
1. 소개
개발자와 데이터 엔지니어는 데이터 늪과 같은 대규모 데이터 컬렉션을 상속받는 경우가 많습니다. 'amt' 열의 실제 정의는 무엇인가요?', '이 데이터 세트가 깨지면 누가 책임을 지지?' 또는 '개인 맞춤 추천 엔진에서 이 표를 사용해도 돼?'
기존의 데이터 카탈로그는 일관성이 없고 오래된 자유 형식 텍스트 태그로 채워진 수동 인벤토리였습니다. 구조를 강제하지 않으므로 프로그래매틱 거버넌스가 거의 불가능합니다.
이를 실용적으로 만들기 위해 이 실습에서는 원시 소매 판매 데이터에 대한 강력한 거버넌스를 설정하여 재무 부서에서 공식 보고에 사용할 수 있도록 하는 시나리오를 살펴봅니다. 이 데이터를 모호한 '늪' 상태에서 관리되는 제품으로 이동합니다.
Knowledge Catalog Universal Catalog는 활성 구조화된 메타데이터 관리 프레임워크를 제공하여 이 문제를 해결합니다. 이를 통해 구조화된 스키마 기반 메타데이터 (관점)와 승인된 비즈니스 정의 (용어집)를 데이터 애셋 (항목)에 직접 연결할 수 있습니다.
이 작업을 대규모로 자동화하는 Python 스크립트나 Terraform 모듈을 작성하려면 기본 객체 모델을 이해해야 합니다.
이 Codelab에서는 Google Cloud 콘솔에서 거버넌스 단계를 수동으로 실행합니다. 데이터를 검색 가능하고 이해 가능하며 신뢰할 수 있도록 만드는 방법을 명확하게 보여주기 위해 항목, 측면 유형, 측면, 용어집 간의 관계를 명시적으로 연결합니다.
기본 요건
- 소유자 또는 편집자 액세스 권한이 있는 Google Cloud 프로젝트
- Google Cloud 콘솔에 대한 기본 지식
- Cloud Shell의 기본 gcloud 및 bq CLI 기술
학습할 내용
- Knowledge Catalog 항목, 관점 유형, 관점 간의 중요한 구분
- 용어의 모호성을 해결하기 위해 비즈니스 용어집을 만드는 방법
- 기술 메타데이터에 엄격한 스키마를 적용하기 위해 관점 유형을 설계하는 방법('태그' 이상)
- 비즈니스 용어집 용어를 특정 BigQuery 열에 연결하는 방법
- 구조화된 측면을 데이터 애셋에 연결하고 입력을 검증하는 방법
- 이 새로운 구조화된 메타데이터에 대해 정확한 검색어를 실행하는 방법
필요한 항목
- Google Cloud 계정 및 Google Cloud 프로젝트
- 웹브라우저(예: Chrome)
주요 개념
- 항목: 카탈로그에 있는 데이터 애셋의 표준 추상적 표현입니다. '포인터' 또는 '명사'로 생각하면 됩니다. BigQuery 테이블을 만들면 Knowledge Catalog에서 자동으로 항목을 만듭니다. 테이블을 직접 관리하는 것이 아니라 항목을 관리합니다.
- 비즈니스 용어집: 조직의 비즈니스 용어를 중앙에서 관리하고 버전이 지정된 사전입니다. 단일 정보 소스입니다. '영업팀에서 재무팀과 다르게 GMV를 정의함' 문제를 방지합니다.
- 관점 유형: 특정 카테고리의 메타데이터 스키마 또는 템플릿입니다. 측면 유형은 필드, 데이터 유형 (문자열, enum, datetime 등), 제약 조건 (필수/선택사항)을 정의합니다. 메타데이터 일관성을 보장하는 계약입니다.
- 관점: 관점 유형에 의해 정의된 구조를 따르는 항목에 연결된 특정 메타데이터입니다. 여기에는 측면 유형의 스키마를 충족하는 실제 데이터가 포함됩니다.
2. 설정 및 요건
Cloud Shell 시작
Google Cloud를 노트북에서 원격으로 실행할 수 있지만, 이 Codelab에서는 Cloud에서 실행되는 명령줄 환경인 Google Cloud Shell을 사용합니다.
Google Cloud Console의 오른쪽 상단 툴바에 있는 Cloud Shell 아이콘을 클릭합니다.
환경을 프로비저닝하고 연결하는 데 몇 분 정도 소요됩니다. 완료되면 다음과 같이 표시됩니다.

가상 머신에는 필요한 개발 도구가 모두 들어있습니다. 영구적인 5GB 홈 디렉터리를 제공하고 Google Cloud에서 실행되므로 네트워크 성능과 인증이 크게 개선됩니다. 이 Codelab의 모든 작업은 브라우저 내에서 수행할 수 있습니다. 아무것도 설치할 필요가 없습니다.
필수 API 사용 설정 및 환경 구성
다음 명령어를 실행하여 프로젝트 ID를 설정하고, 리전을 정의하고, 필요한 서비스 API를 사용 설정합니다.
export PROJECT_ID=$(gcloud config get-value project)
gcloud config set project $PROJECT_ID
export LOCATION="us-central1"
gcloud services enable dataplex.googleapis.com \
bigquery.googleapis.com \
datacatalog.googleapis.com
BigQuery 데이터 세트 만들기 및 샘플 데이터 준비
관리할 구체적인 데이터 애셋이 필요합니다. BigQuery 데이터 세트를 만들고 트랜잭션을 나타내는 작은 샘플 CSV를 로드합니다. Knowledge Catalog가 이 테이블을 자동으로 검색하고 항목을 만듭니다.
# Create the BigQuery Dataset in the us-central1 region
bq --location=$LOCATION mk --dataset \
--description "Retail data for governance codelab" \
$PROJECT_ID:retail_data
# Create a temporary CSV file with the sample data
echo "transaction_id,user_email,gmv,transaction_date
1001,test@example.com,150.50,2025-08-28
1002,user@example.com,75.00,2025-08-28" > /tmp/transactions.csv
# Load the data from the temporary CSV file into BigQuery
bq load \
--source_format=CSV \
--autodetect \
retail_data.transactions \
/tmp/transactions.csv
# (Optional) Clean up the temporary file
rm /tmp/transactions.csv
빠른 쿼리를 실행하여 설정을 확인합니다.
bq query --nouse_legacy_sql "SELECT * FROM retail_data.transactions"
3. 비즈니스 용어집으로 공통 언어 설정
효과적인 거버넌스는 명확한 정의에서 시작됩니다. 개발자가 gmv이라는 열을 볼 때 세금이나 반품이 포함되어 있는지 추측할 필요가 없습니다. 비즈니스 용어집은 비즈니스 정의를 기술 구현과 분리하여 이 문제를 해결합니다.
- Google Cloud 콘솔에서 Knowledge Catalog Universal catalog으로 이동합니다.
- 왼쪽 탐색 메뉴에서 용어집 (메타데이터 관리 아래)을 선택합니다.
- 비즈니스 용어집 만들기를 클릭합니다.
- 다음 세부정보를 입력합니다.
- 이름:
Retail Business Glossary - 위치:
us-central1(또는 설정에서 정의한 위치)
- 이름:
- 만들기를 클릭합니다.
- 새로 만든 소매업 비즈니스 용어집을 클릭하여 입력합니다.

- 카테고리 만들기를 클릭하고 이름을
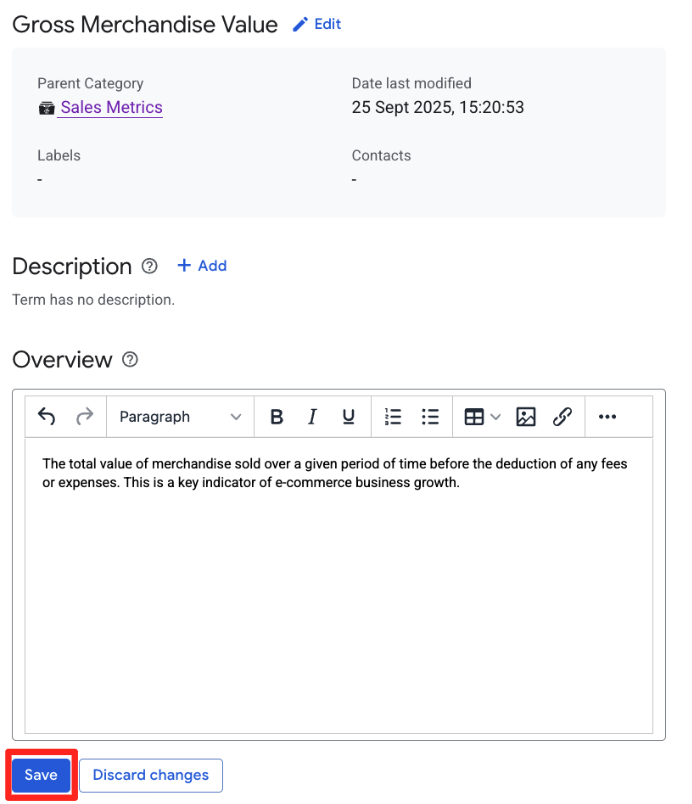
Sales Metrics로 지정한 다음 만들기를 클릭합니다. 카테고리는 관련 용어를 그룹화하는 데 도움이 됩니다. Sales Metrics카테고리를 선택하고 용어 추가를 클릭한 후Gross Merchandise Value라고 이름을 지정하고 만들기를 클릭합니다.- 개요에서 + 추가 버튼을 클릭한 다음 다음 세부정보를 입력합니다.
- 개요:
The total value of merchandise sold over a given period of time before the deduction of any fees or expenses. This is a key indicator of e-commerce business growth.
- 개요:
- 저장을 클릭합니다.
이제 조직 전반의 기술적 애셋에 연결할 수 있는 명확한 정의를 설정했습니다.
4. 관점 유형으로 구조화된 기술 메타데이터 정의
엔지니어링의 엄격성을 위해서는 간단한 'key:value' 태그가 충분하지 않습니다. '데이터 소유자'를 추적해야 하는 경우 한 테이블에 owner:bob 태그를 지정하고 다른 테이블에 contact:alice@example.com 태그를 지정하면 안 됩니다. 소유자가 필수이며 유효한 이메일 형식이어야 함을 적용하려면 스키마가 필요합니다.
관점 유형을 사용하여 이 계약을 정의합니다.
- Knowledge Catalog 왼쪽 탐색 메뉴의 카탈로그에서 관점 유형 및 태그 템플릿을 선택합니다.
- 맞춤 탭을 선택하고 관점 유형 만들기를 클릭합니다.
- 다음 세부정보를 입력합니다.
- Display name(표시 이름):
Data Asset Governance - 위치:
us-central1
- Display name(표시 이름):
- 템플릿 섹션에서
Aspect의 스키마를 정의합니다. 필드 추가를 클릭하여 다음 세 필드를 만듭니다.- 필드 1:
- Display name(표시 이름):
Data Steward - 유형:
Text - 텍스트 유형:
Plain text - 카디널리티: 필수 (체크박스 선택)
- Display name(표시 이름):
- 필드 2 (필드 추가를 다시 클릭):
- Display name(표시 이름):
Data Sensitivity - 유형:
Enum - 값:
Public,Internal,Confidential추가 - 다중성: 선택사항
- Display name(표시 이름):
- 필드 3 (필드 추가를 다시 클릭):
- Display name(표시 이름):
Last Review Date - 유형:
Date and time - 다중성: 선택사항
- Display name(표시 이름):
- 필드 1:
- 저장을 클릭합니다.
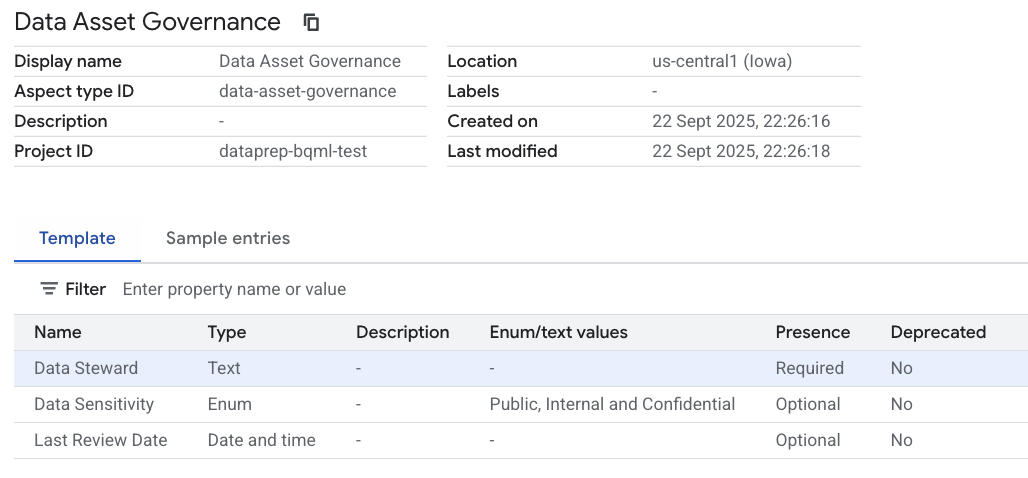
재사용 가능한 메타데이터 계약을 방금 만들었습니다. 아직 아무것도 사용하지 않지만 구조는 존재합니다.
5. 거버넌스를 애셋에 연결
이제 모든 내용을 종합해 보겠습니다. BigQuery 테이블(retail_data.transactions), 비즈니스 정의(Gross Merchandise Value), 거버넌스 스키마((Data Asset Governance)가 있습니다.
BigQuery 테이블의 Knowledge Catalog 항목이 보강됩니다.
비즈니스 컨텍스트 (열 수준)로 스키마 보강
용어집에 연결하여 사용자에게 gmv 열의 실제 의미를 알려주세요.
- Knowledge Catalog 왼쪽 탐색에서 검색을 클릭합니다.
- 오른쪽 상단에서 Knowledge Catalog Universal Catalog 탭이 활성화되지 않은 경우 이를 클릭합니다.
retail_data.transactions를 검색합니다. BigQuery 테이블의 결과를 클릭합니다.
- 항목 세부정보에서 스키마 탭을 클릭합니다.
gmv열 행의 체크박스를 선택하고 비즈니스 용어 추가를 클릭합니다.Gross Merchandise Value기간을 선택합니다.
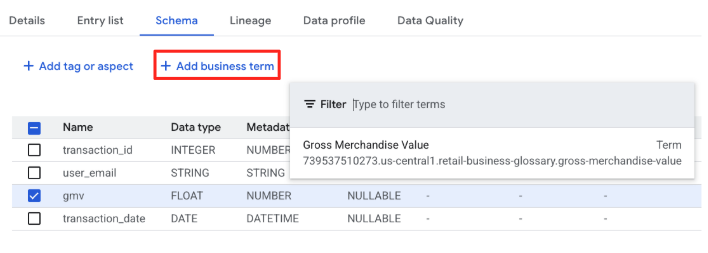
gmv 열은 더 이상 'FLOAT'가 아닙니다. 이제 Gross Merchandise Value의 회사 정의에 연결됩니다.
구조화된 기술 메타데이터 (표 수준)로 항목 보강
다음으로 Data Asset Governance Aspect를 표에 연결하여 소유권과 민감도를 정의합니다.
retail_data.transactions항목 페이지에 머무릅니다.- 태그 또는 관점 추가 탭을 클릭한 다음 드롭다운에서
Data Asset Governance유형을 선택합니다.
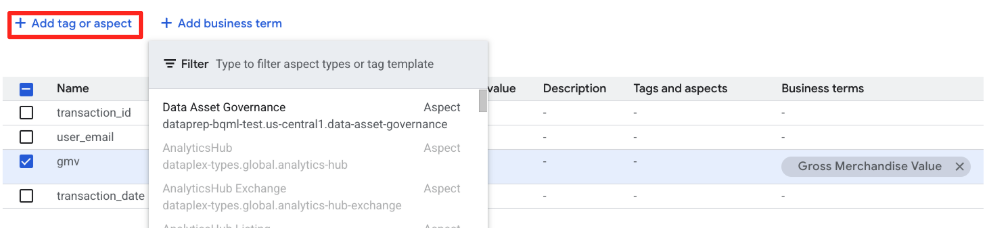
- 이제 양식에 관점 유형 스키마에 정의된 필드가 표시됩니다. 다음과 같이 작성합니다.
- 데이터 스튜어드:
finance-team@example.com - 데이터 민감도:
Internal을 선택합니다. - 최종 검토일: 오늘 날짜를 선택합니다.
- 데이터 스튜어드:
- 저장을 클릭합니다.
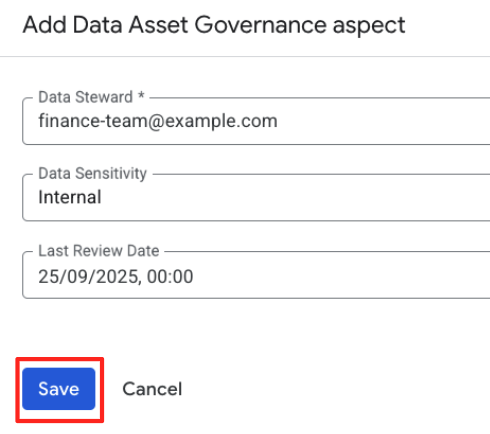
구조화된 측면을 항목에 성공적으로 연결했습니다. 단순 태그와 달리 이 데이터는 사용자가 만든 스키마에 대해 검증됩니다.
6. 통합 검색 및 인증
이 작업은 양식을 작성하기 위해서만 진행한 것이 아닙니다. 데이터를 검색 가능하고 신뢰할 수 있도록 하기 위해 진행했습니다. 이 메타데이터가 검색 및 탐색을 위한 개발자 환경을 어떻게 변화시키는지 살펴보겠습니다.
Knowledge Catalog Universal Catalog의 기본 검색 페이지로 돌아갑니다.
거버넌스를 적용하는 플랫폼 엔지니어라고 가정해 보겠습니다. 특정 관점 유형의 적용을 받는 '내부'로 표시된 모든 애셋을 찾아야 합니다. 스키마에 따라 정확한 술어를 사용해야 합니다.
정확한 쿼리 구문 (자동화에 필수)을 사용하거나 대화형 UI 필터를 사용하여 이를 확인할 수 있습니다.
방법 1: 구조화된 쿼리를 통해 확인
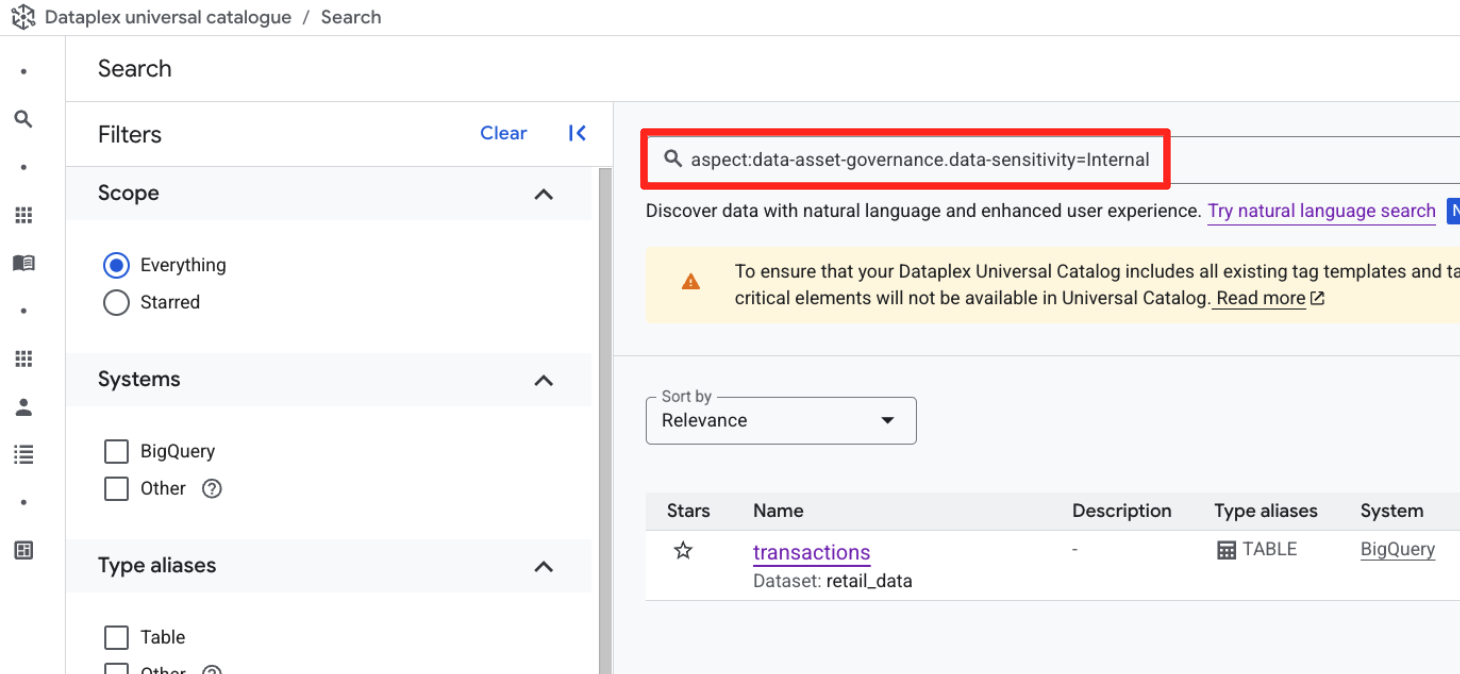
- 검색창 (키워드 검색 모드)에 다음 구조화된 쿼리를 입력합니다.
aspect:data-asset-governance.data-sensitivity=Internal
retail_data.transactions테이블이 표시됩니다.
방법 2: UI 필터 패싯을 통해 확인
- 검색창을 지워 뷰를 재설정합니다.
- 화면 왼쪽에 있는 속성별 필터링 패널을 확인합니다.
- 아래로 스크롤하여 데이터 애셋 거버넌스 섹션을 펼칩니다 (이 섹션은 사용자가 만든 관점 유형을 나타냄).
- 데이터 민감도에서
Internal체크박스를 선택합니다. - 검색 결과가 업데이트되어
retail_data.transactions표가 표시됩니다.
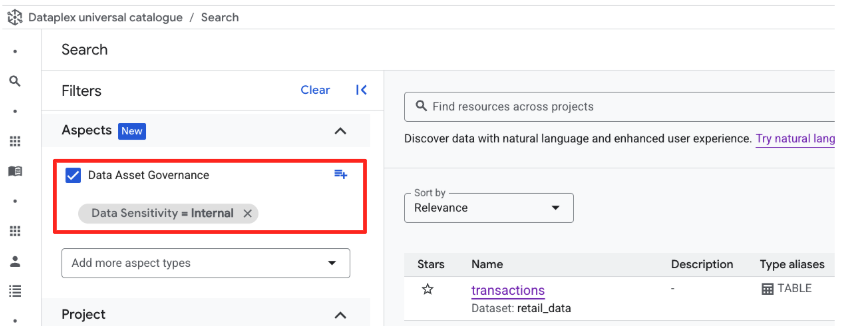
입력된 쿼리를 사용하든 UI 필터를 사용하든 기본 메커니즘은 동일합니다.
이는 Knowledge Catalog와 간단한 위키의 근본적인 차이점을 보여줍니다. 메타데이터가 쿼리 가능한 구조입니다. 이제 이 예측 가능한 구조를 기반으로 자동화된 감사 (예: 'last_review_date가 1년 전보다 큰 모든 테이블 찾기')를 빌드할 수 있습니다.
7. 환경 정리
요금이 계속 청구되지 않도록 하려면 이 Codelab에서 만든 리소스를 삭제합니다.
BigQuery 데이터 세트 삭제
이 명령어는 되돌릴 수 없으며 -f (강제) 플래그를 사용하여 확인 없이 데이터 세트와 모든 테이블을 삭제합니다.
# Re-run these exports if your Cloud Shell session timed out
export PROJECT_ID=$(gcloud config get-value project)
# Manually type this command to confirm you are deleting the correct dataset
bq rm -r -f --dataset $PROJECT_ID:retail_data
Knowledge Catalog 아티팩트 삭제
- Knowledge Catalog Universal catalog UI > 메타데이터 관리 > 카탈로그로 이동합니다.
- 관점 유형 및 태그 템플릿에서 data_asset_governance 관점 유형을 선택하고 삭제합니다.
- 메타데이터 관리 > 용어집으로 이동하여
Retail Business Glossary를 선택하고 삭제합니다. 먼저Gross Merchandise Value용어를 삭제한 후 용어집을 삭제해야 합니다.
8. 축하합니다.
단순한 데이터 태그를 넘어 Knowledge Catalog에서 기본적인 구조화된 거버넌스 모델을 설정했습니다.
다음과 같은 내용을 학습했습니다.
- 용어집은 비즈니스 모호성을 해결합니다.
- 관점 유형은 기술 메타데이터의 스키마 계약을 제공합니다.
- 측면은 실제 데이터 항목에 스키마를 적용합니다.
- Knowledge Catalog 검색은 정확한 검색을 위해 이 구조화된 메타데이터를 활용합니다.
다음 단계
- 코드로서의 거버넌스: Google Cloud Terraform 제공업체를 사용하여 버전 제어에서 측면 유형과 용어를 정의하여 개발/테스트/프로덕션 환경 전반에서 일관된 스키마를 보장합니다.
- 자동 태그 지정: 새 데이터 세트 생성에 의해 트리거되는 Cloud 함수 또는 Cloud Build 단계를 작성하여 기본값 (예:
sensitivity=Internal, steward=TBD)으로 '데이터 애셋 거버넌스' 측면을 자동으로 연결하고 검토를 위해 플래그를 지정합니다.