسترسی هستند.
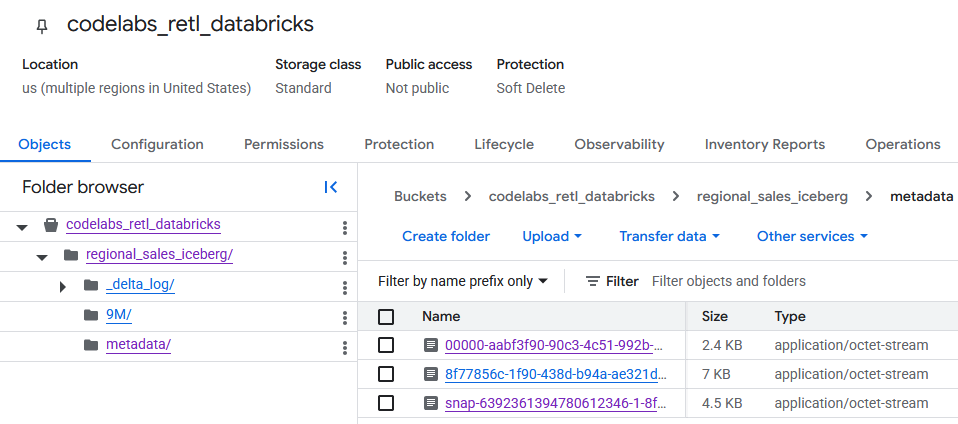
شما میتوانید متادیتای Iceberg را در پوشهی metadata پیدا کنید که توسط نرمافزارهای خارجی (مانند BigQuery) استفاده میشود. متادیتای Delta Lake که Databricks به صورت داخلی از آن استفاده میکند، در پوشهی _delta_log ردیابی میشود.
دادههای واقعی جدول به صورت فایلهای Parquet در پوشهی دیگری ذخیره میشوند که معمولاً با یک رشتهی تصادفی تولید شده توسط Databricks نامگذاری میشوند. برای مثال، در تصویر زیر، فایلهای داده در پوشهی 9M قرار دارند.
۶. راهاندازی BigQuery و BigLake
حالا که جدول Iceberg در فضای ذخیرهسازی ابری گوگل قرار دارد، قدم بعدی این است که آن را برای BigQuery قابل دسترسی کنیم. این کار با ایجاد یک جدول خارجی BigLake انجام خواهد شد.
BigLake یک موتور ذخیرهسازی است که امکان ایجاد جداول در BigQuery را فراهم میکند که دادهها را مستقیماً از منابع خارجی مانند Google Cloud Storage میخوانند. برای این آزمایشگاه، این فناوری کلیدی است که BigQuery را قادر میسازد جدول Iceberg را که به تازگی صادر شده است، بدون نیاز به دریافت دادهها، درک کند.
برای انجام این کار، دو جزء مورد نیاز است:
- اتصال منابع ابری: این یک پیوند امن بین BigQuery و GCS است. این اتصال از یک حساب کاربری سرویس ویژه برای مدیریت احراز هویت استفاده میکند و تضمین میکند که BigQuery مجوزهای لازم برای خواندن فایلها از سطل GCS را دارد.
- تعریف جدول خارجی: این به BigQuery میگوید که فایل متادیتای جدول Iceberg را در GCS کجا پیدا کند و چگونه باید تفسیر شود.
ایجاد اتصال منابع ابری
ابتدا، اتصالی که به BigQuery اجازه دسترسی به GCS را میدهد، ایجاد خواهد شد.
اطلاعات بیشتر در مورد ایجاد اتصالات منابع ابری را میتوانید اینجا بیابید.
- به بیگ کوئری بروید
- روی Connections در قسمت Explorer کلیک کنید
- اگر صفحه اکسپلورر قابل مشاهده نیست، روی آن کلیک کنید

- در صفحه اتصالات ، کلیک کنید
- برای نوع اتصال،
Vertex AI remote models, remote functions, BigLake and Spanner (Cloud Resource)را انتخاب کنید. - شناسه اتصال را روی
databricks_retlتنظیم کنید و اتصال را ایجاد کنید.

- اکنون باید یک ورودی در جدول Connections مربوط به اتصال جدید ایجاد شده مشاهده شود. برای مشاهده جزئیات اتصال، روی آن ورودی کلیک کنید.

- در صفحه جزئیات اتصال، شناسه حساب سرویس را یادداشت کنید زیرا بعداً به آن نیاز خواهیم داشت.
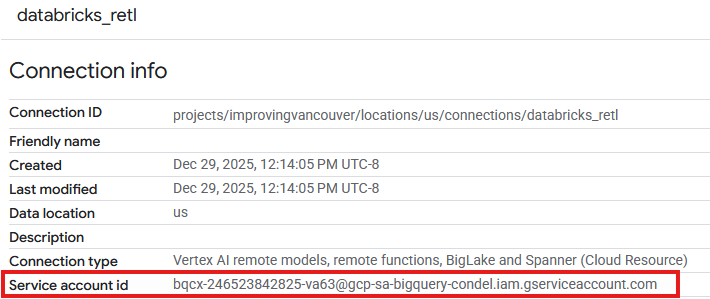
اعطای دسترسی به حساب سرویس اتصال
- به IAM و مدیریت بروید
- روی اعطای دسترسی کلیک کنید
- برای فیلد New principals ، شناسه حساب سرویس منبع اتصال که در بالا ایجاد شده است را وارد کنید.
- برای نقش،
Storage Object Userانتخاب کنید و سپس کلیک کنید
با برقراری اتصال و اعطای مجوزهای لازم به حساب کاربری سرویس، اکنون میتوان جدول خارجی BigLake را ایجاد کرد. ابتدا، یک Dataset در BigQuery مورد نیاز است تا به عنوان ظرفی برای جدول جدید عمل کند. سپس، خود جدول ایجاد میشود و به فایل فراداده Iceberg در سطل GCS اشاره میکند.
- به بیگ کوئری بروید
- در پنل Explorer ، روی شناسه پروژه کلیک کنید، سپس روی سه نقطه کلیک کنید و Create dataset را انتخاب کنید.
- مجموعه داده،
databricks_retlنام خواهد داشت. سایر گزینهها را به صورت پیشفرض رها کنید و روی دکمهی «ایجاد مجموعه داده» کلیک کنید.
- حالا، مجموعه داده جدید
databricks_retlرا در پنل Explorer پیدا کنید. روی سه نقطه کنار آن کلیک کنید و Create table را انتخاب کنید.
- برای ایجاد جدول، تنظیمات زیر را وارد کنید:
- ایجاد جدول از :
Google Cloud Storage - انتخاب فایل از مخزن GCS یا استفاده از یک الگوی URI : به مخزن GCS بروید و فایل JSON فرادادهای که در طول اکسپورت Databricks تولید شده است را پیدا کنید. مسیر باید چیزی شبیه به:
regional_sales/metadata/v1.metadata.jsonباشد. - فرمت فایل :
Iceberg - جدول :
regional_sales - نوع میز :
External table - شناسه اتصال : اتصال
databricks_retlکه قبلاً ایجاد شده است را انتخاب کنید. - بقیه مقادیر را به صورت پیشفرض بگذارید، سپس روی ایجاد جدول کلیک کنید.
- پس از ایجاد، جدول جدید
regional_salesباید در زیر مجموعه دادهdatabricks_retlقابل مشاهده باشد. اکنون میتوان این جدول را با استفاده از SQL استاندارد، درست مانند هر جدول BigQuery دیگری، جستجو کرد.
7. بارگذاری به آچار
به آخرین و مهمترین بخش خط لوله رسیدهایم: انتقال دادهها از جداول BigLake External به Spanner. این مرحله "ETL معکوس" است که در آن دادهها، پس از پردازش و گردآوری در انبار داده، برای استفاده توسط برنامهها در یک سیستم عملیاتی بارگذاری میشوند.
Spanner یک پایگاه داده رابطهای کاملاً مدیریتشده و توزیعشده در سطح جهانی است. این پایگاه داده، ثبات تراکنشی یک پایگاه داده رابطهای سنتی را ارائه میدهد، اما با مقیاسپذیری افقی یک پایگاه داده NoSQL. این ویژگی، آن را به انتخابی ایدهآل برای ساخت برنامههای کاربردی مقیاسپذیر و با دسترسی بالا تبدیل میکند.
این فرآیند به شرح زیر خواهد بود:
- یک نمونه Spanner ایجاد کنید، که تخصیص فیزیکی منابع است.
- یک پایگاه داده در آن نمونه ایجاد کنید.
- یک طرح جدول در پایگاه داده تعریف کنید که با ساختار دادههای
regional_salesمطابقت داشته باشد. - یک کوئری BigQuery
EXPORT DATAاجرا کنید تا دادهها را از جدول BigLake مستقیماً در جدول Spanner بارگذاری کنید.
ایجاد نمونه، پایگاه داده و جدول Spanner
- به آچار بروید
- کلیک کنید
 در صورت وجود، میتوانید از یک نمونه موجود استفاده کنید. در صورت نیاز، الزامات نمونه را تنظیم کنید. برای این آزمایش، از موارد زیر استفاده شد:
در صورت وجود، میتوانید از یک نمونه موجود استفاده کنید. در صورت نیاز، الزامات نمونه را تنظیم کنید. برای این آزمایش، از موارد زیر استفاده شد:
نسخه | تصدی |
نام نمونه | دیتابریک-رتل |
پیکربندی منطقه | منطقه انتخابی شما |
واحد محاسبه | واحدهای پردازش (PU) |
تخصیص دستی | ۱۰۰ |
- پس از ایجاد، به صفحه نمونه Spanner بروید و انتخاب کنید
 در صورت وجود، میتوانید از پایگاه داده موجود استفاده کنید.
در صورت وجود، میتوانید از پایگاه داده موجود استفاده کنید.
- برای این آزمایشگاه، یک پایگاه داده با ... ایجاد خواهد شد.
- نام :
databricks-retl - گویش پایگاه داده :
Google Standard SQL
- پس از ایجاد پایگاه داده، آن را از صفحه Spanner Instance انتخاب کرده و وارد صفحه Spanner Database شوید.
- از صفحه پایگاه داده Spanner، روی کلیک کنید

- در صفحه پرس و جوی جدید، تعریف جدول برای وارد کردن به Spanner ایجاد خواهد شد. برای انجام این کار، پرس و جوی SQL زیر را اجرا کنید.
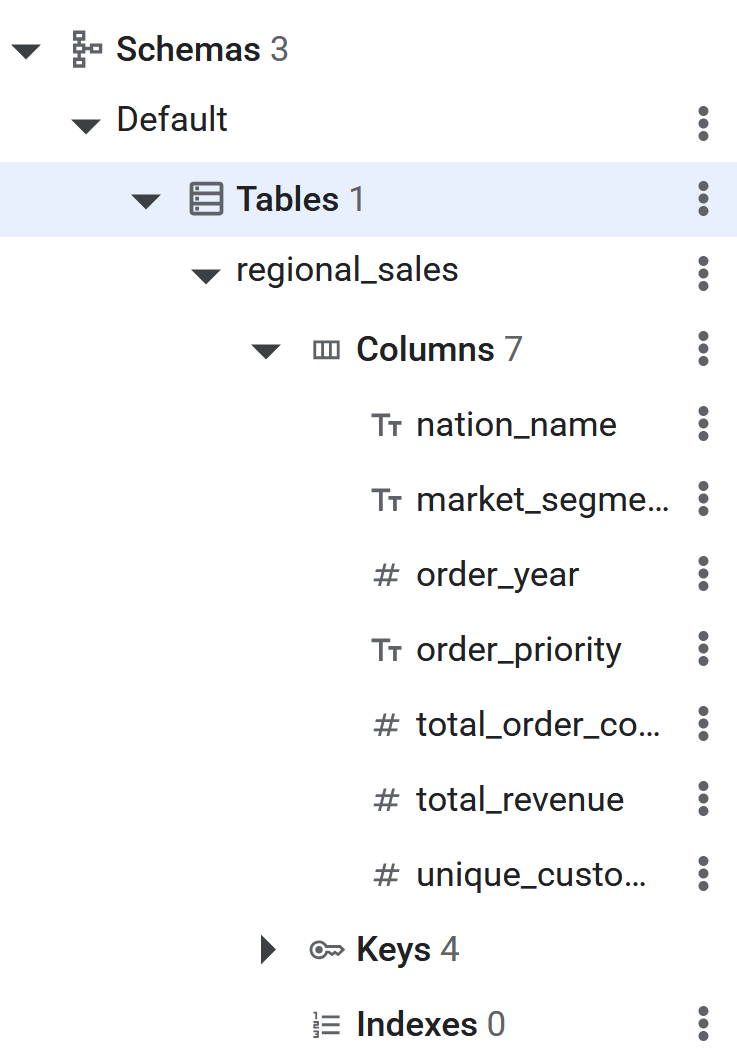
CREATE TABLE regional_sales (
nation_name STRING(MAX),
market_segment STRING(MAX),
order_year INT64,
order_priority STRING(MAX),
total_order_count INT64,
total_revenue NUMERIC,
unique_customer_count INT64
) PRIMARY KEY (nation_name, market_segment, order_year, order_priority);
- پس از اجرای دستور SQL، جدول Spanner اکنون برای BigQuery جهت معکوس کردن ETL دادهها آماده خواهد بود. ایجاد جدول را میتوان با مشاهده فهرست آن در پنل سمت چپ در پایگاه داده Spanner تأیید کرد.
معکوس کردن ETL به Spanner با استفاده از EXPORT DATA
این مرحله نهایی است. با آماده شدن دادههای منبع در جدول BigQuery BigLake و ایجاد جدول مقصد در Spanner، انتقال دادهها به طرز شگفتآوری ساده است. از یک کوئری SQL در BigQuery استفاده خواهد شد: EXPORT DATA .
این کوئری بهطور خاص برای سناریوهایی از این دست طراحی شده است. این کوئری بهطور مؤثر دادهها را از یک جدول BigQuery (از جمله جدولهای خارجی مانند جدول BigLake) به یک مقصد خارجی صادر میکند. در این مورد، مقصد جدول Spanner است. اطلاعات بیشتر در مورد ویژگی صادرات را میتوانید اینجا بیابید.
اطلاعات بیشتر در مورد تنظیم BigQuery برای Spanner Reverse ETL را میتوانید اینجا بیابید.
- به بیگ کوئری بروید
- یک برگه ویرایشگر پرس و جو جدید باز کنید.
- در صفحه پرس و جو، SQL زیر را وارد کنید. به یاد داشته باشید که شناسه پروژه را در
uriو مسیر جدول را با شناسه پروژه صحیح جایگزین کنید.
EXPORT DATA OPTIONS(
uri='https://spanner.googleapis.com/projects/YOUR_PROJECT_ID/instances/databricks-retl/databases/databricks-retl',
format='CLOUD_SPANNER',
spanner_options="""{
"table": "regional_sales",
"priority": "MEDIUM"
}"""
) AS
SELECT * FROM `YOUR_PROJECT_ID.databricks_retl.regional_sales`;
- پس از اتمام دستور، دادهها با موفقیت به Spanner صادر شدهاند!
۸. تأیید دادهها در Spanner
تبریک! یک خط لوله ETL معکوس کامل با موفقیت ساخته و اجرا شد و دادهها را از یک انبار داده Databricks به یک پایگاه داده عملیاتی Spanner منتقل کرد.
مرحله آخر تأیید این است که دادهها طبق انتظار به Spanner رسیدهاند.
- به سراغ آچار بروید.
- به نمونه
databricks-retlخود و سپس به پایگاه دادهdatabricks-retlبروید. - در لیست جداول، روی جدول
regional_salesکلیک کنید. - در منوی ناوبری سمت چپ جدول، روی برگه «دادهها» کلیک کنید.
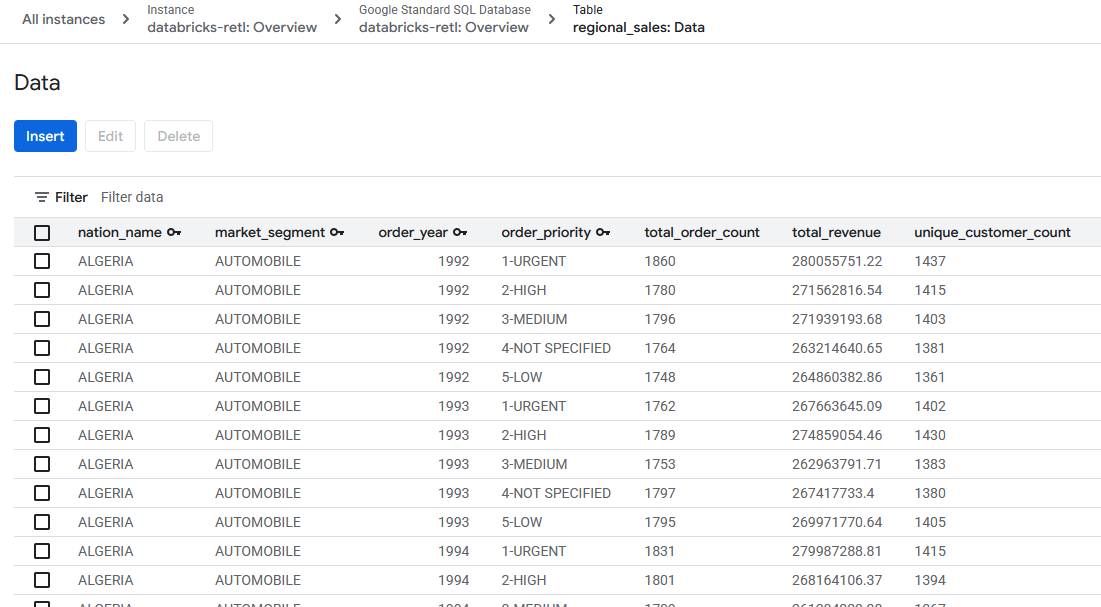
- دادههای فروش جمعآوریشده، که در اصل از Databricks گرفته شده بودند، اکنون باید بارگذاری شده و برای استفاده در جدول Spanner آماده باشند. این دادهها اکنون در یک سیستم عملیاتی قرار دارند و آمادهاند تا یک برنامه زنده را راهاندازی کنند، به یک داشبورد سرویس دهند یا توسط یک API مورد پرسش قرار گیرند.
شکاف بین دنیای دادههای تحلیلی و عملیاتی با موفقیت از بین رفته است.
۹. تمیز کردن
وقتی کارتان با این تمرین تمام شد، تمام جداول اضافه شده و دادههای ذخیره شده را حذف کنید.
تمیز کردن جداول آچار
- آچار گوتو
- روی نمونهای که برای این آزمایش استفاده شده است از لیست با نام
databricks-retlکلیک کنید.

- در صفحه نمونه، روی کلیک کنید

- در کادر تأیید ظاهر شده،
databricks-retlرا وارد کنید و روی ... کلیک کنید.
GCS را تمیز کنید
- برو به GCS
- انتخاب کنید
 از منوی سمت چپ
از منوی سمت چپ - سطل ``codelabs_retl_databricks`` را انتخاب کنید.
- پس از انتخاب، روی آن کلیک کنید
 دکمهای که در بالای بنر ظاهر میشود
دکمهای که در بالای بنر ظاهر میشود

- در کادر تأیید ظاهر شده،
DELETEوارد کنید و روی ... کلیک کنید.
پاکسازی دیتابریکها
حذف کاتالوگ/طرحواره/جدول
- وارد نمونه Databricks خود شوید
- کلیک کنید
 از منوی سمت چپ
از منوی سمت چپ - قبلاً ایجاد شده را انتخاب کنید
 از فهرست کاتالوگ
از فهرست کاتالوگ - در لیست طرحواره، انتخاب کنید
 که ایجاد شد
که ایجاد شد - قبلاً ایجاد شده را انتخاب کنید
 از فهرست جدول
از فهرست جدول - با کلیک کردن روی، گزینههای جدول را گسترش دهید
 و
و Deleteرا انتخاب کنید - کلیک
 در کادر تأیید برای حذف جدول
در کادر تأیید برای حذف جدول - پس از حذف جدول، به صفحه طرحواره بازگردانده خواهید شد.
- با کلیک کردن روی، گزینههای طرحواره را گسترش دهید و
Deleteرا انتخاب کنید - کلیک در کادر تأیید، برای حذف طرحواره
- پس از حذف طرحواره، به صفحه کاتالوگ بازگردانده خواهید شد.
- مراحل ۴ تا ۱۱ را دوباره دنبال کنید تا طرحواره
defaultدر صورت وجود) حذف شود. - از صفحه کاتالوگ، با کلیک روی گزینههای کاتالوگ، آنها را گسترش دهید. و
Deleteرا انتخاب کنید - کلیک در کادر تأیید برای حذف کاتالوگ
حذف مکان/اعتبارنامههای دادههای خارجی
- از صفحه کاتالوگ، روی کلیک کنید
- اگر گزینهی
External Dataرا نمیبینید، ممکن است در منوی کشوییConnectگزینهیExternal Locationرا مشاهده کنید. - روی مکان داده خارجی
retl-gcs-locationکه قبلاً ایجاد شده است کلیک کنید - از صفحه موقعیت مکانی خارجی، با کلیک روی گزینهها، گزینههای موقعیت مکانی را گسترش دهید. و
Deleteرا انتخاب کنید - کلیک در کادر تأیید، برای حذف مکان خارجی
- کلیک کنید
- روی
retl-gcs-credentialکه قبلاً ایجاد شده بود کلیک کنید - از صفحه اعتبارنامه، با کلیک روی موارد زیر، گزینههای اعتبارنامه را گسترش دهید. و
Deleteرا انتخاب کنید - کلیک در کادر گفتگوی تأیید، برای حذف اعتبارنامهها.
۱۰. تبریک
تبریک میگویم که آزمایشگاه کد را تمام کردی.
آنچه ما پوشش دادهایم
- نحوه بارگذاری دادهها در Databricks به عنوان جداول Iceberg
- نحوه ایجاد یک سطل GCS
- نحوه خروجی گرفتن از جدول Databricks به GCS با فرمت Iceberg
- نحوه ایجاد یک جدول خارجی BigLake در BigQuery از جدول Iceberg در GCS
- نحوه راهاندازی یک نمونه Spanner
- نحوه بارگذاری جداول خارجی BigLake در BigQuery به Spanner