
1. Google Cloud Storage और BigQuery का इस्तेमाल करके, Databricks से Spanner तक रिवर्स ईटीएल पाइपलाइन बनाना
परिचय
इस कोडलैब में, Databricks से Spanner तक रिवर्स ईटीएल पाइपलाइन बनाई जाएगी. आम तौर पर, स्टैंडर्ड ईटीएल (एक्सट्रैक्ट, ट्रांसफ़ॉर्म, लोड) पाइपलाइन, डेटा को ऑपरेशनल डेटाबेस से निकालकर, Databricks जैसे डेटा वेयरहाउस में ले जाती हैं, ताकि उसका विश्लेषण किया जा सके. रिवर्स ईटीएल पाइपलाइन, ईटीएल पाइपलाइन के उलट काम करती है. यह प्रोसेस किए गए डेटा को डेटा वेयरहाउस से वापस ऑपरेशनल डेटाबेस में ले जाती है. जैसे, Spanner. यह दुनिया भर में डिस्ट्रिब्यूट किया गया रिलेशनल डेटाबेस है. यह ऐसे ऐप्लिकेशन के लिए सबसे सही है जो हर समय उपलब्ध रहते हैं. यहां डेटा का इस्तेमाल ऐप्लिकेशन को बेहतर बनाने, उपयोगकर्ताओं के लिए उपलब्ध सुविधाओं को बेहतर बनाने या रीयल-टाइम में फ़ैसले लेने के लिए किया जा सकता है.
इसका मकसद, Databricks Iceberg टेबल से एग्रीगेट किए गए डेटासेट को Spanner टेबल में ले जाना है.
इसके लिए, Google Cloud Storage (GCS) और BigQuery का इस्तेमाल इंटरमीडिएट चरणों के तौर पर किया जाता है. यहां डेटा फ़्लो और इस आर्किटेक्चर की वजह के बारे में जानकारी दी गई है:

- Databricks से Google Cloud Storage (GCS) में Iceberg फ़ॉर्मैट में डेटा ट्रांसफ़र करना:
- पहला चरण, डेटा को Databricks से ओपन और अच्छी तरह से परिभाषित फ़ॉर्मैट में निकालना है. टेबल को Apache Iceberg फ़ॉर्मैट में एक्सपोर्ट किया जाता है. इस प्रोसेस में, डेटा को Parquet फ़ाइलों के सेट के तौर पर लिखा जाता है. साथ ही, टेबल के मेटाडेटा (स्कीमा, पार्टिशन, फ़ाइल की जगह) को JSON और Avro फ़ाइलों के तौर पर लिखा जाता है. इस पूरी टेबल स्ट्रक्चर को GCS में स्टेज करने से, डेटा को पोर्टेबल बनाया जा सकता है. साथ ही, इसे ऐसे किसी भी सिस्टम से ऐक्सेस किया जा सकता है जो Iceberg फ़ॉर्मैट को समझता है.
- GCS Iceberg टेबल को BigQuery BigLake की बाहरी टेबल में बदलें:
- GCS से सीधे Spanner में डेटा लोड करने के बजाय, BigQuery का इस्तेमाल एक इंटरमीडियरी के तौर पर किया जाता है. BigQuery में एक BigLake बाहरी टेबल बनाई जाती है, जो सीधे तौर पर GCS में मौजूद Iceberg मेटाडेटा फ़ाइल की ओर ले जाती है. इस तरीके के कई फ़ायदे हैं:
- डेटा डुप्लीकेट नहीं होता: BigQuery, मेटाडेटा से टेबल स्ट्रक्चर को पढ़ता है. साथ ही, Parquet डेटा फ़ाइलों को इन प्लेस क्वेरी करता है. इसके लिए, उन्हें इनजेस्ट नहीं किया जाता. इससे काफ़ी समय और स्टोरेज का खर्च बचता है.
- फ़ेडरेटेड क्वेरी: इसकी मदद से, GCS डेटा पर SQL की जटिल क्वेरी चलाई जा सकती हैं. ऐसा लगता है कि यह BigQuery की नेटिव टेबल है.
- BigLake की बाहरी टेबल से Spanner में ReverseETL:
- आखिरी चरण में, BigQuery से Spanner में डेटा ट्रांसफ़र किया जाता है. यह काम, BigQuery की एक बेहतरीन सुविधा का इस्तेमाल करके किया जाता है. इसे
EXPORT DATAक्वेरी कहा जाता है. यह "रिवर्स ईटीएल" चरण है. - ऑपरेशनल रेडीनेस: Spanner को लेन-देन से जुड़े वर्कलोड के लिए डिज़ाइन किया गया है. यह ऐप्लिकेशन के लिए, डेटा में एकरूपता और उपलब्धता बनाए रखता है. डेटा को Spanner में ट्रांसफ़र करने से, इसे उपयोगकर्ता के लिए उपलब्ध ऐप्लिकेशन, एपीआई, और अन्य ऑपरेशनल सिस्टम के लिए ऐक्सेस किया जा सकता है. इन सिस्टम को कम समय में पॉइंट लुकअप की ज़रूरत होती है.
- स्केलेबिलिटी: इस पैटर्न की मदद से, बड़े डेटासेट को प्रोसेस करने के लिए BigQuery की विश्लेषण क्षमता का फ़ायदा उठाया जा सकता है. इसके बाद, Spanner के ग्लोबल स्तर पर स्केलेबल इन्फ़्रास्ट्रक्चर की मदद से, नतीजों को असरदार तरीके से दिखाया जा सकता है.
सेवाएं और शब्दावली
- DataBricks - यह क्लाउड पर आधारित डेटा प्लैटफ़ॉर्म है, जिसे Apache Spark के आधार पर बनाया गया है.
- Spanner - यह दुनिया भर में उपलब्ध रिलेशनल डेटाबेस है. इसे पूरी तरह से Google मैनेज करता है.
- Google Cloud Storage - Google Cloud की ओर से उपलब्ध कराया जाने वाला, ब्लब स्टोरेज.
- BigQuery - यह बिना सर्वर वाला डेटा वेयरहाउस है. इसका इस्तेमाल डेटा के विश्लेषण के लिए किया जाता है. इसे Google पूरी तरह से मैनेज करता है.
- Iceberg - यह Apache की ओर से तय किया गया ओपन टेबल फ़ॉर्मैट है. यह सामान्य ओपन-सोर्स डेटा फ़ाइल फ़ॉर्मैट पर ऐब्स्ट्रैक्शन उपलब्ध कराता है.
- Parquet - यह Apache का ओपन-सोर्स कॉलम वाला बाइनरी डेटा फ़ाइल फ़ॉर्मैट है.
आपको क्या सीखने को मिलेगा
- Databricks में Iceberg टेबल के तौर पर डेटा लोड करने का तरीका
- GCS बकेट बनाने का तरीका
- Databricks टेबल को Iceberg फ़ॉर्मैट में GCS में एक्सपोर्ट करने का तरीका
- GCS में मौजूद Iceberg टेबल से, BigQuery में BigLake External Table बनाने का तरीका
- स्पैनर इंस्टेंस सेट अप करने का तरीका
- BigQuery में मौजूद BigLake की बाहरी टेबल को Spanner में लोड करने का तरीका
2. सेटअप, ज़रूरी शर्तें, और सीमाएं
ज़रूरी शर्तें
- Databricks खाता, बेहतर होगा कि यह GCP पर हो
- BigQuery से Spanner में डेटा एक्सपोर्ट करने के लिए, BigQuery के Enterprise-tier या उससे ऊपर के रिज़र्वेशन वाला Google Cloud खाता होना ज़रूरी है.
- वेब ब्राउज़र से Google Cloud Console को ऐक्सेस करने की सुविधा
- Google Cloud CLI कमांड चलाने के लिए टर्मिनल
अगर आपके Google Cloud संगठन में iam.allowedPolicyMemberDomains नीति चालू है, तो एडमिन को बाहरी डोमेन के सेवा खातों को अनुमति देने के लिए, अपवाद की अनुमति देनी पड़ सकती है. यह जानकारी, बाद के चरण में दी जाएगी.
ज़रूरी शर्तें
- बिलिंग की सुविधा वाला Google Cloud प्रोजेक्ट.
- कोई वेब ब्राउज़र, जैसे कि Chrome
- Databricks खाता (इस लैब में, GCP में होस्ट किए गए वर्कस्पेस का इस्तेमाल किया गया है)
- EXPORT DATA सुविधा का इस्तेमाल करने के लिए, BigQuery इंस्टेंस Enterprise Edition या इससे ऊपर के वर्शन पर होना चाहिए.
- अगर आपके Google Cloud संगठन में
iam.allowedPolicyMemberDomainsनीति चालू है, तो एडमिन को बाहरी डोमेन के सेवा खातों को अनुमति देने के लिए, अपवाद की अनुमति देनी पड़ सकती है. यह जानकारी, बाद के चरण में दी जाएगी.
Google Cloud Platform IAM की अनुमतियां
इस कोडलैब में दिए गए सभी चरणों को पूरा करने के लिए, Google खाते के पास ये अनुमतियां होनी चाहिए.
सेवा खाते | ||
| इससे सेवा खाते बनाए जा सकते हैं. | |
Spanner | ||
| इससे नया Spanner इंस्टेंस बनाया जा सकता है. | |
| DDL स्टेटमेंट चलाने की अनुमति देता है, ताकि | |
| इसकी मदद से, डेटाबेस में टेबल बनाने के लिए DDL स्टेटमेंट चलाए जा सकते हैं. | |
Google Cloud Storage | ||
| इस विकल्प की मदद से, एक्सपोर्ट की गई Parquet फ़ाइलों को सेव करने के लिए, नया GCS बकेट बनाया जा सकता है. | |
| इस भूमिका की मदद से, एक्सपोर्ट की गई Parquet फ़ाइलों को GCS बकेट में लिखा जा सकता है. | |
| इससे BigQuery को GCS बकेट से Parquet फ़ाइलें पढ़ने की अनुमति मिलती है. | |
| इससे BigQuery को GCS बकेट में मौजूद Parquet फ़ाइलों की सूची बनाने की अनुमति मिलती है. | |
डेटाफ़्लो | ||
| इससे Dataflow से वर्क आइटम को क्लेम करने की अनुमति मिलती है. | |
| इस कुकी से, Dataflow वर्कर को Dataflow सेवा पर वापस मैसेज भेजने की अनुमति मिलती है. | |
| इस भूमिका की मदद से, Dataflow वर्कर को Google Cloud Logging में लॉग एंट्री लिखने की अनुमति मिलती है. | |
इन अनुमतियों वाली पहले से तय की गई भूमिकाओं का इस्तेमाल किया जा सकता है.
|
|
|
|
|
|
|
|
Google Cloud प्रोजेक्ट
प्रोजेक्ट, Google Cloud में संगठन की बुनियादी इकाई होती है. अगर एडमिन ने आपको कोई कोड दिया है, तो इस चरण को छोड़ा जा सकता है.
सीएलआई का इस्तेमाल करके, इस तरह प्रोजेक्ट बनाया जा सकता है:
gcloud projects create <your-project-name>
प्रोजेक्ट बनाने और मैनेज करने के बारे में ज़्यादा जानने के लिए, यहां जाएं.
सीमाएं
इस पाइपलाइन में कुछ सीमाएं और डेटा टाइप से जुड़ी समस्याएं आ सकती हैं. इनके बारे में आपको पता होना चाहिए.
Databricks Iceberg से BigQuery में डेटा ट्रांसफ़र करना
Databricks की ओर से मैनेज की गई Iceberg टेबल (UniForm के ज़रिए) पर क्वेरी करने के लिए BigQuery का इस्तेमाल करते समय, इन बातों का ध्यान रखें:
- स्कीमा में बदलाव: UniForm, Delta Lake के स्कीमा में हुए बदलावों को Iceberg में ट्रांसफ़र करने का काम अच्छी तरह से करता है. हालांकि, ऐसा हो सकता है कि जटिल बदलाव हमेशा आपकी उम्मीद के मुताबिक ट्रांसफ़र न हों. उदाहरण के लिए, Delta Lake में कॉलम का नाम बदलने पर, Iceberg में इसका अनुवाद नहीं होता. Iceberg इसे
dropऔरaddके तौर पर देखता है. स्कीमा में किए गए बदलावों की हमेशा अच्छी तरह से जांच करें. - टाइम ट्रैवल: BigQuery, Delta Lake की टाइम ट्रैवल की सुविधाओं का इस्तेमाल नहीं कर सकता. यह सिर्फ़ आइसबर्ग टेबल के नए स्नैपशॉट को क्वेरी करेगा.
- Delta Lake की ऐसी सुविधाएं जो UniForm के साथ काम नहीं करतीं: Delta Lake की कुछ सुविधाएं, UniForm के साथ काम नहीं करतीं. जैसे, Deletion Vectors और
idमोड के साथ Column Mapping. लैब, कॉलम मैपिंग के लिएnameमोड का इस्तेमाल करता है. यह मोड काम करता है.
BigQuery से Spanner
BigQuery से Spanner में डेटा ट्रांसफ़र करने के लिए इस्तेमाल की जाने वाली EXPORT DATA कमांड, BigQuery के सभी डेटा टाइप के साथ काम नहीं करती. इस तरह की टेबल एक्सपोर्ट करने पर गड़बड़ी होगी:
STRUCTGEOGRAPHYDATETIMERANGETIME
इसके अलावा, अगर BigQuery प्रोजेक्ट GoogleSQL डायलेक्ट का इस्तेमाल कर रहा है, तो Spanner में एक्सपोर्ट करने के लिए, यहां दिए गए संख्या वाले टाइप भी काम नहीं करते:
BIGNUMERIC
सीमाओं की पूरी और अप-टू-डेट सूची देखने के लिए, आधिकारिक दस्तावेज़ देखें: Spanner में एक्सपोर्ट करने से जुड़ी सीमाएं.
समस्या हल करना और ज़रूरी बातें
- अगर GCP Databricks इंस्टेंस पर नहीं हैं, तो GCS में बाहरी डेटा की जगह तय करना मुमकिन नहीं हो सकता. ऐसे मामलों में, फ़ाइलों को Databricks workspace के क्लाउड सेवा देने वाली कंपनी के स्टोरेज समाधान में स्टेज करना होगा. इसके बाद, उन्हें GCS में अलग से माइग्रेट करना होगा.
- ऐसा करने पर, मेटाडेटा में बदलाव करने होंगे, क्योंकि जानकारी में स्टेज की गई फ़ाइलों के लिए हार्ड कोड किए गए पाथ होंगे.
3. Google Cloud Storage (GCS) सेट अप करना
Databricks से जनरेट की गई Parquet डेटा फ़ाइलों को सेव करने के लिए, Google Cloud Storage (GCS) का इस्तेमाल किया जाएगा. इसके लिए, फ़ाइल डेस्टिनेशन के तौर पर इस्तेमाल करने के लिए, पहले एक नया बकेट बनाना होगा.
Google Cloud Storage
नया बकेट बनाना
- Cloud Console में, Google Cloud Storage पेज पर जाएं.
- बाएं पैनल में, बकेट चुनें:
- बनाएं बटन पर क्लिक करें:

- अपने बकेट की जानकारी भरें:
- इस्तेमाल करने के लिए, बकेट का नाम चुनें. इस लैब के लिए,
codelabs_retl_databricksनाम का इस्तेमाल किया जाएगा - बकेट को सेव करने के लिए, कोई रीजन चुनें या डिफ़ॉल्ट वैल्यू का इस्तेमाल करें.
- स्टोरेज क्लास को
standardके तौर पर रखें - कंट्रोल ऐक्सेस के लिए डिफ़ॉल्ट वैल्यू बनाए रखना
- ऑब्जेक्ट डेटा को सुरक्षित रखें के लिए डिफ़ॉल्ट वैल्यू बनाए रखें
- बदलाव करने के बाद,
Createबटन पर क्लिक करें. आपको एक सूचना दिख सकती है, जिसमें यह पुष्टि करने के लिए कहा जाएगा कि सार्वजनिक ऐक्सेस को रोका जाएगा. आगे बढ़ें और पुष्टि करें. - बधाई हो, नई बकेट बन गई है! आपको बकेट पेज पर रीडायरेक्ट कर दिया जाएगा.
- नए बकेट का नाम कहीं कॉपी कर लें, क्योंकि बाद में इसकी ज़रूरत पड़ेगी.
अगले चरणों के लिए तैयारी करना
पक्का करें कि आपने यहां दी गई जानकारी नोट कर ली हो, क्योंकि अगले चरणों में इसकी ज़रूरत पड़ेगी:
- Google प्रोजेक्ट आईडी
- Google Storage बकेट का नाम
4. Databricks को सेटअप करना
TPC-H डेटा
इस लैब के लिए, TPC-H डेटासेट का इस्तेमाल किया जाएगा. यह फ़ैसले लेने में मदद करने वाले सिस्टम के लिए, इंडस्ट्री स्टैंडर्ड बेंचमार्क है. इसका स्कीमा, ग्राहकों, ऑर्डर, सप्लायर, और पार्ट्स के साथ-साथ कारोबार के असल माहौल को मॉडल करता है. इसलिए, यह असल दुनिया के आंकड़ों और डेटा मूवमेंट के उदाहरण को दिखाने के लिए सबसे सही है.
TPC-H की रॉ और सामान्य की गई टेबल का इस्तेमाल करने के बजाय, एक नई एग्रीगेट की गई टेबल बनाई जाएगी. यह नई टेबल, orders, customer, और nation टेबल के डेटा को एक साथ जोड़ देगी. इससे, क्षेत्र के हिसाब से बिक्री की खास जानकारी वाला व्यू तैयार होगा. प्री-एग्रीगेशन, आंकड़ों के विश्लेषण में आम तौर पर इस्तेमाल किया जाता है. इससे डेटा को किसी खास इस्तेमाल के लिए तैयार किया जाता है. इस उदाहरण में, डेटा को ऑपरेशनल ऐप्लिकेशन के इस्तेमाल के लिए तैयार किया जाता है.
एग्रीगेट की गई टेबल का फ़ाइनल स्कीमा यह होगा:
Col | टाइप |
nation_name | स्ट्रिंग |
market_segment | स्ट्रिंग |
order_year | int |
order_priority | स्ट्रिंग |
total_order_count | bigint |
total_revenue | decimal(29,2) |
unique_customer_count | bigint |
डेल्टा लेक के यूनिवर्सल फ़ॉर्मैट (UniForm) के साथ आइसबर्ग सपोर्ट
इस लैब के लिए, Databricks में मौजूद टेबल, Delta Lake टेबल होगी. हालांकि, इसे BigQuery जैसे बाहरी सिस्टम के लिए पढ़ने लायक बनाने के लिए, यूनिवर्सल फ़ॉर्मैट (UniForm) नाम की एक बेहतरीन सुविधा चालू की जाएगी.
UniForm, टेबल के डेटा की एक ही शेयर की गई कॉपी के लिए, Delta Lake के मेटाडेटा के साथ-साथ Iceberg मेटाडेटा अपने-आप जनरेट करता है. इससे आपको दोनों तरीकों की सबसे बेहतर सुविधाओं का फ़ायदा मिलेगा:
- Databricks में: Delta Lake की परफ़ॉर्मेंस और गवर्नेंस से जुड़े सभी फ़ायदे मिलते हैं.
- Databricks के बाहर: इस टेबल को Iceberg के साथ काम करने वाला कोई भी क्वेरी इंजन पढ़ सकता है. जैसे, BigQuery. ऐसा माना जाता है कि यह एक नेटिव Iceberg टेबल है.
इससे डेटा की अलग-अलग कॉपी बनाए रखने या मैन्युअल कन्वर्ज़न जॉब चलाने की ज़रूरत नहीं होती. टेबल बनाते समय, टेबल की कुछ प्रॉपर्टी सेट करके UniForm को चालू किया जाएगा.
Databricks Catalogs
Databricks कैटलॉग, Unity Catalog में डेटा के लिए टॉप-लेवल का कंटेनर होता है. Unity Catalog, Databricks का यूनिफ़ाइड गवर्नेंस सॉल्यूशन है. Unity Catalog, डेटा ऐसेट को मैनेज करने, ऐक्सेस कंट्रोल करने, और लीनेज को ट्रैक करने का एक ही तरीका उपलब्ध कराता है. यह अच्छी तरह से मैनेज किए गए डेटा प्लैटफ़ॉर्म के लिए ज़रूरी है.
यह डेटा को व्यवस्थित करने के लिए, तीन लेवल वाले नेमस्पेस का इस्तेमाल करता है: catalog.schema.table.
- कैटलॉग: यह सबसे ऊपरी लेवल होता है. इसका इस्तेमाल, एनवायरमेंट, कारोबारी यूनिट या प्रोजेक्ट के हिसाब से डेटा को ग्रुप करने के लिए किया जाता है.
- स्कीमा (या डेटाबेस): कैटलॉग में मौजूद टेबल, व्यू, और फ़ंक्शन का लॉजिकल ग्रुप.
- टेबल: वह ऑब्जेक्ट जिसमें आपका डेटा मौजूद है.
TPC-H की एग्रीगेट की गई टेबल बनाने से पहले, इसे रखने के लिए एक खास कैटलॉग और स्कीमा सेट अप करना होगा. इससे यह पक्का होता है कि प्रोजेक्ट को अच्छी तरह से व्यवस्थित किया गया है और यह Workspace में मौजूद अन्य डेटा से अलग है.
नया कैटलॉग और स्कीमा बनाना
Databricks Unity Catalog में, कैटलॉग डेटा ऐसेट के लिए संगठन के सबसे ऊपरी लेवल के तौर पर काम करता है. यह एक सुरक्षित कंटेनर के तौर पर काम करता है, जो कई Databricks वर्कस्पेस में फैला हो सकता है. इसकी मदद से, कारोबार की इकाइयों, प्रोजेक्ट या एनवायरमेंट के आधार पर डेटा को व्यवस्थित और अलग किया जा सकता है. साथ ही, अनुमतियों और ऐक्सेस कंट्रोल को साफ़ तौर पर तय किया जा सकता है.
कैटलॉग में, स्कीमा (इसे डेटाबेस भी कहा जाता है) टेबल, व्यू, और फ़ंक्शन को व्यवस्थित करता है. इस क्रमबद्ध स्ट्रक्चर की मदद से, डेटा ऑब्जेक्ट को बारीकी से कंट्रोल किया जा सकता है. साथ ही, इससे मिलते-जुलते डेटा ऑब्जेक्ट को लॉजिकल ग्रुप में रखा जा सकता है. इस लैब के लिए, टीपीसी-एच डेटा को स्टोर करने के लिए एक खास कैटलॉग और स्कीमा बनाया जाएगा. इससे यह पक्का किया जा सकेगा कि डेटा को अलग रखा गया है और उसे सही तरीके से मैनेज किया जा रहा है.
कैटलॉग बनाना
 पर जाएं
पर जाएं- + पर क्लिक करें. इसके बाद, ड्रॉपडाउन से कैटलॉग बनाएं चुनें
- इन सेटिंग के साथ, एक नया स्टैंडर्ड कैटलॉग बनाया जाएगा:
- कैटलॉग का नाम:
retl_tpch_project - स्टोरेज की जगह: अगर फ़ाइल फ़ोल्डर में स्टोरेज की जगह पहले से सेट है, तो डिफ़ॉल्ट जगह का इस्तेमाल करें. इसके अलावा, नई जगह भी सेट की जा सकती है.
स्कीमा बनाना
- पर जाएं
- बाईं ओर मौजूद पैनल से, बनाया गया नया कैटलॉग चुनें
 पर क्लिक करें
पर क्लिक करें- स्कीमा के नाम
tpch_dataके साथ एक नया स्कीमा बनाया जाएगा
बाहरी डेटा सेट अप करना
Databricks से Google Cloud Storage (GCS) में डेटा एक्सपोर्ट करने के लिए, Databricks में बाहरी डेटा क्रेडेंशियल सेट अप करने होंगे. इससे Databricks को GCS बकेट को सुरक्षित तरीके से ऐक्सेस करने और उसमें डेटा लिखने की अनुमति मिलती है.
- कैटलॉग स्क्रीन पर,
 पर क्लिक करें
पर क्लिक करें
- अगर आपको
External Dataविकल्प नहीं दिखता है, तो हो सकता है कि आपकोExternal Locations,Connectड्रॉपडाउन में दिखे.
 पर क्लिक करें
पर क्लिक करें- नई डायलॉग विंडो में, क्रेडेंशियल के लिए ज़रूरी वैल्यू सेट अप करें:
- क्रेडेंशियल का टाइप:
GCP Service Account - क्रेडेंशियल का नाम:
retl-gcs-credential
- बनाएं पर क्लिक करें
- इसके बाद, बाहर रखी गई जगहें टैब पर क्लिक करें.
- जगह की जानकारी बनाएं पर क्लिक करें.
- नई डायलॉग विंडो में, बाहरी जगह के लिए ज़रूरी वैल्यू सेट अप करें:
- बाहरी जगह का नाम:
retl-gcs-location - स्टोरेज टाइप:
GCP - यूआरएल: GCS बकेट का यूआरएल, इस फ़ॉर्मैट में होना चाहिए
gs://YOUR_BUCKET_NAME - स्टोरेज क्रेडेंशियल: अभी बनाया गया
retl-gcs-credentialचुनें.
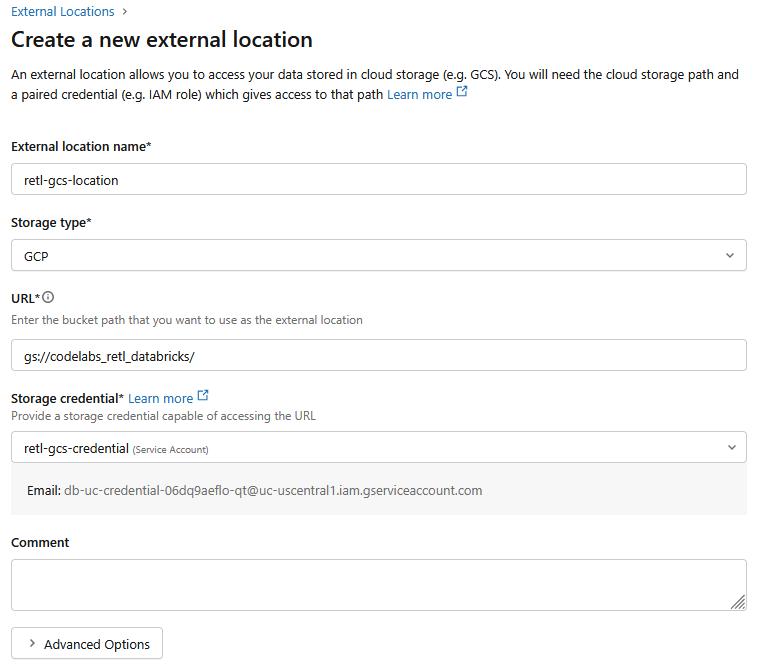
- सेवा खाते का वह ईमेल पता नोट करें जो स्टोरेज क्रेडेंशियल चुनने पर अपने-आप भर जाता है. इसकी ज़रूरत अगले चरण में पड़ेगी.
- बनाएं पर क्लिक करें
5. सेवा खाते की अनुमतियां सेट करना
सेवा खाता एक खास तरह का खाता होता है. इसका इस्तेमाल ऐप्लिकेशन या सेवाएं, Google Cloud संसाधनों को एपीआई कॉल करने के लिए करती हैं.
अब GCS में नई बकेट के लिए बनाए गए सेवा खाते में अनुमतियां जोड़नी होंगी.
- GCS बकेट पेज पर, अनुमतियां टैब को चुनें.
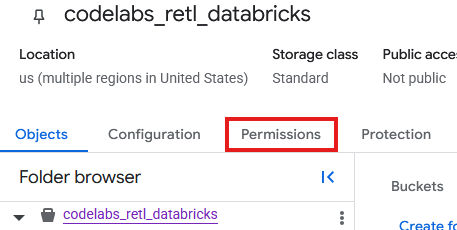
- प्रिंसिपल पेज पर, ऐक्सेस दें पर क्लिक करें
- दाईं ओर से स्लाइड आउट होने वाले ऐक्सेस दें पैनल में, मुख्य खाते वाले नए फ़ील्ड में सेवा खाते का आईडी डालें
- भूमिकाएं असाइन करें में जाकर,
Storage Object AdminऔरStorage Legacy Bucket Readerजोड़ें. इन भूमिकाओं की मदद से, सेवा खाता स्टोरेज बकेट में मौजूद ऑब्जेक्ट को पढ़ सकता है, उनमें बदलाव कर सकता है, और उनकी सूची बना सकता है.
TPC-H डेटा लोड करना
कैटलॉग और स्कीमा बन जाने के बाद, TPCH डेटा को मौजूदा samples.tpch टेबल से लोड किया जा सकता है. यह टेबल, Databricks में इंटरनल तौर पर सेव होती है. साथ ही, इसे नए स्कीमा में नई टेबल के तौर पर इस्तेमाल किया जा सकता है.
आइसबर्ग टेबल बनाने की सुविधा
UniForm के साथ Iceberg का इस्तेमाल करना
Databricks, इस टेबल को Delta Lake टेबल के तौर पर मैनेज करता है. इससे Databricks के नेटवर्क में, Delta की परफ़ॉर्मेंस ऑप्टिमाइज़ेशन और गवर्नेंस से जुड़ी सभी सुविधाओं का फ़ायदा मिलता है. हालांकि, UniForm (यूनिवर्सल फ़ॉर्मैट का छोटा नाम) को चालू करने पर, Databricks को कुछ खास काम करने के लिए कहा जाता है: जब भी टेबल अपडेट होती है, तो Databricks, Delta Lake मेटाडेटा के साथ-साथ उससे जुड़ा Iceberg मेटाडेटा अपने-आप जनरेट करता है और उसे बनाए रखता है.
इसका मतलब है कि अब डेटा फ़ाइलों के एक ही शेयर किए गए सेट (Parquet फ़ाइलें) के बारे में, मेटाडेटा के दो अलग-अलग सेट से जानकारी मिलती है.
- Databricks के लिए: यह टेबल को पढ़ने के लिए,
_delta_logका इस्तेमाल करता है. - बाहरी रीडर (जैसे, BigQuery) के लिए: ये टेबल के स्कीमा, पार्टिशनिंग, और फ़ाइल की जगहों को समझने के लिए, Iceberg मेटाडेटा फ़ाइल (
.metadata.json) का इस्तेमाल करते हैं.
इसका नतीजा एक ऐसी टेबल होती है जो Iceberg के साथ काम करने वाले किसी भी टूल के साथ पूरी तरह और पारदर्शी तरीके से काम करती है. इसमें डेटा डुप्लीकेट नहीं होता. साथ ही, मैन्युअल कन्वर्ज़न या सिंक्रनाइज़ेशन की ज़रूरत नहीं होती. यह एक ऐसा सोर्स है जिसमें सटीक जानकारी होती है. इसे Databricks के विश्लेषण से जुड़े टूल और Iceberg के ओपन स्टैंडर्ड के साथ काम करने वाले टूल के बड़े नेटवर्क, दोनों से आसानी से ऐक्सेस किया जा सकता है.
- नया पर क्लिक करें. इसके बाद, क्वेरी पर क्लिक करें
- क्वेरी पेज के टेक्स्ट फ़ील्ड में, यह एसक्यूएल कमांड चलाएं:
CREATE TABLE retl_tpch_project.tpch_data.regional_sales_iceberg
USING DELTA
LOCATION 'gs://<Your bucket name>/regional_sales_iceberg'
TBLPROPERTIES (
'delta.columnMapping.mode' = 'name',
'delta.enableIcebergCompatV2' = 'true',
'delta.universalFormat.enabledFormats' = 'iceberg'
)
AS
SELECT
n.n_name AS nation_name,
c.c_mktsegment AS market_segment,
YEAR(o.o_orderdate) AS order_year,
o.o_orderpriority AS order_priority,
COUNT(o.o_orderkey) AS total_order_count,
ROUND(SUM(o.o_totalprice), 2) AS total_revenue,
COUNT(DISTINCT c.c_custkey) AS unique_customer_count
FROM samples.tpch.orders AS o
INNER JOIN samples.tpch.customer AS c
ON o.o_custkey = c.c_custkey
INNER JOIN samples.tpch.nation AS n
ON c.c_nationkey = n.n_nationkey
GROUP BY
n.n_name,
c.c_mktsegment,
YEAR(o.o_orderdate),
o.o_orderpriority;
OPTIMIZE retl_tpch_project.tpch_data.regional_sales_iceberg;
DESCRIBE EXTENDED retl_tpch_project.tpch_data.regional_sales_iceberg;
ध्यान दें:
- Using Delta - इससे पता चलता है कि हम डेल्टा लेक टेबल का इस्तेमाल कर रहे हैं. Databricks में मौजूद सिर्फ़ Delta Lake टेबल को बाहरी टेबल के तौर पर सेव किया जा सकता है.
- जगह - इससे यह पता चलता है कि टेबल को कहां सेव करना है. यह जानकारी सिर्फ़ बाहरी टेबल के लिए होती है.
- TablePropertoes -
delta.universalFormat.enabledFormats = ‘iceberg', Delta Lake फ़ाइलों के साथ-साथ, आइसबर्ग के साथ काम करने वाला मेटाडेटा बनाता है. - ऑप्टिमाइज़ करें - इससे UniForm के मेटाडेटा जनरेशन को तुरंत ट्रिगर किया जाता है. आम तौर पर, यह प्रोसेस एसिंक्रोनस तरीके से होती है.
- क्वेरी के आउटपुट में, नई टेबल की जानकारी दिखनी चाहिए

GCS टेबल के डेटा की पुष्टि करना
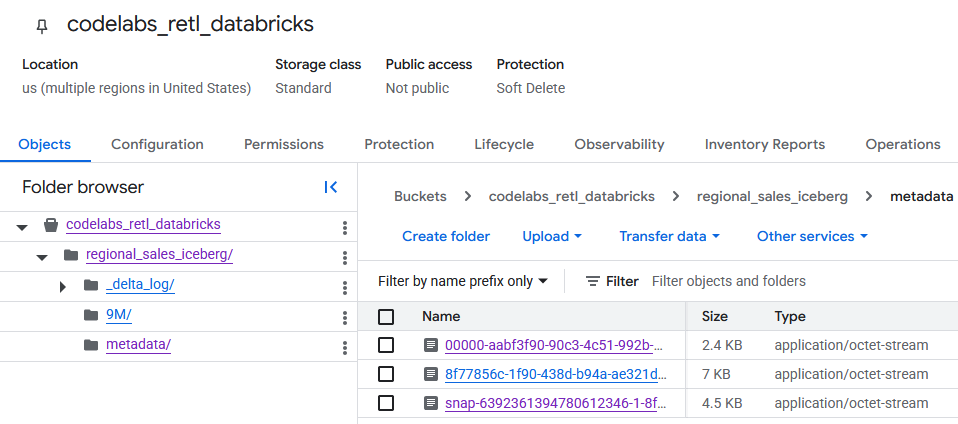
GCS बकेट पर जाकर, अब नई बनाई गई टेबल का डेटा देखा जा सकता है.
आपको metadata फ़ोल्डर में Iceberg मेटाडेटा मिलेगा. इसका इस्तेमाल BigQuery जैसे बाहरी रीडर करते हैं. Databricks, Delta Lake के मेटाडेटा का इस्तेमाल करता है. इसे _delta_log फ़ोल्डर में ट्रैक किया जाता है.
टेबल का असल डेटा, किसी दूसरे फ़ोल्डर में Parquet फ़ाइलों के तौर पर सेव किया जाता है. आम तौर पर, इस फ़ोल्डर का नाम Databricks, रैंडम तरीके से जनरेट की गई स्ट्रिंग के हिसाब से रखता है. उदाहरण के लिए, नीचे दिए गए स्क्रीनशॉट में, डेटा फ़ाइलें 9M फ़ोल्डर में मौजूद हैं.
6. BigQuery और BigLake सेट अप करना
Iceberg टेबल अब Google Cloud Storage में है. अगला चरण, इसे BigQuery के लिए ऐक्सेस किया जा सकने वाला बनाना है. इसके लिए, BigLake की बाहरी टेबल बनाई जाएगी.
BigLake एक स्टोरेज इंजन है. इसकी मदद से, BigQuery में ऐसी टेबल बनाई जा सकती हैं जो Google Cloud Storage जैसे बाहरी सोर्स से सीधे डेटा पढ़ती हैं. इस लैब के लिए, यह मुख्य टेक्नोलॉजी है. इसकी मदद से BigQuery, अभी एक्सपोर्ट की गई Iceberg टेबल को समझ पाता है. इसके लिए, उसे डेटा को प्रोसेस करने की ज़रूरत नहीं पड़ती.
इसके लिए, दो कॉम्पोनेंट की ज़रूरत होती है:
- क्लाउड रिसोर्स कनेक्शन: यह BigQuery और GCS के बीच एक सुरक्षित लिंक होता है. यह पुष्टि करने के लिए, एक खास सेवा खाते का इस्तेमाल करता है. इससे यह पक्का किया जाता है कि BigQuery के पास GCS बकेट से फ़ाइलें पढ़ने की ज़रूरी अनुमतियां हों.
- बाहरी टेबल की परिभाषा: इससे BigQuery को यह पता चलता है कि GCS में Iceberg टेबल की मेटाडेटा फ़ाइल कहां है और इसे कैसे समझा जाना चाहिए.
Cloud Resource Connection बनाना
सबसे पहले, ऐसा कनेक्शन बनाया जाएगा जिसकी मदद से BigQuery, GCS को ऐक्सेस कर पाएगा.
Cloud Resource Connections बनाने के बारे में ज़्यादा जानकारी यहां मिल सकती है
- BigQuery पर जाएं
- एक्सप्लोरर में जाकर, कनेक्शन पर क्लिक करें
- अगर एक्सप्लोरर प्लान नहीं दिख रहा है, तो
 पर क्लिक करें
पर क्लिक करें
- कनेक्शन पेज पर,
 पर क्लिक करें
पर क्लिक करें - कनेक्शन टाइप के लिए,
Vertex AI remote models, remote functions, BigLake and Spanner (Cloud Resource)चुनें - कनेक्शन आईडी को
databricks_retlपर सेट करें और कनेक्शन बनाएं

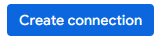
- अब आपको नए कनेक्शन की कनेक्शन टेबल में एक एंट्री दिखेगी. कनेक्शन की जानकारी देखने के लिए, उस एंट्री पर क्लिक करें.

- कनेक्शन की जानकारी वाले पेज पर, सेवा खाते का आईडी नोट कर लें. इसकी ज़रूरत आपको बाद में पड़ेगी.
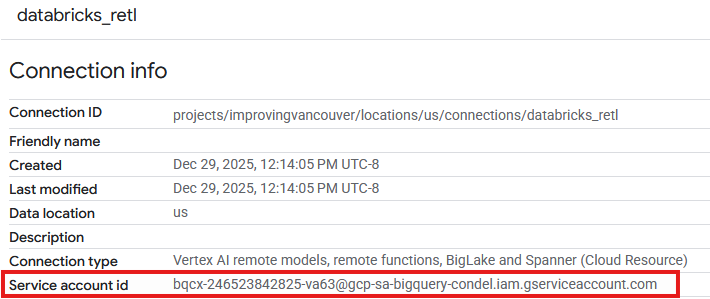
कनेक्शन सेवा खाते का ऐक्सेस देना
- IAM और एडमिन पर जाएं
- ऐक्सेस दें पर क्लिक करें
- नए मुख्य खाते फ़ील्ड के लिए, ऊपर बनाया गया कनेक्शन रिसोर्स का सेवा खाता आईडी डालें.
- भूमिका के लिए,
Storage Object Userको चुनें. इसके बाद, पर क्लिक करें
पर क्लिक करें
कनेक्शन बन जाने और सेवा खाते को ज़रूरी अनुमतियां मिल जाने के बाद, अब BigLake की बाहरी टेबल बनाई जा सकती है. सबसे पहले, नई टेबल के लिए कंटेनर के तौर पर काम करने के लिए, BigQuery में डेटासेट की ज़रूरत होती है. इसके बाद, टेबल अपने-आप बन जाएगी. यह GCS बकेट में मौजूद Iceberg मेटाडेटा फ़ाइल की ओर इशारा करेगी.
- BigQuery पर जाएं
- एक्सप्लोरर पैनल में, प्रोजेक्ट आईडी पर क्लिक करें. इसके बाद, तीन बिंदु वाले आइकॉन पर क्लिक करें और डेटासेट बनाएं को चुनें.
- डेटासेट का नाम
databricks_retlहोगा. अन्य विकल्पों को डिफ़ॉल्ट के तौर पर रहने दें और डेटासेट बनाएं बटन पर क्लिक करें.
- अब एक्सप्लोरर पैनल में जाकर, नया
databricks_retlडेटासेट ढूंढें. इसके बगल में मौजूद तीन बिंदुओं पर क्लिक करें और टेबल बनाएं को चुनें.
- टेबल बनाने के लिए, यहां दी गई सेटिंग की जानकारी डालें:
- इससे टेबल बनाएं:
Google Cloud Storage - GCS बकेट से फ़ाइल चुनें या यूआरआई पैटर्न का इस्तेमाल करें: GCS बकेट पर जाएं और उस मेटाडेटा JSON फ़ाइल को ढूंढें जो Databricks एक्सपोर्ट के दौरान जनरेट हुई थी. पाथ कुछ इस तरह दिखना चाहिए:
regional_sales/metadata/v1.metadata.json. - फ़ाइल फ़ॉर्मैट:
Iceberg - टेबल:
regional_sales - टेबल का टाइप:
External table - कनेक्शन आईडी: पहले से बनाए गए
databricks_retlकनेक्शन को चुनें. - बाकी वैल्यू को डिफ़ॉल्ट के तौर पर छोड़ दें. इसके बाद, टेबल बनाएं पर क्लिक करें.
- नई
regional_salesटेबल बनाने के बाद, वहdatabricks_retlडेटासेट में दिखनी चाहिए. अब इस टेबल को स्टैंडर्ड एसक्यूएल का इस्तेमाल करके क्वेरी किया जा सकता है. ठीक वैसे ही जैसे किसी अन्य BigQuery टेबल को क्वेरी किया जाता है.
7. Spanner में लोड करें
पाइपलाइन के आखिरी और सबसे ज़रूरी हिस्से पर पहुंच गए हैं: BigLake की बाहरी टेबल से डेटा को Spanner में ले जाना. यह "रिवर्स ईटीएल" चरण है. इसमें डेटा वेयरहाउस में प्रोसेस और व्यवस्थित किए गए डेटा को, ऐप्लिकेशन के इस्तेमाल के लिए ऑपरेशनल सिस्टम में लोड किया जाता है.
Spanner, पूरी तरह से मैनेज किया जाने वाला, दुनिया भर में उपलब्ध रिलेशनल डेटाबेस है. यह पारंपरिक रिलेशनल डेटाबेस की तरह ही लेन-देन में एकरूपता बनाए रखता है. हालांकि, इसमें NoSQL डेटाबेस की तरह हॉरिज़ॉन्टल स्केलेबिलिटी होती है. इसलिए, यह ऐसे ऐप्लिकेशन बनाने के लिए सबसे सही विकल्प है जिन्हें आसानी से बढ़ाया जा सकता है और जो हर समय उपलब्ध रहते हैं.
यह प्रोसेस इस तरह होगी:
- Spanner इंस्टेंस बनाएं. यह संसाधनों का फ़िज़िकल बंटवारा होता है.
- उस इंस्टेंस में डेटाबेस बनाएं.
- डेटाबेस में एक टेबल स्कीमा तय करें, जो
regional_salesडेटा के स्ट्रक्चर से मेल खाता हो. - BigQuery
EXPORT DATAक्वेरी चलाकर, BigLake टेबल से डेटा को सीधे Spanner टेबल में लोड करें.
Spanner इंस्टेंस, डेटाबेस, और टेबल बनाना
- Spanner पर जाएं
 पर क्लिक करें . अगर कोई मौजूदा इंस्टेंस उपलब्ध है, तो बेझिझक उसका इस्तेमाल करें. ज़रूरत के मुताबिक, इंस्टेंस की ज़रूरी शर्तें सेट अप करें. इस लैब के लिए, इनका इस्तेमाल किया गया था:
पर क्लिक करें . अगर कोई मौजूदा इंस्टेंस उपलब्ध है, तो बेझिझक उसका इस्तेमाल करें. ज़रूरत के मुताबिक, इंस्टेंस की ज़रूरी शर्तें सेट अप करें. इस लैब के लिए, इनका इस्तेमाल किया गया था:
वर्शन | Enterprise |
इंस्टेंस का नाम | databricks-retl |
क्षेत्र के हिसाब से कॉन्फ़िगरेशन | चुना गया देश/इलाका |
कम्प्यूट यूनिट | प्रोसेसिंग यूनिट (पीयू) |
मैन्युअल तरीके से बंटवारा | 100 |
- बनाने के बाद, Spanner इंस्टेंस पेज पर जाएं और
 को चुनें. अगर कोई मौजूदा डेटाबेस उपलब्ध है, तो बेझिझक उसका इस्तेमाल करें.
को चुनें. अगर कोई मौजूदा डेटाबेस उपलब्ध है, तो बेझिझक उसका इस्तेमाल करें.
- इस लैब के लिए, एक डेटाबेस बनाया जाएगा. इसमें
- नाम:
databricks-retl - डेटाबेस की भाषा:
Google Standard SQL
- डेटाबेस बन जाने के बाद, Spanner इंस्टेंस पेज से उसे चुनें और Spanner डेटाबेस पेज पर जाएं.
- Spanner डेटाबेस पेज पर,
 पर क्लिक करें
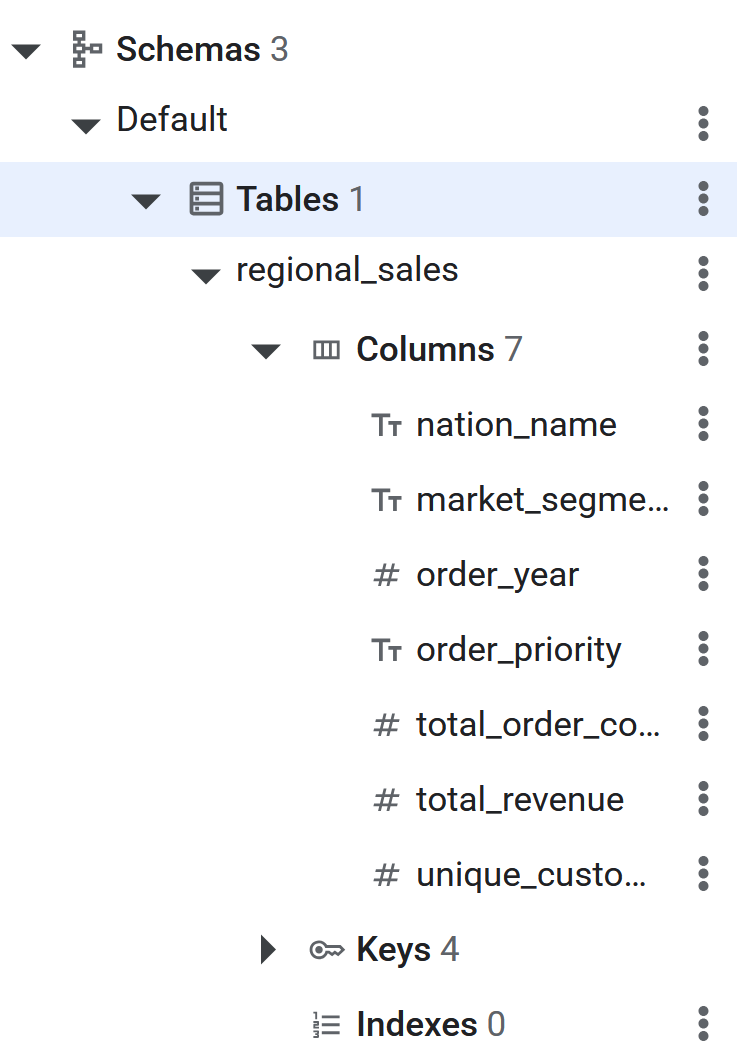
पर क्लिक करें - नई क्वेरी पेज में, Spanner में इंपोर्ट की जाने वाली टेबल की परिभाषा बनाई जाएगी. इसके लिए, यह SQL क्वेरी चलाएं.
CREATE TABLE regional_sales (
nation_name STRING(MAX),
market_segment STRING(MAX),
order_year INT64,
order_priority STRING(MAX),
total_order_count INT64,
total_revenue NUMERIC,
unique_customer_count INT64
) PRIMARY KEY (nation_name, market_segment, order_year, order_priority);
- SQL कमांड के लागू होने के बाद, Spanner टेबल अब BigQuery के लिए डेटा को रिवर्स ईटीएल करने के लिए तैयार हो जाएगी. टेबल बन गई है या नहीं, यह देखने के लिए Spanner डेटाबेस के बाएं पैनल में जाकर देखें.
EXPORT DATA का इस्तेमाल करके, Spanner में रिवर्स ईटीएल करना
यह आखिरी चरण है. BigQuery BigLake टेबल में सोर्स डेटा तैयार होने और Spanner में डेस्टिनेशन टेबल बनने के बाद, डेटा ट्रांसफ़र करना बहुत आसान हो जाता है. एक BigQuery एसक्यूएल क्वेरी का इस्तेमाल किया जाएगा: EXPORT DATA.
इस क्वेरी को खास तौर पर इस तरह के मामलों के लिए डिज़ाइन किया गया है. यह BigQuery टेबल (इसमें BigLake टेबल जैसी बाहरी टेबल भी शामिल हैं) से डेटा को किसी बाहरी डेस्टिनेशन में आसानी से एक्सपोर्ट करता है. इस मामले में, डेस्टिनेशन Spanner टेबल है. डेटा एक्सपोर्ट करने की सुविधा के बारे में ज़्यादा जानकारी यहां मिल सकती है
Spanner Reverse ETL के लिए BigQuery सेट अप करने के बारे में ज़्यादा जानकारी यहां मिल सकती है
- BigQuery पर जाएं
- नया क्वेरी एडिटर टैब खोलें.
- क्वेरी पेज पर, यह एसक्यूएल डालें. **
uri** **में मौजूद प्रोजेक्ट आईडी और टेबल पाथ को सही प्रोजेक्ट आईडी से बदलना न भूलें.**
EXPORT DATA OPTIONS(
uri='https://spanner.googleapis.com/projects/YOUR_PROJECT_ID/instances/databricks-retl/databases/databricks-retl',
format='CLOUD_SPANNER',
spanner_options="""{
"table": "regional_sales",
"priority": "MEDIUM"
}"""
) AS
SELECT * FROM `YOUR_PROJECT_ID.databricks_retl.regional_sales`;
- कमांड पूरी होने के बाद, डेटा को Spanner में एक्सपोर्ट कर दिया जाता है!
8. Spanner में डेटा की पुष्टि करना
बधाई हो! पूरी रिवर्स ईटीएल पाइपलाइन को सफलतापूर्वक बनाया और लागू किया गया है. इससे डेटा को Databricks डेटा वेयरहाउस से Spanner के ऑपरेशनल डेटाबेस में ट्रांसफ़र किया जा सकता है.
आखिरी चरण में, यह पुष्टि करना होता है कि डेटा, Spanner में उम्मीद के मुताबिक पहुंच गया है.
- Spanner पर जाएं.
- अपने
databricks-retlइंस्टेंस पर जाएं. इसके बाद,databricks-retlडेटाबेस पर जाएं. - टेबल की सूची में,
regional_salesटेबल पर क्लिक करें. - टेबल के बाईं ओर मौजूद नेविगेशन मेन्यू में, डेटा टैब पर क्लिक करें.
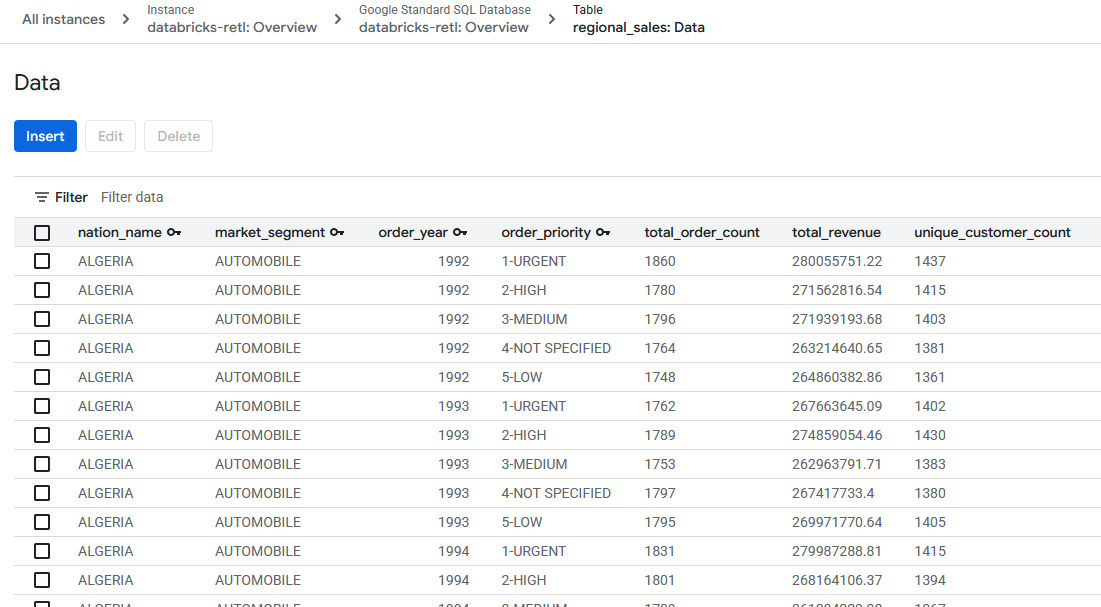
- Databricks से मिलाया गया बिक्री का डेटा अब लोड हो जाना चाहिए. साथ ही, Spanner टेबल में इसका इस्तेमाल किया जा सकता है. यह डेटा अब एक चालू सिस्टम में है. इसका इस्तेमाल लाइव ऐप्लिकेशन को चलाने, डैशबोर्ड दिखाने या एपीआई से क्वेरी करने के लिए किया जा सकता है.
ऐनलिटिकल और ऑपरेशनल डेटा के बीच के अंतर को कम किया गया है.
9. मिटाना
इस लैब का इस्तेमाल पूरा होने के बाद, जोड़ी गई सभी टेबल और सेव किया गया डेटा हटाएं.
Spanner टेबल मिटाना
- Spanner पर जाएं
databricks-retlनाम की सूची में से, उस इंस्टेंस पर क्लिक करें जिसका इस्तेमाल इस लैब के लिए किया गया था

- इंस्टेंस पेज में,
 पर क्लिक करें
पर क्लिक करें - पुष्टि करने के लिए दिखने वाले डायलॉग बॉक्स में
databricks-retlडालें और पर क्लिक करें
पर क्लिक करें
GCS (जीसीएस) का स्टोरेज खाली करना
- GCS पर जाएं
- बाईं ओर मौजूद मेन्यू से,
 चुनें
चुनें - ``codelabs_retl_databricks बकेट चुनें
- चुने जाने के बाद, सबसे ऊपर मौजूद बैनर में दिखने वाले
 बटन पर क्लिक करें
बटन पर क्लिक करें

- पुष्टि करने के लिए दिखने वाले डायलॉग बॉक्स में
DELETEडालें और पर क्लिक करें
Databricks को क्लीन अप करना
कैटलॉग/स्कीमा/टेबल मिटाना
- अपने Databricks इंस्टेंस में साइन इन करें
- बाईं ओर मौजूद मेन्यू में,
 पर क्लिक करें
पर क्लिक करें - कैटलॉग की सूची में से, पहले से बनाया गया
 चुनें
चुनें - स्कीमा की सूची में, बनाया गया
 चुनें
चुनें - टेबल की सूची से, पहले से बनाया गया
 चुनें
चुनें  पर क्लिक करके, टेबल के विकल्पों को बड़ा करें और
पर क्लिक करके, टेबल के विकल्पों को बड़ा करें और Deleteचुनें- टेबल मिटाने के लिए, पुष्टि करने वाले डायलॉग बॉक्स में
 पर क्लिक करें
पर क्लिक करें - टेबल मिटाने के बाद, आपको स्कीमा पेज पर वापस ले जाया जाएगा
- पर क्लिक करके, स्कीमा के विकल्पों को बड़ा करें और
Deleteचुनें - स्कीमा मिटाने के लिए, पुष्टि करने वाले डायलॉग बॉक्स में पर क्लिक करें
- स्कीमा मिटाने के बाद, आपको वापस कैटलॉग पेज पर ले जाया जाएगा
- अगर कोई
defaultस्कीमा मौजूद है, तो उसे मिटाने के लिए, चौथे से ग्यारहवें चरण को फिर से दोहराएं. - कैटलॉग पेज पर जाकर, पर क्लिक करके कैटलॉग के विकल्पों को बड़ा करें. इसके बाद,
Deleteको चुनें - कैटलॉग मिटाने के लिए, पुष्टि करने वाले डायलॉग बॉक्स में पर क्लिक करें
बाहरी डेटा की जगह / क्रेडेंशियल मिटाना
- कैटलॉग स्क्रीन पर, पर क्लिक करें
- अगर आपको
External Dataविकल्प नहीं दिखता है, तो हो सकता है कि आपकोExternal Location,Connectड्रॉपडाउन में दिखे. - पहले से बनाई गई
retl-gcs-locationबाहरी डेटा की जगह पर क्लिक करें - बाहरी जगह की जानकारी वाले पेज पर, पर क्लिक करके जगह के विकल्प को बड़ा करें. इसके बाद,
Deleteचुनें - बाहरी जगह की जानकारी मिटाने के लिए, पुष्टि करने वाले डायलॉग बॉक्स में पर क्लिक करें
- पर क्लिक करें
- पहले से बनाए गए
retl-gcs-credentialपर क्लिक करें - क्रेडेंशियल पेज पर, पर क्लिक करके क्रेडेंशियल के विकल्पों को बड़ा करें और
Deleteचुनें - क्रेडेंशियल मिटाने के लिए, पुष्टि करने वाले डायलॉग बॉक्स में पर क्लिक करें.
10. बधाई हो
कोडलैब पूरा करने के लिए बधाई.
हमने क्या-क्या कवर किया है
- Databricks में Iceberg टेबल के तौर पर डेटा लोड करने का तरीका
- GCS बकेट बनाने का तरीका
- Databricks टेबल को Iceberg फ़ॉर्मैट में GCS में एक्सपोर्ट करने का तरीका
- GCS में मौजूद Iceberg टेबल से, BigQuery में BigLake External Table बनाने का तरीका
- स्पैनर इंस्टेंस सेट अप करने का तरीका
- BigQuery में मौजूद BigLake की बाहरी टेबल को Spanner में लोड करने का तरीका