
1. מבוא
בתור מפתחים ומהנדסי נתונים, אנחנו לרוב מקבלים בירושה אוספים גדולים של נתונים שנראים יותר כמו ביצות נתונים. אנחנו נתקלים באותן נקודות חיכוך שוב ושוב: "מה ההגדרה בפועל של העמודה 'amt'?", "מי אחראי אם מערך הנתונים הזה ייפגם?" או "מותר לנו להשתמש בטבלה הזו במנוע ההמלצות בהתאמה אישית?"
בדרך כלל, קטלוגים של נתונים הם מלאי פסיבי שמלא בתגי טקסט חופשי, שמהר מאוד הופכים ללא עקביים ולמיושנים. הם לא אוכפים מבנה, ולכן כמעט בלתי אפשרי לנהל אותם באופן פרוגרמטי.
כדי להמחיש את התהליך, נשתמש בתרחיש הבא במעבדה הזו: הקמת מערכת פיקוח חזקה על נתוני מכירות קמעונאיים גולמיים, כדי שמחלקת הכספים תוכל להסתמך עליהם לצורך דיווח רשמי. הנתונים האלה יעברו ממצב מעורפל של 'ביצה' למוצר מנוהל.
הקטלוג האוניברסלי של Knowledge Catalog משנה את זה על ידי מתן מסגרת פעילה ומובנית לניהול מטא-נתונים. התכונה הזו מאפשרת לכם לצרף מטא-נתונים מובְנים שמבוססים על סכימה (היבטים) והגדרות עסקיות מקובלות (מילונים) ישירות לנכסי הנתונים שלכם (רשומות).
כדי לכתוב סקריפטים של Python או מודולים של Terraform לאוטומציה של התהליך הזה בקנה מידה נרחב, צריך להבין את מודל האובייקטים הבסיסי.
ב-codelab הזה, נבצע את שלבי הניהול באופן ידני במסוף Google Cloud. אנחנו נסביר בפירוט את הקשר בין רשומות, סוגי היבטים, היבטים ומילונים, כדי שתוכלו להבין איך להפוך את הנתונים שלכם לגלויים, למובנים ולמהימנים.
דרישות מוקדמות
- פרויקט ב-Google Cloud עם גישת בעלים או עריכה.
- היכרות עם מסוף Google Cloud.
- מיומנויות בסיסיות ב-CLI של gcloud ו-bq ב-Cloud Shell.
מה תלמדו
- ההבדל המהותי בין רשומה ב-Knowledge Catalog, סוג מאפיין ומאפיין.
- איך יוצרים מילון מונחים עסקי כדי לפתור בעיות של דו-משמעות בטרמינולוגיה.
- איך מעצבים סוג מאפיין כדי לאכוף סכימה מחמירה למטא-נתונים טכניים (מעבר ל'תגים').
- איך לקשר מונח במילון מונחים עסקי לעמודה ספציפית ב-BigQuery.
- איך מצרפים היבט מובנה לנכס נתונים ומאמתים את הקלט.
- איך להריץ שאילתות חיפוש מדויקות על המטא-נתונים המובנים החדשים האלה.
מה תצטרכו
- חשבון Google Cloud ופרויקט Google Cloud
- דפדפן אינטרנט כמו Chrome
מושגים מרכזיים
- רשומה: ייצוג קנוני מופשט של נכס נתונים בקטלוג. אפשר לחשוב על זה כעל 'מצביע' או 'שם עצם'. כשיוצרים טבלה ב-BigQuery, נוצרת עבורה רשומה באופן אוטומטי ב-Knowledge Catalog. אנחנו לא מנהלים את הטבלה ישירות, אלא את הרשומה שלה.
- מילון מונחים עסקי: מילון מרכזי עם גרסאות של מונחים עסקיים שמשמשים בארגון. זהו המקור היחיד לאמת. הוא מונע את הבעיה של הגדרת GMV שונה על ידי מחלקת המכירות ומחלקת הכספים.
- סוג מאפיין: הסכימה או התבנית של קטגוריה ספציפית של מטא-נתונים. סוג מאפיין מגדיר שדות, סוגי נתונים (מחרוזת, enum, תאריך ושעה וכו') ואילוצים (חובה/אופציונלי). זהו החוזה שמבטיח עקביות של המטא-נתונים.
- מאפיין: נתון מטא-נתונים ספציפי שמצורף לרשומה ופועל לפי המבנה שמוגדר על ידי סוג המאפיין. הוא מכיל את הנתונים בפועל שממלאים את הסכימה של סוג ההיבט.
2. הגדרה ודרישות
מפעילים את Cloud Shell
אפשר להפעיל את Google Cloud מרחוק מהמחשב הנייד, אבל ב-Codelab הזה נשתמש ב-Google Cloud Shell, סביבת שורת פקודה שפועלת בענן.
ב-מסוף Google Cloud, לוחצים על סמל Cloud Shell בסרגל הכלים שבפינה הימנית העליונה:
יחלפו כמה רגעים עד שההקצאה והחיבור לסביבת העבודה יושלמו. בסיום התהליך, יופיע משהו כזה:

המכונה הווירטואלית הזו כוללת את כל הכלים שדרושים למפתחים. יש בה ספריית בית בנפח מתמיד של 5GB והיא פועלת ב-Google Cloud, מה שמשפר מאוד את הביצועים והאימות ברשת. אפשר לבצע את כל העבודה ב-codelab הזה בדפדפן. לא צריך להתקין שום דבר.
הפעלת ממשקי ה-API הנדרשים והגדרת הסביבה
מריצים את הפקודות הבאות כדי להגדיר את מזהה הפרויקט, להגדיר את האזור ולהפעיל את ממשקי ה-API של השירותים הנדרשים.
export PROJECT_ID=$(gcloud config get-value project)
gcloud config set project $PROJECT_ID
export LOCATION="us-central1"
gcloud services enable dataplex.googleapis.com \
bigquery.googleapis.com \
datacatalog.googleapis.com
יצירת מערך נתונים ב-BigQuery והכנת נתונים לדוגמה
אנחנו צריכים נכס נתונים קונקרטי לניהול. ניצור מערך נתונים ב-BigQuery ונטען קובץ CSV קטן לדוגמה שמייצג טרנזקציות. Knowledge Catalog יגלה את הטבלה הזו באופן אוטומטי וייצור עבורה רשומה.
# Create the BigQuery Dataset in the us-central1 region
bq --location=$LOCATION mk --dataset \
--description "Retail data for governance codelab" \
$PROJECT_ID:retail_data
# Create a temporary CSV file with the sample data
echo "transaction_id,user_email,gmv,transaction_date
1001,test@example.com,150.50,2025-08-28
1002,user@example.com,75.00,2025-08-28" > /tmp/transactions.csv
# Load the data from the temporary CSV file into BigQuery
bq load \
--source_format=CSV \
--autodetect \
retail_data.transactions \
/tmp/transactions.csv
# (Optional) Clean up the temporary file
rm /tmp/transactions.csv
כדי לאמת את ההגדרה, מריצים שאילתה מהירה:
bq query --nouse_legacy_sql "SELECT * FROM retail_data.transactions"
3. יצירת שפה משותפת באמצעות מילון מונחים עסקי
ניהול יעיל מתחיל בהגדרות חד-משמעיות. אם מפתח רואה עמודה בשם gmv, הוא לא צריך לנחש אם היא כוללת מיסים או החזרים. מילון מונחים עסקי פותר את הבעיה הזו על ידי הפרדה בין ההגדרה העסקית לבין היישום הטכני.
- במסוף Google Cloud, עוברים אל Knowledge Catalog Universal catalog.
- בתפריט הניווט הימני, בוחרים באפשרות מילוני מונחים (בקטע 'ניהול מטא-נתונים').
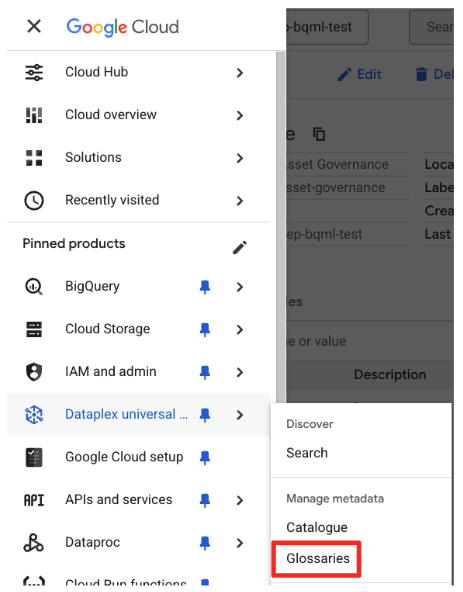
- לוחצים על יצירת מילון המונחים הארגוני.
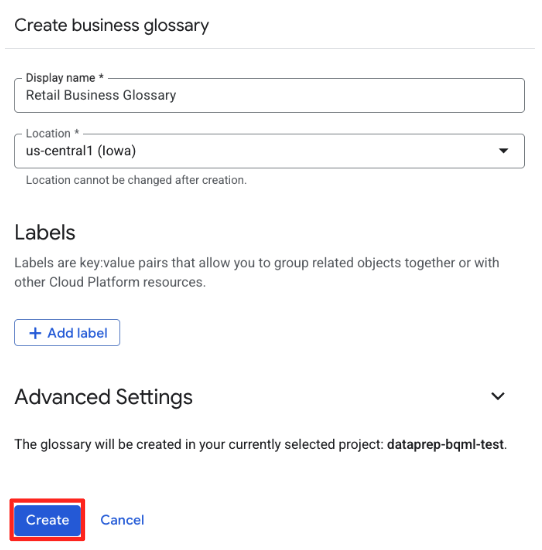
- מזינים את הפרטים הבאים:
- Name (שם):
Retail Business Glossary - מיקום:
us-central1(או המיקום שהגדרתם בהגדרה).
- Name (שם):
- לוחצים על יצירה.
- לוחצים על Retail Business Glossary (מילון מונחים לעסקים קמעונאיים) שנוצר כדי להיכנס אליו.

- לוחצים על יצירת קטגוריה, נותנים לה את השם
Sales Metricsולוחצים על יצירה. קטגוריות עוזרות לקבץ מונחים קשורים. - בוחרים בקטגוריה
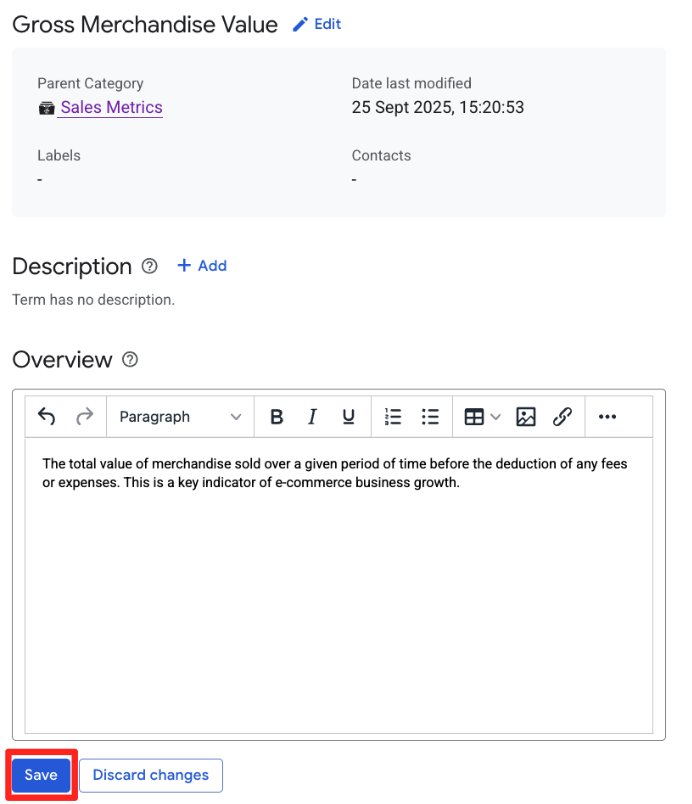
Sales Metrics, לוחצים על הוספת מונח, נותנים לו את השםGross Merchandise Valueולוחצים על יצירה. - לוחצים על הלחצן + הוספה בדף הסקירה הכללית וממלאים את הפרטים הבאים:
- סקירה כללית:
The total value of merchandise sold over a given period of time before the deduction of any fees or expenses. This is a key indicator of e-commerce business growth.
- סקירה כללית:
- לוחצים על שמירה.
עכשיו יש לכם הגדרה ברורה שאפשר לקשר לנכסים טכניים בכל הארגון.
4. הגדרת מטא-נתונים טכניים מובְנים באמצעות סוג היבט
תגי key:value פשוטים לא מספיקים כדי להבטיח את רמת הדיוק הנדרשת בהנדסה. אם אתם צריכים לעקוב אחרי 'בעלי נתונים', אתם לא רוצים שטבלה אחת תתויג owner:bob וטבלה אחרת תתויג contact:alice@example.com. אתם צריכים סכימה כדי לוודא שבעלים הוא שדה חובה ושהפורמט שלו הוא פורמט אימייל תקין.
נשתמש בסוג היבט כדי להגדיר את החוזה הזה.
- בתפריט הניווט הימני של Knowledge Catalog, בקטע Catalogue (קטלוג), בוחרים באפשרות Aspect types & Tag Templates (סוגי מאפיינים ותבניות תגים).
- בוחרים בכרטיסייה בהתאמה אישית ולוחצים על יצירת סוג היבט.
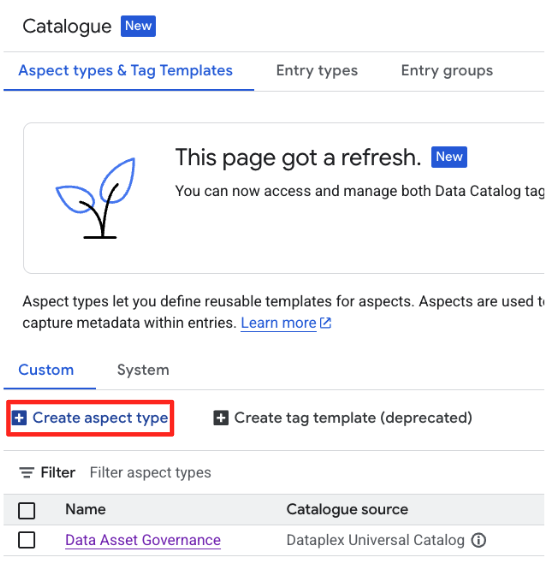
- מזינים את הפרטים הבאים:
- שם לתצוגה:
Data Asset Governance - מיקום:
us-central1
- שם לתצוגה:
- בקטע תבנית, נגדיר את הסכימה של
Aspect. לוחצים על הוספת שדה כדי ליצור את שלושת השדות הבאים:- Field 1:
- שם לתצוגה:
Data Steward - Type (סוג):
Text - סוג הטקסט:
Plain text - קרדינליות: חובה (מסמנים את התיבה)
- שם לתצוגה:
- שדה 2 (לוחצים שוב על הוספת שדה):
- שם לתצוגה:
Data Sensitivity - Type (סוג):
Enum - ערכים: מוסיפים את
Public,Internalו-Confidential - קרדינליות: אופציונלי
- שם לתצוגה:
- שדה 3 (לוחצים שוב על הוספת שדה):
- שם לתצוגה:
Last Review Date - Type (סוג):
Date and time - קרדינליות: אופציונלי
- שם לתצוגה:
- Field 1:
- לוחצים על שמירה.
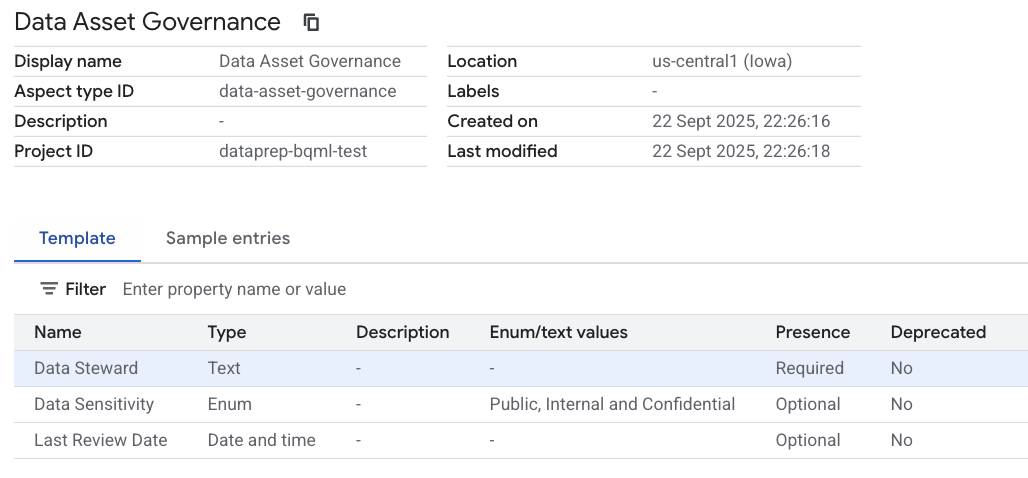
יצרתם עכשיו חוזה מטא נתונים לשימוש חוזר. עדיין לא נעשה בו שימוש, אבל המבנה קיים.
5. קישור הממשל לנכס
עכשיו נסכם את הכול. יש לנו טבלה ב-BigQuery (retail_data.transactions), הגדרה עסקית (Gross Merchandise Value) וסכימת ניהול ((Data Asset Governance).
אנחנו נעדכן את הערך ב-Knowledge Catalog עבור טבלת BigQuery.
הוספת הקשר עסקי לסכימה (ברמת העמודה)
כדאי לקשר את העמודה gmv למילון המונחים כדי שהמשתמשים יבינו מה המשמעות שלה.
- בתפריט הניווט הימני של Knowledge Catalog, לוחצים על חיפוש.
- בצד שמאל למעלה, לוחצים על הכרטיסייה Knowledge Catalog Universal Catalog (קטלוג אוניברסלי של קטלוג הידע) אם היא לא הופעלה.
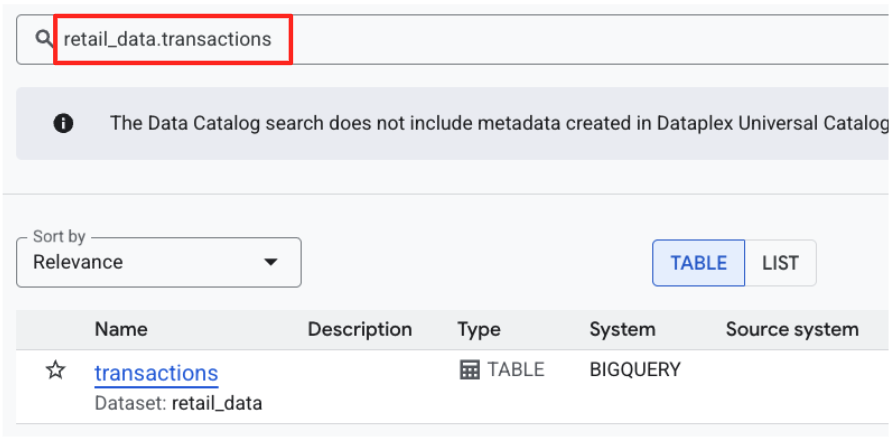
- חיפוש של
retail_data.transactions. לוחצים על התוצאה של הטבלה ב-BigQuery.
- לוחצים על הכרטיסייה סכימה בפרטי הרשומה.
- מסמנים את תיבת הסימון בשורה של העמודה
gmvולוחצים על הוספת מונח עסקי. - בוחרים את המונח
Gross Merchandise Value.
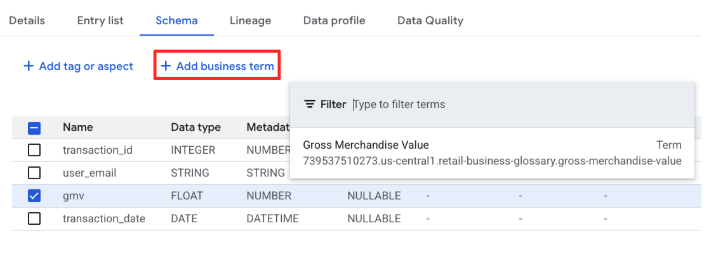
העמודה gmv כבר לא מסוג FLOAT, אלא מקושרת להגדרה הארגונית של Gross Merchandise Value.
הוספת מטא-נתונים טכניים מובְנים לרשומה (ברמת הטבלה)
בשלב הבא נצרף את Data Asset Governance ההיבט לטבלה כדי להגדיר בעלות ורגישות.
- נשארים בדף
retail_data.transactions. - לוחצים על הכרטיסייה הוספת תג או היבט ואז בוחרים את הסוג
Data Asset Governanceמהתפריט הנפתח.
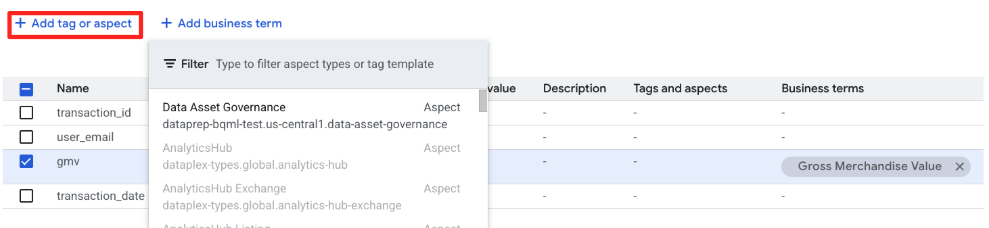
- עכשיו יוצגו בטופס השדות שהוגדרו בסכימה של סוג ההיבט. ממלאים אותם באופן הבא:
- Data Steward:
finance-team@example.com - רגישות הנתונים: בוחרים באפשרות
Internal. - תאריך הבדיקה האחרונה: בוחרים את התאריך הנוכחי.
- Data Steward:
- לוחצים על שמירה.
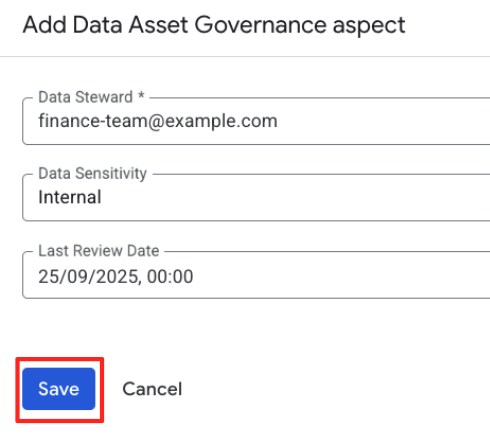
הצלחתם לצרף היבט מובנה לרשומה. בניגוד לתג פשוט, הנתונים האלה עוברים אימות מול הסכימה שיצרתם.
6. גילוי ואימות מאוחדים
לא עשינו את העבודה הזו רק כדי למלא טפסים. עשינו את זה כדי שהנתונים יהיו קלים לאיתור ומהימנים. נראה איך המטא-נתונים האלה משנים את חוויית המפתחים בחיפוש ובגילוי.
חוזרים לדף הראשי חיפוש בקטלוג האוניברסלי של Knowledge Catalog.
נניח שאתם מהנדסי פלטפורמה שאחראים על אכיפת מדיניות. צריך למצוא את כל הנכסים שמסומנים כ'פנימיים' ושכפופים לסוג ההיבט הספציפי שלכם. צריך להשתמש בפרדיקטים מדויקים על סמך הסכימה.
יש שתי דרכים לאמת את זה: באמצעות תחביר מדויק של שאילתה (חיוני לאוטומציה) או באמצעות מסננים אינטראקטיביים בממשק המשתמש.
שיטה 1: אימות באמצעות שאילתה מובנית
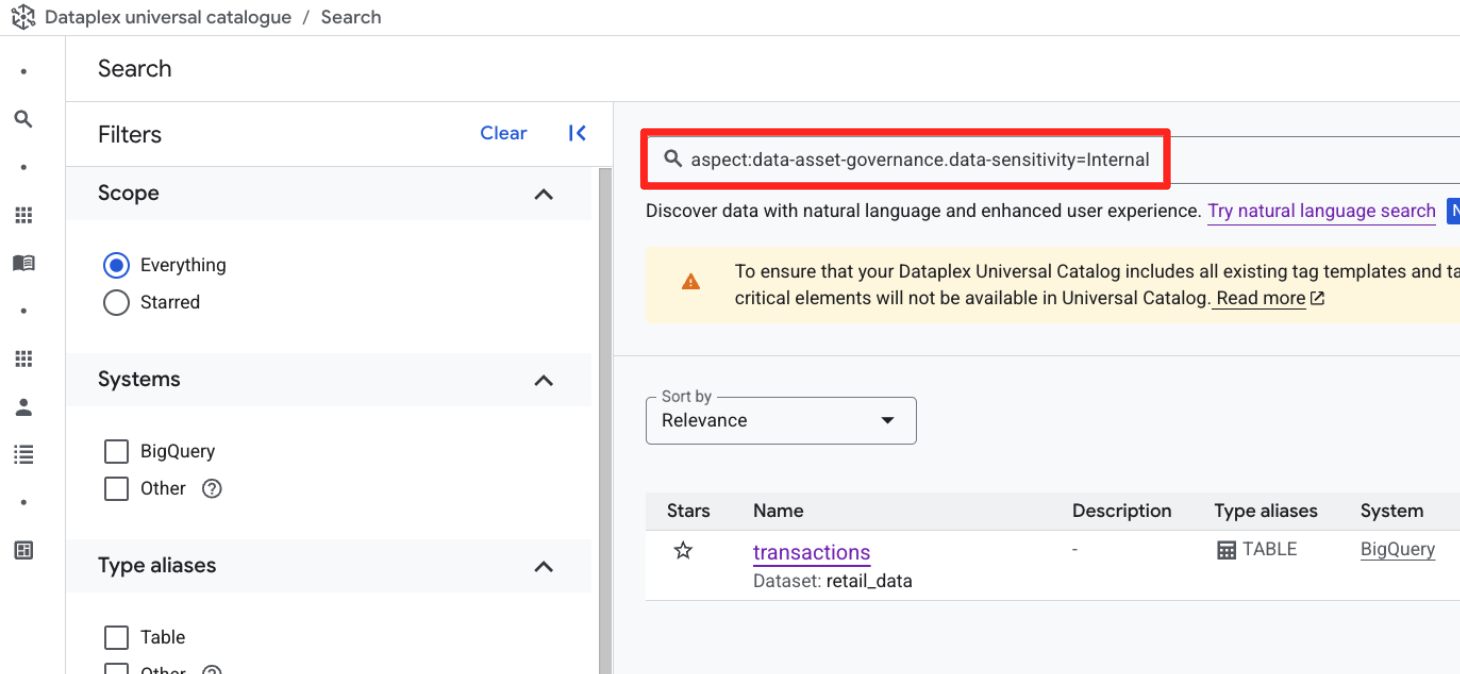
- בסרגל החיפוש (במצב חיפוש מילות מפתח), מזינים את השאילתה המובנית הבאה.
aspect:data-asset-governance.data-sensitivity=Internal
- טבלת
retail_data.transactionsאמורה להופיע.
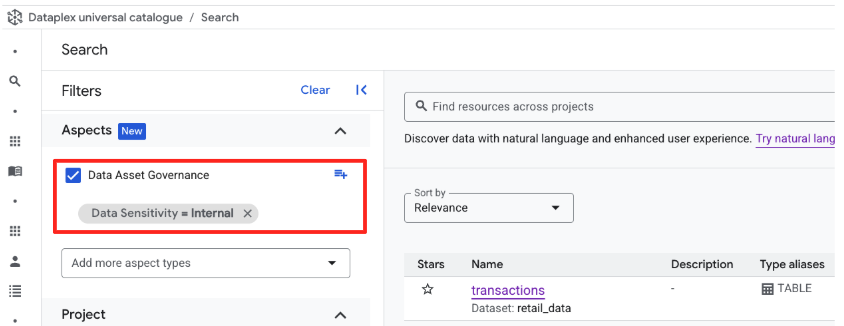
שיטה 2: אימות באמצעות מסננים בממשק המשתמש
- ניקוי סרגל החיפוש כדי לאפס את התצוגה
- מסתכלים על החלונית סינון לפי נכסים בצד ימין של המסך.
- גוללים למטה ומרחיבים את הקטע Data Asset Governance (זהו סוג ההיבט שיצרתם).
- בקטע רגישות נתונים, מסמנים את התיבה
Internal. - תוצאות החיפוש יתעדכנו ויוצג בהן הטבלה
retail_data.transactions.
בין אם משתמשים בשאילתה מוקלדת או במסננים בממשק המשתמש, המנגנון הבסיסי הוא זהה.
ההבדל הזה מדגים את ההבדל המהותי בין Knowledge Catalog לבין ויקי פשוט: המטא-נתונים שלכם הם מבנה שאפשר להריץ עליו שאילתות. עכשיו אפשר לבנות ביקורות אוטומטיות (לדוגמה, "חיפוש של כל הטבלאות שבהן הערך של last_review_date הוא לפני יותר משנה") על סמך המבנה הצפוי הזה.
7. ניקוי הסביבה
כדי להימנע מחיובים שוטפים, מוחקים את המשאבים שנוצרו ב-codelab הזה.
מחיקת מערך הנתונים ב-BigQuery
אי אפשר לבטל את הפקודה הזו, והיא משתמשת בדגל -f (force) כדי להסיר את מערך הנתונים ואת כל הטבלאות שלו ללא אישור.
# Re-run these exports if your Cloud Shell session timed out
export PROJECT_ID=$(gcloud config get-value project)
# Manually type this command to confirm you are deleting the correct dataset
bq rm -r -f --dataset $PROJECT_ID:retail_data
מחיקת ארטיפקטים של קטלוג הידע
- עוברים אל ממשק המשתמש של הקטלוג האוניברסלי של Knowledge Catalog > ניהול מטא-נתונים > קטלוג.
- בקטע Aspect types & tag templates (סוגי היבטים ותבניות תגים), בוחרים את סוג ההיבט data_asset_governance ומוחקים אותו.
- עוברים אל ניהול מטא-נתונים > מילונים, בוחרים את
Retail Business Glossaryומוחקים אותו. חשוב קודם למחוק את המונחGross Merchandise Valueואז למחוק את המילון.
8. מעולה!
התקדמתם מעבר לתיוג נתונים פשוט, וביססתם מודל ניהול מובנה ומהותי ב-Knowledge Catalog.
למדנו ש:
- מילוני מונחים עוזרים לפתור בעיות של דו-משמעות בעסק.
- סוגי ההיבטים מספקים את חוזה הסכימה למטא-נתונים טכניים.
- ההיבטים מחילים את הסכימה על רשומות נתונים בפועל.
- חיפוש ב-Knowledge Catalog מתבסס על המטא-נתונים המובְנים האלה כדי לאפשר גילוי מדויק.
מה השלב הבא?
- ניהול מדיניות כקוד: אפשר להשתמש ב-Google Cloud Terraform provider כדי להגדיר את סוגי ההיבטים והמילונים שלכם בבקרת גרסאות, וכך להבטיח סכימות עקביות בסביבות פיתוח, בדיקה וייצור.
- תיוג אוטומטי: כותבים פונקציה של Cloud Functions או שלב של Cloud Build שמופעל כשנוצר מערך נתונים חדש, ומצרף אוטומטית את ההיבט Data Asset Governance עם ערכי ברירת מחדל (לדוגמה,
sensitivity=Internal, steward=TBD), ומסמן אותו לבדיקה.