
1. สร้างไปป์ไลน์ Reverse ETL จาก Databricks ไปยัง Spanner โดยใช้ Google Cloud Storage และ BigQuery
บทนำ
ใน Codelab นี้ คุณจะได้สร้างไปป์ไลน์ Reverse ETL จาก Databricks ไปยัง Spanner โดยปกติแล้ว ไปป์ไลน์ ETL (Extract, Transform, Load) มาตรฐานจะย้ายข้อมูลจากฐานข้อมูลการดำเนินงานไปยังคลังข้อมูล เช่น Databricks เพื่อการวิเคราะห์ ไปป์ไลน์ Reverse ETL จะทําตรงกันข้ามโดยการย้ายข้อมูลที่ได้รับการดูแลจัดการและประมวลผลจากคลังข้อมูลกลับไปยังฐานข้อมูลการดําเนินงาน เช่น Spanner ซึ่งเป็นฐานข้อมูลเชิงสัมพันธ์ที่กระจายอยู่ทั่วโลกและเหมาะสําหรับแอปพลิเคชันที่มีความพร้อมใช้งานสูง ซึ่งสามารถขับเคลื่อนแอปพลิเคชัน ให้บริการฟีเจอร์ที่แสดงต่อผู้ใช้ หรือใช้สําหรับการตัดสินใจแบบเรียลไทม์
เป้าหมายคือการย้ายชุดข้อมูลที่รวบรวมแล้วจากตาราง Iceberg ของ Databricks ไปยังตาราง Spanner
โดยใช้ Google Cloud Storage (GCS) และ BigQuery เป็นขั้นตอนกลาง รายละเอียดของโฟลว์ข้อมูลและเหตุผลที่อยู่เบื้องหลังสถาปัตยกรรมนี้มีดังนี้

- Databricks ไปยัง Google Cloud Storage (GCS) ในรูปแบบ Iceberg:
- ขั้นตอนแรกคือการนำข้อมูลออกจาก Databricks ในรูปแบบที่เปิดและกำหนดไว้อย่างดี ระบบจะส่งออกตารางในรูปแบบ Apache Iceberg กระบวนการนี้จะเขียนข้อมูลพื้นฐานเป็นชุดไฟล์ Parquet และข้อมูลเมตาของตาราง (สคีมา พาร์ติชัน ตำแหน่งไฟล์) เป็นไฟล์ JSON และ Avro การจัดโครงสร้างตารางที่สมบูรณ์นี้ใน GCS ทำให้ข้อมูลสามารถเคลื่อนย้ายและเข้าถึงได้ในทุกระบบที่เข้าใจรูปแบบ Iceberg
- แปลงตาราง Iceberg ใน GCS เป็นตารางภายนอก BigLake ของ BigQuery:
- เราใช้ BigQuery เป็นสื่อกลางที่มีประสิทธิภาพแทนการโหลดข้อมูลจาก GCS ไปยัง Spanner โดยตรง ระบบจะสร้างตารางภายนอก BigLake ใน BigQuery ซึ่งชี้ไปยังไฟล์ข้อมูลเมตาของ Iceberg ใน GCS โดยตรง แนวทางนี้มีข้อดีหลายประการ ได้แก่
- ไม่มีการทำซ้ำข้อมูล: BigQuery จะอ่านโครงสร้างตารางจากข้อมูลเมตาและค้นหาไฟล์ข้อมูล Parquet ในตำแหน่งโดยไม่ต้องนำเข้า ซึ่งช่วยประหยัดเวลาและค่าใช้จ่ายในการจัดเก็บได้อย่างมาก
- การค้นหาแบบรวม: ช่วยให้เรียกใช้การค้นหา SQL ที่ซับซ้อนในข้อมูล GCS ได้ราวกับว่าเป็นตาราง BigQuery ดั้งเดิม
- ReverseETL ตารางภายนอก BigLake ลงใน Spanner:
- ขั้นตอนสุดท้ายคือการย้ายข้อมูลจาก BigQuery ไปยัง Spanner ซึ่งทำได้โดยใช้ฟีเจอร์ที่มีประสิทธิภาพใน BigQuery ที่เรียกว่า
EXPORT DATAการค้นหา ซึ่งเป็นขั้นตอน "Reverse ETL" - ความพร้อมในการปฏิบัติงาน: Spanner ออกแบบมาสำหรับภาระงานด้านธุรกรรม โดยมอบความสอดคล้องที่อัปเดตทันทีและความพร้อมใช้งานสูงสำหรับแอปพลิเคชัน การย้ายข้อมูลไปยัง Spanner จะทำให้แอปพลิเคชัน API และระบบปฏิบัติการอื่นๆ ที่ต้องมีการค้นหาแบบจุดที่มีเวลาในการตอบสนองต่ำซึ่งผู้ใช้มองเห็นได้เข้าถึงข้อมูลได้
- ความสามารถในการปรับขนาด: รูปแบบนี้ช่วยให้ใช้ประโยชน์จากความสามารถในการวิเคราะห์ของ BigQuery เพื่อประมวลผลชุดข้อมูลขนาดใหญ่ แล้วแสดงผลลัพธ์อย่างมีประสิทธิภาพผ่านโครงสร้างพื้นฐานที่ปรับขนาดได้ทั่วโลกของ Spanner
บริการและคำศัพท์
- DataBricks - แพลตฟอร์มข้อมูลบนระบบคลาวด์ที่สร้างขึ้นจาก Apache Spark
- Spanner - ฐานข้อมูลเชิงสัมพันธ์ที่กระจายอยู่ทั่วโลกซึ่ง Google จัดการครบวงจร
- Google Cloud Storage - ข้อเสนอพื้นที่เก็บข้อมูล Blob ของ Google Cloud
- BigQuery - คลังข้อมูลแบบไร้เซิร์ฟเวอร์สำหรับการวิเคราะห์ ซึ่ง Google เป็นผู้จัดการครบวงจร
- Iceberg - รูปแบบตารางแบบเปิดที่กำหนดโดย Apache ซึ่งให้การแยกข้อมูลเหนือรูปแบบไฟล์ข้อมูลโอเพนซอร์สทั่วไป
- Parquet - รูปแบบไฟล์ข้อมูลไบนารีแบบคอลัมน์โอเพนซอร์สของ Apache
สิ่งที่คุณจะได้เรียนรู้
- วิธีโหลดข้อมูลลงใน Databricks เป็นตาราง Iceberg
- วิธีสร้างที่เก็บข้อมูล GCS
- วิธีส่งออกตาราง Databricks ไปยัง GCS ในรูปแบบ Iceberg
- วิธีสร้างตารางภายนอก BigLake ใน BigQuery จากตาราง Iceberg ใน GCS
- วิธีตั้งค่าอินสแตนซ์ Spanner
- วิธีโหลดตารางภายนอก BigLake ใน BigQuery ไปยัง Spanner
2. การตั้งค่า ข้อกำหนด และข้อจำกัด
ข้อกำหนดเบื้องต้น
- บัญชี Databricks โดยควรเป็นบัญชีใน GCP
- คุณต้องมีบัญชี Google Cloud ที่มีการจองระดับ Enterprise ขึ้นไปของ BigQuery จึงจะส่งออกจาก BigQuery ไปยัง Spanner ได้
- สิทธิ์เข้าถึงคอนโซล Google Cloud ผ่านเว็บเบราว์เซอร์
- เทอร์มินัลเพื่อเรียกใช้คำสั่ง Google Cloud CLI
หากองค์กร Google Cloud มีiam.allowedPolicyMemberDomainsนโยบายที่เปิดใช้ ผู้ดูแลระบบอาจต้องให้ข้อยกเว้นเพื่ออนุญาตบัญชีบริการจากโดเมนภายนอก ซึ่งจะอธิบายในขั้นตอนถัดไป (หากมี)
ข้อกำหนด
- โปรเจ็กต์ Google Cloud ที่เปิดใช้การเรียกเก็บเงิน
- เว็บเบราว์เซอร์ เช่น Chrome
- บัญชี Databricks (แล็บนี้ถือว่ามีพื้นที่ทำงานที่โฮสต์ใน GCP)
- อินสแตนซ์ BigQuery ต้องอยู่ในรุ่น Enterprise ขึ้นไปจึงจะใช้ฟีเจอร์ส่งออกข้อมูลได้
- หากองค์กร Google Cloud มี
iam.allowedPolicyMemberDomainsนโยบายที่เปิดใช้ ผู้ดูแลระบบอาจต้องให้ข้อยกเว้นเพื่ออนุญาตบัญชีบริการจากโดเมนภายนอก ซึ่งจะอธิบายในขั้นตอนถัดไป (หากมี)
สิทธิ์ IAM ของ Google Cloud Platform
บัญชี Google จะต้องมีสิทธิ์ต่อไปนี้จึงจะดำเนินการทุกขั้นตอนใน Codelab นี้ได้
บัญชีบริการ | ||
| อนุญาตให้สร้างบัญชีบริการ | |
Spanner | ||
| อนุญาตให้สร้างอินสแตนซ์ Spanner ใหม่ | |
| อนุญาตให้เรียกใช้คำสั่ง DDL เพื่อสร้าง | |
| อนุญาตให้เรียกใช้คำสั่ง DDL เพื่อสร้างตารางในฐานข้อมูล | |
Google Cloud Storage | ||
| อนุญาตให้สร้าง Bucket ของ GCS ใหม่เพื่อจัดเก็บไฟล์ Parquet ที่ส่งออก | |
| อนุญาตให้เขียนไฟล์ Parquet ที่ส่งออกไปยัง Bucket ของ GCS | |
| อนุญาตให้ BigQuery อ่านไฟล์ Parquet จากที่เก็บข้อมูล GCS | |
| อนุญาตให้ BigQuery แสดงรายการไฟล์ Parquet ในที่เก็บข้อมูล GCS | |
Dataflow | ||
| อนุญาตให้เคลมรายการงานจาก Dataflow | |
| อนุญาตให้ผู้ปฏิบัติงาน Dataflow ส่งข้อความกลับไปยังบริการ Dataflow | |
| อนุญาตให้ Worker ของ Dataflow เขียนรายการบันทึกลงใน Google Cloud Logging | |
คุณสามารถใช้บทบาทที่กำหนดไว้ล่วงหน้าซึ่งมีสิทธิ์เหล่านี้เพื่อความสะดวก
|
|
|
|
|
|
|
|
โปรเจ็กต์ Google Cloud
โปรเจ็กต์คือหน่วยพื้นฐานของการจัดระเบียบใน Google Cloud หากผู้ดูแลระบบได้ระบุไว้ให้ใช้ คุณอาจข้ามขั้นตอนนี้ได้
คุณสร้างโปรเจ็กต์ได้โดยใช้ CLI ดังนี้
gcloud projects create <your-project-name>
ดูข้อมูลเพิ่มเติมเกี่ยวกับการสร้างและจัดการโปรเจ็กต์ได้ที่นี่
ข้อจำกัด
คุณควรทราบข้อจำกัดบางอย่างและความไม่เข้ากันของประเภทข้อมูลที่อาจเกิดขึ้นในไปป์ไลน์นี้
Databricks Iceberg ไปยัง BigQuery
เมื่อใช้ BigQuery เพื่อค้นหาตาราง Iceberg ที่จัดการโดย Databricks (ผ่าน UniForm) โปรดคำนึงถึงสิ่งต่อไปนี้
- การพัฒนาสคีมา: แม้ว่า UniForm จะแปลการเปลี่ยนแปลงสคีมา Delta Lake เป็น Iceberg ได้ดี แต่การเปลี่ยนแปลงที่ซับซ้อนอาจไม่เผยแพร่ตามที่คาดไว้เสมอไป เช่น การเปลี่ยนชื่อคอลัมน์ใน Delta Lake จะไม่ได้รับการแปลเป็น Iceberg ซึ่งจะมองว่าเป็นการ
dropและaddทดสอบการเปลี่ยนแปลงสคีมาอย่างละเอียดเสมอ - การย้อนเวลา: BigQuery ไม่สามารถใช้ความสามารถในการย้อนเวลาของ Delta Lake ได้ โดยจะค้นหาเฉพาะสแนปชอตล่าสุดของตาราง Iceberg
- ฟีเจอร์ Delta Lake ที่ไม่รองรับ: ฟีเจอร์ต่างๆ เช่น เวกเตอร์การลบและการแมปคอลัมน์ที่มีโหมด
idใน Delta Lake ใช้ร่วมกับ UniForm สำหรับ Iceberg ไม่ได้ Lab ใช้โหมดnameสำหรับการแมปคอลัมน์ ซึ่งได้รับการรองรับ
BigQuery ไปยัง Spanner
คำสั่ง EXPORT DATA จาก BigQuery ไปยัง Spanner ไม่รองรับประเภทข้อมูล BigQuery ทั้งหมด การส่งออกตารางที่มีประเภทต่อไปนี้จะทำให้เกิดข้อผิดพลาด
STRUCTGEOGRAPHYDATETIMERANGETIME
นอกจากนี้ หากโปรเจ็กต์ BigQuery ใช้GoogleSQL ไดอะเล็กต์ ระบบจะไม่รองรับการส่งออกไปยัง Spanner สำหรับประเภทตัวเลขต่อไปนี้ด้วย
BIGNUMERIC
ดูรายการข้อจำกัดทั้งหมดและล่าสุดได้ในเอกสารประกอบอย่างเป็นทางการที่หัวข้อข้อจำกัดในการส่งออกไปยัง Spanner
การแก้ปัญหาและข้อควรระวัง
- หากไม่ได้อยู่ในอินสแตนซ์ GCP Databricks คุณอาจกำหนดตำแหน่งข้อมูลภายนอกใน GCS ไม่ได้ ในกรณีดังกล่าว คุณจะต้องจัดเตรียมไฟล์ในโซลูชันพื้นที่เก็บข้อมูลของผู้ให้บริการระบบคลาวด์ของพื้นที่ทํางาน Databricks แล้วจึงย้ายข้อมูลไปยัง GCS แยกต่างหาก
- เมื่อดำเนินการดังกล่าว คุณจะต้องปรับข้อมูลเมตาเนื่องจากข้อมูลจะมีเส้นทางที่ฮาร์ดโค้ดไปยังไฟล์ที่จัดเตรียมไว้
3. ตั้งค่า Google Cloud Storage (GCS)
ระบบจะใช้ Google Cloud Storage (GCS) เพื่อจัดเก็บไฟล์ข้อมูล Parquet ที่สร้างโดย Databricks โดยจะต้องสร้างที่เก็บข้อมูลใหม่ก่อนเพื่อใช้เป็นปลายทางของไฟล์
Google Cloud Storage
การสร้างที่เก็บข้อมูลใหม่
- ไปที่หน้า Google Cloud Storage ใน Cloud Console
- เลือกที่เก็บข้อมูลในแผงด้านซ้าย
- คลิกปุ่มสร้าง

- กรอกรายละเอียด Bucket ดังนี้
- เลือกชื่อ Bucket ที่จะใช้ ในแล็บนี้ เราจะใช้ชื่อ
codelabs_retl_databricks - เลือกภูมิภาคเพื่อจัดเก็บ Bucket หรือใช้ค่าเริ่มต้น
- คงคลาสพื้นที่เก็บข้อมูลเป็น
standard - เก็บค่าเริ่มต้นสำหรับควบคุมการเข้าถึง
- เก็บค่าเริ่มต้นสำหรับปกป้องข้อมูลออบเจ็กต์
- คลิกปุ่ม
Createเมื่อเสร็จแล้ว ข้อความแจ้งอาจปรากฏขึ้นเพื่อยืนยันว่าระบบจะป้องกันการเข้าถึงแบบสาธารณะ โปรดยืนยัน - ขอแสดงความยินดี คุณสร้าง Bucket ใหม่เรียบร้อยแล้ว ระบบจะเปลี่ยนเส้นทางไปยังหน้าของที่เก็บข้อมูล
- คัดลอกชื่อที่เก็บข้อมูลใหม่ไว้ที่ใดที่หนึ่งเนื่องจากคุณจะต้องใช้ชื่อนี้ในภายหลัง
เตรียมพร้อมสำหรับขั้นตอนถัดไป
โปรดจดรายละเอียดต่อไปนี้ไว้ เนื่องจากจะต้องใช้ในขั้นตอนถัดไป
- รหัสโปรเจ็กต์ Google
- ชื่อ Bucket ของ Google Storage
4. ตั้งค่า Databricks
ข้อมูล TPC-H
สำหรับแล็บนี้ เราจะใช้ชุดข้อมูล TPC-H ซึ่งเป็นเกณฑ์มาตรฐานระดับอุตสาหกรรมสำหรับระบบสนับสนุนการตัดสินใจ สคีมาของฐานข้อมูลนี้จำลองสภาพแวดล้อมทางธุรกิจที่สมจริงด้วยลูกค้า คำสั่งซื้อ ซัพพลายเออร์ และชิ้นส่วนต่างๆ จึงเหมาะอย่างยิ่งสำหรับการสาธิตสถานการณ์การวิเคราะห์และการย้ายข้อมูลในโลกแห่งความเป็นจริง
ระบบจะสร้างตารางรวมใหม่แทนการใช้ตาราง TPC-H ดิบที่ได้รับการทำให้เป็นมาตรฐาน ตารางใหม่นี้จะผนวกข้อมูลจากตาราง orders, customer และ nation เพื่อสร้างมุมมองสรุปที่ยกเลิกการทำให้เป็นมาตรฐานของการขายในภูมิภาค ขั้นตอนการรวมข้อมูลล่วงหน้านี้เป็นแนวทางปฏิบัติทั่วไปในการวิเคราะห์ เนื่องจากเป็นการเตรียมข้อมูลสําหรับกรณีการใช้งานที่เฉพาะเจาะจง ในสถานการณ์นี้คือสําหรับการใช้งานโดยแอปพลิเคชันด้านการดำเนินงาน
สคีมาสุดท้ายสำหรับตารางรวมจะเป็นดังนี้
Col | ประเภท |
nation_name | สตริง |
market_segment | สตริง |
order_year | int |
order_priority | สตริง |
total_order_count | bigint |
total_revenue | decimal(29,2) |
unique_customer_count | bigint |
การรองรับ Iceberg ด้วยรูปแบบสากลของ Delta Lake (UniForm)
สำหรับห้องทดลองนี้ ตารางภายใน Databricks จะเป็นตาราง Delta Lake อย่างไรก็ตาม ระบบจะเปิดใช้ฟีเจอร์ที่มีประสิทธิภาพที่เรียกว่ารูปแบบสากล (UniForm) เพื่อให้ระบบภายนอก เช่น BigQuery อ่านได้
UniForm จะสร้างข้อมูลเมตาของ Iceberg โดยอัตโนมัติควบคู่ไปกับข้อมูลเมตาของ Delta Lake สำหรับสำเนาข้อมูลของตารางที่แชร์รายการเดียว ซึ่งจะช่วยให้คุณได้รับประโยชน์จากทั้ง 2 อย่าง ดังนี้
- ภายใน Databricks: คุณจะได้รับประโยชน์ด้านประสิทธิภาพและการกำกับดูแลทั้งหมดของ Delta Lake
- ภายนอก Databricks: เครื่องมือการค้นหาที่รองรับ Iceberg เช่น BigQuery สามารถอ่านตารางได้ราวกับว่าเป็นตาราง Iceberg ดั้งเดิม
จึงไม่ต้องเก็บรักษาสำเนาข้อมูลแยกกันหรือเรียกใช้งานการแปลงด้วยตนเอง ระบบจะเปิดใช้ UniForm โดยการตั้งค่าคุณสมบัติของตารางที่เฉพาะเจาะจงเมื่อสร้างตาราง
แคตตาล็อก Databricks
แคตตาล็อก Databricks เป็นคอนเทนเนอร์ระดับบนสุดสำหรับข้อมูลใน Unity Catalog ซึ่งเป็นโซลูชันการกำกับดูแลแบบรวมของ Databricks Unity Catalog มีวิธีจัดการชิ้นงานข้อมูล ควบคุมการเข้าถึง และติดตามแหล่งที่มาจากส่วนกลาง ซึ่งเป็นสิ่งสำคัญสำหรับแพลตฟอร์มข้อมูลที่มีการกำกับดูแลที่ดี
โดยใช้เนมสเปซ 3 ระดับเพื่อจัดระเบียบข้อมูล catalog.schema.table
- แคตตาล็อก: ระดับสูงสุด ใช้เพื่อจัดกลุ่มข้อมูลตามสภาพแวดล้อม หน่วยธุรกิจ หรือโปรเจ็กต์
- สคีมา (หรือฐานข้อมูล): การจัดกลุ่มตาราง มุมมอง และฟังก์ชันอย่างมีตรรกะภายในแคตตาล็อก
- ตาราง: ออบเจ็กต์ที่มีข้อมูล
ก่อนที่จะสร้างตาราง TPC-H ที่รวบรวมได้ คุณต้องตั้งค่าแคตตาล็อกและสคีมาเฉพาะเพื่อจัดเก็บตารางดังกล่าวก่อน ซึ่งจะช่วยให้โปรเจ็กต์ได้รับการจัดระเบียบอย่างเรียบร้อยและแยกจากข้อมูลอื่นๆ ในพื้นที่ทํางาน
สร้างแคตตาล็อกและสคีมาใหม่
ใน Databricks Unity Catalog แคตตาล็อกจะทำหน้าที่เป็นระดับสูงสุดของการจัดระเบียบสำหรับชิ้นงานข้อมูล โดยทำหน้าที่เป็นคอนเทนเนอร์ที่ปลอดภัยซึ่งครอบคลุมพื้นที่ทำงาน Databricks หลายรายการ ซึ่งช่วยให้คุณจัดระเบียบและแยกข้อมูลตามหน่วยธุรกิจ โปรเจ็กต์ หรือสภาพแวดล้อม โดยมีสิทธิ์และการควบคุมการเข้าถึงที่กำหนดไว้อย่างชัดเจน
ภายในแคตตาล็อก สคีมา (หรือที่เรียกว่าฐานข้อมูล) จะจัดระเบียบตาราง มุมมอง และฟังก์ชันเพิ่มเติม โครงสร้างแบบลำดับชั้นนี้ช่วยให้ควบคุมได้อย่างละเอียดและจัดกลุ่มออบเจ็กต์ข้อมูลที่เกี่ยวข้องอย่างเป็นตรรกะ สำหรับ Lab นี้ เราจะสร้างแคตตาล็อกและสคีมาเฉพาะเพื่อจัดเก็บข้อมูล TPC-H เพื่อให้มั่นใจว่ามีการแยกและการจัดการที่เหมาะสม
การสร้างแคตตาล็อก
- ไปที่

- คลิก + แล้วเลือกสร้างแคตตาล็อกจากเมนูแบบเลื่อนลง
- ระบบจะสร้างแคตตาล็อกมาตรฐานใหม่โดยใช้การตั้งค่าต่อไปนี้
- ชื่อแคตตาล็อก:
retl_tpch_project - ตำแหน่งที่เก็บข้อมูล: ใช้ค่าเริ่มต้นหากมีการตั้งค่าไว้ในพื้นที่ทำงาน หรือสร้างตำแหน่งใหม่
การสร้างสคีมา
- ไปที่
- เลือกแคตตาล็อกใหม่ที่สร้างจากแผงด้านซ้าย
- คลิก
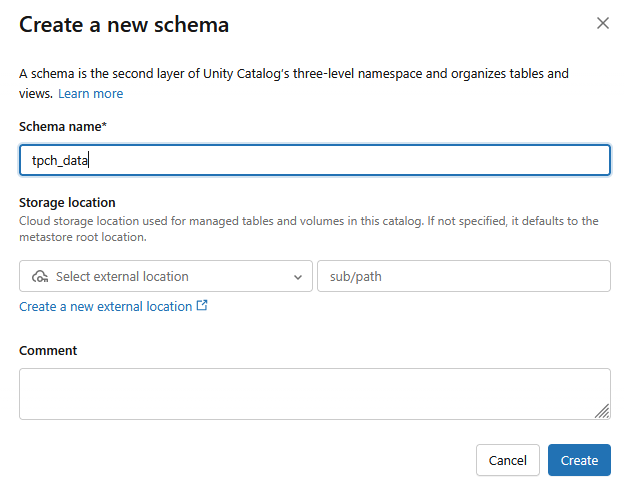
- ระบบจะสร้างสคีมาใหม่โดยใช้ชื่อสคีมาเป็น
tpch_data
การตั้งค่าข้อมูลภายนอก
หากต้องการส่งออกข้อมูลจาก Databricks ไปยัง Google Cloud Storage (GCS) คุณต้องตั้งค่าข้อมูลเข้าสู่ระบบในการเข้าใช้ข้อมูลภายนอกภายใน Databricks ซึ่งจะช่วยให้ Databricks เข้าถึงและเขียนไปยัง Bucket ของ GCS ได้อย่างปลอดภัย
- จากหน้าจอแคตตาล็อก ให้คลิก

- หากไม่เห็นตัวเลือก
External Dataคุณอาจเห็นExternal Locationsแสดงอยู่ในเมนูแบบเลื่อนลงConnectแทน
- คลิก

- ในหน้าต่างกล่องโต้ตอบใหม่ ให้ตั้งค่าที่จำเป็นสำหรับข้อมูลเข้าสู่ระบบ ดังนี้
- ประเภทข้อมูลเข้าสู่ระบบ:
GCP Service Account - ชื่อข้อมูลเข้าสู่ระบบ:
retl-gcs-credential
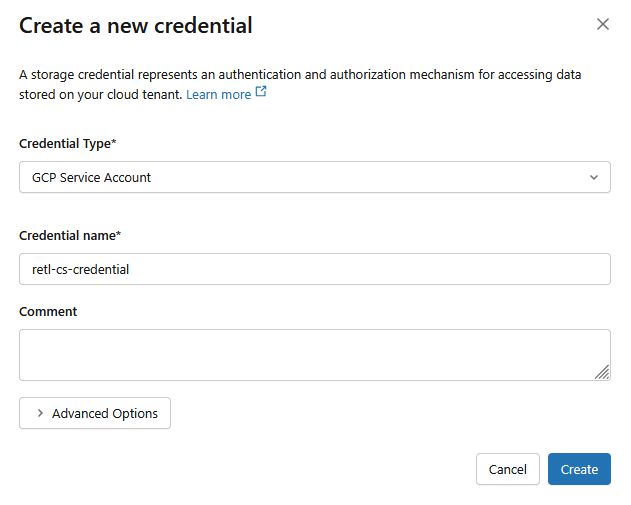
- คลิกสร้าง
- จากนั้นคลิกแท็บสถานที่ภายนอก
- คลิกสร้างสถานที่
- ในหน้าต่างกล่องโต้ตอบใหม่ ให้ตั้งค่าที่จำเป็นสำหรับตำแหน่งภายนอก ดังนี้
- ชื่อสถานที่ภายนอก:
retl-gcs-location - ประเภทพื้นที่เก็บข้อมูล:
GCP - URL: URL ของที่เก็บข้อมูล GCS ในรูปแบบ
gs://YOUR_BUCKET_NAME - ข้อมูลเข้าสู่ระบบของพื้นที่เก็บข้อมูล: เลือก
retl-gcs-credentialที่เพิ่งสร้าง
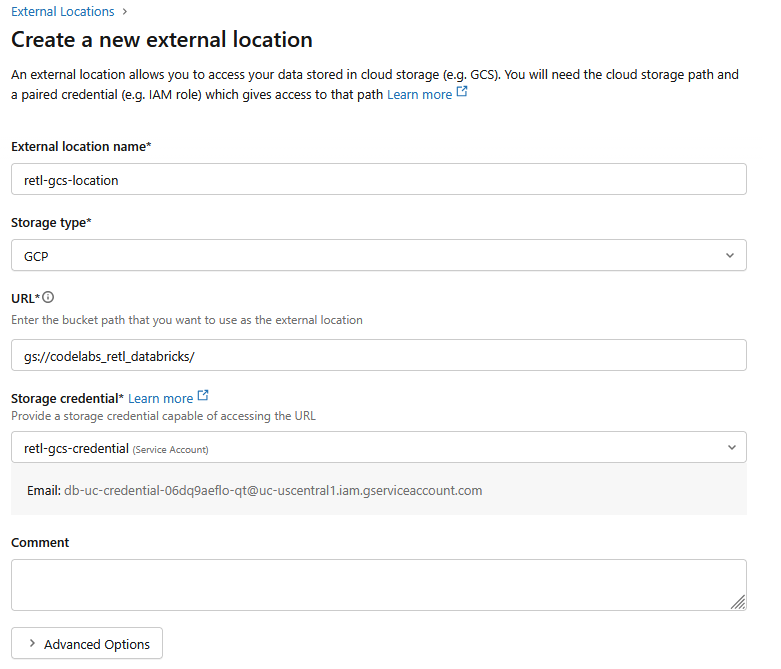
- จดอีเมลบัญชีบริการที่ระบบจะกรอกให้โดยอัตโนมัติเมื่อเลือกข้อมูลเข้าสู่ระบบของพื้นที่เก็บข้อมูล เนื่องจากคุณจะต้องใช้ในขั้นตอนถัดไป
- คลิกสร้าง
5. การตั้งค่าสิทธิ์ของบัญชีบริการ
บัญชีบริการคือบัญชีประเภทพิเศษที่แอปพลิเคชันหรือบริการใช้เพื่อทำการเรียก API ที่ได้รับอนุญาตไปยังทรัพยากร Google Cloud
ตอนนี้คุณจะต้องเพิ่มสิทธิ์ไปยังบัญชีบริการที่สร้างขึ้นสำหรับ Bucket ใหม่ใน GCS
- จากหน้า Bucket ของ GCS ให้เลือกแท็บสิทธิ์
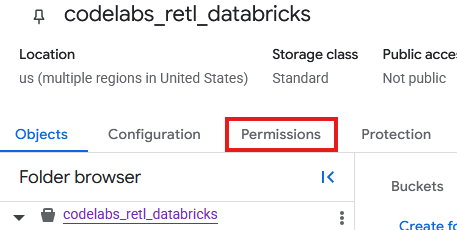
- คลิกให้สิทธิ์เข้าถึงในหน้าผู้ใช้หลัก
- ในแผงให้สิทธิ์เข้าถึงที่เลื่อนออกมาจากทางด้านขวา ให้ป้อนรหัสบัญชีบริการลงในช่องผู้ใช้หลักรายใหม่
- ในส่วนมอบหมายบทบาท ให้เพิ่ม
Storage Object AdminและStorage Legacy Bucket Readerบทบาทเหล่านี้ช่วยให้บัญชีบริการอ่าน เขียน และแสดงรายการออบเจ็กต์ใน Bucket ของพื้นที่เก็บข้อมูลได้
โหลดข้อมูล TPC-H
เมื่อสร้างแคตตาล็อกและสคีมาแล้ว ก็จะโหลดข้อมูล TPCH จากตาราง samples.tpch ที่มีอยู่ซึ่งจัดเก็บไว้ภายใน Databricks และจัดการเป็นตารางใหม่ในสคีมาที่กำหนดใหม่ได้
การสร้างตารางที่รองรับ Iceberg
ความเข้ากันได้ของ Iceberg กับ UniForm
เบื้องหลังการทำงาน Databricks จะจัดการตารางนี้เป็นการภายในในรูปแบบตาราง Delta Lake ซึ่งจะให้ประโยชน์ทั้งหมดจากการเพิ่มประสิทธิภาพและฟีเจอร์การกำกับดูแลของ Delta ภายในระบบนิเวศของ Databricks อย่างไรก็ตาม การเปิดใช้ UniForm (ย่อมาจาก Universal Format) จะเป็นการสั่งให้ Databricks ทำสิ่งพิเศษ นั่นคือ ทุกครั้งที่มีการอัปเดตตาราง Databricks จะสร้างและดูแลรักษาข้อมูลเมตา Iceberg ที่เกี่ยวข้องนอกเหนือจากข้อมูลเมตา Delta Lake โดยอัตโนมัติ
ซึ่งหมายความว่าตอนนี้ชุดไฟล์ข้อมูลที่แชร์ชุดเดียว (ไฟล์ Parquet) จะอธิบายโดยชุดข้อมูลเมตา 2 ชุดที่แตกต่างกัน
- สำหรับ Databricks: ใช้
_delta_logเพื่ออ่านตาราง - สำหรับผู้อ่านภายนอก (เช่น BigQuery): ผู้อ่านจะใช้ไฟล์ข้อมูลเมตา Iceberg (
.metadata.json) เพื่อทำความเข้าใจสคีมา การแบ่งพาร์ติชัน และตำแหน่งไฟล์ของตาราง
ผลลัพธ์ที่ได้คือตารางที่เข้ากันได้อย่างสมบูรณ์และโปร่งใสกับเครื่องมือที่รองรับ Iceberg ไม่มีการทำซ้ำข้อมูล และไม่จำเป็นต้องแปลงหรือซิงค์ด้วยตนเอง ซึ่งเป็นแหล่งข้อมูลที่ถูกต้องแห่งเดียวที่ทั้งโลกการวิเคราะห์ของ Databricks และระบบนิเวศของเครื่องมือที่กว้างขึ้นซึ่งรองรับมาตรฐาน Iceberg แบบเปิดสามารถเข้าถึงได้อย่างราบรื่น
- คลิกใหม่ แล้วคลิกคำค้นหา
- ในช่องข้อความของหน้าคำค้นหา ให้เรียกใช้คำสั่ง SQL ต่อไปนี้
CREATE TABLE retl_tpch_project.tpch_data.regional_sales_iceberg
USING DELTA
LOCATION 'gs://<Your bucket name>/regional_sales_iceberg'
TBLPROPERTIES (
'delta.columnMapping.mode' = 'name',
'delta.enableIcebergCompatV2' = 'true',
'delta.universalFormat.enabledFormats' = 'iceberg'
)
AS
SELECT
n.n_name AS nation_name,
c.c_mktsegment AS market_segment,
YEAR(o.o_orderdate) AS order_year,
o.o_orderpriority AS order_priority,
COUNT(o.o_orderkey) AS total_order_count,
ROUND(SUM(o.o_totalprice), 2) AS total_revenue,
COUNT(DISTINCT c.c_custkey) AS unique_customer_count
FROM samples.tpch.orders AS o
INNER JOIN samples.tpch.customer AS c
ON o.o_custkey = c.c_custkey
INNER JOIN samples.tpch.nation AS n
ON c.c_nationkey = n.n_nationkey
GROUP BY
n.n_name,
c.c_mktsegment,
YEAR(o.o_orderdate),
o.o_orderpriority;
OPTIMIZE retl_tpch_project.tpch_data.regional_sales_iceberg;
DESCRIBE EXTENDED retl_tpch_project.tpch_data.regional_sales_iceberg;
หมายเหตุ:
- Using Delta - ระบุว่าเรากำลังใช้ตาราง Delta Lake จัดเก็บได้เฉพาะตาราง Delta Lake ใน Databricks เป็นตารางภายนอก
- ตำแหน่ง - ระบุตำแหน่งที่จะจัดเก็บตาราง หากเป็นตารางภายนอก
- TablePropertoes -
delta.universalFormat.enabledFormats = ‘iceberg'สร้างข้อมูลเมตา Iceberg ที่เข้ากันได้ควบคู่ไปกับไฟล์ Delta Lake - เพิ่มประสิทธิภาพ - บังคับให้ทริกเกอร์การสร้างข้อมูลเมตา UniForm เนื่องจากโดยปกติแล้วการดำเนินการนี้จะเกิดขึ้นแบบไม่พร้อมกัน
- เอาต์พุตของการค้นหาควรแสดงรายละเอียดเกี่ยวกับตารางที่สร้างขึ้นใหม่

ยืนยันข้อมูลตาราง GCS
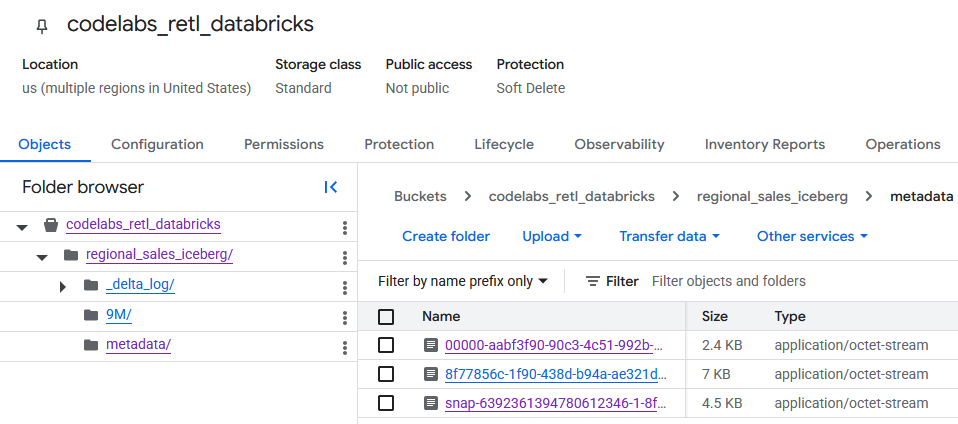
เมื่อไปยัง Bucket ใน GCS คุณจะเห็นข้อมูลตารางที่สร้างขึ้นใหม่
คุณจะเห็นข้อมูลเมตา Iceberg ภายในโฟลเดอร์ metadata ซึ่งใช้โดยผู้อ่านภายนอก (เช่น BigQuery) ข้อมูลเมตา Delta Lake ซึ่ง Databricks ใช้ภายในจะได้รับการติดตามในโฟลเดอร์ _delta_log
ระบบจะจัดเก็บข้อมูลตารางจริงเป็นไฟล์ Parquet ภายในโฟลเดอร์อื่น ซึ่งโดยปกติแล้ว Databricks จะตั้งชื่อด้วยสตริงที่สร้างขึ้นแบบสุ่ม ตัวอย่างเช่น ในภาพหน้าจอด้านล่าง ไฟล์ข้อมูลจะอยู่ในโฟลเดอร์ 9M
6. ตั้งค่า BigQuery และ BigLake
ตอนนี้ตาราง Iceberg อยู่ใน Google Cloud Storage แล้ว ขั้นตอนถัดไปคือการทำให้ BigQuery เข้าถึงได้ โดยการสร้างตารางภายนอก BigLake
BigLake คือเครื่องมือจัดเก็บข้อมูลที่ช่วยให้สร้างตารางใน BigQuery ที่อ่านข้อมูลจากแหล่งข้อมูลภายนอกได้โดยตรง เช่น Google Cloud Storage สำหรับ Lab นี้ เทคโนโลยีนี้เป็นเทคโนโลยีหลักที่ช่วยให้ BigQuery เข้าใจตาราง Iceberg ที่เพิ่งส่งออกโดยไม่ต้องนำเข้าข้อมูล
หากต้องการให้การทำงานนี้เป็นไปได้ คุณจะต้องมี 2 องค์ประกอบต่อไปนี้
- การเชื่อมต่อทรัพยากรระบบคลาวด์: นี่คือลิงก์ที่ปลอดภัยระหว่าง BigQuery กับ GCS โดยจะใช้บัญชีบริการพิเศษเพื่อจัดการการตรวจสอบสิทธิ์ เพื่อให้มั่นใจว่า BigQuery มีสิทธิ์ที่จำเป็นในการอ่านไฟล์จาก Bucket GCS
- คำจำกัดความของตารางภายนอก: คำจำกัดความนี้จะบอก BigQuery ว่าจะค้นหาไฟล์ข้อมูลเมตาของตาราง Iceberg ใน GCS ได้ที่ใด และควรตีความอย่างไร
สร้างการเชื่อมต่อทรัพยากรระบบคลาวด์
ก่อนอื่น ระบบจะสร้างการเชื่อมต่อที่อนุญาตให้ BigQuery เข้าถึง GCS
ดูข้อมูลเพิ่มเติมเกี่ยวกับการสร้างการเชื่อมต่อทรัพยากรระบบคลาวด์ได้ที่นี่
- ไปที่ BigQuery
- คลิกการเชื่อมต่อในส่วนExplorer
- หากไม่เห็นเครื่องบิน Explorer ให้คลิก

- ในหน้าการเชื่อมต่อ ให้คลิก
- สำหรับประเภทการเชื่อมต่อ ให้เลือก
Vertex AI remote models, remote functions, BigLake and Spanner (Cloud Resource) - ตั้งค่ารหัสการเชื่อมต่อเป็น
databricks_retlแล้วสร้างการเชื่อมต่อ

- ตอนนี้คุณควรเห็นรายการในตารางการเชื่อมต่อของการเชื่อมต่อที่สร้างขึ้นใหม่ คลิกรายการนั้นเพื่อดูรายละเอียดการเชื่อมต่อ

- ในหน้ารายละเอียดการเชื่อมต่อ ให้จดรหัสบัญชีบริการไว้เนื่องจากจะต้องใช้ในภายหลัง
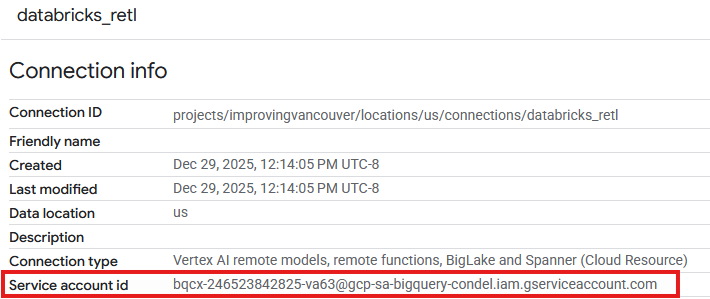
ให้สิทธิ์เข้าถึงบัญชีบริการการเชื่อมต่อ
- ไปที่ IAM และผู้ดูแลระบบ
- คลิกให้สิทธิ์เข้าถึง
- สำหรับช่องผู้ใช้หลักรายใหม่ ให้ป้อนรหัสบัญชีบริการของทรัพยากรการเชื่อมต่อที่สร้างขึ้นด้านบน
- สำหรับบทบาท ให้เลือก
Storage Object Userแล้วคลิก
เมื่อสร้างการเชื่อมต่อและให้สิทธิ์ที่จำเป็นแก่บัญชีบริการแล้ว ตอนนี้คุณก็สร้างตารางภายนอก BigLake ได้แล้ว ก่อนอื่นคุณต้องมีชุดข้อมูลใน BigQuery เพื่อทำหน้าที่เป็นคอนเทนเนอร์สำหรับตารางใหม่ จากนั้นระบบจะสร้างตารางเองโดยชี้ไปยังไฟล์ข้อมูลเมตา Iceberg ใน Bucket ของ GCS
- ไปที่ BigQuery
- ในแผงExplorer ให้คลิกรหัสโปรเจ็กต์ จากนั้นคลิกจุด 3 จุด แล้วเลือกสร้างชุดข้อมูล
- ชุดข้อมูลจะมีชื่อว่า
databricks_retlปล่อยให้ตัวเลือกอื่นๆ เป็นค่าเริ่มต้น แล้วคลิกปุ่มสร้างชุดข้อมูล
- ตอนนี้ให้ค้นหา
databricks_retlชุดข้อมูลใหม่ในแผงเครื่องมือสำรวจ คลิกจุด 3 จุดข้างข้อความ แล้วเลือกสร้างตาราง
- กำหนดการตั้งค่าต่อไปนี้สำหรับการสร้างตาราง
- สร้างตารางจาก:
Google Cloud Storage - เลือกไฟล์จาก Bucket ของ GCS หรือใช้รูปแบบ URI: ไปที่ Bucket ของ GCS แล้วค้นหาไฟล์ JSON ของข้อมูลเมตาที่สร้างขึ้นระหว่างการส่งออกจาก Databricks เส้นทางควรมีลักษณะดังนี้
regional_sales/metadata/v1.metadata.json - รูปแบบไฟล์:
Iceberg - ตาราง:
regional_sales - ประเภทตาราง:
External table - รหัสการเชื่อมต่อ: เลือกการเชื่อมต่อ
databricks_retlที่สร้างไว้ก่อนหน้านี้ - ปล่อยให้ค่าที่เหลือเป็นค่าเริ่มต้น แล้วคลิกสร้างตาราง
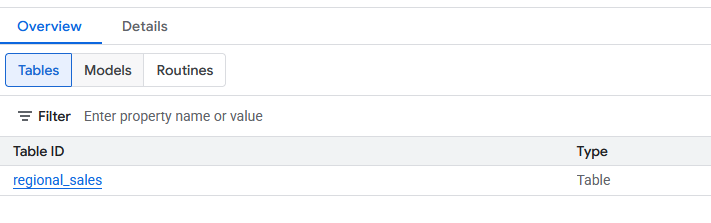
- เมื่อสร้างแล้ว คุณควรเห็นตาราง
regional_salesใหม่ภายใต้ชุดข้อมูลdatabricks_retlตอนนี้คุณค้นหาตารางนี้ได้โดยใช้ SQL มาตรฐานเช่นเดียวกับตาราง BigQuery อื่นๆ
7. โหลดไปยัง Spanner
มาถึงส่วนสุดท้ายและสำคัญที่สุดของไปป์ไลน์แล้ว นั่นคือการย้ายข้อมูลจากตารางภายนอก BigLake ไปยัง Spanner นี่คือขั้นตอน "Reverse ETL" ซึ่งจะโหลดข้อมูลที่ประมวลผลและดูแลจัดการในคลังข้อมูลลงในระบบปฏิบัติการเพื่อให้แอปพลิเคชันใช้งาน
Spanner เป็นฐานข้อมูลเชิงสัมพันธ์ที่มีการจัดการครบวงจรและกระจายอยู่ทั่วโลก โดยมีข้อดีคือความสอดคล้องของการดำเนินการของฐานข้อมูลเชิงสัมพันธ์แบบดั้งเดิม แต่มีความสามารถในการปรับขนาดแนวนอนของฐานข้อมูล NoSQL จึงเป็นตัวเลือกที่เหมาะสำหรับการสร้างแอปพลิเคชันที่ปรับขนาดได้และมีความพร้อมใช้งานสูง
กระบวนการมีดังนี้
- สร้างอินสแตนซ์ Spanner ซึ่งเป็นการจัดสรรทรัพยากรจริง
- สร้างฐานข้อมูลภายในอินสแตนซ์นั้น
- กําหนดสคีมาตารางในฐานข้อมูลให้ตรงกับโครงสร้างของข้อมูล
regional_sales - เรียกใช้
EXPORT DATAการค้นหา BigQuery เพื่อโหลดข้อมูลจากตาราง BigLake ลงในตาราง Spanner โดยตรง
สร้างอินสแตนซ์ ฐานข้อมูล และตาราง Spanner
- ไปที่ Spanner
- คลิก
 คุณใช้อินสแตนซ์ที่มีอยู่ได้หากมี ตั้งค่าข้อกำหนดของอินสแตนซ์ตามต้องการ สำหรับแล็บนี้ เราใช้สิ่งต่อไปนี้
คุณใช้อินสแตนซ์ที่มีอยู่ได้หากมี ตั้งค่าข้อกำหนดของอินสแตนซ์ตามต้องการ สำหรับแล็บนี้ เราใช้สิ่งต่อไปนี้
รุ่น | Enterprise |
ชื่ออินสแตนซ์ | databricks-retl |
การกำหนดค่าภูมิภาค | ภูมิภาคที่คุณเลือก |
หน่วยประมวลผล | หน่วยประมวลผล (PU) |
การจัดสรรด้วยตนเอง | 100 |
- เมื่อสร้างแล้ว ให้ไปที่หน้าอินสแตนซ์ Spanner แล้วเลือก
 คุณใช้ฐานข้อมูลที่มีอยู่ได้หากมี
คุณใช้ฐานข้อมูลที่มีอยู่ได้หากมี
- สำหรับแล็บนี้ ระบบจะสร้างฐานข้อมูลด้วย
- ชื่อ:
databricks-retl - ภาษาถิ่นของฐานข้อมูล:
Google Standard SQL
- เมื่อสร้างฐานข้อมูลแล้ว ให้เลือกจากหน้าอินสแตนซ์ Spanner เพื่อเข้าสู่หน้าฐานข้อมูล Spanner
- จากหน้าฐานข้อมูล Spanner ให้คลิก

- ในหน้าคำค้นหาใหม่ ระบบจะสร้างคำจำกัดความตารางสำหรับตารางที่จะนำเข้าไปยัง Spanner โดยเรียกใช้การค้นหา SQL ต่อไปนี้
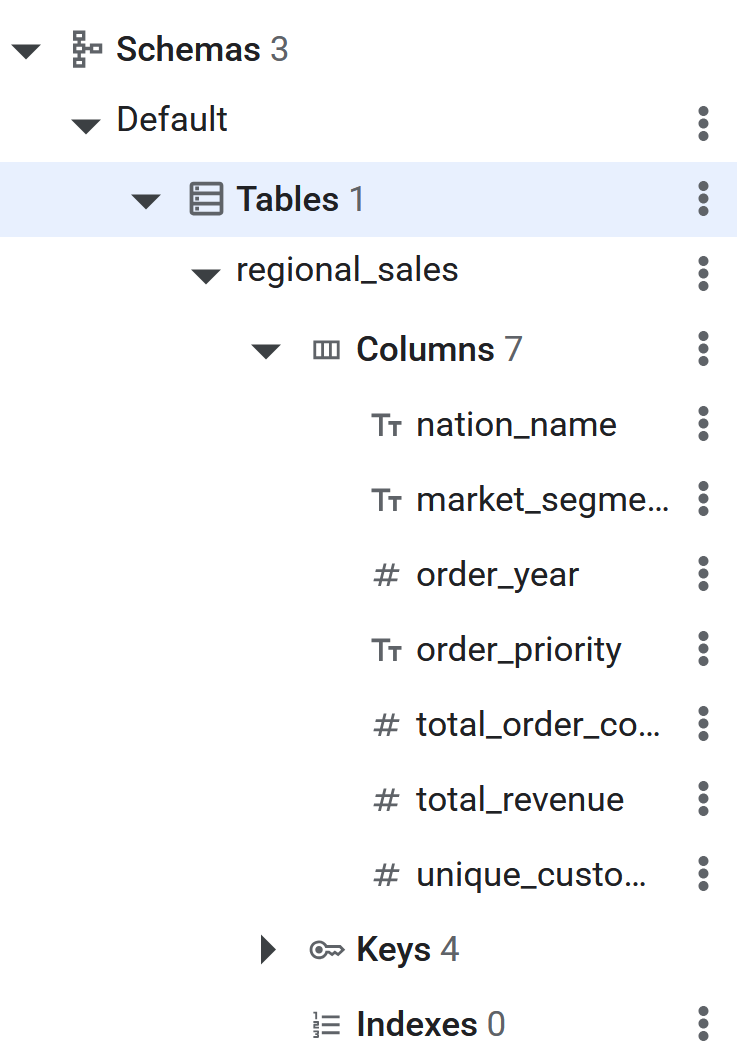
CREATE TABLE regional_sales (
nation_name STRING(MAX),
market_segment STRING(MAX),
order_year INT64,
order_priority STRING(MAX),
total_order_count INT64,
total_revenue NUMERIC,
unique_customer_count INT64
) PRIMARY KEY (nation_name, market_segment, order_year, order_priority);
- เมื่อเรียกใช้คำสั่ง SQL แล้ว ตาราง Spanner จะพร้อมให้ BigQuery ทำการย้อนกลับ ETL ข้อมูล คุณสามารถยืนยันการสร้างตารางได้โดยดูว่าตารางแสดงอยู่ในแผงด้านซ้ายในฐานข้อมูล Spanner หรือไม่
Reverse ETL ไปยัง Spanner โดยใช้ EXPORT DATA
นี่คือขั้นตอนสุดท้าย เมื่อข้อมูลต้นทางพร้อมในตาราง BigLake ของ BigQuery และสร้างตารางปลายทางใน Spanner แล้ว การเคลื่อนย้ายข้อมูลจริงก็ทำได้ง่ายอย่างไม่น่าเชื่อ ระบบจะใช้การค้นหา SQL ของ BigQuery รายการเดียว: EXPORT DATA
คำค้นหานี้ออกแบบมาสำหรับสถานการณ์เช่นนี้โดยเฉพาะ ซึ่งจะส่งออกข้อมูลจากตาราง BigQuery (รวมถึงตารางภายนอก เช่น ตาราง BigLake) ไปยังปลายทางภายนอกได้อย่างมีประสิทธิภาพ ในกรณีนี้ ปลายทางคือตาราง Spanner ดูข้อมูลเพิ่มเติมเกี่ยวกับฟีเจอร์การส่งออกได้ที่นี่
ดูข้อมูลเพิ่มเติมเกี่ยวกับการตั้งค่า BigQuery เป็น Spanner Reverse ETL ได้ที่นี่
- ไปที่ BigQuery
- เปิดแท็บเครื่องมือแก้ไขคำค้นหาใหม่
- ในหน้าคำค้นหา ให้ป้อน SQL ต่อไปนี้ อย่าลืมแทนที่รหัสโปรเจ็กต์ใน **
uri** **และเส้นทางตารางด้วยรหัสโปรเจ็กต์ที่ถูกต้อง**
EXPORT DATA OPTIONS(
uri='https://spanner.googleapis.com/projects/YOUR_PROJECT_ID/instances/databricks-retl/databases/databricks-retl',
format='CLOUD_SPANNER',
spanner_options="""{
"table": "regional_sales",
"priority": "MEDIUM"
}"""
) AS
SELECT * FROM `YOUR_PROJECT_ID.databricks_retl.regional_sales`;
- เมื่อคำสั่งเสร็จสมบูรณ์แล้ว ระบบจะส่งออกข้อมูลไปยัง Spanner เรียบร้อย
8. ยืนยันข้อมูลใน Spanner
ยินดีด้วย ไปป์ไลน์ Reverse ETL ที่สมบูรณ์ได้รับการสร้างและดำเนินการเรียบร้อยแล้ว โดยย้ายข้อมูลจากคลังข้อมูล Databricks ไปยังฐานข้อมูล Spanner ที่ใช้งาน
ขั้นตอนสุดท้ายคือการยืนยันว่าข้อมูลมาถึง Spanner ตามที่คาดไว้
- ไปที่ Spanner
- ไปที่อินสแตนซ์
databricks-retlแล้วไปที่ฐานข้อมูลdatabricks-retl - ในรายการตาราง ให้คลิกตาราง
regional_sales - ในเมนูการนำทางด้านซ้ายของตาราง ให้คลิกแท็บข้อมูล
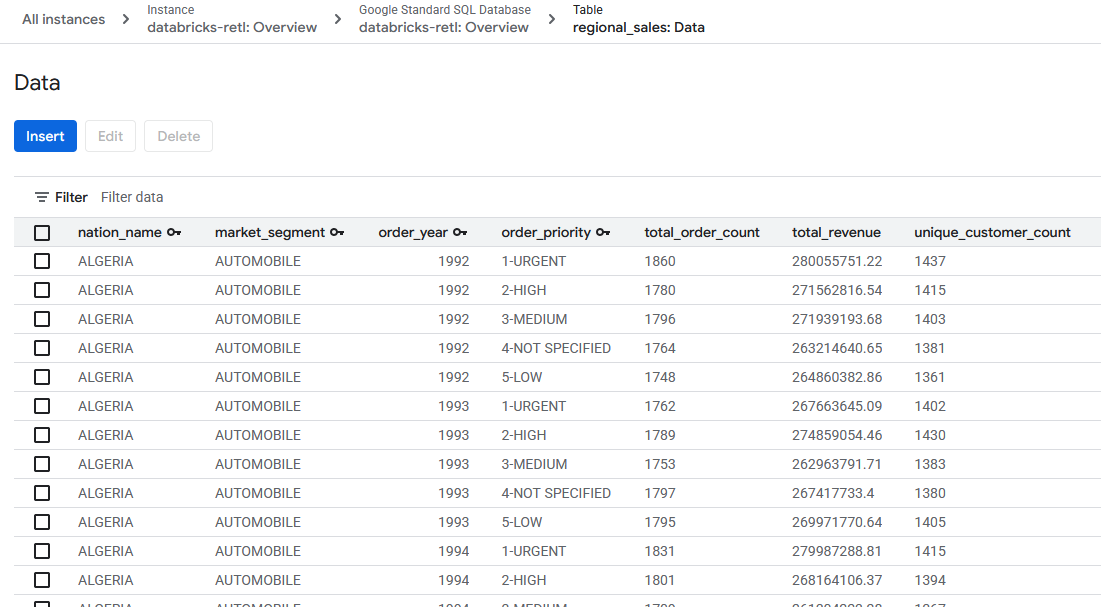
- ตอนนี้ระบบควรโหลดข้อมูลยอดขายรวมซึ่งมาจาก Databricks ในตอนแรกแล้ว และพร้อมใช้งานในตาราง Spanner ตอนนี้ข้อมูลนี้อยู่ในระบบปฏิบัติการแล้ว พร้อมที่จะขับเคลื่อนแอปพลิเคชันที่ใช้งานจริง แสดงแดชบอร์ด หรือให้ API ค้นหา
เราได้เชื่อมช่องว่างระหว่างโลกของข้อมูลเชิงวิเคราะห์และข้อมูลเชิงปฏิบัติการเรียบร้อยแล้ว
9. การจัดระเบียบ
นำตารางที่เพิ่มและข้อมูลที่จัดเก็บทั้งหมดออกเมื่อคุณทำแล็บนี้เสร็จแล้ว
ล้างตาราง Spanner
- ไปที่ Spanner
- คลิกอินสแตนซ์ที่ใช้สำหรับแล็บนี้จากรายการชื่อ
databricks-retl

- คลิก
 ในหน้าอินสแตนซ์
ในหน้าอินสแตนซ์ - ป้อน
databricks-retlในกล่องโต้ตอบการยืนยันที่ปรากฏขึ้น แล้วคลิก
ล้างข้อมูลใน GCS
- ไปที่ GCS
- เลือก
 จากเมนูด้านซ้าย
จากเมนูด้านซ้าย - เลือกที่เก็บข้อมูล ``codelabs_retl_databricks
- เมื่อเลือกแล้ว ให้คลิกปุ่ม
 ที่ปรากฏในแบนเนอร์ด้านบน
ที่ปรากฏในแบนเนอร์ด้านบน

- ป้อน
DELETEในกล่องโต้ตอบการยืนยันที่ปรากฏขึ้น แล้วคลิก
ล้างข้อมูล Databricks
ลบแคตตาล็อก/สคีมา/ตาราง
- ลงชื่อเข้าใช้ในอินสแตนซ์ Databricks
- คลิก
 จากเมนูด้านซ้าย
จากเมนูด้านซ้าย - เลือก
 ที่สร้างไว้ก่อนหน้านี้จากรายการแคตตาล็อก
ที่สร้างไว้ก่อนหน้านี้จากรายการแคตตาล็อก - ในรายการสคีมา ให้เลือก
 ที่สร้างขึ้น
ที่สร้างขึ้น - เลือก
 ที่สร้างไว้ก่อนหน้านี้จากรายการตาราง
ที่สร้างไว้ก่อนหน้านี้จากรายการตาราง - ขยายตัวเลือกตารางโดยคลิก
 แล้วเลือก
แล้วเลือก Delete - คลิก
 ในกล่องโต้ตอบการยืนยันเพื่อลบตาราง
ในกล่องโต้ตอบการยืนยันเพื่อลบตาราง - เมื่อลบตารางแล้ว ระบบจะนำคุณกลับไปที่หน้าสคีมา
- ขยายตัวเลือกสคีมาโดยคลิก แล้วเลือก
Delete - คลิก ในกล่องโต้ตอบการยืนยันเพื่อลบสคีมา
- เมื่อลบสคีมาแล้ว ระบบจะนำคุณกลับไปที่หน้าแคตตาล็อก
- ทำตามขั้นตอนที่ 4-11 อีกครั้งเพื่อลบสคีมา
defaultหากมี - จากหน้าแคตตาล็อก ให้ขยายตัวเลือกแคตตาล็อกโดยคลิก แล้วเลือก
Delete - คลิก ในกล่องโต้ตอบการยืนยันเพื่อลบแคตตาล็อก
ลบตำแหน่ง / ข้อมูลเข้าสู่ระบบของข้อมูลภายนอก
- จากหน้าจอแคตตาล็อก ให้คลิก
- หากไม่เห็นตัวเลือก
External Dataคุณอาจเห็นExternal Locationแสดงอยู่ในเมนูแบบเลื่อนลงConnectแทน - คลิก
retl-gcs-locationตำแหน่งข้อมูลภายนอกที่สร้างไว้ก่อนหน้านี้ - จากหน้าสถานที่ภายนอก ให้ขยายตัวเลือกสถานที่ตั้งโดยคลิก แล้วเลือก
Delete - คลิก ในกล่องโต้ตอบการยืนยันเพื่อลบตำแหน่งภายนอก
- คลิก
- คลิก
retl-gcs-credentialที่สร้างไว้ก่อนหน้านี้ - จากหน้าข้อมูลเข้าสู่ระบบ ให้ขยายตัวเลือกข้อมูลเข้าสู่ระบบโดยคลิก แล้วเลือก
Delete - คลิก ในกล่องโต้ตอบการยืนยันเพื่อลบข้อมูลเข้าสู่ระบบ
10. ขอแสดงความยินดี
ขอแสดงความยินดีที่ทำ Codelab เสร็จสมบูรณ์
สิ่งที่เราได้พูดถึงไปแล้ว
- วิธีโหลดข้อมูลลงใน Databricks เป็นตาราง Iceberg
- วิธีสร้างที่เก็บข้อมูล GCS
- วิธีส่งออกตาราง Databricks ไปยัง GCS ในรูปแบบ Iceberg
- วิธีสร้างตารางภายนอก BigLake ใน BigQuery จากตาราง Iceberg ใน GCS
- วิธีตั้งค่าอินสแตนซ์ Spanner
- วิธีโหลดตารางภายนอก BigLake ใน BigQuery ไปยัง Spanner