
1. 使用 Google Cloud Storage 和 BigQuery 构建从 Databricks 到 Spanner 的反向 ETL 流水线
简介
在此 Codelab 中,您将构建一个从 Databricks 到 Spanner 的反向 ETL 流水线。按照传统做法,标准 ETL(提取、转换、加载)流水线会将数据从运营数据库移动到 Databricks 等数据仓库中以进行分析。反向 ETL 流水线则相反,它将经过整理和处理的数据从数据仓库移回运营数据库(例如 Spanner,这是一种全球分布式关系型数据库,非常适合高可用性应用),以便为应用提供支持、为面向用户的功能提供服务,或用于实时决策。
目标是将汇总的数据集从 Databricks Iceberg 表移至 Spanner 表。
为此,我们使用 Google Cloud Storage (GCS) 和 BigQuery 作为中间步骤。下面详细介绍了数据传输以及此架构背后的原因:

- 以 Iceberg 格式将 Databricks 数据导出到 Google Cloud Storage (GCS):
- 第一步是以开放且定义明确的格式从 Databricks 中提取数据。系统会以 Apache Iceberg 格式导出表。此过程会将底层数据写入为一组 Parquet 文件,并将表的元数据(架构、分区、文件位置)写入为 JSON 和 Avro 文件。在 GCS 中暂存此完整表结构可使数据具有可移植性,并且任何了解 Iceberg 格式的系统都可以访问这些数据。
- 将 GCS Iceberg 表转换为 BigQuery BigLake 外部表:
- 我们不直接将数据从 GCS 加载到 Spanner,而是将 BigQuery 用作强大的中间平台。系统会在 BigQuery 中创建一个BigLake 外部表,该表直接指向 GCS 中的 Iceberg 元数据文件。这样做具有很多优势:
- 无数据重复:BigQuery 从元数据中读取表结构,并直接查询 Parquet 数据文件,而无需提取这些文件,从而节省大量时间和存储费用。
- 联合查询:它允许对 GCS 数据运行复杂的 SQL 查询,就像对原生 BigQuery 表运行查询一样。
- 将 ReverseETL BigLake 外部表导入到 Spanner 中:
- 最后一步是将数据从 BigQuery 迁移到 Spanner。这是通过 BigQuery 中的一项强大功能(称为
EXPORT DATA查询)实现的,该功能是“反向 ETL”步骤。 - 运营就绪状态:Spanner 专为事务性工作负载而设计,可为应用提供强一致性和高可用性。通过将数据迁移到 Spanner 中,面向用户的应用、API 和其他需要低延迟点查询的运营系统可以访问这些数据。
- 可伸缩性:此模式可利用 BigQuery 的分析能力来处理大型数据集,然后通过 Spanner 的全球可伸缩基础架构高效地提供结果。
服务和术语
- DataBricks - 基于 Apache Spark 构建的云端数据平台。
- Spanner - 一种由 Google 全托管式的全球分布式关系型数据库。
- Google Cloud Storage - Google Cloud 的 Blob 存储产品。
- BigQuery - 一种由 Google 全托管式管理的无服务器数据仓库,可用于数据分析。
- Iceberg - 一种由 Apache 定义的开放表格式,可对常见的开源数据文件格式进行抽象化处理。
- Parquet - Apache 的一种开源列式二进制数据文件格式。
学习内容
- 如何将数据加载到 Databricks 中作为 Iceberg 表
- 如何创建 GCS 存储分区
- 如何以 Iceberg 格式将 Databricks 表导出到 GCS
- 如何在 BigQuery 中基于 GCS 中的 Iceberg 表创建 BigLake 外部表
- 如何设置 Spanner 实例
- 如何将 BigQuery 中的 BigLake 外部表加载到 Spanner 中
2. 设置、要求和限制
前提条件
- 一个 Databricks 账号,最好是在 GCP 上
- 若要从 BigQuery 导出到 Spanner,您需要拥有一个 Google Cloud 账号,并具有 BigQuery 企业级或更高级别的预留。
- 通过网络浏览器访问 Google Cloud 控制台
- 用于运行 Google Cloud CLI 命令的终端
如果您的 Google Cloud 组织已启用 iam.allowedPolicyMemberDomains 政策,管理员可能需要授予例外权限,以允许来自外部网域的服务账号。我们将在后面的步骤中介绍相关内容(如适用)。
要求
- 启用了结算功能的 Google Cloud 项目。
- 网络浏览器,例如 Chrome
- Databricks 账号(本实验假设工作区托管在 GCP 中)
- BigQuery 实例必须是企业版或更高版本,才能使用 EXPORT DATA 功能。
- 如果您的 Google Cloud 组织已启用
iam.allowedPolicyMemberDomains政策,管理员可能需要授予例外权限,以允许来自外部网域的服务账号。我们将在后面的步骤中介绍相关内容(如适用)。
Google Cloud Platform IAM 权限
Google 账号需要拥有以下权限才能执行此 Codelab 中的所有步骤。
服务账号 | ||
| 允许创建服务账号。 | |
Spanner | ||
| 允许创建新的 Spanner 实例。 | |
| 允许运行 DDL 语句来创建 | |
| 允许运行 DDL 语句以在数据库中创建表。 | |
Google Cloud Storage | ||
| 允许创建新的 GCS 存储分区来存储导出的 Parquet 文件。 | |
| 允许将导出的 Parquet 文件写入 GCS 存储分区。 | |
| 允许 BigQuery 从 GCS 存储分区读取 Parquet 文件。 | |
| 允许 BigQuery 列出 GCS 存储分区中的 Parquet 文件。 | |
Dataflow | ||
| 允许从 Dataflow 声明工作项。 | |
| 允许 Dataflow 工作器将消息发送回 Dataflow 服务。 | |
| 允许 Dataflow 工作器将日志条目写入 Google Cloud Logging。 | |
为方便起见,您可以使用包含这些权限的预定义角色。
|
|
|
|
|
|
|
|
Google Cloud 项目
项目是 Google Cloud 中的基本组织单元。如果管理员已提供可供使用的密钥,则可以跳过此步骤。
您可以使用如下所示的 CLI 创建项目:
gcloud projects create <your-project-name>
如需详细了解如何创建和管理项目,请点击此处。
限制
请务必注意此流水线中可能会出现的一些限制和数据类型不兼容问题。
从 Databricks Iceberg 到 BigQuery
使用 BigQuery 查询由 Databricks(通过 UniForm)管理的 Iceberg 表时,请注意以下事项:
- 架构演变:虽然 UniForm 在将 Delta Lake 架构更改转换为 Iceberg 方面表现出色,但复杂的更改可能无法始终按预期传播。例如,在 Delta Lake 中重命名列不会转换为 Iceberg,后者会将其视为
drop和add。请务必彻底测试架构更改。 - 时间旅行:BigQuery 无法使用 Delta Lake 的时间旅行功能。它只会查询 Iceberg 表的最新快照。
- 不受支持的 Delta Lake 功能:Delta Lake 中采用
id模式的删除向量和列映射等功能与 UniForm for Iceberg 不兼容。本实验使用name模式进行列映射,该模式受支持。
BigQuery to Spanner
从 BigQuery 到 Spanner 的 EXPORT DATA 命令不支持所有 BigQuery 数据类型。导出具有以下类型的表格会导致错误:
STRUCTGEOGRAPHYDATETIMERANGETIME
此外,如果 BigQuery 项目使用的是 GoogleSQL 方言,则以下数值类型也不支持导出到 Spanner:
BIGNUMERIC
如需查看完整且最新的限制列表,请参阅官方文档:导出到 Spanner 的限制。
问题排查和注意事项
- 如果不是在 GCP Databricks 实例上,则可能无法在 GCS 中定义外部数据位置。在这种情况下,需要先在 Databricks 工作区的云提供商的存储解决方案中暂存文件,然后再单独迁移到 GCS。
- 这样做时,需要调整元数据,因为信息将包含指向暂存文件的硬编码路径。
3. 设置 Google Cloud Storage (GCS)
Google Cloud Storage (GCS) 将用于存储由 Databricks 生成的 Parquet 数据文件。为此,您首先需要创建一个新存储分区作为文件目标位置。
Google Cloud Storage
创建新存储桶
- 在云控制台中,前往 Google Cloud Storage 页面。
- 在左侧面板中,选择存储分区:
- 点击创建按钮:

- 填写您的存储分区详情:
- 选择要使用的存储分区名称。在本实验中,将使用名称
codelabs_retl_databricks - 选择用于存储相应存储分区的区域,或使用默认值。
- 将存储类别保留为
standard - 保留控制访问权限的默认值
- 保留保护对象数据的默认值
- 完成后,点击
Create按钮。系统可能会显示提示,确认将禁止公开访问。继续操作并确认。 - 恭喜,您已成功创建新存储分区!系统会重定向到存储分区页面。
- 将新存储分区名称复制到某个位置,因为稍后需要用到该名称。
为后续步骤做好准备
请务必记下以下详细信息,因为您在后续步骤中需要用到这些信息:
- Google 项目 ID
- Google Storage 存储分区名称
4. 设置 Databricks
TPC-H 数据
在本实验中,我们将使用 TPC-H 数据集,这是决策支持系统的行业标准基准。其架构模拟了包含客户、订单、供应商和零件的真实业务环境,非常适合演示实际的数据分析和数据移动场景。
系统将创建一个新的汇总表,而不是使用原始的标准化 TPC-H 表。这个新表将联接 orders、customer 和 nation 表中的数据,以生成区域销售额的反规范化汇总视图。这种预汇总步骤是分析中的常见做法,因为它可以为特定使用情形(在本场景中,是供运营应用使用)准备数据。
汇总表的最终架构将为:
Col | 类型 |
nation_name | 字符串 |
market_segment | 字符串 |
order_year | int |
order_priority | 字符串 |
total_order_count | bigint |
total_revenue | decimal(29,2) |
unique_customer_count | bigint |
通过 Delta Lake Universal Format (UniForm) 支持 Iceberg
在本实验中,Databricks 中的表将是 Delta Lake 表。不过,为了让 BigQuery 等外部系统能够读取该格式,系统会启用一项名为通用格式 (UniForm) 的强大功能。
UniForm 会自动生成 Iceberg 元数据以及 Delta Lake 元数据,以用于单个共享的表数据副本。这样可以兼具两者的优势:
- 在 Databricks 中:可获得 Delta Lake 的所有性能和治理优势。
- 在 Databricks 之外:任何与 Iceberg 兼容的查询引擎(例如 BigQuery)都可以读取该表,就像读取原生 Iceberg 表一样。
这样一来,您就无需维护单独的数据副本或运行手动转换作业。在创建表时,通过设置特定的表属性来启用 UniForm。
Databricks Catalog
Databricks Catalog 是 Unity Catalog(Databricks 的统一治理解决方案)中数据的顶级容器。Unity Catalog 提供了一种集中管理数据资产、控制访问权限和跟踪沿袭的方法,这对于妥善治理的数据平台至关重要。
它使用三级命名空间来整理数据:catalog.schema.table。
- 目录:最高级别,用于按环境、业务单位或项目对数据进行分组。
- 架构(或数据库):目录中表、视图和函数的逻辑分组。
- 表格:包含数据的对象。
在创建汇总的 TPC-H 表之前,必须先设置一个专用目录和架构来存放该表。这样可确保项目井井有条,并与工作区中的其他数据隔离开。
创建新的目录和架构
在 Databricks Unity Catalog 中,目录是数据资产的最高组织级别,充当可跨多个 Databricks 工作区的安全容器。借助它,您可以根据业务部门、项目或环境来整理和隔离数据,并明确定义权限和访问权限控制。
在目录中,架构(也称为数据库)可进一步整理表、视图和函数。这种分层结构可实现对相关数据对象的精细控制和逻辑分组。在本实验中,我们将创建一个专用目录和架构来存放 TPC-H 数据,以确保适当的隔离和管理。
创建目录
- 前往

- 点击 +,然后从下拉菜单中选择创建目录
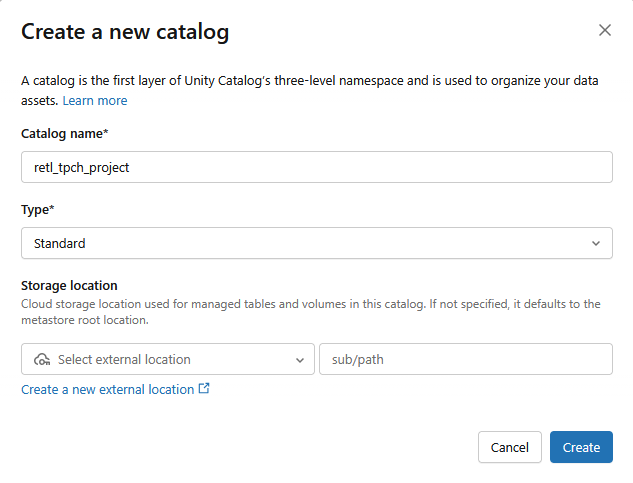
- 系统将创建一个新的标准目录,并采用以下设置:
- 目录名称:
retl_tpch_project - 存储位置:如果工作区中已设置存储位置,请使用默认位置;否则,请创建新的存储位置。
创建架构
- 前往
- 从左侧面板中选择新创建的目录
- 点击
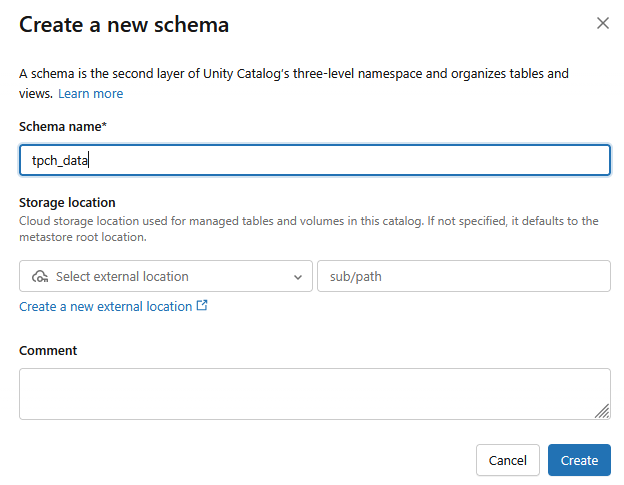
- 系统将创建一个新架构,并将架构名称设为
tpch_data
设置外部数据
如需能够将数据从 Databricks 导出到 Google Cloud Storage (GCS),需要在 Databricks 中设置外部数据凭证。这样一来,Databricks 就可以安全地访问 GCS 存储分区并向其中写入数据。
- 在目录界面中,点击

- 如果您没有看到
External Data选项,可能会在Connect下拉菜单中看到External Locations。
- 点击

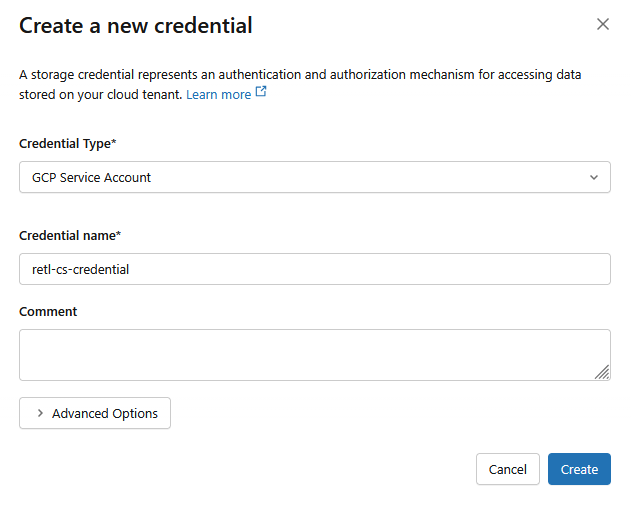
- 在新对话框窗口中,为凭据设置所需的值:
- Credential Type:
GCP Service Account - 凭据名称:
retl-gcs-credential
- 点击创建
- 接下来,点击外部地点标签页。
- 点击创建位置。
- 在新对话框窗口中,为外部位置设置所需的值:
- 外部位置名称:
retl-gcs-location - 存储类型:
GCP - 网址:GCS 存储分区的网址,格式为
gs://YOUR_BUCKET_NAME - 存储凭据:选择刚刚创建的
retl-gcs-credential。
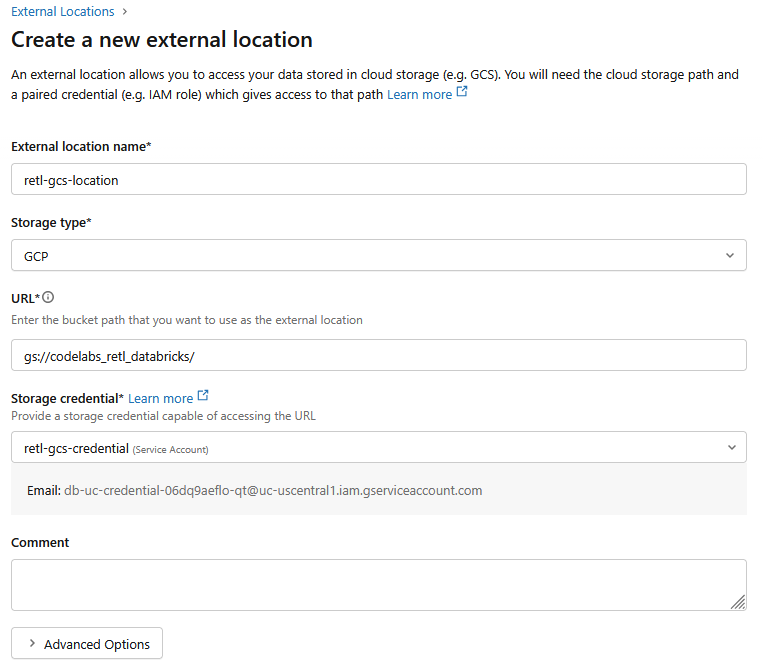
- 记下选择存储空间凭据后自动填写的服务账号电子邮件地址,因为您将在下一步中需要用到它。
- 点击创建
5. 设置服务账号权限
服务账号是一种特殊类型的账号,应用或服务可以使用此类账号对 Google Cloud 资源执行已获授权的 API 调用。
现在,需要向为 GCS 中的新存储分区创建的服务账号添加权限。
- 在 GCS 存储分区页面中,选择权限标签页。
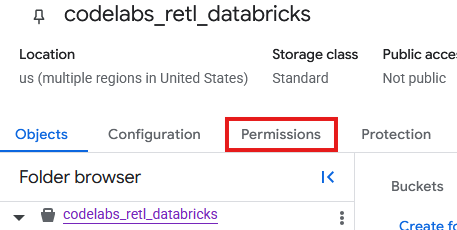
- 在主账号页面中,点击授予访问权限
- 在从右侧滑出的授予访问权限面板中,将服务账号 ID 输入到新的正文字段中
- 在分配角色下,添加
Storage Object Admin和Storage Legacy Bucket Reader。这些角色允许服务账号读取、写入和列出存储分区中的对象。
加载 TPC-H 数据
现在,目录和架构已创建完毕,接下来可以从 Databricks 内部存储的现有 samples.tpch 表中加载 TPCH 数据,并将其处理成新定义的架构中的新表。
创建支持 Iceberg 的表
Iceberg 与 UniForm 的兼容性
在幕后,Databricks 会在内部将此表作为 Delta Lake 表进行管理,从而在 Databricks 生态系统中提供 Delta 的所有性能优化和治理功能。不过,通过启用 UniForm(通用格式的简称),系统会指示 Databricks 执行一项特殊操作:每次更新表时,Databricks 除了生成和维护 Delta Lake 元数据之外,还会自动生成和维护相应的 Iceberg 元数据。
这意味着,一组共享的数据文件(Parquet 文件)现在由两组不同的元数据来描述。
- 对于 Databricks:它使用
_delta_log读取表。 - 对于外部读取器(例如 BigQuery):它们使用 Iceberg 元数据文件 (
.metadata.json) 来了解表的架构、分区和文件位置。
这样一来,生成的表便可完全透明地兼容任何支持 Iceberg 的工具。无需复制数据,也无需手动转换或同步数据。它是一个单一可信来源,Databricks 的分析世界和支持开放 Iceberg 标准的更广泛工具生态系统都可以无缝访问。
- 依次点击新建和查询
- 在查询页面的文本字段中,运行以下 SQL 命令:
CREATE TABLE retl_tpch_project.tpch_data.regional_sales_iceberg
USING DELTA
LOCATION 'gs://<Your bucket name>/regional_sales_iceberg'
TBLPROPERTIES (
'delta.columnMapping.mode' = 'name',
'delta.enableIcebergCompatV2' = 'true',
'delta.universalFormat.enabledFormats' = 'iceberg'
)
AS
SELECT
n.n_name AS nation_name,
c.c_mktsegment AS market_segment,
YEAR(o.o_orderdate) AS order_year,
o.o_orderpriority AS order_priority,
COUNT(o.o_orderkey) AS total_order_count,
ROUND(SUM(o.o_totalprice), 2) AS total_revenue,
COUNT(DISTINCT c.c_custkey) AS unique_customer_count
FROM samples.tpch.orders AS o
INNER JOIN samples.tpch.customer AS c
ON o.o_custkey = c.c_custkey
INNER JOIN samples.tpch.nation AS n
ON c.c_nationkey = n.n_nationkey
GROUP BY
n.n_name,
c.c_mktsegment,
YEAR(o.o_orderdate),
o.o_orderpriority;
OPTIMIZE retl_tpch_project.tpch_data.regional_sales_iceberg;
DESCRIBE EXTENDED retl_tpch_project.tpch_data.regional_sales_iceberg;
注意:
- 使用 Delta - 指定我们使用的是 Delta Lake 表。只有 Databricks 中的 Delta Lake 表可以存储为外部表。
- 位置 - 指定表格的存储位置(如果为外部表格)。
- TablePropertoes -
delta.universalFormat.enabledFormats = ‘iceberg'会在 Delta Lake 文件旁边创建兼容的 Iceberg 元数据。 - 优化 - 强制触发 UniForm 元数据生成,因为该操作通常是异步进行的。
- 查询的输出应显示有关新创建的表的详细信息

验证 GCS 表数据
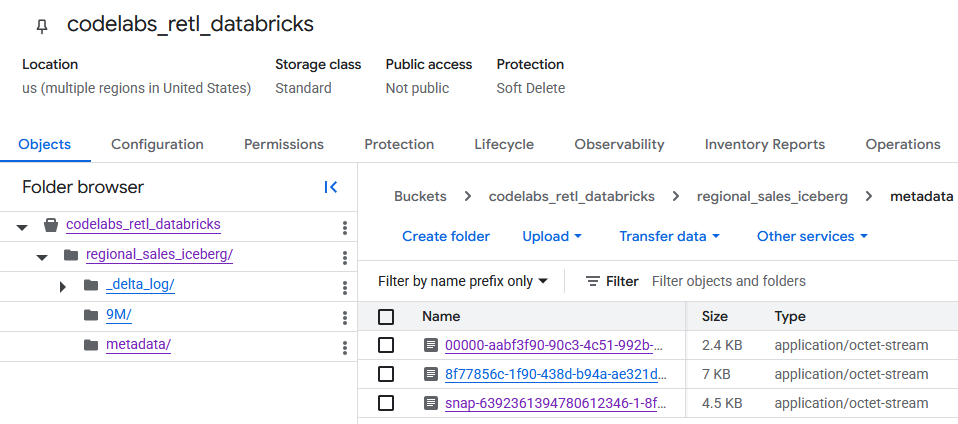
导航到 GCS 存储分区后,您现在可以找到新创建的表数据。
您会在 metadata 文件夹中找到 Iceberg 元数据,该元数据供外部读取器(例如 BigQuery)使用。Databricks 在内部使用的 Delta Lake 元数据在 _delta_log 文件夹中进行跟踪。
实际的表数据以 Parquet 文件的形式存储在另一个文件夹中,该文件夹通常由 Databricks 随机生成一个字符串作为名称。例如,在下面的屏幕截图中,数据文件位于 9M 文件夹中。
6. 设置 BigQuery 和 BigLake
现在,Iceberg 表已位于 Google Cloud Storage 中,下一步是让 BigQuery 可以访问该表。为此,您需要创建 BigLake 外部表。
BigLake 是一种存储引擎,可用于在 BigQuery 中创建直接从 Google Cloud Storage 等外部来源读取数据的表。对于本实验,它是关键技术,可让 BigQuery 了解刚刚导出的 Iceberg 表,而无需注入数据。
为了实现此目的,我们需要两个组件:
- Cloud 资源连接:这是 BigQuery 与 GCS 之间的安全链接。它使用特殊的服务账号来处理身份验证,确保 BigQuery 具有从 GCS 存储分区读取文件所需的权限。
- 外部表定义:此定义会告知 BigQuery 在 GCS 中查找 Iceberg 表的元数据文件的位置,以及应如何解读该文件。
创建云资源连接
首先,系统会创建允许 BigQuery 访问 GCS 的连接。
如需详细了解如何创建 Cloud 资源连接,请点击此处
- 前往 BigQuery
- 在浏览器下点击连接
- 如果探索器窗格未显示,请点击

- 在连接页面上,点击
- 对于连接类型,选择
Vertex AI remote models, remote functions, BigLake and Spanner (Cloud Resource) - 将连接 ID 设置为
databricks_retl并创建连接

- 现在,您应该会在新创建的连接的连接表格中看到相应条目。点击相应条目即可查看连接详情。

- 在连接详情页面中,记下服务账号 ID,因为您稍后会用到它。
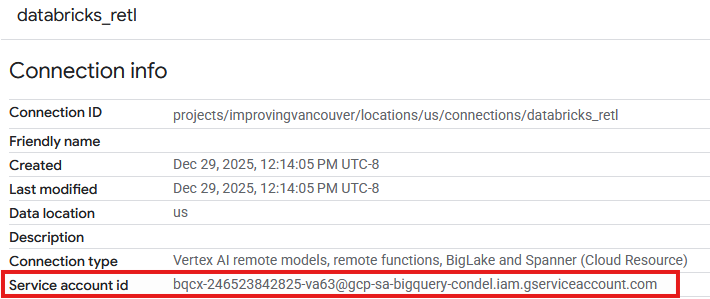
授予对连接服务账号的访问权限
- 前往 IAM 和管理
- 点击授予访问权限
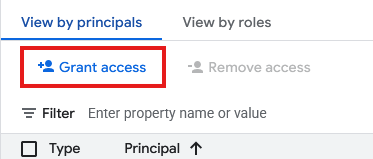
- 在新的主账号字段中,输入上面创建的连接资源的服务账号 ID。
- 对于“角色”,选择
Storage Object User,然后点击
建立连接并向其服务账号授予必要的权限后,现在可以创建 BigLake 外部表了。首先,您需要在 BigQuery 中创建一个数据集,作为新表的容器。然后,系统会创建表本身,并将其指向 GCS 存储分区中的 Iceberg 元数据文件。
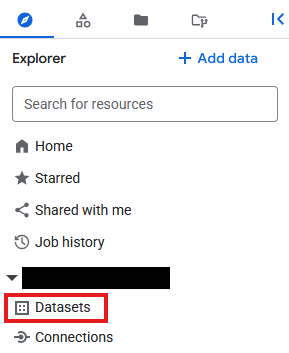
- 前往 BigQuery
- 在探索器面板中,点击项目 ID,然后点击三点状图标并选择创建数据集。
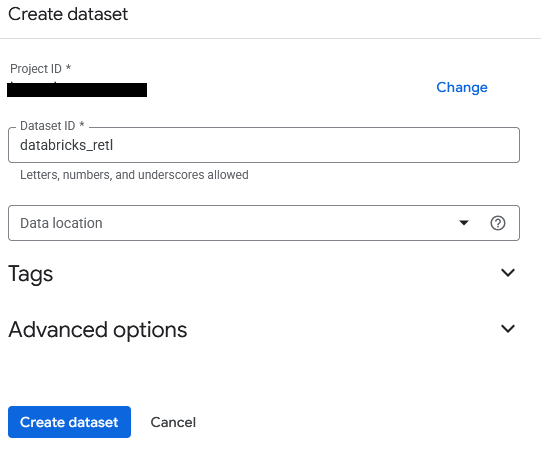
- 数据集将命名为
databricks_retl。将其他选项保留为默认值,然后点击创建数据集按钮。
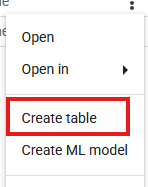
- 现在,在探索器面板中找到新的
databricks_retl数据集。点击该数据集旁边的三点状图标,然后选择创建表。
- 填写以下表格创建设置:
- 基于以下数据源创建表:
Google Cloud Storage - 从 GCS 存储分区中选择文件或使用 URI 模式:浏览到 GCS 存储分区,然后找到在 Databricks 导出期间生成的元数据 JSON 文件。路径应类似于:
regional_sales/metadata/v1.metadata.json。 - 文件格式:
Iceberg - 表格:
regional_sales - 表类型:
External table - 连接 ID:选择之前创建的
databricks_retl连接。 - 将其余值保留为默认值,然后点击创建表。
- 创建完成后,新的
regional_sales表应会显示在databricks_retl数据集下。现在,您可以使用标准 SQL 查询此表,就像查询任何其他 BigQuery 表一样。
7. 加载到 Spanner
流水线的最后也是最重要的部分已经完成:将数据从 BigLake 外部表移至 Spanner。这是“反向 ETL”步骤,其中数据在数据仓库中经过处理和整理后,会被加载到运营系统中,供应用使用。
Spanner 是一种全托管式全球分布式关系型数据库。它提供传统关系型数据库的事务一致性,但具有 NoSQL 数据库的横向可扩缩性。因此,它是构建可扩缩且高度可用的应用的理想选择。
流程如下:
- 创建 Spanner 实例,即资源的物理分配。
- 在该实例中创建数据库。
- 在数据库中定义与
regional_sales数据结构匹配的表架构。 - 运行 BigQuery
EXPORT DATA查询,将数据直接从 BigLake 表加载到 Spanner 表中。
创建 Spanner 实例、数据库和表
- 前往 Spanner
- 点击
 。如果有现有实例,可随意使用。根据需要设置实例要求。在本实验中,我们使用了以下内容:
。如果有现有实例,可随意使用。根据需要设置实例要求。在本实验中,我们使用了以下内容:
版本 | 企业 |
实例名称 | databricks-retl |
区域配置 | 您选择的地区 |
计算单元 | 处理单元 (PU) |
手动分配 | 100 |
- 创建完成后,前往 Spanner 实例页面,然后选择
 。您可以随意使用现有数据库(如果有)。
。您可以随意使用现有数据库(如果有)。
- 在本实验中,系统将创建一个包含以下内容的数据库
- 名称:
databricks-retl - 数据库方言:
Google Standard SQL
- 创建数据库后,在“Spanner 实例”页面中选择该数据库,进入“Spanner 数据库”页面。
- 在“Spanner 数据库”页面中,点击

- 在新查询页面中,系统将创建要导入到 Spanner 中的表的表定义。为此,请运行以下 SQL 查询。
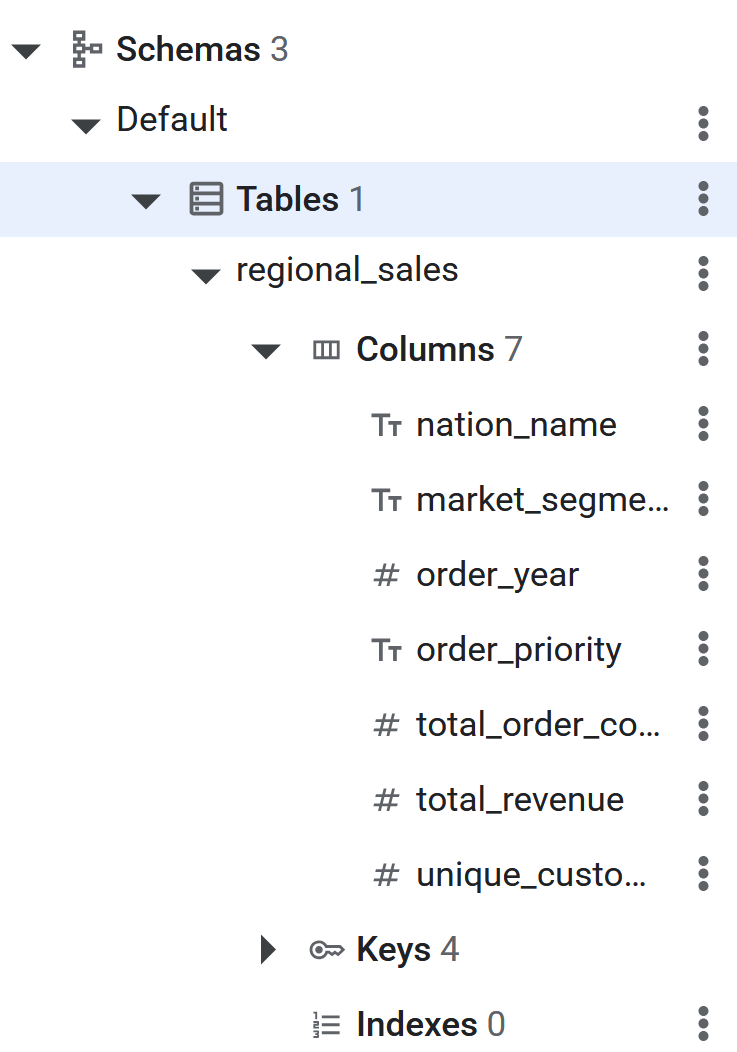
CREATE TABLE regional_sales (
nation_name STRING(MAX),
market_segment STRING(MAX),
order_year INT64,
order_priority STRING(MAX),
total_order_count INT64,
total_revenue NUMERIC,
unique_customer_count INT64
) PRIMARY KEY (nation_name, market_segment, order_year, order_priority);
- SQL 命令执行完毕后,Spanner 表即可供 BigQuery 反向 ETL 数据。您可以在 Spanner 数据库的左侧面板中看到该表,从而验证表的创建情况。
使用 EXPORT DATA 执行反向 ETL 到 Spanner
这是最后一步。在 BigQuery BigLake 表中准备好源数据,并在 Spanner 中创建目标表后,实际的数据迁移过程非常简单。系统将使用单个 BigQuery SQL 查询:EXPORT DATA。
此查询专门针对此类场景而设计。它可以高效地将数据从 BigQuery 表(包括 BigLake 表等外部表)导出到外部目标位置。在这种情况下,目标是 Spanner 表。如需详细了解导出功能,请点击此处
如需详细了解如何设置 BigQuery 到 Spanner 的反向 ETL,请点击此处
- 前往 BigQuery
- 打开新的查询编辑器标签页。
- 在“查询”页面上,输入以下 SQL。请务必将**
uri** **中的项目 ID 和表路径替换为正确的项目 ID。**
EXPORT DATA OPTIONS(
uri='https://spanner.googleapis.com/projects/YOUR_PROJECT_ID/instances/databricks-retl/databases/databricks-retl',
format='CLOUD_SPANNER',
spanner_options="""{
"table": "regional_sales",
"priority": "MEDIUM"
}"""
) AS
SELECT * FROM `YOUR_PROJECT_ID.databricks_retl.regional_sales`;
- 命令完成后,数据已成功导出到 Spanner!
8. 验证 Spanner 中的数据
恭喜!已成功构建并执行完整的反向 ETL 流水线,将数据从 Databricks 数据仓库迁移到 Spanner 运营数据库。
最后一步是验证数据是否已按预期到达 Spanner。
- 前往 Spanner。
- 前往您的
databricks-retl实例,然后前往databricks-retl数据库。 - 在表格列表中,点击
regional_sales表格。 - 在表格的左侧导航菜单中,点击数据标签页。
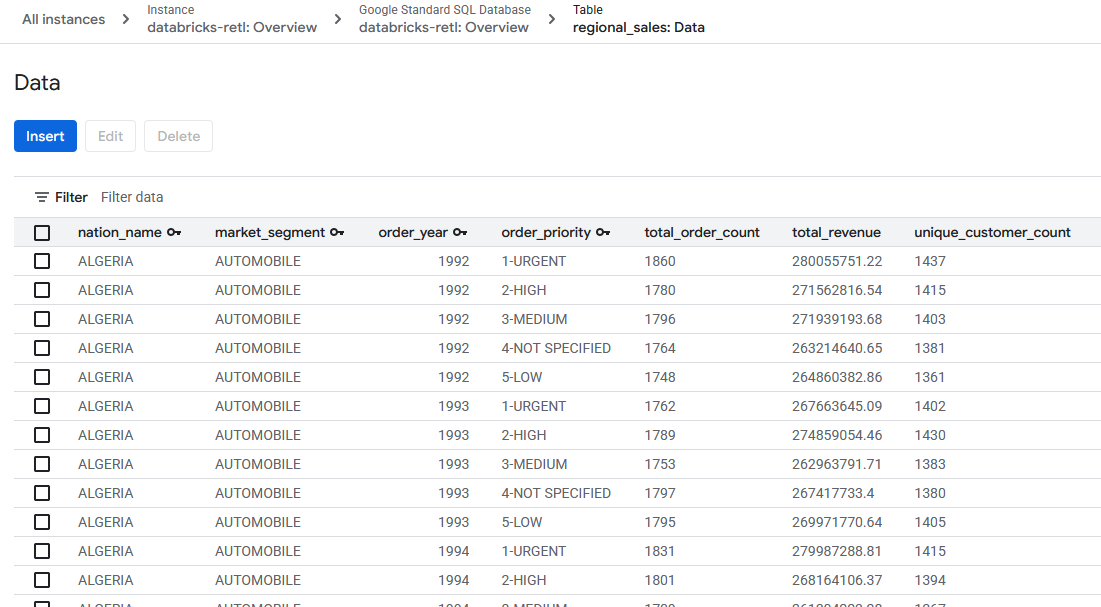
- 最初来自 Databricks 的汇总销售数据现在应已加载完毕,并可在 Spanner 表中使用。这些数据现在位于运营系统中,可用于支持实时应用、提供信息中心或通过 API 进行查询。
分析型数据与运营型数据之间的差距已成功弥合。
9. 清理
完成本实验后,请移除所有添加的表和存储的数据。
清理 Spanner 表
- 前往 Spanner
- 在名为
databricks-retl的列表中,点击本实验所用的实例

- 在实例页面中,点击

- 在随即显示的确认对话框中输入
databricks-retl,然后点击
清理 GCS
- 前往 GCS
- 从左侧菜单中选择
- 选择“codelabs_retl_databricks”存储分区
- 选择完毕后,点击顶部横幅中显示的
 按钮
按钮

- 在随即显示的确认对话框中输入
DELETE,然后点击
清理 Databricks
删除目录/架构/表
- 登录 Databricks 实例
- 点击左侧菜单中的
- 从目录列表中选择之前创建的

- 在架构列表中,选择已创建的

- 从表格列表中选择之前创建的

- 点击
 展开表格选项,然后选择
展开表格选项,然后选择 Delete - 在确认对话框中点击
 以删除表格
以删除表格 - 删除表格后,您将返回到架构页面
- 点击 展开架构选项,然后选择
Delete - 在确认对话框中点击 以删除架构
- 删除架构后,您将返回到目录页面
- 再次按照第 4 步至第 11 步操作,以删除
default架构(如果存在)。 - 在目录页面上,点击 展开目录选项,然后选择
Delete - 在确认对话框中点击 以删除目录
删除外部数据位置 / 凭据
- 在“目录”界面中,点击
- 如果您没有看到
External Data选项,可能会在Connect下拉菜单中看到External Location。 - 点击之前创建的
retl-gcs-location外部数据位置 - 在外部位置页面中,点击 展开位置选项,然后选择
Delete - 在确认对话框中,点击 以删除外部位置
- 点击
- 点击之前创建的
retl-gcs-credential - 在“凭据”页面上,点击 展开凭据选项,然后选择
Delete - 在确认对话框中点击 以删除凭据。
10. 恭喜
恭喜您完成此 Codelab。
所学内容
- 如何将数据加载到 Databricks 中作为 Iceberg 表
- 如何创建 GCS 存储分区
- 如何以 Iceberg 格式将 Databricks 表导出到 GCS
- 如何在 BigQuery 中基于 GCS 中的 Iceberg 表创建 BigLake 外部表
- 如何设置 Spanner 实例
- 如何将 BigQuery 中的 BigLake 外部表加载到 Spanner 中