
1. はじめに
デベロッパーやデータ エンジニアは、データレイクのような大量のデータを引き継ぐことがよくあります。「この『amt』列の実際の定義は何ですか?」「このデータセットが破損した場合、誰が責任を負いますか?」「このテーブルをパーソナライズされたレコメンデーション エンジンで使用してもよいですか?」といった問題に繰り返し直面します。
従来、データカタログは、すぐに不整合が生じて古くなるフリーテキスト タグで埋められた受動的なインベントリでした。構造が適用されないため、プログラムによるガバナンスはほぼ不可能でした。
このラボでは、この問題を解決するために、小売売上生データに対して堅牢なガバナンスを確立し、財務部門が公式レポートで信頼できるようにするシナリオに取り組みます。このデータを曖昧な「レイク」状態から管理されたプロダクトに移行します。
Knowledge Catalog Universal Catalog は、アクティブで構造化されたメタデータ管理フレームワークを提供することで、この問題を解決します。構造化されたスキーマ駆動型メタデータ(アスペクト )と承認されたビジネス定義(用語集 )をデータアセット(エントリ )に直接添付できます。
Python スクリプトまたは Terraform モジュールを作成して、これを大規模に自動化するには、基盤となるオブジェクト モデルを理解する必要があります。
この Codelab では、Google Cloud コンソールでガバナンスの手順を手動で実行します。エントリ、アスペクト タイプ、アスペクト、用語集を明示的に関連付けて、データを検出可能、理解可能、信頼できるものにする方法の確固たるメンタルモデルを提供します。
前提条件
- オーナーまたは編集者のアクセス権を持つ Google Cloud プロジェクト。
- Google Cloud コンソールに関する知識。
- Cloud Shell での gcloud と bq CLI の基本的なスキル。
学習内容
- Knowledge Catalog エントリ、アスペクト タイプ、アスペクトの重要な違い。
- 用語の曖昧さを解消するビジネス用語集 の作成方法。
- 技術メタデータに厳格なスキーマを適用するアスペクト タイプ の設計方法(「タグ」を超えて)。
- ビジネス用語集の用語を特定の BigQuery 列にリンクする方法。
- 構造化されたアスペクトをデータアセットに添付して入力を検証する方法。
- この新しい構造化メタデータに対して正確な検索クエリを実行する方法。
必要なもの
- Google Cloud アカウントと Google Cloud プロジェクト
- ウェブブラウザ(Chrome など)
主なコンセプト
- エントリ: カタログ内のデータアセットの正規の抽象表現。これは「ポインタ」または「名詞」と考えることができます。BigQuery テーブルを作成すると、Knowledge Catalog は自動的にエントリを作成します。テーブルを直接管理するのではなく、そのエントリを管理します。
- ビジネス用語集: 組織のビジネス用語の中央集権型でバージョン管理された辞書。信頼できる唯一の情報源です。「営業部門と財務部門で GMV の定義が異なる」という問題を回避できます。
- アスペクト タイプ: 特定のカテゴリのメタデータのスキーマまたはテンプレート。アスペクト タイプは、フィールド、データ型(文字列、列挙型、日時など)、制約(必須/省略可)を定義します。メタデータの整合性を確保する契約です。
- アスペクト: アスペクト タイプで定義された構造に従ってエントリに添付される特定のメタデータ。アスペクト タイプのスキーマを満たす実際のデータが含まれています。
2. 設定と要件
Cloud Shell の起動
Google Cloud はノートパソコンからリモートで操作できますが、この Codelab では、Google Cloud Shell(Cloud 上で動作するコマンドライン環境)を使用します。
Google Cloud コンソール で、右上のツールバーにある Cloud Shell アイコンをクリックします。
プロビジョニングと環境への接続にはそれほど時間はかかりません。完了すると、次のように表示されます。

この仮想マシンには、必要な開発ツールがすべて用意されています。永続的なホーム ディレクトリが 5 GB 用意されており、Google Cloud で稼働します。そのため、ネットワークのパフォーマンスと認証機能が大幅に向上しています。この Codelab での作業はすべて、ブラウザ内から実行できます。インストールは不要です。
必要な API を有効にして環境を構成する
次のコマンドを実行して、プロジェクト ID を設定し、リージョンを定義して、必要なサービス API を有効にします。
export PROJECT_ID=$(gcloud config get-value project)
gcloud config set project $PROJECT_ID
export LOCATION="us-central1"
gcloud services enable dataplex.googleapis.com \
bigquery.googleapis.com \
datacatalog.googleapis.com
BigQuery データセットを作成してサンプルデータを準備する
管理する具体的なデータアセットが必要です。BigQuery データセットを作成し、トランザクションを表す小さなサンプル CSV を読み込みます。Knowledge Catalog はこのテーブルを自動的に検出し、エントリを作成します。
# Create the BigQuery Dataset in the us-central1 region
bq --location=$LOCATION mk --dataset \
--description "Retail data for governance codelab" \
$PROJECT_ID:retail_data
# Create a temporary CSV file with the sample data
echo "transaction_id,user_email,gmv,transaction_date
1001,test@example.com,150.50,2025-08-28
1002,user@example.com,75.00,2025-08-28" > /tmp/transactions.csv
# Load the data from the temporary CSV file into BigQuery
bq load \
--source_format=CSV \
--autodetect \
retail_data.transactions \
/tmp/transactions.csv
# (Optional) Clean up the temporary file
rm /tmp/transactions.csv
簡単なクエリを実行して設定を確認します。
bq query --nouse_legacy_sql "SELECT * FROM retail_data.transactions"
3. ビジネス用語集で共通言語を確立する
効果的なガバナンスは、曖昧さのない定義から始まります。デベロッパーが gmv という名前の列を見たときに、税金や返品が含まれているかどうかを推測する必要はありません。ビジネス用語集は、ビジネス定義を技術的な実装から切り離すことで、この問題を解決します。
- Google Cloud コンソールで、Knowledge Catalog Universal Catalog に移動します。
- 左側のナビゲーション メニューで、[用語集]([メタデータを管理] の下)を選択します。
- [ビジネス用語集を作成] をクリックします。
- 以下の詳細情報を入力します。
- 名前:
Retail Business Glossary - 場所:
us-central1(または設定で定義した場所)。
- 名前:
- [作成] をクリックします。
- 新しく作成した [Retail Business Glossary] をクリックして入力します。

- [カテゴリを作成] をクリックして
Sales Metricsという名前を付け、[作成] をクリックします。カテゴリを使用すると、関連する用語をグループ化できます。 - [
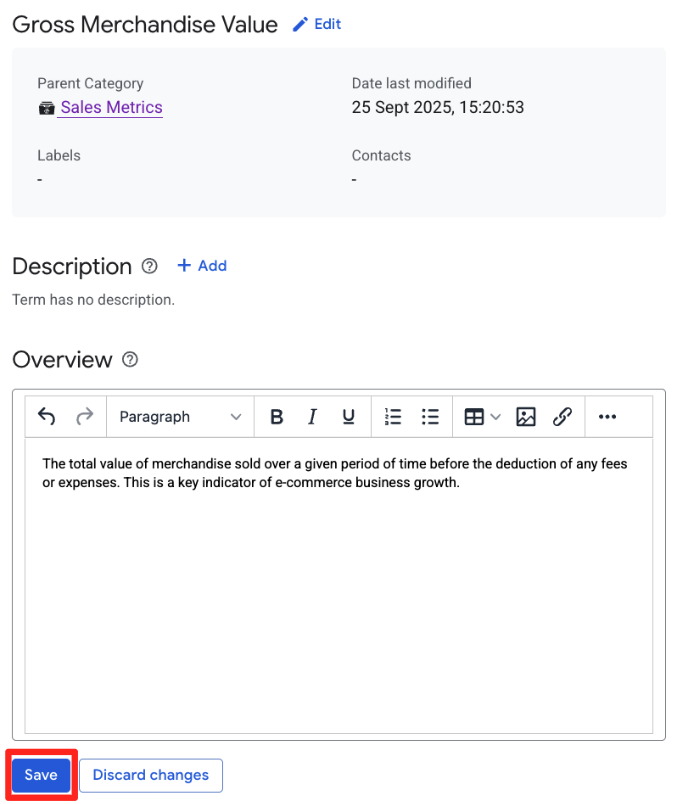
Sales Metricsカテゴリ] を選択して [**用語を追加**] をクリックし、[Gross Merchandise Value] という名前を付けて [**作成**] をクリックします。 - [概要] の [+追加] ボタンをクリックして、次の詳細情報を入力します。
- 概要:
The total value of merchandise sold over a given period of time before the deduction of any fees or expenses. This is a key indicator of e-commerce business growth.
- 概要:
- [保存] をクリックします。
これで、組織全体の技術アセットにリンクできる明確な定義が確立されました。
4. アスペクト タイプで構造化された技術メタデータを定義する
シンプルな「キー:値」タグでは、エンジニアリングの厳密さを確保できません。「データオーナー」を追跡する必要がある場合、あるテーブルに owner:bob というタグが付けられ、別のテーブルに contact:alice@example.com というタグが付けられることは望ましくありません。オーナーが必須であり、有効なメールアドレス形式でなければならないことを強制するスキーマが必要です。
この契約を定義するには、アスペクト タイプ を使用します。
- Knowledge Catalog の左側のナビゲーションで、[カタログ] の [アスペクト タイプとタグ テンプレート] を選択します。
- [カスタム] タブを選択して、[アスペクト タイプを作成] をクリックします。
- 以下の詳細情報を入力します。
- 表示名:
Data Asset Governance - 場所:
us-central1
- 表示名:
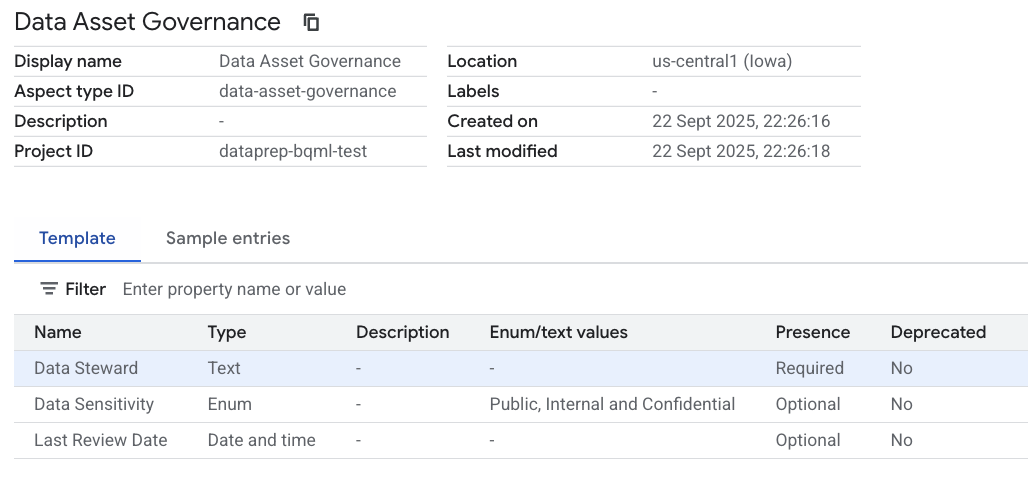
- [テンプレート] セクションで、
Aspectのスキーマを定義します。[フィールドを追加] をクリックして、次の 3 つのフィールドを作成します。- フィールド 1:
- 表示名:
Data Steward - タイプ:
Text - テキストタイプ:
Plain text - カーディナリティ: 必須(チェックボックスをオンにします)
- 表示名:
- フィールド 2 ([フィールドを追加] をもう一度クリックします):
- 表示名:
Data Sensitivity - タイプ:
Enum - 値:
Public、Internal、Confidentialを追加します。 - カーディナリティ: 省略可
- 表示名:
- フィールド 3 ([フィールドを追加] をもう一度クリックします):
- 表示名:
Last Review Date - タイプ:
Date and time - カーディナリティ: 省略可
- 表示名:
- フィールド 1:
- [保存] をクリックします。
再利用可能なメタデータ契約を作成しました。まだ何も使用していませんが、構造は存在します。
5. ガバナンスをアセットに接続する
これで、すべてをまとめます。BigQuery テーブル(retail_data.transactions)、ビジネス定義(Gross Merchandise Value)、ガバナンス スキーマ (Data Asset Governance)があります。
BigQuery テーブルの Knowledge Catalog エントリ を拡充します。
ビジネス コンテキストでスキーマを拡充する(列レベル)
用語集にリンクして、gmv 列の実際の意味をユーザーに伝えます。
- Knowledge Catalog の左側のナビゲーションで、[検索] をクリックします。
- 右上の [Knowledge Catalog Universal Catalog] タブが有効になっていない場合は、クリックします。
retail_data.transactionsを検索します。BigQuery テーブルの結果をクリックします。
- エントリの詳細で [スキーマ] タブをクリックします。
gmv列の行のチェックボックスをオンにして、[ビジネス用語を追加] をクリックします。Gross Merchandise Valueという用語を選択します。
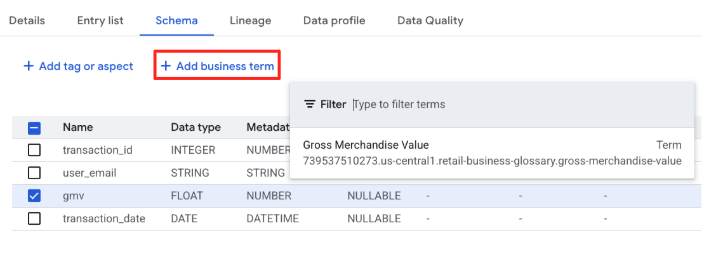
列 gmv は単なる「FLOAT」ではなくなり、Gross Merchandise Value の企業定義にリンクされました。
構造化された技術メタデータ(テーブルレベル)でエントリを拡充する
次に、Data Asset Governance アスペクト をテーブルに添付して、所有権と機密性を定義します。
retail_data.transactionsエントリページにとどまります。- [タグまたはアスペクトを追加] タブをクリックし、プルダウンから
Data Asset Governanceタイプを選択します。
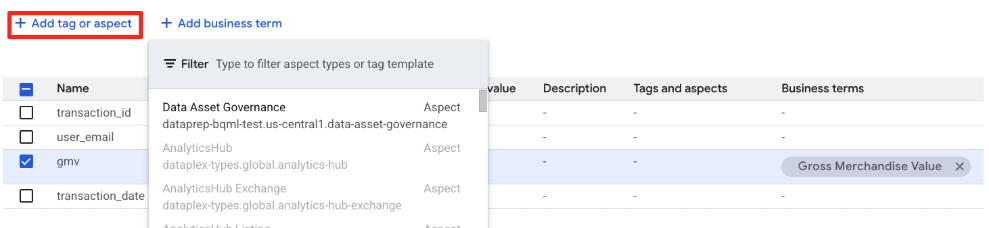
- フォームに、アスペクト タイプのスキーマで定義されたフィールドが表示されます。次のように入力します。
- データ スチュワード:
finance-team@example.com - データの機密性:
Internalを選択します。 - 最終レビュー日: 今日の日付を選択します。
- データ スチュワード:
- [保存] をクリックします。
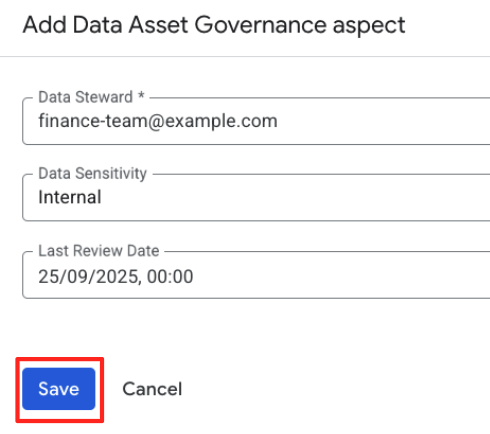
構造化されたアスペクトをエントリに添付しました。単純なタグとは異なり、このデータは作成したスキーマに対して検証されます。
6. 統合された検出と検証
フォームに入力するためだけにこの作業を行ったわけではありません。データを検出可能で信頼できるものにするために行いました。このメタデータが検索と見つけやすさのデベロッパー エクスペリエンスにどのように影響するかを見てみましょう。
Knowledge Catalog Universal Catalog のメインの [検索] ページに戻ります。
ガバナンスを適用するプラットフォーム エンジニアを想定します。特定の Aspect Type に則って管理されている「Internal」とマークされたすべてのアセットを見つける必要があります。スキーマに基づいて正確な述語を使用する必要があります。
これは、正確なクエリ構文(自動化に不可欠)を使用する方法と、インタラクティブな UI フィルタを使用する方法の 2 つの方法で確認できます。
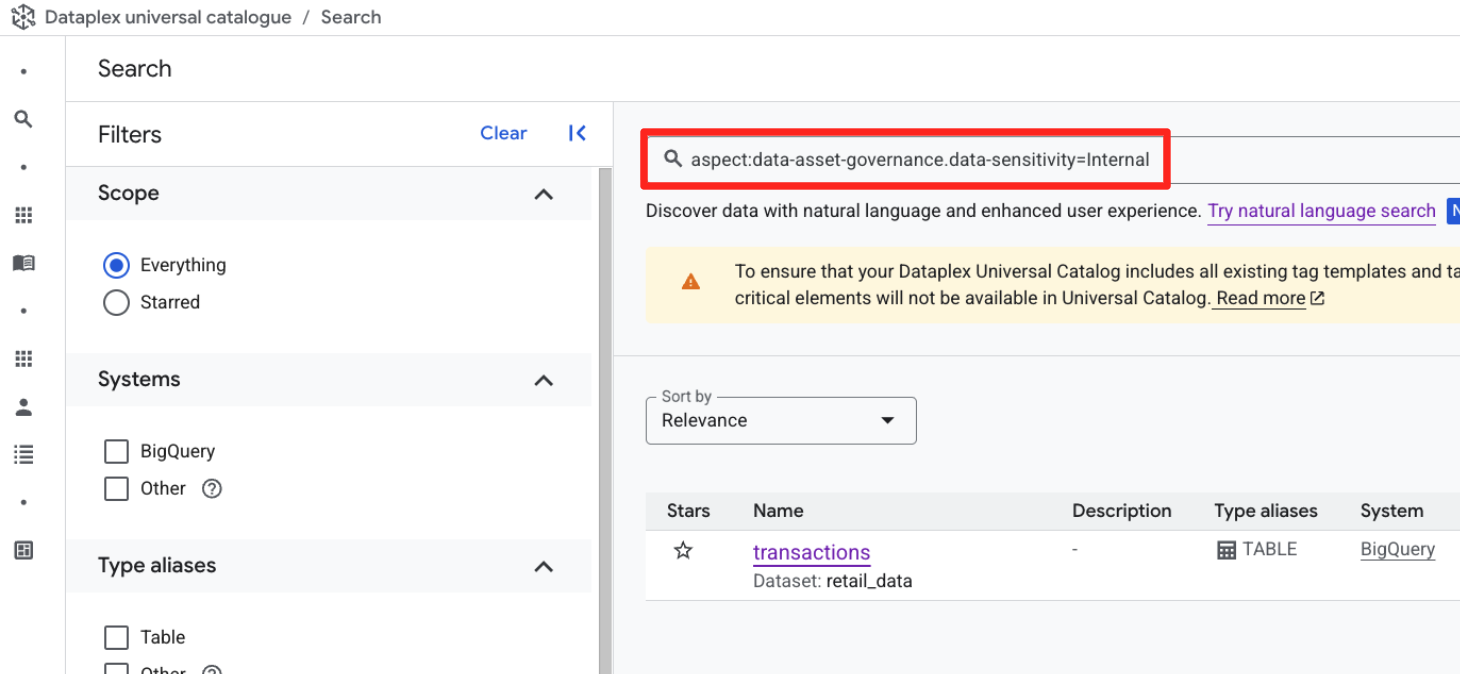
方法 1: 構造化クエリで検証する
- 検索バー(キーワード 検索モード)に、次の構造化クエリを入力します。
aspect:data-asset-governance.data-sensitivity=Internal
retail_data.transactionsテーブルが表示されます。
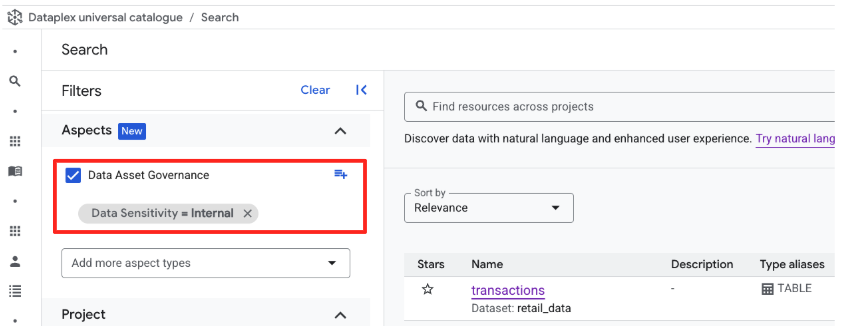
方法 2: UI フィルタ ファセットで検証する
- 検索バーをクリアしてビューをリセットします。
- 画面左側の [プロパティでフィルタ] パネルを確認します。
- 下にスクロールして [Data Asset Governance] セクションを開きます(これは作成したアスペクト タイプを表します)。
- [データの機密性] で、
Internalのチェックボックスをオンにします。 - 検索結果が更新され、
retail_data.transactionsテーブルが表示されます。
入力したクエリを使用する場合でも、UI フィルタを使用する場合でも、基盤となるメカニズムは同じです。
これは、Knowledge Catalog とシンプルな Wiki の根本的な違いを示しています。メタデータはクエリ可能な構造です。この予測可能な構造に依存して、自動監査(「last_review_date が 1 年以上前のすべてのテーブルを検索する」など)を構築できます。
7. 環境をクリーンアップする
継続的な課金を避けるため、この Codelab で作成したリソースを削除します。
BigQuery データセットを削除する
このコマンドは元に戻すことができず、-f(強制)フラグを使用して、確認なしでデータセットとそのすべてのテーブルを削除します。
# Re-run these exports if your Cloud Shell session timed out
export PROJECT_ID=$(gcloud config get-value project)
# Manually type this command to confirm you are deleting the correct dataset
bq rm -r -f --dataset $PROJECT_ID:retail_data
Knowledge Catalog アーティファクトを削除する
- Knowledge Catalog Universal Catalog UI > メタデータを管理 > カタログ に移動します。
- [アスペクト タイプとタグ テンプレート] で、data_asset_governance アスペクト タイプを選択して削除します。
- メタデータを管理 > 用語集 に移動し、
Retail Business Glossaryを選択して削除します。最初にGross Merchandise Valueという用語を削除し、後で用語集を削除してください。
8. 完了
シンプルなデータタグ付けを超えて、Knowledge Catalog に基本的な構造化ガバナンス モデルを確立しました。
次のことを学びました。
- 用語集はビジネスの曖昧さを解消します。
- アスペクト タイプは、技術メタデータのスキーマ契約を提供します。
- アスペクトは、そのスキーマを実際のデータ エントリに適用します。
- Knowledge Catalog Search は、この構造化メタデータを使用して正確な検出を行います。
次のステップ
- コードとしてのガバナンス: Google Cloud Terraform プロバイダを使用して、バージョン管理でアスペクト タイプと用語集を定義し、開発環境、テスト環境、本番環境で一貫したスキーマを確保します。
- 自動タグ付け: 新しいデータセットの作成によってトリガーされる Cloud Functions または Cloud Build ステップを作成し、デフォルト値(
sensitivity=Internal, steward=TBDなど)で「Data Asset Governance」アスペクトを自動的に添付して、レビュー用にフラグを設定します。