
1. Google Cloud Storage と BigQuery を使用して Databricks から Spanner へのリバース ETL パイプラインを構築する
はじめに
この Codelab では、Databricks から Spanner へのリバース ETL パイプラインを構築します。従来、標準の ETL(抽出、変換、読み込み)パイプラインは、分析のためにオペレーショナル データベースから Databricks などのデータ ウェアハウスにデータを移動します。リバース ETL パイプラインは、キュレーションされ処理されたデータをデータ ウェアハウスから運用データベース(高可用性アプリケーションに最適なグローバル分散リレーショナル データベースである Spanner など)に移動します。これにより、アプリケーションの強化、ユーザー向け機能の提供、リアルタイムの意思決定に使用できます。
目標は、集計されたデータセットを Databricks Iceberg テーブルから Spanner テーブルに移動することです。
これを実現するために、Google Cloud Storage(GCS)と BigQuery が中間ステップとして使用されます。このアーキテクチャのデータフローと、その理由の内訳は次のとおりです。

- Iceberg 形式の Databricks から Google Cloud Storage(GCS):
- まず、オープンで明確に定義された形式で Databricks からデータを取得します。テーブルは Apache Iceberg 形式でエクスポートされます。このプロセスでは、基盤となるデータが Parquet ファイルのセットとして書き込まれ、テーブルのメタデータ(スキーマ、パーティション、ファイルの場所)が JSON ファイルと Avro ファイルとして書き込まれます。この完全なテーブル構造を GCS にステージングすると、データがポータブルになり、Iceberg 形式を理解する任意のシステムからアクセスできるようになります。
- GCS Iceberg テーブルを BigQuery BigLake 外部テーブルに変換する:
- GCS から Spanner にデータを直接読み込むのではなく、BigQuery を強力な仲介役として使用します。BigQuery に BigLake 外部テーブルが作成され、GCS の Iceberg メタデータ ファイルを直接指します。このアプローチにはいくつかのメリットがあります。
- データの重複なし: BigQuery は、メタデータからテーブル構造を読み取り、Parquet データファイルをインジェストせずにその場でクエリします。これにより、時間とストレージ費用を大幅に節約できます。
- 連携クエリ: GCS データに対して、ネイティブの BigQuery テーブルであるかのように複雑な SQL クエリを実行できます。
- BigLake 外部テーブルを Spanner に ReverseETL する:
- 最後のステップは、BigQuery から Spanner にデータを移動することです。これは、BigQuery の強力な機能である
EXPORT DATAクエリ(「リバース ETL」ステップ)を使用して実現されます。 - 運用の準備: Spanner はトランザクション ワークロード向けに設計されており、アプリケーションに強整合性と高可用性を提供します。データを Spanner に移動することで、低レイテンシのポイント ルックアップを必要とするユーザー向けアプリケーション、API、その他のオペレーショナル システムからアクセスできるようになります。
- スケーラビリティ: このパターンでは、BigQuery の分析能力を活用して大規模なデータセットを処理し、Spanner のグローバルにスケーラブルなインフラストラクチャを通じて結果を効率的に提供できます。
サービスと用語
- DataBricks - Apache Spark を中心に構築されたクラウドベースのデータ プラットフォーム。
- Spanner - Google がフルマネージドで提供する、グローバルに分散されたリレーショナル データベース。
- Google Cloud Storage - Google Cloud の BLOB ストレージ サービス。
- BigQuery - Google がフルマネージドで提供する分析用のサーバーレス データ ウェアハウス。
- Iceberg - Apache によって定義されたオープン テーブル形式。一般的なオープンソースのデータファイル形式の抽象化を提供します。
- Parquet - Apache によるオープンソースのカラム型バイナリ データファイル形式。
学習内容
- データを Iceberg テーブルとして Databricks に読み込む方法
- GCS バケットの作成方法
- Databricks テーブルを Iceberg 形式で GCS にエクスポートする方法
- GCS の Iceberg テーブルから BigQuery に BigLake 外部テーブルを作成する方法
- Spanner インスタンスを設定する方法
- BigQuery の BigLake 外部テーブルを Spanner に読み込む方法
2. 設定、要件、制限事項
前提条件
- Databricks アカウント(できれば GCP 上)
- BigQuery から Spanner にエクスポートするには、BigQuery の Enterprise ティア以上の予約がある Google Cloud アカウントが必要です。
- ウェブブラウザを介した Google Cloud コンソールへのアクセス
- Google Cloud CLI コマンドを実行するターミナル
Google Cloud 組織で iam.allowedPolicyMemberDomains ポリシーが有効になっている場合、管理者は外部ドメインのサービス アカウントを許可する例外を付与する必要がある場合があります。該当する場合は、後のステップで説明します。
要件
- 課金を有効にした Google Cloud プロジェクト
- ウェブブラウザ(Chrome など)
- Databricks アカウント(このラボでは、GCP でホストされているワークスペースを想定しています)
- EXPORT DATA 機能を使用するには、BigQuery インスタンスが Enterprise エディション以上である必要があります。
- Google Cloud 組織で
iam.allowedPolicyMemberDomainsポリシーが有効になっている場合、管理者は外部ドメインのサービス アカウントを許可する例外を付与する必要がある場合があります。該当する場合は、後のステップで説明します。
Google Cloud Platform IAM 権限
この Codelab のすべての手順を実行するには、Google アカウントに次の権限が必要です。
サービス アカウント | ||
| サービス アカウントの作成を許可します。 | |
Spanner | ||
| 新しい Spanner インスタンスの作成を許可します。 | |
| DDL ステートメントを実行して作成することを許可します | |
| DDL ステートメントを実行してデータベースにテーブルを作成できます。 | |
Google Cloud Storage | ||
| エクスポートされた Parquet ファイルを保存する新しい GCS バケットを作成できます。 | |
| エクスポートされた Parquet ファイルを GCS バケットに書き込むことを許可します。 | |
| BigQuery が GCS バケットから Parquet ファイルを読み取れるようにします。 | |
| BigQuery が GCS バケット内の Parquet ファイルを一覧表示できるようにします。 | |
Dataflow | ||
| Dataflow からの作業項目の取得を許可します。 | |
| Dataflow ワーカーが Dataflow サービスにメッセージを送信できるようにします。 | |
| Dataflow ワーカーが Google Cloud Logging にログエントリを書き込むことを許可します。 | |
便宜上、これらの権限を含む事前定義ロールを使用できます。
|
|
|
|
|
|
|
|
Google Cloud プロジェクト
プロジェクトは、Google Cloud の基本的な組織単位です。管理者が使用するものを指定している場合は、この手順をスキップできます。
プロジェクトは、次のように CLI を使用して作成できます。
gcloud projects create <your-project-name>
プロジェクトの作成と管理について詳しくは、こちらをご覧ください。
制限事項
このパイプラインで発生する可能性のある特定の制限事項とデータ型の非互換性を認識しておくことが重要です。
Databricks Iceberg から BigQuery への移行
BigQuery を使用して Databricks で管理されている Iceberg テーブル(UniForm 経由)にクエリを実行する場合は、次の点に注意してください。
- スキーマの進化: UniForm は Delta Lake スキーマの変更を Iceberg に適切に変換しますが、複雑な変更は想定どおりに伝播されない場合があります。たとえば、Delta Lake で列の名前を変更しても、Iceberg には反映されません。Iceberg では、
dropとaddとして認識されます。スキーマの変更は常に徹底的にテストしてください。 - タイムトラベル: BigQuery は Delta Lake のタイムトラベル機能を使用できません。Iceberg テーブルの最新のスナップショットに対してのみクエリを実行します。
- サポートされていない Delta Lake の機能: Delta Lake の削除ベクトルや
idモードの列マッピングなどの機能は、Iceberg の UniForm と互換性がありません。このラボでは、サポートされている列マッピングにnameモードを使用します。
BigQuery to Spanner
BigQuery から Spanner への EXPORT DATA コマンドは、すべての BigQuery データ型をサポートしていません。次のタイプのテーブルをエクスポートすると、エラーが発生します。
STRUCTGEOGRAPHYDATETIMERANGETIME
また、BigQuery プロジェクトで GoogleSQL 言語が使用されている場合、次の数値型も Spanner へのエクスポートでサポートされません。
BIGNUMERIC
制限事項の完全な最新リストについては、公式ドキュメントの Spanner へのエクスポートの制限事項をご覧ください。
トラブルシューティングと注意点
- GCP Databricks インスタンスにない場合、GCS で外部データ ロケーションを定義できないことがあります。このような場合は、ファイルを Databricks ワークスペースのクラウド プロバイダのストレージ ソリューションにステージングしてから、GCS に個別に移行する必要があります。
- この場合、メタデータにステージングされたファイルへのパスがハードコードされているため、メタデータの調整が必要になります。
3. Google Cloud Storage(GCS)を設定する
Google Cloud Storage(GCS)は、Databricks によって生成された Parquet データファイルの保存に使用されます。そのためには、まずファイルの宛先として使用する新しいバケットを作成する必要があります。
Google Cloud Storage
新しいバケットの作成
- クラウド コンソールで Google Cloud Storage ページに移動します。
- 左側のパネルで [バケット] を選択します。
- [Create] ボタンをクリックします。

- バケットの詳細を入力します。
- 使用するバケット名を選択します。このラボでは、名前
codelabs_retl_databricksを使用します。 - バケットを保存するリージョンを選択するか、デフォルト値を使用します。
- ストレージ クラスを
standardとして保持 - [アクセス制御] のデフォルト値をそのまま使用する
- オブジェクト データを保護するのデフォルト値をそのまま使用する
- 完了したら、
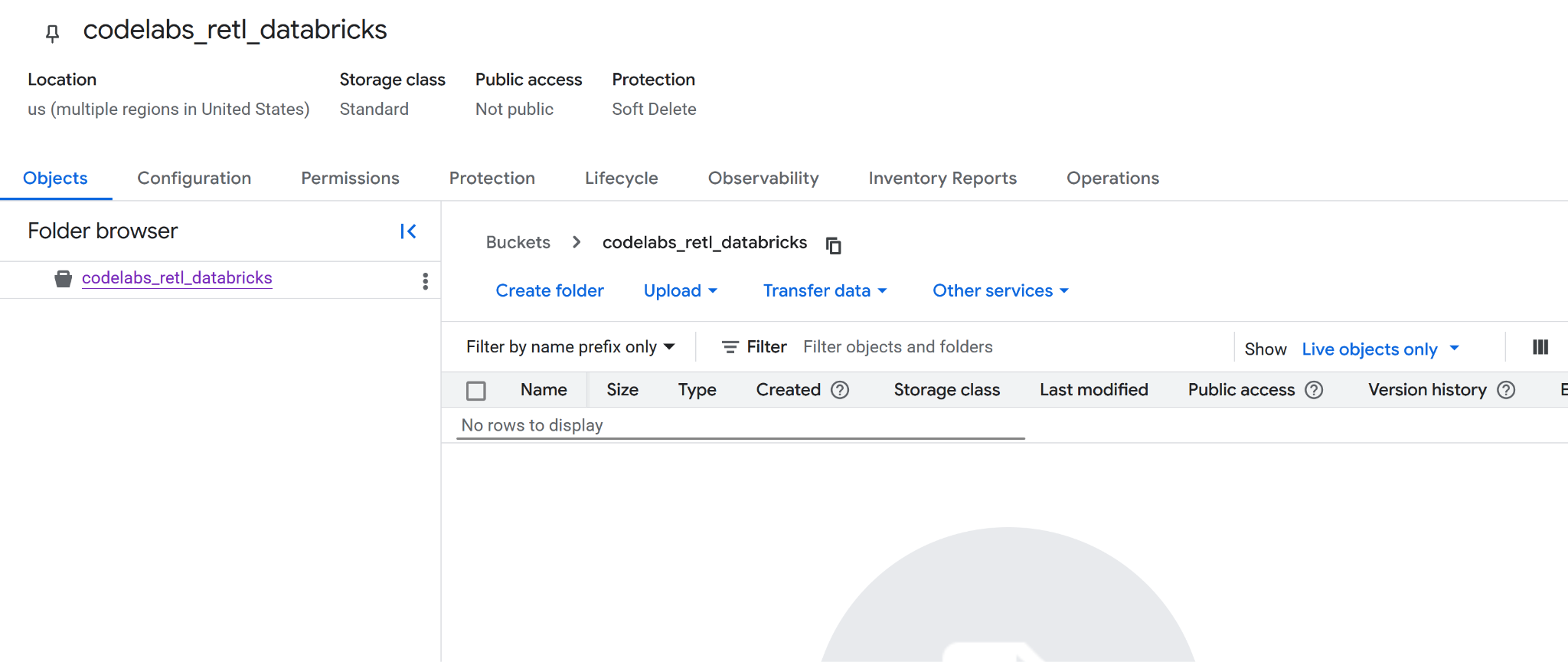
Createボタンをクリックします。公開アクセスが禁止されることを確認するプロンプトが表示されることがあります。確認してください。 - 新しいバケットが正常に作成されました。バケット ページにリダイレクトされます。
- 新しいバケット名は後で必要になるため、どこかにコピーしておきます。
次のステップの準備
次の手順で必要になるため、以下の詳細をメモしておきます。
- Google プロジェクト ID
- Google Storage バケット名
4. Databricks を設定する
TPC-H データ
このラボでは、意思決定支援システムの業界標準ベンチマークである TPC-H データセットを使用します。このスキーマは、顧客、注文、サプライヤー、部品を含む現実的なビジネス環境をモデル化しているため、実際の分析とデータ移動のシナリオをデモンストレーションするのに最適です。
正規化された TPC-H テーブルの代わりに、新しい集計テーブルが作成されます。この新しいテーブルは、orders、customer、nation の各テーブルのデータを結合して、地域別売上の非正規化された概要ビューを生成します。この事前集計ステップは、特定のユースケース(このシナリオでは運用アプリケーションによる使用)向けにデータを準備するため、分析で一般的に行われています。
集計テーブルの最終的なスキーマは次のようになります。
Col | 型 |
nation_name | 文字列 |
market_segment | 文字列 |
order_year | int |
order_priority | 文字列 |
total_order_count | bigint |
total_revenue | decimal(29,2) |
unique_customer_count | bigint |
Delta Lake Universal Format(UniForm)による Iceberg のサポート
このラボでは、Databricks 内のテーブルは Delta Lake テーブルになります。ただし、BigQuery などの外部システムで読み取れるように、ユニバーサル形式(UniForm)という強力な機能が有効になります。
UniForm は、テーブルデータの単一の共有コピーの Delta Lake メタデータとともに Iceberg メタデータを自動的に生成します。これにより、両方の利点を活かすことができます。
- Databricks の内部: Delta Lake のパフォーマンスとガバナンスのメリットをすべて享受できます。
- Databricks の外部: BigQuery などの Iceberg 互換のクエリエンジンは、ネイティブの Iceberg テーブルと同様にテーブルを読み取ることができます。
これにより、データの個別のコピーを保持したり、手動で変換ジョブを実行したりする必要がなくなります。UniForm は、テーブルの作成時に特定のテーブル プロパティを設定することで有効になります。
Databricks カタログ
Databricks カタログは、Databricks の統合ガバナンス ソリューションである Unity Catalog のデータの上位コンテナです。Unity Catalog は、データアセットの管理、アクセスの制御、リネージの追跡を一元的に行う方法を提供します。これは、適切に管理されたデータ プラットフォームにとって不可欠です。
3 レベルの名前空間を使用して、catalog.schema.table のようにデータを整理します。
- カタログ: 最上位レベル。環境、ビジネス ユニット、プロジェクトごとにデータをグループ化するために使用されます。
- スキーマ(またはデータベース): カタログ内のテーブル、ビュー、関数の論理グループ。
- テーブル: データを含むオブジェクト。
集計された TPC-H テーブルを作成する前に、まず専用のカタログとスキーマを設定して、そのテーブルを格納する必要があります。これにより、プロジェクトが整理され、ワークスペース内の他のデータから分離されます。
新しいカタログとスキーマを作成する
Databricks Unity Catalog では、カタログはデータアセットの最上位の組織レベルとして機能し、複数の Databricks ワークスペースにまたがる安全なコンテナとして機能します。これにより、ビジネス ユニット、プロジェクト、環境に基づいてデータを整理して分離し、権限とアクセス制御を明確に定義できます。
カタログ内では、スキーマ(データベースとも呼ばれます)によってテーブル、ビュー、関数がさらに整理されます。この階層構造により、関連するデータ オブジェクトをきめ細かく制御し、論理的にグループ化できます。このラボでは、TPC-H データを格納するための専用のカタログとスキーマを作成し、適切な分離と管理を確保します。
カタログの作成
 に移動します
に移動します- [+] をクリックし、プルダウンから [カタログを作成] を選択します。
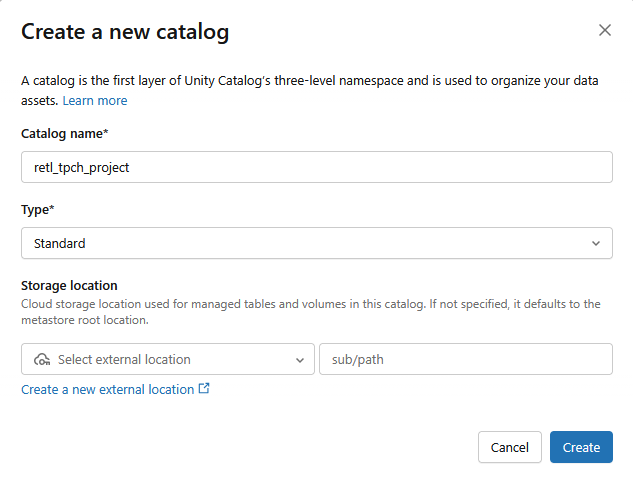
- 次の設定で新しい Standard カタログが作成されます。
- カタログ名:
retl_tpch_project - 保管場所: ワークスペースに設定されている場合はデフォルトを使用するか、新しい保管場所を作成します。
スキーマの作成
- に移動します
- 左側のパネルで、作成した新しいカタログを選択します。
 をクリックします。
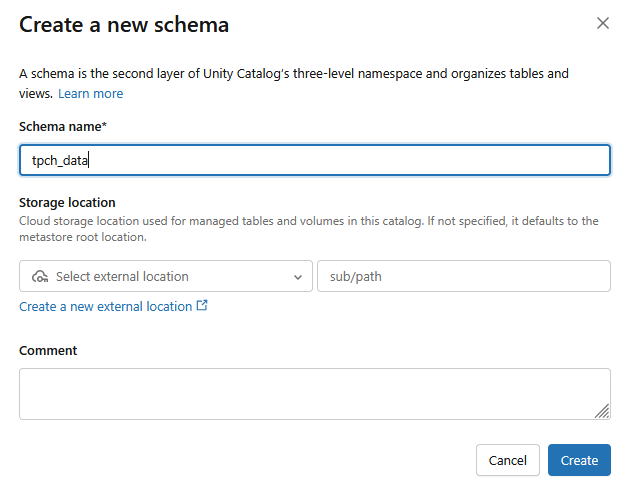
をクリックします。- スキーマ名が
tpch_dataの新しいスキーマが作成されます。
外部データの設定
Databricks から Google Cloud Storage(GCS)にデータをエクスポートするには、Databricks 内で外部データの認証情報を設定する必要があります。これにより、Databricks は GCS バケットに安全にアクセスして書き込むことができます。
- [カタログ] 画面で、
 をクリックします。
をクリックします。
External Dataオプションが表示されない場合は、代わりにConnectプルダウンにExternal Locationsが表示されることがあります。
 をクリックします。
をクリックします。- 新しいダイアログ ウィンドウで、認証情報の必要な値を設定します。
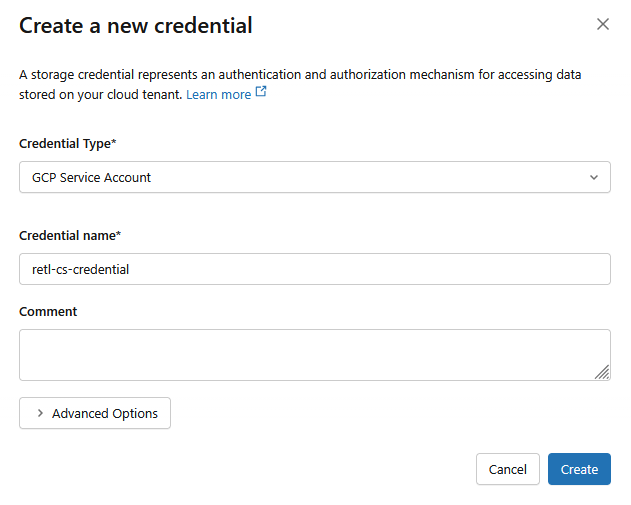
- 認証情報のタイプ:
GCP Service Account - Credential Name:
retl-gcs-credential
- [作成] をクリックします。
- 次に、[外部の場所] タブをクリックします。
- [Create location] をクリックします。
- 新しいダイアログ ウィンドウで、外部ロケーションに必要な値を設定します。
- 外部ロケーション名:
retl-gcs-location - ストレージの種類:
GCP。 - URL: GCS バケットの URL。形式は
gs://YOUR_BUCKET_NAMEです。 - ストレージ認証情報: 作成した
retl-gcs-credentialを選択します。
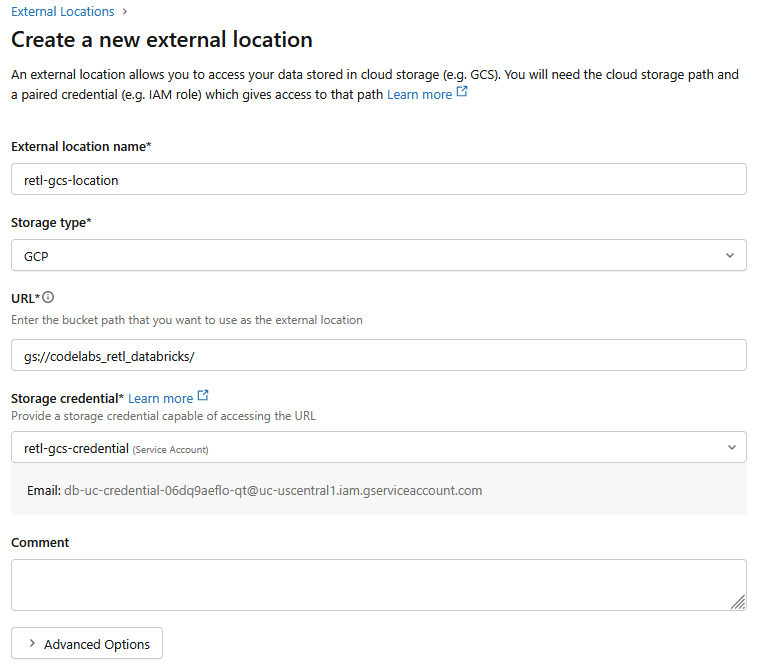
- [ストレージ認証情報] を選択すると自動的に入力されるサービス アカウントのメールアドレスをメモします。これは次のステップで必要になります。
- [作成] をクリックします。
5. サービス アカウントの権限の設定
サービス アカウントは、アプリケーションやサービスが Google Cloud リソースに対して承認済みの API 呼び出しを行うために使用する特別なアカウント タイプです。
GCS の新しいバケット用に作成されたサービス アカウントに権限を追加する必要があります。
- GCS バケットのページで、[権限] タブを選択します。
- プリンシパル ページで [アクセス権を付与] をクリックします。
- 右からスライドアウトする [アクセス権の付与] パネルで、[新しいプリンシパル] フィールドにサービス アカウント ID を入力します。
- [ロールを割り当てる] で、
Storage Object AdminとStorage Legacy Bucket Readerを追加します。これらのロールにより、サービス アカウントはストレージ バケット内のオブジェクトの読み取り、書き込み、一覧表示を行うことができます。
TPC-H データを読み込む
カタログとスキーマが作成されたので、Databricks に内部的に保存されている既存の samples.tpch テーブルから TPCH データを読み込み、新しく定義されたスキーマの新しいテーブルに操作できます。
Iceberg サポートを使用してテーブルを作成する
UniForm との Iceberg の互換性
Databricks は、このテーブルを内部的に Delta Lake テーブルとして管理し、Databricks エコシステム内で Delta のパフォーマンス最適化とガバナンス機能のすべてのメリットを提供します。ただし、UniForm(Universal Format の略)を有効にすると、Databricks に特別な処理が指示されます。テーブルが更新されるたびに、Databricks は Delta Lake メタデータに加えて、対応する Iceberg メタデータを自動的に生成して維持します。
つまり、単一の共有データファイル(Parquet ファイル)が 2 つの異なるメタデータセットで記述されるようになります。
- Databricks の場合:
_delta_logを使用してテーブルを読み取ります。 - 外部リーダー(BigQuery など)の場合: Iceberg メタデータ ファイル(
.metadata.json)を使用して、テーブルのスキーマ、パーティショニング、ファイル ロケーションを把握します。
結果は、Iceberg 対応のツールと完全に透過的に互換性のあるテーブルになります。データの重複はなく、手動での変換や同期は必要ありません。これは、Databricks の分析環境と、オープン Iceberg 標準をサポートする幅広いツール エコシステムの両方からシームレスにアクセスできる信頼できる単一のソースです。
- [新規]、[クエリ] の順にクリックします。
- クエリページのテキスト フィールドで、次の SQL コマンドを実行します。
CREATE TABLE retl_tpch_project.tpch_data.regional_sales_iceberg
USING DELTA
LOCATION 'gs://<Your bucket name>/regional_sales_iceberg'
TBLPROPERTIES (
'delta.columnMapping.mode' = 'name',
'delta.enableIcebergCompatV2' = 'true',
'delta.universalFormat.enabledFormats' = 'iceberg'
)
AS
SELECT
n.n_name AS nation_name,
c.c_mktsegment AS market_segment,
YEAR(o.o_orderdate) AS order_year,
o.o_orderpriority AS order_priority,
COUNT(o.o_orderkey) AS total_order_count,
ROUND(SUM(o.o_totalprice), 2) AS total_revenue,
COUNT(DISTINCT c.c_custkey) AS unique_customer_count
FROM samples.tpch.orders AS o
INNER JOIN samples.tpch.customer AS c
ON o.o_custkey = c.c_custkey
INNER JOIN samples.tpch.nation AS n
ON c.c_nationkey = n.n_nationkey
GROUP BY
n.n_name,
c.c_mktsegment,
YEAR(o.o_orderdate),
o.o_orderpriority;
OPTIMIZE retl_tpch_project.tpch_data.regional_sales_iceberg;
DESCRIBE EXTENDED retl_tpch_project.tpch_data.regional_sales_iceberg;
注:
- Using Delta - Delta Lake テーブルを使用することを指定します。Databricks の Delta Lake テーブルのみを外部テーブルとして保存できます。
- ロケーション - 外部テーブルの場合、テーブルの保存場所を指定します。
- TablePropertoes -
delta.universalFormat.enabledFormats = ‘iceberg'は、Delta Lake ファイルとともに互換性のある Iceberg メタデータを作成します。 - 最適化 - 通常は非同期で行われる UniForm メタデータの生成を強制的にトリガーします。
- クエリの出力には、新しく作成されたテーブルの詳細が表示されます。

GCS テーブルのデータを確認する
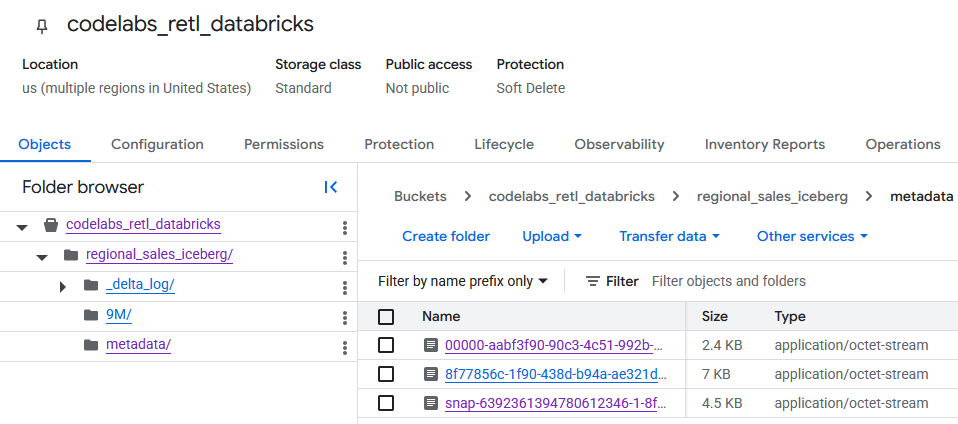
GCS バケットに移動すると、新しく作成されたテーブルデータが見つかります。
Iceberg メタデータは metadata フォルダにあります。このフォルダは、外部リーダー(BigQuery など)で使用されます。Databricks が内部で使用する Delta Lake メタデータは、_delta_log フォルダで追跡されます。
実際のテーブルデータは、別のフォルダ内の Parquet ファイルとして保存されます。通常、このフォルダの名前は Databricks によってランダムに生成された文字列になります。たとえば、次のスクリーンショットでは、データファイルは 9M フォルダにあります。
6. BigQuery と BigLake を設定する
Iceberg テーブルが Google Cloud Storage に配置されたので、次は BigQuery からアクセスできるようにします。これは、BigLake 外部テーブルを作成することで行われます。
BigLake は、Google Cloud Storage などの外部ソースからデータを直接読み取る BigQuery でテーブルを作成できるストレージ エンジンです。このラボでは、このテクノロジーが、データを取り込むことなく、エクスポートされたばかりの Iceberg テーブルを BigQuery が理解できるようにする重要な役割を果たします。
これを機能させるには、次の 2 つのコンポーネントが必要です。
- Cloud リソース接続: BigQuery と GCS 間の安全なリンクです。認証を処理するために特別なサービス アカウントを使用し、BigQuery に GCS バケットからファイルを読み取るために必要な権限があることを確認します。
- 外部テーブル定義: これは、GCS で Iceberg テーブルのメタデータ ファイルを見つける場所と、その解釈方法を BigQuery に伝えます。
クラウド リソース接続を作成する
まず、BigQuery が GCS にアクセスできるようにする接続が作成されます。
Cloud リソース接続の作成の詳細については、こちらをご覧ください。
- BigQuery に移動します。
- [エクスプローラ] の [接続] をクリックします。
- [エクスプローラ] プレーンが表示されていない場合は、
 をクリックします。
をクリックします。
- [接続] ページで、
 をクリックします。
をクリックします。 - [接続タイプ] で
Vertex AI remote models, remote functions, BigLake and Spanner (Cloud Resource)を選択します。 - 接続 ID を
databricks_retlに設定して接続を作成する

- 新しく作成された接続の [接続] テーブルにエントリが表示されます。そのエントリをクリックすると、接続の詳細が表示されます。

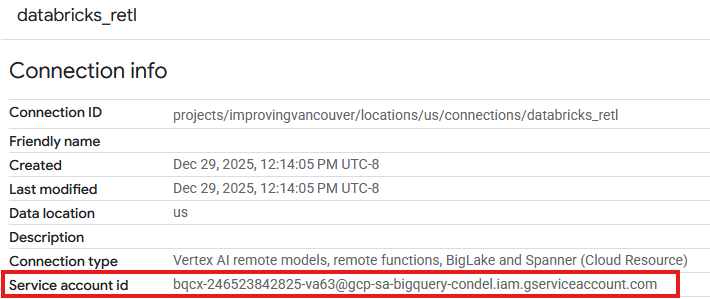
- 接続の詳細ページで、後で必要になるため、サービス アカウント ID をメモしておきます。
接続サービス アカウントへのアクセス権を付与する
- [IAM と管理] に移動します。
- [アクセス権を付与] をクリックします。
- [新しいプリンシパル] フィールドに、上記で作成した接続リソースのサービス アカウント ID を入力します。
- [ロール] で
Storage Object Userを選択し、 をクリックします。
をクリックします。
接続が確立され、そのサービス アカウントに必要な権限が付与されたので、BigLake 外部テーブルを作成できます。まず、新しいテーブルのコンテナとして機能する Dataset が BigQuery に必要です。次に、テーブル自体が作成され、GCS バケット内の Iceberg メタデータ ファイルが指定されます。
- BigQuery に移動します。
- [エクスプローラ] パネルでプロジェクト ID をクリックし、その他アイコンをクリックして [データセットを作成] を選択します。
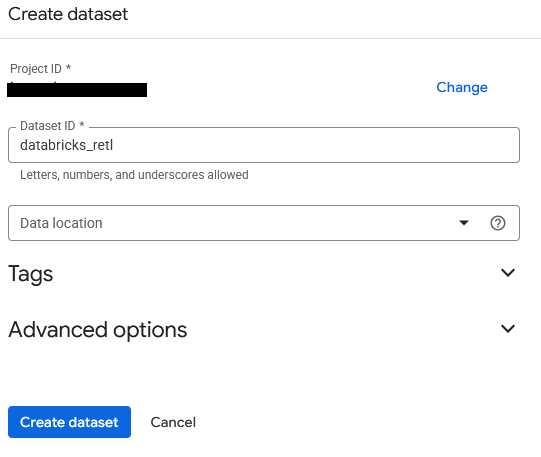
- データセットの名前は
databricks_retlになります。他のオプションはデフォルトのままにして、[データセットを作成] ボタンをクリックします。
- [エクスプローラ] パネルで、新しい
databricks_retlデータセットを見つけます。その横にあるその他アイコンをクリックし、[テーブルを作成] を選択します。
- テーブル作成の次の設定を入力します。
- テーブルの作成元:
Google Cloud Storage - GCS バケットからファイルを選択するか、URI パターンを使用する: GCS バケットを参照し、Databricks のエクスポート時に生成されたメタデータ JSON ファイルを見つけます。パスは
regional_sales/metadata/v1.metadata.jsonのようになります。 - ファイル形式:
Iceberg - テーブル:
regional_sales - テーブルタイプ:
External table - 接続 ID: 先ほど作成した
databricks_retl接続を選択します。 - 残りの値はデフォルトのままにして、[テーブルを作成] をクリックします。
- 作成が完了すると、新しい
regional_salesテーブルがdatabricks_retlデータセットの下に表示されます。このテーブルは、他の BigQuery テーブルと同様に、標準 SQL を使用してクエリできるようになりました。
7. Spanner に読み込む
パイプラインの最終的かつ最も重要な部分に到達しました。BigLake 外部テーブルから Spanner にデータを移動します。これは「リバース ETL」ステップです。データ ウェアハウスで処理およびキュレーションされたデータが、アプリケーションで使用するために運用システムに読み込まれます。
Spanner は、グローバルに分散されたフルマネージドのリレーショナル データベースです。従来のリレーショナル データベースのトランザクション整合性を維持しながら、NoSQL データベースの水平スケーラビリティを実現します。そのため、スケーラブルで高可用性の高いアプリケーションの構築に最適です。
プロセスは次のとおりです。
- リソースの物理割り当てである Spanner インスタンスを作成します。
- そのインスタンス内にデータベースを作成します。
regional_salesデータの構造と一致するテーブル スキーマをデータベースに定義します。- BigQuery の
EXPORT DATAクエリを実行して、BigLake テーブルから Spanner テーブルにデータを直接読み込みます。
Spanner のインスタンス、データベース、テーブルを作成する
- Spanner に移動します。
 をクリックします。既存のインスタンスがある場合は、それを使用してもかまいません。必要に応じてインスタンスの要件を設定します。このラボでは、次のものを使用しました。
をクリックします。既存のインスタンスがある場合は、それを使用してもかまいません。必要に応じてインスタンスの要件を設定します。このラボでは、次のものを使用しました。
エディション | Enterprise |
インスタンス名 | databricks-retl |
リージョン構成 | 選択したリージョン |
コンピューティング ユニット | 処理ユニット(PU) |
手動割り当て | 100 |
- 作成したら、Spanner インスタンス ページに移動して
 を選択します。既存のデータベースがある場合は、それを使用してもかまいません。
を選択します。既存のデータベースがある場合は、それを使用してもかまいません。
- このラボでは、次の構成でデータベースを作成します。
- パラメータ名:
databricks-retl - Database Dialect:
Google Standard SQL
- データベースが作成されたら、Spanner インスタンス ページで選択して、Spanner データベース ページに移動します。
- Spanner データベース ページで、
 をクリックします。
をクリックします。 - 新しいクエリページに、Spanner にインポートするテーブルのテーブル定義が作成されます。これを行うには、次の SQL クエリを実行します。
CREATE TABLE regional_sales (
nation_name STRING(MAX),
market_segment STRING(MAX),
order_year INT64,
order_priority STRING(MAX),
total_order_count INT64,
total_revenue NUMERIC,
unique_customer_count INT64
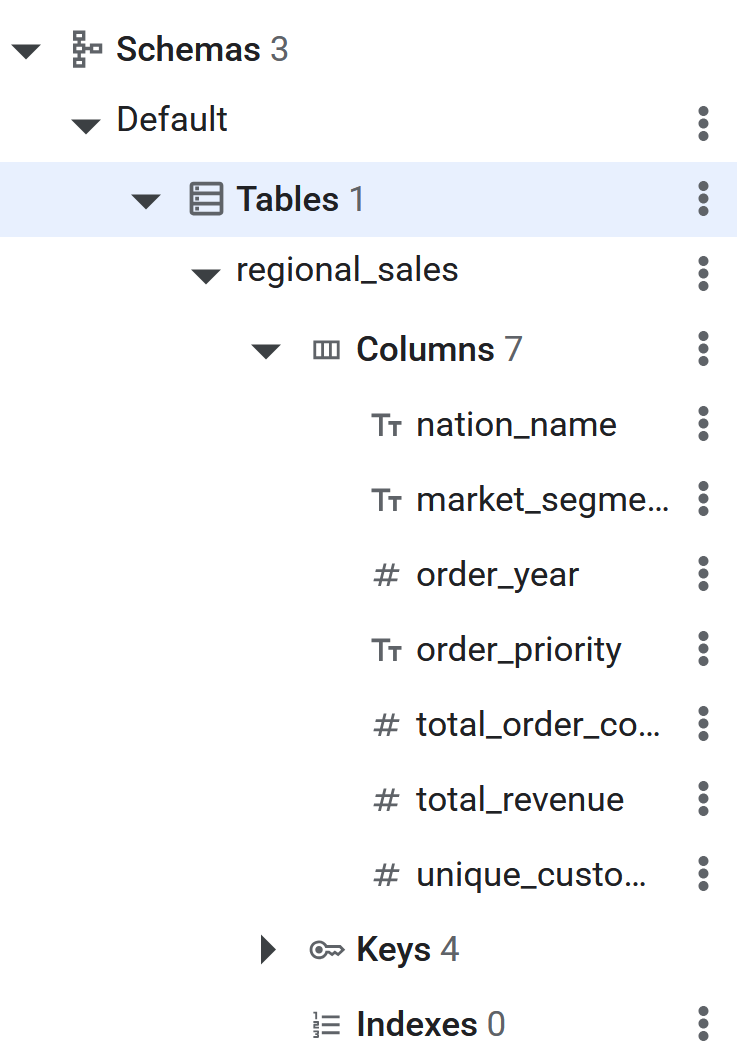
) PRIMARY KEY (nation_name, market_segment, order_year, order_priority);
- SQL コマンドが実行されると、Spanner テーブルは BigQuery がリバース ETL でデータを取得する準備が整います。テーブルの作成は、Spanner データベースの左側のパネルにテーブルが表示されることで確認できます。
EXPORT DATA を使用した Spanner へのリバース ETL
これが最後の手順です。BigQuery BigLake テーブルにソースデータが用意され、Spanner に宛先テーブルが作成されていれば、実際のデータ移動は驚くほど簡単です。単一の BigQuery SQL クエリ EXPORT DATA が使用されます。
このクエリは、このようなシナリオ専用に設計されています。BigQuery テーブル(BigLake テーブルなどの外部テーブルを含む)から外部宛先にデータを効率的にエクスポートします。この場合、宛先は Spanner テーブルです。エクスポート機能について詳しくは、こちらをご覧ください。
BigQuery から Spanner へのリバース ETL の設定の詳細については、こちらをご覧ください。
- BigQuery に移動します。
- 新しいクエリエディタのタブを開きます。
- [クエリ] ページで、次の SQL を入力します。**
uri** **とテーブルパスのプロジェクト ID を正しいプロジェクト ID に置き換えてください。**
EXPORT DATA OPTIONS(
uri='https://spanner.googleapis.com/projects/YOUR_PROJECT_ID/instances/databricks-retl/databases/databricks-retl',
format='CLOUD_SPANNER',
spanner_options="""{
"table": "regional_sales",
"priority": "MEDIUM"
}"""
) AS
SELECT * FROM `YOUR_PROJECT_ID.databricks_retl.regional_sales`;
- コマンドが完了すると、データが Spanner に正常にエクスポートされます。
8. Spanner でデータを検証する
おめでとうございます!完全なリバース ETL パイプラインが正常に構築され、実行されました。これにより、Databricks データ ウェアハウスから運用 Spanner データベースにデータが移動しました。
最後のステップは、データが想定どおりに Spanner に届いたことを確認することです。
- [Spanner] に移動します。
databricks-retlインスタンスに移動し、databricks-retlデータベースに移動します。- テーブルのリストで、
regional_salesテーブルをクリックします。 - テーブルの左側のナビゲーション メニューで、[データ] タブをクリックします。
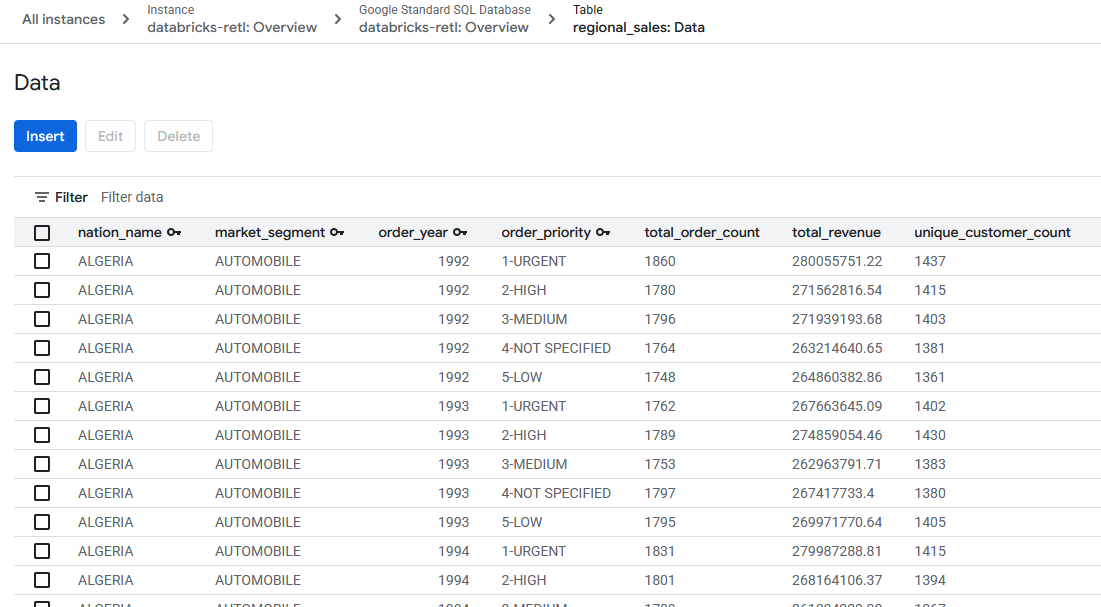
- Databricks から取得した集計販売データが読み込まれ、Spanner テーブルで使用できるようになりました。このデータは運用システムに格納され、ライブ アプリケーションの実行、ダッシュボードの提供、API によるクエリの実行に使用できます。
分析データと運用データのギャップを解消することに成功しました。
9. クリーンアップ
このラボが完了したら、追加したテーブルと保存したデータをすべて削除します。
Spanner テーブルをクリーンアップする
- Spanner に移動します。
databricks-retlという名前のリストから、このラボで使用したインスタンスをクリックします。

- インスタンス ページで
 をクリックします。
をクリックします。 - ポップアップ表示された確認ダイアログで「
databricks-retl」と入力し、[ ] をクリックします。
] をクリックします。
GCS をクリーンアップする
- GCS に移動します。
- 左側のサイドメニューから
 を選択します。
を選択します。 - codelabs_retl_databricks バケットを選択します。
- 選択したら、上部のバナーに表示される
 ボタンをクリックします。
ボタンをクリックします。

- ポップアップ表示された確認ダイアログで「
DELETE」と入力し、[] をクリックします。
Databricks をクリーンアップする
カタログ/スキーマ/テーブルを削除する
- Databricks インスタンスにログインする
- 左側のサイドメニューから
 をクリックします。
をクリックします。 - カタログ リストから、以前に作成した
 を選択します。
を選択します。 - [スキーマ] リストで、作成した
 を選択します。
を選択します。 - テーブル リストから、以前に作成した
 を選択します。
を選択します。  をクリックして表のオプションを開き、
をクリックして表のオプションを開き、Deleteを選択します。- 確認ダイアログで
 をクリックして、テーブルを削除します。
をクリックして、テーブルを削除します。 - テーブルが削除されると、スキーマ ページに戻ります
- をクリックしてスキーマ オプションを開き、
Deleteを選択します。 - 確認ダイアログで をクリックして、スキーマを削除します。
- スキーマが削除されると、カタログ ページに戻ります
- 手順 4 ~ 11 をもう一度実行して、
defaultスキーマが存在する場合は削除します。 - カタログ ページで、 をクリックしてカタログ オプションを開き、
Deleteを選択します。 - 確認ダイアログで をクリックしてカタログを削除します。
外部データの場所 / 認証情報を削除する
- [カタログ] 画面で、 をクリックします。
External Dataオプションが表示されない場合は、代わりにConnectプルダウンにExternal Locationが表示されることがあります。- 以前に作成した
retl-gcs-location外部データ ロケーションをクリックします。 - 外部の場所のページで、 をクリックして場所のオプションを開き、
Deleteを選択します。 - 確認ダイアログで をクリックして、外部ロケーションを削除します。
- をクリックします。
- 前に作成した
retl-gcs-credentialをクリックします。 - 認証情報ページで、 をクリックして認証情報オプションを開き、
Deleteを選択します。 - 確認ダイアログで をクリックして、認証情報を削除します。
10. 完了
以上で、この Codelab は完了です。
学習した内容
- データを Iceberg テーブルとして Databricks に読み込む方法
- GCS バケットの作成方法
- Databricks テーブルを Iceberg 形式で GCS にエクスポートする方法
- GCS の Iceberg テーブルから BigQuery に BigLake 外部テーブルを作成する方法
- Spanner インスタンスを設定する方法
- BigQuery の BigLake 外部テーブルを Spanner に読み込む方法