
1. Google Cloud Storage ve BigQuery'yi kullanarak Databricks'ten Spanner'a ters ETL ardışık düzeni oluşturma
Giriş
Bu codelab'de, Databricks'ten Spanner'a ters ETL ardışık düzeni oluşturacaksınız. Geleneksel olarak standart ETL (Ayıklama, Dönüştürme, Yükleme) ardışık düzenleri, verileri operasyonel veritabanlarından analiz için Databricks gibi bir veri ambarına taşır. Ters ETL işlem hattı ise bunun tam tersini yaparak, veri ambarındaki düzenlenmiş ve işlenmiş verileri alıp Spanner gibi operasyonel veritabanlarına geri taşır. Spanner, yüksek kullanılabilirlik gerektiren uygulamalar için ideal olan, küresel olarak dağıtılmış bir ilişkisel veritabanıdır. Bu veriler, uygulamalara güç sağlamak, kullanıcıya yönelik özellikleri sunmak veya anlık karar verme süreçlerinde kullanılabilir.
Amaç, birleştirilmiş bir veri kümesini Databricks Iceberg tablolarından Spanner tablolarına taşımaktır.
Bunu yapmak için ara adımlar olarak Google Cloud Storage (GCS) ve BigQuery kullanılır. Veri akışı ve bu mimarinin arkasındaki mantıkla ilgili dökümü aşağıda bulabilirsiniz:

- Iceberg biçiminde Databricks'ten Google Cloud Storage'a (GCS) aktarma:
- İlk adım, verileri Databricks'ten açık ve iyi tanımlanmış bir biçimde çıkarmaktır. Tablo, Apache Iceberg biçiminde dışa aktarılır. Bu işlem, temel verileri bir dizi Parquet dosyası olarak, tablonun meta verilerini (şema, bölümler, dosya konumları) ise JSON ve Avro dosyaları olarak yazar. Bu eksiksiz tablo yapısını GCS'de hazırlamak, verileri taşınabilir hale getirir ve Iceberg biçimini anlayan tüm sistemler tarafından erişilebilir kılar.
- GCS Iceberg tablolarını BigQuery BigLake harici tablosuna dönüştürme:
- Veriler doğrudan GCS'den Spanner'a yüklenmek yerine güçlü bir aracı olarak BigQuery kullanılır. BigQuery'de, doğrudan GCS'deki Iceberg meta veri dosyasına işaret eden bir BigLake harici tablosu oluşturulur. Bu yaklaşımın çeşitli avantajları vardır:
- Veri Tekrarı Yok: BigQuery, tablo yapısını meta verilerden okur ve Parquet veri dosyalarını yerinde sorgular. Bu sayede, verileri içe aktarmadan önemli ölçüde zaman ve depolama maliyetlerinden tasarruf edebilirsiniz.
- Birleşik Sorgular: GCS verileri üzerinde, yerel bir BigQuery tablosuymuş gibi karmaşık SQL sorguları çalıştırmanıza olanak tanır.
- BigLake harici tablosunu Spanner'a ters ETL:
- Son adım, verileri BigQuery'den Spanner'a taşımaktır. Bu, BigQuery'deki
EXPORT DATAsorgusu adı verilen güçlü bir özellik kullanılarak gerçekleştirilir. Bu özellik, "ters ETL" adımıdır. - Operasyonel Hazırlık: Spanner, işlemsel iş yükleri için tasarlanmıştır ve uygulamalar için güçlü tutarlılık ve yüksek kullanılabilirlik sağlar. Veriler Spanner'a taşındığında, düşük gecikmeli nokta aramaları gerektiren kullanıcıya yönelik uygulamalar, API'ler ve diğer operasyonel sistemler tarafından erişilebilir hale gelir.
- Ölçeklenebilirlik: Bu kalıp, büyük veri kümelerini işlemek için BigQuery'nin analitik gücünden yararlanmaya ve ardından sonuçları Spanner'ın küresel olarak ölçeklenebilir altyapısı aracılığıyla verimli bir şekilde sunmaya olanak tanır.
Hizmetler ve Terminoloji
- DataBricks: Apache Spark üzerine kurulu bulut tabanlı veri platformu.
- Spanner: Google tarafından tümüyle yönetilen, küresel olarak dağıtılmış bir ilişkisel veritabanı.
- Google Cloud Storage: Google Cloud'un blob depolama teklifi.
- BigQuery: Google tarafından tamamen yönetilen, analitik için sunucusuz bir veri ambarı.
- Iceberg: Apache tarafından tanımlanan ve yaygın açık kaynak veri dosyası biçimleri üzerinde soyutlama sağlayan açık bir tablo biçimidir.
- Parquet: Apache tarafından geliştirilen açık kaynaklı bir sütunlu ikili veri dosyası biçimi.
Neler öğreneceksiniz?
- Verileri Databricks'e Iceberg tabloları olarak yükleme
- GCS paketi oluşturma
- Databricks tablosunu Iceberg biçiminde GCS'ye aktarma
- GCS'deki Iceberg tablosundan BigQuery'de BigLake harici tablosu oluşturma
- Spanner örneği oluşturma
- BigQuery'deki BigLake harici tablolarını Spanner'a yükleme
2. Kurulum, Şartlar ve Sınırlamalar
Ön koşullar
- Tercihen GCP'de bir Databricks hesabı
- BigQuery'den Spanner'a veri aktarmak için BigQuery Enterprise katmanı veya daha yüksek bir rezervasyonuna sahip bir Google Cloud hesabı gerekir.
- Web tarayıcısı üzerinden Google Cloud Console'a erişim
- Google Cloud KSA komutlarını çalıştırmak için bir terminal
Google Cloud kuruluşunuzda iam.allowedPolicyMemberDomains politikası etkinse bir yöneticinin, harici alanlardaki hizmet hesaplarına izin vermek için istisna vermesi gerekebilir. Bu konu, geçerli olduğu durumlarda sonraki bir adımda ele alınacaktır.
Şartlar
- Faturalandırmanın etkin olduğu bir Google Cloud projesi.
- Chrome gibi bir web tarayıcısı
- Databricks hesabı (bu laboratuvarda GCP'de barındırılan bir çalışma alanı olduğu varsayılır)
- EXPORT DATA özelliğini kullanmak için BigQuery örneği Enterprise sürümünde veya daha yüksek bir sürümde olmalıdır.
- Google Cloud kuruluşunuzda
iam.allowedPolicyMemberDomainspolitikası etkinse bir yöneticinin, harici alanlardaki hizmet hesaplarına izin vermek için istisna vermesi gerekebilir. Bu konu, geçerli olduğu durumlarda sonraki bir adımda ele alınacaktır.
Google Cloud Platform IAM İzinleri
Google Hesabı'nın bu codelab'deki tüm adımları yürütmek için aşağıdaki izinlere sahip olması gerekir.
Hizmet Hesapları | ||
| Hizmet hesaplarının oluşturulmasına izin verir. | |
Spanner | ||
| Yeni bir Spanner örneği oluşturmaya izin verir. | |
| DDL ifadelerinin çalıştırılmasına izin vererek | |
| Veritabanında tablo oluşturmak için DDL ifadelerinin çalıştırılmasına izin verir. | |
Google Cloud Storage | ||
| Dışa aktarılan Parquet dosyalarını depolamak için yeni bir GCS paketi oluşturulmasına olanak tanır. | |
| Dışa aktarılan Parquet dosyalarının GCS paketine yazılmasına izin verir. | |
| BigQuery'nin GCS paketindeki Parquet dosyalarını okumasına izin verir. | |
| BigQuery'nin GCS paketindeki Parquet dosyalarını listelemesine olanak tanır. | |
Dataflow | ||
| Dataflow'daki iş öğelerinin talep edilmesine izin verir. | |
| Dataflow çalışanının Dataflow hizmetine mesaj göndermesine izin verir. | |
| Dataflow çalışanlarının Google Cloud Logging'e günlük girişleri yazmasına izin verir. | |
Kolaylık sağlamak için bu izinleri içeren önceden tanımlanmış roller kullanılabilir.
|
|
|
|
|
|
|
|
Google Cloud projesi
Proje, Google Cloud'daki temel düzenleme birimidir. Bir yönetici kullanmak üzere bir tane sağladıysa bu adım atlanabilir.
CLI kullanılarak şu şekilde proje oluşturulabilir:
gcloud projects create <your-project-name>
Proje oluşturma ve yönetme hakkında daha fazla bilgiyi burada bulabilirsiniz.
Sınırlamalar
Bu ardışık düzende ortaya çıkabilecek belirli sınırlamalar ve veri türü uyumsuzlukları hakkında bilgi sahibi olmanız önemlidir.
Databricks Iceberg'den BigQuery'ye
Databricks tarafından yönetilen Iceberg tablolarını (UniForm aracılığıyla) sorgulamak için BigQuery'yi kullanırken aşağıdakileri göz önünde bulundurun:
- Şema Evrimi: UniForm, Delta Lake şema değişikliklerini Iceberg'e çevirme konusunda iyi bir iş çıkarsa da karmaşık değişiklikler her zaman beklendiği gibi yayılmayabilir. Örneğin, Delta Lake'te sütunları yeniden adlandırma, Iceberg'e çevrilmez. Iceberg, bunu
dropveaddolarak görür. Şema değişikliklerini her zaman ayrıntılı bir şekilde test edin. - Time Travel: BigQuery, Delta Lake'in Time Travel özelliklerini kullanamaz. Yalnızca Iceberg tablosunun en son anlık görüntüsünü sorgular.
- Desteklenmeyen Delta Lake Özellikleri: Delta Lake'teki Silme Vektörleri ve
idmodunda Sütun Eşleme gibi özellikler, Iceberg için UniForm ile uyumlu değildir. Laboratuvarda, desteklenennamemodu kullanılarak sütun eşlemesi yapılır.
BigQuery'den Spanner'a
BigQuery'den Spanner'a gönderilen EXPORT DATA komutu, tüm BigQuery veri türlerini desteklemez. Aşağıdaki türleri içeren bir tabloyu dışa aktarmak hataya neden olur:
STRUCTGEOGRAPHYDATETIMERANGETIME
Ayrıca, BigQuery projesi GoogleSQL lehçesini kullanıyorsa Spanner'a aktarma için aşağıdaki sayısal türler de desteklenmez:
BIGNUMERIC
Sınırlamaların tam ve güncel listesi için resmi belgelere (Spanner'a Aktarma Sınırlamaları) bakın.
Sorun giderme ve dikkat edilmesi gereken noktalar
- GCP Databricks örneğinde değilseniz GCS'de Harici Veri Konumu tanımlamak mümkün olmayabilir. Bu gibi durumlarda, dosyaların Databricks çalışma alanının bulut sağlayıcısının depolama çözümünde hazırlanması ve ardından GCS'ye ayrı olarak taşınması gerekir.
- Bu durumda, bilgiler hazırlanan dosyaların sabit kodlanmış yollarını içereceğinden meta verilerde düzenlemeler yapılması gerekir.
3. Google Cloud Storage'ı (GCS) ayarlama
Databricks tarafından oluşturulan Parquet veri dosyalarını depolamak için Google Cloud Storage (GCS) kullanılır. Bunun için öncelikle dosya hedefi olarak kullanılacak yeni bir paket oluşturulması gerekir.
Google Cloud Storage
Yeni paket oluşturma
- Cloud Console'da Google Cloud Storage sayfasına gidin.
- Soldaki panelde Gruplar'ı seçin:
- Oluştur düğmesini tıklayın:

- Paket ayrıntılarınızı girin:
- Kullanılacak bir paket adı seçin. Bu laboratuvarda
codelabs_retl_databricksadı kullanılacak. - Paketin depolanacağı bir bölge seçin veya varsayılan değerleri kullanın.
- Depolama sınıfını
standardolarak tutun. - Erişimi kontrol etme için varsayılan değerleri koruyun.
- Nesne verilerini koru için varsayılan değerleri koruyun.
- İşlemi tamamladığınızda
Createdüğmesini tıklayın. Herkese açık erişimin engelleneceğini onaylamanız için bir istem görünebilir. Devam edip onaylayın. - Tebrikler, yeni paket başarıyla oluşturuldu. Bucket sayfasına yönlendirme yapılır.
- Daha sonra kullanacağınız için yeni paket adını bir yere kopyalayın.
Sonraki adımlara hazırlanma
Aşağıdaki ayrıntıları not edin. Bunlar sonraki adımlarda gereklidir:
- Google proje kimliği
- Google Storage paketi adı
4. Databricks'i ayarlama
TPC-H Verileri
Bu laboratuvarda, karar destek sistemleri için endüstri standardı bir karşılaştırma ölçütü olan TPC-H veri kümesi kullanılacaktır. Şeması, müşteriler, siparişler, tedarikçiler ve parçalarla gerçekçi bir iş ortamını modelliyor. Bu nedenle, gerçek dünya analizi ve veri taşıma senaryosunu göstermek için mükemmel bir seçenek.
Ham, normalleştirilmiş TPC-H tablolarını kullanmak yerine yeni bir toplu tablo oluşturulur. Bu yeni tablo, bölgesel satışlarla ilgili normalleştirilmemiş ve özetlenmiş bir görünüm oluşturmak için orders, customer ve nation tablolarındaki verileri birleştirir. Bu ön toplama adımı, verileri belirli bir kullanım alanına (bu senaryoda, operasyonel bir uygulama tarafından tüketilmek üzere) hazırladığından analizde yaygın olarak kullanılan bir yöntemdir.
Birleştirilmiş tablonun nihai şeması şu şekilde olacaktır:
Col | Tür |
nation_name | dize |
market_segment | dize |
order_year | int |
order_priority | dize |
total_order_count | bigint |
total_revenue | decimal(29,2) |
unique_customer_count | bigint |
Delta Lake Universal Format (UniForm) ile Iceberg Desteği
Bu laboratuvarda, Databricks'teki tablo bir Delta Lake tablosu olacaktır. Ancak bu verilerin BigQuery gibi harici sistemler tarafından okunabilmesi için Evrensel Biçim (UniForm) adlı güçlü bir özellik etkinleştirilir.
UniForm, tablonun verilerinin tek ve paylaşılan bir kopyası için Delta Lake meta verilerinin yanı sıra otomatik olarak Iceberg meta verileri oluşturur. Bu sayede, her iki dünyanın da en iyi özelliklerinden yararlanabilirsiniz:
- Databricks içinde: Delta Lake'in tüm performans ve yönetim avantajlarından yararlanılır.
- Databricks dışında: Tablo, BigQuery gibi Iceberg ile uyumlu herhangi bir sorgu motoru tarafından yerel bir Iceberg tablosu gibi okunabilir.
Bu sayede, verilerin ayrı kopyalarını tutmanız veya manuel dönüşüm işleri çalıştırmanız gerekmez. UniForm, tablo oluşturulurken belirli tablo özellikleri ayarlanarak etkinleştirilir.
Databricks katalogları
Databricks kataloğu, Databricks'in birleşik yönetim çözümü olan Unity Catalog'daki veriler için üst düzey kapsayıcıdır. Unity Catalog, iyi yönetilen bir veri platformu için çok önemli olan veri varlıklarını yönetmek, erişimi kontrol etmek ve soyu izlemek için merkezi bir yol sağlar.
Verileri düzenlemek için üç düzeyli bir ad alanı kullanılır: catalog.schema.table.
- Katalog: Verileri ortama, işletme birimine veya projeye göre gruplandırmak için kullanılan en üst düzeydir.
- Şema (veya Veritabanı): Bir katalogdaki tabloların, görünümlerin ve işlevlerin mantıksal olarak gruplandırılması.
- Tablo: Verilerinizi içeren nesne.
Toplanmış TPC-H tablosu oluşturulmadan önce, bu tabloyu barındırmak için özel bir katalog ve şema oluşturulmalıdır. Bu sayede proje düzenli bir şekilde organize edilir ve çalışma alanındaki diğer verilerden ayrı tutulur.
Yeni katalog ve şema oluşturma
Databricks Unity Catalog'da katalog, veri varlıkları için en üst düzeyde düzenleme görevi görür ve birden fazla Databricks çalışma alanına yayılabilen güvenli bir kapsayıcı görevi görür. Net bir şekilde tanımlanmış izinler ve erişim kontrolleriyle verileri iş birimlerine, projelere veya ortamlara göre düzenlemenize ve izole etmenize olanak tanır.
Kataloglarda şema (veritabanı olarak da bilinir) tabloları, görünümleri ve işlevleri daha da düzenler. Bu hiyerarşik yapı, ayrıntılı kontrol ve ilgili veri nesnelerinin mantıksal olarak gruplandırılmasına olanak tanır. Bu laboratuvarda, TPC-H verilerini barındırmak için özel bir katalog ve şema oluşturulacak. Böylece, uygun izolasyon ve yönetim sağlanacak.
Katalog oluşturma
 adresine gidin.
adresine gidin.- + simgesini tıklayın ve açılır listeden Katalog oluştur'u seçin.
- Aşağıdaki ayarlarla yeni bir Standart katalog oluşturulur:
- Katalog adı:
retl_tpch_project - Depolama konumu: Çalışma alanında ayarlanmış bir konum varsa varsayılanı kullanın veya yeni bir konum oluşturun.
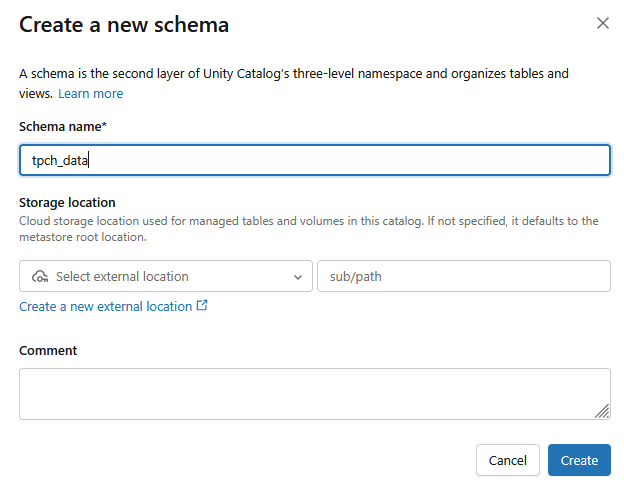
Şema oluşturma
- adresine gidin.
- Soldaki panelden yeni oluşturulan kataloğu seçin.
 simgesini tıklayın.
simgesini tıklayın.- Şema adı
tpch_dataolan yeni bir şema oluşturulur.
Harici verileri ayarlama
Verileri Databricks'ten Google Cloud Storage'a (GCS) aktarabilmek için Databricks'te harici veri kimlik bilgilerinin ayarlanması gerekir. Bu sayede Databricks, GCS paketine güvenli bir şekilde erişip yazabilir.
- Katalog ekranında
 simgesini tıklayın.
simgesini tıklayın.
External Dataseçeneğini görmüyorsanızExternal Locations,Connectaçılır listesinde yer alabilir.
 simgesini tıklayın.
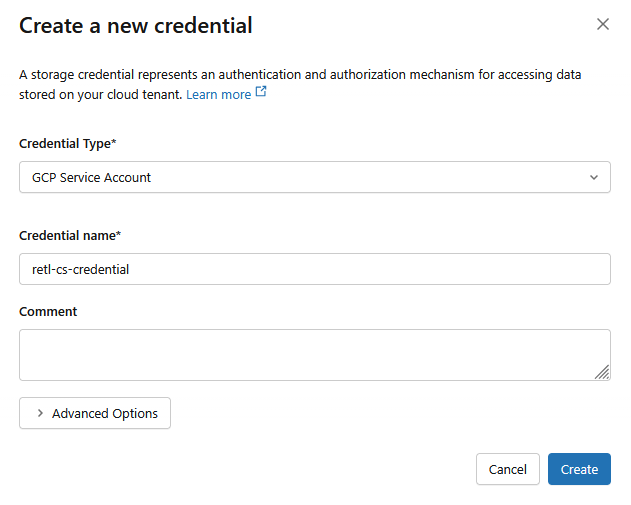
simgesini tıklayın.- Yeni iletişim kutusunda kimlik bilgileri için gerekli değerleri ayarlayın:
- Kimlik Bilgisi Türü:
GCP Service Account - Kimlik Bilgisi Adı:
retl-gcs-credential
- Oluştur'u tıklayın
- Ardından, Harici Konumlar sekmesini tıklayın.
- Konum oluştur'u tıklayın.
- Yeni iletişim kutusunda, harici konum için gerekli değerleri ayarlayın:
- Harici konum adı:
retl-gcs-location - Depolama alanı türü:
GCP - URL: GCS paketinin URL'si (
gs://YOUR_BUCKET_NAMEbiçiminde) - Depolama kimlik bilgisi: Yeni oluşturulan
retl-gcs-credentialöğesini seçin.
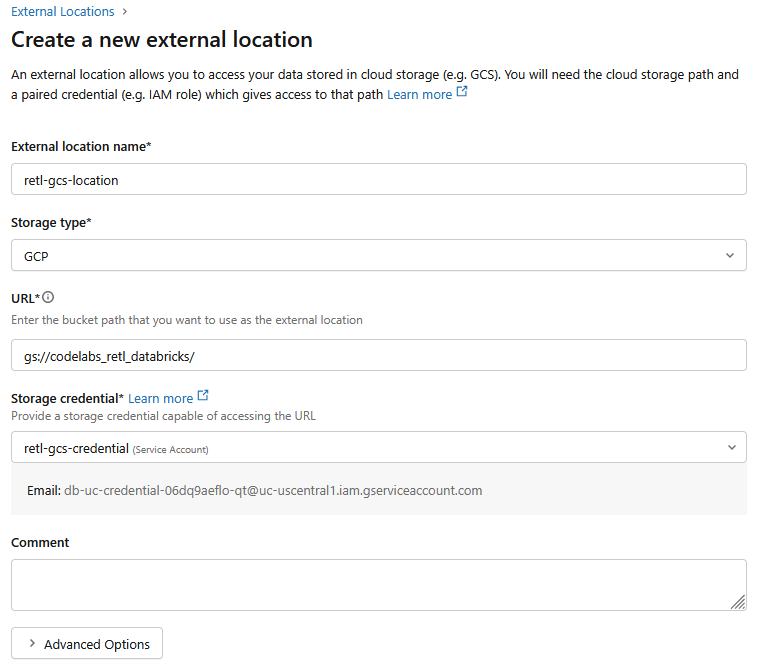
- Depolama kimlik bilgisi seçildiğinde otomatik olarak doldurulan hizmet hesabı e-postasını not edin. Bu bilgi bir sonraki adımda gereklidir.
- Oluştur'u tıklayın
5. Hizmet Hesabı İzinlerini Ayarlama
Hizmet hesabı, uygulamalar veya hizmetler tarafından Google Cloud kaynaklarına yetkili API çağrıları yapmak için kullanılan özel bir hesap türüdür.
Artık GCS'de yeni paket için oluşturulan hizmet hesabına izinler eklenmesi gerekecek.
- GCS paketi sayfasında İzinler sekmesini seçin.
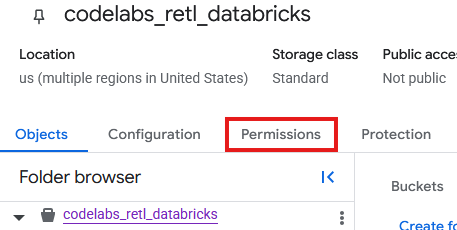
- Ana hesaplar sayfasında Erişim izni ver'i tıklayın.
- Sağdan kayarak açılan Erişim Ver panelinde, Hizmet Hesabı Kimliği'ni Yeni ana hesaplar alanına girin.
- Rol Ata bölümünde
Storage Object AdminveStorage Legacy Bucket Reader'yi ekleyin. Bu roller, hizmet hesabının depolama paketindeki nesneleri okumasına, yazmasına ve listelemesine olanak tanır.
TPC-H verilerini yükleme
Katalog ve Şema oluşturulduktan sonra TPCH verileri, Databricks'te dahili olarak depolanan ve yeni tanımlanan şemada yeni bir tabloya dönüştürülen mevcut samples.tpch tablosundan yüklenebilir.
Iceberg desteğiyle tablo oluşturma
Iceberg'in UniForm ile Uyumluluğu
Arka planda Databricks, bu tabloyu dahili olarak bir Delta Lake tablosu olarak yönetir ve Databricks ekosisteminde Delta'nın performans optimizasyonları ve yönetim özelliklerinin tüm avantajlarını sunar. Ancak UniForm (Universal Format'ın kısaltması) etkinleştirildiğinde Databricks'e özel bir işlem yapması talimatı verilir: Tablo her güncellendiğinde Databricks, Delta Lake meta verilerine ek olarak karşılık gelen Iceberg meta verilerini otomatik olarak oluşturur ve korur.
Bu, tek bir paylaşılan veri dosyası grubunun (Parquet dosyaları) artık iki farklı meta veri grubuyla tanımlandığı anlamına gelir.
- Databricks için: Tabloyu okumak için
_delta_logkullanılır. - Harici Okuyucular (ör. BigQuery) İçin: Tablonun şemasını, bölümlemesini ve dosya konumlarını anlamak için Iceberg meta veri dosyasını (
.metadata.json) kullanırlar.
Sonuç, Iceberg'i destekleyen tüm araçlarla tam ve şeffaf bir şekilde uyumlu olan bir tablodur. Veri tekrarı olmaz ve manuel dönüştürme veya senkronizasyon gerekmez. Hem Databricks'in analitik dünyası hem de açık Iceberg standardını destekleyen daha geniş araç ekosistemi tarafından sorunsuz bir şekilde erişilebilen tek bir doğru kaynaktır.
- Yeni'yi, ardından Sorgu'yu tıklayın.
- Sorgu sayfasının metin alanında aşağıdaki SQL komutunu çalıştırın:
CREATE TABLE retl_tpch_project.tpch_data.regional_sales_iceberg
USING DELTA
LOCATION 'gs://<Your bucket name>/regional_sales_iceberg'
TBLPROPERTIES (
'delta.columnMapping.mode' = 'name',
'delta.enableIcebergCompatV2' = 'true',
'delta.universalFormat.enabledFormats' = 'iceberg'
)
AS
SELECT
n.n_name AS nation_name,
c.c_mktsegment AS market_segment,
YEAR(o.o_orderdate) AS order_year,
o.o_orderpriority AS order_priority,
COUNT(o.o_orderkey) AS total_order_count,
ROUND(SUM(o.o_totalprice), 2) AS total_revenue,
COUNT(DISTINCT c.c_custkey) AS unique_customer_count
FROM samples.tpch.orders AS o
INNER JOIN samples.tpch.customer AS c
ON o.o_custkey = c.c_custkey
INNER JOIN samples.tpch.nation AS n
ON c.c_nationkey = n.n_nationkey
GROUP BY
n.n_name,
c.c_mktsegment,
YEAR(o.o_orderdate),
o.o_orderpriority;
OPTIMIZE retl_tpch_project.tpch_data.regional_sales_iceberg;
DESCRIBE EXTENDED retl_tpch_project.tpch_data.regional_sales_iceberg;
Notlar:
- Using Delta: Delta Lake tablosu kullandığımızı belirtir. Yalnızca Databricks'teki Delta Lake tabloları harici tablo olarak saklanabilir.
- Konum: Tablonun harici olması durumunda nerede depolanacağını belirtir.
- TablePropertoes:
delta.universalFormat.enabledFormats = ‘iceberg', Delta Lake dosyalarının yanında uyumlu Iceberg meta verileri oluşturur. - Optimize: Genellikle eş zamansız olarak gerçekleştiği için UniForm meta veri oluşturma işlemini zorla tetikler.
- Sorgunun çıktısında, yeni oluşturulan tabloyla ilgili ayrıntılar gösterilmelidir.

GCS tablo verilerini doğrulama
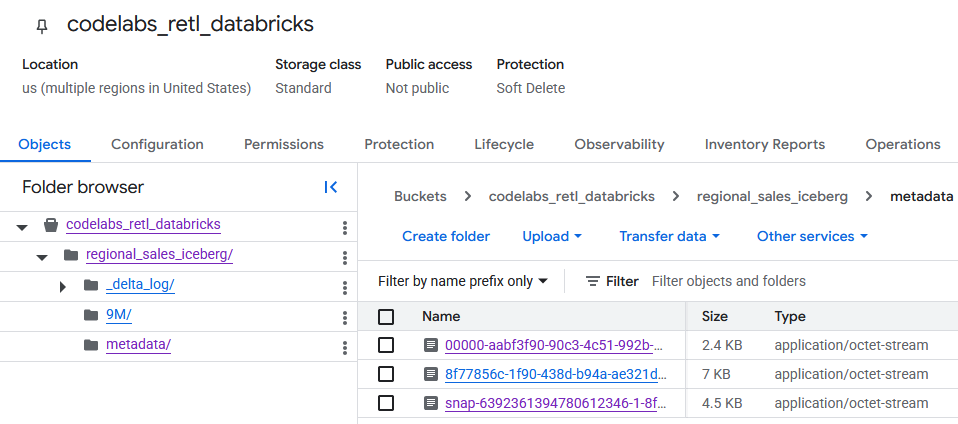
GCS paketine gidildiğinde, yeni oluşturulan tablo verileri bulunabilir.
metadata klasöründe, harici okuyucular (ör. BigQuery) tarafından kullanılan Iceberg meta verilerini bulabilirsiniz. Databricks'in dahili olarak kullandığı Delta Lake meta verileri, _delta_log klasöründe izlenir.
Gerçek tablo verileri, başka bir klasörde Parquet dosyaları olarak depolanır. Bu klasör genellikle Databricks tarafından rastgele oluşturulmuş bir dizeyle adlandırılır. Örneğin, aşağıdaki ekran görüntüsünde veri dosyaları 9M klasöründe yer almaktadır.
6. BigQuery ve BigLake'i kurma
Iceberg tablosu Google Cloud Storage'a taşındığına göre, bir sonraki adım bu tabloyu BigQuery'ye erişilebilir hale getirmektir. Bu işlem, BigLake harici tablosu oluşturularak yapılır.
BigLake, Google Cloud Storage gibi harici kaynaklardan doğrudan veri okuyan BigQuery tabloları oluşturmaya olanak tanıyan bir depolama motorudur. Bu laboratuvarda, verilerin alınmasına gerek kalmadan BigQuery'nin yeni dışa aktarılan Iceberg tablosunu anlamasını sağlayan temel teknolojidir.
Bu özelliğin çalışması için iki bileşen gerekir:
- Cloud Resource Connection: Bu, BigQuery ile GCS arasında güvenli bir bağlantıdır. Kimlik doğrulama için özel bir hizmet hesabı kullanılır. Bu sayede, BigQuery'nin GCS paketindeki dosyaları okumak için gerekli izinlere sahip olması sağlanır.
- Harici Tablo Tanımı: Bu, BigQuery'ye Iceberg tablosunun meta veri dosyasının GCS'de nerede bulunacağını ve nasıl yorumlanacağını söyler.
Bulut Kaynağı Bağlantısı oluşturma
İlk olarak, BigQuery'nin GCS'ye erişmesine izin veren bağlantı oluşturulur.
Bulut kaynağı bağlantıları oluşturma hakkında daha fazla bilgiyi burada bulabilirsiniz.
- BigQuery'ye gidin.
- Gezgin bölümünde Bağlantılar'ı tıklayın.
- Explorer düzlemi görünmüyorsa
 simgesini tıklayın.
simgesini tıklayın.
- Bağlantılar sayfasında
 simgesini tıklayın.
simgesini tıklayın. - Bağlantı türü için
Vertex AI remote models, remote functions, BigLake and Spanner (Cloud Resource)seçeneğini belirleyin. - Bağlantı kimliğini
databricks_retlolarak ayarlayın ve bağlantıyı oluşturun.

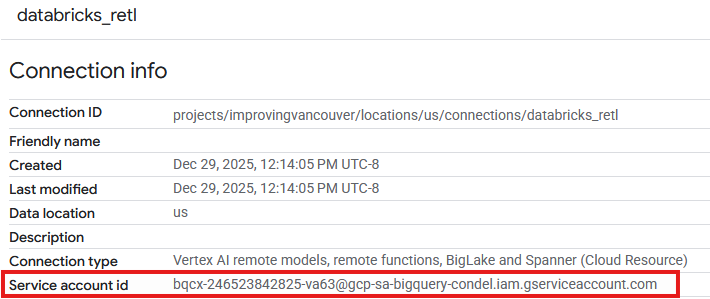
- Yeni oluşturulan bağlantının Bağlantılar tablosunda artık bir giriş görünmelidir. Bağlantı ayrıntılarını görmek için bu girişi tıklayın.

- Bağlantı ayrıntıları sayfasında, daha sonra gerekli olacağı için Hizmet hesabı kimliğini not edin.
Bağlantı hizmeti hesabına erişim izni verme
- IAM ve Yönetici'ye gidin.
- Erişim izni ver'i tıklayın.
- Yeni ana hesaplar alanına, yukarıda oluşturulan bağlantı kaynağının hizmet hesabı kimliğini girin.
- Rol için
Storage Object Userseçeneğini belirleyin ve simgesini tıklayın.
simgesini tıklayın.
Bağlantı oluşturulduktan ve hizmet hesabına gerekli izinler verildikten sonra BigLake harici tablosu oluşturulabilir. Öncelikle, yeni tablo için kapsayıcı görevi görecek bir veri kümesi oluşturmanız gerekir. Ardından, GCS paketindeki Iceberg meta veri dosyasına yönlendiren tablo oluşturulur.
- BigQuery'ye gidin.
- Gezgin panelinde proje kimliğini tıklayın, ardından üç noktayı tıklayıp Veri kümesi oluştur'u seçin.
- Veri kümesi
databricks_retlolarak adlandırılır. Diğer seçenekleri varsayılan olarak bırakıp Veri kümesi oluştur düğmesini tıklayın.
- Şimdi Gezgin panelinde yeni
databricks_retlveri kümesini bulun. Yanındaki üç noktayı tıklayın ve Tablo oluştur'u seçin.
- Tablo oluşturma için aşağıdaki ayarları girin:
- Şu kaynaktan tablo oluşturun:
Google Cloud Storage - GCS paketinden dosya seçin veya URI kalıbı kullanın: GCS paketine göz atın ve Databricks dışa aktarma işlemi sırasında oluşturulan meta veri JSON dosyasını bulun. Yol şu şekilde görünmelidir:
regional_sales/metadata/v1.metadata.json. - Dosya biçimi:
Iceberg - Tablo:
regional_sales - Tablo türü:
External table - Bağlantı kimliği: Daha önce oluşturulan
databricks_retlbağlantısını seçin. - Diğer değerleri varsayılan olarak bırakıp Tablo oluştur'u tıklayın.
- Oluşturulan yeni
regional_salestablosu,databricks_retlveri kümesi altında görünür. Bu tablo artık diğer tüm BigQuery tablolarında olduğu gibi standart SQL kullanılarak sorgulanabilir.
7. Spanner'a yükleme
Ardışık düzenin son ve en önemli kısmı olan verilerin BigLake harici tablolarından Spanner'a taşınması tamamlandı. Bu, "ters ETL" adımıdır. Bu adımda, veri ambarında işlenip düzenlenmiş olan veriler, uygulamalar tarafından kullanılmak üzere bir operasyonel sisteme yüklenir.
Spanner, tümüyle yönetilen, küresel olarak dağıtılmış bir ilişkisel veritabanıdır. Geleneksel bir ilişkisel veritabanının işlemsel tutarlılığını sunar ancak NoSQL veritabanının yatay ölçeklenebilirliğine sahiptir. Bu nedenle, ölçeklenebilir ve yüksek düzeyde kullanılabilir uygulamalar oluşturmak için ideal bir seçimdir.
Süreç şu şekilde işler:
- Kaynakların fiziksel olarak tahsis edildiği bir Spanner örneği oluşturun.
- Bu örnekte bir veritabanı oluşturun.
- Veritabanında
regional_salesverilerinin yapısıyla eşleşen bir tablo şeması tanımlayın. - BigLake tablosundaki verileri doğrudan Spanner tablosuna yüklemek için bir BigQuery
EXPORT DATAsorgusu çalıştırın.
Spanner örneği, veritabanı ve tablo oluşturma
- Spanner'a gidin.
 simgesini tıklayın . Mevcut bir örnek varsa onu kullanabilirsiniz. Örnek gereksinimlerini gerektiği şekilde ayarlayın. Bu laboratuvarda şunlar kullanıldı:
simgesini tıklayın . Mevcut bir örnek varsa onu kullanabilirsiniz. Örnek gereksinimlerini gerektiği şekilde ayarlayın. Bu laboratuvarda şunlar kullanıldı:
Sürüm | Kurumsal |
Örnek Adı | databricks-retl |
Bölge Yapılandırması | Seçtiğiniz bölge |
İşlem Birimi | İşleme birimleri (PU'lar) |
Manuel ayırma | 100 |
- Oluşturulduktan sonra Spanner örneği sayfasına gidip
 simgesini seçin. Mevcut bir veritabanı varsa onu kullanabilirsiniz.
simgesini seçin. Mevcut bir veritabanı varsa onu kullanabilirsiniz.
- Bu laboratuvarda,
- Ad:
databricks-retl - Veritabanı Lehçesi:
Google Standard SQL
- Veritabanı oluşturulduktan sonra Spanner örneği sayfasından seçin ve Spanner veritabanı sayfasına girin.
- Spanner veritabanı sayfasında
 simgesini tıklayın.
simgesini tıklayın. - Yeni sorgu sayfasında, Spanner'a aktarılacak tablonun tablo tanımı oluşturulur. Bunun için aşağıdaki SQL sorgusunu çalıştırın.
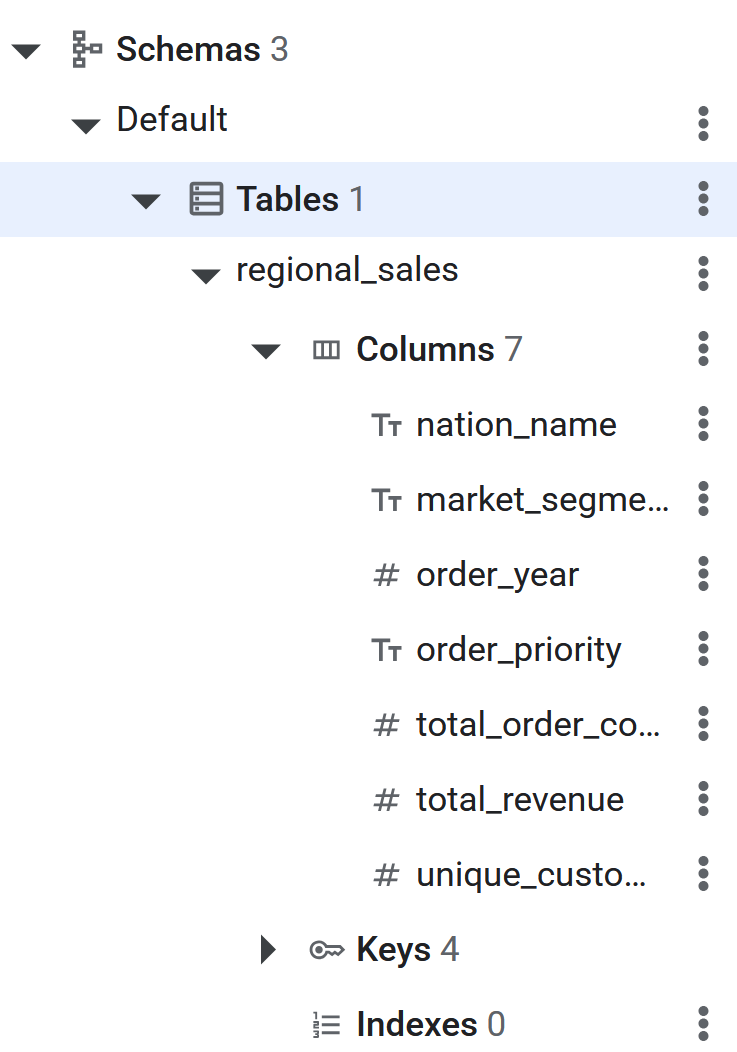
CREATE TABLE regional_sales (
nation_name STRING(MAX),
market_segment STRING(MAX),
order_year INT64,
order_priority STRING(MAX),
total_order_count INT64,
total_revenue NUMERIC,
unique_customer_count INT64
) PRIMARY KEY (nation_name, market_segment, order_year, order_priority);
- SQL komutu yürütüldükten sonra Spanner tablosu, BigQuery'nin verileri ters ETL'ye aktarması için hazır olur. Tablonun oluşturulduğu, Spanner veritabanındaki sol panelde listelenmiş olarak görülebilir.
EXPORT DATA kullanarak Spanner'a ters ETL
Bu son adımdır. Kaynak veriler BigQuery BigLake tablosunda hazır olduğunda ve hedef tablo Spanner'da oluşturulduğunda gerçek veri taşıma işlemi şaşırtıcı derecede basittir. Tek bir BigQuery SQL sorgusu kullanılır: EXPORT DATA.
Bu sorgu, özellikle bu gibi senaryolar için tasarlanmıştır. BigQuery tablosundaki (BigLake tablosu gibi harici olanlar dahil) verileri harici bir hedefe verimli bir şekilde aktarır. Bu durumda hedef, Spanner tablosudur. Dışa aktarma özelliği hakkında daha fazla bilgiyi burada bulabilirsiniz.
BigQuery'yi Spanner Reverse ETL'ye göre ayarlama hakkında daha fazla bilgiyi burada bulabilirsiniz.
- BigQuery'ye gidin.
- Yeni bir sorgu düzenleyici sekmesi açın.
- Sorgu sayfasında aşağıdaki SQL'i girin. **
uri** **içindeki proje kimliğini ve tablo yolunu doğru proje kimliğiyle değiştirmeyi unutmayın.**
EXPORT DATA OPTIONS(
uri='https://spanner.googleapis.com/projects/YOUR_PROJECT_ID/instances/databricks-retl/databases/databricks-retl',
format='CLOUD_SPANNER',
spanner_options="""{
"table": "regional_sales",
"priority": "MEDIUM"
}"""
) AS
SELECT * FROM `YOUR_PROJECT_ID.databricks_retl.regional_sales`;
- Komut tamamlandığında veriler Spanner'a başarıyla aktarılmış olur.
8. Spanner'daki verileri doğrulama
Tebrikler! Databricks veri ambarından operasyonel bir Spanner veritabanına veri taşıyan eksiksiz bir ters ETL ardışık düzeni başarıyla oluşturulup yürütüldü.
Son adım, verilerin Spanner'a beklendiği gibi ulaştığını doğrulamaktır.
- Spanner'a gidin.
databricks-retlörneğinize ve ardındandatabricks-retlveritabanına gidin.- Tablo listesinde
regional_salestablosunu tıklayın. - Tablonun sol gezinme menüsünde Veriler sekmesini tıklayın.
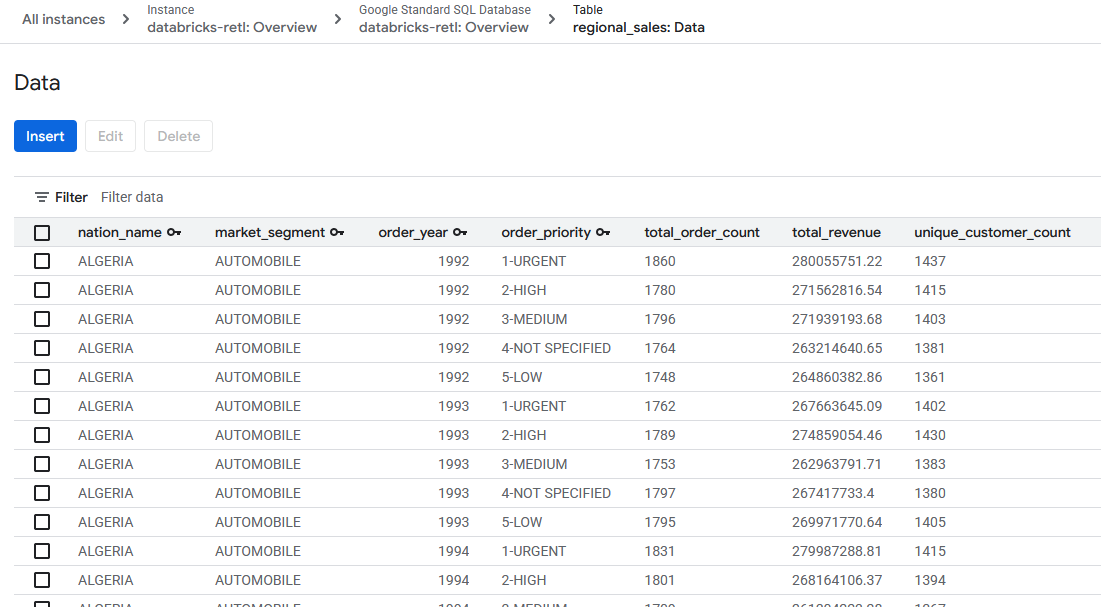
- Başlangıçta Databricks'ten alınan birleştirilmiş satış verileri artık yüklenmiş olmalı ve Spanner tablosunda kullanıma hazır olmalıdır. Bu veriler artık operasyonel bir sistemde olup canlı bir uygulamaya güç vermeye, bir kontrol paneline hizmet etmeye veya bir API tarafından sorgulanmaya hazırdır.
Analitik ve operasyonel veri dünyaları arasındaki boşluk başarıyla kapatıldı.
9. Temizleme
Bu laboratuvarı tamamladığınızda eklenen tüm tabloları ve depolanan verileri kaldırın.
Spanner tablolarını temizleme
- Spanner'a gidin.
databricks-retladlı listede bu laboratuvar için kullanılan örneği tıklayın.

- Örnek sayfasında
 simgesini tıklayın.
simgesini tıklayın. - Açılan onay iletişim kutusuna
databricks-retlgirin ve simgesini tıklayın.
simgesini tıklayın.
GCS'yi temizleme
- GCS'ye gidin.
- Sol taraftaki menüden
 simgesini seçin.
simgesini seçin. - ``codelabs_retl_databricks paketini seçin.
- Seçtikten sonra üst banner'da görünen
 düğmesini tıklayın.
düğmesini tıklayın.

- Açılan onay iletişim kutusuna
DELETEgirin ve simgesini tıklayın.
Databricks'i temizleme
Katalog/Şema/Tablo Silme
- Databricks örneğinizde oturum açma
- Sol taraftaki yan menüden
 simgesini tıklayın.
simgesini tıklayın. - Katalog listesinden daha önce oluşturulan
 öğesini seçin.
öğesini seçin. - Şema listesinde, oluşturulan
 öğesini seçin.
öğesini seçin. - Tablo listesinden daha önce oluşturulan
 öğesini seçin.
öğesini seçin.  simgesini tıklayarak tablo seçeneklerini genişletin ve
simgesini tıklayarak tablo seçeneklerini genişletin ve Deletesimgesini seçin.- Tabloyu silmek için onay iletişim kutusunda
 simgesini tıklayın.
simgesini tıklayın. - Tablo silindikten sonra şema sayfasına geri yönlendirilirsiniz.
- simgesini tıklayarak şema seçeneklerini genişletin ve
Deletesimgesini seçin. - Şemayı silmek için onay iletişim kutusunda simgesini tıklayın.
- Şema silindikten sonra katalog sayfasına geri yönlendirilirsiniz.
- Varsa
defaultşemasını silmek için 4-11. adımları tekrar uygulayın. - Katalog sayfasında, simgesini tıklayarak katalog seçeneklerini genişletin ve
Deletesimgesini seçin. - Kataloğu silmek için onay iletişim kutusunda simgesini tıklayın.
Harici Veri Konumunu / Kimlik Bilgilerini Silme
- Katalog ekranında simgesini tıklayın.
External Dataseçeneğini görmüyorsanızExternal Location,Connectaçılır listesinde yer alabilir.- Daha önce oluşturulan
retl-gcs-locationharici veri konumunu tıklayın. - Harici konum sayfasında, simgesini tıklayarak konum seçeneklerini genişletin ve
Deletesimgesini seçin. - Harici konumu silmek için onay iletişim kutusunda simgesini tıklayın.
- simgesini tıklayın.
- Daha önce oluşturulmuş
retl-gcs-credentialsimgesini tıklayın. - Kimlik bilgisi sayfasında, simgesini tıklayarak kimlik bilgisi seçeneklerini genişletin ve
Deletesimgesini seçin. - Kimlik bilgilerini silmek için onay iletişim kutusunda simgesini tıklayın.
10. Tebrikler
Codelab'i tamamladığınız için tebrik ederiz.
İşlediğimiz konular
- Verileri Databricks'e Iceberg tabloları olarak yükleme
- GCS paketi oluşturma
- Databricks tablosunu Iceberg biçiminde GCS'ye aktarma
- GCS'deki Iceberg tablosundan BigQuery'de BigLake harici tablosu oluşturma
- Spanner örneği oluşturma
- BigQuery'deki BigLake harici tablolarını Spanner'a yükleme