
1. Crea una pipeline ETL inversa da Databricks a Spanner utilizzando Google Cloud Storage e BigQuery
Introduzione
In questo codelab, creerai una pipeline ETL inversa da Databricks a Spanner. Tradizionalmente, le pipeline ETL (Extract, Transform, Load) standard spostano i dati dai database operativi a un data warehouse come Databricks per l'analisi. Una pipeline ETL inversa fa il contrario spostando i dati curati ed elaborati dal data warehouse nei database operativi, come Spanner, un database relazionale distribuito a livello globale ideale per applicazioni ad alta disponibilità, dove può alimentare applicazioni, fornire funzionalità rivolte agli utenti o essere utilizzato per il processo decisionale in tempo reale.
L'obiettivo è spostare un set di dati aggregato dalle tabelle Databricks Iceberg alle tabelle Spanner.
Per raggiungere questo obiettivo, vengono utilizzati Google Cloud Storage (GCS) e BigQuery come passaggi intermedi. Ecco una suddivisione del flusso di dati e del ragionamento alla base di questa architettura:

- Databricks a Google Cloud Storage (GCS) in formato Iceberg:
- Il primo passaggio consiste nell'estrarre i dati da Databricks in un formato aperto e ben definito. La tabella viene esportata nel formato Apache Iceberg. Questo processo scrive i dati sottostanti come un insieme di file Parquet e i metadati della tabella (schema, partizioni, posizioni dei file) come file JSON e Avro. Il trasferimento temporaneo di questa struttura completa della tabella in GCS rende i dati portabili e accessibili a qualsiasi sistema che comprenda il formato Iceberg.
- Converti le tabelle Iceberg GCS in una tabella esterna BigLake BigQuery:
- Anziché caricare i dati direttamente da GCS in Spanner, BigQuery viene utilizzato come potente intermediario. In BigQuery viene creata una tabella esterna BigLake che punta direttamente al file di metadati Iceberg in GCS. Questo approccio presenta diversi vantaggi:
- Nessuna duplicazione dei dati:BigQuery legge la struttura della tabella dai metadati ed esegue query sui file di dati Parquet sul posto senza importarli, il che consente di risparmiare tempo e costi di archiviazione significativi.
- Query federate:consente di eseguire query SQL complesse sui dati GCS come se fossero una tabella BigQuery nativa.
- ETL inverso della tabella esterna BigLake in Spanner:
- Il passaggio finale consiste nello spostare i dati da BigQuery a Spanner. Ciò si ottiene utilizzando una potente funzionalità di BigQuery chiamata query
EXPORT DATA, che è il passaggio "Reverse ETL". - Operational Readiness:Spanner è progettato per i carichi di lavoro transazionali, fornendo elevata coerenza e alta disponibilità per le applicazioni. Spostando i dati in Spanner, questi diventano accessibili ad applicazioni rivolte agli utenti, API e altri sistemi operativi che richiedono ricerche puntuali a bassa latenza.
- Scalabilità:questo pattern consente di sfruttare la potenza analitica di BigQuery per elaborare set di dati di grandi dimensioni e quindi pubblicare i risultati in modo efficiente tramite l'infrastruttura scalabile a livello globale di Spanner.
Servizi e terminologia
- DataBricks: piattaforma di dati basata sul cloud e creata intorno ad Apache Spark.
- Spanner: un database relazionale distribuito a livello globale, completamente gestito da Google.
- Google Cloud Storage: offerta di archiviazione di blob di Google Cloud.
- BigQuery: un data warehouse serverless per l'analisi, completamente gestito da Google.
- Iceberg: un formato di tabella aperto definito da Apache che fornisce un'astrazione sui formati di file di dati open source comuni.
- Parquet: un formato di file di dati binari colonnari open source di Apache.
Obiettivi didattici
- Come caricare i dati in Databricks come tabelle Iceberg
- Come creare un bucket GCS
- Come esportare una tabella Databricks in GCS nel formato Iceberg
- Come creare una tabella esterna BigLake in BigQuery dalla tabella Iceberg in GCS
- Come configurare un'istanza di Spanner
- Come caricare tabelle esterne BigLake in BigQuery in Spanner
2. Configurazione, requisiti e limitazioni
Prerequisiti
- Un account Databricks, preferibilmente su Google Cloud
- Per l'esportazione da BigQuery a Spanner è necessario un account Google Cloud con una prenotazione di livello Enterprise o superiore.
- Accesso alla console Google Cloud tramite un browser web
- Un terminale per eseguire i comandi di Google Cloud CLI
Se la tua organizzazione Google Cloud ha attivato il criterio iam.allowedPolicyMemberDomains, un amministratore potrebbe dover concedere un'eccezione per consentire i service account di domini esterni. Questo aspetto verrà trattato in un passaggio successivo, se applicabile.
Requisiti
- Un progetto Google Cloud con la fatturazione abilitata.
- Un browser web, ad esempio Chrome
- Un account Databricks (questo lab presuppone uno spazio di lavoro ospitato in GCP)
- Per utilizzare la funzionalità EXPORT DATA, l'istanza BigQuery deve essere nella versione Enterprise o successive.
- Se la tua organizzazione Google Cloud ha attivato il criterio
iam.allowedPolicyMemberDomains, un amministratore potrebbe dover concedere un'eccezione per consentire i service account di domini esterni. Questo aspetto verrà trattato in un passaggio successivo, se applicabile.
Autorizzazioni IAM di Google Cloud Platform
L'Account Google deve disporre delle seguenti autorizzazioni per eseguire tutti i passaggi di questo codelab.
Service account | ||
| Consente la creazione di service account. | |
Spanner | ||
| Consente di creare una nuova istanza di Spanner. | |
| Consente l'esecuzione di istruzioni DDL per creare | |
| Consente di eseguire istruzioni DDL per creare tabelle nel database. | |
Google Cloud Storage | ||
| Consente di creare un nuovo bucket GCS per archiviare i file Parquet esportati. | |
| Consente di scrivere i file Parquet esportati nel bucket GCS. | |
| Consente a BigQuery di leggere i file Parquet dal bucket GCS. | |
| Consente a BigQuery di elencare i file Parquet nel bucket GCS. | |
Dataflow | ||
| Consente di rivendicare elementi di lavoro da Dataflow. | |
| Consente al worker Dataflow di inviare messaggi al servizio Dataflow. | |
| Consente ai worker Dataflow di scrivere voci di log in Google Cloud Logging. | |
Per comodità, è possibile utilizzare ruoli predefiniti che contengono queste autorizzazioni.
|
|
|
|
|
|
|
|
Progetto Google Cloud
Un progetto è un'unità di base di organizzazione in Google Cloud. Se un amministratore ne ha fornito uno da utilizzare, questo passaggio può essere saltato.
Un progetto può essere creato utilizzando la CLI nel seguente modo:
gcloud projects create <your-project-name>
Scopri di più sulla creazione e sulla gestione dei progetti qui.
Limitazioni
È importante essere consapevoli di alcune limitazioni e incompatibilità dei tipi di dati che possono verificarsi in questa pipeline.
Databricks Iceberg a BigQuery
Quando utilizzi BigQuery per eseguire query sulle tabelle Iceberg gestite da Databricks (tramite UniForm), tieni presente quanto segue:
- Evoluzione dello schema: anche se UniForm esegue un buon lavoro di conversione delle modifiche dello schema Delta Lake in Iceberg, le modifiche complesse potrebbero non essere sempre propagate come previsto. Ad esempio, la ridenominazione delle colonne in Delta Lake non viene convertita in Iceberg, che la considera come un
drope unadd. Testa sempre a fondo le modifiche allo schema. - Spostamento cronologico: BigQuery non può utilizzare le funzionalità di spostamento cronologico di Delta Lake. Eseguirà query solo sull'ultimo snapshot della tabella Iceberg.
- Funzionalità Delta Lake non supportate: funzionalità come i vettori di eliminazione e la mappatura delle colonne con la modalità
idin Delta Lake non sono compatibili con UniForm per Iceberg. Il lab utilizza la modalitànameper la mappatura delle colonne, che è supportata.
Da BigQuery a Spanner
Il comando EXPORT DATA da BigQuery a Spanner non supporta tutti i tipi di dati BigQuery. L'esportazione di una tabella con i seguenti tipi genererà un errore:
STRUCTGEOGRAPHYDATETIMERANGETIME
Inoltre, se il progetto BigQuery utilizza il dialetto GoogleSQL, i seguenti tipi numerici non sono supportati per l'esportazione in Spanner:
BIGNUMERIC
Per un elenco completo e aggiornato delle limitazioni, consulta la documentazione ufficiale: Limitazioni dell'esportazione in Spanner.
Risoluzione dei problemi e insidie
- Se non si trova su un'istanza GCP Databricks, la definizione di una posizione dati esterna in GCS potrebbe non essere possibile. In questi casi, i file dovranno essere preparati nella soluzione di archiviazione del provider di servizi cloud del workspace Databricks e poi migrati separatamente in GCS.
- In questo caso, saranno necessari aggiustamenti ai metadati, poiché le informazioni avranno percorsi hardcoded ai file di staging.
3. Configurare Google Cloud Storage (GCS)
Google Cloud Storage (GCS) verrà utilizzato per archiviare i file di dati Parquet generati da Databricks. A questo scopo, è necessario creare un nuovo bucket da utilizzare come destinazione del file.
Google Cloud Storage
Creazione di un nuovo bucket
- Vai alla pagina Google Cloud Storage nella console cloud.
- Nel riquadro a sinistra, seleziona Bucket:
- Fai clic sul pulsante Crea:

- Compila i dettagli del bucket:
- Scegli un nome del bucket da utilizzare. Per questo lab, verrà utilizzato il nome
codelabs_retl_databricks - Seleziona una regione in cui archiviare il bucket o utilizza i valori predefiniti.
- Mantieni la classe di archiviazione come
standard - Mantieni i valori predefiniti per Controlla l'accesso
- Mantieni i valori predefiniti per Proteggi i dati degli oggetti
- Al termine, fai clic sul pulsante
Create. Potrebbe essere visualizzato un prompt per confermare che l'accesso pubblico verrà impedito. Procedi con la conferma. - Congratulazioni, è stato creato un nuovo bucket. Verrà eseguito un reindirizzamento alla pagina del bucket.
- Copia da qualche parte il nuovo nome del bucket perché ti servirà in un secondo momento.
Prepararsi per i passaggi successivi
Assicurati di annotare i seguenti dettagli, in quanto ti serviranno nei passaggi successivi:
- ID progetto Google
- Nome bucket Google Storage
4. Configura Databricks
Dati TPC-H
Per questo lab verrà utilizzato il set di dati TPC-H, che è un benchmark standard del settore per i sistemi di supporto alle decisioni. Il suo schema modella un ambiente aziendale realistico con clienti, ordini, fornitori e parti, il che lo rende perfetto per dimostrare uno scenario reale di analisi e spostamento dei dati.
Verrà creata una nuova tabella aggregata anziché utilizzare le tabelle TPC-H non elaborate e normalizzate. Questa nuova tabella unirà i dati delle tabelle orders, customer e nation per produrre una visualizzazione denormalizzata e riepilogativa delle vendite regionali. Questo passaggio di preaggregazione è una pratica comune nell'analisi, in quanto prepara i dati per un caso d'uso specifico, in questo scenario, per il consumo da parte di un'applicazione operativa.
Lo schema finale per la tabella aggregata sarà:
Col | Tipo |
nation_name | stringa |
market_segment | stringa |
order_year | int |
order_priority | stringa |
total_order_count | bigint |
total_revenue | decimal(29,2) |
unique_customer_count | bigint |
Supporto di Iceberg con il formato universale Delta Lake (UniForm)
Per questo lab, la tabella all'interno di Databricks sarà una tabella Delta Lake. Tuttavia, per renderlo leggibile da sistemi esterni come BigQuery, verrà attivata una potente funzionalità chiamata Universal Format (UniForm).
UniForm genera automaticamente i metadati Iceberg insieme ai metadati Delta Lake per una singola copia condivisa dei dati della tabella. In questo modo, avrai il meglio di entrambi i mondi:
- All'interno di Databricks:vengono ottenuti tutti i vantaggi in termini di prestazioni e governance di Delta Lake.
- Al di fuori di Databricks:la tabella può essere letta da qualsiasi motore di query compatibile con Iceberg, come BigQuery, come se fosse una tabella Iceberg nativa.
In questo modo non è necessario mantenere copie separate dei dati o eseguire job di conversione manuale. UniForm verrà abilitato impostando proprietà specifiche della tabella al momento della creazione.
Cataloghi Databricks
Un catalogo Databricks è il contenitore di primo livello per i dati in Unity Catalog, la soluzione di governance unificata di Databricks. Unity Catalog offre un modo centralizzato per gestire gli asset di dati, controllare l'accesso e monitorare la derivazione, il che è fondamentale per una piattaforma dati ben governata.
Utilizza uno spazio dei nomi a tre livelli per organizzare i dati: catalog.schema.table.
- Catalogo:il livello più alto, utilizzato per raggruppare i dati per ambiente, unità aziendale o progetto.
- Schema (o database): un raggruppamento logico di tabelle, viste e funzioni all'interno di un catalogo.
- Tabella:l'oggetto contenente i dati.
Prima di poter creare la tabella TPC-H aggregata, è necessario configurare un catalogo e uno schema dedicati per ospitarla. In questo modo, il progetto è ben organizzato e isolato dagli altri dati dello spazio di lavoro.
Crea un nuovo catalogo e un nuovo schema
In Databricks Unity Catalog, un catalogo funge da livello più alto di organizzazione per gli asset di dati, fungendo da contenitore sicuro che può estendersi su più spazi di lavoro Databricks. Consente di organizzare e isolare i dati in base a unità aziendali, progetti o ambienti, con autorizzazioni e controlli dell'accesso chiaramente definiti.
All'interno di un catalogo, uno schema (noto anche come database) organizza ulteriormente tabelle, viste e funzioni. Questa struttura gerarchica consente un controllo granulare e un raggruppamento logico degli oggetti dati correlati. Per questo lab, verranno creati un catalogo e uno schema dedicati per ospitare i dati TPC-H, garantendo isolamento e gestione adeguati.
Creazione di un catalogo
- Vai a

- Fai clic su + e poi seleziona Crea un catalogo dal menu a discesa.
- Verrà creato un nuovo catalogo Standard con le seguenti impostazioni:
- Nome catalogo:
retl_tpch_project - Località di archiviazione: utilizza quella predefinita, se ne è stata configurata una nello spazio di lavoro, o creane una nuova.
Creazione di uno schema
- Vai a
- Seleziona il nuovo catalogo creato nel riquadro a sinistra.
- Fai clic su
 .
. - Verrà creato un nuovo schema con il nome dello schema come
tpch_data
Configurazione dei dati esterni
Per poter esportare i dati da Databricks a Google Cloud Storage (GCS), è necessario configurare le credenziali dei dati esterni in Databricks. In questo modo, Databricks può accedere in modo sicuro al bucket GCS e scrivervi.
- Nella schermata Catalogo, fai clic su
 .
.
- Se non vedi l'opzione
External Data, potresti trovareExternal Locationsin un menu a discesaConnect.
- Fai clic su
 .
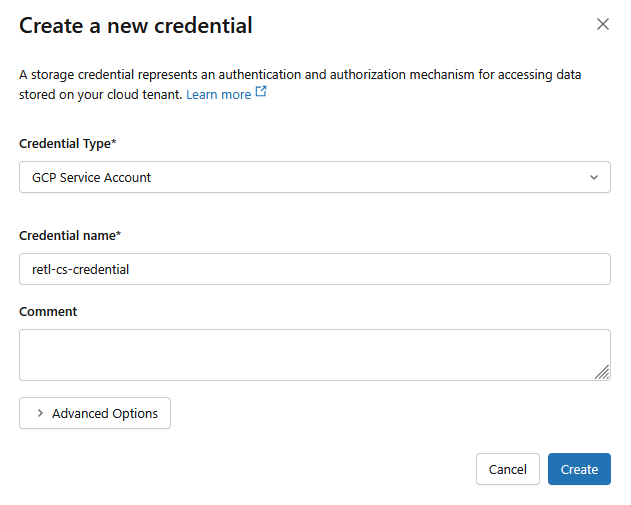
. - Nella nuova finestra di dialogo, configura i valori richiesti per le credenziali:
- Tipo di credenziale:
GCP Service Account - Nome credenziale:
retl-gcs-credential
- Fai clic su Crea
- Poi, fai clic sulla scheda Sedi esterne.
- Fai clic su Crea posizione.
- Nella nuova finestra di dialogo, configura i valori richiesti per la posizione esterna:
- Nome della località esterna:
retl-gcs-location - Tipo di archiviazione:
GCP - URL: l'URL del bucket GCS, nel formato
gs://YOUR_BUCKET_NAME - Credenziale di archiviazione: seleziona
retl-gcs-credentialappena creato.
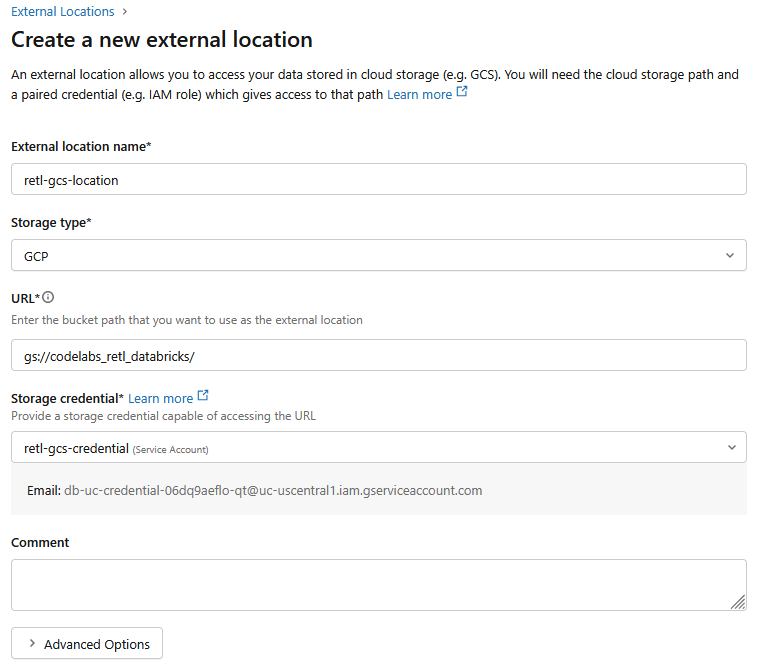
- Prendi nota dell'email del service account che viene compilata automaticamente quando selezioni le credenziali di archiviazione, in quanto ti servirà nel passaggio successivo.
- Fai clic su Crea
5. Impostazione delle autorizzazioni per l'account di servizio
Un service account è un tipo speciale di account utilizzato da applicazioni o servizi per effettuare chiamate API autorizzate alle risorse Google Cloud.
Ora le autorizzazioni dovranno essere aggiunte al service account creato per il nuovo bucket in GCS.
- Nella pagina del bucket GCS, seleziona la scheda Autorizzazioni.
- Fai clic su Concedi l'accesso nella pagina delle entità.
- Nel riquadro Concedi accesso che scorre da destra, inserisci l'ID service account nel campo Nuove entità.
- In Assegna ruoli, aggiungi
Storage Object AdmineStorage Legacy Bucket Reader. Questi ruoli consentono al service account di leggere, scrivere ed elencare gli oggetti nel bucket di archiviazione.
Carica i dati TPC-H
Ora che sono stati creati il catalogo e lo schema, i dati TPCH possono essere caricati dalla tabella samples.tpch esistente, memorizzata internamente in Databricks e manipolata in una nuova tabella nel nuovo schema definito.
Creazione di una tabella con supporto Iceberg
Compatibilità di Iceberg con UniForm
Dietro le quinte, Databricks gestisce internamente questa tabella come tabella Delta Lake, offrendo tutti i vantaggi delle funzionalità di ottimizzazione delle prestazioni e governance di Delta all'interno dell'ecosistema Databricks. Tuttavia, se abiliti UniForm (abbreviazione di Universal Format), Databricks riceve un'istruzione speciale: ogni volta che la tabella viene aggiornata, Databricks genera e gestisce automaticamente i metadati Iceberg corrispondenti in aggiunta ai metadati Delta Lake.
Ciò significa che un singolo insieme condiviso di file di dati (i file Parquet) ora è descritto da due diversi insiemi di metadati.
- Per Databricks:utilizza
_delta_logper leggere la tabella. - Per i lettori esterni (come BigQuery): utilizzano il file di metadati Iceberg (
.metadata.json) per comprendere lo schema, il partizionamento e le posizioni dei file della tabella.
Il risultato è una tabella completamente e trasparentemente compatibile con qualsiasi strumento compatibile con Iceberg. Non sono presenti duplicazioni di dati e non è necessaria la conversione o la sincronizzazione manuale. È un'unica fonte attendibile a cui possono accedere facilmente sia il mondo analitico di Databricks sia l'ecosistema più ampio di strumenti che supportano lo standard aperto Iceberg.
- Fai clic su Nuova e poi su Query.
- Nel campo di testo della pagina della query, esegui il seguente comando SQL:
CREATE TABLE retl_tpch_project.tpch_data.regional_sales_iceberg
USING DELTA
LOCATION 'gs://<Your bucket name>/regional_sales_iceberg'
TBLPROPERTIES (
'delta.columnMapping.mode' = 'name',
'delta.enableIcebergCompatV2' = 'true',
'delta.universalFormat.enabledFormats' = 'iceberg'
)
AS
SELECT
n.n_name AS nation_name,
c.c_mktsegment AS market_segment,
YEAR(o.o_orderdate) AS order_year,
o.o_orderpriority AS order_priority,
COUNT(o.o_orderkey) AS total_order_count,
ROUND(SUM(o.o_totalprice), 2) AS total_revenue,
COUNT(DISTINCT c.c_custkey) AS unique_customer_count
FROM samples.tpch.orders AS o
INNER JOIN samples.tpch.customer AS c
ON o.o_custkey = c.c_custkey
INNER JOIN samples.tpch.nation AS n
ON c.c_nationkey = n.n_nationkey
GROUP BY
n.n_name,
c.c_mktsegment,
YEAR(o.o_orderdate),
o.o_orderpriority;
OPTIMIZE retl_tpch_project.tpch_data.regional_sales_iceberg;
DESCRIBE EXTENDED retl_tpch_project.tpch_data.regional_sales_iceberg;
Note:
- Using Delta: specifica che stiamo utilizzando una tabella Delta Lake. Solo le tabelle Delta Lake in Databricks possono essere archiviate come tabella esterna.
- Percorso: specifica dove deve essere archiviata la tabella, se esterna.
- TablePropertoes:
delta.universalFormat.enabledFormats = ‘iceberg'crea i metadati Iceberg compatibili insieme ai file Delta Lake. - Ottimizza: attiva forzatamente la generazione di metadati UniForm, che in genere avviene in modo asincrono.
- L'output della query dovrebbe mostrare i dettagli della tabella appena creata

Verificare i dati della tabella GCS
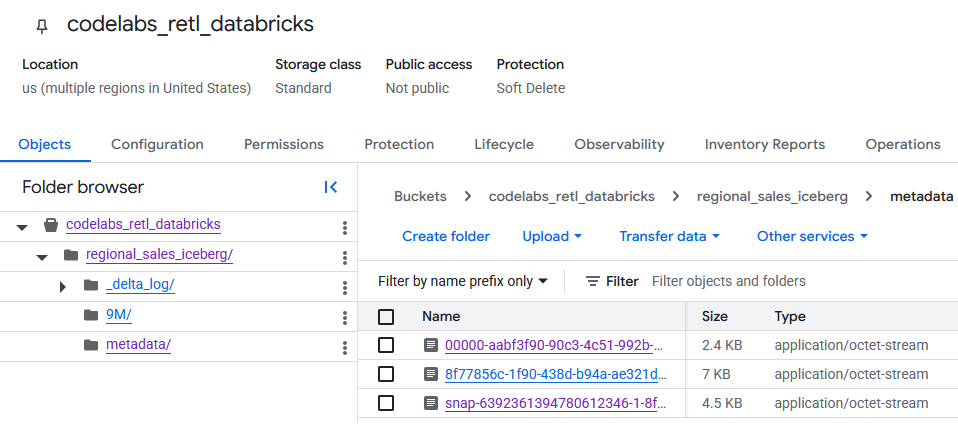
Dopo aver eseguito la navigazione nel bucket GCS, ora puoi trovare i dati della tabella appena creata.
Troverai i metadati Iceberg all'interno della cartella metadata, che viene utilizzata da lettori esterni (come BigQuery). I metadati Delta Lake, utilizzati internamente da Databricks, vengono monitorati nella cartella _delta_log.
I dati effettivi della tabella vengono archiviati come file Parquet all'interno di un'altra cartella, in genere denominata con una stringa generata in modo casuale da Databricks. Ad esempio, nello screenshot seguente, i file di dati si trovano nella cartella 9M.
6. Configurare BigQuery e BigLake
Ora che la tabella Iceberg si trova in Google Cloud Storage, il passaggio successivo consiste nel renderla accessibile a BigQuery. A questo scopo, viene creata una tabella esterna BigLake.
BigLake è un motore di archiviazione che consente di creare tabelle in BigQuery che leggono i dati direttamente da origini esterne come Google Cloud Storage. Per questo lab, è la tecnologia chiave che consente a BigQuery di comprendere la tabella Iceberg appena esportata senza la necessità di importare i dati.
Per far funzionare il tutto, sono necessari due componenti:
- Una connessione alle risorse Cloud:si tratta di un collegamento sicuro tra BigQuery e GCS. Utilizza un service account speciale per gestire l'autenticazione, assicurandosi che BigQuery disponga delle autorizzazioni necessarie per leggere i file dal bucket GCS.
- Una definizione di tabella esterna:indica a BigQuery dove trovare il file di metadati della tabella Iceberg in GCS e come deve essere interpretato.
Crea una connessione alle risorse Cloud
Innanzitutto, verrà creata la connessione che consente a BigQuery di accedere a GCS.
Per saperne di più sulla creazione di connessioni alle risorse Cloud, consulta questa pagina.
- Vai a BigQuery.
- Fai clic su Connessioni in Esplora.
- Se il riquadro Explorer non è visibile, fai clic su
 .
.
- Nella pagina Connessioni, fai clic su
 .
. - Per Tipo di connessione, scegli
Vertex AI remote models, remote functions, BigLake and Spanner (Cloud Resource). - Imposta l'ID connessione su
databricks_retle crea la connessione

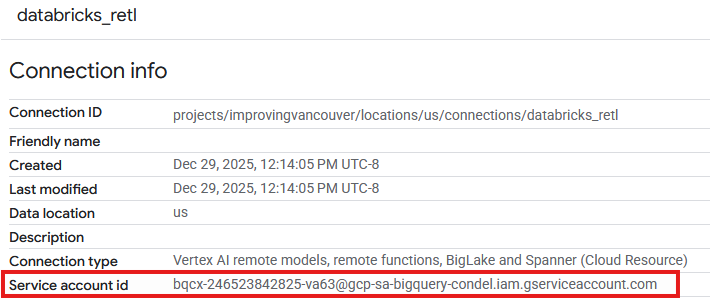
- Ora dovresti vedere una voce nella tabella Connessioni della connessione appena creata. Fai clic sulla voce per visualizzare i dettagli della connessione.

- Nella pagina dei dettagli della connessione, annota l'ID service account, perché ti servirà in un secondo momento.
Concedi l'accesso al service account di connessione
- Vai a IAM e amministrazione
- Fai clic su Concedi l'accesso.
- Per il campo Nuove entità, inserisci l'ID service account della risorsa di connessione creata sopra.
- Per Ruolo, seleziona
Storage Object Usere poi fai clic su .
.
Una volta stabilita la connessione e concesse le autorizzazioni necessarie al service account, è possibile creare la tabella esterna BigLake. Innanzitutto, in BigQuery è necessario un set di dati che funga da contenitore per la nuova tabella. Verrà quindi creata la tabella stessa, che punterà al file di metadati Iceberg nel bucket GCS.
- Vai a BigQuery.
- Nel riquadro Explorer, fai clic sull'ID progetto, poi sui tre puntini e seleziona Crea set di dati.
- Il set di dati verrà denominato
databricks_retl. Lascia invariate le altre opzioni predefinite e fai clic sul pulsante Crea set di dati.
- Ora, trova il nuovo set di dati
databricks_retlnel riquadro Explorer. Fai clic sui tre puntini accanto e seleziona Crea tabella.
- Inserisci le seguenti impostazioni per la creazione della tabella:
- Crea tabella da:
Google Cloud Storage - Seleziona il file dal bucket GCS oppure utilizza un pattern URI: vai al bucket GCS e individua il file JSON dei metadati generato durante l'esportazione di Databricks. Il percorso dovrebbe essere simile a questo:
regional_sales/metadata/v1.metadata.json. - Formato file:
Iceberg - Tabella:
regional_sales - Tipo di tabella:
External table - ID connessione: seleziona la connessione
databricks_retlcreata in precedenza. - Lascia invariati i valori predefiniti rimanenti, poi fai clic su Crea tabella.
- Una volta creata, la nuova tabella
regional_salesdovrebbe essere visibile nel set di datidatabricks_retl. Ora è possibile eseguire query su questa tabella utilizzando SQL standard, proprio come per qualsiasi altra tabella BigQuery.
7. Carica su Spanner
È stata raggiunta la parte finale e più importante della pipeline: lo spostamento dei dati dalle tabelle esterne BigLake a Spanner. Questo è il passaggio "Reverse ETL", in cui i dati, dopo essere stati elaborati e curati nel data warehouse, vengono caricati in un sistema operativo per essere utilizzati dalle applicazioni.
Spanner è un database relazionale completamente gestito e distribuito a livello globale. Offre la coerenza transazionale di un database relazionale tradizionale, ma con la scalabilità orizzontale di un database NoSQL. Ciò lo rende una scelta ideale per la creazione di applicazioni scalabili e ad alta disponibilità.
La procedura sarà la seguente:
- Crea un'istanza di Spanner, ovvero l'allocazione fisica delle risorse.
- Crea un database all'interno di questa istanza.
- Definisci uno schema della tabella nel database che corrisponda alla struttura dei dati
regional_sales. - Esegui una query BigQuery
EXPORT DATAper caricare i dati dalla tabella BigLake direttamente nella tabella Spanner.
Crea l'istanza, il database e la tabella Spanner
- Vai a Spanner.
- Fai clic su
 . Se disponibile, puoi utilizzare un'istanza esistente. Configura i requisiti dell'istanza in base alle esigenze. Per questo lab sono stati utilizzati i seguenti elementi:
. Se disponibile, puoi utilizzare un'istanza esistente. Configura i requisiti dell'istanza in base alle esigenze. Per questo lab sono stati utilizzati i seguenti elementi:
Versione | Enterprise |
Nome istanza | databricks-retl |
Configurazione regione | La regione che preferisci |
Unità di calcolo | Unità di elaborazione (PU) |
Allocazione manuale | 100 |
- Una volta creato, vai alla pagina dell'istanza Spanner e seleziona
 . Se disponibile, puoi utilizzare un database esistente.
. Se disponibile, puoi utilizzare un database esistente.
- Per questo lab, verrà creato un database con
- Nome:
databricks-retl - Dialetto del database:
Google Standard SQL
- Una volta creato il database, selezionalo dalla pagina Istanza Spanner per accedere alla pagina Database Spanner.
- Nella pagina del database Spanner, fai clic su
 .
. - Nella nuova pagina della query verrà creata la definizione della tabella da importare in Spanner. Per farlo, esegui la seguente query SQL.
CREATE TABLE regional_sales (
nation_name STRING(MAX),
market_segment STRING(MAX),
order_year INT64,
order_priority STRING(MAX),
total_order_count INT64,
total_revenue NUMERIC,
unique_customer_count INT64
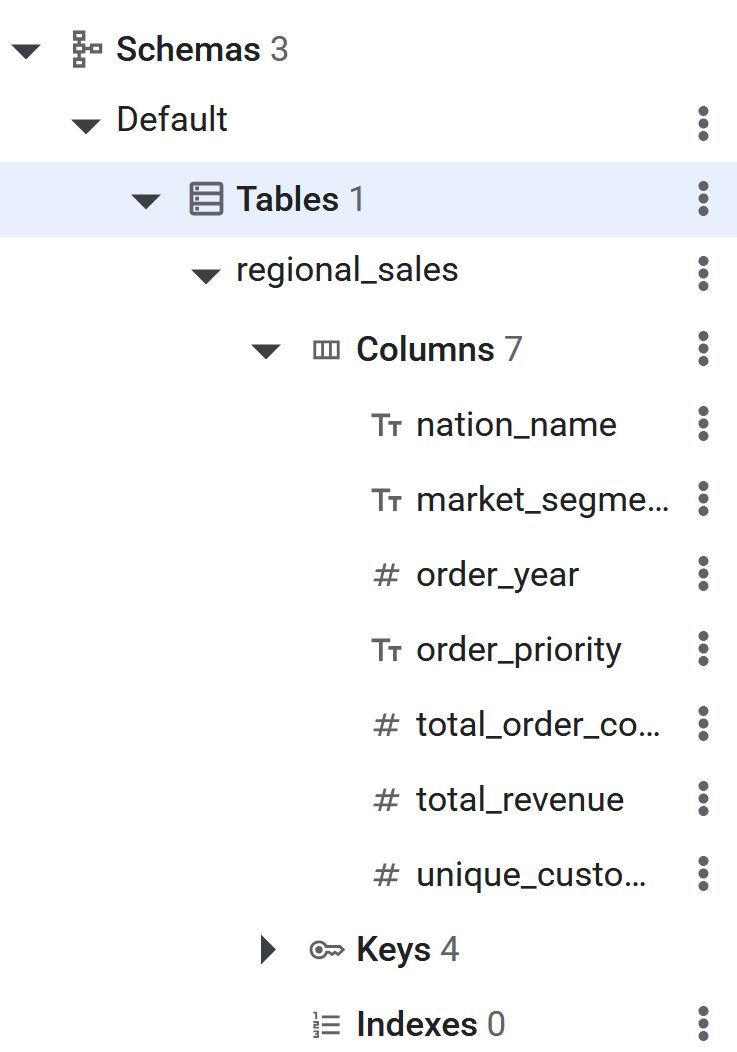
) PRIMARY KEY (nation_name, market_segment, order_year, order_priority);
- Una volta eseguito il comando SQL, la tabella Spanner sarà pronta per BigQuery per eseguire l'ETL inversa dei dati. La creazione della tabella può essere verificata visualizzandola nell'elenco del riquadro a sinistra nel database Spanner.
ETL inverso a Spanner utilizzando EXPORT DATA
Questo è l'ultimo passaggio. Con i dati di origine pronti in una tabella BigLake di BigQuery e la tabella di destinazione creata in Spanner, lo spostamento effettivo dei dati è sorprendentemente semplice. Verrà utilizzata una singola query SQL BigQuery: EXPORT DATA.
Questa query è progettata appositamente per scenari come questo. Esporta in modo efficiente i dati da una tabella BigQuery (incluse quelle esterne come la tabella BigLake) a una destinazione esterna. In questo caso, la destinazione è la tabella Spanner. Per ulteriori informazioni sulla funzionalità di esportazione, fai clic qui.
Per ulteriori informazioni sulla configurazione dell'ETL inverso da BigQuery a Spanner, consulta questa pagina.
- Vai a BigQuery.
- Apri una nuova scheda dell'editor di query.
- Nella pagina Query, inserisci il seguente codice SQL. Ricorda di sostituire l'ID progetto in **
uri** **e il percorso della tabella con l'ID progetto corretto.**
EXPORT DATA OPTIONS(
uri='https://spanner.googleapis.com/projects/YOUR_PROJECT_ID/instances/databricks-retl/databases/databricks-retl',
format='CLOUD_SPANNER',
spanner_options="""{
"table": "regional_sales",
"priority": "MEDIUM"
}"""
) AS
SELECT * FROM `YOUR_PROJECT_ID.databricks_retl.regional_sales`;
- Una volta completato il comando, i dati sono stati esportati correttamente in Spanner.
8. Verifica dei dati in Spanner
Complimenti! È stata creata ed eseguita correttamente una pipeline ETL inversa completa, che sposta i dati da un data warehouse Databricks a un database Spanner operativo.
Il passaggio finale consiste nel verificare che i dati siano arrivati in Spanner come previsto.
- Vai a Spanner.
- Vai all'istanza di
databricks-retle poi al databasedatabricks-retl. - Nell'elenco delle tabelle, fai clic sulla tabella
regional_sales. - Nel menu di navigazione a sinistra della tabella, fai clic sulla scheda Dati.
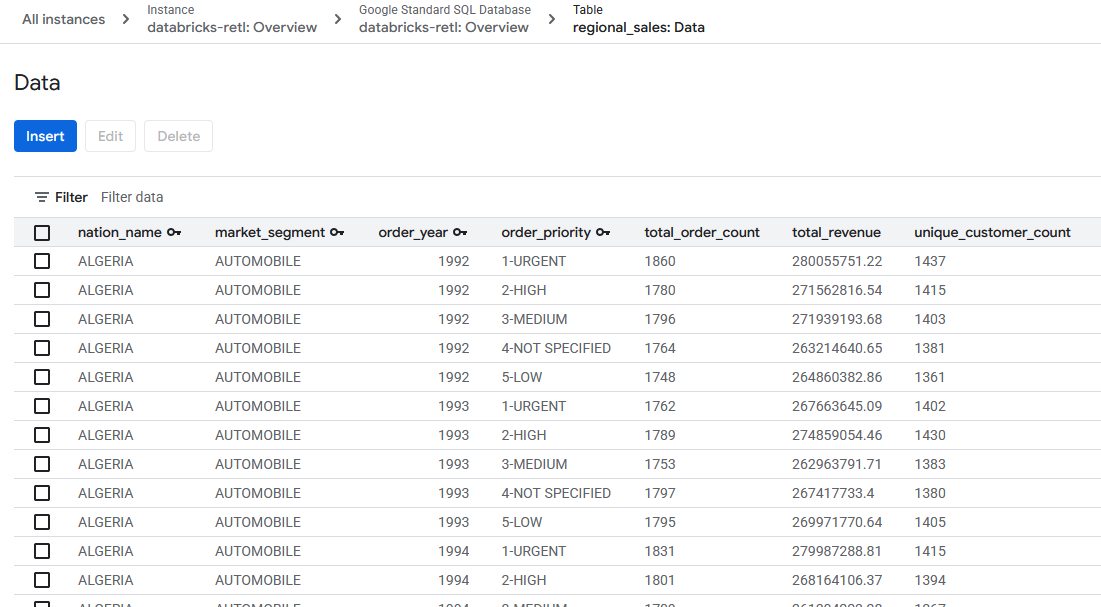
- I dati di vendita aggregati, originariamente provenienti da Databricks, ora dovrebbero essere caricati e pronti per l'uso nella tabella Spanner. Questi dati si trovano ora in un sistema operativo, pronto per alimentare un'applicazione live, mostrare una dashboard o essere interrogato da un'API.
Il divario tra i mondi dei dati analitici e operativi è stato colmato.
9. Eliminazione
Rimuovi tutte le tabelle aggiunte e i dati memorizzati al termine di questo lab.
Liberare spazio nelle tabelle Spanner
- Vai a Spanner
- Fai clic sull'istanza utilizzata per questo lab dall'elenco denominato
databricks-retl.

- Nella pagina dell'istanza, fai clic su
 .
. - Inserisci
databricks-retlnella finestra di dialogo di conferma visualizzata e fai clic su .
.
Liberare spazio in GCS
- Vai a GCS
- Seleziona
 dal menu a sinistra.
dal menu a sinistra. - Seleziona il bucket ``codelabs_retl_databricks
- Una volta selezionato, fai clic sul pulsante
 visualizzato nel banner in alto.
visualizzato nel banner in alto.

- Inserisci
DELETEnella finestra di dialogo di conferma visualizzata e fai clic su.
Liberare spazio in Databricks
Elimina catalogo/schema/tabella
- Accedi all'istanza Databricks
- Fai clic su
 nel menu laterale.
nel menu laterale. - Seleziona il
 creato in precedenza dall'elenco del catalogo.
creato in precedenza dall'elenco del catalogo. - Nell'elenco Schema, seleziona
 creato
creato - Seleziona il
 creato in precedenza dall'elenco della tabella.
creato in precedenza dall'elenco della tabella. - Espandi le opzioni della tabella facendo clic su
 e seleziona
e seleziona Delete. - Fai clic su
 nella finestra di dialogo di conferma per eliminare la tabella.
nella finestra di dialogo di conferma per eliminare la tabella. - Una volta eliminata la tabella, tornerai alla pagina dello schema
- Espandi le opzioni dello schema facendo clic su e seleziona
Delete. - Fai clic su nella finestra di dialogo di conferma per eliminare lo schema.
- Una volta eliminato lo schema, tornerai alla pagina del catalogo
- Ripeti i passaggi da 4 a 11 per eliminare lo schema
default, se esistente. - Nella pagina del catalogo, espandi le opzioni del catalogo facendo clic su e seleziona
Delete. - Fai clic su nella finestra di dialogo di conferma per eliminare il catalogo.
Elimina posizione / credenziali dati esterni
- Nella schermata Catalogo, fai clic su .
- Se non vedi l'opzione
External Data, potresti trovareExternal Locationin un menu a discesaConnect. - Fai clic sulla posizione dei dati esterni
retl-gcs-locationcreata in precedenza. - Nella pagina della posizione esterna, espandi le opzioni della posizione facendo clic su e seleziona
Delete. - Fai clic su nella finestra di dialogo di conferma per eliminare la posizione esterna.
- Fai clic su .
- Fai clic sul
retl-gcs-credentialcreato in precedenza. - Nella pagina delle credenziali, espandi le opzioni delle credenziali facendo clic su e seleziona
Delete. - Fai clic su nella finestra di dialogo di conferma per eliminare le credenziali.
10. Complimenti
Congratulazioni per aver completato il codelab.
Argomenti trattati
- Come caricare i dati in Databricks come tabelle Iceberg
- Come creare un bucket GCS
- Come esportare una tabella Databricks in GCS nel formato Iceberg
- Come creare una tabella esterna BigLake in BigQuery dalla tabella Iceberg in GCS
- Come configurare un'istanza di Spanner
- Come caricare tabelle esterne BigLake in BigQuery in Spanner