
1. Introdução
Neste tutorial, você vai aprender a implantar, gerenciar e monitorar um agente eficiente criado com o Kit de Desenvolvimento de Agente (ADK) no Google Cloud Run. Com o ADK, você pode criar agentes capazes de fluxos de trabalho complexos e multiagentes. Ao aproveitar o Cloud Run, uma plataforma sem servidor totalmente gerenciada, você pode implantar seu agente como um aplicativo escalonável e conteinerizado sem se preocupar com a infraestrutura subjacente. Essa combinação poderosa permite que você se concentre na lógica principal do seu agente enquanto se beneficia do ambiente robusto e escalonável do Google Cloud.
Neste tutorial, vamos explorar a integração perfeita do ADK com o Cloud Run. Você vai aprender a implantar seu agente e depois conhecer os aspectos práticos do gerenciamento do aplicativo em um ambiente semelhante ao de produção. Vamos abordar como lançar novas versões do seu agente com segurança gerenciando o tráfego. Assim, você pode testar novos recursos com um subconjunto de usuários antes de um lançamento completo.
Além disso, você vai ganhar experiência prática no monitoramento da performance do seu agente. Vamos simular um cenário real realizando um teste de carga para observar os recursos de escalonamento automático do Cloud Run em ação. Para ter insights mais detalhados sobre o comportamento e a performance do seu agente, vamos ativar o rastreamento com o Cloud Trace. Isso vai fornecer uma visão detalhada e completa das solicitações conforme elas passam pelo seu agente, permitindo que você identifique e resolva gargalos de desempenho. Ao final deste tutorial, você terá uma compreensão abrangente de como implantar, gerenciar e monitorar com eficiência seus agentes com tecnologia ADK no Cloud Run.
Durante o codelab, você vai usar uma abordagem gradual da seguinte forma:
- Crie um banco de dados PostgreSQL no CloudSQL para ser usado no serviço de sessão do banco de dados do agente do ADK.
- Configurar um agente básico do ADK
- Configurar o serviço de sessão do banco de dados para ser usado pelo executor do ADK
- Implantação inicial do agente no Cloud Run
- Teste de carga e inspeção do escalonamento automático do Cloud Run
- Implante uma nova revisão do agente e aumente gradualmente o tráfego para novas revisões
- Configurar o rastreamento na nuvem e inspecionar o rastreamento da execução do agente
Visão geral da arquitetura
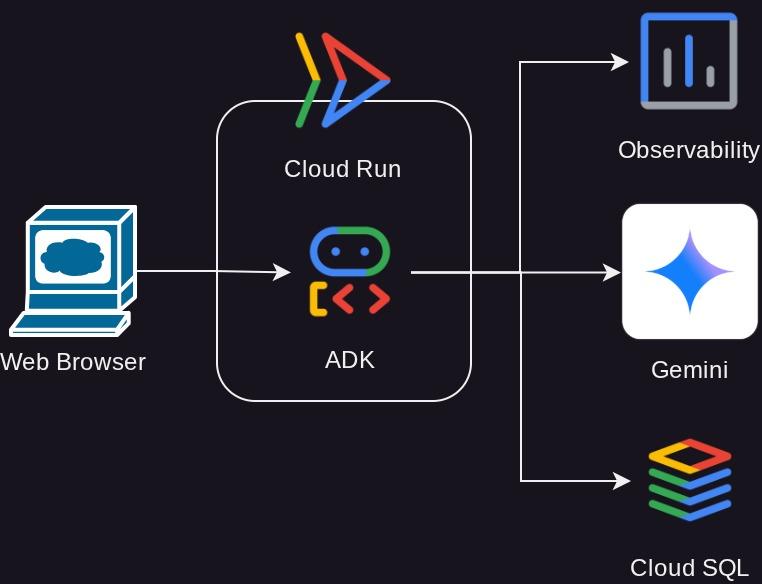
Pré-requisitos
- Conhecimento de Python
- Conhecimento básico da arquitetura full-stack usando o serviço HTTP
O que você vai aprender
- Estrutura do ADK e utilitários locais
- Configurar o agente do ADK com o serviço de sessão do banco de dados
- Configurar o PostgreSQL no Cloud SQL para ser usado pelo serviço de sessão do banco de dados
- Implantar o aplicativo no Cloud Run usando o Dockerfile e configurar as variáveis de ambiente iniciais
- Configurar e testar o escalonamento automático do Cloud Run com teste de carga
- Estratégia de lançamento gradual com o Cloud Run
- Configurar o rastreamento do agente do ADK para o Cloud Trace
O que é necessário
- Navegador da Web Google Chrome
- Uma conta do Gmail
- Um projeto do Cloud com faturamento ativado
Este codelab, criado para desenvolvedores de todos os níveis (inclusive iniciantes), usa Python no aplicativo de exemplo. No entanto, não é necessário ter conhecimento de Python para entender os conceitos apresentados.
2. 🚀 Preparando a configuração do workshop
Agora, vamos usar o Cloud Shell IDE neste tutorial. Clique no botão a seguir para acessar o ambiente.
No Cloud Shell, clone o diretório de trabalho do modelo para este codelab do GitHub executando o seguinte comando: Ele vai criar o diretório de trabalho no diretório deploy_and_manage_adk.
git clone https://github.com/alphinside/deploy-and-manage-adk-service.git deploy_and_manage_adk
Em seguida, execute o seguinte comando no terminal para abrir o repositório clonado como seu diretório de trabalho:
cloudshell workspace ~/deploy_and_manage_adk && cd ~/deploy_and_manage_adk
Depois disso, a interface vai ficar assim:
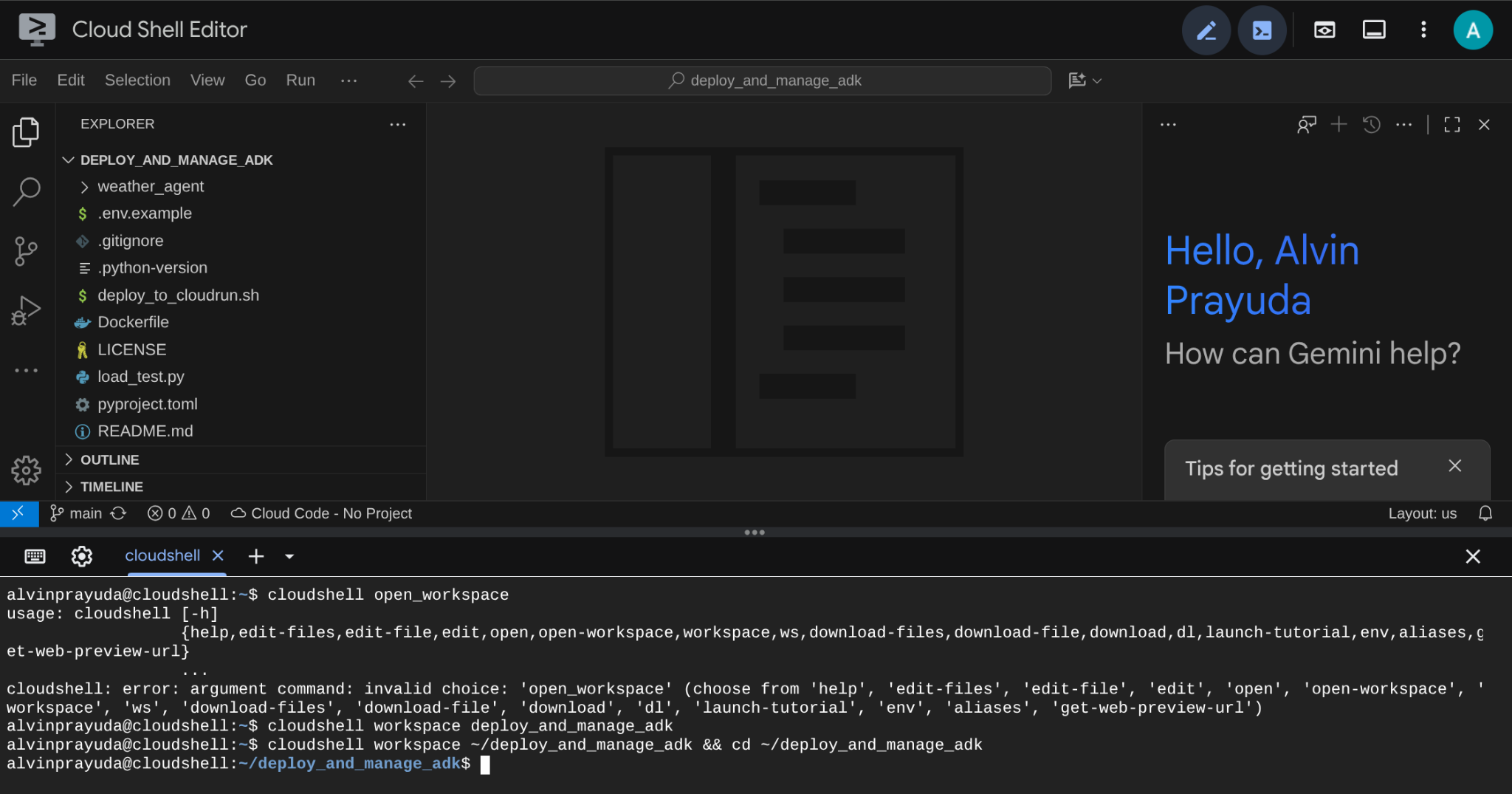
Essa será nossa interface principal, com o IDE na parte de cima e o terminal na parte de baixo. Agora precisamos preparar nosso terminal para criar e ativar o projeto do Google Cloud, que será vinculado à conta de faturamento de teste reivindicada anteriormente. Preparamos um script para garantir que sua sessão de terminal esteja sempre pronta. Execute o comando a seguir ( confirme se você já está no espaço de trabalho deploy_and_manage_adk):
bash setup_trial_project.sh && source .env
Ao executar esse comando, você vai receber uma sugestão de nome para o ID do projeto. Pressione Enter para continuar.

Depois de aguardar um pouco, se você vir esta saída no console, poderá passar para a próxima etapa 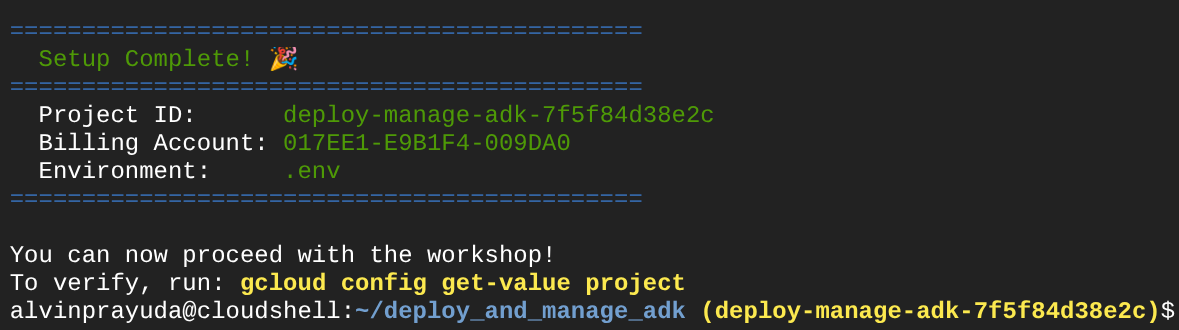
Isso mostra que seu terminal já está autenticado e definido com o ID do projeto correto ( a cor amarela ao lado do caminho do diretório atual). Esse comando ajuda você a criar um projeto, encontrar e vincular o projeto a uma conta de faturamento de teste, preparar o arquivo .env para a configuração da variável de ambiente e também ativar o ID do projeto correto no terminal.
Agora estamos prontos para a próxima etapa
3. 🚀 Ativar APIs
Neste tutorial, vamos interagir com o banco de dados do Cloud SQL, o modelo do Gemini e o Cloud Run. Esses produtos exigem que a seguinte API seja ativada. Execute estes comandos para ativá-los:
Isso pode levar algum tempo.
gcloud services enable aiplatform.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
cloudresourcemanager.googleapis.com \
sqladmin.googleapis.com \
compute.googleapis.com
Após a execução do comando, você vai ver uma mensagem semelhante à mostrada abaixo:
Operation "operations/..." finished successfully.
4. 🚀 Configuração do ambiente Python e variáveis de ambiente
Vamos usar o Python 3.12 neste codelab e o gerenciador de projetos Python uv para simplificar a necessidade de criar e gerenciar a versão do Python e o ambiente virtual. O pacote uv já está pré-instalado no Cloud Shell.
Execute este comando para instalar as dependências necessárias no ambiente virtual no diretório .venv
uv sync --frozen
Em seguida, vamos inspecionar os arquivos de variáveis de ambiente necessários para este projeto. Antes, esse arquivo era configurado pelo script setup_trial_project.sh. Execute o comando a seguir para abrir o arquivo .env no editor:
cloudshell open .env
Você verá as seguintes configurações já aplicadas no arquivo .env.
# .env # Google Cloud and Vertex AI configuration GOOGLE_CLOUD_PROJECT=your-project-id GOOGLE_CLOUD_LOCATION=global GOOGLE_GENAI_USE_VERTEXAI=True # Database connection for session service # DB_CONNECTION_NAME=your-db-connection-name
Neste codelab, vamos usar os valores pré-configurados para GOOGLE_CLOUD_LOCATION e GOOGLE_GENAI_USE_VERTEXAI..
Agora podemos passar para a próxima etapa, que é criar o banco de dados a ser usado pelo nosso agente para persistência de estado e sessão.
5. 🚀 Preparar o banco de dados do Cloud SQL
Vamos precisar de um banco de dados para ser usado pelo agente do ADK mais tarde. Vamos criar um banco de dados PostgreSQL no Cloud SQL. Execute o comando a seguir para criar a instância de banco de dados primeiro. Vamos usar o nome padrão do banco de dados postgres. Por isso, vamos pular a criação do banco de dados aqui. Também precisamos configurar o nome de usuário padrão do banco de dados (também postgres). Para fins de tutorial, vamos usar ADK-deployment123 como senha.
gcloud sql instances create adk-deployment \
--database-version=POSTGRES_17 \
--edition=ENTERPRISE \
--tier=db-g1-small \
--region=us-central1 \
--availability-type=ZONAL \
--project=${GOOGLE_CLOUD_PROJECT} && \
gcloud sql users set-password postgres \
--instance=adk-deployment \
--password=ADK-deployment123
No comando acima, o primeiro gcloud sql instances create adk-deployment comum é um comando que usamos para criar a instância de banco de dados. Estamos usando uma especificação mínima de sandbox para este tutorial. O segundo comando gcloud sql users set-password postgres usado para mudar a senha padrão do nome de usuário postgres
Usamos adk-deployment como nome da instância do banco de dados. Quando terminar, você vai ver uma saída no terminal como a mostrada abaixo, que indica que a instância está pronta e a senha do usuário padrão foi atualizada.
Created [https://sqladmin.googleapis.com/sql/v1beta4/projects/your-project-id/instances/adk-deployment]. NAME: adk-deployment DATABASE_VERSION: POSTGRES_17 LOCATION: us-central1-a TIER: db-g1-small PRIMARY_ADDRESS: xx.xx.xx.xx PRIVATE_ADDRESS: - STATUS: RUNNABLE Updating Cloud SQL user...done.
Como a implantação desse banco de dados vai levar algum tempo, vamos continuar para a próxima seção enquanto aguardamos a conclusão da implantação do banco de dados do Cloud SQL.
6. 🚀 Crie o agente de clima com o ADK e o Gemini 2.5
Introdução à estrutura de diretórios do ADK
Vamos começar analisando o que o ADK tem a oferecer e como criar o agente. A documentação completa do ADK pode ser acessada neste URL . O ADK oferece muitas utilidades na execução de comandos da CLI. Alguns deles são :
- Configurar a estrutura de diretórios do agente
- Teste rapidamente a interação por entrada e saída da CLI
- Configurar rapidamente a interface da Web da IU de desenvolvimento local
Agora, vamos verificar a estrutura do agente no diretório weather_agent.
weather_agent/ ├── __init__.py ├── agent.py └── tool.py
Se você inspecionar init.py e agent.py, verá este código:
# __init__.py
from weather_agent.agent import root_agent
__all__ = ["root_agent"]
# agent.py
import os
from pathlib import Path
import google.auth
from dotenv import load_dotenv
from google.adk.agents import Agent
from weather_agent.tool import get_weather
# Load environment variables from .env file in root directory
root_dir = Path(__file__).parent.parent
dotenv_path = root_dir / ".env"
load_dotenv(dotenv_path=dotenv_path)
# Use default project from credentials if not in .env
_, project_id = google.auth.default()
os.environ.setdefault("GOOGLE_CLOUD_PROJECT", project_id)
os.environ.setdefault("GOOGLE_CLOUD_LOCATION", "global")
os.environ.setdefault("GOOGLE_GENAI_USE_VERTEXAI", "True")
root_agent = Agent(
name="weather_agent",
model="gemini-2.5-flash",
instruction="""
You are a helpful AI assistant designed to provide accurate and useful information.
""",
tools=[get_weather],
)
Explicação de código do ADK
Esse script contém nossa iniciação do agente, em que inicializamos o seguinte:
- Defina o modelo a ser usado como
gemini-2.5-flash. - Forneça a ferramenta
get_weatherpara oferecer suporte à funcionalidade do agente como um agente de clima.
Executar a interface da Web localmente
Agora, podemos interagir com o agente e inspecionar o comportamento dele localmente. O ADK permite que tenhamos uma interface da Web de desenvolvimento para interagir e inspecionar o que está acontecendo durante a interação. Execute o comando a seguir para iniciar o servidor da interface de desenvolvimento local:
uv run adk web --port 8080
Ele vai gerar uma saída como o exemplo a seguir, o que significa que já podemos acessar a interface da Web.
INFO: Started server process [xxxx] INFO: Waiting for application startup. +-----------------------------------------------------------------------------+ | ADK Web Server started | | | | For local testing, access at http://localhost:8080. | +-----------------------------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
Para verificar, clique no botão Visualização da Web na parte superior do Editor do Cloud Shell e selecione Visualizar na porta 8080.
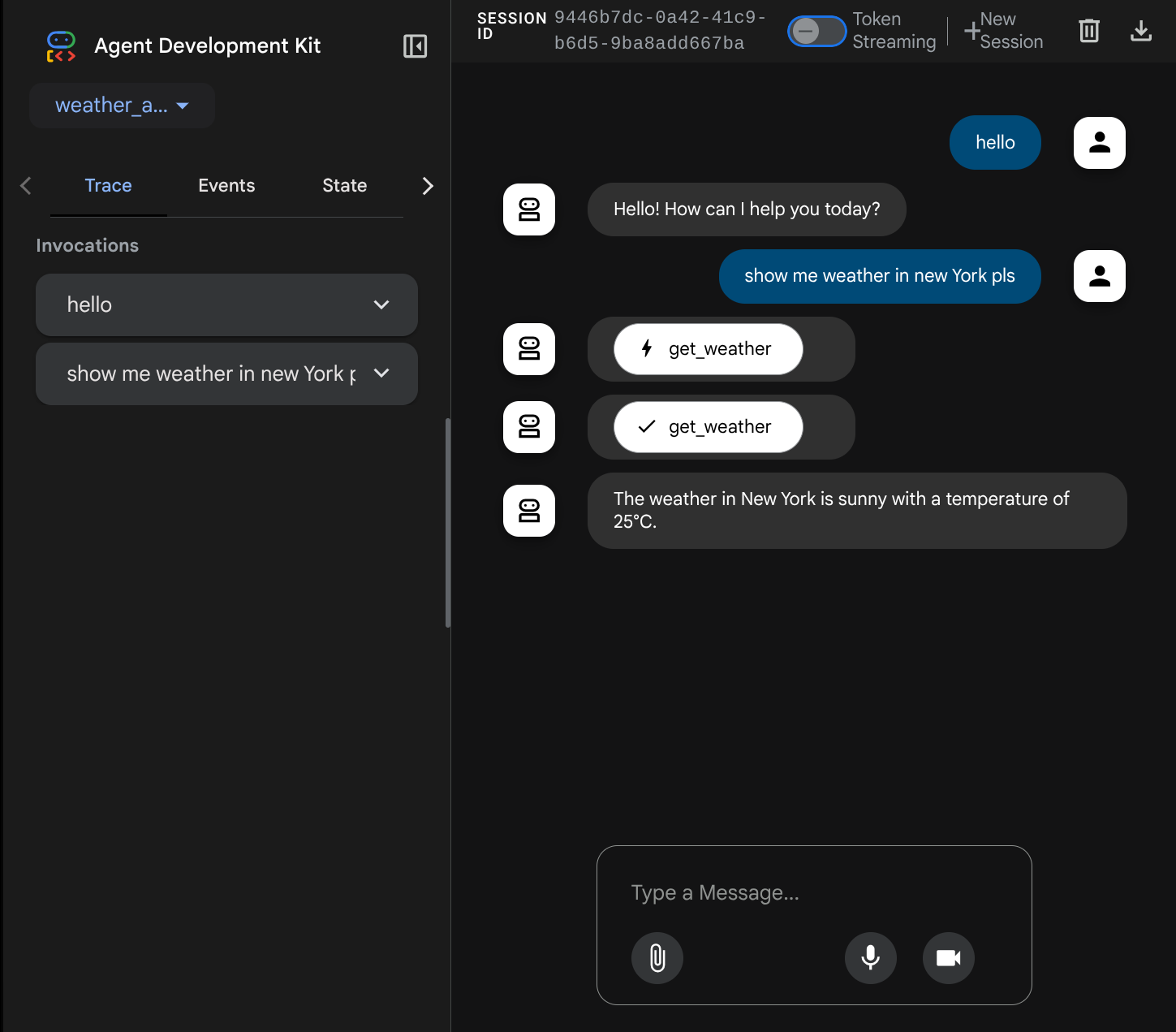
Você vai ver a seguinte página da Web, em que é possível selecionar os agentes disponíveis no botão suspenso no canto superior esquerdo ( no nosso caso, weather_agent) e interagir com o bot. Você vai ver muitas informações sobre os detalhes do registro durante o tempo de execução do agente na janela à esquerda.
Agora tente interagir com ele. Na barra à esquerda, podemos inspecionar o rastreamento de cada entrada para entender quanto tempo leva para cada ação realizada pelo agente antes de formar a resposta final.
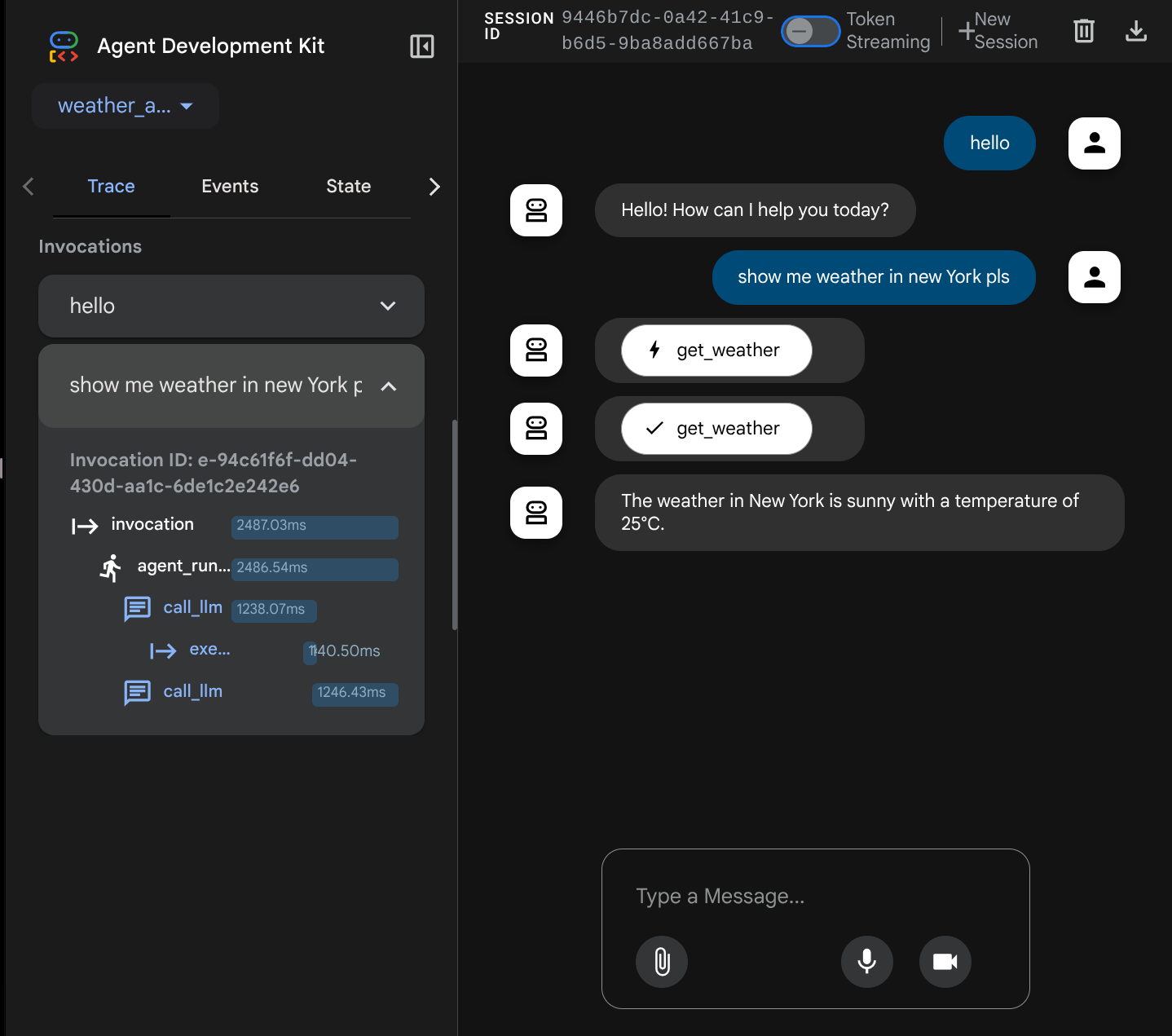
Esse é um dos recursos de capacidade de observação integrados ao ADK. No momento, ele é inspecionado localmente. Mais adiante, vamos ver como isso se integra ao Cloud Tracing para que tenhamos um rastreamento centralizado de todas as solicitações.
7. 🚀 Como implantar no Cloud Run
Agora, vamos implantar esse serviço de agente no Cloud Run. Para fins desta demonstração, esse serviço será exposto como um serviço público que pode ser acessado por outras pessoas. No entanto, lembre-se de que essa não é a prática recomendada, já que não é segura.
Esse cenário de implantação permite personalizar o serviço de back-end do agente. Vamos usar o Dockerfile para implantar o agente no Cloud Run. Neste ponto, já temos todos os arquivos necessários ( o Dockerfile e o server.py) para implantar nossos aplicativos no Cloud Run. Com esses dois itens, você pode personalizar a implantação do agente de maneira flexível ( por exemplo, adicionando rotas de back-end personalizadas e/ou um serviço sidecar adicional para fins de monitoramento). Vamos discutir isso em detalhes mais tarde.
Agora, vamos implantar o serviço primeiro, navegar até o terminal do Cloud Shell e verificar se o projeto atual está configurado para seu projeto ativo. Vamos executar o script de configuração novamente. Também é possível usar o comando gcloud config set project [PROJECT_ID] para configurar seu projeto ativo.
bash setup_trial_project.sh && source .env
Agora, precisamos abrir o arquivo .env de novo. Descomente a variável DB_CONNECTION_NAME e preencha com o valor correto.
# Google Cloud and Vertex AI configuration
GOOGLE_CLOUD_PROJECT=your-project-id
GOOGLE_CLOUD_LOCATION=global
GOOGLE_GENAI_USE_VERTEXAI=True
# Database connection for session service
DB_CONNECTION_NAME=your-db-connection-name
Para acessar o valor DB_CONNECTION_NAME, acesse o painel do Cloud SQL.
e clique na instância que você criou. Acesse a barra de pesquisa na parte de cima do console do Cloud e digite "cloud sql". Em seguida, clique no produto Cloud SQL.
Depois disso, clique na instância criada anteriormente.
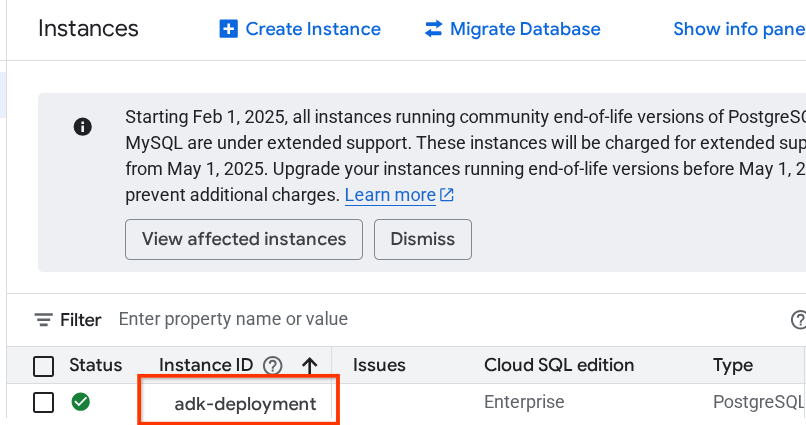
Na página da instância, role para baixo até a seção Conectar-se a esta instância e copie o Nome da conexão para substituir o valor DB_CONNECTION_NAME.
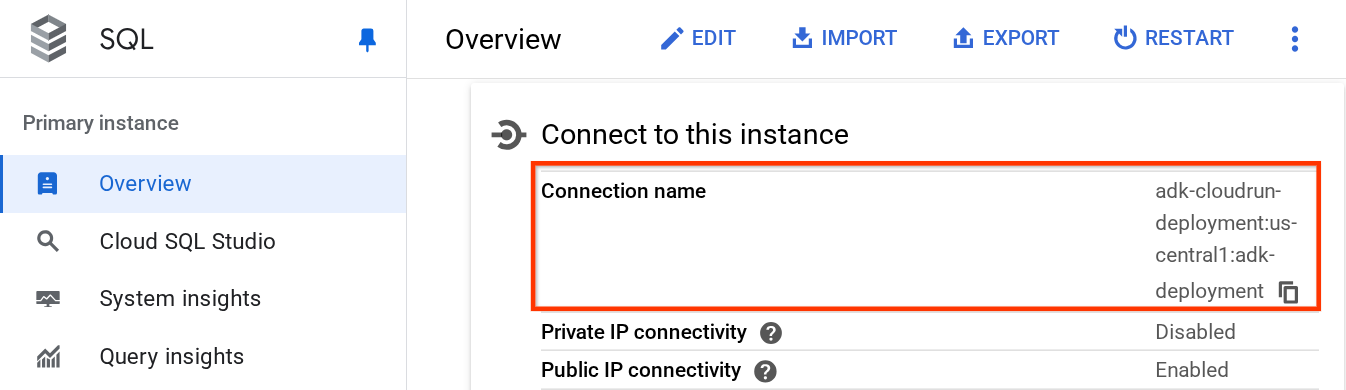
Depois disso, abra o arquivo .env com o seguinte comando:
cloudshell edit .env
e modifique a variável DB_CONNECTION_NAME no arquivo .env. Seu arquivo env vai ficar parecido com o exemplo abaixo
# Google Cloud and Vertex AI configuration
GOOGLE_CLOUD_PROJECT=your-project-id
GOOGLE_CLOUD_LOCATION=global
GOOGLE_GENAI_USE_VERTEXAI=True
# Database connection for session service
DB_CONNECTION_NAME=your-project-id:your-location:your-instance-name
Depois disso, execute o script de implantação.
bash deploy_to_cloudrun.sh
Se você precisar confirmar a criação de um registro de artefato para o repositório do Docker, responda Y.
Enquanto aguardamos o processo de implantação, vamos analisar o arquivo deploy_to_cloudrun.sh.
#!/bin/bash
# Load environment variables from .env file
if [ -f .env ]; then
export $(cat .env | grep -v '^#' | xargs)
else
echo "Error: .env file not found"
exit 1
fi
# Validate required variables
required_vars=("GOOGLE_CLOUD_PROJECT" "DB_CONNECTION_NAME")
for var in "${required_vars[@]}"; do
if [ -z "${!var}" ]; then
echo "Error: $var is not set in .env file"
exit 1
fi
done
gcloud run deploy weather-agent \
--source . \
--port 8080 \
--project ${GOOGLE_CLOUD_PROJECT} \
--allow-unauthenticated \
--add-cloudsql-instances ${DB_CONNECTION_NAME} \
--update-env-vars SESSION_SERVICE_URI="postgresql+pg8000://postgres:ADK-deployment123@postgres/?unix_sock=/cloudsql/${DB_CONNECTION_NAME}/.s.PGSQL.5432",GOOGLE_CLOUD_PROJECT=${GOOGLE_CLOUD_PROJECT} \
--region us-central1 \
--min 1 \
--memory 1G \
--concurrency 10
Esse script vai carregar sua variável .env e executar o comando de implantação.
Se você analisar mais de perto, só precisará de um comando gcloud run deploy para fazer tudo o que é necessário para implantar um serviço: criar a imagem, enviar para o registro, implantar o serviço, definir a política do IAM, criar uma revisão e até mesmo rotear o tráfego. Neste exemplo, já fornecemos o Dockerfile. Portanto, esse comando o usará para criar o app.
Quando a implantação for concluída, você vai receber um link semelhante a este:
https://weather-agent-*******.us-central1.run.app
Depois de receber esse URL, use o aplicativo na janela anônima ou no dispositivo móvel e acesse a interface de desenvolvimento do agente. Enquanto aguardamos a implantação, vamos inspecionar o serviço detalhado que acabamos de implantar na próxima seção.
8. 💡 O Dockerfile e o script do servidor de back-end
Para tornar o agente acessível como um serviço, vamos encapsulá-lo em um app FastAPI, que será executado no comando Dockerfile. Confira abaixo o conteúdo do Dockerfile.
FROM python:3.12-slim
RUN pip install --no-cache-dir uv==0.7.13
WORKDIR /app
COPY . .
RUN uv sync --frozen
EXPOSE 8080
CMD ["uv", "run", "uvicorn", "server:app", "--host", "0.0.0.0", "--port", "8080"]
Podemos configurar os serviços necessários para oferecer suporte ao agente aqui, como preparar o serviço Session, Memory ou Artifact para fins de produção. Este é o código do server.py que será usado.
import os
from dotenv import load_dotenv
from fastapi import FastAPI
from google.adk.cli.fast_api import get_fast_api_app
from pydantic import BaseModel
from typing import Literal
from google.cloud import logging as google_cloud_logging
# Load environment variables from .env file
load_dotenv()
logging_client = google_cloud_logging.Client()
logger = logging_client.logger(__name__)
AGENT_DIR = os.path.dirname(os.path.abspath(__file__))
# Get session service URI from environment variables
session_uri = os.getenv("SESSION_SERVICE_URI", None)
# Prepare arguments for get_fast_api_app
app_args = {"agents_dir": AGENT_DIR, "web": True, "trace_to_cloud": True}
# Only include session_service_uri if it's provided
if session_uri:
app_args["session_service_uri"] = session_uri
else:
logger.log_text(
"SESSION_SERVICE_URI not provided. Using in-memory session service instead. "
"All sessions will be lost when the server restarts.",
severity="WARNING",
)
# Create FastAPI app with appropriate arguments
app: FastAPI = get_fast_api_app(**app_args)
app.title = "weather-agent"
app.description = "API for interacting with the Agent weather-agent"
class Feedback(BaseModel):
"""Represents feedback for a conversation."""
score: int | float
text: str | None = ""
invocation_id: str
log_type: Literal["feedback"] = "feedback"
service_name: Literal["weather-agent"] = "weather-agent"
user_id: str = ""
# Example if you want to add your custom endpoint
@app.post("/feedback")
def collect_feedback(feedback: Feedback) -> dict[str, str]:
"""Collect and log feedback.
Args:
feedback: The feedback data to log
Returns:
Success message
"""
logger.log_struct(feedback.model_dump(), severity="INFO")
return {"status": "success"}
# Main execution
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8080)
Explicação do código do servidor
Estas são as coisas definidas no script server.py:
- Converta nosso agente em um app FastAPI usando o método
get_fast_api_app. Assim, vamos herdar a mesma definição de rota usada na interface de desenvolvimento da Web. - Configure o serviço de sessão, memória ou artefato necessário adicionando os argumentos de palavra-chave ao método
get_fast_api_app. Neste tutorial, se configurarmos a variável de ambienteSESSION_SERVICE_URI, o serviço de sessão vai usá-la. Caso contrário, ele usará a sessão na memória. - Podemos adicionar uma rota personalizada para oferecer suporte a outras lógicas de negócios de back-end. No script, adicionamos um exemplo de rota de funcionalidade de feedback.
- Ative o rastreamento na nuvem nos parâmetros de argumento
get_fast_api_apppara enviar o rastreamento ao Cloud Trace. - Executar o serviço FastAPI usando o uvicorn
Agora, se a implantação já estiver concluída, tente interagir com o agente na interface de desenvolvimento da Web acessando o URL do Cloud Run.
9. 🚀 Inspeção do escalonamento automático do Cloud Run com teste de carga
Agora vamos inspecionar os recursos de escalonamento automático do Cloud Run. Para este cenário, vamos implantar uma nova revisão e ativar a simultaneidade máxima por instância. Na seção anterior, definimos a simultaneidade máxima como 10 ( flag --concurrency 10). Portanto, podemos esperar que o Cloud Run tente escalonar a instância quando realizarmos um teste de carga que exceda esse número.
Vamos inspecionar o arquivo load_test.py. Esse será o script usado para fazer o teste de carga com o framework locust. Esse script vai fazer o seguinte :
- user_id e session_id aleatórios
- Criar session_id para o user_id
- Acesse o endpoint "/run_sse" com o user_id e o session_id criados.
Vamos precisar saber o URL do serviço implantado, caso você não tenha anotado. Podemos acessar o console do Cloud Run
Em seguida, encontre e clique no serviço weather-agent.
O URL do serviço vai aparecer ao lado das informações da região. Exemplo:

Para simplificar, execute o script a seguir para receber o URL do serviço implantado recentemente e armazená-lo na variável de ambiente SERVICE_URL.
export SERVICE_URL=$(gcloud run services describe weather-agent \
--platform managed \
--region us-central1 \
--format 'value(status.url)')
Em seguida, execute o comando a seguir para testar a carga do app do agente.
uv run locust -f load_test.py \
-H $SERVICE_URL \
-u 60 \
-r 5 \
-t 120 \
--headless
Ao executar esse comando, você vai ver métricas como esta. ( Neste exemplo, todas as solicitações foram bem-sucedidas)
Type Name # reqs # fails | Avg Min Max Med | req/s failures/s
--------|------------------------------------|-------|-------------|-------|-------|-------|-------|--------|-----------
POST /run_sse end 813 0(0.00%) | 5817 2217 26421 5000 | 6.79 0.00
POST /run_sse message 813 0(0.00%) | 2678 1107 17195 2200 | 6.79 0.00
--------|------------------------------------|-------|-------------|-------|-------|-------|-------|--------|-----------
Aggregated 1626 0(0.00%) | 4247 1107 26421 3500 | 13.59 0.00
Agora vamos ver o que aconteceu no Cloud Run. Acesse novamente o serviço implantado e confira o painel. Isso vai mostrar como o Cloud Run escalona automaticamente a instância para processar as solicitações recebidas. Como estamos limitando a simultaneidade máxima a 10 por instância, a instância do Cloud Run tentará ajustar automaticamente o número de contêineres para atender a essa condição.
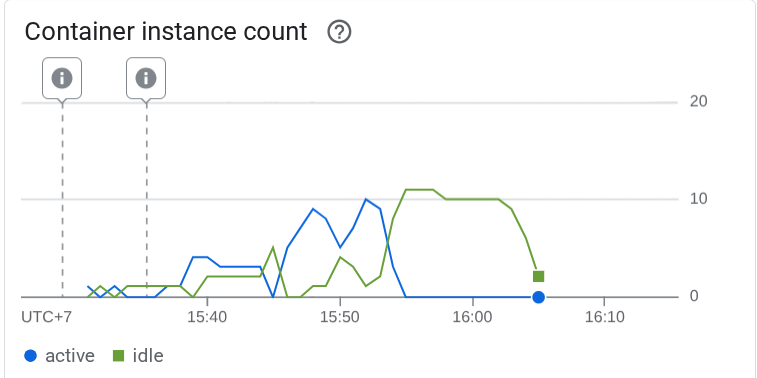
10. 🚀 Lançamento gradual de novas revisões
Agora, vamos considerar o seguinte cenário. Queremos atualizar o comando do agente. Abra o arquivo weather_agent/agent.py com o seguinte comando:
cloudshell edit weather_agent/agent.py
e substitua pelo seguinte código:
# weather_agent/agent.py
import os
from pathlib import Path
import google.auth
from dotenv import load_dotenv
from google.adk.agents import Agent
from weather_agent.tool import get_weather
# Load environment variables from .env file in root directory
root_dir = Path(__file__).parent.parent
dotenv_path = root_dir / ".env"
load_dotenv(dotenv_path=dotenv_path)
# Use default project from credentials if not in .env
_, project_id = google.auth.default()
os.environ.setdefault("GOOGLE_CLOUD_PROJECT", project_id)
os.environ.setdefault("GOOGLE_CLOUD_LOCATION", "global")
os.environ.setdefault("GOOGLE_GENAI_USE_VERTEXAI", "True")
root_agent = Agent(
name="weather_agent",
model="gemini-2.5-flash",
instruction="""
You are a helpful AI assistant designed to provide accurate and useful information.
You only answer inquiries about the weather. Refuse all other user query
""",
tools=[get_weather],
)
Em seguida, você quer lançar novas revisões, mas não quer que todo o tráfego de solicitações vá diretamente para a nova versão. Podemos fazer lançamentos graduais com o Cloud Run. Primeiro, precisamos implantar uma nova revisão, mas com a flag –no-traffic. Salve o script do agente anterior e execute o seguinte comando:
gcloud run deploy weather-agent \
--source . \
--port 8080 \
--project $GOOGLE_CLOUD_PROJECT \
--allow-unauthenticated \
--region us-central1 \
--no-traffic
Depois de terminar, você vai receber um registro semelhante ao processo de implantação anterior, mas com a diferença do número de tráfego atendido. Ela vai mostrar 0% do tráfego veiculado.
Service [weather-agent] revision [weather-agent-xxxx-xxx] has been deployed and is serving 0 percent of traffic.
Em seguida, acesse o painel do Cloud Run.
Em seguida, encontre e clique no serviço weather-agent.
Acesse a guia Revisões para ver a lista de revisões implantadas.
Você vai notar que as novas revisões implantadas estão atendendo a 0%. Clique no botão de três pontos (⋮) e escolha Gerenciar tráfego.
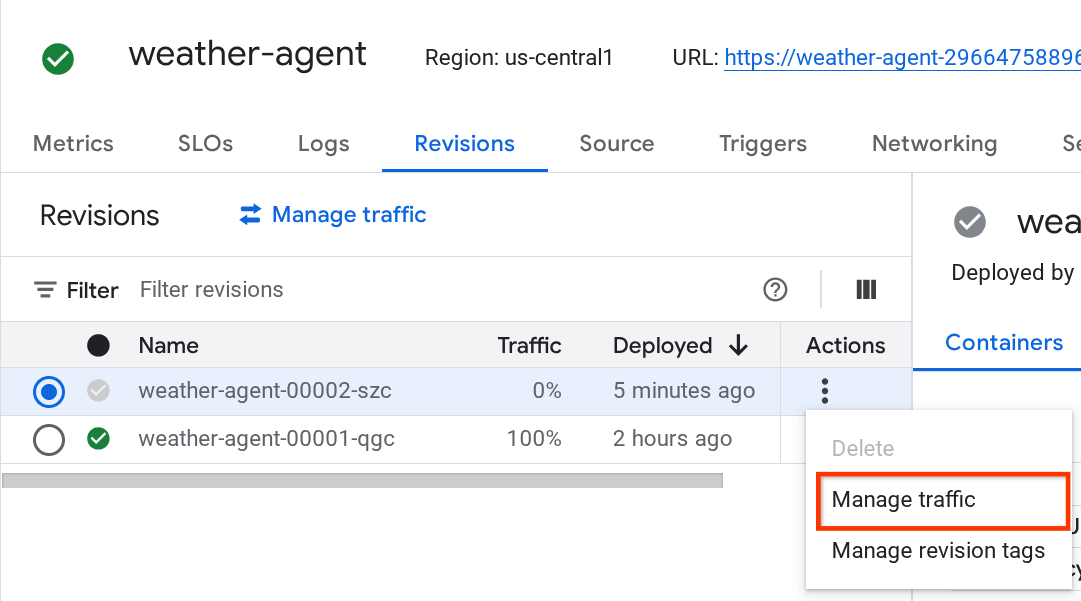
Na janela pop-up, edite a porcentagem do tráfego que vai para cada revisão.
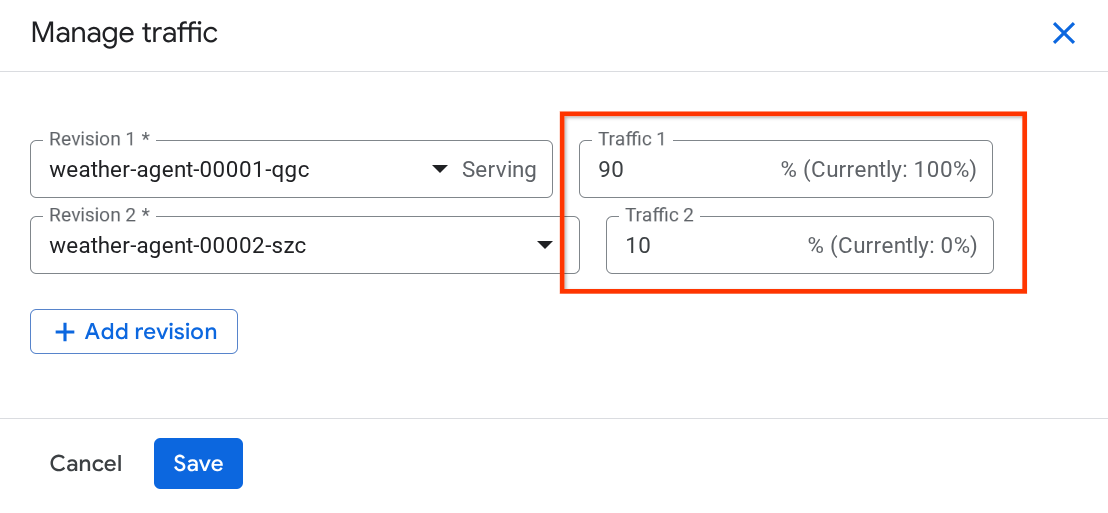
Depois de esperar um pouco, o tráfego será direcionado proporcionalmente com base nas configurações de porcentagem. Assim, podemos reverter facilmente para as revisões anteriores se algo acontecer com a nova versão.
11. 🚀 Rastreamento do ADK
Os agentes criados com o ADK já oferecem suporte ao rastreamento usando a incorporação do OpenTelemetry. Temos o Cloud Trace para capturar e visualizar esses rastreamentos. Vamos inspecionar o server.py para saber como ativar isso no serviço implantado anteriormente.
# server.py
...
app_args = {"agents_dir": AGENT_DIR, "web": True, "trace_to_cloud": True}
...
app: FastAPI = get_fast_api_app(**app_args)
...
Aqui, transmitimos o argumento trace_to_cloud para True. Se você estiver implantando com outras opções, consulte esta documentação para mais detalhes sobre como ativar o rastreamento no Cloud Trace usando várias opções de implantação.
Tente acessar a interface de desenvolvimento da Web do serviço e converse com o agente. Depois disso, acesse a página do Explorador de traces.
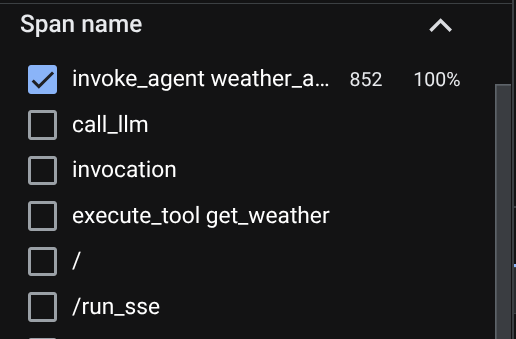
Na página do explorador de rastreamentos, você vai ver que nossa conversa com o rastreamento do agente foi enviada. Na seção Nome do intervalo, filtre o intervalo específico do nosso agente ( chamado agent_run [weather_agent]).
Quando os intervalos já estão filtrados, também é possível inspecionar cada rastreamento diretamente. Ele vai mostrar a duração detalhada de cada ação realizada pelo agente. Por exemplo, veja as imagens abaixo
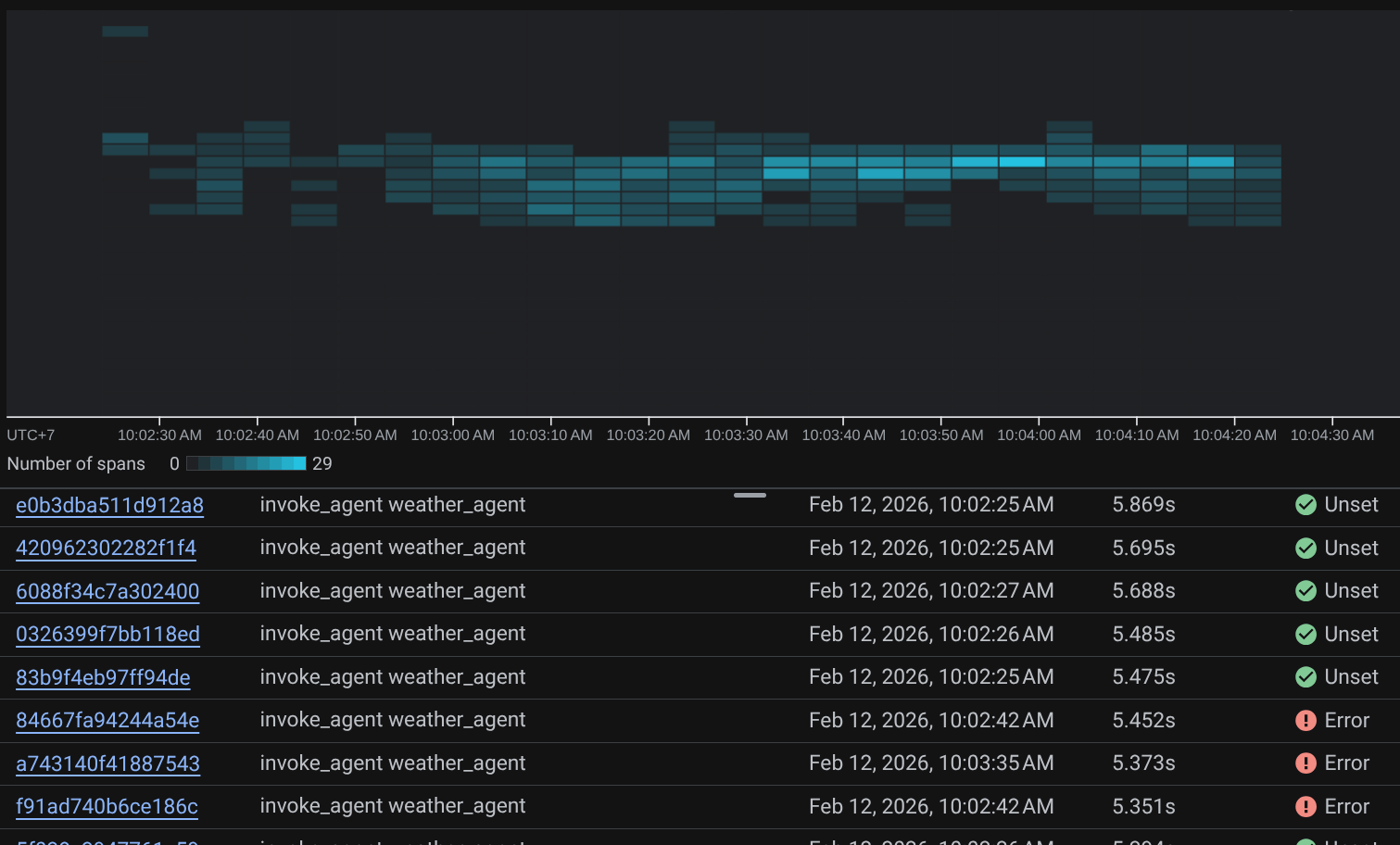
Em cada seção, você pode inspecionar os detalhes nos atributos, como mostrado abaixo
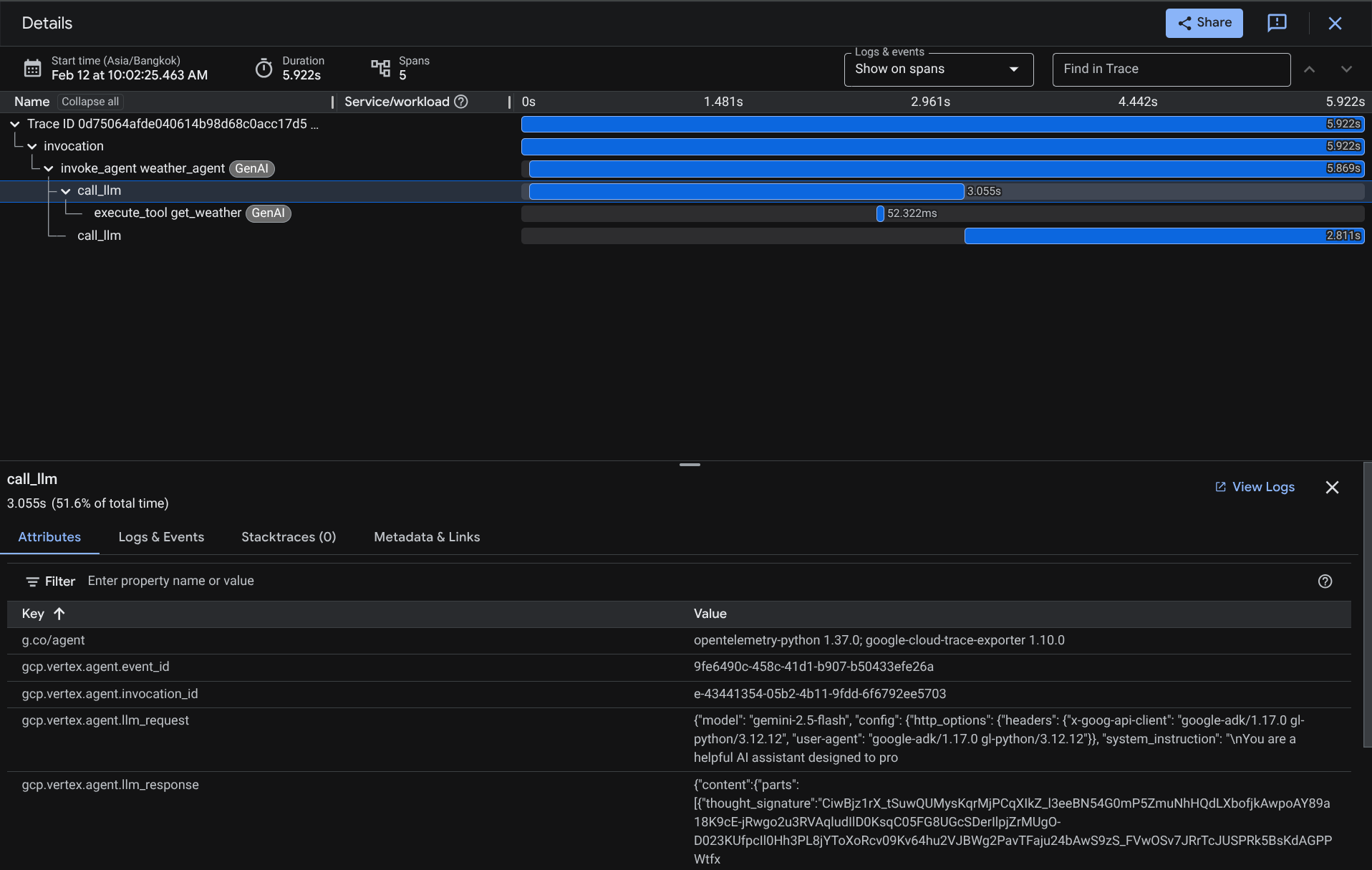
Pronto! Agora temos boa capacidade de observação e informações sobre cada interação do nosso agente com o usuário para ajudar a depurar problemas. Teste várias ferramentas ou fluxos de trabalho.
12. 🎯 Desafio
Teste fluxos de trabalho multiagentes ou com agentes para ver como eles se comportam sob cargas e como fica o rastreamento.
13. 🧹 Limpeza
Para evitar cobranças na sua conta do Google Cloud pelos recursos usados neste codelab, siga estas etapas:
- No console do Google Cloud, acesse a página Gerenciar recursos.
- Na lista de projetos, selecione o projeto que você quer excluir e clique em Excluir.
- Na caixa de diálogo, digite o ID do projeto e clique em Encerrar para excluí-lo.
- Outra opção é acessar Cloud Run no console, selecionar o serviço que você acabou de implantar e excluir.