
1. परिचय
डेवलपर और डेटा इंजीनियर के तौर पर, हमें अक्सर डेटा के बड़े कलेक्शन मिलते हैं. ये कलेक्शन, डेटा स्वैंप की तरह दिखते हैं. हमें बार-बार एक ही तरह की समस्याओं का सामना करना पड़ता है: "इस ‘amt' कॉलम की असल परिभाषा क्या है?", "अगर यह डेटासेट काम नहीं करता है, तो इसकी ज़िम्मेदारी किसकी होगी?" या "क्या हमें इस टेबल का इस्तेमाल, लोगों की दिलचस्पी के हिसाब से सुझाव देने वाले इंजन में करने की अनुमति है?"
आम तौर पर, डेटा कैटलॉग ऐसी इन्वेंट्री होती हैं जिनमें फ़्री-टेक्स्ट टैग भरे होते हैं. ये टैग, कुछ समय बाद पुराने हो जाते हैं और इनमें मौजूद जानकारी भी पुरानी हो जाती है. ये स्ट्रक्चर को लागू नहीं करते हैं. इसलिए, प्रोग्राम के हिसाब से नीतियों को लागू करना लगभग नामुमकिन हो जाता है.
इसे व्यावहारिक बनाने के लिए, हम इस लैब में एक उदाहरण पर काम करेंगे: खुदरा बिक्री के रॉ डेटा पर मज़बूत गवर्नेंस लागू करना, ताकि वित्त विभाग आधिकारिक रिपोर्टिंग के लिए इस पर भरोसा कर सके. इस डेटा को "स्वैंप" की स्थिति से हटाकर, एक नियंत्रित प्रॉडक्ट में ले जाया जाएगा.
Knowledge Catalog Universal Catalog, मेटाडेटा को मैनेज करने के लिए एक चालू और स्ट्रक्चर्ड फ़्रेमवर्क उपलब्ध कराता है. इससे यह समस्या हल हो जाती है. इसकी मदद से, स्ट्रक्चर्ड और स्कीमा पर आधारित मेटाडेटा (पहलू) और कारोबार की मान्य परिभाषाएं (ग्लॉसरी) सीधे तौर पर अपनी डेटा ऐसेट (एंट्री) से जोड़ी जा सकती हैं.
बड़े पैमाने पर इस प्रोसेस को अपने-आप पूरा करने के लिए, Python स्क्रिप्ट या Terraform मॉड्यूल लिखने से पहले, आपको ऑब्जेक्ट मॉडल को समझना होगा.
इस कोडलैब में, हम Google Cloud Console में मैन्युअल तरीके से गवर्नेंस के चरण पूरे करेंगे. हम एंट्री, पहलू के टाइप, पहलुओं, और शब्दावलियों के बीच के अंतर को साफ़ तौर पर बताएंगे, ताकि आपको यह समझने में आसानी हो कि अपने डेटा को खोजे जाने लायक, समझने में आसान, और भरोसेमंद कैसे बनाया जाए.
ज़रूरी शर्तें
- Google Cloud प्रोजेक्ट के लिए, मालिक या बदलाव करने का ऐक्सेस.
- Google Cloud Console के बारे में जानकारी होना.
- Cloud Shell में gcloud और bq सीएलआई की बुनियादी जानकारी.
आपको क्या सीखने को मिलेगा
- नॉलेज कैटलॉग एंट्री, पहलू का टाइप, और पहलू के बीच का अहम अंतर.
- शब्दावली में अस्पष्टता को दूर करने के लिए, कारोबार की शब्दावली बनाने का तरीका.
- टेक्निकल मेटाडेटा के लिए, पहलू का टाइप कैसे डिज़ाइन करें, ताकि स्कीमा को सख्ती से लागू किया जा सके. इसमें "टैग" से आगे की जानकारी शामिल है.
- किसी Business Glossary टर्म को BigQuery के किसी कॉलम से लिंक करने का तरीका.
- डेटा ऐसेट में स्ट्रक्चर्ड पहलू को अटैच करने और इनपुट की पुष्टि करने का तरीका.
- इस नए स्ट्रक्चर्ड मेटाडेटा के आधार पर, सटीक सर्च क्वेरी कैसे लागू करें.
आपको इन चीज़ों की ज़रूरत होगी
- Google Cloud खाता और Google Cloud प्रोजेक्ट
- कोई वेब ब्राउज़र, जैसे कि Chrome
मुख्य सिद्धांत
- एंट्री: यह कैटलॉग में मौजूद डेटा ऐसेट का कैननिकल और ऐब्स्ट्रैक्ट वर्शन होता है. इसे "पॉइंटर" या "संज्ञा" के तौर पर देखा जा सकता है. BigQuery टेबल बनाने पर, Knowledge Catalog इसके लिए अपने-आप एक एंट्री बना देता है. हम टेबल को सीधे तौर पर मैनेज नहीं करते, बल्कि उसकी एंट्री को मैनेज करते हैं.
- कारोबार की शब्दावली: यह आपके संगठन के कारोबारी शब्दों की एक ऐसी डिक्शनरी होती है जिसे एक जगह से ऐक्सेस किया जा सकता है. इसमें शब्दों के अलग-अलग वर्शन भी होते हैं. यह एकमात्र भरोसेमंद सोर्स है. इससे "सेल्स टीम, फ़ाइनेंस टीम से अलग तरीके से जीएमवी तय करती है" समस्या को हल करने में मदद मिलती है.
- पहलू का टाइप: यह मेटाडेटा की किसी खास कैटगरी के लिए स्कीमा या टेंप्लेट होता है. पहलू का टाइप, फ़ील्ड, डेटा टाइप (स्ट्रिंग, इनम, तारीख और समय वगैरह) और शर्तें (ज़रूरी/वैकल्पिक) तय करता है. यह एक ऐसा कानूनी समझौता है जो मेटाडेटा की एकरूपता को पक्का करता है.
- पहलू: यह एंट्री से जुड़ा मेटाडेटा का एक खास हिस्सा होता है. यह पहलू के टाइप के हिसाब से तय किए गए स्ट्रक्चर के मुताबिक होता है. इसमें, पहलू के टाइप के स्कीमा के मुताबिक असल डेटा होता है.
2. सेटअप और ज़रूरी शर्तें
Cloud Shell शुरू करें
Google Cloud को अपने लैपटॉप से रिमोटली ऐक्सेस किया जा सकता है. हालांकि, इस कोडलैब में Google Cloud Shell का इस्तेमाल किया जाएगा. यह क्लाउड में चलने वाला कमांड लाइन एनवायरमेंट है.
Google Cloud Console में, सबसे ऊपर दाएं कोने में मौजूद टूलबार पर, Cloud Shell आइकॉन पर क्लिक करें:
इसे चालू करने और एनवायरमेंट से कनेक्ट करने में सिर्फ़ कुछ सेकंड लगेंगे. यह प्रोसेस पूरी होने के बाद, आपको कुछ ऐसा दिखेगा:

इस वर्चुअल मशीन में, डेवलपमेंट के लिए ज़रूरी सभी टूल पहले से मौजूद हैं. यह 5 जीबी की होम डायरेक्ट्री उपलब्ध कराता है. साथ ही, Google Cloud पर काम करता है. इससे नेटवर्क की परफ़ॉर्मेंस और पुष्टि करने की प्रोसेस बेहतर होती है. इस कोडलैब में मौजूद सभी टास्क, ब्राउज़र में किए जा सकते हैं. आपको कुछ भी इंस्टॉल करने की ज़रूरत नहीं है.
ज़रूरी एपीआई चालू करना और एनवायरमेंट कॉन्फ़िगर करना
अपना प्रोजेक्ट आईडी सेट करने, क्षेत्र तय करने, और ज़रूरी सेवा एपीआई चालू करने के लिए, यहां दिए गए निर्देश चलाएं.
export PROJECT_ID=$(gcloud config get-value project)
gcloud config set project $PROJECT_ID
export LOCATION="us-central1"
gcloud services enable dataplex.googleapis.com \
bigquery.googleapis.com \
datacatalog.googleapis.com
BigQuery डेटासेट बनाना और सैंपल डेटा तैयार करना
हमें डेटा को मैनेज करने के लिए, डेटा ऐसेट की ज़रूरत होती है. हम एक BigQuery डेटासेट बनाएंगे और लेन-देन की जानकारी देने वाली एक छोटी सी CSV फ़ाइल लोड करेंगे. Knowledge Catalog इस टेबल का अपने-आप पता लगा लेगा और इसके लिए एक एंट्री बना देगा.
# Create the BigQuery Dataset in the us-central1 region
bq --location=$LOCATION mk --dataset \
--description "Retail data for governance codelab" \
$PROJECT_ID:retail_data
# Create a temporary CSV file with the sample data
echo "transaction_id,user_email,gmv,transaction_date
1001,test@example.com,150.50,2025-08-28
1002,user@example.com,75.00,2025-08-28" > /tmp/transactions.csv
# Load the data from the temporary CSV file into BigQuery
bq load \
--source_format=CSV \
--autodetect \
retail_data.transactions \
/tmp/transactions.csv
# (Optional) Clean up the temporary file
rm /tmp/transactions.csv
क्विक क्वेरी चलाकर, सेटअप की पुष्टि करें:
bq query --nouse_legacy_sql "SELECT * FROM retail_data.transactions"
3. बिज़नेस ग्लॉसरी की मदद से, एक जैसी भाषा का इस्तेमाल करना
प्रभावी गवर्नेंस के लिए, साफ़ तौर पर बताई गई परिभाषाएं ज़रूरी हैं. अगर किसी डेवलपर को gmv नाम का कॉलम दिखता है, तो उसे यह अनुमान नहीं लगाना चाहिए कि इसमें टैक्स या रिटर्न शामिल हैं या नहीं. कारोबार की शब्दावली, कारोबार की परिभाषा को तकनीकी जानकारी से अलग करके इस समस्या को हल करती है.
- Google Cloud Console में, Knowledge Catalog Universal catalog पर जाएं.
- बाईं ओर मौजूद नेविगेशन मेन्यू में, ग्लॉसरी (मेटाडेटा मैनेज करें में जाकर) चुनें.
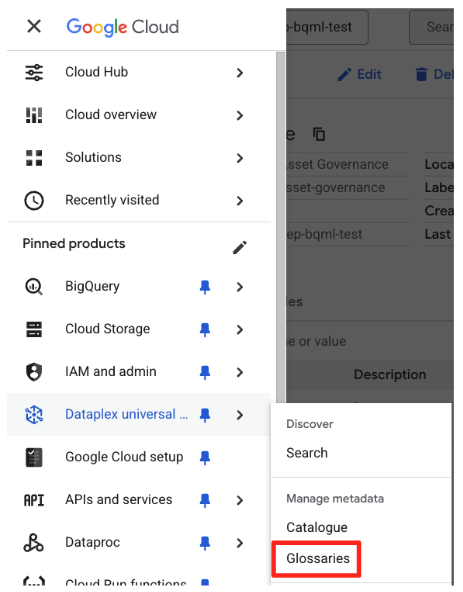
- कारोबार की शब्दावली बनाएं पर क्लिक करें.
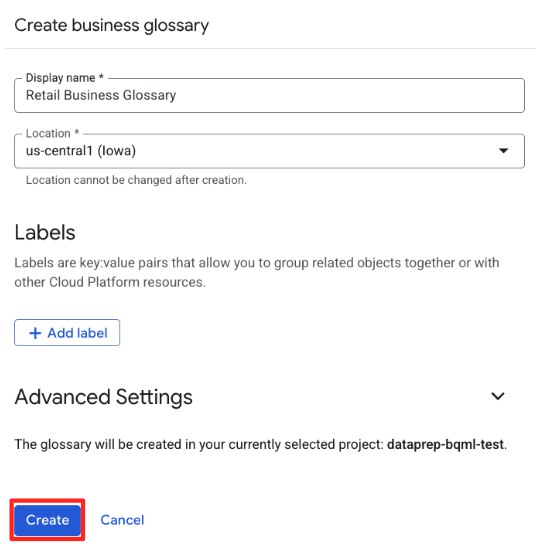
- यह जानकारी डालें:
- नाम:
Retail Business Glossary - जगह की जानकारी:
us-central1(या सेटअप के दौरान तय की गई जगह की जानकारी).
- नाम:
- बनाएं पर क्लिक करें.
- इसमें शामिल होने के लिए, हाल ही में बनाए गए खुदरा कारोबार की शब्दावली पर क्लिक करें.

- कैटेगरी बनाएं पर क्लिक करें और उसका नाम
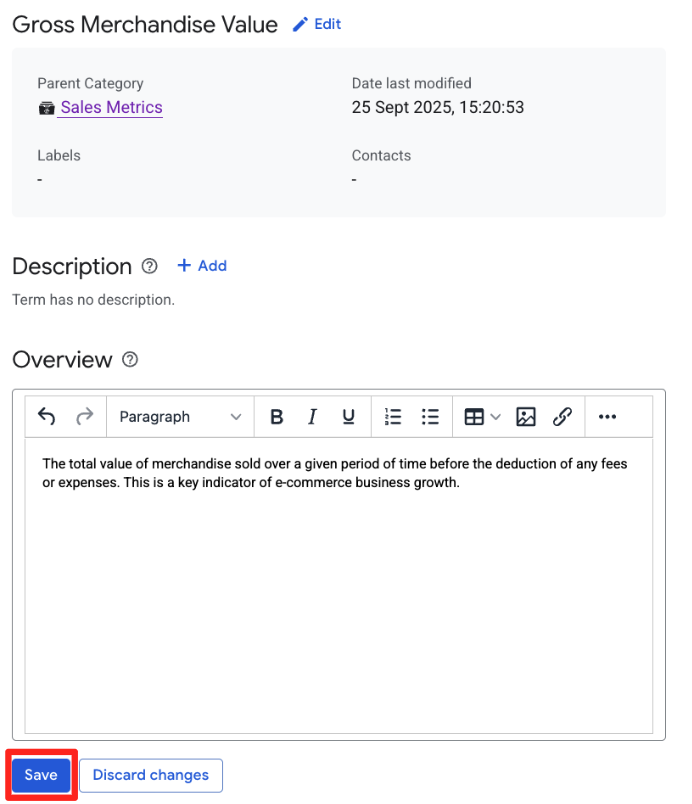
Sales Metricsरखें. इसके बाद, बनाएं पर क्लिक करें. कैटेगरी की मदद से, मिलते-जुलते शब्दों को ग्रुप किया जा सकता है. Sales Metricsकैटगरी चुनें. इसके बाद, शब्द जोड़ें पर क्लिक करें. फिर, इसेGross Merchandise Valueनाम दें. इसके बाद, बनाएं पर क्लिक करें- खास जानकारी वाले पेज पर, + जोड़ें बटन पर क्लिक करें. इसके बाद, यह जानकारी भरें:
- खास जानकारी:
The total value of merchandise sold over a given period of time before the deduction of any fees or expenses. This is a key indicator of e-commerce business growth.
- खास जानकारी:
- सेव करें पर क्लिक करें.
अब आपने एक ऐसी परिभाषा तय कर ली है जिसे आपके संगठन की सभी तकनीकी ऐसेट से लिंक किया जा सकता है.
4. पहलू के टाइप की मदद से, स्ट्रक्चर्ड टेक्निकल मेटाडेटा तय करना
इंजीनियरिंग के लिए, सामान्य "key:value" टैग काफ़ी नहीं हैं. अगर आपको "डेटा के मालिकों" को ट्रैक करना है, तो आपको एक टेबल को owner:bob और दूसरी को contact:alice@example.com के तौर पर टैग नहीं करना है. आपको यह लागू करने के लिए स्कीमा की ज़रूरत होगी कि मालिक का होना ज़रूरी है और उसका ईमेल पता मान्य फ़ॉर्मैट में होना चाहिए.
हम इस अनुबंध को तय करने के लिए, पहलू के टाइप का इस्तेमाल करेंगे.
- नॉलेज कैटलॉग के बाईं ओर मौजूद नेविगेशन में, कैटलॉग में जाकर, पहलू के टाइप और टैग टेंप्लेट चुनें.
- कस्टम टैब चुनें और पहलू का टाइप बनाएं पर क्लिक करें.
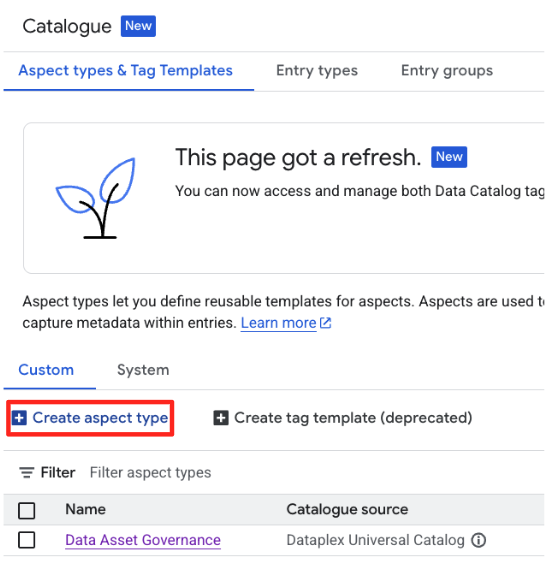
- यह जानकारी डालें:
- डिसप्ले नेम:
Data Asset Governance - जगह की जानकारी:
us-central1
- डिसप्ले नेम:
- टेंप्लेट सेक्शन में, हम अपने
Aspectके लिए स्कीमा तय करेंगे. नीचे दिए गए तीन फ़ील्ड बनाने के लिए, फ़ील्ड जोड़ें पर क्लिक करें:- फ़ील्ड 1:
- डिसप्ले नेम:
Data Steward - टाइप:
Text - टेक्स्ट का टाइप:
Plain text - कार्डिनलिटी: ज़रूरी है (बॉक्स पर सही का निशान लगाएं)
- डिसप्ले नेम:
- दूसरा फ़ील्ड (कोई फ़ील्ड जोड़ें पर फिर से क्लिक करें):
- डिसप्ले नेम:
Data Sensitivity - टाइप:
Enum - वैल्यू:
Public,Internal, औरConfidentialजोड़ें - घटकों की संख्या: ज़रूरी नहीं
- डिसप्ले नेम:
- तीसरा फ़ील्ड (कोई फ़ील्ड जोड़ें पर फिर से क्लिक करें):
- डिसप्ले नेम:
Last Review Date - टाइप:
Date and time - घटकों की संख्या: ज़रूरी नहीं
- डिसप्ले नेम:
- फ़ील्ड 1:
- सेव करें पर क्लिक करें.
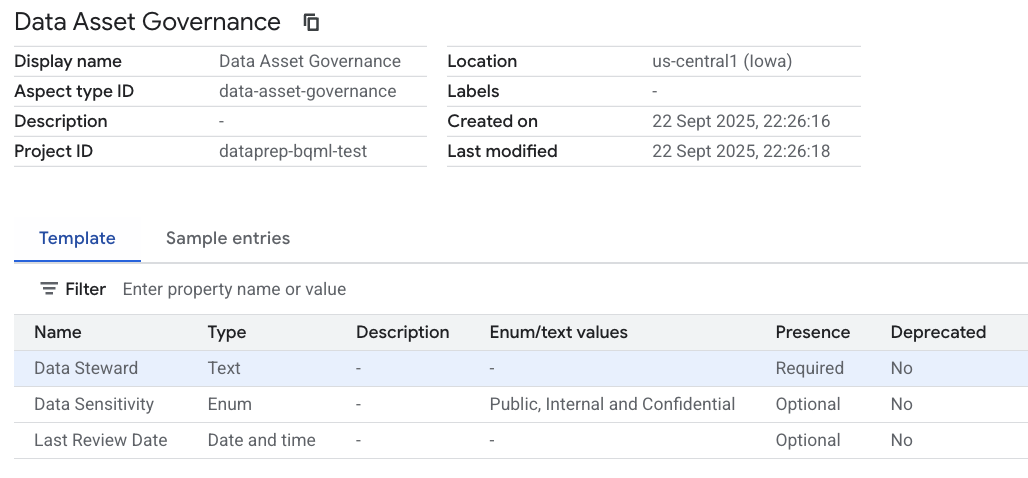
आपने अभी-अभी, फिर से इस्तेमाल किया जा सकने वाला मेटाडेटा अनुबंध बनाया है. फ़िलहाल, इसका इस्तेमाल नहीं किया जा रहा है. हालांकि, इसका स्ट्रक्चर मौजूद है.
5. ऐसेट से जुड़े नियमों को लागू करना
अब हम इन सभी को एक साथ लाएंगे. हमारे पास एक BigQuery टेबल (retail_data.transactions), कारोबार की परिभाषा (Gross Merchandise Value), और गवर्नेंस स्कीमा (Data Asset Governance) है.
हम BigQuery टेबल के लिए, नॉलेज कैटलॉग की एंट्री को बेहतर बनाएंगे.
कारोबार के कॉन्टेक्स्ट के हिसाब से स्कीमा को बेहतर बनाएं (कॉलम लेवल पर)
आइए, gmv कॉलम को शब्दावली से लिंक करके, उपयोगकर्ताओं को बताएं कि इसका क्या मतलब है.
- नॉलेज कैटलॉग के बाईं ओर मौजूद नेविगेशन बार में, खोजें पर क्लिक करें.
- अगर Knowledge Catalog Universal Catalog टैब चालू नहीं है, तो सबसे ऊपर दाईं ओर मौजूद इस टैब पर क्लिक करें.
retail_data.transactionsखोजें. BigQuery टेबल के नतीजे पर क्लिक करें.
- 'एंट्री की जानकारी' में मौजूद, स्कीमा टैब पर क्लिक करें.
gmvकॉलम की लाइन में मौजूद चेकबॉक्स पर सही का निशान लगाएं. इसके बाद, कारोबार से जुड़ा शब्द जोड़ें पर क्लिक करें.Gross Merchandise Valueशब्द चुनें.
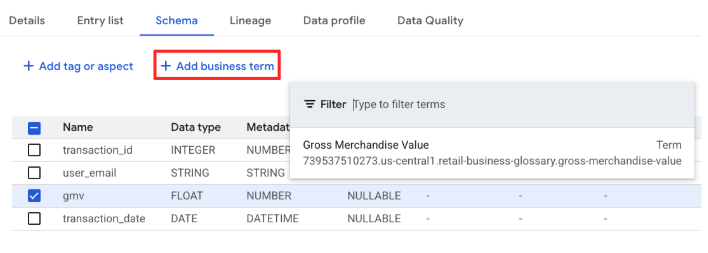
gmv कॉलम अब सिर्फ़ "FLOAT" नहीं है. अब यह Gross Merchandise Value की कॉर्पोरेट परिभाषा से लिंक है.
टेबल लेवल पर स्ट्रक्चर्ड टेक्निकल मेटाडेटा जोड़कर एंट्री को बेहतर बनाएं
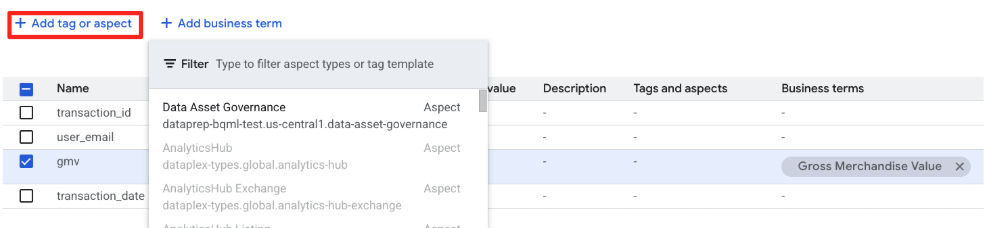
इसके बाद, हम टेबल में Data Asset Governance पहलू जोड़ेंगे, ताकि मालिकाना हक और संवेदनशील जानकारी के बारे में बताया जा सके.
retail_data.transactionsएंट्री पेज पर बने रहें.- टैग या पहलू जोड़ें टैब पर क्लिक करें. इसके बाद, ड्रॉपडाउन से
Data Asset Governanceटाइप चुनें.
- अब फ़ॉर्म में, आपके पहलू के टाइप के स्कीमा में तय किए गए फ़ील्ड दिखेंगे. इन्हें इस तरह भरें:
- डेटा स्टीवर्ड:
finance-team@example.com - डेटा की संवेदनशीलता:
Internalको चुनें. - पिछली समीक्षा की तारीख: आज की तारीख चुनें.
- डेटा स्टीवर्ड:
- सेव करें पर क्लिक करें.
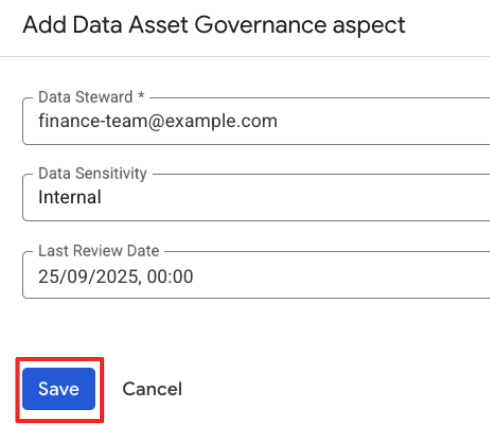
आपने एंट्री में स्ट्रक्चर्ड पहलू जोड़ दिया है. सामान्य टैग के उलट, इस डेटा की पुष्टि आपके बनाए गए स्कीमा के हिसाब से की जाती है.
6. एक ही प्लैटफ़ॉर्म पर खोज और पुष्टि करने की सुविधा
हमने सिर्फ़ फ़ॉर्म भरने के लिए यह काम नहीं किया है. हमने ऐसा इसलिए किया, ताकि डेटा को आसानी से खोजा जा सके और उस पर भरोसा किया जा सके. आइए, देखते हैं कि यह मेटाडेटा, खोजने की सुविधा और सुझाव देने वाले सिस्टम के लिए डेवलपर के अनुभव को कैसे बदलता है.
Knowledge Catalog Universal Catalog में, मुख्य खोज पेज पर वापस जाएं.
मान लें कि आप एक प्लैटफ़ॉर्म इंजीनियर हैं और आपको गवर्नेंस लागू करना है. आपको "इंटरनल" के तौर पर मार्क की गई उन सभी ऐसेट को ढूंढना होगा जिन्हें आपके चुने गए पहलू के टाइप से नियंत्रित किया जाता है. आपको अपने स्कीमा के हिसाब से सटीक प्रेडिकेट इस्तेमाल करने होंगे.
इसकी पुष्टि दो तरीकों से की जा सकती है: सटीक क्वेरी सिंटैक्स का इस्तेमाल करके (ऑटोमेशन के लिए ज़रूरी है) या इंटरैक्टिव यूज़र इंटरफ़ेस (यूआई) फ़िल्टर का इस्तेमाल करके.
पहला तरीका: स्ट्रक्चर्ड क्वेरी के ज़रिए पुष्टि करना
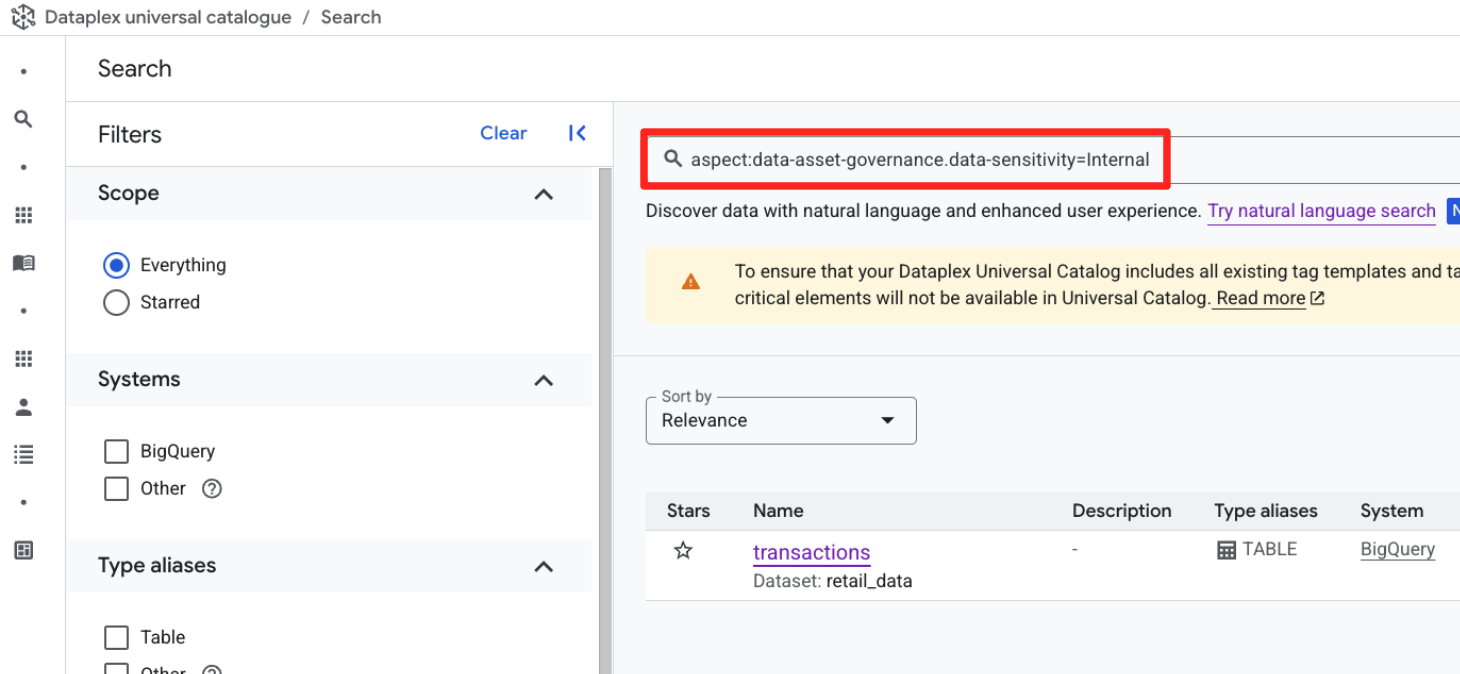
- खोज बार (कीवर्ड सर्च मोड में) में, यह स्ट्रक्चर्ड क्वेरी डालें.
aspect:data-asset-governance.data-sensitivity=Internal
- आपको अपनी
retail_data.transactionsटेबल दिखेगी.
दूसरा तरीका: यूज़र इंटरफ़ेस (यूआई) फ़िल्टर फ़ैसेट के ज़रिए पुष्टि करना
- व्यू को रीसेट करने के लिए, खोज बार से क्वेरी मिटाएं
- स्क्रीन की बाईं ओर मौजूद, प्रॉपर्टी के हिसाब से फ़िल्टर करें पैनल देखें.
- नीचे की ओर स्क्रोल करें और डेटा ऐसेट गवर्नेंस सेक्शन को बड़ा करें. यह आपके बनाए गए पहलू के टाइप को दिखाता है
- डेटा की संवेदनशीलता में जाकर,
Internalके लिए मौजूद बॉक्स पर सही का निशान लगाएं. - खोज के नतीजे अपडेट हो जाएंगे और
retail_data.transactionsटेबल दिखेगी.
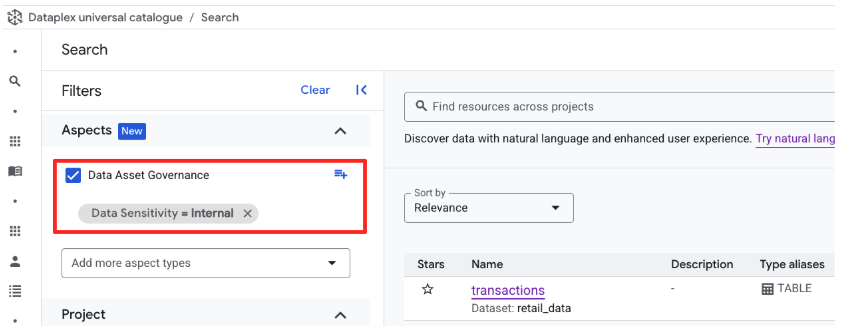
टाइप की गई क्वेरी या यूज़र इंटरफ़ेस (यूआई) फ़िल्टर का इस्तेमाल करने पर, काम करने का तरीका एक जैसा होता है.
इससे, नॉलेज कैटलॉग और सामान्य विकी के बीच का बुनियादी अंतर पता चलता है: आपका मेटाडेटा, क्वेरी किया जा सकने वाला स्ट्रक्चर है. अब इस अनुमानित स्ट्रक्चर के आधार पर, अपने-आप होने वाली ऑडिट बनाई जा सकती हैं. उदाहरण के लिए, "ऐसी सभी टेबल ढूंढें जिनमें last_review_date एक साल से ज़्यादा पुरानी है".
7. अपने एनवायरमेंट को क्लीन अप करना
लगातार लगने वाले शुल्क से बचने के लिए, इस कोडलैब में बनाए गए संसाधनों को मिटाएं.
BigQuery डेटासेट मिटाना
इस कमांड को पहले जैसा नहीं किया जा सकता. साथ ही, यह -f (force) फ़्लैग का इस्तेमाल करके, बिना पुष्टि किए डेटासेट और उसकी सभी टेबल हटा देती है.
# Re-run these exports if your Cloud Shell session timed out
export PROJECT_ID=$(gcloud config get-value project)
# Manually type this command to confirm you are deleting the correct dataset
bq rm -r -f --dataset $PROJECT_ID:retail_data
नॉलेज कैटलॉग के आर्टफ़ैक्ट मिटाना
- Knowledge Catalog Universal catalog UI > Manage metadata > Catalogue पर जाएं.
- पहलू के टाइप और टैग टेंप्लेट में जाकर, data_asset_governance पहलू का टाइप चुनें और उसे मिटाएं.
- मेटाडेटा मैनेज करें > शब्दावलियां पर जाएं. इसके बाद,
Retail Business Glossaryको चुनें और उसे मिटाएं. पक्का करें कि आपने सबसे पहलेGross Merchandise Valueशब्द को मिटाया हो. इसके बाद, शब्दावली मिटाएं.
8. बधाई हो!
आपने डेटा टैगिंग के सामान्य तरीके को छोड़कर, Knowledge Catalog में स्ट्रक्चर्ड गवर्नेंस मॉडल सेट अप कर लिया है.
आपने सीखा कि:
- ग्लोसरी से कारोबार के बारे में अस्पष्टता दूर होती है.
- पहलू के टाइप, तकनीकी मेटाडेटा के लिए स्कीमा अनुबंध उपलब्ध कराते हैं.
- पहलू, उस स्कीमा को असल डेटा एंट्री पर लागू करते हैं.
- नॉलेज कैटलॉग में खोज करने की सुविधा, सटीक खोज के लिए इस स्ट्रक्चर्ड मेटाडेटा का इस्तेमाल करती है.
आगे क्या करना है?
- गवर्नेंस ऐज़ कोड: वर्शन कंट्रोल में अपने पहलू के टाइप और शब्दावलियां तय करने के लिए, Google Cloud Terraform प्रोवाइडर का इस्तेमाल करें. इससे यह पक्का किया जा सकेगा कि डेवलपमेंट/टेस्ट/प्रोडक्शन एनवायरमेंट में एक जैसे स्कीमा इस्तेमाल किए जा रहे हैं.
- ऑटोमेटेड टैगिंग: एक Cloud फ़ंक्शन या Cloud Build चरण लिखें. यह नया डेटासेट बनाने पर ट्रिगर होता है. यह "डेटा ऐसेट गवर्नेंस" पहलू को डिफ़ॉल्ट वैल्यू (जैसे,
sensitivity=Internal, steward=TBD) के साथ अपने-आप जोड़ता है. साथ ही, समीक्षा के लिए इसे फ़्लैग करता है.