
1. Criar um pipeline de ETL reverso do Databricks para o Spanner usando o Google Cloud Storage e o BigQuery
Introdução
Neste codelab, você vai criar um pipeline de ETL reverso do Databricks para o Spanner. Tradicionalmente, os pipelines padrão de ETL (extração, transformação e carregamento) movem dados de bancos de dados operacionais para um data warehouse, como o Databricks, para análise. Um pipeline de ETL reverso faz o contrário, movendo dados tratados e processados do data warehouse de volta para bancos de dados operacionais, como o Spanner, um banco de dados relacional distribuído globalmente ideal para aplicativos de alta disponibilidade, em que pode alimentar aplicativos, veicular recursos voltados ao usuário ou ser usado para tomada de decisões em tempo real.
O objetivo é mover um conjunto de dados agregados das tabelas do Iceberg do Databricks para as tabelas do Spanner.
Para isso, o Google Cloud Storage (GCS) e o BigQuery são usados como etapas intermediárias. Confira um resumo do fluxo de dados e a lógica por trás dessa arquitetura:

- Databricks para o Google Cloud Storage (GCS) no formato Iceberg:
- A primeira etapa é extrair os dados do Databricks em um formato aberto e bem definido. A tabela é exportada no formato Apache Iceberg. Esse processo grava os dados subjacentes como um conjunto de arquivos Parquet e os metadados da tabela (esquema, partições, locais de arquivos) como arquivos JSON e Avro. Ao armazenar essa estrutura completa de tabelas no GCS, os dados ficam portáteis e acessíveis a qualquer sistema que entenda o formato Iceberg.
- Converter tabelas do Iceberg do GCS em tabelas externas do BigLake do BigQuery:
- Em vez de carregar os dados diretamente do GCS para o Spanner, o BigQuery é usado como um intermediário eficiente. Uma tabela externa do BigLake é criada no BigQuery e aponta diretamente para o arquivo de metadados do Iceberg no GCS. Essa abordagem tem várias vantagens:
- Sem duplicação de dados:o BigQuery lê a estrutura da tabela nos metadados e consulta os arquivos de dados do Parquet no local sem ingerir, o que economiza muito tempo e custos de armazenamento.
- Consultas federadas:permite executar consultas SQL complexas em dados do GCS como se fosse uma tabela nativa do BigQuery.
- ReverseETL da tabela externa do BigLake para o Spanner:
- A etapa final é mover os dados do BigQuery para o Spanner. Isso é feito usando um recurso avançado do BigQuery chamado consulta
EXPORT DATA, que é a etapa de "ETL reverso". - Prontidão operacional:o Spanner foi projetado para cargas de trabalho transacionais, oferecendo consistência forte e alta disponibilidade para aplicativos. Ao mover os dados para o Spanner, eles ficam acessíveis a aplicativos voltados ao usuário, APIs e outros sistemas operacionais que exigem pesquisas pontuais de baixa latência.
- Escalonabilidade:esse padrão permite aproveitar o poder analítico do BigQuery para processar grandes conjuntos de dados e veicular os resultados de maneira eficiente pela infraestrutura globalmente escalonável do Spanner.
Serviços e terminologia
- DataBricks: plataforma de dados baseada na nuvem criada com base no Apache Spark.
- Spanner: um banco de dados relacional distribuído globalmente e totalmente gerenciado pelo Google.
- Google Cloud Storage: oferta de armazenamento de blobs do Google Cloud.
- BigQuery: um data warehouse sem servidor para análises totalmente gerenciado pelo Google.
- Iceberg: um formato de tabela aberta definido pelo Apache que oferece abstração em formatos de arquivo de dados de código aberto comuns.
- Parquet: um formato de arquivo de dados binários colunares de código aberto do Apache.
O que você vai aprender
- Como carregar dados no Databricks como tabelas Iceberg
- Como criar um bucket do GCS
- Como exportar uma tabela do Databricks para o GCS no formato Iceberg
- Como criar uma tabela externa do BigLake no BigQuery com base na tabela do Iceberg no GCS
- Como configurar uma instância do Spanner
- Como carregar tabelas externas do BigLake no BigQuery para o Spanner
2. Configuração, requisitos e limitações
Pré-requisitos
- Uma conta do Databricks, de preferência no GCP
- É necessário ter uma conta do Google Cloud com uma reserva de nível Enterprise ou superior do BigQuery para exportar do BigQuery para o Spanner.
- Acesso ao console do Google Cloud por um navegador da Web
- Um terminal para executar comandos da CLI do Google Cloud
Se a organização do Google Cloud tiver a política iam.allowedPolicyMemberDomains ativada, um administrador talvez precise conceder uma exceção para permitir contas de serviço de domínios externos. Isso será abordado em uma etapa posterior, quando aplicável.
Requisitos
- Ter um projeto do Google Cloud com o faturamento ativado.
- Um navegador da Web, como o Chrome;
- Uma conta do Databricks (este laboratório pressupõe um espaço de trabalho hospedado no GCP)
- A instância do BigQuery precisa estar na edição Enterprise ou superior para usar o recurso EXPORT DATA.
- Se a organização do Google Cloud tiver a política
iam.allowedPolicyMemberDomainsativada, um administrador talvez precise conceder uma exceção para permitir contas de serviço de domínios externos. Isso será abordado em uma etapa posterior, quando aplicável.
Permissões do IAM no Google Cloud Platform
A Conta do Google precisa das seguintes permissões para executar todas as etapas deste codelab.
Contas de serviço | ||
| Permite a criação de contas de serviço. | |
Spanner | ||
| Permite criar uma nova instância do Spanner. | |
| Permite executar instruções DDL para criar | |
| Permite executar instruções DDL para criar tabelas no banco de dados. | |
Google Cloud Storage | ||
| Permite criar um bucket do GCS para armazenar os arquivos Parquet exportados. | |
| Permite gravar os arquivos Parquet exportados no bucket do GCS. | |
| Permite que o BigQuery leia os arquivos Parquet do bucket do GCS. | |
| Permite que o BigQuery liste os arquivos Parquet no bucket do GCS. | |
Dataflow | ||
| Permite reivindicar itens de trabalho do Dataflow. | |
| Permite que o worker do Dataflow envie mensagens de volta para o serviço do Dataflow. | |
| Permite que os workers do Dataflow gravem entradas de registro no Google Cloud Logging. | |
Para sua conveniência, é possível usar papéis predefinidos que contêm essas permissões.
|
|
|
|
|
|
|
|
Projeto do Google Cloud
Um projeto é uma unidade básica de organização no Google Cloud. Se um administrador tiver fornecido um para uso, essa etapa poderá ser ignorada.
Um projeto pode ser criado usando a CLI desta forma:
gcloud projects create <your-project-name>
Saiba mais sobre como criar e gerenciar projetos aqui.
Limitações
É importante estar ciente de algumas limitações e incompatibilidades de tipo de dados que podem surgir nesse pipeline.
Databricks Iceberg para BigQuery
Ao usar o BigQuery para consultar tabelas do Iceberg gerenciadas pelo Databricks (via UniForm), lembre-se do seguinte:
- Evolução do esquema: embora o UniForm faça um bom trabalho de tradução das mudanças de esquema do Delta Lake para o Iceberg, as mudanças complexas nem sempre são propagadas como esperado. Por exemplo, renomear colunas no Delta Lake não é traduzido para o Iceberg, que o vê como um
drope umadd. Sempre teste as mudanças de esquema completamente. - Viagem no tempo: o BigQuery não pode usar os recursos de viagem no tempo do Delta Lake. Ela só vai consultar o snapshot mais recente da tabela Iceberg.
- Recursos do Delta Lake sem suporte: recursos como vetores de exclusão e mapeamento de colunas com o modo
idno Delta Lake não são compatíveis com o UniForm para Iceberg. O laboratório usa o modonamepara mapeamento de colunas, que é compatível.
BigQuery para Spanner
O comando EXPORT DATA do BigQuery para o Spanner não é compatível com todos os tipos de dados do BigQuery. A exportação de uma tabela com os seguintes tipos vai resultar em um erro:
STRUCTGEOGRAPHYDATETIMERANGETIME
Além disso, se o projeto do BigQuery estiver usando o dialeto GoogleSQL, os seguintes tipos numéricos também não serão compatíveis com a exportação para o Spanner:
BIGNUMERIC
Para uma lista completa e atualizada de limitações, consulte a documentação oficial: Limitações da exportação para o Spanner.
Solução de problemas e problemas
- Se você não estiver em uma instância do Databricks do GCP, talvez não seja possível definir um local de dados externo no GCS. Nesses casos, os arquivos precisarão ser organizados na solução de armazenamento do provedor de nuvem do espaço de trabalho do Databricks e, em seguida, migrados para o GCS separadamente.
- Ao fazer isso, será necessário ajustar os metadados, já que as informações terão caminhos codificados para os arquivos preparados.
3. Configurar o Google Cloud Storage (GCS)
O Google Cloud Storage (GCS) será usado para armazenar os arquivos de dados Parquet gerados pelo Databricks. Para isso, primeiro crie um bucket para usar como destino do arquivo.
Google Cloud Storage
Como criar um novo bucket
- Acesse a página Google Cloud Storage no console do Google Cloud.
- No painel à esquerda, selecione Buckets:
- Clique no botão Create:

- Preencha os detalhes do bucket:
- Escolha um nome para o bucket. Neste laboratório, vamos usar o nome
codelabs_retl_databricks. - Selecione uma região para armazenar o bucket ou use os valores padrão.
- Manter a classe de armazenamento como
standard - Mantenha os valores padrão para controle de acesso
- Mantenha os valores padrão para proteger dados de objetos
- Clique no botão
Createquando terminar. Uma mensagem pode aparecer para confirmar que o acesso público será bloqueado. Confirme. - Parabéns, um novo bucket foi criado! Você será redirecionado para a página do bucket.
- Copie o nome do novo bucket em algum lugar, porque ele será necessário mais tarde.
Preparação para as próximas etapas
Anote os seguintes detalhes, que serão necessários nas próximas etapas:
- ID do projeto do Google
- Nome do bucket do Google Storage
4. Configurar o Databricks
Dados do TPC-H
Neste laboratório, vamos usar o conjunto de dados TPC-H, que é uma referência padrão do setor para sistemas de suporte a decisões. O esquema dele modela um ambiente de negócios realista com clientes, pedidos, fornecedores e peças, o que o torna perfeito para demonstrar um cenário real de análise e movimentação de dados.
Em vez de usar as tabelas TPC-H brutas e normalizadas, uma nova tabela agregada será criada. Essa nova tabela vai unir dados das tabelas orders, customer e nation para produzir uma visualização desnormalizada e resumida das vendas regionais. Essa etapa de pré-agregação é uma prática comum na análise, já que prepara os dados para um caso de uso específico. Neste cenário, para consumo por um aplicativo operacional.
O esquema final da tabela agregada será:
Col | Tipo |
nation_name | string |
market_segment | string |
order_year | int |
order_priority | string |
total_order_count | bigint |
total_revenue | decimal(29,2) |
unique_customer_count | bigint |
Suporte do Iceberg com o formato universal do Delta Lake (UniForm)
Neste laboratório, a tabela no Databricks será uma tabela Delta Lake. No entanto, para que ele possa ser lido por sistemas externos, como o BigQuery, um recurso avançado chamado Formato universal (UniForm) será ativado.
O UniForm gera automaticamente metadados do Iceberg junto com os metadados do Delta Lake para uma única cópia compartilhada dos dados da tabela. Isso oferece o melhor dos dois mundos:
- No Databricks:todos os benefícios de desempenho e governança do Delta Lake são aproveitados.
- Fora do Databricks:a tabela pode ser lida por qualquer mecanismo de consulta compatível com o Iceberg, como o BigQuery, como se fosse uma tabela nativa do Iceberg.
Assim, não é preciso manter cópias separadas dos dados nem executar jobs de conversão manual. O UniForm é ativado definindo propriedades específicas da tabela quando ela é criada.
Catálogos do Databricks
Um catálogo do Databricks é o contêiner de nível superior para dados no Unity Catalog, a solução de governança unificada do Databricks. O Unity Catalog oferece uma maneira centralizada de gerenciar recursos de dados, controlar o acesso e rastrear a linhagem, o que é fundamental para uma plataforma de dados bem governada.
Ele usa um namespace de três níveis para organizar os dados: catalog.schema.table.
- Catálogo:o nível mais alto, usado para agrupar dados por ambiente, unidade de negócios ou projeto.
- Esquema (ou banco de dados): um agrupamento lógico de tabelas, visualizações e funções em um catálogo.
- Tabela:o objeto que contém seus dados.
Antes de criar a tabela agregada do TPC-H, é necessário configurar um catálogo e um esquema dedicados para armazená-la. Isso garante que o projeto esteja bem organizado e isolado de outros dados no espaço de trabalho.
Criar um novo catálogo e esquema
No Catálogo do Unity do Databricks, um catálogo serve como o nível mais alto de organização para recursos de dados, atuando como um contêiner seguro que pode abranger vários espaços de trabalho do Databricks. Ele permite organizar e isolar dados com base em unidades de negócios, projetos ou ambientes, com permissões e controles de acesso claramente definidos.
Em um catálogo, um esquema (também conhecido como banco de dados) organiza ainda mais tabelas, visualizações e funções. Essa estrutura hierárquica permite o controle granular e o agrupamento lógico de objetos de dados relacionados. Neste laboratório, um catálogo e um esquema dedicados serão criados para armazenar os dados do TPC-H, garantindo isolamento e gerenciamento adequados.
Como criar um catálogo
- Acesse

- Clique em + e selecione Criar um catálogo no menu suspenso.
- Um novo catálogo Padrão será criado com as seguintes configurações:
- Nome do catálogo:
retl_tpch_project - Local de armazenamento: use o padrão se um tiver sido configurado no espaço de trabalho ou crie um novo.
Como criar um esquema
- Acesse
- Selecione o novo catálogo criado no painel à esquerda.
- Clique em
 .
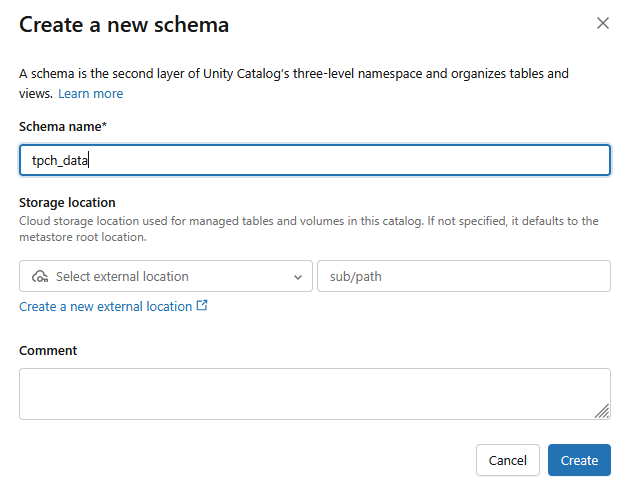
. - Um novo esquema será criado com o nome do esquema como
tpch_data
Configurar dados externos
Para exportar dados do Databricks para o Google Cloud Storage (GCS), é necessário configurar as credenciais de dados externos no Databricks. Isso permite que o Databricks acesse e grave com segurança no bucket do GCS.
- Na tela Catálogo, clique em
 .
.
- Se você não encontrar a opção
External Data, talvez encontreExternal Locationsem um menu suspensoConnect.
- Clique em
 .
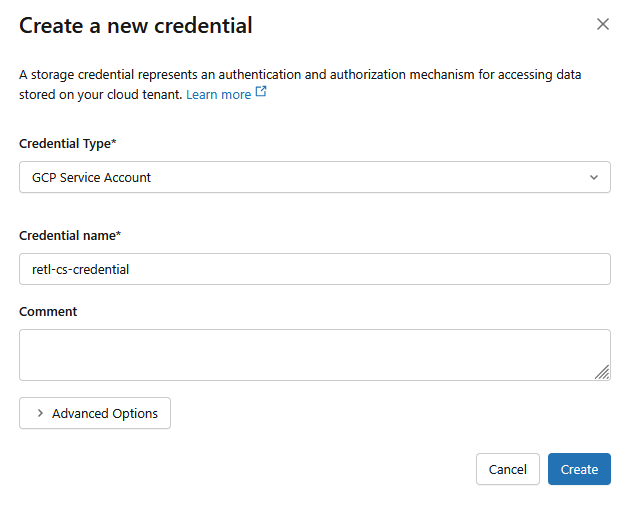
. - Na nova janela de diálogo, configure os valores necessários para as credenciais:
- Tipo de credencial:
GCP Service Account - Nome da credencial:
retl-gcs-credential
- Clique em Criar.
- Em seguida, clique na guia Locais externos.
- Clique em Criar local.
- Na nova janela de diálogo, configure os valores necessários para o local externo:
- Nome do local externo:
retl-gcs-location - Tipo de armazenamento:
GCP - URL: o URL do bucket do GCS, no formato
gs://YOUR_BUCKET_NAME - Credencial de armazenamento: selecione o
retl-gcs-credentialque acabou de ser criado.
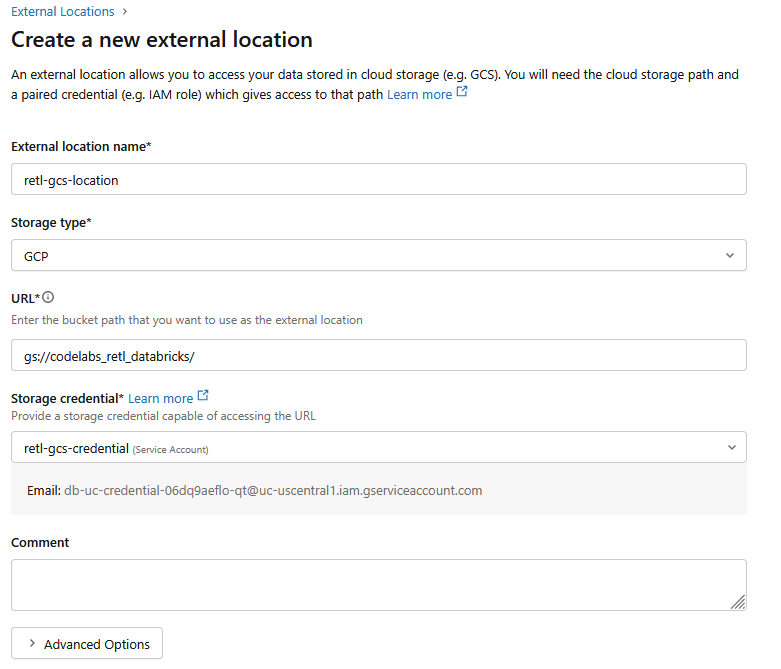
- Anote o e-mail da conta de serviço que é preenchido automaticamente ao selecionar a credencial de armazenamento, já que ele será necessário na próxima etapa.
- Clique em Criar.
5. Como configurar permissões da conta de serviço
Uma conta de serviço é um tipo especial de conta usado por aplicativos ou serviços para fazer chamadas de API autorizadas para recursos do Google Cloud.
Agora, as permissões precisam ser adicionadas à conta de serviço criada para o novo bucket no GCS.
- Na página do bucket do GCS, selecione a guia Permissões.
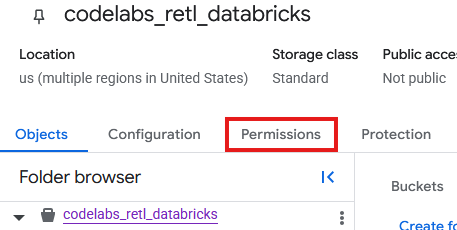
- Clique em Conceder acesso na página de principais.
- No painel Conceder acesso que aparece à direita, insira o ID da conta de serviço no campo Novos principais.
- Em Atribuir papéis, adicione
Storage Object AdmineStorage Legacy Bucket Reader. Esses papéis permitem que a conta de serviço leia, grave e liste objetos no bucket de armazenamento.
Carregar dados do TPC-H
Agora que o catálogo e o esquema foram criados, os dados do TPCH podem ser carregados da tabela samples.tpch armazenada internamente no Databricks e manipulados em uma nova tabela no esquema recém-definido.
Como criar uma tabela com suporte ao Iceberg
Compatibilidade do Iceberg com o UniForm
Nos bastidores, o Databricks gerencia internamente essa tabela como uma tabela Delta Lake, oferecendo todos os benefícios das otimizações de desempenho e recursos de governança do Delta no ecossistema do Databricks. No entanto, ao ativar o UniForm (formato universal), o Databricks recebe uma instrução especial: sempre que a tabela é atualizada, o Databricks gera e mantém automaticamente os metadados correspondentes do Iceberg além dos metadados do Delta Lake.
Isso significa que um único conjunto compartilhado de arquivos de dados (os arquivos Parquet) agora é descrito por dois conjuntos diferentes de metadados.
- Para o Databricks:ele usa o
_delta_logpara ler a tabela. - Para leitores externos (como o BigQuery): eles usam o arquivo de metadados do Iceberg (
.metadata.json) para entender o esquema, o particionamento e os locais dos arquivos da tabela.
O resultado é uma tabela totalmente e transparentemente compatível com qualquer ferramenta compatível com o Iceberg. Não há duplicação de dados nem necessidade de conversão ou sincronização manual. É uma única fonte de verdade que pode ser acessada sem problemas pelo mundo analítico do Databricks e pelo ecossistema mais amplo de ferramentas que oferecem suporte ao padrão aberto Iceberg.
- Clique em Nova e em Consulta.
- No campo de texto da página de consulta, execute o seguinte comando SQL:
CREATE TABLE retl_tpch_project.tpch_data.regional_sales_iceberg
USING DELTA
LOCATION 'gs://<Your bucket name>/regional_sales_iceberg'
TBLPROPERTIES (
'delta.columnMapping.mode' = 'name',
'delta.enableIcebergCompatV2' = 'true',
'delta.universalFormat.enabledFormats' = 'iceberg'
)
AS
SELECT
n.n_name AS nation_name,
c.c_mktsegment AS market_segment,
YEAR(o.o_orderdate) AS order_year,
o.o_orderpriority AS order_priority,
COUNT(o.o_orderkey) AS total_order_count,
ROUND(SUM(o.o_totalprice), 2) AS total_revenue,
COUNT(DISTINCT c.c_custkey) AS unique_customer_count
FROM samples.tpch.orders AS o
INNER JOIN samples.tpch.customer AS c
ON o.o_custkey = c.c_custkey
INNER JOIN samples.tpch.nation AS n
ON c.c_nationkey = n.n_nationkey
GROUP BY
n.n_name,
c.c_mktsegment,
YEAR(o.o_orderdate),
o.o_orderpriority;
OPTIMIZE retl_tpch_project.tpch_data.regional_sales_iceberg;
DESCRIBE EXTENDED retl_tpch_project.tpch_data.regional_sales_iceberg;
Observações:
- Usando Delta: especifica que estamos usando uma tabela do Delta Lake. Somente as tabelas do Delta Lake no Databricks podem ser armazenadas como uma tabela externa.
- Local: especifica onde a tabela será armazenada, se for externa.
- TablePropertoes: o
delta.universalFormat.enabledFormats = ‘iceberg'cria os metadados compatíveis do iceberg junto com os arquivos do Delta Lake. - Otimizar: força o acionamento da geração de metadados do UniForm, já que isso geralmente acontece de forma assíncrona.
- A saída da consulta vai mostrar detalhes sobre a tabela recém-criada.

Verificar dados da tabela do GCS
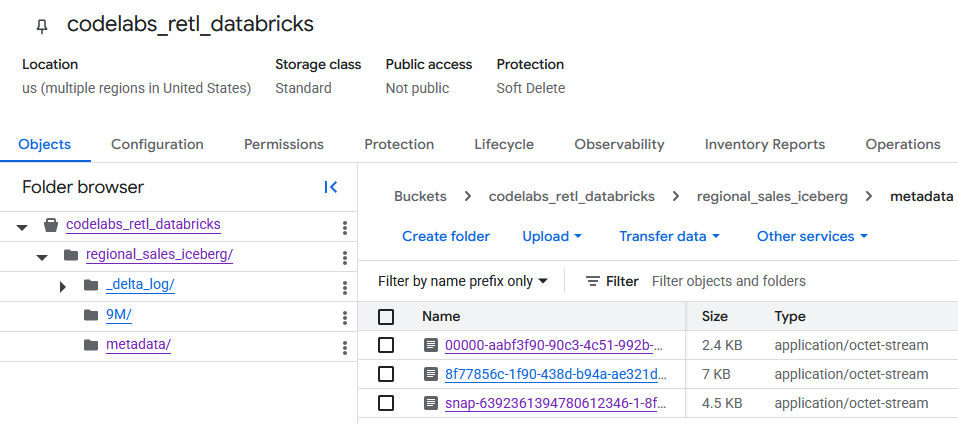
Ao navegar até o bucket do GCS, os dados da tabela recém-criada podem ser encontrados.
Os metadados do Iceberg estão na pasta metadata, que é usada por leitores externos, como o BigQuery. Os metadados do Delta Lake, que o Databricks usa internamente, são rastreados na pasta _delta_log.
Os dados reais da tabela são armazenados como arquivos Parquet em outra pasta, geralmente nomeada com uma string gerada aleatoriamente pelo Databricks. Por exemplo, na captura de tela abaixo, os arquivos de dados estão localizados na pasta 9M.
6. Configurar o BigQuery e o BigLake
Agora que a tabela do Iceberg está no Google Cloud Storage, a próxima etapa é torná-la acessível ao BigQuery. Isso será feito com a criação de uma tabela externa do BigLake.
O BigLake é um mecanismo de armazenamento que permite criar tabelas no BigQuery que leem dados diretamente de fontes externas, como o Google Cloud Storage. Neste laboratório, essa é a tecnologia principal que permite ao BigQuery entender a tabela do Iceberg que acabou de ser exportada sem precisar ingerir os dados.
Para isso, são necessários dois componentes:
- Uma conexão a recursos do Cloud:um link seguro entre o BigQuery e o GCS. Ele usa uma conta de serviço especial para processar a autenticação, garantindo que o BigQuery tenha as permissões necessárias para ler os arquivos do bucket do GCS.
- Uma definição de tabela externa:informa ao BigQuery onde encontrar o arquivo de metadados da tabela Iceberg no GCS e como ele deve ser interpretado.
Criar uma conexão a recursos do Cloud
Primeiro, a conexão que permite ao BigQuery acessar o GCS será criada.
Saiba mais sobre como criar conexões de recursos do Cloud aqui.
- Acesse BigQuery
- Clique em Conexões em Explorer.
- Se o plano Explorer não estiver visível, clique em
 .
.
- Na página Conexões, clique em
- Em Tipo de conexão, escolha
Vertex AI remote models, remote functions, BigLake and Spanner (Cloud Resource). - Defina o ID da conexão como
databricks_retle crie a conexão.

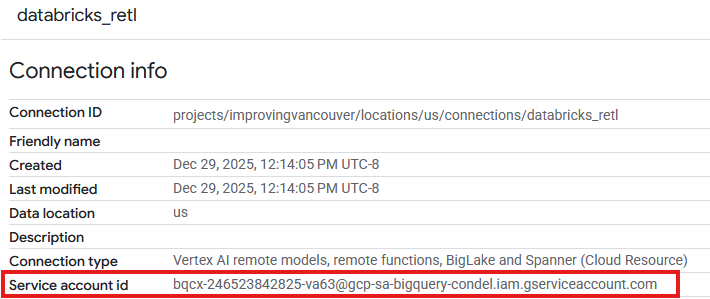
- Uma entrada vai aparecer na tabela Conexões da conexão recém-criada. Clique nessa entrada para ver os detalhes da conexão.

- Na página de detalhes da conexão, anote o ID da conta de serviço, porque você vai precisar dele mais tarde.
Conceder acesso à conta de serviço de conexão
- Acesse IAM e administrador.
- Clique em Conceder acesso.
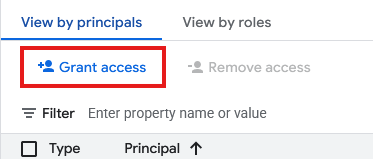
- No campo Novos principais, insira o ID da conta de serviço do recurso de conexão criado acima.
- Em "Papel", selecione
Storage Object Usere clique em .
.
Com a conexão estabelecida e a conta de serviço com as permissões necessárias, a tabela externa do BigLake pode ser criada. Primeiro, é necessário um conjunto de dados no BigQuery para servir como um contêiner da nova tabela. Em seguida, a tabela será criada, apontando para o arquivo de metadados do Iceberg no bucket do GCS.
- Acesse BigQuery
- No painel Explorador, clique no ID do projeto, nos três pontos e selecione Criar conjunto de dados.
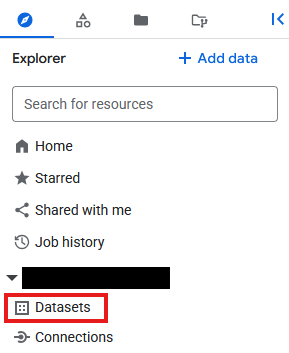
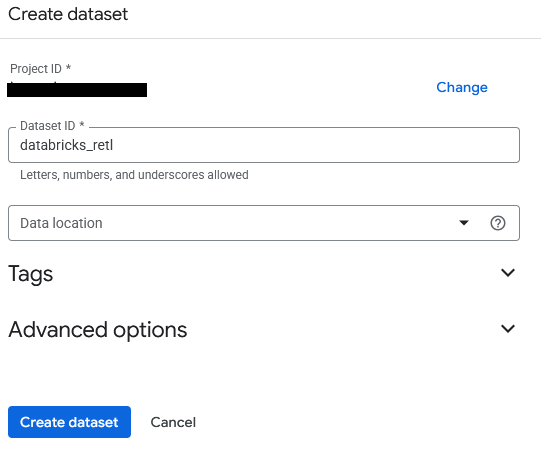
- O conjunto de dados será chamado de
databricks_retl. Deixe as outras opções como padrão e clique no botão Criar conjunto de dados.
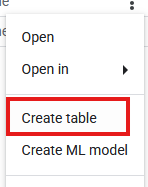
- Agora, encontre o novo conjunto de dados
databricks_retlno painel Explorador. Clique nos três pontos ao lado dele e selecione Criar tabela.
- Preencha as seguintes configurações para a criação da tabela:
- Criar tabela de:
Google Cloud Storage - Selecionar arquivo do bucket do GCS ou usar um padrão de URI: navegue até o bucket do GCS e localize o arquivo JSON de metadados gerado durante a exportação do Databricks. O caminho precisa ser parecido com este:
regional_sales/metadata/v1.metadata.json. - Formato do arquivo:
Iceberg - Tabela:
regional_sales - Tipo de tabela:
External table - ID da conexão: selecione a conexão
databricks_retlcriada anteriormente. - Deixe os outros valores como padrão e clique em Criar tabela.
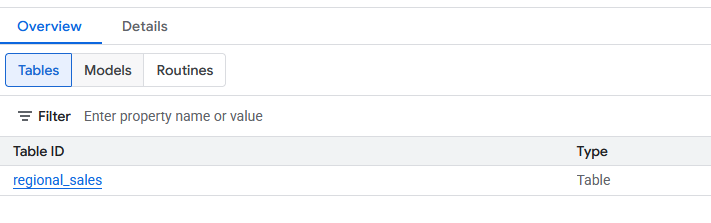
- Depois de criada, a nova tabela
regional_salesvai aparecer no conjunto de dadosdatabricks_retl. Agora, essa tabela pode ser consultada usando o SQL padrão, assim como qualquer outra tabela do BigQuery.
7. Carregar no Spanner
Chegamos à parte final e mais importante do pipeline: mover os dados das tabelas externas do BigLake para o Spanner. Essa é a etapa de "ETL reverso", em que os dados, depois de processados e organizados no data warehouse, são carregados em um sistema operacional para uso por aplicativos.
O Spanner é um banco de dados relacional totalmente gerenciado e distribuído globalmente. Ele oferece a consistência transacional de um banco de dados relacional tradicional, mas com a escalonabilidade horizontal de um banco de dados NoSQL. Isso o torna uma opção ideal para criar aplicativos escalonáveis e altamente disponíveis.
O processo será:
- Crie uma instância do Spanner, que é a alocação física de recursos.
- Crie um banco de dados nessa instância.
- Defina um esquema de tabela no banco de dados que corresponda à estrutura dos dados
regional_sales. - Execute uma consulta
EXPORT DATAdo BigQuery para carregar os dados da tabela do BigLake diretamente na tabela do Spanner.
Criar instância, banco de dados e tabela do Spanner
- Acesse Spanner.
- Clique em
 . Use uma instância atual, se houver uma disponível. Configure os requisitos da instância conforme necessário. Neste laboratório, usamos:
. Use uma instância atual, se houver uma disponível. Configure os requisitos da instância conforme necessário. Neste laboratório, usamos:
Edição | Enterprise |
Nome da instância | databricks-retl |
Configuração da região | Sua região de escolha |
Unidade de computação | Unidades de processamento (PUs) |
Alocação manual | 100 |
- Depois de criada, acesse a página da instância do Spanner e selecione
 . Use um banco de dados atual, se houver um disponível.
. Use um banco de dados atual, se houver um disponível.
- Neste laboratório, um banco de dados será criado com
- Nome:
databricks-retl - Dialeto do banco de dados:
Google Standard SQL
- Depois que o banco de dados for criado, selecione-o na página "Instância do Spanner" e acesse a página "Banco de dados do Spanner".
- Na página do banco de dados do Spanner, clique em
 .
. - Na nova página de consulta, a definição da tabela a ser importada para o Spanner será criada. Para isso, execute a seguinte consulta SQL.
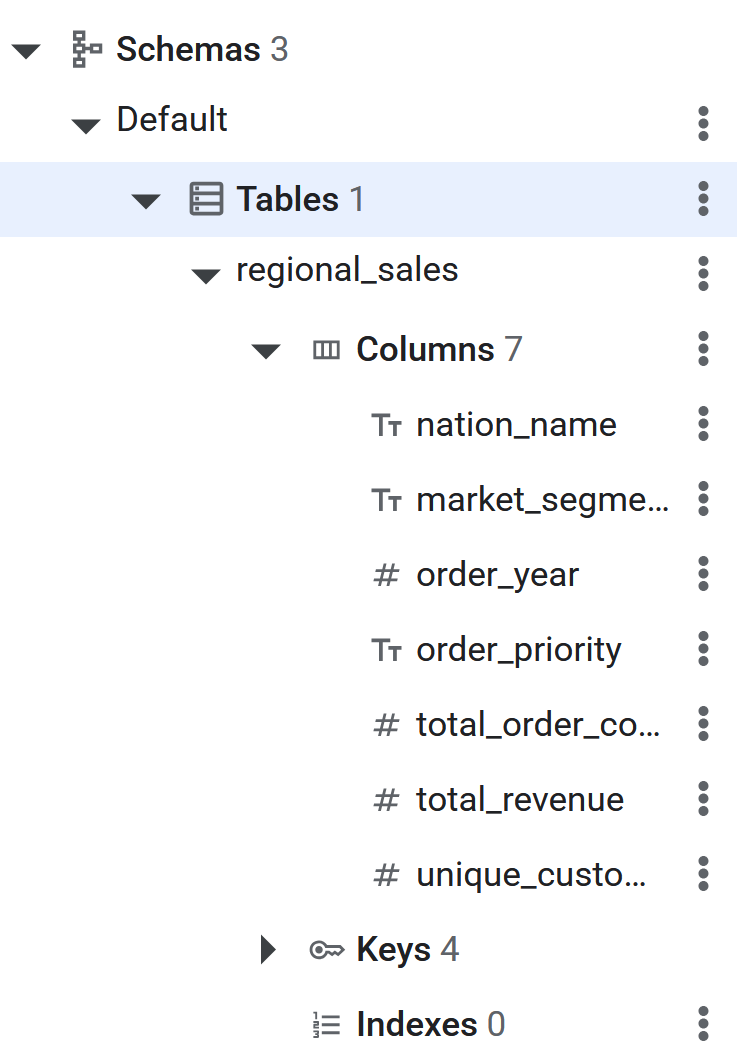
CREATE TABLE regional_sales (
nation_name STRING(MAX),
market_segment STRING(MAX),
order_year INT64,
order_priority STRING(MAX),
total_order_count INT64,
total_revenue NUMERIC,
unique_customer_count INT64
) PRIMARY KEY (nation_name, market_segment, order_year, order_priority);
- Depois que o comando SQL for executado, a tabela do Spanner estará pronta para o BigQuery fazer a ETL reversa dos dados. Para verificar se a tabela foi criada, confira se ela aparece listada no painel à esquerda do banco de dados do Spanner.
ETL reverso para o Spanner usando EXPORT DATA
Esta é a etapa final. Com os dados de origem prontos em uma tabela BigLake do BigQuery e a tabela de destino criada no Spanner, a movimentação de dados real é surpreendentemente simples. Uma única consulta SQL do BigQuery será usada: EXPORT DATA.
Essa consulta foi criada especificamente para cenários como esse. Ele exporta dados de uma tabela do BigQuery (incluindo externas, como a tabela do BigLake) para um destino externo de maneira eficiente. Nesse caso, o destino é a tabela do Spanner. Saiba mais sobre o recurso de exportação neste link.
Clique aqui para mais informações sobre como configurar a ETL reversa do BigQuery para o Spanner.
- Acesse BigQuery
- Abra uma nova guia do editor de consultas.
- Na página "Consulta", insira o seguinte SQL. Substitua o ID do projeto em **
uri** **e o caminho da tabela pelo ID do projeto correto.**
EXPORT DATA OPTIONS(
uri='https://spanner.googleapis.com/projects/YOUR_PROJECT_ID/instances/databricks-retl/databases/databricks-retl',
format='CLOUD_SPANNER',
spanner_options="""{
"table": "regional_sales",
"priority": "MEDIUM"
}"""
) AS
SELECT * FROM `YOUR_PROJECT_ID.databricks_retl.regional_sales`;
- Quando o comando for concluído, os dados serão exportados para o Spanner.
8. Verificar dados no Spanner
Parabéns! Um pipeline completo de ETL reverso foi criado e executado com sucesso, movendo dados de um data warehouse do Databricks para um banco de dados operacional do Spanner.
A última etapa é verificar se os dados chegaram ao Spanner conforme o esperado.
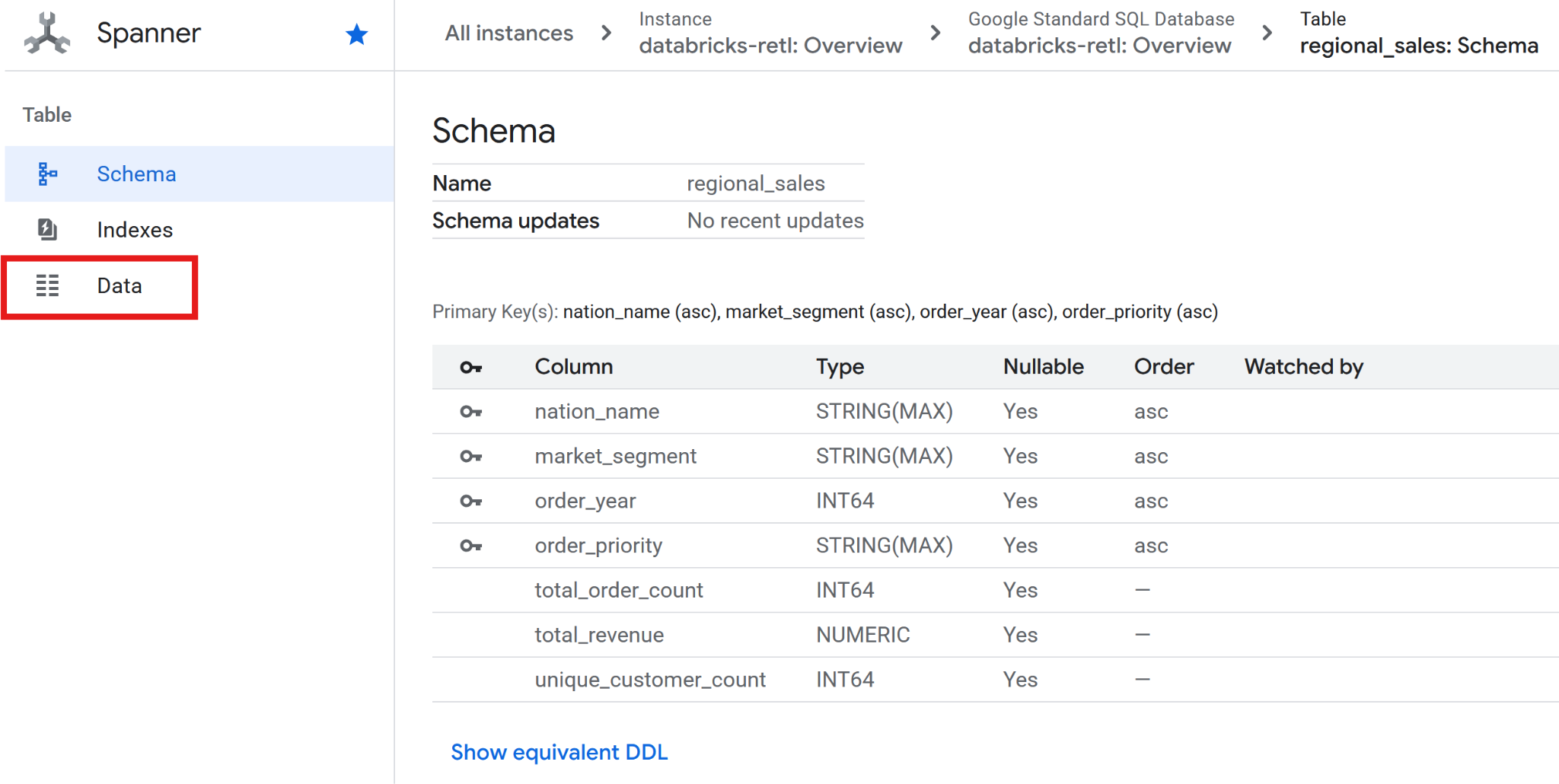
- Acesse Spanner.
- Acesse a instância
databricks-retle o banco de dadosdatabricks-retl. - Na lista de tabelas, clique em
regional_sales. - No menu de navegação à esquerda da tabela, clique na guia Dados.
- Os dados de vendas agregados, originalmente do Databricks, agora devem estar carregados e prontos para uso na tabela do Spanner. Esses dados agora estão em um sistema operacional, prontos para alimentar um aplicativo ativo, disponibilizar um painel ou ser consultados por uma API.
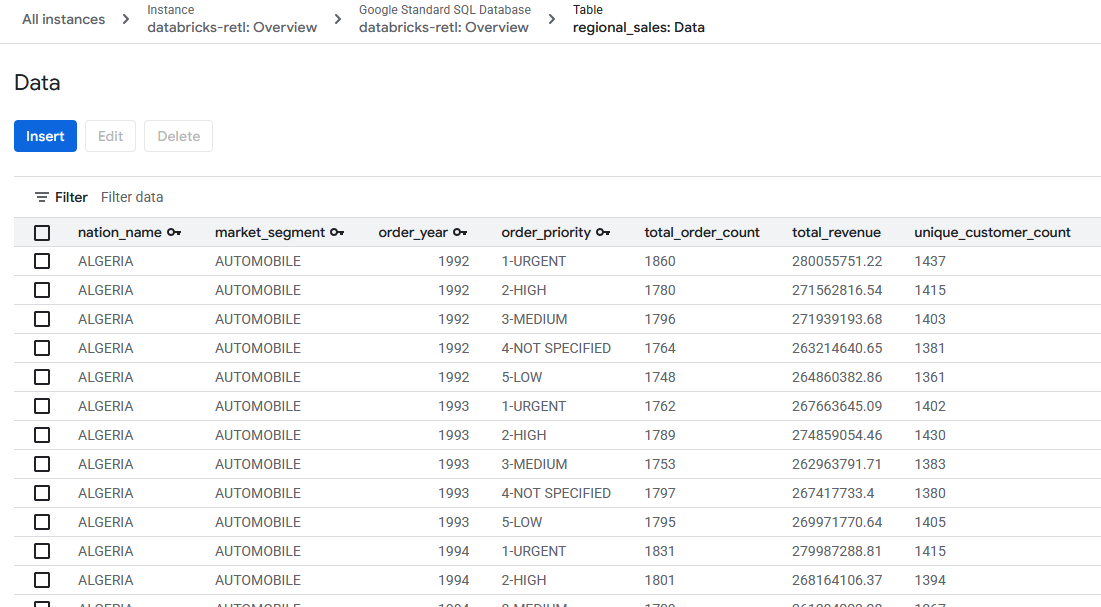
A distância entre os mundos de dados analíticos e operacionais foi reduzida.
9. Limpeza
Remova todas as tabelas adicionadas e os dados armazenados quando terminar este laboratório.
Limpar tabelas do Spanner
- Acesse Spanner
- Na lista chamada
databricks-retl, clique na instância usada neste laboratório.

- Na página da instância, clique em
 .
. - Insira
databricks-retlna caixa de diálogo de confirmação que aparece e clique em .
.
Liberar memória do GCS
- Acesse GCS
- Selecione
 no menu lateral.
no menu lateral. - Selecione o bucket ``codelabs_retl_databricks
- Depois de selecionar, clique no botão
 que aparece no banner da parte de cima.
que aparece no banner da parte de cima.

- Insira
DELETEna caixa de diálogo de confirmação que aparece e clique em.
Liberar espaço no Databricks
Excluir catálogo/esquema/tabela
- Fazer login na instância do Databricks
- Clique em
 no menu lateral esquerdo.
no menu lateral esquerdo. - Selecione o
 criado anteriormente na lista do catálogo.
criado anteriormente na lista do catálogo. - Na lista "Esquema", selecione
 que foi criado.
que foi criado. - Selecione o
 criado anteriormente na lista de tabelas.
criado anteriormente na lista de tabelas. - Clique em
 para expandir as opções da tabela e selecione
para expandir as opções da tabela e selecione Delete. - Clique em
 na caixa de diálogo de confirmação para excluir a tabela.
na caixa de diálogo de confirmação para excluir a tabela. - Depois que a tabela for excluída, você vai voltar para a página de esquema.
- Clique em para abrir as opções de esquema e selecione
Delete. - Clique em na caixa de diálogo de confirmação para excluir o esquema.
- Depois que o esquema for excluído, você vai voltar para a página do catálogo.
- Siga as etapas de 4 a 11 novamente para excluir o esquema
default, se houver um. - Na página do catálogo, clique em para expandir as opções e selecione
Delete. - Clique em na caixa de diálogo de confirmação para excluir o catálogo.
Excluir local / credenciais de dados externos
- Na tela "Catálogo", clique em .
- Se você não encontrar a opção
External Data, talvez encontreExternal Locationem um menu suspensoConnect. - Clique no local de dados externos
retl-gcs-locationcriado anteriormente. - Na página do local externo, clique em para expandir as opções de local e selecione
Delete. - Clique em na caixa de diálogo de confirmação para excluir o local externo.
- Clique em .
- Clique no
retl-gcs-credentialcriado anteriormente. - Na página de credenciais, clique em para expandir as opções e selecione
Delete. - Clique em na caixa de diálogo de confirmação para excluir as credenciais.
10. Parabéns
Parabéns por concluir o codelab.
O que aprendemos
- Como carregar dados no Databricks como tabelas Iceberg
- Como criar um bucket do GCS
- Como exportar uma tabela do Databricks para o GCS no formato Iceberg
- Como criar uma tabela externa do BigLake no BigQuery com base na tabela do Iceberg no GCS
- Como configurar uma instância do Spanner
- Como carregar tabelas externas do BigLake no BigQuery para o Spanner