
1. Einführung
In dieser Anleitung erfahren Sie, wie Sie einen leistungsstarken Agenten, der mit dem Agent Development Kit (ADK) erstellt wurde, in Google Cloud Run bereitstellen, verwalten und überwachen. Mit dem ADK können Sie Agents erstellen, die komplexe Workflows mit mehreren Agents ausführen können. Mit Cloud Run, einer vollständig verwalteten serverlosen Plattform, können Sie Ihren Agent als skalierbare, containerisierte Anwendung bereitstellen, ohne sich um die zugrunde liegende Infrastruktur kümmern zu müssen. Dank dieser leistungsstarken Kombination können Sie sich auf die Kernlogik Ihres Agenten konzentrieren und gleichzeitig von der robusten und skalierbaren Umgebung von Google Cloud profitieren.
In diesem Tutorial wird die nahtlose Integration des ADK in Cloud Run erläutert. Sie erfahren, wie Sie Ihren Agent bereitstellen und dann die praktischen Aspekte der Verwaltung Ihrer Anwendung in einer produktionsähnlichen Umgebung kennenlernen. Wir zeigen Ihnen, wie Sie neue Versionen Ihres Agents sicher einführen können, indem Sie den Traffic verwalten. So können Sie neue Funktionen mit einer Teilmenge von Nutzern testen, bevor Sie sie vollständig veröffentlichen.
Außerdem sammeln Sie praktische Erfahrungen bei der Überwachung der Leistung Ihres Agenten. Wir simulieren ein reales Szenario, indem wir einen Lasttest durchführen, um die automatischen Skalierungsfunktionen von Cloud Run in Aktion zu beobachten. Um detailliertere Informationen zum Verhalten und zur Leistung Ihres Agents zu erhalten, aktivieren wir das Tracing mit Cloud Trace. So erhalten Sie einen detaillierten End-to-End-Überblick über Anfragen, während sie durch Ihren Agent laufen. Dadurch können Sie Leistungsengpässe identifizieren und beheben. Am Ende dieser Anleitung haben Sie ein umfassendes Verständnis davon, wie Sie Ihre ADK-basierten Agenten in Cloud Run effektiv bereitstellen, verwalten und überwachen.
In diesem Codelab gehen Sie schrittweise so vor:
- PostgreSQL-Datenbank in Cloud SQL erstellen, die für den ADK Agent-Datenbanksitzungsdienst verwendet werden soll
- Einfachen ADK-Agent einrichten
- Datenbanksitzungsdienst für die Verwendung durch ADK-Runner einrichten
- Agent in Cloud Run bereitstellen
- Cloud Run-Autoscaling mit Lasttests prüfen
- Neue Agent-Überarbeitung bereitstellen und Traffic zu neuen Überarbeitungen schrittweise erhöhen
- Cloud-Tracing einrichten und Agent-Lauf-Tracing prüfen
Architekturübersicht
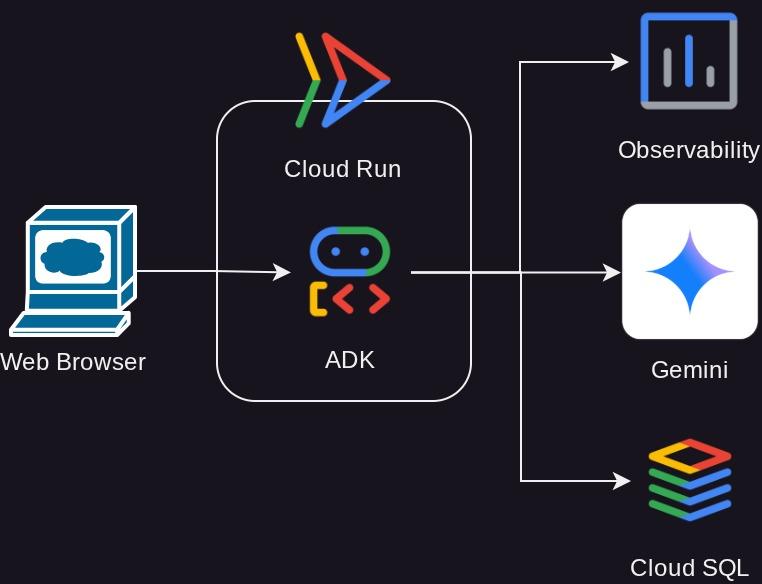
Voraussetzungen
- Vertrautheit mit Python
- Grundkenntnisse der Full-Stack-Architektur mit HTTP-Dienst
Lerninhalte
- ADK-Struktur und lokale Dienstprogramme
- ADK-Agent mit dem Datenbank-Sitzungsdienst einrichten
- PostgreSQL in Cloud SQL für die Verwendung durch den Datenbank-Sitzungsdienst einrichten
- Anwendung mit Dockerfile in Cloud Run bereitstellen und anfängliche Umgebungsvariablen einrichten
- Autoscaling in Cloud Run mit Lasttests konfigurieren und testen
- Strategie für die schrittweise Veröffentlichung mit Cloud Run
- ADK-KI-Agenten-Tracing für Cloud Trace einrichten
Voraussetzungen
- Chrome-Webbrowser
- Ein Gmail-Konto
- Ein Cloud-Projekt mit aktivierter Abrechnung
In diesem Codelab, das sich an Entwickler*innen aller Erfahrungsstufen (auch Anfänger*innen) richtet, wird Python in der Beispielanwendung verwendet. Python-Kenntnisse sind jedoch nicht erforderlich, um die vorgestellten Konzepte zu verstehen.
2. 🚀 Vorbereitung der Workshop-Einrichtung
In dieser Anleitung verwenden wir die Cloud Shell-IDE. Klicken Sie auf die folgende Schaltfläche, um sie aufzurufen.
Klonen Sie in Cloud Shell das Arbeitsverzeichnis für diese Codelab-Vorlage von GitHub, indem Sie den folgenden Befehl ausführen. Das Arbeitsverzeichnis wird im Verzeichnis deploy_and_manage_adk erstellt.
git clone https://github.com/alphinside/deploy-and-manage-adk-service.git deploy_and_manage_adk
Führen Sie dann den folgenden Befehl im Terminal aus, um das geklonte Repository als Arbeitsverzeichnis zu öffnen.
cloudshell workspace ~/deploy_and_manage_adk && cd ~/deploy_and_manage_adk
Danach sollte die Benutzeroberfläche in etwa so aussehen:
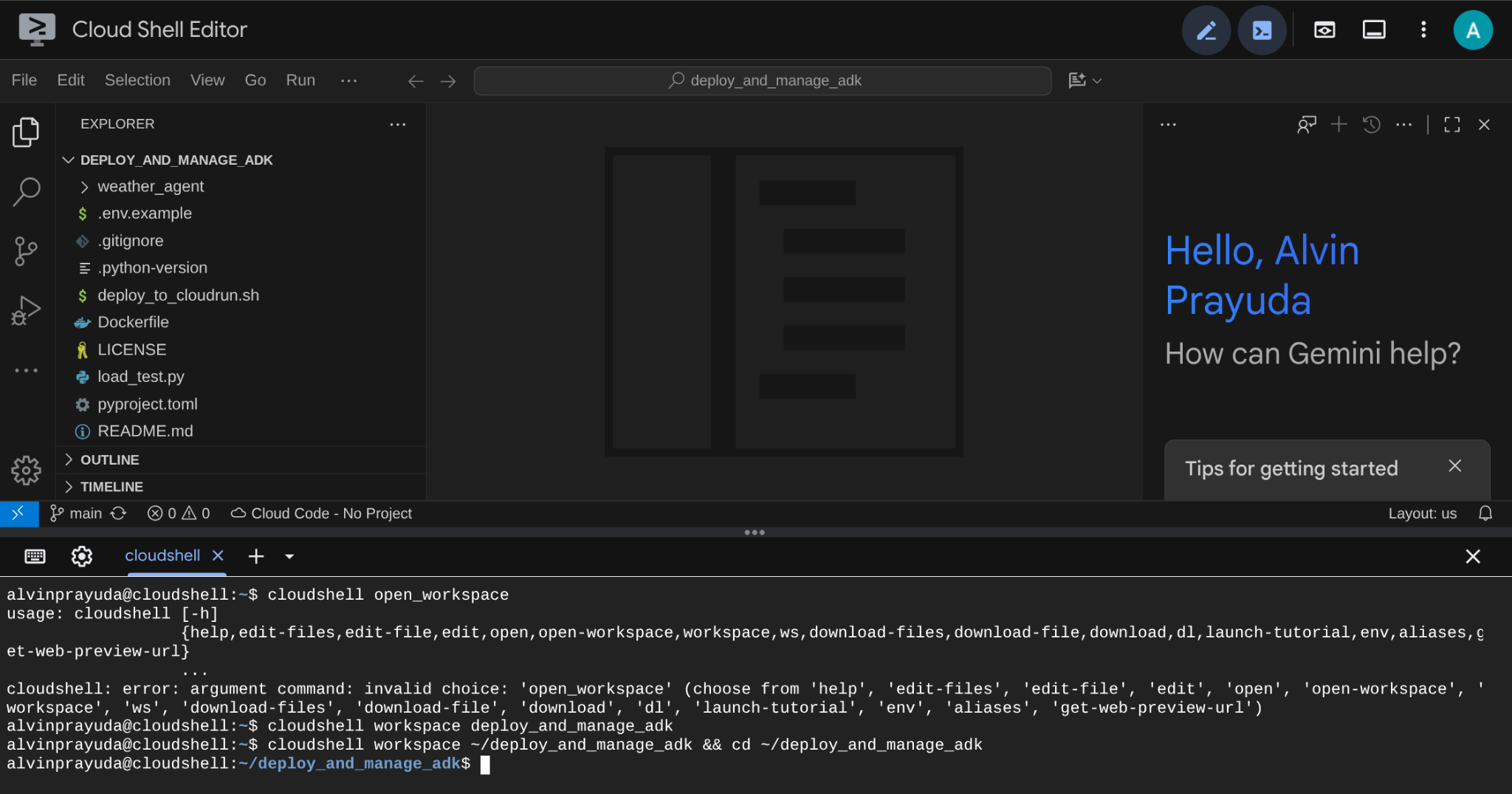
Dies ist unsere Hauptoberfläche. Die IDE befindet sich oben und das Terminal unten. Jetzt müssen wir unser Terminal vorbereiten, um unser Google Cloud-Projekt zu erstellen und zu aktivieren, das mit dem zuvor beanspruchten Testabrechnungskonto verknüpft wird. Wir haben ein Skript für Sie vorbereitet, mit dem Sie dafür sorgen können, dass Ihre Terminalsitzung immer bereit ist. Führen Sie den folgenden Befehl aus ( achten Sie darauf, dass Sie sich bereits im Arbeitsbereich deploy_and_manage_adk befinden):
bash setup_trial_project.sh && source .env
Wenn Sie diesen Befehl ausführen, werden Sie aufgefordert, einen Namen für die Projekt-ID einzugeben. Drücken Sie Enter, um fortzufahren.

Wenn Sie nach einiger Zeit diese Ausgabe in der Console sehen, können Sie mit dem nächsten Schritt fortfahren. 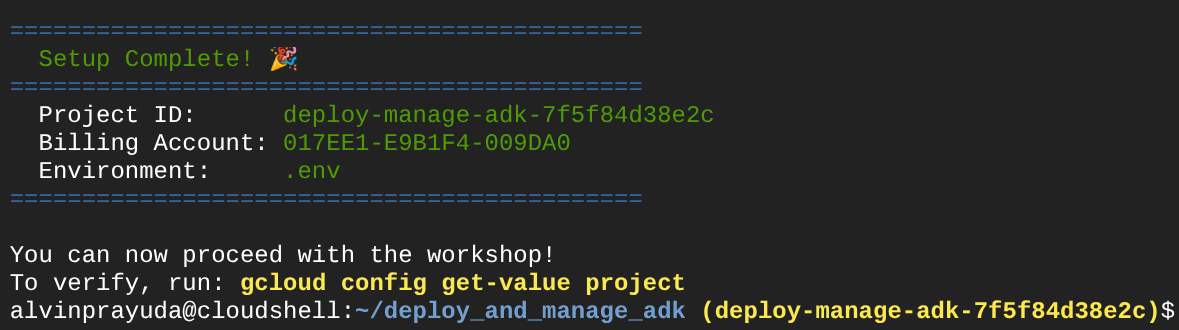
Das zeigt, dass Ihr Terminal bereits authentifiziert und auf die richtige Projekt-ID eingestellt ist ( die gelbe Farbe neben dem aktuellen Verzeichnispfad). Mit diesem Befehl können Sie ein neues Projekt erstellen, das Projekt suchen und mit einem Testabrechnungskonto verknüpfen, die .env-Datei für die Umgebungsvariablenkonfiguration vorbereiten und die richtige Projekt-ID im Terminal aktivieren.
Jetzt sind wir bereit für den nächsten Schritt.
3. 🚀 APIs aktivieren
In diesem Tutorial interagieren wir mit der CloudSQL-Datenbank, dem Gemini-Modell und Cloud Run. Für diese Produkte muss die folgende API aktiviert sein. Führen Sie die folgenden Befehle aus, um sie zu aktivieren.
Das kann etwas dauern.
gcloud services enable aiplatform.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
cloudresourcemanager.googleapis.com \
sqladmin.googleapis.com \
compute.googleapis.com
Bei erfolgreicher Ausführung des Befehls sollte eine Meldung wie die unten gezeigte angezeigt werden:
Operation "operations/..." finished successfully.
4. 🚀 Python-Umgebung einrichten und Umgebungsvariablen festlegen
In diesem Codelab verwenden wir Python 3.12 und den uv-Python-Projektmanager, um das Erstellen und Verwalten von Python-Versionen und virtuellen Umgebungen zu vereinfachen. Das uv-Paket ist bereits in Cloud Shell vorinstalliert.
Führen Sie diesen Befehl aus, um die erforderlichen Abhängigkeiten in der virtuellen Umgebung im Verzeichnis .venv zu installieren.
uv sync --frozen
Als Nächstes sehen wir uns die erforderlichen Umgebungsvariablendateien für dieses Projekt an. Bisher wurde diese Datei mit dem Skript setup_trial_project.sh eingerichtet. Führen Sie den folgenden Befehl aus, um die Datei .env im Editor zu öffnen.
cloudshell open .env
Die folgenden Konfigurationen sind bereits in der Datei .env enthalten.
# .env # Google Cloud and Vertex AI configuration GOOGLE_CLOUD_PROJECT=your-project-id GOOGLE_CLOUD_LOCATION=global GOOGLE_GENAI_USE_VERTEXAI=True # Database connection for session service # DB_CONNECTION_NAME=your-db-connection-name
In diesem Codelab verwenden wir die vorkonfigurierten Werte für GOOGLE_CLOUD_LOCATION und GOOGLE_GENAI_USE_VERTEXAI..
Nun können wir mit dem nächsten Schritt fortfahren und die Datenbank erstellen, die von unserem Agenten für die Status- und Sitzungspersistenz verwendet werden soll.
5. 🚀 CloudSQL-Datenbank vorbereiten
Wir benötigen eine Datenbank, die später vom ADK-Agenten verwendet werden kann. Wir erstellen eine PostgreSQL-Datenbank in Cloud SQL. Führen Sie den folgenden Befehl aus, um zuerst die Datenbankinstanz zu erstellen. Wir verwenden den Standarddatenbanknamen postgres. Die Datenbankerstellung wird daher übersprungen. Wir müssen auch den Standardnutzernamen für die Datenbank konfigurieren (ebenfalls postgres). Für dieses Tutorial verwenden wir ADK-deployment123 als Passwort.
gcloud sql instances create adk-deployment \
--database-version=POSTGRES_17 \
--edition=ENTERPRISE \
--tier=db-g1-small \
--region=us-west1 \
--availability-type=ZONAL \
--project=${GOOGLE_CLOUD_PROJECT} && \
gcloud sql users set-password postgres \
--instance=adk-deployment \
--password=ADK-deployment123
Im obigen Befehl ist der erste allgemeine gcloud sql instances create adk-deployment ein Befehl, mit dem wir die Datenbankinstanz erstellen. In dieser Anleitung verwenden wir eine Sandbox mit minimalen Spezifikationen. Mit dem zweiten Befehl gcloud sql users set-password postgres wird das Passwort für den Standardnutzernamen postgres geändert.
Wir verwenden adk-deployment als Namen der Datenbankinstanz. Wenn der Vorgang abgeschlossen ist, sollte im Terminal eine Ausgabe wie unten zu sehen sein, die angibt, dass die Instanz bereit ist und das Standardnutzerpasswort aktualisiert wurde.
Created [https://sqladmin.googleapis.com/sql/v1beta4/projects/your-project-id/instances/adk-deployment]. NAME: adk-deployment DATABASE_VERSION: POSTGRES_17 LOCATION: us-west1-a TIER: db-g1-small PRIMARY_ADDRESS: xx.xx.xx.xx PRIVATE_ADDRESS: - STATUS: RUNNABLE Updating Cloud SQL user...done.
Die Bereitstellung dieser Datenbank dauert einige Zeit. Fahren Sie daher mit dem nächsten Abschnitt fort, während Sie darauf warten, dass die Bereitstellung der Cloud SQL-Datenbank abgeschlossen ist.
6. 🚀 Wetter-Agent mit ADK und Gemini 2.5 erstellen
Einführung in die ADK-Verzeichnisstruktur
Sehen wir uns zuerst an, was das ADK zu bieten hat und wie Sie den Agent erstellen. Die vollständige ADK-Dokumentation finden Sie unter dieser URL . Das ADK bietet viele Dienstprogramme für die Ausführung von CLI-Befehlen. Einige davon sind :
- Agentenverzeichnisstruktur einrichten
- Schnelles Ausprobieren der Interaktion über die CLI-Ein- und -Ausgabe
- Schnelle Einrichtung der Web-Benutzeroberfläche für die lokale Entwicklung
Sehen wir uns nun die Agentenstruktur im Verzeichnis weather_agent an.
weather_agent/ ├── __init__.py ├── agent.py └── tool.py
Wenn Sie init.py und agent.py untersuchen, sehen Sie diesen Code.
# __init__.py
from weather_agent.agent import root_agent
__all__ = ["root_agent"]
# agent.py
import os
from pathlib import Path
import google.auth
from dotenv import load_dotenv
from google.adk.agents import Agent
from weather_agent.tool import get_weather
# Load environment variables from .env file in root directory
root_dir = Path(__file__).parent.parent
dotenv_path = root_dir / ".env"
load_dotenv(dotenv_path=dotenv_path)
# Use default project from credentials if not in .env
_, project_id = google.auth.default()
os.environ.setdefault("GOOGLE_CLOUD_PROJECT", project_id)
os.environ.setdefault("GOOGLE_CLOUD_LOCATION", "global")
os.environ.setdefault("GOOGLE_GENAI_USE_VERTEXAI", "True")
root_agent = Agent(
name="weather_agent",
model="gemini-2.5-flash",
instruction="""
You are a helpful AI assistant designed to provide accurate and useful information.
""",
tools=[get_weather],
)
ADK Code Explanation (ADK-Codeerklärung)
Dieses Skript enthält unsere Agent-Initialisierung, in der wir Folgendes initialisieren:
- Legen Sie das zu verwendende Modell auf
gemini-2.5-flashfest. - Tool
get_weatherzur Unterstützung der Agent-Funktionalität als Wetter-Agent bereitstellen
Web-UI lokal ausführen
Jetzt können wir mit dem Agenten interagieren und sein Verhalten lokal untersuchen. Mit dem ADK können wir eine Web-UI für die Entwicklung verwenden, um zu interagieren und zu prüfen, was während der Interaktion passiert. Führen Sie den folgenden Befehl aus, um den lokalen Entwicklungsserver für die Benutzeroberfläche zu starten:
uv run adk web --port 8080
Es wird eine Ausgabe wie im folgenden Beispiel erzeugt. Das bedeutet, dass wir bereits auf die Weboberfläche zugreifen können.
INFO: Started server process [xxxx] INFO: Waiting for application startup. +-----------------------------------------------------------------------------+ | ADK Web Server started | | | | For local testing, access at http://localhost:8080. | +-----------------------------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
Klicken Sie nun oben im Cloud Shell Editor auf die Schaltfläche Webvorschau und wählen Sie Vorschau auf Port 8080 aus, um die Vorschau aufzurufen.
Sie sehen die folgende Webseite, auf der Sie oben links im Drop-down-Menü verfügbare Agents auswählen können ( in unserem Fall sollte es weather_agent sein) und mit dem Bot interagieren können. Im linken Fenster werden während der Laufzeit des Agents viele Informationen zu den Protokolldetails angezeigt.
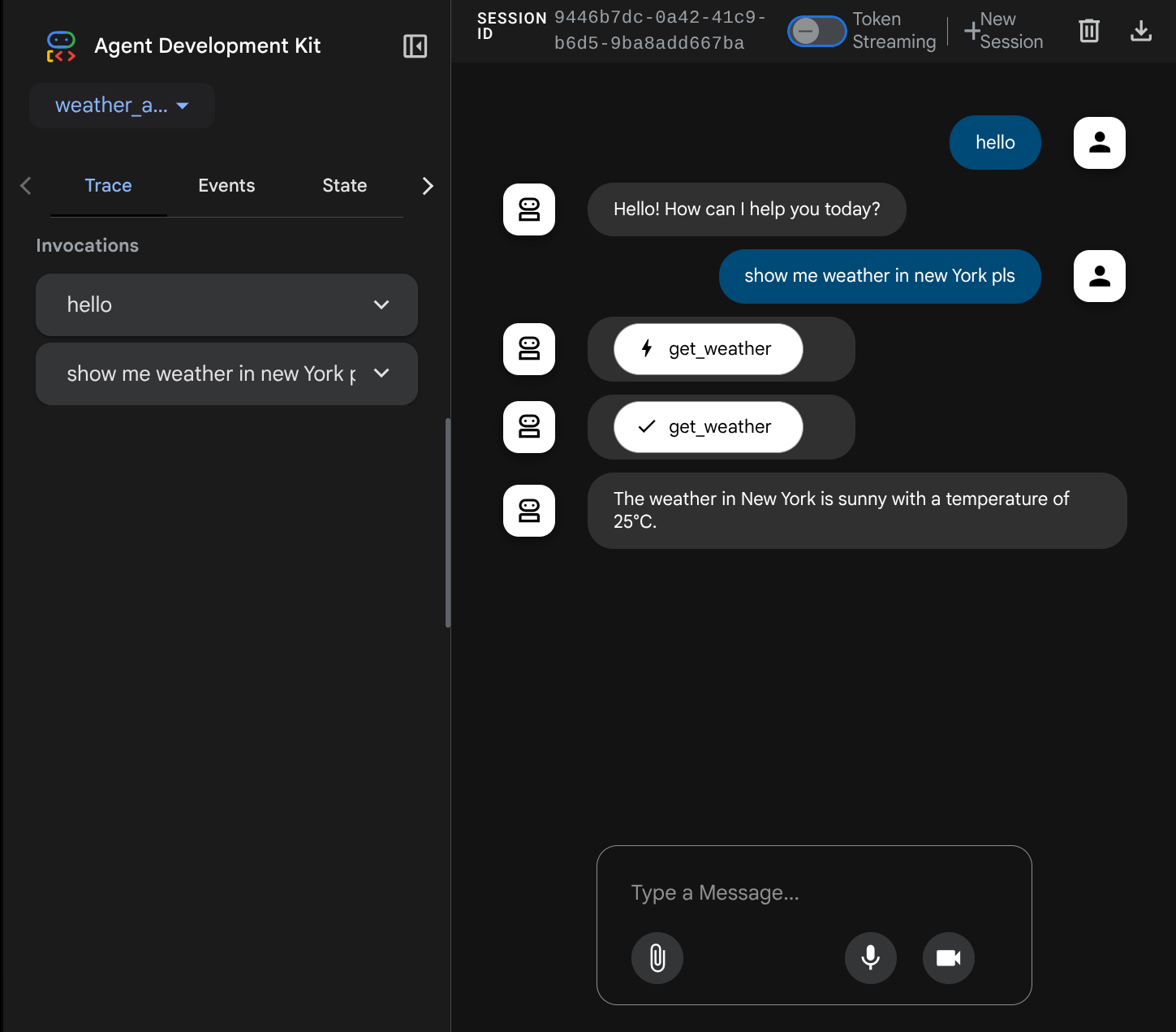
Versuchen Sie jetzt, mit dem Bot zu interagieren. In der linken Leiste können wir den Ablauf für jede Eingabe untersuchen, um zu sehen, wie lange es dauert, bis der Agent die einzelnen Aktionen ausführt, bevor er die endgültige Antwort formuliert.
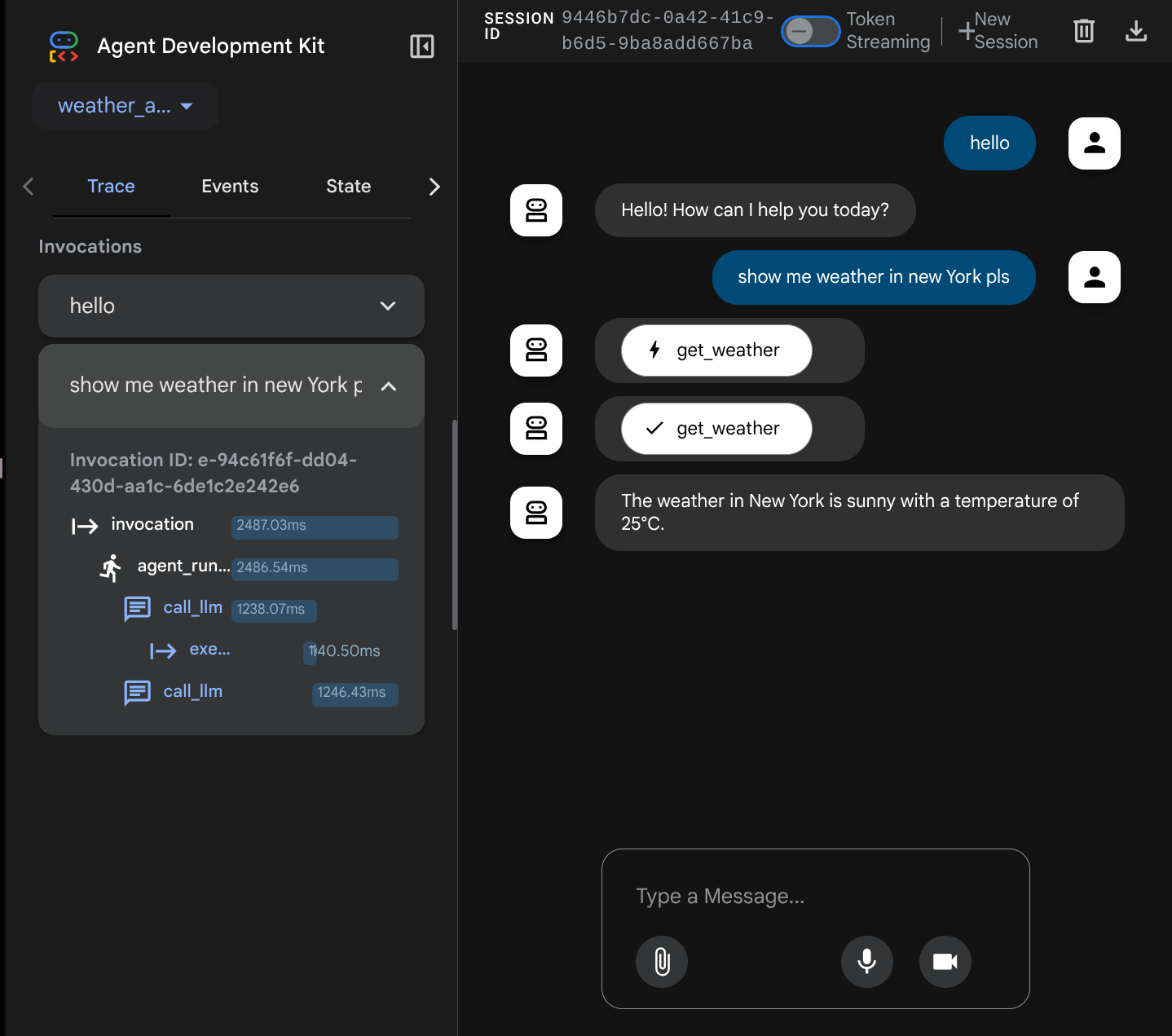
Dies ist eine der Beobachtbarkeitsfunktionen, die in das ADK integriert wurden. Derzeit wird sie lokal geprüft. Später sehen wir, wie dies in Cloud Trace integriert wird, damit wir einen zentralen Trace aller Anfragen haben.
7. 🚀 In Cloud Run bereitstellen
Stellen wir diesen Agent-Dienst nun in Cloud Run bereit. Im Rahmen dieser Demo wird dieser Dienst als öffentlicher Dienst bereitgestellt, auf den andere zugreifen können. Dies ist jedoch nicht die beste Vorgehensweise, da sie nicht sicher ist.
In diesem Bereitstellungsszenario können Sie den Backend-Dienst Ihres Agents anpassen. Wir verwenden Dockerfile, um unseren Agent in Cloud Run bereitzustellen. An diesem Punkt haben wir bereits alle erforderlichen Dateien ( Dockerfile und server.py), um unsere Anwendungen in Cloud Run bereitzustellen. Mit diesen beiden Elementen können Sie die Bereitstellung Ihres Agents flexibel anpassen, z.B. benutzerdefinierte Backend-Routen und/oder einen zusätzlichen Sidecar-Dienst für Überwachungszwecke hinzufügen. Wir werden dies später noch genauer erläutern.
Stellen Sie den Dienst zuerst bereit. Rufen Sie dazu das Cloud Shell-Terminal auf und prüfen Sie, ob das aktuelle Projekt für Ihr aktives Projekt konfiguriert ist. Führen Sie das Einrichtungs-Script noch einmal aus. Optional können Sie auch den Befehl gcloud config set project [PROJECT_ID] verwenden, um Ihr aktives Projekt zu konfigurieren.
bash setup_trial_project.sh && source .env
Jetzt müssen wir die Datei .env noch einmal aufrufen. Öffnen Sie sie. Sie sehen, dass wir die Variable DB_CONNECTION_NAME auskommentieren und mit dem richtigen Wert füllen müssen.
# Google Cloud and Vertex AI configuration
GOOGLE_CLOUD_PROJECT=your-project-id
GOOGLE_CLOUD_LOCATION=global
GOOGLE_GENAI_USE_VERTEXAI=True
# Database connection for session service
DB_CONNECTION_NAME=your-db-connection-name
Um den Wert für DB_CONNECTION_NAME zu erhalten, rufen wir das Cloud SQL-Dashboard auf.
Klicken Sie dann auf die erstellte Instanz. Rufen Sie die Suchleiste oben in der Cloud Console auf und geben Sie „Cloud SQL“ ein. Klicken Sie dann auf das Produkt Cloud SQL.
Danach wird die zuvor erstellte Instanz angezeigt. Klicken Sie darauf.
Scrollen Sie auf der Instanzseite nach unten zum Abschnitt Mit dieser Instanz verbinden. Dort können Sie den Verbindungsnamen kopieren, um den Wert DB_CONNECTION_NAME zu ersetzen.
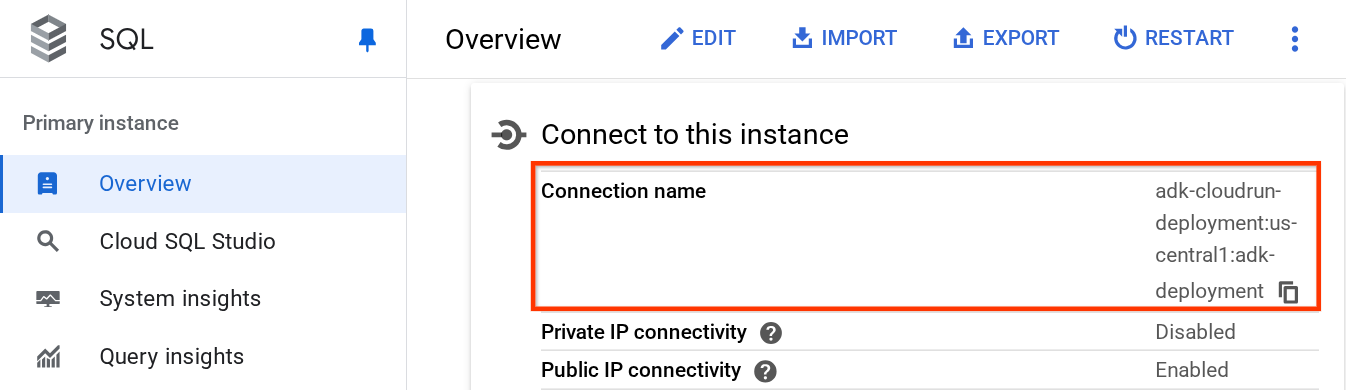
Öffnen Sie dann die Datei .env mit dem folgenden Befehl:
cloudshell edit .env
und ändern Sie die Variable DB_CONNECTION_NAME in der Datei .env. Ihre ENV-Datei sollte wie im folgenden Beispiel aussehen.
# Google Cloud and Vertex AI configuration
GOOGLE_CLOUD_PROJECT=your-project-id
GOOGLE_CLOUD_LOCATION=global
GOOGLE_GENAI_USE_VERTEXAI=True
# Database connection for session service
DB_CONNECTION_NAME=your-project-id:your-location:your-instance-name
Führen Sie danach das Bereitstellungsskript aus.
bash deploy_to_cloudrun.sh
Wenn Sie aufgefordert werden, die Erstellung eines Artifact Registry-Repositorys für Docker zu bestätigen, antworten Sie einfach mit Y.
Während wir auf den Abschluss des Bereitstellungsvorgangs warten, sehen wir uns deploy_to_cloudrun.sh an.
#!/bin/bash
# Load environment variables from .env file
if [ -f .env ]; then
export $(cat .env | grep -v '^#' | xargs)
else
echo "Error: .env file not found"
exit 1
fi
# Validate required variables
required_vars=("GOOGLE_CLOUD_PROJECT" "DB_CONNECTION_NAME")
for var in "${required_vars[@]}"; do
if [ -z "${!var}" ]; then
echo "Error: $var is not set in .env file"
exit 1
fi
done
gcloud run deploy weather-agent \
--source . \
--port 8080 \
--project ${GOOGLE_CLOUD_PROJECT} \
--allow-unauthenticated \
--add-cloudsql-instances ${DB_CONNECTION_NAME} \
--update-env-vars SESSION_SERVICE_URI="postgresql+pg8000://postgres:ADK-deployment123@postgres/?unix_sock=/cloudsql/${DB_CONNECTION_NAME}/.s.PGSQL.5432",GOOGLE_CLOUD_PROJECT=${GOOGLE_CLOUD_PROJECT} \
--region us-west1 \
--min 1 \
--memory 1G \
--concurrency 10
In diesem Skript wird die Variable .env geladen und dann der Bereitstellungsbefehl ausgeführt.
Bei genauerer Betrachtung benötigen wir nur einen gcloud run deploy-Befehl, um alle erforderlichen Schritte auszuführen, die beim Bereitstellen eines Dienstes anfallen: Erstellen des Images, Push in die Registry, Bereitstellen des Dienstes, Festlegen der IAM-Richtlinie, Erstellen der Revision und sogar Weiterleiten des Traffics. In diesem Beispiel stellen wir das Dockerfile bereits zur Verfügung. Dieser Befehl verwendet es also, um die App zu erstellen.
Nach Abschluss der Bereitstellung sollten Sie einen Link ähnlich dem folgenden erhalten:
https://weather-agent-*******.us-west1.run.app
Nachdem Sie diese URL erhalten haben, können Sie Ihre Anwendung über das Inkognitofenster oder Ihr Mobilgerät verwenden und auf die Entwickler-UI des Agents zugreifen. Während wir auf das Deployment warten, sehen wir uns im nächsten Abschnitt den detaillierten Dienst an, den wir gerade bereitstellen.
8. 💡 Dockerfile und Back-End-Server-Script
Damit der Agent als Dienst zugänglich ist, wird er in eine FastAPI-App eingebunden, die mit dem Dockerfile-Befehl ausgeführt wird. Nachfolgend finden Sie den Inhalt des Dockerfile.
FROM python:3.12-slim
RUN pip install --no-cache-dir uv==0.7.13
WORKDIR /app
COPY . .
RUN uv sync --frozen
EXPOSE 8080
CMD ["uv", "run", "uvicorn", "server:app", "--host", "0.0.0.0", "--port", "8080"]
Hier können wir die erforderlichen Dienste zur Unterstützung des Agents konfigurieren, z. B. die Vorbereitung von Session-, Memory- oder Artifact-Diensten für Produktionszwecke. Hier ist der Code der Datei server.py, die verwendet wird.
import os
from dotenv import load_dotenv
from fastapi import FastAPI
from google.adk.cli.fast_api import get_fast_api_app
from pydantic import BaseModel
from typing import Literal
from google.cloud import logging as google_cloud_logging
# Load environment variables from .env file
load_dotenv()
logging_client = google_cloud_logging.Client()
logger = logging_client.logger(__name__)
AGENT_DIR = os.path.dirname(os.path.abspath(__file__))
# Get session service URI from environment variables
session_uri = os.getenv("SESSION_SERVICE_URI", None)
# Prepare arguments for get_fast_api_app
app_args = {"agents_dir": AGENT_DIR, "web": True, "trace_to_cloud": True}
# Only include session_service_uri if it's provided
if session_uri:
app_args["session_service_uri"] = session_uri
else:
logger.log_text(
"SESSION_SERVICE_URI not provided. Using in-memory session service instead. "
"All sessions will be lost when the server restarts.",
severity="WARNING",
)
# Create FastAPI app with appropriate arguments
app: FastAPI = get_fast_api_app(**app_args)
app.title = "weather-agent"
app.description = "API for interacting with the Agent weather-agent"
class Feedback(BaseModel):
"""Represents feedback for a conversation."""
score: int | float
text: str | None = ""
invocation_id: str
log_type: Literal["feedback"] = "feedback"
service_name: Literal["weather-agent"] = "weather-agent"
user_id: str = ""
# Example if you want to add your custom endpoint
@app.post("/feedback")
def collect_feedback(feedback: Feedback) -> dict[str, str]:
"""Collect and log feedback.
Args:
feedback: The feedback data to log
Returns:
Success message
"""
logger.log_struct(feedback.model_dump(), severity="INFO")
return {"status": "success"}
# Main execution
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8080)
Erläuterung zum Servercode
Folgendes wird im Skript server.py definiert:
- Wandeln Sie den Agent mit der Methode
get_fast_api_appin eine FastAPI-App um. So wird dieselbe Routendefinition übernommen, die für die Webentwicklungs-UI verwendet wird. - Konfigurieren Sie den erforderlichen Sitzungs-, Speicher- oder Artefaktdienst, indem Sie die Keyword-Argumente der Methode
get_fast_api_apphinzufügen. Wenn wir in dieser Anleitung die UmgebungsvariableSESSION_SERVICE_URIkonfigurieren, wird sie vom Sitzungsdienst verwendet. Andernfalls wird die In-Memory-Sitzung verwendet. - Wir können eine benutzerdefinierte Route hinzufügen, um andere Backend-Geschäftslogik zu unterstützen. Im Skript fügen wir ein Beispiel für eine Feedbackfunktionsroute hinzu.
- Aktivieren Sie Cloud Tracing in den
get_fast_api_app-Argumentparametern, um Traces an Google Cloud Trace zu senden. - FastAPI-Dienst mit Uvicorn ausführen
Wenn die Bereitstellung bereits abgeschlossen ist, versuchen Sie, über die Cloud Run-URL mit dem Agenten in der Web-Entwicklungsoberfläche zu interagieren.
9. 🚀 Cloud Run-Autoscaling mit Lasttests untersuchen
Sehen wir uns nun die Autoscaling-Funktionen von Cloud Run an. In diesem Szenario stellen wir eine neue Version bereit und aktivieren die maximale Anzahl von Nebenläufigkeiten pro Instanz. Im vorherigen Abschnitt haben wir die maximale Parallelität auf 10 festgelegt ( Flag --concurrency 10). Daher können wir davon ausgehen, dass Cloud Run versucht, die Instanz zu skalieren, wenn wir einen Lastentest durchführen, der diese Zahl überschreitet.
Sehen wir uns die Datei load_test.py an. Dieses Skript verwenden wir für die Lasttests mit dem Locust-Framework. Dieses Skript führt folgende Aktionen aus :
- Zufällige user_id und session_id
- session_id für die user_id erstellen
- Endpunkt „/run_sse“ mit der erstellten „user_id“ und „session_id“ aufrufen
Wir benötigen die URL des bereitgestellten Dienstes, falls Sie sie nicht notiert haben. Wir können die Cloud Run-Konsole aufrufen.
Suchen Sie dann nach dem Dienst weather-agent und klicken Sie darauf.
Die Dienst-URL wird direkt neben den Regionsinformationen angezeigt. Beispiel:

Um die Sache für Sie zu vereinfachen, führen wir das folgende Skript aus, um die URL Ihres zuletzt bereitgestellten Dienstes abzurufen und in der Umgebungsvariable SERVICE_URL zu speichern.
export SERVICE_URL=$(gcloud run services describe weather-agent \
--platform managed \
--region us-west1 \
--format 'value(status.url)')
Führen Sie dann den folgenden Befehl aus, um die Agent-App zu testen:
uv run locust -f load_test.py \
-H $SERVICE_URL \
-u 60 \
-r 5 \
-t 120 \
--headless
Wenn Sie diesen Befehl ausführen, werden Messwerte wie die folgenden angezeigt. ( In diesem Beispiel sind alle Anforderungen erfüllt. )
Type Name # reqs # fails | Avg Min Max Med | req/s failures/s
--------|------------------------------------|-------|-------------|-------|-------|-------|-------|--------|-----------
POST /run_sse end 813 0(0.00%) | 5817 2217 26421 5000 | 6.79 0.00
POST /run_sse message 813 0(0.00%) | 2678 1107 17195 2200 | 6.79 0.00
--------|------------------------------------|-------|-------------|-------|-------|-------|-------|--------|-----------
Aggregated 1626 0(0.00%) | 4247 1107 26421 3500 | 13.59 0.00
Sehen wir uns dann an, was in Cloud Run passiert ist. Rufen Sie dazu noch einmal Ihren bereitgestellten Dienst auf und sehen Sie sich das Dashboard an. So sehen Sie, wie Cloud Run die Instanz automatisch skaliert, um eingehende Anfragen zu verarbeiten. Da wir die maximale Nebenläufigkeit auf 10 Prozesse pro Instanz begrenzen, versucht die Cloud Run-Instanz, die Anzahl der Container automatisch an diese Bedingung anzupassen.
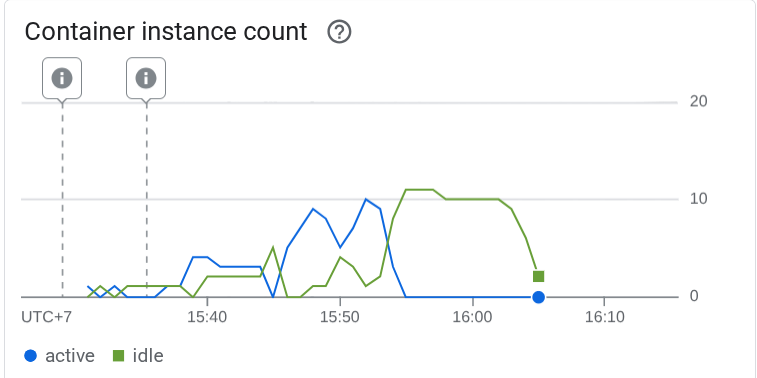
10. 🚀 Neue Überarbeitungen schrittweise veröffentlichen
Sehen wir uns nun das folgende Szenario an. Wir möchten den Prompt des Agents aktualisieren. Öffnen Sie weather_agent/agent.py mit dem folgenden Befehl:
cloudshell edit weather_agent/agent.py
und überschreiben Sie sie mit dem folgenden Code:
# weather_agent/agent.py
import os
from pathlib import Path
import google.auth
from dotenv import load_dotenv
from google.adk.agents import Agent
from weather_agent.tool import get_weather
# Load environment variables from .env file in root directory
root_dir = Path(__file__).parent.parent
dotenv_path = root_dir / ".env"
load_dotenv(dotenv_path=dotenv_path)
# Use default project from credentials if not in .env
_, project_id = google.auth.default()
os.environ.setdefault("GOOGLE_CLOUD_PROJECT", project_id)
os.environ.setdefault("GOOGLE_CLOUD_LOCATION", "global")
os.environ.setdefault("GOOGLE_GENAI_USE_VERTEXAI", "True")
root_agent = Agent(
name="weather_agent",
model="gemini-2.5-flash",
instruction="""
You are a helpful AI assistant designed to provide accurate and useful information.
You only answer inquiries about the weather. Refuse all other user query
""",
tools=[get_weather],
)
Sie möchten dann neue Überarbeitungen veröffentlichen, aber nicht, dass der gesamte Anfragetraffic direkt an die neue Version gesendet wird. Mit Cloud Run können wir eine schrittweise Einführung durchführen. Zuerst müssen wir eine neue Überarbeitung bereitstellen, aber mit dem Flag –no-traffic. Speichern Sie das vorherige Agent-Skript und führen Sie den folgenden Befehl aus:
gcloud run deploy weather-agent \
--source . \
--port 8080 \
--project $GOOGLE_CLOUD_PROJECT \
--allow-unauthenticated \
--region us-west1 \
--no-traffic
Danach erhalten Sie ein ähnliches Log wie beim vorherigen Deployment-Prozess, mit dem Unterschied, dass die Anzahl der bereitgestellten Zugriffe angegeben ist. Es werden 0 % der ausgelieferten Zugriffe angezeigt.
Service [weather-agent] revision [weather-agent-xxxx-xxx] has been deployed and is serving 0 percent of traffic.
Rufen wir als Nächstes das Cloud Run-Dashboard auf.
Suchen Sie dann nach dem Dienst weather-agent und klicken Sie darauf.
Rufen Sie den Tab Überarbeitungen auf. Dort sehen Sie die Liste der bereitgestellten Überarbeitungen.
Die neue bereitgestellte Überarbeitung wird mit 0 % ausgeliefert. Klicken Sie auf das Dreipunkt-Menü (⋮) und wählen Sie Traffic verwalten aus.
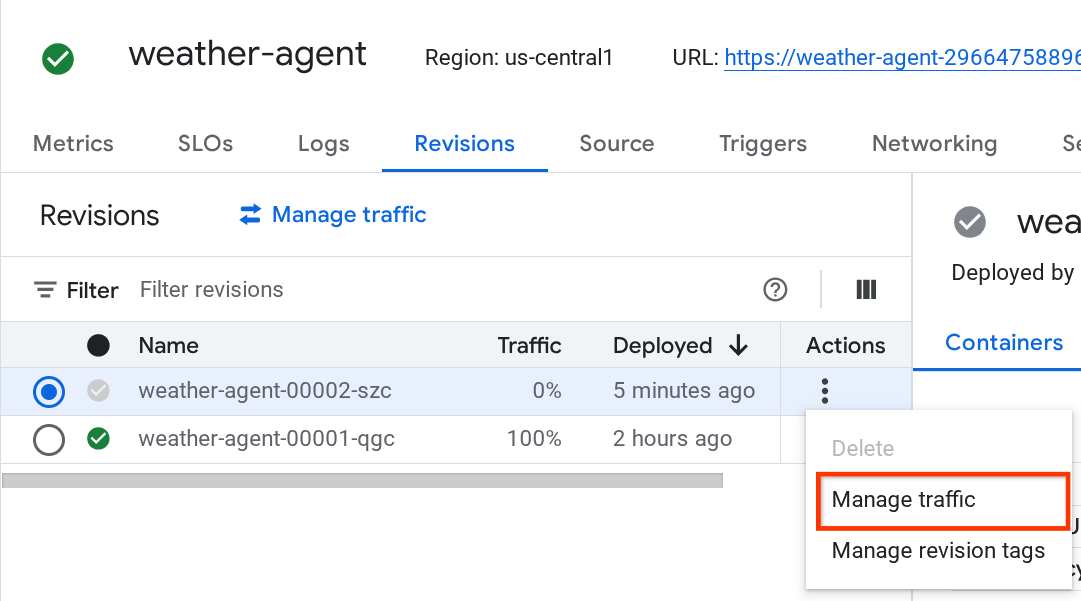
Im neu geöffneten Fenster können Sie den Prozentsatz des Traffics bearbeiten, der an die einzelnen Überarbeitungen gesendet wird.
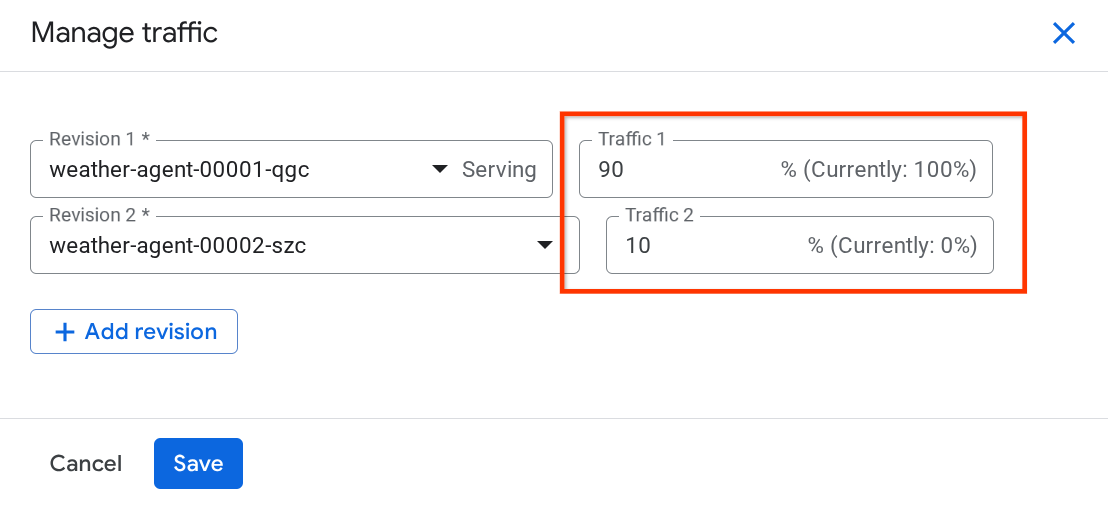
Nach einer Weile wird der Traffic proportional entsprechend den Prozentkonfigurationen weitergeleitet. So können wir bei Problemen mit dem neuen Release ganz einfach ein Rollback zu den vorherigen Überarbeitungen durchführen.
11. 🚀 ADK-Tracing
Mit dem ADK erstellte KI-Agenten unterstützen bereits das Tracing über die Einbettung von OpenTelemetry. Mit Cloud Trace können wir diese Traces erfassen und visualisieren. Sehen wir uns an, wie wir den Dienst in server.py aktivieren.
# server.py
...
app_args = {"agents_dir": AGENT_DIR, "web": True, "trace_to_cloud": True}
...
app: FastAPI = get_fast_api_app(**app_args)
...
Hier übergeben wir das trace_to_cloud-Argument an True. Wenn Sie die Bereitstellung mit anderen Optionen vornehmen, finden Sie in dieser Dokumentation weitere Informationen dazu, wie Sie das Tracing zu Cloud Trace über verschiedene Bereitstellungsoptionen aktivieren.
Versuchen Sie, auf die Web-UI Ihres Dienstes zuzugreifen und mit dem KI-Agenten zu chatten. Rufen Sie dann die Seite „Trace Explorer“ auf.
Auf der Seite „Trace Explorer“ sehen Sie, dass der Trace für die Unterhaltung mit dem Agenten gesendet wurde. Im Bereich Span name (Spannenname) können Sie die Spanne herausfiltern, die für unseren Agenten spezifisch ist (sie heißt agent_run [weather_agent]).
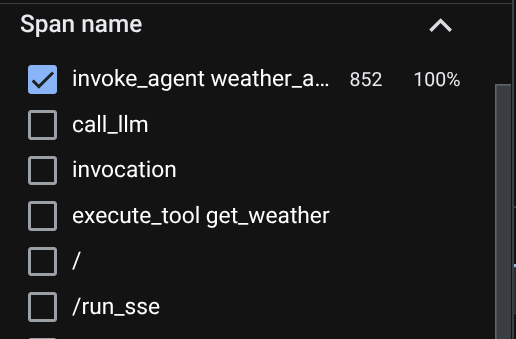
Wenn die Spannen bereits gefiltert sind, können Sie auch jede einzelne Spur direkt untersuchen. Dort wird die genaue Dauer jeder Aktion angezeigt, die vom Agent ausgeführt wurde. Sehen Sie sich beispielsweise die Bilder unten an.
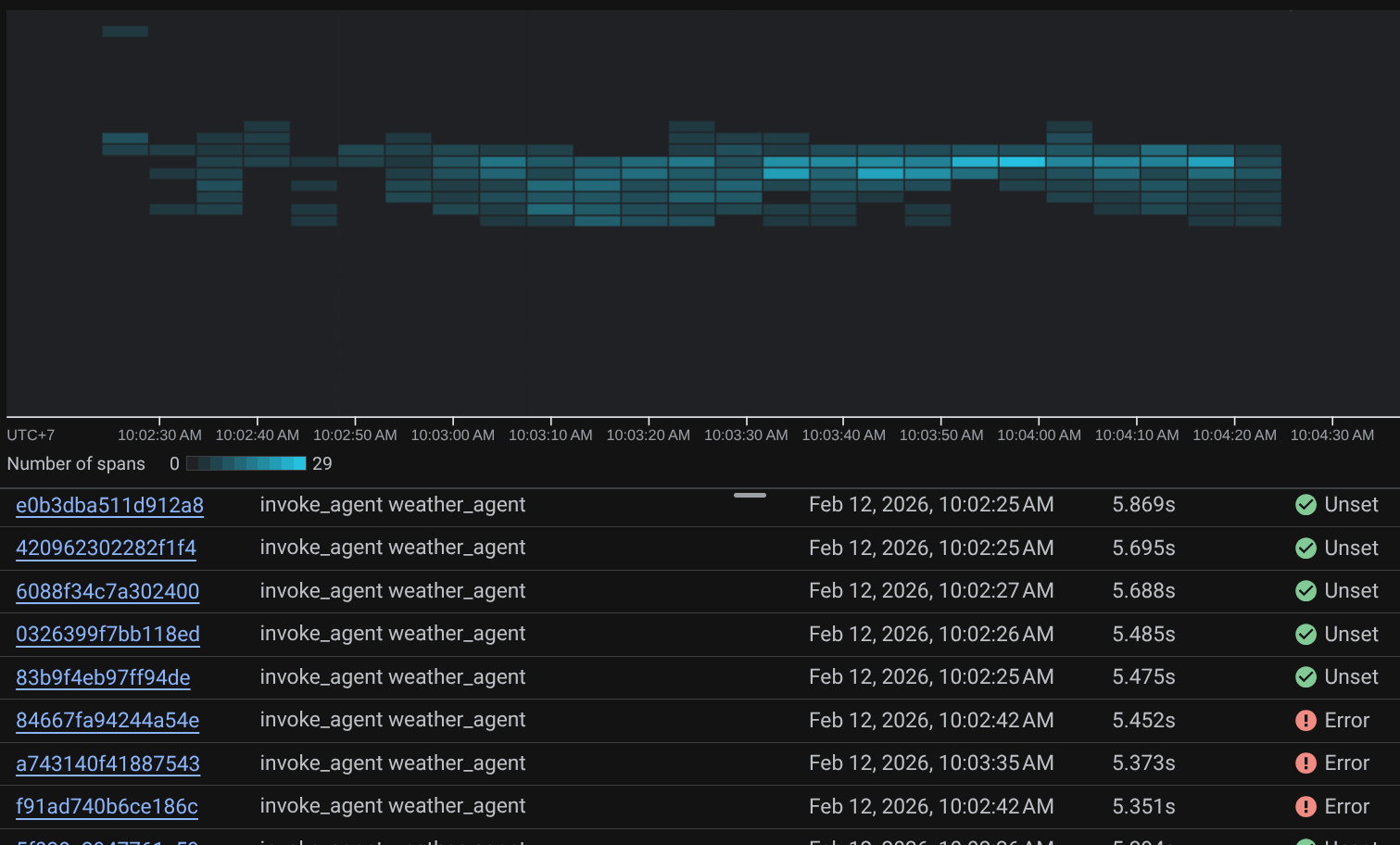
In jedem Abschnitt können Sie die Details in den Attributen prüfen, wie unten dargestellt.
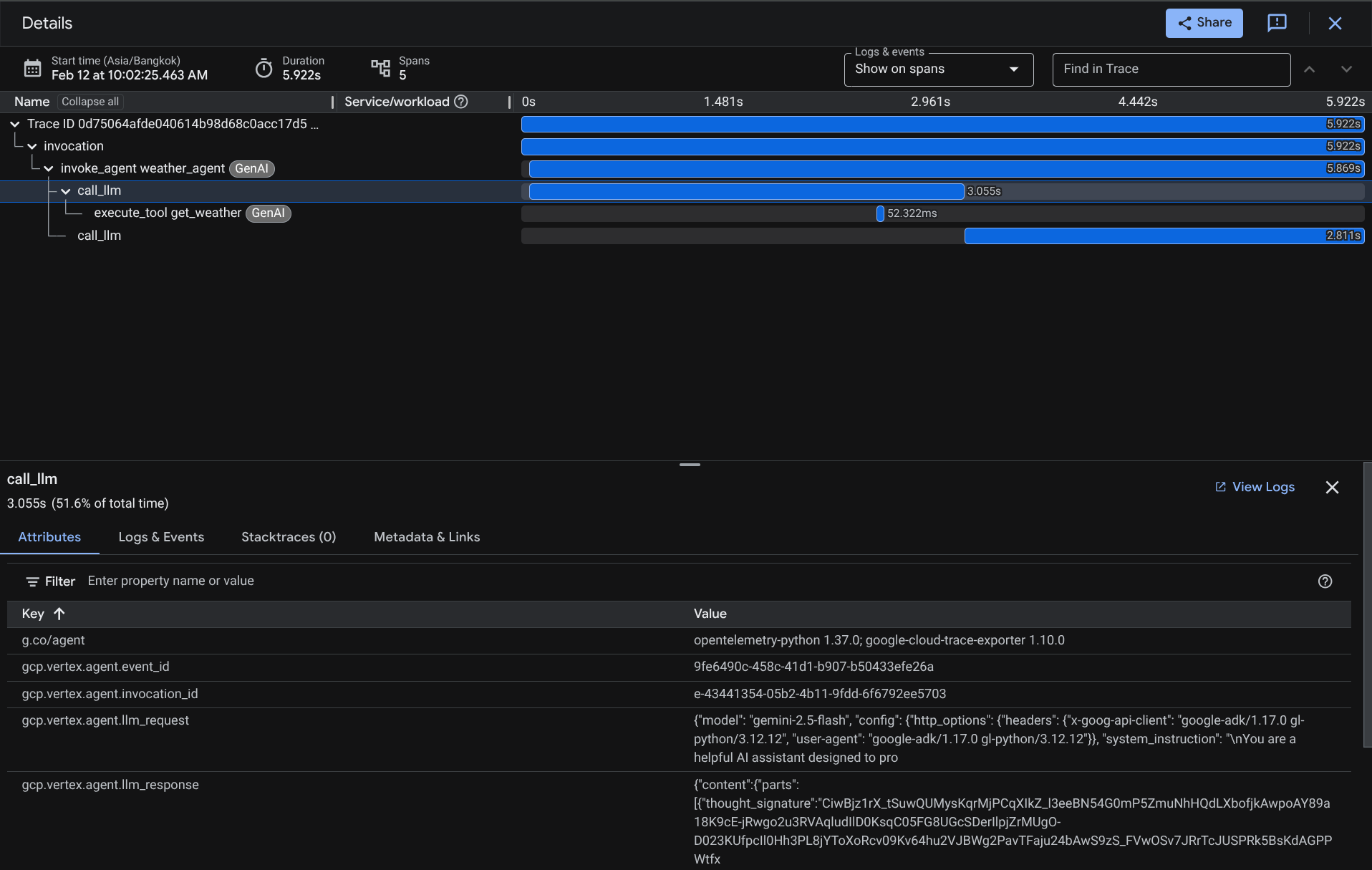
So haben wir eine gute Beobachtbarkeit und Informationen zu jeder Interaktion unseres Agenten mit dem Nutzer, um Probleme zu beheben. Probieren Sie verschiedene Tools oder Workflows aus.
12. 🎯 Herausforderung
Multi-Agent- oder agentische Workflows ausprobieren, um zu sehen, wie sie unter Last funktionieren und wie der Trace aussieht
13. 🧹 Bereinigen
So vermeiden Sie, dass Ihrem Google Cloud-Konto die in diesem Codelab verwendeten Ressourcen in Rechnung gestellt werden:
- Wechseln Sie in der Google Cloud Console zur Seite Ressourcen verwalten.
- Wählen Sie in der Projektliste das Projekt aus, das Sie löschen möchten, und klicken Sie auf Löschen.
- Geben Sie im Dialogfeld die Projekt-ID ein und klicken Sie auf Beenden, um das Projekt zu löschen.
- Alternativ können Sie in der Console zu Cloud Run wechseln, den gerade bereitgestellten Dienst auswählen und löschen.