
1. Tworzenie potoku odwrotnego procesu ETL z Databricks do usługi Spanner z użyciem Google Cloud Storage i BigQuery
Wprowadzenie
W tym ćwiczeniu utworzysz potok odwrotnego procesu ETL z Databricks do usługi Spanner. Tradycyjnie standardowe potoki ETL (Extract, Transform, Load) przenoszą dane z działających baz danych do hurtowni danych, takiej jak Databricks, na potrzeby analizy. Potok Reverse ETL działa odwrotnie: przenosi wyselekcjonowane, przetworzone dane z hurtowni danych z powrotem do operacyjnych baz danych, takich jak Spanner, czyli globalnie rozproszona relacyjna baza danych idealna do aplikacji o wysokiej dostępności. W tych bazach danych może zasilać aplikacje, obsługiwać funkcje dostępne dla użytkowników lub być wykorzystywany do podejmowania decyzji w czasie rzeczywistym.
Celem jest przeniesienie zagregowanego zbioru danych z tabel Iceberg w Databricks do tabel Spanner.
W tym celu jako kroki pośrednie wykorzystywane są Google Cloud Storage (GCS) i BigQuery. Oto opis przepływu danych i uzasadnienie tej architektury:

- Databricks do Google Cloud Storage (GCS) w formacie Iceberg:
- Pierwszym krokiem jest wyeksportowanie danych z Databricks w otwartym, dobrze zdefiniowanym formacie. Tabela jest eksportowana w formacie Apache Iceberg. W ramach tego procesu dane bazowe są zapisywane jako zestaw plików Parquet, a metadane tabeli (schemat, partycje, lokalizacje plików) jako pliki JSON i Avro. Przechowywanie całej struktury tabeli w GCS sprawia, że dane są przenośne i dostępne dla każdego systemu, który rozumie format Iceberg.
- Konwertowanie tabel Iceberg w GCS na zewnętrzne tabele BigLake w BigQuery:
- Zamiast wczytywać dane bezpośrednio z GCS do Spannera, BigQuery jest używany jako wydajny pośrednik. W BigQuery zostanie utworzona zewnętrzna tabela BigLake, która będzie wskazywać bezpośrednio plik metadanych Iceberg w GCS. Takie podejście ma kilka zalet:
- Brak duplikowania danych: BigQuery odczytuje strukturę tabeli z metadanych i wysyła zapytania do plików danych Parquet w miejscu bez ich pozyskiwania, co pozwala zaoszczędzić dużo czasu i kosztów przechowywania.
- Zapytania sfederowane: umożliwiają uruchamianie złożonych zapytań SQL dotyczących danych GCS tak, jakby były one natywną tabelą BigQuery.
- Odwrotne ETL z zewnętrznej tabeli BigLake do Spanner:
- Ostatnim krokiem jest przeniesienie danych z BigQuery do Spannera. Jest to możliwe dzięki zaawansowanej funkcji BigQuery o nazwie
EXPORT DATA, która jest krokiem „odwrotnego ETL”. - Gotowość operacyjna: Spanner został zaprojektowany z myślą o zadaniach transakcyjnych, zapewniając aplikacjom silną spójność i wysoką dostępność. Przeniesienie danych do Spannera sprawia, że stają się one dostępne dla aplikacji, interfejsów API i innych systemów operacyjnych, które wymagają wyszukiwania punktowego z małymi opóźnieniami.
- Skalowalność: ten wzorzec umożliwia wykorzystanie mocy analitycznej BigQuery do przetwarzania dużych zbiorów danych, a następnie wydajne udostępnianie wyników za pomocą globalnie skalowalnej infrastruktury Spanner.
Usługi i terminologia
- DataBricks – platforma danych w chmurze oparta na Apache Spark.
- Spanner – globalnie rozpowszechniona relacyjna baza danych, która jest w pełni zarządzana przez Google.
- Google Cloud Storage – usługa przechowywania obiektów binarnych w chmurze Google.
- BigQuery – bezserwerowa hurtownia danych analitycznych w pełni zarządzana przez Google.
- Iceberg – otwarty format tabeli zdefiniowany przez Apache, który zapewnia abstrakcję nad popularnymi formatami plików danych typu open source.
- Parquet – otwarty format binarnych plików danych w kolumnach opracowany przez Apache.
Czego się nauczysz
- Wczytywanie danych do Databricks jako tabel Iceberg
- Jak utworzyć zasobnik GCS
- Eksportowanie tabeli Databricks do GCS w formacie Iceberg
- Tworzenie tabeli zewnętrznej BigLake w BigQuery na podstawie tabeli Iceberg w GCS
- Konfigurowanie instancji usługi Spanner
- Wczytywanie zewnętrznych tabel BigLake w BigQuery do Spannera
2. Konfiguracja, wymagania i ograniczenia
Wymagania wstępne
- Konto Databricks, najlepiej w GCP
- Aby eksportować dane z BigQuery do Spannera, musisz mieć konto Google Cloud z rezerwacją na poziomie Enterprise lub wyższym w BigQuery.
- Dostęp do konsoli Google Cloud w przeglądarce
- terminal do uruchamiania poleceń Google Cloud CLI;
Jeśli w Twojej organizacji Google Cloud jest włączona zasada iam.allowedPolicyMemberDomains, administrator może przyznać wyjątek, aby zezwolić na konta usługi z domen zewnętrznych. W odpowiednich przypadkach omówimy to w dalszej części procesu.
Wymagania
- Projekt Google Cloud z włączonymi płatnościami.
- przeglądarka, np. Chrome;
- konto Databricks (w tym laboratorium zakłada się, że obszar roboczy jest hostowany w GCP);
- Aby korzystać z funkcji EXPORT DATA, instancja BigQuery musi być w wersji Enterprise lub wyższej.
- Jeśli w Twojej organizacji Google Cloud jest włączona zasada
iam.allowedPolicyMemberDomains, administrator może przyznać wyjątek, aby zezwolić na konta usługi z domen zewnętrznych. W odpowiednich przypadkach omówimy to w dalszej części procesu.
Uprawnienia Google Cloud Platform IAM
Aby wykonać wszystkie czynności w tym ćwiczeniu, musisz mieć na koncie Google te uprawnienia:
Konta usługi | ||
| Umożliwia tworzenie kont usługi. | |
Spanner | ||
| Umożliwia utworzenie nowej instancji usługi Spanner. | |
| Umożliwia uruchamianie instrukcji DDL w celu tworzenia | |
| Umożliwia uruchamianie instrukcji DDL w celu tworzenia tabel w bazie danych. | |
Google Cloud Storage | ||
| Umożliwia utworzenie nowego zasobnika GCS do przechowywania wyeksportowanych plików Parquet. | |
| Umożliwia zapisywanie wyeksportowanych plików Parquet w zasobniku GCS. | |
| Umożliwia BigQuery odczytywanie plików Parquet z zasobnika GCS. | |
| Umożliwia BigQuery wyświetlanie listy plików Parquet w zasobniku GCS. | |
Dataflow | ||
| Umożliwia przejmowanie elementów roboczych z Dataflow. | |
| Umożliwia procesowi roboczemu Dataflow wysyłanie wiadomości z powrotem do usługi Dataflow. | |
| Umożliwia procesom roboczym Dataflow zapisywanie wpisów logów w Google Cloud Logging. | |
Dla wygody możesz użyć zdefiniowanych ról, które zawierają te uprawnienia.
|
|
|
|
|
|
|
|
Projekt Google Cloud
Projekt to podstawowa jednostka organizacji w Google Cloud. Jeśli administrator udostępnił adres e-mail do użycia, ten krok można pominąć.
Projekt można utworzyć za pomocą interfejsu wiersza poleceń w ten sposób:
gcloud projects create <your-project-name>
Więcej informacji o tworzeniu projektów i zarządzaniu nimi znajdziesz tutaj.
Ograniczenia
W tym potoku mogą wystąpić pewne ograniczenia i niezgodności typów danych, o których warto pamiętać.
Databricks Iceberg do BigQuery
Jeśli używasz BigQuery do wykonywania zapytań dotyczących tabel Iceberg zarządzanych przez Databricks (za pomocą UniForm), pamiętaj o tych kwestiach:
- Ewolucja schematu: UniForm dobrze tłumaczy zmiany schematu Delta Lake na Iceberg, ale złożone zmiany mogą nie zawsze być propagowane zgodnie z oczekiwaniami. Na przykład zmiana nazwy kolumn w Delta Lake nie jest przenoszona do Iceberga, który widzi ją jako
dropiadd. Zawsze dokładnie testuj zmiany schematu. - Time Travel: BigQuery nie może korzystać z funkcji Time Travel w Delta Lake. Będzie on wysyłać zapytania tylko do najnowszej migawki tabeli Iceberg.
- Nieobsługiwane funkcje Delta Lake: funkcje takie jak wektory usuwania i mapowanie kolumn w trybie
idw Delta Lake nie są zgodne z UniForm dla Iceberg. Laboratorium używa trybunamedo mapowania kolumn, który jest obsługiwany.
BigQuery do Spanner
Polecenie EXPORT DATA z BigQuery do Spanner nie obsługuje wszystkich typów danych BigQuery. Eksportowanie tabeli z tymi typami danych spowoduje błąd:
STRUCTGEOGRAPHYDATETIMERANGETIME
Jeśli projekt BigQuery używa dialektu GoogleSQL, eksport do Spannera nie obsługuje też tych typów liczbowych:
BIGNUMERIC
Pełną i aktualną listę ograniczeń znajdziesz w oficjalnej dokumentacji: Ograniczenia eksportowania do Spannera.
Rozwiązywanie problemów i pułapki
- Jeśli nie korzystasz z instancji GCP Databricks, zdefiniowanie zewnętrznej lokalizacji danych w GCS może być niemożliwe. W takich przypadkach pliki należy zebrać w rozwiązaniu do przechowywania danych dostawcy chmury, z którego korzysta obszar roboczy Databricks, a następnie przenieść je do GCS osobno.
- W takim przypadku konieczne będzie dostosowanie metadanych, ponieważ informacje będą zawierać zakodowane ścieżki do plików tymczasowych.
3. Konfigurowanie Google Cloud Storage (GCS)
Google Cloud Storage (GCS) będzie używany do przechowywania plików danych Parquet wygenerowanych przez Databricks. W tym celu musisz najpierw utworzyć nowy zasobnik, który będzie miejscem docelowym pliku.
Google Cloud Storage
Tworzenie nowego zasobnika
- W konsoli chmury otwórz stronę Google Cloud Storage.
- W panelu po lewej stronie kliknij Buckets:
- Kliknij przycisk Utwórz:

- Podaj szczegóły zasobnika:
- Wybierz nazwę zasobnika, którego chcesz użyć. W tym module użyjemy nazwy
codelabs_retl_databricks. - Wybierz region, w którym chcesz przechowywać zasobnik, lub użyj wartości domyślnych.
- Pozostaw klasę pamięci masowej jako
standard - Zachowaj domyślne wartości ustawienia Kontroluj dostęp.
- Zachowaj wartości domyślne w przypadku opcji Ochrona danych obiektu.
- Gdy skończysz, kliknij przycisk
Create. Może pojawić się prośba o potwierdzenie, że dostęp publiczny zostanie zablokowany. Potwierdź. - Gratulujemy! Nowy zasobnik został utworzony. Nastąpi przekierowanie na stronę zasobnika.
- Skopiuj nową nazwę zasobnika, ponieważ będzie potrzebna później.
Przygotowanie się do kolejnych kroków
Zapisz te informacje, ponieważ będą potrzebne w dalszych krokach:
- Identyfikator projektu Google
- Nazwa zasobnika Google Storage
4. Konfigurowanie Databricks
Dane TPC-H
W tym laboratorium użyjemy zbioru danych TPC-H, który jest standardowym w branży testem porównawczym systemów wspomagających podejmowanie decyzji. Jego schemat modeluje realistyczne środowisko biznesowe z klientami, zamówieniami, dostawcami i częściami, dzięki czemu idealnie nadaje się do prezentowania rzeczywistego scenariusza analitycznego i przenoszenia danych.
Zamiast korzystać z surowych, znormalizowanych tabel TPC-H, utworzona zostanie nowa, zagregowana tabela. Ta nowa tabela połączy dane z tabel orders, customer i nation, aby utworzyć zdenormalizowany, podsumowany widok sprzedaży regionalnej. Ten krok wstępnej agregacji jest powszechnie stosowany w analityce, ponieważ przygotowuje dane do konkretnego zastosowania – w tym przypadku do wykorzystania przez aplikację operacyjną.
Ostateczny schemat tabeli zbiorczej będzie wyglądać tak:
Col | Typ |
nation_name | ciąg znaków |
market_segment | ciąg znaków |
order_year | int |
order_priority | ciąg znaków |
total_order_count | bigint |
total_revenue | decimal(29,2) |
unique_customer_count | bigint |
Obsługa formatu Iceberg w przypadku uniwersalnego formatu Delta Lake (UniForm)
W tym module tabela w Databricks będzie tabelą Delta Lake. Aby jednak umożliwić odczytywanie danych przez systemy zewnętrzne, takie jak BigQuery, włączona zostanie zaawansowana funkcja o nazwie format uniwersalny (UniForm).
UniForm automatycznie generuje metadane Iceberg wraz z metadanymi Delta Lake dla pojedynczej, udostępnionej kopii danych tabeli. Dzięki temu zyskujesz:
- W Databricks: zyskujesz wszystkie zalety Delta Lake związane ze skutecznością i zarządzaniem.
- Poza Databricks: tabelę może odczytać dowolny silnik zapytań zgodny z Iceberg, np. BigQuery, tak jakby była natywną tabelą Iceberg.
Eliminuje to konieczność przechowywania osobnych kopii danych lub uruchamiania ręcznych zadań konwersji. UniForm zostanie włączony przez ustawienie określonych właściwości tabeli podczas jej tworzenia.
Katalogi Databricks
Katalog Databricks to kontener najwyższego poziomu dla danych w katalogu Unity, ujednoliconym rozwiązaniu do zarządzania Databricks. Unity Catalog zapewnia scentralizowany sposób zarządzania zasobami danych, kontrolowania dostępu i śledzenia historii, co ma kluczowe znaczenie dla dobrze zarządzanej platformy danych.
Do porządkowania danych używa 3-poziomowej przestrzeni nazw: catalog.schema.table.
- Katalog: najwyższy poziom, używany do grupowania danych według środowiska, jednostki biznesowej lub projektu.
- Schemat (lub baza danych): logiczne grupowanie tabel, widoków i funkcji w katalogu.
- Tabela: obiekt zawierający dane.
Zanim będzie można utworzyć zagregowaną tabelę TPC-H, należy najpierw skonfigurować dedykowany katalog i schemat, w których będzie ona przechowywana. Dzięki temu projekt będzie uporządkowany i odseparowany od innych danych w obszarze roboczym.
Tworzenie nowego katalogu i schematu
W katalogu Unity Databricks katalog jest najwyższym poziomem organizacji zasobów danych, pełniąc rolę bezpiecznego kontenera, który może obejmować wiele obszarów roboczych Databricks. Umożliwia organizowanie i izolowanie danych na podstawie jednostek biznesowych, projektów lub środowisk z jasno określonymi uprawnieniami i kontrolą dostępu.
W katalogu schemat (nazywany też bazą danych) dodatkowo porządkuje tabele, widoki i funkcje. Ta hierarchiczna struktura umożliwia szczegółową kontrolę i logiczne grupowanie powiązanych obiektów danych. Na potrzeby tego modułu utworzymy dedykowany katalog i schemat, w których będą przechowywane dane TPC-H, co zapewni odpowiednią izolację i zarządzanie.
Tworzenie katalogu
- Otwórz

- Kliknij +, a potem w menu kliknij Utwórz katalog.
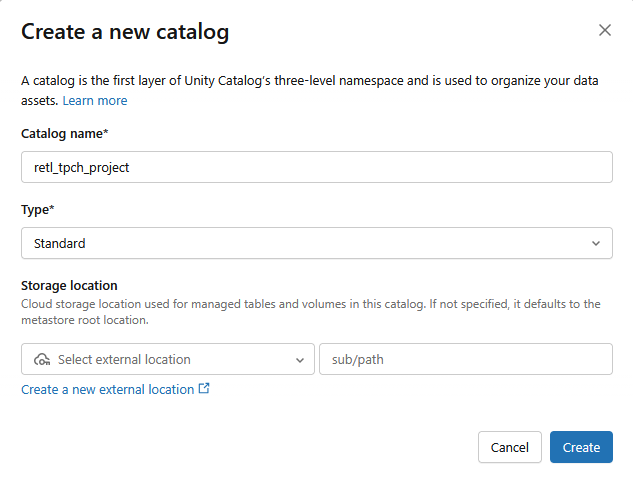
- Zostanie utworzony nowy katalog standardowy z tymi ustawieniami:
- Nazwa katalogu:
retl_tpch_project - Lokalizacja pamięci: użyj domyślnej lokalizacji, jeśli została skonfigurowana w obszarze roboczym, lub utwórz nową.
Tworzenie schematu
- Otwórz
- W panelu po lewej stronie wybierz nowy katalog.
- Kliknij
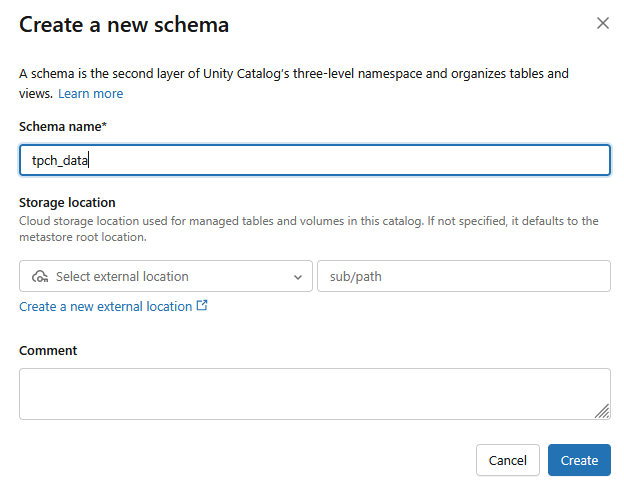
- Zostanie utworzony nowy schemat, którego nazwa będzie mieć postać
tpch_data.
Konfigurowanie danych zewnętrznych
Aby eksportować dane z Databricks do Google Cloud Storage (GCS), musisz skonfigurować w Databricks zewnętrzne dane logowania do źródła danych. Dzięki temu Databricks może bezpiecznie uzyskiwać dostęp do zasobnika GCS i zapisywać w nim dane.
- Na ekranie Katalog kliknij
 .
.
- Jeśli nie widzisz opcji
External Data, możesz znaleźćExternal Locationsna liście w menuConnect.
- Kliknij

- W nowym oknie dialogowym skonfiguruj wymagane wartości danych logowania:
- Typ danych logowania:
GCP Service Account - Nazwa danych logowania:
retl-gcs-credential
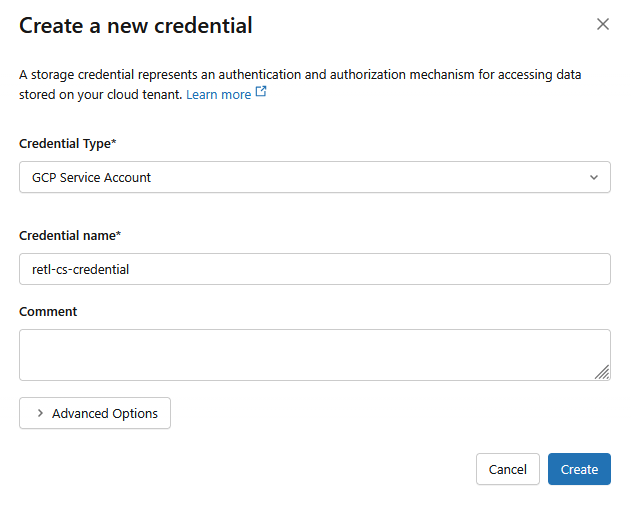
- Kliknij Utwórz.
- Następnie kliknij kartę Lokalizacje zewnętrzne.
- Kliknij Utwórz lokalizację.
- W nowym oknie dialogowym ustaw wymagane wartości dla lokalizacji zewnętrznej:
- Nazwa lokalizacji zewnętrznej:
retl-gcs-location - Typ miejsca na dane:
GCP - URL: adres URL zasobnika GCS w formacie
gs://YOUR_BUCKET_NAME - Dane logowania do pamięci: wybierz utworzone przed chwilą konto
retl-gcs-credential.
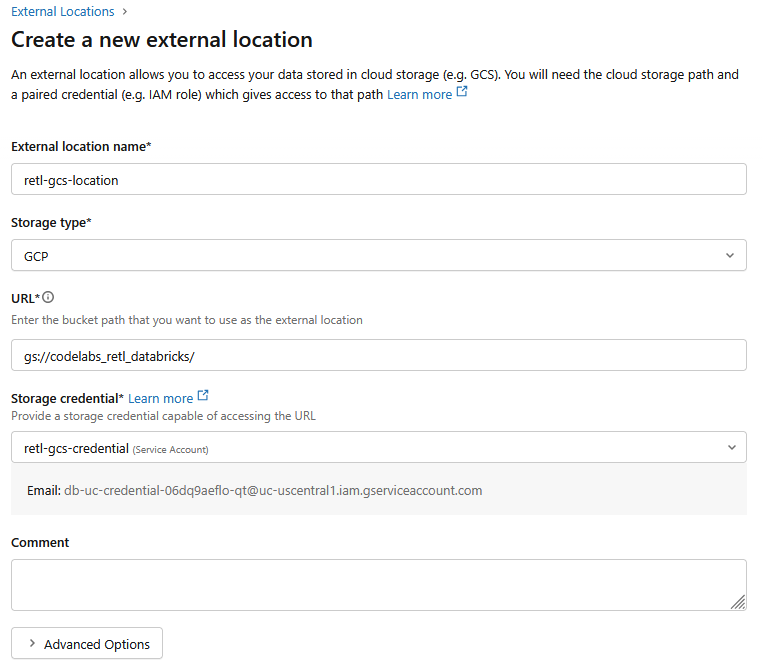
- Zanotuj adres e-mail konta usługi, który zostanie automatycznie wypełniony po wybraniu danych logowania do pamięci masowej, ponieważ będzie potrzebny w następnym kroku.
- Kliknij Utwórz.
5. Ustawianie uprawnień konta usługi
Konto usługi to specjalny rodzaj konta używany przez aplikacje lub usługi do wykonywania autoryzowanych wywołań interfejsu API do zasobów Google Cloud.
Teraz musisz dodać uprawnienia do konta usługi utworzonego dla nowego zasobnika w GCS.
- Na stronie zasobnika GCS kliknij kartę Uprawnienia.
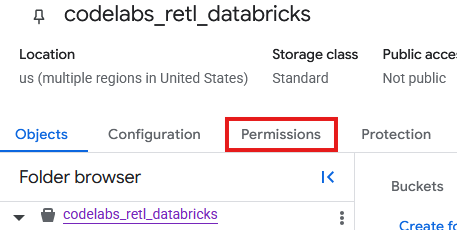
- Na stronie podmiotów zabezpieczeń kliknij Przyznaj dostęp.
- W panelu Przyznaj dostęp, który wysunie się z prawej strony, wpisz identyfikator konta usługi w polu Nowe podmioty zabezpieczeń.
- W sekcji Przypisz role dodaj
Storage Object AdminiStorage Legacy Bucket Reader. Te role umożliwiają kontu usługi odczytywanie, zapisywanie i wyświetlanie obiektów w zasobniku pamięci masowej.
Wczytywanie danych TPC-H
Po utworzeniu katalogu i schematu dane TPCH można wczytać z istniejącej tabeli samples.tpch, która jest przechowywana wewnętrznie w Databricks i przekształcana w nową tabelę w nowo zdefiniowanym schemacie.
Tworzenie tabeli z obsługą formatu Iceberg
Zgodność Iceberg z UniForm
W tle Databricks zarządza tą tabelą jako tabelą Delta Lake, co zapewnia wszystkie korzyści wynikające z optymalizacji wydajności i funkcji zarządzania Delta w ekosystemie Databricks. Jeśli jednak włączysz UniForm (skrót od Universal Format), Databricks otrzyma specjalną instrukcję: za każdym razem, gdy tabela zostanie zaktualizowana, Databricks automatycznie wygeneruje i będzie utrzymywać odpowiednie metadane Iceberg oprócz metadanych Delta Lake.
Oznacza to, że jeden wspólny zestaw plików danych (pliki Parquet) jest teraz opisywany przez 2 różne zestawy metadanych.
- W przypadku Databricks: do odczytywania tabeli używa znaku
_delta_log. - W przypadku zewnętrznych czytników (np. BigQuery): korzystają one z pliku metadanych Iceberg (
.metadata.json), aby poznać schemat tabeli, partycjonowanie i lokalizacje plików.
Wynikiem jest tabela, która jest w pełni i przejrzyście zgodna z każdym narzędziem obsługującym Iceberg. Nie ma duplikowania danych ani potrzeby ręcznej konwersji lub synchronizacji. Jest to jedno źródło informacji, do którego można uzyskać bezproblemowy dostęp zarówno w świecie analitycznym Databricks, jak i w szerszym ekosystemie narzędzi obsługujących otwarty standard Iceberg.
- Kliknij kolejno Nowy i Zapytanie.
- W polu tekstowym na stronie zapytania uruchom to polecenie SQL:
CREATE TABLE retl_tpch_project.tpch_data.regional_sales_iceberg
USING DELTA
LOCATION 'gs://<Your bucket name>/regional_sales_iceberg'
TBLPROPERTIES (
'delta.columnMapping.mode' = 'name',
'delta.enableIcebergCompatV2' = 'true',
'delta.universalFormat.enabledFormats' = 'iceberg'
)
AS
SELECT
n.n_name AS nation_name,
c.c_mktsegment AS market_segment,
YEAR(o.o_orderdate) AS order_year,
o.o_orderpriority AS order_priority,
COUNT(o.o_orderkey) AS total_order_count,
ROUND(SUM(o.o_totalprice), 2) AS total_revenue,
COUNT(DISTINCT c.c_custkey) AS unique_customer_count
FROM samples.tpch.orders AS o
INNER JOIN samples.tpch.customer AS c
ON o.o_custkey = c.c_custkey
INNER JOIN samples.tpch.nation AS n
ON c.c_nationkey = n.n_nationkey
GROUP BY
n.n_name,
c.c_mktsegment,
YEAR(o.o_orderdate),
o.o_orderpriority;
OPTIMIZE retl_tpch_project.tpch_data.regional_sales_iceberg;
DESCRIBE EXTENDED retl_tpch_project.tpch_data.regional_sales_iceberg;
Uwagi:
- Using Delta – określa, że używamy tabeli Delta Lake. Tylko tabele Delta Lake w Databricks można przechowywać jako tabelę zewnętrzną.
- Lokalizacja – określa miejsce przechowywania tabeli, jeśli jest ona zewnętrzna.
- TablePropertoes –
delta.universalFormat.enabledFormats = ‘iceberg'tworzy zgodne metadane Iceberg obok plików Delta Lake. - Optimize – wymusza wygenerowanie metadanych UniForm, ponieważ zwykle odbywa się to asynchronicznie.
- Wynik zapytania powinien zawierać szczegóły nowo utworzonej tabeli.

Weryfikowanie danych tabeli GCS
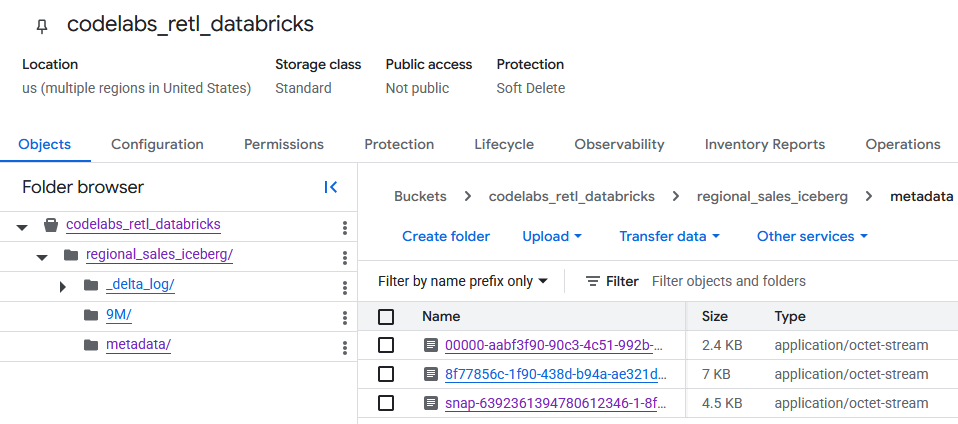
Po przejściu do zasobnika GCS można znaleźć dane nowo utworzonej tabeli.
Metadane Iceberg znajdziesz w folderze metadata, który jest używany przez zewnętrzne czytniki (np. BigQuery). Metadane Delta Lake, których Databricks używa wewnętrznie, są śledzone w folderze _delta_log.
Rzeczywiste dane tabeli są przechowywane jako pliki Parquet w innym folderze, zwykle o nazwie wygenerowanej losowo przez Databricks. Na przykład na zrzucie ekranu poniżej pliki danych znajdują się w folderze 9M.
6. Konfigurowanie BigQuery i BigLake
Tabela Iceberg znajduje się już w Google Cloud Storage. Następnym krokiem jest udostępnienie jej BigQuery. W tym celu utwórz zewnętrzną tabelę BigLake.
BigLake to mechanizm przechowywania danych, który umożliwia tworzenie w BigQuery tabel odczytujących dane bezpośrednio ze źródeł zewnętrznych, takich jak Google Cloud Storage. W tym module jest to kluczowa technologia, która umożliwia BigQuery zrozumienie właśnie wyeksportowanej tabeli Iceberg bez konieczności pozyskiwania danych.
Aby to działało, potrzebne są 2 komponenty:
- Połączenie z zasobem Cloud: jest to bezpieczne połączenie między BigQuery a GCS. Do obsługi uwierzytelniania używa specjalnego konta usługi, dzięki czemu BigQuery ma uprawnienia do odczytywania plików z zasobnika GCS.
- Definicja tabeli zewnętrznej: informuje BigQuery, gdzie w GCS znajduje się plik metadanych tabeli Iceberg i jak należy go interpretować.
Tworzenie połączenia z zasobem Cloud
Najpierw zostanie utworzone połączenie, które umożliwi BigQuery dostęp do GCS.
Więcej informacji o tworzeniu połączeń z zasobami Cloud znajdziesz tutaj
- Otwórz BigQuery
- W sekcji Eksplorator kliknij Połączenia.
- Jeśli panel eksploratora nie jest widoczny, kliknij
 .
.
- Na stronie Połączenia kliknij
 .
. - W polu Typ połączenia wybierz
Vertex AI remote models, remote functions, BigLake and Spanner (Cloud Resource). - Ustaw identyfikator połączenia na
databricks_retli utwórz połączenie.

- W tabeli Połączenia nowo utworzonego połączenia powinien być widoczny wpis. Kliknij ten wpis, aby wyświetlić szczegóły połączenia.

- Na stronie z informacjami o połączeniu zanotuj identyfikator konta usługi, ponieważ będzie on potrzebny później.
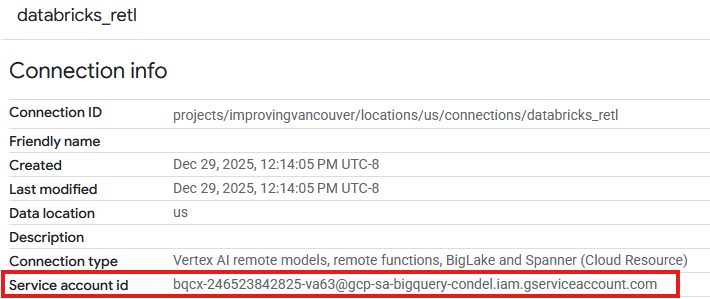
Przyznawanie dostępu do konta usługi połączenia
- Otwórz Uprawnienia i administrację.
- Kliknij Przyznaj dostęp.
- W polu Nowe podmioty zabezpieczeń wpisz utworzony powyżej identyfikator konta usługi zasobu połączenia.
- W polu Rola wybierz
Storage Object User, a następnie kliknij .
.
Po nawiązaniu połączenia i przyznaniu kontu usługi niezbędnych uprawnień można utworzyć zewnętrzną tabelę BigLake. Najpierw w BigQuery potrzebny jest zbiór danych, który będzie kontenerem dla nowej tabeli. Następnie zostanie utworzona sama tabela, która będzie wskazywać plik metadanych Iceberg w zasobniku GCS.
- Otwórz BigQuery
- W panelu Eksplorator kliknij identyfikator projektu, a następnie kliknij 3 kropki i wybierz Utwórz zbiór danych.
- Zbiór danych otrzyma nazwę
databricks_retl. Pozostaw inne opcje bez zmian i kliknij przycisk Utwórz zbiór danych.
- Teraz znajdź nowy zbiór danych
databricks_retlw panelu Eksplorator. Kliknij 3 kropki obok niego i wybierz Utwórz tabelę.
- Skonfiguruj te ustawienia tworzenia tabeli:
- Utwórz tabelę z:
Google Cloud Storage - Wybierz plik z zasobnika w GCS lub użyj wzorca identyfikatora URI: przejdź do zasobnika GCS i znajdź plik JSON z metadanymi, który został wygenerowany podczas eksportowania z Databricks. Ścieżka powinna wyglądać mniej więcej tak:
regional_sales/metadata/v1.metadata.json. - Format pliku:
Iceberg - Tabela:
regional_sales - Typ tabeli:
External table - Identyfikator połączenia: wybierz utworzone wcześniej połączenie
databricks_retl. - Pozostaw pozostałe wartości domyślne, a następnie kliknij Utwórz tabelę.
- Po utworzeniu nowa tabela
regional_salespowinna być widoczna w zbiorze danychdatabricks_retl. Teraz możesz wykonywać na tej tabeli zapytania w standardowej wersji SQL, tak jak w przypadku każdej innej tabeli BigQuery.
7. Wczytywanie do Spannera
Osiągnęliśmy ostatni i najważniejszy etap potoku: przeniesienie danych z tabel zewnętrznych BigLake do Spannera. Jest to krok „Reverse ETL”, w którym dane po przetworzeniu i opracowaniu w hurtowni danych są wczytywane do systemu operacyjnego w celu wykorzystania przez aplikacje.
Spanner to w pełni zarządzana, globalnie rozproszona relacyjna baza danych. Zapewnia spójność transakcyjną tradycyjnej relacyjnej bazy danych, ale z możliwością skalowania w poziomie bazy danych NoSQL. Dzięki temu jest to idealny wybór do tworzenia skalowalnych aplikacji o wysokiej dostępności.
Proces będzie przebiegał w ten sposób:
- Utwórz instancję Spanner, czyli fizyczną alokację zasobów.
- Utwórz bazę danych w tej instancji.
- Zdefiniuj w bazie danych schemat tabeli, który będzie zgodny ze strukturą danych
regional_sales. - Uruchom zapytanie BigQuery
EXPORT DATA, aby wczytać dane z tabeli BigLake bezpośrednio do tabeli Spanner.
Tworzenie instancji, bazy danych i tabeli Spanner
- Otwórz Spanner.
- Kliknij
 . Jeśli jest dostępna, możesz użyć istniejącej instancji. W razie potrzeby skonfiguruj wymagania instancji. Na potrzeby tego laboratorium użyto tych elementów:
. Jeśli jest dostępna, możesz użyć istniejącej instancji. W razie potrzeby skonfiguruj wymagania instancji. Na potrzeby tego laboratorium użyto tych elementów:
Wersja | Enterprise |
Nazwa instancji | databricks-retl |
Konfiguracja regionu | Wybrany region |
Jednostka obliczeniowa | Jednostki przetwarzania |
Przydział ręczny | 100 |
- Po utworzeniu instancji Spannera otwórz jej stronę i kliknij
 . Jeśli masz już bazę danych, możesz jej użyć.
. Jeśli masz już bazę danych, możesz jej użyć.
- Na potrzeby tego laboratorium utworzymy bazę danych z
- Nazwa:
databricks-retl - Dialekt bazy danych:
Google Standard SQL
- Po utworzeniu bazy danych wybierz ją na stronie instancji Spanner, aby przejść na stronę bazy danych Spanner.
- Na stronie Baza danych Spanner kliknij
 .
. - Na nowej stronie zapytania zostanie utworzona definicja tabeli, do której chcesz zaimportować dane do Spannera. Aby to zrobić, uruchom to zapytanie SQL.
CREATE TABLE regional_sales (
nation_name STRING(MAX),
market_segment STRING(MAX),
order_year INT64,
order_priority STRING(MAX),
total_order_count INT64,
total_revenue NUMERIC,
unique_customer_count INT64
) PRIMARY KEY (nation_name, market_segment, order_year, order_priority);
- Po wykonaniu polecenia SQL tabela Spanner będzie gotowa do przeprowadzenia przez BigQuery procesu Reverse ETL. Utworzenie tabeli można sprawdzić, wyświetlając ją na liście w lewym panelu bazy danych Spanner.
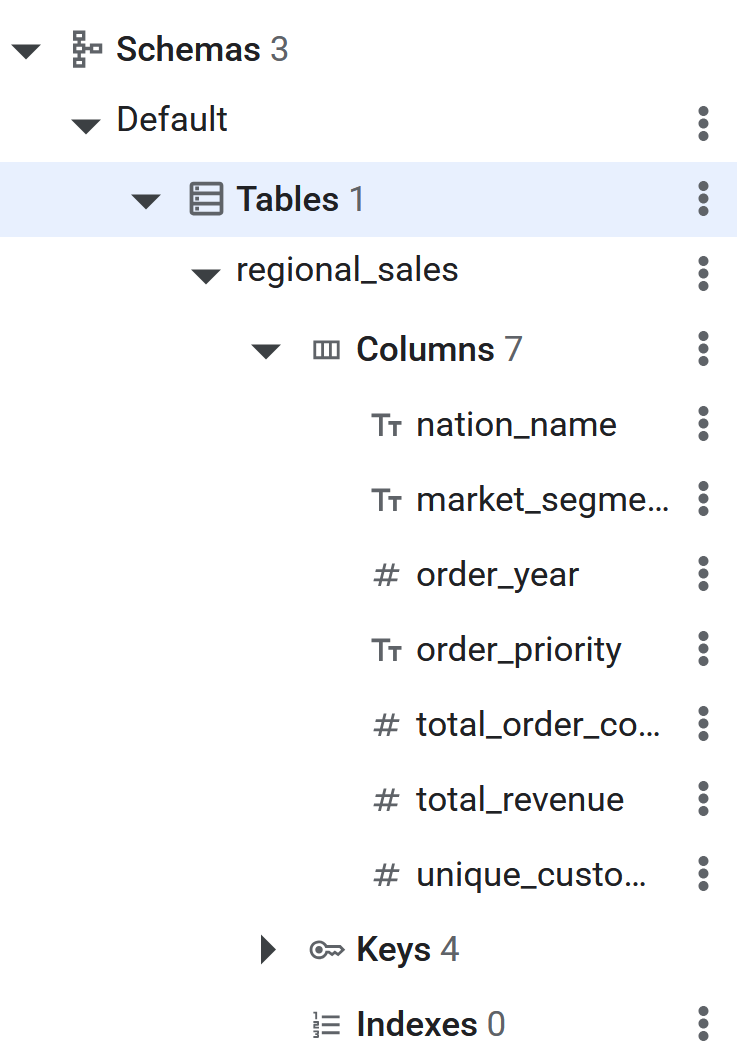
Odwrotny proces ETL do usługi Spanner z użyciem EXPORT DATA
To ostatni krok. Gdy dane źródłowe są gotowe w tabeli BigLake w BigQuery, a tabela docelowa jest utworzona w Spannerze, rzeczywiste przenoszenie danych jest zaskakująco proste. Zostanie użyte jedno zapytanie SQL BigQuery: EXPORT DATA.
To zapytanie zostało zaprojektowane specjalnie na potrzeby takich scenariuszy. Umożliwia wydajne eksportowanie danych z tabeli BigQuery (w tym tabel zewnętrznych, takich jak tabela BigLake) do miejsca docelowego. W tym przypadku miejscem docelowym jest tabela Spannera. Więcej informacji o funkcji eksportowania znajdziesz tutaj.
Więcej informacji o konfigurowaniu odwrotnego ETL z BigQuery do Spanner znajdziesz tutaj.
- Otwórz BigQuery
- Otwórz nową kartę edytora zapytań.
- Na stronie Zapytanie wpisz ten kod SQL. Pamiętaj, aby zastąpić identyfikator projektu w **
uri** **i ścieżkę tabeli prawidłowym identyfikatorem projektu.**
EXPORT DATA OPTIONS(
uri='https://spanner.googleapis.com/projects/YOUR_PROJECT_ID/instances/databricks-retl/databases/databricks-retl',
format='CLOUD_SPANNER',
spanner_options="""{
"table": "regional_sales",
"priority": "MEDIUM"
}"""
) AS
SELECT * FROM `YOUR_PROJECT_ID.databricks_retl.regional_sales`;
- Gdy polecenie zostanie wykonane, dane zostaną wyeksportowane do Spannera.
8. Weryfikowanie danych w usłudze Spanner
Gratulacje! Udało się utworzyć i uruchomić kompletny potok odwrotnego procesu ETL, który przenosi dane z hurtowni danych Databricks do operacyjnej bazy danych Spanner.
Ostatni krok to sprawdzenie, czy dane zostały przesłane do usługi Spanner zgodnie z oczekiwaniami.
- Otwórz Spanner.
- Otwórz instancję
databricks-retl, a potem bazę danychdatabricks-retl. - Na liście tabel kliknij tabelę
regional_sales. - W menu nawigacyjnym po lewej stronie tabeli kliknij kartę Dane.
- Zagregowane dane o sprzedaży, pochodzące pierwotnie z Databricks, powinny być teraz załadowane i gotowe do użycia w tabeli Spanner. Te dane znajdują się teraz w systemie operacyjnym i można ich używać w aplikacji na żywo, wyświetlać w panelu lub wysyłać do nich zapytania za pomocą interfejsu API.
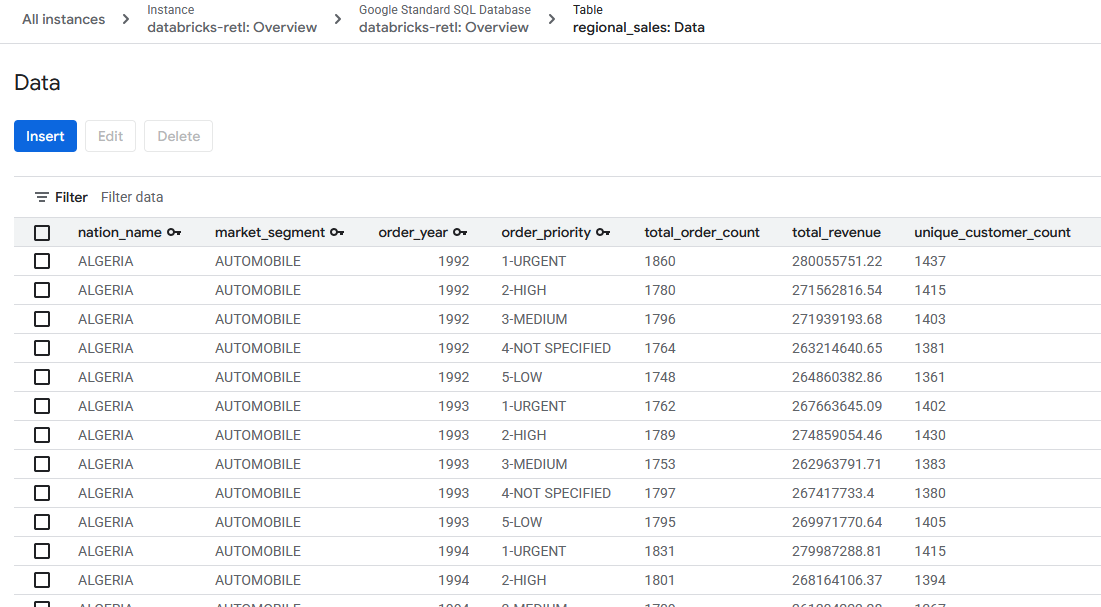
Udało się zlikwidować lukę między światem danych analitycznych a światem danych operacyjnych.
9. Porządkowanie roszczeń
Po zakończeniu tego modułu usuń wszystkie dodane tabele i przechowywane dane.
Zwalnianie miejsca w tabelach Spannera
- Otwórz Spanner
- Na liście o nazwie
databricks-retlkliknij instancję, która została użyta w tym laboratorium.

- Na stronie instancji kliknij
 .
. - W wyświetlonym oknie potwierdzenia wpisz
databricks-retli kliknij .
.
Zwalnianie miejsca w GCS
- Przejdź do GCS
- W menu po lewej stronie kliknij
 .
. - Wybierz zasobnik „codelabs_retl_databricks”.
- Po wybraniu kliknij przycisk
 widoczny na banerze u góry.
widoczny na banerze u góry.

- W wyświetlonym oknie potwierdzenia wpisz
DELETEi kliknij.
Zwalnianie miejsca w Databricks
Usuwanie katalogu, schematu lub tabeli
- Logowanie się w instancji Databricks
- W bocznym menu po lewej stronie kliknij
 .
. - Wybierz z listy katalogu utworzony wcześniej element
 .
. - Na liście Schemat wybierz utworzony wcześniej schemat
 .
. - Wybierz z listy tabeli utworzony wcześniej element
 .
. - Rozwiń opcje tabeli, klikając
 , i wybierz
, i wybierz Delete. - W oknie potwierdzenia kliknij
 , aby usunąć tabelę.
, aby usunąć tabelę. - Po usunięciu tabeli wrócisz na stronę schematu.
- Rozwiń opcje schematu, klikając , i wybierz
Delete. - W oknie potwierdzenia kliknij , aby usunąć schemat.
- Po usunięciu schematu wrócisz na stronę katalogu.
- Aby usunąć schemat
default(jeśli istnieje), ponownie wykonaj kroki 4–11. - Na stronie katalogu rozwiń opcje katalogu, klikając , i wybierz
Delete. - W oknie potwierdzenia kliknij , aby usunąć katalog.
Usuwanie lokalizacji danych zewnętrznych lub danych logowania
- Na ekranie Katalog kliknij .
- Jeśli nie widzisz opcji
External Data, możesz znaleźćExternal Locationna liście w menuConnect. - Kliknij utworzoną wcześniej
retl-gcs-locationzewnętrzną lokalizację danych. - Na stronie lokalizacji zewnętrznej rozwiń opcje lokalizacji, klikając , a następnie wybierz
Delete. - W oknie potwierdzenia kliknij , aby usunąć lokalizację zewnętrzną.
- Kliknij
- Kliknij utworzony wcześniej
retl-gcs-credential. - Na stronie danych logowania rozwiń opcje danych logowania, klikając , i wybierz
Delete. - W oknie potwierdzenia kliknij , aby usunąć dane logowania.
10. Gratulacje
Gratulujemy ukończenia ćwiczenia.
Omówione zagadnienia
- Wczytywanie danych do Databricks jako tabel Iceberg
- Jak utworzyć zasobnik GCS
- Eksportowanie tabeli Databricks do GCS w formacie Iceberg
- Tworzenie tabeli zewnętrznej BigLake w BigQuery na podstawie tabeli Iceberg w GCS
- Konfigurowanie instancji usługi Spanner
- Wczytywanie zewnętrznych tabel BigLake w BigQuery do Spannera