
1. Membangun Pipeline ETL Terbalik dari Databricks ke Spanner menggunakan Google Cloud Storage dan BigQuery
Pengantar
Dalam codelab ini, Anda akan membuat pipeline Reverse ETL dari Databricks ke Spanner. Biasanya, pipeline ETL (Ekstrak, Transformasi, Muat) standar memindahkan data dari database operasional ke data warehouse seperti Databricks untuk analisis. Pipeline ETL Terbalik melakukan hal sebaliknya dengan memindahkan data yang telah diproses dan dikurasi dari data warehouse kembali ke database operasional, seperti Spanner, database relasional yang didistribusikan secara global dan ideal untuk aplikasi dengan ketersediaan tinggi, tempat data tersebut dapat mendukung aplikasi, menyajikan fitur yang terlihat oleh pengguna, atau digunakan untuk pengambilan keputusan real-time.
Tujuannya adalah memindahkan set data gabungan dari tabel Iceberg Databricks ke tabel Spanner.
Untuk mencapainya, Google Cloud Storage (GCS) dan BigQuery digunakan sebagai langkah perantara. Berikut adalah uraian aliran data dan alasan di balik arsitektur ini:

- Databricks ke Google Cloud Storage (GCS) dalam Format Iceberg:
- Langkah pertama adalah mengeluarkan data dari Databricks dalam format terbuka yang terdefinisi dengan baik. Tabel diekspor dalam format Apache Iceberg. Proses ini menulis data pokok sebagai serangkaian file Parquet dan metadata tabel (skema, partisi, lokasi file) sebagai file JSON dan Avro. Menyusun struktur tabel lengkap ini di GCS membuat data dapat diakses dan portabel ke sistem apa pun yang memahami format Iceberg.
- Mengonversi tabel Iceberg GCS menjadi tabel eksternal BigLake BigQuery:
- Daripada memuat data langsung dari GCS ke Spanner, BigQuery digunakan sebagai perantara yang efektif. Tabel eksternal BigLake dibuat di BigQuery yang mengarah langsung ke file metadata Iceberg di GCS. Pendekatan ini memiliki beberapa manfaat:
- Tidak Ada Duplikasi Data: BigQuery membaca struktur tabel dari metadata dan membuat kueri file data Parquet di tempat tanpa menyerapnya, sehingga menghemat waktu dan biaya penyimpanan secara signifikan.
- Kueri Gabungan: Memungkinkan menjalankan kueri SQL yang kompleks pada data GCS seolah-olah data tersebut adalah tabel BigQuery native.
- Membalikkan tabel eksternal BigLake ETL ke Spanner:
- Langkah terakhir adalah memindahkan data dari BigQuery ke Spanner. Hal ini dilakukan menggunakan fitur canggih di BigQuery yang disebut kueri
EXPORT DATA, yang merupakan langkah "Reverse ETL". - Kesiapan Operasional: Spanner dirancang untuk beban kerja transaksional, yang memberikan konsistensi kuat dan ketersediaan tinggi untuk aplikasi. Dengan memindahkan data ke Spanner, data tersebut dapat diakses oleh aplikasi yang berinteraksi dengan pengguna, API, dan sistem operasional lainnya yang memerlukan pencarian titik berlatensi rendah.
- Skalabilitas: Pola ini memungkinkan pemanfaatan kemampuan analisis BigQuery untuk memproses set data besar, lalu menyajikan hasilnya secara efisien melalui infrastruktur Spanner yang skalabel secara global.
Layanan dan Terminologi
- DataBricks - Platform data berbasis cloud yang dibangun di sekitar Apache Spark.
- Spanner - Database relasional yang didistribusikan secara global, yang dikelola sepenuhnya oleh Google.
- Google Cloud Storage - Penawaran penyimpanan blob Google Cloud.
- BigQuery - Data warehouse serverless untuk analisis, yang dikelola sepenuhnya oleh Google.
- Iceberg - Format tabel terbuka yang ditentukan oleh Apache yang menyediakan abstraksi atas format file data open source umum.
- Parquet - Format file data biner kolom open source dari Apache.
Yang akan Anda pelajari
- Cara memuat data ke Databricks sebagai tabel Iceberg
- Cara membuat Bucket GCS
- Cara mengekspor tabel Databricks ke GCS dalam format Iceberg
- Cara membuat Tabel Eksternal BigLake di BigQuery dari tabel Iceberg di GCS
- Cara menyiapkan instance Spanner
- Cara memuat Tabel Eksternal BigLake di BigQuery ke Spanner
2. Penyiapan, Persyaratan & Batasan
Prasyarat
- Akun Databricks, sebaiknya di GCP
- Akun Google Cloud dengan reservasi tingkat Enterprise atau yang lebih tinggi BigQuery diperlukan untuk mengekspor dari BigQuery ke Spanner.
- Akses ke Konsol Google Cloud melalui browser web
- Terminal untuk menjalankan perintah Google Cloud CLI
Jika organisasi Google Cloud Anda mengaktifkan kebijakan iam.allowedPolicyMemberDomains, administrator mungkin perlu memberikan pengecualian untuk mengizinkan akun layanan dari domain eksternal. Hal ini akan dibahas pada langkah selanjutnya jika berlaku.
Persyaratan
- Project Google Cloud yang mengaktifkan penagihan.
- Browser web, seperti Chrome
- Akun Databricks (lab ini mengasumsikan ruang kerja yang dihosting di GCP)
- Instance BigQuery harus menggunakan edisi Enterprise atau yang lebih tinggi untuk menggunakan fitur EKSPOR DATA.
- Jika organisasi Google Cloud Anda mengaktifkan kebijakan
iam.allowedPolicyMemberDomains, administrator mungkin perlu memberikan pengecualian untuk mengizinkan akun layanan dari domain eksternal. Hal ini akan dibahas pada langkah selanjutnya jika berlaku.
Izin IAM Google Cloud Platform
Akun Google akan memerlukan izin berikut untuk menjalankan semua langkah dalam codelab ini.
Akun Layanan | ||
| Mengizinkan pembuatan Akun Layanan. | |
Spanner | ||
| Memungkinkan pembuatan instance Spanner baru. | |
| Mengizinkan menjalankan pernyataan DDL untuk membuat | |
| Memungkinkan menjalankan pernyataan DDL untuk membuat tabel dalam database. | |
Google Cloud Storage | ||
| Memungkinkan pembuatan bucket GCS baru untuk menyimpan file Parquet yang diekspor. | |
| Mengizinkan penulisan file Parquet yang diekspor ke bucket GCS. | |
| Mengizinkan BigQuery membaca file Parquet dari bucket GCS. | |
| Mengizinkan BigQuery mencantumkan file Parquet di bucket GCS. | |
Dataflow | ||
| Mengizinkan klaim item kerja dari Dataflow. | |
| Memungkinkan pekerja Dataflow mengirim pesan kembali ke layanan Dataflow. | |
| Memungkinkan pekerja Dataflow menulis entri log ke Google Cloud Logging. | |
Untuk mempermudah, peran bawaan yang berisi izin ini dapat digunakan.
|
|
|
|
|
|
|
|
Project Google Cloud
Project adalah unit dasar organisasi di Google Cloud. Jika administrator telah menyediakannya untuk digunakan, langkah ini dapat dilewati.
Project dapat dibuat menggunakan CLI seperti ini:
gcloud projects create <your-project-name>
Pelajari lebih lanjut cara membuat dan mengelola project di sini.
Batasan
Penting untuk mengetahui batasan tertentu dan ketidakcocokan jenis data yang dapat muncul dalam pipeline ini.
Databricks Iceberg ke BigQuery
Saat menggunakan BigQuery untuk membuat kueri tabel Iceberg yang dikelola oleh Databricks (melalui UniForm), perhatikan hal-hal berikut:
- Evolusi Skema: Meskipun UniForm berhasil menerjemahkan perubahan skema Delta Lake ke Iceberg, perubahan yang kompleks mungkin tidak selalu diterapkan seperti yang diharapkan. Misalnya, mengganti nama kolom di Delta Lake tidak diterjemahkan ke Iceberg, yang melihatnya sebagai
dropdanadd. Selalu uji perubahan skema secara menyeluruh. - Perjalanan Waktu: BigQuery tidak dapat menggunakan kemampuan perjalanan waktu Delta Lake. Kueri hanya akan dilakukan pada snapshot terbaru tabel Iceberg.
- Fitur Delta Lake yang Tidak Didukung: Fitur seperti Vektor Penghapusan dan Pemetaan Kolom dengan mode
iddi Delta Lake tidak kompatibel dengan UniForm untuk Iceberg. Lab ini menggunakan modenameuntuk pemetaan kolom, yang didukung.
BigQuery ke Spanner
Perintah EXPORT DATA dari BigQuery ke Spanner tidak mendukung semua jenis data BigQuery. Mengekspor tabel dengan jenis berikut akan menghasilkan error:
STRUCTGEOGRAPHYDATETIMERANGETIME
Selain itu, jika project BigQuery menggunakan dialek GoogleSQL, jenis numerik berikut juga tidak didukung untuk diekspor ke Spanner:
BIGNUMERIC
Untuk mengetahui daftar lengkap dan terbaru batasan, lihat dokumentasi resmi: Batasan Mengekspor ke Spanner.
Pemecahan Masalah & Gotcha
- Jika tidak berada di instance GCP Databricks, Lokasi Data Eksternal di GCS mungkin tidak dapat ditentukan. Dalam kasus tersebut, file harus di-stage di solusi penyimpanan penyedia cloud ruang kerja Databricks, lalu dimigrasikan ke GCS secara terpisah.
- Saat melakukannya, penyesuaian akan diperlukan pada metadata karena informasi akan memiliki jalur hard code ke file yang dipentaskan.
3. Menyiapkan Google Cloud Storage (GCS)
Google Cloud Storage (GCS) akan digunakan untuk menyimpan file data Parquet yang dihasilkan oleh Databricks. Untuk melakukannya, bucket baru harus dibuat terlebih dahulu untuk digunakan sebagai tujuan file.
Google Cloud Storage
Membuat bucket baru
- Buka halaman Google Cloud Storage di konsol cloud Anda.
- Di panel kiri, pilih Bucket:
- Klik tombol Buat:

- Isi detail bucket Anda:
- Pilih nama bucket yang akan digunakan. Untuk lab ini, nama
codelabs_retl_databricksakan digunakan - Pilih region untuk menyimpan bucket, atau gunakan nilai default.
- Tetapkan kelas penyimpanan sebagai
standard - Biarkan nilai default untuk kontrol akses
- Pertahankan nilai default untuk lindungi data objek
- Klik tombol
Createsetelah selesai. Mungkin muncul perintah untuk mengonfirmasi bahwa akses publik akan dicegah. Lanjutkan dan konfirmasi. - Selamat, bucket baru berhasil dibuat. Pengalihan ke halaman bucket akan terjadi.
- Salin nama bucket baru di suatu tempat karena akan diperlukan nanti.
Mempersiapkan langkah berikutnya
Pastikan detail berikut dicatat karena akan diperlukan pada langkah berikutnya:
- ID project Google
- Nama bucket Google Storage
4. Menyiapkan Databricks
Data TPC-H
Untuk lab ini, set data TPC-H akan digunakan, yang merupakan benchmark standar industri untuk sistem pendukung keputusan. Skemanya memodelkan lingkungan bisnis yang realistis dengan pelanggan, pesanan, pemasok, dan suku cadang, sehingga cocok untuk mendemonstrasikan skenario analisis dan pergerakan data di dunia nyata.
Daripada menggunakan tabel TPC-H mentah yang dinormalisasi, tabel gabungan baru akan dibuat. Tabel baru ini akan menggabungkan data dari tabel orders, customer, dan nation untuk menghasilkan tampilan penjualan regional yang didenormalisasi dan diringkas. Langkah pra-penggabungan ini adalah praktik umum dalam analisis, karena menyiapkan data untuk kasus penggunaan tertentu—dalam skenario ini, untuk digunakan oleh aplikasi operasional.
Skema akhir untuk tabel gabungan adalah:
Col | Jenis |
nation_name | string |
market_segment | string |
order_year | int |
order_priority | string |
total_order_count | bigint |
total_revenue | desimal(29,2) |
unique_customer_count | bigint |
Dukungan Iceberg dengan Format Universal Delta Lake (UniForm)
Untuk lab ini, tabel di dalam Databricks akan menjadi tabel Delta Lake. Namun, agar dapat dibaca oleh sistem eksternal seperti BigQuery, fitur canggih yang disebut Format Universal (UniForm) akan diaktifkan.
UniForm secara otomatis menghasilkan metadata Iceberg bersama dengan metadata Delta Lake untuk satu salinan data tabel yang dibagikan. Hal ini memberikan yang terbaik dari kedua dunia:
- Inside Databricks: Semua manfaat performa dan tata kelola Delta Lake diperoleh.
- Di luar Databricks: Tabel dapat dibaca oleh mesin kueri yang kompatibel dengan Iceberg, seperti BigQuery, seolah-olah tabel tersebut adalah tabel Iceberg native.
Dengan demikian, Anda tidak perlu mempertahankan salinan data yang terpisah atau menjalankan tugas konversi secara manual. UniForm akan diaktifkan dengan menyetel properti tabel tertentu saat tabel dibuat.
Katalog Databricks
Katalog Databricks adalah container tingkat teratas untuk data di Unity Catalog, solusi tata kelola terpadu Databricks. Unity Catalog menyediakan cara terpusat untuk mengelola aset data, mengontrol akses, dan melacak silsilah, yang sangat penting untuk platform data yang dikelola dengan baik.
Akun ini menggunakan namespace tiga tingkat untuk mengatur data: catalog.schema.table.
- Katalog: Tingkat tertinggi, digunakan untuk mengelompokkan data menurut lingkungan, unit bisnis, atau project.
- Skema (atau Database): Pengelompokan logis tabel, tampilan, dan fungsi dalam katalog.
- Tabel: Objek yang berisi data Anda.
Sebelum tabel TPC-H gabungan dapat dibuat, katalog dan skema khusus harus disiapkan terlebih dahulu untuk menampungnya. Hal ini memastikan project diatur dengan rapi dan diisolasi dari data lain di ruang kerja.
Buat Katalog dan Skema baru
Di Databricks Unity Catalog, Katalog berfungsi sebagai tingkat organisasi tertinggi untuk aset data, yang bertindak sebagai penampung aman yang dapat mencakup beberapa ruang kerja Databricks. Dengan fitur ini, Anda dapat mengatur dan mengisolasi data berdasarkan unit bisnis, project, atau lingkungan, dengan izin dan kontrol akses yang ditentukan dengan jelas.
Dalam Katalog, Skema (juga dikenal sebagai database) mengatur lebih lanjut tabel, tampilan, dan fungsi. Struktur hierarkis ini memungkinkan kontrol terperinci dan pengelompokan logis objek data terkait. Untuk lab ini, Katalog dan Skema khusus akan dibuat untuk menampung data TPC-H, sehingga memastikan isolasi dan pengelolaan yang tepat.
Membuat Katalog
- Buka

- Klik +, lalu pilih Buat katalog dari dropdown
- Katalog Standard baru akan dibuat dengan setelan berikut:
- Nama katalog:
retl_tpch_project - Lokasi penyimpanan: Gunakan default jika telah disiapkan di ruang kerja, atau buat yang baru.
Membuat Skema
- Buka
- Pilih katalog baru yang dibuat dari panel kiri
- Klik
- Skema baru akan dibuat dengan Nama skema sebagai
tpch_data
Menyiapkan Data Eksternal
Untuk dapat mengekspor data dari Databricks ke Google Cloud Storage (GCS), kredensial data eksternal harus disiapkan dalam Databricks. Hal ini memungkinkan Databricks mengakses dan menulis ke bucket GCS dengan aman.
- Dari layar Katalog, klik

- Jika Anda tidak melihat opsi
External Data, Anda mungkin menemukanExternal Locationsyang tercantum di menu dropdownConnect.
- Klik

- Di jendela dialog baru, siapkan nilai yang diperlukan untuk kredensial:
- Jenis Kredensial:
GCP Service Account - Nama Kredensial:
retl-gcs-credential
- Klik Buat
- Selanjutnya, klik tab Lokasi Eksternal.
- Klik Buat lokasi.
- Di jendela dialog baru, siapkan nilai yang diperlukan untuk lokasi eksternal:
- Nama lokasi eksternal:
retl-gcs-location - Jenis penyimpanan:
GCP - URL: URL bucket GCS, dalam format
gs://YOUR_BUCKET_NAME - Kredensial penyimpanan: Pilih
retl-gcs-credentialyang baru saja dibuat.
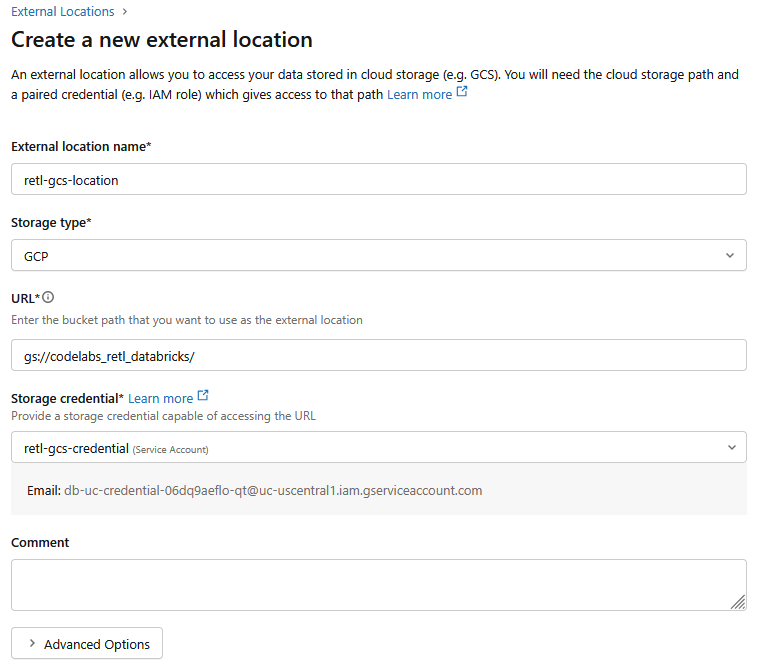
- Catat email Service account yang otomatis diisi saat memilih storage credential karena akan diperlukan pada langkah berikutnya.
- Klik Buat
5. Menetapkan Izin Akun Layanan
Akun layanan adalah jenis akun khusus yang digunakan oleh aplikasi atau layanan untuk melakukan panggilan API yang diotorisasi ke resource Google Cloud.
Izin kini harus ditambahkan ke akun layanan yang dibuat untuk bucket baru di GCS.
- Dari halaman bucket GCS, pilih tab Permissions.
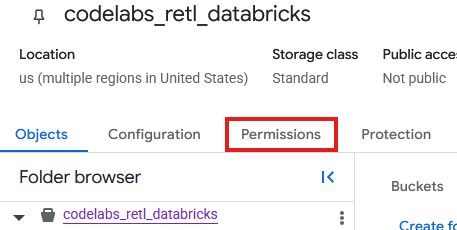
- Klik Grant access di halaman principal
- Di panel Grant Access yang muncul dari kanan, masukkan Service Account ID ke kolom New principals
- Di bagian Assign Roles, tambahkan
Storage Object AdmindanStorage Legacy Bucket Reader. Peran ini memungkinkan Akun Layanan membaca, menulis, dan mencantumkan objek di bucket penyimpanan.
Memuat Data TPC-H
Setelah Katalog dan Skema dibuat, data TPCH dapat dimuat dari tabel samples.tpch yang ada dan disimpan secara internal di Databricks, lalu dimanipulasi menjadi tabel baru dalam skema yang baru ditentukan.
Membuat Tabel dengan dukungan Iceberg
Kompatibilitas Iceberg dengan UniForm
Di balik layar, Databricks secara internal mengelola tabel ini sebagai tabel Delta Lake, sehingga memberikan semua manfaat pengoptimalan performa dan fitur tata kelola Delta dalam ekosistem Databricks. Namun, dengan mengaktifkan UniForm (singkatan dari Universal Format), Databricks akan diinstruksikan untuk melakukan sesuatu yang istimewa: setiap kali tabel diperbarui, Databricks akan otomatis membuat dan mempertahankan metadata Iceberg yang sesuai selain metadata Delta Lake.
Artinya, satu set file data bersama (file Parquet) kini dijelaskan oleh dua set metadata yang berbeda.
- Untuk Databricks: Menggunakan
_delta_loguntuk membaca tabel. - Untuk Pembaca Eksternal (seperti BigQuery): Mereka menggunakan file metadata Iceberg (
.metadata.json) untuk memahami skema, partisi, dan lokasi file tabel.
Hasilnya adalah tabel yang sepenuhnya dan transparan kompatibel dengan alat apa pun yang mendukung Iceberg. Tidak ada duplikasi data dan tidak perlu konversi atau sinkronisasi manual. Ini adalah satu sumber tepercaya yang dapat diakses secara lancar oleh dunia analisis Databricks dan ekosistem alat yang lebih luas yang mendukung standar Iceberg terbuka.
- Klik Baru, lalu Kueri
- Di kolom teks halaman kueri, jalankan perintah SQL berikut:
CREATE TABLE retl_tpch_project.tpch_data.regional_sales_iceberg
USING DELTA
LOCATION 'gs://<Your bucket name>/regional_sales_iceberg'
TBLPROPERTIES (
'delta.columnMapping.mode' = 'name',
'delta.enableIcebergCompatV2' = 'true',
'delta.universalFormat.enabledFormats' = 'iceberg'
)
AS
SELECT
n.n_name AS nation_name,
c.c_mktsegment AS market_segment,
YEAR(o.o_orderdate) AS order_year,
o.o_orderpriority AS order_priority,
COUNT(o.o_orderkey) AS total_order_count,
ROUND(SUM(o.o_totalprice), 2) AS total_revenue,
COUNT(DISTINCT c.c_custkey) AS unique_customer_count
FROM samples.tpch.orders AS o
INNER JOIN samples.tpch.customer AS c
ON o.o_custkey = c.c_custkey
INNER JOIN samples.tpch.nation AS n
ON c.c_nationkey = n.n_nationkey
GROUP BY
n.n_name,
c.c_mktsegment,
YEAR(o.o_orderdate),
o.o_orderpriority;
OPTIMIZE retl_tpch_project.tpch_data.regional_sales_iceberg;
DESCRIBE EXTENDED retl_tpch_project.tpch_data.regional_sales_iceberg;
Catatan:
- Menggunakan Delta - Menentukan bahwa kita menggunakan Tabel Delta Lake. Hanya tabel Delta Lake di Databricks yang dapat disimpan sebagai tabel eksternal.
- Lokasi - Menentukan tempat tabel akan disimpan, jika eksternal.
- TablePropertoes -
delta.universalFormat.enabledFormats = ‘iceberg'membuat metadata iceberg yang kompatibel bersama dengan file Delta Lake. - Optimize - Memicu pembuatan metadata UniForm secara paksa, karena biasanya terjadi secara asinkron.
- Output kueri akan menampilkan detail tabel yang baru dibuat

Memverifikasi data tabel GCS
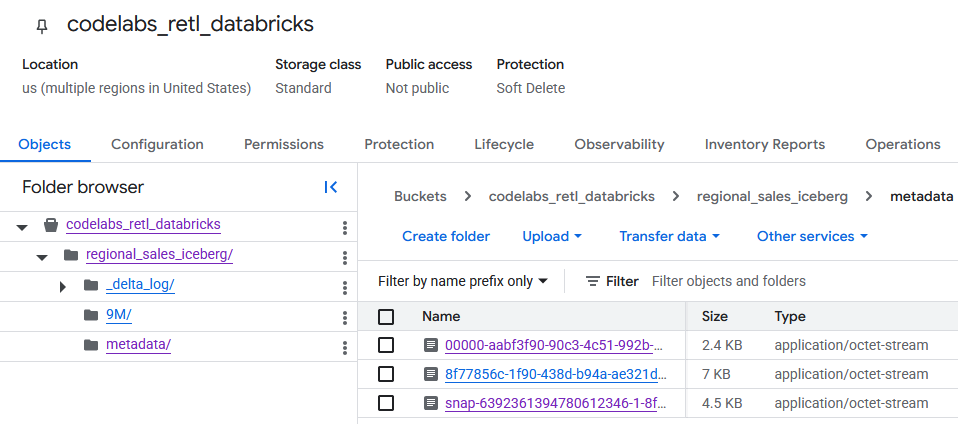
Setelah membuka bucket GCS, data tabel yang baru dibuat kini dapat ditemukan.
Anda akan menemukan metadata Iceberg dalam folder metadata, yang digunakan oleh pembaca eksternal (seperti BigQuery). Metadata Delta Lake, yang digunakan Databricks secara internal, dilacak di folder _delta_log.
Data tabel sebenarnya disimpan sebagai file Parquet dalam folder lain, biasanya diberi nama dengan string yang dibuat secara acak oleh Databricks. Misalnya, pada screenshot di bawah, file data berada di folder 9M.
6. Menyiapkan BigQuery dan BigLake
Setelah tabel Iceberg berada di Google Cloud Storage, langkah berikutnya adalah membuatnya dapat diakses oleh BigQuery. Hal ini akan dilakukan dengan membuat tabel eksternal BigLake.
BigLake adalah mesin penyimpanan yang memungkinkan pembuatan tabel di BigQuery yang membaca data langsung dari sumber eksternal seperti Google Cloud Storage. Untuk lab ini, teknologi tersebut adalah teknologi utama yang memungkinkan BigQuery memahami tabel Iceberg yang baru saja diekspor tanpa perlu menyerap data.
Agar ini berfungsi, dua komponen diperlukan:
- Koneksi Resource Cloud: Ini adalah link yang aman antara BigQuery dan GCS. Proses ini menggunakan akun layanan khusus untuk menangani autentikasi, sehingga memastikan BigQuery memiliki izin yang diperlukan untuk membaca file dari bucket GCS.
- Definisi Tabel Eksternal: Ini memberi tahu BigQuery tempat menemukan file metadata tabel Iceberg di GCS dan cara menafsirkannya.
Membuat Koneksi Resource Cloud
Pertama, koneksi yang memungkinkan BigQuery mengakses GCS akan dibuat.
Info selengkapnya tentang cara membuat Koneksi Resource Cloud dapat ditemukan di sini
- Buka BigQuery
- Klik Connections di bagian Explorer
- Jika bidang Explorer tidak terlihat, klik

- Di halaman Connections, klik
- Untuk Connection type, pilih
Vertex AI remote models, remote functions, BigLake and Spanner (Cloud Resource) - Tetapkan ID koneksi ke
databricks_retldan buat koneksi

- Entri kini akan terlihat di tabel Koneksi dari koneksi yang baru dibuat. Klik entri tersebut untuk melihat detail koneksi.

- Di halaman detail koneksi, catat Service account id karena akan diperlukan nanti.
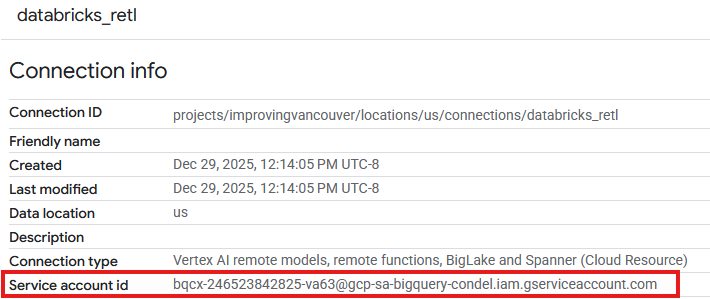
Memberikan Akses ke Akun Layanan Koneksi
- Buka IAM & Admin
- Klik Grant access.
- Untuk kolom New principals, masukkan Service account id Resource Koneksi yang dibuat di atas.
- Untuk Peran, pilih
Storage Object User, lalu klik
Setelah koneksi dibuat dan akun layanannya diberi izin yang diperlukan, tabel eksternal BigLake kini dapat dibuat. Pertama, Dataset diperlukan di BigQuery untuk bertindak sebagai penampung tabel baru. Kemudian, tabel itu sendiri akan dibuat, dengan mengarahkannya ke file metadata Iceberg di bucket GCS.
- Buka BigQuery
- Di panel Explorer, klik project ID, lalu klik tiga titik dan pilih Create dataset.
- Set data akan diberi nama
databricks_retl. Biarkan opsi lainnya sebagai default, lalu klik tombol Create dataset.
- Sekarang, temukan set data
databricks_retlbaru di panel Explorer. Klik tiga titik di sampingnya, lalu pilih Create table.
- Isi setelan berikut untuk pembuatan tabel:
- Buat tabel dari:
Google Cloud Storage - Select file from GCS bucket or use a URI pattern: Jelajahi Bucket GCS dan temukan file JSON metadata yang dibuat selama ekspor Databricks. Jalur akan terlihat seperti:
regional_sales/metadata/v1.metadata.json. - Format file:
Iceberg - Tabel:
regional_sales - Jenis tabel:
External table - Connection ID: Pilih koneksi
databricks_retlyang dibuat sebelumnya. - Biarkan nilai lainnya dalam setelan default, lalu klik Create table.
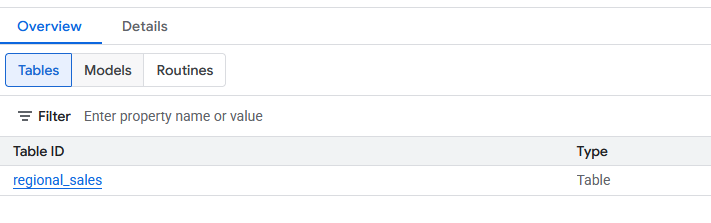
- Setelah dibuat, tabel
regional_salesbaru akan terlihat di bagian set datadatabricks_retl. Tabel ini kini dapat dikueri menggunakan SQL standar, seperti tabel BigQuery lainnya.
7. Memuat ke Spanner
Bagian akhir dan terpenting dari pipeline telah tercapai: memindahkan data dari Tabel eksternal BigLake ke Spanner. Ini adalah langkah "ETL Terbalik", tempat data, setelah diproses dan dikurasi di data warehouse, dimuat ke dalam sistem operasional untuk digunakan oleh aplikasi.
Spanner adalah database relasional yang terkelola sepenuhnya dan didistribusikan secara global. Layanan ini menawarkan konsistensi transaksional database relasional tradisional, tetapi dengan skalabilitas horizontal database NoSQL. Hal ini menjadikannya pilihan ideal untuk membangun aplikasi yang skalabel dan sangat tersedia.
Prosesnya adalah:
- Buat instance Spanner, yang merupakan alokasi resource fisik.
- Buat database dalam instance tersebut.
- Tentukan skema tabel dalam database yang cocok dengan struktur data
regional_sales. - Jalankan kueri BigQuery
EXPORT DATAuntuk memuat data dari tabel BigLake langsung ke tabel Spanner.
Membuat Instance, Database, dan Tabel Spanner
- Buka Spanner
- Klik
 . Anda dapat menggunakan instance yang ada jika tersedia. Siapkan persyaratan instance sesuai kebutuhan. Untuk lab ini, hal berikut digunakan:
. Anda dapat menggunakan instance yang ada jika tersedia. Siapkan persyaratan instance sesuai kebutuhan. Untuk lab ini, hal berikut digunakan:
Edisi | Enterprise |
Nama Instance | databricks-retl |
Konfigurasi Region | Wilayah pilihan Anda |
Unit Komputasi | Unit Pemrosesan (PU) |
Alokasi Manual | 100 |
- Setelah dibuat, buka halaman instance Spanner, lalu pilih
 . Anda dapat menggunakan database yang ada jika tersedia.
. Anda dapat menggunakan database yang ada jika tersedia.
- Untuk lab ini, database akan dibuat dengan
- Nama:
databricks-retl - Dialek Database:
Google Standard SQL
- Setelah database dibuat, pilih database tersebut dari halaman Instance Spanner untuk membuka halaman Database Spanner.
- Dari halaman Spanner Database, klik

- Di halaman kueri baru, definisi tabel untuk tabel yang akan diimpor ke Spanner akan dibuat. Untuk melakukannya, jalankan kueri SQL berikut.
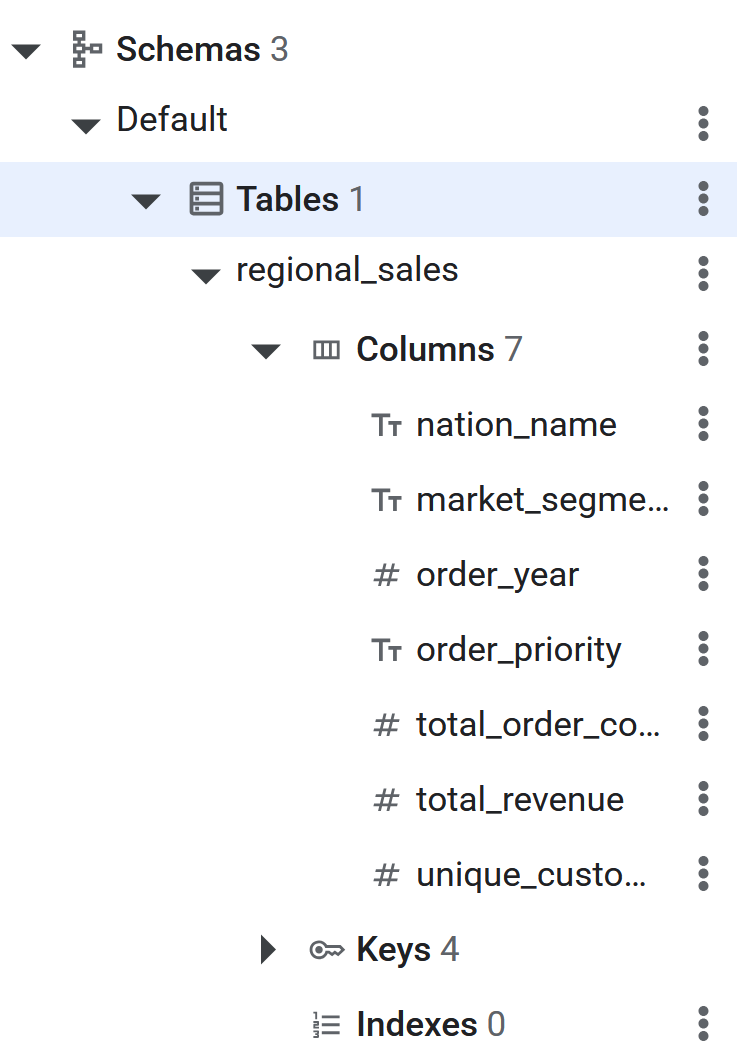
CREATE TABLE regional_sales (
nation_name STRING(MAX),
market_segment STRING(MAX),
order_year INT64,
order_priority STRING(MAX),
total_order_count INT64,
total_revenue NUMERIC,
unique_customer_count INT64
) PRIMARY KEY (nation_name, market_segment, order_year, order_priority);
- Setelah perintah SQL dijalankan, tabel Spanner akan siap untuk BigQuery melakukan ETL Terbalik pada data. Pembuatan tabel dapat diverifikasi dengan melihatnya tercantum di panel kiri dalam database Spanner.
ETL terbalik ke Spanner menggunakan EXPORT DATA
Ini adalah langkah terakhir. Dengan data sumber yang siap di tabel BigLake BigQuery dan tabel tujuan yang dibuat di Spanner, pemindahan data yang sebenarnya sangatlah sederhana. Satu kueri SQL BigQuery akan digunakan: EXPORT DATA.
Kueri ini dirancang khusus untuk skenario seperti ini. Alat ini secara efisien mengekspor data dari tabel BigQuery (termasuk tabel eksternal seperti tabel BigLake) ke tujuan eksternal. Dalam hal ini, tujuannya adalah tabel Spanner. Informasi selengkapnya tentang fitur ekspor dapat ditemukan di sini
Informasi selengkapnya tentang cara menyiapkan BigQuery ke Spanner Reverse ETL dapat ditemukan di sini
- Buka BigQuery
- Buka tab editor kueri baru.
- Di halaman Query, masukkan SQL berikut. Jangan lupa untuk mengganti project ID di **
uri** **dan jalur tabel dengan project ID yang benar.**
EXPORT DATA OPTIONS(
uri='https://spanner.googleapis.com/projects/YOUR_PROJECT_ID/instances/databricks-retl/databases/databricks-retl',
format='CLOUD_SPANNER',
spanner_options="""{
"table": "regional_sales",
"priority": "MEDIUM"
}"""
) AS
SELECT * FROM `YOUR_PROJECT_ID.databricks_retl.regional_sales`;
- Setelah perintah selesai, data telah berhasil diekspor ke Spanner.
8. Memverifikasi Data di Spanner
Selamat! Pipeline ETL Terbalik yang lengkap telah berhasil dibuat dan dijalankan, memindahkan data dari data warehouse Databricks ke database Spanner operasional.
Langkah terakhir adalah memverifikasi bahwa data telah tiba di Spanner seperti yang diharapkan.
- Buka Spanner.
- Buka instance
databricks-retl, lalu buka databasedatabricks-retl. - Dalam daftar tabel, klik tabel
regional_sales. - Di menu navigasi sebelah kiri untuk tabel, klik tab Data.
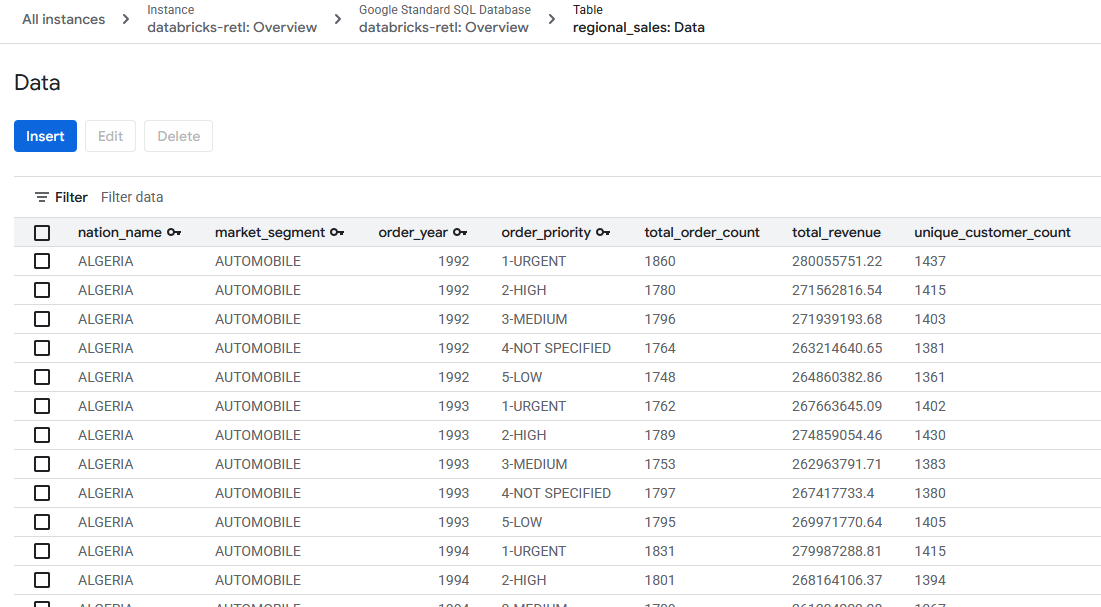
- Data penjualan gabungan, yang awalnya berasal dari Databricks, kini harus dimuat dan siap digunakan dalam tabel Spanner. Data ini kini berada dalam sistem operasional, siap untuk mendukung aplikasi live, menyajikan dasbor, atau dikueri oleh API.
Kesenjangan antara dunia data analitis dan operasional telah berhasil dijembatani.
9. Membersihkan
Hapus semua tabel yang ditambahkan dan data yang disimpan setelah Anda selesai menggunakan lab ini.
Membersihkan Tabel Spanner
- Goto Spanner
- Klik instance yang digunakan untuk lab ini dari daftar bernama
databricks-retl

- Di halaman instance, klik

- Masukkan
databricks-retldi dialog konfirmasi yang muncul, lalu klik
Membersihkan GCS
- Buka GCS
- Pilih
 dari menu samping kiri
dari menu samping kiri - Pilih bucket ``codelabs_retl_databricks
- Setelah dipilih, klik tombol
 yang muncul di banner atas
yang muncul di banner atas

- Masukkan
DELETEdi dialog konfirmasi yang muncul, lalu klik
Membersihkan Databricks
Menghapus Katalog/Skema/Tabel
- Login ke instance Databricks Anda
- Klik
 dari menu sebelah kiri
dari menu sebelah kiri - Pilih
 yang sebelumnya dibuat dari daftar katalog
yang sebelumnya dibuat dari daftar katalog - Di daftar Skema, pilih
 yang dibuat
yang dibuat - Pilih
 yang dibuat sebelumnya dari daftar tabel
yang dibuat sebelumnya dari daftar tabel - Luaskan opsi tabel dengan mengklik
 , lalu pilih
, lalu pilih Delete - Klik
 pada dialog konfirmasi untuk menghapus tabel
pada dialog konfirmasi untuk menghapus tabel - Setelah tabel dihapus, Anda akan diarahkan kembali ke halaman skema
- Luaskan opsi skema dengan mengklik , lalu pilih
Delete - Klik pada dialog konfirmasi untuk menghapus Skema
- Setelah skema dihapus, Anda akan diarahkan kembali ke halaman katalog
- Ikuti langkah 4 - 11 lagi untuk menghapus skema
defaultjika ada. - Dari halaman katalog, luaskan opsi katalog dengan mengklik , lalu pilih
Delete - Klik pada dialog konfirmasi untuk menghapus katalog
Menghapus Lokasi / Kredensial Data Eksternal
- Dari layar Katalog, klik
- Jika Anda tidak melihat opsi
External Data, Anda mungkin menemukanExternal Locationyang tercantum di menu dropdownConnect. - Klik lokasi data eksternal
retl-gcs-locationyang dibuat sebelumnya - Dari halaman lokasi eksternal, luaskan opsi lokasi dengan mengklik , lalu pilih
Delete - Klik pada dialog konfirmasi untuk menghapus lokasi eksternal
- Klik
- Klik
retl-gcs-credentialyang telah dibuat sebelumnya - Dari halaman kredensial, luaskan opsi kredensial dengan mengklik , lalu pilih
Delete - Klik pada dialog konfirmasi untuk menghapus kredensial.
10. Selamat
Selamat, Anda telah menyelesaikan codelab.
Yang telah kita bahas
- Cara memuat data ke Databricks sebagai tabel Iceberg
- Cara membuat Bucket GCS
- Cara mengekspor tabel Databricks ke GCS dalam format Iceberg
- Cara membuat Tabel Eksternal BigLake di BigQuery dari tabel Iceberg di GCS
- Cara menyiapkan instance Spanner
- Cara memuat Tabel Eksternal BigLake di BigQuery ke Spanner