
1. Introducción
En este instructivo, se explica cómo implementar, administrar y supervisar un agente potente creado con el Kit de desarrollo de agentes (ADK) en Google Cloud Run. El ADK te permite crear agentes capaces de realizar flujos de trabajo complejos de varios agentes. Si aprovechas Cloud Run, una plataforma sin servidores completamente administrada, puedes implementar tu agente como una aplicación alojada en contenedores y escalable sin preocuparte por la infraestructura subyacente. Esta potente combinación te permite enfocarte en la lógica principal de tu agente y, al mismo tiempo, beneficiarte del entorno sólido y escalable de Google Cloud.
A lo largo de este instructivo, exploraremos la integración perfecta del ADK con Cloud Run. Aprenderás a implementar tu agente y, luego, te sumergirás en los aspectos prácticos de la administración de tu aplicación en un entorno similar al de producción. Abordaremos cómo lanzar de forma segura versiones nuevas de tu agente administrando el tráfico, lo que te permitirá probar funciones nuevas con un subconjunto de usuarios antes de un lanzamiento completo.
Además, obtendrás experiencia práctica en la supervisión del rendimiento de tu agente. Simularemos una situación real realizando una prueba de carga para observar las capacidades de ajuste de escala automático de Cloud Run en acción. Para obtener estadísticas más detalladas sobre el comportamiento y el rendimiento de tu agente, habilitaremos el registro con Cloud Trace. Esto proporcionará una vista detallada de extremo a extremo de las solicitudes a medida que viajan a través de tu agente, lo que te permitirá identificar y abordar cualquier cuello de botella de rendimiento. Al final de este instructivo, comprenderás cómo implementar, administrar y supervisar de manera eficaz tus agentes potenciados por el ADK en Cloud Run.
En el codelab, seguirás un enfoque paso a paso de la siguiente manera:
- Crea una base de datos de PostgreSQL en Cloud SQL para usarla en el servicio de sesión de la base de datos del agente del ADK
- Configura un agente básico del ADK
- Configura el servicio de sesión de la base de datos para que lo use el ejecutor de ADK
- Implementa inicialmente el agente en Cloud Run
- Realiza pruebas de carga y examina el ajuste de escala automático de Cloud Run
- Implementa una nueva revisión del agente y aumenta gradualmente el tráfico hacia las revisiones nuevas
- Configura el registro de seguimiento en la nube y, luego, inspecciona el registro de seguimiento de la ejecución del agente
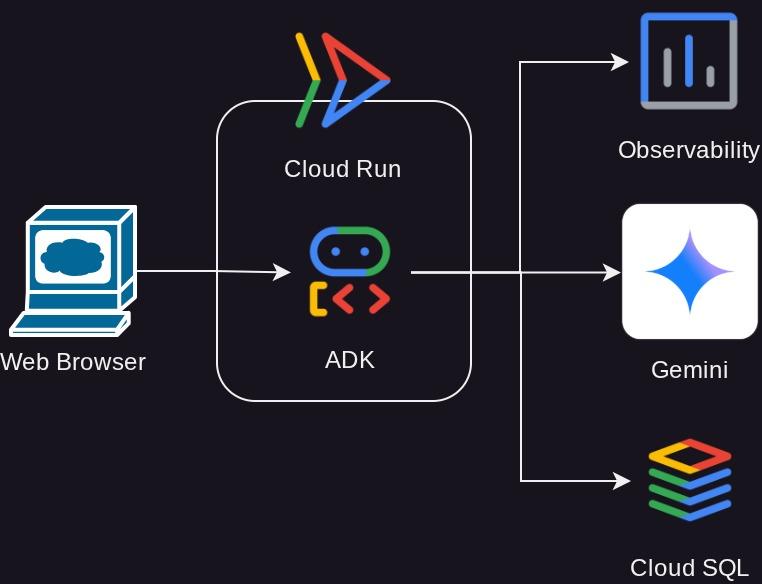
Descripción general de la arquitectura
Requisitos previos
- Comodidad para trabajar con Python
- Conocimiento de la arquitectura básica de pila completa con el servicio HTTP
Qué aprenderás
- Estructura del ADK y utilidades locales
- Configura el agente del ADK con el servicio de sesión de la base de datos
- Configura PostgreSQL en Cloud SQL para que lo use el servicio de sesión de la base de datos
- Implementa la aplicación en Cloud Run con Dockerfile y configura las variables de entorno iniciales
- Configura y prueba el ajuste de escala automático de Cloud Run con pruebas de carga
- Estrategia de lanzamiento gradual con Cloud Run
- Configura el seguimiento del agente del ADK en Cloud Trace
Requisitos
- Navegador web Chrome
- Una cuenta de Gmail
- Un proyecto de Cloud con la facturación habilitada
Este codelab, diseñado para desarrolladores de todos los niveles (incluidos los principiantes), usa Python en su aplicación de ejemplo. Sin embargo, no es necesario tener conocimientos de Python para comprender los conceptos presentados.
2. 🚀 Preparación de la configuración del taller
Ahora, usaremos el IDE de Cloud Shell para este instructivo. Haz clic en el siguiente botón para navegar hasta allí.
Una vez que estés en Cloud Shell, clona el directorio de trabajo de la plantilla para este codelab desde GitHub. Para ello, ejecuta el siguiente comando. Se creará el directorio de trabajo en el directorio deploy_and_manage_adk.
git clone https://github.com/alphinside/deploy-and-manage-adk-service.git deploy_and_manage_adk
Luego, ejecuta el siguiente comando en la terminal para abrir el repositorio clonado como tu directorio de trabajo.
cloudshell workspace ~/deploy_and_manage_adk && cd ~/deploy_and_manage_adk
Después de eso, tu interfaz debería verse similar a la siguiente:
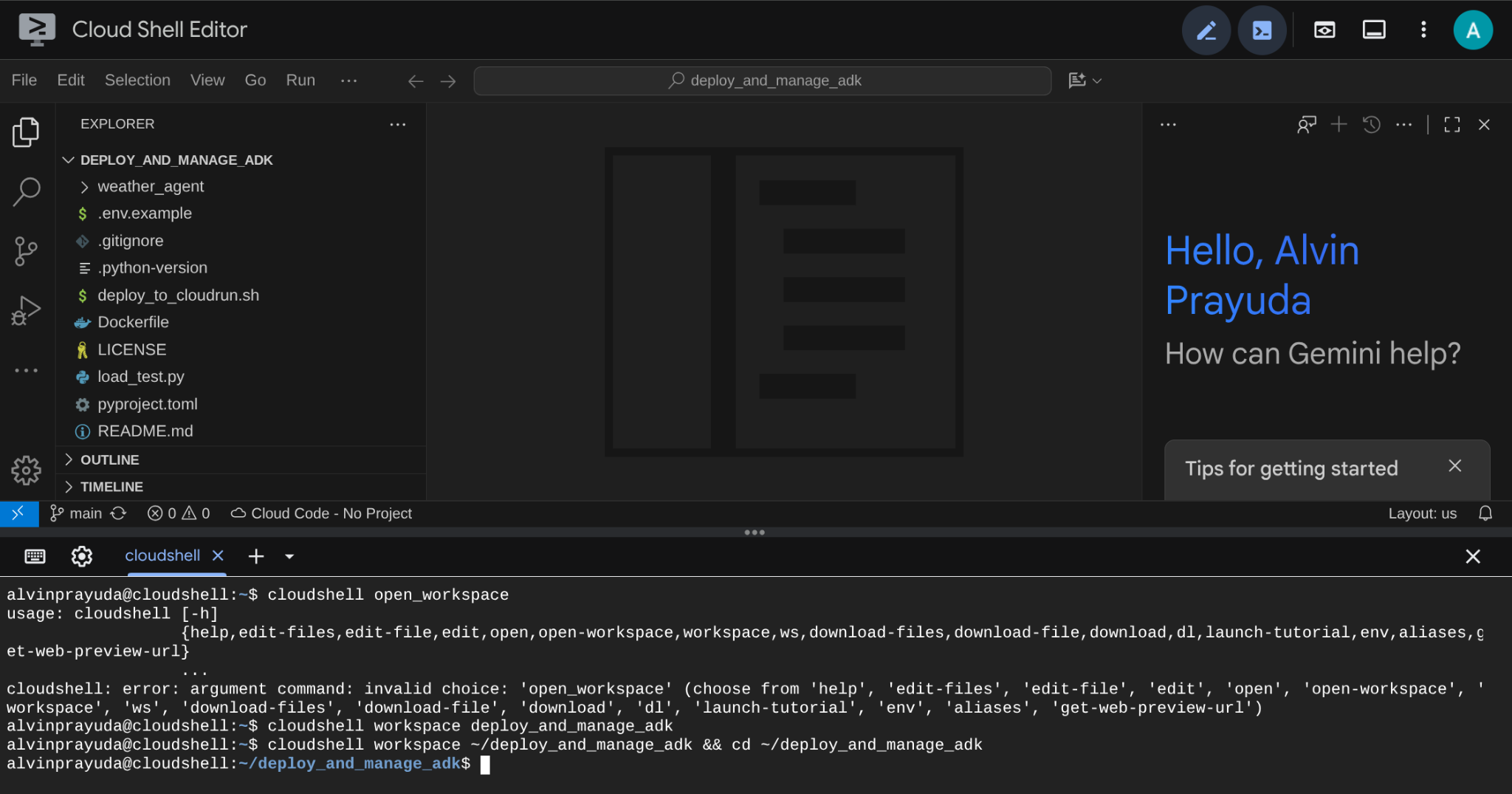
Esta será nuestra interfaz principal, con el IDE en la parte superior y la terminal en la parte inferior. Ahora debemos preparar nuestra terminal para crear y activar nuestro proyecto de Google Cloud, que se vinculará a la cuenta de facturación de prueba reclamada anteriormente. Preparamos un script para que siempre te asegures de que tu sesión de terminal esté lista. Ejecuta el siguiente comando ( asegúrate de que ya estás dentro del espacio de trabajo deploy_and_manage_adk).
bash setup_trial_project.sh && source .env
Cuando ejecutes este comando, se te solicitará un nombre de ID del proyecto sugerido. Puedes presionar Enter para continuar.

Después de esperar un tiempo, si ves este resultado en la consola, puedes continuar con el siguiente paso 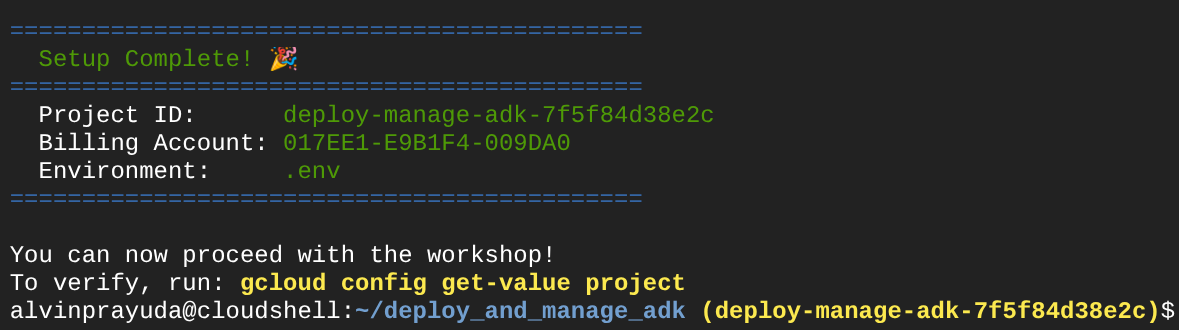 .
.
Esto muestra que tu terminal ya está autenticada y configurada con el ID del proyecto correcto ( el color amarillo junto a la ruta de acceso del directorio actual). Lo que hace este comando es ayudarte a crear un proyecto nuevo, encontrar y vincular el proyecto a una cuenta de facturación de prueba, preparar el archivo .env para la configuración de la variable de entorno y también activar el ID del proyecto correcto en la terminal.
Ahora sí, ya podemos continuar con el siguiente paso.
3. 🚀 Habilita las APIs
En este instructivo, interactuaremos con la base de datos de Cloud SQL, el modelo de Gemini y Cloud Run. Estos productos requerirán que se activen las siguientes APIs. Ejecuta estos comandos para habilitarlas.
Este proceso podría tardar un poco.
gcloud services enable aiplatform.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
cloudresourcemanager.googleapis.com \
sqladmin.googleapis.com \
compute.googleapis.com
Si el comando se ejecuta correctamente, deberías ver un mensaje similar al que se muestra a continuación:
Operation "operations/..." finished successfully.
4. 🚀 Configuración del entorno de Python y variables de entorno
Usaremos Python 3.12 en este codelab y uv python project manager para simplificar la necesidad de crear y administrar la versión de Python y el entorno virtual. Este paquete uv ya está preinstalado en Cloud Shell.
Ejecuta este comando para instalar las dependencias requeridas en el entorno virtual del directorio .venv.
uv sync --frozen
A continuación, inspeccionaremos los archivos de variables de entorno requeridos para este proyecto. Anteriormente, este archivo se configuraba con la secuencia de comandos setup_trial_project.sh. Ejecuta el siguiente comando para abrir el archivo .env en el editor:
cloudshell open .env
Verás los siguientes parámetros de configuración ya aplicados en el archivo .env.
# .env # Google Cloud and Vertex AI configuration GOOGLE_CLOUD_PROJECT=your-project-id GOOGLE_CLOUD_LOCATION=global GOOGLE_GENAI_USE_VERTEXAI=True # Database connection for session service # DB_CONNECTION_NAME=your-db-connection-name
Para este codelab, usaremos los valores preconfigurados para GOOGLE_CLOUD_LOCATION y GOOGLE_GENAI_USE_VERTEXAI..
Ahora podemos pasar al siguiente paso, que es crear la base de datos que utilizará nuestro agente para la persistencia de estado y sesión.
5. 🚀 Preparación de la base de datos de Cloud SQL
Más adelante, necesitaremos una base de datos para que la utilice el agente de ADK. Creemos una base de datos de PostgreSQL en Cloud SQL. Ejecuta el siguiente comando para crear primero la instancia de la base de datos. Usaremos el nombre de la base de datos predeterminada postgres, por lo que omitiremos la creación de la base de datos aquí. También debemos configurar nuestro nombre de usuario predeterminado de la base de datos (también postgres). Para los fines de este instructivo, usaremos ADK-deployment123 como contraseña.
gcloud sql instances create adk-deployment \
--database-version=POSTGRES_17 \
--edition=ENTERPRISE \
--tier=db-g1-small \
--region=us-central1 \
--availability-type=ZONAL \
--project=${GOOGLE_CLOUD_PROJECT} && \
gcloud sql users set-password postgres \
--instance=adk-deployment \
--password=ADK-deployment123
En el comando anterior, el primer gcloud sql instances create adk-deployment común es un comando que usamos para crear la instancia de la base de datos. Usamos una especificación mínima de zona de pruebas para este instructivo. El segundo comando gcloud sql users set-password postgres que se usa para cambiar la contraseña predeterminada del nombre de usuario postgres
Ten en cuenta que usamos adk-deployment como nombre de la instancia de la base de datos. Cuando finalice, deberías ver un resultado en la terminal como el que se muestra a continuación, que indica que la instancia está lista y que se actualizó la contraseña del usuario predeterminado.
Created [https://sqladmin.googleapis.com/sql/v1beta4/projects/your-project-id/instances/adk-deployment]. NAME: adk-deployment DATABASE_VERSION: POSTGRES_17 LOCATION: us-central1-a TIER: db-g1-small PRIMARY_ADDRESS: xx.xx.xx.xx PRIVATE_ADDRESS: - STATUS: RUNNABLE Updating Cloud SQL user...done.
Como la implementación de esta base de datos tardará un tiempo, continuemos con la siguiente sección mientras esperamos que la implementación de la base de datos de Cloud SQL esté lista.
6. 🚀 Crea el agente meteorológico con el ADK y Gemini 2.5
Introducción a la estructura de directorios del ADK
Comencemos por explorar lo que el ADK tiene para ofrecer y cómo compilar el agente. Puedes acceder a la documentación completa del ADK en esta URL . El ADK nos ofrece muchas utilidades dentro de la ejecución de su comando de CLI. Algunos de ellos son los siguientes :
- Configura la estructura del directorio del agente
- Probar rápidamente la interacción a través de la entrada y salida de la CLI
- Configura rápidamente la interfaz web de la IU de desarrollo local
Ahora, verifiquemos la estructura del agente en el directorio weather_agent.
weather_agent/ ├── __init__.py ├── agent.py └── tool.py
Si inspeccionas init.py y agent.py, verás este código.
# __init__.py
from weather_agent.agent import root_agent
__all__ = ["root_agent"]
# agent.py
import os
from pathlib import Path
import google.auth
from dotenv import load_dotenv
from google.adk.agents import Agent
from weather_agent.tool import get_weather
# Load environment variables from .env file in root directory
root_dir = Path(__file__).parent.parent
dotenv_path = root_dir / ".env"
load_dotenv(dotenv_path=dotenv_path)
# Use default project from credentials if not in .env
_, project_id = google.auth.default()
os.environ.setdefault("GOOGLE_CLOUD_PROJECT", project_id)
os.environ.setdefault("GOOGLE_CLOUD_LOCATION", "global")
os.environ.setdefault("GOOGLE_GENAI_USE_VERTEXAI", "True")
root_agent = Agent(
name="weather_agent",
model="gemini-2.5-flash",
instruction="""
You are a helpful AI assistant designed to provide accurate and useful information.
""",
tools=[get_weather],
)
ADK Explicación del código
Este script contiene la inicialización de nuestro agente, en la que inicializamos los siguientes elementos:
- Establece el modelo que se usará en
gemini-2.5-flash - Proporciona la herramienta
get_weatherpara admitir la funcionalidad del agente como agente meteorológico.
Ejecuta la IU web de forma local
Ahora podemos interactuar con el agente y analizar su comportamiento de forma local. El ADK nos permite tener una IU web de desarrollo para interactuar y ver qué sucede durante la interacción. Ejecuta el siguiente comando para iniciar el servidor de la IU de desarrollo local:
uv run adk web --port 8080
Se generará un resultado similar al siguiente ejemplo, lo que significa que ya podemos acceder a la interfaz web.
INFO: Started server process [xxxx] INFO: Waiting for application startup. +-----------------------------------------------------------------------------+ | ADK Web Server started | | | | For local testing, access at http://localhost:8080. | +-----------------------------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
Ahora, para verificarlo, haz clic en el botón Vista previa en la Web en la parte superior del editor de Cloud Shell y selecciona Vista previa en el puerto 8080.
Verás la siguiente página web en la que podrás seleccionar los agentes disponibles en el botón desplegable de la parte superior izquierda ( en nuestro caso, debería ser weather_agent) y, luego, interactuar con el bot. En la ventana de la izquierda, verás mucha información sobre los detalles del registro durante el tiempo de ejecución del agente.
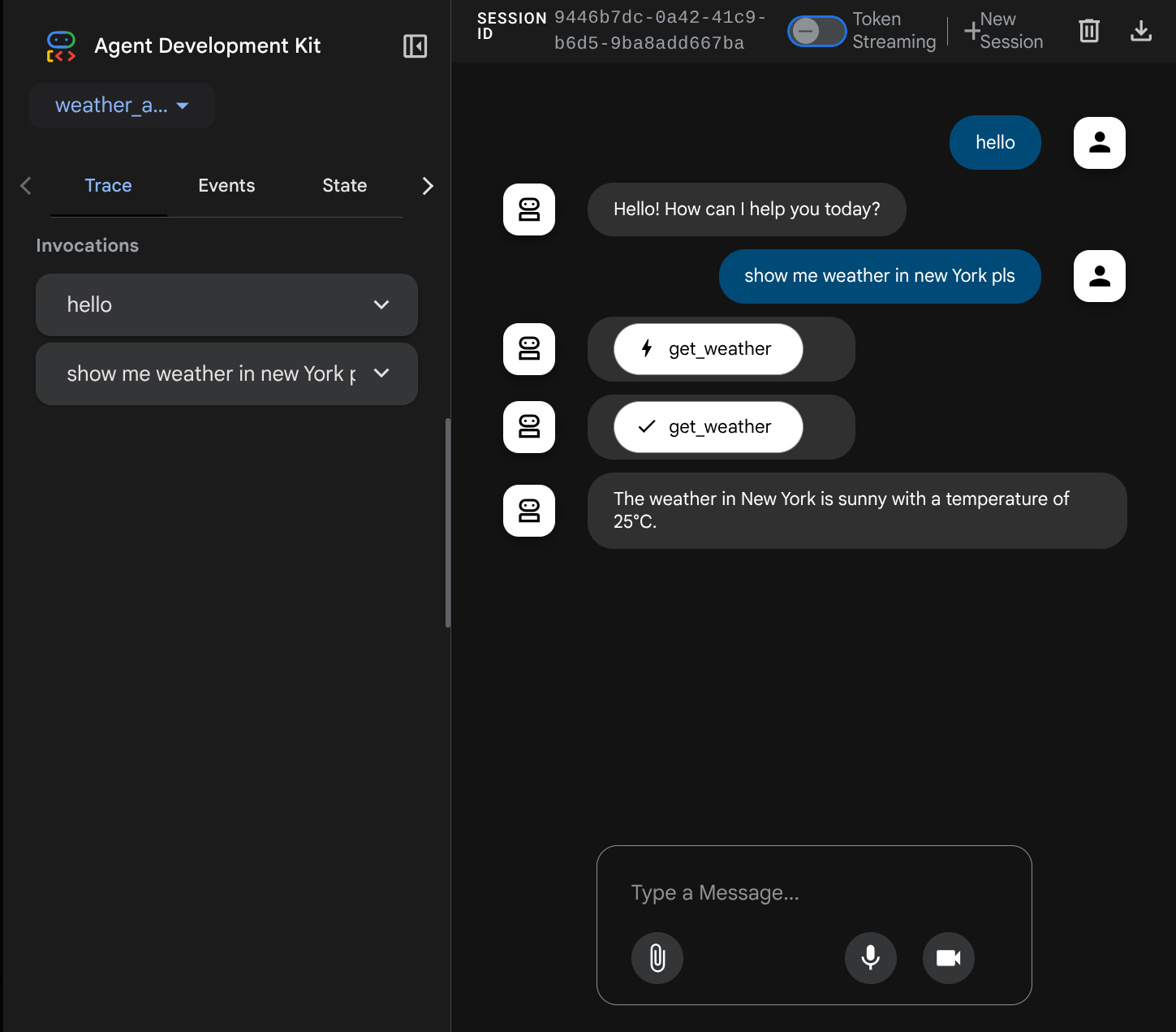
Ahora, intenta interactuar con él. En la barra izquierda, podemos inspeccionar el registro de cada entrada para comprender cuánto tiempo tarda cada acción que realiza el agente antes de formar la respuesta final.
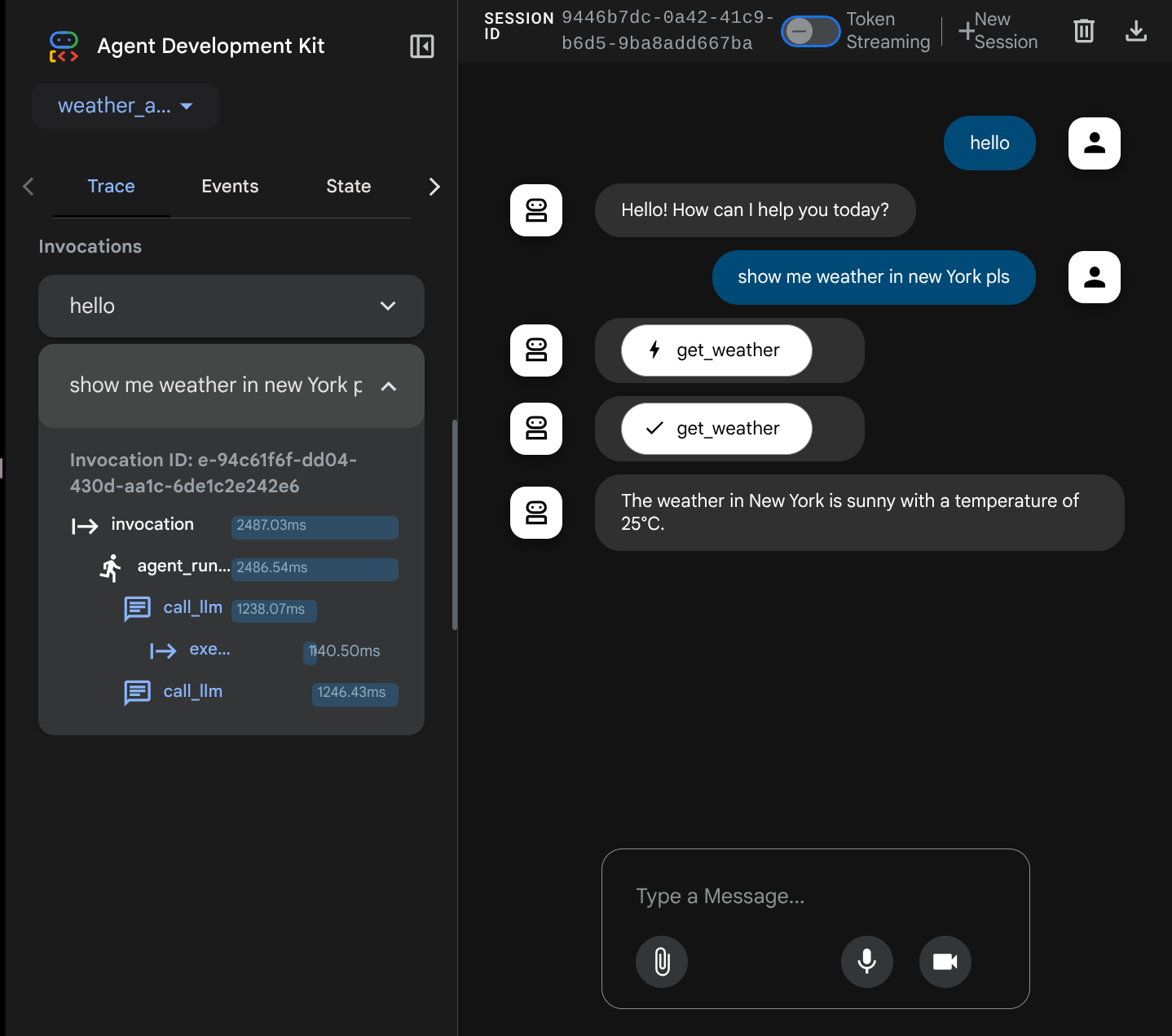
Esta es una de las funciones de observabilidad integradas en el ADK. Actualmente, la inspeccionamos de forma local. Más adelante, veremos cómo se integra esto en Cloud Trace para que tengamos un registro centralizado de todas las solicitudes.
7. 🚀 Implementación en Cloud Run
Ahora, implementemos este servicio de agente en Cloud Run. Para los fines de esta demostración, este servicio se expondrá como un servicio público al que pueden acceder otras personas. Sin embargo, ten en cuenta que esta no es la mejor práctica, ya que no es segura.
Este escenario de implementación te permite personalizar el servicio de backend del agente. Usaremos Dockerfile para implementar nuestro agente en Cloud Run. En este punto, ya tenemos todos los archivos necesarios ( el Dockerfile y el server.py) para implementar nuestras aplicaciones en Cloud Run. Con estos 2 elementos, puedes personalizar de forma flexible la implementación de tu agente ( p.ej., agregar rutas de backend personalizadas o un servicio sidecar adicional para fines de supervisión). Analizaremos esto en detalle más adelante.
Ahora, primero implementemos el servicio. Navega a la terminal de Cloud Shell y asegúrate de que el proyecto actual esté configurado en tu proyecto activo. Ejecutemos el script de configuración de nuevo. De manera opcional, también puedes usar el comando gcloud config set project [PROJECT_ID] para configurar tu proyecto activo.
bash setup_trial_project.sh && source .env
Ahora, debemos volver a visitar el archivo .env, abrirlo y verás que debemos quitar el comentario de la variable DB_CONNECTION_NAME y completarla con el valor correcto.
# Google Cloud and Vertex AI configuration
GOOGLE_CLOUD_PROJECT=your-project-id
GOOGLE_CLOUD_LOCATION=global
GOOGLE_GENAI_USE_VERTEXAI=True
# Database connection for session service
DB_CONNECTION_NAME=your-db-connection-name
Para obtener el valor de DB_CONNECTION_NAME, visitemos el panel de Cloud SQL.
Luego, haz clic en la instancia que creaste. Navega a la barra de búsqueda en la sección superior de la consola de Cloud y escribe "Cloud SQL". Luego, haz clic en el producto Cloud SQL.
Después, verás la instancia creada anteriormente. Haz clic en ella.
En la página de la instancia, desplázate hacia abajo hasta la sección "Conéctate a esta instancia" y podrás copiar el Nombre de la conexión para sustituir el valor de DB_CONNECTION_NAME.
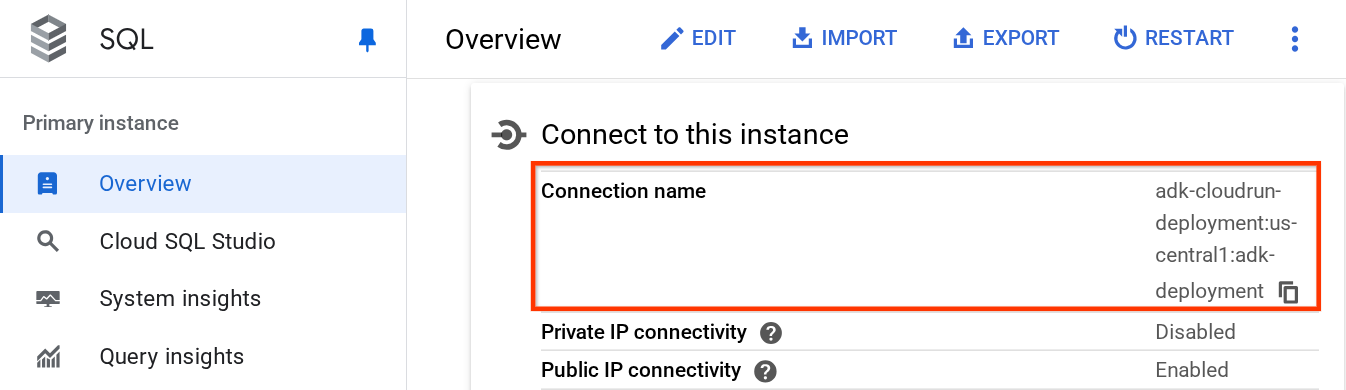
Después, abre el archivo .env con el siguiente comando:
cloudshell edit .env
y modifica la variable DB_CONNECTION_NAME en el archivo .env. Tu archivo .env debería verse como el siguiente ejemplo:
# Google Cloud and Vertex AI configuration
GOOGLE_CLOUD_PROJECT=your-project-id
GOOGLE_CLOUD_LOCATION=global
GOOGLE_GENAI_USE_VERTEXAI=True
# Database connection for session service
DB_CONNECTION_NAME=your-project-id:your-location:your-instance-name
Después de eso, ejecuta la secuencia de comandos de implementación.
bash deploy_to_cloudrun.sh
Si se te solicita que confirmes la creación de un registro de artefactos para el repositorio de Docker, responde Y.
Mientras esperamos el proceso de implementación, veamos el archivo deploy_to_cloudrun.sh.
#!/bin/bash
# Load environment variables from .env file
if [ -f .env ]; then
export $(cat .env | grep -v '^#' | xargs)
else
echo "Error: .env file not found"
exit 1
fi
# Validate required variables
required_vars=("GOOGLE_CLOUD_PROJECT" "DB_CONNECTION_NAME")
for var in "${required_vars[@]}"; do
if [ -z "${!var}" ]; then
echo "Error: $var is not set in .env file"
exit 1
fi
done
gcloud run deploy weather-agent \
--source . \
--port 8080 \
--project ${GOOGLE_CLOUD_PROJECT} \
--allow-unauthenticated \
--add-cloudsql-instances ${DB_CONNECTION_NAME} \
--update-env-vars SESSION_SERVICE_URI="postgresql+pg8000://postgres:ADK-deployment123@postgres/?unix_sock=/cloudsql/${DB_CONNECTION_NAME}/.s.PGSQL.5432",GOOGLE_CLOUD_PROJECT=${GOOGLE_CLOUD_PROJECT} \
--region us-central1 \
--min 1 \
--memory 1G \
--concurrency 10
Esta secuencia de comandos cargará tu variable .env y, luego, ejecutará el comando de implementación.
Si observas con más detalle, solo necesitamos un comando gcloud run deploy para hacer todo lo necesario si quieres implementar un servicio: compilar la imagen, enviar al registro, implementar el servicio, configurar la política de IAM, crear la revisión y hasta enrutar el tráfico. En este ejemplo, ya proporcionamos el Dockerfile, por lo que este comando lo utilizará para compilar la app.
Una vez que se complete la implementación, deberías obtener un vínculo similar al siguiente:
https://weather-agent-*******.us-central1.run.app
Después de obtener esta URL, puedes usar tu aplicación desde la ventana de incógnito o tu dispositivo móvil y acceder a la IU para desarrolladores del agente. Mientras esperas la implementación, inspeccionemos el servicio detallado que acabamos de implementar en la siguiente sección.
8. 💡 El Dockerfile y el script del servidor de backend
Para que el agente sea accesible como servicio, lo encapsularemos en una app de FastAPI que se ejecutará en el comando Dockerfile. A continuación, se muestra el contenido del Dockerfile.
FROM python:3.12-slim
RUN pip install --no-cache-dir uv==0.7.13
WORKDIR /app
COPY . .
RUN uv sync --frozen
EXPOSE 8080
CMD ["uv", "run", "uvicorn", "server:app", "--host", "0.0.0.0", "--port", "8080"]
Aquí podemos configurar los servicios necesarios para admitir el agente, como preparar los servicios Session, Memory o Artifact para fines de producción. Este es el código de server.py que se usará
import os
from dotenv import load_dotenv
from fastapi import FastAPI
from google.adk.cli.fast_api import get_fast_api_app
from pydantic import BaseModel
from typing import Literal
from google.cloud import logging as google_cloud_logging
# Load environment variables from .env file
load_dotenv()
logging_client = google_cloud_logging.Client()
logger = logging_client.logger(__name__)
AGENT_DIR = os.path.dirname(os.path.abspath(__file__))
# Get session service URI from environment variables
session_uri = os.getenv("SESSION_SERVICE_URI", None)
# Prepare arguments for get_fast_api_app
app_args = {"agents_dir": AGENT_DIR, "web": True, "trace_to_cloud": True}
# Only include session_service_uri if it's provided
if session_uri:
app_args["session_service_uri"] = session_uri
else:
logger.log_text(
"SESSION_SERVICE_URI not provided. Using in-memory session service instead. "
"All sessions will be lost when the server restarts.",
severity="WARNING",
)
# Create FastAPI app with appropriate arguments
app: FastAPI = get_fast_api_app(**app_args)
app.title = "weather-agent"
app.description = "API for interacting with the Agent weather-agent"
class Feedback(BaseModel):
"""Represents feedback for a conversation."""
score: int | float
text: str | None = ""
invocation_id: str
log_type: Literal["feedback"] = "feedback"
service_name: Literal["weather-agent"] = "weather-agent"
user_id: str = ""
# Example if you want to add your custom endpoint
@app.post("/feedback")
def collect_feedback(feedback: Feedback) -> dict[str, str]:
"""Collect and log feedback.
Args:
feedback: The feedback data to log
Returns:
Success message
"""
logger.log_struct(feedback.model_dump(), severity="INFO")
return {"status": "success"}
# Main execution
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8080)
Explicación del código del servidor
Estos son los elementos que se definen en la secuencia de comandos server.py:
- Convierte nuestro agente en una app de FastAPI con el método
get_fast_api_app. De esta manera, heredaremos la misma definición de ruta que se utiliza para la IU de desarrollo web. - Configura el servicio de sesión, memoria o artefacto necesario agregando los argumentos de palabras clave al método
get_fast_api_app. En este instructivo, si configuramos la variable de entornoSESSION_SERVICE_URI, el servicio de sesión la usará. De lo contrario, usará la sesión en memoria. - Podemos agregar una ruta personalizada para admitir otra lógica comercial de backend. En la secuencia de comandos, agregamos un ejemplo de ruta de funcionalidad de comentarios.
- Habilita el seguimiento de nube en los parámetros de argumentos
get_fast_api_apppara enviar el registro a Google Cloud Trace. - Ejecuta el servicio de FastAPI con Uvicorn
Ahora, si tu implementación ya finalizó, intenta interactuar con el agente desde la IU web de desarrollo accediendo a la URL de Cloud Run.
9. 🚀 Inspecciona el ajuste de escala automático de Cloud Run con pruebas de carga
Ahora, inspeccionaremos las capacidades de escalamiento automático de Cloud Run. Para este caso, implementaremos una revisión nueva y habilitaremos la máxima simultaneidad por instancia. En la sección anterior, establecimos la simultaneidad máxima en 10 ( marca --concurrency 10). Por lo tanto, podemos esperar que Cloud Run intente escalar su instancia cuando realicemos una prueba de carga que supere este número.
Inspeccionemos el archivo load_test.py. Esta será la secuencia de comandos que usaremos para realizar la prueba de carga con el framework de locust. Esta secuencia de comandos hará lo siguiente :
- user_id y session_id aleatorios
- Crea session_id para el user_id
- Llama al extremo "/run_sse" con el user_id y el session_id creados.
Si no la recuerdas, necesitaremos saber la URL del servicio implementado. Podemos ir a la consola de Cloud Run
Luego, busca tu servicio weather-agent y haz clic en él.
La URL del servicio se mostrará junto a la información de la región. P. ej.,

Para simplificar las cosas, ejecutemos la siguiente secuencia de comandos para obtener la URL del servicio que implementaste recientemente y almacenarla en la variable de entorno SERVICE_URL.
export SERVICE_URL=$(gcloud run services describe weather-agent \
--platform managed \
--region us-central1 \
--format 'value(status.url)')
Luego, ejecuta el siguiente comando para realizar una prueba de carga de nuestra app del agente.
uv run locust -f load_test.py \
-H $SERVICE_URL \
-u 60 \
-r 5 \
-t 120 \
--headless
Si ejecutas este comando, verás métricas como las que se muestran a continuación. ( En este ejemplo, todas las solicitudes se completaron correctamente).
Type Name # reqs # fails | Avg Min Max Med | req/s failures/s
--------|------------------------------------|-------|-------------|-------|-------|-------|-------|--------|-----------
POST /run_sse end 813 0(0.00%) | 5817 2217 26421 5000 | 6.79 0.00
POST /run_sse message 813 0(0.00%) | 2678 1107 17195 2200 | 6.79 0.00
--------|------------------------------------|-------|-------------|-------|-------|-------|-------|--------|-----------
Aggregated 1626 0(0.00%) | 4247 1107 26421 3500 | 13.59 0.00
Luego, veamos qué sucedió en Cloud Run. Vuelve a tu servicio implementado y consulta el panel. Esto mostrará cómo Cloud Run ajusta automáticamente la escala de la instancia para controlar las solicitudes entrantes. Como limitamos la simultaneidad máxima a 10 por instancia, la instancia de Cloud Run intentará ajustar la cantidad de contenedores para satisfacer esta condición automáticamente.
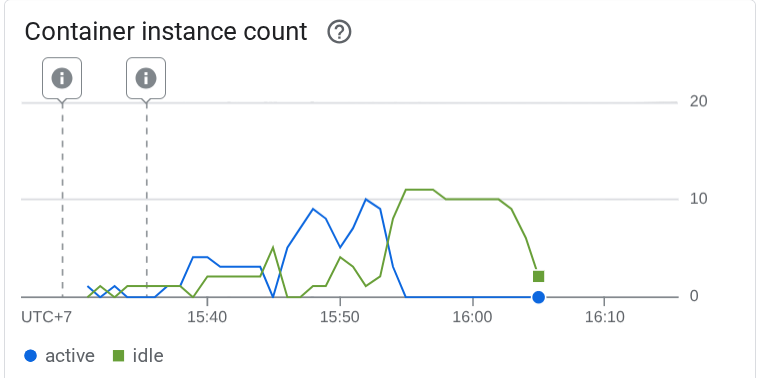
10. 🚀 Lanzamiento gradual de revisiones nuevas
Ahora, veamos la siguiente situación. Queremos actualizar la instrucción del agente. Abre weather_agent/agent.py con el siguiente comando:
cloudshell edit weather_agent/agent.py
y reemplázalo con el siguiente código:
# weather_agent/agent.py
import os
from pathlib import Path
import google.auth
from dotenv import load_dotenv
from google.adk.agents import Agent
from weather_agent.tool import get_weather
# Load environment variables from .env file in root directory
root_dir = Path(__file__).parent.parent
dotenv_path = root_dir / ".env"
load_dotenv(dotenv_path=dotenv_path)
# Use default project from credentials if not in .env
_, project_id = google.auth.default()
os.environ.setdefault("GOOGLE_CLOUD_PROJECT", project_id)
os.environ.setdefault("GOOGLE_CLOUD_LOCATION", "global")
os.environ.setdefault("GOOGLE_GENAI_USE_VERTEXAI", "True")
root_agent = Agent(
name="weather_agent",
model="gemini-2.5-flash",
instruction="""
You are a helpful AI assistant designed to provide accurate and useful information.
You only answer inquiries about the weather. Refuse all other user query
""",
tools=[get_weather],
)
Luego, quieres lanzar revisiones nuevas, pero no quieres que todo el tráfico de solicitudes vaya directamente a la versión nueva. Podemos hacer lanzamientos graduales con Cloud Run. Primero, debemos implementar una revisión nueva, pero con el parámetro –no-traffic. Guarda la secuencia de comandos del agente anterior y ejecuta el siguiente comando:
gcloud run deploy weather-agent \
--source . \
--port 8080 \
--project $GOOGLE_CLOUD_PROJECT \
--allow-unauthenticated \
--region us-central1 \
--no-traffic
Cuando termines, recibirás un registro similar al del proceso de implementación anterior, con la diferencia de la cantidad de tráfico que se atendió. Se mostrará el 0% del tráfico publicado.
Service [weather-agent] revision [weather-agent-xxxx-xxx] has been deployed and is serving 0 percent of traffic.
A continuación, ve al panel de Cloud Run.
Luego, busca tu servicio weather-agent y haz clic en él.
Ve a la pestaña Revisiones y verás la lista de revisiones implementadas.
Verás que las nuevas revisiones implementadas publican el 0% del tráfico. Desde aquí, puedes hacer clic en el botón de kebab (⋮) y elegir Administrar tráfico.
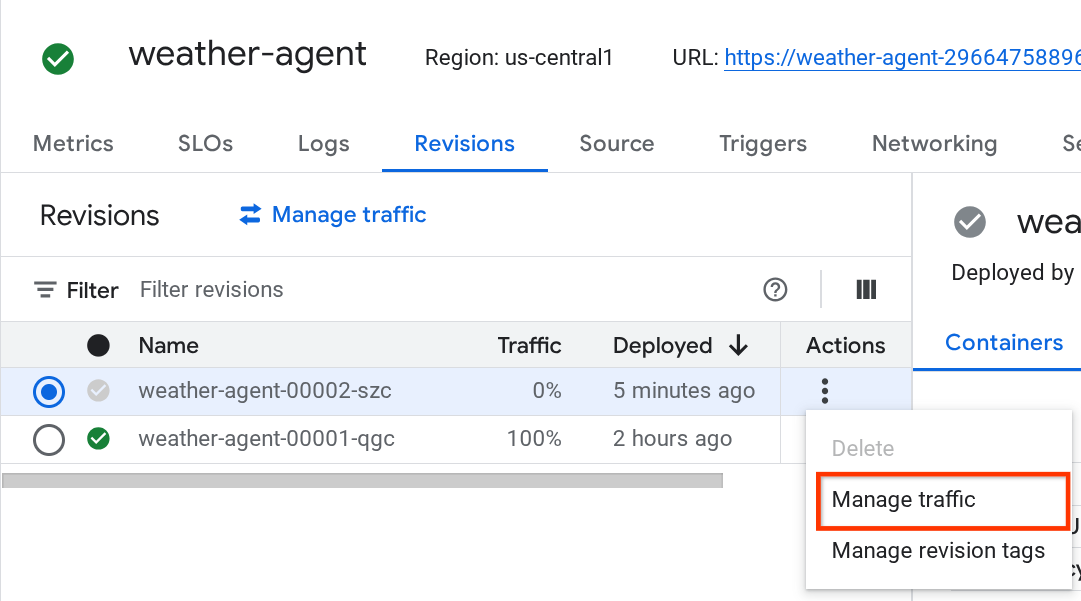
En la ventana emergente nueva, puedes editar el porcentaje de tráfico que se dirige a cada revisión.
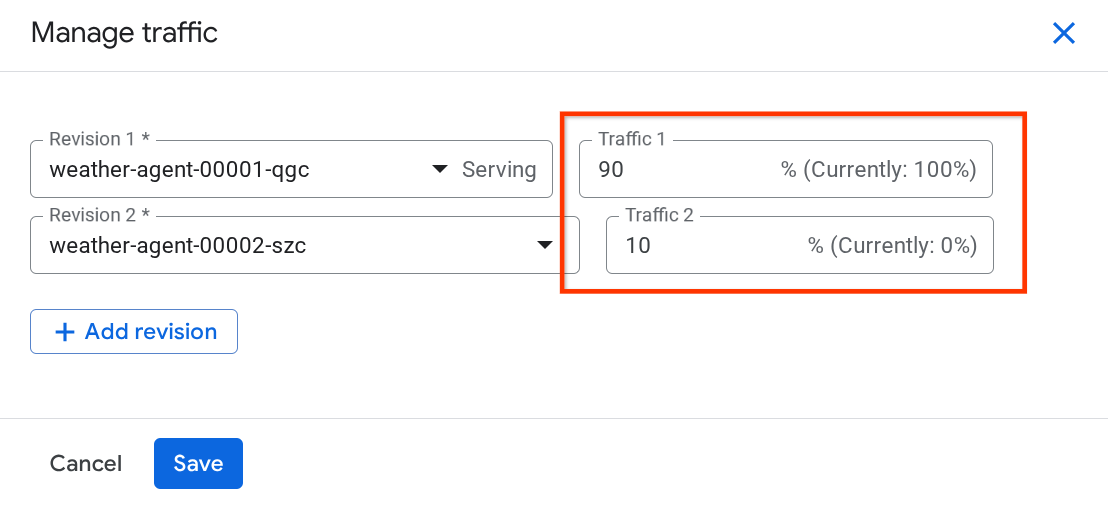
Después de esperar un tiempo, el tráfico se dirigirá de forma proporcional según los porcentajes de configuración. De esta manera, podemos revertir fácilmente a las revisiones anteriores si ocurre algún problema con la nueva versión.
11. 🚀 Registro de ADK
Los agentes compilados con el ADK ya admiten el seguimiento con la incorporación de OpenTelemetry. Tenemos Cloud Trace para capturar esos seguimientos y visualizarlos. Inspeccionemos server.py para ver cómo lo habilitamos en nuestro servicio implementado anteriormente.
# server.py
...
app_args = {"agents_dir": AGENT_DIR, "web": True, "trace_to_cloud": True}
...
app: FastAPI = get_fast_api_app(**app_args)
...
Aquí, pasamos el argumento trace_to_cloud a True. Si realizas la implementación con otras opciones, puedes consultar esta documentación para obtener más detalles sobre cómo habilitar el registro en Cloud Trace desde varias opciones de implementación.
Intenta acceder a la IU web de tu servicio y chatea con el agente. Luego, ve a la página Explorador de seguimiento.
En la página del explorador de registros, verás que se envió el registro de nuestra conversación con el agente. Puedes ver en la sección Nombre del tramo y filtrar el tramo específico de nuestro agente ( se llama agent_run [weather_agent]).
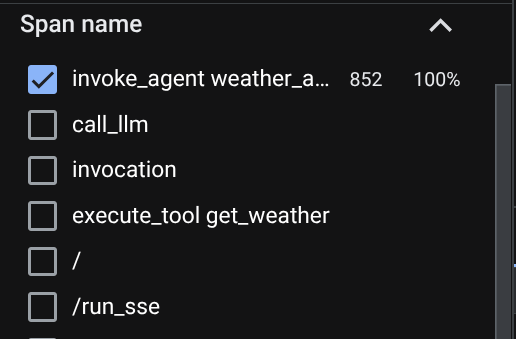
Cuando los intervalos ya están filtrados, también puedes inspeccionar cada registro directamente. Se mostrará la duración detallada de cada acción que realice el agente. Por ejemplo, mira las imágenes a continuación.
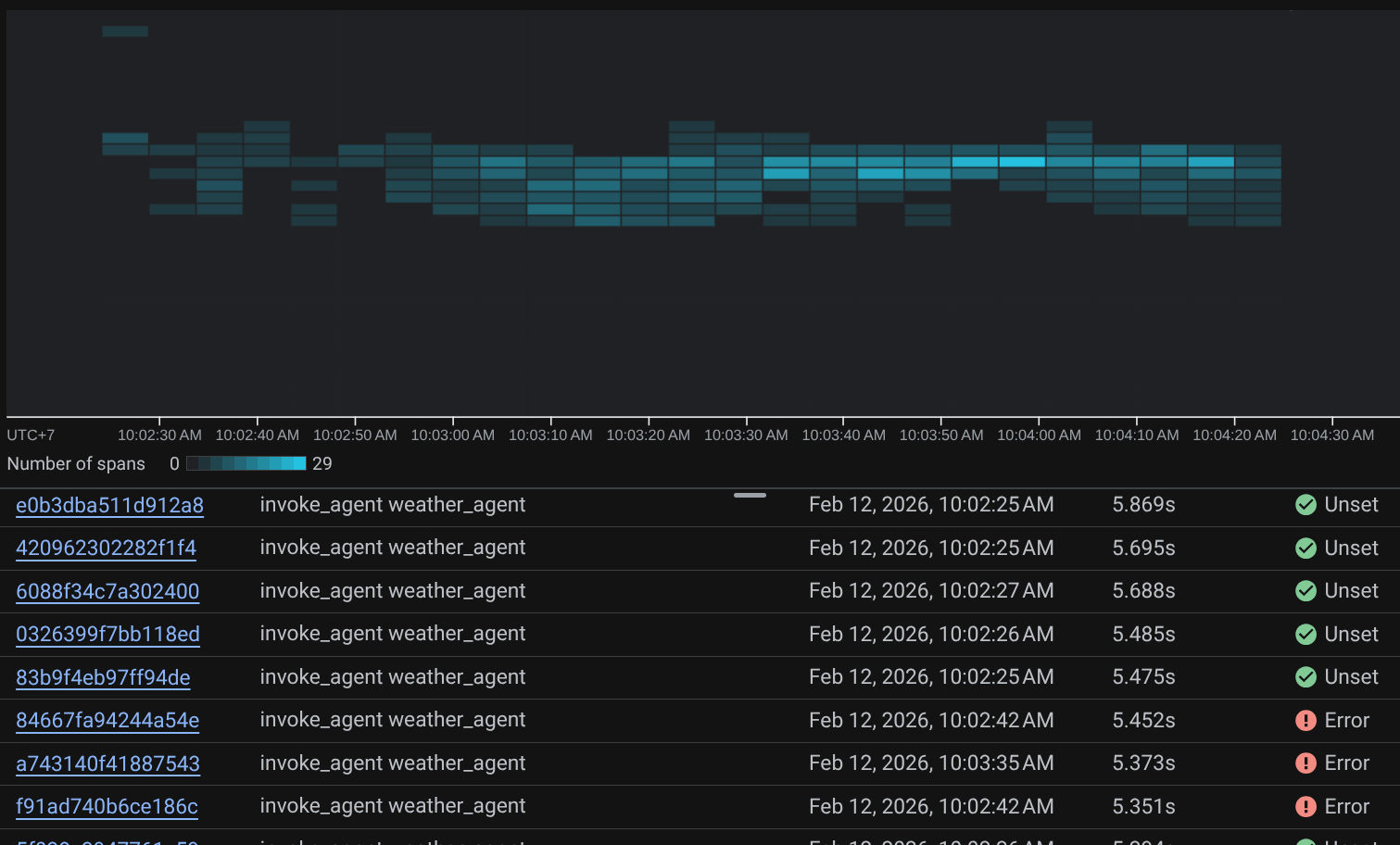
En cada sección, puedes inspeccionar los detalles de los atributos como se muestra a continuación.
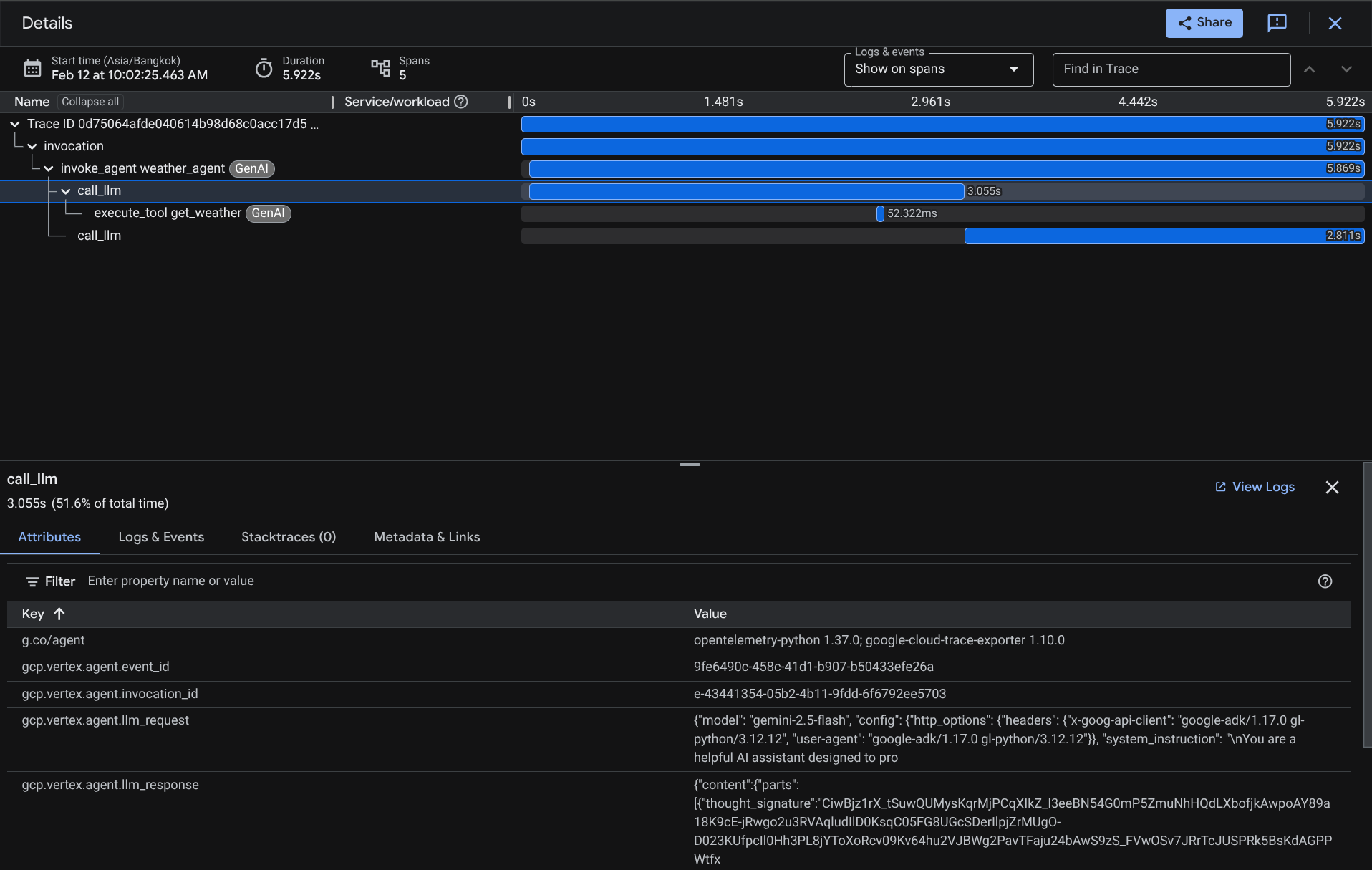
Listo. Ahora tenemos buena observabilidad e información sobre cada interacción de nuestro agente con el usuario para ayudar a depurar problemas. No dudes en probar diferentes herramientas o flujos de trabajo.
12. 🎯 Desafío
Prueba flujos de trabajo multiagente o basados en agentes para ver cómo se desempeñan bajo cargas y cómo se ve el registro.
13. 🧹 Limpieza
Sigue estos pasos para evitar que se apliquen cargos a tu cuenta de Google Cloud por los recursos que usaste en este codelab:
- En la consola de Google Cloud, ve a la página Administrar recursos.
- En la lista de proyectos, elige el proyecto que deseas borrar y haz clic en Borrar.
- En el diálogo, escribe el ID del proyecto y, luego, haz clic en Cerrar para borrarlo.
- Como alternativa, puedes ir a Cloud Run en la consola, seleccionar el servicio que acabas de implementar y borrarlo.