
1. Wprowadzenie
Jako programiści i inżynierowie danych często mamy do czynienia z dużymi zbiorami danych, które przypominają raczej bagna danych. Stale napotykamy te same problemy: „Co dokładnie oznacza kolumna »amt«?”, „Kto ponosi odpowiedzialność, jeśli ten zbiór danych ulegnie uszkodzeniu?” lub „Czy możemy używać tej tabeli w spersonalizowanym systemie rekomendacji?”.
Tradycyjnie katalogi danych były pasywnymi spisami wypełnionymi tagami w postaci tekstu dowolnego, które szybko stawały się niespójne i nieaktualne. Nie wymuszały one struktury, co niemal uniemożliwiało programowe zarządzanie.
Aby to zmienić, w tym laboratorium przeanalizujemy scenariusz: ustanowienie solidnego zarządzania surowymi danymi o sprzedaży detalicznej, tak aby dział finansowy mógł je uznać za wiarygodne na potrzeby oficjalnego raportowania. Przeniesiesz te dane z niejednoznacznego stanu „bagna” do stanu zarządzanego produktu.
Knowledge Catalog Universal Catalog zmienia to, udostępniając aktywny, uporządkowany system zarządzania metadanymi. Umożliwia on dołączanie uporządkowanych metadanych opartych na schemacie (aspektów) i zaakceptowanych definicji biznesowych (glosariuszy) bezpośrednio do zasobów danych (wpisów).
Zanim zaczniesz pisać skrypty w Pythonie lub moduły Terraform, aby zautomatyzować ten proces na dużą skalę, musisz zrozumieć podstawowy model obiektów.
W tym laboratorium wykonamy ręcznie kroki zarządzania w konsoli Google Cloud. Wyraźnie połączymy wpisy, typy aspektów, aspekty i glosariusze, aby stworzyć solidny model mentalny dotyczący tego, jak sprawić, by dane były łatwe do znalezienia, zrozumiałe i wiarygodne.
Wymagania wstępne
- Projekt Google Cloud z dostępem właściciela lub uprawnieniami do edycji.
- Znajomość konsoli Google Cloud.
- Podstawowe umiejętności korzystania z interfejsów wiersza poleceń gcloud i bq w Cloud Shell.
Czego się nauczysz
- Kluczowa różnica między wpisem Knowledge Catalog, typem aspektu i aspektem.
- Jak utworzyć glosariusz firmowy , aby wyeliminować niejednoznaczność terminologii.
- Jak zaprojektować typ aspektu , aby wymusić ścisły schemat metadanych technicznych (wykraczający poza „tagi”).
- Jak połączyć hasło w glosariuszu firmowym z konkretną kolumną BigQuery.
- Jak dołączyć uporządkowany aspekt do zasobu danych i zweryfikować dane wejściowe.
- Jak wykonywać precyzyjne zapytania w wyszukiwarce dotyczące tych nowych uporządkowanych metadanych.
Czego potrzebujesz
- Konto Google Cloud i projekt Google Cloud.
- Przeglądarka internetowa, np. Chrome.
Kluczowe pojęcia
- Wpis:kanoniczna, abstrakcyjna reprezentacja zasobu danych w katalogu. Można go traktować jako „wskaźnik” lub „rzeczownik”. Gdy utworzysz tabelę BigQuery, Knowledge Catalog automatycznie utworzy dla niej wpis. Nie zarządzamy bezpośrednio tabelą, ale jej wpisem.
- Glosariusz firmowy:scentralizowany, wersjonowany słownik terminów biznesowych Twojej organizacji. Jest to jedno źródło wiarygodnych danych. Zapobiega problemowi „dział sprzedaży definiuje GMV inaczej niż dział finansowy”.
- Typ aspektu:schemat lub szablon dla określonej kategorii metadanych. Typ aspektu określa pola, typy danych (ciąg znaków, wyliczenie, data i godzina itp.) oraz ograniczenia (wymagane/opcjonalne). Jest to umowa, która zapewnia spójność metadanych.
- Aspekt:konkretny fragment metadanych dołączony do wpisu, który jest zgodny ze strukturą zdefiniowaną przez typ aspektu. Zawiera rzeczywiste dane zgodne ze schematem typu aspektu.
2. Konfiguracja i wymagania
Uruchamianie Cloud Shell
Chociaż Google Cloud można obsługiwać zdalnie z laptopa, w tym laboratorium będziesz używać Google Cloud Shell, czyli środowiska wiersza poleceń działającego w chmurze.
W konsoli Google Cloud kliknij ikonę Cloud Shell na pasku narzędzi w prawym górnym rogu:
Uzyskanie dostępu do środowiska i połączenie się z nim może zająć kilka chwil. Gdy to się uda, zobaczysz coś takiego:

Ta maszyna wirtualna jest wyposażona we wszystkie narzędzia programistyczne, których będziesz potrzebować. Zawiera również stały katalog domowy o pojemności 5 GB i działa w Google Cloud, co znacznie zwiększa wydajność sieci i usprawnia proces uwierzytelniania. Wszystkie zadania w tym laboratorium możesz wykonać w przeglądarce. Nie musisz niczego instalować.
Włączanie wymaganych interfejsów API i konfigurowanie środowiska
Uruchom te polecenia, aby ustawić identyfikator projektu, zdefiniować region i włączyć niezbędne interfejsy API usługi.
export PROJECT_ID=$(gcloud config get-value project)
gcloud config set project $PROJECT_ID
export LOCATION="us-central1"
gcloud services enable dataplex.googleapis.com \
bigquery.googleapis.com \
datacatalog.googleapis.com
Tworzenie zbioru danych BigQuery i przygotowywanie przykładowych danych
Potrzebujemy konkretnego zasobu danych, którym będziemy zarządzać. Utworzymy zbiór danych BigQuery i wczytamy mały przykładowy plik CSV reprezentujący transakcje. Knowledge Catalog automatycznie wykryje tę tabelę i utworzy dla niej wpis.
# Create the BigQuery Dataset in the us-central1 region
bq --location=$LOCATION mk --dataset \
--description "Retail data for governance codelab" \
$PROJECT_ID:retail_data
# Create a temporary CSV file with the sample data
echo "transaction_id,user_email,gmv,transaction_date
1001,test@example.com,150.50,2025-08-28
1002,user@example.com,75.00,2025-08-28" > /tmp/transactions.csv
# Load the data from the temporary CSV file into BigQuery
bq load \
--source_format=CSV \
--autodetect \
retail_data.transactions \
/tmp/transactions.csv
# (Optional) Clean up the temporary file
rm /tmp/transactions.csv
Aby sprawdzić konfigurację, uruchom szybkie zapytanie:
bq query --nouse_legacy_sql "SELECT * FROM retail_data.transactions"
3. Ustalanie wspólnego języka za pomocą glosariusza firmowego
Skuteczne zarządzanie zaczyna się od jednoznacznych definicji. Jeśli programista zobaczy kolumnę o nazwie gmv, nie powinien zgadywać, czy obejmuje ona podatki lub zwroty. Glosariusz firmowy rozwiązuje ten problem, oddzielając definicję biznesową od implementacji technicznej.
- W konsoli Google Cloud otwórz Knowledge Catalog Universal Catalog.
- W lewym menu nawigacyjnym wybierz Glosariusze (w sekcji Zarządzaj metadanymi).
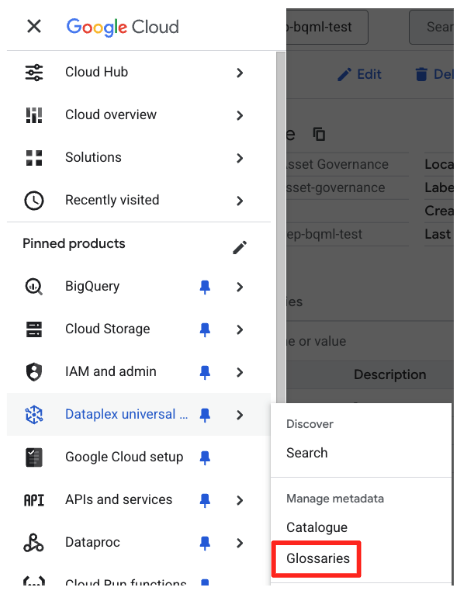
- Kliknij Utwórz glosariusz firmowy.
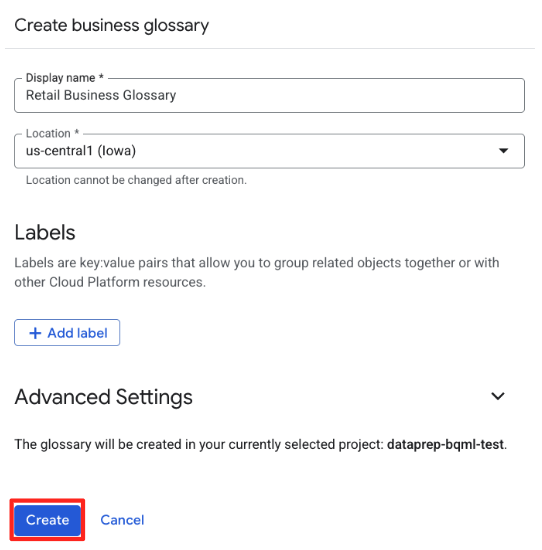
- Wpisz te dane:
- Nazwa:
Retail Business Glossary - Lokalizacja:
us-central1(lub lokalizacja zdefiniowana w konfiguracji).
- Nazwa:
- Kliknij Utwórz.
- Kliknij nowo utworzony Retail Business Glossary , aby go otworzyć.

- Kliknij Utwórz kategorię, nadaj jej nazwę
Sales Metricsi kliknij Utwórz. Kategorie ułatwiają grupowanie powiązanych terminów. - Wybierz kategorię
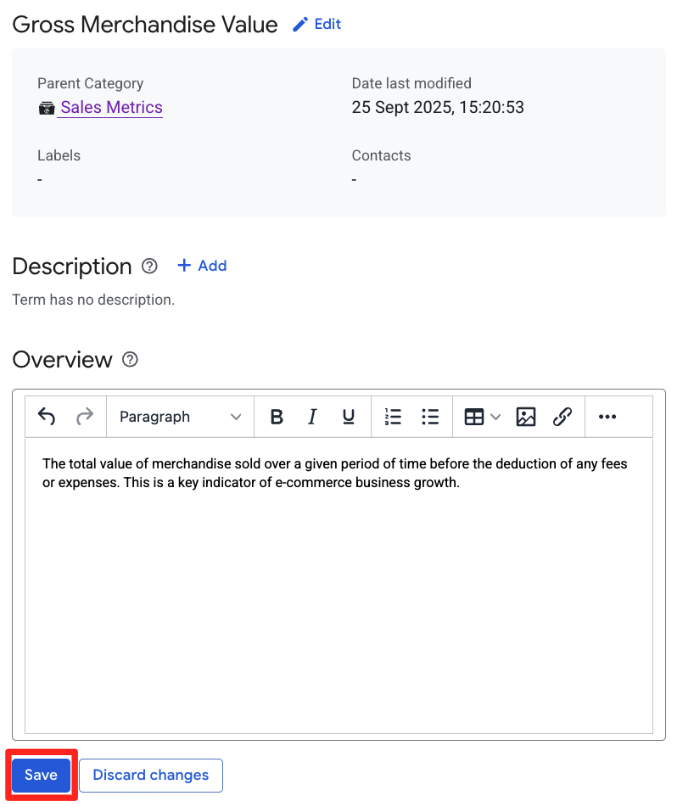
Sales Metricsi kliknij Dodaj hasło, a następnie nadaj mu nazwęGross Merchandise Valuei kliknij Utwórz - Kliknij przycisk + Dodaj w sekcji Przegląd, a następnie wpisz te dane:
- Przegląd:
The total value of merchandise sold over a given period of time before the deduction of any fees or expenses. This is a key indicator of e-commerce business growth.
- Przegląd:
- Kliknij Zapisz.
Udało Ci się utworzyć jasną definicję, którą można połączyć z zasobami technicznymi w całej organizacji.
4. Definiowanie uporządkowanych metadanych technicznych za pomocą typu aspektu
Proste tagi „klucz:wartość” są niewystarczające do zapewnienia rygoru inżynieryjnego. Jeśli musisz śledzić „właścicieli danych”, nie chcesz, aby jedna tabela była oznaczona tagiem owner:bob, a druga contact:alice@example.com. Potrzebujesz schematu, który wymusi, aby właściciel był wymagany i musiał mieć prawidłowy format adresu e-mail.
Do zdefiniowania tej umowy użyjemy typu aspektu.
- W menu po lewej stronie Knowledge Catalog w sekcji Katalog kliknij Typy aspektów i szablony tagów.
- Kliknij kartę Niestandardowy i kliknij Utwórz typ aspektu.
- Wpisz te dane:
- Nazwa wyświetlana:
Data Asset Governance - Lokalizacja:
us-central1
- Nazwa wyświetlana:
- W sekcji Szablon zdefiniujemy schemat naszego
Aspect. Kliknij Dodaj pole , aby utworzyć te 3 pola:- Pole 1:
- Nazwa wyświetlana:
Data Steward - Typ:
Text - Typ tekstu:
Plain text - Kardynalność: wymagana (zaznacz pole)
- Nazwa wyświetlana:
- Pole 2 (ponownie kliknij Dodaj pole ):
- Nazwa wyświetlana:
Data Sensitivity - Typ:
Enum - Wartości: dodaj
Public,InternaliConfidential - Kardynalność: opcjonalna
- Nazwa wyświetlana:
- Pole 3 (ponownie kliknij Dodaj pole ):
- Nazwa wyświetlana:
Last Review Date - Typ:
Date and time - Kardynalność: opcjonalna
- Nazwa wyświetlana:
- Pole 1:
- Kliknij Zapisz.
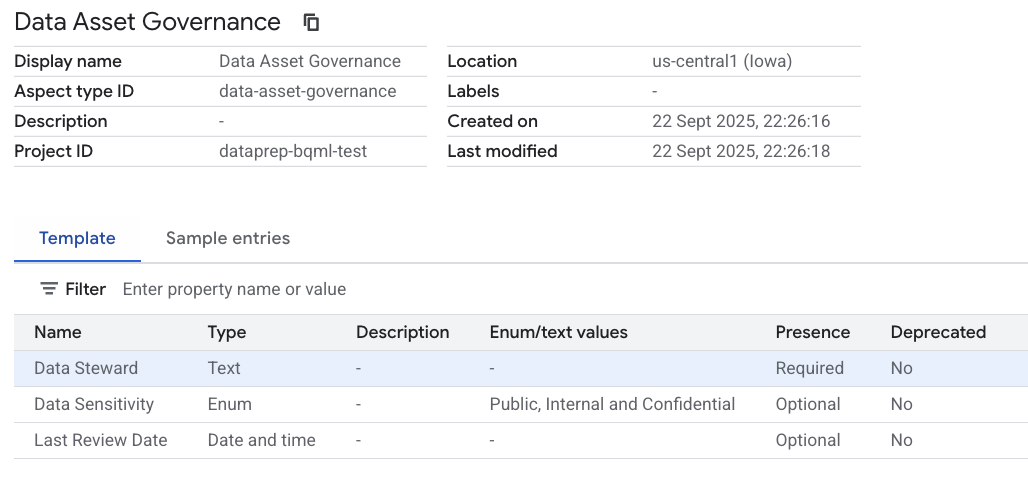
Udało Ci się utworzyć umowę dotyczącą metadanych, którą można wykorzystać wielokrotnie. Na razie nic jej nie używa, ale struktura już istnieje.
5. Łączenie zarządzania z zasobem
Teraz połączymy wszystkie informacje. Mamy tabelę BigQuery (retail_data.transactions), definicję biznesową (Gross Merchandise Value) i schemat zarządzania (Data Asset Governance).
Wzbogacimy wpis Knowledge Catalog dotyczący tabeli BigQuery.
Wzbogacanie schematu o kontekst biznesowy (na poziomie kolumny)
Poinformujmy użytkowników, co oznacza kolumna gmv, łącząc ją z glosariuszem.
- W menu po lewej stronie Knowledge Catalog kliknij Szukaj.
- W prawym górnym rogu kliknij kartę Knowledge Catalog Universal Catalog, jeśli nie została aktywowana.
- Wyszukaj
retail_data.transactions. Kliknij wynik dotyczący tabeli BigQuery.
- W szczegółach wpisu kliknij kartę Schemat.
- Zaznacz pole w wierszu kolumny
gmvi kliknij Dodaj termin biznesowy. - Wybierz termin
Gross Merchandise Value.
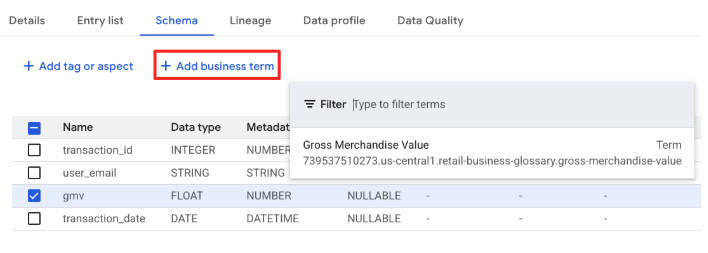
Kolumna gmv nie jest już tylko „FLOAT”; jest teraz połączona z definicją firmową Gross Merchandise Value.
Wzbogacanie wpisu o uporządkowane metadane techniczne (na poziomie tabeli)
Następnie dołączymy do tabeli aspekt Data Asset Governance, aby zdefiniować własność i wrażliwość.
- Pozostań na stronie wpisu
retail_data.transactions. - Kliknij kartę Dodaj tag lub aspekt, a następnie w menu wybierz typ
Data Asset Governance.
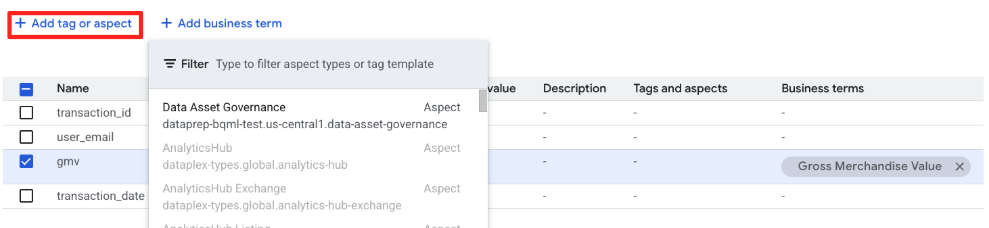
- W formularzu wyświetlą się pola zdefiniowane w schemacie typu aspektu. Wypełnij je w ten sposób:
- Data Steward:
finance-team@example.com - Data Sensitivity: wybierz
Internal. - Last Review Date: wybierz dzisiejszą datę.
- Data Steward:
- Kliknij Zapisz.
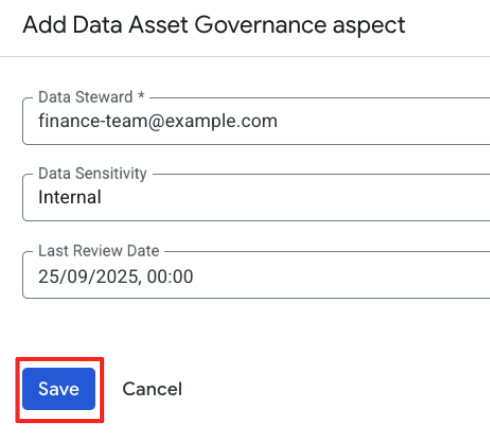
Udało Ci się dołączyć uporządkowany aspekt do wpisu. W przeciwieństwie do prostego tagu te dane są weryfikowane na podstawie utworzonego przez Ciebie schematu.
6. Ujednolicone wykrywanie i weryfikacja
Nie wykonaliśmy tej pracy tylko po to, aby wypełnić formularze. Zrobiliśmy to, aby dane były łatwe do znalezienia i wiarygodne. Zobaczmy, jak te metadane zmieniają sposób, w jaki programiści wyszukują i odkrywają dane.
Wróć na główną stronę Szukaj w Knowledge Catalog Universal Catalog.
Wyobraź sobie, że jesteś inżynierem platformy, który wymusza zarządzanie. Musisz znaleźć wszystkie zasoby oznaczone jako „Internal”, które podlegają Twojemu konkretnemu typowi aspektu. Musisz używać precyzyjnych predykatów opartych na schemacie.
Możesz to sprawdzić na 2 sposoby: za pomocą precyzyjnej składni zapytania (niezbędnej do automatyzacji) lub za pomocą interaktywnych filtrów interfejsu.
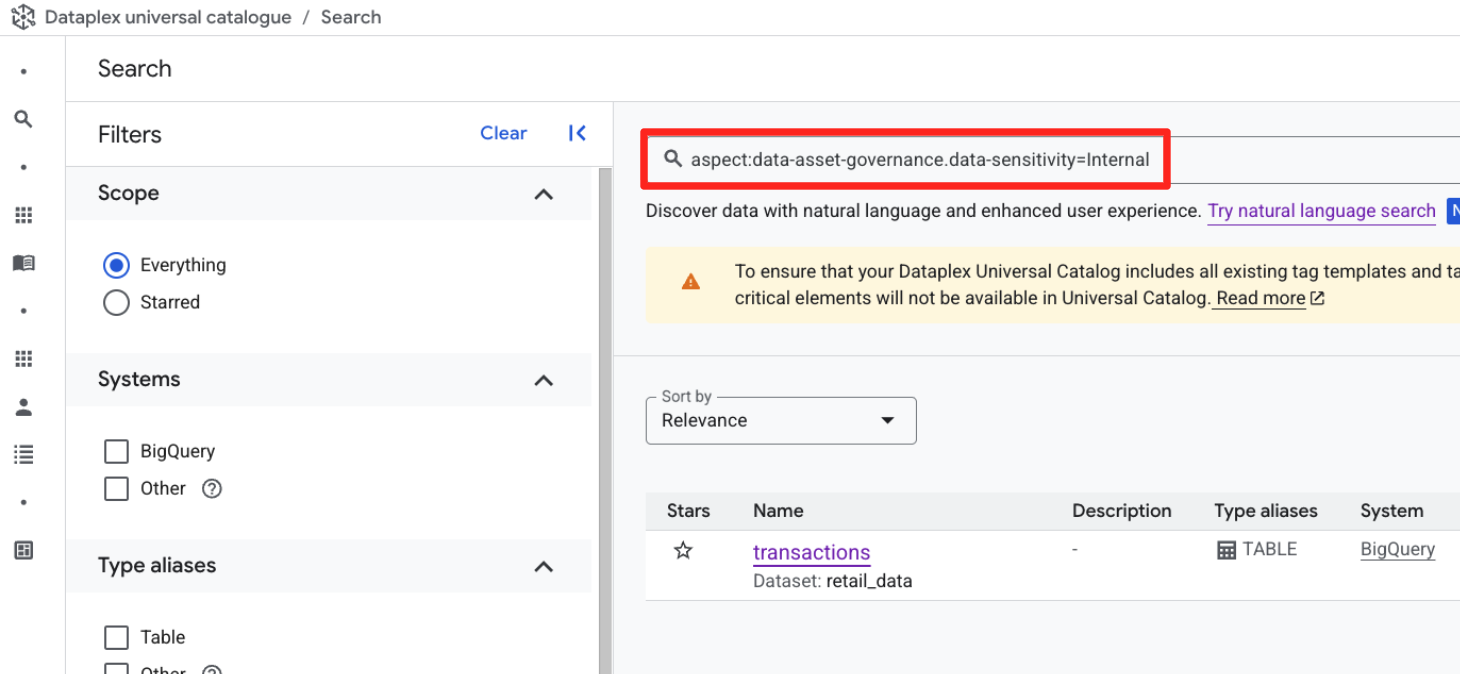
Metoda 1. Sprawdzanie za pomocą zapytania strukturalnego
- Na pasku wyszukiwania (w trybie wyszukiwania słów kluczowych) wpisz to zapytanie strukturalne.
aspect:data-asset-governance.data-sensitivity=Internal
- Powinna się wyświetlić tabela
retail_data.transactions.
Metoda 2. Sprawdzanie za pomocą aspektów filtra interfejsu
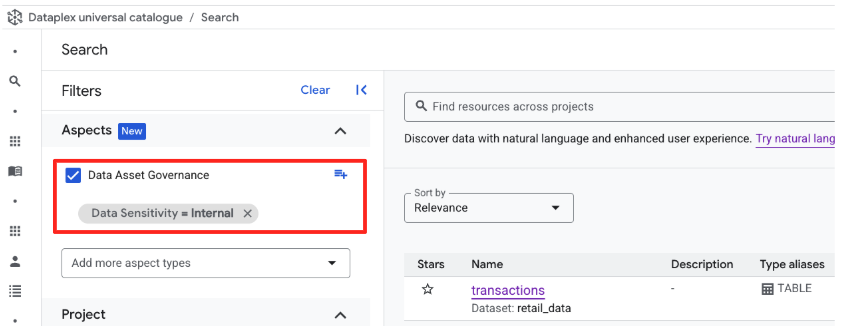
- Wyczyść pasek wyszukiwania, aby zresetować widok.
- Spójrz na panel Filtruj według właściwości po lewej stronie ekranu.
- Przewiń w dół i rozwiń sekcję Data Asset Governance (reprezentuje ona utworzony przez Ciebie typ aspektu).
- W sekcji Data Sensitivity zaznacz pole
Internal. - Wyniki wyszukiwania zostaną zaktualizowane i będzie w nich widoczna tabela
retail_data.transactions.
Niezależnie od tego, czy używasz wpisanego zapytania, czy filtrów interfejsu, mechanizm działania jest taki sam.
Pokazuje to zasadniczą różnicę między Knowledge Catalog a prostą wiki: Twoje metadane to struktura, którą można przeszukiwać. Możesz teraz tworzyć zautomatyzowane audyty (np. „Znajdź wszystkie tabele, w których last_review_date jest starsza niż rok”) oparte na tej przewidywalnej strukturze.
7. Czyszczenie środowiska
Aby uniknąć naliczania opłat, usuń zasoby utworzone w tym laboratorium.
Usuwanie zbioru danych BigQuery
To polecenie jest nieodwracalne i używa flagi -f (force), aby usunąć zbiór danych i wszystkie jego tabele bez potwierdzenia.
# Re-run these exports if your Cloud Shell session timed out
export PROJECT_ID=$(gcloud config get-value project)
# Manually type this command to confirm you are deleting the correct dataset
bq rm -r -f --dataset $PROJECT_ID:retail_data
Usuwanie artefaktów Knowledge Catalog
- Otwórz Knowledge Catalog Universal Catalog UI > Zarządzaj metadanymi > Katalog.
- W sekcji Typy aspektów i szablony tagów wybierz typ aspektu data_asset_governance i usuń go.
- Otwórz Zarządzaj metadanymi > Glosariusze , wybierz
Retail Business Glossaryi usuń go. Najpierw usuń hasłoGross Merchandise Value, a potem glosariusz.
8. Gratulacje!
Udało Ci się wyjść poza proste oznaczanie danych i utworzyć podstawowy, uporządkowany model zarządzania w Knowledge Catalog.
Wiesz już, że:
- Glosariusze eliminują niejednoznaczność biznesową.
- Typy aspektów zapewniają umowę schematu dla metadanych technicznych.
- Aspekty stosują ten schemat do rzeczywistych wpisów danych.
- Wyszukiwarka Knowledge Catalog wykorzystuje te uporządkowane metadane do precyzyjnego wykrywania.
Co dalej?
- Zarządzanie jako kod: użyj aprowizatora Google Cloud Terraform, aby zdefiniować typy aspektów i glosariusze w systemie kontroli wersji, zapewniając spójne schematy w środowiskach deweloperskich, testowych i produkcyjnych.
- Automatyczne oznaczanie: napisz funkcję Cloud lub krok Cloud Build wywoływany przez utworzenie nowego zbioru danych, który automatycznie dołącza aspekt „Data Asset Governance” z wartościami domyślnymi (np.
sensitivity=Internal, steward=TBD), oznaczając go do sprawdzenia.