
1. Xây dựng quy trình ETL ngược từ Databricks sang Spanner bằng Google Cloud Storage và BigQuery
Giới thiệu
Trong lớp học lập trình này, bạn sẽ xây dựng một quy trình Reverse ETL từ Databricks sang Spanner. Theo truyền thống, các quy trình ETL (Trích xuất, Biến đổi, Tải) tiêu chuẩn sẽ di chuyển dữ liệu từ cơ sở dữ liệu hoạt động vào một kho dữ liệu như Databricks để phân tích. Quy trình ETL đảo ngược thực hiện ngược lại bằng cách di chuyển dữ liệu đã được xử lý và tuyển chọn từ kho dữ liệu trở lại cơ sở dữ liệu hoạt động, chẳng hạn như Spanner, một cơ sở dữ liệu quan hệ được phân phối trên toàn cầu, lý tưởng cho các ứng dụng có tính sẵn sàng cao, nơi dữ liệu có thể hỗ trợ các ứng dụng, cung cấp các tính năng cho người dùng hoặc được dùng để đưa ra quyết định theo thời gian thực.
Mục tiêu là di chuyển một tập dữ liệu tổng hợp từ các bảng Databricks Iceberg vào các bảng Spanner.
Để đạt được điều này, Google Cloud Storage (GCS) và BigQuery được dùng làm các bước trung gian. Sau đây là bảng chi tiết về luồng dữ liệu và lý do đằng sau cấu trúc này:

- Databricks đến Google Cloud Storage (GCS) ở định dạng Iceberg:
- Bước đầu tiên là lấy dữ liệu từ Databricks ở định dạng mở, được xác định rõ ràng. Bảng được xuất ở định dạng Apache Iceberg. Quy trình này ghi dữ liệu cơ bản dưới dạng một nhóm tệp Parquet và siêu dữ liệu của bảng (giản đồ, phân vùng, vị trí tệp) dưới dạng tệp JSON và Avro. Việc dàn dựng cấu trúc bảng hoàn chỉnh này trong GCS giúp dữ liệu có thể di chuyển và truy cập được vào mọi hệ thống hiểu định dạng Iceberg.
- Chuyển đổi bảng Iceberg GCS thành bảng bên ngoài BigLake của BigQuery:
- Thay vì tải dữ liệu trực tiếp từ GCS vào Spanner, BigQuery được dùng làm một trung gian mạnh mẽ. Một bảng bên ngoài BigLake được tạo trong BigQuery, trỏ trực tiếp đến tệp siêu dữ liệu Iceberg trong GCS. Phương pháp này có một số ưu điểm:
- Không trùng lặp dữ liệu: BigQuery đọc cấu trúc bảng từ siêu dữ liệu và truy vấn các tệp dữ liệu Parquet tại chỗ mà không cần nhập các tệp này, giúp tiết kiệm đáng kể thời gian và chi phí lưu trữ.
- Truy vấn liên kết: Cho phép chạy các truy vấn SQL phức tạp trên dữ liệu GCS như thể đó là một bảng BigQuery gốc.
- ReverseETL bảng bên ngoài BigLake vào Spanner:
- Bước cuối cùng là di chuyển dữ liệu từ BigQuery vào Spanner. Điều này được thực hiện bằng cách sử dụng một tính năng mạnh mẽ trong BigQuery, được gọi là truy vấn
EXPORT DATA, đây là bước "ETL đảo ngược". - Khả năng sẵn sàng hoạt động: Spanner được thiết kế cho các khối lượng công việc giao dịch, mang lại tính nhất quán cao và khả năng hoạt động cao cho các ứng dụng. Bằng cách di chuyển dữ liệu vào Spanner, dữ liệu sẽ có thể truy cập được đối với các ứng dụng, API và hệ thống vận hành khác mà người dùng sử dụng, yêu cầu tra cứu điểm có độ trễ thấp.
- Khả năng mở rộng: Mẫu này cho phép khai thác sức mạnh phân tích của BigQuery để xử lý các tập dữ liệu lớn, sau đó phân phát kết quả một cách hiệu quả thông qua cơ sở hạ tầng có thể mở rộng trên toàn cầu của Spanner.
Dịch vụ và thuật ngữ
- DataBricks – Nền tảng dữ liệu dựa trên đám mây được xây dựng dựa trên Apache Spark.
- Spanner – Một cơ sở dữ liệu quan hệ được phân phối trên toàn cầu và do Google quản lý toàn bộ.
- Google Cloud Storage – Sản phẩm bộ nhớ blob của Google Cloud.
- BigQuery – Kho dữ liệu không máy chủ để phân tích, do Google quản lý hoàn toàn.
- Iceberg – Một định dạng bảng mở do Apache xác định, cung cấp lớp trừu tượng cho các định dạng tệp dữ liệu nguồn mở phổ biến.
- Parquet – Một định dạng tệp dữ liệu nhị phân dạng cột mã nguồn mở của Apache.
Kiến thức bạn sẽ học được
- Cách tải dữ liệu vào Databricks dưới dạng bảng Iceberg
- Cách tạo một Nhóm lưu trữ GCS
- Cách xuất bảng Databricks sang GCS ở định dạng Iceberg
- Cách tạo Bảng bên ngoài BigLake trong BigQuery từ bảng Iceberg trong GCS
- Cách thiết lập một phiên bản Spanner
- Cách tải Bảng bên ngoài BigLake trong BigQuery lên Spanner
2. Thiết lập, yêu cầu và hạn chế
Điều kiện tiên quyết
- Tài khoản Databricks, tốt nhất là trên GCP
- Bạn cần có tài khoản Google Cloud có mức đặt trước từ cấp doanh nghiệp trở lên để xuất dữ liệu từ BigQuery sang Spanner.
- Quyền truy cập vào Google Cloud Console thông qua trình duyệt web
- Một cửa sổ dòng lệnh để chạy các lệnh Google Cloud CLI
Nếu tổ chức của bạn trên Google Cloud đã bật chính sách iam.allowedPolicyMemberDomains, thì quản trị viên có thể cần cấp một trường hợp ngoại lệ để cho phép tài khoản dịch vụ từ các miền bên ngoài. Chúng ta sẽ đề cập đến vấn đề này trong một bước sau (nếu có).
Yêu cầu
- Một dự án trên Google Cloud đã bật tính năng thanh toán.
- Một trình duyệt web, chẳng hạn như Chrome
- Tài khoản Databricks (phòng thí nghiệm này giả định một không gian làm việc được lưu trữ trong GCP)
- Thực thể BigQuery phải là phiên bản Enterprise trở lên thì mới có thể sử dụng tính năng EXPORT DATA.
- Nếu tổ chức của bạn trên Google Cloud đã bật chính sách
iam.allowedPolicyMemberDomains, thì quản trị viên có thể cần cấp một trường hợp ngoại lệ để cho phép tài khoản dịch vụ từ các miền bên ngoài. Chúng ta sẽ đề cập đến vấn đề này trong một bước sau (nếu có).
Quyền IAM của Google Cloud Platform
Tài khoản Google sẽ cần có các quyền sau để thực hiện tất cả các bước trong lớp học lập trình này.
Tài khoản dịch vụ | ||
| Cho phép tạo Tài khoản dịch vụ. | |
Spanner | ||
| Cho phép tạo một thực thể Spanner mới. | |
| Cho phép chạy các câu lệnh DDL để tạo | |
| Cho phép chạy câu lệnh DDL để tạo bảng trong cơ sở dữ liệu. | |
Google Cloud Storage | ||
| Cho phép tạo một bộ chứa GCS mới để lưu trữ các tệp Parquet đã xuất. | |
| Cho phép ghi các tệp Parquet đã xuất vào bộ chứa GCS. | |
| Cho phép BigQuery đọc các tệp Parquet trong bộ chứa GCS. | |
| Cho phép BigQuery liệt kê các tệp Parquet trong bộ chứa GCS. | |
Dataflow | ||
| Cho phép yêu cầu các mục công việc từ Dataflow. | |
| Cho phép worker Dataflow gửi thông báo trở lại dịch vụ Dataflow. | |
| Cho phép các worker Dataflow ghi các mục nhật ký vào Google Cloud Logging. | |
Để thuận tiện, bạn có thể sử dụng các vai trò được xác định trước có chứa những quyền này.
|
|
|
|
|
|
|
|
Dự án trên Google Cloud
Dự án là đơn vị tổ chức cơ bản trong Google Cloud. Nếu quản trị viên đã cung cấp một khoá để sử dụng, bạn có thể bỏ qua bước này.
Bạn có thể tạo một dự án bằng CLI như sau:
gcloud projects create <your-project-name>
Tìm hiểu thêm về cách tạo và quản lý dự án tại đây.
Các điểm hạn chế
Bạn cần lưu ý đến một số hạn chế và sự không tương thích về kiểu dữ liệu có thể xảy ra trong quy trình này.
Databricks Iceberg sang BigQuery
Khi sử dụng BigQuery để truy vấn các bảng Iceberg do Databricks quản lý (thông qua UniForm), hãy lưu ý những điều sau:
- Phát triển giản đồ: Mặc dù UniForm làm tốt việc dịch các thay đổi về giản đồ Delta Lake sang Iceberg, nhưng các thay đổi phức tạp có thể không phải lúc nào cũng lan truyền như mong đợi. Ví dụ: việc đổi tên các cột trong Delta Lake không được chuyển đổi sang Iceberg, vì Iceberg coi đó là một
dropvà mộtadd. Luôn kiểm thử kỹ lưỡng các thay đổi về giản đồ. - Du hành thời gian: BigQuery không thể sử dụng các tính năng du hành thời gian của Delta Lake. Thao tác này sẽ chỉ truy vấn ảnh chụp nhanh mới nhất của bảng Iceberg.
- Các tính năng không được hỗ trợ của Delta Lake: Các tính năng như Deletion Vectors và Column Mapping với chế độ
idtrong Delta Lake không tương thích với UniForm cho Iceberg. Phòng thí nghiệm sử dụng chế độnameđể lập bản đồ cột và chế độ này được hỗ trợ.
BigQuery đến Spanner
Lệnh EXPORT DATA từ BigQuery đến Spanner không hỗ trợ tất cả các kiểu dữ liệu BigQuery. Việc xuất bảng có các loại sau sẽ dẫn đến lỗi:
STRUCTGEOGRAPHYDATETIMERANGETIME
Ngoài ra, nếu dự án BigQuery đang sử dụng phương ngữ GoogleSQL, thì các kiểu số sau đây cũng không được hỗ trợ để xuất sang Spanner:
BIGNUMERIC
Để xem danh sách đầy đủ và mới nhất về các hạn chế, hãy tham khảo tài liệu chính thức: Các hạn chế khi xuất sang Spanner.
Khắc phục sự cố và các phương pháp hay nhất
- Nếu không có trên một phiên bản GCP Databricks, bạn có thể không xác định được Vị trí dữ liệu bên ngoài trong GCS. Trong những trường hợp như vậy, bạn sẽ cần dàn xếp các tệp trong giải pháp lưu trữ của nhà cung cấp dịch vụ đám mây của không gian làm việc Databricks, sau đó di chuyển riêng các tệp đó sang GCS.
- Khi làm như vậy, bạn cần điều chỉnh siêu dữ liệu vì thông tin sẽ có các đường dẫn được mã hoá cứng đến các tệp được dàn dựng.
3. Thiết lập Google Cloud Storage (GCS)
Google Cloud Storage (GCS) sẽ được dùng để lưu trữ các tệp dữ liệu Parquet do Databricks tạo. Để làm như vậy, trước tiên, bạn cần tạo một vùng chứa mới để dùng làm đích đến của tệp.
Google Cloud Storage
Tạo một nhóm mới
- Chuyển đến trang Google Cloud Storage trong bảng điều khiển đám mây.
- Trên bảng điều khiển bên trái, hãy chọn Thùng chứa:
- Nhấp vào nút Tạo:

- Điền thông tin chi tiết về nhóm:
- Chọn tên nhóm tài nguyên để sử dụng. Đối với lớp học này, tên
codelabs_retl_databrickssẽ được dùng - Chọn một khu vực để lưu trữ nhóm hoặc sử dụng các giá trị mặc định.
- Giữ lớp lưu trữ là
standard - Giữ nguyên các giá trị mặc định cho quyền kiểm soát truy cập
- Giữ nguyên giá trị mặc định cho protect object data (bảo vệ dữ liệu đối tượng)
- Nhấp vào nút
Createkhi hoàn tất. Lời nhắc có thể xuất hiện để xác nhận rằng quyền truy cập công khai sẽ bị ngăn chặn. Hãy xác nhận. - Chúc mừng bạn, bạn đã tạo thành công một vùng chứa mới! Bạn sẽ được chuyển hướng đến trang nhóm.
- Sao chép tên nhóm mới vào một nơi nào đó vì bạn sẽ cần tên này sau.
Chuẩn bị cho các bước tiếp theo
Hãy nhớ ghi lại những thông tin sau vì bạn sẽ cần đến chúng trong các bước tiếp theo:
- Mã dự án trên Google
- Tên bộ chứa Google Storage
4. Thiết lập Databricks
Dữ liệu TPC-H
Đối với lớp học lập trình này, chúng ta sẽ sử dụng tập dữ liệu TPC-H. Đây là điểm chuẩn theo tiêu chuẩn ngành cho các hệ thống hỗ trợ quyết định. Lược đồ này mô hình hoá một môi trường kinh doanh thực tế với khách hàng, đơn đặt hàng, nhà cung cấp và phụ tùng, khiến nó trở nên hoàn hảo để minh hoạ một kịch bản phân tích và di chuyển dữ liệu trong thế giới thực.
Thay vì sử dụng các bảng TPC-H thô, được chuẩn hoá, một bảng tổng hợp mới sẽ được tạo. Bảng mới này sẽ kết hợp dữ liệu từ các bảng orders, customer và nation để tạo ra một chế độ xem được tóm tắt và chuẩn hoá về doanh số bán hàng theo khu vực. Bước tổng hợp trước này là một phương pháp phổ biến trong hoạt động phân tích, vì bước này chuẩn bị dữ liệu cho một trường hợp sử dụng cụ thể – trong trường hợp này, để một ứng dụng vận hành sử dụng.
Giản đồ cuối cùng cho bảng tổng hợp sẽ là:
Col | Loại |
nation_name | chuỗi |
market_segment | chuỗi |
order_year | int |
order_priority | chuỗi |
total_order_count | bigint |
total_revenue | decimal(29,2) |
unique_customer_count | bigint |
Hỗ trợ Iceberg bằng Định dạng chung (UniForm) của Delta Lake
Đối với lớp học lập trình này, bảng trong Databricks sẽ là bảng Delta Lake. Tuy nhiên, để các hệ thống bên ngoài như BigQuery có thể đọc được, một tính năng mạnh mẽ có tên là Định dạng chung (UniForm) sẽ được bật.
UniForm tự động tạo siêu dữ liệu Iceberg cùng với siêu dữ liệu Delta Lake cho một bản sao dữ liệu duy nhất, dùng chung của bảng. Điều này mang lại những lợi ích tốt nhất của cả hai:
- Trong Databricks: Bạn sẽ nhận được tất cả các lợi ích về hiệu suất và hoạt động quản trị của Delta Lake.
- Bên ngoài Databricks: Mọi công cụ truy vấn tương thích với Iceberg (chẳng hạn như BigQuery) đều có thể đọc bảng này như thể đây là một bảng Iceberg gốc.
Nhờ đó, bạn không cần duy trì các bản sao dữ liệu riêng biệt hoặc chạy các công việc chuyển đổi thủ công. UniForm sẽ được bật bằng cách đặt các thuộc tính bảng cụ thể khi bảng được tạo.
Danh mục Databricks
Danh mục Databricks là vùng chứa cấp cao nhất cho dữ liệu trong Unity Catalog, giải pháp quản trị hợp nhất của Databricks. Unity Catalog cung cấp một cách tập trung để quản lý tài sản dữ liệu, kiểm soát quyền truy cập và theo dõi dòng dữ liệu. Đây là những yếu tố quan trọng đối với một nền tảng dữ liệu được quản lý tốt.
Thư viện này sử dụng không gian tên gồm 3 cấp để sắp xếp dữ liệu: catalog.schema.table.
- Danh mục: Cấp cao nhất, dùng để nhóm dữ liệu theo môi trường, đơn vị kinh doanh hoặc dự án.
- Lược đồ (hoặc Cơ sở dữ liệu): Một nhóm logic gồm các bảng, khung hiển thị và hàm trong một danh mục.
- Bảng: Đối tượng chứa dữ liệu của bạn.
Trước khi có thể tạo bảng TPC-H tổng hợp, bạn phải thiết lập một danh mục và giản đồ chuyên dụng để lưu trữ bảng đó. Điều này giúp đảm bảo dự án được sắp xếp gọn gàng và tách biệt với các dữ liệu khác trong không gian làm việc.
Tạo Danh mục và Lược đồ mới
Trong Databricks Unity Catalog, Danh mục đóng vai trò là cấp tổ chức cao nhất cho các tài sản dữ liệu, hoạt động như một vùng chứa bảo mật có thể trải rộng trên nhiều không gian làm việc của Databricks. Nhờ đó, bạn có thể sắp xếp và tách biệt dữ liệu dựa trên các đơn vị kinh doanh, dự án hoặc môi trường, với các quyền và chế độ kiểm soát quyền truy cập được xác định rõ ràng.
Trong một Danh mục, một Lược đồ (còn được gọi là cơ sở dữ liệu) sẽ sắp xếp thêm các bảng, khung hiển thị và hàm. Cấu trúc phân cấp này cho phép kiểm soát chi tiết và nhóm một cách hợp lý các đối tượng dữ liệu có liên quan. Đối với phòng thí nghiệm này, một Danh mục và giản đồ chuyên dụng sẽ được tạo để lưu trữ dữ liệu TPC-H, đảm bảo việc cách ly và quản lý đúng cách.
Tạo danh mục
- Chuyển đến

- Nhấp vào biểu tượng + rồi chọn Tạo danh mục trong trình đơn thả xuống
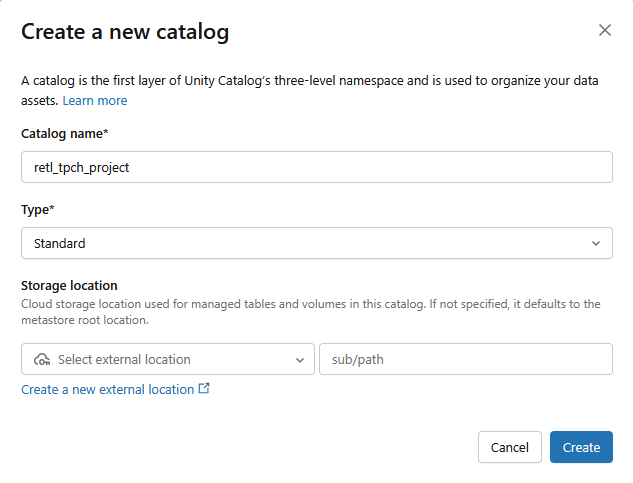
- Một danh mục Chuẩn mới sẽ được tạo với các chế độ cài đặt sau:
- Tên danh mục:
retl_tpch_project - Vị trí lưu trữ: Sử dụng vị trí mặc định nếu bạn đã thiết lập một vị trí trong không gian làm việc hoặc tạo một vị trí mới.
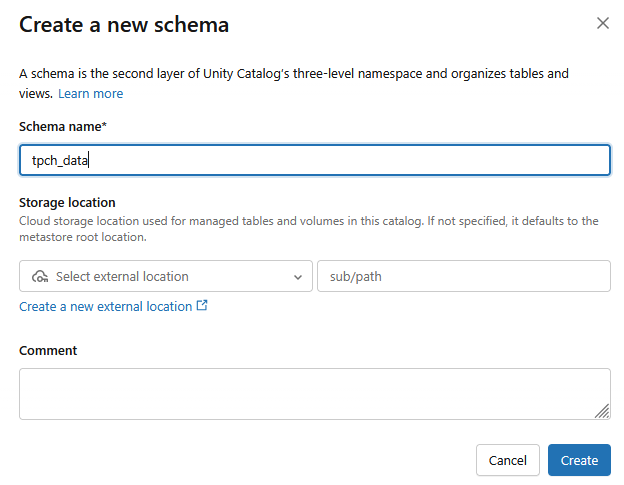
Tạo giản đồ
- Chuyển đến
- Chọn danh mục mới được tạo trong bảng điều khiển bên trái
- Nhấp vào biểu tượng
- Một giản đồ mới sẽ được tạo với Tên giản đồ là
tpch_data
Thiết lập dữ liệu bên ngoài
Để có thể xuất dữ liệu từ Databricks sang Google Cloud Storage (GCS), bạn cần thiết lập thông tin đăng nhập để xem dữ liệu bên ngoài trong Databricks. Điều này cho phép Databricks truy cập và ghi vào bộ chứa GCS một cách an toàn.
- Trên màn hình Danh mục, hãy nhấp vào biểu tượng

- Nếu không thấy biểu tượng
External Data, bạn có thể thấy biểu tượngExternal Locationstrong trình đơn thả xuốngConnect.
- Nhấp vào biểu tượng

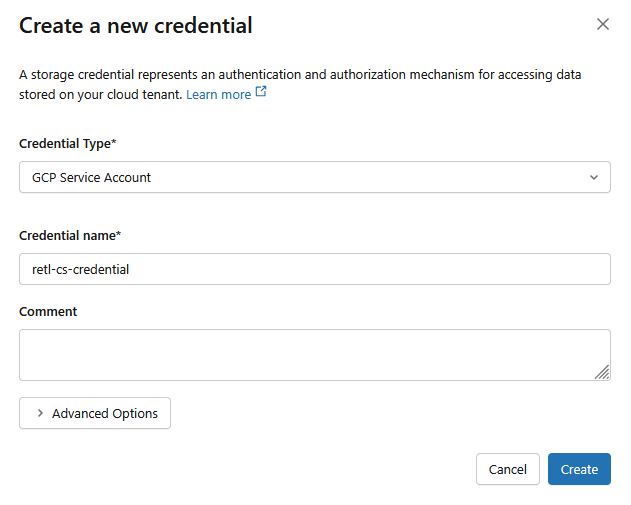
- Trong cửa sổ hộp thoại mới, hãy thiết lập các giá trị bắt buộc cho thông tin đăng nhập:
- Loại thông tin đăng nhập:
GCP Service Account - Tên thông tin xác thực:
retl-gcs-credential
- Nhấp vào Tạo
- Tiếp theo, hãy nhấp vào thẻ Vị trí bên ngoài.
- Nhấp vào Tạo vị trí.
- Trong cửa sổ hộp thoại mới, hãy thiết lập các giá trị bắt buộc cho vị trí bên ngoài:
- Tên vị trí bên ngoài:
retl-gcs-location - Loại bộ nhớ:
GCP - URL: URL của bộ chứa GCS, có định dạng
gs://YOUR_BUCKET_NAME - Thông tin xác thực bộ nhớ: Chọn
retl-gcs-credentialmà bạn vừa tạo.
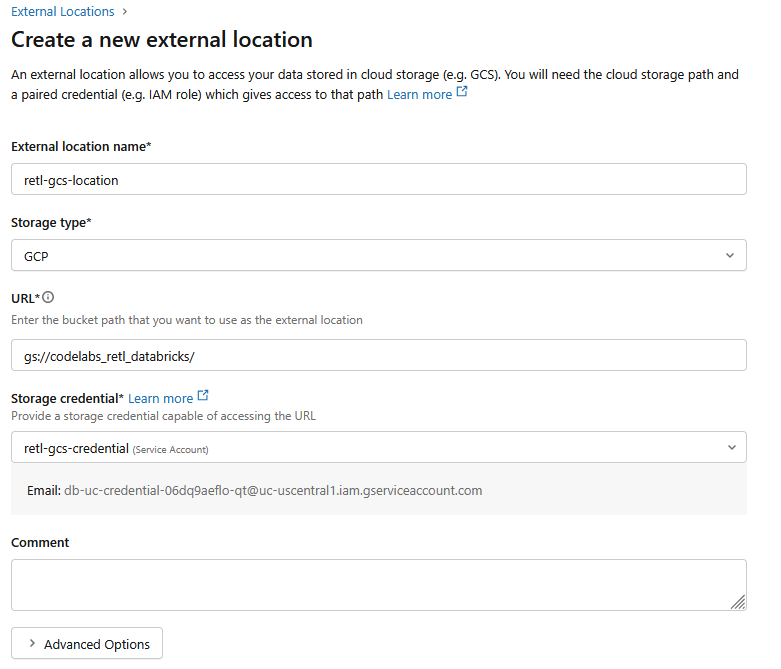
- Ghi lại email tài khoản dịch vụ được điền tự động khi bạn chọn thông tin đăng nhập bộ nhớ vì bạn sẽ cần đến thông tin này ở bước tiếp theo.
- Nhấp vào Tạo
5. Thiết lập quyền cho tài khoản dịch vụ
Tài khoản dịch vụ là một loại tài khoản đặc biệt mà các ứng dụng hoặc dịch vụ dùng để thực hiện các lệnh gọi API được uỷ quyền đến các tài nguyên trên Google Cloud.
Giờ đây, bạn cần thêm các quyền vào tài khoản dịch vụ được tạo cho bộ chứa mới trong GCS.
- Trên trang bộ chứa GCS, hãy chọn thẻ Quyền.
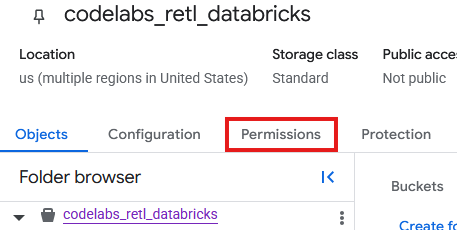
- Nhấp vào Cấp quyền truy cập trong trang người đại diện
- Trong bảng Cấp quyền truy cập trượt ra từ bên phải, hãy nhập Mã tài khoản dịch vụ vào trường Bên giao đại lý mới
- Trong phần Chỉ định vai trò, hãy thêm
Storage Object AdminvàStorage Legacy Bucket Reader. Các vai trò này cho phép Tài khoản dịch vụ đọc, ghi và liệt kê các đối tượng trong bộ chứa lưu trữ.
Tải dữ liệu TPC-H
Giờ đây, sau khi Danh mục và Giản đồ được tạo, dữ liệu TPCH có thể được tải từ bảng samples.tpch hiện có được lưu trữ nội bộ trong Databricks và được thao tác thành một bảng mới trong giản đồ mới xác định.
Tạo bảng có hỗ trợ Iceberg
Khả năng tương thích của Iceberg với UniForm
Đằng sau hậu trường, Databricks quản lý nội bộ bảng này dưới dạng bảng Delta Lake, mang lại tất cả lợi ích của các tính năng tối ưu hoá hiệu suất và quản trị của Delta trong hệ sinh thái Databricks. Tuy nhiên, bằng cách bật UniForm (viết tắt của Universal Format – Định dạng chung), Databricks sẽ được hướng dẫn làm một việc đặc biệt: mỗi khi bảng được cập nhật, Databricks sẽ tự động tạo và duy trì siêu dữ liệu Iceberg tương ứng ngoài siêu dữ liệu Delta Lake.
Điều này có nghĩa là một nhóm tệp dữ liệu dùng chung (tệp Parquet) hiện được mô tả bằng hai nhóm siêu dữ liệu riêng biệt.
- Đối với Databricks: Công cụ này sử dụng
_delta_logđể đọc bảng. - Đối với Trình đọc bên ngoài (chẳng hạn như BigQuery): Các trình đọc này sử dụng tệp siêu dữ liệu Iceberg (
.metadata.json) để hiểu giản đồ, việc phân vùng và vị trí tệp của bảng.
Kết quả là một bảng hoàn toàn tương thích và minh bạch với mọi công cụ nhận biết Iceberg. Không có dữ liệu trùng lặp và bạn không cần chuyển đổi hoặc đồng bộ hoá theo cách thủ công. Đây là một nguồn thông tin duy nhất mà cả thế giới phân tích của Databricks và hệ sinh thái rộng lớn hơn gồm các công cụ hỗ trợ tiêu chuẩn Iceberg mở đều có thể truy cập một cách liền mạch.
- Nhấp vào Mới rồi nhấp vào Truy vấn
- Trong trường văn bản của trang truy vấn, hãy chạy lệnh SQL sau:
CREATE TABLE retl_tpch_project.tpch_data.regional_sales_iceberg
USING DELTA
LOCATION 'gs://<Your bucket name>/regional_sales_iceberg'
TBLPROPERTIES (
'delta.columnMapping.mode' = 'name',
'delta.enableIcebergCompatV2' = 'true',
'delta.universalFormat.enabledFormats' = 'iceberg'
)
AS
SELECT
n.n_name AS nation_name,
c.c_mktsegment AS market_segment,
YEAR(o.o_orderdate) AS order_year,
o.o_orderpriority AS order_priority,
COUNT(o.o_orderkey) AS total_order_count,
ROUND(SUM(o.o_totalprice), 2) AS total_revenue,
COUNT(DISTINCT c.c_custkey) AS unique_customer_count
FROM samples.tpch.orders AS o
INNER JOIN samples.tpch.customer AS c
ON o.o_custkey = c.c_custkey
INNER JOIN samples.tpch.nation AS n
ON c.c_nationkey = n.n_nationkey
GROUP BY
n.n_name,
c.c_mktsegment,
YEAR(o.o_orderdate),
o.o_orderpriority;
OPTIMIZE retl_tpch_project.tpch_data.regional_sales_iceberg;
DESCRIBE EXTENDED retl_tpch_project.tpch_data.regional_sales_iceberg;
Lưu ý:
- Sử dụng Delta – Chỉ định rằng chúng ta đang sử dụng Bảng Delta Lake. Chỉ các bảng Delta Lake trong Databricks mới có thể được lưu trữ dưới dạng bảng bên ngoài.
- Location (Vị trí) – Chỉ định nơi lưu trữ bảng (nếu là bảng bên ngoài).
- TablePropertoes –
delta.universalFormat.enabledFormats = ‘iceberg'tạo siêu dữ liệu iceberg tương thích cùng với các tệp Delta Lake. - Optimize (Tối ưu hoá) – Buộc kích hoạt quá trình tạo siêu dữ liệu UniForm, vì quá trình này thường diễn ra không đồng bộ.
- Đầu ra của truy vấn sẽ cho thấy thông tin chi tiết về bảng mới tạo

Xác minh dữ liệu bảng GCS
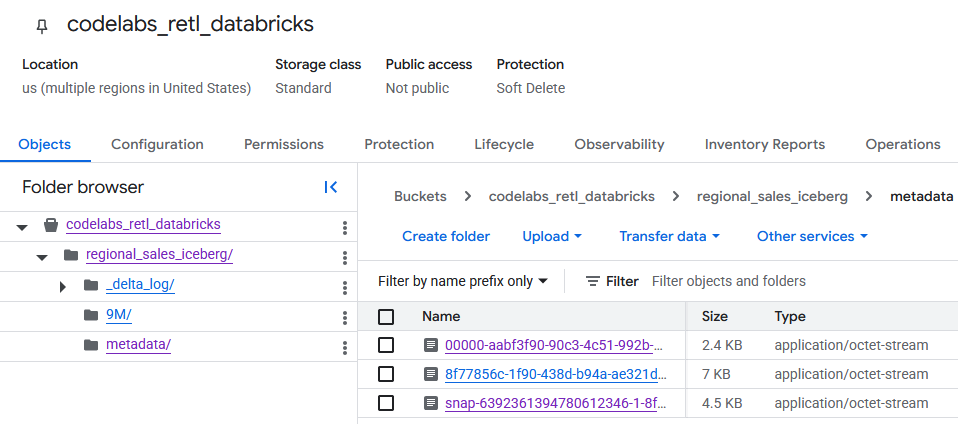
Sau khi chuyển đến bộ chứa GCS, bạn có thể tìm thấy dữ liệu bảng mới tạo.
Bạn sẽ thấy siêu dữ liệu Iceberg trong thư mục metadata. Thư mục này được các trình đọc bên ngoài (chẳng hạn như BigQuery) sử dụng. Siêu dữ liệu Delta Lake mà Databricks sử dụng nội bộ được theo dõi trong thư mục _delta_log.
Dữ liệu bảng thực tế được lưu trữ dưới dạng tệp Parquet trong một thư mục khác, thường được Databricks đặt tên bằng một chuỗi được tạo ngẫu nhiên. Ví dụ: trong ảnh chụp màn hình bên dưới, các tệp dữ liệu nằm trong thư mục 9M.
6. Thiết lập BigQuery và BigLake
Giờ đây, khi bảng Iceberg đã có trong Google Cloud Storage, bước tiếp theo là cấp quyền truy cập cho BigQuery. Việc này sẽ được thực hiện bằng cách tạo một bảng bên ngoài BigLake.
BigLake là một công cụ lưu trữ cho phép tạo các bảng trong BigQuery để đọc dữ liệu trực tiếp từ các nguồn bên ngoài như Google Cloud Storage. Đối với phòng thí nghiệm này, đây là công nghệ chính giúp BigQuery hiểu được bảng Iceberg vừa được xuất mà không cần phải nhập dữ liệu.
Để làm được việc này, bạn cần có 2 thành phần:
- Mối kết nối tài nguyên trên đám mây: Đây là mối liên kết bảo mật giữa BigQuery và GCS. Thao tác này sử dụng một tài khoản dịch vụ đặc biệt để xử lý việc xác thực, đảm bảo BigQuery có các quyền cần thiết để đọc tệp từ bộ chứa GCS.
- Định nghĩa bảng bên ngoài: Định nghĩa này cho BigQuery biết vị trí tìm tệp siêu dữ liệu của bảng Iceberg trong GCS và cách diễn giải tệp đó.
Tạo mối kết nối tài nguyên trên đám mây
Trước tiên, hệ thống sẽ tạo kết nối cho phép BigQuery truy cập vào GCS.
Bạn có thể xem thêm thông tin về cách tạo Cloud Resource Connections tại đây
- Chuyển đến BigQuery
- Nhấp vào Connections (Kết nối) trong Explorer (Trình khám phá)
- Nếu mặt phẳng Explorer (Trình khám phá) không xuất hiện, hãy nhấp vào biểu tượng

- Trên trang Kết nối, hãy nhấp vào biểu tượng
- Đối với Loại mối kết nối, hãy chọn
Vertex AI remote models, remote functions, BigLake and Spanner (Cloud Resource) - Đặt mã nhận dạng kết nối thành
databricks_retlvà tạo kết nối

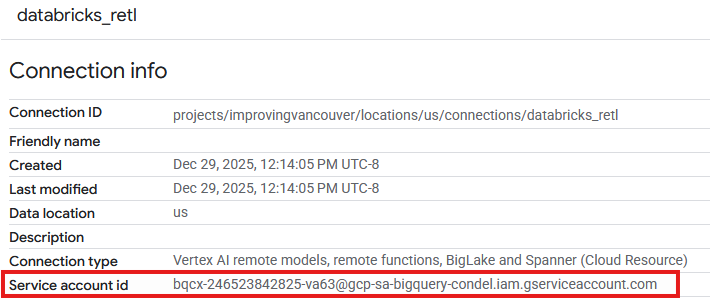
- Giờ đây, bạn sẽ thấy một mục trong bảng Connections (Kết nối) của mối kết nối mới tạo. Nhấp vào mục đó để xem thông tin chi tiết về mối kết nối.

- Trong trang thông tin chi tiết về mối kết nối, hãy ghi lại Mã tài khoản dịch vụ vì bạn sẽ cần mã này sau này.
Cấp quyền truy cập cho tài khoản dịch vụ kết nối
- Chuyển đến phần IAM & Admin (Quản trị và quản lý danh tính và quyền truy cập)
- Nhấp vào Cấp quyền truy cập
- Đối với trường Bên giao đại lý mới, hãy nhập Mã tài khoản dịch vụ của Tài nguyên kết nối mà bạn đã tạo ở trên.
- Đối với Vai trò, hãy chọn
Storage Object Userrồi nhấp vào
Sau khi thiết lập kết nối và cấp cho tài khoản dịch vụ của kết nối các quyền cần thiết, bạn có thể tạo bảng bên ngoài BigLake. Trước tiên, bạn cần có một Tập dữ liệu trong BigQuery để đóng vai trò là một vùng chứa cho bảng mới. Sau đó, chính bảng sẽ được tạo, trỏ đến tệp siêu dữ liệu Iceberg trong vùng chứa GCS.
- Chuyển đến BigQuery
- Trong bảng Explorer (Trình khám phá), hãy nhấp vào mã dự án, sau đó nhấp vào dấu ba chấm rồi chọn Create dataset (Tạo tập dữ liệu).
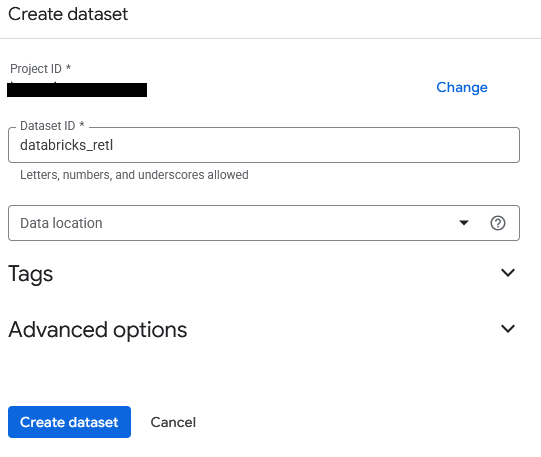
- Tập dữ liệu sẽ có tên là
databricks_retl. Giữ nguyên các lựa chọn khác theo mặc định rồi nhấp vào nút Tạo tập dữ liệu.
- Giờ đây, hãy tìm tập dữ liệu
databricks_retlmới trong bảng điều khiển Explorer (Trình khám phá). Nhấp vào biểu tượng ba dấu chấm bên cạnh rồi chọn Tạo bảng.
- Điền vào các chế độ cài đặt sau để tạo bảng:
- Tạo bảng từ:
Google Cloud Storage - Chọn tệp trong vùng lưu trữ GCS hoặc sử dụng mẫu URI: Duyệt tìm vùng lưu trữ GCS và xác định tệp JSON siêu dữ liệu đã được tạo trong quá trình xuất Databricks. Đường dẫn sẽ có dạng như sau:
regional_sales/metadata/v1.metadata.json. - Định dạng tệp:
Iceberg - Bảng:
regional_sales - Loại bảng:
External table - Mã nhận dạng kết nối: Chọn kết nối
databricks_retlmà bạn đã tạo trước đó. - Để nguyên các giá trị còn lại ở chế độ mặc định, sau đó nhấp vào Tạo bảng.
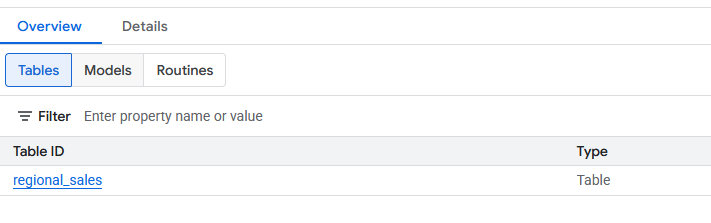
- Sau khi tạo, bạn sẽ thấy bảng
regional_salesmới trong tập dữ liệudatabricks_retl. Giờ đây, bạn có thể truy vấn bảng này bằng SQL chuẩn, giống như với mọi bảng BigQuery khác.
7. Tải vào Spanner
Bạn đã đạt đến phần cuối cùng và quan trọng nhất của quy trình: di chuyển dữ liệu từ các bảng bên ngoài BigLake vào Spanner. Đây là bước "ETL đảo ngược", trong đó dữ liệu sau khi được xử lý và tuyển chọn trong kho dữ liệu sẽ được tải vào một hệ thống vận hành để các ứng dụng sử dụng.
Spanner là một cơ sở dữ liệu quan hệ được quản lý toàn bộ và phân phối trên toàn cầu. Dịch vụ này cung cấp tính nhất quán giao dịch của một cơ sở dữ liệu quan hệ truyền thống nhưng có khả năng mở rộng theo chiều ngang của một cơ sở dữ liệu NoSQL. Nhờ đó, đây là lựa chọn lý tưởng để xây dựng các ứng dụng có khả năng mở rộng và tính sẵn sàng cao.
Quy trình sẽ như sau:
- Tạo một phiên bản Spanner, đây là việc phân bổ tài nguyên thực.
- Tạo một cơ sở dữ liệu trong phiên bản đó.
- Xác định một giản đồ bảng trong cơ sở dữ liệu khớp với cấu trúc của dữ liệu
regional_sales. - Chạy truy vấn BigQuery
EXPORT DATAđể tải dữ liệu từ bảng BigLake trực tiếp vào bảng Spanner.
Tạo thực thể, cơ sở dữ liệu và bảng Spanner
- Chuyển đến Spanner
- Nhấp vào
 . Bạn có thể sử dụng một phiên bản hiện có (nếu có). Thiết lập các yêu cầu về thực thể nếu cần. Trong phòng thí nghiệm này, chúng tôi đã sử dụng những thứ sau:
. Bạn có thể sử dụng một phiên bản hiện có (nếu có). Thiết lập các yêu cầu về thực thể nếu cần. Trong phòng thí nghiệm này, chúng tôi đã sử dụng những thứ sau:
Phiên bản | Doanh nghiệp |
Tên phiên bản | databricks-retl |
Cấu hình vùng | Vùng bạn chọn |
Đơn vị điện toán | Đơn vị xử lý (PU) |
Phân bổ thủ công | 100 |
- Sau khi tạo, hãy chuyển đến trang phiên bản Spanner rồi chọn
 . Bạn có thể sử dụng cơ sở dữ liệu hiện có (nếu có).
. Bạn có thể sử dụng cơ sở dữ liệu hiện có (nếu có).
- Đối với lớp học lập trình này, một cơ sở dữ liệu sẽ được tạo bằng
- Tên:
databricks-retl - Phương ngữ cơ sở dữ liệu:
Google Standard SQL
- Sau khi tạo cơ sở dữ liệu, hãy chọn cơ sở dữ liệu đó trên trang Spanner Instance (Phiên bản Spanner) để truy cập vào trang Spanner Database (Cơ sở dữ liệu Spanner).
- Trên trang Cơ sở dữ liệu Spanner, hãy nhấp vào

- Trong trang truy vấn mới, định nghĩa bảng cho bảng cần nhập vào Spanner sẽ được tạo. Để thực hiện việc này, hãy chạy truy vấn SQL sau.
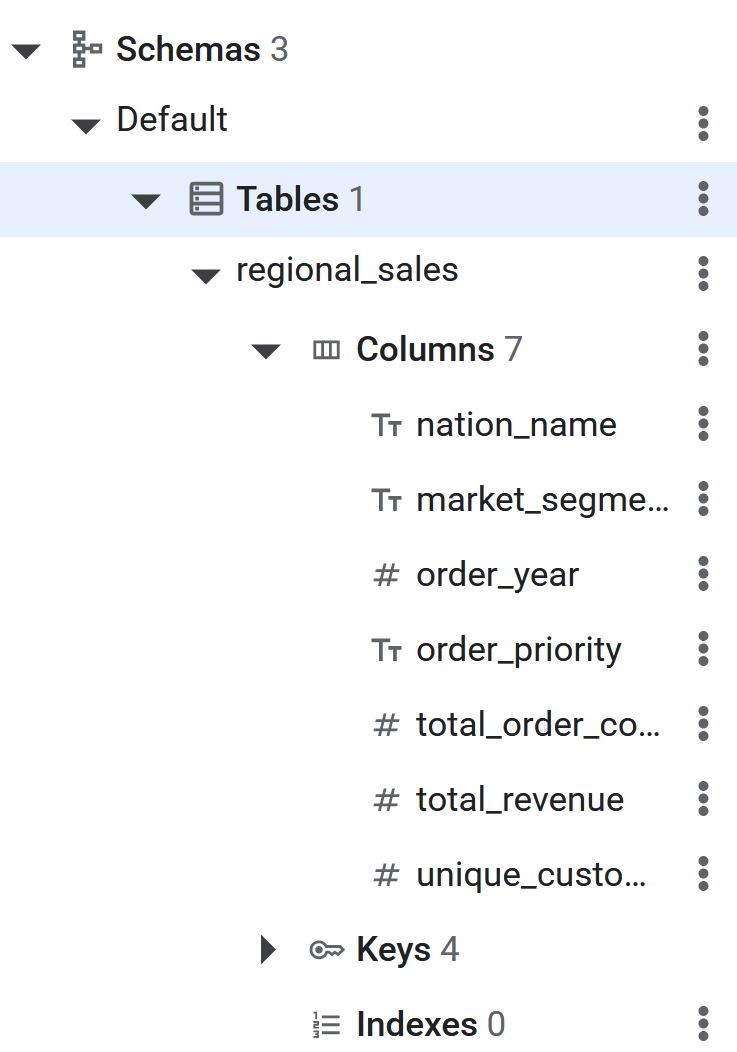
CREATE TABLE regional_sales (
nation_name STRING(MAX),
market_segment STRING(MAX),
order_year INT64,
order_priority STRING(MAX),
total_order_count INT64,
total_revenue NUMERIC,
unique_customer_count INT64
) PRIMARY KEY (nation_name, market_segment, order_year, order_priority);
- Sau khi lệnh SQL thực thi, bảng Spanner sẽ sẵn sàng để BigQuery thực hiện ETL đảo ngược dữ liệu. Bạn có thể xác minh việc tạo bảng bằng cách xem bảng đó trong bảng điều khiển bên trái trong cơ sở dữ liệu Spanner.
Quy trình ETL ngược sang Spanner bằng EXPORT DATA
Đây là bước cuối cùng. Khi dữ liệu nguồn đã sẵn sàng trong bảng BigLake của BigQuery và bảng đích được tạo trong Spanner, quá trình di chuyển dữ liệu thực tế diễn ra rất đơn giản. Một truy vấn SQL BigQuery sẽ được dùng: EXPORT DATA.
Truy vấn này được thiết kế riêng cho những trường hợp như thế này. Công cụ này xuất dữ liệu một cách hiệu quả từ một bảng BigQuery (bao gồm cả các bảng bên ngoài như bảng BigLake) sang một đích đến bên ngoài. Trong trường hợp này, đích đến là bảng Spanner. Bạn có thể xem thêm thông tin về tính năng xuất tại đây
Bạn có thể xem thêm thông tin về cách thiết lập BigQuery thành Spanner Reverse ETL tại đây
- Chuyển đến BigQuery
- Mở một thẻ trình chỉnh sửa truy vấn mới.
- Trên trang Truy vấn, hãy nhập SQL sau. Hãy nhớ thay thế mã dự án trong **
uri** **và đường dẫn bảng bằng mã dự án chính xác.**
EXPORT DATA OPTIONS(
uri='https://spanner.googleapis.com/projects/YOUR_PROJECT_ID/instances/databricks-retl/databases/databricks-retl',
format='CLOUD_SPANNER',
spanner_options="""{
"table": "regional_sales",
"priority": "MEDIUM"
}"""
) AS
SELECT * FROM `YOUR_PROJECT_ID.databricks_retl.regional_sales`;
- Sau khi lệnh hoàn tất, dữ liệu đã được xuất thành công sang Spanner!
8. Xác minh dữ liệu trong Spanner
Xin chúc mừng! Một quy trình ETL ngược hoàn chỉnh đã được xây dựng và thực thi thành công, di chuyển dữ liệu từ kho dữ liệu Databricks sang cơ sở dữ liệu Spanner hoạt động.
Bước cuối cùng là xác minh rằng dữ liệu đã được chuyển đến Spanner như dự kiến.
- Chuyển đến Spanner.
- Chuyển đến phiên bản
databricks-retlcủa bạn, rồi chuyển đến cơ sở dữ liệudatabricks-retl. - Trong danh sách bảng, hãy nhấp vào bảng
regional_sales. - Trong trình đơn điều hướng bên trái của bảng, hãy nhấp vào thẻ Dữ liệu.
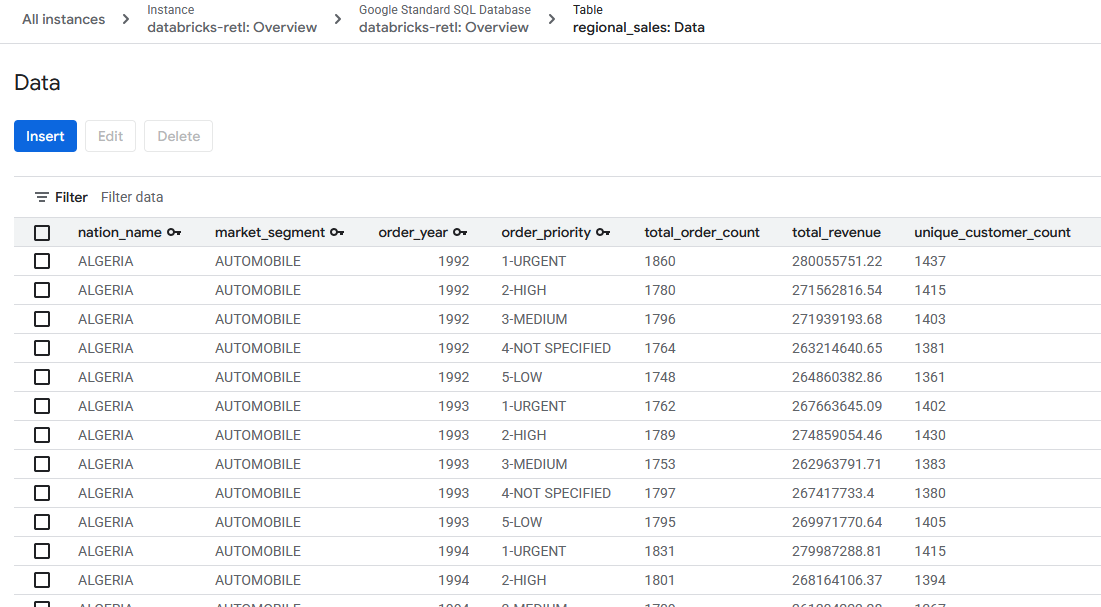
- Dữ liệu bán hàng tổng hợp (ban đầu từ Databricks) hiện đã được tải và sẵn sàng sử dụng trong bảng Spanner. Dữ liệu này hiện nằm trong một hệ thống vận hành, sẵn sàng hỗ trợ một ứng dụng đang hoạt động, cung cấp một trang tổng quan hoặc được truy vấn bằng một API.
Khoảng cách giữa thế giới dữ liệu phân tích và dữ liệu vận hành đã được thu hẹp thành công.
9. Dọn dẹp
Xoá tất cả các bảng đã thêm và dữ liệu đã lưu trữ khi bạn hoàn tất bài thực hành này.
Dọn dẹp các bảng Spanner
- Chuyển đến Spanner
- Nhấp vào thực thể đã dùng cho bài thực hành này trong danh sách có tên
databricks-retl

- Trong trang phiên bản, hãy nhấp vào biểu tượng

- Nhập
databricks-retlvào hộp thoại xác nhận bật lên rồi nhấp vào
Dọn dẹp GCS
- Chuyển đến GCS
- Chọn biểu tượng
 trong trình đơn bên trái
trong trình đơn bên trái - Chọn bộ chứa ``codelabs_retl_databricks
- Sau khi chọn, hãy nhấp vào nút
 xuất hiện ở biểu ngữ trên cùng
xuất hiện ở biểu ngữ trên cùng

- Nhập
DELETEvào hộp thoại xác nhận bật lên rồi nhấp vào
Dọn dẹp Databricks
Xoá danh mục/lược đồ/bảng
- Đăng nhập vào phiên bản Databricks
- Nhấp vào biểu tượng
 trong trình đơn bên trái
trong trình đơn bên trái - Chọn
 đã tạo trước đó trong danh sách danh mục
đã tạo trước đó trong danh sách danh mục - Trong danh sách Lược đồ, hãy chọn
 mà bạn đã tạo
mà bạn đã tạo - Chọn
 đã tạo trước đó trong danh sách bảng
đã tạo trước đó trong danh sách bảng - Mở rộng các lựa chọn về bảng bằng cách nhấp vào
 rồi chọn
rồi chọn Delete - Nhấp vào biểu tượng
 trên hộp thoại xác nhận để xoá bảng
trên hộp thoại xác nhận để xoá bảng - Sau khi xoá bảng, bạn sẽ được đưa trở lại trang giản đồ
- Mở rộng các lựa chọn về giản đồ bằng cách nhấp vào rồi chọn
Delete - Nhấp vào biểu tượng trên hộp thoại xác nhận để xoá Lược đồ
- Sau khi xoá giản đồ, bạn sẽ được đưa trở lại trang danh mục
- Lặp lại các bước từ 4 đến 11 để xoá giản đồ
default(nếu có). - Trên trang danh mục, hãy mở rộng các lựa chọn về danh mục bằng cách nhấp vào rồi chọn
Delete - Nhấp vào biểu tượng trên hộp thoại xác nhận để xoá danh mục
Xoá vị trí / thông tin đăng nhập của dữ liệu bên ngoài
- Trên màn hình Danh mục, hãy nhấp vào biểu tượng
- Nếu không thấy biểu tượng
External Data, bạn có thể thấy biểu tượngExternal Locationtrong trình đơn thả xuốngConnect. - Nhấp vào vị trí dữ liệu bên ngoài
retl-gcs-locationmà bạn đã tạo trước đó - Trên trang vị trí bên ngoài, hãy mở rộng các lựa chọn vị trí bằng cách nhấp vào rồi chọn
Delete - Nhấp vào biểu tượng trên hộp thoại xác nhận để xoá vị trí bên ngoài
- Nhấp vào biểu tượng
- Nhấp vào
retl-gcs-credentialđã được tạo trước đó - Trên trang thông tin xác thực, hãy mở rộng các lựa chọn thông tin xác thực bằng cách nhấp vào rồi chọn
Delete - Nhấp vào biểu tượng trên hộp thoại xác nhận để xoá thông tin đăng nhập.
10. Xin chúc mừng
Chúc mừng bạn đã hoàn thành lớp học lập trình này.
Nội dung đã đề cập
- Cách tải dữ liệu vào Databricks dưới dạng bảng Iceberg
- Cách tạo một Nhóm lưu trữ GCS
- Cách xuất bảng Databricks sang GCS ở định dạng Iceberg
- Cách tạo Bảng bên ngoài BigLake trong BigQuery từ bảng Iceberg trong GCS
- Cách thiết lập một phiên bản Spanner
- Cách tải Bảng bên ngoài BigLake trong BigQuery lên Spanner