
1. Создайте обратный ETL-конвейер от Databricks до Spanner, используя Google Cloud Storage и BigQuery.
Введение
В этом практическом занятии вы создадите обратный ETL- конвейер из Databricks в Spanner. Традиционно стандартные ETL-конвейеры (извлечение, преобразование, загрузка) перемещают данные из операционных баз данных в хранилище данных, такое как Databricks, для аналитики. Обратный ETL-конвейер делает обратное, перемещая обработанные данные из хранилища данных обратно в операционные базы данных, такие как Spanner, — глобально распределенную реляционную базу данных, идеально подходящую для высокодоступных приложений, где они могут обеспечивать работу приложений, предоставлять пользовательские функции или использоваться для принятия решений в режиме реального времени.
Цель состоит в том, чтобы переместить агрегированный набор данных из таблиц Databricks Iceberg в таблицы Spanner.
Для достижения этой цели в качестве промежуточных звеньев используются Google Cloud Storage (GCS) и BigQuery. Вот подробное описание потока данных и обоснование такой архитектуры:

- Передача данных из Databricks в Google Cloud Storage (GCS) в формате Iceberg:
- Первый шаг — извлечение данных из Databricks в открытом, четко определенном формате. Таблица экспортируется в формате Apache Iceberg . В результате этого процесса базовые данные записываются в виде набора файлов Parquet , а метаданные таблицы (схема, разделы, расположение файлов) — в виде файлов JSON и Avro . Размещение всей структуры таблицы в GCS делает данные переносимыми и доступными для любой системы, которая понимает формат Iceberg.
- Преобразовать таблицы GCS Iceberg во внешнюю таблицу BigQuery BigLake:
- Вместо прямой загрузки данных из GCS в Spanner, в качестве мощного посредника используется BigQuery. В BigQuery создается внешняя таблица BigLake , которая напрямую указывает на файл метаданных Iceberg в GCS. Такой подход имеет ряд преимуществ:
- Отсутствие дублирования данных: BigQuery считывает структуру таблицы из метаданных и выполняет запросы к файлам данных Parquet непосредственно в файле , не загружая их, что значительно экономит время и средства на хранение.
- Федеративные запросы: позволяют выполнять сложные SQL-запросы к данным GCS так же, как если бы это была собственная таблица BigQuery.
- Внешняя таблица ReverseETL BigLake в Spanner:
- Последний шаг — перенос данных из BigQuery в Spanner. Это достигается с помощью мощной функции BigQuery, называемой запросом
EXPORT DATA, которая представляет собой этап "обратного ETL". - Операционная готовность: Spanner разработан для транзакционных рабочих нагрузок, обеспечивая высокую согласованность и доступность приложений. Перемещение данных в Spanner делает их доступными для пользовательских приложений, API и других операционных систем, требующих поиска данных с низкой задержкой.
- Масштабируемость: Этот подход позволяет использовать аналитические возможности BigQuery для обработки больших наборов данных и эффективной доставки результатов через масштабируемую инфраструктуру Spanner.
Услуги и терминология
- DataBricks — облачная платформа для работы с данными, построенная на основе Apache Spark.
- Spanner — это глобально распределенная реляционная база данных, полностью управляемая компанией Google.
- Google Cloud Storage — это облачное хранилище больших двоичных объектов от Google.
- BigQuery — это бессерверное хранилище данных для аналитики, полностью управляемое компанией Google.
- Iceberg — открытый формат таблиц, разработанный Apache, обеспечивающий абстракцию от распространенных форматов файлов данных с открытым исходным кодом.
- Parquet — формат двоичных файлов данных с колоночным форматом, разработанный компанией Apache.
Что вы узнаете
- Как загрузить данные в Databricks в виде таблиц Iceberg
- Как создать сегмент GCS
- Как экспортировать таблицу Databricks в GCS в формате Iceberg
- Как создать внешнюю таблицу BigLake в BigQuery из таблицы Iceberg в GCS
- Как настроить экземпляр Spanner
- Как загрузить внешние таблицы BigLake из BigQuery в Spanner
2. Настройка, требования и ограничения
Предварительные требования
- Аккаунт Databricks, предпочтительно в GCP.
- Для экспорта данных из BigQuery в Spanner требуется учетная запись Google Cloud с резервированием уровня BigQuery Enterprise или выше .
- Доступ к консоли Google Cloud через веб-браузер.
- Терминал для выполнения команд Google Cloud CLI
Если в вашей организации Google Cloud включена политика iam.allowedPolicyMemberDomains , администратору может потребоваться предоставить исключение, разрешающее использование учетных записей служб из внешних доменов. Это будет рассмотрено на следующем шаге, где это применимо.
Требования
- Проект Google Cloud с включенной функцией выставления счетов.
- Веб-браузер, например Chrome.
- Для работы потребуется учетная запись Databricks (в данной лабораторной работе предполагается рабочее пространство, размещенное в GCP).
- Для использования функции экспорта данных экземпляр BigQuery должен быть версии Enterprise или выше.
- Если в вашей организации Google Cloud включена политика
iam.allowedPolicyMemberDomains, администратору может потребоваться предоставить исключение, разрешающее использование учетных записей служб из внешних доменов. Это будет рассмотрено на следующем шаге, где это применимо.
Разрешения IAM платформы Google Cloud Platform
Для выполнения всех шагов в этом практическом задании учетной записи Google потребуются следующие разрешения.
Служебные аккаунты | ||
| Позволяет создавать служебные учетные записи. | |
Гаечный ключ | ||
| Позволяет создать новый экземпляр Spanner. | |
| Позволяет выполнять операторы DDL для создания | |
| Позволяет выполнять операторы DDL для создания таблиц в базе данных. | |
Google Облачное хранилище | ||
| Позволяет создать новый сегмент GCS для хранения экспортированных файлов Parquet. | |
| Позволяет записывать экспортированные файлы Parquet в хранилище GCS. | |
| Позволяет BigQuery считывать файлы Parquet из хранилища GCS. | |
| Позволяет BigQuery отображать список файлов Parquet в хранилище GCS. | |
Поток данных | ||
| Позволяет запрашивать права на элементы работы из Dataflow. | |
| Позволяет рабочему процессу Dataflow отправлять сообщения обратно в службу Dataflow. | |
| Позволяет рабочим процессам Dataflow записывать записи в журнал Google Cloud Logging. | |
Для удобства можно использовать предопределенные роли, содержащие эти разрешения.
|
|
|
|
|
|
|
|
Проект Google Cloud
Проект — это базовая организационная единица в Google Cloud. Если администратор предоставил проект для использования, этот шаг можно пропустить.
Создать проект с помощью командной строки можно следующим образом:
gcloud projects create <your-project-name>
Подробнее о создании и управлении проектами можно узнать здесь .
Ограничения
Важно помнить о некоторых ограничениях и несовместимости типов данных, которые могут возникнуть в этом конвейере обработки данных.
От айсберга Databricks до BigQuery
При использовании BigQuery для запросов к таблицам Iceberg, управляемым Databricks (через UniForm), следует учитывать следующее:
- Эволюция схемы : Хотя UniForm хорошо справляется с преобразованием изменений схемы Delta Lake в Iceberg, сложные изменения не всегда могут распространяться должным образом. Например, переименование столбцов в Delta Lake не преобразуется в Iceberg, который воспринимает это как
dropиadd. Всегда тщательно тестируйте изменения схемы. - Путешествие во времени : BigQuery не может использовать возможности путешествия во времени Delta Lake. Он будет запрашивать только последний снимок таблицы Iceberg.
- Неподдерживаемые функции Delta Lake : Такие функции, как векторы удаления и сопоставление столбцов в режиме
idв Delta Lake, несовместимы с UniForm для Iceberg. В лабораторной работе используется режимnameдля сопоставления столбцов, который поддерживается.
BigQuery to Spanner
Команда EXPORT DATA из BigQuery в Spanner не поддерживает все типы данных BigQuery. Экспорт таблицы со следующими типами данных приведет к ошибке:
-
STRUCT -
GEOGRAPHY -
DATETIME -
RANGE -
TIME
Кроме того, если в проекте BigQuery используется диалект GoogleSQL , следующие числовые типы также не поддерживаются для экспорта в Spanner:
-
BIGNUMERIC
Полный и актуальный список ограничений см. в официальной документации: Ограничения экспорта в Spanner .
Устранение неполадок и подводные камни
- Если вы не используете экземпляр GCP Databricks, определить внешнее местоположение данных в GCS может быть невозможно. В таких случаях файлы необходимо будет разместить в хранилище облачного провайдера рабочей области Databricks, а затем отдельно перенести в GCS.
- При этом потребуется внести корректировки в метаданные, поскольку информация будет содержать жестко закодированные пути к подготовленным файлам.
3. Настройка Google Cloud Storage (GCS)
Для хранения файлов данных Parquet, созданных Databricks, будет использоваться Google Cloud Storage (GCS). Для этого сначала необходимо создать новый сегмент (bucket), который будет использоваться в качестве места назначения файлов.
Google Облачное хранилище
Создание нового контейнера
- Перейдите на страницу Google Cloud Storage в консоли облачного сервиса.
- На левой панели выберите «Корзины» :
- Нажмите кнопку «Создать» :

- Укажите данные вашей корзины:
- Выберите имя для используемого сегмента. Для этой лабораторной работы будет использоваться имя
codelabs_retl_databricks - Выберите регион для хранения данных в хранилище или используйте значения по умолчанию.
- Сохраните
standardкласс хранения . - Сохраните значения по умолчанию для параметров управления доступом.
- Сохраняйте значения по умолчанию для защиты данных объекта .
- После завершения нажмите кнопку
Create. Возможно, появится запрос на подтверждение того, что публичный доступ будет заблокирован. Подтвердите. - Поздравляем, новый бакет успешно создан! Вы будете перенаправлены на страницу бакета.
- Скопируйте новое имя корзины куда-нибудь, оно понадобится позже.
Подготовка к следующим шагам
Обязательно запишите следующие данные, так как они понадобятся на следующих этапах:
- Идентификатор проекта Google
- имя сегмента хранилища Google
4. Настройка Databricks
Данные TPC-H
Для этой лабораторной работы будет использоваться набор данных TPC-H , являющийся отраслевым стандартом для систем поддержки принятия решений. Его схема моделирует реалистичную бизнес-среду с клиентами, заказами, поставщиками и комплектующими, что делает его идеальным для демонстрации реального сценария аналитики и перемещения данных.
Вместо использования исходных нормализованных таблиц TPC-H будет создана новая агрегированная таблица. Эта новая таблица объединит данные из таблиц orders , customer и nation , чтобы получить денормализованное, сводное представление региональных продаж. Этот этап предварительной агрегации является распространенной практикой в аналитике, поскольку он подготавливает данные для конкретного сценария использования — в данном случае, для использования операционным приложением.
Итоговая схема агрегированной таблицы будет следующей:
Полковник | Тип |
nation_name | нить |
сегмент рынка | нить |
год заказа | инт |
порядок_приоритета | нить |
total_order_count | бигинт |
общий_доход | decimal(29,2) |
уникальное_количество_клиентов | бигинт |
Поддержка Iceberg с использованием универсального формата Delta Lake (UniForm)
В этой лабораторной работе в Databricks будет использоваться таблица Delta Lake . Однако для обеспечения возможности чтения этой таблицы внешними системами, такими как BigQuery, будет включена мощная функция, называемая универсальным форматом (UniForm) .
UniForm автоматически генерирует метаданные Iceberg вместе с метаданными Delta Lake, создавая единую, общую копию данных таблицы. Это обеспечивает преимущества обоих подходов:
- Внутри Databricks: все преимущества Delta Lake в плане производительности и управления доступны.
- Вне Databricks: Таблицу можно прочитать любым механизмом запросов, совместимым с Iceberg, например BigQuery, как если бы это была собственная таблица Iceberg.
Это устраняет необходимость хранить отдельные копии данных или запускать задачи ручного преобразования. Функция UniForm будет активирована путем задания определенных свойств таблицы при ее создании.
Каталоги Databricks
Каталог Databricks — это контейнер верхнего уровня для данных в Unity Catalog , унифицированном решении Databricks для управления данными. Unity Catalog предоставляет централизованный способ управления информационными активами, контроля доступа и отслеживания происхождения данных, что имеет решающее значение для хорошо управляемой платформы данных.
Для организации данных используется трехуровневое пространство имен: catalog.schema.table .
- Каталог: Самый высокий уровень, используемый для группировки данных по среде, бизнес-подразделению или проекту.
- Схема (или база данных): логическая группировка таблиц, представлений и функций в рамках каталога.
- Таблица: Объект, содержащий ваши данные.
Прежде чем создавать сводную таблицу TPC-H, необходимо сначала настроить специальный каталог и схему для ее размещения. Это обеспечит аккуратную организацию проекта и его изоляцию от других данных в рабочей области.
Создайте новый каталог и схему.
В Databricks Unity Catalog каталог служит высшим уровнем организации данных, выступая в качестве защищенного контейнера, который может охватывать несколько рабочих пространств Databricks. Он позволяет организовывать и изолировать данные на основе бизнес-подразделений, проектов или сред с четко определенными разрешениями и контролем доступа.
В рамках каталога схема (также известная как база данных) дополнительно организует таблицы, представления и функции. Эта иерархическая структура позволяет осуществлять детальный контроль и логическую группировку связанных объектов данных. Для этой лабораторной работы будет создан отдельный каталог и схема для хранения данных TPC-H, обеспечивающие надлежащую изоляцию и управление.
Создание каталога
- Перейти к

- Нажмите кнопку «+» , а затем выберите «Создать каталог» из выпадающего списка.
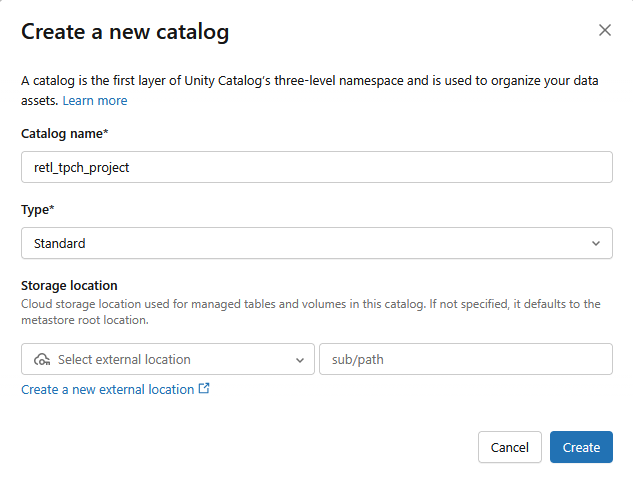
- Будет создан новый стандартный каталог со следующими настройками:
- Название каталога :
retl_tpch_project - Место хранения : используйте место хранения по умолчанию, если оно уже настроено в рабочей области, или создайте новое.
Создание схемы
- Перейти к
- Выберите созданный новый каталог на левой панели.
- Нажмите на
- Будет создана новая схема с именем
tpch_data.
Настройка внешних данных
Для экспорта данных из Databricks в Google Cloud Storage (GCS) необходимо настроить внешние учетные данные в Databricks. Это позволит Databricks безопасно получать доступ к хранилищу GCS и записывать в него данные.
- На экране каталога нажмите на

- Если вы не видите опцию
External Data, вы можете найтиExternal Locationsв выпадающем списке «Connect.
- Нажмите на

- В новом диалоговом окне укажите необходимые значения для учетных данных:
- Тип учетных данных :
GCP Service Account - Имя учетных данных :
retl-gcs-credential
- Нажмите «Создать».
- Далее перейдите на вкладку «Внешние местоположения» .
- Нажмите « Создать местоположение» .
- В новом диалоговом окне задайте необходимые значения для внешнего расположения:
- Внешнее имя местоположения :
retl-gcs-location - Тип хранилища :
GCP - URL : URL-адрес хранилища GCS в формате
gs://YOUR_BUCKET_NAME - Учетные данные хранилища : выберите только что созданные
retl-gcs-credential.
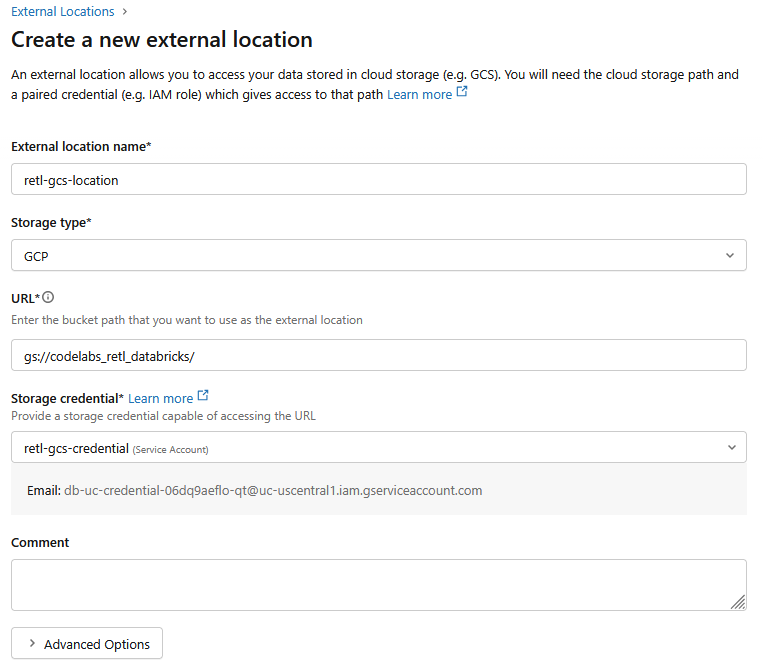
- Запишите адрес электронной почты учетной записи службы , который автоматически заполняется при выборе учетных данных хранилища , поскольку он понадобится на следующем шаге.
- Нажмите «Создать».
5. Настройка прав доступа к служебной учетной записи
Сервисный аккаунт — это особый тип аккаунта, используемый приложениями или сервисами для выполнения авторизованных вызовов API к ресурсам Google Cloud.
Теперь необходимо добавить права доступа к учетной записи службы, созданной для нового сегмента в GCS.
- На странице хранилища GCS выберите вкладку «Разрешения» .
- Нажмите « Предоставить доступ» на странице руководителей.
- В панели «Предоставление доступа» , которая выдвигается справа, введите идентификатор учетной записи службы в поле « Новые субъекты».
- В разделе «Назначение ролей» добавьте роли
Storage Object AdminиStorage Legacy Bucket Reader. Эти роли позволят учетной записи службы читать, записывать и отображать список объектов в сегменте хранилища.
Загрузка данных TPC-H
Теперь, когда каталог и схема созданы, данные TPCH можно загрузить из существующей таблицы samples.tpch , которая хранится внутри Databricks, и перенести в новую таблицу в новой определенной схеме.
Создание таблицы с поддержкой Iceberg
Совместимость Iceberg с UniForm
Внутри Databricks эта таблица управляется как таблица Delta Lake, что обеспечивает все преимущества оптимизации производительности и функций управления Delta в рамках экосистемы Databricks. Однако, включив UniForm (сокращение от Universal Format), Databricks получает указание выполнять особую функцию: при каждом обновлении таблицы Databricks автоматически генерирует и поддерживает соответствующие метаданные Iceberg в дополнение к метаданным Delta Lake.
Это означает, что единый, общий набор файлов данных (файлы Parquet) теперь описывается двумя различными наборами метаданных.
- Для Databricks: для чтения таблицы используется
_delta_log. - Для внешних читателей (например, BigQuery): они используют файл метаданных Iceberg (
.metadata.json), чтобы понять схему таблицы, секционирование и расположение файлов.
В результате получается таблица, полностью и прозрачно совместимая с любым инструментом, поддерживающим Iceberg. Отсутствует дублирование данных и нет необходимости в ручном преобразовании или синхронизации. Это единый источник достоверной информации, к которому могут беспрепятственно получить доступ как аналитические инструменты Databricks, так и более широкая экосистема инструментов, поддерживающих открытый стандарт Iceberg.
- Нажмите «Создать» , затем «Запрос».
- В текстовом поле страницы запроса выполните следующую SQL-команду:
CREATE TABLE retl_tpch_project.tpch_data.regional_sales_iceberg
USING DELTA
LOCATION 'gs://<Your bucket name>/regional_sales_iceberg'
TBLPROPERTIES (
'delta.columnMapping.mode' = 'name',
'delta.enableIcebergCompatV2' = 'true',
'delta.universalFormat.enabledFormats' = 'iceberg'
)
AS
SELECT
n.n_name AS nation_name,
c.c_mktsegment AS market_segment,
YEAR(o.o_orderdate) AS order_year,
o.o_orderpriority AS order_priority,
COUNT(o.o_orderkey) AS total_order_count,
ROUND(SUM(o.o_totalprice), 2) AS total_revenue,
COUNT(DISTINCT c.c_custkey) AS unique_customer_count
FROM samples.tpch.orders AS o
INNER JOIN samples.tpch.customer AS c
ON o.o_custkey = c.c_custkey
INNER JOIN samples.tpch.nation AS n
ON c.c_nationkey = n.n_nationkey
GROUP BY
n.n_name,
c.c_mktsegment,
YEAR(o.o_orderdate),
o.o_orderpriority;
OPTIMIZE retl_tpch_project.tpch_data.regional_sales_iceberg;
DESCRIBE EXTENDED retl_tpch_project.tpch_data.regional_sales_iceberg;
Примечания:
- Использование Delta — указывает на использование таблицы Delta Lake. Только таблицы Delta Lake в Databricks могут храниться как внешние таблицы.
- Местоположение — указывает, где будет храниться таблица, если она находится вне хранилища.
- TablePropertoes - Параметр
delta.universalFormat.enabledFormats = 'iceberg'создает совместимые метаданные iceberg вместе с файлами Delta Lake. - Оптимизация — принудительно запускает генерацию метаданных UniForm, поскольку обычно это происходит асинхронно.
- Результатом выполнения запроса должны стать подробные данные по вновь созданной таблице.

Проверьте данные таблицы GCS.
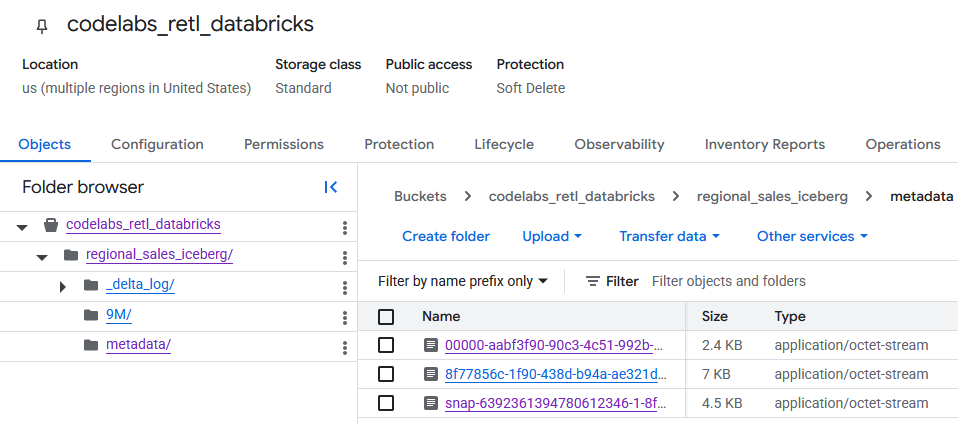
После перехода в хранилище GCS можно найти данные в недавно созданной таблице.
Метаданные Iceberg находятся в папке metadata , которая используется внешними программами чтения (например, BigQuery). Метаданные Delta Lake , которые Databricks использует внутри компании, отслеживаются в папке _delta_log .
Фактические данные таблицы хранятся в виде файлов Parquet в другой папке, обычно названной случайной строкой, сгенерированной Databricks. Например, на скриншоте ниже файлы данных находятся в папке 9M .
6. Настройка BigQuery и BigLake
Теперь, когда таблица Iceberg находится в Google Cloud Storage, следующим шагом будет обеспечение доступа к ней для BigQuery. Это будет сделано путем создания внешней таблицы BigLake .
BigLake — это механизм хранения данных, позволяющий создавать таблицы в BigQuery, которые считывают данные непосредственно из внешних источников, таких как Google Cloud Storage. В рамках этой лабораторной работы это ключевая технология, позволяющая BigQuery понимать только что экспортированную таблицу Iceberg без необходимости загружать данные в нее.
Для этого необходимы два компонента:
- Подключение к облачным ресурсам: это защищенное соединение между BigQuery и GCS. Для аутентификации используется специальная учетная запись службы, гарантирующая, что BigQuery имеет необходимые разрешения для чтения файлов из хранилища GCS.
- Определение внешней таблицы: это указывает BigQuery, где найти файл метаданных таблицы Iceberg в GCS и как его следует интерпретировать.
Создайте подключение к облачному ресурсу.
Сначала будет установлено соединение, позволяющее BigQuery получить доступ к GCS.
Более подробную информацию о создании подключений к облачным ресурсам можно найти здесь.
- Перейдите в BigQuery
- В разделе «Проводник» нажмите «Подключения» .
- Если самолет Explorer не виден, нажмите на

- На странице «Подключения» нажмите
- В качестве типа подключения выберите
Vertex AI remote models, remote functions, BigLake and Spanner (Cloud Resource) - Установите идентификатор подключения на
databricks_retlи создайте подключение.

- Теперь в таблице «Подключения» должна отобразиться запись о только что созданном подключении. Щелкните по этой записи, чтобы просмотреть подробные сведения о подключении.

- На странице сведений о подключении запишите идентификатор учетной записи службы , так как он понадобится позже.
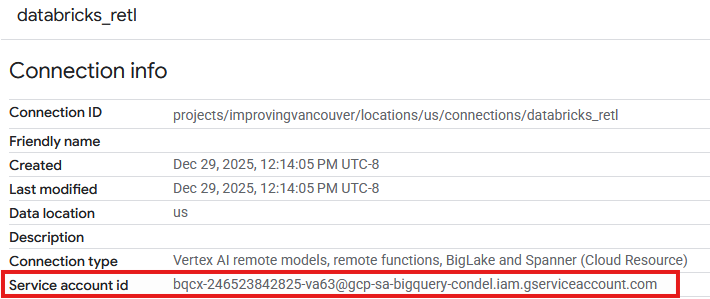
Предоставить доступ к учетной записи службы подключения
- Перейдите в раздел IAM и администрирование.
- Нажмите «Предоставить доступ».
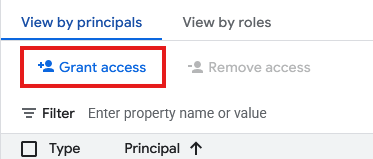
- В поле «Новые субъекты» введите идентификатор учетной записи службы ресурса подключения, созданный выше.
- В поле «Роль» выберите
Storage Object User, а затем нажмите
После установления соединения и предоставления учетной записи службы необходимых разрешений можно создать внешнюю таблицу BigLake. Сначала в BigQuery потребуется набор данных , который будет выступать в качестве контейнера для новой таблицы. Затем будет создана сама таблица, указывающая на файл метаданных Iceberg в хранилище GCS.
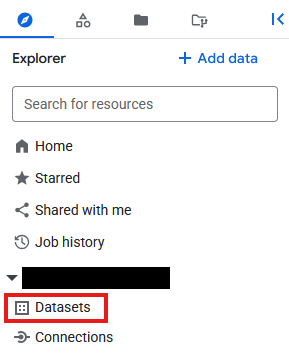
- Перейдите в BigQuery
- В панели «Проводник» щелкните идентификатор проекта, затем щелкните три точки и выберите «Создать набор данных» .
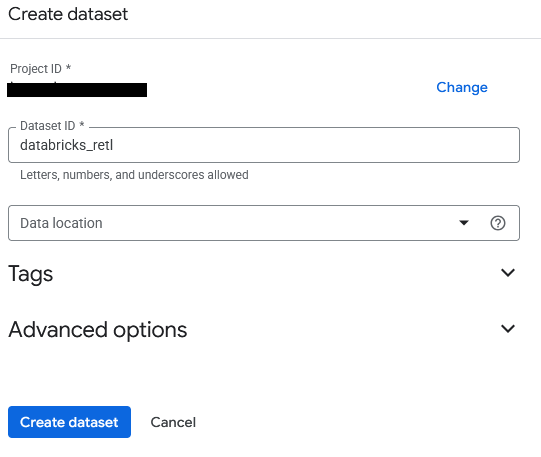
- Набор данных будет называться
databricks_retl. Оставьте остальные параметры по умолчанию и нажмите кнопку « Создать набор данных» .
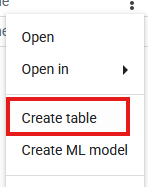
- Теперь найдите новый набор данных
databricks_retlна панели проводника . Щелкните три точки рядом с ним и выберите «Создать таблицу» .
- Для создания таблицы укажите следующие параметры:
- Создать таблицу из :
Google Cloud Storage - Выберите файл из хранилища GCS или используйте шаблон URI : перейдите в хранилище GCS и найдите JSON-файл метаданных , сгенерированный во время экспорта в Databricks. Путь должен выглядеть примерно так:
regional_sales/metadata/v1.metadata.json. - Формат файла :
Iceberg - Таблица :
regional_sales - Тип таблицы :
External table - Идентификатор соединения : Выберите соединение
databricks_retl, созданное ранее. - Оставьте остальные значения по умолчанию, затем нажмите «Создать таблицу» .
- После создания новая таблица
regional_salesдолжна стать видимой в наборе данныхdatabricks_retl. Теперь к этой таблице можно обращаться с помощью стандартного SQL, как и к любой другой таблице BigQuery.
7. Загрузите в гаечный ключ
Достигнут заключительный и наиболее важный этап конвейера: перемещение данных из внешних таблиц BigLake в Spanner. Это этап «обратного ETL», на котором данные, обработанные и отредактированные в хранилище данных, загружаются в операционную систему для использования приложениями.
Spanner — это полностью управляемая, глобально распределенная реляционная база данных. Она обеспечивает транзакционную согласованность традиционной реляционной базы данных, но при этом обладает горизонтальной масштабируемостью NoSQL-базы данных. Это делает её идеальным выбором для создания масштабируемых и высокодоступных приложений.
Процесс будет следующим:
- Создайте экземпляр Spanner, который отвечает за физическое распределение ресурсов.
- Создайте базу данных в рамках этого экземпляра.
- Определите в базе данных схему таблицы, соответствующую структуре данных
regional_sales. - Выполните запрос BigQuery
EXPORT DATA, чтобы загрузить данные из таблицы BigLake непосредственно в таблицу Spanner.
Создайте экземпляр Spanner, базу данных и таблицу.
- Перейти к Гаечному ключу
- Нажмите на
 При желании вы можете использовать существующий экземпляр, если таковой имеется. Настройте требования к экземпляру по мере необходимости. Для этой лабораторной работы использовались следующие экземпляры:
При желании вы можете использовать существующий экземпляр, если таковой имеется. Настройте требования к экземпляру по мере необходимости. Для этой лабораторной работы использовались следующие экземпляры:
Версия | Предприятие |
Имя экземпляра | databricks-retl |
Региональная конфигурация | Выбранный вами регион |
Вычислительный блок | Информационные блоки (ИП) |
Ручное распределение | 100 |
- После создания перейдите на страницу экземпляра Spanner и выберите
 При желании вы можете использовать уже существующую базу данных, если таковая имеется.
При желании вы можете использовать уже существующую базу данных, если таковая имеется.
- Для выполнения этой лабораторной работы будет создана база данных, содержащая
- Имя :
databricks-retl - Диалект базы данных :
Google Standard SQL
- После создания базы данных выберите ее на странице «Экземпляр Spanner» и перейдите на страницу «База данных Spanner».
- На странице базы данных гаечных ключей нажмите на

- На новой странице запроса будет создано определение таблицы для импорта в Spanner. Для этого выполните следующий SQL-запрос.
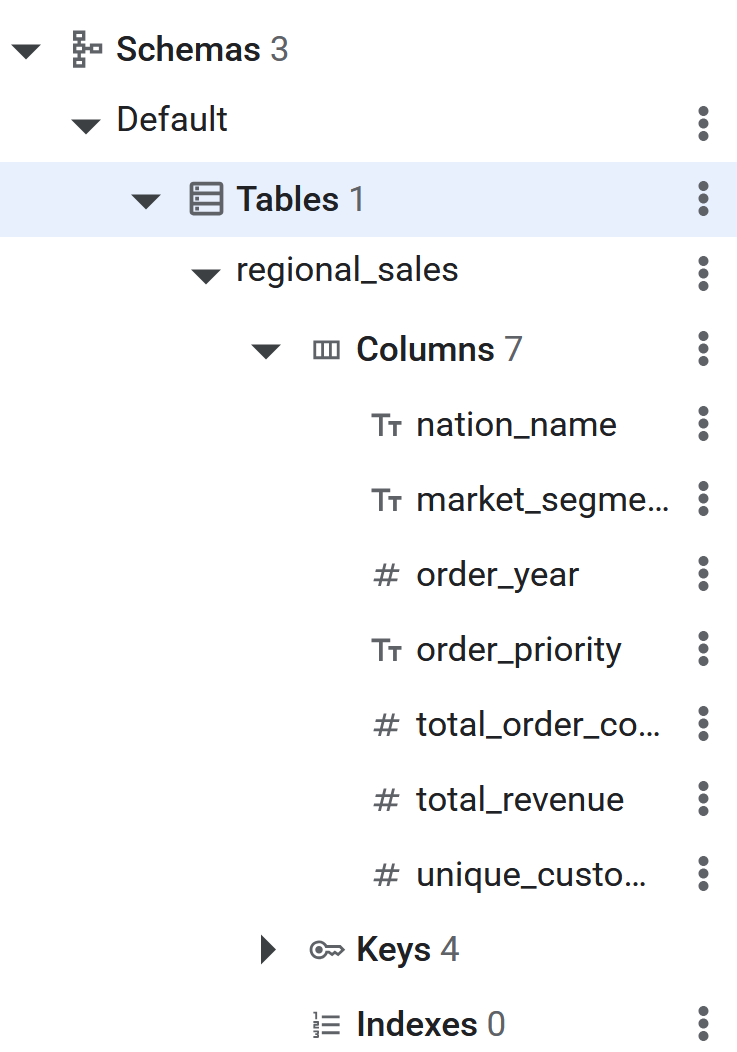
CREATE TABLE regional_sales (
nation_name STRING(MAX),
market_segment STRING(MAX),
order_year INT64,
order_priority STRING(MAX),
total_order_count INT64,
total_revenue NUMERIC,
unique_customer_count INT64
) PRIMARY KEY (nation_name, market_segment, order_year, order_priority);
- После выполнения SQL-команды таблица Spanner будет готова к обратному ETL-извлечению данных с помощью BigQuery. Создание таблицы можно проверить, увидев ее в левой панели базы данных Spanner.
Обратный ETL-процесс в Spanner с использованием EXPORT DATA
Это заключительный шаг. После того, как исходные данные подготовлены в таблице BigQuery BigLake, а целевая таблица создана в Spanner, фактическое перемещение данных оказывается на удивление простым. Будет использован всего один SQL-запрос BigQuery: EXPORT DATA .
Этот запрос разработан специально для подобных сценариев. Он эффективно экспортирует данные из таблицы BigQuery (включая внешние, такие как таблица BigLake) во внешнее целевое хранилище. В данном случае целевым хранилищем является таблица Spanner. Более подробную информацию о функции экспорта можно найти здесь.
Более подробную информацию о настройке обратного ETL-процесса BigQuery для Spanner можно найти здесь.
- Перейдите в BigQuery
- Откройте новую вкладку редактора запросов.
- На странице запросов введите следующий SQL-запрос. Не забудьте заменить идентификатор проекта в
uriи путь к таблице на правильный идентификатор проекта.
EXPORT DATA OPTIONS(
uri='https://spanner.googleapis.com/projects/YOUR_PROJECT_ID/instances/databricks-retl/databases/databricks-retl',
format='CLOUD_SPANNER',
spanner_options="""{
"table": "regional_sales",
"priority": "MEDIUM"
}"""
) AS
SELECT * FROM `YOUR_PROJECT_ID.databricks_retl.regional_sales`;
- После завершения выполнения команды данные будут успешно экспортированы в Spanner!
8. Проверьте данные в гаечном ключе.
Поздравляем! Полностью создан и выполнен конвейер обратного ETL-процесса, обеспечивающий перемещение данных из хранилища данных Databricks в рабочую базу данных Spanner.
Последний шаг — убедиться, что данные поступили в Spanner в соответствии с ожиданиями.
- Перейдите в Spanner .
- Перейдите к своему экземпляру
databricks-retl, а затем к базе данныхdatabricks-retl. - В списке таблиц щелкните по таблице
regional_sales. - В левом навигационном меню таблицы нажмите на вкладку «Данные» .
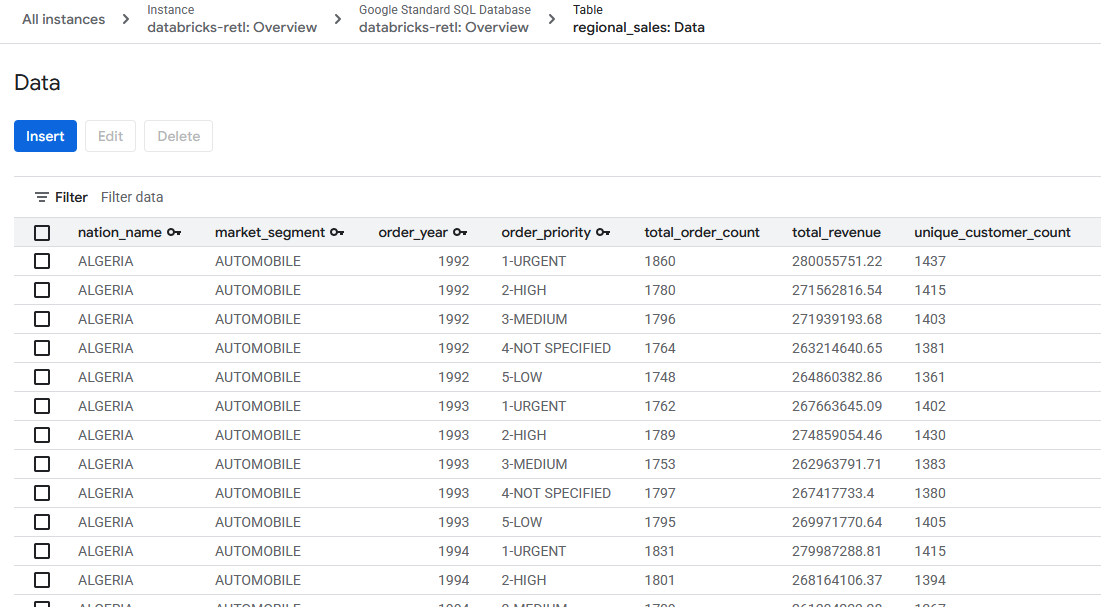
- Агрегированные данные о продажах, первоначально полученные из Databricks, теперь должны быть загружены и готовы к использованию в таблице Spanner. Эти данные теперь находятся в операционной системе и готовы к использованию в работающем приложении, отображению панели мониторинга или запросах через API.
Разрыв между миром аналитических и оперативных данных успешно преодолен.
9. Уборка
После завершения этой лабораторной работы удалите все добавленные таблицы и сохраненные данные.
Уберите столы с гаечными ключами.
- Перейти к Гаечному ключу
- Выберите из списка экземпляр, использованный в этой лабораторной работе, под названием
databricks-retl

- На странице экземпляра нажмите на

- В появившемся диалоговом окне подтверждения введите
databricks-retlи нажмите кнопку.
Очистка GCS
- Перейти в GCS
- Выбирать
 из меню слева
из меню слева - Выберите сегмент `codelabs_retl_databricks`.
- После выбора нажмите на
 кнопка, которая появляется на верхнем баннере
кнопка, которая появляется на верхнем баннере

- В появившемся диалоговом окне подтверждения введите
DELETEи нажмите кнопку.
Очистка Databricks
Удалить каталог/схему/таблицу
- Войдите в свой экземпляр Databricks.
- Нажмите на
 из меню слева
из меню слева - Выберите ранее созданный
 из списка каталога
из списка каталога - В списке «Схема» выберите
 который был создан
который был создан - Выберите ранее созданный
 из списка таблицы
из списка таблицы - Разверните параметры таблицы, нажав на
 и выберите
и выберите Delete - Нажмите
 В диалоговом окне подтверждения удалите таблицу.
В диалоговом окне подтверждения удалите таблицу. - После удаления таблицы вы вернетесь на страницу схемы.
- Разверните параметры схемы, щелкнув по... и выберите
Delete - Нажмите В диалоговом окне подтверждения удалите схему.
- После удаления схемы вы вернетесь на страницу каталога.
- Повторите шаги 4–11, чтобы удалить схему
default, если она существует. - На странице каталога разверните параметры каталога, щелкнув по соответствующему пункту. и выберите
Delete - Нажмите В диалоговом окне подтверждения удалите каталог.
Удаление внешнего местоположения данных / учетных данных
- На экране каталога нажмите на
- Если вы не видите опцию
External Data, возможно, вы найдетеExternal Locationв выпадающем списке «Connect. - Щелкните по ранее созданному внешнему расположению данных
retl-gcs-location - На странице выбора внешнего местоположения разверните параметры местоположения, нажав на соответствующую кнопку. и выберите
Delete - Нажмите В диалоговом окне подтверждения удалите внешнее местоположение.
- Нажмите на
- Щелкните по ранее созданному файлу
retl-gcs-credential - На странице ввода учетных данных разверните параметры учетных данных, щелкнув по соответствующему пункту. и выберите
Delete - Нажмите В диалоговом окне подтверждения удалите учетные данные.
10. Поздравляем!
Поздравляем с завершением практического занятия!
Что мы рассмотрели
- Как загрузить данные в Databricks в виде таблиц Iceberg
- Как создать сегмент GCS
- Как экспортировать таблицу Databricks в GCS в формате Iceberg
- Как создать внешнюю таблицу BigLake в BigQuery из таблицы Iceberg в GCS
- Как настроить экземпляр Spanner
- Как загрузить внешние таблицы BigLake из BigQuery в Spanner