
1. Créer un pipeline ETL inversé de Databricks vers Spanner à l'aide de Google Cloud Storage et BigQuery
Introduction
Dans cet atelier de programmation, vous allez créer un pipeline ETL inversé de Databricks vers Spanner. Traditionnellement, les pipelines ETL (Extract, Transform, Load) standards déplacent les données des bases de données opérationnelles vers un entrepôt de données tel que Databricks pour l'analyse. Un pipeline Reverse ETL fait l'inverse : il transfère les données traitées et organisées depuis l'entrepôt de données vers des bases de données opérationnelles, telles que Spanner, une base de données relationnelle distribuée à l'échelle mondiale, idéale pour les applications à haute disponibilité. Ces données peuvent ensuite alimenter des applications, des fonctionnalités destinées aux utilisateurs ou être utilisées pour la prise de décision en temps réel.
L'objectif est de transférer un ensemble de données agrégées des tables Databricks Iceberg vers les tables Spanner.
Pour ce faire, Google Cloud Storage (GCS) et BigQuery sont utilisés comme étapes intermédiaires. Voici une présentation du flux de données et de la logique de cette architecture :

- Databricks vers Google Cloud Storage (GCS) au format Iceberg :
- La première étape consiste à extraire les données de Databricks dans un format ouvert et bien défini. La table est exportée au format Apache Iceberg. Ce processus écrit les données sous-jacentes sous la forme d'un ensemble de fichiers Parquet et les métadonnées de la table (schéma, partitions, emplacements des fichiers) sous la forme de fichiers JSON et Avro. En stockant cette structure de table complète dans GCS, vous rendez les données portables et accessibles à tout système compatible avec le format Iceberg.
- Convertir des tables Iceberg GCS en tables externes BigLake BigQuery :
- Au lieu de charger les données directement depuis GCS dans Spanner, BigQuery est utilisé comme intermédiaire puissant. Une table externe BigLake est créée dans BigQuery et pointe directement vers le fichier de métadonnées Iceberg dans GCS. Cette approche présente plusieurs avantages :
- Aucune duplication des données : BigQuery lit la structure de la table à partir des métadonnées et interroge les fichiers de données Parquet sur place sans les ingérer, ce qui permet de réaliser des économies de temps et de stockage considérables.
- Requêtes fédérées : elles permettent d'exécuter des requêtes SQL complexes sur des données GCS comme s'il s'agissait d'une table BigQuery native.
- Effectuez un reverse ETL d'une table externe BigLake vers Spanner :
- La dernière étape consiste à transférer les données de BigQuery vers Spanner. Pour ce faire, vous devez utiliser une fonctionnalité puissante de BigQuery appelée requête
EXPORT DATA, qui correspond à l'étape d'ETL inversé. - Aptitude opérationnelle : Spanner est conçu pour les charges de travail transactionnelles, offrant une cohérence forte et une haute disponibilité pour les applications. En transférant les données dans Spanner, vous les rendez accessibles aux applications destinées aux utilisateurs, aux API et aux autres systèmes opérationnels qui nécessitent des recherches ponctuelles à faible latence.
- Évolutivité : ce modèle permet d'exploiter la puissance analytique de BigQuery pour traiter de grands ensembles de données, puis de diffuser les résultats efficacement grâce à l'infrastructure évolutive à l'échelle mondiale de Spanner.
Services et terminologie
- DataBricks : plate-forme de données basée sur le cloud et conçue autour d'Apache Spark.
- Spanner : base de données relationnelle distribuée à l'échelle mondiale et entièrement gérée par Google.
- Google Cloud Storage : offre de stockage d'objets blob de Google Cloud.
- BigQuery : un entrepôt de données sans serveur pour l'analyse, entièrement géré par Google.
- Iceberg : format de table ouvert défini par Apache, qui fournit une abstraction sur les formats de fichiers de données Open Source courants.
- Parquet : format de fichier de données binaires en colonnes Open Source d'Apache.
Points abordés
- Charger des données dans Databricks en tant que tables Iceberg
- Créer un bucket GCS
- Exporter une table Databricks vers GCS au format Iceberg
- Créer une table externe BigLake dans BigQuery à partir de la table Iceberg dans GCS
- Configurer une instance Spanner
- Charger des tables externes BigLake dans BigQuery vers Spanner
2. Configuration, conditions requises et limites
Prérequis
- Un compte Databricks, de préférence sur GCP
- Pour exporter des données de BigQuery vers Spanner, vous devez disposer d'un compte Google Cloud avec une réservation BigQuery de niveau Enterprise ou supérieur.
- Accès à la console Google Cloud via un navigateur Web
- Un terminal pour exécuter les commandes Google Cloud CLI
Si le règlement iam.allowedPolicyMemberDomains est activé dans votre organisation Google Cloud, un administrateur devra peut-être accorder une exception pour autoriser les comptes de service provenant de domaines externes. Nous aborderons ce point ultérieurement, le cas échéant.
Conditions requises
- Un projet Google Cloud avec facturation activée.
- Un navigateur Web, par exemple Chrome
- Un compte Databricks (cet atelier suppose un espace de travail hébergé dans GCP)
- Pour utiliser la fonctionnalité EXPORT DATA, l'instance BigQuery doit être en édition Enterprise ou supérieure.
- Si le règlement
iam.allowedPolicyMemberDomainsest activé dans votre organisation Google Cloud, un administrateur devra peut-être accorder une exception pour autoriser les comptes de service provenant de domaines externes. Nous aborderons ce point ultérieurement, le cas échéant.
Autorisations Google Cloud Platform IAM
Le compte Google doit disposer des autorisations suivantes pour exécuter toutes les étapes de cet atelier de programmation.
Comptes de service | ||
| Permet de créer des comptes de service. | |
Spanner | ||
| Permet de créer une instance Spanner. | |
| Permet d'exécuter des instructions LDD pour créer | |
| Permet d'exécuter des instructions LDD pour créer des tables dans la base de données. | |
Google Cloud Storage | ||
| Permet de créer un bucket GCS pour stocker les fichiers Parquet exportés. | |
| Permet d'écrire les fichiers Parquet exportés dans le bucket GCS. | |
| Permet à BigQuery de lire les fichiers Parquet à partir du bucket GCS. | |
| Permet à BigQuery de lister les fichiers Parquet dans le bucket GCS. | |
Dataflow | ||
| Permet de revendiquer des éléments de travail à partir de Dataflow. | |
| Permet au nœud de calcul Dataflow de renvoyer des messages au service Dataflow. | |
| Permet aux nœuds de calcul Dataflow d'écrire des entrées de journal dans Google Cloud Logging. | |
Pour plus de commodité, vous pouvez utiliser des rôles prédéfinis qui contiennent ces autorisations.
|
|
|
|
|
|
|
|
Projet Google Cloud
Un projet est une unité d'organisation de base dans Google Cloud. Si un administrateur vous en a fourni un, vous pouvez ignorer cette étape.
Vous pouvez créer un projet à l'aide de la CLI comme suit :
gcloud projects create <your-project-name>
Pour en savoir plus sur la création et la gestion de projets, cliquez ici.
Limites
Il est important de connaître certaines limites et incompatibilités de types de données qui peuvent survenir dans ce pipeline.
Databricks Iceberg vers BigQuery
Lorsque vous utilisez BigQuery pour interroger des tables Iceberg gérées par Databricks (via UniForm), gardez les points suivants à l'esprit :
- Évolution du schéma : bien que UniForm traduise correctement les modifications du schéma Delta Lake en Iceberg, les modifications complexes ne sont pas toujours propagées comme prévu. Par exemple, le renommage de colonnes dans Delta Lake n'est pas traduit dans Iceberg, qui le considère comme une
dropet uneadd. Testez toujours minutieusement les modifications de schéma. - Fonctionnalité temporelle : BigQuery ne peut pas utiliser les fonctionnalités temporelles de Delta Lake. Il n'interrogera que le dernier instantané de la table Iceberg.
- Fonctionnalités Delta Lake non compatibles : les fonctionnalités telles que les vecteurs de suppression et le mappage de colonnes avec le mode
iddans Delta Lake ne sont pas compatibles avec UniForm pour Iceberg. L'atelier utilise le modenamepour le mappage des colonnes, qui est compatible.
BigQuery vers Spanner
La commande EXPORT DATA de BigQuery vers Spanner n'est pas compatible avec tous les types de données BigQuery. L'exportation d'une table avec les types suivants générera une erreur :
STRUCTGEOGRAPHYDATETIMERANGETIME
De plus, si le projet BigQuery utilise le dialecte GoogleSQL, les types numériques suivants ne sont pas non plus compatibles avec l'exportation vers Spanner :
BIGNUMERIC
Pour obtenir la liste complète et à jour des limites, consultez la documentation officielle : Limites d'exportation vers Spanner.
Dépannage et problèmes connus
- Si vous n'utilisez pas une instance GCP Databricks, il est possible que vous ne puissiez pas définir d'emplacement de données externe dans GCS. Dans ce cas, les fichiers devront être mis en scène dans la solution de stockage du fournisseur de cloud de l'espace de travail Databricks, puis migrés vers GCS séparément.
- Dans ce cas, vous devrez ajuster les métadonnées, car les informations contiendront des chemins d'accès codés en dur vers les fichiers intermédiaires.
3. Configurer Google Cloud Storage (GCS)
Google Cloud Storage (GCS) sera utilisé pour stocker les fichiers de données Parquet générés par Databricks. Pour ce faire, vous devrez d'abord créer un bucket à utiliser comme destination des fichiers.
Google Cloud Storage
Créer un bucket
- Accédez à la page Google Cloud Storage dans la console cloud.
- Dans le panneau de gauche, sélectionnez Buckets :
- Cliquez sur le bouton Create (Créer).

- Renseignez les informations sur votre bucket :
- Choisissez un nom de bucket à utiliser. Pour cet atelier, le nom
codelabs_retl_databrickssera utilisé. - Sélectionnez une région pour stocker le bucket ou utilisez les valeurs par défaut.
- Conserver la classe de stockage
standard - Conserver les valeurs par défaut pour Contrôler l'accès
- Conserver les valeurs par défaut pour protéger les données des objets
- Lorsque vous avez terminé, cliquez sur le bouton
Create. Un message peut s'afficher pour confirmer que l'accès public sera bloqué. Confirmez. - Félicitations, un bucket a bien été créé. Vous serez redirigé vers la page du bucket.
- Copiez le nom du nouveau bucket quelque part, car vous en aurez besoin plus tard.
Préparation des étapes suivantes
Assurez-vous de noter les informations suivantes, car vous en aurez besoin lors des prochaines étapes :
- ID de projet Google
- Nom du bucket Google Storage
4. Configurer Databricks
Données TPC-H
Pour cet atelier, vous utiliserez l'ensemble de données TPC-H, qui est une référence standard du secteur pour les systèmes d'aide à la décision. Son schéma modélise un environnement commercial réaliste avec des clients, des commandes, des fournisseurs et des pièces, ce qui le rend idéal pour illustrer un scénario d'analyse et de transfert de données réel.
Au lieu d'utiliser les tables TPC-H brutes et normalisées, une nouvelle table agrégée sera créée. Cette nouvelle table joindra les données des tables orders, customer et nation pour produire une vue dénormalisée et récapitulative des ventes régionales. Cette étape de pré-agrégation est une pratique courante dans l'analyse, car elle prépare les données pour un cas d'utilisation spécifique (dans ce scénario, pour la consommation par une application opérationnelle).
Le schéma final de la table agrégée sera le suivant :
Col | Type |
nation_name | chaîne |
market_segment | chaîne |
order_year | int |
order_priority | chaîne |
total_order_count | bigint |
total_revenue | decimal(29,2) |
unique_customer_count | bigint |
Compatibilité d'Iceberg avec le format universel Delta Lake (UniForm)
Pour cet atelier, la table dans Databricks sera une table Delta Lake. Toutefois, pour le rendre lisible par des systèmes externes tels que BigQuery, une fonctionnalité puissante appelée format universel (UniForm) sera activée.
UniForm génère automatiquement des métadonnées Iceberg en plus des métadonnées Delta Lake pour une copie unique et partagée des données de la table. Vous bénéficiez ainsi des avantages suivants :
- Dans Databricks : vous bénéficiez de tous les avantages de Delta Lake en termes de performances et de gouvernance.
- En dehors de Databricks : la table peut être lue par n'importe quel moteur de requête compatible avec Iceberg, comme BigQuery, comme s'il s'agissait d'une table Iceberg native.
Vous n'avez donc pas besoin de gérer des copies distinctes des données ni d'exécuter des jobs de conversion manuels. UniForm sera activé en définissant des propriétés de table spécifiques lors de la création de la table.
Catalogues Databricks
Un catalogue Databricks est le conteneur de premier niveau pour les données dans Unity Catalog, la solution de gouvernance unifiée de Databricks. Unity Catalog offre un moyen centralisé de gérer les ressources de données, de contrôler l'accès et de suivre la traçabilité, ce qui est essentiel pour une plate-forme de données bien gouvernée.
Il utilise un espace de noms à trois niveaux pour organiser les données : catalog.schema.table.
- Catalogue : niveau le plus élevé, utilisé pour regrouper les données par environnement, unité commerciale ou projet.
- Schéma (ou base de données) : regroupement logique de tables, de vues et de fonctions dans un catalogue.
- Table : objet contenant vos données.
Avant de pouvoir créer le tableau TPC-H agrégé, vous devez d'abord configurer un catalogue et un schéma dédiés pour l'héberger. Cela permet d'organiser clairement le projet et de l'isoler des autres données de l'espace de travail.
Créer un catalogue et un schéma
Dans Databricks Unity Catalog, un catalogue sert de niveau d'organisation le plus élevé pour les composants de données. Il agit comme un conteneur sécurisé pouvant s'étendre sur plusieurs espaces de travail Databricks. Il vous permet d'organiser et d'isoler les données en fonction des unités commerciales, des projets ou des environnements, avec des autorisations et des contrôles d'accès clairement définis.
Dans un catalogue, un schéma (également appelé base de données) organise les tables, les vues et les fonctions. Cette structure hiérarchique permet un contrôle précis et un regroupement logique des objets de données associés. Pour cet atelier, un catalogue et un schéma dédiés seront créés pour héberger les données TPC-H, ce qui garantira une isolation et une gestion appropriées.
Créer un catalogue
- Accédez à
 .
. - Cliquez sur +, puis sélectionnez Créer un catalogue dans le menu déroulant.
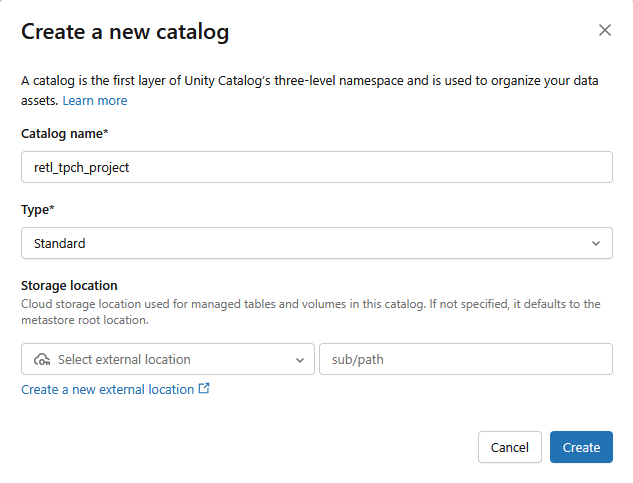
- Un catalogue Standard sera créé avec les paramètres suivants :
- Nom du catalogue :
retl_tpch_project - Emplacement de stockage : utilisez l'emplacement par défaut s'il a été configuré dans l'espace de travail ou créez-en un.
Créer un schéma
- Accédez à .
- Sélectionnez le nouveau catalogue créé dans le panneau de gauche.
- Cliquez sur
 .
. - Un schéma sera créé avec le nom du schéma
tpch_data.
Configurer des données externes
Pour pouvoir exporter des données de Databricks vers Google Cloud Storage (GCS), vous devez configurer des identifiants de données externes dans Databricks. Cela permet à Databricks d'accéder au bucket GCS et d'y écrire des données de manière sécurisée.
- Sur l'écran Catalogue, cliquez sur
 .
.
- Si l'option
External Datane s'affiche pas, vous trouverez peut-être l'optionExternal Locationsdans un menu déroulantConnect.
- Cliquez sur
 .
. - Dans la nouvelle boîte de dialogue, configurez les valeurs requises pour les identifiants :
- Type de justificatif :
GCP Service Account - Nom de l'identifiant :
retl-gcs-credential
- Cliquez sur Créer.
- Cliquez ensuite sur l'onglet Emplacements externes.
- Cliquez sur Créer un emplacement.
- Dans la nouvelle boîte de dialogue, configurez les valeurs requises pour l'emplacement externe :
- Nom du lieu externe :
retl-gcs-location - Type de stockage :
GCP - URL : URL du bucket GCS, au format
gs://YOUR_BUCKET_NAME - Identifiant de stockage : sélectionnez le
retl-gcs-credentialque vous venez de créer.
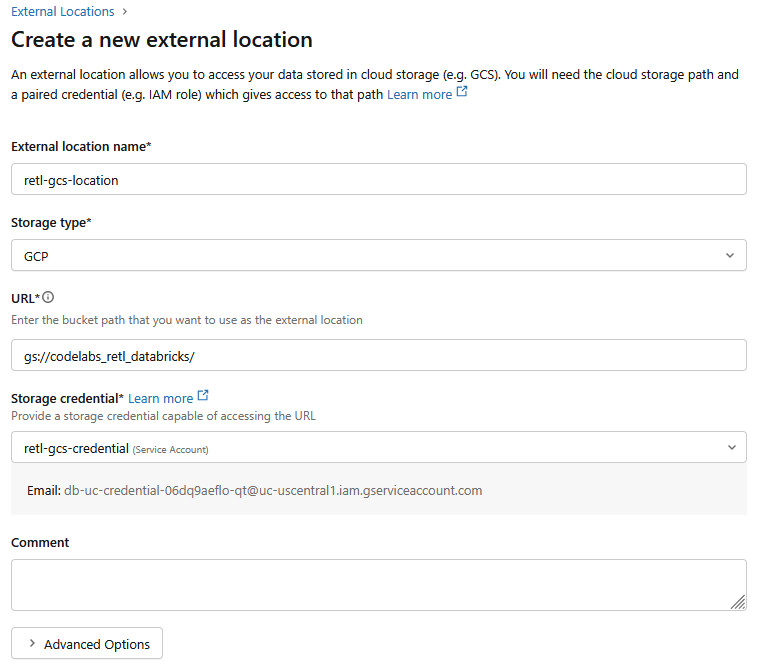
- Notez l'adresse e-mail du compte de service qui est automatiquement renseignée lorsque vous sélectionnez les identifiants de stockage, car vous en aurez besoin à l'étape suivante.
- Cliquez sur Créer.
5. Définir des autorisations de compte de service
Un compte de service est un type de compte spécial utilisé par les applications ou les services pour effectuer des appels d'API autorisés aux ressources Google Cloud.
Vous devez maintenant ajouter des autorisations au compte de service créé pour le nouveau bucket dans GCS.
- Sur la page du bucket GCS, sélectionnez l'onglet Autorisations.
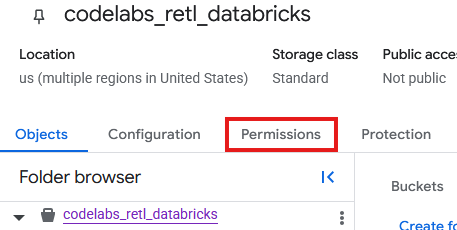
- Cliquez sur Accorder l'accès sur la page des comptes principaux.
- Dans le panneau Accorder l'accès qui s'affiche sur la droite, saisissez l'ID du compte de service dans le champ Nouveaux comptes principaux.
- Sous Attribuer des rôles, ajoutez
Storage Object AdminetStorage Legacy Bucket Reader. Ces rôles permettent au compte de service de lire, d'écrire et de lister les objets dans le bucket de stockage.
Charger les données TPC-H
Maintenant que le catalogue et le schéma sont créés, les données TPCH peuvent être chargées à partir de la table samples.tpch existante, qui est stockée en interne dans Databricks et manipulée dans une nouvelle table du schéma nouvellement défini.
Créer une table compatible avec Iceberg
Compatibilité d'Iceberg avec UniForm
En coulisses, Databricks gère en interne cette table en tant que table Delta Lake, ce qui offre tous les avantages des fonctionnalités d'optimisation des performances et de gouvernance de Delta dans l'écosystème Databricks. Toutefois, en activant UniForm (abréviation de Universal Format), Databricks est invité à effectuer une opération spéciale : chaque fois que la table est mise à jour, Databricks génère et gère automatiquement les métadonnées Iceberg correspondantes en plus des métadonnées Delta Lake.
Cela signifie qu'un ensemble unique et partagé de fichiers de données (les fichiers Parquet) est désormais décrit par deux ensembles de métadonnées différents.
- Pour Databricks : il utilise
_delta_logpour lire la table. - Pour les lecteurs externes (comme BigQuery) : ils utilisent le fichier de métadonnées Iceberg (
.metadata.json) pour comprendre le schéma, le partitionnement et les emplacements des fichiers de la table.
Le résultat est une table entièrement et clairement compatible avec n'importe quel outil compatible avec Iceberg. Il n'y a pas de duplication de données et aucune conversion ni synchronisation manuelle n'est nécessaire. Il s'agit d'une source unique d'informations à laquelle peuvent accéder facilement l'univers analytique de Databricks et l'écosystème plus large d'outils compatibles avec la norme Iceberg ouverte.
- Cliquez sur Nouveau, puis sur Requête.
- Dans le champ de texte de la page de requête, exécutez la commande SQL suivante :
CREATE TABLE retl_tpch_project.tpch_data.regional_sales_iceberg
USING DELTA
LOCATION 'gs://<Your bucket name>/regional_sales_iceberg'
TBLPROPERTIES (
'delta.columnMapping.mode' = 'name',
'delta.enableIcebergCompatV2' = 'true',
'delta.universalFormat.enabledFormats' = 'iceberg'
)
AS
SELECT
n.n_name AS nation_name,
c.c_mktsegment AS market_segment,
YEAR(o.o_orderdate) AS order_year,
o.o_orderpriority AS order_priority,
COUNT(o.o_orderkey) AS total_order_count,
ROUND(SUM(o.o_totalprice), 2) AS total_revenue,
COUNT(DISTINCT c.c_custkey) AS unique_customer_count
FROM samples.tpch.orders AS o
INNER JOIN samples.tpch.customer AS c
ON o.o_custkey = c.c_custkey
INNER JOIN samples.tpch.nation AS n
ON c.c_nationkey = n.n_nationkey
GROUP BY
n.n_name,
c.c_mktsegment,
YEAR(o.o_orderdate),
o.o_orderpriority;
OPTIMIZE retl_tpch_project.tpch_data.regional_sales_iceberg;
DESCRIBE EXTENDED retl_tpch_project.tpch_data.regional_sales_iceberg;
Remarques :
- Using Delta : indique que nous utilisons une table Delta Lake. Seules les tables Delta Lake dans Databricks peuvent être stockées en tant que tables externes.
- Emplacement : indique où la table doit être stockée, si elle est externe.
- TablePropertoes :
delta.universalFormat.enabledFormats = ‘iceberg'crée les métadonnées Iceberg compatibles en même temps que les fichiers Delta Lake. - Optimize (Optimiser) : déclenche de force la génération de métadonnées UniForm, qui se produit généralement de manière asynchrone.
- Le résultat de la requête doit afficher des informations sur la table qui vient d'être créée.

Vérifier les données de la table GCS
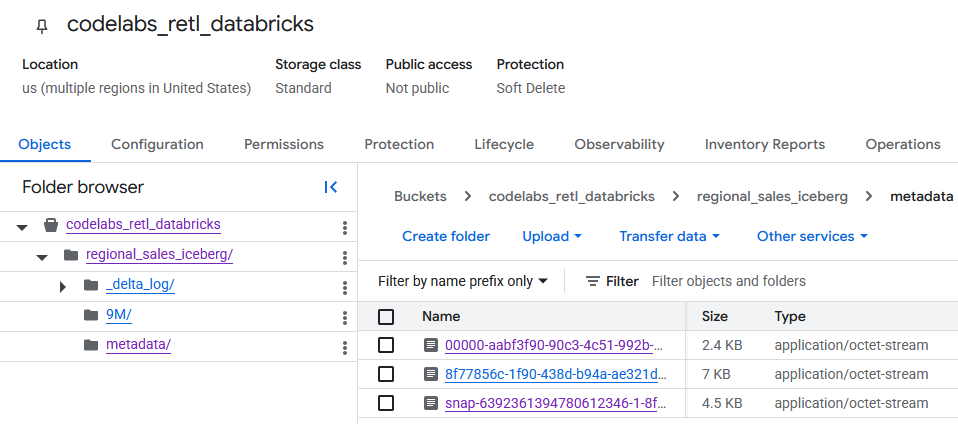
Les données de la table que vous venez de créer sont désormais disponibles dans le bucket GCS.
Vous trouverez les métadonnées Iceberg dans le dossier metadata, qui est utilisé par les lecteurs externes (comme BigQuery). Les métadonnées Delta Lake, que Databricks utilise en interne, sont suivies dans le dossier _delta_log.
Les données de table proprement dites sont stockées sous forme de fichiers Parquet dans un autre dossier, généralement nommé avec une chaîne générée de manière aléatoire par Databricks. Par exemple, dans la capture d'écran ci-dessous, les fichiers de données se trouvent dans le dossier 9M.
6. Configurer BigQuery et BigLake
Maintenant que la table Iceberg se trouve dans Google Cloud Storage, l'étape suivante consiste à la rendre accessible à BigQuery. Pour ce faire, vous devez créer une table externe BigLake.
BigLake est un moteur de stockage qui permet de créer des tables dans BigQuery pour lire les données directement à partir de sources externes telles que Google Cloud Storage. Pour cet atelier, il s'agit de la technologie clé qui permet à BigQuery de comprendre la table Iceberg qui vient d'être exportée sans avoir à ingérer les données.
Pour que cela fonctionne, deux composants sont nécessaires :
- Connexion à une ressource Cloud : il s'agit d'un lien sécurisé entre BigQuery et GCS. Il utilise un compte de service spécial pour gérer l'authentification, ce qui garantit que BigQuery dispose des autorisations nécessaires pour lire les fichiers du bucket GCS.
- Définition d'une table externe : elle indique à BigQuery où trouver le fichier de métadonnées de la table Iceberg dans GCS et comment l'interpréter.
Créer une connexion à une ressource cloud
Vous allez d'abord créer la connexion qui permet à BigQuery d'accéder à GCS.
Pour en savoir plus sur la création de connexions à des ressources cloud, cliquez ici.
- Accédez à BigQuery.
- Cliquez sur Connexions sous Explorateur.
- Si le plan Explorateur n'est pas visible, cliquez sur
 .
.
- Sur la page Connexions, cliquez sur
 .
. - Dans le champ Type de connexion, sélectionnez
Vertex AI remote models, remote functions, BigLake and Spanner (Cloud Resource). - Définissez l'ID de connexion sur
databricks_retlet créez la connexion.

- Une entrée doit maintenant s'afficher dans le tableau Connexions de la connexion que vous venez de créer. Cliquez sur cette entrée pour afficher les détails de la connexion.

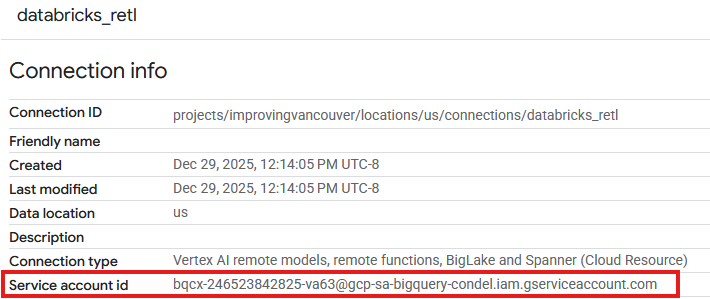
- Sur la page des informations de connexion, notez l'ID du compte de service, car vous en aurez besoin plus tard.
Accorder l'accès au compte de service de connexion
- Accédez à IAM et administration.
- Cliquez sur Accorder l'accès.
- Dans le champ Nouveaux comptes principaux, saisissez l'ID du compte de service de la ressource de connexion créé ci-dessus.
- Pour le rôle, sélectionnez
Storage Object User, puis cliquez sur .
.
Une fois la connexion établie et les autorisations nécessaires accordées à son compte de service, la table externe BigLake peut être créée. Tout d'abord, un ensemble de données est nécessaire dans BigQuery pour servir de conteneur à la nouvelle table. La table elle-même sera ensuite créée, en pointant vers le fichier de métadonnées Iceberg dans le bucket GCS.
- Accédez à BigQuery.
- Dans le panneau Explorateur, cliquez sur l'ID du projet, puis sur les trois points et sélectionnez Créer un ensemble de données.
- L'ensemble de données sera nommé
databricks_retl. Laissez les autres options sur leurs valeurs par défaut, puis cliquez sur le bouton Créer un ensemble de données.
- Recherchez ensuite le nouvel ensemble de données
databricks_retldans le panneau Explorateur. Cliquez sur les trois points à côté, puis sélectionnez Créer une table.
- Renseignez les paramètres suivants pour la création de la table :
- Créer une table à partir de :
Google Cloud Storage - Sélectionner un fichier du bucket GCS ou utiliser un modèle d'URI : accédez au bucket GCS et recherchez le fichier JSON de métadonnées généré lors de l'exportation Databricks. Le chemin d'accès doit ressembler à ceci :
regional_sales/metadata/v1.metadata.json. - File format (Format du fichier) :
Iceberg - Table :
regional_sales - Type de tableau :
External table - ID de connexion : sélectionnez la connexion
databricks_retlcréée précédemment. - Conservez les autres valeurs par défaut, puis cliquez sur Créer une table.
- Une fois créée, la nouvelle table
regional_salesdevrait être visible sous l'ensemble de donnéesdatabricks_retl. Vous pouvez désormais interroger cette table à l'aide du langage SQL standard, comme n'importe quelle autre table BigQuery.
7. Charger dans Spanner
Nous arrivons à la dernière étape, et la plus importante, du pipeline : déplacer les données des tables externes BigLake vers Spanner. Il s'agit de l'étape d'ETL inversé, où les données, après avoir été traitées et organisées dans l'entrepôt de données, sont chargées dans un système opérationnel pour être utilisées par les applications.
Spanner est une base de données relationnelle entièrement gérée et distribuée à l'échelle mondiale. Elle offre la cohérence transactionnelle d'une base de données relationnelle traditionnelle, mais avec l'évolutivité horizontale d'une base de données NoSQL. Il s'agit donc d'un choix idéal pour créer des applications évolutives et à haute disponibilité.
Voici comment procéder :
- Créez une instance Spanner, qui correspond à l'allocation physique des ressources.
- Créez une base de données dans cette instance.
- Définissez un schéma de table dans la base de données qui correspond à la structure des données
regional_sales. - Exécutez une requête
EXPORT DATABigQuery pour charger les données de la table BigLake directement dans la table Spanner.
Créer une instance, une base de données et une table Spanner
- Accéder à Spanner
- Cliquez sur
 . N'hésitez pas à utiliser une instance existante si elle est disponible. Configurez les exigences de l'instance selon vos besoins. Pour cet atelier, les éléments suivants ont été utilisés :
. N'hésitez pas à utiliser une instance existante si elle est disponible. Configurez les exigences de l'instance selon vos besoins. Pour cet atelier, les éléments suivants ont été utilisés :
Édition | Enterprise |
Nom de l'instance | databricks-retl |
Configuration de la région | La région de votre choix |
Unité de calcul | Unités de traitement (PU) |
Attribution manuelle | 100 |
- Une fois l'instance créée, accédez à sa page et sélectionnez
 . N'hésitez pas à utiliser une base de données existante si vous en avez une.
. N'hésitez pas à utiliser une base de données existante si vous en avez une.
- Pour cet atelier, une base de données sera créée avec
- Nom :
databricks-retl - Langage de la base de données :
Google Standard SQL
- Une fois la base de données créée, sélectionnez-la sur la page "Instance Spanner" pour accéder à la page "Base de données Spanner".
- Sur la page "Base de données Spanner", cliquez sur
 .
. - Sur la page de la nouvelle requête, la définition de la table à importer dans Spanner sera créée. Pour ce faire, exécutez la requête SQL suivante.
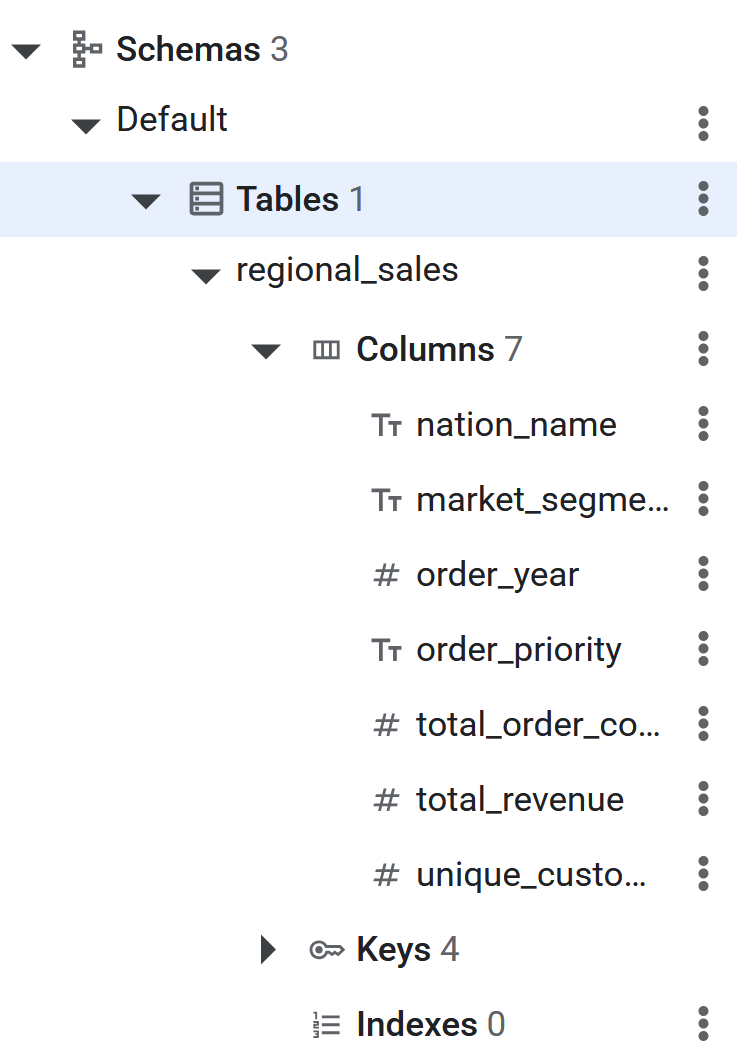
CREATE TABLE regional_sales (
nation_name STRING(MAX),
market_segment STRING(MAX),
order_year INT64,
order_priority STRING(MAX),
total_order_count INT64,
total_revenue NUMERIC,
unique_customer_count INT64
) PRIMARY KEY (nation_name, market_segment, order_year, order_priority);
- Une fois la commande SQL exécutée, la table Spanner sera prête pour que BigQuery effectue l'ETL inversé des données. Vous pouvez vérifier que la table a été créée en la voyant listée dans le panneau de gauche de la base de données Spanner.
ETL inversé vers Spanner à l'aide de EXPORT DATA
Il s'agit de la dernière étape. Une fois les données sources prêtes dans une table BigLake BigQuery et la table de destination créée dans Spanner, le transfert de données proprement dit est étonnamment simple. Une seule requête SQL BigQuery sera utilisée : EXPORT DATA.
Cette requête est spécialement conçue pour ce type de scénario. Il permet d'exporter efficacement les données d'une table BigQuery (y compris les tables externes comme BigLake) vers une destination externe. Dans ce cas, la destination est la table Spanner. Pour en savoir plus sur la fonctionnalité d'exportation, cliquez ici.
Pour en savoir plus sur la configuration de l'ETL inversé BigQuery vers Spanner, cliquez ici.
- Accédez à BigQuery.
- Ouvrez un nouvel onglet de l'éditeur de requête.
- Sur la page "Requête", saisissez le code SQL suivant. N'oubliez pas de remplacer l'ID de projet dans **
uri** **et le chemin d'accès à la table par l'ID de projet approprié.**
EXPORT DATA OPTIONS(
uri='https://spanner.googleapis.com/projects/YOUR_PROJECT_ID/instances/databricks-retl/databases/databricks-retl',
format='CLOUD_SPANNER',
spanner_options="""{
"table": "regional_sales",
"priority": "MEDIUM"
}"""
) AS
SELECT * FROM `YOUR_PROJECT_ID.databricks_retl.regional_sales`;
- Une fois la commande terminée, les données ont été exportées vers Spanner.
8. Vérifier les données dans Spanner
Félicitations ! Un pipeline ETL inversé complet a été créé et exécuté avec succès, ce qui a permis de transférer des données d'un entrepôt de données Databricks vers une base de données opérationnelle Spanner.
La dernière étape consiste à vérifier que les données sont bien arrivées dans Spanner.
- Accédez à Spanner.
- Accédez à votre instance
databricks-retl, puis à la base de donnéesdatabricks-retl. - Dans la liste des tables, cliquez sur la table
regional_sales. - Dans le menu de navigation de gauche du tableau, cliquez sur l'onglet Données.
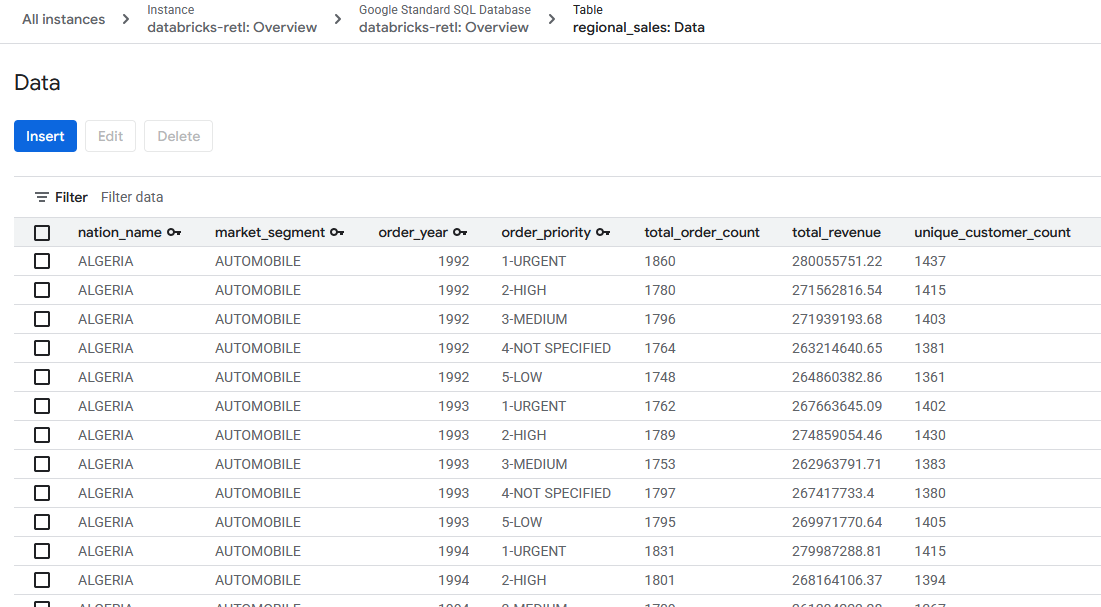
- Les données de ventes agrégées, provenant initialement de Databricks, devraient maintenant être chargées et prêtes à être utilisées dans la table Spanner. Ces données se trouvent désormais dans un système opérationnel, prêt à alimenter une application en direct, à servir un tableau de bord ou à être interrogé par une API.
Le fossé entre les mondes des données analytiques et opérationnelles a été comblé.
9. Effectuer un nettoyage
Supprimez toutes les tables ajoutées et les données stockées lorsque vous avez terminé cet atelier.
Nettoyer les tables Spanner
- Accéder à Spanner
- Dans la liste
databricks-retl, cliquez sur l'instance utilisée pour cet atelier.

- Sur la page de l'instance, cliquez sur
 .
. - Dans la boîte de dialogue de confirmation qui s'affiche, saisissez
databricks-retl, puis cliquez sur .
.
Nettoyer GCS
- Accéder à GCS
- Sélectionnez
 dans le menu de gauche.
dans le menu de gauche. - Sélectionnez le bucket ``codelabs_retl_databricks
- Une fois sélectionné, cliquez sur le bouton
 qui s'affiche dans la bannière supérieure.
qui s'affiche dans la bannière supérieure.

- Dans la boîte de dialogue de confirmation qui s'affiche, saisissez
DELETE, puis cliquez sur.
Nettoyer Databricks
Supprimer un catalogue/schéma/tableau
- Se connecter à votre instance Databricks
- Cliquez sur
 dans le menu de gauche.
dans le menu de gauche. - Sélectionnez le
 précédemment créé dans la liste du catalogue.
précédemment créé dans la liste du catalogue. - Dans la liste des schémas, sélectionnez
 qui a été créé.
qui a été créé. - Sélectionnez le
 précédemment créé dans la liste des tableaux.
précédemment créé dans la liste des tableaux. - Développez les options du tableau en cliquant sur
 , puis sélectionnez
, puis sélectionnez Delete. - Cliquez sur
 dans la boîte de dialogue de confirmation pour supprimer le tableau.
dans la boîte de dialogue de confirmation pour supprimer le tableau. - Une fois la table supprimée, vous serez redirigé vers la page du schéma.
- Développez les options de schéma en cliquant sur , puis sélectionnez
Delete. - Cliquez sur dans la boîte de dialogue de confirmation pour supprimer le schéma.
- Une fois le schéma supprimé, vous serez redirigé vers la page du catalogue.
- Répétez les étapes 4 à 11 pour supprimer le schéma
default, le cas échéant. - Sur la page du catalogue, développez les options en cliquant sur , puis sélectionnez
Delete. - Cliquez sur dans la boîte de dialogue de confirmation pour supprimer le catalogue.
Supprimer les identifiants / l'emplacement des données externes
- Sur l'écran "Catalogue", cliquez sur .
- Si l'option
External Datane s'affiche pas, vous trouverez peut-être l'optionExternal Locationdans un menu déroulantConnect. - Cliquez sur l'emplacement de données externes
retl-gcs-locationcréé précédemment. - Sur la page de l'établissement externe, développez les options en cliquant sur , puis sélectionnez
Delete. - Cliquez sur dans la boîte de dialogue de confirmation pour supprimer l'emplacement externe.
- Cliquez sur .
- Cliquez sur le
retl-gcs-credentialcréé précédemment. - Sur la page des identifiants, développez les options en cliquant sur , puis sélectionnez
Delete. - Cliquez sur dans la boîte de dialogue de confirmation pour supprimer les identifiants.
10. Félicitations
Bravo ! Vous avez terminé cet atelier de programmation.
Points abordés
- Charger des données dans Databricks en tant que tables Iceberg
- Créer un bucket GCS
- Exporter une table Databricks vers GCS au format Iceberg
- Créer une table externe BigLake dans BigQuery à partir de la table Iceberg dans GCS
- Configurer une instance Spanner
- Charger des tables externes BigLake dans BigQuery vers Spanner