
1. 使用 Google Cloud Storage 和 BigQuery,從 Databricks 建構反向 ETL 管道至 Spanner
簡介
在本程式碼研究室中,您將建構從 Databricks 到 Spanner 的反向 ETL 管道。傳統上,標準 ETL (擷取、轉換、載入) 管道會將作業資料庫中的資料移至 Databricks 等資料倉儲,以供分析。反向 ETL 管道則會反向操作,將經過處理的精選資料從資料倉儲移回營運資料庫,例如 Spanner (全球分散式關聯式資料庫,非常適合高可用性應用程式),以便為應用程式提供支援、提供使用者介面功能,或用於即時決策。
目標是將匯總資料集從 Databricks Iceberg 資料表移至 Spanner 資料表。
為此,我們使用 Google Cloud Storage (GCS) 和 BigQuery 做為中繼步驟。以下是資料流程的細目,以及此架構背後的理由:

- 以 Iceberg 格式將 Databricks 匯出至 Google Cloud Storage (GCS):
- 第一步是以開放且定義完善的格式,從 Databricks 匯出資料。資料表會以 Apache Iceberg 格式匯出。這個程序會將基礎資料寫入一組 Parquet 檔案,並將資料表的中繼資料 (結構定義、分區、檔案位置) 寫入 JSON 和 Avro 檔案。在 GCS 中暫存這個完整的資料表結構,可讓資料可攜,且任何瞭解 Iceberg 格式的系統都能存取。
- 將 GCS Iceberg 資料表轉換為 BigQuery BigLake 外部資料表:
- 您不必直接將資料從 GCS 載入 Spanner,而是使用 BigQuery 做為強大的中介服務。BigQuery 中會建立 BigLake 外部資料表,直接指向 GCS 中的 Iceberg 中繼資料檔案。這種方法有幾個優點:
- 無資料重複:BigQuery 會從中繼資料讀取資料表結構,並直接查詢 Parquet 資料檔案,不必擷取這些檔案,因此可大幅節省時間和儲存空間費用。
- 聯合查詢:可讓您對 GCS 資料執行複雜的 SQL 查詢,就像查詢原生 BigQuery 資料表一樣。
- 將 BigLake 外部資料表反向 ETL 匯入 Spanner:
- 最後一個步驟是將資料從 BigQuery 移至 Spanner。這項作業是透過 BigQuery 的強大功能 (稱為「查詢」) 達成,也就是「反向 ETL」步驟。
EXPORT DATA - 運作準備:Spanner 專為交易工作負載設計,可為應用程式提供同步一致性和高可用性。將資料移至 Spanner 後,需要低延遲點查的使用者導向應用程式、API 和其他作業系統,就能存取這些資料。
- 可擴充性:這個模式可充分運用 BigQuery 的分析能力處理大型資料集,然後透過 Spanner 的全球可擴充基礎架構有效提供結果。
服務和術語
- DataBricks - 以 Apache Spark 為基礎建構的雲端資料平台。
- Spanner:Google 全代管的全球分散式關聯式資料庫。
- Google Cloud Storage:Google Cloud 提供的 Blob 儲存空間。
- BigQuery:無伺服器資料倉儲,可進行數據分析,並由 Google 全代管。
- Iceberg:由 Apache 定義的開放式資料表格式,可針對常見的開放原始碼資料檔案格式提供抽象化功能。
- Parquet:Apache 的開放原始碼欄位式二進位資料檔案格式。
課程內容
- 如何將資料載入 Databricks 做為 Iceberg 資料表
- 如何建立 GCS 值區
- 如何以 Iceberg 格式將 Databricks 資料表匯出至 GCS
- 如何從 GCS 中的 Iceberg 資料表,在 BigQuery 中建立 BigLake 外部資料表
- 如何設定 Spanner 執行個體
- 如何將 BigQuery 中的 BigLake 外部資料表載入 Spanner
2. 設定、需求和限制
必要條件
- Databricks 帳戶 (建議使用 GCP 上的帳戶)
- 如要從 BigQuery 匯出至 Spanner,必須使用 Google Cloud 帳戶,並具備 Enterprise 級以上的預訂。
- 透過網路瀏覽器存取 Google Cloud 控制台
- 用於執行 Google Cloud CLI 指令的終端機
如果 Google Cloud 機構已啟用 iam.allowedPolicyMemberDomains 政策,系統管理員可能需要授予例外狀況,允許來自外部網域的服務帳戶。我們會在後續步驟中說明相關內容 (如適用)。
需求條件
- 已啟用計費功能的 Google Cloud 專案。
- 網路瀏覽器,例如 Chrome
- Databricks 帳戶 (本實驗室假設工作區是託管在 GCP 中)
- BigQuery 執行個體必須是 Enterprise 版或更高版本,才能使用 EXPORT DATA 功能。
- 如果 Google Cloud 機構已啟用
iam.allowedPolicyMemberDomains政策,系統管理員可能需要授予例外狀況,允許來自外部網域的服務帳戶。我們會在後續步驟中說明相關內容 (如適用)。
Google Cloud Platform IAM 權限
Google 帳戶需要下列權限,才能執行本程式碼研究室中的所有步驟。
服務帳戶 | ||
| 允許建立服務帳戶。 | |
Spanner | ||
| 可建立新的 Spanner 執行個體。 | |
| 可執行 DDL 陳述式來建立 | |
| 可執行 DDL 陳述式,在資料庫中建立資料表。 | |
Google Cloud Storage | ||
| 可建立新的 GCS bucket,用來儲存匯出的 Parquet 檔案。 | |
| 允許將匯出的 Parquet 檔案寫入 GCS 值區。 | |
| 允許 BigQuery 從 GCS 儲存空間讀取 Parquet 檔案。 | |
| 允許 BigQuery 列出 GCS bucket 中的 Parquet 檔案。 | |
Dataflow | ||
| 允許從 Dataflow 認領工作項目。 | |
| 允許 Dataflow 工作站將訊息傳回 Dataflow 服務。 | |
| 允許 Dataflow 工作站將記錄項目寫入 Google Cloud Logging。 | |
為方便起見,您可以使用具備這些權限的預先定義角色。
|
|
|
|
|
|
|
|
Google Cloud 專案
專案是 Google Cloud 的基本組織單位。如果管理員已提供可用的憑證,則可略過這個步驟。
您可以使用 CLI 建立專案,如下所示:
gcloud projects create <your-project-name>
如要進一步瞭解如何建立及管理專案,請參閱這篇文章。
限制
請務必留意這個管道可能出現的某些限制和資料類型不相容問題。
從 Databricks Iceberg 遷移至 BigQuery
使用 BigQuery 查詢 Databricks 管理的 Iceberg 資料表 (透過 UniForm) 時,請注意下列事項:
- 結構定義演進:UniForm 可將 Delta Lake 結構定義變更轉換為 Iceberg,但複雜的變更可能無法如預期傳播。舉例來說,在 Delta Lake 中重新命名資料欄不會轉換為 Iceberg,因為 Iceberg 會將其視為
drop和add。請務必徹底測試結構定義異動。 - 時空旅行:BigQuery 無法使用 Delta Lake 的時空旅行功能。系統只會查詢 Iceberg 資料表的最新快照。
- 不支援的 Delta Lake 功能:Delta Lake 的刪除向量和欄對應 (採用
id模式) 等功能與 Iceberg 的 UniForm 不相容。本實驗室使用name模式進行資料欄對應,此模式受到支援。
BigQuery 至 Spanner
從 BigQuery 到 Spanner 的 EXPORT DATA 指令不支援所有 BigQuery 資料類型。匯出下列類型的資料表時會發生錯誤:
STRUCTGEOGRAPHYDATETIMERANGETIME
此外,如果 BigQuery 專案使用 GoogleSQL 方言,下列數值型別也不支援匯出至 Spanner:
BIGNUMERIC
如需完整且最新的限制清單,請參閱官方文件:匯出至 Spanner 的限制。
疑難排解與常見錯誤
- 如果不是在 GCP Databricks 執行個體上,可能無法在 GCS 中定義外部資料位置。在這種情況下,檔案必須先暫存在 Databricks 工作區的雲端供應商儲存解決方案中,然後再個別遷移至 GCS。
- 這麼做時,由於資訊會包含暫存檔案的硬式編碼路徑,因此需要調整中繼資料。
3. 設定 Google Cloud Storage (GCS)
Google Cloud Storage (GCS) 會用於儲存 Databricks 產生的 Parquet 資料檔案。如要這麼做,請先建立新 bucket,做為檔案目的地。
Google Cloud Storage
建立新 bucket
- 前往雲端控制台中的 Google Cloud Storage 頁面。
- 在左側面板中選取「儲存區」:
- 按一下「建立」按鈕:

- 填寫 bucket 詳細資料:
- 選擇要使用的 bucket 名稱。在本實驗室中,將使用
codelabs_retl_databricks這個名稱 - 選取要儲存 bucket 的區域,或使用預設值。
- 繼續使用 儲存空間級別 做為
standard - 保留「控制存取權」的預設值
- 保留保護物件資料的預設值
- 完成後,請按一下
Create按鈕。系統可能會顯示提示,要求您確認要禁止公開存取。請確認。 - 恭喜,您已成功建立新的值區!系統會重新導向至 bucket 頁面。
- 將新值區名稱複製到任一處,以便稍後使用。
為後續步驟做好準備
請務必記下下列詳細資料,因為後續步驟會用到:
- Google 專案 ID
- Google Storage bucket 名稱
4. 設定 Databricks
TPC-H 資料
在本實驗室中,我們將使用 TPC-H 資料集,這是決策支援系統的業界標準基準。這個結構定義會模擬真實的商業環境,包含顧客、訂單、供應商和零件,非常適合用來展示實際的數據分析和資料移動情境。
系統會建立新的匯總資料表,而非使用原始的標準化 TPC-H 資料表。這個新資料表會彙整 orders、customer 和 nation 資料表中的資料,產生反正規化的區域銷售摘要檢視畫面。預先彙整資料是數據分析的常見做法,因為這樣可準備好資料,以用於特定用途。在本情境中,資料會用於作業應用程式。
匯總資料表的最終結構定義如下:
Col | 類型 |
nation_name | 字串 |
market_segment | 字串 |
order_year | int |
order_priority | 字串 |
total_order_count | bigint |
total_revenue | decimal(29,2) |
unique_customer_count | bigint |
透過 Delta Lake Universal Format (UniForm) 支援 Iceberg
在本實驗室中,Databricks 內的資料表將是 Delta Lake 資料表。不過,為了讓 BigQuery 等外部系統可讀取,系統會啟用名為「通用格式 (UniForm)」的強大功能。
UniForm 會自動產生 Iceberg 中繼資料,以及資料表單一共用副本的 Delta Lake 中繼資料。這項功能兼具兩者的優點:
- 在 Databricks 中:可享有 Delta Lake 的所有效能和管理優勢。
- Databricks 以外:任何與 Iceberg 相容的查詢引擎 (例如 BigQuery) 都能讀取資料表,就像讀取原生 Iceberg 資料表一樣。
這樣一來,就不必維護資料副本或執行手動轉換工作。建立資料表時,只要設定特定資料表屬性,即可啟用 UniForm。
Databricks 目錄
Databricks 目錄是 Unity Catalog (Databricks 的統一治理解決方案) 中的頂層資料容器。Unity Catalog 提供集中管理資料資產、控管存取權及追蹤沿襲的方式,對於妥善管理的資料平台至關重要。
這項服務會使用三層命名空間來整理資料:catalog.schema.table。
- 目錄:最高層級,用於依環境、業務單位或專案分組資料。
- 結構定義 (或資料庫):目錄中資料表、檢視區塊和函式的邏輯分組。
- 資料表:包含資料的物件。
建立匯總 TPC-H 資料表前,必須先設定專屬的目錄和結構定義來存放該資料表。確保專案井然有序,並與工作區中的其他資料隔離。
建立新的目錄和結構定義
在 Databricks Unity Catalog 中,目錄是資料資產的最高層級組織,可做為安全容器,跨越多個 Databricks 工作區。您可以根據業務部門、專案或環境整理及隔離資料,並清楚定義權限和存取控管機制。
在目錄中,結構定義 (也稱為資料庫) 會進一步整理資料表、檢視區塊和函式。這種階層式結構可精細控管相關資料物件,並進行邏輯分組。在本實驗室中,我們將建立專屬的目錄和結構定義來存放 TPC-H 資料,確保適當的隔離和管理。
建立目錄
- 前往

- 按一下「+」,然後從下拉式選單中選取「建立目錄」
- 系統會建立新的「標準」目錄,並採用下列設定:
- 目錄名稱:
retl_tpch_project - 儲存位置:如果工作區已設定儲存位置,請使用預設位置,否則請建立新的儲存位置。
建立結構定義
- 前往
- 從左側面板選取新建立的目錄
- 按一下
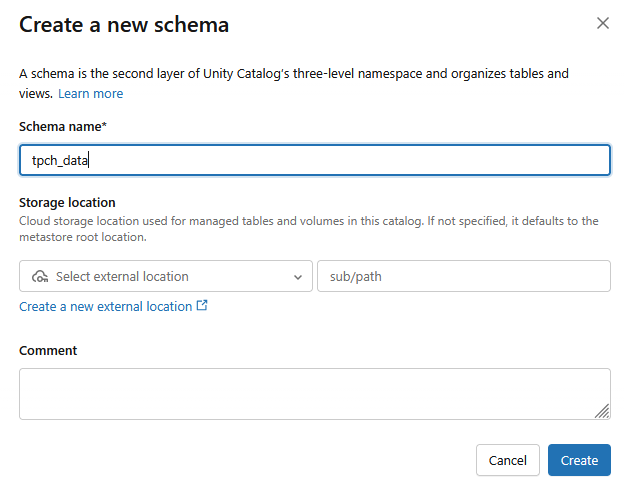
- 系統會以「結構定義名稱」做為
tpch_data建立新結構定義
設定外部資料
如要將資料從 Databricks 匯出至 Google Cloud Storage (GCS),必須在 Databricks 中設定外部資料憑證。這樣 Databricks 就能安全地存取 GCS bucket 並寫入資料。
- 在「目錄」畫面上,按一下

- 如果沒有看到
External Data選項,請改為在Connect下拉式選單中尋找External Locations。
- 按一下

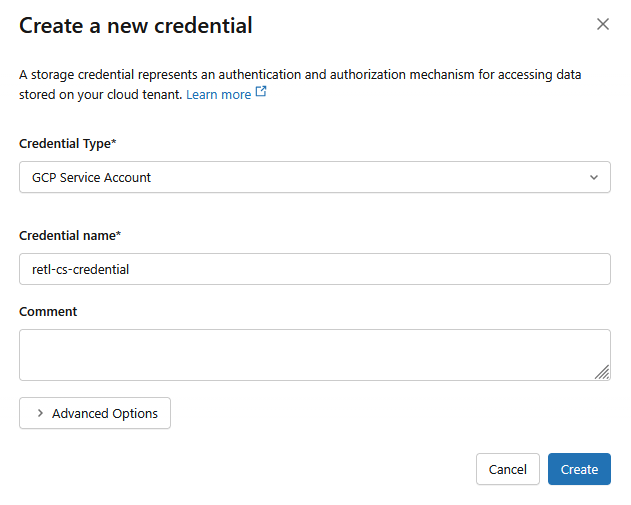
- 在新對話方塊視窗中,設定憑證的必要值:
- 憑證類型:
GCP Service Account - 憑證名稱:
retl-gcs-credential
- 按一下「Create」(建立)
- 接著點選「外部位置」分頁標籤。
- 按一下「建立營業地點」。
- 在新對話方塊視窗中,設定外部位置的必要值:
- 外部位置名稱:
retl-gcs-location - 「Storage type」(儲存空間類型):
GCP - 網址:GCS bucket 的網址,格式為
gs://YOUR_BUCKET_NAME - 儲存空間憑證:選取剛建立的
retl-gcs-credential。
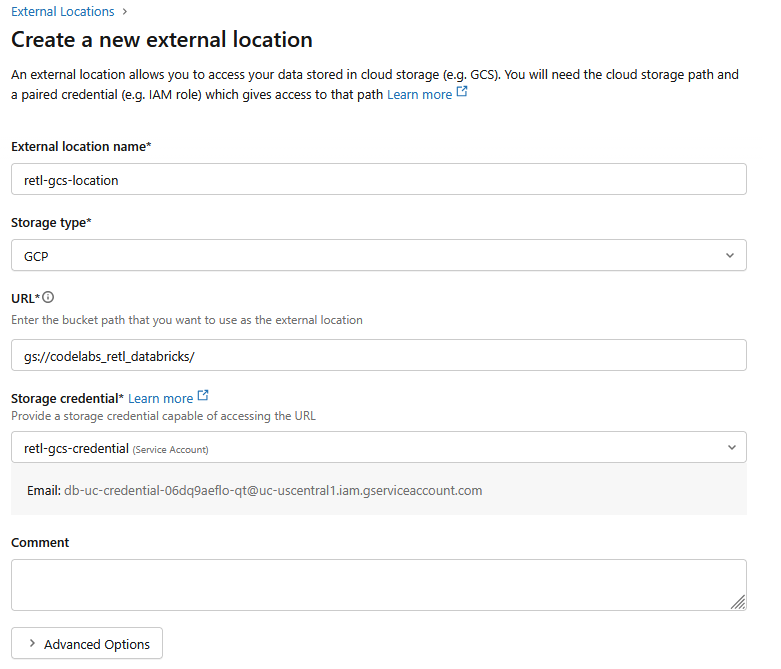
- 選取「storage credential」(儲存空間憑證) 後,系統會自動填入「Service account」(服務帳戶) 電子郵件地址,請記下這個地址,下一個步驟會用到。
- 按一下「Create」(建立)
5. 設定服務帳戶權限
服務帳戶是特殊的帳戶類型,應用程式或服務可透過這種帳戶,對 Google Cloud 資源發出授權 API 呼叫。
現在,您必須為 GCS 中新 bucket 建立的服務帳戶新增權限。
- 在 GCS bucket 頁面中,選取「權限」分頁標籤。
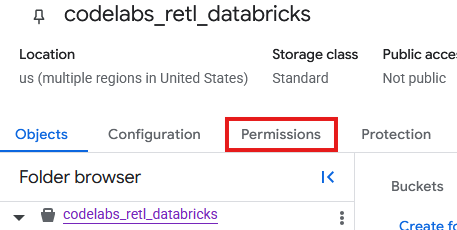
- 在主體頁面中,點選「授予存取權」
- 在從右側滑出的「授予存取權」面板中,將「服務帳戶 ID」輸入「新增主體」欄位。
- 在「指派角色」下方,新增
Storage Object Admin和Storage Legacy Bucket Reader。這些角色可讓服務帳戶讀取、寫入及列出儲存空間 bucket 中的物件。
載入 TPC-H 資料
現在已建立 Catalog 和 Schema,可以從 Databricks 內部儲存的現有 samples.tpch 資料表載入 TPCH 資料,並在新的 Schema 中操作成新資料表。
建立支援 Iceberg 的資料表
Iceberg 與 UniForm 的相容性
在幕後,Databricks 會在內部將這個資料表管理為 Delta Lake 資料表,在 Databricks 生態系統中提供 Delta 效能最佳化和治理功能的所有優點。不過,啟用 UniForm (通用格式的簡稱) 後,Databricks 會收到特殊指令:每次更新資料表時,Databricks 除了 Delta Lake 中繼資料外,還會自動生成並維護對應的 Iceberg 中繼資料。
也就是說,現在有兩組不同的中繼資料,用來描述同一組共用的資料檔案 (Parquet 檔案)。
- Databricks:使用
_delta_log讀取資料表。 - 外部讀取器 (例如 BigQuery):這類讀取器會使用 Iceberg 中繼資料檔案 (
.metadata.json) 瞭解資料表的結構定義、分區和檔案位置。
因此產生的資料表完全相容於任何可辨識 Iceberg 的工具,且相容性一目瞭然。不會重複資料,也不需要手動轉換或同步處理。這個單一可靠來源可供 Databricks 的分析世界,以及支援開放 Iceberg 標準的更廣泛工具生態系統無縫存取。
- 依序按一下「新增」和「查詢」。
- 在查詢頁面的文字欄位中,執行下列 SQL 指令:
CREATE TABLE retl_tpch_project.tpch_data.regional_sales_iceberg
USING DELTA
LOCATION 'gs://<Your bucket name>/regional_sales_iceberg'
TBLPROPERTIES (
'delta.columnMapping.mode' = 'name',
'delta.enableIcebergCompatV2' = 'true',
'delta.universalFormat.enabledFormats' = 'iceberg'
)
AS
SELECT
n.n_name AS nation_name,
c.c_mktsegment AS market_segment,
YEAR(o.o_orderdate) AS order_year,
o.o_orderpriority AS order_priority,
COUNT(o.o_orderkey) AS total_order_count,
ROUND(SUM(o.o_totalprice), 2) AS total_revenue,
COUNT(DISTINCT c.c_custkey) AS unique_customer_count
FROM samples.tpch.orders AS o
INNER JOIN samples.tpch.customer AS c
ON o.o_custkey = c.c_custkey
INNER JOIN samples.tpch.nation AS n
ON c.c_nationkey = n.n_nationkey
GROUP BY
n.n_name,
c.c_mktsegment,
YEAR(o.o_orderdate),
o.o_orderpriority;
OPTIMIZE retl_tpch_project.tpch_data.regional_sales_iceberg;
DESCRIBE EXTENDED retl_tpch_project.tpch_data.regional_sales_iceberg;
注意:
- 使用 Delta - 指定我們使用的是 Delta Lake 資料表。只有 Databricks 中的 Delta Lake 資料表可以儲存為外部資料表。
- 位置:指定資料表的儲存位置 (如為外部資料表)。
- TablePropertoes -
delta.universalFormat.enabledFormats = ‘iceberg'會在 Delta Lake 檔案旁建立相容的 Iceberg 中繼資料。 - 最佳化:強制觸發 UniForm 中繼資料生成作業,因為這項作業通常會以非同步方式進行。
- 查詢輸出內容應會顯示新建立資料表的詳細資料

驗證 GCS 資料表資料
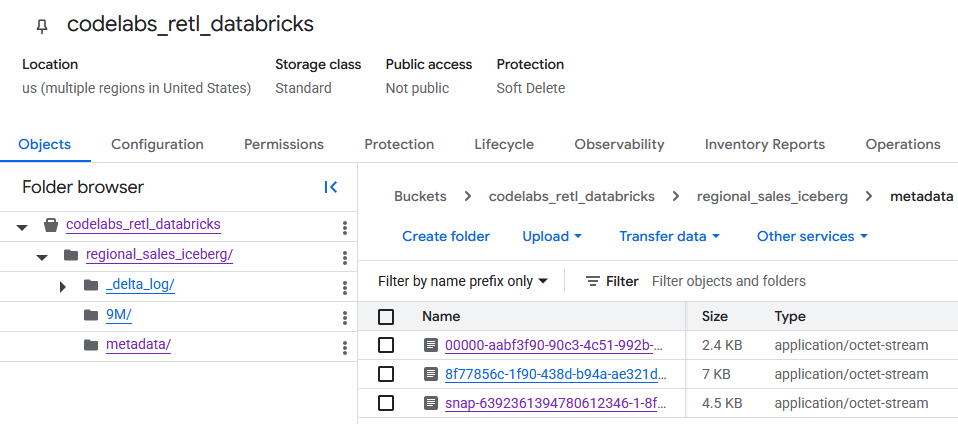
前往 GCS bucket 後,您現在可以找到新建立的資料表資料。
您會在 metadata 資料夾中找到 Iceberg 中繼資料,供外部讀取器 (例如 BigQuery) 使用。Databricks 內部使用的 Delta Lake 中繼資料會追蹤 _delta_log 資料夾。
實際的資料表資料會以 Parquet 檔案的形式儲存在另一個資料夾中,通常由 Databricks 以隨機產生的字串命名。舉例來說,在下方的螢幕截圖中,資料檔案位於 9M 資料夾。
6. 設定 BigQuery 和 BigLake
Iceberg 資料表現在位於 Google Cloud Storage 中,下一步是讓 BigQuery 能夠存取該資料表。方法是建立 BigLake 外部資料表。
BigLake 是一種儲存引擎,可讓您在 BigQuery 中建立資料表,直接從 Google Cloud Storage 等外部來源讀取資料。在本實驗室中,這項技術是 BigQuery 瞭解剛匯出的 Iceberg 資料表的關鍵,不必擷取資料。
如要讓這項功能正常運作,需要兩個元件:
- 雲端資源連線:這是 BigQuery 和 GCS 之間的安全連結。系統會使用特殊服務帳戶處理驗證,確保 BigQuery 具備從 GCS bucket 讀取檔案的必要權限。
- 外部資料表定義:這會告知 BigQuery 在 GCS 中尋找 Iceberg 資料表的中繼資料檔案,以及應如何解讀該檔案。
建立 Cloud 資源連結
首先,系統會建立連線,讓 BigQuery 存取 GCS。
如要進一步瞭解如何建立 Cloud 資源連線,請參閱這篇文章。
- 前往 BigQuery
- 按一下「探索」下方的「連線」
- 如果沒有看到「Explorer」平面,請按一下

- 在「連線」頁面中,按一下
- 在「連線類型」中選擇
Vertex AI remote models, remote functions, BigLake and Spanner (Cloud Resource) - 將連線 ID 設為
databricks_retl,然後建立連線

- 現在應該會在新建連線的「連線」表格中看到項目。按一下該項目即可查看連線詳細資料。

- 在連線詳細資料頁面中,記下「服務帳戶 ID」,稍後會用到。
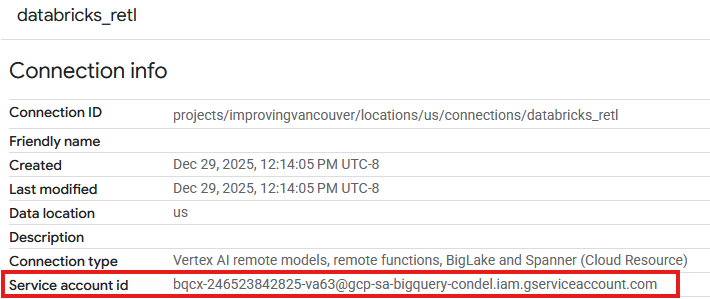
授予連線服務帳戶存取權
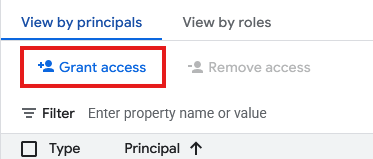
- 在「新增主體」欄位,輸入上述建立的連線資源服務帳戶 ID。
- 選取「角色」的
Storage Object User,然後點選 。
。
建立連線並授予服務帳戶必要權限後,現在可以建立 BigLake 外部資料表。首先,您需要在 BigQuery 中建立資料集,做為新資料表的容器。接著,系統會建立資料表本身,並將其指向 GCS bucket 中的 Iceberg 中繼資料檔案。
- 前往 BigQuery
- 在「Explorer」面板中,點選專案 ID,然後點選三點圖示並選取「建立資料集」。
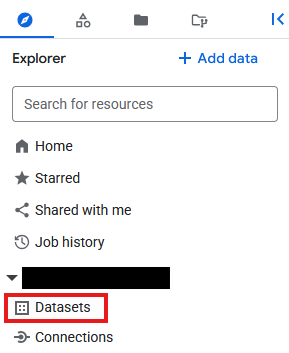
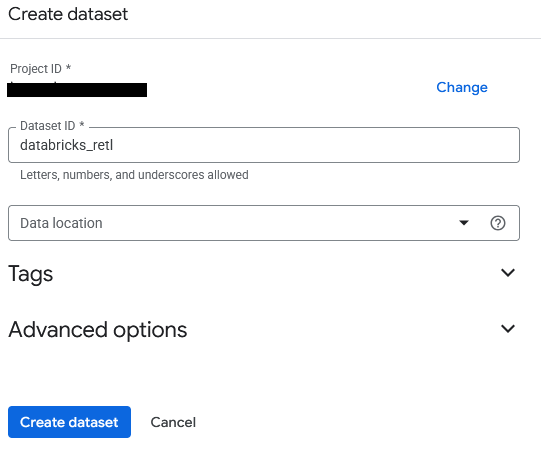
- 資料集名稱為
databricks_retl。其他選項保留預設值,然後按一下「建立資料集」按鈕。
- 現在,請在「Explorer」面板中找出新的
databricks_retl資料集。點選旁邊的三點圖示,然後選取「建立資料表」。
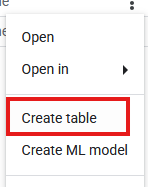
- 填寫下列資料表建立設定:
- 使用下列資料建立資料表:
Google Cloud Storage - 從 GCS bucket 選取檔案或使用 URI 模式:瀏覽至 GCS Bucket,然後找出 Databricks 匯出作業期間產生的中繼資料 JSON 檔案。路徑應如下所示:
regional_sales/metadata/v1.metadata.json。 - 檔案格式:
Iceberg - 表格:
regional_sales - 資料表類型:
External table - 「連線 ID」:選取先前建立的
databricks_retl連線。 - 其餘值保留預設值,然後點選「建立資料表」。
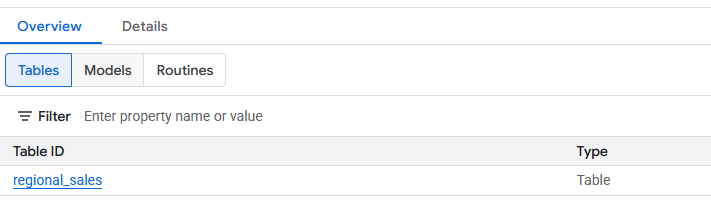
- 建立完成後,新的
regional_sales資料表應會顯示在databricks_retl資料集下方。現在,您可以使用標準 SQL 查詢這個資料表,就像查詢任何其他 BigQuery 資料表一樣。
7. 載入至 Spanner
管道的最後一個也是最重要的部分已完成:將資料從 BigLake 外部資料表移至 Spanner。這是「反向 ETL」步驟,資料在資料倉儲中經過處理和整理後,會載入營運系統供應用程式使用。
Spanner 是全代管的全球分散式關聯式資料庫。Cloud Spanner 具有傳統關聯式資料庫的交易一致性,且能夠水平擴充 NoSQL 資料庫。因此非常適合建構可擴充的高可用性應用程式。
程序如下:
- 建立 Spanner 執行個體,這是資源的實體分配。
- 在該執行個體中建立資料庫。
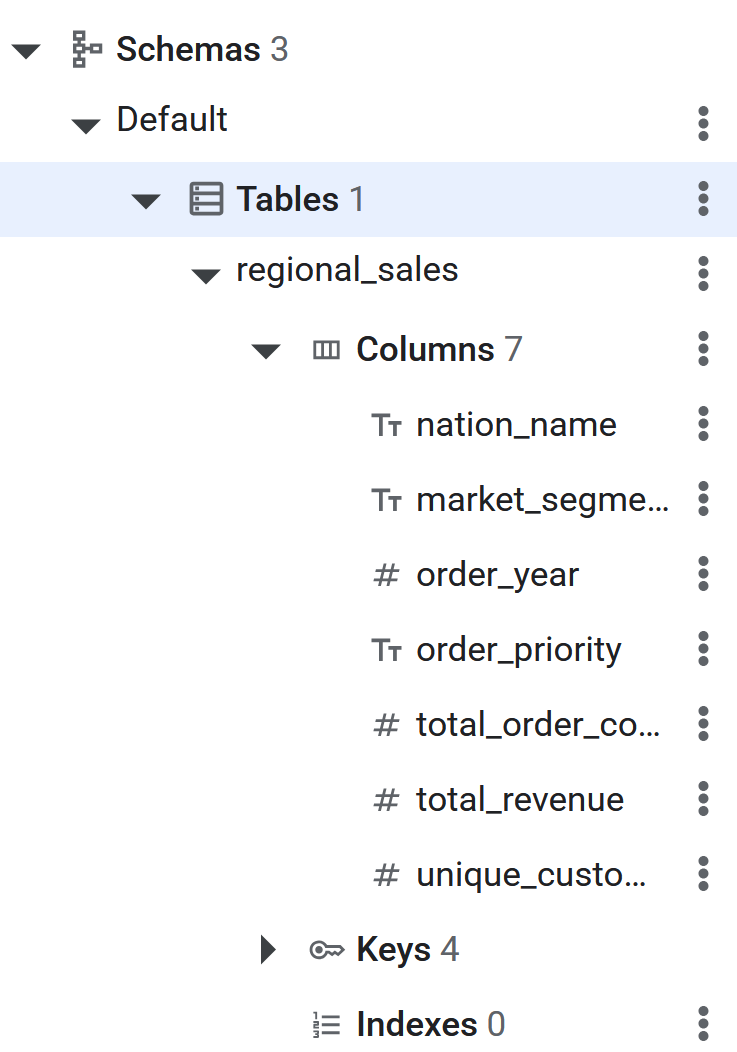
- 在資料庫中定義與
regional_sales資料結構相符的資料表結構定義。 - 執行 BigQuery
EXPORT DATA查詢,將資料從 BigLake 資料表直接載入 Spanner 資料表。
建立 Spanner 執行個體、資料庫和資料表
- 前往 Spanner
- 按一下
 。如有現有執行個體,請隨意使用。視需要設定執行個體需求。本實驗室使用下列項目:
。如有現有執行個體,請隨意使用。視需要設定執行個體需求。本實驗室使用下列項目:
版本 | Enterprise |
執行個體名稱 | databricks-retl |
區域設定 | 你選擇的區域 |
運算單元 | 處理單元 (PU) |
手動分配 | 100 |
- 建立完成後,請前往 Spanner 執行個體頁面,然後選取
 。如有現成資料庫,歡迎直接使用。
。如有現成資料庫,歡迎直接使用。
- 在本實驗室中,您將使用下列項目建立資料庫:
- 名稱:
databricks-retl - 資料庫方言:
Google Standard SQL
- 建立資料庫後,請從 Spanner 執行個體頁面選取資料庫,然後進入 Spanner 資料庫頁面。
- 在 Spanner 資料庫頁面中,按一下

- 在新查詢頁面中,系統會建立要匯入 Spanner 的資料表定義。如要執行這項操作,請執行下列 SQL 查詢。
CREATE TABLE regional_sales (
nation_name STRING(MAX),
market_segment STRING(MAX),
order_year INT64,
order_priority STRING(MAX),
total_order_count INT64,
total_revenue NUMERIC,
unique_customer_count INT64
) PRIMARY KEY (nation_name, market_segment, order_year, order_priority);
- SQL 指令執行完畢後,BigQuery 即可對 Spanner 資料表執行反向 ETL 作業。在 Spanner 資料庫的左側面板中,您會看到資料表列出,藉此確認資料表已建立。
使用 EXPORT DATA 對 Spanner 執行反向 ETL
這是最後一個步驟。在 BigQuery BigLake 資料表中準備好來源資料,並在 Spanner 中建立目的地資料表後,實際的資料移動作業會出乎意料地簡單。系統會使用單一 BigQuery SQL 查詢:EXPORT DATA。
這項查詢專為這類情境設計。可有效率地將資料從 BigQuery 資料表 (包括 BigLake 資料表等外部資料表) 匯出至外部目的地。在本例中,目的地是 Spanner 資料表。如要進一步瞭解匯出功能,請參閱這篇文章
如要進一步瞭解如何設定 BigQuery 到 Spanner 的反向 ETL,請參閱這篇文章
- 前往 BigQuery
- 開啟新的查詢編輯器分頁。
- 在「查詢」頁面中,輸入下列 SQL。請記得將 **
uri** 中的專案 ID 和資料表路徑替換為正確的專案 ID。
EXPORT DATA OPTIONS(
uri='https://spanner.googleapis.com/projects/YOUR_PROJECT_ID/instances/databricks-retl/databases/databricks-retl',
format='CLOUD_SPANNER',
spanner_options="""{
"table": "regional_sales",
"priority": "MEDIUM"
}"""
) AS
SELECT * FROM `YOUR_PROJECT_ID.databricks_retl.regional_sales`;
- 指令完成後,資料就會成功匯出至 Spanner!
8. 驗證 Spanner 中的資料
恭喜!您已成功建構及執行完整的反向 ETL 管道,將資料從 Databricks 資料倉儲移至營運 Spanner 資料庫。
最後一個步驟是確認資料是否已如預期匯入 Spanner。
- 前往 Spanner。
- 前往
databricks-retl執行個體,然後前往databricks-retl資料庫。 - 在資料表清單中,按一下
regional_sales資料表。 - 在資料表的左側導覽選單中,按一下「資料」分頁標籤。
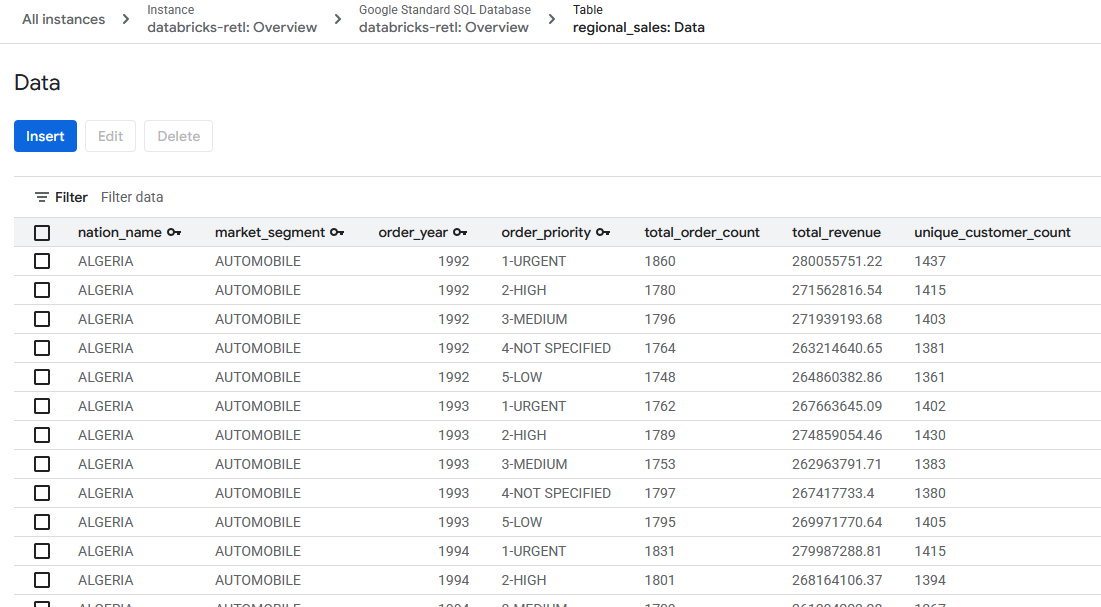
- 原本來自 Databricks 的匯總銷售資料現在應該已載入,並可在 Spanner 資料表中使用。這些資料現在位於作業系統中,可供即時應用程式使用、用於資訊主頁,或透過 API 查詢。
分析和營運資料世界之間的鴻溝已成功彌平。
9. 清除
完成本實驗室後,請移除所有新增的資料表和儲存的資料。
清理 Spanner 資料表
- 前往 Spanner
- 從名為「
databricks-retl」的清單中,點選用於本實驗室的執行個體。

- 在執行個體頁面中,按一下
 。
。 - 在彈出的確認對話方塊中輸入
databricks-retl,然後按一下
清理 GCS
- 前往 GCS
- 選取左側選單中的
- 選取 ``codelabs_retl_databricks bucket
- 選取後,按一下頂端橫幅顯示的
 按鈕
按鈕

- 在彈出的確認對話方塊中輸入
DELETE,然後按一下
清理 Databricks
刪除目錄/結構定義/資料表
- 登入 Databricks 執行個體
- 按一下左側選單中的
- 從目錄清單中選取先前建立的

- 在「結構定義」清單中,選取已建立的

- 從表格清單中選取先前建立的

- 按一下
 展開表格選項,然後選取
展開表格選項,然後選取 Delete - 在確認對話方塊中按一下
 即可刪除表格
即可刪除表格 - 刪除資料表後,系統會將您帶回結構定義頁面
- 按一下 展開結構定義選項,然後選取
Delete - 在確認對話方塊中按一下 ,刪除結構定義
- 刪除架構後,系統會將你帶回目錄頁面
- 如果存在
default架構,請再次按照步驟 4 到 11 刪除。 - 在目錄頁面中,按一下 展開目錄選項,然後選取
Delete - 在確認對話方塊中按一下 ,即可刪除目錄
刪除外部資料位置 / 憑證
- 在「目錄」畫面中,按一下
- 如果沒有看到
External Data選項,請改為在Connect下拉式選單中尋找External Location。 - 按一下先前建立的
retl-gcs-location外部資料位置 - 在外部地點頁面中,按一下 展開地點選項,然後選取
Delete。 - 在確認對話方塊中按一下 ,刪除外部位置
- 按一下
- 按一下先前建立的
retl-gcs-credential - 在憑證頁面中,按一下 展開憑證選項,然後選取
Delete。 - 在確認對話方塊中按一下 ,即可刪除憑證。
10. 恭喜
恭喜您完成本程式碼研究室。
涵蓋內容
- 如何將資料載入 Databricks 做為 Iceberg 資料表
- 如何建立 GCS 值區
- 如何以 Iceberg 格式將 Databricks 資料表匯出至 GCS
- 如何從 GCS 中的 Iceberg 資料表,在 BigQuery 中建立 BigLake 外部資料表
- 如何設定 Spanner 執行個體
- 如何將 BigQuery 中的 BigLake 外部資料表載入 Spanner