
1. פיתוח צינור ETL הפוך מ-Databricks ל-Spanner באמצעות Google Cloud Storage ו-BigQuery
מבוא
ב-Codelab הזה תלמדו איך ליצור פייפליין Reverse ETL מ-Databricks ל-Spanner. באופן מסורתי, צינורות ETL (חילוץ, טרנספורמציה, טעינה) סטנדרטיים מעבירים נתונים ממסדי נתונים תפעוליים לתוך מחסן נתונים כמו Databricks לצורך ניתוח. צינור Reverse ETL עושה את הפעולה ההפוכה: הוא מעביר נתונים מעובדים ומסוננים מ מחסן נתונים בחזרה למסדי נתונים תפעוליים, כמו Spanner, מסד נתונים רלציוני מבוזר גלובלית שמתאים באופן אידיאלי לאפליקציות עם זמינות גבוהה. שם הנתונים יכולים להפעיל אפליקציות, להציג תכונות שפונות למשתמשים או לשמש לקבלת החלטות בזמן אמת.
המטרה היא להעביר קבוצת נתונים מצטברת מטבלאות Databricks Iceberg לטבלאות Spanner.
כדי לעשות את זה, משתמשים ב-Google Cloud Storage (GCS) וב-BigQuery כשלבי ביניים. הנה פירוט של זרימת הנתונים וההיגיון מאחורי הארכיטקטורה הזו:

- Databricks ל-Google Cloud Storage (GCS) בפורמט Iceberg:
- השלב הראשון הוא לייצא את הנתונים מ-Databricks בפורמט פתוח ומוגדר היטב. הטבלה מיוצאת בפורמט Apache Iceberg. במהלך התהליך הזה, הנתונים הבסיסיים נכתבים כקבוצה של קבצי Parquet, והמטא-נתונים של הטבלה (סכימה, מחיצות, מיקומי קבצים) נכתבים כקבצי JSON ו-Avro. העברת המבנה המלא של הטבלה ל-GCS מאפשרת ניוד של הנתונים וגישה אליהם מכל מערכת שמזהה את פורמט Iceberg.
- המרת טבלאות GCS Iceberg לטבלה חיצונית של BigLake ב-BigQuery:
- במקום לטעון את הנתונים ישירות מ-GCS ל-Spanner, נעשה שימוש ב-BigQuery ככלי ביניים יעיל. נוצרת טבלה חיצונית של BigLake ב-BigQuery שמפנה ישירות לקובץ המטא-נתונים של Iceberg ב-GCS. לגישה הזו יש כמה יתרונות:
- ללא שכפול נתונים: BigQuery קורא את מבנה הטבלה מהמטא-נתונים ומריץ שאילתות על קובצי הנתונים בפורמט Parquet במקום בלי להטמיע אותם, וכך חוסך זמן רב ועלויות אחסון.
- שאילתות מאוחדות: מאפשרות להריץ שאילתות SQL מורכבות על נתונים ב-GCS כאילו היו טבלה ב-BigQuery.
- העברת נתונים מ-BigLake ל-Spanner באמצעות ReverseETL:
- השלב האחרון הוא להעביר את הנתונים מ-BigQuery ל-Spanner. הפעולה הזו מתבצעת באמצעות תכונה עוצמתית ב-BigQuery שנקראת
EXPORT DATAשאילתה, שהיא השלב של "העברת נתונים הפוכה". - מוכנות תפעולית: Spanner מיועד לעומסי עבודה טרנזקציוניים, ומספק מודל עקביות חזק וזמינות גבוהה לאפליקציות. העברת הנתונים ל-Spanner מאפשרת גישה אליהם לאפליקציות שפונות למשתמשים, לממשקי API ולמערכות תפעוליות אחרות שנדרשות בהן בדיקות נקודתיות עם השהיה נמוכה.
- מדרגיות: התבנית הזו מאפשרת להשתמש ביכולות הניתוח של BigQuery כדי לעבד מערכי נתונים גדולים, ואז להציג את התוצאות בצורה יעילה באמצעות התשתית הגלובלית של Spanner, שניתנת להרחבה.
שירותים ומינוחים
- DataBricks – פלטפורמת נתונים מבוססת-ענן שנבנתה סביב Apache Spark.
- Spanner – מסד נתונים רלציוני שמפוזר גלובלית ומנוהל באופן מלא על ידי Google.
- Google Cloud Storage – שירות אחסון ה-Blob של Google Cloud.
- BigQuery – מחסן נתונים (data warehouse) ללא שרתים לניתוח נתונים, שמנוהל באופן מלא על ידי Google.
- Iceberg – פורמט טבלה פתוח שהוגדר על ידי Apache, שמספק הפשטה של פורמטים נפוצים של קובצי נתונים בקוד פתוח.
- Parquet – פורמט קובץ בינארי של נתונים עמודתיים בקוד פתוח מבית Apache.
מה תלמדו
- איך טוענים נתונים ל-Databricks כטבלאות Iceberg
- איך יוצרים קטגוריה ב-GCS
- איך מייצאים טבלה של Databricks ל-GCS בפורמט Iceberg
- איך יוצרים טבלה חיצונית ב-BigLake ב-BigQuery מטבלת Iceberg ב-GCS
- איך מגדירים מופע Spanner
- איך טוענים טבלאות חיצוניות של BigLake ב-BigQuery אל Spanner
2. הגדרה, דרישות ומגבלות
דרישות מוקדמות
- חשבון Databricks, רצוי ב-GCP
- כדי לייצא מ-BigQuery ל-Spanner, צריך חשבון Google Cloud עם הזמנה ברמה Enterprise או ברמה גבוהה יותר ב-BigQuery.
- גישה ל-Google Cloud Console דרך דפדפן אינטרנט
- טרמינל להרצת פקודות של Google Cloud CLI
אם המדיניות iam.allowedPolicyMemberDomains מופעלת בארגון שלכם ב-Google Cloud, יכול להיות שאדמין יצטרך להעניק חריגה כדי לאפשר חשבונות שירות מדומיינים חיצוניים. הנושא הזה יוסבר בשלב מאוחר יותר, אם הוא רלוונטי.
דרישות
- פרויקט ב-Google Cloud שהחיוב בו מופעל.
- דפדפן אינטרנט, כמו Chrome
- חשבון Databricks (ב-Lab הזה מניחים שיש לכם סביבת עבודה שמתארחת ב-GCP)
- כדי להשתמש בתכונה EXPORT DATA, מופע BigQuery צריך להיות במהדורת Enterprise או במהדורה גבוהה יותר.
- אם המדיניות
iam.allowedPolicyMemberDomainsמופעלת בארגון שלכם ב-Google Cloud, יכול להיות שאדמין יצטרך להעניק חריגה כדי לאפשר חשבונות שירות מדומיינים חיצוניים. הנושא הזה יוסבר בשלב מאוחר יותר, אם הוא רלוונטי.
הרשאות IAM ב-Google Cloud Platform
כדי לבצע את כל השלבים ב-codelab הזה, לחשבון Google צריכות להיות ההרשאות הבאות:
חשבונות שירות | ||
| מאפשרת יצירה של חשבונות שירות. | |
Spanner | ||
| מאפשר ליצור מופע חדש של Spanner. | |
| מאפשר להריץ הצהרות DDL כדי ליצור | |
| מאפשר להריץ הצהרות DDL כדי ליצור טבלאות במסד הנתונים. | |
Google Cloud Storage | ||
| מאפשר ליצור מאגר חדש ב-GCS לאחסון קובצי Parquet שיוצאו. | |
| מאפשר לכתוב את קובצי Parquet המיוצאים לקטגוריית GCS. | |
| מאפשרת ל-BigQuery לקרוא את קובצי Parquet ממאגר GCS. | |
| מאפשר ל-BigQuery להציג את קובצי Parquet בדלי GCS. | |
Dataflow | ||
| מאפשרת לתבוע פריטי עבודה מ-Dataflow. | |
| מאפשר לעובד Dataflow לשלוח הודעות בחזרה לשירות Dataflow. | |
| מאפשר לעובדי Dataflow לכתוב רשומות ביומן ב-Google Cloud Logging. | |
לנוחותכם, אפשר להשתמש בתפקידים מוגדרים מראש שכוללים את ההרשאות האלה.
|
|
|
|
|
|
|
|
פרויקט ב-Google Cloud
פרויקט הוא יחידה בסיסית של ארגון ב-Google Cloud. אם האדמין סיפק לכם קוד לשימוש, אתם יכולים לדלג על השלב הזה.
אפשר ליצור פרויקט באמצעות ה-CLI באופן הבא:
gcloud projects create <your-project-name>
מידע נוסף על יצירה וניהול של פרויקטים
מגבלות
חשוב להכיר מגבלות מסוימות ואי-תאימויות בין סוגי נתונים שעלולות להתרחש בפייפליין הזה.
Databricks Iceberg ל-BigQuery
כשמשתמשים ב-BigQuery כדי להריץ שאילתות על טבלאות Iceberg שמנוהלות על ידי Databricks (באמצעות UniForm), חשוב לזכור את הנקודות הבאות:
- התפתחות הסכימה: למרות ש-UniForm מבצע עבודה טובה בתרגום שינויים בסכימת Delta Lake ל-Iceberg, יכול להיות ששינויים מורכבים לא תמיד יועברו כצפוי. לדוגמה, שינוי שם של עמודות ב-Delta Lake לא מתורגם ל-Iceberg, שרואה את זה כ-
dropוכ-add. חשוב תמיד לבדוק היטב שינויים בסכימה. - Time Travel: אי אפשר להשתמש ב-BigQuery ביכולות Time Travel של Delta Lake. השאילתה תפנה רק לתמונת המצב העדכנית ביותר של טבלת ה-Iceberg.
- תכונות של Delta Lake שלא נתמכות: תכונות כמו Deletion Vectors ו-Column Mapping עם מצב
idב-Delta Lake לא תואמות ל-UniForm for Iceberg. בשיעור ה-Lab נעשה מיפוי של העמודות במצבname, שנתמך.
BigQuery ל-Spanner
הפקודה EXPORT DATA מ-BigQuery ל-Spanner לא תומכת בכל סוגי הנתונים של BigQuery. ייצוא של טבלה עם הסוגים הבאים יגרום לשגיאה:
STRUCTGEOGRAPHYDATETIMERANGETIME
בנוסף, אם בפרויקט BigQuery נעשה שימוש בניב GoogleSQL, לא תהיה תמיכה גם בסוגים המספריים הבאים לייצוא ל-Spanner:
BIGNUMERIC
רשימה מלאה ועדכנית של המגבלות זמינה במסמכי התיעוד הרשמיים: מגבלות על ייצוא ל-Spanner.
פתרון בעיות ונקודות חשובות
- אם אתם לא משתמשים במופע GCP Databricks, יכול להיות שלא תוכלו להגדיר מיקום נתונים חיצוני ב-GCS. במקרים כאלה, צריך להכין את הקבצים בפתרון האחסון של ספק הענן של סביבת העבודה של Databricks, ואז להעביר אותם ל-GCS בנפרד.
- במקרה כזה, יהיה צורך לבצע שינויים במטא-נתונים, כי המידע יכלול נתיבים מקודדים לקבצים שהועברו.
3. הגדרה של Google Cloud Storage (GCS)
Google Cloud Storage (GCS) ישמש לאחסון קובצי הנתונים בפורמט Parquet שנוצרו על ידי Databricks. לשם כך, קודם צריך ליצור קטגוריה חדשה שתשמש כיעד הקובץ.
Google Cloud Storage
יצירת קטגוריה חדשה
- נכנסים לדף Google Cloud Storage במסוף Cloud.
- בחלונית הימנית, בוחרים באפשרות Buckets:
- לוחצים על הלחצן יצירה:

- ממלאים את פרטי הדלי:
- בוחרים שם של bucket לשימוש. במעבדה הזו נשתמש בשם
codelabs_retl_databricks - בוחרים אזור לאחסון הקטגוריה או משתמשים בערכי ברירת המחדל.
- אני רוצה לשמור את סוג האחסון בתור
standard - השארת ערכי ברירת המחדל של שליטה בגישה
- משאירים את ערכי ברירת המחדל של protect object data (הגנה על נתוני אובייקט)
- בסיום, לוחצים על הלחצן
Create. יכול להיות שתופיע הודעה עם בקשת אישור למניעת גישה ציבורית. אפשר לאשר. - כל הכבוד, יצרת בהצלחה קטגוריה חדשה! המערכת תפנה אתכם לדף של הדלי.
- מעתיקים את השם החדש של הקטגוריה למקום כלשהו, כי תצטרכו אותו בהמשך.
הכנה לשלבים הבאים
חשוב לרשום את הפרטים הבאים כי תצטרכו אותם בשלבים הבאים:
- מזהה הפרויקט ב-Google
- שם קטגוריה של Google Storage
4. הגדרת Databricks
נתונים של TPC-H
בשיעור ה-Lab הזה נשתמש במערך הנתונים TPC-H, שהוא מדד השוואה (benchmark) מקובל בתחום למערכות תמיכה בהחלטות. הסכימה שלו מדמה סביבה עסקית מציאותית עם לקוחות, הזמנות, ספקים וחלקים, ולכן הוא מושלם להדגמת תרחיש של ניתוח נתונים והעברת נתונים בעולם האמיתי.
במקום להשתמש בטבלאות הגולמיות והמנורמלות של TPC-H, תיצור טבלה חדשה ומצטברת. הטבלה החדשה הזו תאחד נתונים מהטבלאות orders, customer ו-nation כדי ליצור תצוגה לא מנורמלת ומסוכמת של מכירות אזוריות. שלב הצבירה המוקדמת הזה הוא שיטה נפוצה בניתוח נתונים, כי הוא מכין את הנתונים לתרחיש שימוש ספציפי – בתרחיש הזה, לשימוש באפליקציה תפעולית.
הסכימה הסופית של הטבלה המצטברת תהיה:
Col | סוג |
nation_name | מחרוזת |
market_segment | מחרוזת |
order_year | int |
order_priority | מחרוזת |
total_order_count | bigint |
total_revenue | decimal(29,2) |
unique_customer_count | bigint |
תמיכה ב-Iceberg עם פורמט אוניברסלי של Delta Lake (UniForm)
בשיעור ה-Lab הזה, הטבלה ב-Databricks תהיה טבלת Delta Lake. עם זאת, כדי שמערכות חיצוניות כמו BigQuery יוכלו לקרוא את הנתונים, תופעל תכונה עוצמתית בשם פורמט אוניברסלי (UniForm).
UniForm יוצר באופן אוטומטי מטא-נתונים של Iceberg לצד המטא-נתונים של Delta Lake, עבור עותק משותף יחיד של נתוני הטבלה. כך נהנים מהיתרונות של שני העולמות:
- בתוך Databricks: מקבלים את כל היתרונות של Delta Lake מבחינת ביצועים וניהול.
- מחוץ ל-Databricks: מנוע שאילתות שתואם ל-Iceberg, כמו BigQuery, יכול לקרוא את הטבלה כאילו היא טבלת Iceberg מקורית.
כך לא תצטרכו לתחזק עותקים נפרדים של הנתונים או להפעיל משימות המרה ידניות. כדי להפעיל את UniForm, צריך להגדיר מאפיינים ספציפיים של הטבלה בזמן יצירת הטבלה.
Databricks Catalogs
קטלוג Databricks הוא הקונטיינר ברמה העליונה של נתונים ב-Unity Catalog, פתרון מאוחד לניהול נתונים של Databricks. Unity Catalog מספק דרך מרכזית לניהול נכסי נתונים, לשליטה בגישה ולמעקב אחר מקורות נתונים, וזה חיוני לפלטפורמת נתונים מנוהלת היטב.
הוא משתמש במרחב שמות בשלוש רמות כדי לארגן את הנתונים: catalog.schema.table.
- קטלוג: הרמה הגבוהה ביותר, שמשמשת לקיבוץ נתונים לפי סביבה, יחידה עסקית או פרויקט.
- סכימה (או מסד נתונים): קיבוץ לוגי של טבלאות, תצוגות ופונקציות בקטלוג.
- Table: האובייקט שמכיל את הנתונים.
לפני שיוצרים את הטבלה המצטברת TPC-H, צריך להגדיר קטלוג וסכימה ייעודיים כדי לאחסן אותה. כך אפשר לוודא שהפרויקט מאורגן בצורה מסודרת ומבודד מנתונים אחרים בסביבת העבודה.
יצירת קטלוג וסכימה חדשים
ב-Databricks Unity Catalog, קטלוג משמש כרמה הגבוהה ביותר של ארגון נכסי נתונים, ופועל כמאגר מאובטח שיכול לכלול כמה סביבות עבודה של Databricks. הוא מאפשר לכם לארגן ולבודד נתונים על סמך יחידות עסקיות, פרויקטים או סביבות, עם הרשאות מוגדרות בבירור ובקרת גישה.
בתוך קטלוג, סכימה (שנקראת גם מסד נתונים) מארגנת עוד יותר את הטבלאות, התצוגות והפונקציות. המבנה ההיררכי הזה מאפשר שליטה מפורטת וקיבוץ הגיוני של אובייקטים קשורים של נתונים. בשיעור ה-Lab הזה, ייווצרו קטלוג וסכימה ייעודיים כדי לאחסן את נתוני TPC-H, וכך תובטח בידוד וניהול נאותים.
יצירת קטלוג
- עוברים אל

- לוחצים על + ובוחרים באפשרות יצירת קטלוג בתפריט הנפתח.
- קטלוג רגיל חדש ייווצר עם ההגדרות הבאות:
- שם הקטלוג:
retl_tpch_project - מיקום האחסון: אפשר להשתמש בברירת המחדל אם היא הוגדרה בסביבת העבודה, או ליצור מיקום חדש.
יצירת סכימה
- עוברים אל
- בוחרים את הקטלוג החדש שנוצר בחלונית הימנית.
- לוחצים על
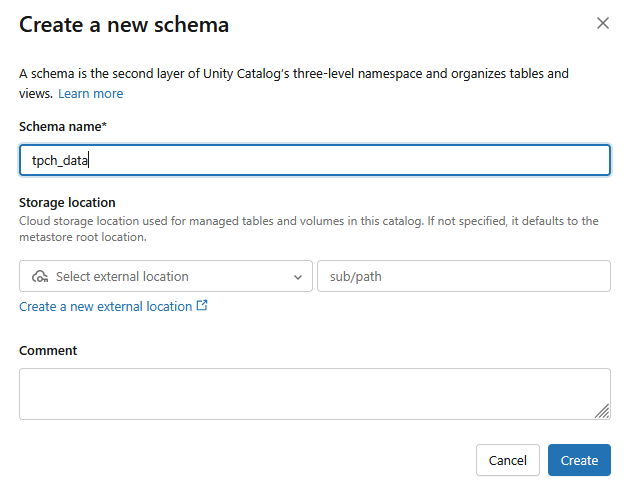
- תיצור סכימה חדשה עם שם הסכימה
tpch_data
הגדרת נתונים חיצוניים
כדי לייצא נתונים מ-Databricks ל-Google Cloud Storage (GCS), צריך להגדיר ב-Databricks פרטי כניסה לצפייה בנתונים חיצוניים. כך, ל-Databricks תהיה גישה מאובטחת לקטגוריית GCS, והיא תוכל לכתוב בה.
- במסך קטלוג לוחצים על
 .
.
- אם לא מופיעה האפשרות
External Data, יכול להיות שהאפשרותExternal Locationsמופיעה בתפריט הנפתחConnect.
- לוחצים על

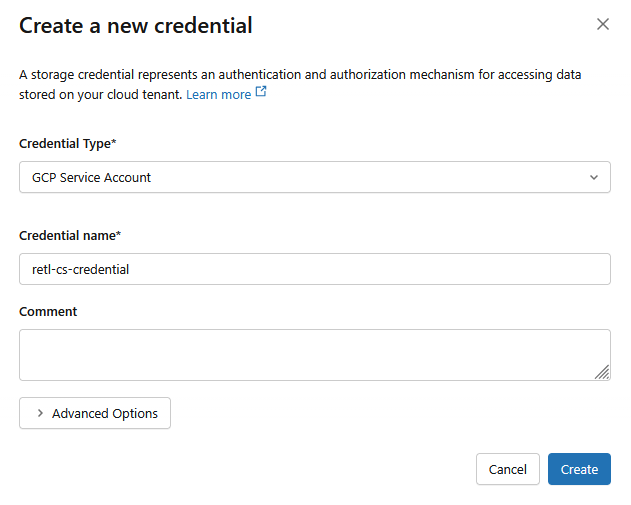
- בתיבת הדו-שיח החדשה, מגדירים את הערכים הנדרשים של פרטי הכניסה:
- סוג האישורים:
GCP Service Account - שם אמצעי התשלום:
retl-gcs-credential
- לחץ על צור.
- לוחצים על הכרטיסייה מיקומים חיצוניים.
- לוחצים על יצירת מיקום.
- בתיבת הדו-שיח החדשה, מגדירים את הערכים הנדרשים למיקום החיצוני:
- שם המיקום החיצוני:
retl-gcs-location - סוג האחסון:
GCP - כתובת URL: כתובת ה-URL של קטגוריית GCS, בפורמט
gs://YOUR_BUCKET_NAME - פרטי כניסה לאחסון: בוחרים את
retl-gcs-credentialשנוצר זה עתה.
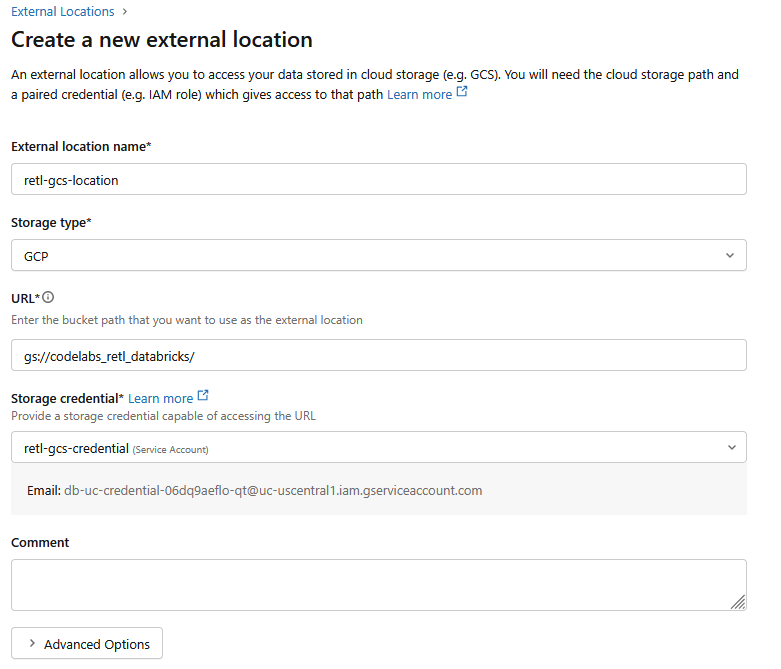
- רושמים את כתובת האימייל של חשבון השירות שמופיעה באופן אוטומטי אחרי שבוחרים את פרטי הכניסה לאחסון, כי תצטרכו אותה בשלב הבא.
- לחץ על צור.
5. הגדרת הרשאות לחשבון שירות
חשבון שירות הוא סוג מיוחד של חשבון שאפליקציות או שירותים משתמשים בו כדי לבצע קריאות מורשות ל-API למשאבי Google Cloud.
עכשיו צריך להוסיף הרשאות לחשבון השירות שנוצר עבור הקטגוריה החדשה ב-GCS.
- בדף של קטגוריית GCS, לוחצים על הכרטיסייה הרשאות.
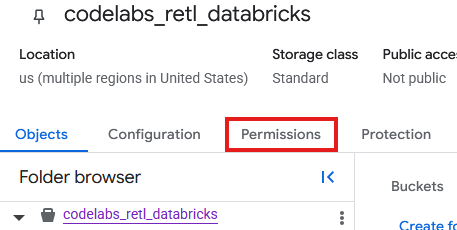
- לוחצים על Grant access בדף של חשבונות המשתמש.
- בחלונית Grant Access שמופיעה בצד ימין, מזינים את Service Account ID בשדה New principals.
- בקטע הקצאת תפקידים, מוסיפים את
Storage Object AdminואתStorage Legacy Bucket Reader. התפקידים האלה מאפשרים לחשבון השירות לקרוא, לכתוב ולרשום אובייקטים בקטגוריית האחסון.
טעינת נתונים של TPC-H
אחרי שיוצרים את הקטלוג והסכימה, אפשר לטעון את נתוני TPCH מהטבלה הקיימת samples.tpch שמאוחסנת באופן פנימי ב-Databricks ולשנות אותה לטבלה חדשה בסכימה שהוגדרה.
יצירת טבלה עם תמיכה ב-Iceberg
תאימות של Iceberg ל-UniForm
מאחורי הקלעים, Databricks מנהלת את הטבלה הזו באופן פנימי כטבלת Delta Lake, וכך נהנים מכל היתרונות של אופטימיזציות הביצועים ותכונות השליטה של Delta בסביבה העסקית של Databricks. עם זאת, אם מפעילים את UniForm (קיצור של Universal Format, פורמט אוניברסלי), מערכת Databricks מקבלת הוראה לבצע פעולה מיוחדת: בכל פעם שהטבלה מתעדכנת, מערכת Databricks יוצרת באופן אוטומטי את המטא-נתונים התואמים של Iceberg ומתחזקת אותם בנוסף למטא-נתונים של Delta Lake.
כלומר, קבוצה אחת משותפת של קובצי נתונים (קובצי Parquet) מתוארת עכשיו על ידי שתי קבוצות שונות של מטא-נתונים.
- ב-Databricks: נעשה שימוש ב-
_delta_logכדי לקרוא את הטבלה. - קוראים חיצוניים (כמו BigQuery): הם משתמשים בקובץ המטא-נתונים של Iceberg (
.metadata.json) כדי להבין את הסכימה, החלוקה למחיצות ומיקומי הקבצים של הטבלה.
התוצאה היא טבלה שתואמת באופן מלא ושקוף לכל כלי שמודע ל-Iceberg. אין כפילויות בנתונים ואין צורך בהמרה או בסנכרון ידניים. זהו מקור יחיד של נתוני אמת שאפשר לגשת אליו בצורה חלקה גם דרך עולם הניתוח של Databricks וגם דרך המערכת האקולוגית הרחבה יותר של כלים שתומכים בתקן Iceberg הפתוח.
- לוחצים על New (חדש) ואז על Query (שאילתה).
- בשדה הטקסט של דף השאילתה, מריצים את פקודת ה-SQL הבאה:
CREATE TABLE retl_tpch_project.tpch_data.regional_sales_iceberg
USING DELTA
LOCATION 'gs://<Your bucket name>/regional_sales_iceberg'
TBLPROPERTIES (
'delta.columnMapping.mode' = 'name',
'delta.enableIcebergCompatV2' = 'true',
'delta.universalFormat.enabledFormats' = 'iceberg'
)
AS
SELECT
n.n_name AS nation_name,
c.c_mktsegment AS market_segment,
YEAR(o.o_orderdate) AS order_year,
o.o_orderpriority AS order_priority,
COUNT(o.o_orderkey) AS total_order_count,
ROUND(SUM(o.o_totalprice), 2) AS total_revenue,
COUNT(DISTINCT c.c_custkey) AS unique_customer_count
FROM samples.tpch.orders AS o
INNER JOIN samples.tpch.customer AS c
ON o.o_custkey = c.c_custkey
INNER JOIN samples.tpch.nation AS n
ON c.c_nationkey = n.n_nationkey
GROUP BY
n.n_name,
c.c_mktsegment,
YEAR(o.o_orderdate),
o.o_orderpriority;
OPTIMIZE retl_tpch_project.tpch_data.regional_sales_iceberg;
DESCRIBE EXTENDED retl_tpch_project.tpch_data.regional_sales_iceberg;
הערות:
- Using Delta – מציין שאנחנו משתמשים בטבלת Delta Lake. אפשר לאחסן כטבלה חיצונית רק טבלאות Delta Lake ב-Databricks.
- מיקום – מציין איפה הטבלה תאוחסן, אם היא חיצונית.
- TablePropertoes –
delta.universalFormat.enabledFormats = ‘iceberg'יוצר את המטא-נתונים התואמים של Iceberg לצד קובצי Delta Lake. - אופטימיזציה – מפעיל בכוח את יצירת המטא-נתונים של UniForm, כי בדרך כלל זה קורה באופן אסינכרוני.
- הפלט של השאילתה צריך להציג פרטים על הטבלה החדשה שנוצרה

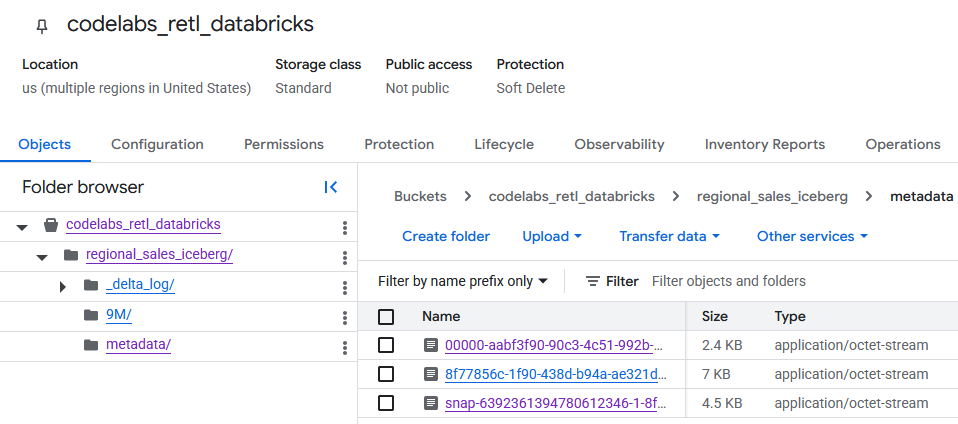
אימות נתונים בטבלה ב-GCS
אחרי שמנווטים אל קטגוריית GCS, אפשר למצוא את נתוני הטבלה החדשה.
המטא-נתונים של Iceberg נמצאים בתיקייה metadata, שמשמשת קוראים חיצוניים (כמו BigQuery). המטא-נתונים של Delta Lake, שמשמשים את Databricks באופן פנימי, מתועדים בתיקייה _delta_log.
נתוני הטבלה בפועל מאוחסנים כקובצי Parquet בתיקייה אחרת, שבדרך כלל נקראת על שם מחרוזת שנוצרה באופן אקראי על ידי Databricks. לדוגמה, בצילום המסך שלמטה, קובצי הנתונים נמצאים בתיקייה 9M.
6. הגדרה של BigQuery ו-BigLake
עכשיו שטבלת Iceberg נמצאת ב-Google Cloud Storage, השלב הבא הוא להפוך אותה לנגישה ל-BigQuery. הפעולה הזו תתבצע על ידי יצירת טבלה חיצונית ב-BigLake.
BigLake הוא מנוע אחסון שמאפשר ליצור טבלאות ב-BigQuery שקוראות נתונים ישירות ממקורות חיצוניים כמו Google Cloud Storage. בשיעור ה-Lab הזה, זו הטכנולוגיה העיקרית שמאפשרת ל-BigQuery להבין את טבלת Iceberg שיוצאה זה עתה בלי צורך להטמיע את הנתונים.
כדי שהשילוב הזה יפעל, צריך שני רכיבים:
- קישור למשאבים ב-Cloud: זהו קישור מאובטח בין BigQuery ל-GCS. הוא משתמש בחשבון שירות מיוחד כדי לטפל באימות, ומוודא של-BigQuery יש את ההרשאות הנדרשות לקריאת הקבצים ממאגר GCS.
- הגדרת טבלה חיצונית: ההגדרה הזו מציינת ל-BigQuery איפה נמצא קובץ המטא-נתונים של טבלת Iceberg ב-GCS ואיך צריך לפרש אותו.
יצירת קישור למשאבים ב-Cloud
קודם כל, תיווצר ההרשאה שמאפשרת ל-BigQuery לגשת ל-GCS.
מידע נוסף על יצירת קישורים למשאבים ב-Cloud זמין כאן.
- עוברים אל BigQuery
- לוחצים על חיבורים בקטע Explorer.
- אם חלונית הסייר לא מוצגת, לוחצים על
 .
.
- בדף Connections (חיבורים), לוחצים על
 .
. - בשדה סוג החיבור, בוחרים באפשרות
Vertex AI remote models, remote functions, BigLake and Spanner (Cloud Resource). - מגדירים את מזהה החיבור ל-
databricks_retlויוצרים את החיבור.

- עכשיו אמור להופיע רשומה בטבלה Connections של החיבור החדש. לוחצים על הרשומה כדי לראות את פרטי החיבור.

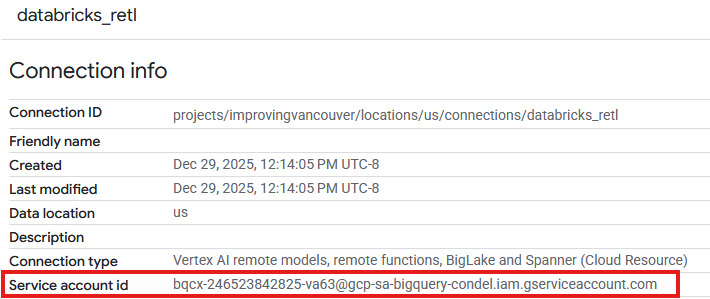
- בדף פרטי החיבור, רושמים את מזהה חשבון השירות כי תצטרכו אותו בהמשך.
הענקת גישה לחשבון השירות של החיבור
- עוברים אל IAM & Admin
- לוחצים על הענקת גישה.
- בשדה New principals (חשבונות משתמשים חדשים), מזינים את מזהה חשבון השירות של משאב החיבור שנוצר בשלב הקודם.
- בקטע Role (תפקיד), בוחרים באפשרות
Storage Object Userולוחצים על .
.
אחרי שהחיבור נוצר וחשבון השירות שלו קיבל את ההרשאות הנדרשות, אפשר ליצור את הטבלה החיצונית של BigLake. קודם צריך מערך נתונים ב-BigQuery שישמש כמאגר לטבלה החדשה. לאחר מכן, המערכת תיצור את הטבלה עצמה, ותפנה אותה לקובץ המטא-נתונים של Iceberg בדלי GCS.
- עוברים אל BigQuery
- בחלונית Explorer, לוחצים על מזהה הפרויקט, ואז לוחצים על סמל האפשרויות הנוספות (3 נקודות) ובוחרים באפשרות Create dataset (יצירת מערך נתונים).
- קבוצת הנתונים תיקרא
databricks_retl. משאירים את שאר האפשרויות כברירת מחדל ולוחצים על הלחצן Create dataset (יצירת מערך נתונים).
- עכשיו מאתרים את מערך הנתונים החדש
databricks_retlבחלונית Explorer. לוחצים על סמל שלוש הנקודות שלצד השאילתה ובוחרים באפשרות יצירת טבלה.
- מזינים את ההגדרות הבאות ליצירת הטבלה:
- יצירת טבלה מ:
Google Cloud Storage - בחירת קובץ ממאגר GCS או שימוש בתבנית URI: עוברים למאגר GCS ומאתרים את קובץ ה-JSON של המטא-נתונים שנוצר במהלך הייצוא מ-Databricks. הנתיב צריך להיראות בערך כך:
regional_sales/metadata/v1.metadata.json. - פורמט הקובץ:
Iceberg - טבלה:
regional_sales - Table type:
External table - מזהה חיבור: בוחרים את החיבור
databricks_retlשנוצר קודם. - משאירים את שאר הערכים כברירת מחדל ולוחצים על יצירת טבלה.
- אחרי שיוצרים את הטבלה החדשה של
regional_sales, היא אמורה להופיע במערך הנתוניםdatabricks_retl. עכשיו אפשר להריץ שאילתות על הטבלה הזו באמצעות SQL סטנדרטי, בדיוק כמו על כל טבלה אחרת ב-BigQuery.
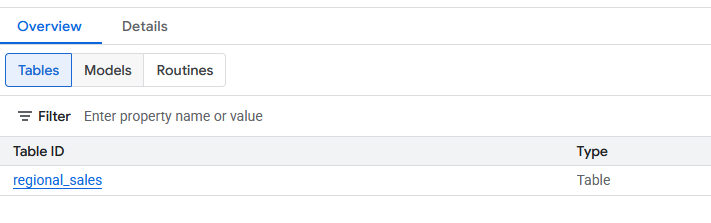
7. טעינה ל-Spanner
הגענו לחלק האחרון והחשוב ביותר בפייפליין: העברת הנתונים מטבלאות חיצוניות של BigLake אל Spanner. זהו השלב של 'העברת נתונים הפוכה', שבו הנתונים, אחרי שעברו עיבוד וארגון במחסן הנתונים, נטענים למערכת תפעולית לשימוש באפליקציות.
Spanner הוא מסד נתונים רלציוני מנוהל שמופץ באופן גלובלי. הוא מציע עקביות טרנזקציונלית של מסד נתונים רלציוני מסורתי, אבל עם יכולת ההרחבה האופקית של מסד נתונים NoSQL. לכן, זו בחירה אידיאלית לבניית אפליקציות שניתנות להרחבה וזמינות מאוד.
התהליך יהיה כזה:
- יוצרים מופע Spanner, שהוא ההקצאה הפיזית של משאבים.
- יוצרים מסד נתונים בתוך המכונה.
- מגדירים סכימת טבלה במסד הנתונים שתואמת למבנה של נתוני
regional_sales. - מריצים שאילתת BigQuery
EXPORT DATAכדי לטעון את הנתונים מטבלת BigLake ישירות לטבלת Spanner.
יצירת מכונת Spanner, מסד נתונים וטבלה
- עוברים אל Spanner.
- לוחצים על
 . אפשר להשתמש במופע קיים אם יש כזה. מגדירים את הדרישות של המופע לפי הצורך. בשיעור ה-Lab הזה השתמשנו ב:
. אפשר להשתמש במופע קיים אם יש כזה. מגדירים את הדרישות של המופע לפי הצורך. בשיעור ה-Lab הזה השתמשנו ב:
מהדורה | Enterprise |
שם המופע | databricks-retl |
הגדרת אזור | האזור שבחרתם |
יחידת מחשוב | יחידות עיבוד (PU) |
הקצאה ידנית | 100 |
- אחרי שיוצרים את המופע, עוברים לדף המופע של Spanner ולוחצים על
 . אפשר להשתמש במסד נתונים קיים אם יש כזה.
. אפשר להשתמש במסד נתונים קיים אם יש כזה.
- בשיעור ה-Lab הזה, תיצור מסד נתונים עם
- Name (שם):
databricks-retl - דיאלקט מסד הנתונים:
Google Standard SQL
- אחרי שיוצרים את מסד הנתונים, בוחרים אותו בדף Spanner Instance ונכנסים לדף Spanner Database.
- בדף Spanner Database, לוחצים על
 .
. - בדף השאילתה החדש, תיווצר הגדרת הטבלה של הטבלה לייבוא ל-Spanner. כדי לעשות זאת, מריצים את שאילתת ה-SQL הבאה.
CREATE TABLE regional_sales (
nation_name STRING(MAX),
market_segment STRING(MAX),
order_year INT64,
order_priority STRING(MAX),
total_order_count INT64,
total_revenue NUMERIC,
unique_customer_count INT64
) PRIMARY KEY (nation_name, market_segment, order_year, order_priority);
- אחרי הפעלת פקודת ה-SQL, הטבלה ב-Spanner תהיה מוכנה לייצוא הפוך של הנתונים מ-BigQuery. כדי לוודא שהטבלה נוצרה, אפשר לבדוק שהיא מופיעה בחלונית הימנית במסד הנתונים של Spanner.
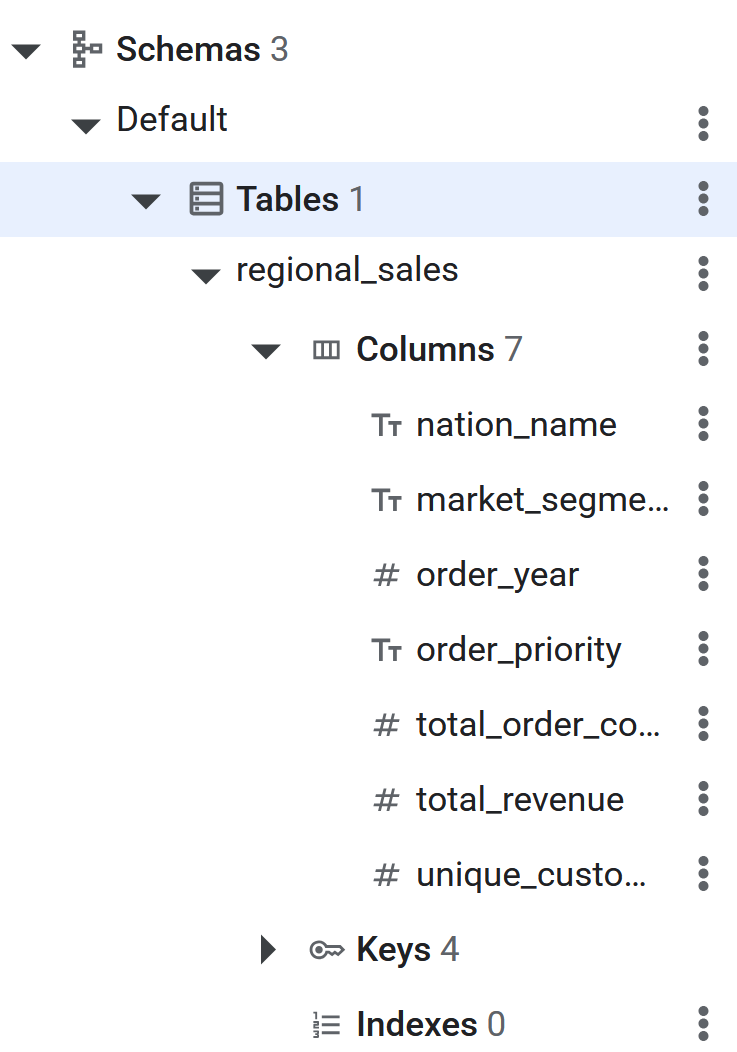
העברת נתונים מ-ETL ל-Spanner באמצעות EXPORT DATA
זה השלב האחרון. אחרי שהנתונים מוכנים בטבלת BigLake ב-BigQuery וטבלת היעד נוצרה ב-Spanner, העברת הנתונים עצמה פשוטה באופן מפתיע. תתבצע שאילתת SQL אחת ב-BigQuery: EXPORT DATA.
השאילתה הזו מיועדת במיוחד לתרחישים מהסוג הזה. הוא מייצא ביעילות נתונים מטבלה ב-BigQuery (כולל טבלאות חיצוניות כמו טבלת BigLake) ליעד חיצוני. במקרה הזה, היעד הוא טבלת Spanner. מידע נוסף על תכונת הייצוא זמין כאן
כאן אפשר למצוא מידע נוסף על הגדרת BigQuery ל-Spanner Reverse ETL.
- עוברים אל BigQuery
- פותחים כרטיסייה חדשה של עורך השאילתות.
- בדף Query, מזינים את ה-SQL הבא. חשוב להחליף את מזהה הפרויקט ב **
uri** **ובנתיב הטבלה במזהה הפרויקט הנכון.**
EXPORT DATA OPTIONS(
uri='https://spanner.googleapis.com/projects/YOUR_PROJECT_ID/instances/databricks-retl/databases/databricks-retl',
format='CLOUD_SPANNER',
spanner_options="""{
"table": "regional_sales",
"priority": "MEDIUM"
}"""
) AS
SELECT * FROM `YOUR_PROJECT_ID.databricks_retl.regional_sales`;
- אחרי שהפקודה מסתיימת, הנתונים יוצאו בהצלחה ל-Spanner.
8. אימות הנתונים ב-Spanner
מעולה! צינור Reverse ETL מלא נבנה והופעל בהצלחה, והעביר נתונים ממחסן נתונים של Databricks למסד נתונים תפעולי של Spanner.
השלב האחרון הוא לוודא שהנתונים הגיעו ל-Spanner כמו שציפיתם.
- עוברים אל Spanner.
- עוברים למופע
databricks-retlואז למסד הנתוניםdatabricks-retl. - ברשימת הטבלאות, לוחצים על הטבלה
regional_sales. - בתפריט הניווט הימני של הטבלה, לוחצים על הכרטיסייה נתונים.
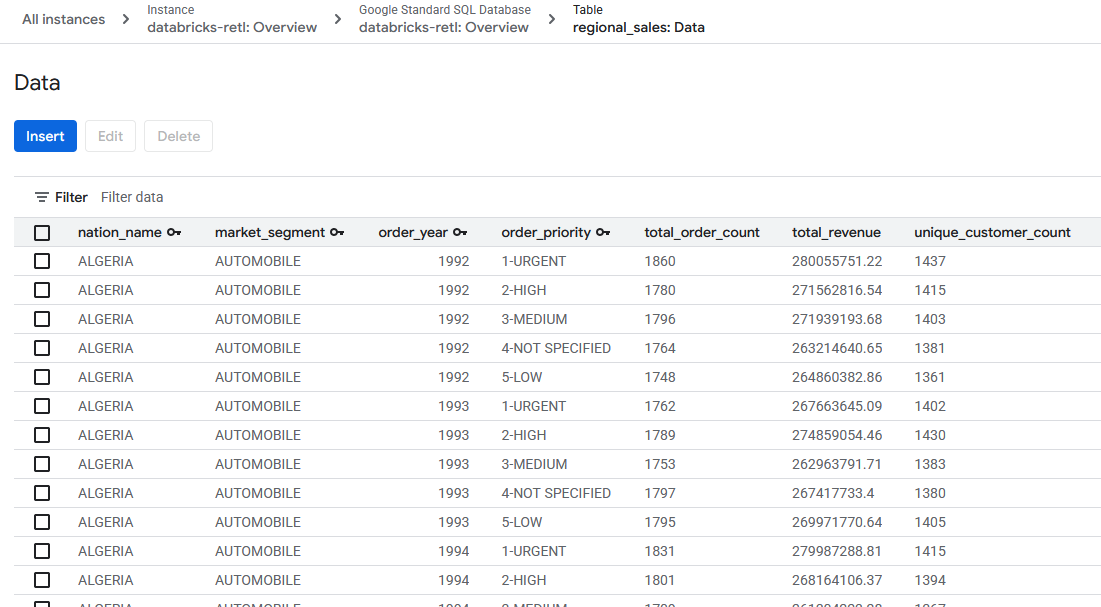
- נתוני המכירות המצטברים, שמקורם ב-Databricks, אמורים להיטען עכשיו ולהיות מוכנים לשימוש בטבלת Spanner. הנתונים האלה נמצאים עכשיו במערכת תפעולית, ומוכנים להפעלה של אפליקציה בזמן אמת, להצגה בלוח בקרה או לשליפת נתונים באמצעות API.
הצלחנו לגשר על הפער בין עולמות הנתונים האנליטיים והתפעוליים.
9. ניקוי תלונות
כשמסיימים את המעבדה הזו, צריך להסיר את כל הטבלאות שנוספו ואת הנתונים שאוחסנו.
ניקוי טבלאות Spanner
- מעבר אל Spanner
- ברשימה שנקראת
databricks-retl, לוחצים על המכונה שבה השתמשתם בשיעור ה-Lab הזה.

- בדף המכונה, לוחצים על

- בתיבת הדו-שיח לאישור שקופצת, מזינים
databricks-retlולוחצים על .
.
ניקוי GCS
- עוברים אל GCS
- בתפריט הצד הימני, בוחרים באפשרות
 .
. - בוחרים את דלי האחסון (bucket) ``codelabs_retl_databricks
- אחרי שבוחרים את האפשרות, לוחצים על הלחצן
 שמופיע בבאנר העליון.
שמופיע בבאנר העליון.

- בתיבת הדו-שיח לאישור שקופצת, מזינים
DELETEולוחצים על.
ניקוי של Databricks
מחיקת קטלוג, סכימה או טבלה
- כניסה למופע Databricks
- לוחצים על
 בתפריט שבצד ימין.
בתפריט שבצד ימין. - בוחרים את
 שיצרתם קודם מהרשימה בקטלוג.
שיצרתם קודם מהרשימה בקטלוג. - ברשימת הסכימות, בוחרים את הסכימה
 שנוצרה.
שנוצרה. - בוחרים את
 שנוצר קודם מרשימת הטבלאות.
שנוצר קודם מרשימת הטבלאות. - מרחיבים את אפשרויות הטבלה בלחיצה על
 ובוחרים באפשרות
ובוחרים באפשרות Delete - לוחצים על
 בתיבת הדו-שיח לאישור כדי למחוק את הטבלה.
בתיבת הדו-שיח לאישור כדי למחוק את הטבלה. - אחרי שהטבלה תימחק, תחזרו לדף הסכימה.
- מרחיבים את אפשרויות הסכימה בלחיצה על ובוחרים באפשרות
Delete - לוחצים על בתיבת הדו-שיח לאישור כדי למחוק את הסכימה.
- אחרי שהסכימה תימחק, תחזרו לדף הקטלוג.
- אם קיימת סכימה של
default, חוזרים על שלבים 4 עד 11 כדי למחוק אותה. - בדף הקטלוג, מרחיבים את אפשרויות הקטלוג על ידי לחיצה על ובוחרים באפשרות
Delete - לוחצים על בתיבת הדו-שיח לאישור כדי למחוק את הקטלוג.
מחיקת מיקום נתונים חיצוניים / פרטי כניסה
- במסך הקטלוג, לוחצים על הסמל .
- אם לא מופיעה האפשרות
External Data, יכול להיות שהאפשרותExternal Locationמופיעה בתפריט הנפתחConnect. - לוחצים על
retl-gcs-locationהמיקום של הנתונים החיצוניים שיצרתם קודם. - בדף המיקום החיצוני, לוחצים על כדי להרחיב את אפשרויות המיקום ובוחרים באפשרות
Delete. - לוחצים על בתיבת הדו-שיח לאישור כדי למחוק את המיקום החיצוני.
- לוחצים על
- לוחצים על
retl-gcs-credentialשנוצר קודם. - בדף פרטי הכניסה, לוחצים על כדי להרחיב את האפשרויות של פרטי הכניסה ובוחרים באפשרות
Delete. - לוחצים על בתיבת הדו-שיח לאישור כדי למחוק את פרטי הכניסה.
10. מזל טוב
כל הכבוד, סיימתם את ה-Codelab.
מה נכלל
- איך טוענים נתונים ל-Databricks כטבלאות Iceberg
- איך יוצרים קטגוריה ב-GCS
- איך מייצאים טבלה של Databricks ל-GCS בפורמט Iceberg
- איך יוצרים טבלה חיצונית ב-BigLake ב-BigQuery מטבלת Iceberg ב-GCS
- איך מגדירים מופע Spanner
- איך טוענים טבלאות חיצוניות של BigLake ב-BigQuery אל Spanner